

Abstract
This paper provides a brief overview on diffusion models, which are extremely powerful on generating high-dimensional data, including images, 3D content, and videos, and provides insights for future work.
Sufficient and high-quality data are a prerequisite for building complex machine learning systems, especially those with a large number of parameters (e.g., ChatGPT). However, it is typically challenging or even impossible to acquire a sufficient amount of real data to train such systems. For example, auto-driving systems may need to learn from various accidental events in order to be reliable in driving, while collecting such real data is difficult or ethically infeasible. Unlike real data, synthetic data are artificially generated using algorithms without real-world occurrences. There are at least three advantages of synthetic data compared to real data: (1) synthetic data can be more cost-effective, as some real data (e.g. real vehicle crash data for auto-driving) can be extremely expensive; (2) synthetic data can be more time-effective to generate as they are not captured from real-world events and (3) synthetic data can be privacy-preserving as they only resemble real data, often with little traceable information about the actual data.
Given these advantages, it is becoming increasingly important to generate synthetic data for at least two purposes: (1) as complementary data to improve machine learning models, especially when real data are scarce or expensive to generate [1]; (2) as a great aid to human artists in computer-generated arts, e.g., by generating initial sketches, suggesting diverse artistic styles or even co-creating artworks [2]. To generate synthetic data in high dimensions, deep generative models (DGMs) are the most powerful approaches. Among various representative models like generative adversarial networks (GANs) [3], diffusion models [4,5] are the most widely used methods for modeling the distribution of continuous-domain data and generating new samples, because of their training stability and strong model capacity. Diffusion models can not only generate creative artist-styled images [6,7] by training with a large number of data examples, but also have the ability to generate novel samples when very few training samples are available [8].
Figure 1 illustrates the basic idea of a diffusion model, which consists of a forward diffusion process  that gradually adds Gaussian noise to a clean data point (e.g. an image)
that gradually adds Gaussian noise to a clean data point (e.g. an image) 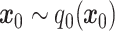 , and then learns a reverse diffusion process
, and then learns a reverse diffusion process  that gradually removes noise to finally generate high-quality data. The forward process is commonly defined as Gaussian distributions
that gradually removes noise to finally generate high-quality data. The forward process is commonly defined as Gaussian distributions  , where the hyperparameters
, where the hyperparameters 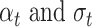 typically satisfy
typically satisfy  . Moreover, let
. Moreover, let  denote the marginal distribution at time t. Then, we can have
denote the marginal distribution at time t. Then, we can have 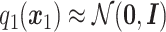 . In other words, the forward process constructs a trajectory from the data distribution to the (approximated) standard Gaussian distribution, and we only need to reverse such a process to draw samples from the data distribution. Concretely, the reverse diffusion process exists and is often defined by gradually denoising from the standard Gaussian
. In other words, the forward process constructs a trajectory from the data distribution to the (approximated) standard Gaussian distribution, and we only need to reverse such a process to draw samples from the data distribution. Concretely, the reverse diffusion process exists and is often defined by gradually denoising from the standard Gaussian 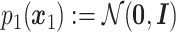 with a noise prediction network
with a noise prediction network  that predicts the noise added to clean data
that predicts the noise added to clean data 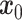 . The unknown parameters of the network are learned by minimizing the objective
. The unknown parameters of the network are learned by minimizing the objective
Figure 1.

An illustration of diffusion models (adapted from [5]).
 |
(1) |
where  is a weighting function that depends on time. Note that the variance of the denoising process has an analytical form and can be estimated in a training-free manner [9]. After training, we have approximately equal marginal distributions (i.e.
is a weighting function that depends on time. Note that the variance of the denoising process has an analytical form and can be estimated in a training-free manner [9]. After training, we have approximately equal marginal distributions (i.e.  ) and then we can draw samples from
) and then we can draw samples from  by gradually denoising
by gradually denoising  with
with 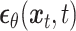 to predict noise. Because of the iterative nature of these models, the computational cost is often higher than other DGMs (e.g. GANs) when scaling to higher resolutions or more complex data types. Many efforts have been devoted to improving the sample efficiency, including the training-free ODE solvers [10] and the distillation methods [11] with some extra training.
to predict noise. Because of the iterative nature of these models, the computational cost is often higher than other DGMs (e.g. GANs) when scaling to higher resolutions or more complex data types. Many efforts have been devoted to improving the sample efficiency, including the training-free ODE solvers [10] and the distillation methods [11] with some extra training.
In many generation tasks, e.g. text-to-image generation [7], we would have some input (e.g. text prompts). One key technique for such applications is classifier-free guidance [12], which trains two weight-sharing models  and
and  for the noise prediction models, where y denotes the input (e.g. text prompt) and
for the noise prediction models, where y denotes the input (e.g. text prompt) and  is the conditional model. Here, we use
is the conditional model. Here, we use  as a special ‘empty’ token for the unconditional model. In a practical implementation, Ho and Salimans [12] chose to randomly set y to the unconditional identifier
as a special ‘empty’ token for the unconditional model. In a practical implementation, Ho and Salimans [12] chose to randomly set y to the unconditional identifier  with some pre-specified probability. Classifier-free guidance then combines these two models as
with some pre-specified probability. Classifier-free guidance then combines these two models as  to trade off the text-image alignment and the sample diversity. The hyperparameter s is known as a ‘guidance scale’, where a larger s usually improves the text-image alignment, but reduces the sample diversity. By choosing a proper guidance scale, pre-trained large-scale text-to-image diffusion models can generate images with comparable quality to human artists.
to trade off the text-image alignment and the sample diversity. The hyperparameter s is known as a ‘guidance scale’, where a larger s usually improves the text-image alignment, but reduces the sample diversity. By choosing a proper guidance scale, pre-trained large-scale text-to-image diffusion models can generate images with comparable quality to human artists.
Besides images, diffusion models (often with proper extension of the guidance) have been adopted for generating high-quality data across various domains, including speech, three-dimensional (3D) contents, human motions, videos and molecules. Specifically, diffusion models can imitate the voice of speaking or singing for a specific person and the generated voices are sometimes hard to distinguish [13]; diffusion models can lift the dimension from two dimensions to three dimensions and generate high-fidelity 3D contents without any 3D training data [14]; diffusion models have also been employed to synthesize human motion corresponding to a given text description [15]; by training with a large amount of video data, diffusion models can even generate short-term videos that are editable by different text prompts with representative systems such as Sora [16] and Vidu [17]. Besides, in bioinformatics and computational biology, diffusion models can facilitate the computational design of proteins and small molecules [18], potentially beneficial to drug discovery and molecular interaction modeling.
For future work, there are various challenges to be addressed in order to apply diffusion models to generate complex data. First, the dependency on large-scale training data to learn a reliable denoising function is one concern, especially in domains where such data are scarce (e.g. 3D contents) or sensitive (e.g. medical images). A possible way forward is to combine the generation of diffusion models with exploration by reinforcement learning methods to effectively interact with the real world. Additionally, the integration of domain knowledge or employing semi-supervised learning approaches could alleviate the dependency on extensive training data. Second, the current design for diffusion models mainly focuses on continuous domains, such as images, videos or audio, but it is hard to train diffusion models for discrete data, such as text. The performance of state-of-the-art diffusion models in language modeling is still worse than autoregressive models. As diffusion models have the potential for parallel decoding for multiple tokens, it is potentially valuable to study how to apply diffusion models in text distributions. Furthermore, the fusion of diffusion models with other generative frameworks like GANs or variational auto-encoders could spawn novel hybrid models with improved generation capabilities. Also, exploring the applicability of diffusion models in emerging domains like augmented reality, virtual reality and real-time multimedia synthesis presents exciting avenues. Lastly, the development of interpretable and controllable diffusion models could foster a deeper understanding and better control over the generated data, which is crucial for critical applications like healthcare and autonomous systems. Through concerted efforts in addressing these challenges and exploring new directions, the evolution of diffusion models is poised to significantly impact the landscape of data generation and even beyond, such as building adversarially robust classifiers from a pre-trained diffusion model [19] or adopting diffusion models to model human behaviors as the policy distribution [20] in reinforcement learning.
Conflict of interest statement. None declared.
REFERENCES
- 1. Sandfort V, Yan K, Pickhardt P et al. Sci Rep 2019; 9: 16884. 10.1038/s41598-019-52737-x [DOI] [PMC free article] [PubMed] [Google Scholar]
- 2. Shahriar S. Displays 2022; 73: 102237. 10.1016/j.displa.2022.102237 [DOI] [Google Scholar]
- 3. Goodfellow I, Pouget-Abadie J, Mirza M et al. Generative adversarial nets. In: Proceedings of the 27th International Conference on Neural Information Processing Systems, Vol. 2. Cambridge: MIT Press, 2014, 2672–80. [Google Scholar]
- 4. Ho J, Jain A, Abbeel P. Denoising diffusion probabilistic models. In: Proceedings of the 34th International Conference on Neural Information Processing Systems. Red Hook: Curran Associates, 2020, 6840–51. [Google Scholar]
- 5. Song Y, Sohl-Dickstein J, Kingma D et al. Score-based generative modeling through stochastic differential equations. International Conference on Learning Representations, Virtual, 3-7 May 2021.
- 6. Ramesh A, Dhariwal P, Nichol A et al. arXiv: 2204.06125.
- 7. Rombach R, Blattmann A, Dominik L et al. High-resolution image synthesis with latent diffusion models. In: 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Los Alamitos: IEEE Computer Society, 2022, 10674–85. 10.1109/CVPR52688.2022.01042 [DOI] [Google Scholar]
- 8. You Z, Zhong Y, Bao F et al. Diffusion models and semi-supervised learners benefit mutually with few labels. In: Proceedings of the 37th International Conference on Neural Information Processing Systems. Red Hook: Curran Associates, 2024, 2755–63. [Google Scholar]
- 9. Bao F, Li C, Zhu J et al. Analytic-DPM: an analytic estimate of the optimal reverse variance in diffusion probabilistic models. International Conference on Learning Representations, Virtual, 25-29 April 2022.
- 10. Lu C, Zhou Y, Bao F et al. DPM-solver: a fast ODE solver for diffusion probabilistic model sampling in around 10 steps. In: Proceedings of the 36th International Conference on Neural Information Processing Systems. Red Hook: Curran Associates, 2024, 5775–87. [Google Scholar]
- 11. Song Y, Dhariwal P, Chen M et al. Consistency models. In: Proceedings of the 40th International Conference on Machine Learning. JMLR, 2023, 32211–52. [Google Scholar]
- 12. Ho J, Salimans T. Classifier-free diffusion guidance. NeurIPS 2021 Workshop on Deep Generative Models and Downstream Applications, virtual, 6-14 December 2021.
- 13. Huang R, Huang J, Yang D et al. arXiv: 2301.12661.
- 14. Wang Z, Lu C, Wang Y et al. ProlificDreamer: high-fidelity and diverse text-to-3D generation with variational score distillation. In: Proceedings of the 37th International Conference on Neural Information Processing Systems. Red Hook: Curran Associates, 2024, 8406–41. [Google Scholar]
- 15. Tevet G, Raab S, Gordon B et al. Human motion diffusion model. International Conference on Learning Representations, Kigali Rwanda, 1-5 May 2023.
- 16. Brooks T, Peebles B, Holmes C et al. Video generation models as world simulators. Technical Report, OpenAI, 2024.
- 17. Bao F, Xiang C, Yue G et al. arXiv: 2405.04233.
- 18. Zhao M, Bao F, Li C et al. Equivariant energy-guided SDE for inverse molecular design. International Conference on Learning Representations, Kigali Rwanda, 1-5 May 2023.
- 19. Chen H, Dong Y, Wang Z et al. Robust classification via a single diffusion model. International Conference on Machine Learning, Vienna, Austria, 21-27 July 2024.
- 20. Chen H, Lu C, Ying C et al. Offline reinforcement learning via high-fidelity generative behavior modeling. International Conference on Learning Representations, Kigali Rwanda, 1-5 May 2023.