

Abstract
Drought is a natural disaster that can affect a larger area over time. Damage caused by the drought can only be reduced through its accurate prediction. In this context, we proposed a hybrid stacked model for rainfall prediction, which is crucial for effective drought forecasting and management. In the first layer of stacked models, Bi-directional LSTM is used to extract the features, and then in the second layer, the LSTM model will make the predictions. The model captures complex temporal dependencies by processing multivariate time series data in both forward and backward directions using bi-directional LSTM layers. Trained with the Mean Squared Error loss and Adam optimizer, the model demonstrates improved forecasting accuracy, offering significant potential for proactive drought management.
Subject terms: Atmospheric dynamics, Cryospheric science
Introduction
Droughts are natural calamities that can lead to many socio-economic effects 1. Draught can cause significant losses. In 2012, almost 80% of the crops were damaged by the drought, which led to a loss of $36 billion 2. Apart from this, the 2010-2011 East Africa drought, the 2011 Texas drought, and the 2012-2015 California drought caused considerable losses to society 3. As represented in Figure 1, all the developing countries are affected by the drought 4. Figure 1 shows that most African countries are affected by the drought.
Fig. 1.
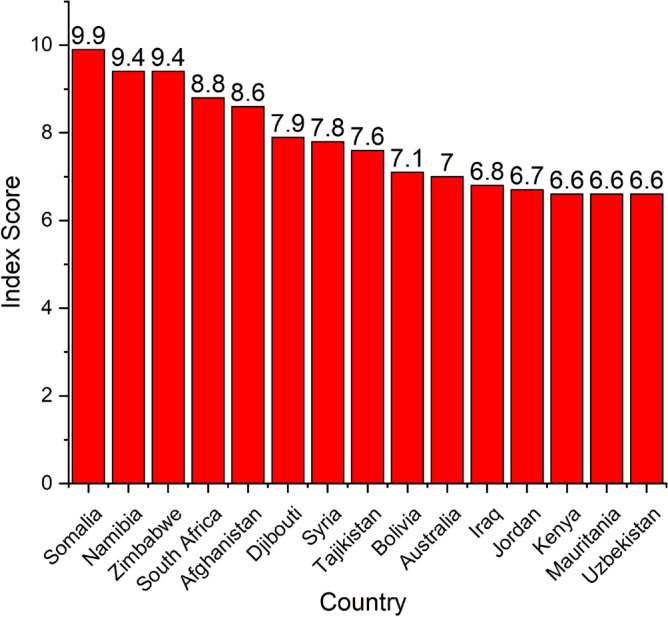
Countries with highest drought exposure in 2024.
Apart from the countries, Fig. 2 present the number of affected peoples by drought. There are several years where the impact of droughts spiked significantly compared to others. Notably, in 1998 and 2008, the numbers were exceptionally high, reaching around 74 million and 207 million people affected, respectively. The peak in 2008 is the highest on the graph, indicating a severe drought event during that year. In more recent years, the numbers remain high but somewhat less erratic than the highest peaks seen in the graph. However, drought still consistently affects a significant number of people.
Fig. 2.
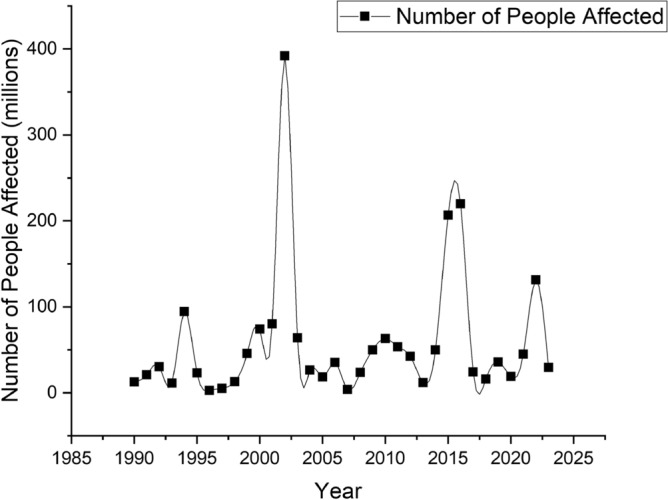
People affected by drought over the year.
Drought has many long-term effects, and we can only manage the effects of drought if a correct and efficient prediction is made. Hence, researchers are developing an efficient drought prediction model 5. However, drought is a natural phenomenon, so it is challenging to predict it 6. In this context, artificial intelligence (AI) has recently shown its significance in drought prediction. I models can easily find the relationship between different features, which improves accuracy.
Contribution
This paper makes several key contributions to the field of time series analysis and drought forecasting:
Hybrid Model Design: We introduce a novel Hybrid Bi-directional LSTM and LSTM model that effectively captures complex temporal dependencies in multivariate time series data, enhancing the accuracy of rainfall predictions.
Improved Forecasting Accuracy: By incorporating both forward and backward sequence processing through Bi-directional LSTM layers, our model improves the ability to learn from contextual information, leading to more accurate predictions.
Robustness Against Overfitting: Using a Dropout layer within the architecture enhances the model’s robustness, preventing overfitting and promoting the learning of generalized features.
Real-world Application: Our model demonstrates significant potential for improving drought management strategies by providing reliable rainfall forecasts and aiding decision-makers in resource allocation and planning.
Future Research Directions: We outline possibilities for extending the model to incorporate additional meteorological variables and apply transfer learning techniques, paving the way for further advancements in adaptable climate modeling across diverse regions.
Organization
The rest of the paper is organized as follows: “Related work” presents the details of related work. “Proposed work” details our proposed work, and the simulation results are presented in “Simulation results”. Finally, “Conclusion” concludes the paper.
Related work
Deep learning models for drought prediction
Wang, X. et al.7 proposed a deep learning model (K-parallel recurrent neural networks (KRNN), convolutional neural networks (CNN), graph convolutional networks (GCN), and multilayer perceptron (MLP)) for the prediction of sub-seasonal drought. The proposed approach used soil moisture to predict drought. However, the primary limitation of this study is its reliance on historical ERA5-Land soil moisture records, which may not fully capture future changes in climate variability. Additionally, the quality and resolution of input data might influence the models’ performance, potentially affecting the accuracy of drought predictions in regions with less detailed soil moisture records.
Dikshit, A. et al.1 used LSTM to predict the Standard Precipitation Evaporation Index (SPEI) through the data collected from the Climatic Research Unit (CRU) that range from 1901 to 2018. However, the study’s reliance on historical data from the Climatic Research Unit (CRU) dataset may limit its ability to account for future climate variability and unforeseen changes in drought patterns.
Anshuka, A. et al.8 proposed an LSTM-based temporal hydrological extreme forecasting. The results are related to the South Pacific region and are based on rainfall data. The study’s reliance on satellite rainfall estimates and sea surface temperature (SST) anomalies may limit its ability to capture localized hydrological extremes influenced by factors not accounted for in the datasets. Additionally, the model’s predictive accuracy might vary with different spatial resolutions and data quality, impacting the generalizability of results across diverse geographical regions.
Maity, R. et al.9 used a CNN model to predict basin-scale drought assessment using air temperature, surface pressure, wind speed, relative humidity, evaporation, soil moisture, and geopotential height. The study’s reliance on primary hydrometeorological precursors may not fully capture the complex interactions and feedback mechanisms influencing droughts, particularly in regions with unique climatological or topographical characteristics. Additionally, the model’s performance may vary when applied to basins with different data availability or quality, potentially impacting its generalizability and effectiveness across diverse environments.
Hybrid models for enhanced drought forecasting
Abbes, A. et al.10 integrates LSTM and Multi-Resolution Analysis Wavelet Transform (MRA-WT) for forecasting drought. This research also focuses on the prediction of the SPEI index. However, the study’s effectiveness may be limited by the availability and quality of input data, such as station data and NDVI from Landsat images, which could affect the model’s accuracy in regions with sparse or unreliable data. Additionally, the model’s performance in capturing non-stationary drought indices might be challenged by extreme weather events not represented in the historical dataset.
Vo Q. T. et al.11 proposed drought prediction using LSTM and climate model. The model’s performance may be limited by biases in the input data and the inherent uncertainties in the climate model GloSea5 (GS5), which could affect the accuracy of drought predictions, especially for long-lead-time cases. Additionally, the model’s effectiveness might vary across different geographical regions due to variations in climate and environmental conditions not fully captured by the input variables.
Al-Ayyoub, M. et al.12 presents a hybrid parallel implementation of the Fuzzy C-Means (FCM) algorithm on a GPU for segmenting 3D medical images from DICOM files. The approach significantly reduces processing time, achieving a 5x speedup compared to the traditional sequential version, making it more feasible for handling large medical datasets.
Moteri, M. A. A. et al.13 proposed a convolutional long short-term memory with self-attention (SA-CLSTM) to predict the SPEI index. However, the model’s reliance on historical data from the Climatic Research Unit (CRU) dataset may not fully capture the unique environmental and climatic variations specific to coastal arid regions, potentially affecting prediction accuracy. Additionally, data quality and availability could challenge the model’s effectiveness, particularly in areas with sparse meteorological monitoring systems.
Explainable AI and neural network approaches
Dikshit, A. et al.14 proposed a deep learning model for drought prediction, in addition to using explainable artificial intelligence (XAI) for explaining the working of deep learning. The study’s reliance on historical data and climatic variables may limit its ability to predict droughts accurately under rapidly changing climate conditions and unforeseen environmental factors. Additionally, the model’s applicability across diverse regions may be constrained by variations in data quality and the specific climatic characteristics of each area.
Poornima S. et al.15 proposed an LSTM-based drought prediction model. The study’s reliance on historical meteorological data for forecasting drought indices may limit its predictive accuracy in rapidly changing climate conditions or regions with sparse data. Additionally, the performance of the LSTM model could be affected by the quality and completeness of the input variables, potentially impacting its generalizability across diverse geographical areas.
IoT and data-driven frameworks
Kaur, A. et al.16 proposed an IoT-based framework for collecting parameters for predicting drought. The author used an Artificial Neural Network (ANN), ANN optimized with Genetic Algorithm (ANN-GA), DNN (Deep Neural Network), and SVM for drought prediction. However, the model’s reliance on IoT data for drought prediction may be limited by the availability and quality of IoT infrastructure in different regions, potentially affecting the accuracy and reliability of forecasts. Additionally, variations in regional climate conditions and data collection standards could impact the model’s generalizability across diverse geographical areas.
Alsmirat M. A et al.17 accelerates Fuzzy C-Means (FCM) segmentation algorithms in medical image processing by leveraging GPU capabilities. This approach significantly enhances processing speed, achieving up to 8.9x faster execution without reducing segmentation accuracy, which is crucial for medical diagnostics. Alsmirat M. A. et al.,18 explore using digital cameras as an alternative to specialized fingerprint devices, explicitly addressing the challenge of image compression. It investigates the optimal compression ratio for maintaining high accuracy in fingerprint identification, establishing that a 30-40% compression ratio is effective without significant accuracy loss.
Nhi, N. T. U. et al.19 introduces a semantic-based image retrieval system that combines a custom C-Tree structure with a neighbor graph (Graph-CTree) to enhance retrieval accuracy. The system employs k-nearest Neighbor (k-NN) for visual word creation and uses an ontology framework with SPARQL queries to improve semantic retrieval. The proposed method demonstrated high precision across several datasets, outperforming comparable approaches.
Dikshit, A et al.20 proposed an attention-based model to forecast meteorological droughts at a short-term forecast range for five sites situated in Eastern Australia. However, the study’s reliance on large-scale climatic indices and historical data may limit its ability to account for sudden or unpredicted climate anomalies, potentially affecting the accuracy of short-term drought forecasts. Additionally, the model’s performance might vary with different geographical regions due to the specific climatic and environmental characteristics not fully represented in the dataset.
Qian, W. et al.21 proposes an enhanced GAN-based image style transfer (IST) method that incorporates a circular local binary pattern (LBP) as a texture before improving image detail. A dense connection residual block and attention mechanism are integrated to enhance high-frequency feature extraction. At the same time, a total variation (TV) regularizer is added to the loss function to reduce noise and smooth results. The method outperforms existing approaches in generating more detailed and higher-quality styled images.
Wang, H et al.22 introduce a visual saliency-guided image retrieval model that integrates the Itti visual saliency model with a multi-feature fusion approach. The model uses a two-stage complexity classification (cognitive load and cognitive level) and a group sparse logistic regression model to enhance retrieval accuracy, especially in complex multimedia scenarios.
Agana, N. An et al.23 proposed a deep belief network consisting of two Restricted Boltzmann Machines for long-term drought prediction using lagged values of SSI as inputs. The proposed approach may limit its ability to capture unexpected climate shifts or anomalies, potentially impacting the accuracy of long-term drought predictions. Additionally, the model’s effectiveness might vary across different regions, influenced by the unique hydrological and climatic conditions not fully captured in the training dataset.
Li, J. et al.24 introduce a new color image watermarking method using Quaternion Hadamard Transform (QHT) and Schur decomposition. The technique leverages the correlation between color channels to embed watermarks resiliently. Additionally, a quaternion Zernike moment-based detection method is employed to handle geometric distortions, making the watermark extraction process robust against such attacks.
Chopra, M. et al.25 provides a comprehensive review of advancements in generative models for text-to-image synthesis, focusing on GAN-based architectures such as DCGAN, StackGAN, StackGAN++, and AttnGAN. By examining these models, the paper highlights how iterative refinement, hierarchical structuring, and attention mechanisms contribute to generating semantically coherent and realistic images from text descriptions.
Proposed approach
Dataset representation and preprocessing
Assume a multivariate time series dataset with observations and features. Each observation at time is represented as a vector:
| 1 |
The dataset is represented as a matrix:
| 2 |
Feature range and differences
To understand the variability and range of features, the following processes are undertaken:
Range of features
The range of a feature is given by:
| 3 |
Calculating the range helps identify the spread of the data, which is crucial for understanding its variability and scaling the model appropriately.
Feature differences
Differencing is used to stabilize variance and make the series stationary:
| 4 |
The differenced dataset is:
| 5 |
Differencing removes trends and seasonality, making the data suitable for time series modeling, particularly with neural networks like BiLSTM and LSTM.
Granger causality test
The Granger Causality Test determines causal relationships between variables in a time series dataset. It assesses whether one variable’s past values help predict another’s future values.
Purpose of the Granger causality test
Granger causality is crucial for identifying dependencies and selecting relevant features for the model. If a variable Granger-causes , including can improve the predictive power for .
Conducting the test
For testing causality between two variables and , construct lagged vectors:
| 6 |
Fit the following models:
Autoregressive model
| 7 |
Extended model with
| 8 |
Where and are coefficient vectors. The significance of coefficients indicates whether Granger-causes .
Normalization
Normalization is a critical preprocessing step that ensures each feature contributes equally to the model. It prevents features with more extensive ranges from dominating the learning process.
Min-max scaling
Min-Max scaling transforms each feature into the range :
| 9 |
This scaling is useful when the data does not have significant outliers and the features are approximately uniformly distributed.
Z-score normalization
Z-score normalization transforms each feature to have a mean of 0 and a standard deviation of 1:
| 10 |
Where and are the mean and standard deviation of feature . This method is beneficial when data follows a Gaussian distribution.
Data splitting
Data splitting involves dividing the dataset into training and testing sets to ensure that the model is evaluated on unseen data. The split is typically performed using a ratio .
Training set
The training set is used to fit the model. It comprises the first observations, where:
| 11 |
Training set:
| 12 |
Testing set
The testing set is used to evaluate the model’s performance:
| 13 |
Splitting ensures that the model’s predictions are unbiased and that its performance can be generalized to new data.
Bi-directional LSTM model
A Bi-directional LSTM processes the input sequence in both forward and backward directions. Given an input sequence , where each is a feature vector:
- ∙ Forward LSTM:
14 - ∙ Backward LSTM:
15 - ∙ Output of bi-directional LSTM:
16
For this model, the bi-directional LSTM has an output dimension of .
LSTM layers
Each LSTM layer applies the following transformations:
- ∙ Forget gate:
17 - ∙ Input gate:
18 19 - ∙ Cell state:
20 - ∙ Output gate:
21 - ∙ Hidden state:
22
The LSTM layers in this model are configured as follows:
First LSTM: 32 units, returns sequences
Second LSTM: 16 units, returns sequences
Third LSTM: 8 units, returns a single sequence
Dropout layer
The Dropout layer randomly sets a fraction of input units to zero during training:
| 23 |
where is a binary mask with dropout probability .
Dense layer
The Dense layer computes the final output using:
| 24 |
This layer produces an output vector with dimensions matching .
Loss function
The model is compiled with the Mean Squared Error (MSE) loss function:
| 25 |
where is the predicted value, is the true value, and is the number of samples.
Optimizer
The Adam optimizer updates model weights using the following:
| 26 |
Where:
is the learning rate.
and are the first and second moment estimates.
is a small constant to prevent division by zero.
Model prediction and evaluation
Prediction
Given an input sequence , the model predicts output :
| 27 |
The BiLSTM and LSTM models leverage sequential data to predict future rainfall patterns accurately.
Comparison of actual and predicted data
Evaluate predictions using Mean Absolute Error (MAE) and Root Mean Square Error (RMSE):
| 28 |
| 29 |
Where is the number of observations in the test set. These metrics provide insight into the accuracy of the model’s predictions by comparing them against actual values.
Results and discussion
Dataset representation
In order to test our proposed model, we used data collected from NASA’s GMAO MERRA-2 assimilation model 26. The data was collected from 2000 to 2020 in Mumbai, India. The data contains precipitation, specific humidity, relative humidity, and temperature. Hence, in this paper, we predict the precipitation using information on particular moisture, relative humidity, and temperature. In our study, we utilized daily time intervals for both training and prediction purposes. Daily data granularity allows our model to capture short-term rainfall fluctuations, which is particularly valuable for identifying immediate drought conditions.
Data preprocessing
In our study, we addressed missing data points through linear interpolation, which fills gaps by estimating values based on neighboring data. This method is effective in maintaining continuity within the time series without introducing significant bias. For anomalous values, we applied a z-score thresholding approach to detect outliers. Any data points that fell beyond three standard deviations from the mean were flagged as potential anomalies. These values were subsequently replaced using the rolling median imputation technique, which is less sensitive to extreme variations and preserves the dataset’s underlying trends.
Granger causality test
Figure 3, presents the correlation information about specific humidity, relative humidity, and temperature concerning precipitation. The figure clearly shows that the correlation between specific humidity and precipitation is 0.724540. Also, the correlation between relative humidity and precipitation is 0.743112. Moreover, the correlation between temperature and precipitation is -0.779399. Hence, from Figure 3 it is clear that all the features are highly correlated to precipitation
Fig. 3.

Correlation matrix of selected features.
We plot the scatter plot to get more information about the correlation between specific humidity, relative humidity, and temperature, as represented in Fig. 4. The figure shows that particular humidity and relative humidity positively correlate with precipitation because precipitation also increases with specific humidity and relative humidity. However, temperature is negatively correlated to precipitation because the precipitation increases with a decrease in temperature.
Fig. 4.

Scatter plot of selected features.
The correlation matrix and scatter plot confirm that the features (specific humidity, relative humidity, and temperature) are related to precipitation. But to get more information about the relationship, we plot the Fig. 5. With a mean of around 20 units, the histogram for specific humidity shows a distinct right-skewed distribution, showing a concentration of greater specific humidity values. By contrast, the relative humidity distribution is bimodal, with maxima about at 50% and 90%, implying two quite common groups in the sample about atmospheric moisture content. The temperature data is likewise very bimodal, with most observations falling around C and C. Crucially for modeling their effect on precipitation patterns, these histograms-overlaid with kernel density estimates-offer a visual grasp of the variability and average values for every meteorological variable.
Fig. 5.

Histogram of selected features.
Performance analysis
To analyze the performance of our proposed model, we plot the model training and validation Loss in Fig. 6. From the figure, it is clear that at the start of the epochs, the training loss is higher than the validation loss. However, as the training increases the value of training loss also decreases, this shows that our purposed model is training efficiently. Finally, the variation in training and validation loss is almost similar after the fifth epoch. Hence, it is evident that our proposed model gets trained very quickly (in 5 epochs).
Fig. 6.
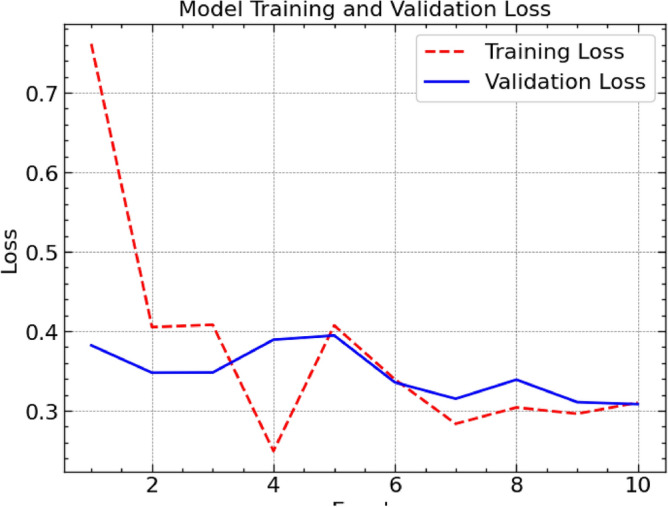
Variation of model training and validation loss over epochs.
To get more information about prediction accuracy, we compare the predicted values from our model with the actual values, as represented in Fig. 7. The figure clearly shows that the forecasting values follow the actual values with a high accuracy value. However, there is some mismatch value for the prediction at the pike values of the actual precipitation. In this context, we will improve our model for better accuracy in the future and test it on more real-world models.
Fig. 7.

Prediction of precipitation by proposed model.
Comparative analysis
In this subsection, we compare our proposed model qualitatively and quantitatively.
Quantitative analysis
We compared the Bi-LSTM and GRU models in the quantitative analysis with our proposed model. Figure 8 presents this quantitative analysis. Figure 8a presents the comparison of accuracy, from the figure it is clear that the proposed approach has the lowest accuracy than the rest of the models. Similarly, Fig. 8b, c present the comparison of Mean Absolute Error (MAE) and Mean Square Error (MSE). The figures show that our proposed model outperformed the other two models.
Fig. 8.

Quantitative analysis.
Qualitative analysis
This section will present the qualitative analysis of current work with our proposed approach. The comparison details are presented in Table 1.
Table 1.
Comparative analysis.
| Model | Hypothesis testing | Technique | Complexity |
|---|---|---|---|
| Wang, X. et al.7 | ✗ | KRNN, CNN, GCN, MLP | High |
| Dikshit, A. et al.1 | ✗ | LSTM | High |
| Anshuka, A. et al.8 | ✗ | LSTM | High |
| Maity, R. et al. 9 | ✗ | CNN | High |
| Abbes, A. et al. 10 | ✗ | LSTM | High |
| Vo Q. T. et. al. 11 | ✗ | LSTM-CM | High |
| Moteri, M. A. A. et al. 13 | ✗ | SA-CLSTM | High |
| Dikshit, A. et. al.14 | ✗ | DL, XAI | High |
| Poornima S. et al.15 | ✗ | LSTM | High |
| Kaur, A. et al.16 | ✗ | ANN, ANN-GA, DNN, SVM | High |
| Dikshit, A et al.20 | ✗ | Attention-based model | High |
| Agana, N. A et. al.23 | ✗ | Deep Belief Network | High |
| Proposed approach | Granger causality test | Bi-LSTM | Low |
The approach proposed by Wang, X. et al.7 is complex because The complexity of this study arises from integrating multiple deep-learning modules within a committee machine framework, which requires sophisticated techniques for series decomposition and feature extraction. This approach demands advanced computational methods to ensure that the models effectively leverage soil moisture memory for accurate sub-seasonal drought forecasting.
The complexity of the model proposed by Dikshit, A. et al.1 stems from utilizing the Long Short-Term Memory (LSTM) model to predict drought characteristics across multiple scales and dimensions. This approach requires sophisticated techniques for data preprocessing, model training, and evaluation, ensuring that the LSTM effectively captures temporal and spatial variations in drought dynamics for improved forecasting accuracy.
Anshuka, A. et al.8 is complex due to using the LSTM model to capture spatio-temporal patterns in hydrological extremes. This involves sophisticated methods for processing multivariate data and incorporating eigenvector values of SST, necessitating advanced computational techniques to accurately model the dynamic interactions within the hydrological and climatological variables.
The model proposed by Maity, R. et al. 9 is complex due to the utilization of a one-dimensional convolutional neural network to extract meaningful insights from diverse hydrometeorological precursors. This approach requires advanced data integration and modeling techniques to accurately capture the intricate relationships between meteorological variables and drought conditions, highlighting the challenges of representing complex environmental processes in a computational framework.
The complexity of the model proposed by Abbes, A. et al. 10 lies in integrating Multi-Resolution Analysis Wavelet Transform (MRA-WT) with Long Short-Term Memory (LSTM) networks to handle non-stationary time-series data. This approach requires advanced techniques for data preprocessing and model training to analyze and forecast complex drought patterns effectively, demonstrating the intricate relationship between temporal and spectral characteristics of drought indices.
The model proposed by Vo Q. T. et al. 11 is complex due to integrating the LSTM model with a climate prediction model (GS5) to leverage physical process simulation and low prediction bias. This hybrid approach requires sophisticated techniques to balance and optimize the strengths of both models, ensuring accurate and reliable drought forecasts while minimizing uncertainties and biases.
The complexity of the model proposed by Moteri, M. A. A. et al. 13 stems from using a convolutional extended short-term memory model with self-attention (SA-CLSTM) to capture the intricate interactions between drought factors in coastal arid regions. This approach requires advanced techniques for integrating multiple data sources and optimizing model parameters to ensure accurate and reliable drought severity, category, and geographic variation forecasts.
The model proposed by Dikshit, A. et al.14 is complex due to integrating XAI with deep learning models to understand local interactions among predictors for different drought conditions. This approach requires sophisticated techniques to analyze and interpret model outputs using Shapley additive explanations (SHAP), ensuring that predictions align with physical model interpretations across various spatio-temporal scales.
The approach by Poornima S. et al.15 is complex because it uses LSTM networks to handle real-time nonlinear data. This approach requires advanced techniques for data preprocessing, model training, and evaluation to effectively capture temporal patterns and improve long-term drought predictions, challenging the conventional statistical methods’ capabilities.
The model proposed by Kaur, A. et al.16 is complex due to the integration of IoT with dimensionality reduction techniques and advanced machine learning models, such as DNN and ANN-GA, to predict drought conditions. This framework requires sophisticated data processing and analysis at both the Fog and Cloud layers, necessitating advanced techniques to handle large-scale data and optimize model performance for accurate drought assessment and management.
The complexity of the model proposed by Dikshit, A et al.20 stems from using an attention-based deep learning model to capture the nonlinear relationships and dependencies between hydrometeorological and climatic factors. This approach requires sophisticated data integration and interpretation techniques to understand how the model forecasts droughts across various lead times, enhancing transparency and trust in the predictions.
The complexity of the model proposed by Agana, N. An et al.23 study arises from employing a Deep Belief Network with two Restricted Boltzmann Machines to address the nonlinear and nonconvex optimization challenges in drought prediction. This approach requires advanced techniques for data preprocessing and model training to effectively capture complex temporal patterns, ensuring superior performance over traditional methods like Multilayer Perceptron (MLP) and Support Vector Regression (SVR).
Conclusion
The paper used a hybrid model to predict rainfall, an essential factor in drought prediction. The proposed hybrid model is the stacked models of Bi-LSTM and LSTM. The stacked model takes the input from NASA’s GMAO MERRA-2 assimilation model and uses time series analysis to predict the rainfall. As the rainfall is directly related to drought, our proposed models help predict drought. We also compared our proposed model with standard deep learning models and previous literature to present the effectiveness of our proposed model. Our proposed hybrid mode outperformed the standard deep learning models in accuracy, mean square error, and mean absolute error. In addition to that, our proposed model is less complex than the current literature. However, our model still needs improvement. Therefore, in future work, we explore additional meteorological variables and transfer learning to improve accuracy and false negatives in our model. Specifically, we plan to explore the integration of satellite data, such as remote sensing data on soil moisture and vegetation indices, to improve the model’s predictive accuracy by incorporating additional environmental factors. This data could offer valuable insights into drought conditions and enhance the model’s performance by providing finer spatial resolution. Additionally, we aim to test the model across diverse regions with varying climatic conditions to assess its generalizability. For instance, applying the model to semi-arid and humid regions would allow us to evaluate its adaptability and robustness in different drought contexts. We also plan to implement transfer learning techniques to leverage pre-trained models on similar datasets, which could improve prediction accuracy while reducing computational requirements.
Acknowledgements
Princess Nourah bint Abdulrahman University Researchers Supporting Project number (PNURSP2024R 343), Princess Nourah bint Abdulrahman University, Riyadh, Saudi Arabia.The authors extend their appreciation to the Deanship of Scientific Research at Northern Border University, Arar, KSA for funding this research work through the project number NBU-FFR-2024-1092-13.
Author contributions
Final Manuscript Revision, funding, Supervision: B.B.G., K.T.C.; study conception and design, analysis, and interpretation of results, methodology development: A.G., V.A., draft manuscript preparation, figure and tables: S.B., A.A., R.W.A.
All authors reviewed the results and approved the final version of the manuscript.
Data availability
The datasets generated and analyzed during the current study are available in the Kaggle repository, https://www.kaggle.com/datasets/poojag718/rainfall-timeseries-data
Declarations
Competing interests
The authors declare no competing interests.
Footnotes
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
These authors contributed equally: Brij B. Gupta, Akshat Gaurav, Razaz Waheeb Attar, Varsha Arya, ShaviBansal, Ahmed Alhomoud and Kwok Tai Chui.
References
- 1.Dikshit, A., Pradhan, B. & Huete, A. An improved spei drought forecasting approach using the long short-term memory neural network. J. Environ. Manag.10.1016/J.JENVMAN.2021.111979 (2021). [DOI] [PubMed] [Google Scholar]
- 2.AghaKouchak, A. et al. Status and prospects for drought forecasting: opportunities in artificial intelligence and hybrid physical-statistical forecasting. Philos. Trans. R. Soc. A10.1098/RSTA.2021.0288 (2022). [Google Scholar]
- 3.Hao, Z., Singh, V. P. & Xia, Y. Seasonal drought prediction: Advances, challenges, and future prospects. Rev. Geophys.56, 108–141 (2018). [Google Scholar]
- 4.Statictica. Countries most exposed to droughts worldwide in 2024, by risk index score. https://www.statista.com/statistics/1395543/countries-most-exposed-to-droughts-by-risk-index-score/ (2024). Accessed 30 June 2024.
- 5.Anshuka, A., Ogtrop, F. v. & Vervoort, R. W. Drought forecasting through statistical models using standardised precipitation index: A systematic review and meta-regression analysis. Nat. Hazards10.1007/S11069-019-03665-6 (2019).
- 6.Houmma, I. H., Mansouri, L. E., Gadal, S., Garba, M. & Hadria, R. Modelling agricultural drought: A review of latest advances in big data technologies. Geomat. Nat. Haz. Risk10.1080/19475705.2022.2131471 (2022).
- 7.Wang, X. et al. Sub-seasonal soil moisture anomaly forecasting using combinations of deep learning, based on the reanalysis soil moisture records. Agric. Water Manag.10.1016/J.AGWAT.2024.108772 (2024). [Google Scholar]
- 8.Anshuka, A., Chandra, R., Buzacott, A. J., Sanderson, D. & van Ogtrop, F. F. Spatio temporal hydrological extreme forecasting framework using lstm deep learning model. Stoch. Environ. Res. Risk Assess.36, 3467–3485 (2022). [Google Scholar]
- 9.Maity, R. et al. Potential of deep learning in drought assessment by extracting information from hydrometeorological precursors. J. Water Clim. Change12, 2774–2796 (2021). [Google Scholar]
- 10.Abbes, A. B., Inoubli, R., Rhif, M. & Farah, I. Combining deep learning methods and multi-resolution analysis for drought forecasting modeling. Earth Sci. Inform.10.1007/S12145-023-01009-4 (2023). [Google Scholar]
- 11.Vo, T. Q., Kim, S.-H., Nguyen, D. & Bae, D. Lstm-cm: a hybrid approach for natural drought prediction based on deep learning and climate models. Stoch. Environ. Res. Risk Assess. (Print)10.1007/S00477-022-02378-W (2023). [Google Scholar]
- 12.Al-Ayyoub, M., AlZu’bi, S., Jararweh, Y., Shehab, M. A. & Gupta, B. B. Accelerating 3d medical volume segmentation using gpus. Multimed. Tools Appl.77, 4939–4958 (2018). [Google Scholar]
- 13.Moteri, M. A. A. et al. An enhanced drought forecasting in coastal arid regions using deep learning approach with evaporation index. Environ. Res.10.1016/J.ENVRES.2024.118171 (2024). [DOI] [PubMed]
- 14.Dikshit, A. & Pradhan, B. Interpretable and explainable ai (xai) model for spatial drought prediction. Sci. Total Environ.10.1016/J.SCITOTENV.2021.149797 (2021). [DOI] [PubMed] [Google Scholar]
- 15.Poornima, S. & Pushpalatha, M. Drought prediction based on spi and spei with varying timescales using lstm recurrent neural network. Soft Comput.10.1007/S00500-019-04120-1 (2019). [Google Scholar]
- 16.Kaur, A. & Sood, S. K. Deep learning based drought assessment and prediction framework. Ecol. Inform.10.1016/J.ECOINF.2020.101067 (2020). [Google Scholar]
- 17.Alsmirat, M. A., Jararweh, Y., Al-Ayyoub, M., Shehab, M. A. & Gupta, B. B. Accelerating compute intensive medical imaging segmentation algorithms using hybrid cpu-gpu implementations. Multimed. Tools Appl.76, 3537–3555 (2017). [Google Scholar]
- 18.Alsmirat, M. A., Al-Alem, F., Al-Ayyoub, M., Jararweh, Y. & Gupta, B. Impact of digital fingerprint image quality on the fingerprint recognition accuracy. Multimed. Tools Appl.78, 3649–3688 (2019). [Google Scholar]
- 19.Nhi, N. T. U. et al. A model of semantic-based image retrieval using c-tree and neighbor graph. Int. J. Semantic Web Inf. Syst. (IJSWIS)18, 1–23 (2022). [Google Scholar]
- 20.Dikshit, A., Pradhan, B., Assiri, M. E., Almazroui, M. & Park, H.-J. Solving transparency in drought forecasting using attention models. Sci. Total Environ.837, 155856 (2022). [DOI] [PubMed] [Google Scholar]
- 21.Qian, W., Li, H. & Mu, H. Circular lbp prior-based enhanced gan for image style transfer. Int. J. Semantic Web Inf. Syst. (IJSWIS)18, 1–15 (2022). [Google Scholar]
- 22.Wang, H., Li, Z., Li, Y., Gupta, B. B. & Choi, C. Visual saliency guided complex image retrieval. Pattern Recognit. Lett.130, 64–72 (2020). [Google Scholar]
- 23.Agana, N. A. & Homaifar, A. A deep learning based approach for long-term drought prediction. SoutheastCon 2017. 10.1109/SECON.2017.7925314 (2017).
- 24.Li, J., Yu, C., Gupta, B. B. & Ren, X. Color image watermarking scheme based on quaternion Hadamard transform and Schur decomposition. Multimed. Tools Appl.77, 4545–4561 (2018). [Google Scholar]
- 25.Chopra, M., Singh, S. K., Sharma, A. & Gill, S. S. A comparative study of generative adversarial networks for text-to-image synthesis. Int. J. Softw. Sci. Comput. Intell. (IJSSCI)14, 1–12 (2022). [Google Scholar]
- 26.Gupta, P. Rainfall timeseries data. https://www.kaggle.com/datasets/poojag718/rainfall-timeseries-data (2023). Accessed 30 Jan 2024.
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.
Data Availability Statement
The datasets generated and analyzed during the current study are available in the Kaggle repository, https://www.kaggle.com/datasets/poojag718/rainfall-timeseries-data