

Abstract
Neural circuits in the brain perform a variety of essential functions, including input classification, pattern completion, and the generation of rhythms and oscillations that support processes such as breathing and locomotion [51]. There is also substantial evidence that the brain encodes memories and processes information via sequences of neural activity. In this dissertation, we are focused on the general problem of how neural circuits encode rhythmic activity, as in central pattern generators (CPGs), as well as the encoding of sequences. Traditionally, rhythmic activity and CPGs have been modeled using coupled oscillators. Here we take a different approach, and present models for several different neural functions using threshold-linear networks. Our approach aims to unify attractor-based models (e.g., Hopfield networks) which encode static and dynamic patterns as attractors of the network.
In the first half of this dissertation, we present several attractor-based models. These include: a network that can count the number of external inputs it receives; two models for locomotion, one encoding five different quadruped gaits and another encoding the orientation system of a swimming mollusk; and, finally, a model that connects the fixed point sequences with locomotion attractors to obtain a network that steps through a sequence of dynamic attractors. In the second half of the thesis, we present new theoretical results, some of which have already been published in [59]. There, we established conditions on network architectures to produce sequential attractors. Here we also include several new theorems relating the fixed points of composite networks to those of their component subnetworks, as well as a new architecture for layering networks which produces “fusion” attractors by minimizing interference between the attractors of individual layers.
Chapter 1 | Introduction
Attractor neural networks play an important role in computational neuroscience by providing a rich framework for modeling the dynamic behavior of neural systems and giving insights into how the brain might process information and perform computations [3,43]. Originally devised as models of associative memory, these networks were designed to store static patterns representing discrete memories as attractors. Their ability to simultaneously encode multiple static patterns, represented as fixed points, made them ideal for this purpose. Perhaps the most well-known example is that of Hopfield networks, a foundational example of attractor neural networks [39]. As illustrated in Figure 1.1A, in the classical Hopfield paradigm, memories are stored in the network as several coexistent stable fixed points, each one accessible via distinct input pulses (represented as color-coded pulses in the figure). The state space is partitioned into basins of attraction, and each input will start the trajectory into one of these basins. Coexistence of attractors, even if it’s just multiple stable fixed points, requires nonlinear dynamics.
Figure 1.1. Summary of models as attractor networks.

(A) Classical Hopfield-like paradigm. Multiple stable fixed points (stable attractors) are encoded in the same network, each one accessible via distinct (colored) input pulses. (B) Multiple stable fixed points are encoded in the same network, each one accessible via identical pulses. Since the pulses are all identical, the network is internally encoding a sequence of fixed points. Each identical pulse causes one transition in the sequence, as indicated by the corresponding numbers in the pulses and arrows. (C) Multiple dynamic attractors encoded in the same network, each one accessible via distinct (colored) input pulses. (D) Internally encoded sequence of dynamic attractors, each step of the sequence accessible via identical inputs.
While Hopfield networks are well-suited for encoding multiple static patterns, some patterns of neural activity are better stored as dynamic attractors. Such is the case for the rhythms and oscillations produced by Central Pattern Generator circuits (CPGs). CPGs are neural circuits that generate rhythmic patterns that control movements like walking, swimming, chewing, and breathing [51]. Unlike static patterns (such as images), these rhythmic processes require attractors whose neurons fire sequentially, meaning that neurons take turns to fire. Furthermore, a single CPG network should potentially be able to encode multiple such patterns. Certainly, animals have several locomotive gaits, all of which activate the same limbs [4,34]. How can all these different overlapping dynamic patterns be produced by the same network? Modeling this using attractors requires multi-stability of dynamic attractors, which is known to be a difficult problem [24,63].
Traditional models of locomotion and other CPGs have tackled these challenges by using coupled oscillators [12,21,31,41,73,74]. In these models, the parameters are typically adjusted depending on the desired pattern, effectively altering the dynamical system in use. For various reasons, this approach presents some challenges. For instance, while there is evidence of pacemaker neurons, not all neurons are intrinsic oscillators [62]. Additionally, assuming that synaptic strengths change every time we transition between different locomotive gaits necessitates additional ingredients for the model, such as synaptic plasticity. Despite this, coupled oscillator models have remained popular for important reasons. One of the reasons they are so widely used is the availability of theoretical results coming from physics and mathematics [5]. Indeed, many CPG models stemmed from the physics and mathematics communities [12,31,73,74].
The availability of theoretical tools is indeed a very compelling argument for using coupled oscillators to model central pattern generators. Here we aim to take a different approach that also leverages recent theoretical advances, but within the world of attractor neural networks. The framework of attractor neural networks differs from traditional coupled oscillator models in two key ways. First, neurons do not intrinsically oscillate; instead, patterns of activity emerge as a result of connectivity. Second, these patterns are true attractors of the system, making them more robust and stable to noise and other perturbations. Additionally, providing models within this framework would unify our approach to CPGs with other classical models, like the aforementioned associative memory models, ring attractors, etc [3,43]. On the biological side, it has also been suggested that cortical circuits involved in associative memory encoding and retrieval have many features in common with CPGs [79].
To accomplish this, we propose the use of Threshold-Linear Networks (TLNs). TLNs are recurrent neural networks with simple non oscillating units and piecewise linear activation [38]. This makes them focus on the role of connectivity in emergent behaviors. TLNs have a rich history as neural models [7,35,46,67,70], and more importantly, they are supported by a wide array of theoretical results [13,14,37,53,77], many of them recent [15,16,54,59].
One such key finding is that threshold-linear networks with symmetric connectivity matrices can only have stable fixed point attractors (static patterns) [36,39], which is why here we use non-symmetric TLNs, introduced in Chapter 2. These are known to give rise to a rich variety of non-linear dynamics including multi-stability, limit cycles, chaos and quasi-periodicity. Therefore, we expect it to be possible to simultaneously encode multiple dynamic patterns of activity, whereas in classical Hopfield networks the stored patterns are all static. Within this unified framework, our aim is to provide attractor models for three broad neural functions, as summarized in Figure 1.1, and detailed below:
First, we propose a simple neural integrator model that is both robust to noise and can count inputs, using fixed point attractors. Neural integration refers to the process in which information from various sources is combined to create an output. For instance, counting the number of left and right cues to make a decision is quite literally integration (summation) in the mathematical sense. Here, we propose to model a discrete counter as a sequence of static attractors, as shown in Figure 1.1B. While this concept is akin to the classical Hopfield model (Figure 1.1A), our aim is to internally encode the sequence of fixed points, meaning that the input pulses are all identical and contain no information about which fixed point comes next in the sequence (i.e. they are just like pushing a single input button).
Second, we aim to devise a (small) network that has attractors corresponding to 4–5 distinct, but overlapping, quadruped gaits. The goal is for the attractors to coexist in the same network so that they can be accessed by different initial conditions, and without changing parameters. This requires the presence of several coexistent dynamic attractors, as pictured in Figure 1.1C, arising as distinct limit cycles in state space. Recall that the simultaneous encoding of multiple dynamic attractors (non fixed point attractors) is a network is challenging, especially when the attractors have overlapping units. While classic models circumvent this challenge by adjusting synaptic weights, we aim to obtain a single fixed network, which in turn means a simpler model with fewer control parameters.
In addition to quadruped gaits, we will also model “Clione’s hunting system ” [58], which is a different CPG example, using the same framework. Previous models for it have also used intrinsically oscillating units and fine-tuned parameters [71]. Here we intend to devise a more robust network for this using attractors to avoid the need for finely-tuned parameters.
Third, we combine the modeling approaches from panels B and C to devise a network that can step through a set of dynamic attractors sequentially, as in Figure 1.1D. Can different attractors be linked together so that they can be activated in sequence, where the sequence itself is stored within the network? This could be useful for modeling sequences of complex movements, such as a choreographed sequence of dance moves, for instance.
Sequences of sequential attractors.
Note that in Figure 1.1C, we are dealing with dynamic attractors, that are sequential themselves, meaning attractors whose nodes activate in an ordered sequence [59]. This definition does not completely exclude attractors in which there is some synchrony in the activations. So for example, we consider both attractors in Figure 1.2 sequential attractors, even though the attractor on the right has nodes 2 and 3 synchronized (we will later formalize the dynamic prescription of the nodes, for now note the sequential of activations of nodes).
Figure 1.2. Examples of sequential attractors.

(A) Nodes 1,2,3 are activating in sequence, as seen by the curves to the left of the graph. (B) Node 1 activates, then 2 and 3 simultaneously, then node 4.
These are great to model rhythmic activations like those of CPGs. In contrast, Figure 1.1D deals with sequences of dynamic attractors, which means that different attractors, either static or dynamic, are activated in a specific ordered sequence (e.g., attractor A, then attractor B, then attractor C). With this distinction clear, our ultimate goal is to achieve an internally encoded sequence of sequential attractors.
Internally encoded sequences of sequential attractors are good models for complex sequences of movements, like choreographed dancing. These complex motor behaviors have also been modeled in the past using threshold-linear recurrent networks that choose and learn motor motifs, but whose choice mechanism requires plasticity, and where the sequence’s order is externally encoded [49]. It is not uncommon to think of broader cognitive sequential processes as a recombination of several pre-stored patterns, which offers an efficient alternative to re-encoding patterns with each occurrence. Studies in this vein include [65], where they utilize a combination of discrete metastable states, leveraging winnerless competition of oscillator neurons. Similar mechanisms have been explored using boolean and spiking networks [69,72].
Desired properties of models.
As it turns out, the versatility of threshold linear networks will prove ideal for modeling both sequential attractors and sequences of them.
To summarize the discussion above, we want our models to satisfy the following properties:
Neurons are not intrinsic oscillators.
Stored static and dynamic patterns should emerge as attractors of the network, rather than being fine-tuned trajectories. Static patterns should manifest as fixed points, while dynamic patterns should arise from non fixed point attractors, like limit cycles.
A network’s attractors should be accessible via different initial conditions, easily implemented via input pulses that target subsets of neurons.
A sequence of attractors should be accessible via a series of identical inputs pulses, with the sequence itself stored within the network (possibly in a separate layer, as observed in some biological brains).
The models should be mathematically tractable–that is, simple enough to be analyzed mathematically.
These properties will distinguish our models from previous coupled oscillator models and position them within the framework of attractor neural networks. We begin by adhering to the last point above, by choosing a framework that fits into the attractor neural network paradigm and also provides mathematically tractable models. With tractability also come great simplifications. Although TLNs are inspired by networks of biological neurons, real neurons and their interactions are of course far more complex than TLNs paint them to be. TLNs remain useful however because they capture two fundamental pieces of biological networks: connectivity and threshold-activation. This is why here we also focus on another simplification of TLNs, known as Combinatorial Threshold-Linear Networks (CTLNs) [15,53,54]. CTLNs are a special family of TLNs, whose connectivity matrix is defined by a simple directed graph (giving rise to binary connections), as in Figure 1.2. Their added simplicity can be used to gain further theoretical results.
Summary of models.
The table below lists all the models included in the dissertation. Each row defines a single model/network, and each is an example of the attractor behaviors described by Figure 1.1:
| Model | Network function | Type of attractor | Chapter |
|---|---|---|---|
| Model 1a | counter | sequence of static attractors | 3 |
| Model 1b | signed counter | sequence of static attractors | 3 |
| Model 1c | dynamic attractor chain | sequence of identical dynamic attractors | 3 |
| Model 2a | quadruped gaits | coexisting distinct dynamic attractors | 4 |
| Model 3a | molluskan swimming | coexisting identical dynamic attractors | 4 |
| Model 2b | sequential control of quadruped gaits | sequence of distinct dynamic attractors | 5 |
| Model 3b | sequential control of molluskan swimming | sequence of identical dynamic attractors | 5 |
In Chapter 3, we introduce three models for sequences of attractors. Models 1a and 1b are two counter networks that step through sequences of fixed points. Models 1a is shown in Figure 1.3A, where we can see that identical pulses move the network into the next stable fixed point, where it stays until it receives another pulse. This network serves as robust discrete neural integrators of inputs, as we show in their chapter by doing a thorough robustness analysis. Additionally, we extend our work to dynamic attractors by presenting an additional network, Model 1c, capable of encoding a sequence of dynamic attractors. These dynamic attractors are all qualitatively identical, and because of this, there are some symmetries in the basins of attractors, and thus all attractors easily accessible via distinct input pulses. However, to effectively model CPGs, we require different types of patterns to coexist simultaneously. How can we achieve this?
Figure 1.3. Summary of models I.

(A) Model 1a: counter network from Chapter 3. Pulses are all identical (in black). (B) Model 2a: quadruped gaits network from Chapter 4. Pulses are attractor-specific (colored according to stimulated node).
That is the content of Chapter 4, where we model two different CPGs, Model 2a and 3a, which require sequential activation of neurons. Model 2a, developed in in Section 4.2, is pictured in Figure 1.3B. It consists of a network encoding five different quadruped gaits as coexistent limit cycles in a 24 unit network. There, we see that all gaits coexist and are accessible via gait-specific pulses. We do a thorough analysis of its dynamics via the set of fixed point supports, and the effect of parameters in modulating gait characteristics. Model 3a, in Section 4.3, consists of a network encoding swimming orientation of a marine mollusk (Clione). Since the attractors are all identical, we manage to prove symmetry of its basins of attraction in Theorem 12.
Finally, in Chapter 5, we merge the concepts introduced in Chapters 3 and 4 to achieve sequences of sequential attractors. From Chapter 3 we get the counter network that will encode the sequence transitions, and from Chapter 4 we get the coexistent sequential attractors. From this integration we obtain Models 2b and 3b: a network for the sequential control of quadruped locomotion and for the sequential control directing swimming movements in Clione. The latter is the one pictured in Figure 1.4, where we observe the attractors from the CPG network “fuse” with the attractors of the counter network, as both are simultaneously active, and look qualitatively like they did when isolated. Figure 1.4 shows the resulting network using Clione’s model, but it can also be done, analogously, with the five-gait network. The fact that we could use the exact same construction with two different networks, led us to believe this is an even more general phenomenon, arising from some structural constraints on these networks, ad they were indeed built with similar principles.
Figure 1.4. Summary of models II.

Model 3b: sequential control of molluskan swimming directions from Chapter 5. Pulses are identical by layer. Attractors are labeled on top of the greyscale by which direction is active (up/down, left/right, front/back). These are also color-coded by node.
Code to reproduce the plots in Figures 1.3 and 1.4, and also all models listed in the table, can be found at https://github.com/juliana-londono/phd-thesis-basic-plots.
Note that in Figure 1.4, we see a “blend” of two different attractors: at the top of they greyscale we see the dynamic attractors coming from layer L3, and at the bottom we see fixed points coming from layer L1. This phenomenon was also observed in [61], where it was called fusion attractors. Fusion attractors offer a clean solution for managing sequences of static and dynamic attractors. Understanding the mechanisms behind this phenomenon motivates us to further explore the underlying structural constraints giving rise to it, from a theoretical standpoint. This is why we now transition from models to theory.
New network theory.
We want to note that all the models we have developed thus far were built within the TLN framework, for which there are plenty of well-established theoretical results. This theoretical foundation made the process of building these models a lot easier. However, our models have now surpassed the available theory and so now they serve as sources of inspiration for the development of new theoretical results. This is why in the second part of the dissertation, we take a reverse approach: while theory initially guided our modeling efforts, now the models are leading the development of new theoretical results.
Chapter 6 presents original theoretical contributions, including several results recently published in the paper I co-authored: "Sequential Attractors in Combinatorial Threshold-Linear Networks" [59]. This chapter is divided in three parts. First, in Section 6.1, we establish some necessary technical results, some of which are earlier version of results that we end up generalizing in this chapter. Then, in Section 6.2, we derive new structural theorems for CTLNs supporting sequential attractors. All of the results within this section are my contribution to [59], which contains several other architectures that support sequential attractors. All theorems I proved are in bold. Most of these results relate the fixed point supports of a network to the fixed point supports of component subnetworks, as follows:
Theorem 21 for “simply-embedded partitions”, constrains the possible fixed point supports of a network to unions of fixed points chosen from a particular menu of component subnetwork fixed point supports. This is generalizing results from [15]. In the same section, Theorem 23 and Corollary 24 give conditions on when a node can be removed from a network without changing the set of fixed points supports. We include here a new result on removable nodes, that has not been published: Theorem 25.
Theorem 28 for “simple linear chains”, showing that the set of fixed point supports of a simple linear chain network is closed under unions of “surviving” component fixed point supports.
Theorem 31 for “strongly simply-embedded partitions”, showing that the set of fixed point supports of a network can be fully determined from knowledge of the component fixed point supports together with knowledge of which of those component fixed points “survive” in the full network.
Finally, in Section 6.3, we extend some of these theorems to TLNs and provide theoretical explanations for the fusion attractors observed in Chapter 5, culminating with:
Theorem 40, which is an important technical result generalizing previous theorems on certain determinant factorizations that control the set of fixed point supports of a network. It relies on a new determinant factorization lemma, Lemma 38, which I have also proven. Theorem 40 is then used as a crucial ingredient in the proofs of: Theorem 42, generalizing Theorem 21 above. Theorem 44, explaining how the fixed points of some special networks are formed from fixed point of smaller component networks. That theorem generalizes both Theorem 17 (from two components to N components) and Theorem 31 (from several CTLN components to several TLN components). And finally, we present a similar result but for “nested” component fixed point supports in Theorem 45.
We also show that the networks in Chapter 5 satisfy these conditions, thus explaining the fusion attractors observed there.
In this dissertation’s final chapter, Chapter 7, we present partial and further theoretical results derived from projects in sections 4.2 and 6.3. In Section 7.1, Lemma 48, gives conditions under which the same attractor can arise from two different networks. This phenomenon is known as degeneracy. All code from this section is available online at https://github.com/juliana-londono/TLN-attractor-interpolation. In Section 7.2, Lemma 55, gives a new way to think about certain Cramer’s determinants, which are at the core of the dynamics of TLNs.
The rest of this dissertation is organized as follows: Chapter 2 introduces the framework, including firing rate models, attractor neural networks, TLNs, and CTLNs. Chapter 3 provides models for sequences of static and dynamic attractors, both internally and externally encoded. In Chapter 4, we provide two CPG models of locomotion, each consisting of several coexistent dynamic attractors, easily accessible via initial conditions or inputs. Chapter 6 explores new architectures and theoretical results, focusing on sequential dynamics complex and networks made up of simpler subnetworks. Finally, Chapter 7 discusses further theoretical results derived from the presented projects, suggesting avenues for further exploration. Appendix A contains the matrices and parameters used to construct all the models, along with some technical calculations of the fixed points of the five-gait quadruped network. That’s all. We hope you enjoy reading this dissertation. We encourage you to keep in mind Figure 1.1, which is the road map guiding us through the chapters on models.
Chapter 2 | Review of relevant background
This section offers a broad overview of the mathematical and historical background necessary for understanding and contextualizing the subject at hand. More detailed technical background specific to each chapter is provided later, as needed. None of the results in this chapter are original work of my own. Thus, the proofs of these results are not included here and can be found in their original publications, as cited.
2.1. Firing rate models and attractors
In this dissertation, we deal with the dynamics of recurrent neural networks. A recurrent neural network consists of a directed graph along with a prescription of the nodes’ dynamics. The nodes are thought of as neurons and edges represent synapses between them. One way to interpret the dynamics of the nodes is as firing rates, which indicate the average frequency at which the neuron generates action potentials (or “fires”) [19]. The dynamics of a firing rate network model can be described by a system of coupled differential equations:
| (2.1) |
where represents the firing rate of neuron , is a matrix prescribing the interaction strengths between neurons, and is some external input to neuron (which might vary in time), for recurrently connected neurons. In Equation 2.1, is referred to as the time constant, representing the rate of decay when there is no input to neuron , and is an activation function (e.g. sigmoid, ReLU).
Also, Equation 2.1 indicates that we are viewing recurrent neural networks here as dynamical systems, contrasting with the typical machine learning perspective that treats neural networks as learning algorithms or black-box function approximators.
While firing rate models are clearly a simplification of biological neural dynamics, they allow us to focus on factors such as the interactions between neurons, activation functions, and external inputs, and help bridge the gap between detailed spiking neuron models and large-scale network behavior. This provides a valuable framework for understanding the functional roles of these factors in neural computations.
Indeed, firing rate models of recurrent neural networks are a popular tool for studying nonlinear dynamics in neuroscience [19,20,23,67], particularly within the context of attractor neural networks. Attractor neural networks have emerged as a framework for studying neural dynamics, covering various cognitive processes like memory recall, decision-making, and perception [3,43]. Understanding how these networks compute is useful for advancing our understanding of how biological networks compute.
Under this framework, attractors of the system are thought of as representations of some cognitive process or pattern encoded in the system. Hopfield networks are a classical example [39]. In these networks, fixed points of the network are interpreted as encoded memories. In Hopfield networks, units can only be in one of two states, and the dynamics are discrete. Importantly, if the connections between neurons are symmetric, then the network is guaranteed to converge to a stable fixed point, which happens to be the minimum of an energy function, pictured as an energy landscape in Figure 2.1A [39,40].
Figure 2.1.

(A) Minima of energy landscape for symmetric network. (B) Diversity of attractors of non-symmetric networks. Adapted from [17].
Such theoretical results are not only available for Hopfield networks, but also more broadly for certain continuous-time recurrent neural networks, which are the main subject of this dissertation: threshold-linear networks (TLNs). In the case of TLNs, in Equations 2.1 (a.k.a. ReLU activation function, Fig. 2.2). TLNs were introduced around the 50s [38], and have been widely used in computational and mathematical neuroscience [7,35,46,67,70] since.
Figure 2.2.

A recurrent neural network, and the ReLU activation function.
A crucial aspect of TLNs is their piecewise linear activation function, which greatly simplifies mathematical analysis. This mathematical tractability has given rise to numerous theoretical results. Notably, as with Hopfield networks, symmetric TLNs were shown to converge to stable fixed points under some extra restrictions on (copositivity) [36]. Furthermore, there exist constraints on which sets of neurons can be co-active at a stable steady state (forbidden and permitted sets in [36]). These results have been further explored in subsequent studies [13,16].
We are however interested in a broader set of attractors, not only stable fixed points. That is why we focus here in non-symmetric inhibition-dominated TLNs, for which W is non-symmetric and non-positive. This choice is motivated by the fact that inhibition fosters competition between neurons, and thus neurons tend to alternate in reaching peak activity levels, leading to sequential behaviors within limit cycles.
Indeed, these networks, even though still piecewise linear, nonetheless permit rich non-linear dynamics like multi-stability, limit cycles, chaos and quasi-periodicity to arise and, moreover, coexist [53,54,61], as in Figure 2.1B. This, along with extra simplifying assumptions (particularly on ), has given rise to a robust body of theoretical work characterizing the dynamics of TLNs [13–16,37,53,54,59,77].
In particular, a main focus of this dissertation is on a special type of non-symmetric TLNs, called combinatorial threshold-linear networks (CTLNs), introduced in [54]. CTLNs are TLNs where the connectivity matrix is prescribed by a simple directed graph, and often the input is assumed to be uniform across neurons.
Below, we formally introduce TLNs and CTLNs, and present some results that we will use throughout the dissertation. The presentation of these results is adapted from [15,59], with slight modifications. Since CTLNs are a special family of TLNs, they inherit many properties from TLNs. Hence, we first provide an overview of the necessary background shared with TLNs, and then state results specific to CTLNs.
2.2. Threshold-linear networks (TLNs)
A threshold-linear network (TLN) is a continuous-time recurrent neural network (Eqns. 2.1) where . In addition, we assume for the time being that the input is constant in time and the timescales are constant and uniform across neurons (without loss of generality, we assume ). More precisely:
Definition 1.
A threshold linear network on neurons is a system of ordinary differential equations
| (2.2) |
where for all , . This can also be written in vector form as
where is an real matrix and .
Under these circumstances, a given TLN is completely determined by the choice of the connectivity matrix and its vector of inputs , so we denote it by . Unless otherwise specified, is the total number of neurons in the network. As mentioned above, here we only consider inhibition-dominated TLNs (a.k.a. competitive). This means we assume for all , . In addition, we pose some extra restrictions on degeneracies. The following definition requires some Cramer’s determinants of some sub-matrices to not vanish, we denote by the matrix the matrix where the column corresponding to the index has been replaced by , where the subindex denotes restriction to the rows/columns given by . In the definition below, and in all that follows, denotes the set of indices .
Definition 2 ([15, Definitions 1 and 2]).
We say that a TLN is competitive if , and for all . We say that it is non-degenerate if
for at least one
for each , and
for each such that for all , the corresponding Cramer’s determinant is nonzero: .
Unless otherwise noted, all TLNs here are competitive and non-degenerate.
A good point of entry to explore the dynamics of a competitive TLN are its fixed points: a fixed point of a TLN is a solution that satisfies for each . Per equations 2.2, this translates into
By the defintiion of the function, when , will evaluate to 0. Thus, these define hyperplanes that divide state space into chambers, and inside each of those chambers, Equations 2.2 define a linear system of ODEs. Under the non-degeneracy assumption, each of those can have exactly one fixed point, though its fixed point might not lie inside the correct chamber.
In Figure 2.3, for example, we have marked the four fixed points associated to the 4 linear systems with corresponding colors, but only the fixed point in chamber {2} (the pink one) is in its correct chamber. This makes it the only true fixed point of the TLN pictured there. Since there is at most one fixed point per chamber, we can label all the fixed points of a network by their support supp . We gather the supports of all fixed points into a set
| (2.3) |
Figure 2.3. Hyperplane chambers cartoon.

2-dimensional state space is divided in 22 chambers by the hyperplanes , inside each the dynamics are truly linear. The fixed points of the linear systems are color-coded by chamber.
We have experimentally observed that often , although no precise number for that “often” are provided. Thus, this set is often non trivial and so it already contains quite a bit of information about the dynamics of , as we will see later. We refer to this set many times throughout this dissertation, so it is good to keep it in mind. Finally, we give an important result about belonging to .
Corollary 3 ([15]).
Let be a TLN on n neurons, and let . The following are equivalent:
This concludes the necessary background on TLNs. Next, we formally introduce CTLNs and review some results particular to them.
2.3. Combinatorial threshold-linear networks (CTLNs)
A big part of this dissertation focuses on a special family of TLNs, called combinatorial threshold-linear networks (CTLNs). In this case, in addition to the network being a competitive non-degenerate TLN, the connectivity matrix in Equation 2.2 is prescribed by a simple directed graph G, as shown in Figure 2.4. We are thinking of the graph as retaining only the excitatory neurons and the connections between them, where the inhibitory neurons and their background inhibition are not represented in the graph, but are included in the equations defining the dynamics.
Figure 2.4. CTLNs.

Right: A neural network with excitatory neurons (black) and inhibitory neurons (gray), producing global inhibition. Left: Only the excitatory connections remain in our graph representation of the network. From [17].
More precisely, if we denote in by not in , we have the following definition
Definition 4.
A combinatorial threshold-linear network is a threshold-linear network whose connectivity matrix is prescribed by a simple directed graph as
| (2.4) |
where , and the input values are kept constant across neurons. When , , and , we say that the parameters are in the legal range.
Although this puts us further from reality, this simplification allows us to retain fundamental properties while being able to derive relationships between structure and function more easily. We are assuming input to be constant across neurons to further isolate the role of connectivity in the network.
When , , and , we say that the parameters are in the legal range. These are chosen both to have all inhibitory connections, but also to satisfy some conditions in some proofs. Parameters in this dissertation are always chosen from the legal range, unless otherwise noted. Before we show an example, it is important to clarify that our convention for the adjacency matrix of a graph is:
to match the connectivity matrix with the conventions.
Figure 2.5 shows an example of a CTLN where the defining graph consists of a 3-cycle. From it, we get the transposed adjacency matrix, and from it we get the connectivity matrix as defined by Equation 2.4 with parameters and . To get the rate curves in the Figure 2.5, we simulate the system of equations 2.2 with . The network activity follows the arrows in the graph. Peak activity occurs sequentially in the cyclic order 123.
Figure 2.5. CTLN example.

From a 3-cycle graph we obtain its adjacency matrix , from which we obtain the resulting connectivity matrix using Equation 2.4, from which we obtain the dynamics of the system using Equation 2.2. The activations follow the arrows of the graph. Modified from [61].
The dependence of the dynamics of a CTLN on its defining graph has given rise to extensive theory relating the dynamics and the combinatorial properties of through the set of its fixed point supports, which we now denote as 1 or , if clear from the context:
This set contains information about all the fixed points of the network, giving insights into the dynamics of the network through a special subset, as it will be seen next. Indeed, we will see that the fixed points shape the dynamics of the network, whether or not they are stable. In the sections that follow, we show connections between this set and the dynamics of the network, and our main entry point are the the core motifs, introduced in the next section. There are special minimal fixed point supports which have been conjectured to correspond to attractors. Since these have proven to be insightful, we provide rules to find them in Subection 2.3.2. We conclude the chapter by showing how to build in certain core motifs into the network, hoping to see the desired attractors, using constructions like cyclic and clique unions [15].
2.3.1. Core motifs
In prior work [59], it has been conjectured that the dynamic attractors of a network correspond to supports that are core motifs:
Definition 5 ([17]).
Let be the graph of a CTLN on nodes. An induced subgraph is a core motif of the network if .
We refer to both the support of the fixed point and the induced subgraph as the core motif. Note that a necessary condition to be a core motif of the network is that is minimal in by inclusion. Core motifs have been observed to be useful in predicting the dynamics of a network. For example, consider Figure 2.6. The CTLN defined by the graph in panel A has two core motifs in it, 123 and 4. 1234 is not a core motif, since it is not minimal in , by inclusion. Panel B shows the results of simulating the CTLN using , , and under two different initial conditions. In the top, the initial condition is a small perturbation of the fixed point supported on 123. The activity spirals out of the unstable fixed point and converges to a limit cycle where the high-firing neurons are the ones in the fixed point support. In the bottom, the initial condition is a small perturbation of the fixed point supported on 4, which is a stable fixed point. Thus, the activity converges to a static attractor where the high-firing neuron is the one in the fixed point support. In panel C, we see that the 1234 fixed point is fundamentally different: small perturbations of the fixed point supported on 1234 produce solutions that either converge to the limit cycle shown in panel B, or to the stable fixed point. This support therefore does not “correspond” to any attractor, but rather acts as a “tipping point” between two distinct attractors.
Figure 2.6. CTLN attractors.

(A) Graph of a CTLN and its set. (B) Solutions to the CTLN with the graph in panel A using two different initial conditions, which are perturbations of the fixed points supported in 123 (top) and 4 bottom. (C) Fixed points and example trajectories which are perturbations of the fixed point supported in 1234, depicted in a three-dimensional projection of the four-dimensional state space. From [61].
Less informally, we will say that a support corresponds to an attractor if initial conditions that are small perturbations from the fixed point lead to solutions that converge to the attractor. Heuristically, the high-firing neurons in the attractor tend to match the support of the fixed point. Core motifs often correspond to attractors [59] and, consequently, understanding the core motifs of a network becomes useful when predicting the dynamics of a given CTLN. We make use of this heuristic often in the dissertation and so we give the set of core motifs of a given network its own notation:
An example where the core-attractor correspondence is perfect is for cycle graphs, that is, a graph (or an induced subgraph) where each node has exactly one incoming and one outgoing edge, and they are all connected in a single directed cycle. First, it is a fact that all cycle graphs are core motifs:
Theorem 6.
If is a cycle, then is a core-motif.
Indeed, it was recently proven that a graph that is an 3-cycle has a corresponding attractor [6].
2.3.2. Graph rules
The connection between attractors and the fixed points has motivated an extensive research program where graph rules were developed [15, 18, 59, 61]. These refer to theoretical results directly connecting the structure of , to the set . Several of those results are independent of the choice of , and thus useful for engineering robust networks with prescribed attractors. We use of some these in the modeling section, and so we reproduce them below.
The first graph rule, central to our work here, concerns a special type of graph. We say that has uniform in-degree if every node has incoming edges from within . In that case, we have:
Theorem 7 (uniform in-degree, [15]).
Let be a graph on n nodes and . Suppose has uniform in-degree . For each , let be the number of edges receives from . Then
Furthermore, if and , then the fixed point is unstable. If , then the fixed point is stable.
From this theorem, we easily get the following Rules for families of uniform in-degree graphs that we use in our models:
Cliques are all-to-all connected graphs and therefore uniform in-degree with , where is the total number of nodes in the clique.
Rule 1 (Cliques, Fig. 2.7A). If is a clique, then supports a stable fixed point if and only if for all receives at most edges from . When no external node receives edges from , we say that is target-free.
Figure 2.7. Three families of uniform in-degree graphs.

Three example families of uniform in-degree graphs, and corresponding Rules.
Cycles are graphs whose vertices are connected in a closed chain and therefore uniform in-degree with .
Rule 2 (Cycles, Fig. 2.7B). If is a cycle, then supports an unstable fixed point if and only if for all receives at most one edge from .
A tournament is an orientation of a (undirected) complete graph. A tournament is called cyclic if the set of all automorphisms of contains . All cyclic tournaments must have an odd number of nodes , and have uniform in-degree [11].
Rule 3 (Cyclic tournaments, Fig. 2.7C). If is a cyclic tournament, then supports an unstable fixed point if and only if for all receives at most edges from , where is the number of nodes in .
All of these graphs are core motifs [11,15] and they indeed have a corresponding attractor, as expected. In the case of cliques, the fixed point is stable. In the case of cycles and cyclic tournaments, their unique fixed point is unstable and the dynamics reveal a corresponding limit cycle attractor.
In addition to providing tools for engineering certain patterns into a network, graph rules can also be used to prove that a given support belongs to in more general cases. Indeed, in Chapter 6, we use such rules to prove new theoretical results. A key one derives from the concept of graphical domination, introduced in [15] and summarized in Figure 2.8:
Figure 2.8. Graphical domination.

Four types of graphical domination from Rule 4. Modified from [17]. Dashed arrows represent optional edges.
Definition 8.
We say that graphically dominates with respect to if the following three conditions hold:
For each , if then .
If , then .
If , then .
If there is graphical domination within a graph, a lot can be said about its fixed points:
Rule 4 (graphical domination, [17]). Let be a graph on nodes, and . Suppose graphically dominates with respect to . Then the following statements hold:
(inside-in) If , then , and thus .
(outside-in) If and , then , and thus .
(inside-out) If and , then implies .
(outside-out) If , then implies .
A good example of the use of Rule 4 in proving more general results on the , is the rule of sources. A source is a node that has in-degree 0. The we have the following result:
Rule 5 (Sources, [15]). Let be a graph on nodes and . If there exists an such that contains a proper source in , then .
Proof. Suppose there exists an such that is a proper source in with . Then graphically dominates since has no inputs in and . Hence, by Theorem 4, and so by Corollary 3. □
We conclude this section with a cool application of Rule 4, which we use in Subection 6.3.1 to present an alternative proof of one of the results in [59]. The proof of the result below can be found in [60].
Theorem 9.
Let be a graph on n nodes, and suppose there is such that graphically dominates with respect to . Then .
2.3.3. Cyclic unions and sequential attractors
These graph rules allow us to construct graphs with prescribed fixed point supports , and facilitate the analysis of in terms of the structure of . This in turns allows for the derivation of more general structure theorems, supported on simpler building blocks. One of these structures, which does the heavy lifting of pattern generation in Chapter 4, is the cyclic union, pictured in Figure 2.9A:
Figure 2.9. Cyclic unions.

(A) A cyclic union of components, and Theorem 11. (B - C) Two examples of a cyclic union, and its sequential activation of the nodes. Nodes whose activations are synchronized appear in parenthesis.
Definition 10.
Given a set of component subgraphs , on subsets of nodes , the cyclic union of is constructed by connecting these subgraphs in a cyclic fashion so that there are edges forward from every node in to every node in (cyclically identifying with ), and there are no other edges between components
Cyclic unions are great for pattern generation because, as it can be seen in Figure 2.9B-C, they give rise to sequential attractors whose order of activation coincides with the overall structure and direction of the cyclic union. Indeed, this is a general fact, that derives from the way in which the set is made up for cyclic unions:
Theorem 11 (cyclic unions, theorem 13 in [15]).
Let be a cyclic union of component subgraphs . For any , we have
Moreover,
This means that the global fixed point supports can be completely understood in terms of the component fixed point supports. Theorem 11 guarantees that every fixed point of hits every component. In simulations we have observed that this ensures that the every component is active in corresponding attractors. Moreover, neurons are activated in the order of the components in cyclic order.
Indeed, Figure 2.10 shows an example of this. There, is a cyclic union of four component subgraphs . Thick colored edges from a node to a component indicate that the node send edges out to all the nodes in the receiving component. can be easily computed using graph rules, and it is shown below the graph in color-coded components. To simplify notation for , we denote a subset by . For example, 12 denotes the set {1,2}. follows the same color convention and consists of unions of component fixed point supports, exactly one per component. A solution for the corresponding CTLN is pictured. It shows that the attractor visits every component, in the cyclic union order.
Figure 2.10. of cyclic union.

Example of a cyclic union, how its set is made up of from component pieces (color-coded), and how the sequential activations of the nodes follow the cyclic union structure. Modified from [59].
There exists generalization of cyclic unions that also give rise to sequential attractors, see [59].
Theorem 11 is thus helpful when engineering networks that must follow a sequential activation, because the order of activation of neurons will match the direction of the cyclic union. This is exactly what we look for in central pattern generators models, which are the main topic of Chapter 4.
2.3.4. Fusion attractors
In the previous subsection, we saw by example that cyclic unions naturally gave rise to sequential attractors. Cyclic unions are one of the three block-structures first introduced in [15], that relate the parts to the whole. The two other structures are the clique union and the disjoint union of component networks.
We review the clique union here because it is special in that it gives rise to “fusion attractors”, introduced in [61]. Clique unions are built by partitioning the vertices of the graph into components , and putting all edges between all pairs of components. For example, the fusion 3-cycle from [61], in Figure 2.11, is the clique union of and . What we observe in the dynamics is the “fusion” of what seems to be two different attractors: the stable fixed point supported in 4, and the limit cycle supported in 123. That’s why it is called fusion attractor. However clique unions are a bit too restrictive. How can we relax the assumptions on the structure of the network, and still get fusion attractors? This is partly the topic of Chapter 6. Later, we will generalize this concept for layered TLNs to get attractors for sequential control of quadruped gaits and other CPGs.
Figure 2.11.

The fusion 3-cycle from [61].
Chapter 3 | Sequences of attractors
Recall that in Hopfield networks [39], memories are encoded as fixed points. Many memories can be encoded simultaneously, but accessing these fixed points usually requires attractor-specific inputs (equivalently, attractor-specific initial conditions), as illustrated in Figure 3.1A. Thus, we obtain a sequence of fixed points with whose transitions are controlled by external inputs, this means that, in a way, the order of the sequence is encoded in the external pulses, i.e. externally encoded. Would it be possible to have the sequence’s order internally encoded, as in Figure 3.1B, where the transitions happen in response to identical external pulses who do not know what comes next? This could be useful to model highly stereotyped sequences, like songbird songs [50] or as a counting mechanism, like in discrete neural integrators [30].
Figure 3.1. Sequences of attractors.

Reproduction of Figure 1.1. The focus of this chapter is Panel B: Internally encoded sequence of stable fixed points, each step of the sequence accessible via identical inputs. We also briefly touch on the situations of Panel C and D.
The first half of this chapter focuses on internally encoded sequences of static attractors, as depicted in Figure 3.1B. The second half will attempt to model the situation in Figures 3.1C,D, where several dynamic attractors coexist and are easily accessed via attractor-specific inputs. Our model will have a catch though, and it is that all attractors are identical to each other. Later, in Chapter 4, we will focus on modeling the situation of Figure 3.1C again, but this time all dynamic attractors are different. Finally, in Chapter 5, we join the models from this chapter and Chapter 4 to present a model/mechanism for the situation of Figure 3.1D, where we have an internally encoded sequence of diverse dynamic attractors.
This is, again, a good place to recall that we are using sequence/sequential in two different contexts. On one hand, we have sequential attractors (Figs. 3.1C,D), which refer to attractors whose nodes fire in sequence e.g. limit cycles. On the other hand, we have sequences of attractors, where the elements of the sequence are not the nodes, but the attractor themselves (Figs. 3.1B,D).
In this section, we leverage theoretical results from [15] to engineer networks with prescribed FP(G) sets. In doing so, we have a strong indication that the network will support the desired attractor. Throughout the chapter, we hope the important role of the theoretical results in facilitating the engineering work will become evident. Indeed, we begin the work by recalling the rules from Chapter 2 that followed from Theorem 7, and that we use in the sections that follow to design our attractors:
Rule 1. If is a clique, then supports a stable fixed point if and only if for all , receives at most edges from . When no external node receives edges from , we say that is target-free.
Rule 2. If is a cycle, then supports an unstable fixed point if and only if for all , receives at most one edge from .
Rule 3. If is a cyclic tournament, then supports an unstable fixed point if if and only if for all , receives at most edges from .
3.1. Sequences of fixed point attractors
In this section we model a discrete counter as a sequence of static attractors, each accessible via identical inputs. Neural integration is an important correlate of processes such as oculomotor and head orientation control, short term memory keeping, decision making, and estimation of time intervals [9,10,30,52,68]. Understanding how neurons integrate information has been a longstanding problem in neuroscience. How exactly do brain circuits generate a persistent output when presented with transient synaptic inputs?
Many of models have been proposed to model neural integrators, but classic models are known to be very fine-tuned, requiring exact values for the parameters in order to achieve perfect integration. By contrast, some robuster models tend to be rather insensitive to weaker inputs, requiring strong inputs to switch between adjacent states [30,68]. The models we propose here represent a very simple alternative to classic discrete neural integrators. Our models are both robust and respond well to a wide variety of input strengths. Importantly, since they are encoding sequences of stable fixed points, they could be also useful to model highly stereotyped sequences, like songbird songs [50].
CTLN counter.
Our initial model is a simple and robust CTLN that can keep a count of the number of input pulses it has received via well separated discrete states, providing a straightforward readout mechanism of the encoded count. We henceforth refer to this network, informally, as a “counter network”. Counting the number of inputs can be achieved with an ordered sequence of stable fixed points, each representing one position in the count. Each transition between fixed points indicates an increase in the count, and so in order to be integrating the external inputs, we want them to cause the fixed point transitions.
First, to encode a set of stable fixed points in a network we can appeal to Rule 1, reproduced again in Figure 3.2A, which says that a clique will yield a stable fixed point if it is target free. Thus, our network must have as many cliques as desired stable fixed points, and we need to embed them in the network in such a way that they will survive as fixed points, that is but also .
Figure 3.2. Construction of counter.

(A) Rule 1 from Chapter 2. A clique will yield a stable fixed point if and only if it is target free. (B) Rule 2 from Chapter 2. A cycle will be a fixed point support if and only if it every other node in the network receives at most one edge from the cycle. (C) Resulting construction of the CTLN counter network.
We also need some mechanism to be able to transition between these stable fixed points. Emphasis on stable, as this indicates we will need a strong enough perturbation to leave that steady state. We can potentially achieve this by adding some edges in the graph that will permit the activity to flow from clique to clique in response to input pulses. Graph-wise, these are all the ingredients we need to construct our network.
We get to work and assemble the network by chaining together several target-free 2-cliques, as shown in Figure 3.2C. Each of these cliques is embedded in a target-free way. More specifically, Rule 1 says that the 2-cliques will survive as fixed point supports as long as they do not have more than outgoing edge to any other node in the graph, and this is in fact the case for all of them. This would not be the case if, for example, we were to add the edge 1 → 4 in the network of Figure 3.2C, because then node 4 would be a target of {1,2}.
Note that the top and bottom cycles ({1,3,5,7,9,11}, {2,4,6,8,10,12}) also each support a fixed point of the network by Rule 2 (Fig. 3.2B), since no node receives more than one edge from these cycles either. This cycles will provide the perturbation we are looking for to be able to exit the fixed points we just built-in. We made the cycles wrap around to ensure activity will not stale in the last clique of the chain, and it will continue cycling. Adding six 2-cliques was an arbitrary decision, we could have had more or less.
In this way, we have built a network whose , by design, should contain all the cliques ({1,2}, {3,4}, {5,6}, {7,8}, {9,10}, {11,12}) and the bottom and top cycles as core fixed point supports. Computationally, we confirm these inclusions and find, more precisely that (yes, 141 fixed points, this is not that crazy because there are up to 212 linear systems that could potentially lead to a fixed point of the network) and that
| (3.1) |
Based on the core motif and attractor heuristic correspondence, this is indicative that we will have a stable fixed point attractor per clique, and two unstable fixed points, most likely giving rise to dynamic attractors (but also maybe not, as the heuristic is a heuristic and not a theorem or perfect correspondence, only the simulation will tell).
We have designed this network to have 6 stable fixed points, which we computationally checked that indeed it has. Since the set does not depend on , so far no mention of it has been necessary, and those stable fixed points will be there regardless of the value of , as long as it is in the legal range. However, if we aim to transition between stable fixed points, we will need exercise the perturbation somehow. And that’s where hysteresis comes. The perturbation will come in the form of external pulses, or -pulses, defined below.
External pulses are communicated the network by transiently changing the value of the external input in Equations 2.2, which we recall to be given by
Because we are using CTLNs, is prescribed by the graph of Figure 3.3A, using the rule
Figure 3.3. Hysteresis.

(A) 2-clique counter network. (B) Close-up of the pre- and post-pulse dynamics of counter network. (C) Three different 2-dimesional slices of the 4-dimensional state, at three time points: before the pulse, , when the network is settled in the fixed point where the only high-firing neurons are the blue ones. Right at the beginning of the pulse, , when the hyperplanes move, and the trajectory has to adapt to this change. And after the pulse has ceased, at , where the network stabilized in a different fixed point, the one where the green nodes are the high-firing. Nullclines are colored piecewise lines. The -pulse causes a translation of the nullclines, pushing the state of the network into the basin of attraction of a different stable fixed point. Black points indicate current state of the network, grey points indicate the current state of the network when the state does not lie in that plane, but it is projected to that plane.
Now, in the CTLN setup the external input would typically constant, but because we want to use pulses, the external input can no longer be constant. Because now we will have a temporary identical perturbation for all the neurons, above must be defined as a step function, pictured right at the very top of Figure 3.3B, that also does not depend on i, because we assume the pulses to be identical across neurons.
We refer to as the baseline and to as the pulse. It is important to note that this varying external pulse will cause our network to no longer be a CTLN (which requires external input to be constant and uniform across neurons), but rather a TLN, or a piecewise CTLN, if you wish. But because we will only need two different values, and we designed the network with CTLN principles, and because it really is a piecewise CTLN, we continue to call this network a CTLN.
Now, how does hysteresis arise from the pulse? Figure 3.3 explores how this transient change is affecting the dynamics of the network, at three time-stamps. First, note that the nullclines of the system are piecewise linear functions given by
That is, because TLNs are piecewise linear, the nullclines are piecewise linear as well. These are pictured in Figure 3.3C for neurons 1 to 4 of the network from panel A of the same figure, using corresponding colors.
By changing the value of , we are actually causing the nullclines of the system to shift in state space. More specifically, looking at Figure 3.3C, we see that at we are at the baseline , and the system is at rest in the stable fixed point supported on (cf. panel B). When the pulse arrives, at time , the nullclines experience a translation in state space, causing the trajectory to move towards the new fixed point (always at the intersection of the nullclines). When the pulse ceases, at , it is too late for the trajectory to go back, it has fallen in the basin of attraction of a different fixed point, the one supported on !
It is important to note that newer, more robust models of neural integration, also make use of hysteresis, but it typically arises from the use of bistable units [29,45,56]. In our case, hysteresis emerged as a property of connectivity, since CTLN units are not bistable by themselves (as they just die off), only when connected to each other, and so the multistability in our model is a property of the network, not of each unit.
What we explained above is exactly what we observe in simulations. We simulated the network using the parameters , , a baseline , and an input pulse . However, note that since Theorem 7 does not depend on the values of these parameters, any (C)TLN with dynamics prescribed by Equation 2.2, whose connectivity matrix is build from the graph of Figure 3.4A according to the binary synapse prescription of Equation 2.4, will have the supports of Eqn 3.1. This is true for any values of and , provided they are within the legal range.
Figure 3.4. CTLN counters.

(A) Counter. Pulses shown in the middle plot are sent to all neurons in the network. Activity slides to the next clique (stable fixed point) after reception of the pulse. Pulse duration is 3 time units, with no refractory period. (B) Signed counter. Black pulses are sent to odd-numbered neurons and red pulses are sent to even-numbered neurons. Activity slides to the right for black pulses, and to the left for red pulses. Pulse duration is 2 time units, with 3 time units of refractory period where .
The predictions about the dynamics are partly confirmed by simulations. We do observe the stable fixed points arise, but not the limit cycle. In any case, the rate curves of Figure 3.4A confirm the counting mechanism works: activity remains in the stable fixed point that the network was initialized to, unless a uniform -pulse is sent to all neurons in the network. When the network receives the pulse, activity slides down to the next stable state in the chain. Activity is maintained in this state indefinitely until future pulses are provided to the system. Indeed, the network is effectively counting the number of input pulses it has received via the position of the attractor in the linear chain of attractor states. This network is a very simple alternative to the neural integrator models often used to maintain a count in working memory of some number of input cues. The matrix and parameters needed to reproduce this Figure are available in Appendix A, Equation A.1.
Good! We have successfully encoded a sequence of fixed point attractors, all accessible via identical pulses. But can we adapt this construction to be able to decrease the count when presented with a negative input?
CTLN signed counter.
The architecture that made the transitions possible before, the cycles, can be so slightly modified to allow for the count to be decreased: making the bottom cycle travel in the opposite direction, as seen in Figure 3.4B, allows us to perturb the network with pulses so that the fixed points can also transition backwards in the chain, decreasing the count. This means that the pulses are now signed, and thus we informally refer to this modified network as “signed counter network”. The core motif analysis in this case is the same, as the cliques remain target-free and the two cycles again survive by Rule 2. Indeed, computationally, we found and
| (3.2) |
Again the predicted behavior of the network is confirmed by the rate curves of Figure 3.4B. The dynamics of the signed counter are analogous to those of the previous counter, except now pulses are signed, and the count can be decreased. More specifically, neurons are divided into two opposite populations (top and bottom cycles or, equivalently, odd and even nodes), and pulses are sent to either one of them. Note that pulses are now followed by a brief refractory period where to allow the system to reset. The color of the pulse in Figure 3.4B indicates which group of neurons received the pulse. Black pulses are sent to the top cycle (odd-numbered nodes), and red pulses are sent to the bottom cycle (even-numbered nodes). When the network receives a black pulse, the attractor slides to the right. If it receives a red pulse, the attractor slides to the left. That is, the activity travels in the direction of the cycle that received the pulse. This network can not only keep a count, but also store net displacement, position on a line, or relative number of left and right cues. The matrix and parameters needed to reproduce this Figure are available in Appendix A, Equation A.2.
Both counter models are simple in that they only require twice as many neurons as stable states, and pulses input to the system are given to all neurons on the network. Although both counter networks pictured in Figure 3.4 are able to keep a count modulo 6 (number of chained cliques), this can be generalized to an arbitrary (but finite) number of cliques, allowing to keep a memory of an arbitrary large count. This means that the number of possible states approaches infinity as the number of links in the chain approaches infinity as well, and so the count is effectively continuous. In addition, since the networks are able to keep a modular count of the number of pulses, it could be useful to estimate modular counts like time intervals or angles. Both counters thus constitute a simple alternative to traditional discrete neural integrators, but are they really that much robust?
Robustness of CTLN counters.
In general, CTLNs are expected to perform robustly, since a lot of their dynamic information is contained in and we know this set is preserved across the legal range.
To asses the performance of both counters across parameter space, we ran the simulations of Figure 3.4 using various pairs of parameters, and various combinations of pulses strengths and durations. We found three different possible outcomes, exemplified in Figure 3.5A. We classified these according to whether the function is preserved (keeps the correct count), corrupted (counts in multiples of two) or lost (does not keep a consistent count) as vary.
Figure 3.5. Good parameter grid for CTLN counters.

(A) Examples of what can go wrong in a single simulation. In the first plot the signed counters enter a “roulette” behavior (function is lost), in the second plot the pulses do not move the counter from the current fixed point (function is lost), and in the third plot the counter consistently slides two positions (function is corrupted). (B) Various counter behaviors for fixed values of baseline , with pulses for counter, and for signed counter. , vary according to the axes. Shaded in blue are parameter pairs outside the legal range . (C) Various counter behaviors for a fixed values of , and baseline , with pulse height and duration varying.
The results for all pairs of parameters and various combinations of pulses strengths and durations are recorded in the bottom row of Figure 3.5, where green indicates preserved, yellow indicates corrupted and red indicates lost performance. One dot corresponds to one simulation of 7 pulses, with a running time of time units for the counter and time units for the signed counter. We found that there is a good range of parameters where the counters behave as expected, successfully keeping the count of the number of input pulses received.
This robustness across parameter space was given to us by the theoretical results. But will the performance of the counters survive to added noise in the input and connections? To verify robustness to noise, we computed the proportion of failed transitions among pulses in both fixed point counters. This was done by introducing varying percentages of noise into the input, varied every of a time unit, and into the connectivity matrix , as specified in the axes of Figure 3.6. A failed transition is defined as any behavior that does not advance the counter a single clique forward/backwards, depending on the sign of the pulse. Figure 3.6 contains examples of all possible transition failures, as well as examples successful transitions in noisy conditions, as detailed below. All plots simulations used to quantify the failures were done with , .
Figure 3.6. Noisy CTLN counters.

(A) Example of a 20% noisy counter that performs well. (B) Example of a noisy counter with four failures, marked with red crosses: first it slides too many cliques down, and then it gets stuck in the same clique indefinitely. (C) Percentage of failed transitions for the counter in 100 trials, for several percentages of noise in and . (D) Example of a 20% noisy signed counter that performs well. (E) Example of a noisy signed counter with two failures, marked with red crosses: first it slides too many cliques down, and then it rolls around the counter until it settles in some arbitrary clique. (F) Percentage of failed transitions for the signed counter in 100 trials, for several percentages of noise in and .
Panel A of Figure 3.6 is an example of a very noisy counter that still preforms well. Each pulse advances the counter a single clique forward, as expected. Panel B of Figure 3.6 shows a noisy counter with two types of failures: first the counter advances too many steps, and then it gets stuck in one of the cliques (altogether these would count as four failures in out analysis, even though there is probably just two defective cliques). Panel D of Figure 3.6 is an example of a very noisy signed counter that performs perfectly well. Panel E of Figure 3.6 is an example of things that can go wrong in the signed counter. The first failure advances the counter one more than expected, the second failure makes the counter go into this kind of roulette behavior until it stops in a given clique. We have also observed the signed counter getting stuck at some point, as in Figure 3.6B.
The percentages of noise in Figure 3.6 were calculated as follows: The noise in the external input is i.i.d random noise from the interval , and it was introduced to vary every 0.1 fraction of a unit time. The noise in the connectivity matrix is obtained by perturbing the adjacency matrix with i.i.d random noise from the interval (0, 1). More precisely, if denote by , , the noisy versions of , , ; where is the transpose of the adjacency matrix of the graph defining the network, then the noisy versions are:
where , are the percentages of noise introduced, and , are random matrices the same size as , with entries between (0,1) and (−1, 1), respectively, and 1 is a matrix of 1’s the same size as . This is equivalent to perturbing by an amount proportional to length of the interval , that is:
We choose to perturb the adjacency matrix instead for computational easy. For each percentage of noise pair , we ran 20 simulations, each one consisting of 5 (signed) pulses in the CTLN (signed) counter, as exemplified in Figure 3.6. The results of counting over all these pulses are summarized in panels C and F of Figure 3.6. Each pixel represents the fraction of failed transitions for each pair . We found that discrete counters perform perfectly well up to 5% noise, proving that perfect synapses are not necessary. When the noise limits are pushed beyond, counters lose stability and start to slide too many attractors, or to get stuck in one of the cycles. The (unsigned) counter, not surprisingly, proved to be a lot more robust, being barely affected by the amount of noise in . Although not as robust, the signed counter accurately kept the count 50% of times under 20% noise. Not too bad.
Having successfully encoded sequences of stable fixed points, it is natural to now ask: can we use the same ideas to construct a network that encodes a sequence of dynamic attractors instead? Maybe by chaining together other kinds of core motifs, instead of cliques?
3.2. Sequences of dynamic attractors of the same type
Here we use one of the core motifs giving rise to a dynamic attractor from Chapter 2 to construct a network that steps through a sequence of dynamic attractors. In the previous section, we chained together repeated core motifs that we knew gave rise to stable fixed points to obtained a network that steps through a sequence of stable fixed points. We use the same idea as before, but a cyclic tournament instead of a 2-clique.
To construct the network, we chain together overlapping 5-stars, which are cyclic tournaments. These were introduced in Chapter 2 and are the motifs composing the networks shown in Figures 3.7C, D (a single 5-star is, for instance, the subgraph induced by 1 to 5). Rule 3 says that each 5-star will yield an unstable fixed point support, since each 5-star is connected in such a way that it survives to the larger network. Thus, we should get:
Figure 3.7. Dynamic attractor chains.

(A) Coexistent dynamic attractors. Each attractor is accessed via attractor-specific pulses. The sequential information is externally encoded. (B) Coexistent dynamic attractors. Each attractor is accessed via identical pulses sent to the network. The sequential information is internally encoded. (C) Patchwork of six 5-stars. Pulses are sent, one at the time, to neurons 6,9,12,15,18,3 (colored) in that order. Each pulse makes the attractor slide to the next limit cycle down the chain. Pulse duration is 1 time unit. (D) Same network as in panel A receives simultaneous pulses to neurons 3,6,9,12,15,18 (bold nodes). Pulse duration is 1 time unit. Two cycles go through the network in the direction opposite to attractor sliding. Despite their apparent symmetry, the green cycle is a core motif of the network, but the red cycle is not (it dies by Rule 2).
Indeed, computational work shows that contains precisely the six supports above, each for one 5-star. We also found (which again, is not surprising since there are up to 218 linear systems) and that
| (3.3) |
Notice that we got an extra core motif, the last one in Equation 3.3. This is a cycle that is also uniform in-degree, and that survives by Rule 2 (colored in green in Figure 3.7D). In contrast, the colored red cycle of Figure 3.7D, at first glance symmetric to the green cycle, will not support a fixed point, by Rule 2 again (because, for instance, node 7 has two inputs from it). The attractor corresponding to the core motif has not yet been found computationally.
We therefore expect to see at least six limit cycles, each one corresponding to a 5-star. Simulations confirm these predictions. In this case, both selective stimulation of specific nodes (Fig. 3.7C) and identical stimulation of all multiple-of-three nodes (Fig. 3.7D) can move the attractor to the next limit cycle in the chain. Indeed, in Figure 3.7C pulses are sent to specific nodes (color coded) which activate the attractor associated with the core motif that the node belongs to. For example, stimulating node 9 will activate the limit cycle associated with the core motif , to which 9 belongs. Note that the order in which pulses are sent matches the order in which the attractors are chained. Simulations show that is it not always possible to jump between non-adjacent 5-stars. The matrix and parameters needed to reproduce this Figure are available in Appendix A, Equation A.3.
By contrast, in Figure 3.7D, pulses are identically sent to the nodes (yes, all the multiples of 3), each producing a transition to the next limit cycle down the chain, analogous to the mechanism observed in the previous two counters, where pulses contain no information about which attractor comes next, but the state of the network counts pulses.This difference is more clearly conceptualized in the cartoon above each type of stimulation (Fig. 3.7A vs Fig. 3.7B).
Robustness of dynamic attractor chain.
We performed similar robustness simulations for both kinds of stimulation types in the dynamic attractor chain as we did for the fixed point counters. That is, we ran simulations for several parameter pairs , and several percentages of noise in and . The results of these noise simulations are summarized in Figure 3.8.
Figure 3.8. Noisy dynamic attractors chain.

(A) Example of a noisy dynamic attractor chain network that performs well for specific stimulation of all multiple-of-three nodes. (B) Example of a noisy dynamic attractor chain network with 3 failures, global stimulation. (C) Example of a noisy dynamic attractor chain network with 4 failures, global stimulation. (D) Percentage of failed transitions for specific and global stimulation in the dynamic attractor chain network in 120 trials for several percentages of noise in and . (E) Different behaviors of the dynamic attractor chain for various pairs of , parameter values.
First, we analyze the performance under varying levels of noise. All the noise simulations were done with , . The robustness to noise of the dynamic attractor chain, in both types of stimulation, was calculated as in Section 3.1. Recall that this was done by computing the proportion of failed transitions among pulses in both fixed point counters. This was done by introducing varying percentages of noise into the input, varied every of a time unit, and into the connectivity matrix , as specified in the axes of Figure 3.8D. This time however, to accommodate the 6-pulse simulation, for 20 simulations per percentage of noise pair . As expected, our dynamic attractor chain is not nearly as robust as our CTLN counters of static attractors. Interestingly, global stimulation performed slightly better than specific stimulation in the presence of noise, but even this was barely robust at 5% noise. Nevertheless, although not very robust to noise, the dynamic attractor chain still performs well under a wide range of , , parameters, as seen in Figure 3.8E, where the red dot indicates that the attractor was qualitatively identical to the ones originally observed in Figure 3.7C,D.
By chaining together identical graphs, we have successfully constructed a network that steps through a set of dynamic attractors that were all repetitions of motifs of the same type, namely the 5-stars. Can we patch together a more diverse set of dynamic attractors in a single network, all accessible via initial conditions and/or pulses? In the next section, we present a toy model that requires coexistence of diverse dynamic attractors, where each attractor is accessible via targeted pulses. Later, we will put these networks together with a counter to step through a set of disparate dynamic attractors.
Chapter 4 | Central pattern generators
In the last chapter, we leveraged network symmetry to provide an example of a network that can support several coexistent dynamic attractors, all easily accessible via attractor-specific inputs, and also accessible in sequence. A natural neuroscience application of coexistent dynamic attractors, and the one we seek to model in this section, is pattern generation. Central Pattern Generators (CPGs) are networks of neurons that can generate rhythmic output in the absence of rhythmic driving input [51]. However, unlike the dynamic attractor chain of the previous section, CPGs may need to support many different types of dynamic patterns simultaneously. So, in addition to coexistence of dynamic attractors, we now also want diversity of said attractors, as schematized in Figure 4.1C.
Figure 4.1. Coexistent dynamic attractors.

Reproduction of Figure 1.1. The focus of this chapter is Panel C: Multiple dynamic attractors encoded in the same network, each one accessible via targeted (colored) inputs.
In this chapter we focus on CPGs that have been of interest in neuroscience for a long time, and recently in robotics: animal locomotion [21,22,51,57,71]. Quadruped locomotion is probably the most popular example of a CPG in neuroscience [21,32,41], and beyond [25,55]. Modeling the different modes of locomotion, called gaits, has been challenging because of the overlap in units controlling legs between different gaits. Most models overcome this difficulty by requiring changes in network parameters, such as synaptic weights [21,32], in order to transition between different gaits. In contrast, here we present a CTLN capable of reproducing five coexistent quadrupedal gaits (bound, pace, trot, walk and pronk). Gaits coexist as distinct limit cycle attractors in the network, without any change of parameters needed to access different gaits. Instead, different gaits are obtained from different initial conditions, or by -stimulation of a specific neuron involved in the gait. Also, where most models for locomotion use oscillating units, the oscillatory behavior we obtain is a result of connectivity alone, since none of our units are intrinsically oscillating.
Although several types of architectures have been proposed to model distinct CPGs (recurrent neural network based, half-center oscillator based and abstract oscillator based CPGs) [22], coexistence of different attractors in the same circuit (as would be needed to model different modes of locomotion, controlled by the same set of neurons) has been challenging to many models. In this chapter we leverage cyclic unions (Thm. 11, Ch. 2), to present two different locomotion CPGs where patterns arise as attractors, and are thus very robust to noise and perturbations: a network that supports five different quadrupedal gaits and molluskan hunting mechanism.
4.1. Cyclic unions as pattern generators
Recall from Chapter 2 that for cyclic unions (reproduced in Fig. 4.2A), the neural activity flows through the components in cyclic order. Thus, cyclic unions are particularly well suited to model networks that must follow a sequential activation of the nodes, like CPGs, because attractors themselves will follow the direction of the cyclic union. This is true for other, less constricted architectures. These are the subject of [59], some of whose results are work of my own and thus presented in Chapter 6.
Figure 4.2. Cyclic unions as pattern generators.

(A) Cyclic unions, and Theorem 11. (B) Example of a cyclic union giving rise to sequential activation of the nodes.
Recall also from Theorem 11 in Chapter 2 that the core motifs of the cyclic unions are made up of core motifs coming from each component and thus cyclic union of core motifs is core. For instance, in Figure 4.2B, we have an example of a cyclic union of four core motifs: two 2-cliques ({1,2}, {4,5}) and two single nodes ({3}, {6}). The set of the whole graph is made up of pieces taken from each , colored-coded by component. Because all components were core motifs, the whole graph is now core motif, as seen by its in Figure 4.2B. The activity of the network, pictured below its set, follows the direction of the cyclic union. Note that neurons 1 and 2 are synchronized, neurons 5 and 4 are synchronized, and then there is a successively cycling through these pairs, half a period apart.
As mentioned earlier, not only cyclic unions yield sequential attractors, as seen in Figure 4.3: both the graphs at the top of the figure are examples of cyclic unions with three components, and the activity for these networks traverses the components in cyclic order. Compare these with the the bottom graphs of the figure, which do not have a perfect cyclic union structure (each graph has some added back edges or dropped forward edges highlighted in magenta), but have very similar dynamics to the ones above them. Despite the deviations from the cyclic union architecture, these graphs still produce sequential dynamics.
Figure 4.3. Cyclic unions and generalizations.

(C1,D1) Cyclic unions with firing rate plots showing solutions to the corresponding CTLN. (C2,D2) These graphs are all variations on the cyclic unions above them, with some edges added or dropped (in magenta). Solutions of the bottom CLTNs qualitatively match the solutions of top CTLNs. Modified from [59].
4.2. Quadruped gaits
In this section we present a CTLN capable of reproducing five coexistent quadrupedal gaits: bound, pace, trot, walk and pronk. Figure 4.4 shows how the gaits are characterized by their relative phases. For example, the bound gait is characterized by having both front legs synchronized, both back legs synchronized, and then successively cycling through these pairs, half a period apart. This is why back legs have a relative phase of 0, and front legs both have a relative phase of 0.5. The rest of the gaits in Figure 4.4 are read similarly. Yes, pronk is a little all-legs jump. Gazelles do it.
Figure 4.4. Gait phase relations.

Diagram showing the relative phases of the limbs for each gait considered here. Modified from [2,8].
We begin by modeling each one of these on its own, using cyclic unions, as foreshadowed by the example of Figure 4.2B.
4.2.1. Construction of gaits
Single gaits
In the example of Figure 4.2B, we actually constructed the bound gait: two pairs of nodes are synchronized, half a period apart. There, we did it using only six nodes. In what follows, we aim to glue several gaits together, so it is not convenient to have such a small number of nodes per gait (very few nodes with a lot of edges will form cliques, which yield stable fixed points, which we do not want for gaits), since adding new gaits will results in more and more connections between leg nodes and this would make everything collapse into a giant clique, resulting in a stable fixed point. This is why we now propose a slightly different construction for bound, and other gaits, by adding a few extra auxiliary neurons to overcome this issue.
To re-model the bound gait, we replace the old 2-clique components by a square made up of four 2-cliques, like that of Figure 4.5C. Why? The of such a square is given by all the individual 2-cliques composing its sides, as seen in Figure 4.5C. And since cyclic unions will grab a piece from every component, we are sure that a given pair of legs will still be part of some core motif of the network. More precisely: since the bound gait is characterized by having both front legs synchronized, both back legs synchronized, and then successively cycling through these pairs, half a period apart, as in Figure 4.6A, it is natural to group front legs in a single component and back legs in a single component, and to connect them through two auxiliary 1-node components.
Figure 4.5. Building blocks.

(A) An isolated node. (B) A 3-clique. (C) A “square” made out of 2-cliques. Only A and B are core motifs.
Figure 4.6. Design of two different quadrupedal gaits.

Colored circles represent node-leg assignment. Shading groups nodes in the same component. Thick colored arrows represent edges from/to all nodes in a single component. Nodes 1 through 4 control the legs (LB, LF, RF, RB). The first four rows of the greyscale, squared in pink and reproduced vertically, show the activity of the legs. (A) Souslik’s bound. Pictured modified from [25]. (B) Bound network and its corresponding CTLN solution. Nodes 5 to 10 are auxiliary nodes.The network was initialized at x9(0) = 0.1 and all other neurons at 0. (C) Horse’s walk. Pictured modified from [25]. (D) Walk network and its corresponding CTLN solution. Nodes 5 to 16 are auxiliary nodes. The network was initialized at x14(0) = 0.1 and all other neurons at 0.
To achieve this, we split the nodes into four components, as shown Figure 4.6B. The resulting components are , , , and . Theorem 11 now says that the set of the bound gait of Figure 4.6B is obtained by selecting a support from each component and forming their union: , where and . This will include, among others, the support corresponding to the bound gait attractor seen in the rate curves of Figure 4.6B. It is because we made sure to built-in the support that we can easily see and access the attractor reproducing the bound gait.
A slightly different construction consists of the gait walk, where legs move cyclically with a quarter period difference, as seen in Figure 4.6C. In the same manner, we use Theorem 11 to group each leg in a component along with its auxiliary neurons and add four auxiliary neurons to ensure that the phase between legs is a quarter period apart (Figure 4.6D). The building block for the leg components is now the 3-clique of Figure 4.5B. Since the building block is a core motif, the of the walk gait consists of a single element, formed by taking a core motif from each component in Figure 4.6D, resulting in . This core motif promises to give rise to the attractor reproducing the walk gait. Indeed, the resulting dynamics of this network are depicted in Figure 4.6D, and the network once again behaves as expected, reproducing the walk gait. The matrix and parameters needed to reproduce these simulations, and other individual gaits, are available in Appendix A, Equations A.4 to A.8.
Other individual gaits can be similarly constructed, as shown in Figure 4.7A. In pace, left legs are synchronized, right legs are synchronized, half a period apart, and so we group neurons into appropriate components, in the same way we did bound. Similarly with trot, where diagonal legs are synchronized, half a period apart. The core motifs of pace and trot are similarly derived, using the “square” building block of Figure 4.5C, along with Theorem 11. The last gait our model will include is pronk, where all legs are synchronized, requiring now a single component to group all legs together along with a pair of auxiliary nodes that control the frequency of the pronking movement.
Figure 4.7.

(A) Graphs for individually constructed gaits. (B) Solution for isolated gaits. (C) Solution for embedded gaits. (D) Induced subgraphs of embedded gaits. (E) Solution for subgraphs of embedded gaits. (F) Five-gait network. (G) Gait transitions via -pulses.
Note that all gaits have been constructed as a cyclic union of the three basic building blocks of Figure 4.5: a “square” made out of 2-cliques, a 3-clique and an isolated node. From these pieces, and by Theorem 11, the set for each gait can be readily obtained as we did with bound: by selecting a support from each component and forming their union . For a detailed analysis of the sets see Tables A.2 and A.3 in Appendix A.
Since each gait was constructed to have include the leg nodes, along with the appropriate auxiliary nodes, we expect the graphs of Figure 4.7A to give rise to a CLTN that reproduces these gaits. Indeed, in Figure 4.7B we have simulated the individually constructed gait networks. As expected, we see an attractor reproducing the respective gait. Initial conditions are plotted to the right of each greyscale, and were chosen to have all neurons off, except one colored auxiliary neuron on.
Matrices and parameters needed to reproduce the simulations of Figure 4.7 are available in Appendix A.
Now, can we make these attractors we are seeing here coexist into a single network, with leg nodes overlapping? Said differently, can we glue together (in topology sense) the networks in Figure 4.7A by leg nodes, and other shared nodes? As we will see below, the answer is yes.
4.2.2. Coexistent gaits
To construct the five-gait network, we glued together the networks in Figure 4.7A by identifying common neurons (1 through 6) and induced edges between them. Figure 4.7F shows the resulting glued network. More precisely, this gluing identifies all nodes from 1 to 6 coming from each isolated gait into a single one in the glued network. This operation does not exactly correspond to any graph operation, and it is more like a gluing in a topological way, where the gluing instructions are given by the vertex numbers and the edges between them.
As mentioned before, the inclusion of several auxiliary nodes was necessary to merge the five networks into a single one. Indeed, nodes 1 to 4 are shared by all gaits and represent the leg assignment (1. LB - left back, 2. LF - left front, 3. RF - right front, 4. RB - right back), but nodes 5 to 8 are shared by bound, pace and trot, while not representing any leg assignment. The rest of the nodes are gait-specific, meaning that they are uniquely associated to a single gait and therefore only active when such gait is active, and off otherwise. These nodes play the very important roles of keeping the phase between foot steps in each gait and activating a specific gait by stimulating one of them. These nodes are: nodes 9 to 12 which are there to augment the walk cliques, and so they are specific to walk; and nodes 13 to 23 which are specific to a unique gait, as color coded in Figure 4.7A.
Although the complex structure of the merged network makes it hard to analytically derive the , we found computationally that (again, coming from up to 224 linear systems), and
| (4.1) |
Although sadly none of the core motifs in Equation 4.1 there correspond to the gait attractors, in Figure 4.7C it can be seen that all gaits are actually preserved when embedded in the big network with all gaits, as the dynamics of each gait when embedded in the glued network are indeed remarkably the same as when isolated (cf. panel B). The greyscale and rate curves for each gait embedded within the glued network are plotted in the same column as its corresponding graph in Figure 4.7A. Also, it is important to note that even though the isolated gait networks (Fig. 4.7A) are not the same as the induced gait networks (Fig. 4.7D), they support the same (qualitatively) attractor, as seen in the rate curves of Figure 4.7E.
To see that each gait is accessible via different initial conditions when embedded in the five-gait network, notice in Figure 4.7B that when all neurons, but neuron 13, are initialized to zero, the system evolves into the bound gait. This is because neuron 13 corresponds uniquely to bound. Similarly, when the network is initialized in neuron 15, it goes into pace. When it is initialized in neuron 17, it goes into trot. And so on. Recall that walk has two different sets of gait-specific neurons (9 – 12 and 19 – 22), and both kinds will send the network into the walk gait. Hence, our five-gait network successfully encodes these coexistent dynamic attractors, each accessible via initial conditions, that have several overlapping active nodes (nodes 1 to 8), with no interference between attractors. Moreover, the attractors are not overly sensitive to the value of initial conditions, as long as the highest firing neuron in the initial condition is the one associated with the desired gait.
In particular, since all gaits coexist as distinct limit cycle attractors in the network, each accessible via different initial conditions, it is also possible to smoothly transition between gaits by means of a gait-specific external pulse . To effectively change gaits, it suffices to stimulate a the appropriate gait-specific auxiliary neuron with a pulse. The network quickly settles into the dynamic attractor corresponding to the gait of the auxiliary neuron stimulated, as seen in Figure 4.7G. There, pulses of 2 time units are sequentially sent to neurons 17,19,15,13,23 and 17, producing the expected transitions between gaits. The network smoothly transitions to the corresponding gait. The order in which neurons are stimulated does not matter, any sequence of pulses sent to gait-specific auxiliary neurons will produce the respective transitions, regardless of which gait comes before or after.
However, not all gaits are created equal, and this becomes evident in some transitions. From the construction of the graph we suspect that bound, pace and trot are on equal footing, since they were created analogously, only differing by which pairs of legs are synchronized. Consequently, we expect some symmetry in their basins of attraction, so that transitioning to and from these gaits is easier, and this has been indeed observed in simulations. By contrast, we have observed that walk and pronk (both at the boundary of how many legs can be synchronized with 1 leg and 4 legs respectively) seem to have a bigger basins of attraction, since the network requires a higher stimuli to transition out of these two gaits. All in all, this network provides a straightforward mechanism to switch between the desired attractors, fulfilling our initial goal of controlling coexistent dynamic attractors in a single network.
4.2.3. Parameter analyses
Good parameters.
A common drawback in many models is that sometimes they require very fine-tuned values of their parameters to perform as expected. Also since dynamic attractors are known to be less robust than fixed point attractors, it makes sense to assess the robustness of the network in Figure 4.7F. Individual gaits were designed as a cyclic union (Thm. 11) of building blocks (Fig. 4.5) whose is parameter independent [15], meaning that its set is preserved across the legal range of parameters . Since cyclic unions of parameter independent components are also parameter independent, all isolated gaits are parameter independent as well. Indeed, it is a simple consequence of Theorem 11:
Corollary 1.
Let be a cyclic union of component subgraphs . Then is parameter independent if and only if is parameter independent for all .
Proof. Suppose for all , , in the legal range. By Theorem 11, for all , , in the legal range and all , meaning that is also parameter independent. The other implication is analogous. □
This implies that the set does not vary with parameter changes within the legal range, and so we can expect the gait attractors to be present in each individual gait network for a wide range of parameter values, so each gait, isolated, turns out to be very robust! The same unfortunately cannot be said about the glued five-gait network, since it is not truly a cyclic union, but rather a gluing of cyclic unions, for which we do not have theoretical results yet. So, how sensitive is our network to the choice of , , parameters? Are the five attractors still present, and easily accessible, if we vary our parameter values?
To answer this question, we tried to reproduce the simulations of Figure 4.7C using different , , parameters. First, we observed how the attractor corresponding to each gait behaved under several values of , in the five-gait network. We found that there were three different possibilities: either the attractor is preserved, meaning that it is identical in qualitative behavior to the attractors in Figure 4.7C (up to a change in amplitude or period); corrupted, indicating that the auxiliary neurons corresponding uniquely to that gait are still active and firing cyclically, but the leg nodes have lost its symmetry; or lost, when the auxiliary neurons corresponding uniquely to that gait are not firing cyclically (this usually translated into a gait becoming a different attractor, which could either be another gait, a stable fixed point or a chaotic-looking attractor).
An example of each of these outcomes is exemplified in Figure 4.8A, where only the last 200 time units of the simulation are shown, for clarity. In the left example, the network was initialized to the bound gait, and the gait is perfectly preserved. In the middle plot, the network was initialized to the pronk gait, and even though the auxiliary neurons corresponding to pronk are still active, the leg neurons lost their symmetry towards the end. In the right plot, the network was initialized to the trot gait, but near the end of the simulation the network settles into a corrupted form of pronk, as indicated by the auxiliary neurons of pronk being active. The results of all those simulations are summarized in Figure 4.8B. Green denotes preserved attractor, yellow denotes corrupted attractor and red denotes lost attractor. The intersection of the green dotted regions is the range in which all gaits are preserved: , , for at least the first 500 units of time. These are the “good parameters”.
Figure 4.8. Gaits survival under several values of , , .

All plots were generated with a running time of 500 time units. (A) Three examples of what can happen to an attractor under three different parameter values. (B) Gaits are classified according to whether the attractors are either preserved (green dots), corrupted (yellow dots) or lost to a different attractor (red dots) when , vary. All the dots were generated using fixed. (C) Two examples of what can happen to an attractor under two different parameter values. (D) Gaits are classified according to whether the attractors are either preserved (green dots), corrupted (yellow dots) or lost to a different attractor (red dots) when varies. All the dots were generated using and .
We then did the same thing but varying the parameter only. Figure 4.8C shows examples of what can happen in this case. In the first example, the network was initialized to the walk gait, and the gait is perfectly preserved. In the right example, on the other hand, the network was initialized to the pace gait, but immediately went into pronk. Figure 4.8D shows the same summary of results, but carried out for constant values , , and varying . These values were arbitrarily chosen from the , good parameters from above.
In conclusion, we have computationally found that all the attractors corresponding to the five gaits in our network are preserved for all , and , for at least 500 units of time. Having a range of parameters available raises the question: what part do they play in modulating the non-qualitative characteristics of our gaits such as period and amplitude? These are important questions because period and amplitude in firing rates affect muscle tension [1,75].
Parameter modulation.
In this section, we compute the period and amplitude, of each gait within the five-gait network, using the good parameters from above. To do so, we ran a single simulation for time units and then we used the MATLAB function findpeaks to find the location and value of the peaks of a single rate curve. Examples of this can be seen in Figure 4.9I. The black bars in the rate curves show the amplitude, and the black triangles mark the time of the peaks, both calculated using only the first leg . We found these peaks only during the last half of the simulation to avoid taking into account the time before settling into the attractor. To find the periods we subtracted all the consecutive peak locations. We had to get rid of the first and last period and amplitude data point because they became corrupted by chopping the curve. Then we averaged the periods and peak values to obtain a single period and a single amplitude per simulation. This is the value shown in Figures 4.9A-H.
Figure 4.9. Amplitude and period of the gaits in the five-gait network.

Values of period and amplitude for a (0.05,0.23) × (0.2,0.6) grid of values and all gaits. (A) Period values. The data points for bound, pace and trot are superimposed. (B) Cross section of plot in panel A corresponding to . (C) Cross section of plot in panel A corresponding to . (D) Amplitude values. The data points for bound, pace and trot are superimposed. (E) Cross section of plot in panel D corresponding to . (F) Cross section of plot in panel D corresponding to . (G) Values of period for the cross sections in panels B and C (, ) and varying values of . (H) Values of amplitude for the cross sections in panels E and and varying values of . (I) Three examples of how period and amplitude were computed.
There, each point corresponds to a single simulation. The color of the point corresponds to a given gait, as specified in the label of Figure 4.9A. Note that, since bound, pace and trot have virtually the same structure, the data point for these are overlapped in Figures 4.9A-H. We also show crossections for Figures 4.9A,D. The blue shaded corner of the 3-dimensional plots corresponds to values outside the legal range. In Figures 4.9A-F we are varying only and , with a fixed value of . In Figures 4.9G-H, we use the fixed values of , in the slices above to vary the value of .
Notice that for fixed values of , , , period decreases with and ; whereas amplitude increases for walk, and decreases for all other gaits. Period is seen to be invariant to changes, and amplitude increases with increasing values of . It is known that an increased firing rate produces an increase in muscle tension by summation of more frequent successive motor contractions [1,75]. This implies that in our model, period would correspond to how fast/slow muscles contract and relax (bigger period means muscles contract and relax faster). Period therefore is controlling how fast the movement is executed, that is, the speed of the gait. Amplitude of firing rate corresponds to tension in muscle, because the more action potentials, the more muscle units are activated.
Great. But while we have showed that there is a fairly wide range of parameters under which our network behaves as expected, and where we can module the properties of the firing rates, there is still the assumption that all synaptic connections are perfect and identical: either or . Is our network robust to noise in the synapses? What about the inputs? Are transitions still possible in the light of noisy connections?
4.2.4. Robustness to noise
To explore these questions, we added uniform noise to and and computationally tested whether the attractor was lost. A gait is said to be lost when the attractor corresponding to said gait degenerates into a different attractor, which is clear from which auxiliary neurons are active. We did not measure if the attractor was corrupt or not, because any amount of noise will break the symmetry of the legs. This was done in the same way as we did in Chapter 3. We ran a single noisy simulation and observed if the attractor was lost or not. Examples of the behaviors we observed can be found in Figure 4.10A-C. In A, the networks was initialized to trot, but it chaotically jumps between different attractors, until it settles to pronk. In B, the network was initialized to walk, and it remains there, as good as it can. This means, the legs lost their symmetry, but the high-firing neurons are the same as in walk, in the same order. This classifies as not lost in our analysis. In C, we observe the same situation but with pronk. Here, the asymmetry of the legs is more notable. These are wobbly gaits.
Figure 4.10. Percentage of lost gaits in noisy five-gait networks.

(A) Example of lost trot. (B) Example of a very noisy network, where walk is not lost, but it is corrupt. (C) Example of a very noisy network, where pronk is not lost, but it is corrupt. (D) Percentage of lost gaits in 10 trials, for several percentages of noise in and . (E) Examples of noisy transitions.
Figure 4.10D summarizes our findings. We simulated each gait 10 times, and then calculated the percentage of lost gaits in those 10 trials, for varying percentages of noise in and . The color of the pixel in Figure 4.10D represents the percentage of lost gaits out of these 10 trials. A trial corresponds to a single noisy pair , which was used to test all gaits once. All simulations used to quantify the failures were done with , and -noise with .
In around 90% of trials, gaits were not lost at 2% noisy and , indicating that that the perfect binary synapses of CTLNs are not necessary for this network to produce the desired gaits, but bigger levels of noise will break the network’s performance anyway. Interestingly, at bigger levels of noise, the gaits were lost most commonly to pronk, again. Pronk also happens to be one of the two most robust gaits (see pronk in Figure 4.10D). This supports our suspicion that pronk’s basin of attraction is bigger. It is also evident again the way in which the construction of the first three gaits differs from the last two gaits. This raises the question of what would happen to the robustness of the network if there was no pronk or walk, so that the network is perfectly symmetric.
Finally, we also tested the ability of the network to transition under 1% and 5% noise in , as shown in Figure 4.10E. Transitions are robust at 1% added noise, but past 5% gaits are commonly lost to pronk and thus transitions are not successful.
4.3. Molluskan hunting
A dynamically different example of a CPG is Clione’s hunting mechanism. Clione is a marine mollusk without a visual system, so when it chemically senses its prey, it must explore its surroundings by swimming in its vicinity until it finds it. The direction of swimming is controlled by Clione’s tail, which receives input from Clione’s gravitational sensory organs, the statocyst. The statocyst is covered by mechanoreceptors that receive inputs from the statolith, a stone-like structure moving inside the statocyst under the effect of gravity [58].
The model we propose here is inspired by the model in [71]. There, the authors propose a six-neuron model, with Lotka-Volterra-type units and inhibitory non-symmetric connections. This fosters competition and lead to a state of winnerless competition, where no single neuron dominates the activity. This in turns result in complex spatiotemporal patterns that mimic random changes in direction in the gravitational field. These patterns drive the unpredictable and random-like hunting behavior observed in Clione.
In that model, each node represents a receptor neuron in the gravity sensory organ, the statocyst. These receptor neurons are part of the sensory network that processes information related to the body’s position relative to the gravitational field and are influenced by the central hunting neuron during hunting behavior in Clione. Here we propose a very similar model, also consisting of six-units, connected via inhibitory non-symmetric connections. However, our units are not intrinsic oscillators, and so the mechanism of pattern generation in our case arises purely from connectivity.
Recall that cyclic unions are particularly well-suited to model CPGs, so here we construct our network as a cyclic union of three components: each component is an independent set of opposing directions, as shown in Figure 4.11A. This will create competition between opposing directions, and force the choice among them (thus avoiding invalid combinations where two opposing directions are simultaneously high-firing). This should result in the 8 possible combinations of directions in 3-dimensional space (up/down, right/left, front/back), as shown in Figure 4.11B.
Figure 4.11. Clione’s hunting mechanism.

(A) Clione’s network as a cyclic union and as an octahedron. (B) All possible swimming directions in 3-dimensional space, each one corresponding to an attractor as labeled. (C) CTLN solution for Clione’s network. Attractor-specific pulses are sent to the network. Often producing a change in the attractor, labeled at the top.
Each neuron represents swimming in a given direction: up, down, right, left, front, and back. Any valid combination of these three directions will uniquely define a direction in 3-dim space in which Clione will find itself swimming. All possible swimming directions will then correspond to the eight octants of 3-dimensional space, as illustrated in Figure 4.11B. Antagonist directions are colored in the same color with different shades. A more intuitive view of the network is given by the octahedral shape in Figure 4.11A, hence we also sometimes refer to this network as “octahedral network”.
Since our network is a cyclic union of independent sets, the computation of core motifs becomes straightforward. By Theorem 11, the core motifs are obtained by choosing a core motif from each component. The core motifs of an independent set are each singleton node [15, Rule 3]. This results in the following core motifs:
| (4.2) |
which correspond to the 8 possible swimming directions, as expected. Computationally, we also found that , as expected from Theorem 11, as well.
Simulations show that each core motif in Equation 4.2 corresponds to an attractor, and that each attractor is accessible via initial conditions, as shown in the simulations of Figure 4.11. In addition, as in the five-gait network, it is possible for the octahedral network to transition between attractors by sending a -pulse to the direction we want to switch to. For example, in Figure 4.11C, the network was was initialized in the attractor corresponding to up-right-back, and even though a first pulse fails to transition the network, the second pulse, sent to neuron 2 (left) changes the attractor in this single direction, that is from up-right-back to up-left-back. We observe that subsequent pulses do produce the desired effect of transitioning a single direction. The matrix and parameters needed to reproduce the simulations of Figure 4.11 are available in Appendix A, Equation A.10.
But why is it that the first pulse failed to make the network transition attractors? Figure 4.12 offers some insights. Note that in Figure 4.12B, neuron 2 (left) received a pulse, thereby sending the network into the down-left-back attractor, as wanted and expected. However in Figure 4.11C, a pulse was sent to switch from up to down, and nothing really happened.
Figure 4.12. Clione’s basins of attraction.

(A) Reproduction of Clione’s network. (B) Effective pulse transition. (C) Ineffective pulse transition.
Looking closely, we observe that in D, the dark green rate curve surpasses the light green rate curve, and the transition is successful. In E, by contrast, the dark blue rate curve was very close to surpassing the light blue rate curve, however, at the end of the pulse the dark rate curve was still below the light blue curve, so the transition fails. It can be proven that this is a general phenomenon: the network will transition attractors into an opposing direction only if the neuron that received the pulse “wins” at end of the pulse.
4.3.1. Analysis of basins of attraction
Indeed, the next theorem shows that the network will change from direction to direction at time only if , for , opposite directions. To formalize the opposite directions notation we introduce a permutation that prescribes which nodes are opposite. We then have:
Theorem 12.
Let denote the core-motifs of the octahedral network ( above) and suppose there exists an attractor of the octahedral network, corresponding to one of the core motifs , and that there are no attractors that do not correspond to a core motif. Then there are exactly 8 attractors, one for each core motif, and their respective basins of attraction are contained in the sets
| (4.3) |
where .
Proof. Note that the octahedral network is symmetric under the following permutations in S6:
so that . Therefore the group of symmetries of the network is . As a consequence of these symmetries, the existence of an attractor corresponding to a core motif implies the existence of all other attractors corresponding to the rest of the core motifs in . Since there are no other attractors by assumption, the state space must be partitioned into exactly eight symmetric basins of attraction .
On the other hand, since and receive input from the same neurons (for ), it is impossible to cross the hyperplanes , as we show next. Suppose that for some . The dynamic equations for neurons and are
Both summation terms are the same, since and receive input from the same neurons. Since by assumption, we have that , and therefore for all . This proves that it is impossible to cross the hyperplanes . This implies that the sets
are forward-invariant and also partition the state space into eight sets. Since the basins of attraction are also forward-invariant and partition the state space into eight sets, we get the desired result. □
This theorem says that, under some reasonable assumptions, the basins of attraction partition state space symmetrically, a direct consequence of the symmetry of the graph. A notable consequence of the theorem is that the transitions depend on the intensity and duration of the pulse and in turn, of the timing of the pulse arrival. This would partially explain the observed randomness in direction switching of Clione. If Clione receives an external signal (from a prey encounter, for instance), then this signal must arrive at the right time and have the right duration and strength for Clione to change directions. This introduces a great amount of randomness into the system, because several conditions must align for Clione to effectively change directions.
Chapter 5 | Sequential control of dynamic attractors
Let us recall the path that brought us here, as re-told by Figure 5.1. Networks that support many stable fixed point attractors, each accessible via attractor-specific inputs, as in Figure 5.1A, have been around for a while. In Chapter 3, Section 3.1, we built two networks that internally encode a sequences of fixed point attractors, each accessible via identical inputs, as in Fig. 5.1B. In the same chapter, in Section 3.2, we also presented a network supporting several dynamic attractors, each accessible via both targeted and identical inputs, as in Fig. 5.1B,C. Those attractors were all of the same type, and so in Chapter 4 we gave an example model of a neural function that required coexistence and accessibility of several different dynamic attractors, also as in Fig. 5.1C.
Figure 5.1. Coexistent dynamic attractors.

Reproduction of Figure 1.1. The focus of this chapter is Panel D: Internally encoded sequence of dynamic attractors, each step of the sequence accessible via identical inputs.
Now, in this chapter, motivated by the hierarchical complex motor control of biological brains [66], we aim to combine Figs. 5.1B and 5.1C to obtain Fig. 5.1D, but whose attractors can be flexibly recombined. A key difference between Fig. 5.1D as done in Chapter 3, and the network we build in this chapter, is that in the dynamic attractor chain network of Fig. 3.7D, the order of the sequence was built into the network, meaning we could reorder attractors arbitrarily, and each new element of the sequence required storing the same pattern in the network again in the form of an extra motif.
By contrast, the construction we propose here encodes the order of the sequence in a network separate from that supporting the dynamic attractors that will be the sequence elements. This very akin to how birds and humans sequence complex movements [50,78]. This approach has many advantages, among which we have the capacity to recombine attractors in any order and that to add an attractor we do not need to make a whole new copy of it and embedded into the network.
The general construction of such a network, illustrated in Figure 5.2, goes as follows: the CTLN fixed point counter network from Chapter 3 will encode the order of the sequence. A separate network will encode the dynamic attractors that are to be the elements of the sequence. In Figure 5.2 we see this as several coexistent (dynamic) attractors, each one accessed via global -pulses sent to the CTLN counter network (shaded in gray). We represent these global pulses by a hand pushing a button in Figure 5.2. Each pulse activates the next clique down the chain, which will activate a different attractor in the network above, as prescribed by the orange arrows. With this construction, the order of the sequence is encoded in the orange connections, separately from the attractors themselves. Notice that the only difference between panels A and B are the orange arrows, and each wiring will result in two different sequences, whose elements are the same, but accessed in different order.
Figure 5.2. Flexible sequencing of dynamic attractors.

(A) Schematic of sequential control when the attractors are encoded independently from sequential order information. (B) A different sequence encoded in the same structure. Note that the only difference between sequences I and II are the orange arrows.
To give a proof of concept of this idea, we illustrate the construction using both networks from Chapter 4 as our networks encoding the dynamic attractors that are to be the sequence elements.
5.1. Sequences of quadruped gaits
In this section, we apply the construction outlined in the previous paragraph by using our five-gait network from Section 4.2 as the network supporting the attractors will be the sequence elements. The resulting network, consisting of less than 50 units, is shown in Figure 5.3A. The network is composed of three layers: L1, the unsigned CTLN counter from Section 3.1, with as many cliques as sequence steps. L2, a intermediate layer with one node per attractor in the sequence. And L3, the five-gait network of Section 4.2, encoding the set of dynamic attractors that are the elements of the sequence.
Figure 5.3. Sequential control of quadruped gaits.

(A) Layered network for sequential control. (B) Greyscale, pulses and rate curves for layered network of panel A. (C) matrix for the network in panel A.
Layers are connected in such a way that each node in L2 is connected to a node in L3 activating one of the sequence elements; and the connections from L1 to L2 determine the order in which each attractor in L3 will be accessed. The shaded squares in L1 indicate that all the shaded nodes send edges, which are drawn as a single thick arrow stemming from the shaded region. Each of these layers, and the connections between them, play an important role, as described below:
L1 in Figure 5.3A, the counter network layer, advances the sequence upon reception of each input pulse. Recall that when the neurons in the counter receive a uniform input pulse, the activity slides to the next stable fixed point in the chain, thus advancing the sequence one step by activation of the next clique. This shift in activity is effectively communicated as a pulse to the intermediate layer L2.
L2 in Figure 5.3A, because each of its nodes is connected to a single clique from L1, is sort of summarizing the input from L1 to communicate it to L3. This “summary” of activity will prevent L1, and its high firing rates, to interfere with L3, and its attractors. Neurons in this layer must also receive a pulse simultaneously with L1 to successfully advance the sequence, but not as strong.
L3’s job is to support the dynamic attractors. Recall that each of these can be accessed via -stimulation of a specific neuron uniquely associated with each gait. This fact is precisely what makes this construction possible. Otherwise it would not be possible for L2 to select a specific attractor in L3 by communicating the “pulses” coming from L1 to the specific neuron associated with the desired attractor. In the five-gait network, these are the auxiliary nodes corresponding to different gaits, which are redrawn at the bottom of L1 for clarity in Figure 5.3A (nodes 32,34,36,38,42).
Finally, connections between L1 and L2 is where the order of the sequence is encoded: the order in which the nodes in L1 connect to the nodes in L2 will dictate the order in which the attractors are accessed. In Figure 5.3A, for instance, the cliques connect to L2, in such a way that nodes in L2 activate the auxiliary nodes of L3 corresponding to pace (34), bound (32), pronk (42), trot (36), walk (38), pronk (42), and trot (36), and so the sequence will be executed in that exact order.
The formal layering scheme is prescribed by the matrix in Figure 5.3C, and formalized in the next section. This matrix, along with Equations 2.2 and pulses in Figure 5.3B, is what we used to simulate the dynamics. The dynamics behave as we hoped when we first put together the layering scheme in our imaginations, as seen in Figure 5.3C, and as described below:
The first plot shows the greyscale of all neurons. Below the greyscale, the pulses that L1 and L2 receive are pictured, colored by layered. L1, pictured in blue, has a baseline of b = 1 and a pulse b = 6. L2’s pulse, colored in red has a baseline b = 0 and a pulse b = 12, double that of L1. The idea behind having a 0 baseline, is that neurons in L2, the only ones connecting to L3, will die out and won’t interfere with the dynamics of L3 for long. Finally, L3 has b = 1 constant, so this layer is not receiving external pulses at all. Instead, external pulses are sent to all neurons in layers L2 and L3, as opposed to specific neurons controlling each gait (as in Ch. 4). This means that the sequence is fully encoded within the network, and the pulse themselves carry no information about what the next step is. The “pulses” that L3 is receiving from L2 are attractor-specific, even though the pulses sent to the network are not.
All of these predictions about the behavior can be clearly seen in the rate curves of Figure 5.3B. Since the baseline b is zero for neurons in L2, the rate curves of L2 nodes show peaks only at pulse times, but otherwise neurons die off. We also observe the dynamics of L1, remarkably the same as in 3.1; each pulse moves L1 one step to the right, activating the next sequence element, L2 communicates this transition to L3. The sequence of gaits can be read off from the rate curves of the leg nodes, as labeled above the greyscale, and it is exactly the same sequence encoded in the connection from L1 to L2. Transitions seem as effective as sending specific pulses to the five-gait network on its own, as in Section 4.2. Note that the color of the rate curves of L1 and L2 match those of the auxiliary neurons on Figure 5.3A. The matrix needed to reproduce the simulation of Figure 5.3B is available in Appendix A, Equation A.11.
As L2 effectively acts as transient pulses to L3, it seems like all it takes to make this construction possible is to have the attractors in L3 be easily accessible via targeted pulses. If that is the case, can we generalize this architecture to other CPGs? As we will see below, the answers is yes, at least for the CPG all the CPGs we presented in Chapter 4.
5.2. Sequences of molluskan hunting
Here, we offer a proof of concept by using the molluskan hunting network of Section 4.3. Since all attractors of the molluskan hunting network are accessible via changes in initial conditions, or targeted (long or strong) -pulses, we are able to use an analogous construction to internally encode a sequence of its attractors.
Indeed, in Figure 5.4A we layered our octahedral network with the same L1 and L2 layers from last section to obtain a network that can encode sequences of attractors in Clione’s swimming direction. We have prescribed the order of the attractors (orange arrows from L1 to L2) in such a way that a transition is always required, so that it is clearly seen that transitions are indeed taking place.
Figure 5.4. Sequential control of swimming directions.

(A) Layered network for sequential control. (B) Greyscale, pulses and rate curves for layered network of panel A. (C) matrix for the network in panel A.
Again, network performs as in last section, as seen in Figure 5.4B. Attractors are labeled by the initials of up/down, left/right and front/back, as before, and it can be seen above the greyscale that they are accessed in the order prescribed by the orange arrows. Only the stimulated direction is making the switch. Also, in the rate curves it can be seen that there are no failed transitions, and this partly thanks to Theorem 12 as well; because now we can make sure to send pulses that are long/strong enough to make the transition happen. It is important here that other nodes in L2 are not overly active, because again by Theorem 12, it could mean that the wrong node is being stimulated. The matrix needed to reproduce the simulation of 5.4B is available in Appendix A, Equation A.11.
This second example shows that this construction is truly versatile, as long as attractors in L3 are easily accessible. This construction also comes with great advantages:
Sequential information is internally encoded.
Since our counter network from Section 3.1 sequentially steps through stable fixed points, we leveraged this sequence of fixed point activations to encode a sequence of pulses as wirings between layers that are to receive uniform pulses, and the CPG layer.
To transition CPG attractors, we simply send a uniform, non-specific pulse to all neurons in the counter layer (and cycle layer) so as to advance the counter, and therefore send a targeted pulse to the next gait down the chain.
This means that pulses are attractor-specific locally in the CPG layer, but not globally, as the counter and cycle layers are the ones encoding the sequential information, and they only require uniform, non-specific pulses. The sequence is therefore truly encoded within the network, and the pulse themselves carry no information about what the next step is. This fact contrasts with other models for sequential control where the information about the order of the sequence is not encoded in the network itself, and so it requires motif-specific inputs to activate each element in the sequence [48,49]. Having the sequence encoded within the network would be advantageous for highly stereotyped patterns, like songbird, choreographed dance or other sequential tasks that reuse motifs.
Sequential information is independently encoded from motor commands.
As mentioned before, the order of the sequence is encoded in the connections from L2 to L3, whereas the dynamic attractors are completely encoded within L3. This means that sequential information is independently encoded from motor commands and so to access an attractor multiple times in the sequence, it suffices to create a new connection from L2 to L3. In Figure 5.3C, for example, both pronk and trot are activated twice in the sequence, but there was no need to add a whole new set of neurons that are re-encoding pronk or trot. That is, we are re-using our attractors in an efficient and flexible manner. This is remarkable property of this construction, as dynamic attractors are usually very sensitive to any interference.
This also implies that to add a new element to the sequence, it is only necessary to add three extra neurons and a few connections between them (an extra 2-clique, one cycle node, and connect this to the appropriate neuron in the five-gait network). This greatly improves efficiency, since the repeated pattern does not have to be stored again, separately into the network. Also, new elements in the sequence do not do not interfere with other elements, controlled by the same network. This is because since the cycle neurons are active one at the time, the new inhibition stemming from the new sequence element will not affect the CPG dynamics whatsoever until the new neuron is active. When the new neuron is active, it will uniformly inhibit everyone in the CPG, except the aux neuron it is connected to. At pulse reception, when the new neuron is active, the jump in neural activity will simply act as pulse to transition the CPG into the appropriate gait. This model can thus generate all kinds of transitions, and the sequence can be as long as desired.
This mechanism is not unlike to how our brain represents complex sequences of movement [47,76]. Also, the structure of our model resembles very much they way in which songbird is encoded, where propagation of syllables is mediated by a synaptic chain of neurons [50]. Also, and although not anatomically separated, similar mechanisms of complex motor sequence generation have also been found in humans’ neocortex [78] and basal ganglia [33].
Timing and sequential information are independent.
Notice also that timing of the sequence is controlled by these external pulses and therefore a sequence’s execution can be sped up or slowed, or rhythm altered altogether, without interfering with attractors or sequence order. Moreover, there is no need to change synaptic time constants, physiological variables, to alter the timing of the sequence. This disassociation also implies efficiency. This is an important characteristic of sequential control in premotor cortex areas and serves, among others, the purpose of independently controlling the speed of movements from the order of execution [44]. Notice also that timing of the sequence is controlled by these external pulses and therefore a sequence’s execution can be sped up or slowed, or rhythm altered altogether, without interfering with attractors or sequence order.
Can this construction be generalized to other CPG networks? We conjecture that the five-gait network could potentially be replaced by any other network that has coexistent attractors, each accessible via changes in initial conditions or specific stimulation of neurons. The mechanism would be the same: the order of the sequence is determined by the connections from the cycle layer (L2) to the multi-attractor network, and any sequential ordering is possible, with as many sequence steps as desired.
From the matrices in Figures 5.3B, it can be seen that these networks are not CTLNs, but rather a TLN whose “layers” are CLTNs. Can we find theoretical grounds to support this seemingly generalizable construction? We should be able to leverage all those zeros!
Chapter 6 | New theoretical results
Why are the networks of Chapter 5 so neat? In this chapter, we provide theoretical explanations on why we see the “fusion attractors” of Chapter 5 arise so seamlessly. First, we introduce some technical background that will help us prove new theoretical results, along with some extra CTLN background theorems. Then, we present new CTLN results generalizing certain structures from [15] (these “certain structures” are reviewed in the technical background section). The new CTLN results are published in [59], and only my contributions to that paper are included here, with only small changes to the presentation. Finally, we generalize some of those results to TLNs. Since the new TLN results are generalizing the CTLN results, we have omitted the proofs for the following CTLN results: Lemma 20, Theorem 21, Lemma 30 and Theorem 31.
6.1. Technical background
A characterization of that we often use in the proofs that follow, developed in [15], relies on Cramer’s determinants. For any , define to be the relevant Cramer’s determinant:
| (6.1) |
where denotes the determinant obtained by replacing the column of with the vector and denotes the matrix obtained from the restricted matrix by replacing the column corresponding to the index with the restricted vector . Note that might ot might not be in , both are possible.
In [15, Lemma 2], a formula for was proven that directly connects it to the relevant quantity in the “off"-neuron condition:
| (6.2) |
Combining this with Cramer’s rule, it was shown that can be fully characterized in terms of the signs of the . It turns out these signs are also connected to the index of a fixed point. For each fixed point of a CTLN , labeled by its support , we define the index as
Since we assume our CTLNs are nondegenerate, and thus .
For each fixed point of a TLN labeled by its support , we define the def index as . In [15] it was shown that can be fully characterized in terms of the signs of the , which are also connected to the index of the fixed point. This is the tool we use constantly in this chapter to prove that some support belongs to , so it is worth keeping in mind:
Theorem 13 (sign conditions, [15]).
Let be a TLN on n neurons. For any nonempty ,
In that case we say that is permitted (and forbidden otherwise), and for all . Furthermore,
Also recall from Chapter 2:
Corollary 3.
Let be a TLN on n neurons, and let . The following are equivalent:
for all
and for all
for all
Note from the above corollary that a given might be permitted, but it can be the case that . This is because since might not survive the addition of extra neurons to the network. In that case, we say that dies in the larger network. To make this distinction formal, we define, for any , the sets of surviving and dying fixed points supports :
It is possible to characterize exactly the fixed points supports of some networks in terms of its dying and surviving fixed points. These networks are the transversal topic of this chapter. To begin exploring the special structures of those, we go back to when the simply-added structure was introduced in [15]:
Definition 14 (simply-added split).
Let be a graph on nodes. For any nonempty such that , we say is simply-added onto if for each , either is a projector onto , i.e., for all , or is a non-projector onto , so for all . In this case, we say that is simply-embedded in , and we say that is a simply-added split of the subgraph , for .
This structure is beneficial because when the graph has a simply-added split, the ’s easily factor, which makes it straightforward to compute their signs and apply Theorem 13.
Theorem 15 ( [15]).
Let be a graph on nodes, and let , be such that is simply-added to . For , define and . Then
where has the same value for every .
Notice that being simply-added is not a bidirectional property, and Theorem 15 only provides factorization for each . A factorization that holds for every node requires the simply-added property be bidirectional, i.e.:
Definition 16 (bidirectional simply-added split).
Let be a graph on nodes. For any nonempty , such that and , we say that has a bidirectional simply-added split if is simply-added onto and is simply-added onto . In other words, for all , either for all or for all , and for all , either for all or for all .
In this case, the factor for every 1. With this structure, we can see exactly how the sets of fixed points supports is formed:
Theorem 17 ( [15]).
Let be a graph with bidirectional simply-added split . For any nonempty , let where and . Then if and only if one of the following holds:
and , or
and .
In other words, if and only if is either a union of surviving fixed points , at most one from and at most one from , or it is a union of dying fixed points, exactly one from and one from .
In the sections that follow, we generalize this theorem to more than two components, and to TLNs.
Finally, some of the results we use only hold for TLNs with uniform external input . That is, is such that for every , . In this case, we abuse notation and denote the TLN by just . The next theorem is one of those results and it relates the magnitudes of the ’s to . This is a TLN version of Rule 4. For this, [15] defines the domination quantity for :
where . We say that dominates with respect to , if . The theorem then states that precisely when these domination quantities are perfectly balanced within , so that is domination-free, and when every external node is “inside-out” dominated by nodes inside :
Theorem 18 (general domination, Theorem 15 in [15]).
Let be a TLN with uniform input, and let . Then
That is, is permitted if and only if is domination-free. If , then if and only if for each , there exists such that , i.e. such that inside-out dominates .
That is all the extra technical background that we will reference in the proofs below (in addition to that of Ch. 2).
6.2. Simply-embedded CLTN structures
The results in this section are my contribution to [59]. Again, Lemma 20, Theorem 21, Lemma 30 and Theorem 31 are presented with no proof, because the proofs now follow from more general theorems in Section 6.3. Old proofs can be found in the original publication. The exposition and figures below come from that paper, with small modifications.
The aim of this section is to generalize Theorem 11 by further constraining the simply-added architecture. The simply-added structure of cyclic unions was restrictive enough to allow us to completely characterize the fixed point supports of the graph in term of its components. However, it can be relaxed a little further to obtain similar results.
6.2.1. Simply-embedded partitions
We begin by generalizing simply-added splits (Def. 14) and introduce the more general notion of a simply-embedded partition. Recall that given a graph and a partition of its nodes into two components, , we say that is simply-embedded in if is simply-added onto . We can generalize this idea to more components by making every simply-embedded in :
Definition 19 (simply-embedded partition).
Given a graph , a partition of its nodes is called a simply-embedded partition if every is simply-embedded in . In other words, for each and each , either for all or for all .
Notice that the definition is trivially satisfied when there are no or there is only a single for every . Thus, every graph has two trivial simply-embedded partitions: one where all the nodes are in one component and one where every node is in its own component. Neither of these partitions is useful for giving information about the structure of . But when a graph has a nontrivial simply-embedded partition, this structure is sufficient to dramatically constrain the possible fixed point supports of to unions of fixed points chosen from a menu of component fixed point supports, . To prove this fact, we need a lemma connecting the values to the values from the component subgraphs.
Lemma 20.
Let have a simply-embedded partition , and consider . Let . Then for any ,
Combining this lemma with the sign conditions characterization of fixed point supports (Thm. 13), we get the desired result:
Theorem 21 ( menu for simply-embedded partitions).
Let have a simply-embedded partition . For any , let . Then
In other words, every fixed point support of is a union of component fixed point supports , at most one per component.
Example 22 (Example 3.1 in [59]).
Consider the component subgraphs shown in Figure 6.1A together with their . By Theorem 21, any graph with a simply-embedded partition of these component subgraphs has a restricted menu for consisting of the component fixed point supports (the set of all possible supports derived from this menu is shown on the bottom of panel A). Note that an arbitrary graph on 7 nodes could have up to 27 − 1 = 127 possible fixed point supports, but the simply-embedded partition structure narrows the options to only 15 candidate fixed points. Figure 6.1B-E show four possible graphs with simply-embedded partitions of these component subgraphs, together with for each of the graphs.
Figure 6.1. Graphs with a simply-embedded partition from Example 22.

(A) (Top) A collection of component subgraphs with their . (Bottom) The set of possible fixed point supports for any graph that has these subgraphs in the simply-embedded partition. (B-E) Example graphs with a simply-embedded partition with the component subgraphs from A, together with their . In (C-E), thick colored edges from a node to a component indicate that the node projects edges out to all the nodes in the receiving component. Figure reproduced from [59].
Observe that the graph in Figure 6.1B is a disjoint union of its component subgraphs. For this graph, consists of all possible unions of at most one fixed point support per component subgraph (see [15, Thm. 11]). Thus, every choice from the menu provided by Theorem 21 does in fact yield a fixed point for .
In contrast, the graph in Figure 6.1C is a cyclic union of the component subgraphs. For this graph, only has sets that contain a fixed point support from every component, i.e., for all (by Thm. 11). Thus, any subset from the menu of Theorem 21 that does not intersect every does not produce a fixed point for .
Meanwhile, the graph in Figure 6.1D is a simply-embedded partition with heterogeneity in the outgoing edges from a component (notice different nodes in treat differently). has a mixture of types of supports: there are some that do not intersect every component, and others that do.
Finally, the graph in Figure 6.1E is another simply-embedded partition with heterogeneity (notice different nodes in treat and differently). However, for this graph, there is a uniform rule for the fixed point supports: every fixed point consists of exactly one fixed point support per component subgraph (identical to for the graph in panel C).
Even though Theorem 21 is not sufficient to fully determine , it significantly limits the options for fixed point supports (menu). In particular, one direct consequence of Theorem 21 is that if there is some node in that does not participate in any fixed points of , then cannot participate in any fixed point of the full graph . Thus the supports of all the fixed points of are confined to . It turns out that if the removal of node does not change the fixed points of the component subgraph, i.e. if , then we can actually remove from the full graph without changing . Thus we have the following theorem.
Theorem 23 (removable nodes).
Let have a simply-embedded partition . Suppose there exists a node such that . Then .
Proof. To see that , notice that for all , we have by Theorem 21. Then by Corollary 3(2), we must have , and so .
For the reverse containment, we will show that every fixed point in survives the addition of node by appealing to Theorem 13 (sign conditions). There are two cases to consider: and , where and .
Case 1: . Since is not contained in the support of any fixed point of , there must be at least one other node in , since cannot be empty. Since is a simply-embedded partition, we have that is simply-embedded onto meaning that every node in receives identical inputs from the rest of the graph. Recall from Equation 6.2, that . Then since , we have that and receive identical inputs from , so for all , and thus . Since , we have for all by Theorem 13 (sign conditions). Thus, we also have and survives the addition of node , so .
Case 2: . First observe that has the same simply-embedded partition structure as , but with rather than . Thus implies that by Theorem 21 (menu). By hypothesis, , and so . Then by Theorem 13 (sign conditions), since , we have for all . And by Lemma 20, this ensures for all . Since , we have that is identical for all , not just , and so for all . Thus by Theorem 13 (sign conditions), survives the addition of node , so . □
Theorem 23 shows that if a node is locally removable without altering fixed points of its component, then node is also globally removable without altering the fixed points of the full graph . This result gives a new tool for determining that two graphs have the same collection of fixed points.
Corollary 24.
Let have a simply-embedded partition and suppose there exists such that . Let be any graph that can be obtained from by deleting or adding outgoing edges from to any other component without altering the simply-embedded structure of . Then .
Proof. Observe that by deleting all the outgoing edges from to a component , node has simply changed from a projector onto to a non-projector. Alternatively, by adding all the outgoing edges to , node switches from being a non-projector onto to being a projector. In either case, is still simply-added onto , and so has the same simply-embedded partition as had. Additionally, since no edges within have been altered, we have that . Thus both and satisfy the hypotheses of Theorem 23. Moreover, since the only differences between and were in edges involving node , which has been removed. Thus, by Theorem 23, . □
The result below is new, but fits into the narrative of [59], which is the paper where the above results are published. That is why we include it here.
Theorem 25.
If is simply-embedded in , then if dominates in
Proof. If dominates in , because is simply-embedded, both and receive the same inputs from the rest of the graph. Thus, dominates with respect to and by Theorem 9 . □
6.2.2. Simple linear chains
In this section we add a chain-like architecture to a simply-embedded partition, and term this new architecture simple linear chains:
Definition 26 (simple linear chain).
Let be a graph with node partition . We say that is a simple linear chain if the following two conditions hold:
the only edges between components go from nodes in to , and
for every , either for every or for every .
A key structural advantage of linear chains is that if , then it turns out that ; in other words, survival of the addition of the next component is sufficient to guarantee survival in the full network. This occurs because has no outgoing edges to any nodes outside of . Lemma 27 shows that whenever a permitted motif has no outgoing edges to a node , then it is guaranteed to survive the addition of node .
Lemma 27.
Let be a graph on nodes, let be nonempty, and . If for all , then
In other words, if has no outgoing edges to node then is guaranteed to survive the addition of node whenever is permitted.
Proof. For any , we have that inside-out dominates . Thus by Rule 4c, if and only if .
It turns out that the simply-embedded partition structure of the simple linear chain with the added restriction that does not send edges to any other than gives significant structure to the values of and thus to the domination quantities . This structure is the key to the proof of the following theorem.
Theorem 28 (simple linear chains).
Let be a simple linear chain with components .
If , then for all , where .
- Consider a collection of . If additionally for all , then
In other words, is closed under unions of component fixed point supports that survive in .
Proof. (i) follows directly from Theorem 21 by noting that the simple linear chain structure endows with a simply-embedded partition: for every , the nodes in are each either a projector or non-projector onto , while all nodes outside of are all non-projectors onto .
To prove (ii), consider where for all . Notice that by Lemma 27, the fact that implies that since has no outgoing edges to any external node outside of . Thus, we may assume for all . We will prove that this guarantees that by induction on the number of components of the simple linear chain.
For , the result is trivially true. For , observe that the simple linear chain on actually has the structure of a bidirectional simply-embedded split , and thus Theorem 17 gives the complete structure of in terms of the surviving fixed points of the component subgraphs and the dying fixed points . The sets of interest here, with , are precisely the elements of . Theorem 17(1) then guarantees that whenever , and so the result holds when .
Now, suppose the result holds for any simple linear chain with components. For ease of notation, denote and let . We will show the result holds for any simple linear chain with components.
Observe that if , we have by the inductive hypothesis, and we need only show that this implies that . On the other hand, if , then , where by Lemma 27, since and has no outgoing edges to any external nodes outside of . Notice that the simple linear chain structure of ensures that is a bidirectional simply-embedded split. Thus by Theorem 17, since is a surviving fixed point support, if and only if . Therefore for any , it suffices to show that , and the result will follow.
Notice that by the inductive hypothesis, , and thus to show , we need only show that survives the addition of the nodes in . There are two cases to consider here based on whether intersects or not. Observe that if , then has no outgoing edges to since only nodes in can send edges forward to by the linear chain structure. In this case, we have for all and all , and so Lemma 27 guarantees that since we already had .
For the other case where , we will prove by appealing to Theorem 18 (general domination) and demonstrating that each is inside-out dominated by some node . First notice that and by the simple linear chain structure of , we have that is simply-embedded onto . Thus by Theorem 15,
| (6.3) |
where has the same value for every . Using this, we can now compute the domination quantities and for and . For , we have:
On the other hand, for we have the following formula for , where we use the fact that for all since there are no edges from nodes in to :
Moreover, since , we have that must inside-out dominate the external node , so . Combining this with the fact that , we see that
Thus and so inside-out dominates for all . Thus by Theorem 18, , and so as desired. □
Figure 6.2 illustrates Theorem 28 with an example simple linear chain. By Theorem 28(i), every fixed point support in restricts to a fixed point in . Next consider a collection of such that for all . First observe that each actually survives to the full network, and so . This is guaranteed because has no outgoing edges to nodes outside of (Rule 4C). Moreover, by Theorem 28(ii), we see that every union of surviving component fixed points yields a fixed point of the full network, but additional fixed point supports are also possible.
Figure 6.2. Simple linear chain.

(A) An example simple linear chain together with its . The first row of gives the surviving fixed points from each component subgraph; the second row shows that all unions of these component fixed points are also in (Theorem 28(ii)); the third row shows the additional fixed point supports in that arise from the broader menu (Theorem 28(i)). (B) for each component subgraph from A, and the list of which of these supports survive the addition of the next component in the chain. Figure reproduced from [59].
6.2.3. Strongly simply-embedded partitions
Recall that the difference between a simply-added split and a bidirectional simply-added split is that, for bidirectional splits, not only is simply-embedded in , but is also simply-embedded in . To achieve an analogous bidirectionality in the case of simply-embedded partitions we must now additionally require that every is simply-embedded in as well. This means that not only is treated the same by the rest of the graph, but it must also treat the rest of the graph the same. We term this new, more rigid, partition structure a strongly simply-embedded partition.
Definition 29 (strongly simply-embedded partition).
Let be a graph with a partition of its nodes . The partition is called strongly simply-embedded if for every node in , either for all or for all , where is the component containing .
The simplest examples of graphs with a strongly simply-embedded partition are disjoint unions and clique unions, which are building block constructions first studied in [15]. In a disjoint union of component subgraphs , there are no edges between components. In this case, every node in is a non-projector onto the rest of the graph. At the other extreme, a clique union has bidirectional edges between every pair of nodes in different components. In a clique union, every node is a projector onto the rest of the graph.
The key fact that allowed to characterize the fixed points of disjoint and clique unions in [15] was a complete complete factorization of the values in terms of the of the component fixed point supports. But recall that we can only get this complete factorization when the simply-added structure is bidirectional. Strongly simply-embedded partitions now satisfy that is also a bidirectional simply-added split. This means we can prove a result analogous to Theorem 15, but for a partition, and for every . Moreover, the values are fully determined by whether is a surviving or a dying fixed point of . Recall that we denote the sets of surviving and dying fixed points as:
Lemma 30.
Let be a graph on n nodes with a strongly simply-embedded partition . For any , denote , and and let . Then for every ,
where has the same value for every .
Moreover, for any and :
while for any ,
Similar to simple linear chains, it turns out that strongly simply-embedded partitions also have the property that is closed under unions of surviving fixed point supports of the component subgraphs. With the added structure of the strongly simply-embedded partition, though, we can actually say something stronger – can be fully determined from knowledge of the component fixed point supports together with knowledge of which of those component fixed points survive in the full network. This complete characterization of is given in Theorem 31 below.
Theorem 31.
Suppose has a strongly simply-embedded partition , and let for any . Then if and only if for each , and either
every is in , or
none of the are in .
In other words, if and only if is either a union of surviving fixed points , at most one per component, or it is a union of dying fixed points, exactly one from every component.
This theorem generalizes Theorem 17, characterizing every element of in terms of the sets of surviving and dying component fixed points supports, and . Notice that in the statement of Theorem 31, all the fixed point supports of type (a) have the form for and , while those of type (b) have the form for .
More generally, though, a strongly simply-embedded partition can have a mix of surviving and dying component fixed points, so that has a mix of both type (a) and type (b) fixed point supports. Figure 6.3A gives an example strongly simply-embedded partition, and panel B shows both the set of component fixed point supports, , and the subset of those that survive to yield fixed points of the full network. Since there are dying fixed points in every component, we see that has a mix of both type (a) and type (b) fixed point supports.
Figure 6.3. Strongly simply-embedded partition with .

(A) A graph with a strongly simply-embedded partition . Projector nodes are colored brown. (B) (Top) for each component subgraph together with the supports from each component that survive within the full graph. (Bottom) for the strongly simply-embedded partition graph. The first two lines of consist of unions of surviving fixed points, at most one per component. The third line gives the fixed points that are unions of dying fixed point supports, exactly one from every component. Figure reproduced from [59].
A special case of a bidirectional simply-added split occurs whenever a graph contains a node that is projector/non-projector onto the rest of the graph. Specifically, since any subset is always simply-added onto a single node trivially, we see that we have a bidirectional simply-added split whenever is either a projector or a non-projector onto the rest of the graph. Recall that if is a non-projector onto , then has no outgoing edges in , and so it is a sink. Moreover, we have seen that sinks are the only single nodes that can support fixed points since a singleton is trivially uniform in-degree 0, and thus only survives when it has no outgoing edges, by Theorem 7. Combining this observation with the bidirectional simply-added split for a sink, we see there is certain internal structure that must be present in whenever it contains any singleton sets.
Proposition 32.
Let be a graph such that there is some singleton . Then for any (with ),
If , then ; i.e., is closed under unions with singletons.
If , then ; i.e., is closed under set differences with singletons.
Proof. First notice that since , is a sink in by Theorem 7 (since a singleton is trivially uniform in-degree 0, and thus survives exactly when it has no outgoing edges), and therefore is a bidirectional simply-added split.
To prove (1), suppose . Since is a bidirectional simply-added split, Theorem 17 guarantees that if and only if , both survive or both die. By assumption, both sets are in , so both survive. Thus, .
To prove (2), suppose . By Theorem 17, if and only if both survive or both die. By assumption, , and so as well. □
Corollary 33.
Let be a graph such that contains singleton sets , and let be the set of singletons. Then for any and any
Moreover, let . Then has the direct product structure:
where denotes the power set of . In other words, every fixed point support in has the form where and .
Proof. The first statement follows by iterating Proposition 32(1) times for each of the added singletons in . To prove the second statement, we will show that every is the union of a surviving fixed point (or the empty set) with a subset of (including empty set); moreover, every such union yields a fixed point (other than ). The direct product structure of immediately follows from this decomposition of the fixed point supports. By the first result, we see that every such union is contained in . Thus, all that remains to show is that every element of is such a union. Let and let and , so that . If or are empty, then we’re done, so suppose both are nonempty. Then we can iteratively apply Proposition 32(2) times to see that . Thus, every fixed point support arises as a union of some with an arbitrary subset of , where (and for every , we have as well by Corollary 3(2)). □
As an application of Theorem 31, we can immediately recover characterizations of the fixed points of disjoint unions and clique unions previously given in [15, Theorems 11 and 12]. In a disjoint union, every component fixed point support survives to the full network since it has no outgoing edges (by Rule 4: inside-out domination). Thus, for a disjoint union, consists of all the fixed points of type (a) from Theorem 31: unions of (surviving) component fixed points , at most one per component. In contrast, in a clique union, every component fixed point support dies in the full network since it has a target that outside-in dominates it (in fact, every node outside of is a target of any subset of ). Thus, for a clique union, consists of all the fixed points of type (b): unions of (dying) component fixed points , exactly one from every component. Both the disjoint union and clique union characterizations of [15, Theorems 11 and 12] are now immediate corollaries of Theorem 31.
Corollary 34.
Let be a graph with partition .
If is a disjoint union of , then if and only if for all .
If is a clique union of , then if and only if for all .
6.3. Layered CTLNs
The results here are inspired by the sequential construction of Chapter 5. Our goal is to provide theoretical explanations for why the networks of Chapter 5 work so well. Leaving the world of CTLNs, we allowed off-diagonal blocks to not be strictly constrained by a graph. Consequently, the networks in Chapter 5 are best described as layered CTLNs, because the diagonal blocks are CTLNs but the off-diagonal blocs are not. Here we derive Theorem 31 for TLNs in general, not only layered CTLNs. The diagonal blocks, or layers, can also be TLNs. It is convenient to choose CTLNs as the layers, because we have plenty of results to build in the desired attractors.
Throughout the chapter, TLNs with a vector of heterogeneous (but constant in time) inputs are denoted as , as usual. When the input is also constant across neurons, we abuse notation and denote it as instead of . We start by showing that any node with non-positive input cannot be involved in any fixed points of the network. This will allow us to restrict, moving forward, to networks where all inputs are positive.
Definition 35.
We say that is a competitive TLN on neurons if and for all , .
Attention! This definition is different from the one in [15], which requires for all too.
Lemma 36.
Let be a competitive non-degenerate TLN on neurons, and suppose that for some we have . Then, is a fixed point of if and only if and is a fixed point of , where .
Proof. Denote and let .
(⇒) Suppose is a fixed point of . We have that for all , , and thus
Since and , we obtain , as desired.
Now let’s see that is a fixed point of . Indeed, for all we have that
where the second equality follows from the definition of , , and the third one because .
Suppose is a fixed point of and . Then we have that for all , . Let’s see that is a fixed point of . Indeed,
where the second equality once again follows from the assumption that , and the third equality from definition of , , . □
We then easily see that neurons with negative input do not participate of any fixed point support:
Corollary 37.
Let be a competitive non-degenerate TLN. If for some , then . In particular, for all .
Proof. Denote and let . Observe that
there exists a fixed point of such that
, and is a fixed point of
, and .
Where the second equivalence follows from Lemma 36. Thus, and for all , as desired. □
The above lemma explains the fusion attractors we saw in last chapter.
Examples from Chapter 5.
We begin by analyzing the network from Section 5.1, the sequential control of gaits, whose connectivity matrix is reproduced in Figure 6.4. We focus on deriving outside of pulse times, which is precisely when the network settles in the attractors we observe. Since outside of pulses, , by Lemma 37, . But
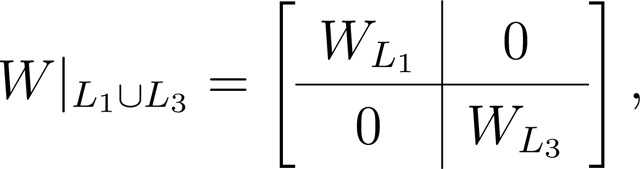 |
(6.4) |
and thus layers are decoupled and it is now easy to see that attractors from and will be preserved, since they do not really affect each other’s dynamics.
Figure 6.4.

Matrices from Chapter 5.
Analogously, the same mechanism is doing the work in the network of Section 5.2, as once again we have , with as in Equation 6.4. Layers and are transiently connected during pulse times through , which allows to communicate its attractor transitions to . Once the transition is communicated, and pulse ends, the network will settle in the chosen attractor. Neat.
The results in this section were inspired by a combination of the networks of Chapter 5, and past results (in Secs. 6.1 and 6.2). One of the things the proofs have in common is the following simple linear algebra lemma, which allow us to factor determinants whose top right block is rank 1:
Lemma 38.
Let
 |
be an matrix, consisting of the blocks , , and , where adjacent blocks overlap in one row/column. Note that is the single entry where all four matrices overlap. If or is rank 1 and , then
Proof. Let
Note that
and . Assume first that is rank 1, then we can take all columns of to be multiples of its first column. Let be such that
with . Subtracting times the -th column of from its -th column, we get
 |
because and . If C is rank 1, the proof is similar. □
This determinant lemma is a key technical tool for proofs in this section, as well as in [15,59], but also in Section 6.2. The fact that allows us to get a rank 1 block here, and in the past, is the simply-embeddedness of a given component network. This translates into said component receiving certain uniform inputs from other neurons. Below we make this notion precise by extending Definition 39 beyond CTLNs to apply more generally to TLNs:
Definition 39.
Let be a competitive non-degenerate TLN. We say that is simply-embedded in the network if for every , for all , . That is, if and , then:
 |
(6.5) |
With this definition, we can readily obtain the TLN version of Theorem 15, key in the proofs of [15,59], and in this section. The reasoning is as follows: if we can factor the ’s, we can inherit their signs to the component networks, if we can inherit their signs to the component networks then we can compare these signs to asses who is a fixed point support of the whole and parts via Theorem 13. This is why the next lemma is so important.
Theorem 40.
Let be simply-embedded in and for . Let . Then for any , we have
where has the same value for every .
Proof. Since is simply-embedded with uniform input, has the form
 |
where is a column vector of all ones of size , and so that
Let , then
 |
Since the upper right block , is rank 1 and , by Lemma 38,
 |
note that the last matrix, equal to , does not depend on . □
With the factorization, we can now see how the signs of the ’s are inherited to simply-embedded components:
Lemma 41.
Suppose is a partition of the vertices of a TLN , with constant input. For any , let . If for every we have simply-embedded in , then for any ,
Proof. Since each is simply-embedded in , and input is assumed to be uniform across all components, by Theorem 40 we have for all , where has the same value for every . Hence, for all , , we have that if and only if if and only if . □
With the inheritance, we can now start to see how the supports of the parts relate to supports of the whole. The next theorem generalizes Theorem 1.4 in [59] for TLNs with a simply-embedded structure, but constant input. Now we know that a fixed point of the whole network must have come from supports of the component parts.
Theorem 42 (TLN version of Theorem 1.4 in [59]).
Let be composed of layers , such that each layer is simply-embedded in the network, with uniform input. For any , let . Then
In other words, every fixed point support of is a union of component fixed point supports , at most one per component.
Proof. For , we have
for any , and , by Theorem 13 (sign conditions). Then by Lemma 41, we see that whenever ,
and so satisfies the sign conditions in . Thus for every nonempty . □
The next lemma generalizes Lemma 30 to TLNs, the structure below is the analog of a strongly simply-embedded partition. Recall that this lemma assumed several simply-embeddednesses to obtain a full factorization of the ’s. Also recall the sets of surviving and dying fixed points supports .
Lemma 43.
Let be a TLN on n nodes with uniform input. And suppose that for , if , we have for all . That is, if , has the form
 |
(6.6) |
For any , denote , and and let . Then for every ,
where has the same value for every . Moreover, for any and :
while for any ,
Proof. Since is simply-embedded in ,
by Theorem 40. On the other hand, since is also simply-embedded, we also have
Therefore, the above factorization holds for all . Similarly, since both and are simply-embedded,
by Theorem 40, and so . Continuing in this fashion, we see that for any ,
Note that if , then , and thus for all ,
The fact that has the same value for every is a direct consequence of Theorem 40.
Finally, to prove the last statements about the signs of , observe that for , the values of are fully determined by Theorem 13 (sign conditions) since by hypothesis. In particular, if , then survives the addition of every , and so by Theorem 13 (sign conditions). On the other hand, if then dies in and so there is some for which . But by the first part of the theorem, all the values are identical for , and thus for all such .
Finally, we arrive to the main theorem of last section, Theorem 31, TLN version. This is the big result. It generalizes Theorem 31 from [59], and also Theorem 17 from [15]. The proof is a generalized version of what it was in both of those publications.
Theorem 44.
Let be such that
 |
(6.7) |
and . Let for any . Then if and only if for each , and either
every is in , or
none of the are in .
In other words, if and only if is either a union of surviving fixed points , at most one per component, or it is a union of dying fixed points, exactly one from every component.
Proof. Note that satisfies the conditions for Lemma 43 above, and thus, assuming def without loss of generality that , we have that for and ,
with is constant across for each .
Suppose . By Lemma 43, . Next, by Theorem 42,

for every , and by the sgn formula of Lemma 43. Denote by . For any , there exists such that , then we have
| (6.8) |
Now, observe that if contained a mix of and , then there would be , such that for some , while for some and thus and . But this contradicts the fact that by Theorem 13 (since we assumed , ). Thus, we must have either for all , as in (a), or for all as in (b).
Now to see that when for all , we must have , suppose to the contrary that so that there is some such that . Then, for , we have for all , by Lemma 43, since . Thus .
On the other hand, if , with , we have
Where the first equality follows from Equation 6.8, and the second because in this case.
But then for and , which contradicts by Theorem 13. Thus when for all .
Suppose (a) holds and so for all . Let us check the sign conditions for .
For any , there exists such that . Then by Equation 6.8, we have
since in this case. On the other hand, for , we have for all , by Lemma 43, since . Thus
Therefore by Theorem 13 (sign conditions).
Next, suppose (b) holds so for all (so ). Then for any ,

there is such that and by Equation 6.8, we have
since .
Now, let , with . Since with (because ), we have and thus
Thus sign conditions are satisfied, and so . □
Note that the structure of the network in Theorem 44 is such that the graph can be decomposed as shown in Figure 6.5B. In contrast, in Figure 6.5A we have the less restrictive structure of Theorem 42, where the edges to two different components might be different.
Figure 6.5. Simply-embedded layers cartoon.

(A) The structure of Theorem 42. (B) The structure of Theorem 44.
We can also consider a mid point between these two structures, where nested components are simply-embedded, to obtain:
Theorem 45.
Let such that is simply-embedded in for every . That is, if then has the form
 |
(6.9) |
Then for any and any we have
where .
This means that the fixed point supports of the whole network must come from supports of “ordered, nested” parts.
Proof. Since , by Theorem 13 we have that
By Lemma 41, since for every is simply-embedded, we have
This means that satisfies the sign conditions in and so . □
Corollary 46.
Let be simply-embedded in . Then for any ,
6.3.1. Updated results on simply-embedded partitions
As mentioned before, the results in this section generalized those published in [59], for which we omitted the proofs when we presented them in Section 6.2. Here we include references to which theorems from Section 6.3 will prove theorems of Section 6.2.
First, note that Definition 39 is generalizing Definition 19 now. That’s how we straightforwardly get:
Lemma 20.
Let have a simply-embedded partition , and consider . Let . Then for any ,
Proof. Follows directly from Lemma 41. □
Theorem 21 ( menu for simply-embedded partitions).
Let have a simply-embedded partition . For any , let . Then
In other words, every fixed point support of is a union of component fixed point supports , at most one per component.
Proof. Follows directly from Theorem 42. □
Lemma 30.
Let be a graph on n nodes with a strongly simply-embedded partition . For any , denote , and and let . Then for every ,
where has the same value for every .
Moreover, for any and :
while for any ,
Proof. Follows directly from Lemma 43. □
Theorem 31.
Suppose has a strongly simply-embedded partition , and let for any . Then if and only if for each , and either
every is in , or
none of the are in .
In other words, if and only if is either a union of surviving fixed points , at most one per component, or it is a union of dying fixed points, exactly one from every component.
Proof. Follows directly from Theorem 44. □
Chapter 7 | Further theoretical results, and open questions
In this chapter, we explore two seemingly unrelated results originating from our work in Chapters 4 and 6. The first part of this chapter emerges from our attempt to extend our five-gait quadruped network approach to model hexapod gaits. We wondered whether CLTNs could learn hexapod gaits using a combination of theoretical insights from CTLNs and computational machine learning techniques. While we did not ultimately answer this question, during our exploration, we made an interesting observation: many different networks could support the same attractor. This observation isn’t entirely novel [27,28,42], which prompted us to study this phenomenon using CTLNs from a dynamical systems perspective. What conditions are sufficient for two different networks to support the same attractor? Our progress in addressing this question is discussed in Section 7.1.
The second half of the chapter derived from Chapter 6. Recall that in that chapter, we repeatedly invoked the ability to fully factorize the si values from Equation 6.1 when using a simply-embedded structure. This has been the case in 2016 [15], 2020 [59], and 2023 6.3. Now we extend this approach to even more general structures. As it turns out, these si values are elements of a chirotope. Section 7.2 explores the concept of chirotopes, their relation to TLNs, and partially computes the chirotope of a TLN that has some simply-embedded subnetworks.
These projects are still in their early stages, which explains their inclusion, together, in the final chapter.
7.1. Degeneracy
One of the aims of neuroscience is to identify the relationship between function and the underlying structure responsible for that function. However, a wide variety of different structures can produce the same function, a concept known as degeneracy [42]. Degeneracy manifests in various contexts in neuroscience, ranging from single cells with different properties generating the same behavior [27] to different neuronal circuits producing similar circuit performance [28]. That is, there is not a unique, one-to-one correspondence between function and structure. This holds true for models as well. A myriad of different parameters in a single model can yield the same output [26,64]. What fraction of neurons need to be observed to reconstruct a network’s behavior?
In the context of TLNs, the degeneracy problem translates into: for a given pattern of firing , how many TLNs can generate that pattern? Furthermore, is there a precise notion under which two distinct networks and are considered equivalent? Can we derive a general principle that yields a family of "equivalent" networks? The degeneracy problem also raises the question: if several different networks can reproduce the same attractor, how do we identify conditions for accurate model fitting or parameter estimation? This would also require a precise notion under which two attractors are the same, and then conditions that facilitate this verification.
In the special case of TLNs, we have observed that even networks as small as 3 neurons can reproduce the same limit cycle, under different parameters. Figure 7.1 shows an example. On top, there is a binary-synapse matrix , arising as the CTLN connectivity matrix of a 3-cycle graph, and an all uniform input defining a network that supports a limit cycle, as shown by the rate curves. Below, a slightly different matrix and a non-uniform input is reproducing (apparently) the same limit cycle.
Figure 7.1. Two different TLNs reproducing the same limit cycle.

One partial result in this direction states that if the vector fields of two TLNs match at some point, then they match at that point for all TLNs that are convex combinations of the original two TLNs. More precisely:
Definition 47.
Let and be two TLNs on nodes, with vector fields
for . For any , define the convex combination as the TLN with
Lemma 48.
Let be the vector field of a TLN convex combination , for . Suppose there exists a certain point such that the vector fields match: . Then, for all , .
Proof. First, observe that if , then for any we also have
Moreover, this will hold for , where some entries are positive and others are negative, and (as negative entries need not agree). Now suppose . It follows that
and hence, for ,
This implies that . □
This implies in particular that fixed points survive to interpolations in convex combinations:
Corollary 49.
If is a fixed point of both and , then it is a fixed point for all convex combinations .
Proof. If , then for all . □
Also, any attractor that appears identically in two distinct TLNs - that is, with identical vector field along all point in the attractor - must also appear in all “in between” TLNs formed as convex combinations of the original two.
Corollary 50.
If , for , is a trajectory of both and , then it is also a trajectory for all convex combinations .
Several questions arise from our exploration of attractor degeneracy in the context of TLNs. First, can any of these results be generalized to any convex hull, beyond line segments? If so, can we identify distinct "chunks" of TLN parameter space that yield the same attractor? If such chunks exist, can we systematically characterize them to obtain partitions of TLN space by attractors? We could begin tackling this from a computational perspective by developing algorithms to efficiently identify and characterize regions of parameter space that produce equivalent attractors.
Some answers could also help elucidate the relationship between structure and function. For example, are there specific structural properties or network configurations that lead to the emergence of these shared attractors? This is a challenging question, but computationally, we could at least attempt to answer how different network architectures impact the existence and distribution of shared attractors.
Further-reaching questions include: what implications do these findings have for our understanding of neural circuit function and plasticity? How might the presence of degenerate attractors influence information processing and computational capabilities within neural networks? Are there practical applications of understanding attractor degeneracy in the design of artificial neural networks? These questions go beyond the immediate scope of our current investigation but are worth exploring to gain deeper insights into neural network dynamics and their computational properties.
7.2. Chirotope
7.2.1. Background
Given any set of vectors , the Grassmann-Plucker (G-P) relations give us a series of identities relating determinants formed from elements of . Specifically, given any and ,
| (7.1) |
For different choices of ’s and ’s, Equation 7.1 yields all possible G-P relations on . Note that if for some , then the G-P relation is trivial.
What do G-P relations tell us about TLNs? Recall that the rows of the matrix are the vectors
For a TLN of dimension , we are interested in the set of vectors
corresponding to . G-P relations for TLNs will relate determinants formed from these vectors, and this in turn will produce relationships among elements of the associated chirotope :
Definition 51.
The chirotope of a TLN is the map , where
for any .
The reason we are interested in the chirotope is that it encodes the full combinatorial geometry of a TLN. In particular, encodes all fixed point supports in .
Proposition 52.
Let be a TLN on n neurons, and let be its associated chirotope. Then
where
| (7.2) |
Recall that for , we use the notation to indicate or , with for and for (see Eq. 7.2). We will also use the facts:
Also, recall that:
Finally, we will use the notation:
| (7.3) |
Note that for , we always have . Assuming , then for we obtain
| (7.4) |
and for we have
| (7.5) |
So altogether, we get:
For any , and , , , we can define:
Note that and , so the above determinant does not repeat or terms, provided , and is generically expected to be nonzero. For , this new determinant reduces to:
7.2.2. New results
If you follow the proofs of Chapter 6, you will notice that there is a recurrent strategy: assume a component is simply-embedded to obtain a factorization of the si’s, whose signs greatly control the set of fixed points supports of a network. In this section we aim to leverage again the simply-embedded structure to see if we can easily completely compute the chirotope for networks that have some simply-embedded structure in them. The first results in this direction find that there is plenty of elements that end up vanishing:
Lemma 53.
Consider a CTLN with graph on nodes. Let be simply-embedded in . Then
for all , , and .
Proof. If , then trivially ( gets repeated). So suppose . without loss of generality, let , let , and . Then,
Now, recall that for a CTLN we have for all , so the last column is of the form
Furthermore, since is simply-embedded and all nonzero entries in the -th column are identical and equal to , so that this column has the form
In other words, the -th column is a scalar multiple of the last column, so . □
In fact, we can prove that there are far more elements that vanish:
Lemma 54.
Consider a CTLN with graph . Let be simply-embedded in . Any chirotope element whose only elements come from , and does not contain , for some , , will vanish.
Proof. Let . It suffices to prove:
| (7.6) |
as other determinants satisfying the conditions in the theorem are either permutations or index relabelings of the LHS of Equation 7.6. Let , and then
 |
But since is simply-embedded, for all and and therefore columns and are linearly dependent:
 |
Note however that the other columns may or may not be linearly dependent, as the * indicates the possible presence of a 1, so it is indeed necessary to have and not appear in the determinant. Also, note that the proof still holds if . □
Lemma 53 now follows from Lemma 54:
It is clear from the last determinant that and are missing, with , . In this case, in the proof above. Note that the indices above give a total of elements: with an extra , for a total of elements.
We can still push a little further:
Lemma 55.
Let and suppose one of the following holds:
There exist , , such that is simply-embedded in . That is, and for all , . (Assume no restrictions on b).
There exists such that is simply-embedded in , , and for all (it can be anything outside of ).
Then, any chirotope determinant whose only elements come from (i.e. ), and does not contain or , will vanish.
Proof. Let . It suffices to prove:
| (7.7) |
as other determinants satisfying the conditions in the theorem are either permutations or index relabelings of the LHS of Equation 7.7. First, suppose (i) holds. Let , and , then
 |
where the ∗ are blocks of mostly zeros and some ones, coming from the rows. Now, since is simply-embedded in , it follows that columns and are linearly dependent and thus the determinant vanishes.
For (ii), let , and . Then the determinant looks like
 |
and so in this case columns and are linearly dependent too, and the determinant vanishes. □
As mentioned above, our goal was to completely compute the chirotope for networks that have some simply added structure. More specifically, if a given CTLN has a strongly simply-embedded partition, can the chirotope be factorized, just like the ’s can? We still don’t know.
Supplementary Material
Acknowledgments
I want to extend my deepest gratitude to my advisor, Prof. Carina Curto, for her constant support, guidance, and encouragement. Her expertise and mentorship have been invaluable in shaping not only my current research program but also my identity as a researcher. Her belief in me and the strong role model she is has been a truly transformative experience in this journey.
I would also like to express my appreciation to all my collaborators for their contributions to our shared projects, especially to Prof. Katie Morrison for her incredible support and valuable advice, which greatly contributed to the research presented in this dissertation.
Thanks also to labmates, but especially to Nikki Sanderson, for their continuous academic, professional, and personal support, which has been instrumental in navigating the challenges of graduate school.
I extend my appreciation to my committee members for taking the time to provide valuable feedback, constructive criticism, and insightful suggestions to this work. Their expertise has been instrumental in refining my ideas and strengthening the quality of my current and future work.
I would also like to acknowledge the Department of Mathematics for providing a nurturing environment for research, learning, and teaching. The resources offered by the department have played a crucial role in strengthening my professional profile. Special thanks to Profs. Cheryl Hile and Kathryn Stewart for their exceptional mentorship during my time as a graduate instructor. I am the most fortunate to have had such dedicated and inspiring teaching mentors.
I am also indebted to all those who have supported me personally during this time. Their presence in my life has been indispensable in keeping a healthy research-life balance.
Finally, I am immensely grateful for the funding provided by the Department of Mathematics, the NIH grant R01 EB022862 and NSF grant DMS-1951165, without which this research would not have been possible. The material in Chapter 7 is based upon work supported by the National Science Foundation under Grant No. DMS-1929284 while the author was in residence at the Institute for Computational and Experimental Research in Mathematics in Providence, RI, during the Math + Neuroscience program. The findings and conclusions in this dissertation do not necessarily reflect the view of the funding agencies.
Footnotes
Bibliography
- [1].Neuroscience. Sinauer Associates, 2 edition, 2001.
- [2].McN R. Alexander. The gaits of bipedal and quadrupedal animals. The International Journal of Robotics Research, 3(2):49–59, 1984. [Google Scholar]
- [3].Amit Daniel J. Modeling brain function: The world of attractor neural networks. Cambridge University Press, 1989. [Google Scholar]
- [4].Arriaga M. and Han E. B. Dedicated hippocampal inhibitory networks for locomotion and immobility. J. Neurosci., 37:9222–9238, 2017. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [5].Ashwin P., Coombes S., and Nicks R. Mathematical Frameworks for Oscillatory Network Dynamics in Neuroscience. J Math Neurosci, 6(1):2, Dec 2016. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [6].Bel A., Cobiaga R., Reartes W., and Rotstein H. G. Periodic solutions in threshold-linear networks and their entrainment. SIAM J. Appl. Dyn. Syst., 20(3):1177–1208, 2021. [Google Scholar]
- [7].Biswas Tirthabir and Fitzgerald James E. Geometric framework to predict structure from function in neural networks. Phys. Rev. Res., 4:023255, Jun 2022. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [8].Buono P. L. and Golubitsky M. Models of central pattern generators for quadruped locomotion. I. Primary gaits. J Math Biol, 42(4):291–326, Apr 2001. [DOI] [PubMed] [Google Scholar]
- [9].Büttner U. and Büttner-Ennever J.A. Present concepts of oculomotor organization. In Büttner-Ennever J.A, editor, Neuroanatomy of the Oculomotor System, volume 151 of Progress in Brain Research, pages 1–42. Elsevier, 2006. [DOI] [PubMed] [Google Scholar]
- [10].Cain Nicholas and Shea-Brown Eric. Computational models of decision making: integration, stability, and noise. Current Opinion in Neurobiology, 22(6):1047–1053, 2012. Decision making. [DOI] [PubMed] [Google Scholar]
- [11].Carlos Joaquín Castañeda Castro. Ctlns definidos por torneos, 2023.
- [12].Collins J. J. and Stewart I. N. Coupled nonlinear oscillators and the symmetries of animal gaits. Journal of Nonlinear Science, 3(1):349–392, Dec 1993. [Google Scholar]
- [13].Curto C., Degeratu A., and Itskov V. Encoding binary neural codes in networks of threshold-linear neurons. Neural Comput., 25:2858–2903, 2013. [DOI] [PubMed] [Google Scholar]
- [14].Curto C., Geneson J., and Morrison K. Stable fixed points of combinatorial threshold-linear networks. Available at https://arxiv.org/abs/1909.02947 [DOI] [PMC free article] [PubMed]
- [15].Curto C., Geneson J., and Morrison K. Fixed points of competitive threshold-linear networks. Neural Comput., 31(1):94–155, 2019. [DOI] [PubMed] [Google Scholar]
- [16].Curto Carina and Morrison Katherine. Pattern completion in symmetric threshold-linear networks. Neural Computation, 28:2825–2852, 12 2016. [DOI] [PubMed] [Google Scholar]
- [17].Curto Carina and Morrison Katherine. Graph rules for recurrent neural network dynamics. Notices of the American Mathematical Society, 70(04):536–551, 2023. [Google Scholar]
- [18].Curto Carina and Morrison Katherine. Graph rules for recurrent neural network dynamics: extended version, 2023.
- [19].1965 Dayan Peter and Abbott L. F. Theoretical neuroscience : computational and mathematical modeling of neural systems. Computational neuroscience. Massachusetts Institute of Technology Press, Cambridge, Mass., 2001. [Google Scholar]
- [20].Durstewitz Daniel, Koppe Georgia, and Thurm Max Ingo. Reconstructing computational system dynamics from neural data with recurrent neural networks. Nature Reviews Neuroscience, 24(11):693–710, Nov 2023. [DOI] [PubMed] [Google Scholar]
- [21].Dutta Sourav, Parihar Abhinav, Khanna Abhishek, Gomez Jorge, Chakraborty Wriddhi, Jerry Matthew, Grisafe Benjamin, Raychowdhury Arijit, and Datta Suman. Programmable coupled oscillators for synchronized locomotion. Nature Communications, 10(1):3299, Jul 2019. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [22].Dzeladini Florin, Ait-Bouziad Nadine, and Ijspeert Auke. CPG-Based Control of Humanoid Robot Locomotion, pages 1–35. Springer Netherlands, Dordrecht, 2018. [Google Scholar]
- [23].Bard Ermentrout G. and David H. Terman. Firing Rate Models, pages 331–367. Springer; New York, New York, NY, 2010. [Google Scholar]
- [24].Feudel Ulrike, Pisarchik Alexander N., and Showalter Kenneth. Multistability and tipping: From mathematics and physics to climate and brain—minireview and preface to the focus issue. Chaos: An Interdisciplinary Journal of Nonlinear Science, 28(3):033501, 2018. [DOI] [PubMed] [Google Scholar]
- [25].Gambaryan P. P. How mammals run: anatomical adaptations. Wiley, New York, 1974. [Google Scholar]
- [26].Gjorgjieva Julijana, Drion Guillaume, and Marder Eve. Computational implications of biophysical diversity and multiple timescales in neurons and synapses for circuit performance. Curr Opin Neurobiol, 37:44–52, 4 2016. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [27].Goaillard Jean and Marder Eve. Ion channel degeneracy, variability, and covariation in neuron and circuit resilience. Annu Rev Neurosci, 44:335–357, 7 2021. [DOI] [PubMed] [Google Scholar]
- [28].Goaillard Jean, Taylor Adam, Schulz David, and Marder Eve. Functional consequences of animal-to-animal variation in circuit parameters. Nature Neuroscience, 12:1424–1430, 11 2009. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [29].Goldman M. S. Robust Persistent Neural Activity in a Model Integrator with Multiple Hysteretic Dendrites per Neuron. Cerebral Cortex, 13(11):1185–1195, November 2003. [DOI] [PubMed] [Google Scholar]
- [30].Goldman Mark S, Compte A, and Wang X. J. Neural Integrator Models, pages 165–178. Elsevier Ltd, 2010. [Google Scholar]
- [31].Golubitsky M., Stewart I., Buono P-L, and Collins J.J. Symmetry in locomotor central pattern generators and animal gaits. Nature, 401:693–695, 1999. [DOI] [PubMed] [Google Scholar]
- [32].Golubitsky Martin, Stewart Ian, Buono Pietro-Luciano, and Collins J.J. A modular network for legged locomotion. Physica D: Nonlinear Phenomena, 115(1):56–72, 1998. [Google Scholar]
- [33].Graybiel Ann M. The basal ganglia and chunking of action repertoires. Neurobiology of Learning and Memory, 70(1):119–136, 1998. [DOI] [PubMed] [Google Scholar]
- [34].Grillner S. and Wallén P. Cellular bases of a vertebrate locomotor system – steering, intersegmental and segmental co-ordination and sensory control. Brain Res. Rev., 40:92–106, 2002. [DOI] [PubMed] [Google Scholar]
- [35].Hahnloser R. H., Sarpeshkar R., Mahowald M.A., Douglas R.J., and Seung H.S. Digital selection and analogue amplification coexist in a cortex-inspired silicon circuit. Nature, 405:947–951, 2000. [DOI] [PubMed] [Google Scholar]
- [36].Hahnloser R. H., Seung H.S., and Slotine J.J. Permitted and forbidden sets in symmetric threshold-linear networks. Neural Comput., 15(3):621–638, 2003. [DOI] [PubMed] [Google Scholar]
- [37].Richard Hahnloser H. Sebastian Seung, and Jean-Jacques Slotine. Permitted and forbidden sets in symmetric threshold-linear networks. Neural Comput, 15:621–638, 3 2003. [DOI] [PubMed] [Google Scholar]
- [38].HARTLINE H. K. and RATLIFF F. Spatial summation of inhibitory influences in the eye of Limulus, and the mutual interaction of receptor units. J Gen Physiol, 41(5):1049–1066, May 1958. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [39].Hopfield J.J. Neural networks and physical systems with emergent collective computational abilities. Proc. Natl. Acad. Sci., 79(8):2554–2558, 1982. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [40].Hopfield J.J. Neurons with graded response have collective computational properties like those of two-sate neurons. Proc. Natl. Acad. Sci., 81:3088–3092, 1984. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [41].Ijspeert Auke Jan. Central pattern generators for locomotion control in animals and robots: A review. Neural Networks, 21(4):642–653, 2008. Robotics and Neuroscience. [DOI] [PubMed] [Google Scholar]
- [42].Kamaleddin Mahdi. Degeneracy in the nervous system: from neuronal excitability to neural coding. Bioessays, 44:e2100148, 1 2022. [DOI] [PubMed] [Google Scholar]
- [43].Khona Mikail and Fiete Ila R. Attractor and integrator networks in the brain. Nature Reviews Neuroscience, 23(12):744–766, Dec 2022. [DOI] [PubMed] [Google Scholar]
- [44].Kornysheva Katja and Diedrichsen Jörn. Human premotor areas parse sequences into their spatial and temporal features. eLife, 3:e03043, aug 2014. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [45].Koulakov Alexei A., Raghavachari Sridhar, Kepecs Adam, and Lisman John E. Model for a robust neural integrator. Nature Neuroscience, 5(8):775–782, Aug 2002. [DOI] [PubMed] [Google Scholar]
- [46].Lappalainen Janne K., Tschopp Fabian D., Prakhya Sridhama, Mason McGill Aljoscha Nern, Shinomiya Kazunori, Shin ya Takemura Eyal Gruntman, Macke Jakob H., and Turaga Srinivas C. Connectome-constrained deep mechanistic networks predict neural responses across the fly visual system at single-neuron resolution. bioRxiv, 2023. [DOI] [PMC free article] [PubMed]
- [47].Lashley Karl S. The problem of serial order in behavior. 1951.
- [48].Latorre Roberto, Varona Pablo, and Rabinovich Mikhail I. Rhythmic control of oscillatory sequential dynamics in heteroclinic motifs. Neurocomputing, 331:108–120, 2019. [Google Scholar]
- [49].Laureline Logiaco L.F. Abbott, and Sean Escola. Thalamic control of cortical dynamics in a model of flexible motor sequencing. Cell Reports, 35(9):109090, 2021. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [50].Long Michael A., Jin Dezhe Z., and Fee Michale S. Support for a synaptic chain model of neuronal sequence generation. Nature, 468(7322):394–399, Nov 2010. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [51].Marder E. and Bucher D. Central pattern generators and the control of rhythmic movements. Curr. Bio., 11(23):R986–996, 2001. [DOI] [PubMed] [Google Scholar]
- [52].Mazurek Mark E., Roitman Jamie D., Ditterich Jochen, and Shadlen Michael N. A Role for Neural Integrators in Perceptual Decision Making. Cerebral Cortex, 13(11):1257–1269, 11 2003. [DOI] [PubMed] [Google Scholar]
- [53].Morrison K. and Curto C. Predicting neural network dynamics via graphical analysis. Book chapter in Algebraic and Combinatorial Computational Biology, edited by Robeva R. and Macaulay M. Elsevier, 2018.
- [54].Morrison K., Degeratu A., Itskov V., and Curto C. Diversity of emergent dynamics in competitive threshold-linear networks. Available at https://arxiv.org/abs/1605.04463
- [55].Eadweard. Muybridge. Attitudes of Animals in Motion, Illustrated with the Zoopraxiscope. University of Pennsylvania, 1891.
- [56].Nikitchenko Maxim and Koulakov Alexei. Neural integrator: a sandpile model. Neural computation, 20(10):2379–2417, Oct 2008. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [57].Sara Oliveira Santos Nils Tack, Su Yunxing, Cuenca-Jiménez Francisco, Morales-Lopez Oscar, Gomez-Valdez P. Antonio, and Wilhelmus Monica M . Pleobot: a modular robotic solution for metachronal swimming. Scientific Reports, 13(1):9574, Jun 2023. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [58].Panchin Y. V., Arshavsky Y. I., Deliagina T. G., Popova L. B., and Orlovsky G. N. Control of locomotion in marine mollusk clione limacina. ix. neuronal mechanisms of spatial orientation. Journal of Neurophysiology, 73(5):1924–1937, 1995. [DOI] [PubMed] [Google Scholar]
- [59].Parmelee Caitlyn,Londono Alvarez Juliana, Curto Carina, and Morrison Katherine. Sequential attractors in combinatorial threshold-linear networks. SIAM Journal on Applied Dynamical Systems, 21(2):1597–1630, 2022. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [60].Parmelee Caitlyn, Castañeda Joaquin, Morrison Katherine, and Curto Carina. New core motifs paper.
- [61].Parmelee Caitlyn, Moore Samantha, Morrison Katherine, and Curto Carina. Core motifs predict dynamic attractors in combinatorial threshold-linear networks. PLOS ONE, 17(3):1–21, 03 2022. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [62].Penn Yaron, Segal Menahem, and Moses Elisha. Network synchronization in hippocampal neurons. Proceedings of the National Academy of Sciences, 113(12):3341–3346, 2016. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [63].Pisarchik Alexander N. and Feudel Ulrike. Control of multistability. Physics Reports, 540(4):167–218, 2014. Control of multistability. [Google Scholar]
- [64].Prinz Astrid A., Bucher Dirk, and Marder Eve. Similar network activity from disparate circuit parameters. Nature Neuroscience, 7:1345–1352, 12 2004. [DOI] [PubMed] [Google Scholar]
- [65].Rabinovich Mikhail I. and Varona Pablo. Discrete sequential information coding: Heteroclinic cognitive dynamics. Frontiers in Computational Neuroscience, 12, 2018. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [66].Sakai Katsuyuki, Kitaguchi Katsuya, and Hikosaka Okihide. Chunking during human visuomotor sequence learning. Exp. Brain Res., 152(2):229–242, September 2003. [DOI] [PubMed] [Google Scholar]
- [67].Seung H.S. and Yuste R. Principles of Neural Science, chapter Appendix E: Neural networks, pages 1581–1600. McGraw-Hill Education/Medical, 5th edition, 2012. [Google Scholar]
- [68].Sebastian Seung H., Daniel D.Lee, Reis Ben Y, and Tank David W. Stability of the memory of eye position in a recurrent network of conductance-based model neurons. Neuron, 26(1):259–271, 2000. [DOI] [PubMed] [Google Scholar]
- [69].Su Cui and Pang Jun. Sequential temporary and permanent control of boolean networks. In Computational Methods in Systems Biology: 18th International Confer-ence, CMSB 2020, Konstanz, Germany, September 23–25, 2020, Proceedings, page 234–251, Berlin, Heidelberg, 2020. Springer-Verlag. [Google Scholar]
- [70].Tsodyks M. V., Skaggs W. E., Sejnowski T. J., and McNaughton B. L. Paradoxical effects of external modulation of inhibitory interneurons. J Neurosci, 17(11):4382–4388, Jun 1997. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [71].Varona Pablo, Rabinovich Mikhail I., Selverston Allen I., and Arshavsky Yuri I. Winnerless competition between sensory neurons generates chaos: A possible mechanism for molluscan hunting behavior. Chaos: An Interdisciplinary Journal of Nonlinear Science, 12(3):672–677, 2002. [DOI] [PubMed] [Google Scholar]
- [72].Vasa Suresh, Ma Tao, Byadarhaly Kiran V., Perdoor Mithun, and Minai Ali A. A spiking neural model for the spatial coding of cognitive response sequences. In 2010 IEEE 9th International Conference on Development and Learning, pages 140–146, 2010.
- [73].White J.A., Chow C.C., Ritt J., Soto-Treviño C., and Kopell N. Synchronization and oscillatory dynamics in heterogeneous, mutually inhibited neurons. J. Comput. Neurosci., 5(1):5–16, 1998. [DOI] [PubMed] [Google Scholar]
- [74].Whittington M.A., Traub R.D., Kopell N., Ermentrout B., and Buhl E.H. Inhibitionbased rhythms: experimental and mathematical observations on network dynamics. Int. J. Psychophysiol., 38(3):315–336, 2000. [DOI] [PubMed] [Google Scholar]
- [75].Williams Thelma L. A new model for force generation by skeletal muscle, incorporating work-dependent deactivation. J. Exp. Biol., 213(4):643–650, February 2010. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [76].Wong Aaron L and Krakauer John W. Why are sequence representations in primary motor cortex so elusive? Neuron, 103(6):956–958, September 2019. [DOI] [PubMed] [Google Scholar]
- [77].Xie X., Hahnloser R. H., and Seung H.S. Selectively grouping neurons in recurrent networks of lateral inhibition. Neural Comput., 14:2627–2646, 2002. [DOI] [PubMed] [Google Scholar]
- [78].Yokoi Atsushi and Diedrichsen Jörn. Neural organization of hierarchical motor sequence representations in the human neocortex. Neuron, 103(6):1178–1190.e7, 2019. [DOI] [PubMed] [Google Scholar]
- [79].Yuste R., MacLean J.N., Smith J., and Lansner A. The cortex as a central pattern generator. Nat. Rev. Neurosci., 6:477–483, 2005. [DOI] [PubMed] [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.