

Abstract
Due to the influence of construction quality, engineering geology and hydrological environment, defects such as dehollowing and insufficient compaction can occur in tunnels. Aiming at the problems of complex detection model, poor real-time performance and low accuracy of the current tunnel lining defect detection methods, the study proposes a lightweight defect detection algorithm of tunnel lining based on knowledge distillation. Firstly, a high-precision teacher model based on yolov5s was constructed by constructing a C3CSFM module that combines residual structure and attention mechanism, a MDFPN network structure with multi-scale feature fusion and a reweighted RWNMS re-screening mechanism. Secondly, in the distillation process, the feature and output dimension results are fused to improve the detection accuracy, and the mask feature relationship is learned in the space and channel dimension to improve the real-time detection. Tests on the tunnel lining radar defect image dataset showed that the number of parameters of the improved model was reduced from 16.03 MB to 3.20 MB, a reduction of 80%, and the average accuracy was improved from 83.4 to 86.5%, an increase of 3.1%. On the basis of maintaining the structure and detection performance of the model, the lightweight degree of the model is greatly improved, and the high-precision and real-time detection of tunnel lining defects is realized.
Keywords: Tunnel detection, Deep learning, Model compression algorithms, Knowledge distillation
Subject terms: Civil engineering, Electrical and electronic engineering
Introduction
China stands as one of the most active nations globally in tunnel construction, according to statistics, China has already opened and operated 14,547 railroad tunnels with a total length of about 15,326 km, 3,825 railroad tunnels under construction with a total length of about 8,125 km, and 5,596 tunnels under design and planning with a total length of about 13,331 km, and It is projected that by 2030, the total length of China’s railroad tunnels will surpass 30,000 km. However, due to factors such as construction conditions, geology and hydrology, and operational age, tunnels may have defects such as incompactness, dehollowing, cavities, and water-filling, which can seriously affect the service life of the tunnels1, and therefore, effective tunnel lining defect detection is the basis for ensuring the safe operation of the tunnels. Traditional tunnel lining defect detection methods, such as visual inspection, acoustic wave detection, multi-sensor detection, etc., mainly rely on manual measurement, which is not only inefficient and inaccurate, but also dangerous and time-consuming, affecting the efficiency of safety assessment of the tunnel lining structure.
In the face of the existing problems of tunnel lining defect detection, how to realize intelligent detection of tunnel lining defects has become an urgent problem of tunnel engineering in the international arena. A series of image processing algorithms based on threshold segmentation, edge detection, feature extraction and region growth are widely used in tunnel, railroad, bridge inspection and other fields with the advantage of automated processing and have made great breakthroughs in performance. Although these algorithms have very high detection accuracy, with the development of edge devices, the complexity of deep neural network algorithms and the number of parameters has become a major obstacle to the intelligent detection of tunnel lining defects.
To address the high complexity and large number of parameters in deep neural network algorithms, researchers have proposed model compression algorithms such as pruning, quantization, and distillation. As early as in the 1980s, some scholars proposed the idea of model pruning for the simplification and acceleration of neural network models, and in the subsequent research, scholars have successively studied the pruning based on fine-grained pruning2, gradient-based pruning3, pruning based on the Hessian matrix4, and pruning based on sparse features5, etc. Although the pruning method can greatly increase the degree of lightweighting, the destruction of the model structure can not be recovered, so it has not been widely used. and therefore have not been widely used. In the early computer vision field, quantization techniques6were used to reduce the parameter quantity storage space requirements, with the development of deep neural networks, scholars proposed weight-based quantization7, activation-based quantization8, and network layer-based quantization9, which can realize the compression of parameter quantity storage, but need to adjust the network parameters secondly to recover the accuracy, and thus are not applicable to real-time detection engineering. Aiming at the shortcomings of pruning and quantization techniques, Hinton et al10. proposed a transfer learning method to train student models through teacher models in 2015, which realizes the transfer of “dark knowledge” from teacher models by adjusting the distillation temperature T as well as the soft and hard loss functions, and the knowledge distillation11 method can greatly reduce model storage and computation overheads while maintaining model performance. The knowledge distillation method can greatly reduce the model storage and computation overhead while maintaining the model performance, and realize the model lightweight. However, due to the traditional knowledge distillation algorithm’s single dependence on labeling information, which can lead to poor model robustness and imbalance between foreground and background information, it is necessary to further improve the plurality of feature knowledge learning.
Aiming at the complexity of the detection model, poor real-time performance and low accuracy of tunnel lining defect detection at the current stage, this study proposes a lightweight defect detection algorithm of tunnel lining based on knowledge distillation.
Related work
In recent years, there are two main aspects of research on lightweight defect detection algorithms, on the one hand, the improvement of the network structure, and on the other hand, the research on model compression algorithms.
Regarding the improvement of network structure, researchers have proposed such as MobileNet network12, ShuffleNet network13, GhostNet network14, GoogleNet network15, etc. Applied to the detection of tunnel lining defects, Liu et al. have developed a lightweight tunnel detection equipment through multi-sensor fusion and YOLOv5 technology16. however, the complexity of the tunnel environment leads to a significant reduction in the speed of detection and reasoning in the process of practical application; In order to improve the detection inference speed, Liao et al. constructed a mobile imaging module and an automatic detection module, and designed a lightweight tunnel defect detection convolutional neural network, which reduced the number of model parameters to 3.4 M, and achieved an inference speed of 17 FPS17. but the detection accuracy cannot meet the demand due to the introduction of the model lightweight module; Therefore Tan et al. improved the detection speed by improving the lightweight segmentation network LSNet, while utilizing the ShuffleNet v2 encoder to ensure the accuracy of tunnel water filling defect detection18, but the marginalized deployment is still problematic because the introduction of residual connections increases the network capacity.
Regarding the model compression algorithms, they are mainly designed to achieve efficient detection in resource-constrained environments, for example, Situ et al. improved the sewer defect detection algorithm by using transfer learning as well as pruning techniques based on YOLOv5, which reduced the amount of model parameters by 80%19, but the pruning operation led to the irreversibility of the model structure, which made the model generalization ability decrease; Therefore, Zhang et al. transformed the continuous texture information of steel plate defects into intensity level information based on CNN quantization coding technique, which improves the learning ability of defect features and reduces the parameter storage space at the same time20, but this method needs to be fine-tuned with parameters after quantization, which cannot meet the real-time detection requirements; In order to improve the real-time detection, Li et al. designed a real-time defect detection framework for concrete dams based on improved YOLOv5 combined with pruning and knowledge distillation algorithm21, but this combination of pruning and distillation is difficult to train and still has some defects. Ruan, D., Han, J., Yan, J. et al22. proposed a two-step method to build a cell-based light CNN by Neural Architecture Search (NAS) and weights-ranking-based model pruning, compared with base CNN, the parameter size of the 2-cells CNN was reduced from 9.677 MB to 0.197 MB, which provides a good reference for our research.
In summary, the existing technology, whether from the network structure or model compression algorithm improvement can significantly optimize part of the detection performance, but in the context of the complex and changing tunnel environment often can not give full play to the superiority of the performance. Therefore, intelligent tunnel lining defect detection algorithms in complex tunnel environments not only need to meet the improvement of detection accuracy and real-time, but also need to focus on model lightweight23 to achieve the deployment of marginalized devices, which is still a challenge for the current research.
Scope and innovation
This paper focuses on addressing two deficiencies of existing tunnel lining defect detection algorithms as follows:
Difficulty in model feature extraction. In the complex environment of the tunnel due to the influence of noise, structure, etc., the deep learning network is difficult to extract key features in the feature extraction process. Feature extraction networks such as ResNet10123and DarkNet5324 used in existing research are often affected by background information during training resulting in poor feature extraction, which cannot meet the needs of defect detection in complex tunnel environments.
Complex model structure. Improving detection accuracy for tunnel lining defects often requires deep networks, but these networks can be too complex to deploy on edge devices. Existing research on the lightweight design of the network structure as well as pruning25, quantization26, distillation algorithms will cause damage to the network structure, and at the same time can not meet the needs of the tunnel defect detection project in terms of accuracy and lightweight at the same time.
Aiming at the above two deficiencies, this paper proposes an intelligent tunnel lining defect detection algorithm based on the idea of knowledge distillation and the improvement of YOLOv5, and the main contributions of this algorithm are as follows:
Aiming at the problem of difficult feature extraction in the model, the YOLOv5 master teacher network is constructed to effectively suppress the influence of background information on feature extraction and realize the high-precision detection of tunnel lining defects.
The multi-dimensional knowledge distillation algorithm is improved based on the idea of knowledge distillation, which greatly improves the lightness of the model on the basis of maintaining the model structure and detection performance, and realizes the high-precision and real-time detection of tunnel lining defects.
The remainder of the paper is organized as follows: section “Methods” describes the design process of the improved knowledge distillation algorithm, section “Data set of tunnel lining defect” describes the data acquisition and enhancement process, and section “Experiment of tunnel lining defect detection” gives the experimental details and results of the tunnel lining defect detection.
Methods
YOLOv5-master
YOLOv5, as a single-stage target detection model with high real-time and high accuracy, firstly unifies the input image size during the training process, then generates candidate frames on the feature map after a series of convolution and pooling operations, and then uses the NMS27 algorithm to filter the candidate frames, and finally optimizes the position and size of the target frames through the regression algorithm.
To enhance the feature extraction ability during the training process and optimize the model detection accuracy, the study is based on YOLOv5 for improvement. Firstly, a C3CSFM module is designed to enhance the ability of extracting target features by combining the residual structure and the attention mechanism in the backbone network; secondly, Secondly, a multi-level dense feature pyramid network was constructed in the neck network to improve the feature learning ability; and finally, a re-weighted re-screening mechanism RWNMS is designed in the prediction segment and the loss function is adjusted to solve the problem of redundancy in the detection frame. The improved YOLOv5 structure is shown in Fig. 1.
Fig. 1.

Improved YOLOv5 model structure.
Aiming at the small target information in the deep learning process is easy to be filtered resulting in the loss of important information, causing the model overfitting and average accuracy decline and other problems, research based on the attention mechanism to improve the module CSFM, and applied to the C328 module constitutes the C3CSFM module as shown in Fig. 2. The C3CSFM module constructed in this paper is improved based on the CBAM attention mechanism, which improves the pooling latitude, improves the activation function, and adds the split operation, which makes the feature information extraction more comprehensive, can solve the problems of gradient vanishing and explosion, and improves the calculation speed.
Fig. 2.

C3CSFM module structure.
The C3CSFM module achieves the effect of deep feature extraction by serial processing of channel and spatial layers, the process is shown in Eq. 1 and Eq. 2:
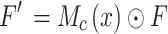 |
1 |
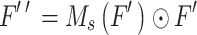 |
2 |
where 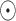 is the feature addition of the elements,
is the feature addition of the elements, 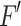 is the output of the channel layer and also serves as an intermediate layer feature input to the spatial layer, and
is the output of the channel layer and also serves as an intermediate layer feature input to the spatial layer, and 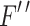 is the output of the spatial layer, which is also the final output of the model, and
is the output of the spatial layer, which is also the final output of the model, and 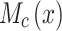 and
and 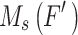 can be expressed as Eq. 3 and Eq. 4:
can be expressed as Eq. 3 and Eq. 4:
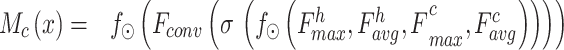 |
3 |
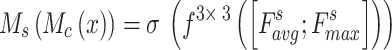 |
4 |
where 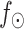 denotes feature addition,
denotes feature addition, 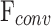 denotes the convolution operation performed,
denotes the convolution operation performed, 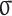 denotes the ReLU activation function, and
denotes the ReLU activation function, and 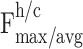 denotes the average pooling and maximum pooling operations of the input features in the
denotes the average pooling and maximum pooling operations of the input features in the 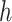 and
and 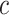 dimensions.
dimensions.
Aiming at the traditional feature pyramid network multi-scale feature fusion efficiency is low, the computational volume is large and other problems, the research in the process of zooming in and out of the feature map weighted normalization process to construct the MDFPN pyramid structure is shown in Fig. 3.
Fig. 3.

MDFPN pyramid structure.
By performing multiple convolution and pooling operations on the input image, feature maps of different sizes are obtained and the last three layers are selected to form the MDFPN network input as in Eq. 5 and Eq. 6:
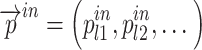 |
5 |
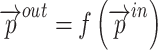 |
6 |
Where 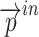 and
and 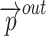 denote the inputs and intermediate layer outputs, respectively, and the feature fusion is performed by cascading the feature maps from different levels in the channel dimension using a cascade algorithm. The normalization process adopts the fast normalization method so as to fuse the feature maps from different scales more effectively as in Eq. 7:
denote the inputs and intermediate layer outputs, respectively, and the feature fusion is performed by cascading the feature maps from different levels in the channel dimension using a cascade algorithm. The normalization process adopts the fast normalization method so as to fuse the feature maps from different scales more effectively as in Eq. 7:
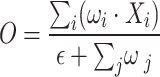 |
7 |
Figure 4 shows a comparison of the three output layer scale characteristic diagrams of the MDFPN module in the yolov5 network. The analysis shows that different sizes focus on different images, and the high-level features are difficult to accurately detect the target location information due to the low resolution, while the low-level features cannot accurately represent the target category information due to the lack of semantic information, so the fusion and utilization of different levels of information can greatly improve the network detection performance.
Fig. 4.

Characteristic diagram of different scales of MDFPN module.
Since the same target is covered by multiple prediction frames in detection resulting in redundant result detection frames, the study introduces the EIOU loss function and incorporates a weighted smoothing strategy into the NMS process in order to reduce the problems such as noise and oscillations. The process of the improved RWNMS mechanism is shown in Fig. 5.
Fig. 5.

RWNMS process.
Improved knowledge distillation algorithm
Transitioning from traditional manual inspection methods to intelligent inspection techniques is the main goal of tunnel lining defect detection, with the ultimate goal of achieving the deployment of intelligent defect detection algorithms by marginalized devices such as drones. This deployment requires the detection model to be characterized by high accuracy, light weight, and real-time performance. In the process of knowledge distillation, the complex teacher model is first used to train the original data and record the model feature representation, and then these feature representations are passed as dark knowledge to the lightweight student model for training, and combined with the student model’s own feature representation for training, the higher the network complexity of the model contains more “dark knowledge The higher the network complexity, the more “dark knowledge” the model contains that can be provided to the student model. The process is shown in Fig. 6.
Fig. 6.

Flow of knowledge distillation method.
The Softmax function is utilized in the loss function computation process to transform the logical units into the characteristics of the category probabilities as in Eq. 8:
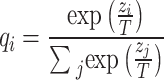 |
8 |
Where  denotes the output of the teacher model,
denotes the output of the teacher model, 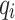 denotes the output after Softmax transformation, T denotes the distillation “temperature”, the higher the distillation temperature the more average the model output probability distribution. Since the prediction results will tend to zero in the case of multi-classification, it is necessary to construct the cross-entropy loss function as in Eq. 9:
denotes the output after Softmax transformation, T denotes the distillation “temperature”, the higher the distillation temperature the more average the model output probability distribution. Since the prediction results will tend to zero in the case of multi-classification, it is necessary to construct the cross-entropy loss function as in Eq. 9:
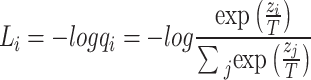 |
9 |
Where 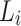 denotes the cross-entropy loss function of the ith sample and
denotes the cross-entropy loss function of the ith sample and 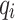 denotes the model output of the ith sample, by minimizing the cross-entropy loss function, the student model output can be made to approximate the teacher model output, and the final target loss function of the teacher model and the student model is obtained as in Eq. 10:
denotes the model output of the ith sample, by minimizing the cross-entropy loss function, the student model output can be made to approximate the teacher model output, and the final target loss function of the teacher model and the student model is obtained as in Eq. 10:
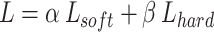 |
10 |
Where 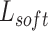 denotes the soft loss of cross-entropy between the teacher model and the student model,
denotes the soft loss of cross-entropy between the teacher model and the student model, 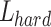 denotes the hard loss of cross-entropy between the student model and the true value, and
denotes the hard loss of cross-entropy between the student model and the true value, and 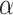 and
and 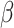 denote the weights of the two parts of the loss. In this study based on the improved multidimensional knowledge distillation algorithm training process is shown in Fig. 7.
denote the weights of the two parts of the loss. In this study based on the improved multidimensional knowledge distillation algorithm training process is shown in Fig. 7.
Fig. 7.

Flow of the improved multidimensional knowledge distillation algorithm.
where T-Model denotes the teacher model, S-Model denotes the student model, Feature Distill denotes the feature layer distillation, Output Distill denotes the output layer distillation, Distillation loss denotes the soft loss function, Student loss denotes the hard loss function. Distillation based on spatial and channel dimensions is used throughout the training process to increase the training rate.
Due to the low efficiency of ordinary distillation and poor learning of feature information, attentional distillation is utilized to improve the learning efficiency for small target space and channel feature capturing ability.
In the distillation network based on feature dimension and output dimension, the combination of fitting intermediate layer features and output layer features is used for learning, the output feature is mapped to get the significance representation of that feature, after which the difference between the two features is represented by the cross-entropy loss function, and finally the student network is optimized by back-propagation and the weight relationship is obtained, and the process is shown in Fig. 8.
Fig. 8.

Spatial and feature dimension feature fusion process.
Each intermediate and output layer optimizes the loss function process as in Eq. 11:
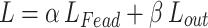 |
11 |
Where 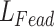 denotes the feature layer loss function,
denotes the feature layer loss function, 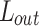 denotes the output layer loss function,
denotes the output layer loss function, 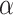 and
and 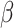 denote the weights of the two parts of the loss, and
denote the weights of the two parts of the loss, and 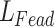 can be expressed as Eq. 12:
can be expressed as Eq. 12:
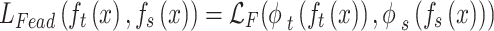 |
12 |
where 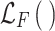 denotes the similarity function for matching the feature maps of the teacher and student models based on the cross-entropy loss function,
denotes the similarity function for matching the feature maps of the teacher and student models based on the cross-entropy loss function, 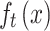 and
and 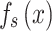 denote the feature maps of the intermediate layers of the teacher and student models, respectively, and
denote the feature maps of the intermediate layers of the teacher and student models, respectively, and 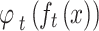 and
and 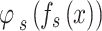 denote the feature-size matching algorithms using the bilinear interpolation algorithm.
denote the feature-size matching algorithms using the bilinear interpolation algorithm.
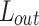 consists of a hard target loss and a soft target loss, and the hard target loss
consists of a hard target loss and a soft target loss, and the hard target loss 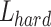 is defined as the cross-entropy loss between the real label and the student model as in Eq. 13:
is defined as the cross-entropy loss between the real label and the student model as in Eq. 13:
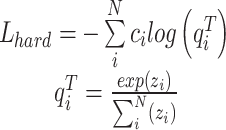 |
13 |
Where N denotes the total number of samples, 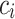 denotes the value of ground truth on the ith class,
denotes the value of ground truth on the ith class, 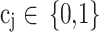 ,
, 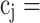 1 if the sample label is positive, and
1 if the sample label is positive, and 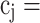 0 if the label is negative,
0 if the label is negative,  denotes the output of the student network, and
denotes the output of the student network, and 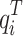 the value of the student network’s Softmax output on the ith class at a temperature of
the value of the student network’s Softmax output on the ith class at a temperature of 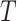 . The soft target loss
. The soft target loss 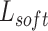 is defined as the cross-entropy loss between the teacher model and the student model as in Eq. 14:
is defined as the cross-entropy loss between the teacher model and the student model as in Eq. 14:
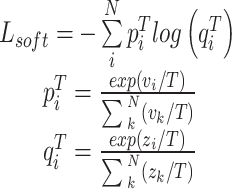 |
14 |
where 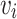 denotes the output of the teacher network, and
denotes the output of the teacher network, and 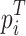 denotes the value of the Softmax output of the teacher network on class i at a temperature of
denotes the value of the Softmax output of the teacher network on class i at a temperature of 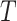 .
.
Combining the idea of attention mechanism, the important channel features and spatial features are distilled based on the channel and spatial dimensions as in Eq. 15 and Eq. 16:
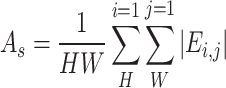 |
15 |
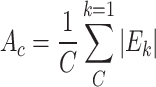 |
16 |
where 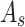 and
and 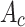 denote spatial attention and channel attention, respectively,
denote spatial attention and channel attention, respectively, 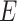 denotes input features, and
denotes input features, and 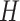 ,
, 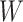 , and
, and 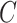 denote height, width, and number of channels, respectively. The L2 loss is used to describe the attention loss as in Eq. 17:
denote height, width, and number of channels, respectively. The L2 loss is used to describe the attention loss as in Eq. 17:
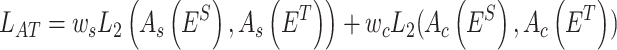 |
17 |
where 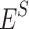 and
and 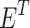 denote teacher network input features and student network input features, respectively, and
denote teacher network input features and student network input features, respectively, and 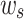 and
and 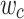 denote spatial and channel layer weight parameters, respectively. The spatial attention mask and channel attention mask are constructed as Eq. 18 and Eq. 19:
denote spatial and channel layer weight parameters, respectively. The spatial attention mask and channel attention mask are constructed as Eq. 18 and Eq. 19:
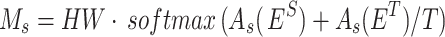 |
18 |
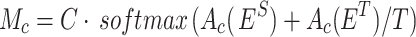 |
19 |
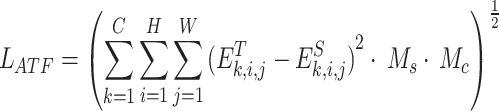 |
20 |
where 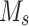 and
and 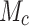 denote feature masks based on spatial attention and channel attention, respectively, and
denote feature masks based on spatial attention and channel attention, respectively, and 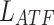 denotes the attentional dimension loss function.
denotes the attentional dimension loss function.
Data set of tunnel lining defect
Dataset acquisition
Research for the current tunnel lining data acquisition faces challenges such as high detection costs, difficulties in detection, and limited penetration of technical equipment, the latest radar detection equipment TGRI-GPR to obtain data, the work process is shown in Fig. 9.
Fig. 9.

TGRI-GPR working process.
TGRI-GPR identifies different cross-sections or objects by sending short pulses of electromagnetic waves and recording the reflected signals, and identifying different cross-sections or objects by time-domain analysis of the propagation time and amplitude of the reflected signals, with the specific parameters shown in Table 1.
Table 1.
TGRI-GPR device parameters.
| Name | Configure |
|---|---|
| Equipment Model | TGRI-GPR |
| Center Frequency | 200 MHz |
| Operating Bandwidth | 100 MHz-500 MHz |
| Depth of detection | 3 m |
| Dynamic Range | 40dB |
Dataset processing
We used the latest radar detection equipment, TGRI-GPR, to acquire the data, collected a total of 3,713 defect images from a tunnel research and design institute in Xi’an and a tunnel project in Zhengzhou, and rotated, cropped, and panned the images, added noise, performed flipping and mirroring, and scaled and applied Cutout and CutMix techniques to the original dataset to Enhancements were made to generate an additional 5,709 defective images to improve the robustness of the model. In selecting the dataset, we considered noise, color gradient, and multiple defects, aiming to construct a highly generalized dataset. Figure 10 shows examples of different types of tunnel lining cracks. The construction of this dataset was guided by domain experts and manual labeling was done. To ensure the authenticity of feature extraction and validation, We divided the dataset according to the ratio of training set: test set: validation set as 7:2:1. The training set is used for model training and weight determination, the validation set influences the optimization of network structure and hyperparameters, and the test set is used to test the optimization performance of the model.
Fig. 10.

Original defect image.
The defect images are categorized into five types such as BM, TK, KD, CS and YBM, which represent five types of defects, namely, incompactness, dehiscence, voids, water-filling and severe incompactness, respectively. Table 2 demonstrates the distribution of the dataset species defect images.
Table 2.
Distribution of defective datasets.
| Type | Training | Validation | Test | Label |
|---|---|---|---|---|
| BM | 1301 | 114 | 76 | 0 |
| TK | 1815 | 127 | 139 | 1 |
| KD | 904 | 78 | 254 | 2 |
| CS | 1136 | 80 | 197 | 3 |
| YBM | 1175 | 111 | 107 | 4 |
Experiment of tunnel lining defect detection
The experimental study of tunnel lining defect detection is divided into three parts: (1) ablation experiments on the effect of improved C3CSFM, MDFPN, and RWNMS on the accuracy of the YOLOv5 teacher network model; (2) comparison experiments between the improved multidimensional knowledge distillation algorithm and the original knowledge distillation algorithm; (3) evaluating the performance of improved multidimensional knowledge distillation algorithm through a test set. For software the operating system is Linux, the programming language is Python 3.7 version, the deep learning framework is Pytorch1.8.2, and mmcv and mmdetection etc. are used as the network base framework to build, the versions are 0.5.6 and 2.0.0 respectively, and all the code is integrated into Pycharm2020.3 to carry out. The hardware used GPU is NVIDIA-RTX3090 with 24G video memory and CPU is Intel(R) Core i3-8100.
Table 3 shows some of the trainable parameters in the deep learning model, which are obtained by backpropagation and optimization on the training data to minimize the loss function of the model.
Table 3.
Parameter settings for the training process.
| Name | Value |
|---|---|
| Pixel | 640 × 640 |
| Epoch | 100 |
| Batch size | 32 |
Experiment indicators
In this study, the experimental main mean accuracy value (mAP) and parametric quantitative indicators are used to evaluate the effectiveness of the model in detecting defects in tunnel roadbeds as in Eqs. 21–23:
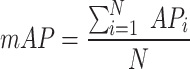 |
21 |
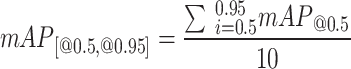 |
22 |
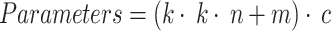 |
23 |
where AP denotes the recall rate, i.e., the proportion of all positive cases that are detected as positive as in Eq. 24:.
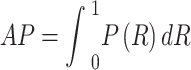 |
24 |
where P denotes the average accuracy value, i.e., the proportion of samples detected as positive cases that are truly positive cases as in Eq. 25:
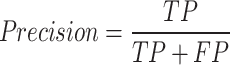 |
25 |
where TP denotes the number of detection frames with positive detection results and FP denotes the number of detection frames with negative detection results.
Teacher model ablation experiment
In order to verify the effectiveness of each improvement module proposed in the study for ablation experiments, YOLOv5 is selected as the detection framework, and the experiments are conducted from the three aspects of the attention mechanism, the feature pyramid network, and the non-extremely large value suppression, and the experimental data are shown in Table 4.
Table 4.
Results of ablation experiments.
| Model | mAP@0.5 (%) |
Size (MB) |
|
|---|---|---|---|
| Yolov5 | 83.4 | 16.03 | |
| Attention mechanism | CA29 | 82.8 | 13.8 |
| CBAM30 | 83.9 | 14.3 | |
| CSFM31 | 84.9 | 13.2 | |
| C3CSFM | 87.7 | 13.7 | |
| FPN | SPD32 | 85.8 | 16.7 |
|
Mobile- Netv333 |
83.2 | 2.97 | |
| ASPP34 | 86.4 | 29.5 | |
| BiFPN35 | 85.7 | 13.7 | |
| MDFPN | 87.6 | 16.8 | |
| NMS |
Alpha -NMS |
85.0 | 13.7 |
|
Merge -NMS |
84.5 | 13.7 | |
| RWNMS | 85.4 | 16.0 | |
| YOLOv5-master | 89.4 | 16.8 | |
As shown in the table, it can be seen that the three improved modules have increased the accuracy by 6% under the premise of ensuring that the number of parameters of the original model is basically unchanged, and can be used as a teacher model in the subsequent distillation process.
Knowledge distillation contrast experiment
Firstly, the loss function data of the YOLO model, the teacher model, the student model and the multi-dimensional knowledge distillation model are represented by scatter plots, and the loss function curve shown in Fig. 11 is obtained. By observing the image, it can be seen that in the 20th round, the loss function begins to converge and then tends to stabilize, and the convergence and stabilization of the loss function value indicates that the model gradually reaches the optimal state.
Fig. 11.

Comparison of the loss function curves of the four models, in which orange is the original model, purple is the improved teacher model, green is the student model, and red is the multidimensional knowledge distillation model.
In addition, to validate the generalization ability of the model to highlight the importance of each module, the study counted the detection results of each model on different defect types, as shown in Fig. 12. The data show that the multi-dimensional distillation model proposed in this paper is better than the original model in various types of tunnel subgrade defects, which further verifies the effectiveness of the model in the detection of tunnel subgrade defects. It also reflects the fact that in the process of knowledge distillation, the student model is as accurate as possible while maintaining lightweight.
Fig. 12.

The accuracy of each framework is compared in the absence of defect types.
In order to verify the feasibility of the multidimensional distillation algorithm proposed in the study was carried out with pruning, quantization and other comparative experiments results are shown in Table 5.
Table 5.
Comparative experimental results.
| Model | P | Q | D | MD | mAP (%) |
Size (MB) |
FPS (img/s) |
|---|---|---|---|---|---|---|---|
| YOLOv5 | × | × | × | × | 83.4 | 16.03 | 16.5 |
| YOLOv5 | √ | × | × | × | 25.7 | 15.08 | 24.0 |
| YOLOv5 | × | √ | × | × | 40.7 | 13.3 | 19.5 |
| YOLOv5-master | × | × | √ | × | 89.4 | 16.8 | 15.5 |
| YOLOv5-master | × | × | × | √ | 85.1 | 4.49 | 14.9 |
| YOLOv5-master | × | × | √ | √ | 86.5 | 3.20 | 14.0 |
Where P denotes pruning, Q denotes quantization, D denotes knowledge distillation, and MD denotes the improved multidimensional knowledge distillation proposed in the study. Through the analysis of the table, it can be seen that, although pruning and quantization can reduce the number of model parameters, the accuracy has dropped significantly, and it requires continuous adjustment of parameters to restore some accuracy later, which is far from meeting our needs. By comparing the two experiments of traditional distillation and multidimensional distillation, it can be seen that the multidimensional distillation algorithm proposed in this paper realizes the compression of 80% of the number of model parameters, and at the same time, the detection accuracy is also improved by 3.1% compared with the original model, even though the FPS is slightly smaller.
Test set validation
The study further tested the tunnel defect dataset and presented the test results through heat map visualization as shown in Fig. 13. As can be seen from the previous analysis, the improved multidimensional knowledge distillation algorithm improves the detection efficiency significantly relative to the original YOLOv5 algorithm, in which the number of references is reduced by 80.0% from 16.03 MB to 3.20 MB; the accuracy is improved by 3.1% from 83.4 to 86.5%; the prediction accuracies of the various types of defects are also significantly improved, and the detection frames are more closely matched with the targets to be inspected; at the same time, the proposed improved algorithm is also able to detect defects missed or detected by the original yolov5 algorithm by adding residual networks as well as RWNMS, which is shown in Fig. 13. The accuracy of the prediction of various types of defects is also significantly improved, and the matching between the detection frame and the target to be detected is much closer; meanwhile, the algorithm proposed in this study is also able to detect small targets that are missed or wrongly detected by the original algorithm. At the same time, the proposed algorithm is also able to detect small targets that are missed or wrongly detected by the original algorithm. These improvements highlight the superiority and effectiveness of the proposed algorithm over the existing algorithms.
Fig. 13.

Comparison chart of results visualization.
Conclusion
A new intelligent tunnel lining defect detection algorithm based on the idea of knowledge distillation is proposed. The algorithm effectively solves the problems of complex detection model, poor real-time performance and low accuracy of the current tunnel lining defect detection methods. The main conclusions are as follows:
By adding C3CSFM module, MDFPN network, and RWNMS mechanism to the YOLOv5 model, the YOLOv5-master teacher model is proposed. The influence of background information on feature extraction is suppressed, and high-precision detection of tunnel lining defects is realized.
By comparing the performance of pruning, quantization and distillation algorithms and improving the multidimensional knowledge distillation algorithm based on the idea of knowledge distillation, the lightweight degree of the model is greatly improved, and the space required for parameter storage is reduced.
The number of parameters of the improved multidimensional rectification algorithm is reduced by 80.0%, from 16.03 MB to 3.20 MB; the accuracy is improved by 3.1%, from 83.4 to 86.5%; at the same time, the situation of error detection and omission detection of small targets is improved.
On the basis of this work, we put forward the following prospects:
To address the difficulty in obtaining data on tunnel lining defects and the lack of sample data, we plan to increase the number of samples through adversarial generation.
Conduct deeper research on the problem that small and unbalanced samples affect the generalization ability and accuracy of the model in deep learning.
Considering the effect of temperature T on the learning effect in the distillation process, how to dynamically adjust T to maximize the efficiency in the distillation process will also become a major problem.
Acknowledgements
This study is funded by the Key Science and Technology Project of Henan Province (222102210135).
Authors’ contributions
Conceptualization, ZAF; Methodology, XJX; Software, XJX and GH; Validation, GZL and WB; Formal analysis, WJ; Investigation, XL and ZSX; Resources, GH; Data curation, WJ; Writing—original draft, WJ; Writing—review & editing, XJX; Supervision, ZAF and YZP; Project administration, YZP. All authors have read and agreed to the published version of the manuscript.
Data availability
Data supporting the results of this study are available from the corresponding author upon reasonable request.
Declarations
Competing interests
The authors declare no competing interests.
Footnotes
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
References
- 1.Jiang, Y., Zhang, X. & Taniguchi, T. Quantitative Condition Inspection and Assessment of Tunnel Lining (Automation in Construction, 2019). [Google Scholar]
- 2.Han, S. et al. Learning both weights and connections for efficient neural network [J]. Advances in neural information processing systems. (2015).
- 3.Molchanov, P., Tyree, S., Karras, T., Aila, T. & Kautz, J. Pruning convolutional neural networks for resource efficient transfer learning (2016). [Google Scholar]
- 4.Hassibi, B. & Stork, D. G. Second Order Derivatives for Network Pruning: Optimal Brain Surgeon (Neural Information Processing Systems, 1992). [Google Scholar]
- 5.Wen, W. et al. Learning structured sparsity in deep neural networks [J]. Advances in neural information processing systems. (2016).
- 6.Rui, Y., Huang, T. S. & Chang, S-F. Image retrieval: current techniques, promising directions, and open issues [J]. J. Visual Communication Image Representation. 10 (1), 39–62 (1999). [Google Scholar]
- 7.Choi, J., Wang, Z., Venkataramani, S., Chuang, I. J. & Gopalakrishnan, K. Pact: parameterized clipping activation for quantized neural networks (2018). [Google Scholar]
- 8.Zhou, A., Yao, A., Guo, Y., Xu, L. & Chen, Y. Incremental network quantization: towards lossless cnns with low-precision weights (2017). [Google Scholar]
- 9.Gong, R. et al. Differentiable Soft quantization: bridging full-Precision and low-bit neural networks. 2019 IEEE/CVF Int. Conf. Comput. Vis. (ICCV). 4851, 4860 (2019). [Google Scholar]
- 10.Hinton, G., Vinyals, O. & Dean, J. Distilling the knowledge in a neural network. Comput. Sci.14 (7), 38–39 (2015). [Google Scholar]
- 11.Gou, J., Yu, B., Maybank, S. J. & Tao, D. Knowledge distillation: a survey. Int. J. Comput. Vision. 129 (6), 1789–1819 (2021). [Google Scholar]
- 12.Howard, A. G. et al. Mobilenets: efficient convolutional neural networks for mobile vision applications (2017). [Google Scholar]
- 13.Zhang, X., Zhou, X., Lin, M. & Sun, J. Shufflenet: an extremely efficient convolutional neural network for mobile devices (2017). [Google Scholar]
- 14.Han, K., Wang, Y., Tian, Q., Guo, J. & Xu, C. GhostNet: More Features From Cheap Operations. 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). IEEE. (2020).
- 15.Szegedy C. et al. "Going deeper with convolutions," 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 1–9 (Boston, 2015). 10.1109/CVPR.2015.7298594.
- 16.Liu, J. et al. Lightweight defect detection equipment for Road tunnels. IEEE Sens. J.10.1109/JSEN.2023.3320816 (2024). [Google Scholar]
- 17.Liao, J. et al. Automatic Tunnel Crack Inspection Using an Efficient Mobile Imaging Module and a Lightweight CNN, in IEEE Transactions on Intelligent Transportation Systems, vol. 23, no. 9, pp. 15190–15203, Sept. 2022, doi: (2022). 10.1109/TITS.2021.3138428.\
- 18.Tan, L., Xiaoxi, H., Tang, T. & Yuan, D. A lightweight metro tunnel water leakage identification algorithm via machine vision, Engineering Failure Analysis. 150, 107327. https://doi.org/10.1016/j.engfailanal.2023.107327 (2023).
- 19.Situ, Z., Teng, S., Liao, X., Chen, G. & Zhou, Q. Real-time sewer defect detection based on YOLO network, transfer learning, and channel pruning algorithm. J. Civil Struct. Health Monit.14, 41–57 (2023). [Google Scholar]
- 20.Zhang, C. et al. “Attention mechanism and texture contextual information for steel plate defects detection.” J. Intell. Manuf.35, 2193–2214 (2023).
- 21.Li, Y. & Bao, T. A real-time multi-defect automatic identification framework for concrete dams via improved YOLOv5 and knowledge distillation. J. Civil Struct. Health Monit.13, 1333–1349 (2023). [Google Scholar]
- 22.Ruan, D. et al. Light convolutional neural network by neural architecture search and model pruning for bearing fault diagnosis and remaining useful life prediction. Sci. Rep.13, 5484. 10.1038/s41598-023-31532-9 (2023). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 23.Zhang, Y. et al. Surface defect detection of wind turbine based on lightweight YOLOv5s model. Measurement. 220, 113222 (2023). [Google Scholar]
- 24.He, K., Zhang, X., Ren, S. & Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition 770–778 (2016). [Google Scholar]
- 25.Mahasin, M. & Dewi, I. A. Comparison of cspdarknet53, cspresnext-50, and efficientnet-b0 backbones on Yolo v4 as object detector. Int. J. Eng. Sci. Inform. Technol.2 (3), 64–72 (2022). [Google Scholar]
- 26.Vadera, S. & Ameen, S. Methods for pruning deep neural networks. IEEE Access.10, 63280–63300 (2022). [Google Scholar]
- 27.Gholami, A. et al. A survey of quantization methods for efficient neural network inference. In Low-Power Computer Vision (291–326). Chapman and Hall/CRC. (2022). [Google Scholar]
- 28.Gong, M. et al. A review of non-maximum suppression algorithms for deep learning target detection. In Seventh Symposium on Novel Photoelectronic Detection Technology and Applications (Vol. 11763, pp. 821–828). SPIE. (2021).
- 29.Park, H. et al. “C3: Concentrated-Comprehensive Convolution and its application to semantic segmentation.” arXiv: Computer Vision and Pattern Recognition. n. pag. (2018).
- 30.Hou, Q., Zhou, D. & Feng, J. Coordinate attention for efficient mobile network design. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition 13713–13722 (2021). [Google Scholar]
- 31.Woo, S., Park, J., Lee, J. Y. & Kweon, I. S. Convolutional block attention module. In Proceedings of the European conference on computer vision (ECCV) 3–19 (2018). [Google Scholar]
- 32.Cui, H., Shen, S., Gao, X. & Hu, Z. CSfM: Community-based structure from motion. In 2017 IEEE International Conference on Image Processing (ICIP) 4517–4521 (2017) (IEEE). [Google Scholar]
- 33.Azushima, A., Kopp, R., Korhonen, A., Yang, D. Y., Micari, F., Lahoti, G. D., … Yanagida,A. (2008). Severe plastic deformation (SPD) processes for metals. CIRP annals, 57(2),716–735.
- 34.Koonce, B. & Koonce, B. MobileNetV3. Convolutional Neural Networks with Swift for Tensorflow125–144 (Image Recognition and Dataset Categorization, 2021). [Google Scholar]
- 35.Sullivan, A. & Lu, X. A. S. P. P. ASPP: a new family of oncogenes and tumour suppressor genes. Br. J. Cancer. 96 (2), 196–200 (2007). [DOI] [PMC free article] [PubMed] [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.
Data Availability Statement
Data supporting the results of this study are available from the corresponding author upon reasonable request.