

Abstract
Object detection in point clouds is essential for various applications, including autonomous navigation, household robots, and augmented/virtual reality. However, during voxelization and Bird’s Eye View transformation, local point cloud data often remains sparse due to non-target areas and noise points, posing a significant challenge for feature extraction. In this paper, we propose a novel mechanism named Keypoint Guided Sparse Attention (KGSA) to enhance the semantic information of point clouds by calculating Euclidean distances between selected keypoints and others. Additionally, we introduce Instance-wise Box Aligning, a method for expanding predicted boxes and clustering the points within them to achieve precise alignment between predicted bounding boxes and ground-truth targets. Experimental results demonstrate the superiority of our proposed SPBA-Net in 3D object detection on point clouds compared to other state-of-the-art methods.The datasets used and/or analysed during the current study available from the corresponding author on reasonable request.
Keywords: 3D object detection, Keypoint guided sparse attention, Instance-wise box aligning
Subject terms: Computer science, Information technology
Introduction
Currently, real-time monitoring of surrounding environment is integral to tasks such as autonomous driving, navigation1,2, housekeeping robots3, and augmented/virtual reality4. To achieve this objective, many studies leverage multiple sensors to capture information about the surrounding environment, with the primary focus on obtaining images and point cloud data through cameras and LiDARs.
While cameras provide valuable visual data, they often struggle with challenges such as object shadows and varying lighting conditions, which can significantly hinder object detection. In contrast, LiDARs generate point clouds that are less affected by these environmental factors, offering a more robust alternative. However, the sparsity of point clouds generated by LiDARs, especially after voxelization5, presents its own set of challenges. Non-target points and noise contribute to substantial sparsity in local point cloud data, complicating feature extraction and reducing the accuracy of target detection.
To address the challenges of sparse point clouds, we introduce our Keypoint Guided Sparse Attention, a novel attention mechanism that focuses on identifying key points and using Euclidean distance to filter out noise and outliers, improving feature extraction beyond previous methods.
We also propose Instance-wise Box Aligning to improve bounding box accuracy. This method includes Box Extension to expand predicted boxes and Semantic Clustering using Point Pair Features (PPF) to accurately align boxes with the true target boundaries, overcoming alignment issues present in previous methods.
Generally, this study is interested in:
Introducing Keypoint Guided Sparse Attention. We propose a novel attention mechanism specifically designed to address the challenges of sparse point clouds. Unlike existing methods such as SVGA-Net6, our Keypoint Guided Sparse Attention approach focuses on identifying key points and assessing their similarity using Euclidean distance. This effectively filters out outliers and noise, improving the robustness of feature extraction.
Instance-wise Box Aligning. To address the issue of bounding boxes misaligning with voxel boundaries, we introduce a two-step method. First, we expand the predicted box boundaries in the Box Extension stage. Second, we apply Semantic Clustering stage based on Point Pair Features (PPF) to accurately align the boxes with the true target boundaries. This method ensures a more precise alignment and enhances the accuracy of 3D object detection in sparse point cloud scenarios.
Related work
Point cloud object detection
In recent years, owing to the rapid advancement of deep learning technologies, various outstanding 3D object detection methods based on point clouds have been proposed.
PointNet7, as a pioneering research, introduced convolution operations to point cloud tasks. It models point cloud information at a global level, yet its capability to extract local structures is not ideal. PointNet++8 addressed this issue by utilizing farthest point sampling (FPS), but it also incurred higher computational costs. Given the similarity between point cloud structures and graph structures, PointConv9 proposed a 3D convolution based on density function weighting, along with corresponding deconvolution operations, enhancing the model’s ability to learn local features of point clouds while accelerating training speed. Kernel Point10 selects all neighboring points within a certain radius for each central point, and similarly employs a kernel function for convolution.
Simultaneously, the immense success of ViT11 in the 2D visual tasks has demonstrated the potential of Transformer structures in computer vision. In recent years, many Transformer-based point cloud models have been proposed12–15. Among them, MLCVNet13, based on VoteNet16, enhances feature representations by encoding contextual information and utilizing self-attention mechanisms to capture the relationship between point clouds and vote clusters, achieving outstanding performance on the ScanNet dataset. Meanwhile, 3DETR15, as the first end-to-end 3D DETR model, achieved an excellent score of 65% on the ScanNetv2 dataset.
These advancements in point cloud processing reflect a broader trend toward enhancing both recognition and tracking capabilities in 3D environments. SOE-Net17 focuses on place recognition by leveraging self-attention and orientation encoding to capture both local and long-range contextual information. CASSPR18 addresses the specific challenge of fine-grained geometric feature matching through a fusion of point-based and voxel-based approaches using cross-attention transformers. Complementing these recognition methods, DMT19 tackles the problem of 3D single object tracking by eliminating the reliance on complex 3D detectors, opting instead for a motion-prediction-based approach that is not only more efficient but also more accurate.
Sparsity in 3D object detection
Point clouds face a significant challenge of sparsity in 3D object detection, with fundamental causes such as long distances and reflections. For instance, in the KITTI1 dataset, only about 3% of the pixels in the corresponding RGB images have corresponding point cloud data when projected. Additionally, mainstream 3D object detection methods, such as VoxelNet5, uniformly divide the acquired point cloud into voxel space, resulting in over 90% of voxels being empty. This excessive sparsity leads to inefficiencies in feature extraction and hinders the accuracy of object detection.
Researchers have proposed various methods to alleviate the sparsity issue in point clouds. For example, 3DSSD20 introduces a fused downsampling strategy combining distance and feature downsampling to balance the quantity of foreground points, ensuring an adequate number of these points. While this method achieves good accuracy and maintains real-time performance (25FPS) on datasets like KITTI1 and nuScenes21, it still relies heavily on downsampling, which can result in the loss of critical spatial information, especially in extremely sparse regions.
Similarly, SASA22 utilizes S-FPS, integrating semantic features and distance information to emphasize foreground points during downsampling. However, this approach may still struggle with capturing sufficient contextual information in areas with extreme sparsity, leading to potential misclassifications.
AGO-Net23 attempts to address sparsity by using point cloud completion and a Siamese network to learn features from complete point clouds. While this method reduces the adverse effects of sparsity, the reliance on completion algorithms introduces an assumption that may not hold in real-world scenarios, where complete data is often unavailable.
In addition to these point cloud-based methods, Sparse Fuse Dense24 explores the fusion of RGB images and point cloud data, considering multi-modal feature-weighted fusion and cross-modal alignment. However, the dependency on high-quality image data may not always be practical in adverse conditions such as poor lighting or occlusion.
Attention mechanism in point cloud tasks
In recent years, following the success of transformers in NLP and 2D vision domains, many studies have attempted to introduce attention mechanisms into point cloud tasks.
For instance, SOE-Net17 improved high-dimensional feature representation by incorporating attention mechanisms. Specifically, this research tackled the problem of place recognition from point cloud data by introducing a self-attention mechanism that incorporates long-range context into point-wise local descriptors. The attention mechanism here emphasizes the long-range contextual relationships between points, ultimately aiming to enhance the network’s feature extraction and recognition capabilities across the entire point cloud, which is crucial for many downstream tasks.
Similarly, PointASNL25 incorporates a local-nonlocal (L-NL) module that leverages attention mechanisms to capture both local and long-range dependencies, significantly enhancing the network’s resilience to noise.
CASSPR18 addresses the specific challenge of fine-grained geometric feature matching by fusing point-based and voxel-based approaches through cross-attention transformers. The emphasis is on using attention mechanisms to merge point-level and voxel-level information, enabling the model to aggregate features from two different levels.
Unlike the above studies, our research introduces the Keypoint Guided Sparse Attention mechanism, specifically designed to address the challenges posed by local point cloud sparsity in object detection tasks. This innovation focuses on overcoming the difficulties associated with sparse point clouds, which can adversely affect the accuracy of target detection.
SPBA-Net
In this section, we introduce our proposed SPBA-Net network for 3D point cloud detection in detail. As shown in Fig. 1, our SPBA-Net mainly consists of three parts: a backbone network, a Keypoint Guided Sparse Attention mechanism, and an Instance-wise Box Aligning module.
Figure 1.

Overview of our porposed SPBA-Net. The input cloud firstly undergoes the backbone, where PointConv9 is used for feature extraction. Afterward, the features are enhanced via our Keypoint Guided Sparse Attention, followed by classification using an RCNN model. The RCNN outputs are refined using Instance-wise Box Aligning to improve the precision of the bounding boxes.
We adopt PointCov9 as our backbone network, as it utilizes 3D relative coordinates and inverse density together with multi-layer perceptrons (MLP) to approximate a weight function for convolving point clouds, enabling better extraction of features from point clouds.
Given a cloud of , with each point , where x, y, z is the coordinates on each axis, is the cloud density at , is the normal vector, and is the reflectivity. Voxelization is a commonly used method which maps a large 3D space into smaller voxels with a fixes resolution. For example, a space of could be mapped into 1,000 voxels with size. Each voxel contains a different numbe of points .
Keypoint guided sparse attention
Despite the high resolution of LiDAR clouds, only a small subset could provide task-related indormation, with other points( non-target area, noise) are not helpful. Target points in clouds remain sparse and easily confused by noise, which hinders semantic feature extraction and reduces detection accuracy.
To address the challenge posed by sparsity of clouds, we propose our Keypoint Guided Sparse Attention (KGSA), a novel attention schema designed to enhance extracted cloud features of PointConv9.
Commonly, the high-dimensional semantic features extracted from the backbone are usually directly input to the subsequent detection head to generate proposals. However, considering the local sparsity of the input point cloud, we first input to a multi-head attention mechanism. Based on the Euclidean distance between each point and key points, a score vector is calculated to enhance the semantic information in , mitigating to some extent the semantic information loss caused by sparsity.
Specifically, given an original point cloud , where N represents the point cloud resolution, we first extract M key points, , using the USIP26 method. These key points are selected as they represent the most informative and stable features within the point cloud. For any key point and any point , the similarity between them is defined as:
| 1 |
where is a hyperparameter used to regularize the distance between and . Using Euclidean distance and regularization parameter help to focus more on the relevance of semantic information in local areas, especially when considering the local sparsity of the point cloud. The non-linear modeling approach of similarity better adapts to the relationships between points and key points in the point cloud.
Next, we compute the attention score for :
| 2 |
where is also a hyperparameter, serving as a threshold to penalize outliers and noise. score effectively integrates the computation of similarity between multiple key points and a given point, applying the softmax function to comprehensively consider multiple contributions from key points.
Instance-wise box aligning
In point cloud object detection, a common challenge is the lack of strict alignment between the predicted bounding boxes and the ground-truth boundaries of objects. This phenomenon is often attributed to the use of voxel-based dimensions in previous studies (Fig. 2). To address this issue, we propose our Instance-wise Box Aligning, which is aimed at enhancing the alignment between the predicted bounding boxes and the ground-truth ones. Our Instance-wise Box Aligning comprises two sub-steps: Box Extension and Semantic Clustering
Figure 2.

The predicted bounding box (pred) and the actual ground truth (gt) box exhibit certain discrepancies, potentially missing some regions of the ground truth or encompassing more background areas than the ground truth.
Box extension
Firstly, in the Box Extension, considering a predicted bounding box from the model as . Assuming that this model has undergone sufficient training, making relatively reliable. To address detail errors, we suggest expanding along the both positive and negative directions of each XYZ axes by k voxels, resulting in the extended bounding box , as shown in Fig. 3. Without exceeding the boundaries, the parameters of can be computed as follows:
| 3 |
Through Box Extension, the range of is expanded. Given that itself is already relatively close to the actual object boundaries, and has been expanded in various directions, it is reasonable to assume that encompasses the detected target without missing any part of it.
Figure 3.
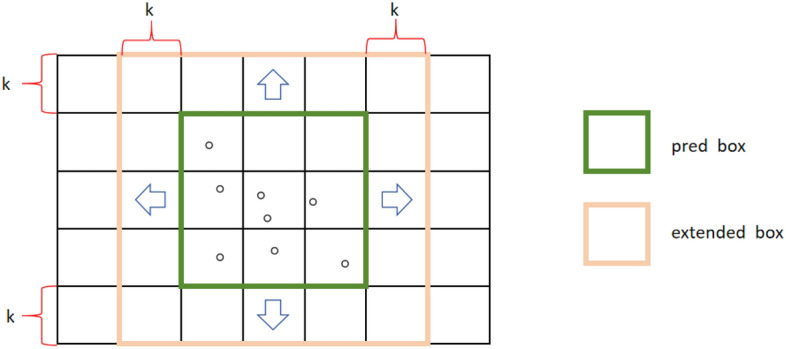
is obtained by extending along both directions of each axes by k voxels.
Semantic clustering
The extended bounding box obtained through Box Extension may encompass noise (points not belong to any detected object). Points belonging to the detected object are defined as . To distinguish between noise and object points, head-crafted feature extraction is firstly performed on all points in , denoted as , where D represents the dimension of the features.
Afterward, a k-means clustering algorithm is applied based on F. Let denote the set of clusters, where is the number of clusters:
| 4 |
Assuming that the k is properly valued in Box Extension, hereby the number of noisy points is considerably fewer than the number of object points |T|. Consequently, from the K clusters, the largest cluster is expected to be the detected instances:
| 5 |
Ultimately, as shown in Fig. 4, by analyzing the coordinates of all points in , the final output is defined as:
| 6 |
Figure 4.
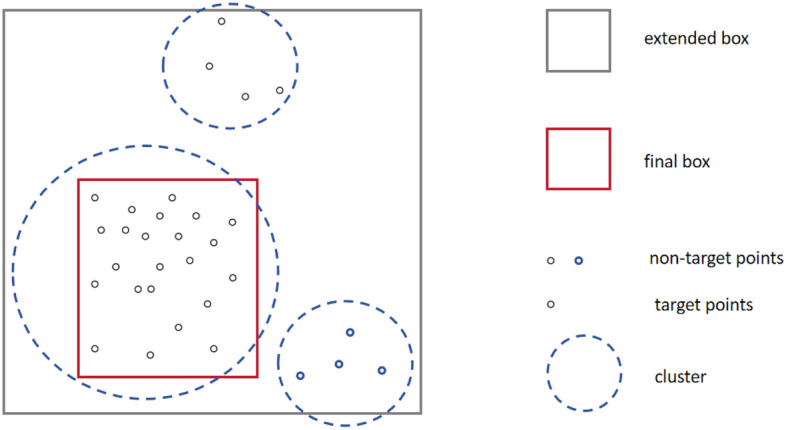
Through k-means clustering, where the largest cluster is considered as the target region, a final bounding box output is derived by analyzing the coordinates of all points within this cluster.
Computational complexity
Keypoint guided sparse attention
Given an input feature map , where C is the number of channels, N is the resolution, and D is the dimension, our Keypoint Guided Sparse Attention mechanism computes a similarity score for each point.
The similarity calcution (Eq. 1) involves the Euclidean distance between the key points and the input cloud, resulting in an intermediate similarity matrix of size , where M is the number of key points. The complexity of this step is then due to the pairwise distance computation across all dimensions. Next, Eq. (2) aggregates the similarity values, incurs a complexity of .
Overall, the computational complexity of our KGSA is dominated by the similarity calculation, leading to a total complexity of .
Instance-wise box aligning
The primary computational complexity of our Instance-wise Box Aligning method lies in the Semantic Clustering stage.
Let’s consider P points inside the box. The PPF feature computation between every pair of points have a complexity of . After that, clusering is applied to group points into semantically meaningful regions. If we use an algorithm like k-means for this operation, which has a complexity around , where T is the number of iterations and k is the number of clusters, the overall complexity would be around .
Experiment
KITTI1 is currently the largest and most popular dataset for object detection in autonomous driving scenarios. It contains high-frequency, real-world image data collected from various urban, rural, and highway scenes, encompassing categories such as cars, pedestrians, and more.
The dataset is divided into training (7481 samples) and testing (7518 samples) sets, covering a wide range of road and traffic scenarios. This large-scale dataset provides researchers with ample resources for developing and evaluating object detection algorithms.
Furthermore, this dataset categorizes the difficulty of detecting different objects into three classes: “Easy,” “Moderate,” and “Hard.” In “Moderate” and “Hard” targets, over 47% and 54% of samples have a resolution of less than 60, with their shapes and structures being extremely incomplete, posing significant challenges to 3D object detection.
Due to its realism and diversity, the KITTI1 dataset has become a preferred benchmark for object detection algorithm research in the field of autonomous driving. Researchers can utilize this dataset for algorithm validation, performance evaluation, and comparison of different algorithms.
We focus on this comparison experiment conducted on the KITTI1 dataset, because it is particularly suitable for our purposes due to its categorization of objects into easy, moderate, and hard difficulty levels, which effectively demonstrates the challenges posed by sparsity in point cloud detection.
Settings
The experiments were conducted on a system equipped with an Intel i7 12700K processor, NVIDIA RTX 3090 GPU, 32GB of RAM running at 3600MHz, Python 3.10, and PyTorch 1.12.0. Throughout the experiments, a learning rate of 0.001, momentum of 0.9, and the Adam optimizer were utilized.
Based on the results in Table 1, we observe the performance of various methods on the KITTI dataset across different difficulty levels. Firstly, we note that as the difficulty increases from Easy to Hard, the object regions become increasingly sparse, thereby increasing the detection challenge. This trend is consistent across all methods, as indicated by the significant decrease in all metrics at the Hard level.
Table 1.
Results on the KITTI dataset. Bold and italics denote best and second best performance, respectively.
| Method | Car | Pedestrain | Cyclist | ||||||
|---|---|---|---|---|---|---|---|---|---|
| Easy | Moderate | Hard | Easy | Moderate | Hard | Easy | Moderate | Hard | |
| VoxelNet5 | 77.82 | 64.74 | 51.57 | – | – | – | – | – | – |
| CenterPoint27 | 81.17 | 73.96 | 67.48 | 47.25 | 38.28 | 36.78 | 73.04 | 56.57 | 50.60 |
| PointPillars28 | 82.58 | 74.31 | 68.99 | 51.45 | 41.92 | 38.89 | 77.10 | 58.56 | 51.92 |
| 3DSSD20 | 88.36 | 79.57 | 74.55 | 56.64 | 44.27 | 40.23 | 82.48 | 64.10 | 56.90 |
| PointRCNN29 | 86.96 | 75.64 | 70.70 | 47.98 | 39.37 | 36.01 | 74.96 | 58.82 | 52.53 |
| PointPainting30 | 82.11 | 71.70 | 67.08 | 50.32 | 40.97 | 37.87 | 77.63 | 63.78 | 55.89 |
| SVGA6 | 87.33 | 80.47 | 75.91 | 48.48 | 40.39 | 37.92 | 78.58 | 62.28 | 54.88 |
| PointGNN31 | 86.96 | 75.64 | 70.70 | 47.98 | 39.37 | 36.01 | 74.96 | 58.82 | 52.53 |
| SPBA-Net(ours) | 86.14 | 81.65 | 77.27 | 48.19 | 42.81 | 40.74 | 78.29 | 66.12 | 57.24 |
For detections at the Moderate and Hard difficulty levels, we observe that SPBA-Net exhibits the best performance for the Car category, achieving 81.65% and 77.27% mAP respectively. Following closely are SVGA6 and 3DSSD20. Similarly, for the Pedestrian and Cyclist categories, SPBA-Net also demonstrates the best performance at the Moderate and Hard levels, being surpassed only by 3DSSD20 in the Moderate difficulty for Pedestrian. Overall, SPBA-Net outperforms 3DSSD20 and SVGA6 slightly at the Moderate level and surpasses all other methods at the Hard level.
Meanwhile, as a reference, we conducted experiments on the nuScenes dataset. Unlike KITTI, nuScenes is a relatively new dataset, and the performance of some older studies may not be optimal on nuScenes. Therefore, we selected studies from the past four years for comparison. As shown in Table 2, our SPBA-Net achieved the best performance in multiple categories such as Truck and Bus. Particularly, in categories like Pedestrian, characterized by severe occlusion and sparsity, the advantage of SPBA-Net over other methods is more pronounced, reaching nearly 88% AP.
Table 2.
Comparison with advanced model on nuScenes dataset. Bold and italics denote best and second best performance, respectively.
| Car | Truck | Bus | Trailer | Constr.Vehicle | Pedestrain | Motorcycle | Bicycle | Traffic cone | Barrier | |
|---|---|---|---|---|---|---|---|---|---|---|
| RAANet32 | 86.87 | 54.60 | 63.60 | 55.30 | 23.70 | 85.60 | 63.30 | 34.00 | 79.40 | 74.90 |
| VISTA33 | 84.49 | 54.20 | 64.00 | 55.00 | 29.10 | 83.60 | 71.00 | 45.20 | 78.60 | 71.80 |
| PointPainting30 | 82.25 | 43.60 | 41.60 | 41.70 | 16.70 | 84.40 | 55.90 | 43.40 | 70.80 | 60.20 |
| CVFNet34 | 86.01 | 47.90 | 56.30 | 53.00 | 13.70 | 80.30 | 46.60 | 27.50 | 72.40 | 67.80 |
| AOPNet35 | 85.38 | 50.80 | 60.90 | 58.00 | 22.00 | 84.60 | 64.20 | 34.00 | 77.90 | 68.40 |
| SPBA-Net | 85.74 | 56.82 | 68.03 | 63.74 | 28.70 | 87.92 | 72.18 | 41.66 | 81.80 | 72.39 |
Sparsity study
To further validate the superiority of our proposed SPBA-Net on sparse objects, we conducted experiments on the Car category of the KITTI1 dataset. We randomly sampled all objects in this category at different resolutions. As the sampling rate decreased, the objects became increasingly sparse, posing more significant challenges to the tested model.
In this experiment, we gradually reduced the density of the test data from dense to sparse. We chose the Car category for this experiment because most car targets have relatively high resolutions. Unlike targets of Pedestrian or Cyclist, which inherently exhibit some degree of sparsity, Car targets better demonstrate the process from dense to sparse during sampling. As the sampling rate decreased, the performance metrics of various methods on Car targets decreased more significantly, highlighting the performance of different methods at different target resolutions.
As a reference, we conducted similar experiments on the nuScenes21 dataset. The nuScenes dataset is also collected for autonomous driving scenarios but is sparser in terms of sensor coverage, precision, and density compared to KITTI1.
Figures 5 and 6 illustrate the experimental results on the two datasets. Overall, although our SPBA-Net did not achieve the best performance at higher resolutions (100% and 90%), it gradually demonstrated its advantages as the resolution decreased, particularly performing best at 70% and 60% resolutions, achieving an AP over 70%. In terms of the performance degradation of each method, while methods like 3DSSD20 and RAANet32 performed well at higher resolutions, their performance degraded significantly at lower resolutions. In contrast, the performance degradation of our SPBA-Net was relatively minor.
Figure 5.
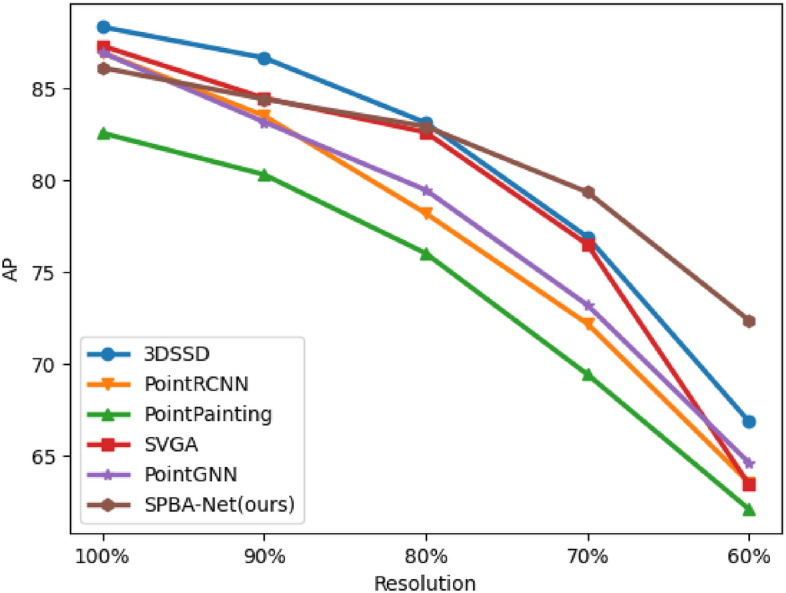
Average precision of different methods on Car category of KITTI dataset with various percent resolutions.
Figure 6.
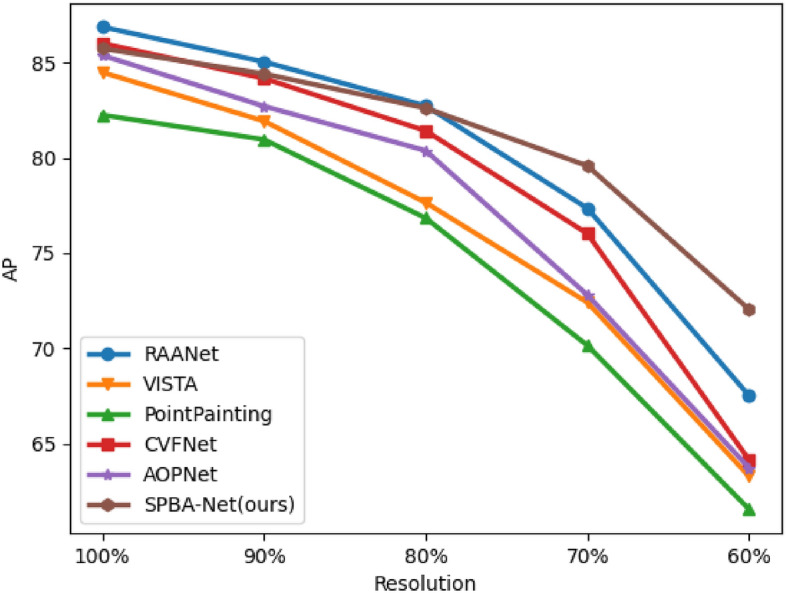
Average precision of different methods on Car category of nuScenes dataset with various percent resolutions.
Ablation study
In this experiment, we compared the baseline model (base) with models that incorporated KGSA, IBA and both KGSA and IBA simultaneously. Results are illustrated in Table 3.
Table 3.
Ablation results. KGSA and IBA denote for keypoint guided sparse attentionand instance-wise box aligning, respectively.
| Method | Car | Pedestrain | Cyclist | ||||||
|---|---|---|---|---|---|---|---|---|---|
| Easy | Moderate | Hard | Easy | Moderate | Hard | Easy | Moderate | Hard | |
| Base | 84.81 | 76.79 | 72.25 | 45.37 | 37.27 | 36.47 | 74.84 | 59.12 | 50.02 |
| Base+KGSA | 84.96 | 79.38 | 75.67 | 46.73 | 42.13 | 40.54 | 75.36 | 63.58 | 55.11 |
| Base+IBA | 85.74 | 80.55 | 74.92 | 47.89 | 40.91 | 39.62 | 76.70 | 62.77 | 54.76 |
| Base+KGSA+IBA | 86.14 | 81.65 | 77.27 | 48.19 | 42.81 | 40.74 | 78.29 | 66.12 | 57.24 |
The results presented in Table 3 effectively validate the distinct roles of KGSA and IBA. Specifically, KGSA addresses the detection challenges posed by point cloud sparsity, while IBA refines the predicted boxes generated by the model. Therefore, for objects with higher resolutions like the Easy level, the improvement brought by KGSA may not be as pronounced as IBA, as IBA can rely on rich semantic feature information to refine the boxes. However, as the difficulty level increases and the target regions become increasingly sparse, the efficacy of KGSA becomes more apparent. The significant improvement observed in the Moderate and Hard levels can be attributed to KGSA, complementing the role of IBA.
Incorporating both KGSA and IBA simultaneously, optimal performance is achieved across all categories and difficulty levels, reaffirming the effectiveness of KGSA and IBA. Particularly noteworthy is the superior performance in the Cyclist category under the Hard difficulty level, surpassing all other models, achieving an AP at 57%, which further verifies the significance of KGSA and IBA in addressing point cloud sparsity issues and enhancing detection performance.
In summary, KGSA and IBA, as two innovative components, effectively enhance the base model’s performance. Their combined effect yields the best results, further confirming their importance in addressing point cloud sparsity issues and improving detection performance.
Time efficiency
In this section, we performed a comparison among different methods in terms of time efficiency. As shown in Table 4, our method shows competitive time efficiency across different cloud resolutions. At 50,000 points, it processes in 21 milliseconds, outperforming PointRCNN and CenterPoint, though SVGA is faster at 8 milliseconds. As the resolution increases to 100,000 points, our method’s time of 74 milliseconds remains efficient, surpassing CenterPoint and PointRCNN, even though SVGA still leads.
Table 4.
Time efficiency comparison between different methods in different cloud resolution. The results are in the unit of milliseconds.
Conclusion
In conclusion, this study proposed SPBA-Net, a novel approach for 3D object detection in point clouds. Through extensive experiments, we demonstrated the effectiveness of SPBA-Net in addressing the challenges posed by sparse point cloud data. By incorporating Keypoint Guided Sparse Attention and Instance-wise Box Aligning, SPBA-Net achieved significant improvements in detection performance, particularly in scenarios with sparse and challenging environments. Furthermore, by conducting experiments on both KITTI and nuScenes datasets, we validated the robustness and generalization ability of SPBA-Net across different datasets with varying levels of sparsity. Notably, SPBA-Net showcased superior performance as the resolution of the targets decreased, underscoring its effectiveness in handling sparse objects. Overall, the results highlight the importance of addressing point cloud sparsity issues in 3D object detection tasks, and SPBA-Net offers a promising solution to enhance detection performance in challenging real-world scenarios. Future research directions may involve further optimizations and extensions of SPBA-Net to tackle additional challenges in the field of autonomous driving and beyond.
Limitation
Although our method has achieved good experimental results, we have also noticed a number of other aspects, such as masking36,37, in the future work we will consider the solution of this problem
Author contributions
Haojie Sha and Hao Zeng:Conceptualization, Methodology, SoftwarePriya Singh.: Data curation, Writing- Original draft preparation.Kai Li and Qingrui.Gao: Visualization, Investigation. Wang Li and Xuande Zhang: Software, Validation.Xiaohui Wang:Writing- Reviewing and Editing.
Declarations
Competing interests
The authors declare no competing interests.
Footnotes
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
These authors contributed equally: Qingrui Gao and Hao Zeng.
References
- 1.Geiger, A., Lenz, P. & Urtasun, R. Are we ready for autonomous driving? The kitti vision benchmark suite. In 2012 IEEE Conference on Computer Vision and Pattern Recognition. 3354–3361 (IEEE, 2012).
- 2.Gomez-Ojeda, R., Briales, J. & Gonzalez-Jimenez, J. Pl-svo: Semi-direct monocular visual odometry by combining points and line segments. In 2016 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). 4211–4216 (IEEE, 2016).
- 3.Oh, Y.-J. & Watanabe, Y. Development of small robot for home floor cleaning. In Proceedings of the 41st SICE Annual Conference. SICE 2002. Vol. 5. 3222–3223 (IEEE, 2002).
- 4.Park, Y., Lepetit, V. & Woo, W. Multiple 3D object tracking for augmented reality. In 2008 7th IEEE/ACM International Symposium on Mixed and Augmented Reality. 117–120 (IEEE, 2008).
- 5.Zhou, Y. & Tuzel, O. Voxelnet: End-to-end learning for point cloud based 3D object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 4490–4499 (2018).
- 6.He, Q., Wang, Z., Zeng, H., Zeng, Y. & Liu, Y. Svga-net: Sparse voxel-graph attention network for 3D object detection from point clouds. Proc. AAAI Conf. Artif. Intell. 36, 870–878 (2022). [Google Scholar]
- 7.Qi, C. R., Su, H., Mo, K. & Guibas, L. J. Pointnet: Deep learning on point sets for 3D classification and segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 652–660 (2017).
- 8.Qi, C. R., Yi, L., Su, H. & Guibas, L. J. Pointnet++: Deep hierarchical feature learning on point sets in a metric space. Adv. Neural Inf. Process. Syst. 30 (2017).
- 9.Wu, W., Qi, Z. & Fuxin, L. Pointconv: Deep convolutional networks on 3d point clouds. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 9621–9630 (2019).
- 10.Thomas, H. et al. Kpconv: Flexible and deformable convolution for point clouds. In Proceedings of the IEEE/CVF International Conference on Computer Vision. 6411–6420 (2019).
- 11.Dosovitskiy, A. et al. An image is worth 16 x 16 words: Transformers for image recognition at scale. arXiv preprint arXiv:2010.11929 (2020).
- 12.Pan, X., Xia, Z., Song, S., Li, L. E. & Huang, G. 3d object detection with pointformer. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 7463–7472 (2021).
- 13.Xie, Q. et al. Mlcvnet: Multi-level context votenet for 3D object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 10447–10456 (2020).
- 14.Liu, Z., Zhang, Z., Cao, Y., Hu, H. & Tong, X. Group-free 3d object detection via transformers. In Proceedings of the IEEE/CVF International Conference on Computer Vision, 2949–2958 (2021).
- 15.Misra, I., Girdhar, R. & Joulin, A. An end-to-end transformer model for 3d object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision. 2906–2917 (2021).
- 16.Qi, C. R., Litany, O., He, K. & Guibas, L. J. Deep hough voting for 3d object detection in point clouds. In proceedings of the IEEE/CVF International Conference on Computer Vision. 9277–9286 (2019).
- 17.Xia, Y. et al. Soe-net: A self-attention and orientation encoding network for point cloud based place recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 11348–11357 (2021).
- 18.Xia, Y. et al. Casspr: Cross attention single scan place recognition. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV). 8461–8472 (2023).
- 19.Xia, Y., Wu, Q., Li, W., Chan, A. B. & Stilla, U. A lightweight and detector-free 3d single object tracker on point clouds. IEEE Trans. Intell. Transport. Syst. 24, 5543–5554 (2023). [Google Scholar]
- 20.Yang, Z., Sun, Y., Liu, S. & Jia, J. 3dssd: Point-based 3d single stage object detector. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 11040–11048 (2020).
- 21.Caesar, H. et al. nuscenes: A multimodal dataset for autonomous driving. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 11621–11631 (2020).
- 22.Chen, C., Chen, Z., Zhang, J. & Tao, D. SASA: Semantics-augmented set abstraction for point-based 3d object detection. Proc. AAAI Conf. Artif. Intell. 36, 221–229 (2022). [Google Scholar]
- 23.Du, L. et al. Ago-net: Association-guided 3d point cloud object detection network. IEEE Trans. Pattern Anal. Mach. Intell. 44, 8097–8109 (2021). [DOI] [PubMed] [Google Scholar]
- 24.Wu, X. et al. Sparse fuse dense: Towards high quality 3d detection with depth completion. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 5418–5427 (2022).
- 25.Yan, X., Zheng, C., Li, Z., Wang, S. & Cui, S. Pointasnl: Robust point clouds processing using nonlocal neural networks with adaptive sampling. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 5589–5598 (2020).
- 26.Li, J. & Lee, G. H. Usip: Unsupervised stable interest point detection from 3d point clouds. In Proceedings of the IEEE/CVF International Conference on Computer Vision. 361–370 (2019).
- 27.Yin, T., Zhou, X. & Krahenbuhl, P. Center-based 3d object detection and tracking. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 11784–11793 (2021).
- 28.Lang, A. H. et al. Pointpillars: Fast encoders for object detection from point clouds. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 12697–12705 (2019).
- 29.Shi, S., Wang, X. & Li, H. Pointrcnn: 3d object proposal generation and detection from point cloud. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 770–779 (2019).
- 30.Vora, S., Lang, A. H., Helou, B. & Beijbom, O. Pointpainting: Sequential fusion for 3d object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 4604–4612 (2020).
- 31.Shi, W. & Rajkumar, R. Point-gnn: Graph neural network for 3d object detection in a point cloud. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 1711–1719 (2020).
- 32.Lu, Y. et al. Range-aware attention network for lidar-based 3d object detection with auxiliary point density level estimation. arXiv:2111.09515 (2022).
- 33.Deng, S., Liang, Z., Sun, L. & Jia, K. Vista: Boosting 3D object detection via dual cross-view spatial attention. arXiv:2203.09704 (2022).
- 34.Gu, J. et al. Cvfnet: Real-time 3d object detection by learning cross view features. arXiv:2203.06585 (2022).
- 35.Xu, Y., Fazlali, H., Ren, Y. & Liu, B. Aop-net: All-in-one perception network for joint lidar-based 3d object detection and panoptic segmentation. arXiv:2302.00885 (2023).
- 36.Xia, Y., Xu, Y., Wang, C. & Stilla, U. Vpc-net: Completion of 3d vehicles from mls point clouds. ISPRS J. Photogramm. Remote Sens. 166-181. 10.1016/j.isprsjprs.2021.01.027 (2021).
- 37.Xia, Y. et al. Asfm-net: Asymmetrical Siamese Feature Matching Network for Point Completion (Cornell University, 2021). [Google Scholar]