

Abstract
Predicting the evolution of systems with spatio-temporal dynamics in response to external stimuli is essential for scientific progress. Traditional equations-based approaches leverage first principles through the numerical approximation of differential equations, thus demanding extensive computational resources. In contrast, data-driven approaches leverage deep learning algorithms to describe system evolution in low-dimensional spaces. We introduce an architecture, termed Latent Dynamics Network, capable of uncovering low-dimensional intrinsic dynamics in potentially non-Markovian systems. Latent Dynamics Networks automatically discover a low-dimensional manifold while learning the system dynamics, eliminating the need for training an auto-encoder and avoiding operations in the high-dimensional space. They predict the evolution, even in time-extrapolation scenarios, of space-dependent fields without relying on predetermined grids, thus enabling weight-sharing across query-points. Lightweight and easy-to-train, Latent Dynamics Networks demonstrate superior accuracy (normalized error 5 times smaller) in highly-nonlinear problems with significantly fewer trainable parameters (more than 10 times fewer) compared to state-of-the-art methods.
Subject terms: Applied mathematics, Computational science, Engineering
Predicting the evolution of dynamical systems remains challenging, requiring high computational effort or effective reduction of the system into a low-dimensional space. Here, the authors present a data-driven approach for predicting the evolution of systems exhibiting spatiotemporal dynamics in response to external input signals.
Introduction
Mathematical models based on differential equations, such as Partial Differential Equations (PDEs) and Stochastic Differential Equations (SDEs), can yield quantitative predictions of the evolution of space-dependent quantities of interest in response to external stimuli. Pivotal examples are given by fluid dynamics and turbulence1, wave propagation phenomena2, the deformation of solid bodies and biological tissues3, molecular dynamics4, price evolution of financial assets5, epidemiology6. However, the development of traditional modeling-and-simulation approaches carry several mathematical and computational challenges. Model development requires a deep understanding of the physical processes, the adoption of physics first principles or empirical rules, and their translation into mathematical equations. The values of parameters and of boundary and initial conditions required to close the model are often unknown, increasing the intrinsic dimensionality of the solution space. Finally, the computational cost that accompanies the (possibly many-query) numerical approximation of such mathematical models may be prohibitive and hinder their use in relevant applications7,8.
In recent years, we are witnessing the introduction of a new paradigm, namely data-driven modeling9–15, as opposed to traditional physics-based modeling, enabled by recent advances in optimization, high-performance computing, GPU-based hardware, artificial neural networks (NNs) and Machine/Deep Learning in general. Data-driven modeling methods hold promise in overcoming the limitations of traditional physics-based models, either as a replacement for them or in synergy with them16,17. On the one hand, data-driven techniques are employed to learn a model directly from experimental data9,10. On the other hand, instead, they are used to build a surrogate for a high-fidelity model – the latter being typically based on the numerical approximation of systems of differential equations – from a dataset of precomputed high-fidelity simulation snapshots14,16. This paradigm is successful in many-query contexts, that is when the computational resources spent in the offline phase (generation of the training data and construction of the data-driven surrogate model) are repaid by a large number of evaluations of the trained model (online phase), as is the case of sensitivity analysis, parameter estimation and uncertainty quantification. Another case of interest is when real-time responses are needed, like, e.g., in clinical scenarios18.
Several methods have been recently proposed for automatically learning the dynamics of systems exhibiting spatio-temporal behavior12,19–23. Typically, these methods discretize the space-dependent output field into a high-dimensional vector (e.g., by point-wise evaluation on a grid, or by expansion with respect to a Finite Element basis or to a Fourier basis) and then compress it by means of dimensionality reduction techniques, based e.g. either on proper orthogonal decomposition (POD) of a set of snapshots7,24–26, or on fully connected auto-encoders, or else on convolutional auto-encoders19,20,27–30. The underlying assumption is that the dynamics can be represented by a limited number of state variables, called latent variables, whose time evolution is learned either through NNs with recurrent structure (such as RNNs31, LSTMs20,29 or ODE-Nets32), dynamic mode decomposition27, SINDy12,33, fully-connected NNs (FCNNs)30, or DeepONets19.
When a high-fidelity model is available, there are also techniques for building reduced-order models by exploiting knowledge of the equations34–41. These latter methods are however intrusive, unlike the formers, which learn a model in a data-driven manner using only a dataset of input-output pairs. Intrusive techniques are typically based on projecting the high-fidelity model into a low-dimensional space, obtained by POD or by greedy algorithms. In the case of nonlinear models, however, such techniques require special arrangements, such as the (discrete) empirical interpolation method42–44, but this entails a difficult trade-off between accuracy and computational cost. Furthermore, many problems feature a slow decay of the Kolmogorov n-width, an index of the amenability of the solution manifold to be approximated by an n-dimensional linear subspace45,46. In many cases of interest, such as advection-dominated problems or high Reynolds number flow equations, POD-based methods achieve reasonable accuracy only for high values of n28. This limits their use in practical applications.
In this paper, we introduce a family of NNs, called Latent Dynamics Networks (LDNets), that can effectively learn, in a data-driven manner, the temporal dynamics of space-dependent fields and predict their evolution for unseen time-dependent input signals and unseen scalar parameters. LDNets automatically discover a compact encoding of the system state in terms of (typically a few) latent scalar variables. Remarkably, the latent representation is learned without the need of using an auto-encoder to explicitly compress a high-dimensional discretization of the system state. Furthermore, LDNets are based on an intrinsically space-dependent reconstruction of the output fields. Indeed, instead of yielding a discrete representation of the fields (e.g. point values on a spatial mesh), LDNets are able to generate output fields defined at any point of space, in a meshless manner. As a consequence, the (typically high-dimensional) discrete representation of the output is never explicitly constructed. These features make the training of LDNets extremely lightweight, and boost their generalization ability even in the presence of few training samples and even in time-extrapolation regimes, that is for longer time horizons than those seen during training.
We denote by an output field we aim to predict, where is the space domain and T > 0 is the final time. The evolution of y is driven by the input , that is, a set of time-dependent signals or, more simply, constant parameters. Our goal is to unveil, starting from data, the laws underlying the dependence of y on u. We denote by the set of training samples. For each , we assume to have available some observations of ui(τ) and of yi(ξ, τ), sampled at a finite set of points ξ ∈ Ω and times τ ∈ [0, T], originating, for example, from a collection of sensors.
An important (albeit not exclusive) example is the case when the dynamics we aim to learn underlies a differential model in the form of
| 1 |
where z(x, t) is the state variable, is a differential operator and is the observation operator. Meaningful examples are provided in the Results section. In particular, LDNets can be also used to generate a reduced-order model of (1), by passing through data generated via a numerical approximation of (1), e.g. by the Finite Element method, called full-order model (FOM).
An LDNet consists of two sub-networks, and , that is two FCNNs with trainable parameters wdyn and wrec, respectively (see Fig. 1). The first NN, namely , evolves the dynamics of the latent variables according to the differential equation
| 2 |
We remark that, thanks to the hidden nature of s(t), we can assume without loss of generality the initial condition s(0) = 0 (see47 for a discussion on this topic in a similar framework). The inputs of are the latent states s(t) and the input signal u(t) at the current time t. Instead, the second NN, , is used to reconstruct , an approximation of the output field y at any time t ∈ [0, T] and at any query point x ∈ Ω:
| 3 |
We remark that the reconstruction network is independently queried for every point x ∈ Ω for which the solution is sought. The input signal u(t) can optionally be given as input to the reconstruction network (an example is given in Test Case 2). Normalization layers are employed to facilitate training. They are defined to guarantee that each feature approximately spans the interval [ − 1,1]. We also normalize the time variable, by dividing the time steps by a characteristic time scale Δtref, considered as an hyperparameter of the model. In case an output feature has a long-tailed distribution, we supplement the normalization layer with a non-trainable nonlinear layer to compress the tails. See Methods for further details.
Fig. 1. LDNet architecture.

The network receives the input u(t) and the latent state s(t) and returns the time derivative of the latent state, thus defining its dynamics. The network , instead, is evaluated only when an estimate of the output field y is sought. More precisely, an approximation of y(x, t) is recovered by giving as an input to the latent state at time t and the query space coordinate x ∈ Ω. In general, the reconstruction network might take as an input u(t) as well (see e.g. Results, Test Case 2); for simplicity, in the figure we represent the special case when does not depend on u(t).
Optionally, the architecture of and are adapted to enforce a-priori knowledge. On the one hand, in case data are collected starting from an equilibrium configuration associated with the input ueq, we define as
where is a trainable FCNN, thus enforcing by construction the equilibrium condition. On the other hand, if the value of the output fields is a priori known on a subset of the domain Ω, we define as
where is a trainable FCNN, ylift is the lifting of the value to be prescribed, that is an extension to the whole domain, and is a mask, that is a smooth function vanishing on the region where the output is prescribed. See Methods for further details.
The two NNs, and , are simultaneously trained via empirical risk minimization, that is by minimizing the quadratic difference between predictions and observations on the training dataset. Tikhonov regularization on the NNs’ weights is employed to mitigate overfitting. Thanks to the simultaneous end-to-end training of the two NNs, the latent space is discovered at the same time as learning the dynamics of the system. This generalizes the approach presented in47 for the case of time signals as outputs.
To train the parameters, we employ a two stage strategy, consisting of a few hundreds epochs of the Adam optimizer48, followed by the BFGS algorithm49. BFGS is more accurate than Adam, but more prone to get stuck in local minima, which is why it is useful to precede it with some Adam iterations, which provide a good initial guess. To tune hyperparameters, we employ a Bayesian approach, namely the Tree-structured Parzen Estimator algorithm50, combined with Asynchronous Successive Halving scheduler to early terminate bad hyperparameters configurations51.
Further details about the time discretization of (2), features normalization, parameters training and hyperparameter tuning are provided in Methods.
Results
We demonstrate the effectiveness of LDNets through several test cases. First, we consider a linear PDE model to analyze the ability of LDNets to extract a compact latent representation of models that are progressively less amenable to reduction. Then, we consider the time-dependent version of a benchmark problem in fluid dynamics. Finally, we compare LDNets with state-of-the-art methods in a challenging task, that is, learning the dynamics of the Monodomain equation coupled with the Aliev-Panfilov model52, a highly non-linear excitation-propagation PDE model used in the field of cardiac electrophysiology modeling, of which we consider both a one-dimensional and a two-dimensional version. For more details on the test cases and on the results, we refer the interested reader to SI.
We focus on synthetically generated data obtained by numerical approximation of differential models, thus allowing us to test LDNet predictions against ground-truth results. We evaluate the prediction accuracy of the trained models using two metrics: the normalized root-mean-square error (NRMSE) and the Pearson dissimilarity, 1 − ρ, where ρ is the Pearson correlation coefficient.
Test Case 1: advection-diffusion-reaction equation
We consider the linear advection-diffusion-reaction (ADR) equation on the interval Ω = ( − 1, 1):
| 4 |
This PDE is widely used, e.g., to describe the concentration z(x, t) of a substance dissolved in a channel53. The constant parameters μ1, μ2 and μ3 respectively represent diffusion, advection and reaction coefficients, while the forcing term f(x, t) is a prescribed external source. We consider an initial condition z(x, 0) = z0(x) and periodic boundary conditions.
To generate the training dataset, we employ a high-fidelity FFT-based solver on 101 equally spaced grid points, combined with an adaptive-time integration scheme for stiff problems54,55. Then, we subsample the time domain in 100 equally distributed intervals. We challenge LDNets in predicting the space-time evolution of the target variable y(x, t) = z(x, t) by considering three cases of increasing complexity (Test Cases 1a, 1b, 1c), in which the input u is associated either with the parameters μ1, μ2 and μ3, or with the forcing term f(x, t).
Test Case 1a: finite latent dimension, constant parameters
First, we consider and f ≡ 0. We aim at predicting the evolution of z(x, t), depending on the constant parameters u(t) ≡ (μ1, μ2, μ3). Due to the linearity of the equation, the solution is, at any time t, a sine wave with period 2, and can be thus unambiguously identified by two scalars (namely, the wave amplitude and phase, or equivalently, the real and imaginary part of the Fourier transform at frequency 0.5). In other terms, the intrinsic dimension of the solution manifold is strictly equal to 2. This provides therefore an ideal testbed for the capability of LDNets to recognize and learn a low-dimensional encoding of the system state from data.
The LDNet, trained on 100 samples, achieves an excellent accuracy when tested on 500 unseen samples. Indeed, the NRMSE is 1.88 ⋅ 10−5 on the test set, against a training NRMSE of 1.81 ⋅ 10−5. Pearson dissimilarity is 3.30 ⋅ 10−9 on the test set and 3.00 ⋅ 10−9 on the training set. The very small differences in the accuracy metrics between training and test sets provide evidence that the trained LDNet reproduces the FOM dynamics with great fidelity and without overfitting, that is with remarkably good generalization capabilities.
Test Case 1b: finite latent dimension, time-dependent inputs
We now consider the case of time-dependent inputs, with a forcing term , where u(t) = (u1(t), u2(t)) represents an input signal that can vary in time within a bounded set. Similarly to Test Case 1a, the solution manifold has dimension 2 (thanks to the equation being linear and to the forcing term having constant frequency), but learning the dynamics becomes more challenging due to the presence of time-dependent inputs.
We test the accuracy of LDNets for an increasing number of training samples, ranging from 25 to 400 (Fig. 2a). Remarkably, LDNets generalize well to unobserved samples even for a very small number of training samples, such as 25. As desirable, the accuracy of predictions improves as the time discretization step size is reduced and as the number of training samples increases (Fig. 2b). Indeed, because of the non-intrusive nature of LDNets, their ability to discover system dynamics is limited by the information contained in the training set, as it is common in data-driven model reduction/discovery methods22,23,47. Still, as the input space is covered more densely, LDNets are able to leverage that information as attested by the significantly decreasing test error.
Fig. 2. Results of Test Case 1.

a–c Testing accuracy of Test Case 1b, as a function of the number of training samples (with Δt = 0.05 and 2 latent variables), of Δt (with 100 training samples and 2 latent variables), and of the number of latent variables (with Δt = 0.05 and 100 training samples). For each setting we perform 5 training runs with random weights initialization. Each dot corresponds to a training run, while the solid line is the geometric mean. d FOM against LDNet predictions on 8 testing samples for Test Case 1b. The abscissa corresponds to space and the ordinate to time. e Mapping from the latent space trajectories and the Fourier space coefficients of the FOM solution for the testing samples of Test Case 1b. f Testing accuracy of Test Case 1c as a function of the number of latent states and of the maximum input frequency . g FOM against LDNet predictions on 4 testing samples for Test Case 1c, obtained by employing 5 latent states, for different maximum input frequencies (reported above the figure).
In this test case, despite the FOM state is discretized using 101 space points, the intrinsic dimension of the solution manifold is much lower, namely 2. In fact, a compact representation of the system state is obtained by means of the Fourier transform at frequency 0.5 (denoted by ) and consists of two scalars (i.e. and ). Therefore, we test whether LDNets can discover an equivalent encoding of the system state: in Fig. 2e, we plot and along the testing trajectories in the latent space (s1, s2). In this figure a well-defined mapping emerges from the two latent states to the two Fourier coefficients: LDNets are capable of discovering a compact encoding based on an operator that is equivalent to the Fourier transform, without being explicitly instructed to do so, that is in a fully data-driven manner.
Finally, we train LDNets for increasing number of latent variables, ranging from 1 to 5 (Fig. 2c). As expected, the prediction accuracy significantly drops when going from 1 to 2 latent variables, that is when the intrinsic solution manifold dimension is reached. With more than 2 latent variables, it reaches a plateau, showing only a slight decrease due to increased model capacity, accompanied by a larger variance in the output.
Test Case 1c: infinite latent dimension
Finally, we consider a forcing term , where u(t) = (u1(t), u2(t), u3(t)) is the time-dependent input signal. The forcing frequency u3(t) varies within an interval . Hence, the solution manifold of (4) has a potentially infinite dimension, being z the superimposition of a continuum of frequencies. Still, the results show that LDNets are able to discover effective low-dimensional encodings of the state.
First, we set and we train LDNets for increasing number of latent states, from 2 to 7. Remarkably, as the number of latent states increases, LDNets discover more effective encodings, that reflect in an increasing prediction accuracy (Fig. 2f, blue line). Unlike Test Case 1b, where the intrinsic size of the solution manifold is 2 and this leads to a stagnation of the error, here the error decreases significantly even for higher numbers of latent variables. Still, for higher numbers of latent variables, we have a slowdown in the decreasing trend of the error, due to two factors: on the one hand, the finite size (100 samples) of the training set (see in this regard Fig. 2a), on the other hand, the optimizer that may not find the global minimum of the loss function. By increasing to 1 and 2, the FOM state gets less prone to be represented by a compact encoding, since the spectrum of the solution is wider. Prediction accuracy is indeed lower than in the case , but it improves greatly by increasing the number of latent variables.
To further assess the crucial role of including latent states in the model, we analyze the results obtained by removing the latent variables, namely by considering an ODE-Net fed by the input signal and the query point, and tracking the evolution of the output at the considered point (see SI for more details). We train this architecture by considering Test Case 1c, with . To ensure a fair comparison, we employ the same dataset and the same hyperparameter tuning algorithm used for LDNets. The results (see Fig. 3) reveal that without latent states the prediction accuracy of the model is significantly reduced. Moreover, the greater the number of latent states, the greater the ability of the model to capture finer and finer features of the dynamics. We conclude that the presence of a latent state is a crucial architectural choice for LDNets. The latent variables allow nonlocal information to propagate across the computational domain Ω. With the architecture considered in this comparison, instead, the solution evolves in each point unaware of the state of surrounding points, despite the point coordinate is provided to the ODE-Net. Conversely, LDNets are able to learn systems whose dynamics is determined by spatial correlations. Notable examples are provided in the next sections.
Fig. 3. Test Case 1c: impact of latent states.

We compare, for a sample belonging to the test dataset, the results obtained by using LDNets with increasing number of latent states (2, 3, 5, 7) and by using an ODE-Net fed by the input signal and the query point (denoted by (x, u(t))-ODE-Net). The left-most column reports the FOM solution (the abscissa denotes time, the ordinate denotes space). For each method we report: a the space-time solution; b the space-time error with respect to the FOM solution; c the time-evolution of the latent variables; d–f three snapshots of the space-dependent output field at t = 2, 5 and 7, in which we compare the predicted solution (red solid line) with the FOM solution (black dashed line).
Test Case 2: unsteady Navier–Stokes
The 2D lid-driven cavity is a well-known benchmark problem in fluid dynamics56, which may exhibit a wide range of flow patterns and vortex structures when increasing the Reynolds number. We challenge LDNets in learning an unsteady version of the lid-driven cavity problem, where the velocity prescribed on the lid Γtop (the top portion of the boundary) is a time-dependent input u(t) (see Fig. 4a). During the simulations, the Reynolds number varies over time by reaching peaks of nearly 1500. This problem is challenging also because of discontinuities in the velocity field at the two top corners. The goal here is to predict the velocity field (that is, we set y(x, t) = v(x, t)) for each prescribed u(t):
| 5 |
where the dependence of the velocity v and pressure p on space and time is understood. As shown in57, a simple quadratic loss function is not adequate for capturing small vortex structures, because of their small impact, compared to medium- and large-scale structures, on the loss function. Therefore, we use the following goal-oriented metric, where we denote by v and the reference and predicted velocities, respectively:
| 6 |
with hyperparameters γ and ϵ ≪ 1, and where vnorm is a reference velocity magnitude. The second term of the metric (6) allows to match the flow direction, even in the regions of small flow magnitude.
Fig. 4. Test Case 2.

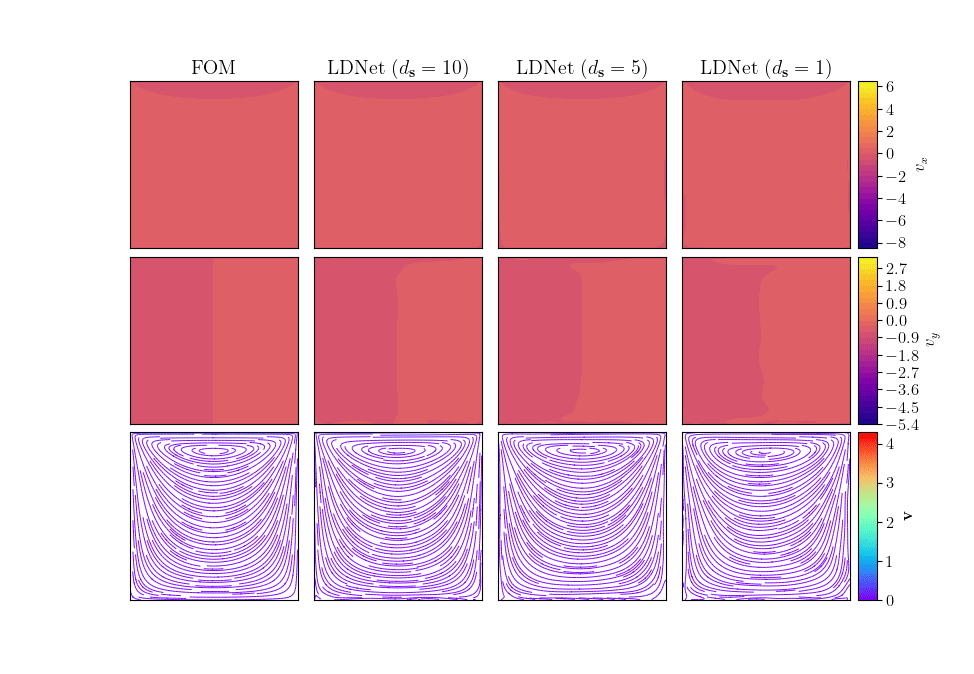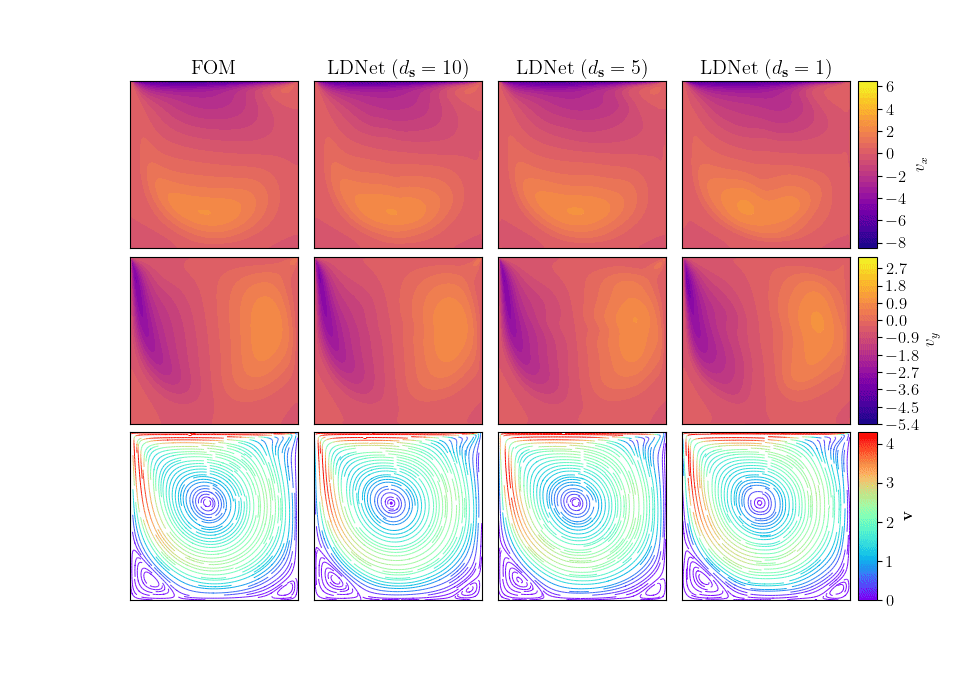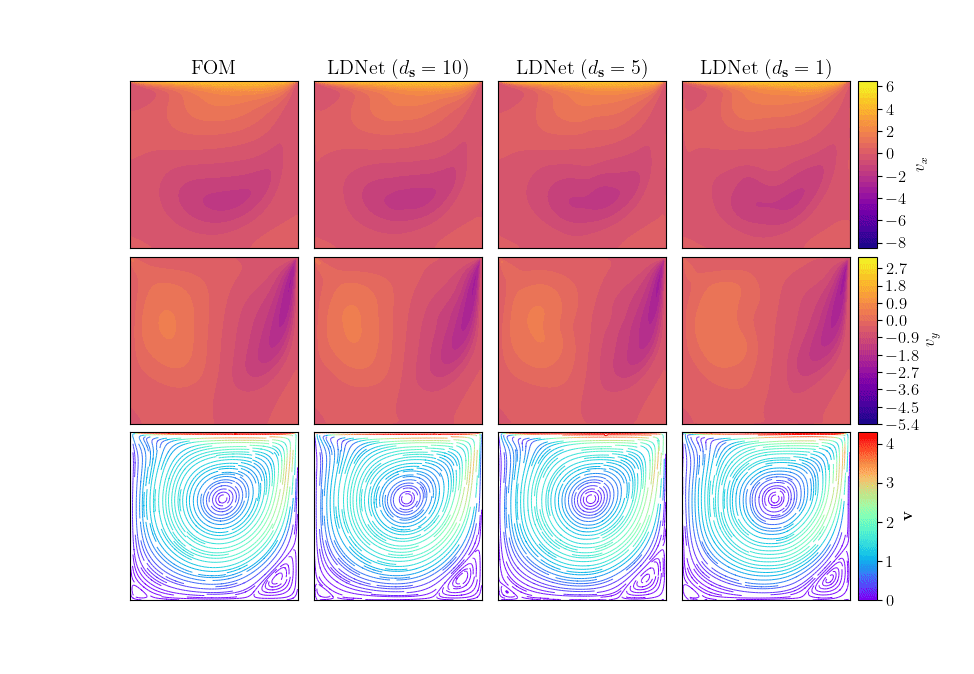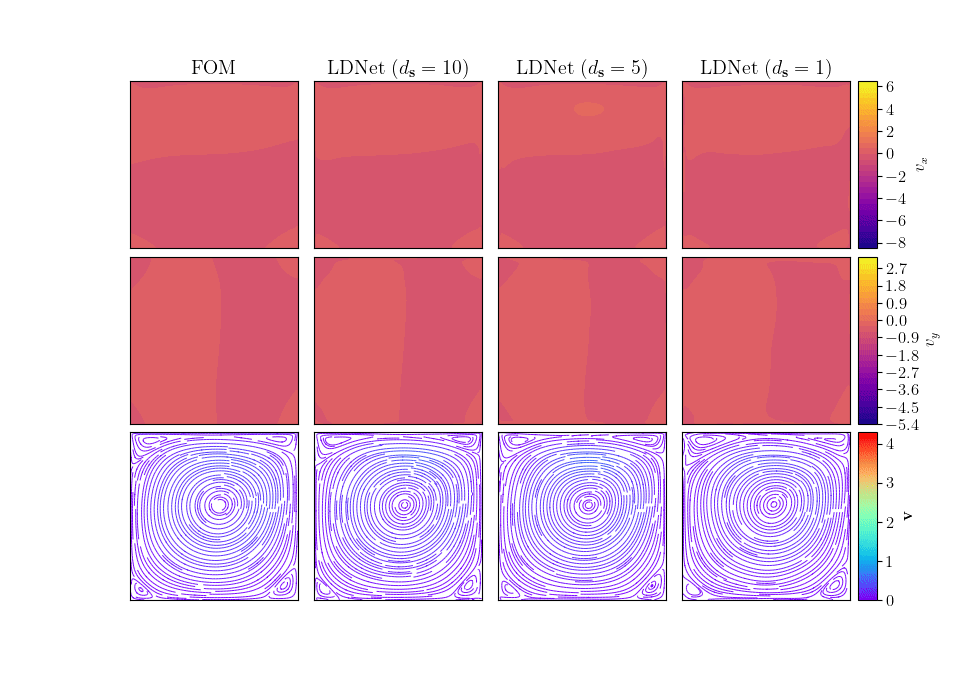
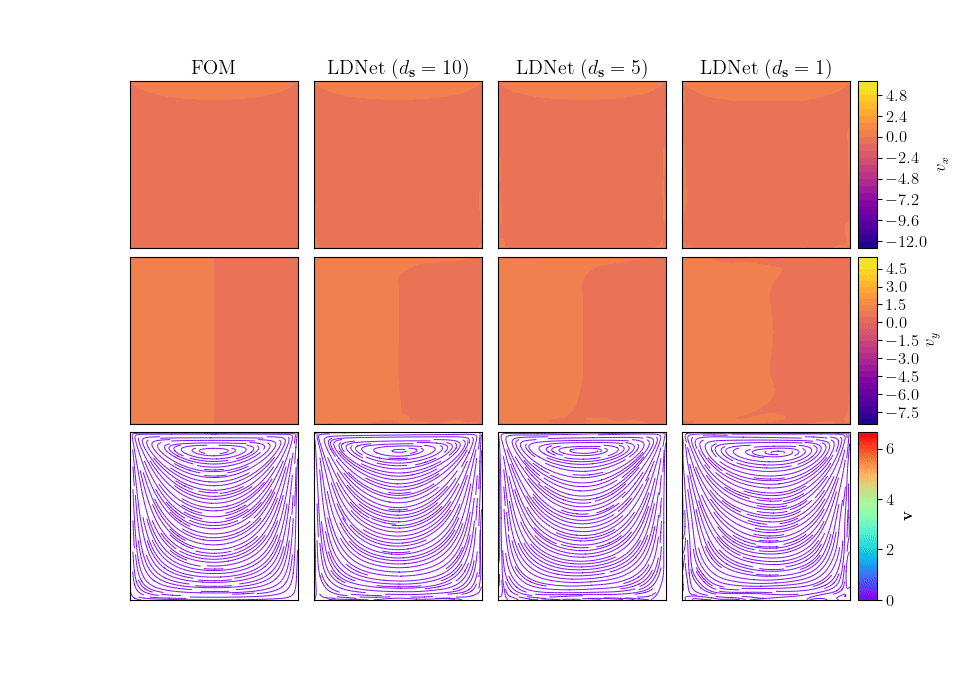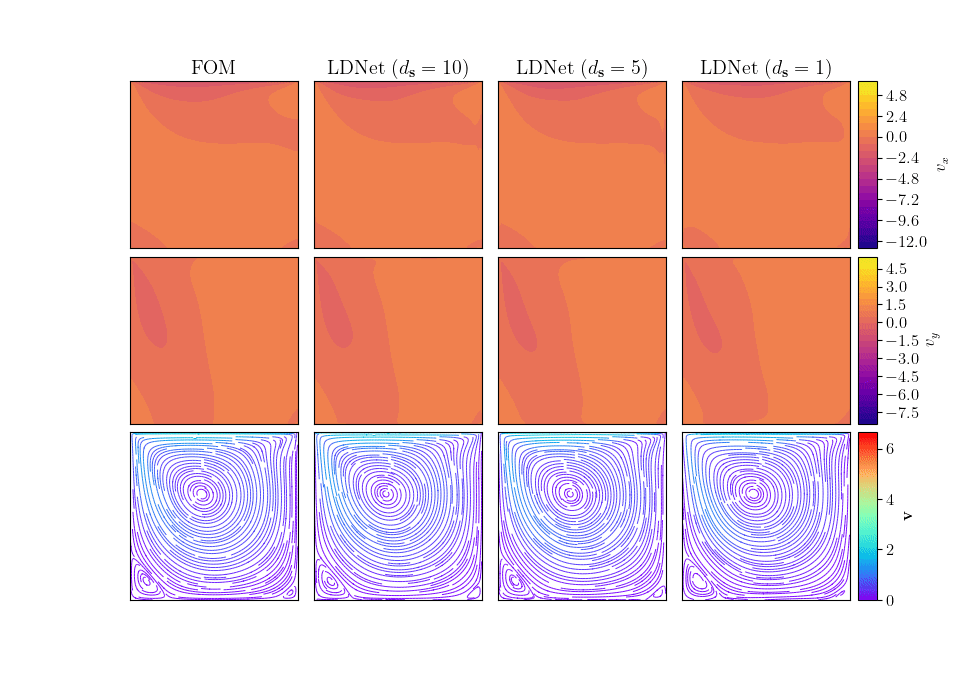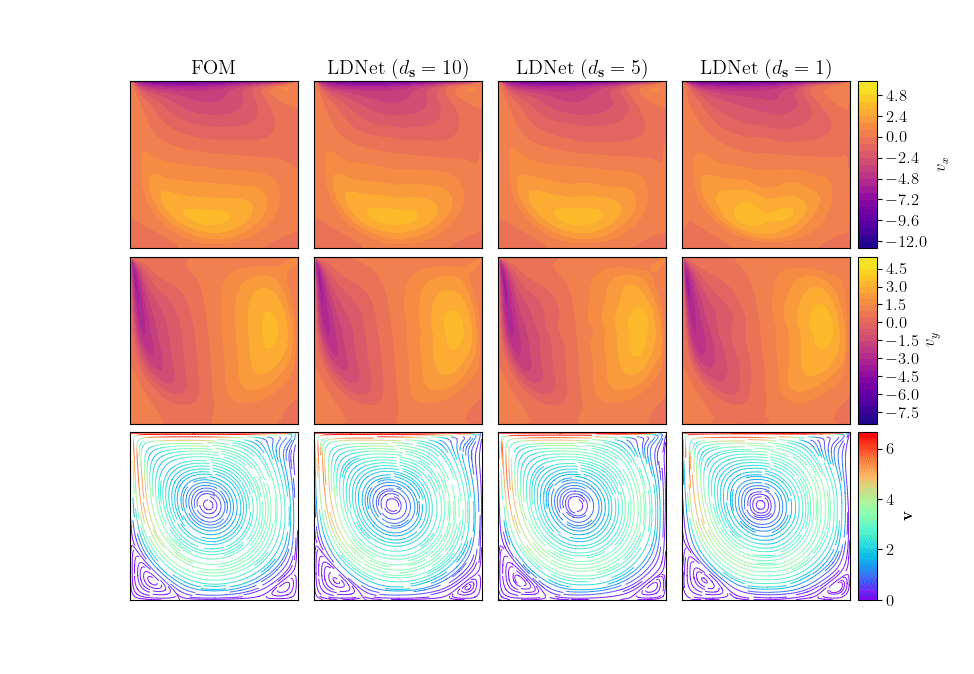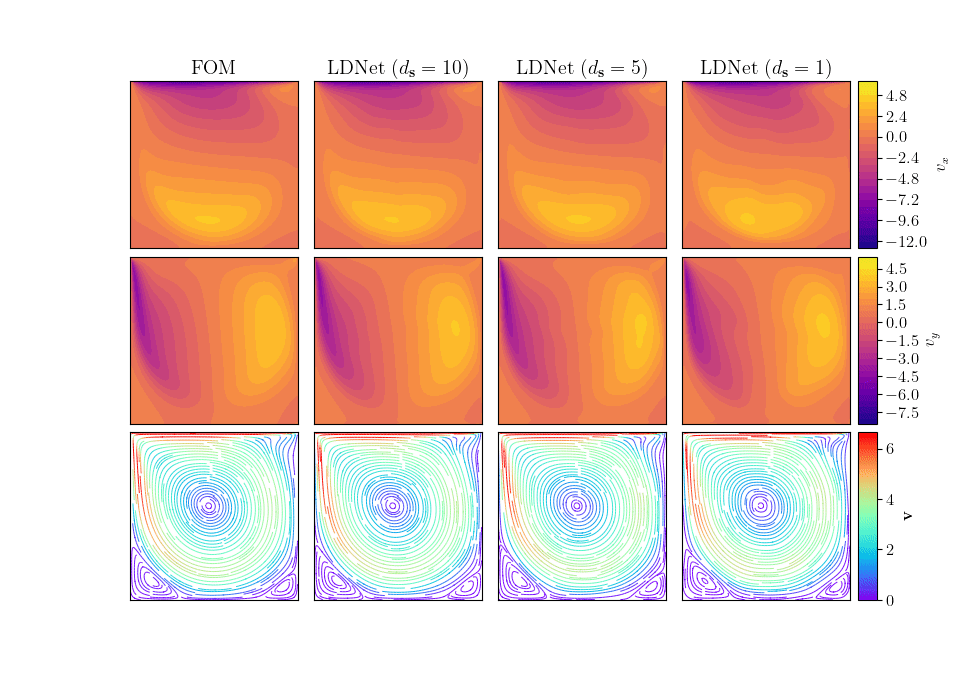
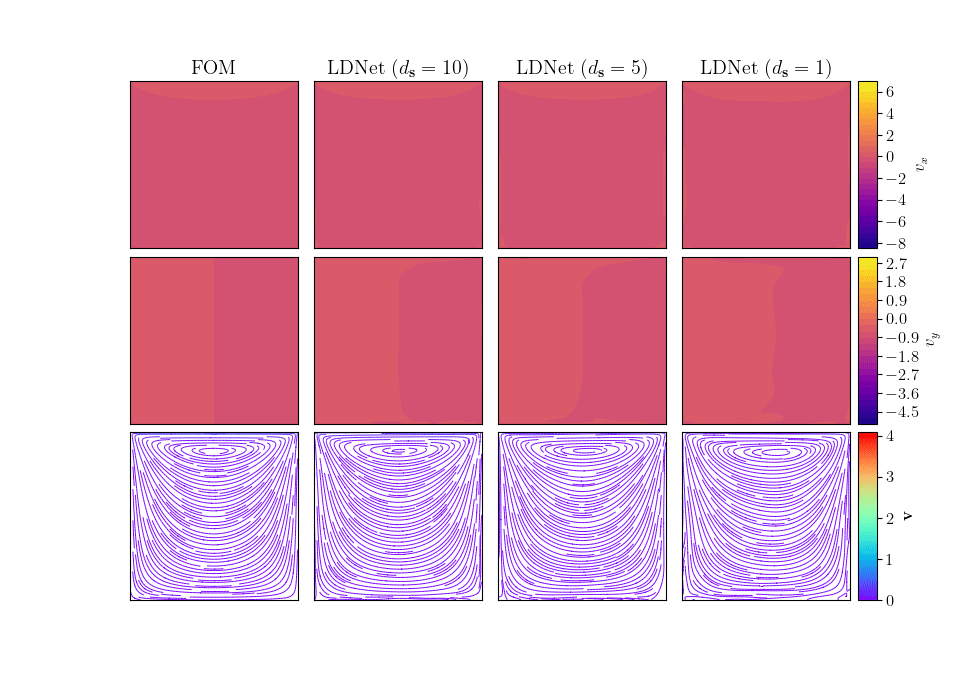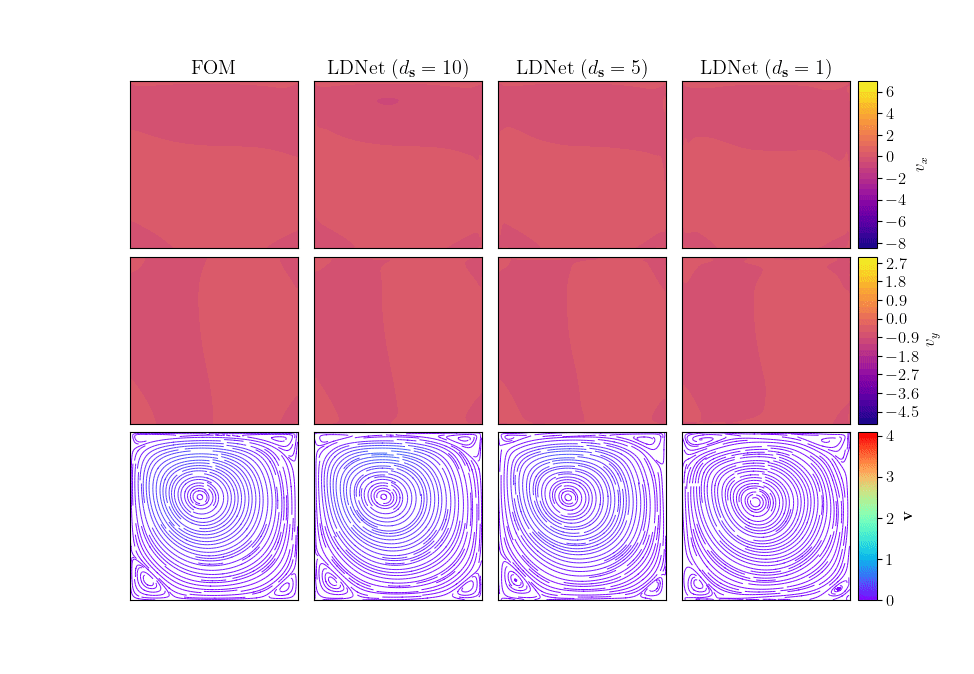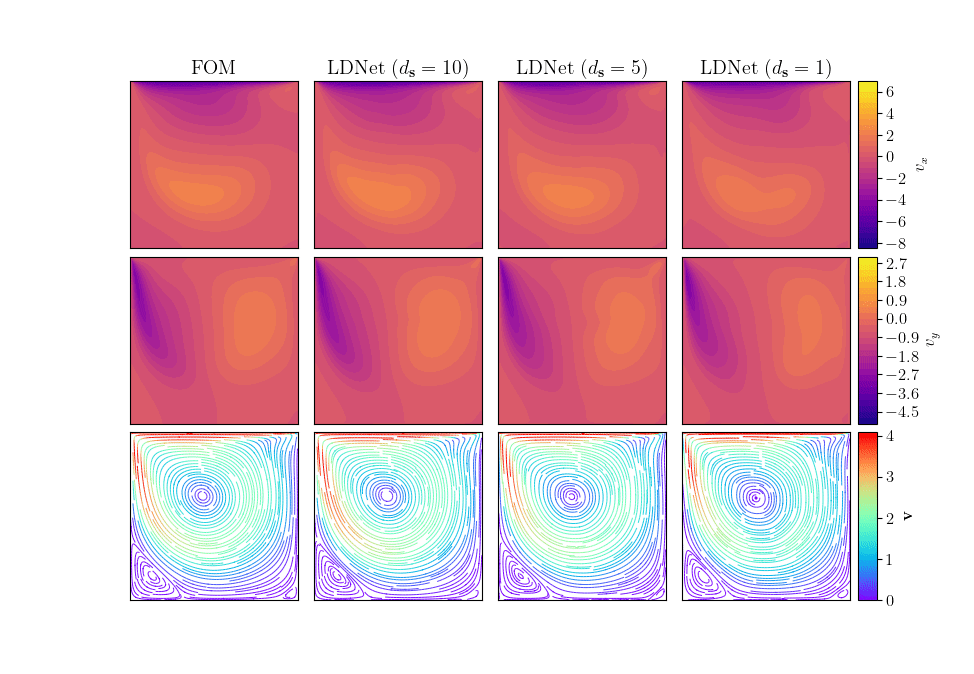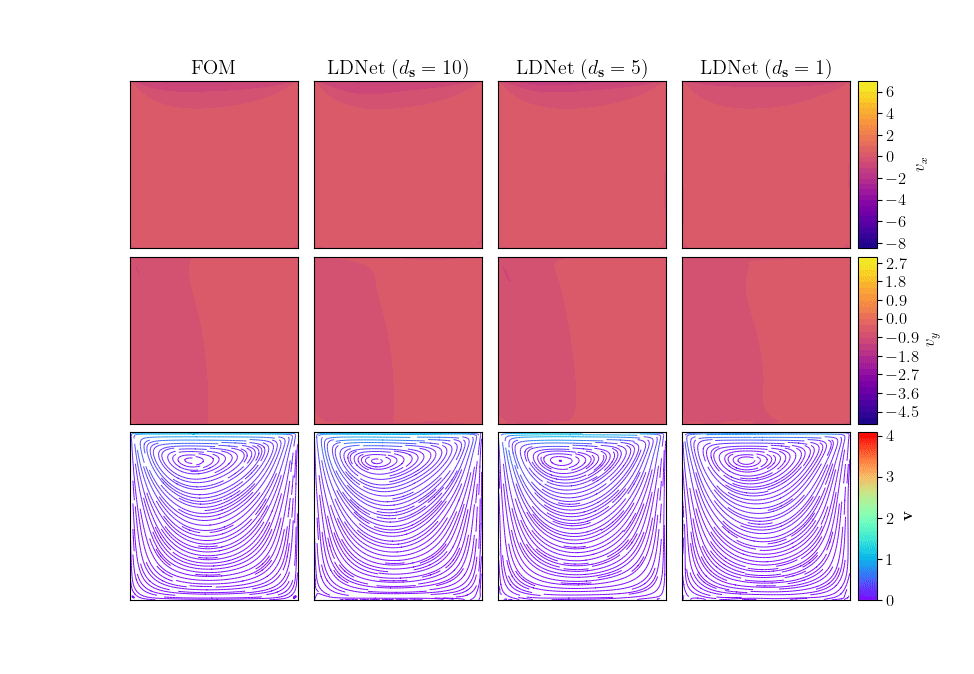
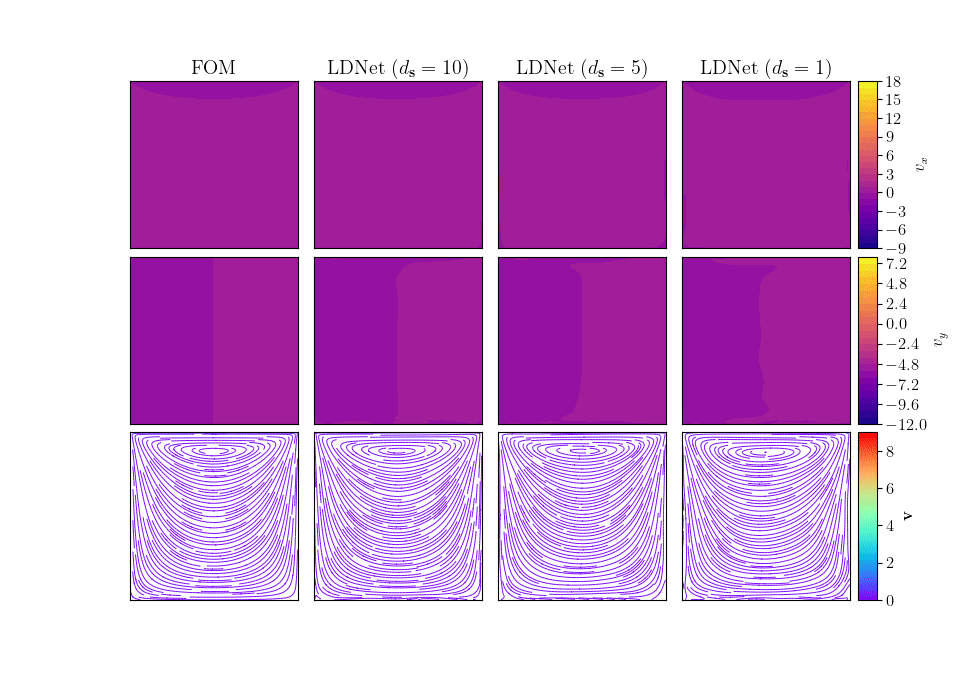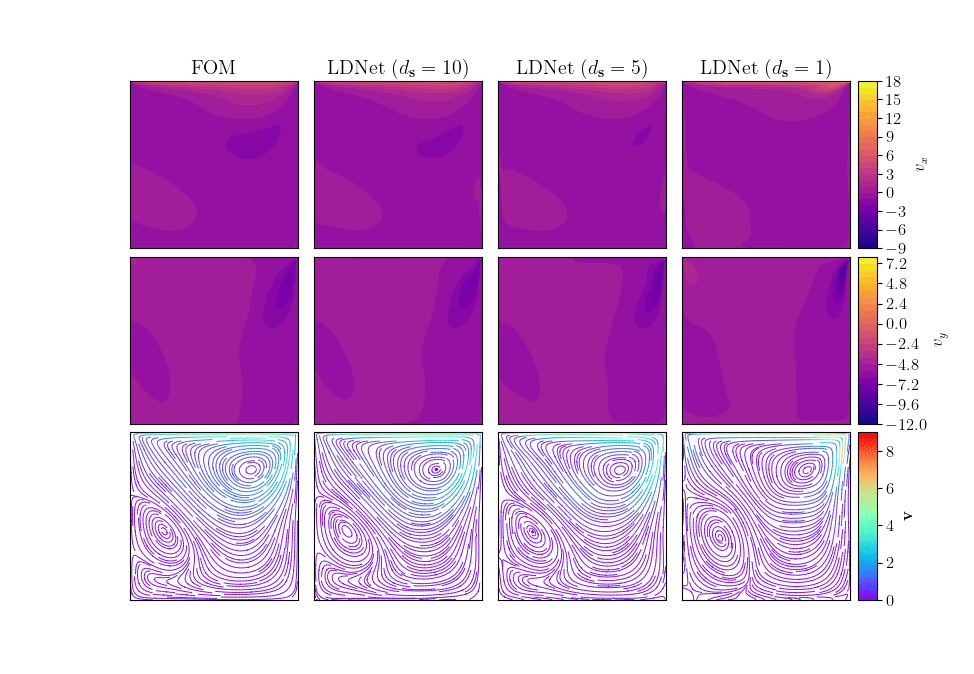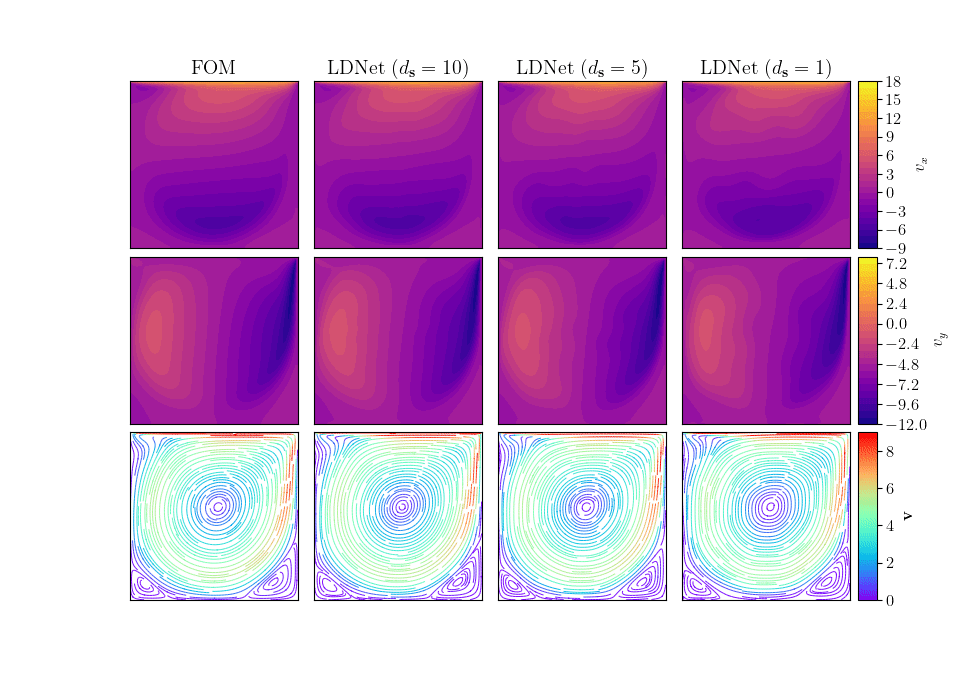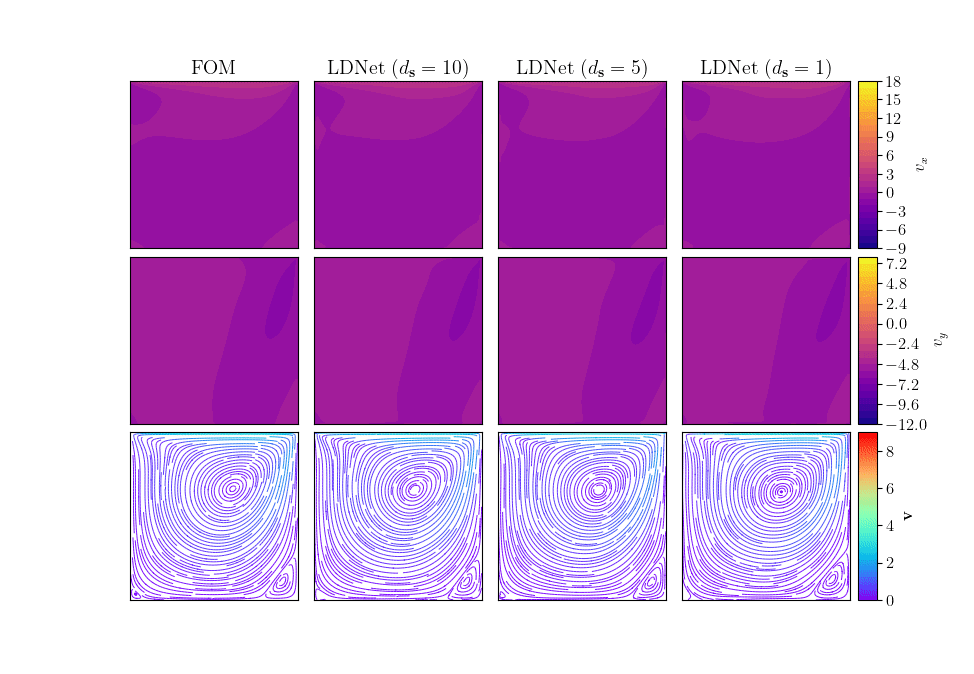
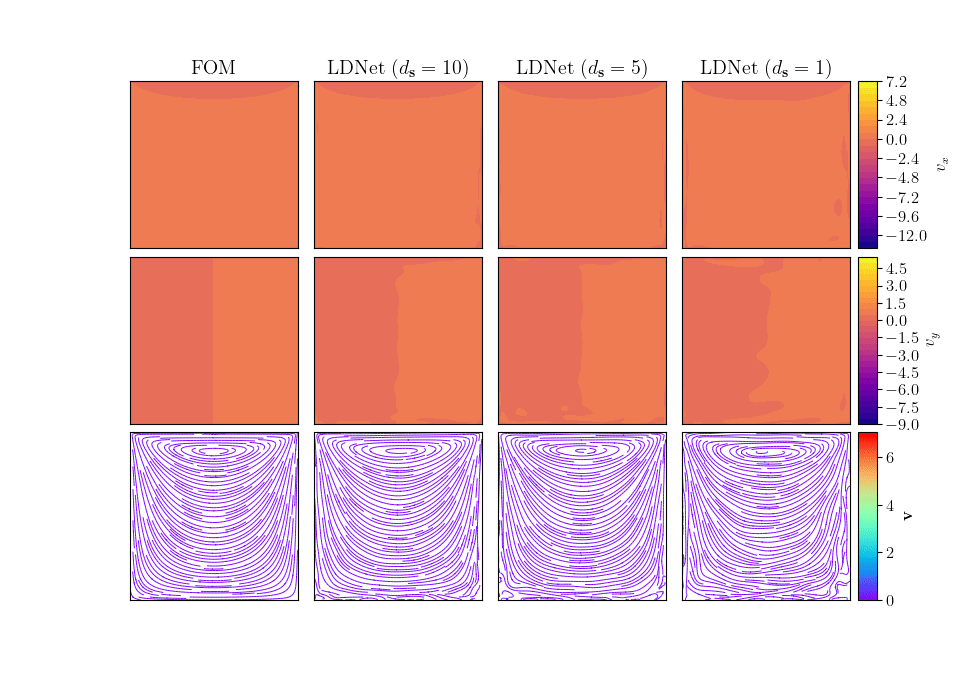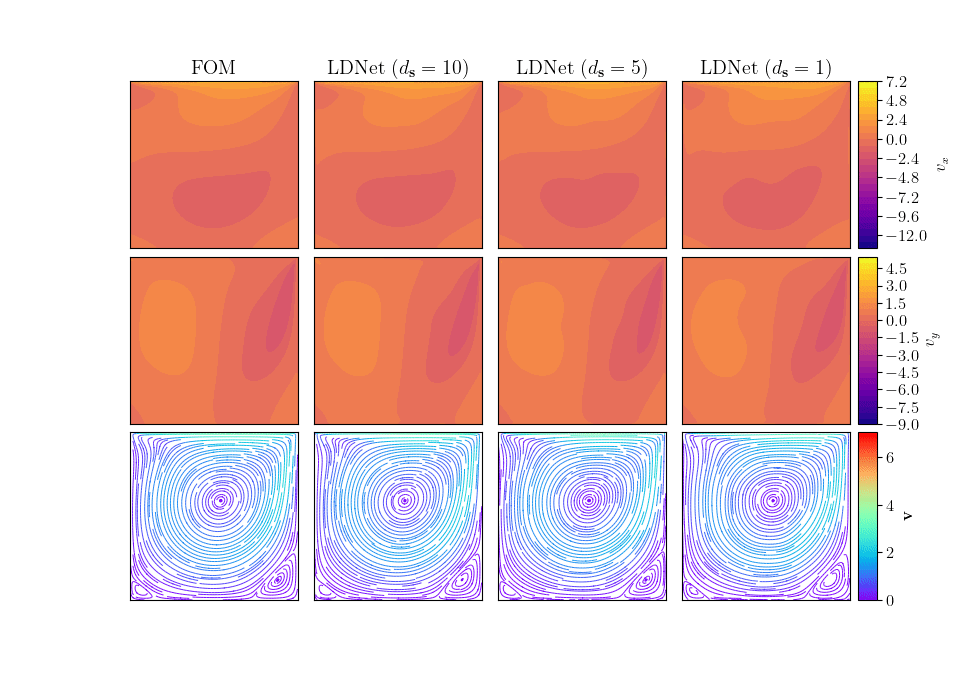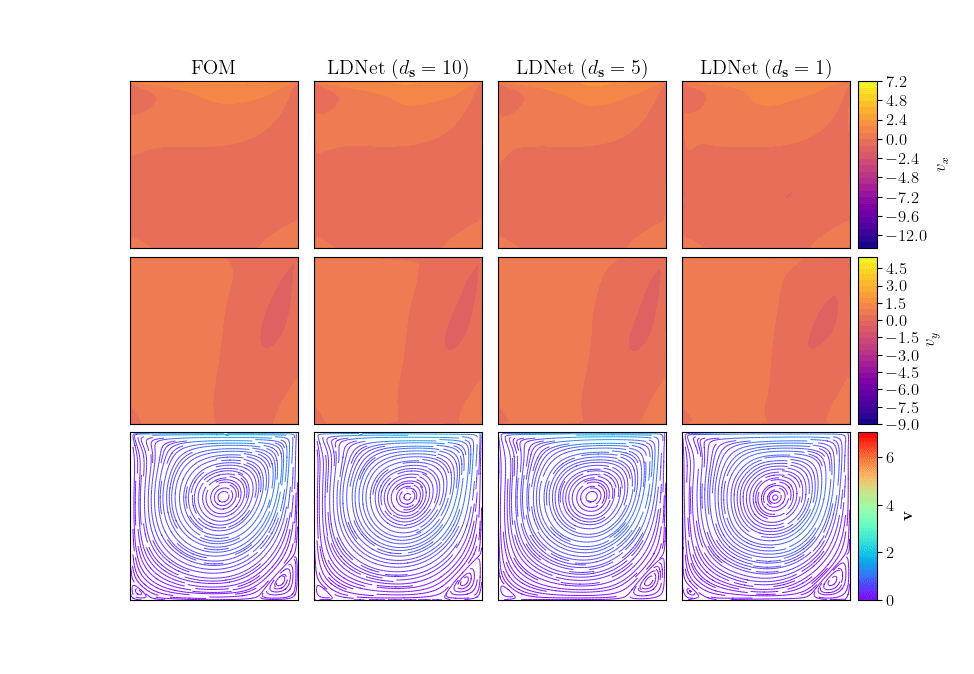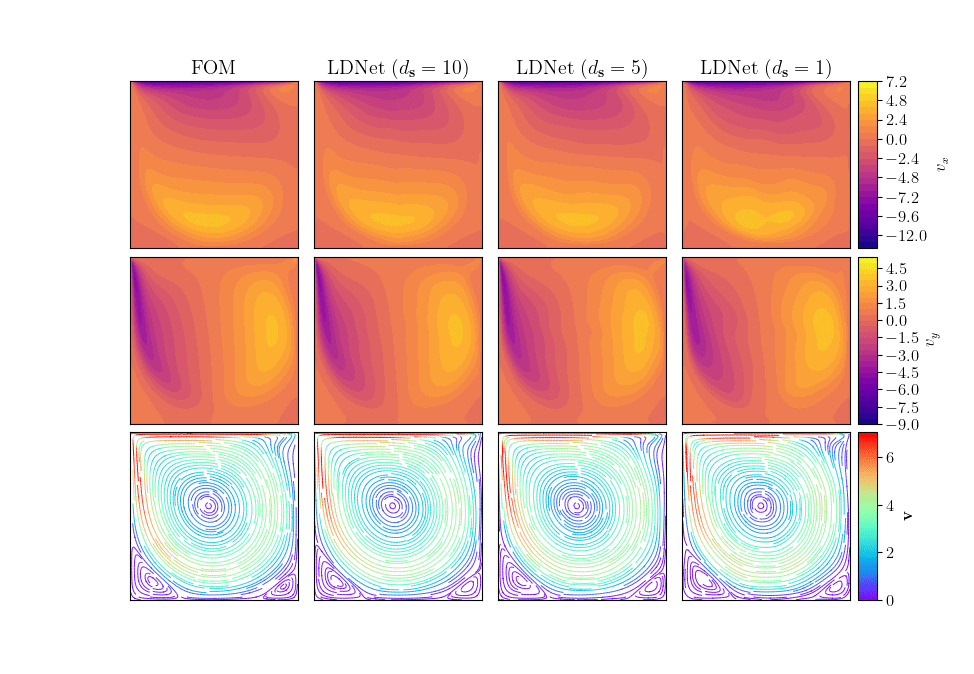
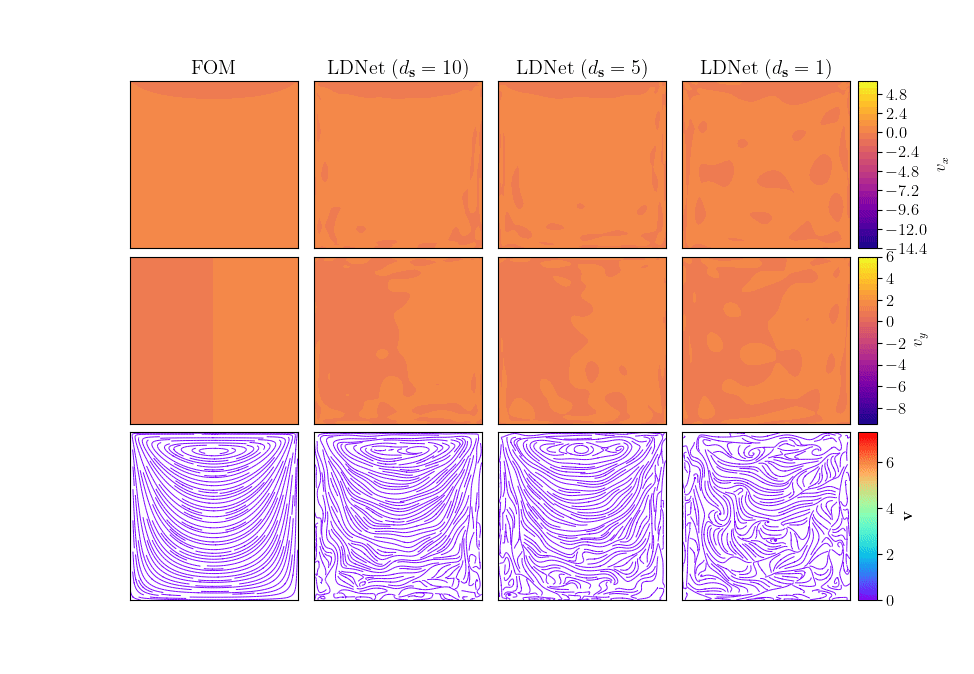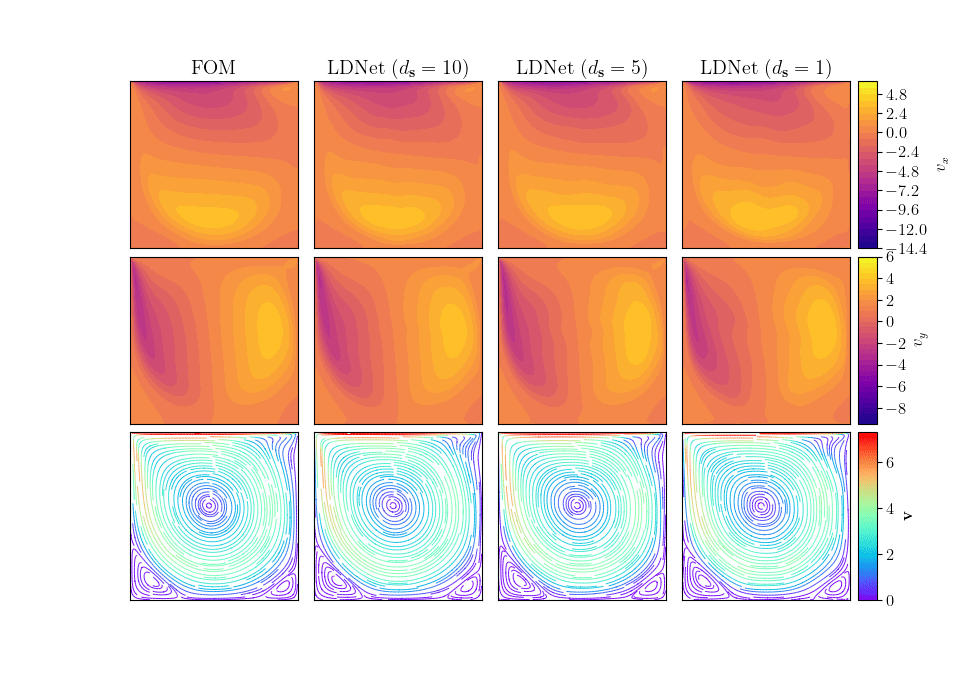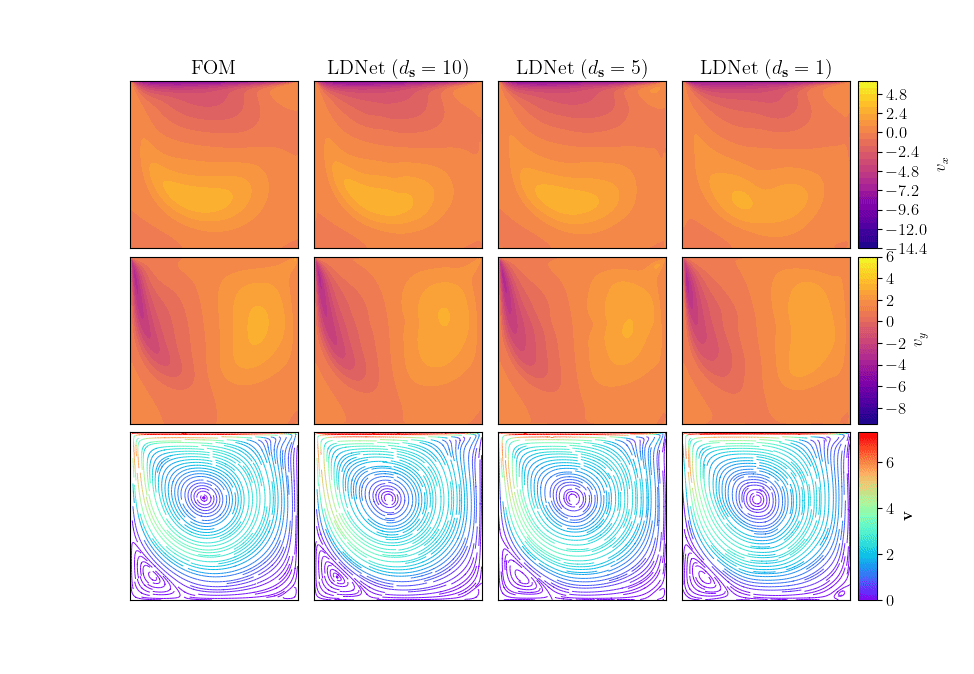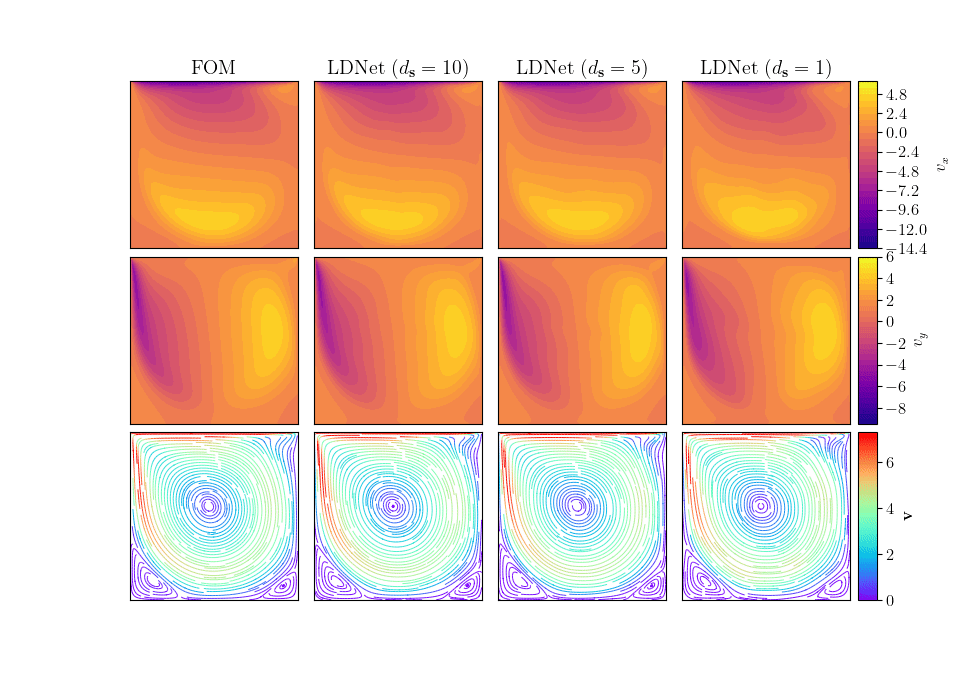
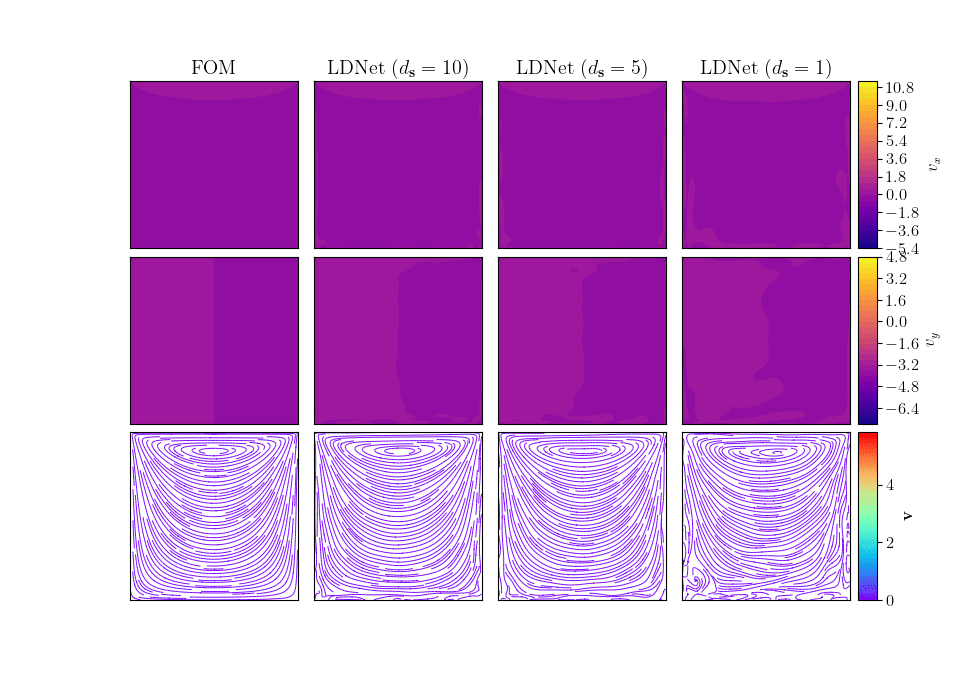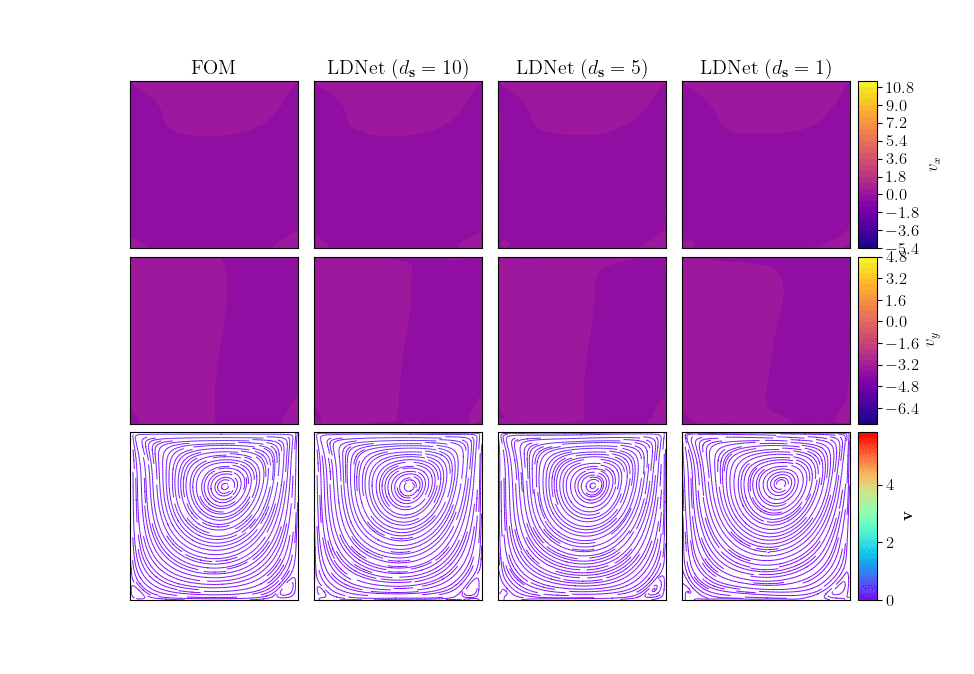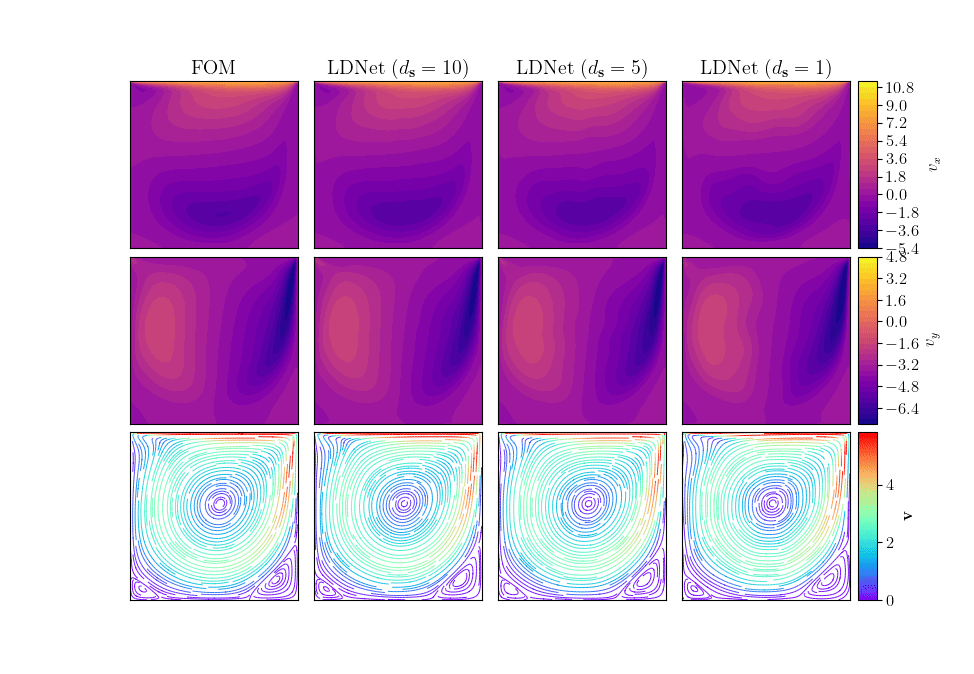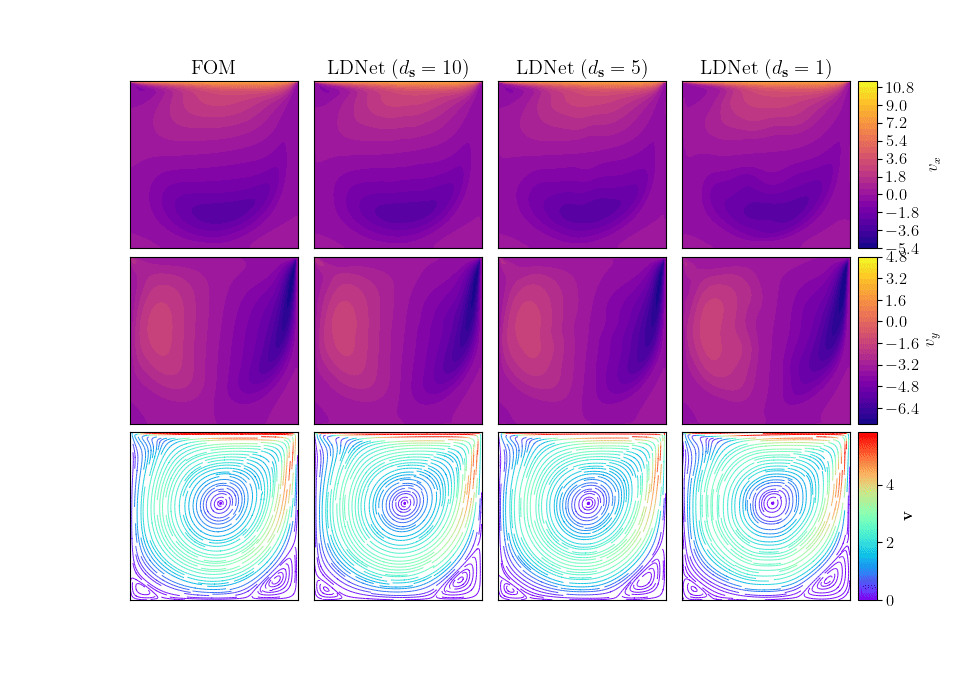
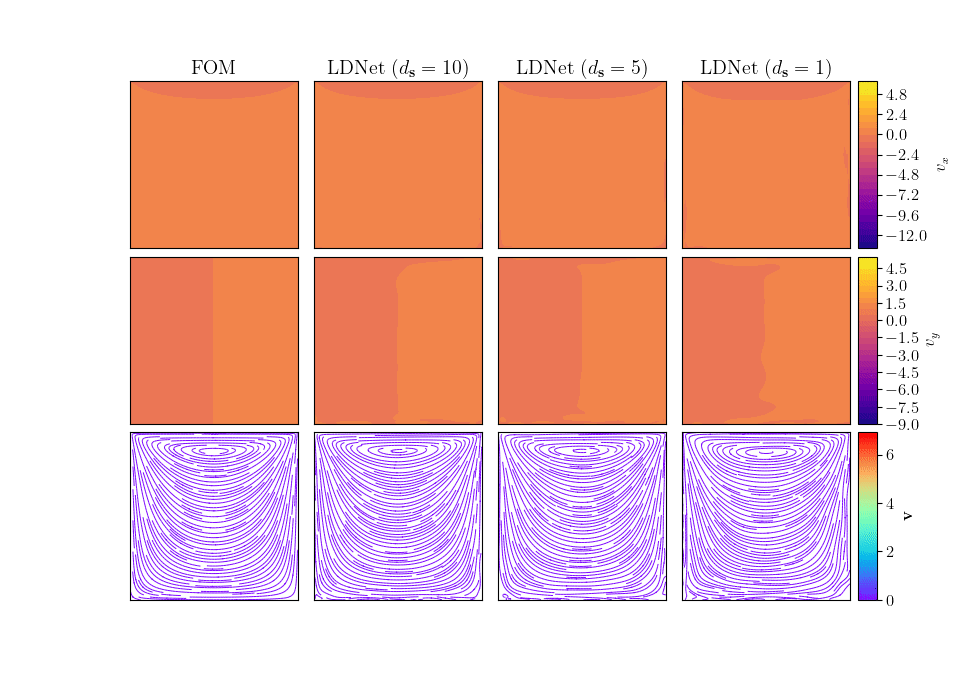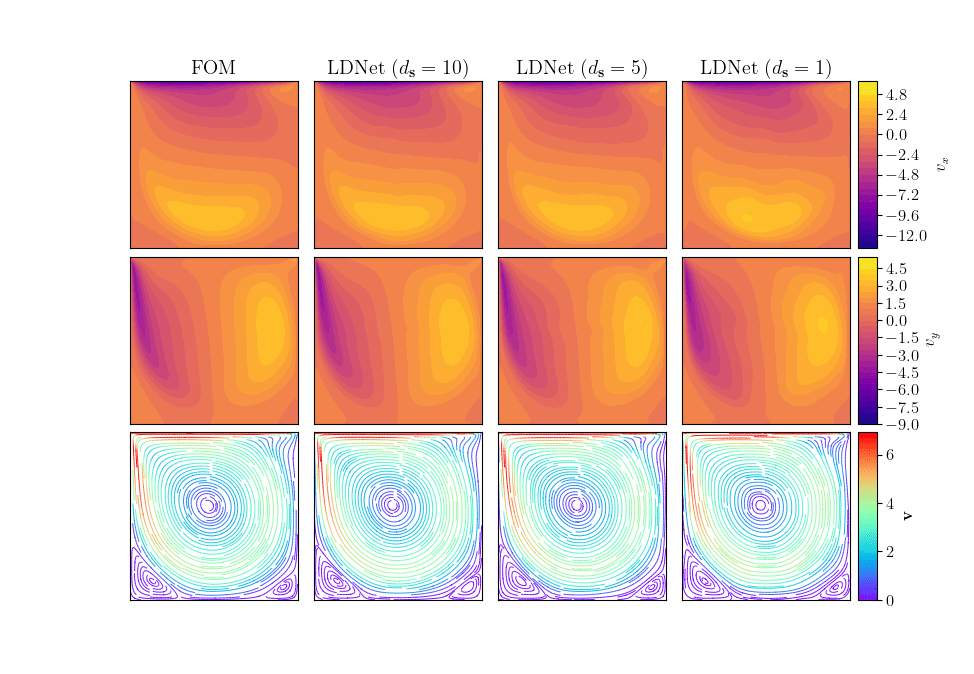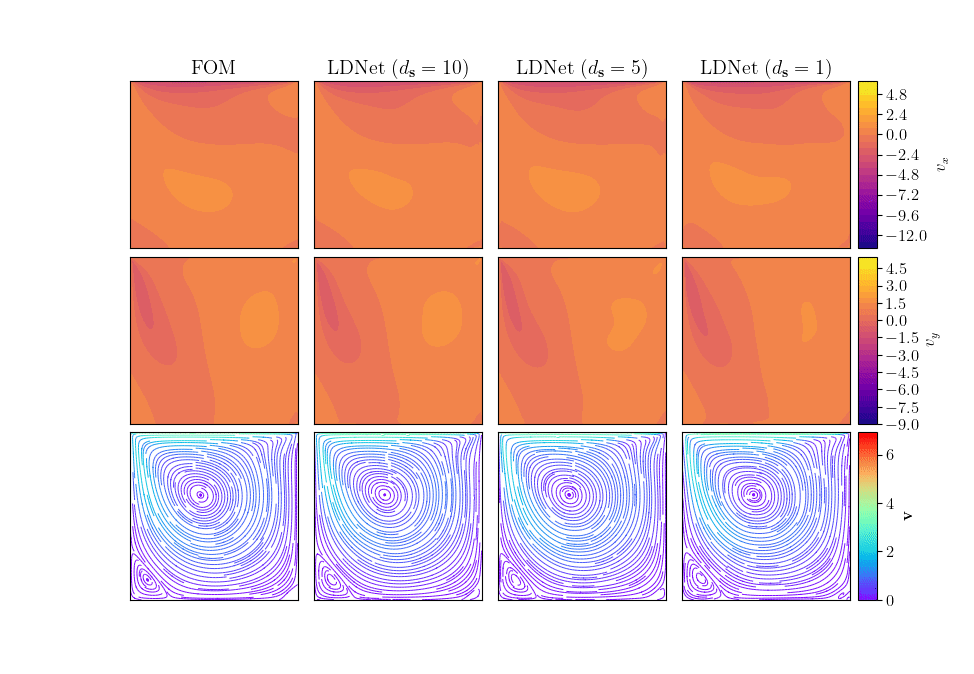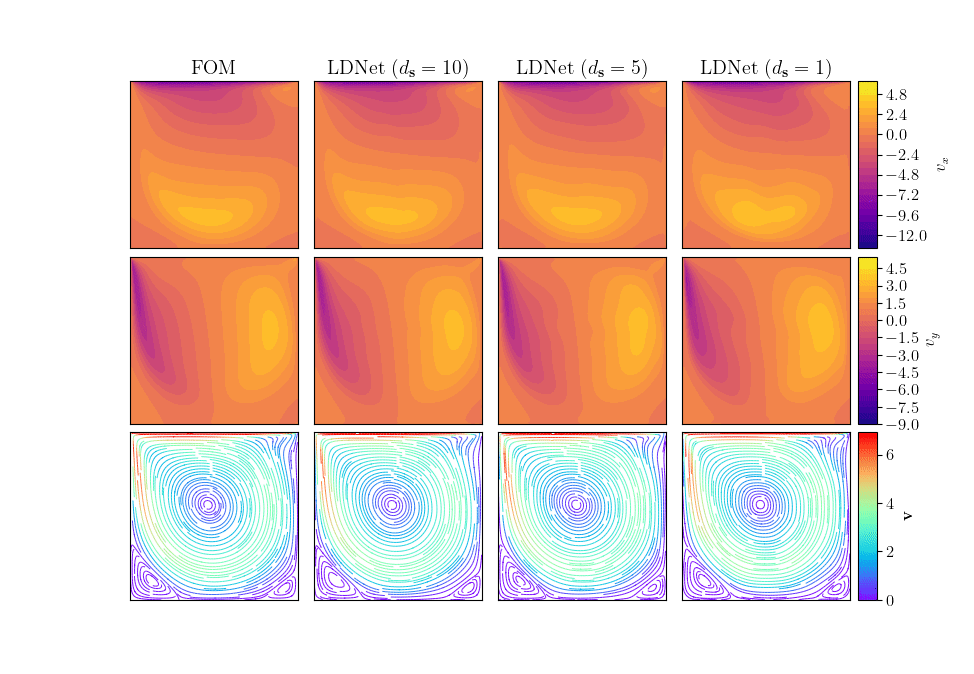
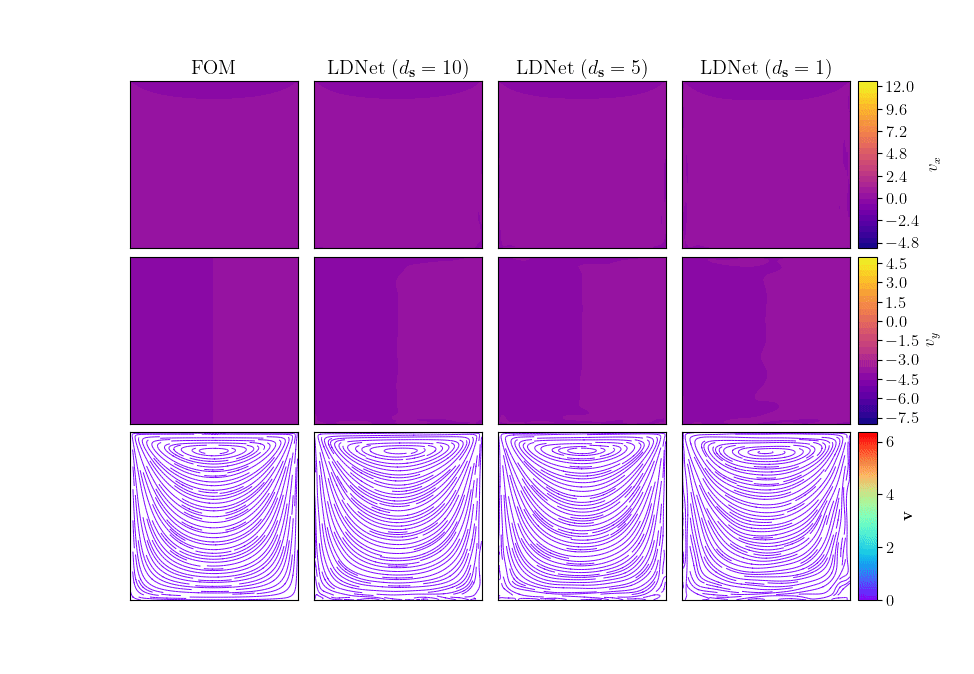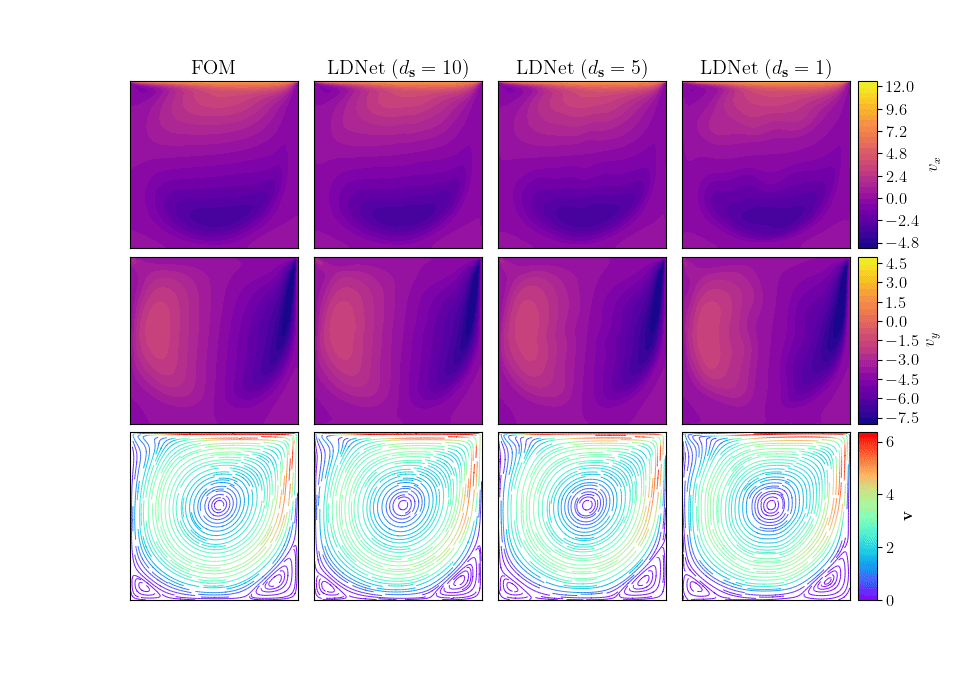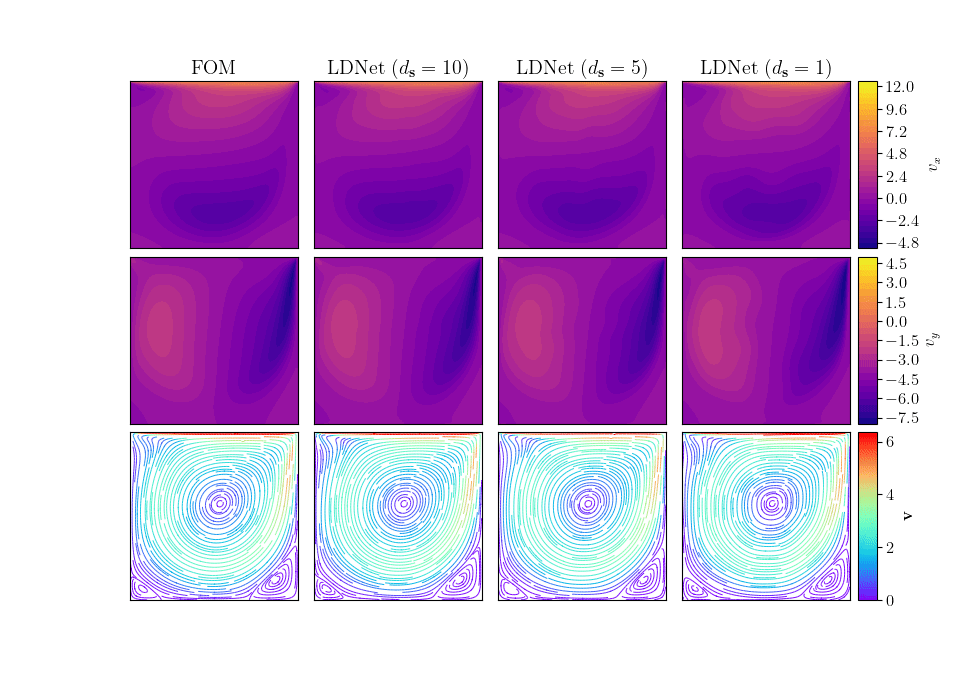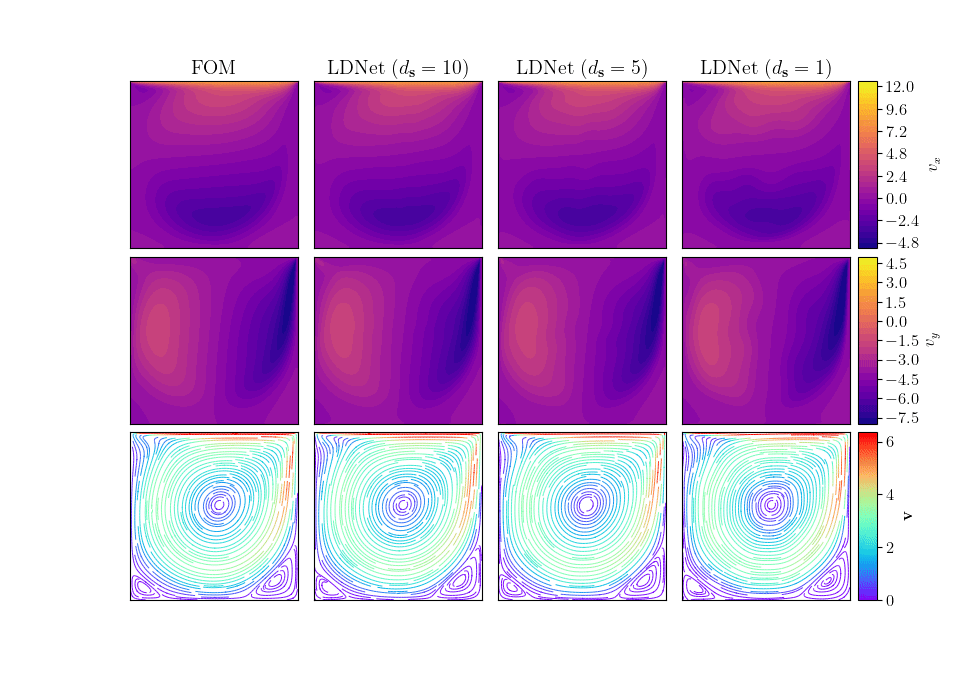
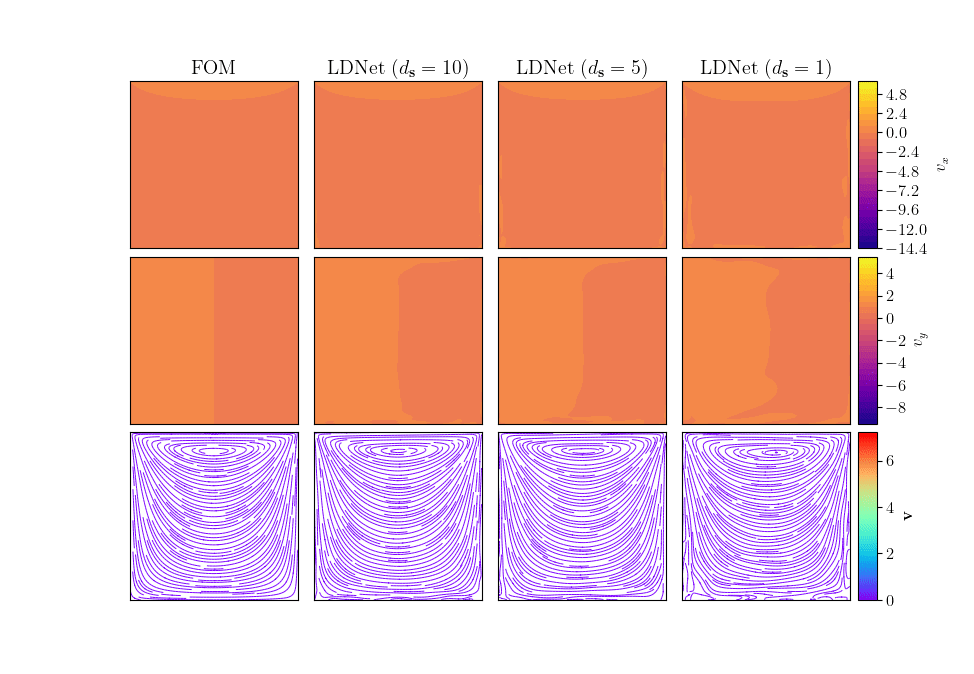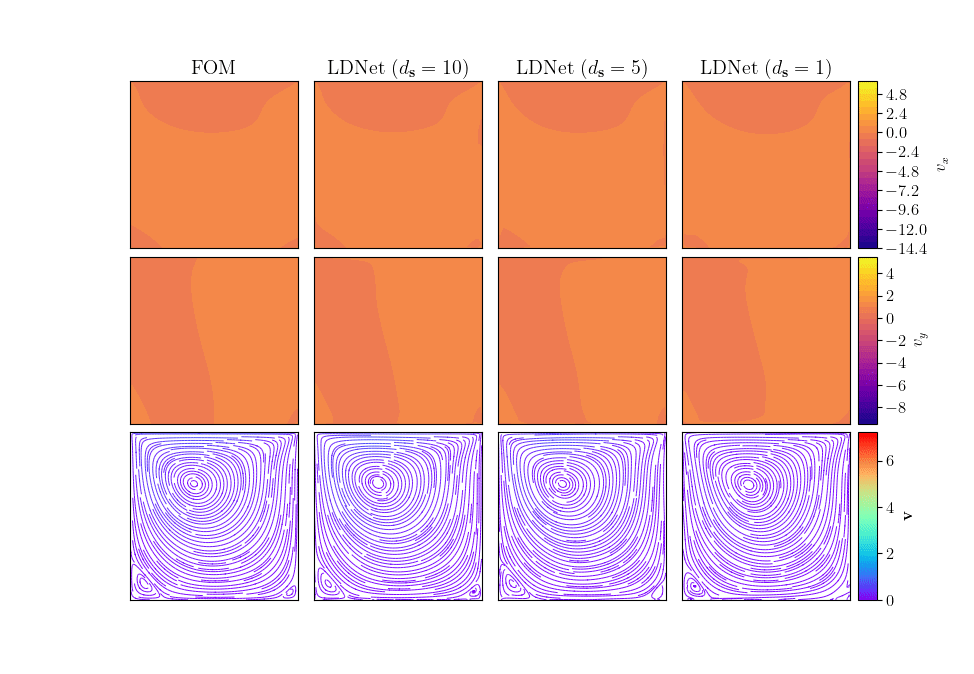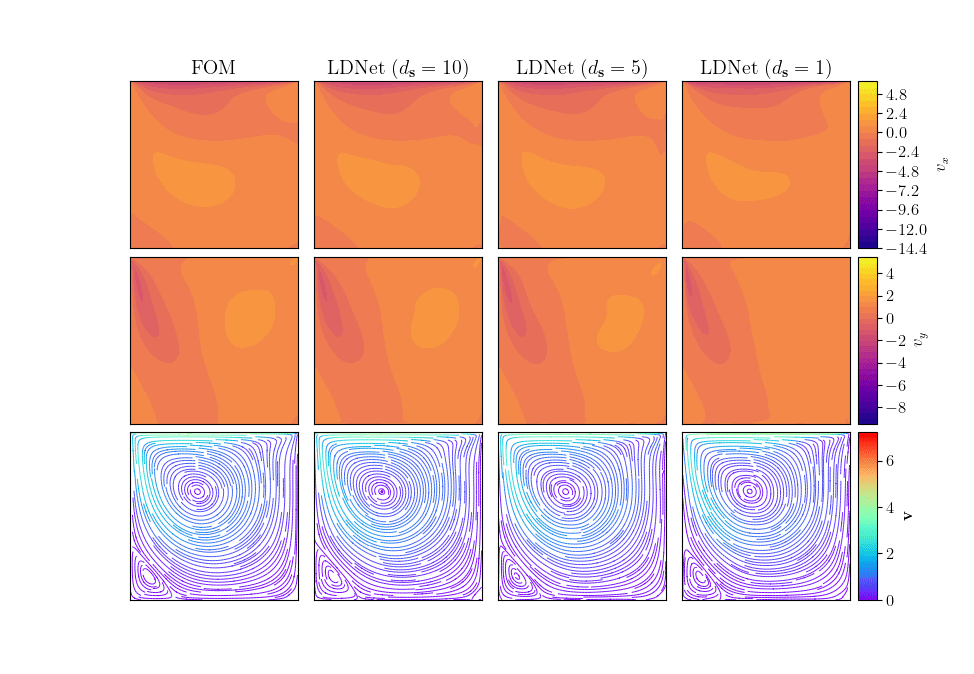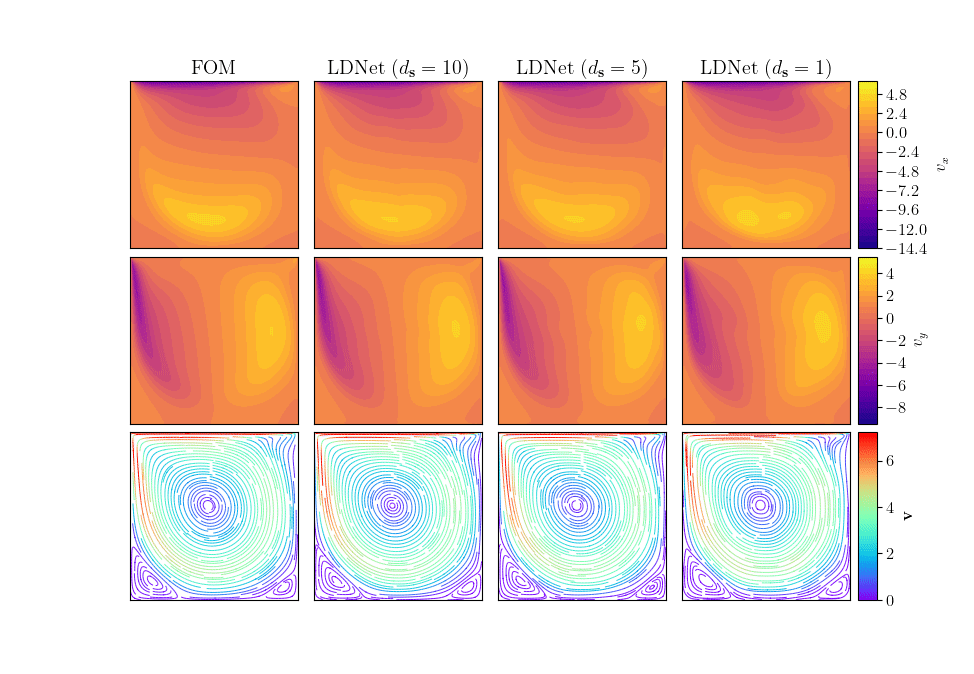
a Computational domain and equations of the FOM. b Error metrics (NRMSE and Pearson dissimilarity) of LDNets for different number of latent variables (ds = 1, 5 and 10). The training dataset consists of 80 simulations with T = 20, while the test dataset comprises 200 simulations with T = 40. The blue lines refer to the test error obtained in the interval t ∈ [0, 20] (that is the same interval seen during training), while orange lines refer to the test error in the interval t ∈ [0, 40]. c A snapshot of the velocity field within the interval t ∈ [0, 20] (interpolation interval) of a testing sample. d A snapshot of the velocity field within the interval t ∈ [20, 40] (extrapolation interval) of a testing sample. For an animated version of this figure, see Supplementary Movies 1–10.
We generate training data through a FEM-based solver of (5), on a 100 × 100 triangular grid, accounting for nearly 91K degrees of freedom. To train LDNets, we take 100 evenly distributed snapshots in time, and we randomly take 200 points in space for each time step. We train three LDNets, by increasing the number of latent states from 1 to 5 and 10. The accuracy in the flow prediction for unseen inputs increases with the number of latent states (Fig. 4b and c). Furthermore, we challenge the trained LDNets in predicting the flow evolution even on a longer time horizon than that considered in the training dataset (specifically, twice as long). Remarkably, we observe a negligible propagation of the approximation error along the prolonged time frame, making the trained LDNets reliable also for time-extrapolation (Fig. 4b and d).
Test Case 3: 1D electrophysiology model
We consider a nonlinear system of partial and ordinary differential equations describing the propagation of the electrical potential z(x, t) in an excitable tissue, namely the Monodomain equation coupled with the Aliev-Panfilov (AP) model52,58. The AP model envisages a recovery variable w(x, t) that tracks the refractoriness of the tissue by modulating the repolarization phase. The model, supplemented with homogeneous Neumann boundary conditions (encoding electrical insulation) and zero initial conditions for both the variables, reads
| 7 |
The excitation-propagation process is triggered by an external stimulus , applied at two stimulation points, respectively located at x = 1/4L and x = 3/4L, and consisting of square impulses, to mimic the action of a (natural of artificial) pacemaker. The AP model solution features the fast-slow dynamics of a cardiac action potential (steep depolarization fronts followed by slow repolarization of the electrical potential to its resting value) and the wavefront propagation in space generating collisions of waves from different stimulation points. These features make this problem a challenging test case for comparing the proposed method against popular approaches to learning space-time dynamics of complex systems.
We compare LDNets with state-of-the-art approaches in which dimensionality reduction is achieved by training an auto-encoder (AE) on a discrete representation of the output z( ⋅ , t). Once trained, the encoder is employed to compute the trajectories of the latent states throughout the training set, and the dynamics in the latent space is learned either through an ODE-Net32 or an LSTM59. We denote the resulting models by AE/ODE and AE/LSTM, respectively. Then, we further train the NN that tracks the dynamics of the latent states simultaneously with the decoder, that is in an end-to-end (e2e) fashion, and we denote the resulting models by AE/ODE-e2e and AE/LSTM-e2e, respectively. Furthermore, we benchmark LDNets against a classical method of model-order reduction of PDE models, namely the POD-DEIM method60,61. These methods are described in detail in the SI.
We challenge LDNets and the above-mentioned methods in the task of predicting the space-time dynamics of the target value y(x, t) = z(x,t), given the time series of impulses in the two stimulation points. To ensure a fair comparison, we rely on an automatic tuning algorithm to select the optimal hyperparameter values for the different methods, setting an upper bound of ds≤12 on the latent space dimension. The reported results are obtained with the optimal hyperparameter configuration selected by the tuning algorithm, independently for each method.
The results of this comparison are reported in Figs. 5–6 and Table 1. Due to the presence of traveling fronts, this problem features a slow decay of the Kolmogorov n-width7, that reflects in a poor accuracy of the electrical potential reconstruction given by the POD-DEIM method when 12 modes are used. As shown in the SI (see also Supplementary Movies 21–30), more than 24 modes are needed to achieve acceptable results, but this is accompanied by an increase of the computational cost in the prediction phase (see Table 1). A better accuracy is achieved by both auto-encoder-based methods and by LDNets, thanks to their ability to express a nonlinear relationship between the latent states and the solution. Still, LDNet outperforms the other methods, with a testing NRMSE equal to 7⋅10−3. The testing NRMSE of auto-encoder-based methods is nearly 5 times larger than with LDNets or more. Remarkably, our method achieves better accuracy with significantly fewer trainable parameters: auto-encoder-based methods require more than tenfold the number of parameters. This testifies to the good architectural design of LDNets.
Fig. 5. Test Case 3: methods comparison.

We compare the results obtained with different methods for a sample belonging to the test dataset. The left-most column reports the FOM solution of the AP model (the abscissa denotes time, the ordinate denotes space). For each method we report: a the space-time solution; b the space-time error with respect to the FOM solution; c the time-evolution of the 12 latent variables; d–f three snapshots of the space-dependent output field at t = 250, 300 and 350, in which we compare the predicted solution (red solid line) with the FOM solution (black dashed line). For an animated version of this figure, see Supplementary Movies 11–20.
Fig. 6. Results of Test Case 3.

a Boxplots of the distribution of the testing (blue) and training (light blue) errors obtained with each method. The boxes show the quartiles while the whiskers extend to show the rest of the distribution. The red diamonds represent the average error on each dataset. b Number of trainable parameters of each method. The bin encoder is present only for auto-encoder-based methods, but not for LDNets. The bin dynamics refers to the NN that evolves the latent states. The POD-DEIM method is not included, as it does not envisage a training stage.
Table 1.
Test Case 3: metrics of methods comparison
| NRMSE | Number of trainable parameters | Wall time (s) | ||||||
|---|---|---|---|---|---|---|---|---|
| training | testing | total | offline | online | ||||
| FOM | 37.321 | |||||||
| POD-DEIM (ds = 12) | 4.05 ⋅ 10−1 | 3.92 ⋅ 10−1 | 797 | 5.839 | ||||
| POD-DEIM (ds = 24) | 3.59 ⋅ 10−1 | 3.47 ⋅ 10−1 | 799 | 7.720 | ||||
| POD-DEIM (ds = 36) | 1.71 ⋅ 10−1 | 1.62 ⋅ 10−1 | 861 | 7.442 | ||||
| POD-DEIM (ds = 48) | 7.48 ⋅ 10−2 | 7.57 ⋅ 10−2 | 1124 | 7.976 | ||||
| POD-DEIM (ds = 60) | 2.97 ⋅ 10−2 | 2.90 ⋅ 10−2 | 1242 | 8.408 | ||||
| AE/LSTM | 1.90 ⋅ 10−1 | 1.98 ⋅ 10−1 | 8562 | 8651 | 720 | 17,933 | 11,009 | 0.005 |
| AE/LSTM-e2e | 2.05 ⋅ 10−2 | 5.87 ⋅ 10−2 | 8562 | 8651 | 720 | 17,933 | 33,851 | 0.005 |
| AE/ODE | 2.09 ⋅ 10−2 | 4.58 ⋅ 10−2 | 8562 | 8651 | 5484 | 22,697 | 23,982 | 0.017 |
| AE/ODE-e2e | 1.78 ⋅ 10−2 | 3.37 ⋅ 10−2 | 8562 | 8651 | 5484 | 22,697 | 97,821 | 0.017 |
| LDNet | 7.09 ⋅ 10−3 | 7.37 ⋅ 10−3 | 0 | 1480 | 228 | 1708 | 22,887 | 0.014 |
Training and test errors obtained with the different methods, number of trainable parameters, and wall time associated with the offline phase and online phase. Computational times are obtained on a Intel Xeon Processor E5-2640 2.4 GHz. The offline phase refers to the construction of the model: for POD/DEIM, this involves building the basis for the solution manifold and for DEIM, while for the other methods it is associated with the NN training. The online phase, instead, involves predicting the evolution of the system for a new sample once the model has been constructed. This timeframe is referred to a single sample and excludes the evaluation of the output field, given its dependence on the number of considered time and space points. Further details are provided in the main text.
Furthermore, we observe that the POD-DEIM method results in a very limited speed-up with respect to the other methods considered. This limitation is intertwined with the necessity, due to numerical stability reasons, for the POD-DEIM model to be solved on the same temporal discretization as the high-fidelity model. This requirement represents a considerable constraint compared to the other methods outlined in this paper. As a matter of fact, as shown in Table 1, the computational cost for each sample with the FOM is about 37 s, the POD-DEIM method with 60 modes allows it to be reduced to about 8 s, when the other methods all lead to times less than 0.02 s. To this amount of time must be added the time required to evaluate the solution given the latent state variables, which, however, depends on the number of time steps and points at which this is required. For auto-encoder methods, the points at which this evaluation occurs are pre-established, taking 8.9 ⋅ 10−7 s for each timestep. Conversely, LDNets, thanks to their mesh-less nature, offer the flexibility to evaluate at arbitrary locations, requiring 1.9 ⋅ 10−7 s for each point in time and space. In this test case, should we want to evaluate the solution at all time steps and training points, this would correspond to about 4.5 ⋅ 10−4 s for auto-encoder-based methods and 9.5 ⋅ 10−3 s for LDNets. That said, we observe that, with the exception of POD/DEIM, the inference times associated with the other methods are virtually negligible compared to the time required to evaluate the Full Order Model (FOM).
Concerning the offline time, associated with model construction, the training cost of LDNets (22,887 s) is lower than that of auto-encoder-based methods, except for AE/LSTM (11,009 s), which, however, yields a poor accuracy in the predictions. In fact, the accuracy achieved by AE/LSTM is matched by LDNets after just 1354 s of training. On the other hand, the accuracy levels of AE/ODE and AE/ODE-e2e are attained by LDNet after 6510 and 9090 s, respectively. The POD-DEIM method, as expected, is characterized by a less heavy offline phase, which, however, does not lead to a speed-up comparable to the other methods in evaluation.
Test Case 4: 2D electrophysiology model with reentrant activity
We consider the induction and sustainment of reentrant activity based on a two-dimensional version of the electrophysiological model (7). The experiment, inspired by62, involves a first rightward propagating wavefront, followed by a second circular stimulus applied at the center of the square domain. Depending on the radius of the stimulus and on the stimulation time, three possible scenarios arise:
tissue refractoriness: the solution does not present a second activation because the circular stimulus is delivered while the tissue is still in a refractory state;
focal activation: the solution presents a single second focal activation originated by delivering the circular stimulus after the so-called vulnerable window;
reentrant drivers: the solution presents two self-sustained reentrant drivers that continuously reactivate the tissue.
Differently from Test Case 3, where we considered a one-dimensional wave propagation, here more complex spatial patterns with bifurcating phenomena are possible, as described above. We therefore want to test the ability of the proposed method in learning the spatio-temporal dynamics of this electrophysiological model, upon variations of the stimulation radius and timing. Moreover, we further compare LDNets against state-of-the-art methods. For the sake of brevity, we only examine the three methods that have proven to perform best in Test Case 3, namely LDNet, AE/ODE and AE/ODE-e2e. Again, we select hyperparameters, independently for each algorithm, by means of the tuning algorithm described above, so as to ensure a fair comparison. The selected hyperparameters and further details on this test case are reported in the SI.
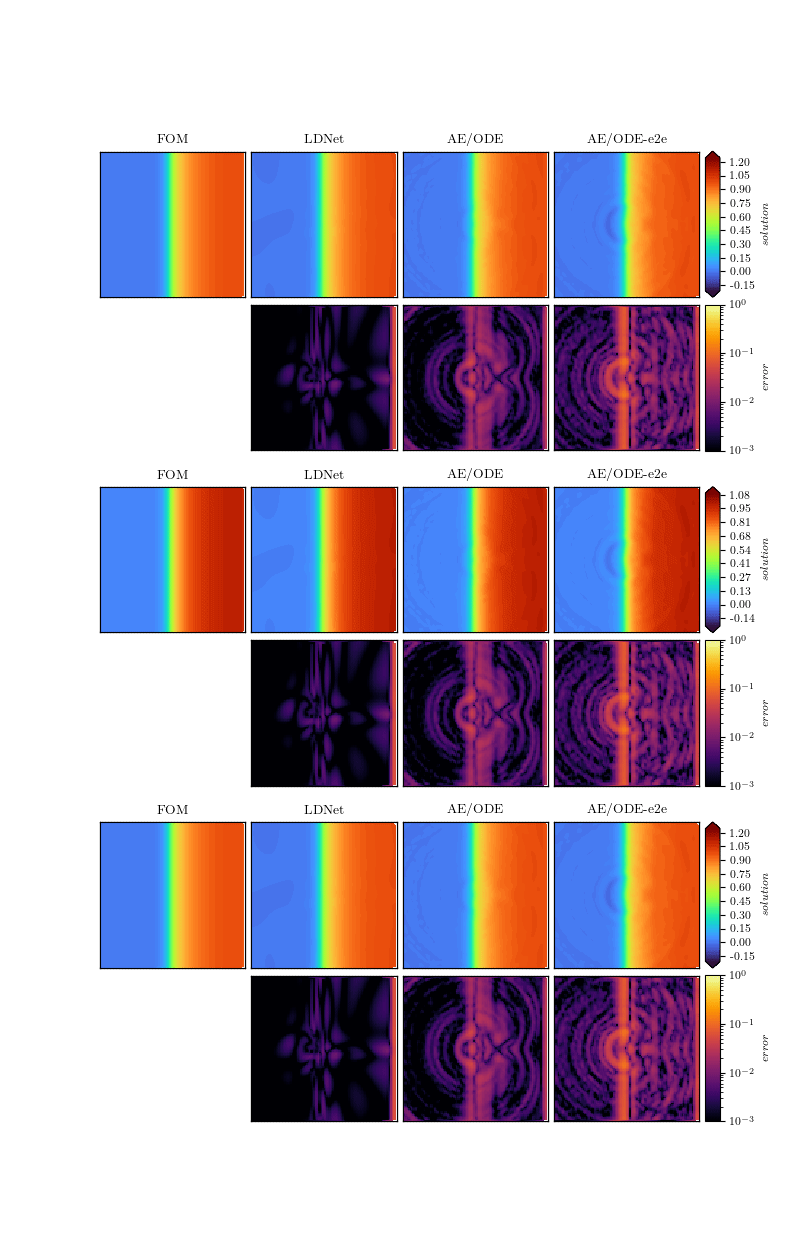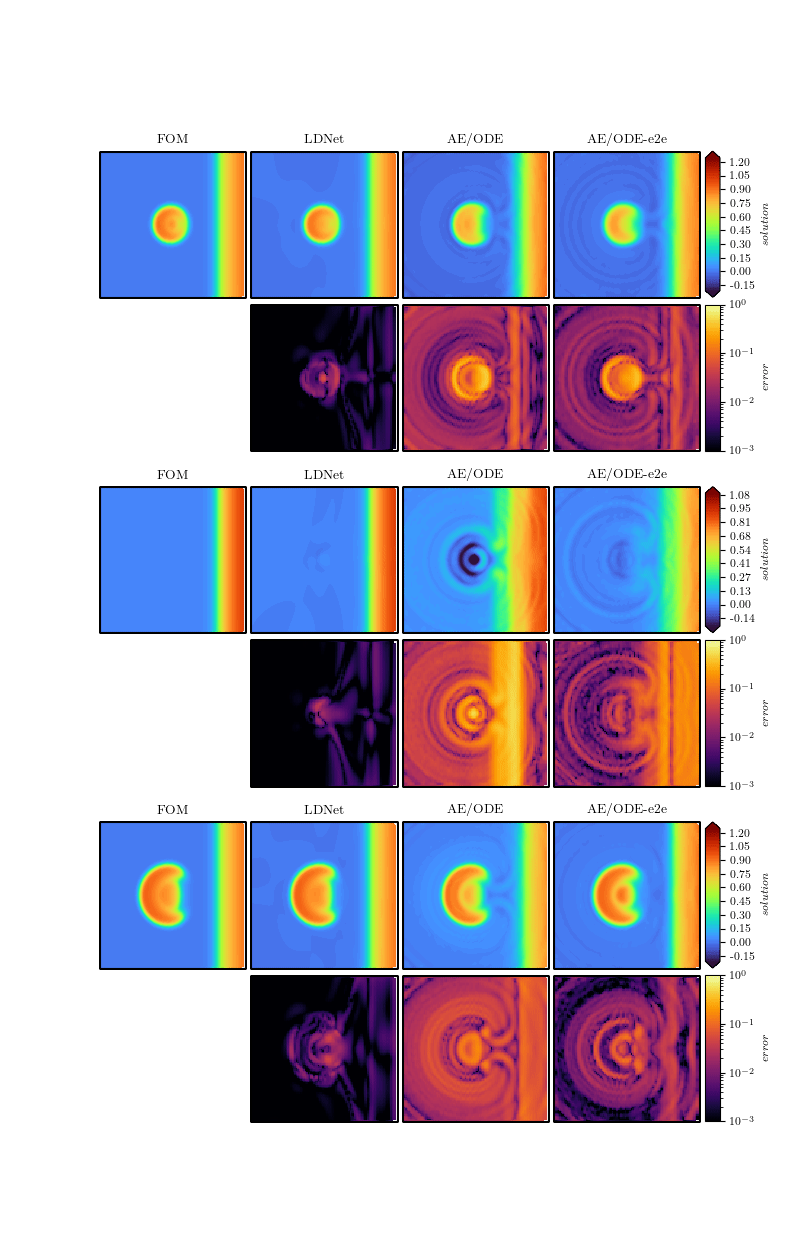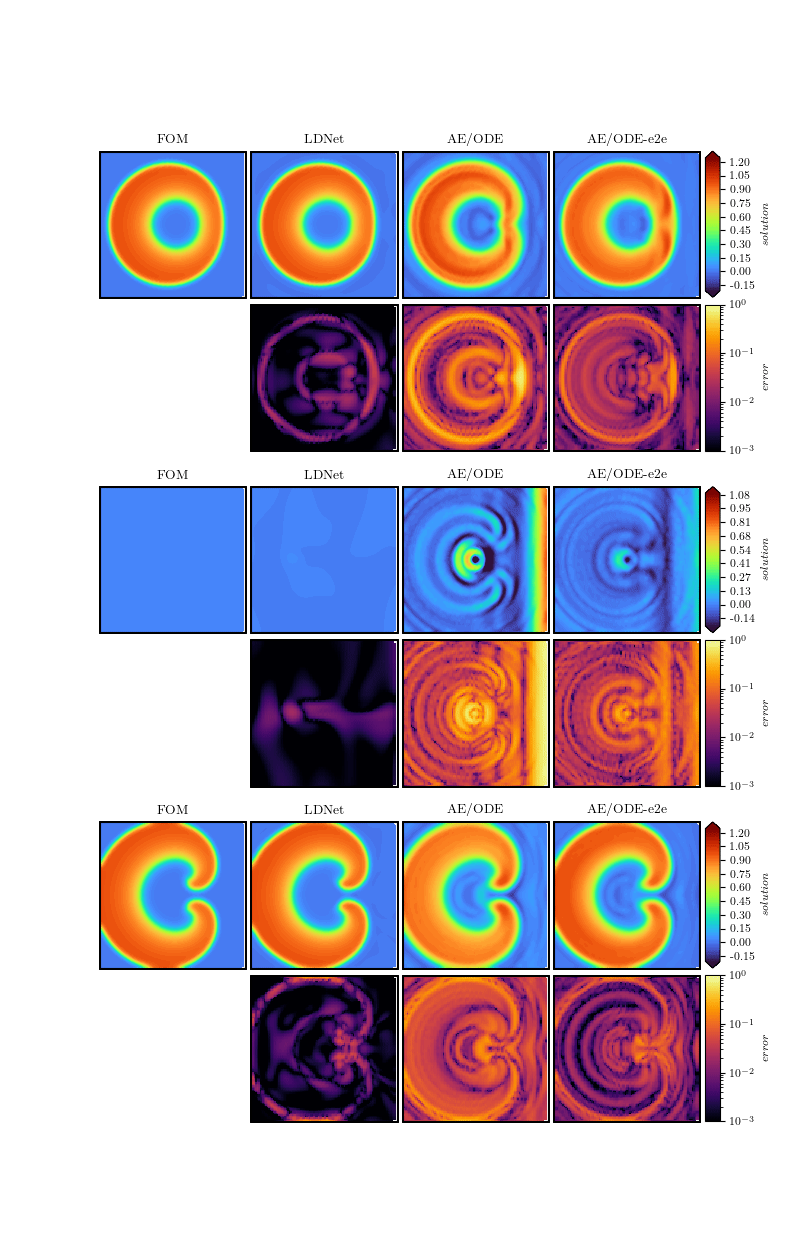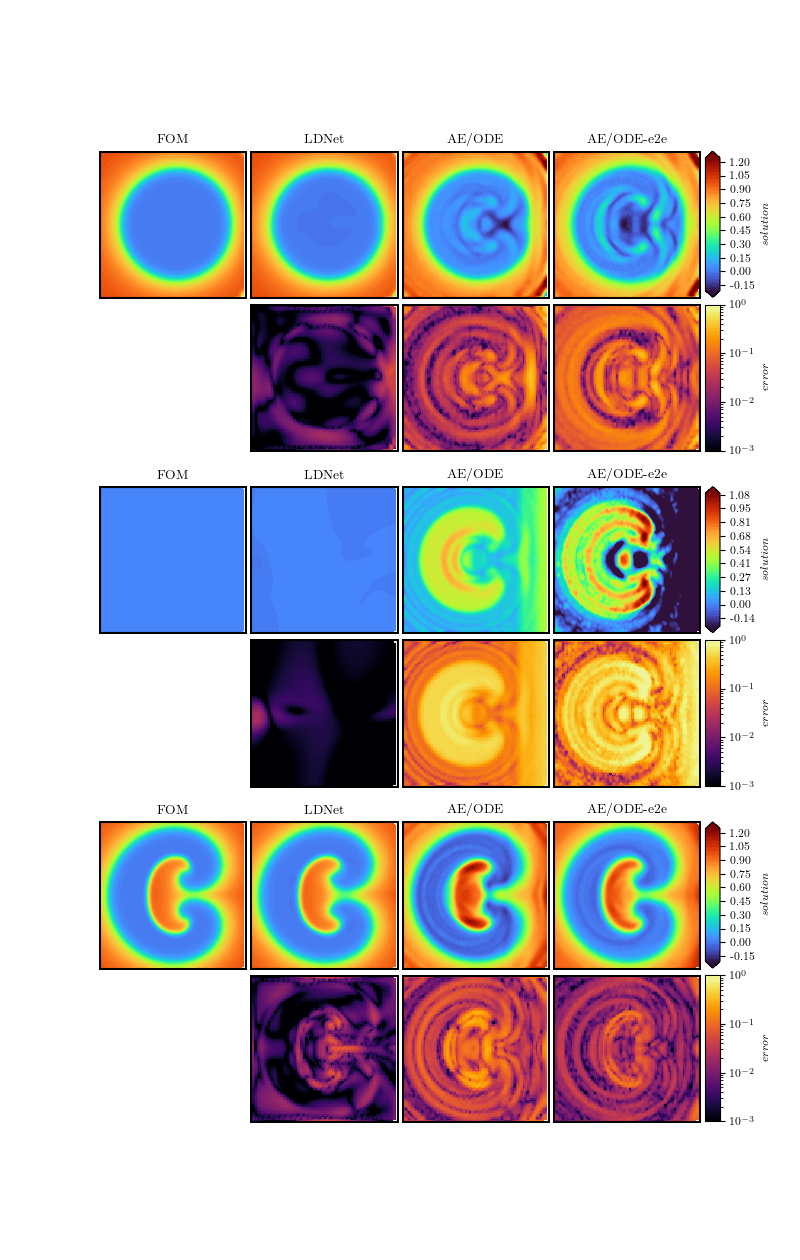
The comparison results are shown in Figs. 7–8 and Table 2. The results show that in this test case, which, compared to Test Case 3, has the added complexity of an extra spatial dimension, the advantage of LDNets over the considered methods is even more marked. As shown in Fig. 8, auto-encoder-based methods exhibit diverse artifacts in the solution, and, in particular, they fall short in accurately representing scenarios where tissue refractoriness does not result in signal propagation. The LDNet, on the other hand, produces predictions that are almost indistinguishable from those of the FOM, and is able to well capture the three different behaviors presented by the system considered in this test case. As a matter of fact, the LDNet achieves an RMSE on the test set that is more than 5.5 times smaller with respect to the other methods, despite using a significantly more parsimonious number of parameters (2.2 thousand, compared with more than 1 million for auto-encoder-based methods). The trained model inference time (online time) is comparable among the three methods considered. The time required to reconstruct the solution from the latent states for auto-encoder-based methods is 1.1 ⋅ 10−4 s per time instant, while for LDNet it is 3.9 ⋅ 10−6 s per time and space point. In all cases, the methods considered lead to a remarkable speedup with respect to the time required by the FOM (807 s per simulation). As for the offline stage, the time required to complete training with the three models is similar (nearly between 75,000 and 95,000 s). The LDNets, however, achieve higher levels of accuracy in less time. In fact, the accuracy achieved with AE/ODE is reached by LDNet after only 3569 s, while that of AE/ODE-e2e after 4530 s.
Fig. 7. Results of Test Case 4.

a: Boxplots of the distribution of the testing (blue) and training (light blue) errors obtained with different methods. The boxes show the quartiles while the whiskers extend to show the rest of the distribution. The red diamonds represent the average error on each dataset. b: Number of trainable parameters of each method. The bin encoder is present only for auto-encoder-based methods, but not for LDNets. The bin dynamics refers to the NN that evolves the latent states. The inset shows an enlargement relative to LDNet.
Fig. 8. Test Case 4: solution comparison.

Snapshots of the solution obtained with the different methods (reported on the left) at different time instants (reported on top). The figure refers to three samples belonging to the test set, corresponding to three different behaviors of the system: a tissue refractoriness; b focal activation; c reentrant drivers. For an animated version of this figure, see Supplementary Movie 31.
Table 2.
Test Case 4: metrics of methods comparison
| NRMSE | Number of trainable parameters | Wall time (s) | ||||||
|---|---|---|---|---|---|---|---|---|
| training | testing | total | offline | online | ||||
| FOM | 807.210 | |||||||
| AE/ODE | 6.96 ⋅ 10−2 | 7.83 ⋅ 10−2 | 594,889 | 597,574 | 1269 | 1193,732 | 75,315 | 0.191 |
| AE/ODE-e2e | 3.97 ⋅ 10−2 | 4.23 ⋅ 10−2 | 594,889 | 597,574 | 1269 | 1193,732 | 95,479 | 0.188 |
| LDNet | 7.31 ⋅ 10−3 | 7.57 ⋅ 10−3 | 0 | 2276 | 513 | 2789 | 90,349 | 0.139 |
Training and test errors obtained with the different methods, number of trainable parameters, and wall time associated with the offline phase and online phase. See caption of Fig. 1 for more details.
Discussion
We have introduced LDNets, a class of NNs that learn in a data-driven manner the evolution of systems exhibiting spatio-temporal dynamics in response to external input signals.
An LDNet is trained in a supervised way from observations of input-output pairs, which can either come from experimental measurements or be synthetically generated through the numerical approximation of mathematical models of which one seeks a surrogate or reduced-order model. This latter case is the one considered in this manuscript to demonstrate the capabilities of the proposed method.
LDNets provide a paradigm-shift from state-of-the-art methods based on dimensionality reduction (e.g., exploiting POD or auto-encoders) of a high-dimensional discretization of the system state. Specifically, LDNets automatically discover a compact representation of the system state, without necessitating the explicit construction of an encoder. This enables the training algorithm to select a compact representation of the state that is functional not only in reconstructing the space-dependent field for each time instant, but also in predicting its dynamics; an auto-encoder, conversely, when trained, extracts features on a purely statistical basis, being agnostic of the importance of each feature in determining the evolution of the system. The latent states allow indeed the trained model to capture non-Markovian effects by tracking the system history, and to propagate nonlocal information across the domain.
Unlike standard approaches that reconstruct a high-dimensional discretization of the output, corresponding e.g. to evaluations at the vertices of a computational mesh, our approach is in this sense meshless. The reconstruction NN is indeed queried for each point in space independently. This design principle gives LDNets several benefits. First, the meshless nature of LDNets combined with the automatic discovery of the latent space allows them to operate in a low-dimensional space without ever going through a high-dimensional discretization, as auto-encoder-based methods do. This makes LDNets very lightweight structures, easy to train, and not prone to overfitting. The LDNet architecture enables the sharing of the trainable parameters needed to evaluate the solution at different points (that is, the same weights are employed regardless of the query point). The low overfitting of LDNets is thus not surprising, as weight-sharing is often the key of good generalization properties of many architectures, such as CNNs and RNNs49. Second, it provides a continuous representation of the output, and, thus, allows for additional and possibly physics-informed terms to be introduced into the loss function63, opening up countless possibilities for extending the purely black-box method proposed in this paper to grey-box approaches. Third, the loss function can be defined by stochastically varying the points in space at which the error is evaluated (see Test Case 2 and 4), thus lightening the computational burden associated with training. Note that this is not possible when the model returns the entire batch of observations. This aspect also opens up to multiple developments, such as stochastic, minibatch-based training algorithms, or even adaptive refinements of the evaluation points, by sampling more densely where the error is larger.
The time-dynamics of LDNets is based on a recurrent architecture that is consistent, by construction, with the arrow of time. This differentiates LDNets from other approaches in which time is seen as a parameter30, or approaches, based e.g. on DeepONets, that take as input the entire time-history of u(t) with a fixed length19,64. The latter approaches do not easily allow for predictions over time frames longer than those used during training, or allow for time-extrapolation only in periodic o quasi-periodic problems65. LDNets, on the other hand, allow predictions for arbitrarily long times. We remark that the reliability of time-extrapolation is constrained by the characteristics of the problem at hand and the available training data. For example, if the system is characterized by a divergent behavior such that, as time progresses, the state enters regions increasingly distant from the initial condition, then the reliability of the predictions is not guaranteed in time-extrapolation regimes. When the system state remains bounded, however, the predictions of LDNets are significantly accurate even in time-extrapolation regimes, as showcased in Test Case 2.
We notice that the trajectories of the latent states s(t) obtained with LDNets are smoother than those obtained with auto-encoder-based methods (see Fig. 5). This difference can be understood by considering how the latent state is constructed within auto-encoder-based methods. First, these methods learn a compact encoding of the high-dimensional output, thus defining a low-dimensional set of state variables, and then they attempt to find a law ruling their time evolution. However, while training the auto-encoder, the latent space is constructed with the sole purpose of allowing the output to be accurately reconstructed, without it necessarily being significant to the system dynamics. This issue is partially mitigated by a subsequent end-to-end training phase, which partially redefines the state variables in a way that is functional not only to reconstruct the solution, but also to capture the dynamics of the system. LDNets, instead, thanks to the simultaneous training of the dynamics NN and the reconstruction NN, do not incur in this issue, as the training algorithm seeks the latent space that simultaneously pursue the twofold role of tracking the system dynamics and reconstructing the output at each time.
LDNets represent, as proved by the results of this work, an innovative tool capable of learning spatio-temporal dynamics with great accuracy and by using a remarkably small number of trainable parameters. They are able to discover, simultaneously with the system dynamics, compact representations of the system state, as shown in Test Case 1 where the Fourier transform of a sinusoidal signal is automatically discovered. Once trained, LDNets provide predictions for unseen inputs with negligible computational effort (order of milliseconds for the considered Test Cases). LDNets provide a flexible and powerful tool for data-driven emulators that is open to a wide range of variations in the definition of the loss function (like, e.g., including physics-informed terms), in the training strategies, and, finally, in the NN architectures. The comparison with state-of-the-art methods on a challenging problem, such as predicting the excitation-propagation pattern of a biological tissue in response to external stimuli, highlights the full potential of LDNets, which outperform the accuracy of existing methods while still using a significantly lighter architecture.
A limitation of our work is that it does not consider the case of space-dependent inputs and of variable initial conditions, which will be the subject of future works; still, we remark that the class of problems that can be tackled with the proposed method encompass a broad range of real-life applications. Future developments will also focus on the topic of interpretability of the latent space, which is not covered in this work.
Methods
Notation
We denote input signals as u: [0, T] → U, taking values in the set , and we denote by the set of admissible input signals. Then, we denote by y: Ω × [0, T] → Y the output (space-time dependent) field, with values in . For each time t ∈ [0, T], the output field is defined within a space domain . Finally, we denote by the space of possible outputs. We assume that the map u ↦ y is well defined (i.e. the output y is unambiguously determined by the input u) and it is consistent with the arrow of time (i.e. y(x, t) depends on u(s)∣s∈[0, t] but not on u(s)∣s∈(t, T)).
A relevant case is represented by a map u ↦ y defined as the composition of an observation operator and the solution map u ↦ z of a partial differential equation (PDE) in the form of (1), where , with , is the state variable (typically, is a Sobolev space). Here, z0: Ω → Z is the initial state, is a differential operator, and is the observation operator. We remark that, in this paper, neither knowledge nor even the existence of a model such as (1) is required: the training of an LDNet only requires input-output pairs.
Remark 1
The case when the output field y is determined not only by some time-dependent inputs u, but also by some inputs that are time-independent (typically called parameters) is a special case of the one considered here. Still, to keep the notation compact, we use the same symbol u to collectively denote time-dependent inputs (i.e. signals) and time-constant inputs (i.e. parameters).
Remark 2
The full-order model (FOM) of (1) is an autonomous system. The non-autonomous case can be recovered as a special case by setting u(t) ⋅ ek = t for some k, where ek is the kth element of the canonical base of .
Training data
The training data are collected by considering a finite number of realizations of the map u ↦ y, each one referred to as a training sample. For each training sample , we collect the following discrete observations:
ui(τ), for ;
yi(ξ, τ), for ;
where and are discrete sets of observations. We remark that the observation times and points can be either shared among samples (i.e. and for any i and for any τ) or be different from one sample to another.
Our goal is to learn the map u ↦ y, that is to infer the output y(x, t) corresponding to inputs u(t) outside the training set.
LDNets
An LDNet is made of two fully-connected neural networks (FCNNs), namely the dynamics network , with trainable parameters wdyn, and the reconstruction network , with trainable parameters wrec. The LDNet defines a map from a time-dependent input signal to a space-time dependent field through the solution of the following system of ordinary differential equations (ODEs):
| 8 |
where is the vector of latent states. The number of latent states ds is set by the user, and should be regarded as an hyperparameter. The latent variables s(t) allow to keep track of the state of the system. These, however, are not defined a priori (unlike methods based on dimensionality reduction techniques, see SI), but the latent space is discovered during the training process. This is similar to47 for the case of time signals as outputs and to the Recurrent Neural Operator (RNO)22,23, used to learn microscopic internal variables capable of tracking the history dependence in multiscale materials. However, while in the RNO the latent variables correspond to a local material memory, LDNets have a single set of latent variables for the entire domain. In this work, we always consider hyperbolic tangent () activation functions.
Remark 3
The formulation (8) is the most general one. A special case is the one where does not depend on u(t). Whether or not to include the latter dependency in is an architectural choice that shall be regarded as a hyperparameter, possibly subject to selection via cross-validation. In many cases, however, the choice can be driven by the physics of the underlying process. Specifically, we will leave an explicit dependency whenever the output y(x,t) depends on the input u(t) instantaneously. The case where the dependency is neglected is the one that we mostly consider in our test cases, expect for Test Case 2, in which we allow to depend on u(t) in a direct way.
In practice, the ODE system (8) is discretized by a suitable numerical method. In this work, we employ a Forward Euler scheme with a uniform time step size Δt, but other schemes could be considered as well (e.g. time-adaptive Runge-Kutta schemes53). In case the observation times do not coincide with the discrete times kΔt, for k = 1,…, we perform a re-sampling of u through a piecewise linear interpolation. Similarly, to evaluate the predicted output in correspondence of the observation times , we interpolate the discrete solution of s(t) at the time instants τ.
We denote with the symbol (to evoke its recurrent nature) the operator mapping the time series of inputs associated with a given sample i to the latent state si evolution. More precisely, we have, for any sample i and at any time t ∈ [0, T]:
With this notation, the LDNet output is the result of the composition of with :
| 9 |
To train the LDNet, we define the loss function:
where the symbol  denotes the average operator (that is the sum over a set divided by the cardinality of the set), and where are the outputs of the LDNet associated with the trainable parameters wdyn and wrec as defined in (9). The discrepancy metric is typically defined as
denotes the average operator (that is the sum over a set divided by the cardinality of the set), and where are the outputs of the LDNet associated with the trainable parameters wdyn and wrec as defined in (9). The discrepancy metric is typically defined as
| 10 |
with ynorm being a normalization factor defined from case to case and where ∥ ⋅ ∥ denotes the euclidean norm. The first term of represents therefore the normalized mean square error between observations and LDNet predictions. Moreover, to mitigate overfitting, suitable regularization terms on the NN weights could be introduced, with weighting factors αdyn and αrec. In this work, we define as the mean of the squares of the NN weights (yielding the so-called L2-regularization or Tikhonov regularization).
Remark 4
The quadratic discrepancy metric (10), while being the most natural choice, is not the unique one. For instance, it can be replaced by goal-oriented metrics (an example is given in Test Case 2).
Training an LDNet consists in employing suitable optimization methods to approximate the solution of the following non-convex minimization problem:
The two NNs are simultaneously trained.
Normalization layers
In order to facilitate training, we normalize the inputs and the outputs of the NNs. Specifically:
- We normalize the signals u, the output fields y and the space variables x, so that each entry approximately spans the interval [ − 1, 1]. We normalize each entry independently of the others. More precisely we normalize each scalar variable α through the affine transformation where α0 is a reference value and αw is a reference width. To define α0 and αw, we follow two different strategies.
- If the variable takes values in a bounded interval , we set
- If the variable is sampled from a distribution with unbounded support (e.g., when α is normally distributed), we set α0 equal to the sample mean and αw equal to three times the sample standard deviation.
We also normalize the time variable, by dividing the time steps by a characteristic time scale Δtref. The normalization constant Δtref impacts the output of , that is dimensionally proportional to the inverse of time. Since finding a good value for Δtref is in general not straightforward, we typically consider it as a hyperparameter, tuned through a suitable automatic algorithm (described below).
We do not normalize the latent states s, since their distribution is not known before training. Indeed, when hyperparameters are well tuned, the training algorithm tends to generate models that produce latent states with approximately normalized values.
In practice, normalization can be achieved either by modifying the training data accordingly, or by embedding the two NNs between two normalization layers (namely, one input layer and one output layer) each. Formally, the second approach consists in defining and as follows, where we and are two FCNNs:
where ⊙ and ⊘ denote the Hadamard (i.e. element-wise) product and division, respectively.
In case the distribution of a given output field features long tails, we introduce a nonlinear layer aimed at compressing them. The layer applies the transformation y ↦ (y3 + βy)/(1 + β), where the hyperparameter β > 0 tunes the compression strength.
Imposing a-priori physical knowledge
The architecture of LDNets reflects certain features of the physics they are meant to capture. With respect to the space variable, the representation is continuous, unlike methods that reconstruct a discretized solution thus losing the correspondence between neighboring points. With respect to the time variable, the dynamics is driven by a system of differential equations which makes LDNets consistent with the arrow of time (i.e., with the causality principle47). These features make it natural to introduce a-priori physical knowledge in the construction and training of LDNets. In this regard, we distinguish between weak imposition and strong imposition.
Weak imposition consists of introducing physics-informed terms63 into the loss function, aimed at promoting solutions that satisfy certain requirements (such as irrotationality of a velocity field, to make an example). In this paper we do not show examples in this regard, but simply highlight that the continuous representation of the output field used by LDNets makes the introduction of such terms very straightforward through the use of automatic differentiation.
Strong imposition, on the other hand, consists of modifying the architecture of the LDNet components in order to obtain models that automatically satisfy certain properties66,67. In what follows, we provide two examples of how this can be applied to ensure both temporal (acting on ) and spatial (acting on ) properties.
Equilibrium configuration imposition
In many real-life applications, data are collected starting from an equilibrium configuration. This entails that the initial state should be an equilibrium for the latent dynamics as well, in virtue of the interpretation of s as a compact encoding of the full-order system state. Therefore, we define the right-hand side of the latent state evolution equation as follows, where is a trainable FCNN and where ueq ∈ U is the input at equilibrium:
As a consequence, the initial state s = 0 of the model is an equilibrium for any choice of the trainable parameters wdyn.
Prescribed solution in subsets of the domain (e.g. Dirichlet boundary conditions)
The evolution of the output field is often unknown except on a subset of the domain Ω, such as for example a portion ΓD of its boundary ∂Ω. This happens, e.g., when there is a FOM that features a Dirichlet boundary condition like
| 11 |
In this case, the solution is constrained to satisfy (11) by defining as
where is a trainable FCNN, ylift is the lifting of the boundary datum, that is an extension of yD to the whole domain Ω, and is a mask, that is a smooth function such that ψ(x) = 0 if and only if x ∈ ΓD. See57 for further details and68 for a general approach to construct the mask ψ based on approximate distance functions.
Training algorithm
To train the LDNet, we employ a two stage strategy. First, we perform a limited number of epochs (typically, a few hundreds) with the Adam optimizer48, starting with a learning rate of 10−2. Then, we switch to a second-order accurate optimizer, namely BFGS49.
To evaluate the gradient of the loss function with respect to the trainable parameters, we combine back-propagation-through-time for with back-propagation for 49. To initialize the parameters of the two NNs, we employ a Glorot uniform strategy for weights and zero values for the biases49.
Training ODE-Nets often presents challenges and typically involves an adaptive time integration to deal with stiff dynamics, which makes the computational graph potentially very deep and the computational cost often prohibitive69–72. In this work, instead, we rely on a fixed time step size to integrate the latent variables. Thanks to the fact that the latent variables are not fixed a priori, but are defined at training stage, the training algorithm tends to define latent variables with non-stiff dynamics, whose evolution is well captured through a fixed time step size, regardless of the stiffness of full-order model employed to generate the data. An evidence for this is provided by Test Case 3: the ground-truth model (Aliev-Panfilov, Eq. (7)) features, as it is well known, very stiff dynamics58, thus imposing the use of a timestep of 5 ⋅ 10−6 s, whereas the LDNet succeeds in fitting the results with great accuracy while using a much larger timestep (equal to 1 ⋅ 10−3 s). This behavior is observed in our preliminary work73 as well.
Hyperparameter tuning algorithms
The hyperparameters of the proposed method are the number of layers and neurons of and , the L2 regularization weights αdyn and αrec, the normalization time constant Δtref and, whenever necessary in the different test cases, the number of latent states ds. To automatically tune them, we employ the Tree-structured Parzen Estimator (TPE) Bayesian algorithm50,74. The hyperparameters search space is defined as an hypercube, with a log-uniform sampling. We perform K-fold cross validation while monitoring the value of the discrepancy metric in Eq. (10). We also employ the Asynchronous Successive Halving (ASHA) scheduler to early terminate hyperparameters configurations that are either bad or not promising51,75.
We simultaneously train multiple NNs associated to different hyperparameters settings on a supercomputer endowed with several CPUs via Message Passing Interface (MPI). Each NN exploits Open Multi-Processing (OpenMP) for Hyper-Threading, which allows for a speed-up in the computationally-intensive tensor operations involved during the training phase. For the implementation, we rely on the Ray Python distributed framework76.
Supplementary information
Description of Additional Supplementary Files
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Acknowledgements
F.R., S.P. and L.D. are members of the INdAM research group GNCS. This project has been partially supported by the INdAM GNCS Project CUP_E55F22000270001. The present research is part of the activities of “Dipartimento di Eccellenza 2023-2027”, Department of Mathematics, Politecnico di Milano. L.D. acknowledges the support of the FAIR (Future Artificial Intelligence Research) project, funded by the NextGenerationEU program (Italy) within the PNRR-PE-AI scheme (M4C2, investment 1.3, line on Artificial Intelligence).
Author contributions
F.R. conceived the methodology and developed its software implementation. F.R., S.P., and M.S. implemented the test cases and performed the analysis. F.R., S.P., and M.S. wrote the the manuscript. L.D. and A.Q. reviewed the manuscript and supervised the work.
Peer review
Peer review information
Nature Communications thanks Pantelis Vlachas, and the other, anonymous, reviewer(s) for their contribution to the peer review of this work. A peer review file is available.
Data availability
The data necessary to reproduce the results presented here are publicly available on Zenodo in the repository77, available at the URL 10.5281/zenodo.10436489.
Code availability
The software implementation of the proposed methodology and the code supporting the results presented here are publicly available in the LDNets repository at https://github.com/FrancescoRegazzoni/LDNets.
Competing interests
The authors declare no competing interests.
Footnotes
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary information
The online version contains supplementary material available at 10.1038/s41467-024-45323-x.
References
- 1.Patera AT. A spectral element method for fluid dynamics: laminar flow in a channel expansion. J. Comput. Phys. 1984;54:468–488. doi: 10.1016/0021-9991(84)90128-1. [DOI] [Google Scholar]
- 2.Monaghan JJ. Simulating free surface flows with SPH. J. Comput. Phys. 1994;110:399–406. doi: 10.1006/jcph.1994.1034. [DOI] [Google Scholar]
- 3.Regazzoni F, et al. A cardiac electromechanical model coupled with a lumped-parameter model for closed-loop blood circulation. J. Comput. Phys. 2022;457:111083. doi: 10.1016/j.jcp.2022.111083. [DOI] [Google Scholar]
- 4.Bird, G. A. Molecular gas dynamics and the direct simulation of gas flows. Molecular gas dynamics and the direct simulation of gas flows. (Oxford university press, 1994).
- 5.Scalas E, Gorenflo R, Mainardi F. Fractional calculus and continuous-time finance. Phys. Stat. Mech. Appl. 2000;284:376–384. doi: 10.1016/S0378-4371(00)00255-7. [DOI] [Google Scholar]
- 6.Lai S, et al. Effect of non-pharmaceutical interventions to contain COVID-19 in China. Nature. 2020;585:410–413. doi: 10.1038/s41586-020-2293-x. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 7.Quarteroni, A., Manzoni, A., and Negri, F. Reduced basis methods for partial differential equations: an introduction, Vol. 92. (Springer, 2015).
- 8.Peherstorfer B, Willcox K. Dynamic data-driven reduced-order models. Comput. Methods Appl. Mech. Eng. 2015;291:21–41. doi: 10.1016/j.cma.2015.03.018. [DOI] [Google Scholar]
- 9.Bongard J, Lipson H. Automated reverse engineering of nonlinear dynamical systems. Proc. Natl. Acad. Sci. 2007;104:9943–9948. doi: 10.1073/pnas.0609476104. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 10.Schmidt M, Lipson H. Distilling free-form natural laws from experimental data. Science. 2009;324:81–85. doi: 10.1126/science.1165893. [DOI] [PubMed] [Google Scholar]
- 11.Peherstorfer B, Gugercin S, Willcox K. Data-driven reduced model construction with time-domain Loewner models. SIAM J. Sci. Comput. 2017;39:A2152–A2178. doi: 10.1137/16M1094750. [DOI] [Google Scholar]
- 12.Rudy SH, Brunton SL, Proctor JL, Kutz JN. Data-driven discovery of partial differential equations. Sci. Adv. 2017;3:e1602614. doi: 10.1126/sciadv.1602614. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 13.Xu X, D’Elia M, Foster JT. A machine-learning framework for peridynamic material models with physical constraints. Comput. Methods Appl. Mech. Eng. 2021;386:114062. doi: 10.1016/j.cma.2021.114062. [DOI] [Google Scholar]
- 14.Bar-Sinai Y, Hoyer S, Hickey J, Brenner MP. Learning data-driven discretizations for partial differential equations. Proc. Natl. Acad. Sci. 2019;116:15344–15349. doi: 10.1073/pnas.1814058116. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 15.Cenedese M, Axås J, Bäuerlein B, Avila K, Haller G. Data-driven modeling and prediction of non-linearizable dynamics via spectral submanifolds. Nature Commun. 2022;13:1–13. doi: 10.1038/s41467-022-28518-y. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 16.Alber M, et al. Integrating machine learning and multiscale modeling-perspectives, challenges, and opportunities in the biological, biomedical, and behavioral sciences. NPJ Digit. Med. 2019;2:115. doi: 10.1038/s41746-019-0193-y. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 17.Zhang W, Rossini G, Kamensky D, Bui-Thanh T, Sacks MS. Isogeometric finite element-based simulation of the aortic heart valve: integration of neural network structural material model and structural tensor fiber architecture representations. Int. J. Numer. Methods Biomed. Eng. 2021;37:e3438. doi: 10.1002/cnm.3438. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 18.Peirlinck M, et al. Precision medicine in human heart modeling: perspectives, challenges, and opportunities. Biomech. Model. Mechanobiol. 2021;20:803–831. doi: 10.1007/s10237-021-01421-z. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 19.Oommen, V., Shukla, K., Goswami, S., Dingreville, R. & Karniadakis, G. E. Learning two-phase microstructure evolution using neural operators and autoencoder architectures. Preprint at arXiv:2204.07230, (2022).
- 20.Vlachas PR, Arampatzis G, Uhler C, Koumoutsakos P. Multiscale simulations of complex systems by learning their effective dynamics. Nature Mach. Intell. 2022;4:359–366. doi: 10.1038/s42256-022-00464-w. [DOI] [Google Scholar]
- 21.Floryan, D. & Graham, M. D. Data-driven discovery of intrinsic dynamics. Nature Mach. Intell., 1–8, (2022).
- 22.Bhattacharya K, Liu B, Stuart A, Trautner M. Learning Markovian homogenized models in viscoelasticity. Multiscale Model. Simul. 2023;21:641–679. doi: 10.1137/22M1499200. [DOI] [Google Scholar]
- 23.Liu, B., Ocegueda, E., Trautner, M., Stuart, A. M. & Bhattacharya, K. Learning macroscopic internal variables and history dependence from microscopic models. J. Mech. Phys. Solids, 105329, (2023).
- 24.Sirovich L. Turbulence and the dynamics of coherent structures part I: coherent structures. Q. Appl. Math. 1987;45:561–571. doi: 10.1090/qam/910462. [DOI] [Google Scholar]
- 25.Hesthaven, J. S., Rozza, G. & Stamm, B. Certified reduced basis methods for parametrized partial differential equations. (Springer, 2016).
- 26.Guo M, Hesthaven JS. Data-driven reduced order modeling for time-dependent problems. Comput. Methods Appl. Mech. Eng. 2019;345:75–99. doi: 10.1016/j.cma.2018.10.029. [DOI] [Google Scholar]
- 27.Brunton SL, Noack BR, Koumoutsakos P. Machine learning for fluid mechanics. Annu. Rev. Fluid Mech. 2020;52:477–508. doi: 10.1146/annurev-fluid-010719-060214. [DOI] [Google Scholar]
- 28.Lee K, Carlberg KT. Model reduction of dynamical systems on nonlinear manifolds using deep convolutional autoencoders. J. Comput. Phys. 2020;404:108973. doi: 10.1016/j.jcp.2019.108973. [DOI] [Google Scholar]
- 29.Maulik R, Lusch B, Balaprakash P. Reduced-order modeling of advection-dominated systems with recurrent neural networks and convolutional autoencoders. Phys. Fluids. 2021;33:037106. doi: 10.1063/5.0039986. [DOI] [Google Scholar]
- 30.Fresca S, Dede’ L, Manzoni A. A comprehensive deep learning-based approach to reduced order modeling of nonlinear time-dependent parametrized PDEs. J. Sci. Comput. 2021;87:1–36. doi: 10.1007/s10915-021-01462-7. [DOI] [Google Scholar]
- 31.Liu Y, Kutz JN, Brunton SL. Hierarchical deep learning of multiscale differential equation time-steppers. Philos. Trans. R. Soc. A. 2022;380:20210200. doi: 10.1098/rsta.2021.0200. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 32.Chen, R. T., Rubanova, Y., Bettencourt, J. & Duvenaud, D. K. Neural ordinary differential equations. Advances in neural information processing systems (NeurIPS 2018 Proceedings), 31, (2018).
- 33.Brunton, S. L., Proctor, J. L. & Kutz, J. N. Discovering governing equations from data by sparse identification of nonlinear dynamical systems. In Proc. National Academy of Sciences, 201517384, (2016). [DOI] [PMC free article] [PubMed]
- 34.Prud’Homme C, et al. Reliable real-time solution of parametrized partial differential equations: reduced-basis output bound methods. J. Fluids Eng. 2002;124:70–80. doi: 10.1115/1.1448332. [DOI] [Google Scholar]
- 35.Benner, P., Mehrmann, V. & Sorensen, D. C. Dimension reduction of large-scale systems, Vol. 35. (Springer, 2005).
- 36.Antoulas, A. C. Approximation of large-scale dynamical systems, Vol. 6. (Siam, 2005).
- 37.Bui-Thanh T, Willcox K, Ghattas O. Model reduction for large-scale systems with high-dimensional parametric input space. SIAM J. Sci. Comput. 2008;30:3270–3288. doi: 10.1137/070694855. [DOI] [Google Scholar]
- 38.Benner P, Gugercin S, Willcox K. A survey of projection-based model reduction methods for parametric dynamical systems. SIAM Rev. 2015;57:483–531. doi: 10.1137/130932715. [DOI] [Google Scholar]
- 39.Benner, P. et al. Model Order Reduction - Volume 2: Snapshot-Based Methods and Algorithms. De Gruyter, Berlin, (Boston, 2021).
- 40.Hesthaven JS, Pagliantini C, Rozza G. Reduced basis methods for time-dependent problems. Acta Numer. 2022;31:265–345. doi: 10.1017/S0962492922000058. [DOI] [Google Scholar]
- 41.Bruna, J., Peherstorfer, B. & Vanden-Eijnden, E. Neural Galerkin scheme with active learning for high-dimensional evolution equations. Preprint at arXiv:2203.01360, (2022).
- 42.Barrault M, Maday Y, Nguyen NC, Patera AT. An ‘empirical interpolation’ method: application to efficient reduced-basis discretization of partial differential equations. Comptes Rendus Mathematique. 2004;339:667–672. doi: 10.1016/j.crma.2004.08.006. [DOI] [Google Scholar]
- 43.Canuto C, Tonn T, Urban K. A posteriori error analysis of the reduced basis method for nonaffine parametrized nonlinear PDEs. SIAM J. Numer. Anal. 2009;47:2001–2022. doi: 10.1137/080724812. [DOI] [Google Scholar]
- 44.Chaturantabut S, Sorensen DC. Nonlinear model reduction via discrete empirical interpolation. SIAM J. Sci. Comput. 2010;32:2737–2764. doi: 10.1137/090766498. [DOI] [Google Scholar]
- 45.Binev P, et al. Convergence rates for greedy algorithms in reduced basis methods. SIAM J. Math. Anal. 2011;43:1457–1472. doi: 10.1137/100795772. [DOI] [Google Scholar]
- 46.Buffa A, Maday Y, Patera AT, Prud’homme C, Turinici G. A priori convergence of the greedy algorithm for the parametrized reduced basis method. ESAIM: Math. Modelli. Numer. Anal. 2012;46:595–603. doi: 10.1051/m2an/2011056. [DOI] [Google Scholar]
- 47.Regazzoni F, Dedè L, Quarteroni A. Machine learning for fast and reliable solution of time-dependent differential equations. J. Comput. Phys. 2019;397:108852. doi: 10.1016/j.jcp.2019.07.050. [DOI] [Google Scholar]
- 48.Kingma, D. P. & Ba, J. Adam: a method for stochastic optimization. Preprint at arXiv:1412.6980, (2014).
- 49.Goodfellow, I., Bengio, Y., Courville, A., and Bengio, Y. Deep learning, Vol. 1. (MIT Press Cambridge, 2016).
- 50.Bergstra, J., Bardenet, R., Bengio, Y., and Kégl, B. Algorithms for hyper-parameter optimization. Advances in neural information processing systems, 24, https://papers.nips.cc/paper_files/paper/2011/hash/86e8f7ab32cfd12577bc2619bc635690-Abstract.html (2011).
- 51.Li, L. et al. A system for massively parallel hyperparameter tuning. Preprint at arXiv:1810.05934, (2020).
- 52.Aliev RR, Panfilov AV. A simple two-variable model of cardiac excitation. Chaos, Solitons & Fractals. 1996;7:293–301. doi: 10.1016/0960-0779(95)00089-5. [DOI] [Google Scholar]
- 53.Quarteroni, A. and Valli, A. Numerical approximation of partial differential equations, Vol. 23. (Springer Science & Business Media, 2008).
- 54.Brunton, S. L. and Kutz, J. N.Data-driven science and engineering: Machine learning, dynamical systems, and control. (Cambridge Univ. Press, 2022).
- 55.Petzold L. Automatic selection of methods for solving stiff and nonstiff systems of ordinary differential equations. SIAM J. Sci. Stat. Comput. 1983;4:136–148. doi: 10.1137/0904010. [DOI] [Google Scholar]
- 56.Zienkiewicz, O. C. and Taylor, R. L. The finite element method for solid and structural mechanics. (Elsevier, 2005).
- 57.Regazzoni F, Pagani S, Quarteroni A. Universal solution manifold networks (USM-Nets): Non-intrusive mesh-free surrogate models for problems in variable domains. J. Biomech. Eng. 2022;144:121004. doi: 10.1115/1.4055285. [DOI] [PubMed] [Google Scholar]
- 58.Franzone, P. C., Pavarino, L. F., and Scacchi, S. Mathematical cardiac electrophysiology, Vol. 13. (Springer, 2014).
- 59.Hochreiter S, Schmidhuber J. Long short-term memory. Neural Comput. 1997;9:1735–1780. doi: 10.1162/neco.1997.9.8.1735. [DOI] [PubMed] [Google Scholar]
- 60.Pagani S, Manzoni A, Quarteroni A. Numerical approximation of parametrized problems in cardiac electrophysiology by a local reduced basis method. Comput. Methods Appl. Mech. Eng. 2018;340:530–558. doi: 10.1016/j.cma.2018.06.003. [DOI] [Google Scholar]
- 61.Santo, N. D., Manzoni, A., Pagani, S., and Quarteroni, A. Reduced-order modeling for applications to the cardiovascular system, 251–278. De Gruyter, Berlin, (Boston, 2021).
- 62.Pagani S, Manzoni A. Enabling forward uncertainty quantification and sensitivity analysis in cardiac electrophysiology by reduced order modeling and machine learning. Int. J. Numer. Methods Biomed. Eng. 2021;37:e3450. doi: 10.1002/cnm.3450. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 63.Raissi M, Perdikaris P, Karniadakis GE. Physics-informed neural networks: a deep learning framework for solving forward and inverse problems involving nonlinear partial differential equations. J. Comput. Phys. 2019;378:686–707. doi: 10.1016/j.jcp.2018.10.045. [DOI] [Google Scholar]
- 64.Lu L, Jin P, Pang G, Zhang Z, Karniadakis GE. Learning nonlinear operators via deeponet based on the universal approximation theorem of operators. Nature Mach. Intelli. 2021;3:218–229. doi: 10.1038/s42256-021-00302-5. [DOI] [Google Scholar]
- 65.Zhu, M., Zhang, H., Jiao, A., Karniadakis, G. E. & Lu, L. Reliable extrapolation of deep neural operators informed by physics or sparse observations. Preprint at arXiv:2212.06347, (2022).
- 66.As’ad F, Avery P, Farhat C. A mechanics-informed artificial neural network approach in data-driven constitutive modeling. Int. J. Numer. Methods Eng. 2022;123:2738–2759. doi: 10.1002/nme.6957. [DOI] [Google Scholar]
- 67.Linka K, Kuhl E. A new family of constitutive artificial neural networks towards automated model discovery. Comput. Methods Appl. Mech. Eng. 2023;403:115731. doi: 10.1016/j.cma.2022.115731. [DOI] [Google Scholar]
- 68.Berrone S, Canuto C, Pintore M, Sukumar N. Enforcing Dirichlet boundary conditions in physics-informed neural networks and variational physics-informed neural networks. Heliyon. 2023;9:e18820. doi: 10.1016/j.heliyon.2023.e18820. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 69.Dupont, E., Doucet, A. & Teh, Y. W. Augmented Neural ODEs. In Proceedings of the 33rd International Conference on Neural Information Processing Systems. Article No. 282, 3140–3150, (2019).
- 70.Liu, X. et al. Neural SDE: stabilizing neural ODE networks with stochastic noise. Preprint at arXiv:1906.02355, (2019).
- 71.Finlay, C., Jacobsen, J.-H., Nurbekyan, L. & Oberman, A. How to train your neural ode: the world of jacobian and kinetic regularization. In International Conference on Machine Learning, 3154–3164. PMLR, (2020).
- 72.Ghosh A, Behl H, Dupont E, Torr P, Namboodiri V. Steer: simple temporal regularization for neural ODE. Adv. Neural Inf. Process. Syst. 2020;33:14831–14843. [Google Scholar]
- 73.Regazzoni, F., Dedè, L. & Quarteroni, A. Active contraction of cardiac cells: a reduced model for sarcomere dynamics with cooperative interactions. Biomech. Model. Mechanobiol. 17, 1663–1686, (2018). [DOI] [PubMed]
- 74.Akiba, T., Sano, S., Yanase, T., Ohta, T. & Koyama, M. Optuna: a next-generation hyperparameter optimization framework. In Proc. 25rd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, (2019).
- 75.Li L, Jamieson K, DeSalvo G, Rostamizadeh A, Talwalkar A. Hyperband: a novel bandit-based approach to hyperparameter optimization. J. Mach. Learn. Res. 2017;18:6765–6816. [Google Scholar]
- 76.Moritz, P. et al. Ray: a distributed framework for emerging AI applications. In Proc. 13th USENIX Conference on Operating Systems Design and Implementation, 561–577, (2018).
- 77.Regazzoni, F., Pagani, S., Salvador, M., Dede’, L. & Quarteroni, A. “Learning the intrinsic dynamics of spatio-temporal processes through Latent Dynamics Networks”: Dataset, (2023). [DOI] [PMC free article] [PubMed]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.
Supplementary Materials
Description of Additional Supplementary Files
Data Availability Statement
The data necessary to reproduce the results presented here are publicly available on Zenodo in the repository77, available at the URL 10.5281/zenodo.10436489.
The software implementation of the proposed methodology and the code supporting the results presented here are publicly available in the LDNets repository at https://github.com/FrancescoRegazzoni/LDNets.