

Abstract
The international community has formally negotiated over climate change since 1991. The annual meetings that host these negotiations have seen an ever-growing number of individuals representing countries, international organizations, or non-governmental organizations. These meetings and their attendees have accordingly become the focal point of international climate change cooperation for both the international community and scholars studying climate change politics. Yet, researchers have been unable to access and analyze comprehensive attendee-level data pertaining to these negotiations in terms of attendees’ names, genders, job titles, delegations, divisions, and affiliations. In applying text-as-data techniques to attendance roster PDFs, we extract and build attendee-level datasets for all annual negotiations held under the United Nations Framework Convention on Climate Change and its precursor, 1991–2023. These data include original language and English-translated information on 27,470 unique delegations and 310,200 attendees over a 32-year period. Summaries and validations in turn highlight the promise of our data for the study of attendance patterns and characteristics across delegations and over time.
Subject terms: Government, Climate-change mitigation
Background & Summary
The annual Conference of the Parties (COPs) to the United Nations Framework Convention on Climate Change (UNFCCC), alongside earlier talks leading up to the UNFCCC’s formation, together encompass the primary venues for international climate change negotiation for more than thirty years to date. To this end, representatives from national governments have attended these meetings since 1991 in an effort to negotiate cooperative solutions to the global climate change problem. An ever-expanding number of individuals representing non-state entities, including nongovernmental organizations (NGOs), intergovernmental organizations (IGOs), and international organizations (IOs) likewise attend and participate in these meetings as observer delegations or in some cases as members of national delegations. Through these varied efforts, the UNFCCC has fostered major cooperative breakthroughs, including 1997’s Kyoto Protocol and 2015’s Paris Agreement.
It therefore comes as no surprise that researchers now widely study the UNFCCC’s COPs to understand international climate change cooperation dynamics. Such understandings can illuminate the drivers of (un)successful global climate change cooperation, and therefore the pathway(s) to an effective solution to the Earth’s climate change problem. Consequently, social scientists have come to increasingly leverage quantitative methods to study UNFCCC COP processes via (e.g.) high level COP speeches1–3, written documents associated with the UNFCCC4–6, surveys of those participating in various COPs7–9, and patterns of COP attendance10–16. The latter research agenda has proven to be especially effective in understanding the causes and/or effects of delegations' leadership, civil society participation, size, and minority/gender representations in this venue11,14–17.
Yet one limitation to the studies mentioned immediately above is that they primarily focus on the delegation level of analysis. Assessing delegations at the UNFCCC’s COPs15 including simple counts of delegates13 facilitates understandings of the overall extent of COP participation across time and/or across nation-states (and determinants thereof). However, this often paints an incomplete picture of the depth of COP participation18, to the extent that it misses the diversity, seniority, and cross-delegation linkages of delegation representatives. Thus far, research suggests that these omissions may in turn have significant implications for our understanding of negotiation (outcomes) at the UNFCCC’s COPs19–21. At least partly in response, scholars have begun to study more nuanced characteristics of delegations such as their gender and civil society compositions11,12,14,16,17. However, these commendable extensions continue to ignore additional information at the individual attendee level. Indeed, and beyond their association with a formal (national or observer group) delegation, individual attendees also commonly report their first and last names, honorifics, job titles, departmental/organizational divisions, and additional affiliations. This textual information associated with these individual attendee characteristics stands to dramatically expand researchers’ abilities to understand the drivers and consequences of climate change negotiations. Honorifics, job titles, and attendee names may, for example, facilitate more nuanced measures and understandings of minority and gender representation at the UNFCCC’s COPs. Likewise, attendee names and delegation affiliations could be leveraged to study the causes and consequences of repeat COP attendance among delegation representatives. And textual information on attendees’ delegations, divisions, and affiliations could be used to develop (i) more fine-grained measures of civil society or industry influence or (ii) measures of social networks among attendees and their associated entities.
Given this potential, the present project extracts and provides attendee-level data for all UNFCCC and UNFCCC-precursor meetings from 1991 through 2023. These 30 years of attendee data span 28 UNFCCC COPs and 11 pre-COP meetings. To our knowledge, no empirical study has included the latter meetings’ information within analyses of climate change delegations, nor have studies of UNFCCC COP delegations encompassed the length of COP attendee data that we provide. Our final datasets contain detailed information on each individual COP and pre-COP attendee in terms of their official delegation and its type; the associated (pre-)COP meeting and its year and location; full individual attendee names and attendee honorifics; and (when provided) attendee job titles, divisions, and affiliations. These datasets come in two versions, one with the relevant string variables (e.g., job title) maintained in its originally submitted language, and one where a subset of these string variables have been translated to English to better facilitate comparisons between individuals.
To extract these data, we obtained PDFs of every UNFCCC COP and pre-COP attendance roster through COP 27, and then also downloaded a pair of Excel-based attendance rosters for COP 28. The former PDFs were highly heterogeneous in terms of (i) the text formatting contained within them, (ii) whether they were stored as PDF text or PDF image files, (iii) the overarching language of the attendance roster details, and (iv) overall PDF length. We accordingly developed and applied specialized text-as-data tools to extract and classify all relevant attendee information, which was then further corrected via manual (human) verification. Our subsequent validation efforts confirmed that this approach was relatively accurate and reliable, both in relation to comparable human coding and relative to the UNFCCC’s own aggregate statistics on individual delegation and attendee participation.
Methods
Project scope
Beginning in the early 1990s, and in response to growing public concern over climate change, intergovernmental climate talks coalesced at the global level. Initially, the talks were held under an Intergovernmental Negotiating Committee (INC)–as established by the UNGA Resolution 45/212 at the 71st plenary meeting in 1990–which first convened in 1991 in Washington, D.C. The primary purpose of the INC was to elaborate upon and craft an internationally effective Framework Convention on Climate Change. By the second half of the INC’s fifth session in New York City in 1992, countries had achieved this aim in their establishment of the United Nations Framework Convention on Climate Change (UNFCCC). The UNFCCC in turn entered into force in 1994 following its ratification by 50 Parties. Note here that Parties are the member states that signed UNFCCC and who have voting rights and veto power under this framework (https://unfccc.int/cop7/issues/briefhistory.html). With its entry into force, the UNFCCC’s annual meetings referred to as Conferences of the Parties (COPs), which replaced INC meetings, have come to serve as the primary venue for intergovernmental climate change negotiations since then.
During the period between the design of the UNFCCC and its eventual entrance into force, there were 11 formal INC meetings, though some meetings were held in two parts. We refer to the meetings during this period (1991–1995) as the pre-COPs era since it predates the formalization of the COPs mandated by the UNFCCC. These pre-COP meetings were attended by formal representatives of national governments, UN Secretariate units, other UN agencies and bodies, intergovernmental organizations (IGOs), and non-governmental organizations (NGOs). The last INC session was held in New York City in 1995, with the first UNFCCC COP occurring that same year in Berlin.
Beginning in 1995, the UNFCCC’s COPs have become the “supreme decision-making body of the Convention” (https://tinyurl.com/yvcn2xb5). In this capacity, the UNFCCC works to advance the commitments of member states in implementing strategies to address climate change problems both domestically and globally. Its COPs in turn serve as a place where countries holding Party status to the Convention design legal tools regulating climate change policies, negotiate over climate change priorities, assess the progress made towards past climate change goals, and consider taking further actions needed to tackle the problem effectively. Since 1995, 28 annual COPs have been held at rotating locations across the UN’s five recognized regions (https://www.un.org/en/climatechange/un-climate-conferences).
The UNFCCC’s COPs, similar to the INC’s pre-COPs, are attended by a diverse array of actors who hold different statuses during these sessions. Two major sets of actors participating in each COP session are state actors and non-state organizations. The former includes formal UNFCCC Parties as well as a dwindling number of Observer States. Nonstate organizations hold a similar observer status to that of Observer States. These non-state organizations include the United Nations System and its Specialized Agencies (IOs), intergovernmental organizations (IGOs), and non-governmental organizations (NGOs). Alongside these core participants, additional actors are also allowed to attend each COP in various support capacities. This includes press and media members as well as supplemental staff and overflow members. The general public is not accredited to attend COP sessions absent an affiliation with one of the entities mentioned above.
Before and after each COP, the UNFCCC Secretariat posts provisional and final (in some cases, termed “revised”) lists of participants, respectively. These participant lists, typically stored in PDF form, often first provide brief summary statistics on a given COP’s aggregate levels of attendance by attendance group, followed by detailed individual-level information on each attendee. To this end, these attendee rosters only provide comprehensive information for participants attending on behalf of Parties, Observer States, and the different nonstate entities mentioned above. Members of the media, staff, and overflow are not listed individually. For some COPs, the expected and eventual composition of delegations changes. In these situations, instead of releasing fully revised lists, the UNFCCC Secretariat makes corrections by releasing a corrigendum to the final attendance list after a particular COP meeting. These corrigendas include updated information on the delegates of some countries or organizations. The final lists and corrigenda for each pre-COP and COP serve as the primary sources for the data described below.
Documents
We leverage the UN’s final attendance lists and corrigenda for all pre-COP and COP meetings to extract data on each participant. We refer to these lists hereafter as “attendance rosters”. For both our pre-COPs and COPs, we first identified and downloaded all associated attendance documents in PDF format from the UNFCCC’s website (https://unfccc.int/documents) where we used search filters to narrow down the search by type of document and period of interest. One exception, as discussed below, was a pair of attendance rosters for COP 28, which were available in Excel format and combined below. For our PDF attendance rosters, some of these PDFs (primarily those for the pre-COPs and early COPs) were image files. Nearly all attendance roster PDFs were available in English with respect to headers and the original names provided for Parties, Observer States, and nonstate organizations, with a small number instead being recorded in French. The latter documents are translated and standardized to English within the processing described further below.
The PDF attendance rosters varied a great deal in structure and quality across the 32 years of pre-COPs and COPs under study. In some cases, a particular (pre-)COP had all attendees listed in a single PDF whereas other (pre-)COPs stored this information across multiple PDFs due to the large number of participants. In total, we were able to download 15 PDF documents for our pre-COPs, among which there were 3 corrigenda. For the UNFCCC’s COPs, we downloaded 54 documents, among which 8 were corrigenda. Information contained within each separate (pre-)COP PDF was ultimately combined (as described further below) after extraction.
The pre-COP and COP attendance rosters have slightly different structures. The COP documents usually include summary statistics of all attendees on the first two pages, while pre-COP rosters do not. On the other hand, pre-COP rosters sometimes list participants by their affiliated Party, Observer State, or nonstate organization while also including an alphabetized list of all participants. To avoid duplicate records, we focus only on the initial list in these pre-COP cases. There is also variation in structure and storage formats across and within pre-COP and COP rosters, including whether information is stored as text or images, and the column structure of listings. Uniquely, COP 28 archives attendance information in a series of Microsoft Excel entries, which we merged with our data. Figures 1 and 2 summarize the document characteristics for COP and pre-COP rosters, respectively.
Fig. 1.

Overview of document types and their distribution in the COPs attendance rosters.
Fig. 2.
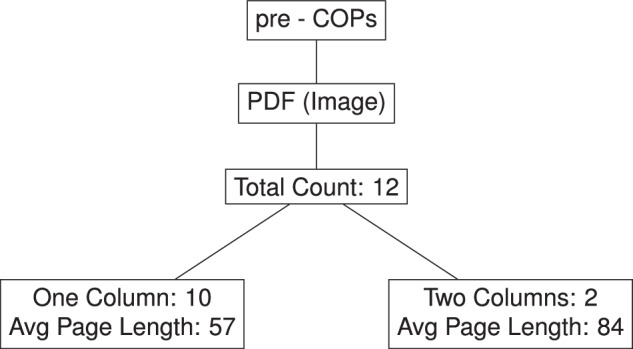
Overview of document types and their distribution in the pre-COPs attendance rosters.
In total, we analyzed attendance rosters from 46 UNFCCC COP documents (spanning COP 1 to COP 28) and 12 pre-COP documents (spanning 11 INC meetings). For our attendance roster PDFs, the length of our associated PDFs varied markedly. For our pre-COP and COP PDFs, this is represented visually in Fig. 3 via a pair of violin plots. Together these plots illustrate the range and typical lengths of PDF documents (in terms of number of total pages) for all 11 pre-COP meetings and for COPs 1–27. We can observe here that our COP attendance roster PDFs are typically longer and more variable in length when compared to our pre-COP PDFs. To this end, we can note that our COP rosters ranged from 60 to 357 pages, averaging 158.7 pages with a median of 137. By comparison, our pre-COP rosters varied from 31 to 90 pages, averaging 61.1 pages with a median of 55. Across each COP or pre-COP, there was also a variable number of associated PDFs depending on their approach to archiving attendees and/or the number of associated sessions held. Note furthermore that a small number of (pre-)COPs had more than one meeting in a particular year. Altogether, 10 pre-COPs had attendance rosters combined into a single PDF and 16 COPs had attendance rosters combined into single PDFs. One pre-COP and 12 COPs instead saw their attendance rosters split into two or three separate PDFs. Three pre-COPs and eight COPs also included separate corrigenda PDFs that correct the (pre-)COP’s stated attendance roster information. Finally, COP 28 archives all attendance information in a series of Microsoft Excel entries and tabs rather than a PDF. All files described above were extracted in our data collection efforts. We now turn to discussing the process of extracting individual-level attendee data from our pre-COP and COP attendance rosters.
Fig. 3.

Distribution of (pre-)COP attendance roster page lengths.
Text extraction
Recall that a majority of our COP and pre-COP attendance rosters are stored in PDF format, either in text or image format depending on the (pre-)COP and PDF under consideration. Depending on the (pre-)COP, the recorded attendance information therein is further organized into formats of single, double, and triple columns across different pages. An example of the attendee content for a triple-column formatted attendance roster appears in Fig. 4. With these file formats and structures in mind, we now turn to describe how we extracted our individual attendee-level information from this set of PDFs. An overview of our extraction process is presented in Fig. 5.
Fig. 4.

Example of attendee content in original PDF file formatted with triple columns, before text extraction.
Fig. 5.
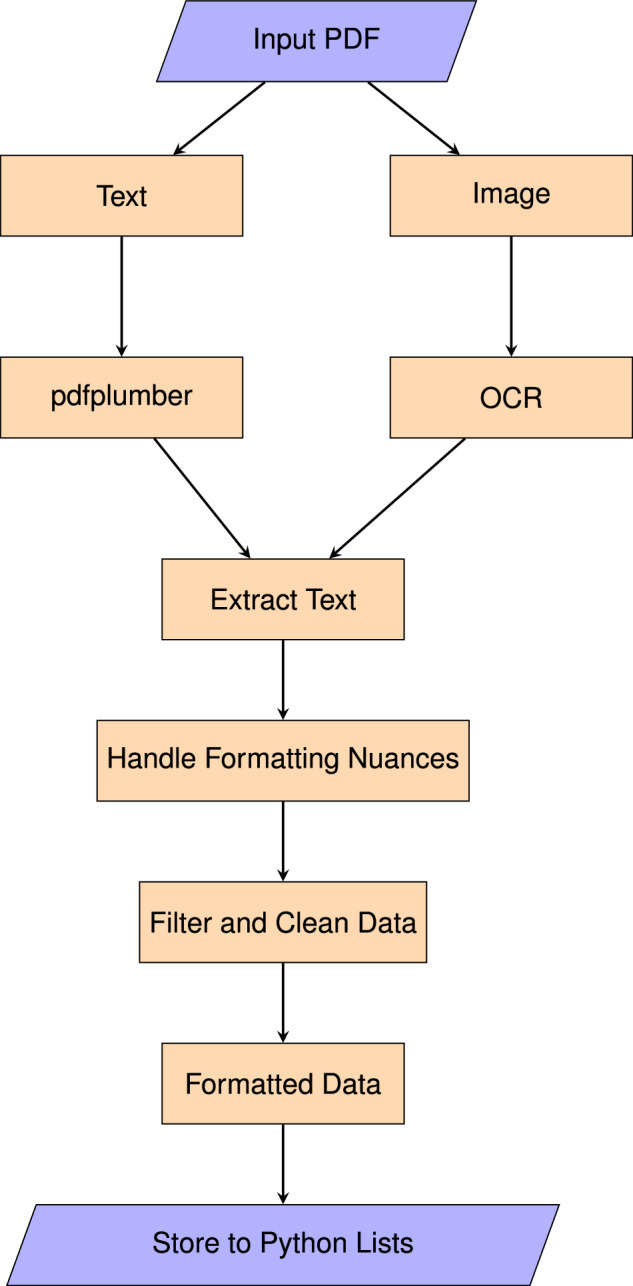
The text extraction process from PDFs using different tools.
For each PDF file, our first objective is to extract data from each individual PDF page therein, with specific attention given to the content often being presented in multi-column format. In such cases, we need to read the page-level text-as-data vertically, column by column. Within each column, the content of interest is further divided into sections or subsection content that includes group types, delegation names, and individual person details. Individual entries within each section are separated by empty lines for a clear distinction.
Starting with our text-based PDFs, our text extraction efforts began by differentiating and identifying each PDF column based on x-axis and y-axis coordinates. We then extract the data vertically within each column. This task required a robust solution to address potential alignment issues in the PDFs (particularly in relation to instances where some columns may prematurely end) and to accurately detect empty lines. These empty lines are critical as they delineate individual entries, with each person’s details separated by these spaces in the text-based attendance roster PDFs. Additionally, entities mentioned in bold font within these text PDFs were found to represent a unique identifier of “Delegation” text, which was leveraged during extraction.
Given these requirements–and in light of the fact that our PDFs had variable columns and uneven degrees of text quality given their variable image versus text storage formats–we evaluated several Python PDF text extraction tools. Our selection criteria of optimal tools for our current tasks were based on each tool’s ability to (1) accurately identify columns through x- and y-axis coordinates, (2) extract data in a column-wise manner, (3) identify line breaks and empty lines to segregate individual entries, and (4) detect the bold font that is used for delegation names.
For our text-based PDFs, our assessments determined that the pdfplumber package (https://github.com/jsvine/pdfplumber) was uniquely suited to our needs. It provided the necessary functionality to extract individual-level attendance data based on spatial coordinates, thereby facilitating our column-wise text extraction tasks. It also allowed for the identification of line breaks and empty lines. As alluded to above, these were critical for distinguishing between individual attendee entries. Moreover, pdfplumber’s ability to recognize text attributes, such as bold font, was instrumental in identifying and separating participants by the overarching group types (i.e., section headers) that their representing delegation belonged to within our attendance rosters. These overarching group types were: Parties, Observer States, Intergovernmental Organizations, and Non-Governmental Organizations.
For image-based PDF files, pdfplumber could not be used directly because it was designed for PDFs that already contain selectable text. For image-based PDFs, we instead developed an initial step of converting our PDF images to text using optical character recognition (OCR) before any text extraction or analysis could be performed. In these cases, and particularly for image PDFs organized into two or three columns, we first evaluated the PyTesseract Python package (https://github.com/madmaze/pytesseract). However, this OCR approach proved unable to reliably identify columns for subsequent text extraction. After considering other OCR software and Python packages, we ultimately utilized an OCR online tool (https://www.ilovepdf.com/) to convert these image PDFs into text PDFs with sufficient accuracy. This conversion enabled us to apply a similar text extraction process as we did for text-based PDFs. However, for single-column PDF files, we encountered significant challenges with OCR accuracy using the final OCR approach described above, particularly relating to the introduction of special characters and the failure to extract text effectively. In these cases, we returned to PyTesseract to convert single-column, image-based PDFs into plain text via OCR, effectively capturing the necessary text content, thereby obviating the need for additional extraction tools.
As the subsequent steps of Fig. 5 detail, we followed our (text-based PDF and image-based PDF) text extraction steps with a comprehensive cleaning and formatting process to address encoding issues, filter unwanted text, manage text splits across columns and pages, and format all text for subsequent classification. Each of these cleaning and formatting steps are provided in detail with the code accompanying this article. A snapshot of the attendance roster content that was obtained after completing the extraction steps described above appears in Fig. 6. With this extracted text in hand, we turned towards properly classifying each text segment into its relevant attendee characteristic.
Fig. 6.

Text in list [array] after extraction.
Text classification
For each COP attendee, our next objective was to classify our extracted text for that attendee into seven predefined categories associated with that attendee’s individual details. Classifying these individual details presented unique challenges due to the (often) multi-column format of attendee records in each associated attendance document, which we address in more detail below. With this constraint in mind, we can note that our target categories for classification were Group Type (that is, whether the attendee’s overall delegation was categorized as a formal UNFCCC COP party, an observer country or entity, a non-governmental organization, an inter-governmental organization, a unit to the UN, or another affiliated organization), Delegation (the name of the formal country delegation or non-state organization that the individual is representing at that COP), Honorific (as self-reported by the attendee), Person Name (the attendee’s full name), Job Title (the attendee’s optionally provided job title), Division (any additional optional information provided by the attendee for the division associated with their delegation and/or job title), and Affiliation (a secondary organization or unit affiliation, as optionally reported by the attendee).
Note that Division and Affiliation, in particular, exhibit a degree of variability and inconsistency in attendee usage. In addition to both categories being optional–and hence being jointly or individually left blank by many attendees–most attendees using these designations tended to treat Division as the Delegation sub-unit that they worked within or represented and Affiliation as any separate or overarching entity that they were affiliated with beyond their official Delegation. However, some attendees reversed this usage, whereas others repeated their Delegation under Affiliation, and still others reported a Division in relation to their Affiliation entity, even if that entity was distinct from their formal Delegation. The detailed classification approach presented below endeavored to address these issues by classifying entries in these fields based upon the most common usage pattern described above (i.e., assignment of Division as sub-units of Delegations and Affiliations separate or overarching entities in relation to Delegations). That being said, ambiguous Division and Affiliation entries were left in the order provided by attendees, implying that these two fields should be treated carefully by end-users.
As illustrated in Fig. 7, a significant challenge was the extracted text’s organization within the original attendance roster PDFs. For each individual attendee’s recorded information, their associated details were often abruptly split across lines in these PDFs due to column-width constraints. This associated text accordingly did not contain structured document information or markers that allow for the systematic segmentation and categorization of information pertaining to characteristics such as Division, Affiliation, or Job Title. Furthermore, these latter characteristics were optional for attendees to provide, meaning that any attendee could provide any one or more (or none) of these additional characteristics.
Fig. 7.

Highlighted text classification.
For any individual’s extracted attendance details, the above qualities made it challenging to ascertain whether any text following that attendee’s name entry was attributable to the different additional characteristics mentioned above. In Fig. 7, which illustrates an example of ideal text classification, attendee information is presented across three columns, and each relevant attendee detail is marked with a unique color. Therein, a significant challenge arises within individual entries due to the abrupt continuation of text onto subsequent lines, complicating the classification task. Furthermore, the consistency of the column sequence is not maintained. For instance, in the third entry of the third column of Fig. 7 the text labeled ‘Affiliation’ precedes that of ‘Division’, deviating from the expected order and thereby complicating the extraction of information. Variations in text encoding across different attendance roster documents presented another layer of complexity. As a result, pdfplumber, the tool employed for text extraction, failed to recognize some unique characters, substituting them with ‘CID’ (a glyph identifier). To address this issue, a comprehensive dictionary mapping these ‘CID’ values to their corresponding characters in the original PDF documents was developed. This mapping facilitated the replacement of ‘CID’ values extracted by pdfplumber with the correct characters from the PDFs, ensuring the integrity and accessibility of the extracted text.
To address classification challenges, we evaluated Generative AI technologies such as ChatGPT (OpenAI API), Doc Analyzer.ai, and LLama2 13B through their respective APIs. These models were computationally intensive and cost-prohibitive for our dataset’s scale. Additionally, we encountered accuracy and replicability issues, including hallucinated text irrelevant to the input data. We also explored pre-trained large language models like BERT and RoBERTa but faced similar challenges, including insufficient training data. Thus, we opted against using generative AI and LLMs, necessitating a more bespoke approach for segmenting and categorizing individuals’ attendance information.
Given the lack of a sufficiently sized annotated dataset, we used pre-defined natural language processing (NLP) packages to address classification challenges. We combined these NLP packages with established heuristics (rules) and implemented a structured manual correction process to ensure accurate classification of the extracted text. Below, we describe these steps in detail.
Detailed classification approach
An overview of our text classification strategy appears in Fig. 8. Recall that one primary challenge encountered in classifying an attendee’s text into the Person Name, Job Title, Division, and Affiliation columns was the structure of our attendee documents. Specifically, an attendee’s text details for these characteristics were often split across lines without consistent line break patterns and with the possibility of variable (including no) information on their Job Title, Division, and Affiliation characteristics. For this latter information, it is crucial to determine the correct column for classification. To this end, it was in turn necessary to determine whether the split in an attendee’s recorded information from one line to the subsequent line was from column width constraints within the previous line versus a carriage return associated with a new type of characteristic being provided.
Fig. 8.

Detailed process flow of text extraction and classification.
To account for these issues, we adopted pre-trained named entity recognition (NER) models, specifically spaCy (https://github.com/explosion/spaCy) and flair, (https://github.com/flairNLP/flair) to categorize “Person” and “Organization” names. For our purposes, the strength of spaCy lies in its precision in identifying specific entities, ensuring accurate extraction of individual names and organizational affiliations crucial for our analysis. Complementing these strengths, flair enhances our approach with contextual embeddings, enabling deeper semantic understandings within our linguistic contexts. This dual-model strategy not only enhances the accuracy of entity recognition but also addresses challenges posed by ambiguous and/or complex entries within our attendance records. These NER models were supplemented with a series of predefined rules derived from our qualitative readings of these PDFs. To facilitate accurate data segmentation, we constructed data dictionaries containing a list of frequently occurring surnames, occupational designations, departmental divisions, and organizational affiliations. We derived these dictionaries iteratively, from a diverse array of sources, including publicly accessible internet resources, a hand-coded version of a portion of the attendees to COP 11 (Montreal), our own qualitative review of six additional COP attendance documents, and from conversational models such as ChatGPT. These dictionaries were also lemmatized to ensure that variations of a word could be recognized, allowing us to classify our attendance text to the appropriate column based on the person details present in a line.
This methodology–a hybrid of manual rules (including, e.g., merging lines based on stopwords, observed list of keywords, special characters at ends or starts, line length exceeding a threshold, and lowercase starts indicating splits), data dictionaries, and the use of spaCy and flair NER tools–enabled us to accurately allocate our extracted text to its associated individuals and to reconstruct text that was split across lines in a replicable manner. Given the iterative nature of our classification process, we implemented the LRU cache (https://docs.python.org/3/library/functools.html) to optimize the performance of frequently called functions (e.g., classification functions and translation). This caching mechanism significantly reduced the computational overhead, enabling more efficient processing of all associated attendance rosters and extracted text under consideration. Additionally, to handle words present in multiple languages, we translated non-English terms into English using the argostranslate Python package, and lemmatized them temporarily for classification purposes. This allowed us to measure the similarity of even non-English words with our dictionary entries, thereby facilitating the accurate classification of words to their appropriate Job Title, Division, and Affiliation column across various languages using the argostranslate Python package (https://github.com/argosopentech/argos-translate).
Group Type and Delegation identification
Differentiation between Group Type and Delegation names within our attendance rosters posed a challenge, primarily due to the lack of distinct formatting styles and the use of non-standard Group Type and Delegation names across our PDFs. Our solution involved first identifying Group Type names at the beginning of each attendance roster section (specifically in the Participants Statistics section, when present). For each associated attendance roster, these were then used to identify the Group Type(s) used throughout each attendance roster given the former’s consistent positioning as a reliable indicator. Delegations were then identified through their presentation in bold font within our text-based PDFs. In image PDFs, variations such as indentation and capitalization were key markers used in identifying each attendee’s associated delegations. Despite these methods, we also undertook manual verification to address potential errors, as described further below.
Honorific
We developed a robust regular expression that encompassed all potential honorifics across the multiple languages used within our attendance rosters. Examples include Mr., Ms., Sr., and Sra., as well as more complex or lesser used honorifics such as H.E. Mr., S.E. Mme., and Rev. This regular expression was designed to recognize patterns at the beginning of lines. A key condition for a match to qualify as an Honorific during classification was the presence of an empty line preceding it, reflecting the common formatting practice where each individual’s details commence following a line break.
Person name
The primary indicator for identifying an Honorific, and subsequently a Person’s Name, during classification was the presence of an empty line preceding it. Leveraging this pattern, along with accurately matching the Honorific that precedes the Person’s Name, facilitated effective person name identification.
However, one challenge arose with longer Person Names that spilled over to a subsequent line due to the multi-column layout of many associated PDFs. To discern whether the continued text pertains to a Person’s Name or a Job Title, we utilized spaCy and flair to ascertain the nature of the text in the new line, in combination with a set of rules that we developed to enhance classification accuracy. When this approach was implemented, it combined any identified spill-over last names to the previously classified Person Name entry for a given attendee only in those instances where the spill-over text was identified as a last name.
To address potential inaccuracies arising from the above approach, manual verification was undertaken. To enhance this manual review, names that were potentially linked across lines and determined to be a name rather than a Job title, Division, or Affiliation were highlighted for manual reviewers within output files for verification. Note that the manual verification process that we used for all classified text is described in detail further below.
Job title
A dictionary containing 930 lemmatized and unique words aided in identifying Job Titles, especially in the most common instance wherein the Job Title text follows a Person Name. To construct this dictionary, we developed a list of common job title terms from websites such as Enchanted Learning Jobs (https://www.enchantedlearning.com/wordlist/jobs.shtml), from hand-coded examples based upon our actual attendance rosters, and also from the ChatGPT. Furthermore, although NER models do not explicitly recognize Job Titles, they can identify person and organizational names, which significantly reduced the likelihood of misclassifying an attendee’s Job Title as their Person Name or Affiliation. The above features were then coupled with checks against a predefined word list of terms for Person Names, Divisions, and Affiliations. For non-English entries, temporary translation into English was performed to determine a text segment’s relevance as a Job Title, and to assist with subsequent manual review. The original, non-English Job Titles were then maintained (after adjustments and manual corrections) within one set of the final classified data.
Division
Division names typically followed Job Titles and preceded Affiliations. Such names presented their own set of challenges, including their being split across lines or merged with Job Titles. To handle this, a tailored dictionary of 80 lemmatized words was used to enhance the accuracy of Division classification.
Affiliation
The identification of affiliations was markedly improved by leveraging the NER capabilities of spaCy and flair. These capabilities were particularly effective in identifying text segments classified as an organization. This approach was complemented by a dedicated dictionary containing 150 specific terms. Insights gained during the classification process then further informed the development of rules that significantly enhanced the precision of Affiliation categorizations. For example, cases such as “Ministry of” or “Government of” led us to develop routines for the handling of special patterns (such as entries starting with “The”) and the recombining Affiliation names that were split due to formatting, thereby enhancing precision in Affiliation categorization.
Manual verification
Despite the automation of our classification process, subsequent manual verification remained a critical component. Upon our manual review, we identified instances of uncertain classifications, wherein text appeared to be relevant to multiple columns. In these cases, it was unclear at the automated code-level which specific column that text should belong to. Given the free text nature of the information categories we considered, we also saw instances where two attendees from the same organization would input the same information in reverse order across the Division and Affiliation columns. Finally, there were additional rare instances where our automated steps (partially) misclassified content, especially across the Job Title, Affiliation, and Division categories–recalling that attendees could include some, all, or none of these three categories. Therefore, after generating each resultant (PDF-level) file of extracted and classified text, we manually reviewed and corrected any misclassifications or ambiguous text.
All three authors of this paper undertook components of this manual verification, and manual correction was applied to every associated COP and pre-COP. During this final manual correction phase, the presence of text in multiple languages posed a significant challenge in determining the appropriate classification due to our limitations in each manual reviewer’s language proficiency. To address this issue, we incorporated an additional step at the manual correction stage wherein text in languages other than English was translated and placed in adjacent entries to that of the original non-English text. For this translation process, we opted for the argostranslate package. This package was favored for its speed, reliability, and broad language support. Additionally, to identify the source language of the text accurately, we utilized the langdetect package in Python (https://github.com/Mimino666/langdetect). This combination of tools has proven to be highly effective in managing multilingual text, thus significantly improving the accuracy of our manual review and classification tasks. Altogether, this strategy enabled more accurate and consistent classification by ensuring a comprehensive understanding of the text content. The files that we prepared for manual verification then similarly highlighted (i) instances where excess text did not fit within our predefined categories and (ii) instances where our automated classification approach was uncertain about the intended location for a segment of identified text.
Our final manual verification and correction strategy followed a structured set of steps. Initially, we uploaded all extracted information into Google Sheets, dedicating one sheet per extracted PDF. Each team member selected a specific sheet to evaluate in a column-by-column fashion. When doing so, they cross-referenced that Google Sheet’s entries with the corresponding PDF for accuracy. In cases where data was extracted from PDF images, Google’s spell checker was manually applied to the Google Sheet in order to identify and correct any OCR errors. Each column in the Google Sheet (e.g., Person Name, Job Title, Division, Affiliation) underwent meticulous review and corrections were made where necessary. To this end, team members systematically moved incorrect entries to their appropriate columns, ensuring accuracy through reference to translated versions as needed. For instance, they first scrutinized the Person Name column to rectify instances where Person Name and Job Title were incorrectly segmented. They then addressed the Job Title column to prevent misallocation of Division information to that column. This process was repeated for Division and Affiliation, involving subjective decisions due to variations in how attendees inputted information in these two fields. To maintain consistency, all three manual coders held bi-weekly calibration meetings throughout this process, discussing and aligning on decisions related to data corrections.
After completing manual checks for all pre-COPs and COPs files, we incorporated corrections from 11 corrigenda across these documents. Each corrigendum, averaging 2 pages in length, provided specific instructions for corrections such as updating delegation information, adding new participants, or removing previously listed ones. These corrections were manually applied to the Google Sheets files used in our process. Overall, this approach allowed us to extract individual attendee entries and group types from 44 COP and 12 pre-COP PDFs. Following the extraction of attendee text, we segmented and categorized this information into fields including Group Type, Delegation, Honorific, Person Name, Job Title, Division, and Affiliation. Human coders manually reviewed the extracted data from all COP and pre-COP PDFs, correcting any errors discovered. Additionally, attendee characteristics from COP28’s Excel-based entries were integrated with our extracted pre-COP and COP (1–27) data.
Text standardization and variable creation
Starting with the corrected Google Sheet files and Excel file mentioned above, we next applied a final set of text cleaning and standardization routines to our manually corrected data. Before doing so, the English-translated columns mentioned above–which were solely intended to aid in manual verification–were omitted. We then converted all Google Sheet and Excel files into CSV files and imported them into R. The ensuing R tasks allowed us to further clean and standardize our extracted text, before also then combining them into single CSV files for (i) all COPs and (ii) all pre-COPs.
For our final automated routines, an initial step involved standardizing column names (i.e., Group Types) across (pre-)COPs by removing spaces and adjusting for variation in the use of capital letters in Group Types. To this end, note that the naming conventions for Group Types changed slightly from (pre-)COP to (pre-)COP. For example, the non-governmental organizations Group Type was designated in our (pre-)COP PDFs as “NON-GOVERNMENTAL ORGANIZATIONS,” in some cases and in other cases as “ORGANISATIONS NON-GOUVERNEMENTALES” and in other COPs as “Non-Governmental Organizations.” Standardizing these facilitates the use of Group Type as a categorical variable across all (pre-)COPs. Altogether, these final steps were crucial for creating a uniform data framework conducive to analysis across the diverse structures inherent in our (pre-)COP data. Once standardization was complete, additional binary variables for each Group Type were also added to the dataset.
Following this, we refined our attendees' extracted name and title fields, including the ordering by which attendees include honorifics such as “H.E.” and “Dr.” either before or after their more standard honorific (e.g., Mrs. or Mr.). We further applied standardization to the use of periods and capitalization within honorifics, as well as corrections to several common OCR errors. With more standardized honorifics, we then also extracted a separate variable that recorded whether each attendee was female, male, or NA based upon attendees’ provided honorifics. Following this, we removed excess whitespace across each extracted entry and then standardized naming conventions across all (pre-)COPs. Regarding the latter item, note that some (pre-)COPs used “First, LAST” naming conventions whereas others used “LAST, first.” This was adjusted to ensure that each Person Name always followed a “First Last” convention with more consistent use of capitalization for only the first letter in each first and last name.
We then standardized the entities reported under our (pre-)COPs’ Delegations. Standardizing delegations was particularly relevant for Party and Observer country delegations, where slightly different naming conventions for the same country across different COPs–due in some cases to OCR errors or differences in a PDF’s overarching language–were standardized to ensure comparability in analyses of these data over time. For example, Lao People’s Democratic Republic was occasionally designated as “Lao People’s Democratic Republic” and in other COPs as “Lao Peoples Democratic Republic” and in still other cases as “Republique Democratique Populaire Lao.” Each of these variants was standardized to “Lao People’s Democratic Republic.”
We then further standardized Job Titles, Divisions, and Affiliations by correcting for common text extraction, classification, or formatting errors. Finally, the cleaned and standardized data were combined into a single CSV for all COPs and a separate CSV for all pre-COPs. In doing so, additional variable fields were added to each attendee so as to designate the relevant (pre-)COP, year, and location for that attendee, as well as (for COP 28) whether the attendee was an in-person or virtual attendee. Altogether, the additional variables added during the automated text cleaning and standardization stage are as follows:
Virtual: A binary variable that distinguishes between physical and virtual participation, where 0 denotes physical and 1 indicates virtual attendance.
Year: For a given attendee, the year in which the (pre-)COP meeting that they attended occurred, as extracted directly from the file name of the original (pre-)COP document.
Meeting: A concatenation of “COP” or “pre-COP” with the meeting’s relevant number (e.g., “COP 27”). This variable accordingly provides a unique identifier for the (pre-)COP that a given attendee record corresponds to.
Location: This string variable indicates the geographic location the (pre-)COP session that an attendee attended. It has been standardized and corrected for typographical and OCR errors.
Female: A binary variable that distinguishes between female, male, and other attendees, where 0 denotes a non-female attendee, 1 indicates a female attendee, and NA denotes an attendee that we could not assign to either the male or female designation based upon their provided honorific or absence thereof.
Group Affiliations: These include separate indicator variables for IGO (Intergovernmental Organizations), NGO (Non-Governmental Organizations), Observer, Party, and IO (related to “United Nations Secretariat Units and Bodies” and “Specialized Agencies and Related Organizations”). These binary variables classify participants into categories reflecting the organizational affiliations and roles of their delegations at each (pre-)COP.
Country Delegation Identifiers: To facilitate the merging of external country(-year) variables, two identifier variables were also included: Delegation_COW and Delegation_ISO. Each provides “country” identifiers for cases where an attendee’s delegation was either a UNFCCC COP Party or Observer. Delegation_COW specifically provides numeric Correlates of War (COW) country codes and Delegation_ISO specifically provides 3166-1 alpha-3 country codes. For attendees whose delegation type is not a Party or Observer, Delegation_COW and Delegation_ISO are coded as missing. Likewise, for the rare cases of attendees whose Party or Observer country delegation nation does not exist as a country in COW or in 3166-1 alpha-3, the corresponding country delegation identifier variable is coded as missing.
The above steps created separate COP and pre-COP datasets containing variables denoting Group_Type, Delegation, Honorific, Person_Name, Job_Title, Division, Affiliation, Virtual, Year, Meeting, Location, Female, IGO, NGO, Observer, Party, and IO. All R and Python code and datasets associated with the extraction, classification, and standardization of these datasets found at GitHub (https://github.com/bagozzib/UNFCCC-Attendance-Data) while the final datasets described immediately above and below can also be found at Harvard’s Dataverse22.
Our (pre-)COP datasets are multilingual, containing significant amounts of text in French and Spanish, especially within fields like Delegation, Job_Title, Division, and Affiliation. While original language entries may be most relevant for many researchers, others may prefer English-standardized content for easier comparisons and for extraction of additional measures. To meet these needs, we utilized Google Translate’s API to automatically detect and translate non-English text in these specified variables within our final CSV files. This translation process was programmatically executed using Python’s googletrans (https://github.com/ssut/py-googletrans) library, focusing on texts identified in Spanish or French. We implemented error management strategies to ensure data integrity. Altogether this yielded separate English-translated versions of our final pre-COP and COP CSV files.
Data Records
The four final datasets derived from this work include (i) an original language dataset of COP attendees (1995–2023), (ii) an original language dataset of pre-COP attendees (1991–1995), (iii) an English-translated dataset of COP attendees (1995–2023), and (iv) an English-translated dataset of pre-COP attendees (1991–1995). Each can be downloaded in CSV format from Harvard’s Dataverse22. Likewise, all relevant R and Python code–and intermediate input and output datasets–associated with the above datasets’ creation can be found at GitHub (https://github.com/bagozzib/UNFCCC-Attendance-Data). In the ensuing subsection, we describe these final datasets and their relevant characteristics in further detail.
Data Details
As discussed, the final CSV files associated with this article are distinctively categorized into two sets: one set of separate pre-COP and COP attendee records that includes original language entries for Delegation, Job_Title, Division, and Affiliation and one set of separate pre-COP and COP attendee records that includes English-standardized entries for several variables. More specifically:
Original language pre-COP CSV
Corresponds to attendee records for our pre-COP meetings (INCs 1-11) in their original language. The variables included are Group_Type, Delegation, Honorific, Person_Name, Job_Title, Division, Affiliation, Virtual, Year, Meeting, Location, Female, IGO, NGO, Observer, Party, IO, Delegation_COW, and Delegation_ISO.
Original language COP CSV
Contains attendee records from all COP meetings (COPs 1–28) in the original language. The variables included are Group_Type, Delegation, Honorific, Person_Name, Job_Title, Division, Affiliation, Virtual, Year, Meeting, Location, Female, IGO, NGO, Observer, Party, IO, Delegation_COW, and Delegation_ISO.
English-translated pre-COP CSV
Includes attendee records for our pre-COP meetings (INCs 1–11) wherein entries that were originally in Spanish or French for Delegation, Job_Title, Division, and Affiliation were translated to English. The variables included are Group_Type, Delegation, Honorific, Person_Name, Job_Title, Division, Affiliation, Virtual, Year, Meeting, Location, Female, IGO, NGO, Observer, Party, IO, Delegation_COW, and Delegation_ISO.
English-translated COP CSV
Contains attendee records from all COP meetings (COPs 1–28) wherein entries that were originally in Spanish or French for Delegation, Job_Title, Division, and Affiliation were translated to English. The variables included are Group_Type, Delegation, Honorific, Person_Name, Job_Title, Division, Affiliation, Virtual, Year, Meeting, Location, Female, IGO, NGO, Observer, Party, IO, Delegation_COW, and Delegation_ISO.
An example of our raw data–taken from the first pre-COP in our pre-COP-specific dataset–can be found in Table 1. For the three attendee entries therein, one can observe complete data for Group_Type, Delegation, Honorific, and Person_Name, as is standard. However, the remaining attendee-specified variables–Job_Title, Division, and Affiliation–are incomplete as providing this information was optional for attendees. The remaining variables in Table 1 correspond to the auxiliary variables that we extracted during the final standardization steps outlined further above.
Table 1.
Example data entries from the dataset.
| Group_Type | Delegation | Honorific | Person_Name | Job_Title | Division | Affiliation | Virtual | Year | Meeting | Location | Female | IGO | NGO | Observer | Party | IO | Delegation_COW | Delegation_ISO |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Parties | Austria | Ms | Manuela Moser | NA | Energy and Environment | Federal Chancellery | 0 | 1995 | COP 1 | Berlin | 1 | 0 | 0 | 0 | 1 | 0 | 305 | AUT |
| Parties | Austria | Ms | Ilona Graenitz | NA | NA | State Parliament | 0 | 1995 | COP 1 | Berlin | 1 | 0 | 0 | 0 | 1 | 0 | 305 | AUT |
| Parties | Austria | Mr | Karlheinz Kopf | NA | NA | State Parliament | 0 | 1995 | COP 1 | Berlin | 0 | 0 | 0 | 0 | 1 | 0 | 305 | AUT |
| Parties | Austria | Ms | Monika Langthaler | NA | NA | State Parliament | 0 | 1995 | COP 1 | Berlin | 1 | 0 | 0 | 0 | 1 | 0 | 305 | AUT |
| Parties | Austria | Mr | Thomas Barmuller | NA | NA | State Parliament | 0 | 1995 | COP 1 | Berlin | 0 | 0 | 0 | 0 | 1 | 0 | 305 | AUT |
| Parties | Austria | Mr | Wolfgang Mehl | NA | NA | Climate Alliance | 0 | 1995 | COP 1 | Berlin | 0 | 0 | 0 | 0 | 1 | 0 | 305 | AUT |
| Parties | Austria | Mr | Georg Gunsberg | NA | NA | Oko Biro | 0 | 1995 | COP 1 | Berlin | 0 | 0 | 0 | 0 | 1 | 0 | 305 | AUT |
| Parties | European Community | Mr | Jorgen Henningsen | Director | European Commission | European Community | 0 | 1995 | COP 1 | Berlin | 0 | 0 | 0 | 0 | 1 | 0 | NA | NA |
| Parties | European Community | Mr | Michel Ayral | Director | DGXVIL (Energy) | European Community | 0 | 1995 | COP 1 | Berlin | 0 | 0 | 0 | 0 | 1 | 0 | NA | NA |
| Parties | European Community | Mr | Kevin Leydon | Head | DGXVII (Energy) | European Community | 0 | 1995 | COP 1 | Berlin | 0 | 0 | 0 | 0 | 1 | 0 | NA | NA |
| Parties | European Community | Mr | Reggie Hernaus | NA | NA | European Community | 0 | 1995 | COP 1 | Berlin | 0 | 0 | 0 | 0 | 1 | 0 | NA | NA |
| Parties | Venezuela | Ms | Evelyn Bravo Diaz | Spokesman | Direction of Energy Planning | Ministry of Energy and Mines | 0 | 1995 | COP 1 | Berlin | 1 | 0 | 0 | 0 | 1 | 0 | 101 | VEN |
| Observer States | Yemen | Mr | S. Al-Mashjary | Director General | Environment Protection Council | Republic of Yemen | 0 | 1995 | COP 1 | Berlin | 0 | 0 | 0 | 1 | 0 | 0 | 679 | YEM |
| Observer States | Yemen | Ms | Martino Smits | Adviser | NA | Environmental Protection Council | 0 | 1995 | COP 1 | Berlin | 1 | 0 | 0 | 1 | 0 | 0 | 679 | YEM |
| Observer States | Yemen | Mr | Ameen Mujahed Saeed | Environment Officer | NA | Ministry of Foreign Affairs | 0 | 1995 | COP 1 | Berlin | 0 | 0 | 0 | 1 | 0 | 0 | 679 | YEM |
The consolidated (original language or English-translated) datasets that we derived from our COP and pre-COP meetings encompass a total of 27,470 unique delegations and 310,200 total attendees. The pre-COP attendees accounted for 2,299 of these unique delegations and 7,830 total attendees. By comparison, the 28 COPs under consideration saw significantly higher participation with 25,171 unique delegations and a total of 302,370 attendees. The average number of unique delegations per COP stands at 899, with an average attendee count of 10,799 per meeting. This can be contrasted with averages of 209 unique delegations and 712 attendees for our pre-COPs. The total number of non-missing observations for our pre-COPs and COPs appears for each variable in Table 2, alongside each variable’s percentage of missing observations and a brief mention of each variable’s level of measurement. These table quantities are equally applicable to either the original language or English-translated datasets. This granular breakdown also begins to elucidate the varying scales of engagement across different types of meetings.
Table 2.
Non-missing observations and variable details for pre-COPs and COPs.
| Variable | Pre-COP | Pre-COP Missing % | COP | COP Missing % | Details |
|---|---|---|---|---|---|
| Group_Type | 7829 | 0.01 | 302369 | 0.00 | String (Categorical) |
| Delegation | 7829 | 0.01 | 302370 | 0.00 | String (Free Text) |
| Honorific | 7657 | 2.21 | 299522 | 0.94 | String (Free Text) |
| Person_Name | 7830 | 0.00 | 300083 | 0.76 | String (Free Text) |
| Job_Title | 5251 | 32.94 | 217320 | 28.13 | String (Free Text) |
| Division | 2195 | 71.97 | 112143 | 62.91 | String (Free Text) |
| Affiliation | 4993 | 36.23 | 191952 | 36.52 | String (Free Text) |
| Virtual | 7830 | 0.00 | 302370 | 0.00 | Binary |
| Year | 7830 | 0.00 | 302370 | 0.00 | Numeric (Interval) |
| Meeting | 7830 | 0.00 | 302370 | 0.00 | String (Free Text) |
| Location | 7830 | 0.00 | 302370 | 0.00 | String (Free Text) |
| Female | 7551 | 3.56 | 298913 | 1.14 | Binary |
| IGO | 7830 | 0.00 | 302370 | 0.00 | Binary |
| NGO | 7830 | 0.00 | 302370 | 0.00 | Binary |
| Observer | 7830 | 0.00 | 302370 | 0.00 | Binary |
| Party | 7830 | 0.00 | 302370 | 0.00 | Binary |
| IO | 7830 | 0.00 | 302370 | 0.00 | Binary |
| Delegation_COW | 7830 | 30.08 | 302370 | 52.40 | Numeric (Interval) |
| Delegation_ISO | 7830 | 29.60 | 302370 | 51.63 | String (Free Text) |
We can further note that the percentage of missing observations reported for our variables in Table 2 primarily highlights the relatively higher level of missingness among our three optionally-provided attendee fields (Job_Title, Division, and Affiliation). That being said, three of our additional variables have notable levels of missingness by design. Delegation_COW and Delegation_ISO each can only potentially include non-missing entries for attendees whose delegations are Party or Observer States, which limits the number of non-missing entries on these two variables. Likewise, Female only records a 0 or 1 for instances where an attendee’s gender was able to be determined to be Male or Female based upon their provided honorific. All other cases are coded as missing on this particular variable, ensuring a higher rate of missingness on Female than for Honorific itself. Finally, one can also observe slightly higher percentages of missingness on Group_Type, Delegation, and Honorific for our pre-COP attendees as opposed to COP attendees. This is largely attributable to the slightly lower rate of standardization of attendee information within initial pre-COP meetings and associated documentation.
Technical Validation
We perform two formal validations of our data below. In the first, we compare our final extracted data for a portion of one COP to a separate human-extracted version of these same data. This allows us to benchmark our approach’s accuracy against human coding at the individual attendee-level. Our second validation exercise compares aggregate counts of attendees and unique groups to the same aggregate counts as reported by the UNFCCC for separate COPs. This allows us to more comprehensively validate our data across a wider range of COPs than our first validation exercise, albeit in a more aggregate manner.
Comparison to hand-coded data
To evaluate the accuracy of our full text extraction-classification-standardization pipeline, we first conducted a detailed comparison of our final data against a separate human-coded version of the same data. To do so, we had an undergraduate research assistant manually extract attendee information for Group_Type, Delegation, Honorific, Person_Name, Job_Title, Division, and Affiliation for 2,006 attendees at COP 11 in Montreal. This was implemented more specifically for Part 2 of COP 11’s attendance roster PDF, which corresponds to non-state attendees such as NGOs. We then compared this human-coded data to our own extracted data for these same 2,006 attendees at COP 11. For these comparisons, all text entries in our data and in the human-coded data were normalized to removing special characters, eliminating excess white-space, and convert all text to lowercase. Treating the human-coded version as a gold standard, we report the percentage of human-assigned values that were correctly classified by our approach in Table 3. Note here, however, that even our human-coded data had a small number of transcription errors, meaning it was not perfect ground truth.
Table 3.
Percentage of Correct Classifications for 2,006 COP 11 Attendees.
| Variable | Correctly Classified |
|---|---|
| Group Type | 100.00% |
| Delegation | 100.00% |
| Honorific | 100.00% |
| Person_Name | 100.00% |
| Job_Title | 94.72% |
| Division | 90.43% |
| Affiliation | 90.88% |
As one can observe in Table 3, our approach perfectly recovers attendees’ Group_Type, Delegation, Honorific, and Person_Name information. However, our approach is less accurate in classifying attendees’ Job_Title, Division, and Affiliation, which respectively saw only 95%, 90%, and 91% of all 2,006 human-coded attendee entries correctly classified. Delving more deeply into the sources of these latter discrepancies, we found that:
Job Title: Misclassifications were primarily due to the inadvertent merging of Job_Title text from adjacent Division or Affiliation columns. This issue underscores the challenge of delineating clear boundaries in our attendance roster data, owning not only to the absence of consistent identifiers that allow one to separate Job_Title information but also to the reality that many reported Job Titles include division information (e.g., Head of Carbon Management Department) or provide a Job Title that itself relates directly to a subsequently provided Division and/or Affiliation (e.g., Head, Carbon Management Department).
Division and Affiliation: Misclassifications in these cases most often arose from instances where one of these two designations was not provided by an attendee, leading to ambiguity in whether an attendee’s provided Division or Affiliation information should be allocated to the Division versus Affiliation column in our data. This ambiguity is further compounded by the inherent subjectivity in distinguishing between Division and Affiliation for certain entities. For example, “Ministry of Agriculture and Forests” could be construed as either a Division or an Affiliation, depending on the perspective. This subjective nature of classification presents a unique challenge, as there is no definitive right or wrong categorization in many of these instances.
Even with the above issues in mind, Table 3 suggests that our approach is over 90% accurate in extracting and classifying attendee information across Group_Type, Delegation, Honorific, Person_Name, Job_Title, Division, and Affiliation. Moreover, accuracy was 95%-100% for a majority of these attendee-level variables. Only Division and Affiliation saw lower accuracy levels (of 90% and 91%). Even in these cases, we can also note that if one were to concatenate all Division and Affiliation information into a single “Division and Affiliation” column, one would obtain 94.75% classification accuracy for this combined variable. As such, this validation exercise suggests that our approach is highly accurate in extracting and classifying attendee-level information on Group_Type, Delegation, Honorific, Person_Name, Job_Title, Division, and Affiliation–though researchers should be cautious in treating the latter three columns as a gold standard.
Comparison to COP summary data.
Our second validation assessment drew upon the UNFCCC’s own aggregate COP participation statistics. These aggregate participation statistics were consistently provided as summary information within the first few pages of each COP attendance roster PDF starting with COP 6 (which was uniquely held in two parts). This summary information was calculated and reported by the UNFCCC itself as a way of providing a snapshot of aggregate attendance patterns at each specific COP. The attendee-level and delegation-level aggregations reported in these summary cases are broken down into the following groupings: Parties, Observer States, UN Secretariat Units and Bodies, Specialized Agencies and Related Organizations, IGOs, NGOs, and the media. We omit the media from our comparisons given that individual media member attendance data is not provided within the UNFCCC’s COP attendance rosters. Note also that in some cases, overflow participants, staff, members whose badges were issued in conjunction with the Global Climate Action, host country guests, and others are also provided within the UNFCCC’s summary sections, though these again are of less interest to our current validation assessments given that these additional attendees are not recorded individually in the UNFCCC’s attendance rosters.
We accordingly aggregate our final attendee data for each COP from COPs 6–28 according to both (i) unique delegations by each of the Group_Types outlined above and (ii) unique attendees by each of the Group_Type outlined above. We then compare these aggregate counts to those reported by the UNFCCC for COPs 6–28. We begin by summarizing the accuracy of our approach in recovering unique delegations, broken down by Group_Type and COP. Our criteria for defining success is the recovery of a unique delegation total within five delegations of the number reported in the UNFCCC’s summary data. Given that the total reported delegations per COPs 6–28 ranged widely from 304 to 2,470 with an average of 980, we consider differences within this 5 delegation range to be within a reasonable margin of error.
Our analysis indicates that our approach achieved a high level of accuracy, recovering the total numbers of unique delegations within five delegations (or fewer) of the UNFCCC’s reported figures in 141 of 144 (98%) possible comparisons. The exceptions occurred in COPs 7-8, where discrepancies amounted to differences between six and ten unique delegations. These discrepancies are likely attributable to the challenges associated with accurately extracting data from the low-resolution PDF image files used for these particular COPs.
Overall, our approach demonstrates strong validity in estimating the number of unique delegations represented at each COP, with a 98% accuracy rate within a margin of five delegations. These findings underscore the reliability of our dataset in capturing detailed participant records from the UNFCCC’s attendance rosters.
We next turn to evaluate the accuracy of our data in relation to the UNFCCC’s reported number of attendees, broken down by Group_Types and COP. Our assessment criteria here denoted “success” in any instance where our approach recovered a unique attendee total within 20 attendees of the attendee total reported in the UNFCCC’s own summary data. Given that total attendees per COPs 6–28 ranged widely from 2,932 to 36,951 with an average of 10,735, differences within this 20 attendee total range are considered reasonable.
Upon reviewing our data, we find that our attendee counts for each COP and Group_Type typically fall within 20 attendees (or fewer) of the UNFCCC’s reported figures in 122 of 144 (85%) of all possible comparisons. This accuracy rate, while slightly lower than that observed for our comparisons of delegation-level totals, underscores the reliability of our approach in estimating unique attendee numbers across various COPs.
Moreover, a review of the attendee totals that were not within 20 attendees of the UNFCCC’s summary totals suggests that, for at least six COPs (COPs 20–25), these discrepancies arose from actual discrepancies between the UNFCCC’s attendee level rosters and their summary totals, rather than errors in our extraction and classification approach. For these six COPs, the discrepancies in Party attendees (and hence total attendees) numbered in the thousands.
In investigating the attendee rosters for these six COPs, we more specifically determined that it was impossible for the UNFCCC’s provided attendee rosters to match the UNFCCC’s summary numbers. We performed this verification in two ways. First, we calculated the maximum number of attendees that could fit on a single PDF page given the column format and font size for each PDF, then multiplied this by the total number of Party-specific PDF pages. Second, we developed and applied a robust regular expression routine to accurately count participants in the PDFs for COPs 20–25. This method determined that the number of total and Party attendees based on our regular expression approach was significantly closer to our reported counts than to the UNFCCC’s summary statistics. Thus, in each case, it is clear that the UNFCCC’s PDF attendee rosters could not contain the number of attendees suggested by the UNFCCC’s summary statistics.
In sum, our approach’s ability to recover accurate numbers of COP attendees, both overall and across specific Group_Types, exhibits a notable degree of accuracy. Our findings indicate an 85% accuracy rate across all comparisons, which likely represents a conservative estimate once accounting for inconsistencies in the UNFCCC’s reported attendee-level summary data across several COPs. When potentially erroneous data for COP 20–25 is omitted, our attendee totals fall within 20 or fewer unique attendees of the UNFCCC’s corresponding totals in 122 of 131 (93%) of the remaining comparisons.
Based on these findings and our earlier validation exercises, we conclude that our datasets closely mirror the actual participant details present in the UNFCCC’s COP attendance rosters, providing compelling evidence of our approach’s accuracy and reliability.
Usage Notes
While our final pre-COP and COP attendee datasets are stored separately in terms of pre-COP and COP files, these files can be easily combined in instances where a researcher wishes to study attendance patterns across both the pre-COP and COP meetings. In doing so, users should take care to decide whether to analyze the English-translated or original language versions of our (pre-)COP attendance data. Since these English-translated and original language datasets contain the same exact attendee records, combining all datasets will create duplicate entries for each attendee. For most analyses, the original language datasets will be ideal. However, for analyses that endeavor to study text-as-data or networks based upon information within one or more of the included Delegation, Job_Title, Division, and Affiliation fields, the English-translated versions may be preferred.
For users importing the datasets into R, Python, or other tools, care should be taken to assign the encoding of each file to UTF-8. As noted further above, the datasets can also be combined (e.g., merged) with external data, particularly country(-year) level datasets overlapping with our 1991–2023 period of coverage. Our two attendee-delegation-(pre-)COP level country identifier variables–Delegation_COW and Delegation_ISO–most directly facilitate such merges. Note that for combining external country(-year) level covariates via these identifiers, such variables will only be matched to attendees whose official delegations are either a UNFCCC (pre-)COP Party or Observer nation. Also note that the Delegation_COW (COW) numeric country identifiers exist and hence are recorded for a slightly smaller set of Party and Observer nations that are covered by the Delegation_ISO (3166-1 alpha-3) country codes.
Researchers analyzing data across COPs should be cognizant of the inclusion of virtual attendees within the COP 28 attendee data. Since such attendees were unique to this COP, longitudinal analyses across multiple COPs may at times benefit from omitting all virtual attendees from COP 28 for comparability purposes. This can be easily done by only retaining attendees for whom Virtual = 0. Finally, and more generally, researchers should be cautious when analyzing information contained in the Division and Affiliation columns of our datasets. Our manual review of these entries suggests that attendees often had different mental models as to what these two categories meant–both relative to one another and to an attendee’s overall Delegation. Analyses that are primarily interested in measuring similarities or patterns across one or both of these fields may benefit from concatenating the textual information in Division and Affiliation before analysis.
One central focus for data users will be extensions to, and new measures derived from, the attendee names (Person_Name) that we include. Here we provide guidance on several potential extensions in this area. First, researchers may wish to measure repeat attendance by specific attendees over time. While there is no perfect way to identify repeat attendees in the UNFCCC’s (pre-)COP attendance data, there are several potential strategies and associated tradeoffs. First, researchers can treat exact first and last name matches (via Person_Name) over different (pre-)COPs as repeat attendees. This will yield high recall in that virtually all repeat attendees will be identified based upon Person_Name matches alone. However, it will come at a cost to precision in that false positives will arise under this scenario in instances where multiple attendees share the same name. An alternative is to identify repeat attendees across (pre-)COPs based on exact matches on both Delegation and Person_Name. This will address many of the false positives mentioned earlier, and associated threats to precision. However, it will come at a cost to recall as some repeat attendees will go unrecorded under a Delegation + Person_Name approach due to changes in some attendees’ associated Delegation names over time. Researchers should favor one of these proposed strategies over the other depending on their own respective precision-recall thresholds. Or, they may wish to conduct exact matches on Person_Name while leveraging Delegation embedding within a neural similarity approach to more flexibly identify fuzzy matches according to Delegation. Doing so would strike a middle-ground in precision-vs-recall vis-à-vis the two approaches outlined above, albeit with requirements of training data and/or subjective similarity thresholds.
Researchers may also wish to extract additional attendee characteristics in an automated fashion based upon Person_Name. For example, a variety of recently developed approaches may allow researchers to extract the race, nationality, and/or ethnicity of individual attendees23–25. As such approaches may be imperfect, validation of extracted race, nationality, and/or ethnicity information on attendees will be critical. To this end, attendees’ associated Country information within our Delegation variable (at least for attendees representing Party or Observer State entities) can serve as an imperfect validation source. Similarly, data users can leverage Person_Name alongside recently developed gender detection tools to extract information on attendees’ (perceived) gender26,27. However, here again, biases and inaccuracies may arise, and researchers may wish to leverage attendees’ own self-reported gender information, via Honorific or our Female variable, for validation.
Acknowledgements
The authors wish to thank Austin Shultz for his research assistance on components of this project. The authors would also like to thank panel participants and audience members at the 2024 Southern Political Science Association (SPSA) conference and 2024 American Political Science Association (ASPA) conference for their feedback on earlier drafts of this work.
Author contributions
B.B. and D.B. conceived the project. D.B. collected the original source documents. R.E. and B.B. developed and implemented data extraction, classification, and standardization. D.B., B.B., and R.E. contributed to manual verification, validation, and data summary. All authors wrote and reviewed the manuscript.
Code availability
All code associated with extracting, classifying, and formatting our data–along with a series of necessary input datasets–has been made publicly available on GitHub (https://github.com/bagozzib/UNFCCC-Attendance-Data). This page also includes a ReadMe, a dedicated Wiki, and additional code for extracting and generating the descriptive data plots reported earlier. The final datasets discussed above are co-located both on the above page and on a dedicated Harvard Dataverse page22. All R-based code for this project was implemented in R version 4.3.1. All Python-based code for this project was implemented in Python 3.8.2.
Competing interests
The authors declare no competing interests.
Footnotes
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
These authors contributed equally: Daria Blinova, Rakesh Emuru, Benjamin E. Bagozzi.
References
- 1.Bagozzi, B. E. The multifaceted nature of global climate change negotiations. Review of International Organizations10, 439–464 (2015). [Google Scholar]
- 2.Lesnikowski, A. et al. Frontiers in data analytics for adaptation research: Topic modeling. WIREs Climate Change10, 1–15 (2019). [Google Scholar]
- 3.Genovese, F., McAlexander, R. J. & Urpelainen, J. Institutional roots of international alliances - party groupings and position similarity at global climate negotiations. Review of International Organizations18, 329–359 (2023). [Google Scholar]
- 4.Genovese, F. States’ interests at international climate change negotiations: New measures of bargaining positions. Environmental Politics23, 610–631 (2014). [Google Scholar]
- 5.Wright, S. J., Sietsma, A., Korswagen, S., Athanasiadis, I. N. & Biesbroek, R. How do countries frame climate change? A global comparison of adaptation and mitigation in unfccc national communications. Regional Environmental Change129 (2023).
- 6.Höhne, C., Kahmann, C. & Lohaus, M. Translating the norm bundle of an international regime: States’ pledges on climate change around the 2015 Paris conference. Journal of International Relations and Development26, 185–213 (2023). [Google Scholar]
- 7.Hjerpe, M. & Linner, B.-O. Functions of cop side-events in climate-change governance. Climate Policy10, 167–180 (2010). [Google Scholar]
- 8.Parker, C. F., Karlsson, C. & Hjerpe, M. Climate change leaders and followers: Leadership recognition and selection in the UNFCCC negotiations. International Relations29, 434–454 (2015). [Google Scholar]
- 9.Romanak, K., Fridahl, M. & Dixon, T. Attitudes on carbon capture and storage (ccs) as a mitigation technology within the unfccc. Energies14, 629 (2021). [Google Scholar]
- 10.Cabré, M. M. N. Issue-linkages to climate change measured through ngo participation in the UNFCCC. Global Environmental Politics11, 10–22 (2011). [Google Scholar]
- 11.Böhmelt, T. A closer look at the information provision rationale: Civil society participation in states’ delegations at the UNFCCC. The Review of International Negotiations8, 55–80 (2013). [Google Scholar]
- 12.Hanegraaff, M. When does the structural power of business fade? Assessing business privileged access at global climate negotiations. Environmental Politics32, 427–451 (2023). [Google Scholar]
- 13.Neeff, T. How many will attend Paris? UNFCCC COP participation patterns 1995–2015. Environmental Science & Policy31, 157–159 (2013). [Google Scholar]
- 14.Böhmelt, T., Koubi, V. & Bernauer, T. Civil society participation in global governance: Insights from climate politics. European Journal of Political Research53, 18–36 (2014). [Google Scholar]
- 15.Kaya, A. & Schofield, L. S. Which countries send more delegates to climate change conferences? analysis of UNFCCC COPs, 1995–2015. Foreign Policy Analysis16, 478–491 (2020). [Google Scholar]
- 16.Kruse, J. Women’s representation in the UN climate change negotiations: A quantitative analysis of state delegations, 1995–2011. International Environmental Agreements: Politics, Law and Economics14, 349–370 (2014). [Google Scholar]
- 17.Böhmelt, T., Koubi, V. & Bernauer, T. Why populism may facilitate non-state actors’ access to international environmental institutions. Environmental Politics32, 511–531 (2023). [Google Scholar]
- 18.Chan, N. Beyond delegation size: Developing country negotiating capacity and ngo 'support’ in international climate negotiations. International Environmental Agreements: Politics, Law and Economics21, 201–217 (2021). [Google Scholar]
- 19.Martinez, G. S. et al. Delegation size and equity in climate negotiations: An exploration of key issues. Carbon Management10, 431–435, 10.1080/17583004.2019.1630243 (2019). [Google Scholar]
- 20.Maguire, R., Carter, G., Mangubhai, S. & Lewis, H.-R. S. Bridget. UNFCCC: A feminist perspective. Environmental Policy and Law56, 369–383 (2023). [Google Scholar]
- 21.Zhao, B. Granting legitimacy from non-state actor deliberation: An example of women’s groups at the united nations framework convention on climate change. Environmental Policy and Governance34, 236–255 (2024). [Google Scholar]
- 22.Blinova, D., Emuru, R. & Bagozzi, B. E. Individual Attendance Data for UNFCCC COPs and pre-COPs. Harvard Dataverse, V2, 10.7910/DVN/TGKS9E (2024).
- 23.Kang, Y. Name-nationality classification technology under Keras deep learning. In Proceedings of the 2020 2nd International Conference on Big Data Engineering, BDE ‘20, 70–74, 10.1145/3404512.3404517 (Association for Computing Machinery, New York, NY, USA, 2020).
- 24.Chintalapati, R., Laohaprapanon, S. & Sood, G. Predicting race and ethnicity from the sequence of characters in a name (2023).
- 25.Jain, V., Enamorado, T. & Rudin, C. The importance of being Ernest, Ekundayo, or Eswari: An interpretable machine learning approach to name-based ethnicity classification. Harvard Data Science Review4, https://hdsr.mitpress.mit.edu/pub/wgss79vu (2022).
- 26.Hu, Y. et al. What’s in a name? Gender classification of names with character based machine learning models. Data Min Knowl Disc35, 1537–1563, 10.1007/s10618-021-00748-6 (2021). [Google Scholar]
- 27.Das, S. & Paik, J. H. Context-sensitive gender inference of named entities in text. Information Processing Management58, 102423, 10.1016/j.ipm.2020.102423 (2021). [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.
Data Availability Statement
All code associated with extracting, classifying, and formatting our data–along with a series of necessary input datasets–has been made publicly available on GitHub (https://github.com/bagozzib/UNFCCC-Attendance-Data). This page also includes a ReadMe, a dedicated Wiki, and additional code for extracting and generating the descriptive data plots reported earlier. The final datasets discussed above are co-located both on the above page and on a dedicated Harvard Dataverse page22. All R-based code for this project was implemented in R version 4.3.1. All Python-based code for this project was implemented in Python 3.8.2.