

Abstract
In many applications, the objective is to build regression models to explain a response variable over a region of interest under the assumption that the responses are spatially correlated. In nearly all of this work, the regression coefficients are assumed to be constant over the region. However, in some applications, coefficients are expected to vary at the local or subregional level. Here we focus on the local case. Although parametric modeling of the spatial surface for the coefficient is possible, here we argue that it is more natural and flexible to view the surface as a realization from a spatial process. We show how such modeling can be formalized in the context of Gaussian responses providing attractive interpretation in terms of both random effects and explaining residuals. We also offer extensions to generalized linear models and to spatio-temporal setting. We illustrate both static and dynamic modeling with a dataset that attempts to explain (log) selling price of single-family houses.
Keywords: Bayesian framework, Multivariate spatial processes, Prediction, Spatio-temporal modeling, Stationary Gaussian process
1. INTRODUCTION
The broad availability of fast, inexpensive computing along with the development of very capable, user-friendly geographic information systems (GIS) software has led to the increased collection of spatial and spatio-temporal data in such diverse fields as real estate/finance, epidemiology, environmetrics/ecology, and communications. In turn, this has fueled increased spatial modeling and data analysis activity within the statistical community.
In many applications, the objective is to build regression models to explain a response variable observed over a region of interest, say , under the assumption that the responses are spatially associated. That is, whereas some spatial modeling may be accomplished through the mean, it is still anticipated that the responses are dependent and that this dependence becomes stronger as pairs of responses become closer in space. With continuous response that is point referenced, if a normality assumption (perhaps on a transformed scale) seems plausible, this dependence is typically modeled directly using a Gaussian process. The literature here is enormous. The book by Cressie (1993) is perhaps a place to start. In the case of, say, binary or count response, a hierarchical model is often adopted using an exponential family model at the first stage and then introducing normally distributed spatial random effects into the mean structure on a transformed scale related by a link function (see, e.g., Diggle, Tawn, and Moyeed 1998).
In nearly all of this work, the regression coefficients are assumed to be constant across the region. In certain applications, this would not be appropriate. The coefficients may be expected to vary at the local or subregion level. For instance, Assunçao, Gamerman, and Assunçao (1999) introduced a Bayesian space varying parameter model to examine microregion factor productivity and the degree of factor substitution in the Brazilian agriculture. Agarwal, Gelfand, Sirmans, and Thibadeau (2003), in the context of locally stationary spatial modeling, introduced local regression models for factors affecting house price at the school district (and sub-school district) level. A flexible modeling approach for space-varying regression models was developed with a simulation study by Gamerman, Moreira, and Rue (2001). These authors all made the rather restrictive assumption that for a given coefficient, it is constant on specified areal units. The levels of the surface on these units is modeled using independent or conditionally autoregressive specifications. Concerns arise about the arbitrariness of the scale of resolution, the lack of smoothness of the surface, and the inability to interpolate the value of the surface to individual locations. When working with point-referenced data, it will be more attractive to allow the coefficients to vary by location, to envision a spatial surface for a particular coefficient. For instance, in our application we also model the (log) selling price of single family houses. Customary explanatory variables include the age of the house, the square feet of living area, the square feet of other area, and the number of bathrooms. If the region of interest is a city or greater metropolitan area, then it is evident that the capitalization rate (e.g., for age), will vary across the region. Older houses will have higher value in some parts of the region than in other parts. By allowing the coefficient of age to vary with location, we can remedy the foregoing concerns. With practical interest in mind, say real estate appraisal, we can predict the coefficient for arbitrary properties, not just for those that sold during the period of investigation. Similar issues arise in modeling environmental exposure to a particular pollutant, where covariates might include temperature and precipitation.
One possible approach would be to model the spatial surface for the coefficient parametrically. In the simplest case this would require the rather arbitrary specification of a polynomial surface function; a range of surfaces too limited or inflexible might result. More flexibility could be introduced using a spline surface over two-dimensional space (see, e.g., Luo and Wahba 1998). However, this requires selection of a spline function and determination of the number of and locations of the knots in the space. Also, with multiple coefficients, a multivariate specification of a spline surface is required. The approach that we adopt here is arguably more natural and at least as flexible. We model the spatially varying coefficient surface as a realization from a spatial process. For multiple coefficients, we use a multivariate spatial process model. In fact, we use a stationary specification in which desired degree of smoothness of process realization can be modeled through the choice of covariance function (e.g., the Matèrn class). Kent (1989) and Stein (1999a) have provided discussions of univariate process; Banerjee and Gelfand (2003), of multivariate process. A nonstationary model results for the data.
We adopt a Bayesian approach for our modeling framework. This is attractive in the proposed setting, because we are specifically interested in inference for the random spatial effects. In particular, we obtain an entire posterior for the spatial coefficient process at both observed and unobserved locations, as well as posteriors for all model parameters. Interpolation for a process that is neither observed nor arising as a residual seems inaccessible in any other framework. For Gaussian responses, although some inference is possible through likelihood methods, it is more limited, and in particular, interval estimation relies on possibly inappropriate asymptotics. For non-Gaussian data, approximations will almost surely be required, possibly in the form that we provide in Section 7, but still inference will be limited.
To clarify interpretation and implementation, we first develop our general approach in the case of a single covariate, and thus we have two spatially varying coefficient processes, one for “intercept” and one for “slope.” We then turn to the case of multiple covariates. Because even in the basic multiple regression setting, coefficient estimates typically reveal some strong correlations, the collection of spatially varying coefficient processes is expected to be dependent. Hence we use a multivariate process model. Indeed, we present a further generalization to build a spatial analog of a multivariate regression model (see, e.g., Goldstein 1995). We also consider flexible spatio-temporal possibilities. The previously mentioned real estate setting provides site level covariates whose coefficients are of considerable practical interest and a dataset of single-family home sales from Baton Rouge, LA enables illustration. Except for regions exhibiting special topography, we anticipate that a spatially varying coefficient model will prove more useful than, for instance, a trend surface model. That is, incorporating a polynomial in latitude and longitude into the mean structure would not be expected to serve as a surrogate for allowing the variability across the region of a coefficient for say age or living area of a house.
The article is organized as follows. Section 2 details the Gaussian modeling approach for a single covariate. Section 3 addresses the multiple-covariate case. Section 4 proposes a sequence of varying coefficient specifications in the spatio-temporal setting. Section 5 comments briefly on model comparison. Section 6 presents an example using the aforementioned single-family home sales data. Section 7 concludes with some discussion of the generalized linear model setting.
2. THE MODELING APPROACH FOR A SINGLE COVARIATE
Recall the usual Gaussian stationary spatial process model as in, for example, Cressie (1993),
| (1) |
where and is a white noise process, that is, , and is a second-order stationary mean 0 process independent of the white noise process; that is, , where is a valid two-dimensional correlation function.
The are viewed as spatial random effects, and (1) implicitly defines a hierarchical model. Letting , write and define . Then can be interpreted as a random spatial adjustment at location to the overall intercept . Equivalently, can be viewed as a random intercept process. For an observed set of locations given and , the , are conditionally independent. The first-stage likelihood is
| (2) |
In obvious notation, the distribution of is
| (3) |
where . For all of the discussion and examples that follow, we adopt the Matèrn correlation function, . Here is a modified Bessel function, , where is a decay parameter and is a smoothness parameter (see Stein 1999a for a more in-depth discussion). With a prior on , and , specification of the Bayesian hierarchical model is completed. Under (2) and (3), we can integrate over , obtaining the marginal likelihood
| (4) |
where .
We note analogies with usual Gaussian random-effects models where , with and . In this case, replications are needed to identify (separate) the variance components. Because of the dependence between the , replications are not needed in the spatial case, as (4) reveals. Also, if denotes the total error in the regression model, then is partitioned into “intercept process” error and “pure” error.
If the Bayesian model is fitted using the marginal likelihood in (4) with simulation-based model fitting, then samples essentially from the posterior are obtained. But then samples from can be obtained one-for-one because
| (5) |
where
We can also obtain samples from the posterior of the process at a new location, say , to provide interpolation for the surface. Specifically,
| (6) |
The first density under the integral is a univariate normal that can be written down directly from the specification of . For the prediction of given , we require
| (7) |
The first term under the integral sign is a normal density. Again, it is straightforward to obtain samples from this predictive distribution.
The foregoing development immediately suggests how to formulate a spatially varying coefficient model. Suppose that we write
| (8) |
In (8), is a second-order stationary mean 0 Gaussian process with variance and correlation function . Also, let . Now can be interpreted as a random spatial adjustment at location to the overall slope . Equivalently, can be viewed as a random slope process. In effect, we are using an infinite-dimensional function to explain the relationship between and .
Expression (8) yields an obvious modification of (2) and (3). In particular, the resulting marginalized likelihood becomes
| (9) |
where is diagonal with . Moreover, with , we can sample and using obvious analogs of (5) and (6).
Note that (8) provides a heterogeneous, nonstationary process for the data regardless of the choice of covariance function for the process. Here, and . As a result, we observe that in practice, (8) is sensible only if we have . In fact, centering and scaling, usually advocated for better-behaved model fitting, is inappropriate here. With centered ’s, we would find the likely untenable behavior that decreases and then increases in . Worse, for an essentially central , we would find essentially independent of for any . Also, scaling the ’s accomplishes nothing. would be inversely rescaled, because the model identifies only .
This leads to concerns regarding possible approximate collinearity of , the vector of ’s, with the vector . Expression (9) shows that a badly behaved likelihood will arise if . Fortunately, we can reparameterize (8) to , where is centered and scaled with obvious definitions for and . Now , where is the sample standard deviation of the ’s.
As after (4), we can draw an analogy with usual longitudinal linear growth curve modeling where , that is, a random slope for each individual. Also, , the total error in the regression model (8), is now partitioned into “slope process” error and “pure” error.
The general specification encompassing (1) and (7) would be
| (10) |
Expression (10) parallels the usual linear growth curve modeling by introducing both an intercept process and a slope process. The model in (10) requires a bivariate process specification to determine the joint distribution of and . We return to this in Section 3, but, under independence of the processes, (10) can be easily marginalized over and , yielding
| (11) |
Again, simulation from , and is straightforward. The possibility of predicting the spatial surface at arbitrary locations makes a compelling case for a Bayesian inference approach. Classical kriging methods cannot address this problem, because no or are observed. Also, in (10), the total error has been partitioned into three independent pieces with obvious interpretation. The relative sizes of the error components at any can be studied through , and . To compare the relative variability contributions, we could calculate , and , where . In the case where and are isotropic, posteriors for the ranges can be obtained to compare spatial range of the intercept process with that of the slope process. The posterior mean surfaces and can be obtained over an arbitrary grid of locations and displayed graphically using standard software.
Bayesian models using the marginal likelihoods in either (4), (9), or (11) are easily fitted using a slice Gibbs sampler as discussed by Agarwal and Gelfand (2001) (see Neal 2002, as well). In particular, under, say (11), we add an auxiliary variable . Then the posterior ), where is the prior on the marginalized parameters. The slice Gibbs sampler updates with a uniform draw and updates the other parameters with a prior draw subject to the indicator restriction. This algorithm is “off-the-shelf,” requiring no tuning. It converges faster than Metropolis alternatives and avoids the autocorrelation problem that often arises with these alternatives.
3. A MULTIVARIATE SPATIALLY VARYING COEFFICIENT MODEL
Here we turn to the case of a multivariate covariate vector at location , where, for convenience, includes a 1 as its first entry to accommodate an intercept. We generalize (10) to
| (12) |
where is assumed to follow a -variate spatial process model. With observed locations , let be block diagonal having as block for the ith row . Then we can write , where is , the concatenated vector of the and .
In practice, to assume that the component processes of are independent is likely inappropriate. That is, in the simpler case of simple linear regression, negative association between slope and intercept is usually seen. (This is intuitive if one envisions overlaying random lines that are likely relative to a fixed scattergram of data points.) The dramatic improvement in model performance when dependence is incorporated is shown in the example of Section 6. To formulate a multivariate Gaussian process for , we require the mean and the cross-covariance function. For the former, following Section 2, we take this to be . For the latter, we require a valid -variate choice. In the sequel we work with a computationally convenient separable choice following Mardia and Goodall (1993) (see also Banerjee and Gelfand 2002 in this regard).
More precisely, let be the matrix with entry and let
| (13) |
where is a valid scalar correlation function in two dimensions and is such that is positive-definite symmetric. In other words, is the covariance matrix associated with an observation vector at any spatial location, and captures the attenuation in association across space. If we collect the set of into an matrix as in the previous section, then, with denoting the Kronecker product, the distribution of is
| (14) |
As in the previous section, if , then we can write (12) as
| (15) |
In (15), the total error in the regression model is partitioned into pieces each with an obvious interpretation. Following Section 2, using (12) and (14), we can integrate over to obtain
| (16) |
The possibly daunting form (16) still involves only matrices.
The Bayesian model is completed with a prior ) which we assume to take the product form . Later, these components are normal, inverse gamma, inverse Wishart and gamma, and gamma, where under the Matèrn correlation function. The model using (16) and such a prior is readily fitted through a sliced Gibbs sampler similar to that described at the end of the previous section.
With regard to prediction analogous to (5), can be sampled one-for-one with the posterior samples from using , which is , where and is , but for sampling , only a Cholesky decomposition of is needed and only for the retained posterior samples. Prediction at a new location, say , requires, analogous to (6), . Defining to be the vector with ith row entry , this distribution is normal with mean and covariance matrix . Finally, the predictive distribution for is sampled analogously to (7).
We conclude this section by noting an extension of (12) when we have repeated measurements at location . That is, suppose that we have
| (17) |
where with the number of measurements at and the still white noise. As an illustration, in the real estate context that we mentioned earlier, might denote the location for an apartment block and indexes apartments in this block that have sold, with the lth apartment having characteristics . Suppose further that denotes an vector of site level characteristics. For an apartment block, these characteristics might include amenities provided or distance to the central business district. Then (17) can be extended to a multilevel model in the sense of Goldstein (1995) or Raudenbush and Bryk (2002). In particular, we can write
| (18) |
In (18), is an vector associated with and is a mean multivariate Gaussian spatial process as, for example, earlier. In (18), if the were independent, then we would have a usual multilevel model specification. In the case where is a scalar capturing just an intercept, we return to the initial model of this section.
4. SPATIALLY VARYING COEFFICIENTS MODELS WITH SPATIO-TEMPORAL DATA
A natural extension of the modeling of the previous sections is to the case in which data are correlated at spatial locations across time. Such data frequently arise in ecological, environmental, and meteorological settings. If we assume that time is discretized to a finite set of equally spaced points on a scale, then we can conceptualizea time series of spatial processes that are observed only at the spatial locations .
Adopting a general notation that parallels (10), let
| (19) |
That is, we introduce spatio-temporally varying intercepts and spatio-temporally varying slopes. Alternatively, if we write , then we are partitioning the total error into spatio-temporal intercept pieces including , each with an obvious interpretation. So we continue to assume that the are iid , but we need to specify a model for . Regardless, (19) defines a nonstationary process with and .
We propose four models for . Paralleling the customary longitudinaldata modeling assumption when the time series are usually short, we could set
where is modeled as in the previous sections. Model 1 can be viewed as a local linear growth curve model.
Next, we have
where is again as in model 1. In modeling , we examine two possibilities. The first possibility treats the as time dummy variables, taking this set of variables to be a priori independent and identically distributed. The second possibility models the as a random walk or autoregressive process. The components could be assumed to be independent across , but for greater generality, we take them to be dependent, using an analog of (13), replacing with and , now a valid correlation function in one dimension. Such additivity in space and time has been discussed in the case of usual modeling of the error structure by, for example, Gelfand, Ecker, Knight, and Sirmans (2003).
In model 3 we consider an analog of the nested-effects areal unit specification of Waller, Carlin, Xia, and Gelfand (1997). (see also Gelfand et al. 2002). In particular, we have
Here we have spatially varying coefficient processes nested within time. The processes are assumed to be independent across (essentially time dummy processes) and permit temporal evolution of the coefficient process. Following Section 3, the process would be mean 0, second-order stationary Gaussian with cross-covariance specification at time , where . We have specified model 3 with a common across time, which enables some comparability with the other models that we have proposed. However, we can increase flexibility by replacing with .
Finally, model 4 proposes a separable covariance specification in space and time, extending work of Gelfand, Zhu, and Carlin (2001):
where is a valid two-dimensional correlation function, is a valid one-dimensional choice, and is positive-definite symmetric. Here obtains spatial association as in the earlier sections, which is attenuated across time by . The resulting covariance matrix for the full vector , blocked by site and time within site, has the convenient form .
In each of the aforementioned models, we can marginalize over as we did in the earlier sections. Depending on the model, it may be more computationally convenient to block the data by site or by time. We omit the details, noting only that with sites and time points, the resulting likelihood will involve the determinant and inverse of an matrix.
Note that all of the foregoing modeling can be applied to the case of cross-sectional data in which the set of observed locations varies with . This is the case with, for instance, our real estate data. We observe a selling price only at the time of a transaction. With locations in year , the likelihood for all but model 3 will involve a matrix.
5. MODEL COMPARISON
In either the purely spatial case or the spatio-temporal case, we may seek to compare models. For instance, in the spatial case from Sections 2 and 3, we can consider models in which only a subset of the coefficients vary spatially, where the coefficient processes are independent, or where the multivariate dependence version is assumed. In the spatio-temporal case, we can consider models 1–4 (with possible submodels in the cases of models 2 and 3).
We use the posterior predictive loss approach of Gelfand and Ghosh (1998). Illustrating in the spatio-temporal context, for each () in (19), let be a new observation obtained at that location and time for the given . If under a particular model, and denote the mean and variance of the predictive distribution of given (the set of all observed ’s), then the criterion becomes
| (20) |
In (20), the first term is a goodness-of-fit component , and the second term is a penalty for model complexity component . The constant weights these components and is often set to 1. The model yielding the smallest value of (20) is chosen.
6. AN EXAMPLE
We draw our data from a database of real estate transactions in Baton Rouge, LA, during the 8-year period 1985–1992. In particular, we focus on modeling the log selling price of single family homes. In the literature it is customary to work with log selling price in order to achieve better approximate normality. A range of house characteristics are available. We use four of the most common choices: age of house, square feet of living area, square feet of other area (e.g., garages, carports, storage) and number of bathrooms. For the static spatial case, a sample of 237 transactions was drawn from 1992. Figure 1 shows the parish of Baton Rouge and the locations contained in an encompassing rectangle within the parish.
Figure 1.
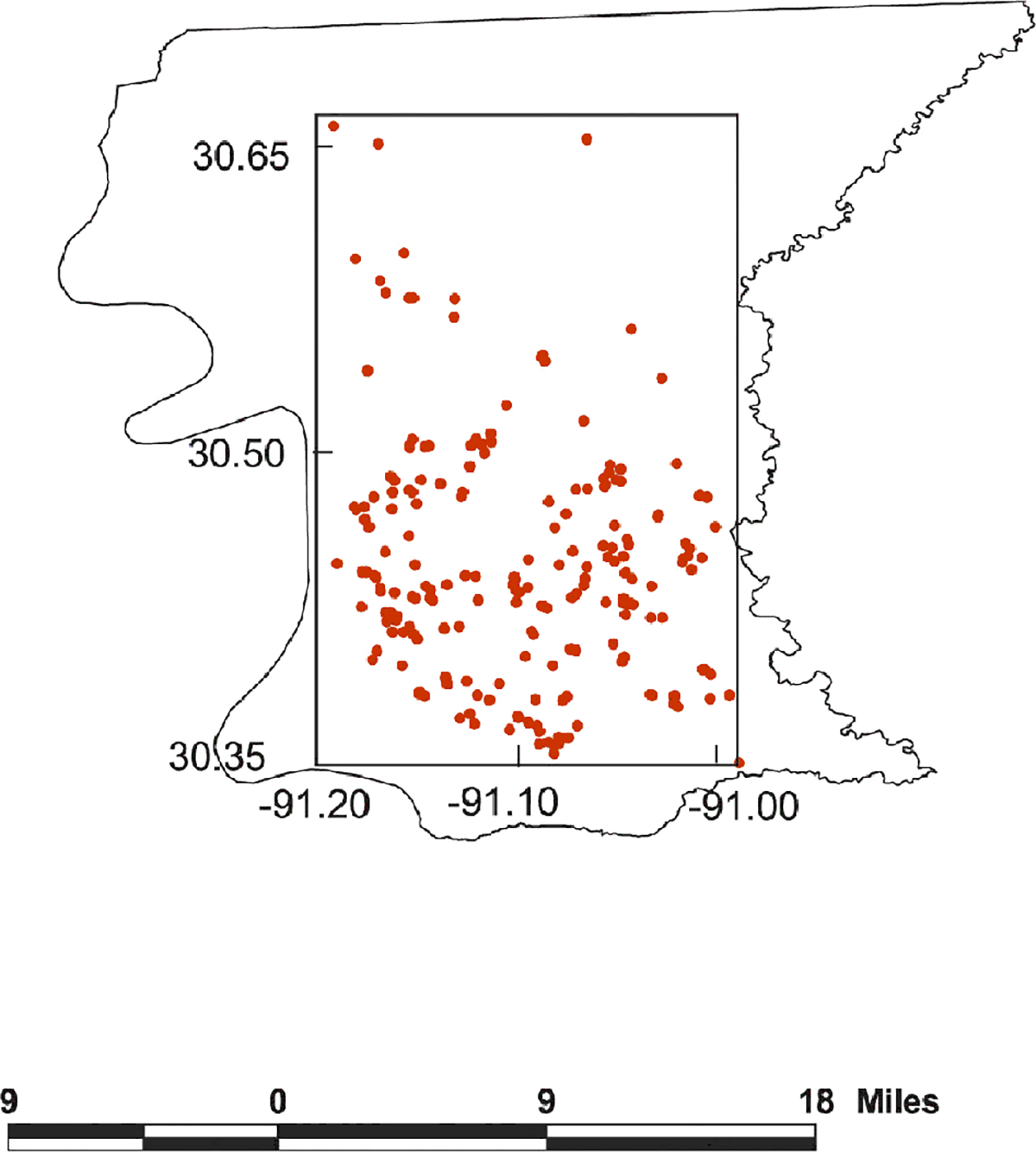
Locations Sampled Within the Parish of Baton Rouge for the Static Spatial Models.
We fitted the following collection of models. In all cases the correlation function is from the Matèrn class, that is, . We used priors that are fairly noninformative and comparable across models as sensible. We began with a spatial-varying intercept and one spatially varying slope coefficient. (The remaining coefficients do not vary). The intercept and coefficient processes follow a two-dimensional version of (13). There are four such models. The model comparison results are given in Table 1. The model with a spatially varying living area coefficient is best here. We then introduce two spatially varying slope coefficient processes along with a spatially varying intercept using a three-dimensional version of (13). There are six models here. Table 2 shows that the model with spatially varying age and living area is best. Finally, we allow five spatially varying processes; an intercept and four coefficients. We tried a model with five independent processes along with a five-dimensional version of (13). From Table 3 the five-dimensional model using (13) is far superior, and the independence model is clearly worst, supporting our earlier intuition.
Table 1.
Values of Posterior Predictive Model Choice Criterion for Two-Dimensional Models (intercept process is always included)
| Model | G | P | D |
|---|---|---|---|
|
| |||
| Living area | 69.87 | 46.24 | 116.11 |
| Age | 74.52 | 44.58 | 119.10 |
| Other area | 70.24 | 49.87 | 120.11 |
| Bathrooms | 78.02 | 52.93 | 130.95 |
Table 2.
Values of Posterior Predictive Model Choice Criterion for Three-Dimensional Models (intercept process is always included)
| Model | G | P | D |
|---|---|---|---|
|
| |||
| Age, living area | 61.38 | 47.83 | 109.21 |
| Age, other area | 63.80 | 48.45 | 112.25 |
| Age, bathrooms | 67.25 | 48.66 | 114.91 |
| Living area, other area | 72.35 | 50.75 | 123.10 |
| Living area, bathrooms | 78.47 | 49.28 | 127.75 |
| Other area, bathrooms | 74.58 | 47.44 | 122.02 |
Table 3.
Values of Posterior Predictive Model Choice Criterion (over all models)
| Model | G | P | D |
|---|---|---|---|
|
| |||
| Five-dimensional model | 42.21 | 36.01 | 78.22 |
| Three-dimensional model (best) | 61.38 | 47.83 | 109.21 |
| Two-dimensional model (best) | 69.87 | 46.24 | 116.11 |
| Independent process model | 94.36 | 59.34 | 153.70 |
The prior specification used for the five-dimensional dependent process model are as follows. We take vague for ; a five-dimensional inverted wishart, , for , and inverted gamma, , for (mean 1, infinite variance). For the Màtern correlation function parameters and , we assume gamma priors (with mean 20 and variance 200). For all of the models, three parallel chains were run to assess convergence. Satisfactory mixing was obtained within 3,000 iterations for all the models; another 2,000 samples were generated and retained for posterior inference. The resulting posterior inference summary is provided in Table 4. We note a significant negative overall age coefficient with significant positive overall coefficients for the other three covariates. These are as expected. The contribution to spatial variability from the components of is captured through the diagonal elements of the matrix scaled by the corresponding covariates after the discussion at the end of Section 2. We see that the spatial intercept process contributes most to the error variability with, perhaps surprisingly, the “bathrooms” process second. Clearly, spatial variability overwhelms the pure error variability , showing the importance of the spatial model. The dependence between the processes is evident in the posterior correlation between the components. In fact, under (13), it is straightforward to calculate that , regardless of . We find the anticipated negative association between the intercept process and the slope processes (apart from that with the “other area” process). Under the Matérn correlation function, by inverting for a given value of the decay parameter and the smoothing parameter , we obtain the range, that is, the distance beyond which spatial association becomes negligible. Posterior samples of produce posterior samples for the range. The resulting posterior median is roughly 4 km over a somewhat sprawling parish, which measures roughly 22 km × 33 km. The smoothness parameter suggests processes with mean squared differentiable realizations . Figure 2 shows the posterior mean spatial surfaces for each of the processes. The contour plots are evidently quite different. Table 5 considers a sample of 20 holdout sites on which the model can be validated; in fact, the validation is done with all of the models from Table 3. The entries in bold indicate validation failures. We find that for the first model, 19 of 20 predictive intervals contain the true value while for the independence model, 18 of 20 do so. More importantly, notice how much shorter these intervals are using the five-dimensional model.
Table 4.
Inference Summary for the Five-Dimensional Multivariate Spatially Varying Coefficients Model
| Parameter | 2.5 % | 50 % | 97.5 % |
|---|---|---|---|
|
| |||
| (intercept) | 9.908 | 9.917 | 9.928 |
| (age) | −.008 | −.005 | −.002 |
| (living area) | .283 | .341 | .401 |
| (other area) | .133 | .313 | .497 |
| (bathrooms) | .183 | .292 | .401 |
| .167 | .322 | .514 | |
| .029 | .046 | .063 | |
| .013 | .028 | .047 | |
| .034 | .045 | .066 | |
| .151 | .183 | .232 | |
| −.219 | −.203 | −.184 | |
| −.205 | −.186 | −.167 | |
| .213 | .234 | .257 | |
| −.647 | −.583 | −.534 | |
| −.008 | .011 | .030 | |
| .061 | .077 | .098 | |
| −.013 | .018 | .054 | |
| −.885 | −.839 | −.789 | |
| −.614 | −.560 | −.507 | |
| .173 | .232 | .301 | |
| (decay parameter) | .51 | 1.14 | 2.32 |
| (smoothness parameter) | .91 | 1.47 | 2.87 |
| range (in km) | 2.05 | 4.17 | 9.32 |
| .033 | .049 | .077 | |
Figure 2.
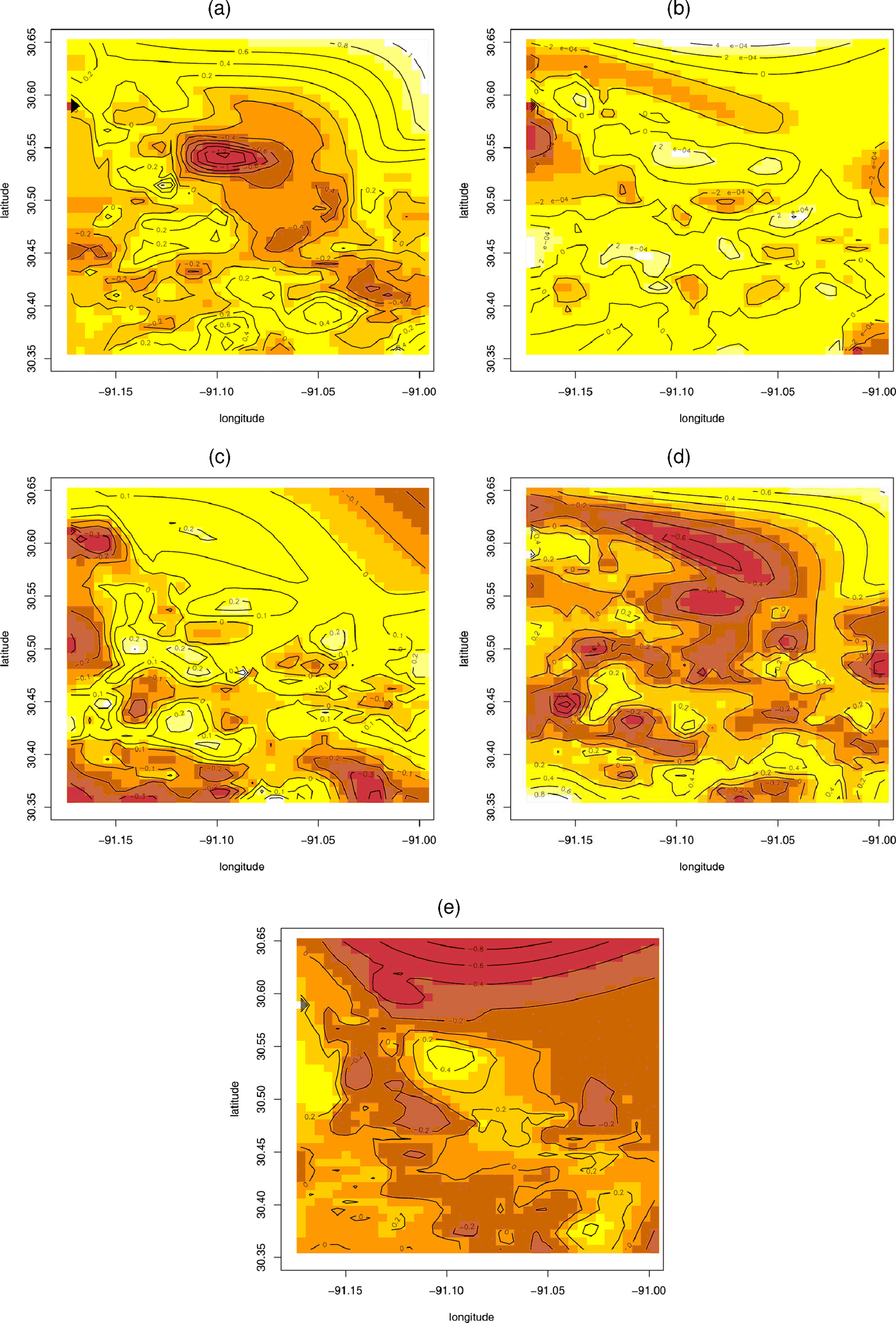
Mean Posterior Spatial Surfaces for the 5-D SVC Model: (a) Intercept Process, (b) Age Process, (c) Living Area Process, (d) Other Area Process, (e) Bathrooms Process.
Table 5.
Cross-Validatory Posterior Predictive Intervals for 20 Locations in Baton Rouge
| True value | Five-dimensional | Three-dimensional (best) | Two-dimensional (best) | Independent |
|---|---|---|---|---|
|
| ||||
| 11.18 | (10.85, 11.53) | (10.74, 11.68) | (10.56, 11.52) | (10.44, 11.79) |
| 10.86 | (10.54, 11.22) | (10.47, 11.31) | (10.52, 11.35) | (10.71, 12.08) |
| 11.16 | (11.05, 11.68) | (11.03, 11.96) | (10.97, 11.98) | (10.68, 12.06) |
| 11.46 | (11.39, 11.78) | (11.28, 12.11) | (11.35, 12.26) | (11.51, 12.34) |
| 12.29 | (12.01, 12.72) | (12.09, 12.94) | (12.06, 13.01) | (11.87, 13.24) |
| 10.18 | (9.81, 10.59) | (9.80, 10.60) | (9.73, 10.88) | (9.68, 10.75) |
| 11.26 | (11.03, 11.51) | (11.17, 11.76) | (11.08, 11.72) | (11.21, 12.13) |
| 10.97 | (10.82, 11.42) | (11.00, 11.97) | (10.77, 11.35) | (10.71, 11.52) |
| 11.55 | (11.27, 11.91) | (11.21, 11.86) | (11.28, 12.01) | (11.27, 12.08) |
| 12.22 | (12.11, 12.76) | (12.20, 12.84) | (12.15, 13.05) | (12.29, 13.25) |
| 12.05 | (11.81, 12.55) | (11.85, 12.53) | (11.85, 12.51) | (11.78, 12.49) |
| 11.68 | (11.50, 11.89) | (11.47, 11.92) | (11.49, 11.90) | (11.53, 12.18) |
| 11.95 | (11.60, 12.22) | (11.72, 12.24) | (11.64, 12.18) | (11.52, 12.21) |
| 12.22 | (11.77, 12.35) | (11.62, 12.27) | (11.89, 12.84) | (11.74, 12.82) |
| 11.34 | (11.02, 11.76) | (11.23, 11.86) | (11.22, 11.90) | (11.26, 11.85) |
| 11.05 | (11.10, 11.75) | (10.96, 11.78) | (11.01, 11.81) | (11.12, 12.09) |
| 10.53 | (10.04, 10.86) | (10.05, 10.89) | (10.07, 10.86) | (10.05, 10.88) |
| 11.42 | (11.26, 11.64) | (11.18, 11.82) | (11.16, 11.88) | (11.18, 12.05) |
| 10.68 | (10.58, 11.29) | (10.76, 11.53) | (10.73, 11.78) | (10.57, 11.58) |
| 12.16 | (11.66, 12.19) | (11.85, 12.62) | (11.94, 12.89) | (11.78, 12.82) |
Turning to the dynamic models proposed in Section 5, we returned to the Baton Rouge database, drawing a sample of 120 transactions at distinct spatial locations for the years 1989–1992. We compare models 1–4. In particular, we have two versions of model 2; 2a has the as four iid time dummies, and 2b uses the multivariate temporal process model for . We also have two versions of model 3; 3a has a common across , whereas 3 b uses . In all cases, we used the five-dimensional spatially varying coefficient model for ’s. Table 6 gives the results. Model 3, in which space is nested within time, turns out to be the best, with model 4 following closely behind. Finally Table 7 summarizes the posterior inference summary for model 3b. The overall coefficients do not change much over time; however, there is some indication that spatial range does change over time.
Table 6.
Model Choice Criteria for Various Spatio-Temporal Process Models (see Sec. 6)
| Model | G | P | D |
|---|---|---|---|
|
| |||
| Independent process | |||
| Model 1 | 88.58 | 56.15 | 144.73 |
| Model 2a | 77.79 | 50.65 | 128.44 |
| Model 2b | 74.68 | 50.38 | 125.06 |
| Model 3a | 59.46 | 48.55 | 108.01 |
| Model 3b | 57.09 | 48.41 | 105.50 |
| Model 4 | 53.55 | 52.98 | 106.53 |
| Dependent process | |||
| Model 1 | 54.54 | 29.11 | 83.65 |
| Model 2a | 47.92 | 26.95 | 74.87 |
| Model 2b | 43.38 | 29.10 | 72.48 |
| Model 3a | 43.74 | 20.63 | 64.37 |
| Model 3b | 42.35 | 21.04 | 63.39 |
| Model 4 | 37.84 | 26.47 | 64.31 |
Table 7.
Inference Summary for the 5-Dimension Multivariate Spatio-Temporal Model 3 (space nested within time)
| Parameter | 1989 | 1990 | 1991 | 1992 |
|---|---|---|---|---|
|
| ||||
| β0 (intercept) | 9.697 (9.438, 9.956) | 9.164 (8.782, 9.613) | 9.56 (9.237, 9.860) | 9.716 (9.445, 9.980) |
| β1 (age) | −.005 (−.007, −.001) | −.004 (−.007, −.002) | −.004 (−.007, −.002) | −.005 (−.008, −.002) |
| β2 (living area) | .383 (.314, .490) | .357 (.252, .460) | .402 (.232, .574) | .348 (.278, .416) |
| β3 (other area) | .246 (.068, .410) | .248 (.075, .422) | .305 (.137, .486) | .326 (.146, .515) |
| β4 (bathrooms) | .301 (.195, .407) | .296 (.193, .395) | .311 (.197, .420) | .304 (.201, .416) |
| ϕ (decay parameter) | 1.63 (.68, 3.52) | 1.77 (.85, 3.15) | 1.05 (.42, 2.33) | 1.17 (.57, 2.38) |
| ν (smoothness parameter) | 1.48 (.92, 3.05) | 1.51 (.93, 3.05) | 1.54 (.86, 3.16) | 1.47 (.88, 2.92) |
| range (in km) | 2.95 (1.40, 7.04) | 2.80 (1.55, 5.65) | 4.55 (2.07, 11.31) | 4.11 (2.03, 8.4) |
| τ 2 | .038 (.024, .082) | |||
7. THE GENERALIZED LINEAR MODEL SETTING
We briefly consider a generalized linear model version of (12), replacing the Gaussian first stage with
| (21) |
where, using a canonical link, . The specification generates the models of Diggle et al. (1998). In (19), we could include a dispersion parameter with little additional complication.
The resulting first-stage likelihood becomes
| (22) |
Taking the prior on in (14), the Bayesian model is completely specified with a prior on , and .
This model can be fitted using a conceptually straightforward Markov chain Monte Carlo algorithm in the form of a Gibbs sampler, which would update the components of and using adaptive rejection sampling (Gilks and Wild 1992). With an inverse Wishart prior on , the resulting full conditional of is again inverse Wishart. Updating is usually very awkward, because it enters in the Kronecker form in (14). Metropolis updates are hard to design but offer perhaps the best possibility. Also problematic is the repeated componentwise updating of . This hierarchically centered parameterization (Gelfand, Sahu, and Carlin 1995, 1996) is preferable to working with and , but the algorithm still runs very slowly with autocorrelation problems.
An alternative to componentwise updating is to introduce blocked Metropolis updating through a Langevin diffusion (see, e.g., Roberts, Gelman, and Gilks 1997; Christensen, Möller, and Waagepetersen 2000). Updating the entire vector seems unrealistic. Blocking by component process is essentially computationally intractable, and blocking by site creates strong autocorrelation problems. Clearly, more work is needed to provide efficient model-fitting strategies for these models.
Acknowledgments
A portion of Gelfand’s work was supported by National Science Foundation grant DMS 9971206. Kim was supported in part by National Science Foundation/Environmental Protection Agency grant “Statistical Methods for Environmental Social Sciences” and in part by the Center for Real Estate and Urban Economic Studies.
Contributor Information
Alan E. Gelfand, Institute of Statistics and Decision Sciences, Duke University, Durham, NC 27708-0251.
Hyon-Jung Kim, Department of Mathematical Sciences, University of Oulu, Finland..
C. F. Sirmans, Center for Real Estate and Urban Economic Studies, University of Connecticut, Storrs, CT 06269-1041..
Sudipto Banerjee, Division of Biostatistics, University of Minnesota, Minneapolis, MN 55455..
REFERENCES
- Agarwal DK, and Gelfand AE (2001), “Slice Gibbs Sampling for Simulation-Based Fitting of Spatial Models,” technical report, University of Connecticut, Dept. of Statistics. [Google Scholar]
- Agarwal DK, Gelfand AE, Sirmans CF, and Thibadeau TG (2003), “Nonstationary Spatial House Price Models,” Journal of Statistical Planning and Inference, [Google Scholar]
- Assunçao JJ, Gamerman D, and Assunçao RM (1999), “Regional Differences in Factor Productivities of Brazilian Agriculture: A Space-Varying Parameter Approach,” technical report, Universidade Federal do Rio de Janeiro, Statistical Laboratory. [Google Scholar]
- Banerjee S, and Gelfand AE (2002), “Prediction, Interpolation and Regression for Spatially Misaligned Data,” Sankhya, Ser. A, 64, 227–245. [Google Scholar]
- — (2003), “On Smoothness Properties of Spatial Processes,” Journal of Multivariate Analysis, to appear. [Google Scholar]
- Cressie NAC (1993), Statistics for Spatial Data (2nd ed.), New York: Wiley. [Google Scholar]
- Christensen OF, Moller J, and Waagepetersen R (2000), “Analysis of Spatial Data Using Generalized Linear Mixed Models and Langevin-Type Markov Chain Monte Carlo,” Research Report R-00–2009, Aalborg University. [Google Scholar]
- Diggle PJ, Tawn JA, and Moyeed RA (1998), “Model-Based Geostatistics” (with discussion), Applied Statistics, 47, 299–350. [Google Scholar]
- Gamerman D, Moreira ARB, and Rue H (2002), “Space-Varying Regression Models,” technical report, Universidade Federal do Rio de Janeiro, Statistical Laboratory. [Google Scholar]
- Gelfand AE, Ecker MD, Knight JR, and Sirmans CF (2003), “The Dynamics of Location In Home Price,” Journal of Real Estate Finance and Economics, to appear. [Google Scholar]
- Gelfand AE, and Ghosh SK (1998), “Model Choice: A Minimum Posterior Predictive Loss Approach,” Biometrika, 85, 1–11. [Google Scholar]
- Gelfand AE, Sahu SK, and Carlin BP (1995), “Efficient Parametrization for Normal Linear Mixed Effects Models,” Biometrika, 82, 479–488. [Google Scholar]
- — (1996), “Efficient Parametrization for Generalized Linear Mixed Models,” in Bayesian Statistics 5, eds. Bernardo J et al. , Oxford, U.K.: Clarendon Press, pp. 165–180. [Google Scholar]
- Gelfand AE, Zhu L, and Carlin BP (2001), “On the Change of Support Problem for Spatio-Temporal Data,” Biostatistics, 2, 31–45. [DOI] [PubMed] [Google Scholar]
- Gilks WR, and Wild P (1992), “Adaptive Rejection Sampling for Gibbs Sampling,” Journal of the Royal Statistical Society C, 41, 337–348. [Google Scholar]
- Goldstein H (1995), Multilevel Statistical Models (2nd ed.), London: Arnold. [Google Scholar]
- Kent JT (1989), “Continuity Properties for Random Fields,” Annals of Probability, 17, 1432–1440. [Google Scholar]
- Luo Z, and Wahba G (1998), “Spatio-Temporal Analogues of Temperature Using Smoothing Spline ANOVA,” Journal of Climatology, 11, 18–28. [Google Scholar]
- Mardia KV, and Goodall C (1993), “Spatio-Temporal Analyses of Multivariate Environmental Monitoring Data,” in Multivariate Environmental Statistics, eds. Patil GP and Rao CR, Amsterdam: Elsevier, 347–386. [Google Scholar]
- Neal R (2002), “Slice Sampling,” The Annals of Statistics, December issue. [Google Scholar]
- Raudenbush SW, and Bryk AS (2002), Hierarchical Linear Models (2nd ed.), Newbury Park, CA: Sage. [Google Scholar]
- Roberts G, Gelman A, and Gilks W (1997), “Weak Convergence and Optimal Scaling of Random Walk Metropolis Algorithms,” Annals of Applied Probability, 7, 110–120. [Google Scholar]
- Stein ML (1999a), Interpolation of Spatial Data: Some Theory for Kriging, New York: Springer. [Google Scholar]
- — (1999b), “Predicting Random Fields With Increasingly Dense Observations,” Annals of Applied Probability, 9, 242–273. [Google Scholar]
- Waller L, Carlin BP, Xia H, and Gelfand AE (1997), “Hierarchical Spatio-Temporal Mapping of Disease Rates,” Journal of the American Statistical Association, 92, 607–617. [Google Scholar]