

Abstract
The goal of this work was to quantify the effect of school closure during the first year of coronavirus disease 2019 (COVID-19) pandemic in Switzerland. This allowed us to determine the usefulness of school closures as a pandemic countermeasure for emerging coronaviruses in the absence of pharmaceutical interventions. The use of multivariate endemic-epidemic modelling enabled us to analyse disease spread between age groups which we believe is a necessary inclusion in any model seeking to achieve our goal. Sophisticated time-varying contact matrices encapsulating four different contact settings were included in our complex statistical modelling approach to reflect the amount of school closure in place on a given day. Using the model, we projected case counts under various transmission scenarios (driven by implemented social distancing policies). We compared these counterfactual scenarios against the true levels of social distancing policies implemented, where schools closed in the spring and reopened in the autumn. We found that if schools had been kept open, the vast majority of additional cases would be expected among primary school-aged children with a small fraction of cases filtering into other age groups following the contact matrix structure. Under this scenario where schools were kept open, the cases were highly concentrated among the youngest age group. In the scenario where schools had remained closed, most reduction would also be expected in the lowest age group with less effects seen in other groups.
Supplementary Information
The online version contains supplementary material available at 10.1186/s12879-024-09674-6.
Keywords: COVID-19, Endemic–epidemic modelling, Surveillance data, Social contacts, School closure
Introduction
The coronavirus disease 2019 (COVID-19) pandemic disrupted daily life and changes to routines were made in accordance with public health regulations. In 2020, non-pharmaceutical interventions were put in place to reduce exposure to and spread of the disease. It is known that school closures have an effect on social mixing and so school closures are considered useful for some infectious disease outbreaks but not necessarily all [7]. The implications of school closures are manifold and are not restricted to changes in numbers of cases (knock-on effects include decreased socialisation skills among children and economic impacts through the reduced labour of guardians having to shift their focus to child rearing) meaning it is not a policy decision to be made lightly. As not everyone in a population attends school, we need age-stratified surveillance data to answer the question of what the impact of school closure is. In this work, we wish to determine the impact of school closures for COVID-19 control in Switzerland though the methods are applicable to other countries.
In earlier work [2] we considered evidence which suggested the effect of school closure in the canton of Zurich seemed to not be large for the early coronavirus outbreak. The evidence was evaluated in terms of reduction in disease transmission observed through a decrease in cases. The canton of Zurich is the most populous region of Switzerland. The analysis of data from the canton of Zurich suffered from low numbers of observed cases in the youngest age group. This proof-of-concept study provided a starting ground for further developing the methods used to examine these kinds of policy questions using endemic-epidemic models with time-varying weights. We now consider a longer time frame (until the end of 2020) and a greater population (the whole of Switzerland). This also allows us to evaluate the performance of the analysis at a greater resolution. Considering cases at national level rather than regional level induces additional challenges as social distancing policy varies across the country. As our study is not stratified by geographical region–our focus is age groups–these differences in policy need to be incorporated. Here we showcase how to incorporate policy indicators which are more nuanced than those used in our previous work.
The endemic-epidemic framework for infectious disease modelling is a class of time-series based regression models used for the analysis of infectious disease case counts arising from routine surveillance systems. It is a versatile framework which has been applied to the analysis of many disease outbreaks with varying characteristics. Endemic-epidemic modelling is considered a useful tool for emergency response related to infectious disease outbreaks as it fulfils many of the requirements for disaster response models raised by Brandeau et al. [6]. In particular, endemic-epidemic modelling addresses real-world infectious disease problems such as detection of outbreaks and populations at increased risk and is designed for maximum usability by response planners by virtue of being released as open source publications and software which means we avoid issues with disease knowledge being pay-walled during ongoing outbreaks as seen in the 2014 Ebola virus disease outbreak [8]. The framework also makes a good compromise between simplicity and complexity, and due to its statistical nature is designed in a manner which captures inherent uncertainties. Endemic-epidemic modelling facilitates knowing when disease is endemic (prevalence levels are in the range of expected values) and when disease is epidemic (incidence is higher than expected), at which point control measures may need introducing or intensifying. This work provides an insight into how control measures can be incorporated in endemic-epidemic models through the inclusion of time-varying contact matrices.
To accomplish our goal, we fit an endemic-epidemic model to a multivariate time series of age-stratified COVID-19 cases in Switzerland and then examine two counterfactual scenarios of the policy implemented; the true school closures consisted of schools being closed early in the year and reopening for the second half of the year (scenario A). We consider the counterfactual scenarios where schools did not close (always open; scenario B and where the schools remain closed during the second half of the year (always closed; scenario C). The additional scenario is possible due to the longer time frame considered in this work. Scenario B is similar to the scenario considered in our earlier analysis.
Methods
This work is preregistered and has a study protocol [3] which is considered a useful manner of working but currently rare in epidemic modelling. The protocol outlines the modelling considerations we made before work began and may serve as a useful resource for the interested reader.
Data
In this work we consider daily data () where the study period commences on 24th February 2020 and the final observation at time T occurs on 31st December 2020. COVID-19 case data is provided by the Swiss public health authority (Bundesamt für Gesundheit) and includes case counts by date reported stratified by age group. We asked for cases given by the same age groups we considered in our Zurich analysis as this roughly divides the population into those of compulsory education age including compulsory kindergarten/pre-school/reception (0–14 year olds), higher education and young workers (15–24), parents (25–44), middle-aged workers (45–65), retirees (66–79), and the elderly (80+). Our age group thresholds include the commonly used cut-off of 65 years of age considered in epidemiology, when health is expected to change.
Figure 1 shows the case data; the daily number of cases per 100,000 age group population (upper panel), the distribution of cases per 100,000 population over time (middle panel), and cases by weekday reported (lower panel). The upper panel shows the oscillatory behaviour known to epidemic curves as well as weekly systematic fluctuations in surveillance. The middle panel shows a shift in the age distribution of cases across the study period which further motivates the inclusion of age groups in our modelling approach. The lower panel shows the distribution of cases across the days of the week, where we see a systematic fluctuation in the reporting system. The legal workdays in Switzerland are Monday through Friday. Most cases are reported on Mondays which is the start of the week according to European norms and the number of reported cases drops across the week while fewer cases are reported on weekends (Saturday and Sunday).
Fig. 1.

Daily COVID-19 cases per 100,000 population by age group (upper). Relative incidence by age group (middle). Number of cases reported by weekday (lower)
To capture baseline transmission opportunities between age groups we include a contact matrix in our endemic-epidemic model. Contact matrices encapsulate the number of contacts an average person in the population has with other population members of the same and different ages in different settings such as the workplace or school. Their inclusion in the endemic-epidemic framework was an approach introduced by Meyer and Held [17] which provided more realism than making an assumption of mixing patterns for the population. Existing contact diary-based contact matrices for Switzerland are only based on a small number of observations (54 observations) [15], which led us to use a synthetic contact matrix in place of this empirical one. A synthetic contact matrix is constructed on the basis of demographic information. In particular national statistics on household composition, average school class size, age, and employment is used to create a synthetic population. The contact network of this synthetic population is used to determine the contact matrix. Finally, the synthetic contact matrix is calibrated with empirical matrices created for Europe. An overview of other developments for contact matrices can be found in Bekker-Nielsen Dunbar [1].
We chose to use the synthetic matrices by Mistry et al. [18] as they were both 1) newer and 2) given with a certain level of uncertainty which we could incorporate into our modelling approach. The synthetic contact matrix is constructed on the basis of household size, school enrolment records, and employment data (see [18], for details).
From the synthetic contact matrix we obtain the per capita relative frequency of contact between age group a and age group in setting s (shown in Fig. 2 which describes the pattern of mixing in each setting considered) and the disease-specific weights in setting s for constructing contact matrices for respiratory disease, which are 4.11 for household setting, 11.41 for school setting, 8.07 for work setting, and 2.79 for general community setting (shown in Fig. 3). This means school has the largest weight and so changes to these contacts are expected to have the biggest impact. In high income countries (of which Switzerland has the highest income globally), most contacts occur in educational settings [19], so the choice does not seem unreasonable. These construction weights are provided with standard errors. When constructing we used the Swiss population (Table 1) rather than the Zurich population which we considered in earlier work (see [2], for the analysis of Zurich) such that the population used to weight the synthetic contact matrix was the one being studied. This means the contact matrix used in this work is not exactly the same as the one considered previously. The Mistry et al. [18] contact matrices are created with respiratory diseases in mind where school closure is a first line of defence against disease outbreaks. The synthetic contact matrix was used to inform the time-varying transmission weights which determine the amount of transmission between age group a and age group at time t, which is explained in more detail below.
Fig. 2.

Unweighted contact matrices from Mistry et al. [18] via Laboratory for the Modeling of Biological and Socio-technical Systems [16]
Fig. 3.
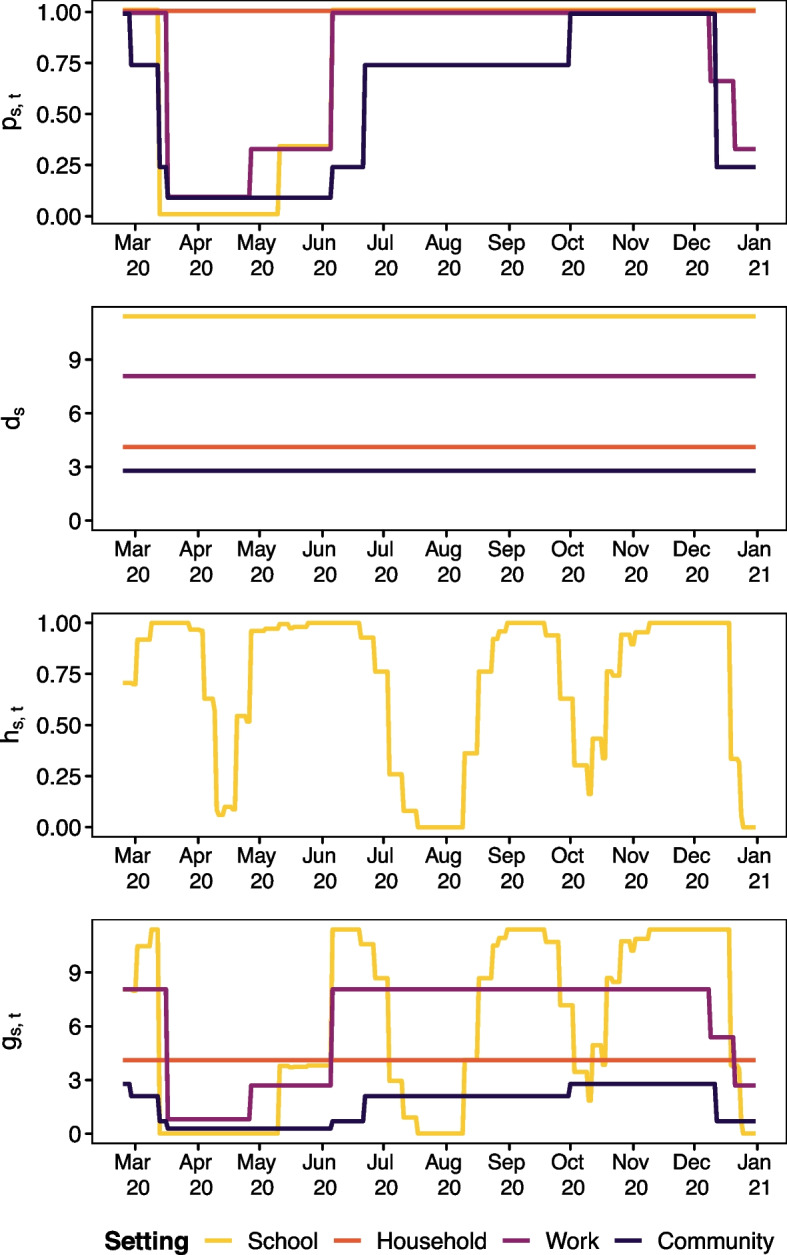
Time series of indicators (), disease setting-specific weights for contact matrices (), and holiday score ( for the school setting). The lowest panel shows the product,
Table 1.
Swiss population counts in 2021 by age group
| Age group | Population count | Proportion |
|---|---|---|
| 0-14 | 1,294,918 | 0.150 |
| 15-24 | 901,783 | 0.105 |
| 25-44 | 2,383,179 | 0.277 |
| 45-65 | 2,511,163 | 0.292 |
| 66-79 | 1,061,320 | 0.123 |
| 80+ | 453,670 | 0.053 |
Contact setting-specific daily policy adjustments are informed by information provided by the Swiss authorities. This information is used to quantify the amount of disease control measures enacted. We focus on those measures which have the aim to decrease contact. Following the Oxford University policy classifications we consider: school closure (“C1”), workplace closure (“C2”), and restrictions on gatherings (“C4”). We code our policy indicators to take the same levels as the Oxford scheme allowing researchers familiar with the controlled vocabulary established by that research group to comprehend our indicators. We reversed and rescaled the indicators such that where 0 reflects a situation of maximal measures in place and 1 is full relaxation of measures (source information is in our study protocol https://osf.io/fgrdy).
The non-pandemic school closure adjustment is created based on information from Schweizerische Konferenz der kantonalen Erziehungsdirektoren [23] and reflects closures of school during the academic year due to half term and other school holidays. These closures reduce contact independently of disease control measures; notably Easter is a period where less contacts in school settings would be expected as Switzerland is a predominantly Christian country. The adjustment takes values where 0 means that all schools in Switzerland are closed on that day and 1 means all schools are open. The values takes for the school setting are shown in Fig. 3 while for all other contact settings (meaning no adjustment). The calculation of is informed by population data from Eurostat [11] (population by region). The construction of , , and is explained in more detail in the following section.
Model
The endemic-epidemic model is a time series regression model used for infectious disease surveillance which sees frequent use for applications which require the incorporation of transmisson between population strata [12, 20, 26]. In an age-stratified endemic-epidemic model, case counts are indexed by time t and age group a. The age groups considered are 0–14, 15–24, 25–44, 45–65, 66–79, and 80+ years; the same used in Bekker-Nielsen Dunbar et al. [2]. Case counts given past cases are assumed to follow an overdispersed negative binomial distribution with age-dependent overdispersion parameters . The mean is additively decomposed into endemic and epidemic components. Log-linear predictors for the endemic and epidemic components are given by and respectively. The endemic component is additionally weighted by population fractions , where we used population data from Eurostat [10] (population by age group), given in Table 1 to inform this part of the model. This functions as a model offset (see [17], for description of model offsets).
The epidemic component is an autoregressive process additionally driven by cases in other age groups in previous time periods up to a maximum lag of where determines by how much previous cases are weighted. We chose to use a Poisson-distributed lag distribution such that the majority of the weight need not be given to the immediately preceeding cases allowing for a serial interval of more than a single day. The maximum lag represents the maximum length of the serial interval we might conceive in our modelling efforts; we chose as the literature suggests early types of COVID-19 have a serial interval within a week [21].
Our endemic-epidemic model with time dependent [2, 13] contact matrix weights [17] and higher order lag [5] is given by
| 1 |
Transmission between age groups is determined by a time-dependent contact matrix . The time-varying contact matrix is the total average contacts at time t constructed by a weighted sum
| 2 |
where is a weight that depends on the setting s the contact occurred in and changes occuring at time t. It is created from the combination of the weights used to construct contact matrices ( given by Mistry et al. [18] which depend on setting s), the time-dependent setting-specific policy adjustments ( which depend on time t and setting s) and whether an adjustment needs to be made to incorporate non-pandemic school closure due to school holidays ( which depends on setting s as it only affects schools and time t):
| 3 |
Since school holidays in Switzerland vary not only between regions, but also within them, we construct binary indicators for all of the sub-regions r within a region R where we assign 1 to a specific day t if t is not a school holiday and 0 otherwise. In a second step, we average the binary indicators of all sub-regions r within a region R in order to obtain a regional average indicator for that day. Subsequently, we use population weights to calculate the national indicator . The sub-regions are unweighted in our averaging as we were not able to determine population sizes at school district level. We calculate
| 4 |
where is an indicator function and denotes the number of sub-regions within region R. This gives us a population-weighted indicator with values which incorporates the variation of number of school children in regions.
We fit the model (1) with predictors
| 5 |
where denotes a fixed effect of age group a, is an indicator for public holidays, is an indicator for weekends, and are effect-coded weekday effects with Monday as the reference value (six in total). Effect-coded variables are also known as sum-to-zero contrasts. This means Monday always takes the value and the weekday of interest takes the value 1 while all other weekdays are 0. We include a non-linear time trend in the form of a sinusoidal wave expressed by its amplitude and phase [22]. Our model has 31 parameters (estimates are given in Table 3) which are estimated using a maximum likelihood approach computed with standard errors. Information on the full model selection procedure (where we also considered effects of temperature, testing rate, and a linear time trend) can be found in the supporting information.
Table 3.
Model parameter estimates
| Endemic | Epidemic | Other parameters | ||||||
|---|---|---|---|---|---|---|---|---|
| Coefficient | Estimate | Std. Error | Coefficient | Estimate | Std. Error | Coefficient | Estimate | Std. Error |
| 2.806 | 0.218 | -3.776 | 0.059 | 0.229 | 0.030 | |||
| 4.868 | 0.185 | -2.482 | 0.043 | 0.125 | 0.013 | |||
| 4.036 | 0.185 | -2.172 | 0.027 | 0.067 | 0.007 | |||
| 2.673 | 0.288 | -2.170 | 0.023 | 0.059 | 0.006 | |||
| 2.246 | 0.321 | -1.883 | 0.027 | 0.074 | 0.009 | |||
| -0.945 | 0.018 | 0.043 | 0.009 | |||||
| 0.378 | 0.021 | |||||||
| 0.119 | 0.022 | |||||||
| -0.032 | 0.022 | |||||||
| 0.001 | 0.022 | |||||||
| -0.404 | 0.023 | |||||||
| -0.684 | 0.024 | |||||||
| -0.850 | 0.100 | |||||||
| -0.582 | 0.462 | -0.327 | 0.063 | |||||
| 2.070 | 0.191 | 0.711 | 0.018 | |||||
| -2.487 | 0.030 | 1.447 | 0.012 | |||||
| 0.082 | ||||||||
Counterfactual scenario prediction
Determining the expected size of the outbreak is crucial to policy makers who need to determine how resources are to be allocated. As the outbreak is ongoing, the predicted final size considered here is the predicted number of infections over the time window considered rather than the traditional metric used by compartmental modellers: the total number of infections over the entire outbreak period. Predicted cases are based on a path trajectory (a long-term expected prediction calculated recursively on the basis of one-step predictions) following Held et al. [14] assuming no changes to the model parameters across the scenarios considered. This means we predict the model (1) with the given and fitted , , and effects for three different versions of (for scenarios A, B, and C). The two counterfactual scenarios are implemented by including transmission weights informed by where g now depends on age group. In particular we consider three scenarios (provided with the shorthand names we use based on their effect on the youngest age group):
Scenario A (“true measures”) This is the true measures scenario where schools closed in the spring and reopened in the summer where is populated by the relevant policy information without adjustment as in (2). This is the same scenario considered in model fitting to obtain the model coefficients used in prediction of final size and simulation of uncertainty for the prediction.
- Scenario B (“schools open”) This is a scenario where schools are never closed for the youngest age group (0–14), i.e. remain open across the entire study period. All other measures are as in Scenario A.
6 - Scenario C (“schools closed”) This is a scenario where schools close and remain closed. School closure once again affects age group 0–14 and their contacts. All other measures are as in Scenario A. We implement this by setting
where denotes the date schools are first closed (16th March 2020).7
The changes only affect age group 0–14 when the contact matrix is multiplied by so the 0–14 row and column in Fig. 2 are changed in the school setting (school aged children and their contacts). The time series of all four setting-specific policy indicators can be seen in Fig. 3 (the building blocks of (2), (6), (7)). The truth (scenario A) is expected to lie somewhere between the two counterfactual scenarios (scenarios B and C), see Table 2. Examining the deviation these scenarios have allows us to evaluate the effect of disease control measures used. It is implicitly assumed that the fitted effects , , do not vary across scenarios.
Table 2.
Overview of starting dates and scenarios considered in 90 day projection windows
| First scenario window | Second scenario window | |
|---|---|---|
| 16th March 2020 | 12th May 2020 | |
| A | Closed | Open |
| B | Open (change) | Open |
| C | Closed | Closed (change) |
To incorporate parameter uncertainty in our projections, we utilise Monte Carlo simulation. We sample the weights with uncertainty estimates given in Mistry et al. [18] assuming they are independently normally distributed. To incorporate model uncertainty we sample the coefficients , , , , of our fitted endemic-epidemic model assuming a multivariate normal distribution; the asymptomatic normal distribution of the maximum-likelihood estimates. Using these samples we then use the path trajectory prediction approach to obtain n simulated expected case counts under the scenarios considered. This enables us to incorporate uncertainty in our projections. We examine the expected increase in cases when schools are always open (scenario B) and the expected decrease in cases when schools are always closed (scenario C) and compare this with the expected number of cases under the policy used (scenario A).
We also conducted sensitivity analyses of the assumptions made in constructing the transmission weights . The sensitivity analyses attempt to provide further realism with respect to how household contacts may be affected by school closure. This provides additional extensions to the analysis of Zurich data as here we only considered household contacts to not be affected by policy . The sensitivity analyses can be found in the supporting information.
Results
In total 256 models were fit to the outbreak data and Bayesian information criterion was used as a goodness-of-fit measure to determine the best fitting model (see the supporting information for details). We chose this as Bayesian information criterion should fit the correct model in theory while Akaike information criterion would be expected to overfit. Due to diverging estimates in the model–likely due to low values in the transmission weights matrix or low case counts observed in certain age groups–models which did not have converging effects were excluded from the selection process. Divergence was determined on the basis of the size of the standard deviation of the estimated model coefficients. It may happen that the additive decomposition into endemic and epidemic components is not identifiable.
In particular, (the fixed effect of the oldest age group in the endemic component) was excluded due to having a very small estimate with a huge standard error. This means the coefficient was restricted to be zero on the log-scale while the corresponding epidemic effect was estimated from the data. The best fitting model has 31 parameters including the lag parameter . The model contains systematic fluctuations in the form of weekly effects, as we expected based on the exploration of the case data, and additional fluctuations in the form of the sinusoidal waves. As we only use one year’s worth of data in this work, we cannot denote this fluctuating trend “seasonality” but with a longer time frame it would be expected to capture such effects. There is not much knowledge about seasonal variation of COVID-19 at the time of analysis so we note that with only one harmonic in the epidemic component and not even a whole year of data, this may induce additional uncertainty in our simulations and predictions.
Model fit
The model has a good fit to the case data based on visual inspection (Fig. 4 upper panel). The endemic proportion is relatively small, about 14% for the two youngest age groups but below 2% for the age groups 45–65 and 66–79. The serial interval peaks somewhat early (Fig. 4 lower panel) compared with what is expected from the literature. This has been observed in other endemic-epidemic models for COVID-19 and is thus likely an artefact of the model.
Fig. 4.

Model fit (coloured area) and observed cases (points) in the different age groups (above) and estimated serial interval distribution (below). The age groups have different y-axis limits in the model fit plots
The parameter estimates in Table 3 suggest fewer cases on weekends and public holidays, which aligns with our intuition based on the exploratory data analysis of the case counts and could reflect changes in contact patterns hence transmission opportunities on those days. The endemic rate is approximately halved during weekends. The other endemic time effects (public holidays and sinusoidal amplitude) are estimated with relatively large uncertainty, which relates to their smaller contribution to the mean. The weekday effects of the epidemic component imply above-average autocorrelation on Tuesdays and Wednesdays, with a similar reduction of about 50% during weekends. The amount of variation in the age-specific parameters is comparable in both model components: the estimates for (scaling the population fractions) range from 9.45 to 130 (with the value for the 80+ group fixed at 1), and the epidemic coefficients (that scale weighted past cases) range from 0.023 to 0.389. The largest overdispersion (excess variance) is found for the youngest age group while the smallest value is found for the oldest age group .
Disease control scenarios
The path trajectories allow us to examine temporal changes that are not evident when projections are summarised as a final size estimate. The counterfactual scenarios’ path trajectories are compared in Fig. 5 which shows the ratio of predicted cases under a counterfactual scenario and predicted cases under the original scenario A for the 90 days after measures were introduced (scenario B, 90 days from 17th March 2020) or lifted (scenario C, 90 days from 12th May 2020). This means we conditioned on fewer days when predicting for scenario B and had higher case counts included in our prediction of scenario C (as April was included). Scenarios A and C show much more distinct behaviour for school-aged children. We see the difference in patterns for age group 0–14 seems to be correlated with school holidays (Fig. 3).
Fig. 5.

Comparison between simulated number of mean cases over 90 days from 17th March 2020 for scenarios A (true measures) and Scenario B (schools open) and 90 days from 12th May 2020 for scenarios A (true measures) and C (schools closed). Showcased are the 10th, 50th, and 90th percentiles of ratios of simulated path trajectories. The ratios of predicted mean cases for scenario B (schools open) divided by those predicted under scenario A (true measures, left) and for scenario C (schools closed) over the number of cases predicted in scenario A (right). The y-axis is log-transformed and is provided with different limits to showcase the different patterns between the age groups as well as focus on the individual patterns themselves
The final epidemic size estimates (with uncertainty bounds) within each scenario are given in Fig. 6 and are calculated by summing the predicted number of cases across the 90 day projection window. Large differences are not found in the final epidemic size estimates (Fig. 6). Table 4 shows the differences and ratios between expected cases of scenario A and scenarios B and C for the 90 day periods. Due to the time-sensitive nature of the policy questions being considered, the focus of this work was not calibration (the match of observations and predictions) but rather the differences in scenarios. We discuss the difficulties of forecasting in more detail in our discussion. We are most interested in the ratio between the predicted case counts: the percentage increase and decrease in cases is at most ten per cent for both scenarios (the ratio is 1.11 for scenario B and 0.99 for scenario C). Most of the effect is found among the youngest group, which have 82 per cent more cases for scenario B and 8 per cent fewer cases for scenario C. The relative difference in expected cases between scenarios A and B suggests that case numbers in the other age groups would not have increased a lot if schools were left open and regarding scenario C, as expected; closing schools decreases cases.
Fig. 6.

Comparison between simulated number of cases over 90 days from 17th March 2020 (left) for scenarios A (true measures) and Scenario B (schools open) and 90 days from 12th May 2020 (right) for scenarios A (true measures) and C (schools closed). Showcased are the 10th, 50th, and 90th percentiles (referenced as P10, P50, and P90, respectively) as well as the observed case counts in the period considered
Table 4.
Comparisons of the number of cases in scenario A (true measures) with the number of cases in scenarios B (schools open) between 17th March 2020 and 90 days and C (schools closed) between 12th May 2020 and 90 days
| B - A | B / A | C - A | C / A | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Age | P10 | P50 | P90 | P10 | P50 | P90 | P10 | P50 | P90 | P10 | P50 | P90 |
| 0-14 | 162.9 | 240.0 | 404 | 1.76 | 1.82 | 1.87 | -27.5 | -20.85 | -16.98 | 0.91 | 0.92 | 0.93 |
| 15-24 | 45.1 | 89.9 | 218 | 1.06 | 1.09 | 1.12 | -16.6 | -9.38 | -5.98 | 0.99 | 0.99 | 1.00 |
| 25-44 | 192.9 | 362.3 | 821 | 1.10 | 1.12 | 1.15 | -64.4 | -36.03 | -23.15 | 0.98 | 0.99 | 0.99 |
| 45-65 | 153.3 | 311.5 | 773 | 1.07 | 1.09 | 1.12 | -55.2 | -30.08 | -18.96 | 0.98 | 0.99 | 0.99 |
| 66-79 | 48.9 | 113.8 | 323 | 1.04 | 1.06 | 1.08 | -13.5 | -6.92 | -4.05 | 0.98 | 0.99 | 0.99 |
| 80+ | 37.3 | 90.5 | 271 | 1.04 | 1.05 | 1.07 | -9.5 | -4.69 | -2.62 | 0.98 | 0.99 | 0.99 |
| Total (summed) | 641.7 | 1,207.1 | 2,820 | 1.09 | 1.11 | 1.13 | -186.0 | -107.83 | -71.69 | 0.98 | 0.99 | 0.99 |
Discussion
In our earlier work attempting to provide evidence-based information for policy makers, we found that an endemic-epidemic model (a two-component model for infectious disease) provided a good fit for data from Zurich, Switzerland [2]. The model had effects of day of the week, public holidays, testing rate, and age in the endemic components and the same effects as well as a centred linear time trend in the epidemic component. This model suggested if there was no school closure, an increase in cases would be expected in the youngest age group (0–14) in April and later in other age groups. After the youngest age group, the next age group expected to experience an increase in cases compared with the true school closure implemented are the parents of the first age group (25–44; parents). In examining Zurich, the main group of concern was the oldest age group (80+) and they were found to be consistently the lowest in terms of expected increase in cases compared with what was projected when schools were closed.
Here we extended this work further motivated by the fact the usefulness of school closure to combat COVID-19 was not fully determined by end of the “first wave”. Schools in Switzerland re-opened after the summer of 2020 but at the time questions of whether to close them remained. Ulyte et al. [24] tested Swiss school children for COVID-19 during the outbreak and concluded that not much transmission was occuring in schools. In our work we were able to examine school closure at greater spatial and temporal scale than previously which is a strength of the approach. Other countries were observed to have different levels of school closure during the study period compared with Switzerland and so the “ideal” amount of closure remains to be determined. We note that school closures are a primary measure for disease control but other measures such as masked students or vaccinated students which seek to reduce within-class disease risk may be a better option later in the outbreak [9]. We remain cognisant that the purpose of school is not just educational and it is important to investigate the impact of this as the knock-on effects to children’s health of remote learning are expected to be a topic of interest for years to come. While the current work considers only the options of schools open or closed, the methodology used could also be used to examine use of masks in educational settings, provided evidence is available to inform the time-varying transmission weights and so is very versatile.
In the age group 80+ we find that incidence is completely explained by the epidemic component so the endemic component was not identifiable and diverged. It is not ideal that was restricted to be zero but the alternative approach of setting all values to be the same would also not have been ideal since the results imply they differ across age groups (Table 3). The analysis we present is ecological as we aggregated our indicators across the federation of Switzerland although they differ across regions. Ideally we would have liked to have done a spatio-temporal analysis across age groups but as we were interested in specific age groups rather than ten-year age bands, we could not utilise the openly available data from the public health authorities, and had to choose to focus on age over age and space.
The uncertainty shown in Fig. 5 is the uncertainty of the predicted mean. Scenario C has more data to predict in the one-step prediction approach used to calculate this mean due to its prediction window starting later. We suspect fewer cases early on in the study period to be the cause of more uncertainty in the left panels of Fig. 5. There is less uncertainty on the predictions in scenario C but we also observed fewer cases (the incidence was low in the summer). Due to the time-sensitive nature of the policy questions being considered, the focus of this work was not calibration (the match of observations and predictions) but rather the differences in scenarios. However, we note that there are greater discrepancies between the predicted number of cases and the true number of cases for the real scenario in the analysis of scenario B (Fig. 6). Scenario B underestimates the number of cases while Scenario C sometimes overestimates the number while the total number of observed cases is within the predictions. The predicted means are made on the basis of the same model which was fit over the entire study period (Fig. 1). The reason for predicting a 90 day window rather than the entire year is that we find it unlikely that a decision maker at a public health agency would not revisit a decision made within a 90 day period, so predicting cases until the end of the period the model is fit on strikes us as a less useful exercise. The large increase in cases at the end of the study period (which the model is fit to) might influence the models ability to predict lower case counts.
We briefly summarise the comparison of results with the Zurich analysis (see [2], for details). By virtue of the shorter time frame of the earlier analysis, we are unable to note similarities and differences with scenario C as this information is not available at Zurich level. The model for Zurich contains more effects than the model used here. The Zurich model has , , , and . Notably, the Zurich analysis has additional time effects while our current model only contains a non-linear time effect in the form of the sinusoidal waves. While the models are different, the estimated discrete-time serial interval is similar. Some of the building blocks used to construct the models are the same for the two studies: and are the same in the two studies. The relative increase (determined by calculating the ratio of predicted cases under scenario B and scenario A) takes values closer to 1 (no difference) for all age groups but the youngest. For Zurich the relative increase in these age groups is no more than five per cent, while it is slightly larger for the current work (ranging from 1.05 to 1.82 compared to 1.01 to 1.05). Many of the 90th percentiles ( values) in Table 4 are a ten-fold increase with those found for Zurich. The ratio for the youngest age group (0–14) is much greater in the current work with no overlap with the values found in the previous work.
One of the limitations of our work is that as we work with observational data, we find associations rather than causes. This makes interpretation difficult. To examine the robustness of our association, we conducted a sensitivity analysis assuming a trade off between household contacts and school contacts to reflect more time spent at home by the school-aged children. We have not considered an effect on the workplace setting as a result of school closure due to the composition of most Swiss households. Namely, according to the World Bank, the labour force participation among women in Switzerland is 62.4 per cent (the proportion of the population aged 15 and older that is economically active) and only 30.3 per cent of middle and senior management is women. Culturally, Swiss women are expected to be stay at home parents, and this is seen in statistics on “employment models in couple households” collected by the Swiss Federal Statisics Office which shows that for households with children the adult woman is either part-time employed or economically inactive. As a result of the model selection performed in this paper, we would not expect to see large changes to the workplace setting when schools are closed, as additional resources for childcare at home will not be needed.
COVID-19 is a notifiable disease in Switzerland. This means cases detected must be reported to the authorities. Using case counts from routine surveillance systems means we are working with the reported cases. Cases not detected by the surveillance system contribute to underreporting. For univariate endemic-epidemic models it is possible to correct for underreporting however this requires additional, external information to inform a single reporting rate parameter [4]. The underreporting may differ throughout the week, as reflected in the distrbution seen in Fig. 1 (lower panel), and hence the correction may need not be constant as expected for routine surveillance settings. Underreporting may be expected as a result of asymptomatic cases. In Switzerland, testing was subject to having symptoms or exposure to a confirmed case and testing beyond this was self-funded rather than government-funded. We have previously included a testing rate in endemic-epidemic models for COVID-19 [13] to capture the impact of underreporting as testing has an inverse relationship with underreporting. As a result of our model selection, the final model does not include testing (shown in the supporting information).
Finally we note that the existence of pharmaceutical countermeasures does not guarantee their use. Vaccines are recommended to prevent disease, disability, and death in children [25]. However, with novel vaccines for pandemic control, children may be included in secondary but not primary trials and so may not be included in immunisation programmes as soon as a prophylaxis is tested safe and made available to the population. For this reason, we believe gaining an understanding of the impact of school closures in the absence of vaccine to still be an interesting and relevant area of research.
Supplementary Information
Acknowledgements
This work is funded by the Swiss National Science Foundation (https://data.snf.ch/covid-19/snsf/196247). The authors declare no conflicts of interest besides some being guardians of children and some being residents of Switzerland and so have an interest in determining the overall benefit of disease control measures in the Swiss setting.
Authors’ contributions
All authors fulfil the contribution requirement for authorship.
Funding
See acknowledgements.
Availability of data and materials
The protocol for this study can be accessed at https://osf.io/fgrdy which includes description of where to source data used. The code used in this work can be accessed at https://gitlab.switch.ch/suspend/COVID-19-school-CH. The majority of the data used in this work is publicly available; descriptions and access options can be found in the study protocol.
Declarations
Ethics approval and consent to participate
Not applicable.
Consent for publication
Not applicable.
Competing interests
The authors declare no competing interests.
Footnotes
Publisher’s Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
S. Meyer and L. Held are joint last authors.
Contributor Information
M. Bekker-Nielsen Dunbar, Email: bl328@uni-heidelberg.de
L. Held, Email: leonhard.held@uzh.ch
References
- 1.Bekker-Nielsen Dunbar M. Transmission matrices used in epidemiologic modelling. Infect Dis Model. 2024;9(1):185–94. 10.1016/j.idm.2023.11.009. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 2.Bekker-Nielsen Dunbar M, Hofmann F, Held L. Assessing the effect of school closures on the spread of COVID-19 in Zurich. J R Stat Soc A. 2022. 10.1111/rssa.12910. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 3.Bekker-Nielsen Dunbar M, Hofmann F, Meyer S, Held L. Assessing the impact of school closure on the spread of COVID-19 among different age groups in Switzerland: Pre-existing data analysis protocol and statistical analysis plan. 2022. 10.17605/OSF.IO/QH3GD.
- 4.Bracher J, Held L. A marginal moment matching approach for fitting endemic-epidemic models to underreported disease surveillance counts. Biometrics. 2021;77(4):1202–14. 10.1111/biom.13371. [DOI] [PubMed] [Google Scholar]
- 5.Bracher J, Held L. Endemic-epidemic models with discrete-time serial interval distributions for infectious disease prediction. Int J Forecast. 2022;38(3):1221–33. 10.1016/j.ijforecast.2020.07.002. [Google Scholar]
- 6.Brandeau ML, McCoy JH, Hupert N, Holty JE, Bravata DM. Recommendations for Modeling Disaster Responses in Public Health and Medicine: A Position Paper of the Society for Medical Decision Making. Med Decis Mak. 2009;29(4):438–60. 10.1177/0272989X09340346. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 7.Cowling BJ, Lau EHY, Lam CLH, Cheng CKY, Kovar J, Chan KH, et al. Effects of school closures, 2008 winter influenza season, Hong Kong. Emerg Infect Dis. 2008;14(10). 10.3201/eid1410.080646. [DOI] [PMC free article] [PubMed]
- 8.Dahn B, Mussah V, Nutt C. Opinion: Yes, We Were Warned About Ebola. 2015. https://www.nytimes.com/2015/04/08/opinion/yes-we-were-warned-about-ebola.html. Accessed 11 Jan 2022.
- 9.Endo A, Uchida M, Hayashi N, Liu Y, Atkins KE, Kucharski AJ, et al. Within and between classroom transmission patterns of seasonal influenza among primary school students in Matsumoto city, Japan. Proc Natl Acad Sci. 2021;118(46):e2112605118. 10.1073/pnas.2112605118. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 10.Eurostat. Population on 1 January by age and sex (demo_pjan). 2021. https://ec.europa.eu/eurostat/databrowser/view/demo_pjan/default/table?lang=en. Accessed 11 Jan 2022.
- 11.Eurostat. Population on 1 January by age group, sex and NUTS 3 region (demo_r_pjangrp3). 2021. https://ec.europa.eu/eurostat/databrowser/view/demo_r_pjangrp3/default/table?lang=en. Accessed 11 Jan 2022.
- 12.Giuliani D, Dickson MM, Espa G, Santi F. Modelling and predicting the spatio-temporal spread of COVID-19 in Italy. BMC Infect Dis. 2020;20(700). 10.1186/s12879-020-05415-7. [DOI] [PMC free article] [PubMed]
- 13.Grimée M, Bekker-Nielsen Dunbar M, Hofmann F, Held L. Modelling the effect of a border closure between Switzerland and Italy on the spatio-temporal spread of COVID-19 in Switzerland. Spat Stat. 2021;100552. 10.1016/j.spasta.2021.100552. [DOI] [PMC free article] [PubMed]
- 14.Held L, Meyer S, Bracher J. Probabilistic forecasting in infectious disease epidemiology: the 13th Armitage lecture. Stat Med. 2017;36(22):3443–60. 10.1002/sim.7363. [DOI] [PubMed] [Google Scholar]
- 15.Hoang T, Coletti P, Melegaro A, Wallinga J, Grijalva CG, Edmunds JW, et al. A Systematic Review of Social Contact Surveys to Inform Transmission Models of Close-contact Infections. Epidemiology. 2019;30(5). 10.1097/EDE.0000000000001047. [DOI] [PMC free article] [PubMed]
- 16.Laboratory for the Modeling of Biological and Socio-technical Systems. mixing-patterns. GitHub. 2021. https://github.com/mobs-lab/mixing-patterns. Accessed 11 Jan 2022.
- 17.Meyer S, Held L. Incorporating social contact data in spatio-temporal models for infectious disease spread. Biostatistics. 2017;18:338–51. 10.1093/biostatistics/kxw051. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 18.Mistry D, Litvinova M, Pastore y Piontti A, Chinazzi M, Fumanelli L, Gomes MFC, et al. Inferring high-resolution human mixing patterns for disease modeling. Nat Commun. 2021;12(323). 10.1038/s41467-020-20544-y. [DOI] [PMC free article] [PubMed]
- 19.Mousa A, Winskill P, Watson OJ, Ratmann O, Monod M, Ajelli M, et al. Social contact patterns and implications for infectious disease transmission - a systematic review and meta-analysis of contact surveys. eLife. 2021;10(e70294). 10.7554/eLife.70294. [DOI] [PMC free article] [PubMed]
- 20.Nguyen MH, Nguyen THT, Molenberghs G, Abrams S, Hens N, Faes C. The impact of national and international travel on spatio-temporal transmission of SARS-CoV-2 in Belgium in 2021. BMC Infect Dis. 2023;23(428). 10.1186/s12879-023-08368-9. [DOI] [PMC free article] [PubMed]
- 21.Nishiura H, Linton NM, Akhmetzhanov AR. Serial interval of novel coronavirus (COVID-19) infections. Int J Infect Dis. 2020;93:284–6. 10.1016/j.ijid.2020.02.060. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 22.Paul M, Held L, Toschke AM. Multivariate modelling of infectious disease surveillance data. Stat Med. 2008;27(29):6250–67. 10.1002/sim.3440. [DOI] [PubMed] [Google Scholar]
- 23.Schweizerische Konferenz der kantonalen Erziehungsdirektoren. Schulferien 2020. 2018. https://edudoc.ch/record/131016?ln=de.
- 24.Ulyte A, Radtke T, Abela IA, Haile SR, Ammann P, Berger C, et al. Evolution of SARS-CoV-2 seroprevalence and clusters in school children from June 2020 to April 2021: prospective cohort study Ciao Corona. Swiss Med Wkly. 2021;151(w30092). 10.4414/SMW.2021.w30092. [DOI] [PubMed]
- 25.World Health Organization. Pocket book of primary health care for children and adolescents: guidelines for health promotion, disease prevention and management from the newborn period to adolescence. 2022. https://www.euro.who.int/en/publications/abstracts/ocket-book-of-primary-health-care-for-children-and-adolescents-guidelines-for-health-promotion,-disease-prevention-and-management-from-the-newborn-period-to-adolescence-2022. Accessed 11 Jan 2022.
- 26.Zhu G, Xiao J, Liu T, Zhang B, Hao Y, Ma W. Spatiotemporal analysis of the dengue outbreak in Guangdong Province, China. BMC Infect Dis. 2019;19(493). 10.1186/s12879-019-4015-2. [DOI] [PMC free article] [PubMed]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.
Supplementary Materials
Data Availability Statement
The protocol for this study can be accessed at https://osf.io/fgrdy which includes description of where to source data used. The code used in this work can be accessed at https://gitlab.switch.ch/suspend/COVID-19-school-CH. The majority of the data used in this work is publicly available; descriptions and access options can be found in the study protocol.