

Abstract
Estimating sample size and statistical power is an essential part of a good epidemiological study design. Closed-form formulas exist for simple hypothesis tests but not for advanced statistical methods designed for exposure mixture studies. Estimating power with Monte Carlo simulations is flexible and applicable to these methods. However, it is not straightforward to code a simulation for non-experienced programmers and is often hard for a researcher to manually specify multivariate associations among exposure mixtures to set up a simulation. To simplify this process, we present the R package mpower for power analysis of observational studies of environmental exposure mixtures involving recently-developed mixtures analysis methods. The components within mpower are also versatile enough to accommodate any mixtures methods that will developed in the future. The package allows users to simulate realistic exposure data and mixed-typed covariates based on public data set such as the National Health and Nutrition Examination Survey or other existing data set from prior studies. Users can generate power curves to assess the trade-offs between sample size, effect size, and power of a design. This paper presents tutorials and examples of power analysis using mpower.
Keywords: power analysis, environmental chemical mixtures, observational study, Monte Carlo simulation, R package
1. Introduction
Researchers need to estimate sample size and statistical power as part of good study planning. The power of a test is the probability that it rejects the null hypothesis at a specific significance level under a prespecified alternative hypothesis. Calculating power requires assumptions about relevant quantities, such as variance, effect size, and sample size. For standard hypothesis tests, including one or two sample t-tests, one-way balanced ANOVA, and chi-squared tests, closed-form equations exist to calculate the power. However, in general, power formulas are not available for complex analysis methods, such as statistical models recently developed for mixtures analysis. In these situations, we can estimate power using Monte Carlo (MC) simulations, an approach that is flexible and applicable to a large class of statistical models (Gelman and Hill, 2007). Each simulation involves first sampling data from a hypothesized data generative model and then fitting an inference model to the data. Out of a large number of simulations, the proportion of times in which a hypothesis test is rejected can be used to estimate power. Biomedical research has used simulations for power calculation in randomized trials (Arnold et al, 2011), longitudinal studies (Gastañaga et al, 2006), and observational studies with measurement error or drop out (Landau and Stahl, 2013), to name a few. To our knowledge, this is the first software developed specifically for power calculations in observational studies of chemical exposure mixtures, where controlling for several covariates and multiple correlated exposures is important.
Furthermore, power calculation should be based on the intended inference model, which aligns with the analysis goals. Exposure mixture studies are almost always observational in nature due to ethical constraints in exposing subjects to potentially harmful chemicals. Researchers then use regression methods to parse out associations between chemical mixtures and health outcomes of interest. Statistical models for mixtures aim to achieve several goals, including but not limited to: (1) identifying individual chemicals critical to the health outcome of interest; (2) estimating the health effects of individual (or combinations of) chemicals in the presence of multicollinearity; and (3) examining synergistic interactions between chemicals (Sun et al, 2013). Several challenges are associated with these goals, and no single approach is best at addressing all of them. For instance, regularized multiple regression with main effects and interactions can identify critical chemicals, and examine synergistic effects, but tend to be limited to pairwise interactions (Bien et al, 2013; Lim and Hastie, 2015). Kernel-based regressions can account for high-order interactions and nonlinear effects but tend to not scale well with the number of chemicals or observations (Hamra and Buckley, 2018). Many models incorporate factor analysis for dimensionality reduction to deal with multicollinearity (Sun et al, 2013; Ferrari and Dunson, 2020b,a). The choice of the model depends on the goal of analysis and characteristics of the data set (Sun et al, 2013). Therefore, power analysis should be conducted for the specific method used in the analysis. MC simulation enables power calculation for different combinations of hypothesized exposure-response relationships and inference models.
We present the R package mpower containing building blocks to set up MC simulations for estimating power for observational studies of environmental exposure mixtures. Some packages exist for conducting power analysis using MC simulations, including simr (Green and MacLeod, 2016), skpr (Morgan-Wall and Khoury, 2021), and simglm (LeBeau, 2022). However, existing packages are not tailored to exposure mixture studies or compatible with mixture inference methods. Package skpr (Morgan-Wall and Khoury, 2021) provides options to simulate data from optimal factorial designs and split-plot designs, often not applicable to observational epidemiological studies. Arnold et al (2011) provided example R code to do power analysis through MC simulations for complex cluster design, but it is unclear how to incorporate continuous exposures. Package simglm (LeBeau, 2022) provides a general framework for power analysis for multi-leveled, mixed-scaled data but does not facilitate the simulation of correlated exposures. Package simr (Green and MacLeod, 2016) conducts simulations based on models fitted on real-world data but only works with generalized linear mixed models.
Our package mpower allows users to simulate realistic exposure data and mixed-typed covariates based on existing data sets such as the National Health and Nutrition Examination Survey (NHANES). It enables users to easily conduct power analysis for recently-developed statistical methods for mixtures that lack closed-form power formulas, including Bayesian Kernel Machine Regression (BKMR) (Bobb et al, 2015), Bayesian Model Averaging (BMA) (Hoeting et al, 1999), MixSelect (MS) (Ferrari and Dunson, 2020b), Factor Analysis for Interactions (FIN) (Ferrari and Dunson, 2020a), Bayesian Weighted Sums (BWS) (Hamra et al, 2021), and Quantile G-Computation (QGC) (Keil et al, 2020). These features enable researchers, even those not experienced with R, to quickly set up MC simulations for exposure mixture studies. Simultaneously, the building blocks within mpower are versatile enough to integrate with other R packages and user-defined functions, empowering advanced R users to work with statistical models for mixtures beyond those provided in mpower. Because simulation-based power analysis for complex models can be computationally intensive, we allow parallel computation when users have access to multi-core computer processors. In Section 2, we describe algorithms for power analysis using MC simulations, simulation of correlated mixed-scaled covariates and exposures, automatic scaling of effect size, and state-of-the-art statistical methods for chemical mixtures. In Section 3, we provide a tutorial on the package’s functionalities with example codes. In Section 4, we provide a tutorial on end-to-end power analyses with synthetic data and NHANES, demonstrating that simulation is a reliable approach to estimating power and a potentially useful tool for inference model comparison.
2. Methodology
2.1. Power analysis using Monte Carlo simulation
We can use MC simulation to estimate power given a data generative model and an inference model. Let be the number of simulations, be the sample size of one simulation, , be the outcome of the ith subject, and be the parameters (i.e., intercepts, main effects, interactions, variance components, correlations among predictors,…) in a data generative model that realistically represents the multivariate association among the predictors and a hypothesis about the relationships between the predictors and outcome. As a result, this data generative model involves a generative model for the predictors and a generative model for the outcome. The parameters may be chosen based on prior knowledge of the associations among predictors, effect size or estimates from previous studies (Arnold et al, 2011; Green and MacLeod, 2016).

We may repeat Algorithm 1 with different values for and to create a power curve. Power curves are useful to study the trade-offs between power, sample size, and effect size.
2.2. Simulate correlated predictors
We provide three methods to construct a generative model for correlated predictors. One approach to simulate samples from a realistic joint distribution of the predictors is to resample them from existing data. Another option is to estimate the joint distribution of the existing data and simulate from it. In this package, we use a semiparametric Bayesian Gaussian copula (SBGC) (Hoff, 2007) to estimate the joint distribution of mixed binary, ordinal, and continuous data. This method is based on Sklar’s Theorem that any multivariate probability distribution can be written in terms of its univariate marginal probability distributions and the copula. For example, let be random variables with marginal univariate CDF’s , not necessarily continuous, and an unknown joint distribution we want to estimate. The transformed variables ‘s all have uniform marginals. A copula models the joint distribution of , which also describes the dependence amongst the ‘s separately from . We use a Gaussian copula which has the following form:
| (1) |
| (2) |
where ’s are latent variables, is a correlation matrix of the latent variables, is the pseudo-inverse of , and the CDF of a standard normal. Since the closed form of the ’s are often unknown in practice, we can estimate them using the empirical distributions from observations . Hoff proposed using the extended rank likelihood to estimate without depending on estimates of ’s (Hoff, 2007), which works well for mixed-scaled data, and implemented the Bayesian inference algorithm in the R package sbgcop (Hoff, 2018). The uncertainty in the estimation can be propagated through the whole power calculation straightforwardly by sampling from the copula’s parameters’ posteriors before simulating new data. Additionally, no specification of prior distributions or parametric form of the univariate marginal distributions is necessary, ensuring ease of use. We summarize how to simulate data from a generative model defined by a Gaussian copula in Algorithm 2.

Alternatively, if we have no existing data to estimate the correlation matrix of the latent variables and the marginal CDF’s of the observed variables, we can specify them manually. For instance, we may assume a continuous predictor to be normally distributed with a given mean and standard deviation, or an ordinal predictor to be from a multinomial distribution with given probabilities. As for the correlation matrix , given reasonable guesses on pairwise correlations between predictors, we can sample positive definite matrices with desirable structures using Algorithm 3 from (Lewandowski et al, 2009). This can add additional uncertainty into the samples of hypothetical data and ensure that is a valid correlation matrix. Let be the partial correlation of the and variables while holding the variable and variables in set constant, where contains indices distinct from . We can calculate partial correlation using the following formula from (Lewandowski et al, 2009):
| (3) |
The partial correlation where is the empty set is equivalent to the correlation between the and variables. Equation 3 shows that a random correlation matrix can be parametrized in terms of pairwise correlations and partial correlations . These choices of partial correlations correspond to a C-vine (Bedford and Cooke, 2002). They can independently take values on the interval (−1, 1) following any density with the right support (Lewandowski et al, 2009). We sample them from independent distributions (scaled to be on (−1, 1)) with appropriate hyperparameters to induce a correlation matrix with desirable structures. Applying Equation 3 iteratively to smaller index sets , we can calculate every element of the correlation matrix from these partial correlations (Algorithm 3). For example, where , and are Beta random variables. More details can be found in (Joe, 2006; Lewandowski et al, 2009). When choosing , take into consideration that the mean of a Beta random variable is , and the larger or is, the smaller the variability of the samples. To automatically set reasonable parameters for , we use the following heuristics given guesses of pairwise correlations, which are easier to specify than partial correlations. First, we calculate a partial correlation using the conditional multivariate normal formula (Eaton, 2007) from the rough guesses of pairwise correlations. If the guessed correlation matrix is singular, the generalized inverse can be used in the conditional normal formula. We then set and where controls the magnitude of the parameters. We find the heuristics to work well when the guessed pairwise correlations are not too extreme (e.g. 0.99). Simply put, we can turn rough guesses of pairwise correlations into a valid sampling distribution for the predictors.

2.3. A general notion of effect size
It is not straightforward to set an effect size for nonlinear or complex mean functions. We propose using the signal-to-noise ratio (SNR) as a general proxy to the joint effect size for any mean function. The SNR can be viewed as an estimate for the ratio between the variation in the outcome explained by the true predictors and the variation due to noise. For the model with independent, additive Gaussian noise , it is defined as:
| (4) |
Fixing either the mean function variance or the noise variance, it is straightforward to scale the other so that a SNR is achieved. We can estimate the variance of any mean function with , where are i.i.d. realizations of predictors for a large number . The specific calculations are summarized in Algorithm 4 and 5. We may extend this measure of effect size to binary or count outcomes using the SNR estimator for generalized linear models (GLM) proposed by (Czanner et al, 2008). The estimator is defined as:
| (5) |
where w, h are vectors of realizations of outcome and mean model respectively, and . The residual deviance Dev (w, h) is a measure of discrepancy between the observed and predicted data, with the following forms for binary and count outcome (McCullagh and Nelder, 1983):
| (6) |
| (7) |
For binary or count outcomes, we can adjust parameters in the mean model until we get a desirable estimated .


2.4. Statistical methods for environmental mixtures
Our package interfaces with several existing and newly developed analysis strategies for assessing associations between correlated exposures and health outcomes. These strategies can be used as inference models for Algorithm 1. We provide an overview of methods and their unique strengths. We do not go into the mathematical description, and instead give intuitions that help researchers select the correct model given characteristics of the data. For a more detailed review of recent methodological developments, see Joubert et al (2022).
Bayesian Model Averaging
Model selection is a common strategy to deal with multicollinearity or large dimensionality in the predictors. Instead of selecting for one best model that might be sensitive to the given observed data set, BMA provides a posterior over the space of all possible models (Hoeting et al, 1999). Thus, BMA allows for direct model selection and robust effect estimation by averaging the posteriors of the parameters under all models weighted by their posterior model probabilities. Unlike other model selection methods (i.e. forward/backward selection), BMA quantifies uncertainty more fully, including model uncertainty. Interactions and nonlinear effects can be included by transformation of the design matrix. Additionally, BMA can be used with many models, such as linear regression, generalized linear models, and survival models. Our package integrates the implementation of BMA in package BMA (Raftery et al, 2021). As the dimension of the model space grows exponentially with the number of predictors, for high-dimensional data sets, implementations of BMA often approximate the model posterior by doing preliminary step-wise model selection (e.g. in package BMA) or by sampling the model space. In the presence of high correlations among many predictors, BMA is prone to produce low marginal inclusion probabilities for the correlated predictors, making it difficult to identify critical predictors of the outcome.
Bayesian Kernel Machine Regression
Bayesian kernel machine regression can flexibly model nonlinear, high-order interaction effects of multiple predictors jointly using a kernel function (Bobb et al, 2015). BKMR incorporates component-wise variable selection, producing a posterior inclusion probability for each individual variable, allowing for identification of critical components. Similar to BMA, BKMR is prone to produce low posterior inclusion probabilities for a large number of highly correlated variables even when many or all of them are important. To alleviate this issue, BKMR also implements hierarchical variable selection, which selects on groups of highly correlated variables. Researchers will need to specify the groups based on domain knowledge of the data set. BKMR can be prone to overfitting (Ferrari and Dunson, 2020b). Our package integrates the implementation of BKMR from the package bkmr available on CRAN (Bobb et al, 2018).
MixSelect
MixSelect decomposes the fitted mean function of the outcome into linear main effects, pairwise interactions, and a nonlinear deviation (Ferrari and Dunson, 2020b). MS also include variable selection on the linear main effects and hierarchical variable selection on the interactions. This means that a pairwise interaction is included only if the main effects of one or both variables are selected. The nonlinear deviation models the residuals of the linear terms, using a kernel function similar to BKMR. Unlike BKMR, MS uses Bayesian model selection to decide whether to include the nonlinear deviation in the model. Thus, it automatically simplifies to a linear model with variable selection if only linear effects are present in the data. While BKMR relies solely on visualizations for interpretation of marginal effects, MS produces posteriors for the linear terms from which the mean, credible intervals, and other statistics can be calculated. However, MS does not offer group-wise variable selection like BKMR. Like BKMR, MS suffers with data of large dimensionality, sample size, and extensive multicollinearity. We use the implementation provided by the authors at https://github.com/fedfer/MixSelect.
Factor Analysis for Interactions
Factor analysis is a common choice to deal with multicollinearity in the predictors. It can infer group structures in the predictors, i.e. latent factors, while being informed by their relationships to the outcome, effectively reducing the dimension of the data. (Ferrari and Dunson, 2020a) proposed the FIN model that accounts for pairwise interactions between the factors and transforms the parameters to produce linear main effects, quadratic main effects and pairwise interactions in the original predictors. Thus, it examines effects of combinations of predictors as well as individual predictor at a reduced model complexity. Reasonable assumptions about group structures in the predictors must hold. FIN does not produce exact variable selection, though it induces shrinkage on the effect estimates. FIN might not be effective at identifying individual critical predictors, especially when other correlated predictors are not important. We use the implementation provided in the package inf initefactor (Poworoznek, 2020) available on CRAN.
Bayesian Weighted Sums
Bayesian Weighted Sums aims at estimating a combined effect and individual variable importance by summing multiple predictors into a single exposure variable using quantitative weights (Hamra et al, 2021). Thus, BWS reduces the dimension of the problem and produces a parsimoneous model. BWS may be thought of as a factor model that assumes only one latent factor affects the outcome. The weights can be interpreted as proportions of the combined effect explained by each component. Unlike QGC (discussed next), BWS provides uncertainty quantification on the weights. BWS is currently limited to modeling linear additive effects and constrains all components of the mixtures to have effects of the same sign. We use the implementation of BWS in the package bws (Nguyen, 2022) available on CRAN.
Quantile G-Computation
Similar to BWS, QGC aims to estimate the combined effects of multiple predictors. QGC first transforms the predictors into categorical variables whose categories correspond to quantiles of the original predictors. QGC then fits a generalized linear model to the categorical variables, and the sum of all regression coefficients produces the g-computation estimator. Since the underlying model is a generalized linear model, if these three assumptions hold: 1) the relationship is in fact linear, 2) quantization of predictors is appropriate, and 3) there are no unmeasured confounders, then the g-computation estimator gives a causal dose-response parameter (Keil et al, 2020). Unlike BWS, QGC allows predictors to have effects of different signs and allows the inclusion of nonlinear and interaction terms. Identification of critical components may be difficult because the weights lack confidence intervals or p-values. We use the R package qgcomp available on CRAN (Keil, 2021).
3. Tutorial: Functionalities
We will walk through all functionality of the package. There are three data models that are building blocks to running a power analysis with this package: a generative model for the predictors, a generative model for the outcome given the predictors, and an inference model.
3.1. Specifying a predictors model
If sufficient existing data are available, simulated predictors may be created by resampling. For example, if we were planning a study of metabolic disease and phthalates, we could sample phthalate levels from NHANES data:
R> xmod <- MixtureModel (method = ‘resampling’, data = nhanes, + resamp_prob = weights)
A vector of sampling probabilities of the observations, which must sum to 1, may be given to argument resamp_prob. If limited data exist, predictors may be sampled from a semi-parametric Bayesian copula parametrized by the empirical univariate marginals and a correlation matrix (Hoff, 2007). The marginals and correlation matrix of the latent variables may be estimated directly as discussed in Section 2.2. This method can handle mixed-scaled data (i.e., continuous, binary, ordinal). The generated predictors are on the same scale as the original data. Note that categorical and ordinal data must be formatted as numeric (e.g. using one-hot-encoding). Users may pass a list of named arguments, including the number of MCMC samples (nsamp), how much to thin a chain (odens), and whether to print MCMC progress (verb) to the argument sbg_args. See function sbgcop.mcmc() from package sbgcop for the full list of arguments.
R> sbg_args <− list (nsamp = 2000, odens = 2, verb = TRUE) R> xmod <− MixtureModel (method = ‘estimation’, + data = existing_data, + sbg_args = sbg_args)
Alternatively, if no existing data are available to estimate the correlation matrix of the latent variables and univariate marginals, users can specify them manually using Algorithm 3. The argument G takes a matrix of rough guesses of pairwise correlations between all variables. Larger values for the argument m corresponds to smaller deviation from G in the random samples. In the code below, we generate random matrices with high pairwise correlations around 0.9, as well as a random matrix with group structures:
R> set. seed (1) R> p <− 40 R> variable_names <− paste0 (‘x’, 1:p) R> G <− diag (1, p) R> G[upper. tri (G)] <− 0.9 R> G[lower. tri (G)] <− 0.9 R> cvine_marginlas <− lapply (1 : p, function (i) ‘qnorm(mean = 0, sd = 1)’) R> colnames (G) <− rownames (G) <− names(cvine_marginals) <− variable_names R> small_devi <− MixtureModel (method = ‘cvine’, G = G, m = 100, + cvine_marginals = cvine_marginals) R>large_devi <− MixtureModle (method = ‘cvine’, G = G, m = 100, + cvine_marginals = cvine_marginals) R> G_group <− matrix (c(rep (c (rep (0.8, p/2), rep (0.3, p/2)), p/2), + rep (c(rep (0.3, p/2), rep (0.7, p/2)), p/2)), p, p) R> diag (G_group) <− 1 R> group <− MixtureModel (method = ‘cvine’, G = G_group, m = 100, + cvine_marginals = cvine_marginals)
The sampled correlations concentrate more around 0.9 when m=100 than when m=10 (Figure 1 left and Figure 1 middle). The right-most subplot of Figure 1 shows an example matrix created by an input G with group structures. The argument cvine_marginals takes a named list of strings describing the quantile function and named parameters of the marginal distribution of each variable. Valid strings include standard distributions from the R package stats. See our documentation for a complete list of supported distributions. For an example of how to create independent binary, count, and ordinal variables, see the first example in Section 4.
Fig. 1.
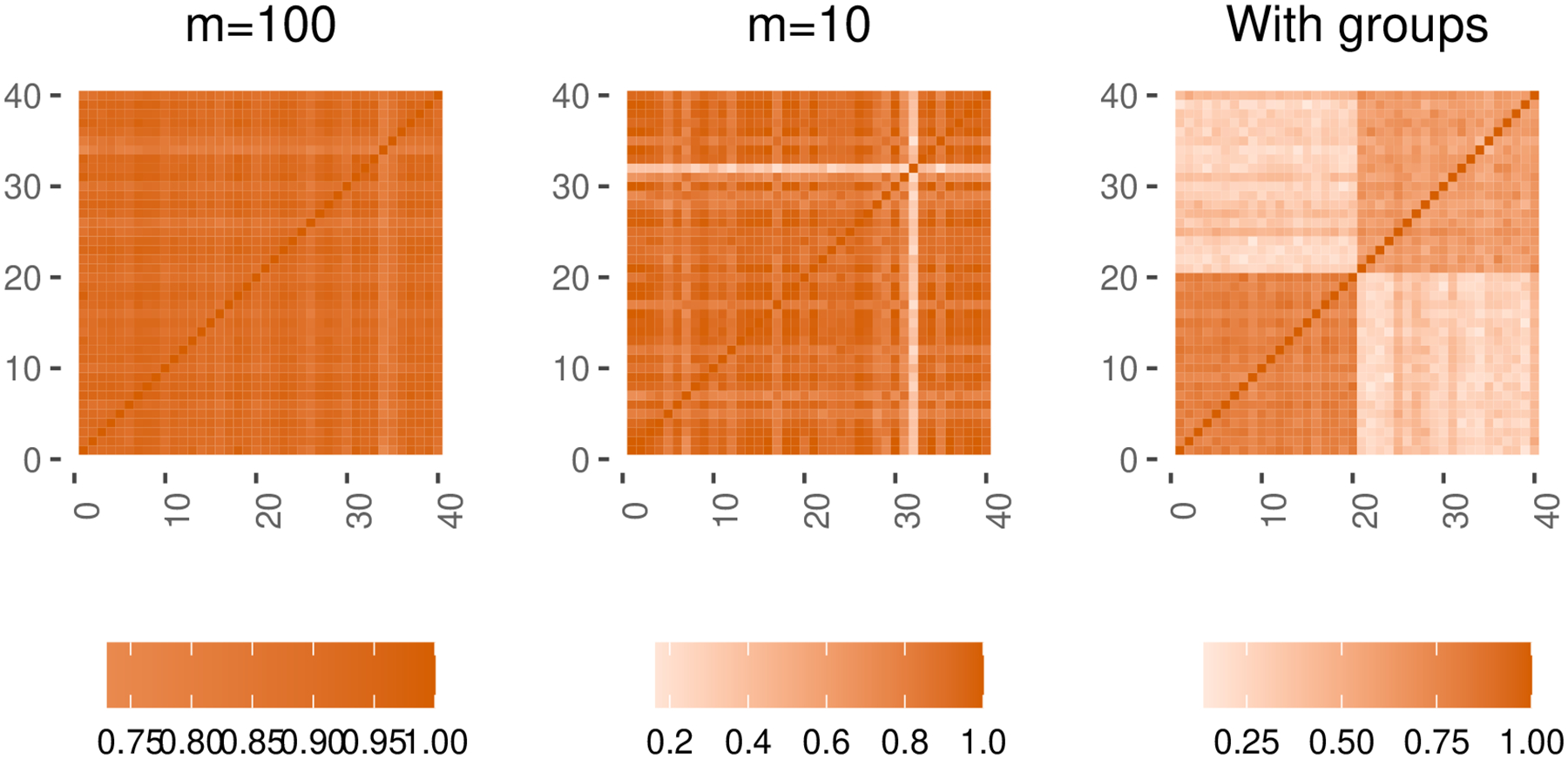
Examples of random correlation matrices generated using Algorithm 3.
3.2. Specifying an outcome model
Users need to specify a hypothesized model for the outcome given the predictors. This can be thought of as the “true” relationship between the predictors and outcome. This model may be informed from prior knowledge or pilot studies. When little information is available, investigators may wish to test a variety of outcome models to get a sense of robustness to assumptions about predictor-outcome relationships. The model for the mean is given as a string of R code. For example, if the continuous outcomes are modeled as random draws from a Gaussian , we can use the following code:
R> ymod <− OutcomeModel (f = ‘2*(x1 + x2) ’ , family = ‘gaussian’, sigma = 1)
The function can generate binary and count data using an appropriate link function (i.e., logit) when family is set to ‘binomial’ or ‘poisson’ respectively. A fitted model of the outcome to existing data may also be used but needs to be wrapped inside a function that takes a predictor matrix |x| and returns a vector of mean values. Below is an example of wrapping an 1m model to be used with our package:
R> pilot_mod <− Im (y ~ xl, data = pilot_study)
R> pilot_f <− function (x) {
+ predict (pilot_mod, as. data. frame (x)) $fit
+ }
R> pilot_sigma <− sigma (pilot_mod)
R> ymod <− OutcmeModel (f = pilot_f, family = ‘gaussian’,
+ sigma = pilot_sigma)
3.3. Specifying an inference model
While the outcome and the inference models are ideally the same, in practice our model will at best approximate the “true” predictor-response relationships. In the code below, we show how to use BKMR as the inference model. The model argument also accepts one of the following values: ‘glm’, ‘mixselect’, ‘qgcomp’, ‘bws’, ‘fin’, and ‘bma’. Advanced users may also define custom inference models (see first example in Section 4). Additional arguments specific to the inference model (e.g. iter, varsel) can be passed as done below:
R> imod <− InferenceModel (model = ‘bkmr’, iter = 10000, varsel = TRUE)
The built-in inference functions return values, such as p-value or posterior inclusion probability, as “significance” criteria. Table 1 list the criteria available for each built-in inference model.
Table 1.
Definitions of effect criteria for built-in inference models given a threshold .
| Inference method | Individual effect | Value to crit |
|---|---|---|
| BMA | posterior inclusion probability (PIP) of a main effect or an interaction term ≥ . | ‘pip’ |
| GLM | the smallest p-value of the regression coefficients (i.e., main effect, interactions) involving a predictor ≤ . | ‘pval’, ‘main_pval’ (main effect only), ‘int_pval’ (interactions only) |
| BKMR | PIP of a non-zero length-scale parameter ≥ . | ‘pip’ (component-wise), ‘group_pip’ (group-wise) |
| MS | PIP of a main effect or a length-scale parameter ≥ . | ‘pip’, ‘linear_pip’ (main effect alone), ‘gp_pip’ (lenghth-scale alone) |
| FIN | % CI of a main effect or an interaction term doesn’t include zero. Equivalent to where is the posterior probability of an effect being less than 0. | ‘beta’, ‘linear_beta’ (main effect alone) |
| BWS | % CI of the joint effect doesn’t include zero. Equivalent to where is the posterior probability of the joint effect being less than 0. | ‘beta’ |
| QGC | p-value of the joint effect ≤ . | ‘pval’ |
3.4. Running a power analysis
Function sim_power() executes steps 2 to 6 of Algorithm 1 given a predictors generative model, an outcome generative model, an inference model, a sample size, and the number of MC iterations. In the code below, we simulate 2000 data points specified by the predictors and outcome model, fit an inference model and repeat the whole process 10000 times:
R> res <− sim_power (xmod, ymod, imod, s=10000, n = 2000, + snr_iter = 100000, cores = 2, errorhandling = ‘stop’, + cluster_export = c(‘pilot_mod’))
Each simulation is independent and thus may be parallelized for faster computation. When multiple cores are available on the computer, increase cores to parallelize the simulation. Internally, we use the doSNOW (Corporation and Weston, 2022) and foreach (Microsoft and Weston, 2020) packages for this feature. While using parallelism, if an error occurs in any iteration, errorhandling specifies whether to remove that iteration (‘remove’), return the error message verbatim in the output (‘pass’), or terminate the loop (‘stop’). The ‘pass’ and ‘stop’ options are useful for debugging. Larger values for snr_iter results in more precise estimates of the SNR. Finally, any global variable not explicitly passed in as an argument (e.g. a custom outcome model) needs to be exported to the parallel cluster using cluster_export.
3.5. Creating a power curve
It is often desirable to study the trade-offs between power, Type I error rate, sample size, and effect size. Function sim_curve() generates a power curve by running the power analysis described previously on a combination of sample sizes and outcome models. Different effect sizes may be baked into the outcome models and measured by the signal to noise ratio. Function sim_curve() takes a list of outcome model and a vector of sample sizes, but only one predictors model and one inference model at a time. Below we conduct power analyses for 9 combinations of sample sizes 1000, 2000, and 5000 and 3 outcome generative models:
R> res_curve <− sim_curve (xmod = xmod, imod = imod, + ymod=list (ymod1, ymod2, ymod3), s = 10000, n = c(1000, 2000, 5000))
3.6. Estimating the signal-to-noise ratio
As we discuss in Section 2, the SNR is a good proxy for a generalization of an effect size to non-linear outcome model. The SNR can be viewed as an estimate for the ratio between the variation in the outcome explained by the true predictors and the variation due to noise. To estimate the SNR of a data generating process and its bootstrap standard error (s.e.), we can pass a predictors model and an outcome model to the following function:
R> estimate_snr (xmod, ymod, m = 100000, R = 1000)
Argument m define the number of samples drawn from the predictors and outcome models to estimate SNR and R the number of bootstrap replicates. See the Appendix A for an illustration of how the estimated SNR changes as m varies.
If the outcome generative model has Gaussian white noise, we can automatically scale the mean function (use scale_f()) or the noise variance (use scale_sigma()) to get a desired SNR as discussed in Algorithms 4 and 5. The code below modifies a given outcome model and returns a new one with the specified SNR:
R> desired_snr <−0.5 R> new_ymod <− scale_f (desired_snr, cur_ymod, xmod) R> new_ymod <− scale_sigma (desired_snr, cur_ymod, xmod)
3.7. Getting the summary
The summary() function produces summaries statistics and plots for the power analysis. It takes a ‘Sim’ object or a ‘SimCurve’ object returned by sim_power() or sim_curve(). The crit argument specifies the significance criterion; the thres argument specifies the significance threshold; and how describes how the criterion should be compared to the threshold (‘lesser’ or ‘greater’). For example, for BMA, if PIP > 0.5 is considered “significant”, then the criterion is PIP and the threshold is 0.5. For Bayesian parametric models, credible interval can also be used as a criterion, and p-values for frequentist models (e.g. QGC). Table 1 shows criteria available for each built-in inference model and corresponding values to give to crit. The code below shows how to extract summaries for a BMA with PIP greater than 0.5, a GLM with p-values less than 0.01, and a BWS model with zero-coverage of the 90% or larger credible interval as “significance” thresholds:
R> summary(bma_res, crit = ‘pip’, thres = 0.5, how = ‘greater’) R> summary(glm_res, crit = ‘pval’, thres = 0.01, how = ‘lesser’) R> summary(bws_res, crit = ‘beta’, thres = 0.1, how = ‘lesser ‘)
Different thresholds will affect the power of the test. We may plot how the power changes for different thresholds:
R> plot_summary (bma_res, crit = ‘pip’, + thres = c(0.5,0.6,0.7,0.8), how = ‘greater’)
4. Tutorial: Examples
In this section, we provide four examples of doing end-to-end power analysis with the functionality presented in the last section. The first two examples demonstrate that simulation provides precise estimates of power that match theoretical values. The first example involves using C-vine for simulating predictors and generating power curve for a general linear F-test. The second example involves simulating exposures from estimates of multivariate associations based on NHANES and again calculating power of a general linear F-test. The last two examples shows the importance of using the intended inference model for power analysis, especially in the presence of multicollinearity in the predictors. The third example shows a example of sample size planning for a mixtures study using closed-form formula compared to using MC simulation. The final example conducts power analyses for two mixtures methods that have different analysis goals.
4.1. Manual specification of multivariate associations among predictors
In the first example, we generate predictors using the C-vine method and calculate power for a general linear F-test. A closed-form power formula exists for the F-test and can be used to validate power estimated with MC simulations. The code below defines a generative model for two continuous, one binary, and one ordinal predictor with 3 levels, all independent of one another:
R> xmod <− MixtureModel (method = ‘cvine’, G = diag (1, 4), + cvine_marginals = list (x1 = ‘qnorm (mean=0, sd=1)’, + x2 = qnorm (mean=0, sd=1)’, + x3 = ‘qbinom (size=1, prob=0.7)’, + x4 = ‘qmultinom (probs=c (0.5, 0.3, 0.2))’))
Figure 2 shows the marginals and correlation matrix of the mixture model. Note that the C-vine correlation matrix is for latent variables in Algorithm 2. We hypothesize the continuous outcome to be a linear function of and Gaussian white noise with variance 1. Mathematically, where indexes the observation, and are the regression coefficients. The code below defines three hypotheses on the outcome model with decreasing SNRs:
R> ymod_list <− list ( + OutcomeModel (f = ‘0.3 * x1 + 0.3 * x2’, sigma = 1, family = ‘gaussian’), + OutcomeModel (f = ‘0.2 * x1 + 0.2 * x2’, sigma = 1, family = ‘gaussian’), + OutcomeModel (f = ‘0.1 * x1 + 0.1 * x2’, sigma = 1, family = ‘gaussian’) + )
Fig. 2.
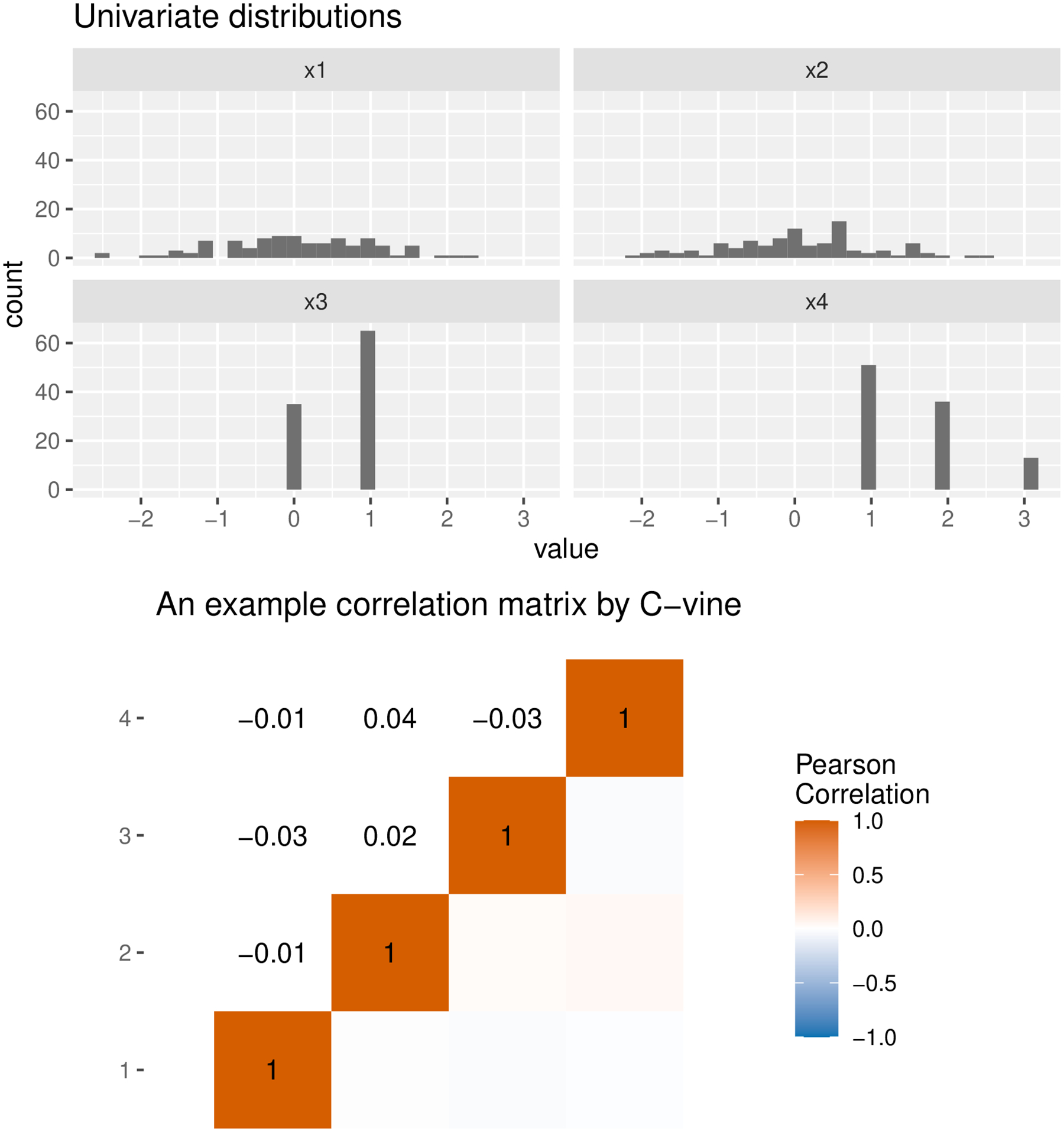
Output of plotting the C-vine mixture model with mplot(xmod). Note that the C-vine correlation matrix is for latent variables in Algorithm 2.
Since and are Gaussian, the SNR can be calculated exactly analytically, e.g., for the first, 0.08 for the second, and 0.02 for the third outcome model. Nevertheless, note that the empirical estimates of SNRs might deviate slightly from the truth, as discussed in the last section. Note also that in the “true” generative model, and are unrelated to , but this is unknown to the analyst. Next, we define an inference model including all four predictors. Since the F-test is not a built-in inference model, we will need to define it in a way that is compatible with the InferenceModel object. Specifically, it needs to take two arguments x, y for a predictors matrix and a vector of outcomes respectively, and to return a named list of significance criteria and values to be compared to a threshold later. For the F-test, one significance criterion is the p-value from the overall F-test:
R> ftest <− function (y, x) {
+ dat <− as. data. frame (cbind (y, x))
+ lm_mod <− lm(y ~ ., data = dat)
+ fstat <− summary. lm (lm_mod) $ fstat
+ fpval <− pf (fstat [1] , fstat [2] , fstat [3] , lower.tail = F)
+ names (fpval) <− ‘F–test’
+ return (list (pval = fpval))
+ }
R> imod <− InferenceModle (model = ftest, name = ‘F–test’)
We now have all the components to run power analysis for sample sizes 50, 100, 150, and 200. Since we consider 4 sample sizes and 3 hypothesized outcome models, we will use function sim_curve() to estimate 12 power calculations using 1000MC simulations each:
R> set. seed (1) R> curve <− sim_curve (xmod, ymod_list , imod s = 1000, + n = c (50, 100, 150, 200), cores = 1)
We can extract the estimated power of the ovarll F-test based on the significance criterion “p-value <0.05 “ as a data frame with summary () :
R> curve_df <− summary (curve, crit = ‘pval’, thres = 0.05, how = ‘lesser ’)
Figure 3 shows that the power curve estimated with MC simulations closely resembles the analytical power calculations:
Fig. 3.
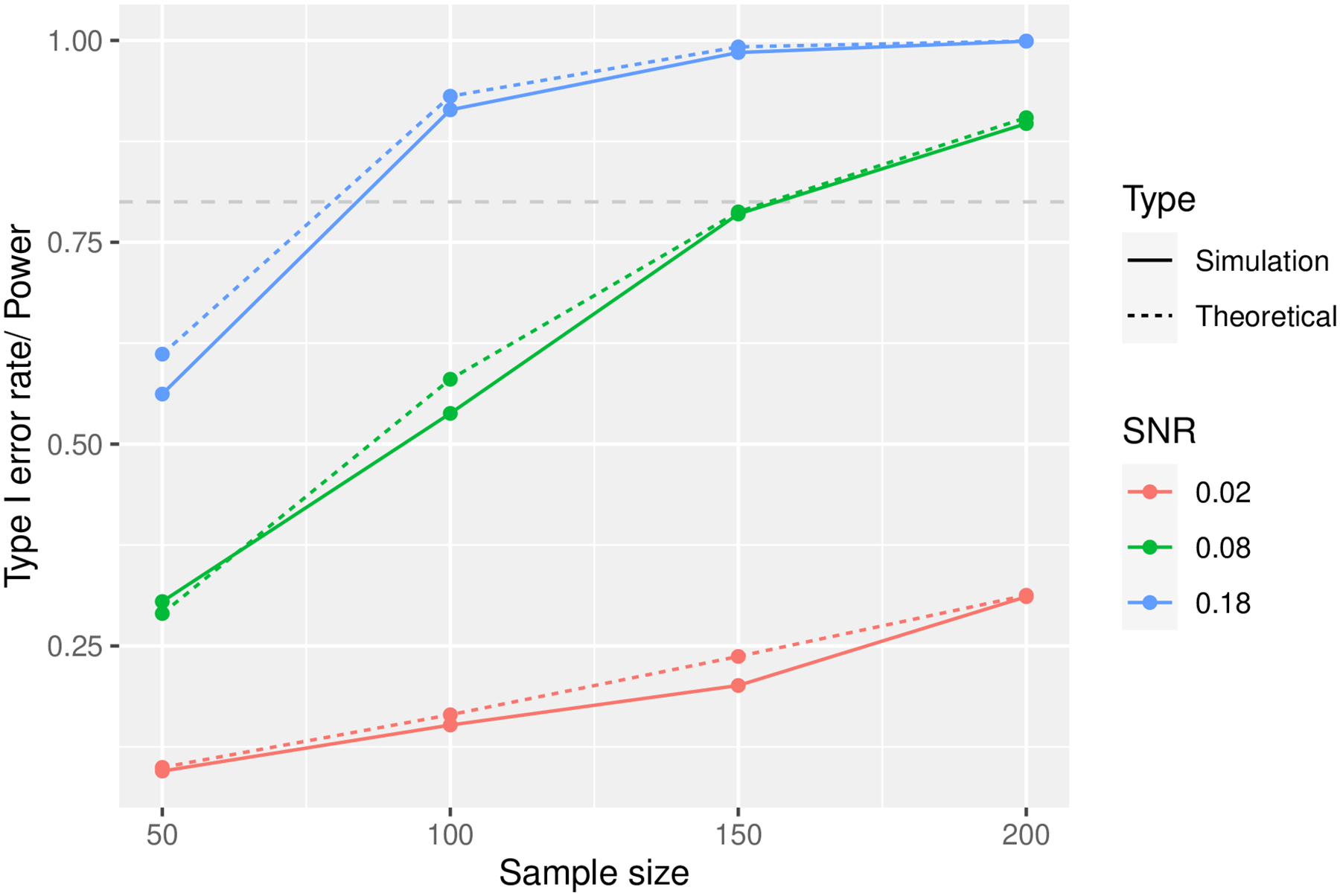
Comparison of power curves for F-test using closed-form formula (theoretical) and MC simulations in C-vine example.
4.2. Estimation of mixtures in NHANES
In the second example, we generate predictors by estimating multivariate associations in NHANES data. We download publicly available demographic, examination and laboratory data from (https://www.cdc.gov/nchs/nhanes.htm). We combine data from the 2015–2016 and 2017–2018 cycles and adjust the survey weights as instructed in the official documentation (https://wwwn.cdc.gov/nchs/nhanes/tutorials/module3.aspx). The data is included in our package as ‘nhanes1518’. We use a data subset that includes 5483 observations with no missing data and the following variables: age (RIDAGEYR), gender (RIAGENDR), household income (INDHHIN2), BMI (BMXBMI), Creatinine (URXUCR), and 16 phthalate metabolites. We choose this data subset because it has continuous, binary, and ordinal predictors and has extensive correlations between many of them. We log-transform the phthalate metabolites and Creatinine. We use the Bayesian Gaussian copula to simulate synthetic data that preserves the dependence structure among the predictors. Figure 4 shows similar Spearman’s correlation matrices between the original data (left) and a simulated data set of 500 observations (right):
R> set.seed (1) R> data (‘nhanes1518’, package = ‘mpower’) R> nhanes <− nhanes1518%>% + select(starts_with (‘URX’), BMXBMI, INDHHIN2, RIDAGEYR, RIAGENDR) %>% + filter (complete.cases (.)) %>% + mutate(across(starts_with(‘URX’), log)) R> xmod<− MixtureModel (method = ‘estimation ’ , data = nhanes, + sbg_args = list (nsamp = 2000))
Fig. 4.
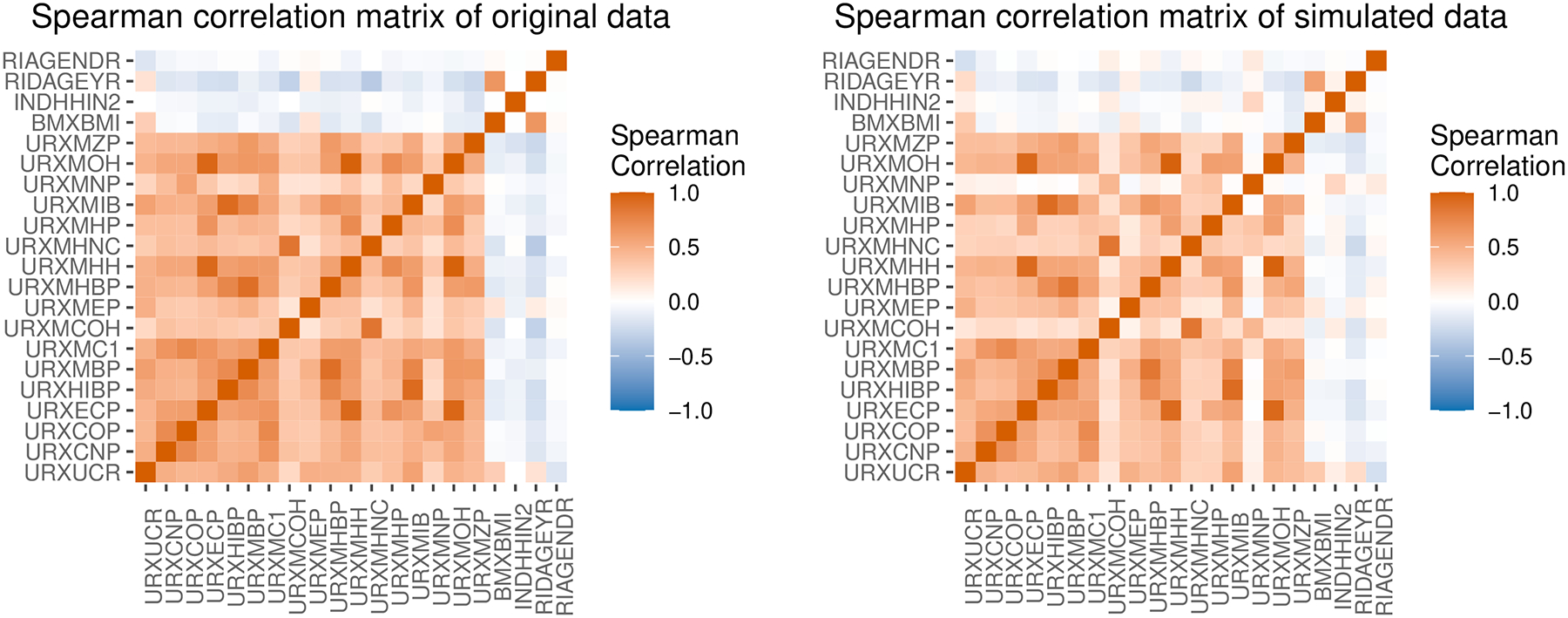
Correlation matrices of mixture data from the NHANES 2015–2018 cycles (left) and of 500 observations simulated from an estimation mixture model (right).
We then define the mean function for a continuous outcome as a linear combination between age, gender (male), Creatinine, and three correlated phthalate metabolites:
R> ymod<− OutcomeModel (sigma=1, family = ‘gaussian’, + f = ‘ 0.02* RIDAGEYR +0.1*I(RIAGENDR==1)+0.1* URXUCR + 0.15*URXMHH + 0.07*URXMOH − 0. 1*URXMHP’)
We can use the function to define effects of different levels in a categorical variable. We consider the F-test defined in the first example again for the power analysis using 1000 MC simulations for a sample size of 100 :
R> set. seed (1) R> power <− sim_power (xmod, ymod, imod, s = 1000, n = 100, + cores = 1, errorhandling = ‘stop’)
The estimated SNR is between 0.27 and 0.28. For linear regression, the SNR is equivalent to the Cohen’s effect size of all predictors. The closed-form formula for the general linear F-test at the 0.05 significance level with 21 predictors, 100 observations and an between 0.27 and 0.28 returns a power between 81% to 85%. At the same significance level, the MC estimate is:
R > summary_df <− summary (power, crit = ‘pval’, thres = 0.05, how = ‘lesser’)
*** POWER ANALYSIS SUMMARY ***
Number of Monte Carlo simulations: 1000
Number of observations in each simulation: 100
Estimated SNR: 0.28
Inference model: F-test
Significance criterion: pval
Significance threshold: 0.05
| | power| |:−−−−−−|−−−−−:| |F−test | 0.822|
We see from the example above that MC simulation is a reliable way to estimate power of a test.
4.3. Sample size planning for a study to identify critical chemicals
In the prior two examples, we demonstrate scenarios where both the closed-form formula and MC simulations produce nearly identical estimates. In this third example, we present a setting where closed-form formulae that don’t account for the multicollinearity among predictors can produce inaccurate power estimates. Specifically, we show that sample size planning using simulation is advantageous compared to closed-form formulae when the study’s objective is to identify individual critical chemicals from a correlated group. First, we simulate 11 phthalates exposures from NHANES by resampling the original data:
R> chems <− c (‘URXUCR’, ‘URXMEP’, ‘URXMBP’, ‘URXMIB’, ‘URXMHP’, + ‘URXMOH’, ‘URXMHH’, ‘URXECP’, ‘URXMZP’, ‘URXCOP’, ‘URXMC1’) R> nhanes <− nhanes1518%>% select (all_of (chems)) R> xmod <− MixtureModel (method = ‘resampling’, data = nhanes)
We define a synthetic outcome that is normally distributed around a linear function of log MEHHP (variable URXMHH in the nhanes1518 data table). Mathematically, . The code below defines the generative model for this outcome:
R> ymod <− OutcomeModel ( + f = ‘0.15*log(URXMHH) ’, + sigma=1, family = ‘gaussian’)
The true regression coefficients and important metabolites are again unknown to the researcher. The researcher is interested in designing a study to identify individual chemical that has an effect on the outcome. She plans to use a Bayesian linear model with variable selection (e.g. BMA) as the inference model. One naive approach to calculate the sample size for this study is to use the general linear F-test formula. Given that the full model is a multiple linear regression with 11 metabolites, and the reduced model is a multiple linear model withou MEHHP, we can calculate the true effect size of MEHHP to be (Cohen, 2013). We calculate the sample size using function WebPower: :wp.regression() in R (Zhang and Mai, 2023). At the 0.01 significance level, the analytical formula indicates we need a sample size of 600 to achieve 80% power in detecting a small effect of one metabolite, controlling for the other 10 metabolites. We compare this estimate with sample size estimates by MC simulation. To do this, we first define two InferenceModels. One is a general linear F-test testing for the effect of MEHHP above and beyond the other 10 metabolites, and the other is a BMA:
R> ftest <− function (y, x) {
+ dat <− as. data.frame(cbind (y, x))
+ full_lm <− lm(y ˜., dat)
+ reduced_lm <− lm(y ˜. − URXMHH, dat)
+ return (list (pval = anova (reduced_lm, full_lm) [[6]] [2]))
+ }
R> imod_f <− InferenceModel (model = ftest, glm. family = ‘gaussian’)
R> imod_bma <− InferenceModel (model = ‘bma’, glm.family = ‘gaussian’)
The BMA model will regress the outcome on all 11 chemicals simultaneously. We then generate power curves for sample sizes 600, 1000, 3000, and 5736 (since the original data has 5736 observations):
R> set.seed (1) R> results_bma <− sim_curve (xmod, ymod, imod_bma, s = 100, + n = c (600, 1000, 3000, 5736), + cores = 3, errorhandling = ‘stop’, snr_iter = 5000) R> results_f <− sim_curve (xmod, ymod, imod_ftest, s = 100, + n = c (600, 1000, 3000, 5736), + cores = 3, errorhandling = ”stop”, snr_iter = 5000)
To plot the power curve to detect the effect of MEHHP above and beyond the effects of the other 10 metabolites at the 0.01 significance level, we use the following code:
R> plot_summary (results_f, crit = ‘pval’, thres = 0.01, + how = ‘lesser’, digits = 3)
To plot power curves for the posterior inclusion probability of each metabolite being higher than 75%, we use the following code:
R> plot_summary (results_bma, crit = ‘pip’, thres = 75, + how=‘greater’, digits = 3)
In the left side of Figure 5, the MEHHP line shows that BMA has less than 10% power to identify MEHHP as an important chemical with 600 study subjects, controlling for the other metabolites, given that 1 unit increase in log MEHHP is associated with 0.15 unit increase in the outcome. As the number of subjects increases to approximately 5500, BMA’s power increases to 80%. These results suggest that almost 60000 observations are needed to detect individual critical chemicals with at least 80% power. The lines for all other chemicals (Creatinine, MBzP, etc.) show the Type I error rate (proportion of rejected tests among all simulations when there is actually zero effect) as a function of sample size.
Fig. 5.
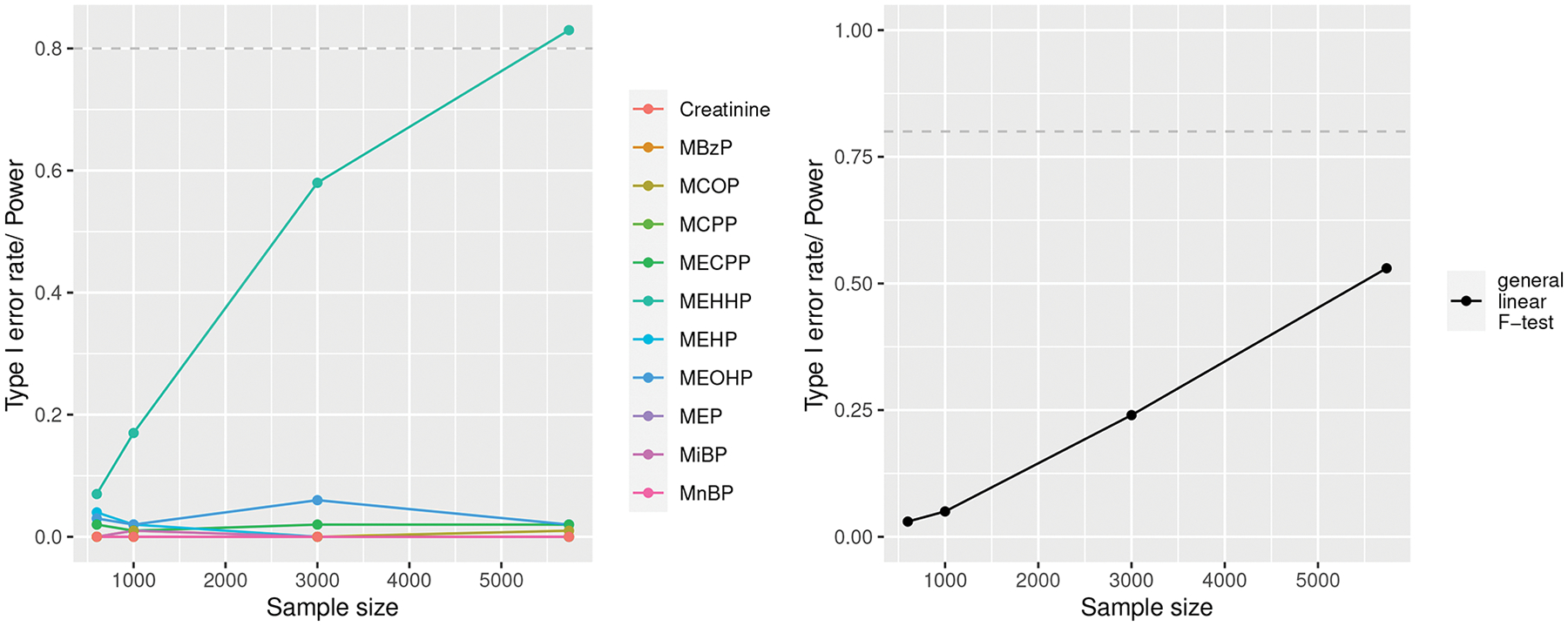
Left: Power curve of the posterior inclusion probability of MEHHP in a Bayesian linear model averaging being higher than 75%, while controlling for other metabolites. Lines for metabolites other than MEHHP show Type I error curves. Right: Power curve to detect a small effect of MEHHP above and beyond the effects of the other 10 metabolites at the 0.01 significance level.
In the right side of Figure 5, we see that the general linear F-test has close to 0% power to detect the small effect of MEHHP while controlling for other metabolites with 600 subjects. This is considerably lower than the estimate provided by the analytical formula. This discrepancy arises because the chemical mixtures involves multicollinearity, which inflates the variances in unregularized multiple linear regressions. Additionally, we see that BMA is more powerful than the F-test at identifying individual important chemicals for a fixed sample size.
4.4. An example in reproducing a study
A recent study (Wu et al, 2020) considers the relationships between mixed exposures to various chemicals and obesity in children and adolescents using NHANES 2005–2010 data. Obesity in the study is measured by BMI z-scores and an indicator of BMI z-scores being over the 95th percentile. All exposures are log transformed for the analysis. The results from various statistical models suggest that Dichlorophenol25 and MEP may be important risk factors for obesity. Suppose that we want to design a study to replicate these results, possibly in a specific population of interest. An important first step is to calculate a sample size to ensure that the study is well-powered and that we avoid dedicating resources to collecting more data than needed. We may specify the target power to be 80% and the target Type I error rate to be 0.05, which are common practices. We also need to specify effect sizes appropriately. One may simply use the estimated effects of 2,5-DCP and MEP from the original study using the NHANES 2005–2010 data provided by the authors. Specifically, the original study finds one unit increase in Dichlorophenol25 (on log scale) is associated with a times increase and MEP (on log scale) with a times increase in the odds of obesity in an multivariate logistic regression adjusted for all covariates and chemicals (Wu et al, 2020, see Additional file 1 Table S1). We additionally hypothesize that there may be a modest interaction between MEP and Methylparaben. Thus, we will use the following conditional mean function for the binary response obesity:
We conduct power analysis for three sample sizes 200, 500, and 1000 using both a logistic regression as well as BWS as inference models. We can summarize the power at each sample size by evaluating the p-values at the 0.05 significance level for each predictor separately in the logistic regression. Likewise, we look at the 95% credible interval of the joint effect in the BWS model. The following code demonstrates how to do that with our package:
R> set.seed (1) R> data_url <− paste0 (‘https://static-content.springer.com/esm/’, + ‘art%3A10.1186%2Fs12940−020−00642−6/MediaObjects/’, + ‘12940_2020_642_MOESM2_ESM.xlsx’) R> nhanes <− openxlsx ∷ read.xlsx (data_url) R> chems <− c(‘UrinaryBisphenolA’, ‘UrinaryBenzophenone3’, + ‘Methylparaben’, ‘Propylparaben’, + ‘dichlorophenol25’, ‘dichlorophenol24’, + ‘MBzP’, ‘MEP’, ‘MiBP’) R> xmod <− MixtureModel (data = nhanes [, chems], method = ‘resampling’) R> ymod <− OutcomeModel ( + f = ‘ 0.55*dichlorophenol 25 + 0.31*MEP + 0.2*MEP*Methylparaben’, + family = ‘binomial’) R> bws_logit <− InferenceModel (model = ‘bws’, iter = 5000, chains = 1, + refresh = 0, family = ‘binomial’) R> glm_logit <− InferenceModel (model = ‘glm’, family = ‘binomial’) R> n_cores <− 1 R> s <− 100 R> n <− c (200, 500, 1000) R> bws_out <− sim curve (xmod = xmod, ymod = ymod, imod = bws_logit, + s = s, n = n, cores = n_cores) R> glm_out <− sim_curve (xmod = xmod, ymod = ymod, imod = glm_logit, + s = s, n = n, cores = n_cores)
The top subplot in Figure 6 shows estimated power curves to detect individual effects in a multiple logistic regression for Dichlorophenol25, MEP, and Methylparaben. The Dichlorophenol25 line shows that we need around 1000 study subjects to achieve 80% power to detect an odds-ratio of 1.73 between subjects that differ by 1 unit of this chemical, controlling for all other chemicals in a logistic regression. We need a sample considerately larger than 1000 to detect the interaction between MEP and Methylparaben. The curves for chemicals with no true effect on the outcome indicate Type I error rate as a function of the sample size.
Fig. 6.
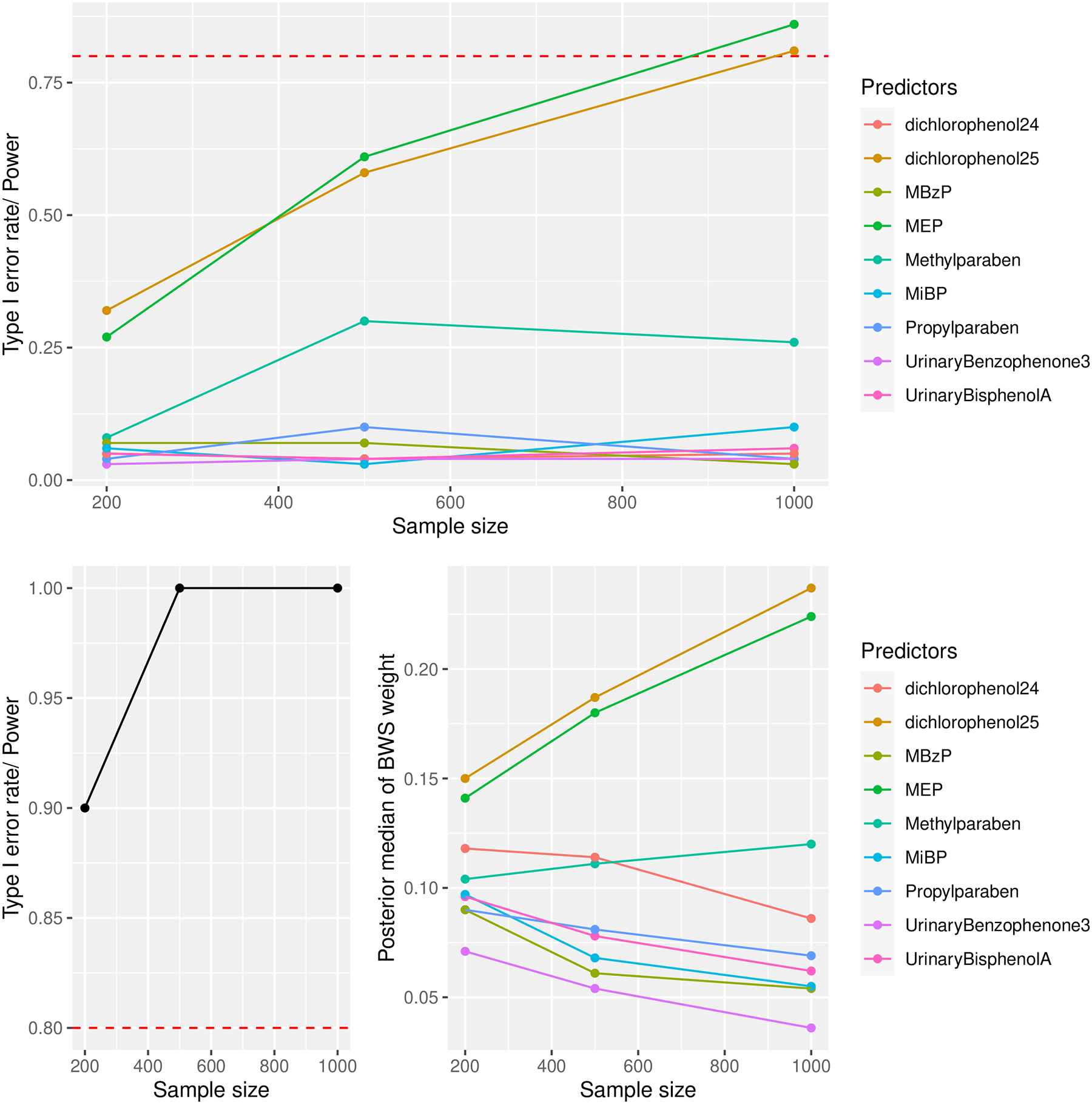
Top: Power curves for Dichlorophenol25, MEP, and Methylparaben from a logistic regression at a 0.05 significance level. The other curves are Type I error rate curves for chemicals with null effects. Bottom left: Power curve of the joint effect from a BWS using a 95% credible interval. Bottom right: The posterior median BWS weights of the predictors. In all subplots, the dotted red line represents the popular 80% threshold for having adequate power.
The subplot in the bottom left of Figure 6 shows that the power to detect the joint effect in BWS is much higher than the power to detect individual effects in a logistic regression for small samples. There is 90% power to detect a joint effect, which represents the effect of a weighted sum of all chemicals, at a sample size of 200. The weights from BWS, however, could be misleading since they erroneously show Dichlorophenol24, a compound closely related to Dichlorophenol25, having a moderate contribution to the joint effect. However, this error diminishes as the sample size increases. Thus, if the researchers are mainly interested in the joint effect of a chemical mixtures, they may save resources by collecting fewer observations and using an inference model such as BWS or QGC. However, if individual effects are of interest, a large sample is needed, and logistic regression, BMA, or BKMR may be preferred.
5. Conclusion
We provide an R package that allows researchers to quickly set up MC simulation for power analysis of observational studies of environmental exposure mixture. The package supports power analysis for recently developed statistical methods for mixtures that lack closed-form power formulas. It allows users to simulate realistic multivariate associations among exposures and mixed-scaled predictors using existing data. This is important to mixture studies because moderate to high correlations among the predictors can diminish the power of many statistical tests. Through our examples, we highlight the importance of conducting power calculations and sample size planning using the mixture method intended to be used for data analysis, while also emphasizing the advantages of simulation-based power analysis in exposure mixture studies.
Acknowledgments.
This work was partially supported by grants R01ES027498 and R01ES028804 of the National Institute of Environmental Health Sciences of the United States National Institutes of Health.
Appendix A. Estimated signal-to-noise ratio as a function of m
We will estimate the SNR of the following data-generating process using different values for m:
R> set.seed (1)
R> xmod <− MixtureModel (method = ‘ resampling’,
+ data = data.frame (x1 = rnorm(200000, mean = 0, sd = 1),
+ x2 = rnorm(200000, mean = 0, sd = 1)))
R> ymod <− OutcomeModel (f = ‘0.3 * x1 + 0.3 * x2’,
+ sigma = 1, family = ‘gaussian’)
R> for (m in c(500, 5000, 50000, 100000)){
+ estimate_snr(ymod, xmod, m = m, R = 1000)
+ }
Since the predictors are independent standard normal distributions, and the noise variance is 1, we can calculate the true SNR as [0.32(1) + 0.32(1)]/1 = 0.18. Figure A1 shows the estimated and 1000-bootstrap s.e. for m ∈ {500, 5000, 50000, 10000, 200000}. A larger m results in a more precise estimate. When the mixture model is defined based on resampling, it may not be possible to choose a large m without duplicating observations and underestimating the signal.
Fig. A1.
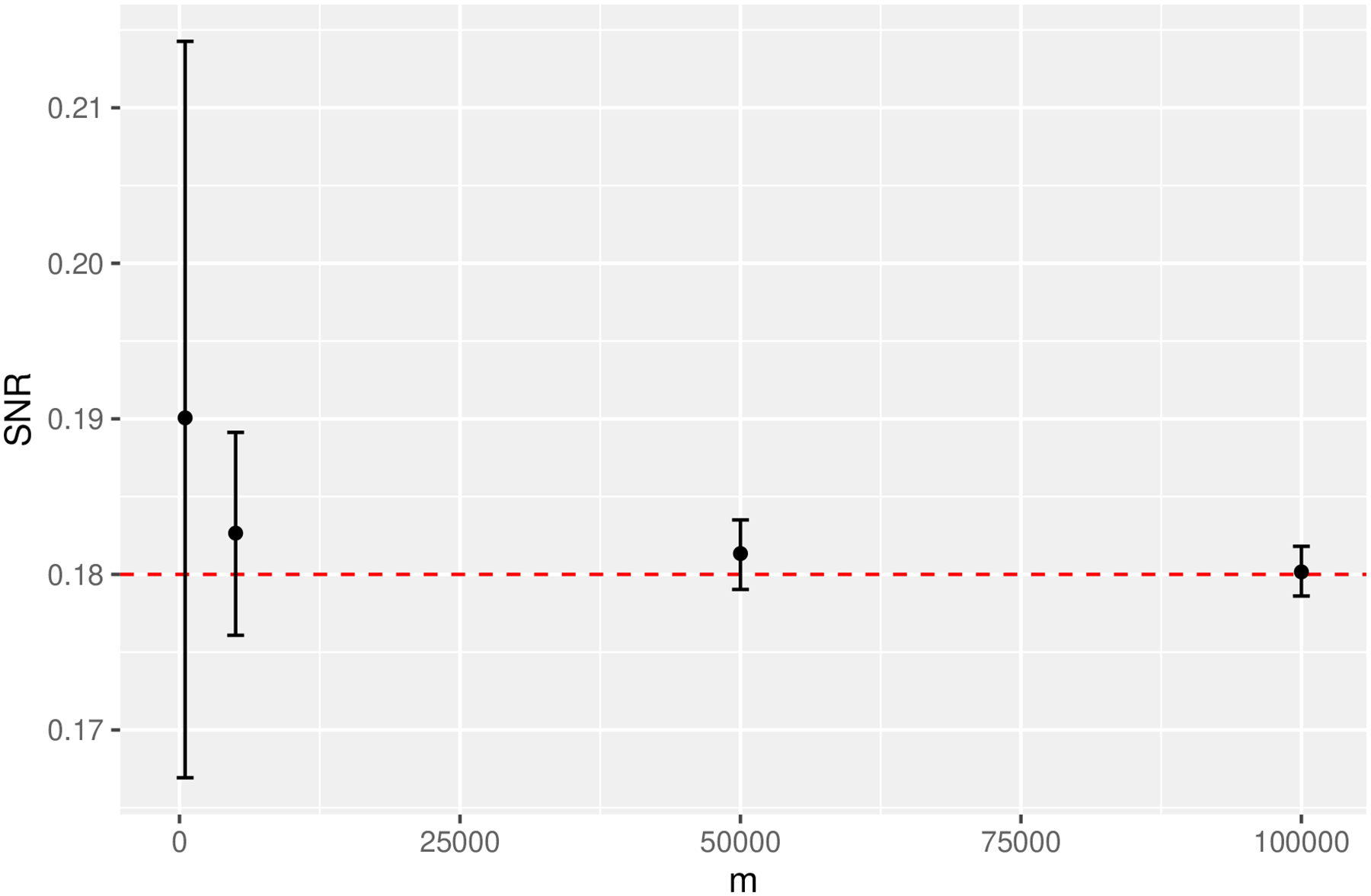
The estimated SNR for the linear model example is unbiased but the standard error might be large with a small sample of simulated data. The red horizontal line is the ground truth SNR.
Footnotes
Competing interests
The authors have no competing interests to declare that are relevant to the content of this article.
Code availability
Publicly available on Github (https://github.com/phuchonguyen/mpower).
Availability of data and materials
Publicly available on Github (https://github.com/phuchonguyen/mpower).
References
- Arnold BF, Hogan DR, Jr JMC, et al. (2011) Simulation methods to estimate design power: An overview for applied research. BMC Medical Research Methodology 11(94). 10.1186/1471-2288-11-94 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Bedford T, Cooke RM (2002) Vines: A new graphical model for dependent random variables. The Annals of Statistics 30(4):1031–1068 [Google Scholar]
- Bien J, Taylor J, Tibshirani R (2013) A lasso for hierarchical interactions. The Annals of Statistics 41(3):1111. 10.1214/13-AOS1096 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Bobb JF, Valeri L, Henn BC, et al. (2015) Bayesian kernel machine regression for estimating the health effects of multi-pollutant mixtures. Biostatistics 16(3):493–508. 10.1093/biostatistics/kxu058 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Bobb JF, Henn BC, Valeri L, et al. (2018) Statistical software for analyzing the health effects of multiple concurrent exposures via bayesian kernel machine regression. Environmental Health 17(67). 10.1186/s12940-018-0413-y [DOI] [PMC free article] [PubMed] [Google Scholar]
- Cohen J (2013) Statistical power analysis for the behavioral sciences. Academic press [Google Scholar]
- Corporation M, Weston S (2022) doSNOW: Foreach Parallel Adaptor for the snow Package. URL https://CRAN.R-project.org/package=doSNOW, R package version 1.0.20
- Czanner G, Sarma SV, Eden UT, et al. (2008) A signal-to-noise ratio estimator for generalized linear model systems. Proceedings of the World Congress on Engineering 2 [Google Scholar]
- Eaton ML (2007) Multivariate statistics: A vector space approach. Institute of Mathematical Statistics Lecture; Notes - Monograph Series 53:512. 10.1214/lnms/1196285102 [DOI] [Google Scholar]
- Ferrari F, Dunson DB (2020a) Bayesian factor analysis for inference on interactions. Journal of the American Statistical Association 0(0):1–12. 10.1080/01621459.2020.1745813 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Ferrari F, Dunson DB (2020b) Identifying main effects and interactions among exposures using gaussian processes. The Annals of Applied Statistics 14(4):1743–1758. 10.1214/20-AOAS1363 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Gastañaga VM, McLaren CE, Delfino RJ (2006) Power calculations for generalized linear models in observational longitudinal studies: A simulation approach in sas. Computer methods and programs in biomedicine 84(1):27–33 [DOI] [PubMed] [Google Scholar]
- Gelman A, Hill J (2007) Data Analysis Using Regression and Multilevel/Hierarchical Models. Cambridge University Press [Google Scholar]
- Green P, MacLeod CJ (2016) SIMR: An R package for power analysis of generalized linear mixed models by simulation. Methods in Ecology and Evolution 7(4):493–498. 10.1111/2041-210X.12504 [DOI] [Google Scholar]
- Hamra GB, Buckley JP (2018) Environmental exposure mixtures: Questions and methods to address them. Current Epidemiology Reports 5(2):160–165. URL 10.1007/s40471-018-0145-0 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Hamra GB, MacLehose RF, Croen L, et al. (2021) Bayesian weighted sums: a flexible approach to estimate summed mixture effects. International Journal of Environmental Research and Public Health 18(4):1373. 10.3390/ijerph18041373 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Hoeting JA, Madigan D, Raftery AE, et al. (1999) Bayesian model averaging: A tutorial. Statistical Science 14(4):382–401. URL http://www.jstor.org/stable/2676803 [Google Scholar]
- Hoff P (2018) sbgcop: Semiparametric Bayesian Gaussian Copula Estimation and Imputation. URL https://CRAN.R-project.org/package=sbgcop, R package version 0.980
- Hoff PD (2007) Extending the rank likelihood for semiparametric copula estimation. The Annals of Applied Statistics 1(1):265–283. 10.1214/07-AOAS107, URL 10.1214/07-AOAS107 [DOI] [Google Scholar]
- Joe H (2006) Generting random correlation matrices based on partial correlations. Journal of Multivariate Analysis 97:2177–2189 [Google Scholar]
- Joubert BR, Kioumourtzoglou MA, Chamberlain T, et al. (2022) Powering research through innovative methods for mixtures in epidemiology (prime) program: Novel and expanded statistical methods. International Journal of Environmental Research and Public Health 19(3). 10.3390/ijerph19031378, URL https://www.mdpi.com/1660-4601/19/3/1378 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Keil A (2021) qgcomp: Quantile G-Computation. URL https://CRAN.R-project.org/package=qgcomp, R package version 2.7.0
- Keil AP, Buckley JP, O’Brien KM, et al. (2020) A quantile-based g-computation approach to addressing the effects of exposure mixtures. Environmental Health Perspectives 128(4). 10.1289/EHP5838 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Landau S, Stahl D (2013) Sample size and power calculations for medical studies by simulation when closed form expressions are not available. Statistical methods in medical research 22(3):324–345 [DOI] [PubMed] [Google Scholar]
- LeBeau B (2022) simglm: Simulate Models Based on the Generalized Linear Model. URL https://CRAN.R-project.org/package=simglm, R package version 0.8.9
- Lewandowski D, Kurowicka D, Joe H (2009) Generating random correlation matrices based on vines and extended onion method. Journal of Multivariate Analysis 100(9):1989–2001. 10.1016/j.jmva.2009.04.008 [DOI] [Google Scholar]
- Lim M, Hastie T (2015) Learning interactions via hierarchical group-lasso regularization. Journal of Computational and Graphical Statistics 24(3):627–654. 10.1080/10618600.2014.938812 [DOI] [PMC free article] [PubMed] [Google Scholar]
- McCullagh P, Nelder JA (1983) Generalized Linear Models. Chapman and Hall [Google Scholar]
- Microsoft, Weston S (2020) foreach: Provides Foreach Looping Construct. URL https://CRAN.R-project.org/package=foreach, R package version 1.5.1
- Morgan-Wall T, Khoury G (2021) Optimal design generation and power evaluation in R: The skpr package. Journal of Statistical Software 99(1):1–36. 10.18637/jss.v099.i01, URL https://www.jstatsoft.org/index.php/jss/article/view/v099i01 [DOI] [Google Scholar]
- Nguyen PH (2022) bws: Bayesian Weighted Sums. URL https://CRAN.R-project.org/package=bws, R package version 0.1.0
- Poworoznek E (2020) infinitefactor: Bayesian Infinite Factor Models. URL https://CRAN.R-project.org/package=infinitefactor, R package version 1.0
- Raftery A, Hoeting J, Volinsky C, et al. (2021) BMA: Bayesian Model Averaging. URL https://CRAN.R-project.org/package=BMA, R package version 3.18.15
- Sun Z, Tao Y, Li S, et al. (2013) Statistical strategies for constructing health risk models with multiple pollutants and their interactions: Possible choices and comparisons. Environmental Health 12(1). 10.1186/1476-069X-12-85 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Wu B, Jiang Y, Jin X, et al. (2020) Using three statistical methods to analyze the association between exposure to 9 compounds and obesity in children and adolescents: Nhanes 2005–2010. Environmental Health 19(94). 10.1186/s12940-020-00642-6 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Zhang Z, Mai Y (2023) WebPower: Basic and Advanced Statistical Power Analysis. URL https://CRAN.R-project.org/package=WebPower, r package version 0.9.3
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.
Data Availability Statement
Publicly available on Github (https://github.com/phuchonguyen/mpower).