

Abstract
The goal of theoretical neuroscience is to develop models that help us better understand biological intelligence. Such models range broadly in complexity and biological detail. For example, task-optimized recurrent neural networks (RNNs) have generated hypotheses about how the brain may perform various computations, but these models typically assume a fixed weight matrix representing the synaptic connectivity between neurons. From decades of neuroscience research, we know that synaptic weights are constantly changing, controlled in part by chemicals such as neuromodulators. In this work we explore the computational implications of synaptic gain scaling, a form of neuromodulation, using task-optimized low-rank RNNs. In our neuromodulated RNN (NM-RNN) model, a neuromodulatory subnetwork outputs a low-dimensional neuromodulatory signal that dynamically scales the low-rank recurrent weights of an output-generating RNN. In empirical experiments, we find that the structured flexibility in the NM-RNN allows it to both train and generalize with a higher degree of accuracy than low-rank RNNs on a set of canonical tasks. Additionally, via theoretical analyses we show how neuromodulatory gain scaling endows networks with gating mechanisms commonly found in artificial RNNs. We end by analyzing the low-rank dynamics of trained NM-RNNs, to show how task computations are distributed.
1. Introduction
Humans and animals show an innate ability to adapt and generalize their behavior across various environments and contexts. This suggests that the neural computations producing these behaviors must have flexible dynamics that are able to adjust to these novel conditions. Given the popularity of recurrent neural networks (RNNs) in studying such neural computations, a key question is whether this flexibility is (1) adequately and (2) accurately portrayed in RNN models of computation.
Traditional RNN models have fixed input, recurrent, and output weight matrices. Thus, the only way for an input to impact a dynamical computation is via the static input weight matrix. Prior work has shown that flexible, modular computation is possible with these models [1], but neurobiology suggests alternative mechanisms that may be at play. In particular, experimental neuroscience research has shown that synaptic strengths in the brain (akin to weight matrix entries in RNNs) are constantly changing — in part due to the influence of neuromodulatory signals [2].
Neuromodulatory signals are powerful and prevalent influences on neural activity and subsequent behavior. Dopamine, a well-known example, is implicated in motor deficits resulting from Parkinson’s disease and has been the subject of extensive study by neuroscientists [3]. For computational study, neuromodulators are especially interesting because of their effects on synaptic connections and learning [4]. In particular, neuromodulators have been shown to alter synaptic strength between neurons, effectively reconfiguring circuit dynamics [5].
In this work, we seek to incorporate a neuromodulatory signal into task-trained RNN models. We propose a model consisting of a pair of RNNs: a small “neuromodulatory” RNN and a larger, low-rank “output-generating” RNN. The neuromodulatory RNN controls the weights of the output-generating RNN by scaling each rank-1 component of its recurrent weight matrix. This allows the network to produce flexible, yet structured dynamics that unfold over the course of a task. We first review background work in both the machine learning and computational neuroscience literature. Next, we introduce the model and provide some intuition for the impact of neuromodulation on the model’s dynamics, relating it to the canonical long short-term memory (LSTM) network [6]. We end by presenting the performance and generalization capabilities of neuromodulated RNNs on a variety of neuroscience and machine learning tasks, showcasing the ability of a relatively simple, biologically-motivated augmentation to enhance the capacity of RNN models.
2. Background
First, we review related work in the theoretical neuroscience and machine learning literature.
2.1. Modeling neuromodulatory signals
Our work builds on a body of literature dating back to the 1980s, when pioneering computational neuroscientists added neuromodulation to small biophysical circuit models (for reviews, see [7–9]). These models consist of coupled differential equations whose biophysical parameters are carefully specified to simulate biologically-accurate spiking activity. As Marder [5] relates in her retrospective review, such neuromodulatory models were created in response to neuronal circuit models that viewed circuit dynamics as “hard-wired”. Neuromodulatory mechanisms offered an answer to experimental observations that anatomically fixed biological circuits were capable of producing variable outputs [10, 11]. Of particular relevance to this work, Abbott [12] showed in his 1990 paper that adding a neuromodulatory parameter to an ODE model of spiking activity allows a network of neurons to display capacity for both long- and short-term memory and gate the learning process, anticipating the LSTMs that would become prominent a few years later. We also draw comparisons between our model and the LSTM in the sections that follow. However, our work does not aim to model any specific biophysical system; rather, it aims to bridge the gap between these highly biologically-accurate models and general network models (i.e. RNNs) of neuronal activity by adding a biologically-motivated form of structured flexibility.
More recent attempts to model neuromodulation have taken advantage of increased computational power. Kennedy et al. [13] modeled modulatory influence in spiking RNNs by linearly scaling the firing rates of a subset of neurons. Papadopoulos et al. [14] also use spiking RNNs, and incorporate arousal-mediated modulatory signals to induce phase transitions. Stroud et al. [15] use a balanced excitatory/inhibitory RNN to model motor cortex, and incorporate modulatory signals as constant multipliers on each neuron’s activity. Liu et al. [16] study how neuromodulatory signals facilitate credit assignment during learning in spiking neural networks. Our work also aims to incorporate a modulatory signal into an existing neural network model, however, we specifically examine the potential of neuromodulation to augment task-trained low-rank RNNs.
The work of Tsuda et al. [17] is most similar to what we present here. The authors train RNNs using constant, multiplicative neuromodulatory signals applied to pre-specified subsets of the recurrent weights. They show that these neuromodulatory signals allow an otherwise fixed network to perform variations of a task. In contrast, we employ time-dependent neuromodulatory signals that allow dynamics to evolve throughout tasks. Instead of pre-specifying the values and regions of impact of neuromodulators, we allow the model to learn the time-varying neuromodulatory signal and what segment of the neuronal population it impacts.
2.2. Hypernetworks
Our approach is closely related to recent work using hypernetworks to enhance model capacity in machine learning. Ha et al. [18] use small networks (termed hypernetworks) to generate parameters for layers of larger networks. In their HyperRNN, a hypernetwork generates the weight matrix of an RNN as the linear combination of a learned set of matrices. We also allow our neuromodulatory network to specify the weight matrix of a larger RNN as a linear combination of a learned set of matrices; however, our learned matrices are rank-1 to facilitate easier dynamical analysis and faster training. It is also worth noting that in practice, Ha et al. [18] simplify their HyperRNN so that the hypernetwork scales the rows of a learned weight matrix, which could be seen as postsynaptic scaling in our model. Similarly, von Oswald et al. [19] study the ability of hypernetworks to learn in the multitask and continual learning setting. They find that hypernetworks trained to produce task-specific weight realizations achieve high performance on continual learning benchmarks. In exploring potential neuroscience applications of their work, they remark that while their approach might be unrealistic, a hypernetwork that outputs lower-dimensional modulatory signals could assist in implementing task-specific mode-switching. We seek to obtain similar performance gains with a more biologically plausible model of neuromodulation.
2.3. Low-rank recurrent neural networks
For a variety of tasks of interest, measured neural recordings are often well-described by a set of lower dimensional latent variables [20, 21] (although alternative views have been presented [22, 23]). Likewise, artificial neural networks trained to solve tasks that mimic those found in neural experiments also often exhibit low-rank structure. Based on these findings, recurrent neural networks with low-rank weight matrices (also called low-rank RNNs, LR-RNNs) have emerged as a popular class of models for studying neural dynamics [24–26]. Importantly, low-rank RNNs are able to model nonlinear dynamics that evolve in a low-rank subspace, offering potential for visualization and interpretation. Here, we leverage low-rank RNNs as ideal candidates for neuromodulation, with each factor of the low-rank recurrence matrix becoming a possible target for synaptic scaling.
3. Neuromodulated recurrent neural networks
Motivated by the appealing dynamical structure of low-rank RNNs and the ability of neuromodulation to add structured flexibility, we propose the neuromodulated RNN (NM-RNN). The NM-RNN consists of two linked subnetworks corresponding to neuromodulation and output generation. The output generating subnetwork is a low-rank RNN, which admits a natural way to implement neuromodulation. We allow the output of the neuromodulatory subnetwork to scale the low-rank factors of the output generating subnetwork’s weight matrix. In particular, we propose incorporating neuromodulatory drive via a coupled ODE with neuromodulatory subnetwork state and output-generating state :
| (1) |
| (2) |
| (3) |
where the dynamics matrix is a function of the neuromodulatory subnetwork state via a neuromodulatory signal , which scales each low-rank component of :
| (4) |
The output-generating subnetwork is modeled as a size- low-rank RNN where are the inputs, are the input weights, and is the tanh nonlinearity. The neuromodulatory subnetwork is modeled as a small “vanilla” RNN with its own time-constant , recurrence weights , and input weights . To limit the capacity of the neuromodulatory subnetwork, we take its dimension to be smaller than the output-generating subnetwork’s dimension . We take since neuromodulatory signals are believed to evolve relatively slowly [27]. The neuromodulatory subnetwork state alters the rank- dynamics matrix via a -dimensional linear readout . The components of act as linear scaling factors on each rank-1 component of . For ease of notation, in the rest of the text we write to mean . The output of the NM-RNN is a linear readout of .
This augmentation to the RNN framework allows for structured flexibility in computation. In traditional RNNs, the recurrent weight matrix is fixed, and thus the inputs to the system can only perturb the state of the network. In the NM-RNN, the neuromodulatory subnetwork can use information from the inputs to dynamically up- and down-weight individual low-rank components of the recurrent weight matrix, offering greater computational flexibility. As we will see below, this flexibility also allows the network to reuse dynamical components across different tasks and task conditions.
3.1. Mathematical intuition
To gain some intuition for the potential impacts of neuromodulation on RNN dynamics, first consider the case where is symmetric (i.e., ) with the forming an orthonormal set, where the nonlinearity is removed (i.e., ), and where there are no inputs (i.e., ). We can then reparameterize the system with a new hidden state , where is the matrix whose columns are (so that ). This produces decoupled dynamics:
| (5) |
where . Solving this ODE gives an equation for the components of :
From this equation and the visualization in fig. 2A, we see that the decay rate of each component is governed by its corresponding neuromodulatory signal . In this way, can effectively speed up or slow down decay of dynamic modes, similar to gating in an LSTM.
Figure 2:

A. Illustration of how neuromodulatory signals s(t) affect decay rates of the state w(t) in a 1-D, simplified model. B. & C. Visual comparison of an LSTM and an NM-RNN. Corresponding parts of the networks are highlighted with shaded rectangles. Blue: a forget gate computation. Green: an input gate to recurrent dynamics. Purple: recurrent feedback onto the modulatory state variable.
3.2. Connection to LSTMs
Having observed that neuromodulation can alter the timescales of dynamics, note further that the low-rank update for the linearized NM-RNN in eq. (5) mirrors the cell-state update equation for a long short-term memory (LSTM) cell [6]. Specifically, the neuromodulatory signal resembles the forget gate of an LSTM (fig. 2B). Indeed, as in eq. (5), if we linearize the output-generating subnetwork of the NM-RNN and assume that (so that is symmetric), and , then for and , the discretized low-rank dynamics are given by
| (6) |
LSTMs have two states that recurrently update across each timestep : a hidden state and a cell state . Equation (6) closely mirrors the cell-state update of the LSTM:
| (7) |
Here, the forget gate is a form of modulation that depends on the LSTM hidden state , much like the NM-RNN’s neuromodulatory signal is a form of modulation depending on the NM-RNN’s neuromodulatory subnetwork state . The second term can be viewed as a gated transformation of the input signal . In fact, under suitable assumptions, we show that the dynamics of an NM-RNN can be reproduced by those of an LSTM (see Theorem 1).
As a gated analog of the RNN, the LSTM has enjoyed greater success than ordinary RNNs in performing tasks that involve keeping track of long-distance dependencies in the input signal [28]. Thus, highlighting the connection between the NM-RNN and LSTM suggests NM-RNNs may be able to model long-timescale dependencies better than regular RNNs (see Section 6).
4. Time interval reproduction
To evaluate the potential of neuromodulated RNNs to add structured flexibility, we first consider a timing task since neuromodulators such as dopamine are implicated in time measurement and perception [29]. In the Measure-Wait-Go (MWG) task (fig. 3A) [30], the network receives a 3-channel input containing the measure, wait, and go cues. The network must measure the interval between the measure and wait cues and reproduce it at the go cue by outputting a linear ramp of the same duration. Tasks such as this one are commonly used to study the neural underpinnings of timing perception in humans and non-human primates [31, 32].
Figure 3:

A. Visualization of Measure-Wait-Go task. B. Theoretical predictions (dashed lines) match closely with empirical results (solid lines) for rank-1 network. C. L2 loss comparsion for parameter-matched LR-RNNs and NM-RNNs. Performance of visualized models are starred. D. Comparison of model-generated output ramps for both trained and extrapolated intervals. E.Three-dimensional neuromodulatory signal s(t) for trained/extrapolated intervals. Left, traces are aligned to start of trial. Right, traces are aligned to ‘go’ cue. F. Resulting output traces when ablating each component of s(t). In all panels, colors reflect trained/extrapolated intervals (see legend). For output plots, dashed grey lines are targets. Additional model visualizations in figs. S1 and S2.
4.1. Experiment matches theory for rank-1 networks
To investigate how the NM-RNN’s neuromodulatory signal is constrained by the task requirements, we first consider a class of analytically tractable NM-RNNs: networks for which the output-generating subnetwork is linear (i.e., the tanh nonlinearity is replaced with the identity function) and rank-1. In this case, there is one pair of row and column factors, and , respectively. If the target output signal is given by and there are no inputs, then an NM-RNN that successfully produces this output signal will precisely have the neuromodulatory signal,
where our readout is and is the component of evolving outside of the column space of (viewed as a matrix in ). For the full derivation, see Appendix B. If we assume further that is sufficiently small and is also sufficiently small, then we may make the approximation,
| (8) |
In the MWG task, no inputs are provided to the network during the ramping period following the go cue, so eq. (8) applies. In fig. 3B, we show that the neuromodulatory signal of a trained rank-1 NM-RNN during the ramping period matches closely with the theoretical prediction made by eq. (8) for both trained and extrapolated target intervals.
4.2. Improved generalization and interpretability on timing task for rank-3 networks
To continue our analysis of NM-RNNs on the MWG task, we increase the rank of the output-generating subnetwork to three. We do this to compare to the networks shown in Beiran et al. [30] and to showcase networks with more degrees of structured flexibility. In Beiran et al. [30], the authors show that rank-3 low-rank RNNs perform and extrapolate better on this task when provided a tonic context-dependent input, which varies depending on the length of the desired interval. As we have mentioned, such sensory inputs to the network may only alter the resulting dynamics by being passed through the input weight matrix. We propose the NM-RNN as an alternative mechanism by which inputs may alter the network dynamics.
We trained parameter-matched LR-RNNs and NM-RNNs ) to reproduce four intervals, then tested their extrapolation to longer and shorter intervals. In each of the networks, the low-rank matrix was chosen to have rank 3, as in Beiran et al. [30]. In fig. 3B, we plot the losses for ten instances of each model, showing that the NM-RNN consistently achieves a lower loss on both the trained and extrapolated intervals. In fig. 3C, we then show outputs for two typical networks (performance of these visualized networks indicated by stars in fig. 3B). The outputs of the NM-RNN have more accurate slope and shape for both trained and extrapolated intervals, with the LR-RNN struggling on shorter extrapolated intervals.
We then investigate how the neuromodulatory signal contributes to the task computation. Figure 3E shows the three dimensions of plotted over the full range of trained and extrapolated intervals. Each dimension shows activity correlated to particular stages of the task. In fig. 3E (right), we see that and have activity highly correlated to the measured interval. In particular, after the go cue, ramps at different speeds to saturate at 1, depending on the length of the interval. Figure 3F shows the result of ablating each dimension of by keeping that component fixed around its initial value. We see that performance suffers in all cases, especially when ablating the effect of and . Most dramatically, ablating destroys the ability of the network to change the slope of the output ramp appropriately. These results show how the network uses its neuromodulatory signal to generalize across task conditions.
5. Reusing dynamics for multitask learning
Next, we move beyond generalization within a single task to investigate the capabilites of the NM-RNN when switching between tasks. There has been recent interest in studying how neural network models might reassemble learned dynamical motifs to accomplish multiple tasks [1, 33]. Driscoll et al. [1] showed that an RNN trained to perform an array of tasks shares modular dynamical motifs across task periods and between tasks. With this result in mind, we were curious how the NM-RNN might use its neuromodulatory signal to flexibly reconfigure dynamics across tasks.
We performed our analysis using the four-task set from Duncker et al. [34], which includes the tasks DelayPro, DelayAnti, MemoryPro, and MemoryAnti illustrated in fig. 4A. In the DelayPro task, the network receives a three-channel input consisting of a fixation input and two sensory inputs which encode an angle as . The fixation input starts and remains at 1, then drops to 0 to signal the start of the readout period, when the network must generate its response. The sensory inputs appear after a delay, and persist throughout the trial. The goal of the network is to produce a three-channel output which reproduces the fixation and sensory inputs. In the MemoryPro task, the sensory inputs disappear before the readout period, requiring the network to store . In the ‘Anti’ tasks, the networks must instead produce the opposite sensory outputs, , during the readout period. The task context is fed in as an additional one-hot input. These tasks are analogous to variants of the center-out reaching task, which has been used to study the neural mechanisms of arm movement in non-human primates [35].
Figure 4:

A. Depiction of inputs and targets for four tasks. Networks were trained on the first three tasks, then context-processing weights were retrained on the fourth task (in grey). B. Comparison of percent correct metric between parameter-matched low-rank and neuromodulated RNNs, for initial three tasks and retrained MemoryAnti task. C. Neuromodulatory signal for an example network. D. Dynamical analysis of network activity during different stages of the tasks. (Left) PCs 1&2 during the stimulus period show a ring attractor which stores the measured angle. (Right) Sign of PC5 during readout period corresponds to Pro/Anti. Additional model visualizations in figs. S3 and S4.
To study the potential of NM-RNNs to flexibly reconfigure dynamics to perform a new task, we only fed the contextual inputs to the neuromodulatory subnetwork, and not to the output-generating subnetwork. This required the model to reuse the output-generating subnetwork’s weights when adding a new task. We trained an NM-RNN to perform the first three tasks in the set (DelayPro, DelayAnti, MemoryPro), then froze the weights of the output-generating subnetwork and retrained only the neuromodulatory subnetwork’s weights on the fourth task, MemoryAnti. We compared this to retraining the input weights of a LR-RNN, to investigate two strategies of processing context.
We trained parameter-matched LR-RNNs and NM-RNNs ) in this training/retraining framework. Figure 4B shows performance of example networks on the trained and retrained tasks, using the percent correct metric from Driscoll et al. [1]. While both models are able to learn the first three tasks, the NM-RNN more consistently performs the fourth task with high accuracy. This performance gain is not the result of retraining more parameters; in fact, due to the contrasting sizes of the neuromodulatory and low-rank subnetworks, the input weight matrix of the comparison low-rank RNN contains more parameters than the entire neuromodulatory subnetwork, since it must process all inputs (context, sensory, and fixation). To see exactly how the recurrent dynamics were rearranged for this new task, we plotted the neuromodulatory signal of an example network for learned and extrapolated tasks in fig. 4C.
We then analyzed the dynamical structure of one of the NM-RNNs by performing PCA on the output-generating subnetwork’s state for a variety of input angles. Figure 4D (left) shows the first two PCs of the neural activity during the stimulus presentation period (before the stimulus shut off for Memory trials). During this period, the neural activity spreads out to arrange on a ring according to the measured angle. After the stimulus disappears in the MemoryPro/Anti tasks, the neural activity decays back along these axes, but it is still decodable based on its angle from the origin (see fig. S4). To find how this model encoded Pro/Anti versions of tasks, we performed another PCA on the neural activity during the readout period. As shown in fig. 4D (right), the sign of PC5 during this period is correlated with whether the task is Pro or Anti. Curiously, the positive/negative relationship flips for , likely relating to the symmetric structure of sine and cosine. These results show the ability of the NM-RNN to flexibly reconfigure the dynamics of the output-generating subnetwork, both to solve multiple tasks simultaneously and to generalize to a novel task.
6. Capturing long-term dependencies via neuromodulation
Inspired by the similarity between the coupled NM-RNN and the LSTM (see section 3.2), we designed a sequence-related task with long-term dependencies, called the Element Finder Task (EFT). On this task, gated models like the NM-RNN outperform ordinary RNNs. When endowed with suitable feedback coupling from the output-generating subnetwork to the neuromodulatory subnetwork, the NM-RNN demonstrates LSTM-like performance on the EFT, while vanilla RNNs (with matched parameter count) fail to solve this task.
In the EFT (fig. 5A), the input stream consists of a query index, followed by a sequence of randomly chosen integers. The goal of the model is to recover the value of the element at index from the sequence of integers. At each time for , the th element of the sequence is passed as a one-dimensional input to the model. At time , the model must output the value of the element at index in the sequence. For our results (shown below), we took .
Figure 5:

A. Visualization of the Element Finder Task. B. MSE losses attained across multiple runs in different classes of models trained on the EFT (median is indicated by black lines). C. Training loss curves for selected models. D. Visualization of selected components of for an example NM-RNN, shown across different query indices. E. Trajectories for the top two PCs of across different query indices. The different trajectories converge to an approximate line attractor (black) encoding query index. The time at which the queried element arrives is marked in red. F. Top two PCs of , visualized for different query indices and target element values. Each trajectory converges to a fixed point on an approximate line attractor encoding element value. Each curve shown in D, E, and F is averaged over 100 trials. Additional visualizations are shown in figs. S5 and S6
We trained several NM-RNNs, LR-RNNs, full-rank RNNs, and LSTMs on the EFT, conserving the total parameter count across networks. To emphasize its connection to the LSTM, each NM-RNN included an additional feedback coupling from to :
| (9) |
Each model used a linear readout with no readout bias. The resulting performances of each model tested are shown in fig. 5B. Figure 5C moreover illustrates the learning dynamics (as measured by MSE loss) for a single run of selected networks. Like LSTMs, NM-RNNs successfully perform the task, whereas low- and full-rank RNNs largely fail to do so.
To understand how a particular NM-RNN () uses neuromodulatory gating to solve the EFT, we visualize the trial-averaged behavior of different components of across query indices ), revealing that certain components of transition between 0 and 1 on a timescale correlated to the query index (fig. 5D; left and right); while other components zero out (fig. 5D; middle). Visualizing a low-dimensional projection of across different query indices reveals that settles to a fixed point on an approximate line attractor encoding query index (fig. 5E). These findings show that attends to the query index, facilitating gate-switching behavior in upon arrival of the queried element.
Next, we analyze by visualizing its top 2 principal components across each combination of the query indices , and 15 and the target element values −10, −5, 0, 5, and 10 (fig. 5F). Trajectories with different element values but the same query index start at the same location. Each trajectory converges towards the origin, and upon arrival of the query timestep, rapidly moves to a fixed point on an approximate line attractor that encodes element value. The arrangement of fixed points along this line moreover preserves the ordering of their corresponding element values. In summary, these results show that the NM-RNN solves the EFT by distributing its computations across the neuromodulatory subnetwork, which attends to the query index, and the output-generating subnetwork, which retrieves the target element value.
7. Discussion
As we have shown, neuromodulated RNNs display an increased ability to both perform and generalize on tasks, both in the single-task setting and between different tasks. This performance is enabled by the structured flexibility neuromodulation adds to the dynamics of the network. Curiously, the gating-like dynamics introduced by adding neuromodulation create strong comparsions (and even equivalence) to the canonical LSTM.
Limitations.
One limitation of this work relates to the scale of the networks tested. Our networks were on the scale of N ≈ 100 neurons at their largest, as opposed to other related works which use neuron counts in the thousands. However, we found that this number of neurons was adequate to perform the tasks we presented. We also have yet to compare our results to neural data, limiting our ability to draw biological conclusions.
Future Work.
We are excited at the potential of future work to further bridge the gap between biophysical and recurrent neural network models. To expand on the NM-RNN model, we aim to embrace the broad range of roles neuromodulation can play in neural circuits. Potential future avenues include: (1) sparsifying the rank-1 components of the recurrent weight matrix to better imitate the ability of neuromodulators to act on spatially localized subpopulations of cells; (2) changing the readout function of to enable it to take both negative and positive values, in line with the ability of neuromodulators to act in both excitatory and inhibitory manners; and (3) investigating how different neuromodulatory effects may act on different timescales, both during task completion and learning over longer timescales [4, 5]. More generally, each neuron (or synapse) could have an internal state beyond its firing rate which is manipulated by neuromodulators, as in recent work investigating the role of modulation in generating novel dynamical patterns [36, 37]. Beyond neuromodulators, there exist a multitude of extrasynaptic signaling mechanisms in the brain, such as neuropeptides and hormones, which could function similarly in some cases, but also suggest new modeling directions.
In this work, we only analyzed networks post-training. We are also curious how our computational mechanism of neuromodulation impacts the network during learning. Prior work has modeled the role of neuromodulation in learning, for example, by augmenting the traditional Hebbian learning rule with neuromodulation to implement a three-factor learning rule [38], and by using neuromodulation to create a more biologically plausible learning rule for RNNs [39]. An interesting direction for future work is to study whether the neuomodulatory signal in the NM-RNN could produce similar learning dynamics.
Supplementary Material
Figure 1:
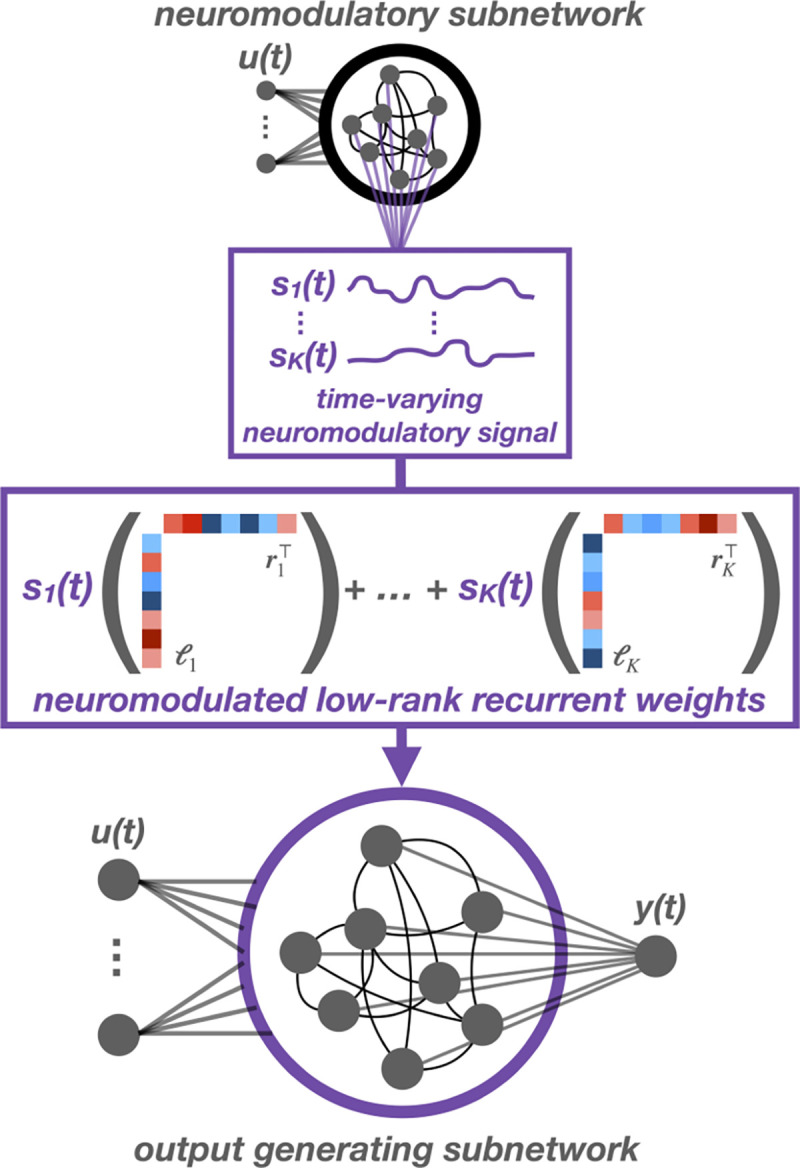
The NM-RNN consists of two subnetworks: a low-rank subnetwork that generates the output (bottom) and a smaller, full-rank neuromodulatory subnetwork (top).
Acknowledgements
We thank Laura Driscoll, Lea Duncker, Gyu Heo, Bernardo Sabatini, and the members of the Linderman Lab for helpful feedback throughout this project. This work was supported by grants from the NIH BRAIN Initiative (U19NS113201, R01NS131987, & RF1MH133778) and the NSF/NIH CRCNS Program (R01NS130789). J.C.C. is funded by the NSF Graduate Research Fellowship, Stanford Graduate Fellowship, and Stanford Diversifying Academia, Recruiting Excellence (DARE) Fellowship. D.M.Z. is funded by the Wu Tsai Interdisciplinary Post-doctoral Research Fellowship. S.W.L. is supported by fellowships from the Simons Collaboration on the Global Brain, the Alfred P. Sloan Foundation, and the McKnight Foundation. The authors have no competing interests to declare.
A. Formal connection between NM-RNNs and LSTMs
In this section, we mathematically formalize the connection between the NM-RNN and the LSTM. We show that, when considering suitable linearized analogs of the NM-RNN and the LSTM, the internal states and outputs of an NM-RNN may be reproduced by an LSTM. To that end, we begin by stating the necessary definitions.
First, we define a linearized NM-RNN via the following discretized dynamics:
| (10) |
| (11) |
| (12) |
As defined in the main text, we have that , where and . Note that we have added a prefactor to in eq. (10). However, this does not fundamentally change the computation in Equation eq. (10) because we may imagine that this prefactor is absorbed by the matrices and . Explicitly having the prefactor will be make the presentation of Proposition 1 more convenient.
Observe that the linearized NM-RNN is an NM-RNN with and where all nonlinear transfer functions have been made to be the identity function. Notably, we have also added a feedback coupling term (given by the feedback weights ) from to ; this will serve to enhance the connection between this model and the LSTM.
Turning to the LSTM, we similarly define a suitable linearized relaxation – the semilinear LSTM – given by the following equations:
| (13) |
| (14) |
| (15) |
Here, denotes the sigmoid nonlinearity, denotes the input, and are the hidden and cell states, respectively. The notation signifies concatenation of vectors. Each of the parameters , , for , are learnable.
A.1. Conditions leading to equivalence
Now, we formalize the connection between these two classes of models. It will be revealing to analyze the linearized NM-RNN in the case where .
Proposition 1.
Consider a rank-K linearized NM-RNN, where the hidden size of the (linearized) output-generating network is , and the hidden size of the neuromodulatory RNN is . Moreover, assume that and that the columns of are pairwise orthogonal, in the sense that . Finally, across all input sequences on which the NM-RNN is tested, assume that the components of the states and are uniformly bounded over all timesteps. Then, this model’s underlying K-dimensional dynamics (given by the low-rank variable ), as well as its neuromodulatory states and outputs , can be reproduced within a semilinear LSTM with a linear readout, whose inputs are . Here, denotes the input to the NM-RNN at time (with by convention). Moreover, such a semilinear LSTM can be made to have hidden size and utilize learnable parameters.
Proof of Proposition 1.
Assuming has uniformly bounded components, there exists some constant such that for each and all . Consequently, this means for all . Now, consider the update equation for in the linearized NM-RNN:
For the th column of , the given orthogonality condition implies that , or in the large limit. Defining to the rank-K representation of , we have that . That is, the low-rank mode corresponding to also has uniformly bounded components over time, i.e., the underlying -dimensional dynamics of the output-generating network do not diverge.
Now, to show that the dynamics of a linearized NM-RNN satisfying the conditions given in the theorem statement can be replicated by a semilinear LSTM, we must effectively show that each of the update equations for the linearized NM-RNN (i.e., eqs. (10), (11) and (12)) can be suitably replicated through the semilinear LSTM architecture. In essence, we must suitably map the parameters of the given NM-RNN onto those of a semilinear LSTM.
First, we analyze the update equation for in the output-generating network. Its corresponding -dimensional (low-rank) update is
Accordingly, define the cell state of the corresponding semilinear LSTM to be
| (16) |
where denotes the vector of 1 ‘s in for (and, by convention, we set ). In particular, note that can be recovered from the cell state via the relation , where denotes the projection matrix that sends onto its first components, namely, .
We may also set all the parameters in and (part of the input gate ) to be 0, so that (after applying the sigmoid nonlinearity). Then, define so that it equals . Indeed,
can be made to have its first entries form the vector if we set and zero out all columns of that do not correspond to , and further by zeroing out the last rows of . In block matrix form, we have defined
Before explicitly computing the other gates, we first analyze how the semilinear LSTM might reproduce the update for the neuromodulatory state :
Note further that
where we have again used that . Thus, substituting this expression into our update equation for above, we have
| (17) |
Accordingly, define the output gate of the semilinear LSTM to be
Recalling that , the above gating is achieved by setting and zeroing out the first rows of . The next rows of can be set to produce the middle entry in shown above, and the last rows of can similarly be set so as to produce the vector . That is, in block matrix form, we may take to be
where is a suitable matrix (defined below) mapping the hidden state of the semilinear LSTM to , so that . Then, computing gives
| (18) |
Now, observe that , where
(Thus, our earlier construction of output gate as is valid.) In particular, the equation precisely corresponds to the update equation for in the linearized NM-RNN given by eq. (17). Thus, at each time , the hidden state of the semilinear LSTM is a “deconstructed” version of , meaning that the model effectively reproduces and its dynamics through .
Finally, we set the forget gate so that it evaluates to . Recalling that , we can achieve this gating by taking the first entries of to be . We can also ensure that the last entries of form the vector by zeroing out the last rows of and making the last entries of the bias vector to be sufficiently large (so that applying the sigmoid function to these entries effectively yields 1). In other words, in block matrix form, we have
and where may be chosen such that
(The above supremum is taken over all components of , all timesteps – finitely or infinitely many – and all input sequences being considered. We then invoke uniform boundedness of the components of to grant the existence of such a .)
Putting together our gate computations, the cell state update equation for the semilinear LSTM (eq. (14)) can be made to reproduce the low-rank update equation of the linearized NM-RNN’s output-generating network:
Having seen that the corresponding semilinear LSTM is capable of replicating the low-rank update equation for as well as (implicitly) reproducing the update equation for , we at last turn to analyzing the outputs generated by the NM-RNN. The output readout for the NM-RNN (at time , where ) can be expressed as
where we have used our earlier equation . Furthermore, in the last equality, we have defined and that (in block matrix form) as
Therefore, we find that the outputs of the NM-RNN can be reproduced via a linear readout from the hidden state of the semilinear LSTM.
Here, it should be noted that the semilinear LSTM we have constructed “lags” behind the NM-RNN by one timestep, i.e., the hidden state is used to produce the th output state . This is a consequence of the fact that at each timestep in the NM-RNN, the neuromodulatory state is updated before , whereas in the semilinear LSTM, the cell state (loosely corresponding to ) is updated before the hidden state (loosely corresponding to ); as a result, the outputs of the semilinear LSTM are staggered by one timestep. In practice, this does not change the fact that the semilinear LSTM can replicate the outputs of the NM-RNN.
Having constructed a semilinear LSTM with hidden size that reproduces the states of the linearized NM-RNN, we finally turn to counting the total number of learnable parameters used by the semilinear LSTM (along with its linear readout):
only transforms the hidden state (i.e., , where ), giving us ) parameters. The bias vector gives an additional parameters, for a total of parameters.
: We zero out all of these parameters, giving us a count of 0.
: The only parameters used in this computation are those that linearly transform into -dimensional space (i.e., the elements of ), so the parameter count here is .
: The bias term was set to 0 and we defined the matrix so that the middle rows of contained nontrivial entries, and the bottom rows have nontrivial parameters stemming from the identity matrix . Consequently, we obtain a contribution of parameters from the output gate computation.
Readout: We have that and uses a total of nontrivial parameters, giving us a total of parameters used.
Thus, the number of nontrivial parameters used by this semilinear LSTM is
B. Derivation of exact neuromodulatory signal for rank-1 NM-RNNs
In this section, we precisely quantify how the neuromodulatory signal in a rank-1 NM-RNN is constrained by the target output signal. First, we derive the exact neuromodulatory signal in a general (possibly nonlinear) rank-1 NM-RNN that has successfully learned to produce a target output signal . Then, we specialize to the case in which the rank-1 NM-RNN has linear dynamics.
We start with a general rank-1 NM-RNN that produces the scalar output at each time , and for which the output-generating network’s nonlinearity is denoted by (which could be tanh, but also any other function). Because , we have , . Furthermore, treating and as vectors in , let , where are unit vectors, and define . Additionally, let denote the input signal over time. Then, for , the dynamics of the output-generating network read:
We now define the rank-1 dynamics variable and a residual mode , so that is a combination of a rank-1 mode and a residual component. This gives us the dynamics equations
Using the basic theory of ordinary differential equations, we may solve the latter ODE to obtain
| (19) |
As a special case, in the absence of any inputs, we would have . For ease of notation, we define the function by
| (20) |
Now, recall that our desired output signal is some prespecified function . Letting the linear readout (of the output-generating network) be given as , then solving for and differentiating yields the equations
| (21) |
| (22) |
Now, observe that
meaning that
| (23) |
Substituting in our earlier expressions for and into the formula for , we obtain the formula
Moreover, in the absence of any inputs to the system, the neuromodulatory signal would be
| (24) |
Furthermore, if we also know that that is sufficiently small and that has sufficiently small entries, then (owing to the exponential decay of ) we may further approximate as
Thus, for NM-RNNs in which the output-generating network’s nonlinearity is removed (i.e., where , eq. (24) implies that, in the absence of inputs, the neuromodulatory signal is
If we assume further that is sufficiently small and is also sufficiently small, then we may make the approximation
| (25) |
In particular, for a linear ramp (such as during the ramping phase of the MWG task), eq. (25) implies that should follow a power law.
C. Computing details
C.1. Code, data, and instructions
The code required to reproduce our main results is included in the nm-rnn GitHub repository: https://github.com/lindermanlab/nm-rnn. All code was written using Python, using fast compilation and optimization code from the JAX and Optax packages [40, 41]. Experiments and models were logged using the Weights and Biases ecosystem [42].
Instructions.
To generate the results that we have presented, we have included the package folder “nmrnn” and folder of training scripts “scripts”. The packages needed to replicate our coding environment are in “requirements.txt”.
Each training script has a “config” dictionary near the top of the file that allows you to set hyperparameters, it is specifically set up to work with Weights and Biases. In the Jax framework, different initializations are set by changing the “keyind” value in the config dictionary.
C.2. Data generation
All data was generated synthetically.
Rank-1 Measure-Wait-Go.
Rank-1 linearized NM-RNNs were trained on 40 trials, generated using the target intervals [12, 14, 16, 18] and by setting the (integer-valued) timestep at which the measure cue appeared to be between 10 and 19, inclusive. The delay period was fixed to be 15 (timesteps). For any given target interval , the target output ramp was the ramping function given by
The total number of timesteps was set to be 110. In generating Figure 3B of the main text, a trained network was tested on the intervals 7 (extrapolation below), 15 (interpolation of trained intervals), and 23 (extrapolation above). The theoretically expected neuromodulatory signal and rank-1 state were computed using eqs. (8) and (21), respectively.
Rank-3Measure-Wait-Go.
All networks were trained on 40 trials, generated using desired intervals [12, 14, 16, 18] and by setting the integer-valued delay period (interval between wait and go cues) between 10 and 19. Networks were tested on these trials plus corresponding extrapolated trials with interval lengths [4, 6, 8, 10, 20, 22, 24, 26].
Rank-3 Multitask.
Initial training was completed on 3000 randomly sampled trials from [DelayPro, DelayAnti, MemoryPro], with random angles and task period lengths. Retraining was completed on 1000 trials of MemoryAnti with random angles and task period lengths. Testing was completed on a different, fixed set of 1000 samples of each task.
Element Finder Task.
All networks were trained on one-dimensional input sequences of length 26. For each input sequence used during training, the input at the first timestep was the query index , which was uniformly sampled at random from {0, 1,…, 24}. Each input in the proceeding sequence of 25 inputs was uniformly sampled at random from {−10, −9,…, 9, 10}.
C.3. Training details
Training was performed via Adam with weight decay regularization and gradient clipping [43, 44]. Specific AdamW hyperparameters varied by task, see below for exact details.
Rank-1 Measure-Wait-Go.
Training was performed via full-batch gradient descent for 50k iterations using the standard Adam optimizer with learning rate 10−3. The linearized NM-RNN trained had the hyperparameters , , , , . Training took about 20 minutes. A single network was trained to produce the results shown in Figure 3B, and many more networks were trained while producing preliminary results.
Rank-3 Measure-Wait-Go.
Training was performed with initial learning rate 10−2. For NM-RNNs, we first trained the neuromodulatory subnetwork parameters and output-generating subnetwork parameters separately for 10k iterations each, followed by training all parameters for 50k iterations. We set specific hyperparameters as follows:
NM-RNN: .
LR-RNN: As above, except for parameter matching.
Models were trained using at least 32 parallel CPUs (1G memory each) on a compute cluster. Training the NM-RNNs took about 15 minutes each, and training the LR-RNNs took about 9 minutes each. Ten of each model were used to produce the results shown in the paper; however, we trained many more while producing preliminary results.
Rank-3 Multitask.
Training on first three tasks was performed with initial learning rate 10−3, for 150k iterations. Retraining on the MemoryAnti task was performed with initial learning rate 10−2 for 50k iterations. We set specific hyperparameters as follows:
NM-RNN: .
LR-RNN: As above. In this case, since the LR-RNN receives contextual inputs as well as sensory/fixation inputs (compared to the NM-RNN’s output generation subnetwork which only receives sensory/fixation inputs), the LR-RNN has more parameters.
Models were trained using at least 32 parallel CPUs (1G memory each) on a compute cluster. Training the NM-RNNs took about 2 hours each, and training the LR-RNNs took about 2.5 hours each. These times include both training and retraining. Ten of each model were used to produce the results shown in the paper; however, we trained many more while producing preliminary results.
Element Finder Task.
For all networks, training was done over 20k iterations of gradient descent using a batch size of 128. Each batch consisted of newly randomly generated input sequences. The standard Adam optimizer was used, and the learning rate and hyperparameters were varied across the different models tested:
LSTM: We trained LSTMs of hidden size using a learning rate of 10−2.
NM-RNN: We trained multiple NM-RNNs across the hyperparameter combinations , fixing and , and using a learning rate of 10−2.
LR-RNN: We trained multiple LR-RNNs across the hyperparameter combinations , fixing , and using a learning rate of 10−2.
(Full-rank) RNN: We trained multiple RNNs with hidden size , fixing , and across the learning rates .
All trained models were parameter-matched (~ 500 total parameters). For each model type, hyperparameter combination, and learning rate, ten such models were trained; the resulting model performances are illustrated in Figure 5B of the main text. Figure 5C was illustrated using a single run of an LSTM (), a full-rank RNN (), and three NM-RNNs , where all models used a learning rate of 10−2. Finally, Figure 5D–F show results for a single NM-RNN (, lr = 10−2). Training each network took roughly 5 minutes. Many more models were trained while producing preliminary results.
C.4. Metric for multitask setting
For the multitask setting, we used the percent correct metric from [1]. A trial was counted as correct if (1) the fixation output stayed above 0.5 until the fixation input switched off, (2) the angle read out at the final timestep was within of the desired angle.
References
- [1].Driscoll Laura, Shenoy Krishna, and Sussillo David. Flexible multitask computation in recurrent networks utilizes shared dynamical motifs. bioRxiv, pages 2022–08, 2022. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [2].Citri Ami and Malenka Robert C. Synaptic plasticity: multiple forms, functions, and mechanisms. Neuropsychopharmacology, 33(1):18–41, 2008. [DOI] [PubMed] [Google Scholar]
- [3].Jahanshahi Marjan, Jones Catherine RG, Zijlmans Jan, Katzenschlager Regina, Lee Lucy, Quinn Niall, Frith Chris D, and Lees Andrew J . Dopaminergic modulation of striato-frontal connectivity during motor timing in parkinson’s disease. Brain, 133(3):727–745, 2010. [DOI] [PubMed] [Google Scholar]
- [4].Dayan Peter. Twenty-five lessons from computational neuromodulation. Neuron, 76(1):240–256, 2012. [DOI] [PubMed] [Google Scholar]
- [5].Marder Eve. Neuromodulation of neuronal circuits: back to the future. Neuron, 76(1):1–11, 2012. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [6].Hochreiter Sepp and Schmidhuber Jürgen. Long short-term memory. Neural Computation, 9(8):1735–1780, November 1997. [DOI] [PubMed] [Google Scholar]
- [7].Fellous Jean-Marc and Linster Christiane. Computational models of neuromodulation. Neural Computation, 10(4):771–805, 1998. [DOI] [PubMed] [Google Scholar]
- [8].Harris-Warrick Ronald M and Marder Eve. Modulation of neural networks for behavior. Annual Review of Neuroscience, 14(1):39–57, 1991. [DOI] [PubMed] [Google Scholar]
- [9].Williams Alex H, Hamood Albert W, and Marder Eve. Neuromodulation in small networks. In Encyclopedia of Computational Neuroscience, pages 2300–2313. Springer, 2022. [Google Scholar]
- [10].Marder Eve. Mechanisms underlying neurotransmitter modulation of a neuronal circuit. Trends in Neurosciences, 7(2):48–53, 1984. [Google Scholar]
- [11].Marder Eve and Hooper Scott L. Neurotransmitter modulation of the stomatogastric ganglion of decapod crustaceans. In Model Neural Networks and Behavior, pages 319–337. Springer, 1985. [Google Scholar]
- [12].Abbott Larry F. Modulation of function and gated learning in a network memory. Proceedings of the National Academy of Sciences, 87(23):9241–9245, 1990. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [13].Kennedy Ann, Kunwar Prabhat S, Li Ling-yun, Stagkourakis Stefanos, Wagenaar Daniel A, and Anderson David J. Stimulus-specific hypothalamic encoding of a persistent defensive state. Nature, 586(7831):730–734, 2020. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [14].Papadopoulos Lia, Jo Suhyun, Zumwalt Kevin, Wehr Michael, McCormick David A, and Mazzucato Luca. Modulation of metastable ensemble dynamics explains optimal coding at moderate arousal in auditory cortex. bioRxiv, April 2024. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [15].Stroud Jake P, Porter Mason A, Hennequin Guillaume, and Vogels Tim P. Motor primitives in space and time via targeted gain modulation in cortical networks. Nature Neuroscience, 21(12):1774–1783, December 2018. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [16].Liu Yuhan Helena, Smith Stephen, Mihalas Stefan, Shea-Brown Eric, and Sümbül Uygar. Cell-type–specific neuromodulation guides synaptic credit assignment in a spiking neural network. Proceedings of the National Academy of Sciences, 118(51):e2111821118, 2021. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [17].Tsuda Ben, Pate Stefan C, Tye Kay M, Siegelmann Hava T, and Sejnowski Terrence J. Neuromodulators generate multiple context-relevant behaviors in a recurrent neural network by shifting activity hypertubes. bioRxiv, pages 2021–05, 2021. [Google Scholar]
- [18].Ha David, Dai Andrew M., and Le Quoc V.. Hypernetworks. In International Conference on Learning Representations, 2017. [Google Scholar]
- [19].von Oswald Johannes, Henning Christian, Sacramento João, and Grewe Benjamin F.. Continual learning with hypernetworks. In International Conference on Learning Representations, 2020. [Google Scholar]
- [20].Cunningham John P and Yu Byron M. Dimensionality reduction for large-scale neural recordings. Nature Neuroscience, 17(11):1500–1509, 2014. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [21].Vyas Saurabh, Golub Matthew D, Sussillo David, and Shenoy Krishna V. Computation through neural population dynamics. Annual Review of Neuroscience, 43:249–275, 2020. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [22].Stringer Carsen, Pachitariu Marius, Steinmetz Nicholas, Carandini Matteo, and Harris Kenneth D. High-dimensional geometry of population responses in visual cortex. Nature, 571(7765):361–365, 2019. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [23].Pospisil Dean A and Pillow Jonathan W. Revisiting the high-dimensional geometry of population responses in visual cortex. bioRxiv, pages 2024–02, 2024. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [24].Mastrogiuseppe Francesca and Ostojic Srdjan. Linking connectivity, dynamics, and computations in low-rank recurrent neural networks. Neuron, 99(3):609–623.e29, August 2018. [DOI] [PubMed] [Google Scholar]
- [25].Dubreuil Alexis, Valente Adrian, Beiran Manuel, Mastrogiuseppe Francesca, and Ostojic Srdjan. The role of population structure in computations through neural dynamics. Nature Neuroscience, 25(6):783–794, 2022. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [26].Beiran Manuel, Dubreuil Alexis, Valente Adrian, Mastrogiuseppe Francesca, and Ostojic Srdjan. Shaping dynamics with multiple populations in low-rank recurrent networks. Neural Computation, 33(6):1572–1615, May 2021. [DOI] [PubMed] [Google Scholar]
- [27].Marder Eve and Calabrese Ronald L. Principles of rhythmic motor pattern generation. Physiological Reviews, 76(3):687–717, 1996. [DOI] [PubMed] [Google Scholar]
- [28].Yu Yong, Si Xiaosheng, Hu Changhua, and Zhang Jianxun. A Review of Recurrent Neural Networks: LSTM Cells and Network Architectures. Neural Computation, 31(7):1235–1270, July 2019. [DOI] [PubMed] [Google Scholar]
- [29].Hamilos Allison E, Spedicato Giulia, Hong Ye, Sun Fangmiao, Li Yulong, and Assad John A. Slowly evolving dopaminergic activity modulates the moment-to-moment probability of reward-related self-timed movements. Elife, 10, December 2021. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [30].Beiran Manuel, Meirhaeghe Nicolas, Sohn Hansem, Jazayeri Mehrdad, and Ostojic Srdjan. Parametric control of flexible timing through low-dimensional neural manifolds. Neuron, 111(5):739–753, 2023. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [31].Zarco Wilbert, Merchant Hugo, Prado Luis, and Mendez Juan Carlos . Subsecond timing in primates: comparison of interval production between human subjects and rhesus monkeys. Journal of Neurophysiology, 102(6):3191–3202, 2009. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [32].Mita Akihisa, Mushiake Hajime, Shima Keisetsu, Matsuzaka Yoshiya, and Tanji Jun. Interval time coding by neurons in the presupplementary and supplementary motor areas. Nature Neuroscience, 12(4):502–507, 2009. [DOI] [PubMed] [Google Scholar]
- [33].Yang Guangyu Robert, Joglekar Madhura R, Song H Francis, Newsome William T, and Wang Xiao-Jing. Task representations in neural networks trained to perform many cognitive tasks. Nature Neuroscience, 22 (2):297–306, 2019. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [34].Duncker Lea, Driscoll Laura, Shenoy Krishna V, Sahani Maneesh, and Sussillo David. Organizing recurrent network dynamics by task-computation to enable continual learning. Advances in Neural Information Processing Systems, 33:14387–14397, 2020. [Google Scholar]
- [35].Chestek Cynthia A, Batista Aaron P, Santhanam Gopal, Byron M Yu, Afshar Afsheen, Cunningham John P, Gilja Vikash, Ryu Stephen I, Churchland Mark M, and Shenoy Krishna V. Single-neuron stability during repeated reaching in macaque premotor cortex. Journal of Neuroscience, 27(40):10742–10750, 2007. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [36].Aitken Kyle and Mihalas Stefan. Neural population dynamics of computing with synaptic modulations. Elife, 12:e83035, 2023. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [37].Aitken Kyle, Campagnola Luke, Garrett Marina E, Olsen Shawn R, and Mihalas Stefan. Simple synaptic modulations implement diverse novelty computations. Cell Reports, 43(5), 2024. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [38].Frémaux Nicolas and Gerstner Wulfram. Neuromodulated spike-timing-dependent plasticity, and theory of three-factor learning rules. Frontiers in Neural Circuits, 9:85, 2016. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [39].Liu Yuhan Helena, Smith Stephen, Mihalas Stefan, Shea-Brown Eric, and Sümbül Uygar. Biologically-plausible backpropagation through arbitrary timespans via local neuromodulators. Advances in Neural Information Processing Systems, 35:17528–17542, 2022. [Google Scholar]
- [40].Bradbury James, Frostig Roy, Hawkins Peter, Johnson Matthew James, Leary Chris, Maclaurin Dougal, Necula George, Paszke Adam, VanderPlas Jake, Wanderman-Milne Skye, and Zhang Qiao. JAX: composable transformations of Python+NumPy programs, 2018. URL http://github.com/google/jax. [Google Scholar]
- [41].DeepMind, Babuschkin Igor, Baumli Kate, Bell Alison, Bhupatiraju Surya, Bruce Jake, Buchlovsky Peter, Budden David, Cai Trevor, Clark Aidan, Danihelka Ivo, Dedieu Antoine, Fantacci Claudio, Godwin Jonathan, Jones Chris, Hemsley Ross, Hennigan Tom, Hessel Matteo, Hou Shaobo, Kapturowski Steven, Keck Thomas, Kemaev Iurii, King Michael, Kunesch Markus, Martens Lena, Merzic Hamza, Mikulik Vladimir, Norman Tamara, Papamakarios George, Quan John, Ring Roman, Ruiz Francisco, Sanchez Alvaro, Sartran Laurent, Schneider Rosalia, Sezener Eren, Spencer Stephen, Srinivasan Srivatsan, Stanojević Miloš, Stokowiec Wojciech, Wang Luyu, Zhou Guangyao, and Viola Fabio. The DeepMind JAX Ecosystem, 2020. URL http://github.com/google-deepmind. [Google Scholar]
- [42].Biewald Lukas. Experiment tracking with weights and biases, 2020. URL https://www.wandb.com/. Software available from wandb.com. [Google Scholar]
- [43].Kingma Diederik P and Adam Jimmy Ba: A method for stochastic optimization. arXiv preprint arXiv:1412.6980, 2014. [Google Scholar]
- [44].Loshchilov Ilya and Hutter Frank. Decoupled weight decay regularization. arXiv preprint arXiv:1711.05101, 2017. [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.