

Abstract
3D imaging enables accurate diagnosis by providing spatial information about organ anatomy. However, using 3D images to train AI models is computationally challenging because they consist of 10x or 100x more pixels than their 2D counterparts. To be trained with high-resolution 3D images, convolutional neural networks resort to downsampling them or projecting them to 2D. We propose an effective alternative, a neural network that enables efficient classification of full-resolution 3D medical images. Compared to off-the-shelf convolutional neural networks, our network, 3D Globally-Aware Multiple Instance Classifier (3D-GMIC), uses 77.98%–90.05% less GPU memory and 91.23%–96.02% less computation. While it is trained only with image-level labels, without segmentation labels, it explains its predictions by providing pixel-level saliency maps. On a dataset collected at NYU Langone Health, including 85,526 patients with full-field 2D mammography (FFDM), synthetic 2D mammography, and 3D mammography, 3D-GMIC achieves an AUC of 0.831 (95% CI: 0.769–0.887) in classifying breasts with malignant findings using 3D mammography. This is comparable to the performance of GMIC on FFDM (0.816, 95% CI: 0.737–0.878) and synthetic 2D (0.826, 95% CI: 0.754–0.884), which demonstrates that 3D-GMIC successfully classified large 3D images despite focusing computation on a smaller percentage of its input compared to GMIC. Therefore, 3D-GMIC identifies and utilizes extremely small regions of interest from 3D images consisting of hundreds of millions of pixels, dramatically reducing associated computational challenges. 3D-GMIC generalizes well to BCS-DBT, an external dataset from Duke University Hospital, achieving an AUC of 0.848 (95% CI: 0.798–0.896).
Keywords: Deep learning, convolutional neural networks, breast cancer screening, digital breast tomosynthesis, mammography
I. Introduction
Mammography is the standard medical imaging modality in breast cancer screening programs, which are crucial in the early detection of the leading cause of cancer-related death among women worldwide [1]. Digital breast tomosynthesis (DBT) or “3D mammography”, has been introduced to improve quality of diagnosis in breast cancer screening. Full-field digital mammography (FFDM) projects the three-dimensional information of breasts to two-dimensional planes, which can obscure lesions with other breast tissues. Because DBT images are three-dimensional, they more accurately capture the three-dimensional information than FFDM and enable better identification of suspicious findings. Thus, DBT leads to more cancers being found and a reduction in recall rates [2], [3], [4], [5], [6], [7]. However, as DBT images contain 70 slices on average (about 340 million pixels on average), it almost doubles its interpretation time for radiologists compared to FFDM [8]. Therefore, there is a need for tools for computer-aided detection and diagnosis to reduce interpretation time for DBT images.
One cannot naively apply large-capacity neural networks to high-resolution multi-slice DBT images with modern GPUs without running out of memory. Attempts to downsample 3D images or project each 3D image into one 2D image lead to losing the benefit of DBT: separation of lesions from nearby structures. If pixel-level or lesion-level ground truth labels (segmentations of regions of interest) were available, it is possible to train neural networks by utilizing small subset of large 3D images at a time. However, collecting these annotations is a time-consuming and mostly manual process, which requires experts (e.g., radiologists) to annotate suspicious areas on dozens of slices.
To address these limitations, we propose 3D Globally-Aware Multiple Instance Classifier (3D-GMIC), a deep neural network which predicts malignancy of lesions and localizes them in 3D images. Our architecture extends the Globally-Aware Multiple Instance Classifier (GMIC) [9], a highly effective neural network architecture for large 2D images, to 3D data. 3D-GMIC acts by first determining the most important regions utilizing a low-capacity network, to which a high-capacity network is applied. 3D-GMIC learns to highlight the regions important to predicting image-wise classification labels. This enables applying 3D-GMIC to learn from data without segmentation labels. To implement 3D-GMIC, we introduce a number of technical advances. Importantly, among similar regions in nearby slices, 3D-GMIC selects the region in the most important slice and avoids processing duplicate information. This enables training deep neural networks with entire DBT images without downsampling or performance degradation. In addition, we improve the stability of learning in low-data regimes when using backbone networks with ReLU nonlinearity. Furthermore, we devise a novel approach to adeptly handle the varying number of slices in DBT images. Lastly, we have designed 3D-GMIC to learn effectively with mini-batch size of 1 DBT image per GPU using 4 GPUs in parallel by using group normalization [10] and synchronized batch normalization. A detailed discussion of these technical advances is provided in section V-B.
To demonstrate the effectiveness of 3D-GMIC, we compare its performance to models trained on equivalent 2D datasets. We train and evaluate the models on three different imaging modalities used in breast cancer screening; (1) FFDM: Full-Field Digital Mammography, (2) DBT: Digital Breast Tomosynthesis and (3) synthetic 2D: 2D image generated by combining information from different slices of DBT images using the proprietary C-View™ algorithm [11]. We show that our 3D-GMIC model enables end-to-end training with whole DBT images by using 77.98%–90.05% less GPU memory and 91.23%–96.02% less computation compared to off-the-shelf deep convolutional neural networks. In addition, we show that 3D-GMIC trained on our internal dataset generalizes well to an external dataset from Duke University Hospital [12], [13], [14]. Hence 3D-GMIC may allow other researchers to perform classification and weakly-supervised semantic segmentation with other types of 3D data. Our model code and model weights are released at https://github.com/nyukat/3D_GMIC.
II. Related Work
Prior works on building deep neural networks for DBT images have at least one of the following four disadvantages.
First, many of them work with synthesized 2D images rather than the entire 3D image. These images are generated from the DBT images by proprietary algorithms bundled with the scanner [15] or by third-party methods aggregating information from all slices such as dynamic feature image [16] or maximum intensity projection [17]. In addition, there exist approaches which create attention-weighted summaries of small subsets of DBT slices, resulting in multiple “slabs” that resemble 2D mammography [18]. The resulting images may suffer from the same disadvantage as FFDM: the lesion could be hidden by nearby structures located at different depths. Therefore, the performances of the model on synthesized 2D images could suffer compared to model on DBT images. In addition, models trained on synthesized 2D images will not be able to predict which slices in DBT images contain the suspicious findings, limiting the usefulness in assisting the radiologists in reading DBT images.
Second, the studies that use DBT instead of synthetic 2D images still do not utilize the entire image at once in training. Some utilize a subset of DBT slices [19] whereas others process small region of interest (ROI) patches pre-extracted from lesions [17], [20], [21]. A model utilizing a subset of slices risks missing those potentially most informative to the diagnosis. A model processing image patches does not learn to utilize the global context of the entire breast.
Third, some of the works require more detailed labels such as bounding-boxes or pixel-level segmentations [12], [17], [20], [21], [22], [23], [24]. While training the model with pixel or lesion-level labels may improve the performance compared to just using image-level labels, the former are more labor-intensive and time-consuming to collect, especially for 3D data. Collecting segmentation or bounding box labels requires experts to perform manual work, while study-level labels can be reliably extracted from hospital information systems.
Lastly, most of the prior works were evaluated on datasets with small sample sizes [23], [25], [26], [27] or patient cohorts with specific inclusion criteria. In addition, they do not perform any external validation of their models using datasets from other hospitals. This limits drawing reliable conclusions about the potential clinical utility of such models.
More details on the related works on AI for DBT can be found in Bai et al. [28]. For example, Singh et al. [17] achieved an AUC of 0.847, Tardy and Mateus [18] achieved an AUC of 0.73. Please note that the reported performances of the related works are not directly comparable because they are not evaluated on the same dataset.
In addition, there exist general-purpose computation- and memory-saving techniques such as gradient checkpointing [29] and swapping CPU and GPU memory [30], [31] which reduce the maximum GPU memory usage to enable training high-capacity neural networks with large 3D images without downsampling. However, these techniques do not reduce the amount of required computation. In fact, they add additional overhead for recomputing forward passes, saving and loading gradients, and/or swapping memories between devices.
III. Dataset
A. Internal Dataset
Our retrospective study was approved by the NYU Langone Health Institutional Review Board (study ID# i18–00712_CR3) and was compliant with the Health Insurance Portability and Accountability Act. Informed consent was waived. To perform this study, we created a dataset consisting of exams containing both FFDM and DBT images. We refer to this dataset as “NYU Combo v1”. The NYU Combo v1 dataset consists of 99,862 exams from 85,526 patients screened between January 2016 and June 2018 at NYU Langone Health. Each exam contains the four standard views used in screening mammography (R-CC, L-CC, R-MLO, and L-MLO) for all three imaging modalities (FFDM, DBT, synthetic 2D). The manufacturer and model name of all images in this dataset are ‘HOLOGIC, Inc.’ and ‘Selenia Dimensions’. Since 99% of DBT images have 96 slices or less, we discarded exams that contain DBT images with more than 96 slices. This is to keep the efficiency of data loading and confine the VRAM usage to a predictable amount during our experiments. Note that it is possible to utilize more than 96 slices for both training and inference as long as sufficient VRAM is available.
Only a small number of breasts are associated with pathology labels. Among the 199,724 breasts in the NYU Combo v1 dataset, 2,579 breasts (1.29%) had benign findings and 635 breasts (0.32%) had malignant findings. 150 (0.08%) breasts had both benign and malignant findings. All benign and malignant findings were pathology-proven. Exams not associated with any pathology report were assigned a negative label, indicating the absence of any biopsied findings. Note that NYU Combo v1 dataset is about half the size of the dataset used in Wu et al. [32] and Shen et al. [9].
We divided NYU Combo v1 into training, validation, and test sets. First, we sorted patients in the chronological order of their most recent exams. We designated the first (i.e., the ones who had their last exam earlier than other patients) 80% of the patients (68,412) to the training set, the next 10% of the patients (8,543) to the validation set, and the remaining (most recent) 10% (8,571) to the test set. This results in 78,702, 10,266 and 10,894 exams in the training, validation, and the test set respectively. There are 518, 64, 53 malignant breasts and 2095, 245, 239 benign breasts in the training, validation, test sets respectively.
To acquire lesion annotations on DBT images in the test set, we asked a group of 16 radiologists from NYU Langone Health to annotate the location of biopsied lesions by segmenting them with ITK-SNAP [33]. They annotated the location, shape and size of the biopsied lesions by drawing over them. Each image was annotated only once. Thus, there could be some interobserver variability affecting the evaluation, which we do not attempt to solve here. While it is possible to annotate the same lesion multiple times by different radiologists and take the average to minimize interobserver variability, this would limit the number of images we would be able annotate. We used these labels only for evaluating semantic segmentation performance in the test set. They were not used during training and validation.
In addition, as only a small number of exams have benign or malignant findings, we utilize transfer learning to improve the performance of our models as described by Wu et al. and Shen et al. [9], [32]. In this pretraining, we utilized BI-RADS labels extracted from radiology reports, which are the radiologist’s assessment of a patient’s risk of having breast cancer based on the screening mammography. We use all BI-RADS scores but group them into 3 classes: (a) incomplete or high suspicion (BI-RADS category 0, 4, 5), (b) normal (BI-RADS category 1), and (c) benign (BI-RADS category 2 and 3). We utilized both the NYU Breast Cancer Screening Dataset v1.0 (BCSDv1) [34] and NYU Combo v1 in pretraining a part of our model. When combining the two datasets, we only selected patients from BCSDv1 who do not overlap with the patients in the validation and test sets of NYU Combo v1 to avoid an information leak. As a result, we were able to utilize additional 210,389 2D screening mammography exams for pretraining our models with BI-RADS labels. More details of pretraining and transfer learning are in section V-D.1.
B. External Dataset
In an additional evaluation of our models, we utilize BCSDBT, an external dataset from Duke University Hospital [12], [13], [14], specifically the subset that was released as the training dataset of the DBTex challenge1 [35]. This dataset consists of 19,148 DBT images from 4,838 studies that belong to 4,362 patients. We utilize all images, including the ones with 96 slices or more. The manufacturer and model name of all images in this dataset are ‘HOLOGIC, Inc.’ and ‘Selenia Dimensions’. It contains 87 bounding-box labels for malignant lesions, and 137 bounding-box labels for benign lesions. Even though this dataset uses the same manufacturer and model as NYU Combo V1 dataset, BCS-DBT still serves as an effective dataset for external validation. This is because there are variations in data collection and processing between datasets collected from different hospitals, which could degrade cross-institutional generalization [36].
IV. Task Definition
We formulate the task of predicting the probability of presence of benign and malignant lesions as a multi-label classification problem. That is, given an image , our models make probability predictions corresponding to the labels for each image, where indicate the presence of at least one biopsy-confirmed benign or malignant lesion in , respectively.
V. AI Architecture
The proposed architecture, 3D-GMIC, consists of two subnetworks: the global module and the local module (Fig. 1).
Fig. 1.
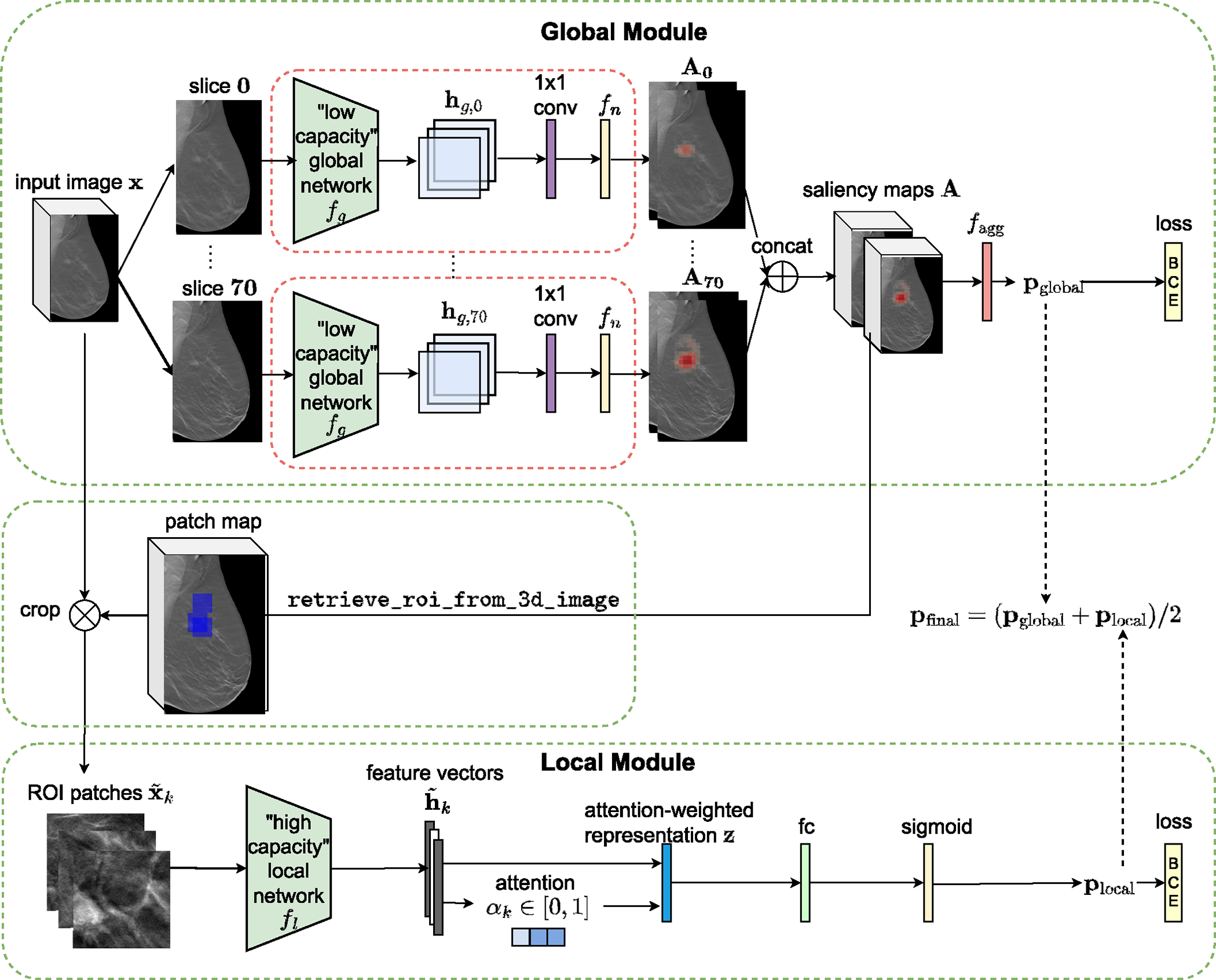
Architecture of 3D-GMIC. 3D-GMIC first applies the same low-capacity global network to all slices of a DBT image to generate the saliency map. The retrieve_roi_from_3d_image algorithm crops ROI patches from the regions corresponding to the highest values in the saliency map. The model then applies the high-capacity local network to the cropped patches to focus the computation in the sampled regions. Finally, the model combines the predictions from the global and local modules to create the overall prediction for the input image.
A. High-Level Overview of 3D-GMIC
1). The Global Module:
The proposed model, 3D-GMIC (Fig. 1), extends GMIC [9] to 3D data. The low-capacity global network is a convolutional neural network which processes 2D input images. As in the original GMIC, the global network is parameterized as ResNet-22 [32] which is narrower and has larger strides compared to the canonical ResNet architectures [37]. 3D-GMIC applies the global network separately to each slice of a 3D image in parallel. For each slice in the input 3D image with slices, the global network first extracts the hidden representation where are the hidden dimensions. The hidden representation is turned into saliency maps using a semantic segmentation layer, which is a combination of a 1 × 1 convolution layer with a nonlinear function . Concretely,
| (1) |
The saliency maps for all slices of are then aggregated to form the 3D saliency map . These saliency maps identify the most important regions and slices of the input image for the benign and malignant categories.
Then, for each class , we use an aggregation function to transform the saliency map into image-level class prediction :
| (2) |
We define the aggregation function as
| (3) |
where denotes the set containing locations of top values in as described in section V-B.3.
2). The Local Module:
In the local module of 3D-GMIC, we select the most important regions of according to the saliency maps . Concretely, we greedily select square patches which corresponds to the high values in the saliency maps as in the retrieve_roi algorithm from Shen et al. [9]. We adapt and modify this algorithm for 3D images to prohibit selecting a patch if one of the previously selected patches were at the same xy-location and from neighboring slices. This prevents cropping multiple patches with duplicate information from nearby slices. We name this algorithm retrieve_roi_from_3d_image (Algorithm 1). The width and height of the patches are fixed to 256 in all experiments. This algorithm identifies image patches to maximize the criterion in line 7 at each selection as follows: = retrieve_roi_from_3d_image().
We can then apply the high-capacity local network to utilize fine-grained details from the selected image patches by computing . The extracted feature vectors are then aggregated using a gated attention mechanism [38]. Attention scores, , indicating the relevance of each patch are calculated as follows:
| (4) |
where denotes an element-wise multiplication, and are learnable parameters. In all experiments, we set and . This process yields an attention-weighted representation
| (5) |
We then apply a fully connected layer with sigmoid nonlinearity to to generate the prediction , where are learnable parameters.
3). 3D-GMIC Output:
We average the predictions from the global and local modules of 3D-GMIC to produce the final class predictions as .
4). The Loss Function Used in the Training of 3D-GMIC:
3D-GMIC is trained end-to-end by minimizing binary crossentropy (BCE) losses for the predictions from the two stages and . In addition, we encourage sparsity on the saliency maps by imposing regularization :
| (6) |
This enables successful semantic segmentation of important regions in the saliency map. In summary, the training loss has the following form:
| (7) |
where is a hyperparameter. We calculate the two BCE losses separately and sum them up rather than calculating one BCE loss with the arithmetic average between the two predictions and . This is because the latter leads to underutilization of one of the modules [39]. In other words, optimizing the latter BCE loss leads to one of the modules learning to predict the cancer accurately and the other module just predicting the same probability for all images.
B. Technical Advances Enabling Learning From Datasets With Small Number of Large Images
DBT is a relatively recent imaging modality and therefore researchers might have a limited number of DBT exams available. In addition, DBT is an imaging modality consisting of hundreds of millions of pixels and training AI models on such large images is technically challenging. In this section, we describe the components which enable processing DBT images without compromising performance.
1). Group Normalization:
For the global network, we replace batch normalization [40] with group normalization [10] with 8 groups to retain performance with small batch size and avoid treating each slice of image as different examples in batch normalization. Since group normalization is mostly robust to the choice of the number of groups, we choose 8 as it showed good performance in the original paper and all channel sizes are divisible by 8.
2). Patch Sampling in 3D:
In DBT, a lesion appears across multiple slices with varying focus. Cropping patches from all of these slices is unnecessary as they are redundant. Therefore, the retrieve_roi_from_3d_image algorithm (Algorithm 1) is designed to avoid cropping redundant patches. Specifically, when cropping each patch, we remove saliency from nearby slices at the same xy-location as the best candidate patch to prevent cropping redundant patches in the following steps. In addition, during training, we uniformly sample one of the patches from nearby slices ( slices) at the same xy-location as a part of input data augmentation.
3). Saliency Aggregation Independent of Image Slices:
For the benign and malignant classes, the aggregation function in the global module of standard GMIC pools the top t% of the values from the saliency maps and . It can be viewed as a balance between global average pooling and global max pooling. In the standard GMIC, this top t% pooling leads to superior performances in comparison to either of the extremes.
The size of the saliency maps and for a DBT image is where is the height, is the width, and is the number of slices in the input image (therefore, also in the saliency map). If the aggregation function pools of the pixels with respect to the entire and , then the number of pooled pixels in each saliency map is . Since this formula is dependent on , the aggregation function pools different numbers of pixels from the saliency maps from images with different numbers of slices. However, the sizes of lesions in DBT images do not depend on the number of slices.2 Since the sizes of the lesions are independent of the sizes of the breasts, the formula’s dependence on can cause contradictory training signals and outputs.
Algorithm 1.
retrieve_roi_from_3d_image
| Input: , | |
| Output: | |
| 1: | |
| 2: | for each class do |
| 3: | |
| 4: | end for |
| 5: | |
| 6: | denotes an arbitrary rectangular patch on |
| 7: | |
| 8: | for each do |
| 9: | |
| 10: | = position of in |
| 11: | if and (model.training) then |
| 12: | = uniformly sample a patch from the neighboring slices of |
| 13: | end if |
| 14: | |
| 15: | area including neighboring slices |
| 16: | , set |
| 17: | end for |
| 18: | return |
For example, suppose there exist two DBT images that contain an identical malignant lesion but consist of different numbers of slices. Since the lesions show the same characteristics such as shape and size, it will highlight the same number of pixels in the saliency maps corresponding to these two images. Nonetheless, the aggregation function will pool different number of pixels from these saliency maps because they have different number of slices. This can lead to the predictions of malignancy of the global module to greatly differ between these two images even though the lesions are identical. This inconsistency could make the learning more difficult than necessary and degrade the performance.
Ideally, should not depend on the size of the breast and only depend on the detected lesions. To do so, 3D-GMIC applies to the saliency maps to pool the values in a way that does not depend on the number of slices in the input image . Specifically, we define the pooling percentage t% with respect to a single slice of a 3D image. For example, from saliency maps of size and size , setting will pool values from both saliency maps which accounts for 4% and 2.5% of the entire 3D saliency map, respectively. This is still a small subset of the entire 3D saliency maps, which allows 3D-GMIC to localize the important regions. At the same time, the number of pooled values from the saliency maps no longer changes across images with different number of slices.
4). The Initialization of the Semantic Segmentation Layer:
In the the global module of standard GMIC, the weights of the semantic segmentation layer are randomly initialized. However, we find that this often leads to the failure of weakly-supervised semantic segmentation in low-data regimes such as in this work,3 as shown in Fig. 2.
Fig. 2.
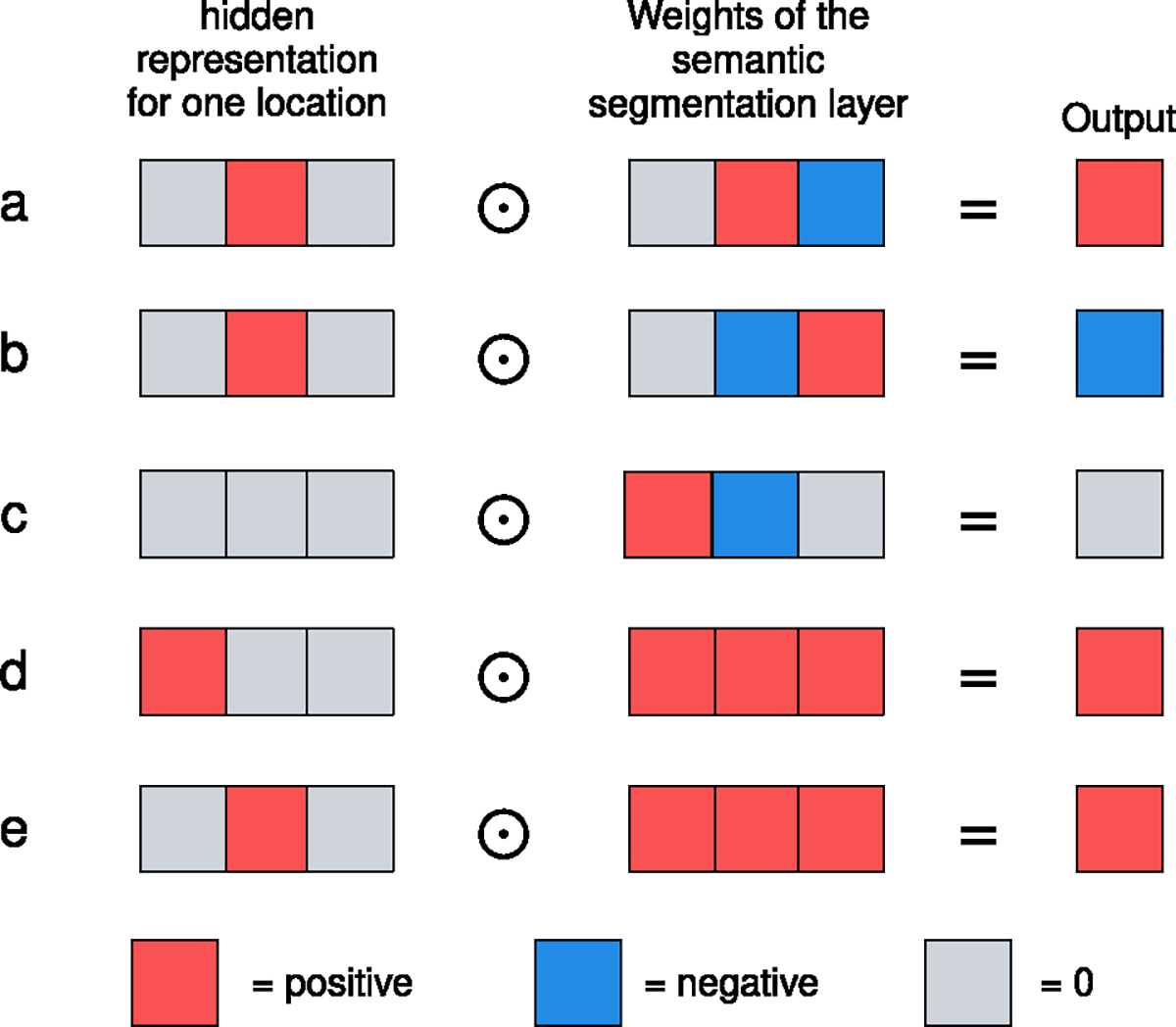
The problem with randomly initialized weights of the 1 × 1 convolution filter in the semantic segmentation layer. Randomly initialized weights (a-c) can map high values of the hidden representation to negative outputs (b). This leads potentially useful features to have lower values in the saliency maps than those from the background. In comparison, weights initialized with a constant (d-e) always map high hidden representation values to positive output. This ensures that the values in the saliency maps from interesting regions will be higher than those from the background, which is a more reasonable starting point for model training and leads to consistent success of semantic segmentation.
The problem with randomly initialized weights in the convolutional layer occurs when performing transfer learning from a pretrained ReLU network with top pooling, as shown in Fig. 2a~c. The pretrained CNN with ReLU nonlinearity tends to output high positive logit values in some channels for locations where small, important features are. Ideally, this value should be multiplied with some positive weight in the semantic segmentation layer such that we can preserve this information as shown in Fig. 2a. With random initialization, however, negative weights often get assigned to these channels which detect important features as shown in Fig. 2b. The outputs from such important features will then be lower than the output of the unimportant regions shown in Fig. 2c.
In such a case, the important regions will not be pooled to as shown in Fig. 3. Instead, will pool from the background and normal regions without any pathology since the values in the saliency maps corresponding to these regions will be higher than those where malignant or benign lesions are. As a result, the saliency pooled from normal regions from malignant breasts will be encouraged to output 1, teaching the model to highlight the wrong portions of the images. This leads to the failure of weakly-supervised semantic segmentation.
Fig. 3.

Failure of weakly-supervised semantic segmentation. As explained in section V-B.4, the areas in the saliency map (right) corresponding to the biopsied lesion (left) have lower values than the unimportant regions and the background after BI-RADS pretraining. In this case, it is difficult for model to learn to highlight lesions correctly with top-t% pooling.
To address this issue, we initialize the layer in the semantic segmentation layer with constant, positive weights (Fig. 2d~e). No matter which channel of the pretrained model reacts to important regions in the image, it will be correctly captured as high value in the saliency maps since the model weighs all channels equally at the beginning. In this configuration, will pool from important regions in positive exams and encourage the pooled values to be closer to 1.
5). The Choice of Nonlinearity :
When using constant initialization of the semantic segmentation layer, sigmoid function is no longer an ideal choice for nonlinearity . For the sigmoid function to suppress the probability predictions corresponding to background regions, the 1 × 1 convolution layer in the semantic segmentation layer must output highly negative values for uninteresting regions. When using the constant weight initialization and sigmoid nonlinearity, the low logits from the background regions are mapped close to 0.5 probability in the saliency map, and the high logits from the suspicious regions are mapped to probability values that are somewhat higher than 0.5 at the beginning of training. To decrease the 0.5 probability predictions from the background regions, the backbone network must learn to output non-zero logits for some channels from all such background regions and then the 1 × 1 convolution layer must associate negative weights for such logits. However, if the model had not already learned to do so during the pretraining phase, it could be hard to learn when fine-tuning with the downstream task. To learn this behavior during the fine-tuning, the pretrained backbone network must change significantly, which could risk catastrophic forgetting.
To mitigate this issue, an ideal nonlinearity should naturally map the near-zero outputs of the 1 × 1 convolution layer into zero probabilities in the saliency maps. One might think that shifting the sigmoid function horizontally could achieve this. However, the input interval corresponding to the highest rate of change in nonlinearity also shifts away from 0, which hinders learning. The ideal nonlinearity for constant weight initialization would map near-zero values to 0 and would have the highest rate of change near zero.
To satisfy these criteria, we propose ReLU(tanh(x)) for as shown in Fig. 4. Like sigmoid, ReLU(tanh(x)) also maps all input values to the [0, 1] interval. Unlike sigmoid, ReLU(tanh(x)) turns the near-zero outputs of the 1 × 1 convolution layer into zero values in the saliency map. At the same time, the highest rate of change occurs with the input values around zero. This simplifies the learning and no longer requires a change of behavior in the backbone network . We observe that ReLU(tanh(x)), combined with the constant initialization of the semantic segmentation layer, leads to consistent success of weakly-supervised semantic segmentation in the saliency maps with the NYU Combo v1 dataset which is smaller than the dataset used in Shen et al. [9].
Fig. 4.
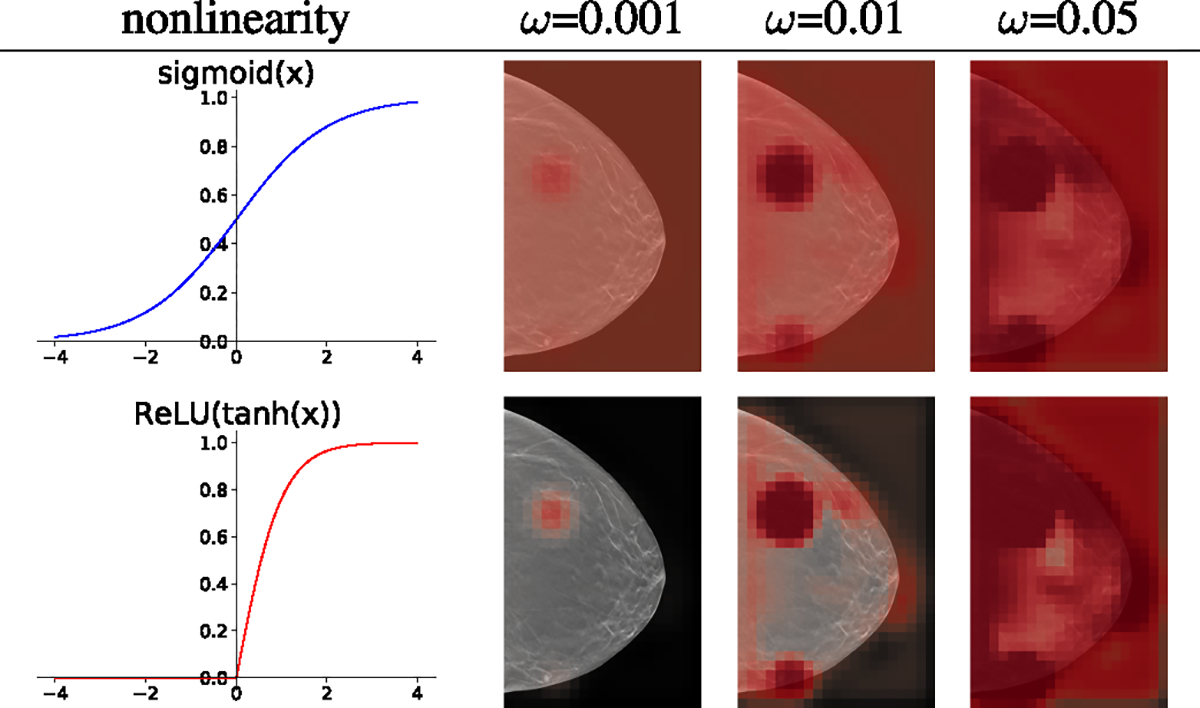
The effect of different nonlinearity functions and the weight initialization constant on a global module pretrained with BI-RADS labels. The visualizations of saliency maps are made with different initialization constants before any further training on the pathology labels. Sigmoid (top) leads to initially predicting 0.5 everywhere in the background, which requires the model to learn to suppress saliency in the background in the downstream training. On the other hand, ReLU(tanh(x)) (bottom) maps all the unimportant near-zero hidden representations to near-zero in the saliency maps from the beginning, which is an easier starting point that ensures the success of semantic segmentation. The effect of three different values of for each nonlinearity is shown in the right panel. With the pretrained global module, we observe that between 0.001 and 0.1 results in saliency maps that sparsely highlight the important regions.
C. Fusion Module
The standard GMIC includes a fusion module to combine the hidden representations of the global and local modules to output the final prediction. In the preliminary experiments, however, we found that the fusion module does not provide benefit with DBT and ReLU(tanh(x)) nonlinearity, and thus we exclude it. We hypothesize that this is because more information is lost in max pooling from 3D representations than max pooling from 2D, which might prevent the learning.
D. Training Procedure
To train the model architectures on different modalities we take the following steps, as shown in Fig. 5:
Fig. 5.
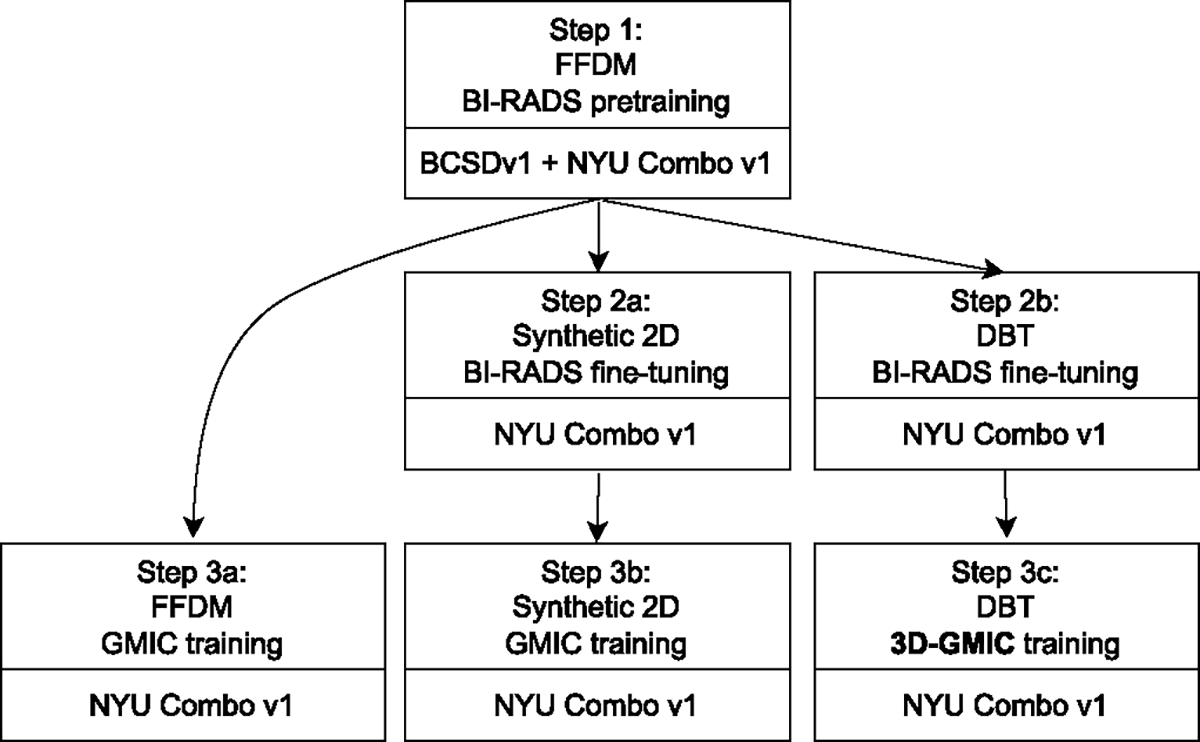
The training pipeline for the three imaging modalities.
Pretrain the global network on BI-RADS labels with the BCSDv1 + NYU Combo v1 combined dataset using FFDM modality only described in section V-D.1).
- BI-RADS fine-tuning: transfer the model from (1) and further train on the BI-RADS classification task to fine-tune the pretrained weights to each modality.
- BI-RADS fine-tuning is performed on the synthetic 2D images from NYU Combo v1 dataset, using the weight from step 1.
- BI-RADS fine-tuning is performed on the DBT images from NYU Combo v1 dataset, using the weight from step 1.
- Training GMIC and 3D-GMIC.
- GMIC is trained on FFDM images from NYU Combo v1 dataset using the weight from step 1.
- GMIC is trained on synthetic 2D images from NYU Combo v1 dataset using the weight from step 2a.
- 3D-GMIC is trained on DBT images from NYU Combo v1 dataset using the weight from step 2b.
Note that the resulting models from the steps 3a, 3b, 3c are different models trained on different imaging modalities. For example, to train 3D-GMIC, only steps 1, 2b, 3c are required. We compare performances from models created in steps 3a, 3b, 3c in Table II, Table III, Table IV, Table V, and Table VI.
TABLE II.
Breast-Wise Test Performances (AUC) for the Global-Only and Full Architectures.For Each Single-Modality Model,We Indicate Its Training Steps as Defined in Section V-D and Fig. 5.For Both Global-Only and Full Architectures, We Find That 3D-GMIC Performs Comparably With Other Models Trained With 2D Imaging Modalities. In Addition, a Multi-Modal Ensemble Including All Three Modalities Leads to the Best Performance in Predicting the Presence of Malignant Lesions.We Compute 95% Confidence Intervals Using 1,000 Iterations of the Bootstrap Method [47]
| global-only | full | |||
|---|---|---|---|---|
|
|
||||
| Modality (Training path) | Malignant | Benign | Malignant | Benign |
|
| ||||
| FFDM (steps 1-3a) | 0.802 (0.734–0.864) | 0.710 (0.681–0.739) | 0.816 (0.737–0.878) | 0.728 (0.695–0.758) |
| Synthetic 2D (steps 1-2a-3b) | 0.790 (0.719–0.856) | 0.696 (0.662–0.727) | 0.826 (0.754–0.884) | 0.699 (0.666–0.732) |
| DBT (steps 1-2b-3c) | 0.811 (0.747–0.869) | 0.714 (0.683–0.747) | 0.831 (0.769–0.887) | 0.717 (0.687–0.745) |
|
| ||||
| Ensemble ot FFDM + Synthetic 2D | 0.805 (0.734–0.873) | 0.709 (0.679–0.737) | 0.832 (0.757–0.892) | 0.720 (0.689–0.751) |
| Ensemble of DBT + Synthetic 2D | 0.807 (0.733–0.871) | 0.712 (0.682–0.744) | 0.840 (0.775–0.894) | 0.715 (0.682–0.746) |
| Ensemble of DBT + FFDM | 0.812 (0.743–0.871) | 0.721 (0.691–0.749) | 0.837 (0.767–0.892) | 0.728 (0.695–0.759) |
| Ensemble of all 3 modalities | 0.811 (0.739–0.875) | 0.717 (0.687–0.745) | 0.841 (0.768–0.895) | 0.723 (0.692–0.754) |
TABLE III.
Breast-Wise Test Performances (Specificity at 90% Sensitivity) for the Global-Only and Full Architectures.For Each Single-Modality Model, We Indicate Its Training Steps as Defined in Section V-D and Fig. 5.We Compute 95% Confidence Intervals Using 1,000 Iterations of the Bootstrap Method [47]
| global-only | full | |||
|---|---|---|---|---|
|
|
||||
| Modality (Training path) | Malignant | Benign | Malignant | Benign |
|
| ||||
| FFDM (steps 1-3a) | 0.401 (0.146–0.689) | 0.365 (0.282–0.439) | 0.448 (0.120–0.716) | 0.348 (0.262–0.436) |
| Synthetic 2D (steps 1-2a-3b) | 0.450 (0.089–0.610) | 0.365 (0.258–0.418) | 0.474 (0.162–0.673) | 0.345 (0.250–0.411) |
| DBT (steps 1-2b-3c) | 0.503 (0.218–0.666) | 0.349 (0.312–0.444) | 0.554 (0.249–0.703) | 0.383 (0.304–0.437) |
|
| ||||
| Ensemble of FFDM + Synthetic 2D | 0.427 (0.138–0.667) | 0.379 (0.271–0.472) | 0.475 (0.074–0.724) | 0.413 (0.259–0.458) |
| Ensemble of DBT + Synthetic 2D | 0.489 (0.123–0.629) | 0.389 (0.314–0.438) | 0.597 (0.181–0.713) | 0.378 (0.304–0.437) |
| Ensemble of DBT + FFDM | 0.417 (0.179–0.707) | 0.374 (0.312–0.434) | 0.585 (0.197–0.729) | 0.379 (0.288–0.435) |
| Ensemble of all 3 modalities | 0.466 (0.126–0.692) | 0.399 (0.313–0.446) | 0.553 (0.141–0.744) | 0.400 (0.293–0.446) |
TABLE IV.
Breast-Wise Test Performances (Matthew’s Correlation Coefficient at 90% Sensitivity) for the Global-Only and Full Architectures.For Each Single-Modality Model, We Indicate Its Training Steps as Defined in Section V-D and Fig. 5.We Compute 95% Confidence Intervals Using 1,000 Iterations of the Bootstrap Method [47]
| global-only | full | |||
|---|---|---|---|---|
|
|
||||
| Modality (Training path) | Malignant | Benign | Malignant | Benign |
|
| ||||
| FFDM (steps 1-3a) | 0.031 (0.008–0.064) | 0.057 (0.042–0.072) | 0.035 (0.001–0.067) | 0.054 (0.038–0.071) |
| Synthetic 2D (steps 1-2a-3b) | 0.035 (−0.005–0.052) | 0.057 (0.037–0.068) | 0.037 (0.006–0.063) | 0.054 (0.036–0.067) |
| DBT (steps 1-2b-3c) | 0.040 (0.011–0.061) | 0.054 (0.046–0.073) | 0.046 (0.015–0.068) | 0.061 (0.045–0.072) |
|
| ||||
| Ensemble of FFDM + Synthetic 2D | 0.033 (0.003–0.060) | 0.060 (0.040–0.078) | 0.038 (−0.005–0.070) | 0.066 (0.037–0.076) |
| Ensemble of DBT + Synthetic 2D | 0.039 (0.001–0.054) | 0.062 (0.047–0.072) | 0.051 (0.009–0.068) | 0.060 (0.046–0.072) |
| Ensemble of DBT + FFDM | 0.032 (0.008–0.068) | 0.059 (0.047–0.070) | 0.049 (0.010–0.071) | 0.060 (0.043–0.071) |
| Ensemble of all 3 modalities | 0.037 (0.002–0.063) | 0.064 (0.048–0.074) | 0.045 (0.004–0.072) | 0.064 (0.045–0.074) |
TABLE V.
Breast-Wise Test Performances (Sensitivity at 95% Specificity) For the Global-Only and Full Architectures.For Each Single-Modality Model, We Indicate Its Training Steps as Defined in Section V-D and Fig. 5.We Compute 95% Confidence Intervals Using 1,000 Iterations of the Bootstrap Method [47]
| global-only | full | |||
|---|---|---|---|---|
|
|
||||
| Modality (Training path) | Malignant | Benign | Malignant | Benign |
|
| ||||
| FFDM (steps 1-3a) | 0.340 (0.213–0.480) | 0.138 (0.093–0.183) | 0.358 (0.236–0.500) | 0.176 (0.128–0.229) |
| Synthetic 2D (steps 1-2a-3b) | 0.377 (0.243–0.508) | 0.130 (0.085–0.175) | 0.472 (0.333–0.600) | 0.172 (0.114–0.223) |
| DBT (steps 1-2b-3c) | 0.396 (0.269–0.533) | 0.167 (0.122–0.219) | 0.472 (0.319–0.600) | 0.163 (0.117–0.209) |
|
| ||||
| Ensemble of FFDM + Synthetic 2D | 0.377 (0.236–0.516) | 0.151 (0.105–0.192) | 0.491 (0.347–0.625) | 0.180 (0.130–0.233) |
| Ensemble of DBT + Synthetic 2D | 0.377 (0.256–0.520) | 0.172 (0.124–0.221) | 0.472 (0.339–0.606) | 0.167 (0.121–0.216) |
| Ensemble of DBT + FFDM | 0.377 (0.250–0.524) | 0.159 (0.109–0.206) | 0.453 (0.323–0.600) | 0.172 (0.125–0.225) |
| Ensemble of all 3 modalities | 0.358 (0.241–0.508) | 0.163 (0.113–0.205) | 0.453 (0.323–0.600) | 0.172 (0.129–0.226) |
TABLE IV.
Breast-Wise Test Performances (Sensitivity at 99% Specificity) For The Global-Only and Full Architectures.For Each Single-Modality Model, We Indicate Its Training Steps as Defined in Section V-D and Fig. 5.We Compute 95% Confidence Intervals Using 1,000 Iterations of the Bootstrap Method [47]
| global-only | full | |||
|---|---|---|---|---|
|
|
||||
| Modality (Training path) | Malignant | Benign | Malignant | Benign |
|
| ||||
| FFDM (steps 1-3a) | 0.038 (0.000–0.100) | 0.033 (0.012–0.058) | 0.151 (0.064–0.254) | 0.042 (0.016–0.070) |
| Synthetic 2D (steps 1-2a-3b) | 0.170 (0.078–0.281) | 0.038 (0.017–0.063) | 0.208 (0.100–0.344) | 0.033 (0.014–0.062) |
| DBT (steps 1-2b-3c) | 0.075 (0.016–0.157) | 0.025 (0.008–0.046) | 0.226 (0.118–0.357) | 0.038 (0.016–0.067) |
|
| ||||
| Ensemble of FFDM + Synthetic 2D | 0.151 (0.061–0.265) | 0.033 (0.012–0.056) | 0.189 (0.082–0.292) | 0.042 (0.018–0.074) |
| Ensemble of DBT + Synthetic 2D | 0.170 (0.069–0.264) | 0.021 (0.004–0.043) | 0.189 (0.091–0.311) | 0.038 (0.014–0.064) |
| Ensemble of DBT + FFDM | 0.057 (0.000–0.127) | 0.017 (0.004–0.036) | 0.189 (0.085–0.296) | 0.042 (0.017–0.069) |
| Ensemble of all 3 modalities | 0.151 (0.058–0.268) | 0.017 (0.004–0.040) | 0.189 (0.088–0.298) | 0.042 (0.019–0.072) |
1). BI-RADS Pretraining:
For the global network of our models, we apply transfer learning from networks pretrained with BI-RADS labels as described by Wu et al. [32] and Geras et al. [41]. We modify the BI-RADS pretraining procedure so that instead of predicting BI-RADS labels utilizing all of the four views in an exam at once, we predict BI-RADS labels for each image separately. We first pretrain a model parameterized with ResNet-22 architecture [32] using the FFDM images, and transfer to further BI-RADS pretraining on other modalities and training GMIC models as described above. For the pretraining phase for the models with DBT images, we use the same ResNet-22 model but apply it to all slices in each image in parallel. And then, we aggregate the average-pooled representation from all slices using a gated attention mechanism [38] before applying logistic regression.
While BI-RADS labels are more noisy than labels derived from pathology reports, we have 46,680 exams with BI-RADS 0 or BI-RADS 2 labels in the training set of NYU Combo V1 dataset. In addition, in the training set obtained by combining BCSDv1 and NYU Combo v1 datasets as discussed in section III-A, we have 159,471 exams with BI-RADS 0 or BI-RADS 2 labels. In comparison, 2,391 exams are associated with positive pathology-driven labels in the training set of NYU Combo V1 dataset. Therefore, BI-RADS is a good target to pretrain our models so that they can learn to recognize important visual features of mammograms, which will be useful for the downstream training with pathology-derived labels. In addition, this step is of vital importance to 3D-GMIC whose contributions on top of GMIC assumes that the global network is pretrained. BIRADS fine-tuning is designed to learn visual features that are specific to synthetic 2D and DBT images and thus to improve performances compared to just using the weights pretrained with FFDM images only.
2). Training 2D GMIC:
We use GMIC for training models with FFDM and synthetic 2D data. For a fair comparison, we apply the same modifications made to 3D-GMIC when we can. Specifically, we apply the same ReLU(tanh(x)) nonlinearity for the generation of the saliency map, replace the fusion module with the average prediction between global and local modules, and replace batch normalization with group normalization in the global module. While these changes do not necessarily improve the best possible performances with 2D-GMIC, our initial experiments indicated that applying them makes learning more stable when learning with fewer data.
3). Image Augmentation:
FFDM images have dimensions (4096, 3328) or (3328, 2560). DBT and synthetic 2D image sizes are either (2457, 1996) or (2457, 1890). The corresponding FFDM, DBT, and synthetic 2D images have the same field of view. We crop each image to a predefined input size using the procedure described by Wu et al. [32]. FFDM images are cropped to the size of 2866 × 1814 pixels, whereas synthetic 2D images and DBT images are cropped to the size of 2116 × 1339 pixels to capture the equivalent field of view. These window sizes were selected as they yield an equivalent field of view for all modalities, considering that the original image resolutions differ between modalities. We also apply random shifting and resizing during training and testing phases for a maximum of 100 pixels in any direction. At test time, we apply 10 random augmentations to get 10 predictions for each image and average them to make a final prediction.
4). Mixed-Precision Training:
To decrease GPU RAM usage, we use the Apex library4 for mixed-precision training [42].
5). Distributed Training:
To maximize the training speed and increase batch size, we parallelize the training over 4 Nvidia v100 GPUs when training models on the 3D modality. The effective batch size per update is 4 images. For the local module, we use a synchronized batch normalization layer to share batch statistics between GPUs.
6). Hyperparameter Tuning:
We optimize network hyperparameters with random search [43]. For all models, we randomly sample the learning rate from log-uniform distribution and the initialization constant from log-uniform distribution .
For 2D GMIC, we randomly sample the pooling percentage with respect to the entire image from uniform distribution , the number of patches with equal probabilities, and the regularization weight from log-uniform distribution .
For 3D-GMIC, we choose a different range of some hyperparameters compared to 2D to mitigate the differences between the imaging modalities. For example, the lesions in the DBT contain 10.97 times more pixels on average compared to the lesions in synthetic 2D images, regardless of the number of slices in DBT images. As this suggests that more salient pixels will be highlighted in the saliency maps for DBT images than the corresponding synthetic 2D images, we increase the minimum and maximum value of the pooling percentage 10.97 times to capture a comparable amount of highlighted area in the saliency maps . In addition, we decrease the minimum and maximum value of regularization weight 10.97 times so that the regularization term has a comparable magnitude to the remaining terms in the final loss function used to train 3D-GMIC.
Finally, we adjust the number of sampled patches for 3D-GMIC to account for the depth in DBT data. Even though there are about 70 slices on average, we do not increase by 70 times compared to GMIC on 2D images. This is because our method is more efficient than applying GMIC on all slices in parallel. Since our retrieve_roi_from_3d_image algorithm avoids cropping duplicate information from nearby patches, 3D-GMIC can focus its computation on much smaller proportion of the input image compared to GMIC. Nonetheless, as a precaution, we increase the number of patches by a conservative factor of 2 compared to GMIC on 2D images as some patches might still be located within the same xy coordinates but at different slices. In such a case, the total number of xy-coordinates from which patches are sampled in 3D-GMIC could be decreased compared to GMIC on 2D mammography, and we want to mitigate this. In Table VIII, we show that this increase was not strictly necessary, as both GMIC and 3D-GMIC utilizing the same number of patches achieve comparable performances.
TABLE VIII.
Ablation Study: The Breast-Wise Test Performances of Models Trained With Each Modality When Cropping 8 ROI Patches in retrieve_roi_from_3d_image Algorithm. We Train Three Models for Each Setting and Show Ensemble Performances With Ten Random Augmentations, Along With the 95% Confidence Intervals.3D-GMIC on DBT Is StillShowing Comparable Performances to GMIC on 2D Images, Even When the Models Use the Same Number of Patches
| AUC (M) | AUC (B) | |
|---|---|---|
|
| ||
| FFDM | 0.796 (0.719–0.860) | 0.707 (0.676–0.740) |
| Synthetic 2D | 0.821 (0.744–0.886) | 0.705 (0.672–0.735) |
| DBT | 0.834 (0.773–0.888) | 0.717 (0.686–0.749) |
As a result, we randomly sample the pooling percentage t from uniform distribution with respect to one slice of an image5 from uniform distribution, number of patches in image with equal probabilities, and the regularization weight from log-uniform distribution .
For all models described in this paper, we optimize their hyperparameters with 40 random search trials. All models were trained for a maximum of 40 epochs but the ones which do not show any improvement in validation performances for 15 consecutive epochs are early stopped. We selected 5 models with the highest AUC scores in identifying images with malignant findings on the validation set.
Training 3D-GMIC for 40 epochs takes about three days when utilizing four Tesla V100 GPUs with 32GB GPU memory in parallel. Training GMIC with FFDM and synthetic 2D data for 40 epochs on a Tesla V100 GPU with 16GB GPU memory takes about 18 hours and about 12 hours, respectively.
VI. Evaluation Metrics
A. Computational Efficiency
To compare 3D-GMIC and other architectures, we measure the maximum GPU memory usage during training and the number of computations in Giga Multiply-ACcumulate operations (GMACs) by benchmarking with a single DBT image with 96 slices. Since it is not possible to run off-the-shelf models with all of 96 slices, we estimate their metrics using linear extrapolation with DBT images with 4, 8, 16 slices.
B. Classification
To evaluate the classification performance, we calculate area under the receiver operating characteristic curve (AUC) on two levels of granularity:
Image-wise AUC, where the performance of the model is evaluated using the predictions for each image.
Breast-wise AUC, where the performance of the model is evaluated using the averaged prediction between CC and MLO views of each breast. This is the main evaluation metric of this work.
To address the class imbalance of the dataset, we additionally report specificity at 90% sensitivity, Matthew’s correlation coefficient [44] at 90% sensitivity, sensitivity at 95% specificity, and sensitivity at 99% specificity.6
C. Semantic Segmentation
We calculate the Dice similarity coefficient (DSC) and pixel average precision (PxAP) [45] to evaluate the ability of 3D-GMIC to perform weakly-supervised semantic segmentation based on the saliency maps. DSC and PxAP are computed as an average over the images with visible biopsy-confirmed findings. It is worth noting that while comparing these values to different models learning from the same imaging modality is fair, comparing them between models learning from different imaging modalities is not necessarily so. FFDM images have higher resolutions than both DBT and synthetic 2D images, and therefore each superpixel in the saliency maps corresponds to a smaller physical region. This results in finer saliency maps for FFDM images. In addition, DBT has a lower ratio of important regions compared to the entire image because the lesions only appear in a small fraction of slices in each image. Therefore, DSC or PxAP values will be lower for DBT even if the model similarly highlights important regions in the slices where they are visible. To partially mitigate this issue and make these values more comparable between 2D and 3D imaging modalities, we do not report the DSC or PxAP on DBT images and instead calculate these metrics after max-projecting both saliency maps and the segmentation labels in the depth dimension. This way, we can get a better sense of how 3D-GMIC is predicting the location of lesions in the xy-dimension by comparing its score to the 2D models.
VII. Results
We evaluated the classification and semantic segmentation performances of GMIC and 3D-GMIC architectures on the internal NYU Combo v1 dataset as well as an external DBT dataset from Duke University hospital.
A. Computational Efficiency
Compared to off-the-shelf deep convolutional neural networks, 3D-GMIC uses 77.98%–90.05% less GPU memory and 91.23%–96.02% less computation as shown in Table I.
TABLE I.
Computational Efficiency of Processing a DBT Image With 96 Slices. 3D-GMIC Uses 77.98%–90.05% Less GPU Memory and 91.23%–96.02% Less Computation Than Other Architectures
B. Classification
For each imaging modality, we trained the GMIC or 3D-GMIC architecture as well as a variant with only the global module (global-only). This measures the benefit of adding the local module in the GMIC architecture. The results are in Table II, Table III, Table IV, Table V, and Table VI. We also show the ensemble performances where the predictions of different models, trained with different modalities and/or for a different number of epochs are averaged.
For both global-only and full architectures, we find that 3D-GMIC performs comparably with other models trained with 2D imaging modalities. Ensembling models trained with different modalities does help, but which modalities lead to the best performance differs between models and target tasks.
In addition, we demonstrate our models’ classification performances on the BCS-DBT dataset from Duke University Hospital [12], [13], [14]. 3D-GMIC achieved image-wise AUC of 0.848 (95% CI: 0.798–0.896) in identifying images with malignant findings and image-wise AUC of 0.741 (95% CI: 0.697–0.785) in identifying images with benign findings. In comparison, on the DBT images in the test set of NYU Combo v1 dataset, the same 3D-GMIC models achieve image-wise AUC of 0.809 (95% CI: 0.761–0.852) in identifying images with malignant findings and image-wise AUC of 0.704 (95% CI: 0.683–0.728) in identifying images with benign findings. Even though the model did not use any images from Duke during training, it generalizes well and even shows higher performances than on our own internal data set.
C. Semantic Segmentation
Table VII shows DSC and PxAP scores for the three modalities. Even though semantic segmentation in 3D data can be more difficult, 3D-GMIC reaches comparable performances. A sample set of model visualizations, produced for the same breast, is shown in Fig. 6.
TABLE VII.
Weakly-Supervised Semantic Segmentation Performances on the Test Set. The Mean and Standard Deviation of Individual Performances of the Five Best Models and Their Ensemble Performances. “DBT Max-projected” Refers to the Evaluation Where Both Saliency Maps and the Annotations Were Max-Projected in the Depth Dimension. 3D-GMIC Reaches Comparable DSC and PxAP Scores
| DSC(M) | DSC(B) | PxAP(M) | PxAP(B) | |
|---|---|---|---|---|
|
| ||||
| FFDM | 0.193 ± 0.019 | 0.120 ± 0.025 | 0.100 ± 0.016 | 0.049 ± 0.013 |
| Synthetic 2D | 0.166 ± 0.025 | 0.144 ± 0.023 | 0.092 ± 0.016 | 0.070 ± 0.009 |
| DBT max-projected | 0.150 ± 0.018 | 0.123 ± 0.017 | 0.065 ± 0.008 | 0.055 ± 0.009 |
|
| ||||
| FFDM ensemble | 0.208 | 0.138 | 0.111 | 0.053 |
| Synthetic 2D ensemble | 0.181 | 0.162 | 0.101 | 0.082 |
| DBT max-projected ensemble | 0.162 | 0.141 | 0.066 | 0.060 |
Fig. 6.
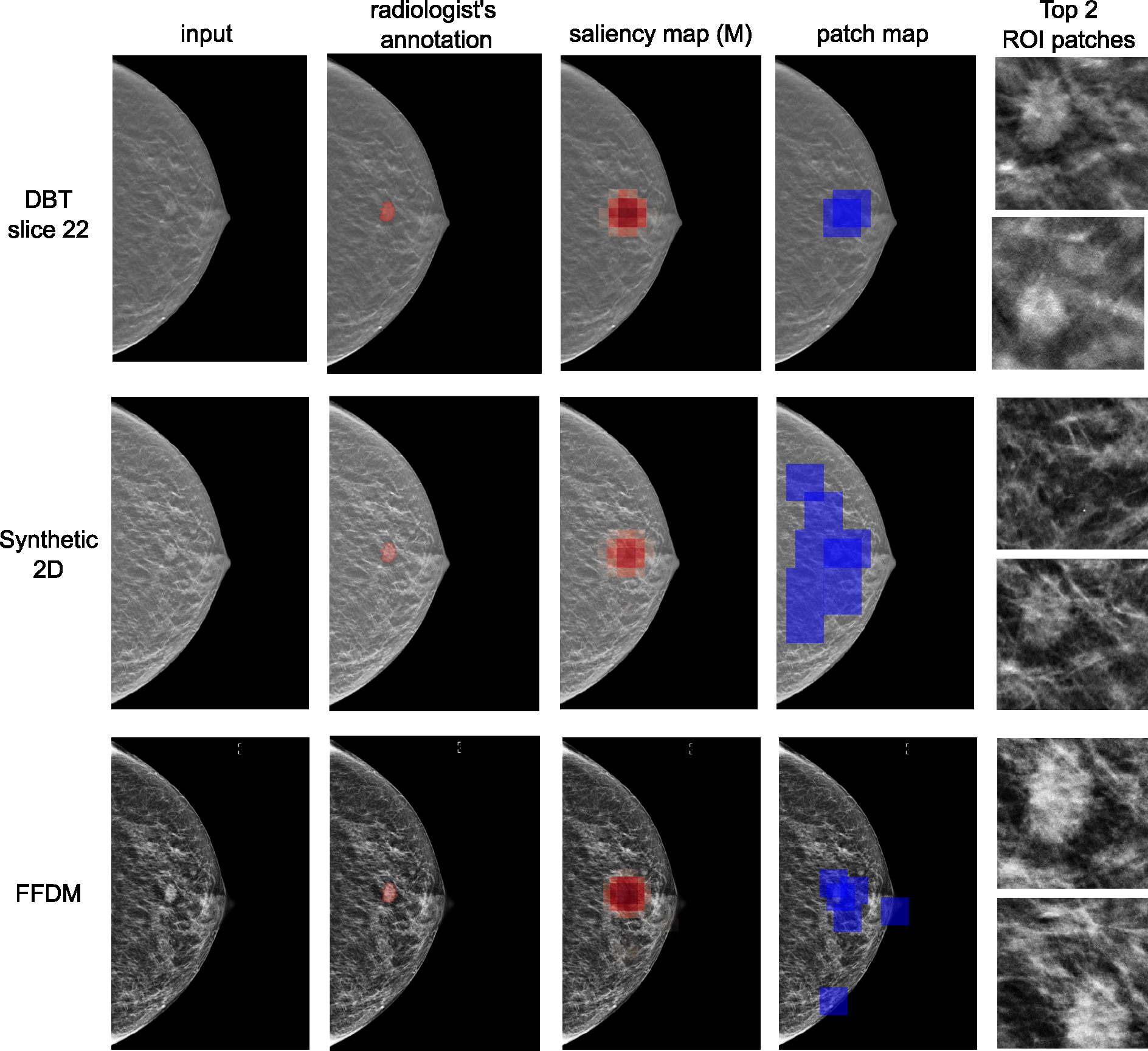
Visualization of results for an example for DBT, synthetic 2D and FFDM modalities. From left to right: input images, patch maps indicating the locations of cropped ROI patches as blue squares, saliency maps for benign category, saliency maps for malignant category, and the cropped patches with the two highest attention scores. This example contains an irregular mass in the central right breast at mid depth was diagnosed as malignant on ultrasound-guided core biopsy.
D. Ablation Studies
We performed several ablation studies to assess the effects of different hyperparameters on 3D-GMIC.
1). Comparing Modalities Using the Same Number of Patches:
Table VIII shows the comparison of model performances when using the same number of patches. We observe that 3D-GMIC on DBT still shows comparable performances to GMIC on 2D images.
2). The Half-Width of Slice-Wise Sampling :
The default value of was set in initial experiments before systematically tuning the hyperparameters and was used in our experiments. In this ablation study, we investigate the effect of the half-width of slice-wise sampling during training by keeping the rest of the hyperparameters the same. The purpose of this ablation study is twofold. First, we aim to observe if slice-wise patch sampling provides an unfair advantage to 3D-GMIC compared to other GMIC models trained on 2D modalities. Second, we want to verify if the default value of was optimal. The results are in Table IX. We show that the performance of and are indistinguishable, which means that the slice-wise sampling of the image patches did not give an unfair advantage to 3D-GMIC compared to GMIC with 2D imaging modalities. In addition, we observe that leads to an improved performance.
TABLE IX.
Ablation Study: Effect of a Choice of ζ on the AUC of Identifying Breasts With Malignant Findings, Along With the 95% Confidence Intervals
| AUC (M) | |
|---|---|
|
| |
| ζ=0 | 0.830 (0.774–0.880) |
| ζ=5 | 0.852 (0.789–0.901) |
| ζ=10 | 0.834 (0.773–0.888) |
| ζ=∞ | 0.835 (0.770–0.895) |
3). The Amount of DBT Data in Training:
In Table X, we report the breast-level test AUCs of 3D-GMIC models trained with the same seed and hyperparameters, using different pretrained weights as starting points. In addition, we also vary the amount of DBT data in training step 3c. For quick results, we only perform inference over the test dataset once without random augmentation. As a reference, the breast-level test AUC of a 3D-GMIC model trained by following steps 1–2b-3c as defined in section V-D and Fig. 5, which is the default approach in our work, is 0.8.
TABLE X.
Ablation Study: The Effect of Training Data on the Breast-Level Test AUCs of 3D-GMIC Models. We Vary Amounts of DBT Exams We Used for the Step 3c (100%, 50%, and 25%). The Models Are Trained Following Steps 1-3c and 1-3a-3c (Both of Which Are Non-Standard Paths) as Defined in Section V-D and Fig. 5. We Observe the Decline in Model Performance as the Amount of Training Data Is Reduced
| Steps | 100% data | 50% data | 25% data |
|---|---|---|---|
|
| |||
| 1-3c | 0.81 | 0.77 | 0.74 |
| 1-3a-3c | 0.82 | 0.81 | 0.78 |
When following steps 1–3c, the performance of the model decreases as we decrease the amount of training data, which is expected. Moreover, the drop from 100% to 50% of training data is similar to the drop observed from 50% to 25%. This suggests that the model performance has not yet saturated, and our models could still benefit from additional data.
When following steps 1–3a-3c, the drop in the performance by reducing the number of DBT training images is lower compared to when following steps 1–3c. This is to be expected as the network already utilized 100% of pathology-derived labels in the NYU Combo V1 dataset, even though it was the FFDM images for which the model used these labels. This suggests that, if starting from a model that is trained on a lot of FFDM images with pathology-derived labels, 3D-GMIC might only require a relatively small number of DBT images for saturating performance.
Note that the training paths of the models in this ablation study (1–3c and 1–3a-3c) diverge from the standard training path of 3D-GMIC, which is 1–2b-3c. We opted for the path 1–3c as a substitute for 1–2b-3c because it is time-consuming to repeat step 2b with varying amount of DBT data in the standard path of 1–2b-3c. Furthermore, we selected the path 1–3a-3c to represent a use case where there is a surplus of 2D data but a limited quantity of 3D data.
VIII. Discussion and Conclusion
In this work, we propose 3D-GMIC, a novel deep neural network capable of learning and predicting from high-resolution 3D medical images in a computationally efficient manner. 3D-GMIC effectively focuses its computation to the small subset of important regions by first identifying the regions of interest with a low-capacity sub-network and selectively applying a high-capacity sub-network to the regions of interest while avoiding processing duplicate information from nearby slices. 3D-GMIC enables training deep neural networks for high-resolution 3D images with small regions of interests without requiring expensive annotation labels or compromising performance. Our model is efficient enough to train with a batch size of 4 images using 4 GPUs with 32GB of GPU memory.
3D-GMIC focuses its computation on a lower proportion of the input image compared to GMIC. This is done by avoiding cropping patches with duplicate information as explained in section V-A.2. For example, consider GMIC on synthetic 2D image of size (2116 × 1339) and 3D-GMIC on DBT image of size (2116 × 1339 × 70), both cropping 8 two-dimensional patches of size 256 × 256 as shown in Table VIII. Then the local networks of either model will utilize 256*256*8=524,288 pixels. While this corresponds to 18.50% of the synthetic 2D image, it corresponds to only 0.26% of the DBT image.
The reason for processing slices independently with the global network and the local network rather than applying a 3D convolution to process them together with nearby slices is that DBT is not a true 3D image. Instead, DBT is a collection of the reconstructed slices for the goal of increasing lesion conspicuity. Each structure is visible from most slices with varying focus. Therefore, our architecture aims to maximally utilize the information from individual slices, thus maximally benefiting from the advantage of DBT which is in enabling distinguishing lesions from other structures from nearby slices.
We demonstrate the performance of the proposed architecture with a large dataset where each exam contains the three imaging modalities of screening mammography: FFDM, synthetic 2D, and DBT. 3D-GMIC achieved comparable performances compared to GMIC on FFDM or synthetic 2D. This demonstrates that 3D-GMIC successfully classified large 3D images despite focusing its computation on a smaller percentage of its input compared to GMIC. Furthermore, the performance is improved when we ensemble predictions from multiple imaging modalities. This suggests that the model might have learned different behaviors for each modality depending on their relative strengths and weaknesses. This accentuates the benefit of training AI systems which can handle the DBT images even when the 2D imaging modalities with equivalent information are available.
The reported semantic segmentation and classification performances of 2D modalities are lower than the values reported in the original GMIC paper. The reason for this is twofold. First, the NYU Combo v1 dataset is smaller than the BCSDv1 dataset used in the original GMIC paper. Our work utilizes only half the number of exams with biopsy labels and this leads to worse generalization. Second, the two papers have different test sets and two AUCs calculated from different datasets are not directly comparable. As a result, the method presented in this paper demonstrates potential for future development but has yet to reach the level of clinical applicability. As it stands, the performance requires further refinement for practical use. For example, Wu et al. [32] showed that their method for FFDM images with an AUC of 0.895 is comparable with radiologists and can improve radiologists’ performance when ensembled with their predictions. In addition, Shen et al. [9] showed that their method for FFDM images with an AUC of 0.930 outperforms radiologists.
IX. Limitations
We note that 3D-GMIC shares some limitations with the standard GMIC model. Namely, training 3D-GMIC is more complicated than training 3D ResNet models because there are two separate networks to optimize. The learning speeds for the global and local modules could be different and they could start overfitting at different epochs. This could prevent 3D-GMIC from reaching the best possible performance. To mitigate this, separate learning rates could be used for global and local modules as done in Wu et al. [39].
We ackowledge that our DSC and PxAP evaluations have certain limitations in accounting for false positive findings of our methods, which we elaborate below. One one hand, all of the images with biopsied findings were used in calculating Dice and PxAP metrics for both benign and malignant classes, regardless of whether the said biopsied finding was benign or malignant. This means that images with benign findings were also used in evaluating Dice for the malignant category and vice versa. Therefore, it accounts for some of the false positive findings of the algorithm. On the other hand, this metric is not able to measure the false positive semantic segmentation from the images that are not associated with biopsied findings. However, since this method is applied consistently across different models, we measure the performance on images with lesions fairly across different models. Finally, it is common for papers on medical semantic segmentation to use datasets which consist only of images with annotated objects, and thus report segmentation performances calculated only with positive images [48], [49].
We acknowledge that our ground-truth annotation labels contain a degree of subjectivity. Variability in annotation could stem from different radiologists’ training, experience, and personal interpretative skills, potentially leading to inconsistencies in the marked location, size, and shape of the biopsied lesions. This could also introduce noise into the evaluation of our semantic segmentation performance. Ideally, having multiple radiologists annotate the same lesion and averaging out their input could help minimize this interobserver variability. However, due to resource constraints, this was not feasible within the scope of this study.
Acknowledgment
The authors would like to thank Catriona C. Geras for correcting earlier versions of this manuscript and Mario Videna and Abdul Khaja for supporting our computing environment. They also like to thank the support of Nvidia Corporation with the donation of some of the GPUs used in this research.
This work was supported in part by the National Institutes of Health under Grant P41EB017183 and Grant R21CA225175, in part by the National Science Foundation under Grant 1922658, in part by the Gordon and Betty Moore Foundation under Grant 9683, in part by the Polish National Science Center under Grant 2021/41/N/ST6/02596, and in part by the Polish National Agency for Academic Exchange under Grant PPN/IWA/2019/1/00114/U/00001.
This work involved human subjects or animals in its research. Approval of all ethical and experimental procedures and protocols was granted by NYU Langone Health Institutional Review Board (IRB) under Reference No. i18–00712_CR3, and performed in line with the Declaration of Helsinki.
Footnotes
The thickness of a compressed breast completely determines the number of slices in the corresponding DBT image. Specifically, for the NYU Combo v1 dataset, the number of slices of a DBT image is equal to the thickness of the corresponding compressed breast in millimeters + 6. For example, if a compressed breast is 55mm thick, then its DBT image has 61 slices.
Even though the training set consists of 78,702 exams from 68,412 patients, it contains only 518 breasts with malignant findings, therefore we say this is low-data regime.
Even though the pooling percentage can be larger than 100% of a slice of a saliency map, it is still a small subset of the entire 3D saliency map.
If no threshold leads to exactly 90% sensitivity, then the threshold that leads to the closest sensitivity value is chosen. When calculating confidence intervals with bootstrapping, trials for which the difference between the ideal and actual sensitivity is greater than 2.5 percentage points are discarded. The same approach applies to 95% and 99% specificity.
Contributor Information
Jungkyu Park, Department of Radiology, NYU Langone Health, New York, NY 10016 USA.
Jakub Chłędowski, Faculty of Mathematics and Computer Science, Jagiellonian University, 30-348 Kraków, Poland.
Stanisław Jastrzębski, Department of Radiology, NYU Langone Health, New York, NY 10016 USA.
Jan Witowski, Department of Radiology, NYU Langone Health, New York, NY 10016 USA.
Yanqi Xu, Center for Data Science, New York University, New York, NY 10011 US.
Linda Du, Department of Radiology, NYU Langone Health, New York, NY 10016 USA.
Sushma Gaddam, Department of Radiology, NYU Langone Health, New York, NY 10016 USA.
Eric Kim, Department of Radiology, NYU Langone Health, New York, NY 10016 USA.
Alana Lewin, Department of Radiology, NYU Langone Health, New York, NY 10016 USA.
Ujas Parikh, Department of Radiology, NYU Langone Health, New York, NY 10016 USA.
Anastasia Plaunova, Department of Radiology, NYU Langone Health, New York, NY 10016 USA.
Sardius Chen, Department of Radiology, NYU Langone Health, New York, NY 10016 USA.
Alexandra Millet, Department of Radiology, NYU Langone Health, New York, NY 10016 USA.
James Park, Department of Radiology, NYU Langone Health, New York, NY 10016 USA.
Kristine Pysarenko, Department of Radiology, NYU Langone Health, New York, NY 10016 USA.
Shalin Patel, Department of Radiology, NYU Langone Health, New York, NY 10016 USA.
Julia Goldberg, Department of Radiology, NYU Langone Health, New York, NY 10016 USA.
Melanie Wegener, Department of Radiology, NYU Langone Health, New York, NY 10016 USA.
Linda Moy, Department of Radiology, NYU Langone Health, New York, NY 10016 USA.
Laura Heacock, Department of Radiology, NYU Langone Health, New York, NY 10016 USA.
Beatriu Reig, Department of Radiology, NYU Langone Health, New York, NY 10016 USA.
Krzysztof J. Geras, Department of Radiology, NYU Langone Health, New York, NY 10016 USA
References
- [1].Sung H et al. , “Global cancer statistics 2020: GLOBOCAN estimates of incidence and mortality worldwide for 36 cancers in 185 countries,” CA, A Cancer J. Clinicians, vol. 71, no. 3, pp. 209–249, May 2021. [DOI] [PubMed] [Google Scholar]
- [2].Kopans DB, “Digital breast tomosynthesis from concept to clinical care,” Amer. J. Roentgenol, vol. 202, no. 2, pp. 299–308, Feb. 2014. [DOI] [PubMed] [Google Scholar]
- [3].McDonald ES, Oustimov A, Weinstein SP, Synnestvedt MB, Schnall M, and Conant EF, “Effectiveness of digital breast tomosynthesis compared with digital mammography: Outcomes analysis from 3 years of breast cancer screening,” J. Amer. Med. Assoc. Oncol, vol. 2, no. 6, pp. 737–743, 2016. [DOI] [PubMed] [Google Scholar]
- [4].Rafferty EA et al. , “Breast cancer screening using tomosynthesis and digital mammography in dense and nondense breasts,” J. Amer. Med. Assoc, vol. 315, no. 16, pp. 1784–1786, 2016. [DOI] [PubMed] [Google Scholar]
- [5].Conant EF et al. , “Association of digital breast tomosynthesis vs digital mammography with cancer detection and recall rates by age and breast density,” JAMA Oncol, vol. 5, no. 5, 2019. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [6].Conant EF et al. , “Five consecutive years of screening with digital breast tomosynthesis: Outcomes by screening year and round,” Radiology, vol. 295, no. 2, pp. 285–293, May 2020. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [7].Bahl M, Mercaldo S, Dang PA, McCarthy AM, Lowry KP, and Lehman CD, “Breast cancer screening with digital breast tomosynthesis: Are initial benefits sustained?” Radiology, vol. 295, no. 3, pp. 529–539, Jun. 2020. [DOI] [PubMed] [Google Scholar]
- [8].Aase HS et al. , “A randomized controlled trial of digital breast tomosynthesis versus digital mammography in population-based screening in Bergen: Interim analysis of performance indicators from the to-be trial,” Eur. Radiol, vol. 29, no. 3, pp. 1175–1186, Mar. 2019. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [9].Shen Y et al. , “An interpretable classifier for high-resolution breast cancer screening images utilizing weakly supervised localization,” Med. Image Anal, vol. 68, Feb. 2021, Art. no. 101908. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [10].Wu Y and He K, “Group normalization,” in Proc. ECCV, Sep. 2018, pp. 3–19. [Google Scholar]
- [11].Smith AE. (2016). Synthesized 2D Mammographic Imaging Theory and Clinical Performance. [Online]. Available: https://www.hologic.com/sites/default/files/2017/Products/Image%20Analytics/PDFs/C-View-White-Paper.pdf [Google Scholar]
- [12].Buda M et al. , “A data set and deep learning algorithm for the detection of masses and architectural distortions in digital breast tomosynthesis images,” JAMA Netw. Open, vol. 4, no. 8, Aug. 2021, Art. no. e2119100. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [13].Buda M et al. , “Breast cancer screening—Digital breast tomosynthesis (breast-cancer-screening-DBT),” Cancer Imag. Arch., 2020, doi: 10.7937/E4WT-CD02. [DOI] [Google Scholar]
- [14].Clark K et al. , “The cancer imaging archive (TCIA): Maintaining and operating a public information repository,” J. Digit. Imag., vol. 26, no. 6, pp. 1045–1057, Dec. 2013. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [15].Matthews TP et al. , “A multi-site study of a breast density deep learning model for full-field digital mammography images and synthetic mammography images,” Radiol., Artif. Int, vol. 3, no. 1, 2020, Art. no. e200015. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [16].Liang G et al. , “Joint 2D-3D breast cancer classification,” in Proc. IEEE Int. Conf. Bioinf. Biomed. (BIBM), Nov. 2019, pp. 692–696. [Google Scholar]
- [17].Singh S et al. , “Adaptation of a deep learning malignancy model from full-field digital mammography to digital breast tomosynthesis,” Proc. SPIE, vol. 11314, Mar. 2020, Art. no. 1131406. [Google Scholar]
- [18].Tardy M and Mateus D, “Trainable summarization to improve breast tomosynthesis classification,” in Proc. MICCAI. Cham, Switzerland: Springer, 2021, pp. 140–149. [Google Scholar]
- [19].Zhang X et al. , “Classification of whole mammogram and tomosynthesis images using deep convolutional neural networks,” IEEE Trans. Nanobiosci, vol. 17, no. 3, pp. 237–242, Jul. 2018. [DOI] [PubMed] [Google Scholar]
- [20].Samala RK, Chan H-P, Hadjiiski LM, Helvie MA, Richter C, and Cha K, “Evolutionary pruning of transfer learned deep convolutional neural network for breast cancer diagnosis in digital breast tomosynthesis,” Phys. Med. Biol, vol. 63, no. 9, May 2018, Art. no. 095005. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [21].Li X et al. , “Digital breast tomosynthesis versus digital mammography: Integration of image modalities enhances deep learning-based breast mass classification,” Eur. Radiol, vol. 30, no. 2, pp. 778–788, Feb. 2020. [DOI] [PubMed] [Google Scholar]
- [22].Fan M, Li Y, Zheng S, Peng W, Tang W, and Li L, “Computer-aided detection of mass in digital breast tomosynthesis using a faster region-based convolutional neural network,” Methods, vol. 166, pp. 103–111, Aug. 2019. [DOI] [PubMed] [Google Scholar]
- [23].Lai X, Yang W, and Li R, “DBT masses automatic segmentation using U-Net neural networks,” Comput. Math. Methods Med, vol. 2020, Jan. 2020, Art. no. 7156165. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [24].Lotter W et al. , “Robust breast cancer detection in mammography and digital breast tomosynthesis using an annotation-efficient deep learning approach,” Nature Med, vol. 27, no. 2, pp. 244–249, 2021. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [25].Samala RK, Chan H-P, Hadjiiski L, Helvie MA, Wei J, and Cha K, “Mass detection in digital breast tomosynthesis: Deep convolutional neural network with transfer learning from mammography,” Med. Phys, vol. 43, no. 12, pp. 6654–6666, Nov. 2016. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [26].Fotin SV, Yin Y, Haldankar H, Hoffmeister JW, and Periaswamy S, “Detection of soft tissue densities from digital breast tomosynthesis: Comparison of conventional and deep learning approaches,” Proc. SPIE, vol. 9785, Mar. 2016, Art. no. 97850X. [Google Scholar]
- [27].Mendel K, Li H, Sheth D, and Giger M, “Transfer learning from convolutional neural networks for computer-aided diagnosis: A comparison of digital breast tomosynthesis and full-field digital mammography,” Academic Radiol, vol. 26, no. 6, pp. 735–743, Jun. 2019. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [28].Bai J, Posner R, Wang T, Yang C, and Nabavi S, “Applying deep learning in digital breast tomosynthesis for automatic breast cancer detection: A review,” Med. Image Anal, vol. 71, Jul. 2021, Art. no. 102049. [DOI] [PubMed] [Google Scholar]
- [29].Chen T, Xu B, Zhang C, and Guestrin C, “Training deep nets with sublinear memory cost,” 2016, arXiv:1604.06174. [Google Scholar]
- [30].Matzek S, Grossman M, Cho M, Yusifov A, Nelson B, and Juneja A, “Data-parallel distributed training of very large models beyond GPU capacity,” 2018, arXiv:1811.12174. [Google Scholar]
- [31].Rasley J, Rajbhandari S, Ruwase O, and He Y, “DeepSpeed: System optimizations enable training deep learning models with over 100 billion parameters,” in Proc. 26th ACM SIGKDD Int. Conf. Knowl. Discovery Data Mining, Aug. 2020, pp. 3505–3506. [Google Scholar]
- [32].Wu N et al. , “Deep neural networks improve radiologists’ performance in breast cancer screening,” IEEE Trans. Med. Imag, vol. 39, no. 4, pp. 1184–1194, Apr. 2020. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [33].Yushkevich PA et al. , “User-guided 3D active contour segmentation of anatomical structures: Significantly improved efficiency and reliability,” NeuroImage, vol. 31, no. 3, pp. 1116–1128, Jul. 2006. [DOI] [PubMed] [Google Scholar]
- [34].Wu N et al. , “The NYU breast cancer screening dataset v1.0,” NYU, New York, NY, USA, Tech. Rep., 2019. [Online]. Available: https://cs.nyu.edu/~kgeras/reports/datav1.0.pdf [Google Scholar]
- [35].Park J et al. , “Lessons from the first DBTex challenge,” Nature Mach. Intell, vol. 3, no. 8, pp. 735–736, Jul. 2021. [Google Scholar]
- [36].Zech JR, Badgeley MA, Liu M, Costa AB, Titano JJ, and Oermann EK, “Variable generalization performance of a deep learning model to detect pneumonia in chest radiographs: A cross-sectional study,” PLOS Med, vol. 15, no. 11, Nov. 2018, Art. no. e1002683. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [37].He K, Zhang X, Ren S, and Sun J, “Deep residual learning for image recognition,” 2015, arXiv:1512.03385. [Google Scholar]
- [38].Ilse M, Tomczak JM, and Welling M, “Attention-based deep multiple instance learning,” 2018, arXiv:1802.04712. [Google Scholar]
- [39].Wu N, Jastrzębski S, Park J, Moy L, Cho K, and Geras KJ, “Improving the ability of deep neural networks to use information from multiple views in breast cancer screening,” in Proc. 3rd Conf. Med. Imag. With Deep Learn., 2020, pp. 827–842. [PMC free article] [PubMed] [Google Scholar]
- [40].Ioffe S and Szegedy C, “Batch normalization: Accelerating deep network training by reducing internal covariate shift,” in Proc. ICML, 2015, pp. 448–456. [Google Scholar]
- [41].Geras KJ et al. , “High-resolution breast cancer screening with multi-view deep convolutional neural networks,” 2017, arXiv:1703.07047. [Google Scholar]
- [42].Micikevicius P et al. , “Mixed precision training,” 2017, arXiv:1710.03740. [Google Scholar]
- [43].Bergstra J and Bengio Y, “Random search for hyper-parameter optimization,” J. Mach. Learn. Res, vol. 13, no. 2, pp. 1–25, 2012. [Google Scholar]
- [44].Matthews BW, “Comparison of the predicted and observed secondary structure of t4 phage lysozyme,” Biochimica et Biophys. Acta (BBA) Protein Struct., vol. 405, no. 2, pp. 442–451, Oct. 1975. [DOI] [PubMed] [Google Scholar]
- [45].Choe J, Oh SJ, Lee S, Chun S, Akata Z, and Shim H, “Evaluating weakly supervised object localization methods right,” in Proc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR; ), Jun. 2020, pp. 3130–3139. [Google Scholar]
- [46].Hara K, Kataoka H, and Satoh Y, “Can spatiotemporal 3D CNNs retrace the history of 2D CNNs and ImageNet?” in Proc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit., Jun. 2018, pp. 6546–6555. [Google Scholar]
- [47].Johnson RW, “An introduction to the bootstrap,” Teaching Statist., vol. 23, no. 2, pp. 49–54, 2001. [Google Scholar]
- [48].Jha D et al. , “Kvasir-SEG: A segmented polyp dataset,” in Proc. Int. Conf. Multimedia Modeling. Daejeon, South Korea: Springer, Jan. 2020, pp. 451–462. [Google Scholar]
- [49].Bernal J, Sánchez FJ, Fernández-Esparrach G, Gil D, Rodríguez C, and Vilariño F, “WM-DOVA maps for accurate polyp highlighting in colonoscopy: Validation vs. saliency maps from physicians,” Computerized Med. Imag. Graph, vol. 43, pp. 99–111, Jul. 2015. [DOI] [PubMed] [Google Scholar]