

Abstract
Consider a sequential process in which each step outputs a system and updates a side information register E. We prove that if this process satisfies a natural “non-signalling” condition between past outputs and future side information, the min-entropy of the outputs conditioned on the side information E at the end of the process can be bounded from below by a sum of von Neumann entropies associated with the individual steps. This is a generalisation of the entropy accumulation theorem (EAT) (Dupuis et al. in Commun Math Phys 379: 867–913, 2020), which deals with a more restrictive model of side information: there, past side information cannot be updated in subsequent rounds, and newly generated side information has to satisfy a Markov condition. Due to its more general model of side-information, our generalised EAT can be applied more easily and to a broader range of cryptographic protocols. As examples, we give the first multi-round security proof for blind randomness expansion and a simplified analysis of the E91 QKD protocol. The proof of our generalised EAT relies on a new variant of Uhlmann’s theorem and new chain rules for the Rényi divergence and entropy, which might be of independent interest.
Introduction
Suppose that Alice and Eve share a quantum state . From her systems , Alice would like to extract bits that look uniformly random to Eve, except with some small failure probability [1]. The number of such random bits that Alice can extract is given by the smooth min-entropy [2]. This quantity plays a central role in quantum cryptography: for example, the main task in security proofs of quantum key distribution (QKD) protocols is usually finding a lower bound for the smooth min-entropy.
Unfortunately, for many cryptographic protocols deriving such a bound is challenging. Intuitively, the reason is the following: the state is usually created as the output of a multi-round protocol, where each round produces one of Alice’s systems and allows Eve to execute some attack to gain information about . These attacks can depend on each other, i.e., Eve may use what she learnt in round to plan her attack in round i. This non-i.i.d. nature of the attacks makes it hard to find a lower bound on that holds for any possible attack that Eve can execute. In contrast, it is typically much easier to compute a conditional von Neumann entropy associated with a single-round of the protocol, where the non-i.i.d. nature of Eve’s attack plays no role. Therefore, it is desirable to relate the smooth min-entropy of the output of the multi-round protocol to the von Neumann entropies associated with the individual rounds.
From an information-theoretic point of view, this question can be phrased as follows: can the smooth min-entropy be bounded from below in terms of von Neumann entropies for some (yet to be determined) systems and states related to ? While for general states no useful lower bound can be found, previous works have established such bounds under additional assumptions on the state .
The first bound of this form was proven via the asymptotic equipartition property (AEP) [3]. It assumes that the system E is n-partite (i.e., we replace E by ) and that the state is a product of identical states. Then, the AEP shows that1
For applications in cryptography, the assumption that is an i.i.d. product state is usually too strong: it corresponds to the (unrealistic) assumption that Eve executes the same independent attack in each round, a so-called collective attack.
The entropy accumulation theorem (EAT) [1] is a generalisation of the AEP which requires far weaker assumptions on the state . Specifically, the EAT considers states that result from a sequential process that starts with a state and in every step outputs a system and a piece of side information . The system is not acted upon during the process. The full side information at the end of this process is . We can represent such a process by the following diagram, where are quantum channels.  The EAT requires an additional condition on the side information: the new side information generated in round i must be independent from the past outputs conditioned on the existing side information . Mathematically, this is captured by the condition that the systems form a Markov chain for any initial state . With this Markov condition, the EAT states that2
The EAT requires an additional condition on the side information: the new side information generated in round i must be independent from the past outputs conditioned on the existing side information . Mathematically, this is captured by the condition that the systems form a Markov chain for any initial state . With this Markov condition, the EAT states that2
| 1.1 |
where is a purifying system isomorphic to and the infimum is taken over all states on systems .3
Let us discuss the model of side information used by the EAT in more detail. The EAT considers side information consisting of two parts: the initial side information (which is not acted upon during the process) and the outputs . This splitting of side information into a “static” part and a part which is generated in each step of the process is particularly suited to device-independent cryptography: there, Eve prepares a device in an initial state , where is the device’s internal memory and is Eve’s initial side information from preparing the device. Then, Alice (and Bob, though we only consider Alice’s system here) executes a multi-round protocol with this device, where each round leaks some additional piece of information to Eve, so that Eve’s side information at the end of the protocol is . Indeed, the EAT has been used to establish tight security proofs in the device-independent setting, see e.g., [4, 5].
The Markov condition in the EAT captures the following intuition: if we want to find a bound on in terms of single-round quantities, it is required that side information about is itself output in step i, as otherwise we cannot hope to estimate the contribution to the total entropy from step i. To illustrate what could happen without such a condition, consider a case where is classical and no side information is output in the first rounds, but the side information in the last round contains a copy of the systems (which can be passed along during the process in the systems ). Then, clearly , but for the first rounds, each single-round entropy bound that only considers the systems and can be positive.
Main result In this work, we further relax the assumptions on how the final state is generated. Specifically, we consider sequential processes as in the EAT, but with a fully general model of side information, i.e., the side information can be updated in each step in the process. Diagrammatically, such a process can be represented as follows:
Our generalised EAT then states the following.
Theorem 1.1
Consider quantum channels that satisfy the following “non-signalling” condition (discussed in detail below): for each , there must exist a quantum channel such that
| 1.2 |
Then, the min-entropy of the outputs conditioned on the final side information can be bounded as
| 1.3 |
where is a purifying system for the input to and the infimum is taken over all states on systems .4
We give a formal statement and proof in Sect. 4 and also show that, similarly to the EAT, statistics collected during the process can be used to restrict the minimization over (see Theorem 4.3 for the formal statement). By a simple duality argument, Eq. (1.3) also implies an upper bound on the smooth max-entropy , which we explain in Appendix A. This generalises a similar result from [1], although in [1] one could not make use of duality due to the Markov condition and instead had to prove the statement about separately, again highlighting that our generalised EAT is easier to work with.
The intuition behind the non-signalling condition in our generalised EAT is similar to the Markov condition in the original EAT: by the same reasoning as for the Markov condition, since the lower bound is made up of terms of the form , it is required that side information about that is present in the final system is already present in . This means that side information about should not be passed on via the R-systems and later be included in the E-systems. The non-signalling condition captures this requirement: it demands that if one only considers the marginal of the new side information (without the new output ), it must be possible to generate this state from the past side information alone, without access to the system . This means that any side information that contains about the past outputs must have essentially already been present in and could not have been stored in .
The name “non-signalling condition” is due to the fact that Eq. (1.2) is a natural generalisation of the standard non-signalling conditions in non-local games: if we view the systems and as the inputs and outputs on “Alice’s side” of , and and as the inputs and outputs on “Eve’s side”, then Eq. (1.2) states that the marginal of the output on Eve’s side cannot depend on the input on Alice’s side. This is exactly the non-signalling condition in non-local games, except that here the inputs and outputs are allowed to be fully quantum.
To understand the relation between the Markov and non-signalling conditions, it is instructive to consider the setting of the original EAT as a special case of our generalised EAT. In the original EAT, the full side information available after step i is , and past side information is not updated during the process. For our generalised EAT, we therefore set and consider maps , where is the map used in the original EAT. We need to check that with this choice of systems and maps, the Markov condition of the original EAT implies the non-signalling condition of our generalised EAT. The Markov condition requires that for any state input , the output state satisfies .5 It is then a standard result on quantum Markov chains [6] that there must exist a quantum channel such that . Remembering that we defined (so that ) and adding the systems (on which both and act as identity), we find that satisfies the non-signalling condition:
Then, noting that all conditioning systems on which acts as the identity map can collectively be replaced by a single purifying system isomorphic to the input, we see that we recover the original EAT (Eq. (1.1)) from our generalised EAT (Eq. (1.3)).
We emphasise that while the original EAT with the Markov condition can be recovered as a special case, our model of side information and the non-signalling condition are much more general than the original EAT; arguably, for a sequential process they are the most natural and general way of expressing the notion that future side information should not contain new information about past outputs, which appears to be necessary for an EAT-like result. To demonstrate the greater generality of our result, in Sect. 5 we use it to give the first multi-round proof for blind randomness expansion, a task to which the original EAT could not be applied, and a more direct proof of the E91 QKD protocol than was possible with the original EAT. Our generalised EAT can also be used to prove security of a much larger class of QKD protocols than the original EAT. Interestingly, for (device-dependent) QKD protocols, no “hidden system” R is needed and therefore the non-signalling condition is trivially satisfied, i.e., the advantage of our generalised EAT for QKD security proofs stems entirely from the more general model of side information, not from replacing the Markov condition by the non-signalling condition; see Sect. 5.2 for an informal comparison of how the original and generalised EAT can be applied to QKD, and [7] for a detailed treatment of the application of our generalised EAT to QKD, including protocols to which the original EAT could not be applied.
Proof sketch. The generalised EAT involves both the min-entropy, which can be viewed as a “worst-case entropy”, and the von Neumann entropy, which can be viewed as an “average case entropy”. These two entropies are special cases of a more general family of entropies called Rényi entropies, which are denoted by for a parameter (see Sect. 2.2 for a formal definition).6 The min-entropy can be obtained from the Rényi entropy by taking , whereas the von Neumann entropy corresponds to the limit . Hence, the Rényi entropies interpolate between the min-entropy and the von Neumann entropy, and they will play a crucial role in our proof.
The key technical ingredient for our generalised EAT is a new chain rule for Rényi entropies (Theorem 3.6 in the main text).
Lemma 1.2
Let , a quantum state, and a quantum channel which satisfies the non-signalling condition in Eq. (1.2), i.e. there exists a channel such that . Then
| 1.4 |
for a purifying system , where the infinimum is over all quantum states on systems .
We first describe how this chain rule implies our generalised EAT, following the same idea as in [1, 8]. For this, recall that our goal is to find a lower bound on for a sequence of maps satisfying the non-signalling condition . As a first step, we use a known relation between the smooth min-entropy and the Rényi entropy [3], which (up to a small penalty term depending on and ) reduces the problem to lower-bounding
To this, we can apply Lemma 1.2 by choosing , , , , , , and . Then, since the map satisfies the non-signalling condition, Lemma 1.2 implies that
We can now repeat this argument for the term . After n applications of Lemma 1.2, we find that
To conclude, we use a continuity bound from [8] to relate to . It can be shown that for a suitable choice of , the penalty terms we incur by switching from the min-entropy to the Rényi entropy and then to the von Neumann entropy scale as . Therefore, we obtain Eq. (1.3). We also provide a version that allows for “testing” (which is crucial for application in quantum cryptography and explained in detail in Sect. 4.2) and features explicit second-order terms similar to those in [8].
We now turn our attention to the proof of Lemma 1.2. For this, we need to introduce the (sandwiched) Rényi divergence of order between two (possibly unnormalised) quantum states and , denoted by . We refer to Sect. 2.2 for a formal definition; for this overview, it suffices to know that is a measure of how different is from , and that the conditional Rényi entropy is related to the Rényi divergence by
Our starting point for proving Lemma 1.2 is the following chain rule for the Rényi divergence from [9]:
| 1.5 |
where and are (not necessarily trace preserving) quantum channels from RE to , and and are any quantum states on ARE. The optimization is over all quantum states on n copies of the systems (with as before).
Making a suitable choice of (which depends on ) and (which depends on ), one can turn Eq. (1.5) into the following chain rule for the conditional Rényi entropy:
| 1.6 |
This chain rule resembles Lemma 1.2, but is significantly weaker and cannot be used to prove a useful entropy accumulation theorem. The reason for this is twofold:
-
(i)
Equation (1.6) provides a lower bound in terms of , not . The additional conditioning on the R-system can drastically lower the entropy: for example, in a device-independent scenario, R would describe the internal memory of the device. Then, Alice’s output A contains no entropy when conditioned on the internal memory of the device that produced the output, i.e. . On the other hand, Alice’s output conditioned only on Eve’s side information E may be quite large (and can usually be certified by playing a non-local game), i.e. .
-
(ii)
Equation (1.6) contains the regularised quantity . Due to the limit , this quantity cannot be computed numerically and therefore the bound in Eq. (1.6) cannot be evaluated for concrete examples.
We now describe how we overcome each of these issues in turn.
-
(i)We prove a new variant of Uhlmann’s theorem [10], a foundational result in quantum information theory. The original version of Uhlmann’s theorem deals with the case of ; we show that for , a similar result holds, but an additional regularisation is required. Concretely, we prove that for any states and :
The proof of this result relies heavily on the spectral pinching technique [11, 12] and we refer to Lemma 3.3 for details as well as a non-asymptotic statement with explicit error bounds. We make use of this extended Uhlmann’s theorem as follows: for the case we are interested in, the map in Eq. (1.5) satisfies a non-signalling condition. We can show that this condition implies that for any state :1.7
Applying Eq. (1.5) to the r.h.s. of this equality results in a bound that contains . We can now minimise over all states and take the limit . Then, Eq. (1.7) allows us to drop the R-system. Therefore, under the non-signalling condition on , we obtain the following improved chain rule for the sandwiched Rènyi divergence, which might be of independent interest:
Using this chain rule, we can show that Eq. (1.6) still holds if is replaced by . -
(ii)To remove the need for a regularisation in Eq. (1.6), we show that due to the permutation-invariance of and , for and one can replace the optimization over with a fixed input state, namely the projector onto the symmetric subspace of . For this replacement, one incurs a small loss in , replacing it by (which is only slightly larger than in the typical regime where is close to 1). The projector onto the symmetric subspace has a known representation as a mixture of tensor product states [13]. Combining these two steps, we show that the optimization over can be restricted to tensor product states, which means that the regularisation in Eq. (1.6) can be removed (see Sect. 3.2 for details):
Combining these results yields Lemma 1.2 and, as a result, our generalised EAT.
Sample application: blind randomness expansion. The main advantage of the generalised EAT over previous results is its broader applicability. For example, as demonstrated in [7], the generalised EAT can be used to prove the security of prepare-and-measure QKD protocols, which is of immediate practical relevance, and can also simplify the analysis of entanglement-based QKD protocols as discussed in Sect. 5.2. Here, we focus on the application of our generalised EAT to mistrustful device-independent (DI) cryptography. In mistrustful DI cryptography, multiple parties each use a quantum device to execute a protocol with one another. Each party trusts neither its quantum device nor the other parties in the protocol. Hence, from the point of view of one party, say Alice, all the remaining parties in the protocol are collectively treated as an adversary Eve, who may also have prepared Alice’s untrusted device.
While the original EAT could be used to analyse DI protocols in which the parties trust each other, e.g. DIQKD [14], the setting of mistrustful DI cryptography is significantly harder to analyse because the adversary Eve actively participates in the protocol and may update her side information during the protocol in arbitrary ways. Analysing such protocols requires the more general model of side information we deal with in this paper. As a concrete example for mistrustful DI cryptography, we consider blind randomness expansion, a primitive introduced in [15]. Previous work [15, 16] could only analyse blind randomness expansion under the i.i.d. assumption. Here, we give the first proof that blind randomness expansion is possible for general adversaries. The proof is a straightforward application of our generalised EAT and briefly sketched below; we refer to Sect. 5.1 for a detailed treatment.
In blind randomness expansion, Alice receives an untrusted quantum device from the adversary Eve. Alice then plays a non-local game, e.g. the CHSH game, with this device and Eve, and wants to extract certified randomness from her outputs of the non-local game, i.e. we need to show that Alice’s outputs contain a certain amount of min-entropy conditioned on Eve’s side information. Concretely, in each round of the protocol Alice samples inputs x and y for the non-local game, inputs x into her device to receive outcome a, and sends y to Eve to receive outcome b; Alice then checks whether (x, y, a, b) satisfies the winning condition of the non-local game. For comparison, recall that in standard DI randomness expansion [17–21], Alice receives two devices from Eve and uses them to play the non-local game. This means that in standard DI randomness expansion, Eve never learns any of the inputs and outputs of the game. In contrast, in blind randomness expansion Eve learns one of the inputs, y, and is free to choose one of the outputs, b, herself. Hence, Eve can choose the output b based on past side information and update her side information in each round of the protocol using the values of y and b.
To analyse such a protocol, we use the setting of Theorem 1.1, with representing the output of Alice’s device D from the non-local game in the i-th round, the internal memory of D after the i-th round, and Eve’s side information after the i-th round, which can be generated arbitrarily from entanglement shared between Eve and D at the start of the protocol and information Eve gathered during the first i rounds of the protocol. The map describes one round of the protocol, and because Alice’s device and Eve cannot communicate during the protocol it is easy to show that the non-signalling condition from Theorem 1.1 is satisfied. Therefore, we can apply Theorem 1.1 to lower-bound Alice’s conditional min-entropy in terms of the single-round quantities .7 This single-round quantity corresponds to the i.i.d. scenario, i.e. the generalised EAT has reduced the problem of showing blind randomness expansion against general adversaries to the (much simpler) problem of showing it against i.i.d. adversaries. The quantity can be computed using a general numerical technique [22], and for certain classes of non-local games it may also be possible to find an analytical lower bound using ideas from [15, 16]. Inserting the single-round bound, we obtain a lower bound on that scales linearly with n, showing that blind randomness expansion is possible against general adversaries. We also note that as explained in [15], this result immediately implies that unbounded randomness expansion is possible with only three devices, whereas previous works required four devices [21, 23, 24].
Future work In this work, we have developed a new information-theoretic tool, the generalised EAT. The generalised EAT deals with a more general model of side information than previous techniques and is therefore more broadly and easily applicable. In particular, our generalised EAT can be used to analyse mistrustful DI cryptography. We have demonstrated this by giving the first proof of blind randomness expansion against general adversaries. We expect that the generalised EAT could similarly be used for other protocols such as two-party cryptography in the noisy storage model [25] or certified deletion [16, 26, 27]. In addition to mistrustful DI cryptography, our result can also be used to give new proofs for device-dependent QKD, as demonstrated in Sect. 5.2 and [7], and is applicable to proving the security of commercial quantum random number generators, which typically have correlations between rounds due to experimental imperfections [28].
Beyond cryptography, the generalised EAT is useful whenever one is interested in bounding the min-entropy of a large system that can be decomposed in a sequential way. Such problems are abundant in physics. For example, the dynamics of an open quantum system can be described in terms of interactions that take place sequentially with different parts of the system’s environment [29]. In quantum thermodynamics, such a description is commonly employed to model the thermalisation of a system that is brought in contact with a thermal bath. For a lack of techniques, the entropy flow during a thermalisation process of this type is usually quantified in terms of von Neumann entropy rather than the operationally more relevant smooth min- and max-entropies [30]. The generalised EAT may be used to remedy this situation. A similar situation arises in quantum gravity, where smooth entropies play a role in the study of black holes [31].
In a different direction, one can also try to further improve the generalised EAT itself. Compared to the original EAT [1], our generalised EAT features a more general model of side information and a weaker condition on the relation between different rounds, replacing the Markov condition of [1] with our weaker non-signalling condition in Eq. (1.2). It is natural to ask whether a further step in this direction is possible: while the model of side information we consider is fully general, it may be possible to replace the non-signalling condition with a weaker requirement. We have argued above that our non-signalling condition appears to be the most general way of stating the requirement that future side information does not reveal information about past outputs, which seems necessary for an EAT-like theorem.8 It would be interesting to formalise this intuition and see whether our theorem is provably “tight” in terms of the conditions placed on the sequential process. Furthermore, it might be possible to improve the way the statistical condition in Theorem 4.3 is dealt with in the proof, e.g. using ideas from [33, 34].
Finally, one could attempt to extend entropy accumulation from conditional entropies to relative entropies. Such a relative entropy accumulation theorem (REAT) would be the following statement: for two sequences of channels and (where need not necessarily be trace-preserving), and ,
Here, is the -smooth max-relative entropy [11] and we used the (regularised) channel divergences defined in Definition 2.5. The key technical challenge in proving this result is to show that the regularised channel divergence is continuous in at , which is an important technical open question. If one had such a continuity statement and the maps additionally satisfied a non-signalling condition (which is not required for the statement above), one could also use our Theorem 3.1 to derive a more general REAT, which would imply our generalised EAT.
Preliminaries
Notation
Throughout this paper, we restrict ourselves to finite-dimensional Hilbert spaces. The set of positive semidefinite operators on a quantum system A (with associated Hilbert space ) is denoted by . The set of quantum states is given by . The set of completely positive maps from linear operators on A to linear operators on is denoted by . If such a map is additionally trace preserving, we call it a quantum channel and denote the set of such maps by . The identity channel on system A is denoted as . The spectral norm is denoted by .
A cq-state is a quantum state on a classical system X (with alphabet ) and a quantum system A, i.e. a state that can be written as
for subnormalised . For , we define the conditional state
If , we also write for .
Rényi divergence and entropy
We will make extensive use of the sandwiched Rényi divergence [35, 36] and quantities associated with it, namely Rényi entropies and channel divergences. We recall the relevant definitions here.
Definition 2.1
(Rényi divergence). For , , and the (sandwiched) Rényi divergence is defined as
for , and otherwise.
From the Rényi divergence, one can define the conditional Rényi entropies as follows (see [11] for more details).
Definition 2.2
(Conditional Rényi entropy). For a bipartite state and , we define the following two conditional Rényi entropies:
From the definition it is clear that  . Importantly, a relation for the other direction also holds.
. Importantly, a relation for the other direction also holds.
Lemma 2.3
([11, Corollary 5.3]). For and :
In the limit the sandwiched Rényi divergence converges to the relative entropy:
Accordingly, the conditional Rényi entropy converges to the conditional von Neumann entropy:
Conversely, in the limit , the Rényi entropy  converges to the min-entropy. We will make use of a smoothed version of the min-entropy, which is defined as follows [2].
converges to the min-entropy. We will make use of a smoothed version of the min-entropy, which is defined as follows [2].
Definition 2.4
(Smoothed min-entropy). For and , the -smoothed min-entropy of A conditioned on B is
where denotes the spectral norm and is the -ball around in term of the purified distance [11].
Finally, we can extend the definition of the Rényi divergence from states to channels. The resulting quantity, the channel divergence (and its regularised version), will play an important role in the rest of the manuscript.
Definition 2.5
(Channel divergence). For , , and , the (stabilised) channel divergence9 is defined as
| 2.1 |
where without loss of generality . The regularised channel divergence is defined as
We note that the channel divergence is in general not additive under the tensor product [37, Proposition 3.1], so the regularised channel divergence can be strictly larger that the non-regularised one, i.e., . The regularised channel divergence, however, does satisfy an additivity property:
| 2.2 |
where we switched to the index for the second equality.
Spectral pinching
A key technical tool in our proof will be the use of spectral pinching maps [38], which are defined as follows (see [12, Chapter 3] for a more detailed introduction).
Definition 2.6
(Spectral pinching map). Let with spectral decomposition , where are the distinct eigenvalues of and are mutually orthogonal projectors. The (spectral) pinching map associated with is given by
We will need a few basic properties of pinching maps.
Lemma 2.7
(Properties of pinching maps). For any , the following properties hold:
-
(i)
Invariance: .
-
(ii)
Commutation of pinched state: .
-
(iii)
Pinching inequality: .
-
(iv)
Commutation of pinching maps: if , then .
-
(v)
Partial trace: .
Proof
Properties (i)–(iii) follow from the definition and [3, Chapter 2.6.3] or [12, Lemma 3.5].
For the fourth statement, note that since , there exists a joint orthonormal eigenbasis of and . Let be the projector onto the eigenspace of with eigenvalue , and the projector onto the eigenspace of with eigenvalue . We can expand
Since is a family of orthonormal vectors,
which implies commutation of the pinching maps.
For the fifth statement, note that if we write with eigenprojectors , then the set of eigenprojectors of is simply . Hence,
It is often useful to use the pinching map associated with tensor power states, i.e., . This is because for , the factor from the pinching inequality (see Lemma 2.7) only scales polynomially in n (see e.g. [12, Remark 3.9]):
| 2.3 |
In fact, we can show a similar property for all permutation-invariant states, not just tensor product states.
Lemma 2.8
Let be permutation invariant and denote . Then
Proof
By Schur-Weyl duality and Schur’s lemma (see e.g. [39, Lemma 0.8 and Theorem 1.10]), since is permutation-invariant, we have
where denotes equality up to unitary conjugation (which leaves the spectrum invariant), is the set of Young diagrams with n boxes and at most d rows, and are systems whose details need not concern us, and . From this it is clear that
It is known that and (see e.g. [40, Section 6.2]). Hence
Corollary 2.9
Let and . Then
Proof
Note that is itself not a product state because the eigenprojectors of do not have a product form. However, since every eigenspace of is permutation-invariant, is permutation-invariant, too, so we can apply Lemma 2.8.
Strengthened Chain Rules
One of the crucial properties of entropies are chain rules, which allow us to relate entropies of large composite systems to sums of entropies of the individual subsystems. In this section, we prove two new such chain rules, one for the Rényi divergence (Theorem 3.1, which is a generalisation of [9, Corollary 5.1]) and one for the conditional entropy (Theorem 3.6). The chain rule from Theorem 3.6 is the key ingredient for our generalised EAT, to which we will turn our attention in Sect. 4. Theorem 3.6 plays a similar role for our generalised EAT as [1, Corollary 3.5] does for the original EAT, but while the latter requires a Markov condition, the former does not. As a result, our generalised EAT based on Theorem 3.6 also avoids the Markov condition.
The outline of this section is as follows: we first prove a generalised chain rule for the Rényi divergence (Theorem 3.1). This chain rule contains a regularised channel divergence. As the next step, we show that in the special case of conditional entropies, we can drop the regularisation (Sect. 3.2). This allows us to derive a chain rule for conditional entropies from the chain rule for channels (Sect. 3.3).
Strengthened chain rule for Rényi divergence
The main result of this section is the following chain rule for the Rényi divergence.
Theorem 3.1
Let , , , , and . Suppose that there exists such that . Then
| 3.1 |
This is a stronger version of an existing chain rule due to [9], which we will use in our proof of Theorem 3.1:
Lemma 3.2
([9, Corollary 5.1]). Let , , , , and . Then
| 3.2 |
The difference between Theorem 3.1 and Lemma 3.2 is that on the r.h.s. of Eq. (3.1), we only have the divergence between the two reduced states on system A. In contrast, if we used Eq. (3.2) with systems AR, then we would get the divergence between the full states. In particular, the weaker Lemma 3.2 can easily be recovered from Theorem 3.1 by taking the system R to be trivial, in which case the condition becomes trivial, too.
While the difference between Theorem 3.1 and Lemma 3.2 may look minor at first sight, the two chain rules can give considerably different results: in general, the data processing inequality ensures that , but the gap between the two quantities can be significant, i.e., there exist states for which . In such cases, Theorem 3.1 yields a significantly tighter bound. This turns out to be crucial if we want to apply this chain rule repeatedly to get an EAT.
We also note that the statement of Theorem 3.1 is known to be correct also for [37, Theorem 3.5]. However, this requires a separate proof and does not follow from Theorem 3.1 as it is currently not known whether the function is continuous in the limit .10
We now turn to the proof of Theorem 3.1. The key question for the proof is the following: given states and , does there exist an extension of such that ? For the special case of , an affirmative answer is given by Uhlmann’s theorem [10] (see also [11, Corollary 3.14]). This also holds for , but not in general for as discussed in Sect. B. The following lemma shows that a similar property still holds for on a regularised level.
Lemma 3.3
Consider quantum systems A and R with . For , we define , where are copies of the system A, and likewise . Then for , , and we have
Proof
The inequality
follows directly from the data processing inequality for taking the partial trace over , and additivity of under tensor product [11].
For the other direction, we consider n-fold tensor copies of and , which we denote by and . We define the following two pinched states
| 3.3 |
By definition of and using the pinching inequality (see Lemma 2.7(iii)) twice, we have
Using the operator monotonicity of the sandwiched Rényi divergence in the first argument [11] we find for any state
| 3.4 |
with the error term
To prove the lemma, we now need to bound the error term and construct a specific choice for for which and . We first bound . Since , we have from Eq. (2.3) that , where . To bound , we note that by Eq. (3.3) and Lemma 2.7(v)
| 3.5 |
We can therefore use Lemma 2.9 to obtain . Hence,
| 3.6 |
It thus remains to construct satisfying the properties mentioned above. To do so we first establish a number of commutation statements.
- (i)
- (ii)
-
(iii)Taking the partial trace over in Eq. (3.9), we get
3.10
Having established these commutation relations, we define by11
By construction,
| 3.11 |
We define
| 3.12 |
To see that this is a valid choice of , i.e., that , we use Eqs. (3.8), (3.9) and (3.10) to find
Using Eqs. (3.11) and (3.12) followed by the data processing inequality [11], we obtain
| 3.13 |
By Eqs. (3.7) and (3.3) we have . Therefore, continuing from Eq. (3.13) and using followed by the data processing inequality gives
Inserting this and our error bound from Eq. (3.6) into Eq. (3.4) proves the desired statement.
With this, we can now prove Theorem 3.1.
Proof of Theorem 3.1
Because is additive under tensor products, for any we have
| 3.14 |
where the second equality holds because , so for any that satisfies . From the chain rule in Lemma 3.2 we get that for any :
where for the second line we used additivity of the regularised channel divergence (see Eq. (2.2)). Combining this with Eq. (3.14), we get
| 3.15 |
Finally, using Lemma 3.3 and the fact that and are constants independent of n, we have
Therefore, taking in Eq. (3.15) and inserting this yields the theorem statement.
Removing the regularisation
The chain rule presented in Theorem 3.1 contains a regularised channel divergence term, which cannot be computed easily and whose behaviour as is not understood. In this section we show that in the specific case relevant for entropy accumulation, this regularisation can be removed. From this, we then derive a chain rule for Rényi entropies in Theorem 3.6.
Definition 3.4
(Replacer map). The replacer map is defined by its action on an arbitrary state :
Note that as usual, when we write , we include an implicit tensoring with the identity channel, i.e. .
Lemma 3.5
Let , , and , where is the replacer map. Then we have
Proof
Due to the choice of , we have that for any state (with ):
From [41, Proposition II.4] and [2, Lemma 4.2.2] we know that for every n, there exists a symmetric pure state such that
where and the supremum in the definition of the channel divergence is achieved because the conditional entropy is continuous in the state. Let and . We define the state
| 3.16 |
where is the Haar measure on pure states. We now claim that in the limit , we can essentially replace the optimizer by the state in Eq. (3.16). More precisely, we claim that
| 3.17 |
To show this, we first use Lemma 2.3 to get
It is know that is the maximally mixed state on (see e.g. [13]). Therefore,
is a valid quantum state (i.e. positive and normalised). Hence, we can write
Using [1, Lemma B.5], it follows that
Since vanishes as , taking the limit and using  proves Eq. (3.17).
proves Eq. (3.17).
Having established Eq. (3.17), we can now conclude the proof of the lemma as follows
where we used joint quasi-convexity [11, Proposition 4.17] in the fourth line and additivity under tensor products in the last line.
Strengthened chain rule for conditional Rényi entropy
We next combine Theorem 3.1 with Lemma 3.5 to derive a new chain rule for the conditional Rényi entropy which then allows us to prove the generalised EAT in Sect. 4.
Lemma 3.6
Let , , and such that there exists such that . Then
| 3.18 |
for a purifying system .
Proof
We define the following maps12
Note that in Eq. (3.18), we can replace by , as the system does not appear in Eq. (3.18). With and , we can write
We now claim that there exists a map such that . To see this, observe that by assumption, for some . Then, we can define by its action on an arbitrary state :
for any extension of . Therefore, we can apply Theorem 3.1 to find
By definition of , we have . Since the channel divergence is stabilised (see Footnote 9), tensoring with has no effect, i.e.,
To this, we can apply Lemma 3.5 and obtain
with . Combining all the steps yields the desired statement.
Generalised Entropy Accumulation
We are finally ready to state and prove the main result of this work which is a generalisation of the EAT proven in [1]. We first state a simple version of this theorem, which follows readily from the chain rule Theorem 3.6 and captures the essential feature of entropy accumulation: the min-entropy of a state produced by applying a sequence of n channels can be lower-bounded by a sum of entropy contributions of each channel . However, for practical applications, it is desirable not to consider the state , but rather that state conditioned on some classical event, for example “success” in a key distribution protocol – a concept called “testing”. Analogously to [1], we present an EAT adapted to that setting in Sect. 4.2.
Generalised EAT
Theorem 4.1
(Generalised EAT). Consider a sequence of channels such that for all , there exists such that . Then for any and any
for a purifying system . For a statement with explicit constants, see Eq. (4.1) in the proof.
Proof
By [1, Lemma B.10], we have for
with . From Theorem 3.6, we have
Repeating this step times, we get
where the final step uses the monotonicity of the Rényi divergence in [11, Corollary 4.3]. From [1, Lemma B.9] we have for each and sufficiently close to 1,
Setting and combining the previous steps, we obtain
| 4.1 |
Using yields the result.
Generalised EAT with testing
In this section, we will extend Theorem 4.1 to include the possibility of “testing”, i.e., of computing the min-entropy of a cq-state conditioned on some classical event. This analysis is almost identical to that of [8]; we give the full proof for completeness, but will appeal to [8] for specific tight bounds. The resulting EAT (Theorem 4.3) has (almost) the same tight bounds as the result in [8], but replaces the Markov condition with the more general non-signalling condition. Hence, relaxing the Markov condition does not result in a significant loss in parameters (including second-order terms).
Consider a sequence of channels for , where are classical systems with common alphabet . We require that these channels satisfy the following condition: defining , there exist channels and such that and , where and have the form
| 4.2 |
where and are families of mutually orthogonal projectors on and , and is a deterministic function Similarly, and are families of mutually orthogonal projectors on and , and is a deterministic function. (Note that even though we use the same symbol for both, in principle there does not have to be any relationship between the single-round projectors and the projector (and likewise for and ), although in practice the latter will usually be the tensor product of the former.) Intuitively, this condition says that for each round, the classical statistics can be reconstructed “in a projective way” from the systems and in that round, and furthermore the full statistics information can be reconstructed in a projective way from the systems and at the end of the process. The latter condition is not implied by the former because future rounds may modify the -system in such a way that can no longer be reconstructed from the side information at the end of the protocol. To rule this out, we need to specify the latter condition separately. In particular, this requirement is always satisfied if the statistics are computed from classical information contained in and and this classical information is not deleted from in future rounds. This is the scenario in all applications that we are aware of, but we state Eq. (4.2) more generally to allow for the possibility of protocols where the statistics are constructed in a more general way.
Let be the set of probability distributions on the alphabet of , and let be a system isomorphic to . For any we define the set of states
| 4.3 |
where denotes the probability distribution over with the probabilities given by . In other words, is the set of states that can be produced at the output of the channel and whose reduced state on is equal to the probability distribution q.
Definition 4.2
A function is called a min-tradeoff function for if it satisfies
Note that if , then f(q) can be chosen arbitrarily.
Our result will depend on some simple properties of the tradeoff function, namely the maximum and minimum of f, the minimum of f over valid distributions, and the maximum variance of f:
where and is the distribution with all the weight on element x. We write for the distribution on defined by . We also recall that in this context, an event is defined by a subset of , and for a state we write for the probability of the event and
for the state conditioned on .
Theorem 4.3
Consider a sequence of channels for , where are classical systems with common alphabet and the sequence satisfies Eq. (4.2) and the non-signalling condition: for each , there exists such that . Let , , , , and f be an affine13 min-tradeoff function with . Then,
| 4.4 |
where is the probability of observing event , and
with .
Remark 4.4
The parameter in in Theorem 4.3 can be optimized for specific problems, which leads to tighter bounds. Alternatively, it is possible to make a generic choice for to recover a theorem that looks much more like Theorem 4.1, which is done in Corollary 4.6. We also remark that even tighter second order terms have been derived in [42]. To keep our theorem statement and proofs simpler, we do not carry out this additional optimization explicitly, but note that this can be done in complete analogy to [42].
To prove Theorem 4.3, we will need the following lemma (which is already implicit in [1, Claim 4.6], but we give a simplified proof here).
Lemma 4.5
Consider a quantum state that has the form
where is a subset of the alphabet of the classical system C, and for each c, is subnormalised and is a quantum state. Then for ,
Proof
Let such that
Then
Hence,
Recalling the definitions of (Definition 2.1) and  (Definition 2.2), we see that the lemma follows by taking the logarithm and multiplying by .
(Definition 2.2), we see that the lemma follows by taking the logarithm and multiplying by .
Proof of Theorem 4.3
As in the proof of Theorem 4.1, we first use [1, Lemma B.10] to get
| 4.5 |
for and . We therefore need to find a lower bound for
| 4.6 |
where the equality holds because of Eq. (4.2) and [1, Lemma B.7].
Before proceeding with the formal proof, let us explain the main difficulty compared to Theorem 4.1. The state for which we need to compute the entropy in Eq. (4.6) is conditioned on the event . This is a global event, in the sense that it depends on the classical outputs of all rounds. We essentially seek a lower bound that involves for some , i.e., for every round we only want to minimize over output states of the channel whose distribution on matches the frequency distribution of the n rounds we observed. This means that we must use the global conditioning on to argue that in each round, we can restrict our attention to states whose outcome distribution matches the (worst-case) frequency distribution associated with . The chain rule Theorem 3.1 does not directly allow us to do this as the r.h.s. of Eq. (3.18) always minimizes over all possible input states.
To circumvent this, we follow a strategy that was introduced in [1] and optimized in [8] (see also [16, 21, 43] for related ideas and [44] for follow-up work). For every i, we introduce a quantum system with and define by
For every , the state is defined as the mixture between a uniform distribution on and a uniform distribution on that satisfies
where stands for the distribution with all the weight on element x. This is clearly possible if .
We define and denote
The state has the right form for us to apply Lemma 4.5 and get
| 4.7 |
where
We treat each term in Eq. (4.7) in turn.
-
(i)For the term on the l.h.s., it is easy to see that , so

4.8 -
(ii)For the first term on the r.h.s., we compute
where the last equality holds because f is affine.4.9 -
(iii)For the second term on the r.h.s., we first use [1, Lemma B.5] to remove the conditioning on the event , and then use that removing the classical system and switching from
 to can only decrease the entropy:
to can only decrease the entropy:
where we used . Now noting that , we see that the non-signalling condition on implies the non-signalling condition on . We can therefore apply the chain rule in Theorem 3.6 to find
where we introduced the shorthand and the purifying system . Noting that for we have , we can now use [8, Corollary IV.2] to obtain
where and are quantities from [8, Proposition V.3] that satisfy
where . Note that the above expressions derived in [8, Proposition V.3] also hold in our case due to the first part of Eq. (4.2). Furthermore, as in the proof of [8, Proposition V.3], we have
Therefore, the second term on the r.h.s. of Eq. (4.7) is bounded by
4.10
Combining our results for each of the three terms (i.e. Eqs. (4.8), (4.9) and (4.10)) and recalling , Eq. (4.7) becomes
Inserting this into Eqs. (4.5) and (4.6), and defining we obtain
| 4.11 |
as desired.
Corollary 4.6
For the setting given in Theorem 4.3 we have
where the quantities and are given by
with
Proof
We first note that for any with non-zero probability, . Therefore, if , it is easy to check that , so the statement of Corollary 4.6 becomes trivial. We may therefore assume that .
As in the proof of Theorem 4.3, we define . The first part of the proof works for any for ; later we will make a specific choice of in this interval. Then, and . Therefore, using as defined in the proof of Theorem 4.3 and noting that in the interval this quantity is monotonically increasing in , we have
Hence, we can simplify the statement of Theorem 4.3 to
| 4.12 |
We now choose as a function of n and so that the terms proportional to and match:
Inserting this choice of into Eq. (4.12) and combining terms yields the constants in Corollary 4.6. The final step is to show that this choice of indeed satisfies for . For this, we note that for , we have
We can now use that since , so
where the last inequality holds because .
In many applications, e.g. randomness expansion or QKD, a round can either be a “data generation round” (e.g. to generate bits of randomness or key) or a “test round” (e.g. to test whether a device used in the protocol behaves as intended). More formally, in this case the maps can be written as
| 4.13 |
where the output of on system is from some alphabet that does not include , so the alphabet of system is . The parameter is called the testing probability, and for efficient protocols we usually want to be as small as possible.
For maps of the form in Eq. (4.13), there is a general way of constructing a min-tradeoff function for the map based only on the statistics generated by the map . This was shown in [8] and we reproduce their result (adapted to our notation) here for the reader’s convenience.
Lemma 4.7
([8, Lemma V.5]). Let be channels satisfying the same conditions as in Theorem 4.3 that can furthermore be decomposed as in Eq. (4.13). Suppose that an affine function satisfies for any and any
| 4.14 |
where is a purifying system. Then, the affine function defined by
is a min-tradeoff function for . Moreover,
Sample Applications
To demonstrate the utility of our generalised EAT, we provide two sample applications. Firstly, in Sect. 5.1 we prove security of blind randomness expansion against general attacks. The notion of blind randomness was defined in [15] and has potential applications in mistrustful cryptography (see [15, 16] for a detailed motivation). Until now, no security proof against general attacks was known. In particular, the original EAT is not applicable because its model of side information is too restrictive. With our generalised EAT, we can show that security against general attacks follows straightforwardly from a single-round security statement.
Secondly, in Sect. 5.2 we give a simplified security proof for the E91 QKD protocol [45], which was also treated with the original EAT [1]. This example is meant to help those familiar with the original EAT understand the difference between that result and our generalised EAT. In particular, this application highlights the utility of our more general model of side information: in our proof, the non-signalling condition is satisfied trivially and the advantage over the original EAT stems purely from being able to update the side information register . We point out that while here we focus on the E91 protocol to allow an easy comparison with the original EAT, our generalised EAT can be used for a large class of QKD protocols for which the original EAT was not applicable at all. A comprehensive treatment of this is given in [7].
Blind randomness expansion
We start by recalling the idea of standard (non-blind) device-independent randomness expansion [17–21]. Alice would like to generate a uniformly random bit string using devices and prepared by an adversary Eve. To this end, in her local lab (which Eve cannot access) she isolates the devices from one another and plays multiple round of a non-local game with them, e.g. the CHSH game. On a subset of the rounds of the game, she checks whether the CHSH condition is satisfied. If this is the case on a sufficiently high proportion of rounds, she can conclude that the devices’ outputs on the remaining rounds must contain a certain amount of entropy, conditioned on the input to the devices and any quantum side information that Eve might have kept from preparing the devices. Using a quantum-proof randomness extractor, Alice can then produce a uniformly random string.
Blind randomness expansion [15, 16] is a significant strengthening of the above idea. Here, Alice only receives one device , which she again places in her local lab isolated from the outside world. Now, Alice plays a non-local game with her device and the adversary Eve: she samples questions for a non-local game as before, inputs one of the questions to , and sends the other question to Eve. and Eve both provide an output. Alice then proceeds as in standard randomness expansion, checking whether the winning condition of the non-local game is satisfied on a subset of rounds and concluding that the output of her device must contain a certain amount of entropy conditioned on the adversary’s side information.
For the purpose of applying the EAT, the crucial difference between the two notions of randomness expansion is the following: in standard randomness expansion, the adversary’s quantum side information is not acted upon during the protocol, and additional side information (the inputs to the devices, which we also condition on) are generated independently in a round-by-round manner. This allows a relatively straightforward application of the standard EAT [4]. In contrast, in blind randomness expansion, the adversary’s quantum side information gets updated in every round of the protocol and is not generated independently in a round-by-round fashion. This does not fit in the framework of the standard EAT, which requires the side information to be generated round-by-round subject to a Markov condition. As a result, [15, 16] were not able to prove a general multi-round blind randomness expansion result.
In the rest of this section, we will show that our generalised EAT is capable of treating multi-round blind randomness expansion, using a protocol similar to [14, Protocol 3.1]. A formal description of the protocol is given in Protocol 1.
The following proposition shows a lower bound on on the amount of randomness Alice can extract from this protocol, as specified by the min-entropy. For this, we assume a lower-bound on the single-round von Neumann entropy. Such a single-round bound can be found numerically using a generic method as explained after the proof of Lemma 5.1.
Proposition 5.1
Suppose Alice executes Protocol 1 with a device D that cannot communicate with Eve. We denote by and the (arbitrary) quantum systems of the device D and the adversary Eve after the i-th round, respectively. Eve’s full side-information after the i-th round is . A single round of the protocol can be described by a quantum channel . We also define to be the same as , except that always picks . Let be the state at the end of the protocol and the event that Alice does not abort.
Let be an affine function satisfying the conditions
| 5.1 |
where is a purifying system. Then, for any , either or
for independent of n and
where is the expected winning probability and the error tolerance from Protocol 1. If we treat and as constants, then and .
Furthermore, if there exists a quantum strategy that wins the game G with probability , there is an honest behaviour of D and Eve for which .
Remark 5.2
The condition on g(p) in Eq. (5.1) is formulated in terms of the entropy
with . However, the map corresponding to the i-th round does not act on the systems . Therefore, we can view these systems as part of the purifying system. Since the infimum in Eq. (5.1) already includes a purifying , we can drop these additional systems and without loss of generality choose to be isomorphic to those input systems on which acts non-trivially, i.e. . This means that we can replace the upper bound on g in Eq. (5.1) by the equivalent condition
| 5.2 |
with . For the proof of Lemma 5.1 we will use Eq. (5.1) since it more closely matches the notation of Theorem 4.3, but intuitively, Eq. (5.2) is more natural as it only involves quantities related to the i-th round of the protocol.
Proof of Lemma 5.1
To show the min-entropy lower bound, we will make use of Corollary 4.6. For this, we first check that the maps satisfy the required conditions. Since is a deterministic function of the (classical) variables and , it is clear that Eq. (4.2) is satisfied. For the non-signalling condition, we define the map as follows: samples and as Alice does in Step 5.1 of Protocol 1. then performs Eve’s actions in the protocol (which only act on and , which is part of ). It is clear that the distribution on and produced by is the same as for . By the assumption that D and Eve cannot communicate, the marginal of the output of on Eve’s side must be independent of the device’s system . Hence, .
To construct a min-tradeoff function, we note that we can split , with always picking and always picking . Then, we get from Lemma 4.7 and the condition that the affine function f defined by
is an affine min-tradeoff function for .
Viewing the event as a subset of the range of the random variable and comparing with the abort condition in Protocol 1, we see that implies . Therefore, for and denoting ,
where the last inequality holds because g is affine and the distribution satisfies . The proposition now follows directly from Corollary 4.6 and the scaling of and is easily obtained from the expressions in Corollary 4.6.
To show that an honest strategy succeeds in the protocol with high probability, we define a random variable by if , and otherwise. If D and Eve execute the quantum strategy that wins the game G with probability in each round, then . Using the abort condition in the protocol, we then find
where in the last line we used a Chernoff bound.
To make use of Lemma 5.1, we need to construct a function g(p) that satisfies the condition in Eq. (5.1). For this, we will use the equivalent condition Eq. (5.2). A general way of obtaining such a bound automatically is using the recent numerical method [22].14 Specifically, using the assumption that Alice’s lab is isolated, the maps describing a single round of the protocol take the form described in Fig. 1.
Fig. 1.
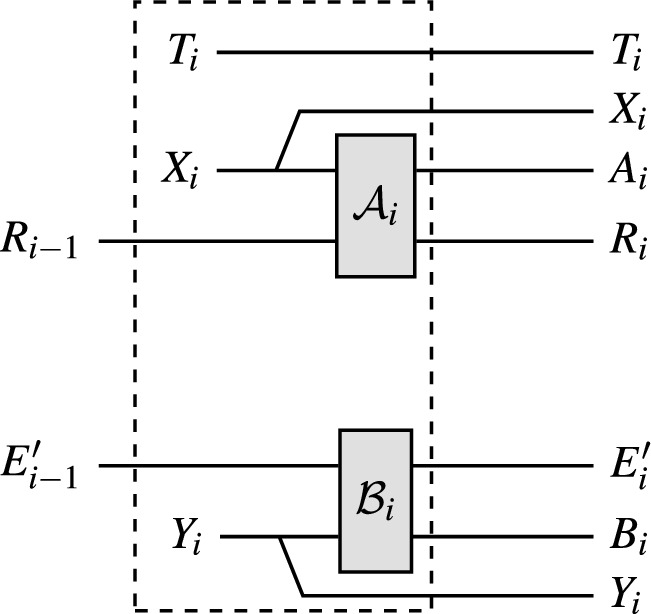
Circuit diagram of . For every round of the protocol, a circuit of this form is applied, where and are the (arbitrary) channels applied by Alice’s device and Eve, respectively. As in the protocol, is a bit equal to 1 with probability , and and are generated according to q whenever , and are fixed to otherwise. We did not include the register in the figure as it is a deterministic function of
The method of [22] allows one to obtain lower bounds on the infimum of
over all input states and for any map of the form depicted in Fig. 1. Importantly, for any we may also restrict the infimum to states that are consistent with the observed statistics, i.e., for some distribution p on , using the notation of Lemma 5.1. Using this numerical method for the CHSH game, we obtain the values shown in Fig. 2. From this, one can also construct an explicit affine min-tradeoff function g(p) in an automatic way using the same method as in [46]. As our focus is on illustrating the use of the generalised EAT, not the single-round bound, we do not carry out these steps in detail here.
Fig. 2.
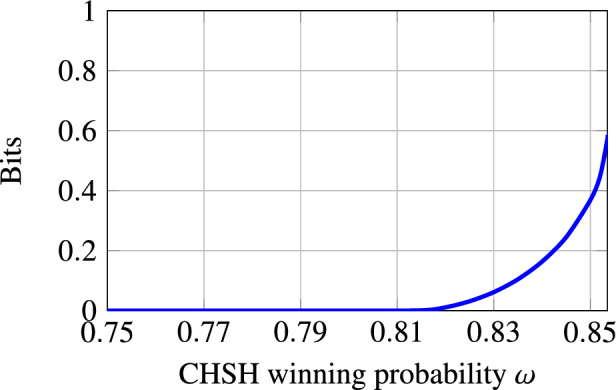
Lower bound on the conditional entropy for any state generated as in Fig. 1 and such that on test rounds the obtained winning probability for the CHSH game is . This lower bound was obtained by using the method from [22]. For each input , the channel is modelled as , where are orthogonal projectors summing to the identity, and similarly for the map . It is simple to see that this is without loss of generality
Combining this single-round bound and Lemma 5.1, one obtains that for Protocol 1 instantiated with the CHSH game, sufficiently close to the maximal winning probability of , and , one can extract bits of uniform randomness from while using only bits of randomness to run the protocol. In other words, Protocol 1 achieves exponential blind randomness expansion with the CHSH game.
E91 quantum key distribution protocol
The E91 protocol is one of the simplest entanglement-based QKD protocols [45, 47]. This protocol was already treated using the original EAT in [1]. Here, we do not give a formal security definition and proof, only an informal comparison of how the original EAT and our generalised EAT can be applied to this problem; the remainder of the security proof is then exactly as in [1]. For a detailed treatment of the application of our generalised EAT to QKD, see [7]. To facilitate the comparison with [1], in this section we label systems the same as in [1] even though this differs from the system labels used earlier in this paper. The protocol we are considering is described explicitly in Protocol 2. It is the same as in [1] except for minor modifications to simplify the notation.
We consider the systems as in Protocol 2 and additionally define the system storing the statistical information used in the parameter estimation step:
Denoting by E the side information gathered by Eve during the distribution step, we can follow the same steps as for [1, Equation (57)] to show that the security of Protocol 2 follows from a lower bound on
| 5.3 |
Here, is the state at the end of the protocol conditioned on acceptance.
We first sketch how the original EAT (whose setup was described in Sect. 1) is applied to this problem in [1]. One cannot bound directly using the EAT because a condition similar to Eq. (4.2) has to be satisfied. Therefore, one modifies the systems from Protocol 2 by setting if and then applies the EAT to find a lower bound on
| 5.4 |
For this, a round of Protocol 2 is viewed as a map , which chooses as in Protocol 2, applies Alice and Bob’s (trusted) measurements on systems to generate , and generates as described before. To apply the EAT, takes the role of the “hidden sytem”, and and are the output and side information of the i-th round, respectively. It is easy to see that with this choice of systems, the Markov condition of the EAT is satisfied, so, using a min-tradeoff function derived from an entropic uncertainty relation [48], one can find a lower bound on Eq. (5.4).
However, adding the system in this manner has the following disadvantage: to relate the lower bound on to the desired lower bound on one needs to use a chain rule for min-entropies, incurring a penalty term of the form . This penalty term is relatively easy to bound for the case of the E91 protocol, but can cause problems in general.15
We now turn our attention to proving Eq. (5.3) using our generalised EAT. For this, we first observe that
so it suffices to find a lower bound on the r.h.s. This step is similar to adding the systems in Eq. (5.4) in that its purpose is to satisfy Eq. (4.2). However, it has the advantage that here, can be added to the conditioning system and therefore lowers the entropy, not raises it like going from Eqs. (5.3) to (5.4). The same step is not possible in the original EAT due to the restrictive Markov condition.
Using the same system names as before, we define .16 Then, analogously to the original EAT, we can describe a single round of Protocol 2 by a map . (Compared to the map we described above for the original EAT, we have traced out , added a copy of , and added identity maps on the other additional systems in .) Denoting by the joint state of Alice and Bob’s systems before measurement and the information E that Eve gathered during the distribution step, the state at the end of the protocol is . To apply Corollary 4.6 to find a lower bound on
we first observe that the condition in Eq. (4.2) is satisfied because the system is part of , and the non-signalling condition is trivially satisfied because there is no -system. A min-tradeoff function can be constructed in exactly the same way as in [1, Claim 5.2] by noting that all systems in on which does not act can be viewed as part of the purifying system.
This comparison highlights the advantage of the more general model of side information in our generalised EAT: for the original EAT, one has to first bound (rather than ) in order to be able to satisfy the Markov condition, and then perform a separate step to remove the system. In our case, the non-signalling condition, the analogue of the Markov condition, is trivially satisfied because we need no -system. This is because we can add the quantum systems to the side information register at the start and then, since we allow side information to be updated and Alice and Bob act on using trusted measurement devices, we can remove the systems one by one during the rounds of the protocol.
Acknowledgements
We thank Rotem Arnon-Friedman, Peter Brown, Kun Fang, Raban Iten, Joseph M. Renes, Martin Sandfuchs, Ernest Tan, Jinzhao Wang, John Wright, and Yuxiang Yang for helpful discussions. We further thank Mario Berta and Marco Tomamichel for insights on Lemma 3.2, and Frédéric Dupuis and Carl Miller for discussions about blind randomness expansion.
Dual Statement for Smooth Max-Entropy
In the main text we have focused on deriving a lower bound on the smooth min-entropy. Here, we show that this also implies an upper bound on the smooth max-entropy by applying a simple duality relation between min- and max-entropy. A similar upper bound was also derived in [1]. However, that bound is subject to a Markov condition and cannot be derived by a simple duality argument since the “dual version” of the Markov condition is unwieldy. We show that the bound from [1] follows as a special case of our more general bound even without any Markov conditions or other non-signalling constraints. For simplicity, we restrict ourselves to an asymptotic statement without “testing”, i.e. we derive an -version of Theorem 4.1. By applying the same duality relation to the more involved statement in Theorem 4.3, one can also obtain an -bound with explicit constants and testing.
Recall that for and , the -smoothed max-entropy of A conditioned on B is defined as
where denotes the trace norm and is the -ball around in terms of the purified distance [11]. The smooth min- and max-entropy satisfy the following duality relation [11, Proposition 6.2]: for a pure quantum state ,
For the setting of Theorem 4.1, let be the Stinespring dilation of the map , and let be a purification of the input state . Then, is a purification of , so by the duality of the smooth min- and max-entropy,
Furthermore, by concavity of the conditional entropy the infimum in Theorem 4.1 can be restricted to pure states , so is a purification of . Then, by the duality relation for von Neumann entropies,
Therefore, we obtain the following dual statement to Theorem 4.1:
| A.1 |
where the maximisation is over pure states on . This holds for any sequence of isometries for which the maps given by satisfy the non-signalling condition of Theorem 4.1: for each i, there must exist a map such that .
To gain some intuition for the above statement, consider a setting where an information source generates systems and by applying isometries to some pure intial state . We might be interested in compressing the information in in such a way that given , one can reconstruct except with some small failure probability . Then, the amount of storage needed for the compressed information is given by . To apply Eq. (A.1), for we split the systems into in such a way that the channel defined above satisfies the non-signalling condition, and set (so that is trivial). Then Eq. (A.1) gives an upper bound on . Note that this bound depends on how we split the systems : the non-signalling condition can always be trivially satisfied by choosing to be trivial, but Eq. (A.1) tells us that if we can describe the source in such a way that is relatively small and is relatively large while still satisfying the non-signalling condition, we obtain a tighter bound on the amount of required storage.
From Eq. (A.1) we can also recover the max-entropy version of the original EAT, but without requiring a Markov condition. To facilitate the comparison with [1], we first re-state their theorem with their choice of system labels, but add a bar to every system label to avoid confusion with our notation from before. The max-entropy statement in [1] considers a sequence of channels and asserts that under a Markov condition, for any initial state with a purifying system :
| A.2 |
where . We want to recover this statement from Eq. (A.1) without any Markov condition. For this, we consider the Stinepring dilations of . We make the following choice of systems:
and choose to be trivial. By tensoring with the identity, we can then extend to an isometry . Then, the maps satisfy the non-signalling condition since acts as identity on . Therefore, remembering that and is trivial, we see that Eq. (A.1) implies Eq. (A.2). Note that our derivation did not require any conditions on the channels we started with, i.e. we have shown Eq. (A.2) holds for any sequence of channels , not just channels satisfying a Markov or non-signalling condition.
Uhlmann Property for the Rényi Divergence
We establish that for the max-divergence (where ), Uhlmann’s theorem holds.
Proposition B.1
Let and . Then we have
| B.1 |
In addition, if and all commute, then for any , we have
| B.2 |
Proof
We start with Eq. (B.1). The inequality is a direct consequence of the data-processing inequality for . For the inequality , we use semidefinite programming duality, see e.g., [50]. Observe that we can write as the following semidefinite program
Using semidefinite programming duality, this is also equal to
| B.3 |
We can also write a semidefinite program for . We introduce the variable and get
Again, by semidefinite programming duality, we get that it is equal to
| B.4 |
Eliminating the variable , we can write this last program as
which is the same as Eq. (B.3). This proves Eq. (B.1). Equation (B.2) follows immediately by choosing and using the commutation conditions.
However, for and arbitrary , , the Uhlmann property given by Eq. (B.2) does not hold. A concrete example is with
and . In this case, whereas
This computation was performed by numerically solving the semidefinite programs via CVXQUAD [51]. Putting everything together shows that Eq. (B.2) does not hold for :
Funding
Open access funding provided by Swiss Federal Institute of Technology Zurich. TM and RR acknowledge support from the National Centres of Competence in Research (NCCRs) QSIT (funded by the Swiss National Science Foundation under grant number 51NF40-185902) and SwissMAP, the Air Force Office of Scientific Research (AFOSR) via project No. FA9550-19-1-0202, the SNSF project No. 200021_188541 and the QuantERA project eDICT. OF acknowledges funding from the European Research Council (ERC Grant AlgoQIP, Agreement No. 851716), from the European Union’s Horizon 2020 QuantERA II Programme (VERIqTAS, Agreement No 101017733) and from a government grant managed by the Agence Nationale de la Recherche under the Plan France 2030 with the reference ANR-22-PETQ-0009. Part of this work was carried out when DS was with the Institute for Theoretical Physics at ETH Zurich.
Data Availability
No experimental data has been generated as part of this project. The introduction of this work has been published as an extended abstract in the proceedings of FOCS 2022 [49].
Declarations
Conflict of interest
The authors have no Conflict of interest to declare.
Footnotes
Since is a product of identical states, all of the terms are equal, i.e., for any i. We write the sum here explicitly to highlight the analogy with the EAT presented below.
The EAT from [1] also makes an analogous statement about an upper bound on the max-entropy . We derive a generalisation of that statement in Appendix A but only focus on in the introduction and main text since that is the case that is typically relevant for applications.
In fact, the EAT is more general in that it allows taking into account observed statistics to restrict the minimization over , but we restrict ourselves to the simpler case without statistics in this introduction.
As usual, the channels act as identity on any additional systems that may be part of the input state, i.e. is a state on . In particular, the register containing a purification of the input is also part of the output state.
Strictly speaking, the EAT as stated in [1] only requires that this Markov property holds for any input state in the image of the previous maps . The same is true for the non-signalling condition, i.e., one can check that our proof of the generalised EAT still works if the map only satisfies Eq. (1.2) on states in the image of . To simplify the presentation, we use the stronger condition Eq. (1.2) throughout this paper.
We note that the definition of Rényi entropies can be extended to , but we will only need the case .
In fact, in order for this single-round quantity to be positive one has to restrict the infimum to input states that allow the non-local game to be won with a certain probability. This requires using the generalised EAT with testing (Sect. 4.2), not Theorem 1.1. We refer to Sect. 5.1 for details.
In an EAT-like theorem, the entropy contribution from a particular round i has to be calculated conditioned on the side information revealed in that round because we want to analyse the process round-by-round, not globally. If a future round revealed additional side information, then the total entropy contributed by round i would decrease, but there is no way of accounting for that in an EAT-like theorem that simply sums up single-round contributions. As an extreme case, the last round of the process could reveal all prior outputs as side information, so that the total amount of conditional entropy produced by the process is 0, but single-round entropy contributions could be positive. This demonstrates the need for some condition that enforces that future side information does not reveal information about past outputs. We note that this does not mean that there is no way of proving an entropy lower bound in more general settings: for example, [32] do show a bound on the entropy produced by parallel repeated non-local games, but this requires a global analysis.
“Stabilised” refers to the fact that the supremum in Eq. (2.1) maximises over states in , not just , i.e. the maximisation includes a purifying system . One can also consider non-stabilised channel divergences, where the supremum is only over states in . However, in this paper we only use the stabilised channel divergence.
It is well-known [3, Lemma 8] that , but it is unclear whether the same holds for the regularised quantity.
In case does not have full support, we only take the inverse on the support of .
The map in the theorem statement is also implicitly tensored with an identity map on A, but for the definition of we make this explicit to avoid confusion when applying Theorem 3.1.
A function f on the convex set is called affine if it is linear under convex combinations, i.e., for and , . Such functions are also sometimes called convex-linear.
The main result of [15] (Theorem 14) does not appear to be sufficient for this. The reason is that the statement made in [15] essentially concerns the randomness produced on average over the question distribution q of the game G. However, choosing a question at random consumes randomness, so to achieve exponential randomness expansion, in Protocol 1 we fix the inputs used for generation rounds. To the best of our knowledge, the results of [15] do not give a bound on the randomness produced in the non-local game for any fixed inputs . If one could prove an analogous statement to [15, Theorem 14] that also certifies randomness on fixed inputs for a large class of games, our Lemma 5.1 would then imply exponential blind randomness expansion for any such game. Alternatively, one can also assume that public (non-blind) randomness is a free resource and use this to choose the inputs for the non-local game. Then, no special inputs are needed in Protocol 1 to “save randomness” and the result of [15] combined with our generalised EAT implies that such a conversion from public to blind randomness is possible for any complete-support game.
An error correction scheme is reliable if, except with negligible probability, either Bob’s guess of Alice’s string is correct or the protocol aborts.
In Protocol 2, instead of Alice distributing the systems and Eve gathering side information E by intercepting , we can equivalently imagine that Eve first prepares a state and distributes to Alice and Bob in each round. Then, the choice of intuitively captures the side information available to Eve from the first i rounds: Eve still possesses the systems to be distributed in future rounds, has gathered classical information , and keeps the static side information E from preparing the initial state.
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
References
- 1.Dupuis, F., Fawzi, O., Renner, R.: Entropy accumulation. Commun. Math. Phys. 379(3), 867–913 (2020) [DOI] [PMC free article] [PubMed] [Google Scholar]
- 2.Renner, R.: Security of quantum key distribution. Int. J. Quantum Inf. 6(01), 1–127 (2008) [Google Scholar]
- 3.Tomamichel, M., Colbeck, R., Renner, R.: A fully quantum asymptotic equipartition property. IEEE Trans. Inf. Theory 55(12), 5840–5847 (2009) [Google Scholar]
- 4.Arnon-Friedman, R., Dupuis, F., Fawzi, O., Renner, R., Vidick, T.: Practical device-independent quantum cryptography via entropy accumulation. Nat. Commun. 9(1), 459 (2018) [DOI] [PMC free article] [PubMed] [Google Scholar]
- 5.Bamps, C., Massar, S., Pironio, S.: Device-independent randomness generation with sublinear shared quantum resources. Quantum 2, 86 (2018) [Google Scholar]
- 6.Petz, D.: Sufficient subalgebras and the relative entropy of states of a von Neumann algebra. Commun. Math. Phys. 105(1), 123–131 (1986) [Google Scholar]
- 7.Metger, T., Renner, R.: Security of quantum key distribution from generalised entropy accumulation. Preprint at arXiv:2203.04993 (2022) [DOI] [PMC free article] [PubMed]
- 8.Dupuis, F., Fawzi, O.: Entropy accumulation with improved second-order term. IEEE Trans. Inf. Theory 65(11), 7596–7612 (2019) [Google Scholar]
- 9.Fawzi, H., Fawzi, O.: Defining quantum divergences via convex optimization. Quantum 5, 387 (2021) [Google Scholar]
-
10.Uhlmann, A.: The “transition probability’’ in the state space of a
 -algebra. Rep. Math. Phys. 9(2), 273–279 (1976) [Google Scholar]
-algebra. Rep. Math. Phys. 9(2), 273–279 (1976) [Google Scholar] - 11.Tomamichel, M.: Quantum Information Processing with Finite Resources: Mathematical Foundations, vol. 5. Springer, Cham, Switzerland (2015) [Google Scholar]
- 12.Sutter, D.: Approximate Quantum Markov Chains. Springer, Cham (2018) [Google Scholar]
- 13.Christandl, M., König, R., Renner, R.: Postselection technique for quantum channels with applications to quantum cryptography. Phys. Rev. Lett. 102(2), 020504 (2009) [DOI] [PubMed] [Google Scholar]
- 14.Arnon-Friedman, R., Renner, R., Vidick, T.: Simple and tight device-independent security proofs. SIAM J. Comput. 48(1), 181–225 (2019) [Google Scholar]
- 15.Miller, C.A., Shi, Y.: Randomness in nonlocal games between mistrustful players. Quantum Inf. Comput. 17(7), 595 (2017) [PMC free article] [PubMed] [Google Scholar]
- 16.Honghao, F., Miller, C.A.: Local randomness: examples and application. Phys. Rev. A 97(3), 032324 (2018) [DOI] [PMC free article] [PubMed] [Google Scholar]
- 17.Colbeck, R.: Quantum and relativistic protocols for secure multi-party computation. PhD Thesis, University of Cambridge (2006)
- 18.Colbeck, R., Kent, A.: Private randomness expansion with untrusted devices. J. Phys. A Math. Theor. 44(9), 095305 (2011) [Google Scholar]
- 19.Pironio, S., Acín, A., Massar, S., de La Giroday, A.B., Matsukevich, D.N., Maunz, P., Olmschenk, S., Hayes, D., Le Luo, L., Manning, T.A., et al.: Random numbers certified by Bell’s theorem. Nature 464(7291), 1021–1024 (2010) [DOI] [PubMed] [Google Scholar]
- 20.Vazirani, U., Vidick, T..: Certifiable quantum dice: or, true random number generation secure against quantum adversaries. In: Proceedings of the Forty-Fourth Annual ACM Symposium on Theory of Computing, pp. 61–76 (2012)
- 21.Miller, C.A., Shi, Y.: Robust protocols for securely expanding randomness and distributing keys using untrusted quantum devices. J. ACM (JACM) 63(4), 1–63 (2016) [Google Scholar]
- 22.Brown, P., Fawzi, H., Fawzi, O.: Computing conditional entropies for quantum correlations. Nat. Commun. 12(1), 1–12 (2021) [DOI] [PMC free article] [PubMed] [Google Scholar]
- 23.Chung, K.M., Shi, Y., Wu, X.: Physical randomness extractors: generating random numbers with minimal assumptions. Preprint at arXiv:1402.4797 (2014)
- 24.Coudron, M., Yuen, H..: Infinite randomness expansion with a constant number of devices. In: Proceedings of the Forty-Sixth Annual ACM Symposium on Theory of Computing, STOC ’14, pp. 427-436, New York, NY, USA. Association for Computing Machinery (2014)
- 25.Kaniewski, J., Wehner, S.: Device-independent two-party cryptography secure against sequential attacks. New J. Phys. 18(5), 055004 (2016) [Google Scholar]
- 26.Broadbent, A., Islam, R.: Quantum encryption with certified deletion. In: Theory of Cryptography Conference, pp. 92–122. Springer (2020)
- 27.Kundu, S., Tan, E.: Composably secure device-independent encryption with certified deletion. Preprint at arXiv:2011.12704 (2020)
- 28.Frauchiger, D., Renner, R., Troyer, M.: True randomness from realistic quantum devices. Preprint at arXiv:1311.4547 (2013)
- 29.Campbell, S., Vacchini, B.: Collision models in open system dynamics: A versatile tool for deeper insights? Europhys. Lett. 133(6), 60001 (2021) [Google Scholar]
- 30.del Rio, L., Hutter, A., Renner, R., Wehner, S.: Relative thermalization. Phys. Rev. E 94(2), 022104 (2016) [DOI] [PubMed] [Google Scholar]
- 31.Akers, C., Penington, G.: Leading order corrections to the quantum extremal surface prescription. J. High Energy Phys. 2021(4), 1–73 (2021)35342281 [Google Scholar]
- 32.Jain, R., Kundu, S.: A direct product theorem for quantum communication complexity with applications to device-independent QKD. In: 2021 IEEE 62nd Annual Symposium on Foundations of Computer Science (FOCS), pp. 1285–1295. IEEE (2022)
- 33.Zhang, Y., Fu, H., Knill, E.: Efficient randomness certification by quantum probability estimation. Phys. Rev. Res. 2, 013016 (2020) [DOI] [PMC free article] [PubMed] [Google Scholar]
- 34.Knill, E., Zhang, Y., Bierhorst, P.: Generation of quantum randomness by probability estimation with classical side information. Phys. Rev. Res. 2, 033465 (2020) [Google Scholar]
- 35.Müller-Lennert, M., Dupuis, F., Szehr, O., Fehr, S., Tomamichel, M.: On quantum Rényi entropies: a new generalization and some properties. J. Math. Phys. 54(12), 122203 (2013) [Google Scholar]
- 36.Wilde, M.M., Winter, A., Yang, D.: Strong converse for the classical capacity of entanglement-breaking and Hadamard channels via a sandwiched Rényi relative entropy. Commun. Math. Phys. 331(2), 593–622 (2014) [Google Scholar]
- 37.Fang, K., Fawzi, O., Renner, R., Sutter, D.: Chain rule for the quantum relative entropy. Phys. Rev. Lett. 124, 100501 (2020) [DOI] [PubMed] [Google Scholar]
- 38.Hayashi, M.: Quantum Information Theory. Springer, Berlin Heidelberg (2017) [Google Scholar]
- 39.Christandl, M.: The Structure of Bipartite Quantum States-Insights from Group Theory and Cryptography. Ph. D. Thesis (2006)
- 40.Harrow, A.W.: Applications of coherent classical communication and the Schur transform to quantum information theory. Preprint at arXiv:quant-ph/0512255 (2005)
- 41.Leditzky, F., Kaur, E., Datta, N., Wilde, M.M.: Approaches for approximate additivity of the Holevo information of quantum channels. Phys. Rev. A 97(1), 012332 (2018) [Google Scholar]
- 42.Liu, W.-Z., Li, M.-H., Ragy, S., Zhao, S.-R., Bai, B., Liu, Y., Brown, P.J., Zhang, J., Colbeck, R., Fan, J., et al.: Device-independent randomness expansion against quantum side information. Nat. Phys. 17(4), 448–451 (2021) [Google Scholar]
- 43.Miller, C.A., Shi, Y.: Universal security for randomness expansion from the spot-checking protocol. SIAM J. Comput. 46(4), 1304–1335 (2017) [Google Scholar]
- 44.Arqand, A., Hahn, T.A., Tan, E.Y.-Z.: Generalized renyi entropy accumulation theorem and generalized quantum probability estimation. Preprint at arXiv:2405.05912 (2024)
- 45.Ekert, A.K.: Quantum cryptography based on Bell’s theorem. Phys. Rev. Lett. 67, 661–663 (1991) [DOI] [PubMed] [Google Scholar]
- 46.Brown, P., Ragy, S., Colbeck, R.: A framework for quantum-secure device-independent randomness expansion. IEEE Trans. Inf. Theory 66(5), 2964–2987 (2019) [Google Scholar]
- 47.Christandl, M., Renner, R., Ekert, A.: A generic security proof for quantum key distribution. Preprint at arXiv:quant-ph/0402131 (2004)
- 48.Berta, M., Christandl, M., Colbeck, R., Renes, J.M., Renner, R.: The uncertainty principle in the presence of quantum memory. Nat. Phys. 6(9), 659–662 (2010) [Google Scholar]
- 49.Metger, T., Fawzi, O., Sutter, D., Renner, R.: Generalised entropy accumulation. In: 2022 IEEE 63rd Annual Symposium on Foundations of Computer Science (FOCS), pp. 844–850. IEEE (2022)
- 50.Watrous, J.: The Theory of Quantum Information. Cambridge University Press, Cambridge (2018) [Google Scholar]
- 51.Fawzi, H., Fawzi, O.: Efficient optimization of the quantum relative entropy. J. Phys. A Math. Theor. 51(15), 154003 (2018) [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.
Data Availability Statement
No experimental data has been generated as part of this project. The introduction of this work has been published as an extended abstract in the proceedings of FOCS 2022 [49].