

Abstract
In order to solve the limitations of flipped classroom in personalized teaching and interactive effect improvement, this paper designs a new model of flipped classroom in colleges and universities based on Virtual Reality (VR) by combining the algorithm of Contrastive Language-Image Pre-Training (CLIP). Through cross-modal data fusion, the model deeply combines students’ operation behavior with teaching content, and improves teaching effect through intelligent feedback mechanism. The test data shows that the similarity between video and image modes reaches 0.89, which indicates that different modal information can be effectively integrated to ensure the semantic consistency and intuitive understanding of teaching content. The minimum Kullback–Leibler (KL) divergence is 0.12, which ensures the stability of data distribution and avoids information loss. The accuracy of automatically generating feedback reaches 93.72%, which significantly improves the efficiency of personalized learning guidance. In the adaptability test of virtual scene, the frequency of scene adjustment is 2.5 times/minute, and the consistency score is stable above 8.6, ensuring the consistency of teaching goals under complex interaction. This paper aims to enhance personalized learning experience, improve teaching efficiency and autonomous learning effect through VR technology and intelligent feedback, and promote the innovation of interactive teaching mode.
Keywords: Flipped classroom, CLIP, Cross-modal data fusion, VR, Deep learning
Subject terms: Mathematics and computing, Applied mathematics, Computational science, Computer science, Information technology, Pure mathematics, Scientific data, Software, Statistics
Introduction
Research background and motivations
With the rapid development of Virtual Reality (VR) and Deep Learning (DL) technologies, the field of education is gradually trying to integrate these technologies into classroom teaching to promote the innovation of teaching mode1,2. As an educational model that innovates the traditional teaching paradigm, the core of flipped classroom lies in the separation of knowledge transfer and internalization, and by giving students more autonomy in learning, it reshapes the interactive structure and teaching focus of the classroom3. In this mode, autonomous learning before class becomes the basic link, and students use multimedia resources such as videos and texts to initially construct a framework for understanding knowledge. Classroom time is transformed into deep interaction between teachers and students, and knowledge is internalized through problem discussion and group cooperation. After-class consolidation links focus on personalized task assignment to strengthen students’ mastery and application of knowledge. However, the ability of traditional flipped classroom in dynamic adaptability, personalized feedback generation and accurate monitoring of students’ behavior is still insufficient, which limits its wide application in complex teaching scenes4–6.
The conceptual framework of flipped classroom not only emphasizes the optimal allocation of time and space, but also requires a high degree of flexibility and pertinence in teaching strategies. Its design needs to cover the organization of learning resources, the dynamic adjustment of classroom activities and the efficient response of student feedback. However, due to the constraints of traditional technical means, the performance of flipped classroom in high-frequency interactive scenes is affected to some extent, especially in the face of diverse student groups and complex teaching objectives, it is difficult to achieve real-time adjustment and accurate intervention7–9. At present, the artificial intelligence generated content (AIGC) based on DL provides a brand-new technical support for the further development of flipped classroom. AIGC lays a foundation for constructing a highly conscious generative learning mode with more dynamic adaptability through the synergistic effect of autonomous learning and self-supervised learning mechanism. In this context, the combination of virtual reality technology with its highly immersive interactive experience and cross-modal data processing ability of deep learning can not only improve the personalized teaching effect of flipped classroom, but also provide more intelligent solutions for real-time adjustment and feedback generation of classroom design. Therefore, it is not only an important subject of educational technology innovation, but also a key direction to promote the teaching reform of higher education to explore a new flipped classroom model based on VR and DL technology and optimize students’ learning experience and teaching interaction efficiency.
Research objectives
Based on the Contrastive Language-Image Pre-Training (CLIP) model and the Transformer’s cross-modal attention mechanism, this paper designs a Virtual Reality Flipped Classroom Teaching Improvement (VR-Flipped) model. The motivation of choosing CLIP model lies in its excellent performance in multi-modal data representation and association, especially its ability to align visual and text features in high-dimensional semantic space and ensure the cross-modal consistency of complex teaching content10–12. By introducing Transformer’s cross-modal attention mechanism, VR-Flipped model further enhances the ability of feature interaction and collaborative processing between modes, and enables the dynamic fusion of visual, text and interactive behavior data in virtual reality environment. This design can not only capture students’ learning behaviors in the virtual environment in real time, but also generate highly personalized learning feedback by analyzing the matching degree between these behaviors and the teaching content to help students understand knowledge more deeply. Through the intelligent adjustment of cross-modal mechanism, the model can dynamically adjust teaching strategies and scene content according to students’ learning trajectory to realize accurate personalized learning path13.
Compared with the traditional flipped classroom mode, the VR-Flipped model aims to bridge the gap between the existing teaching mode in multimodal interaction and dynamic feedback. There is a big-time lag in knowledge transfer and student feedback in the traditional flipped classroom. It lacks in-depth insight into real-time learning behavior, and it is difficult to effectively support personalized needs, especially in diverse learning scenarios. By combining VR technology and intelligent feedback mechanism, VR-Flipped model provides students with an immersive learning scene, which enables them not only to explore knowledge independently, but also to get real-time and accurate guidance in virtual experiments. At the same time, the multi-modal fusion technology of VR-Flipped model solves the problem of isolation of teaching information such as vision, text and audio, and makes the collaborative application of cross-modal information possible. This efficient and integrated design improves the teaching flexibility and adaptability of flipped classroom, and provides quantitative multi-modal data support for teachers to optimize classroom interaction and teaching strategies, thus promoting the transformation of flipped classroom from passive teaching to dynamic interactive teaching.
Literature review
In recent years, with the popularization of flipped classroom teaching mode, researchers gradually explore its application in improving students’ learning effect. Fidan (2023) studied the influence of flipped classroom supported by micro-learning on pre-service teachers. The results showed that the combination of micro-learning and flipped classroom could effectively improve learning performance, intrinsic motivation and participation. He found that the students’ participation in pre-class activities in the experimental group was significantly improved, especially in the flipped classroom supported by micro-learning, which was more prominent in stimulating learning motivation14. At the same time, Shen and Chang (2023) pointed out that the flipped classroom was not limited to the optimization of pre-class preparation, but also helped students develop deeper learning ability through the four-element flipped learning model. The experimental results showed that students’ DL ability in the cognitive field had improved significantly15. Together, these studies show that flipped classroom can effectively improve students’ learning performance and participation when combined with modern teaching tools and strategies.
In addition, the advantages of flipped classroom have also been verified in distance teaching. Al-Saidet al. (2023) discussed the application of flipped classroom in distance teaching during the epidemic period. The results showed that flipped classroom not only promoted students’ enthusiasm, but also significantly improved their academic performance. In the experimental group, the proportion of outstanding students increased by 17.9%, which showed that flipped classroom could help students adjust themselves better in the distance learning environment16. Related to this, Huanget al. (2023) further improved the effect of flipped classroom by introducing a personalized video recommendation system supported by AI, especially among students with moderate learning motivation, personalized recommendation significantly improved their learning participation and performance17. This showed that the combination of flipped classroom and artificial intelligence (AI) technology could effectively cope with the differentiation of students’ personalized learning needs and play an important role in the optimization of personalized learning paths.
In the fields of science, technology, engineering, and mathematics (STEM), the application effect of flipped classroom has also been widely concerned. Gong et al. (2024) made a meta-analysis of 53 research literatures, which showed that flipped classroom had a significant positive impact on STEM discipline, which further proved the application potential of this model in more structured and technical disciplines18. At the same time, the research of Solissa et al. (2023) showed that flipped classroom played a significant role in improving students’ critical thinking ability, especially in large classes, helping students develop higher-level thinking skills19. In addition, Zhu et al. (2023) discussed the application of flipped classroom combined with music and DL in physical education. The results also showed that flipped classroom could significantly improve students’ autonomous learning ability, showing the potential of this model in non-traditional disciplines20. These studies further strengthen the effectiveness of flipped classroom in different disciplines and its role in promoting students’ various abilities.
However, despite the obvious advantages of flipped classroom in improving academic performance and personalized feedback, the existing research still has shortcomings in dealing with complex interactive scenarios and dynamic adaptability. Previous studies mainly focused on the effect evaluation in a single scene, lacking in-depth analysis of teaching coherence and personalized feedback in a complex dynamic environment. Therefore, by introducing VR technology and VR-Flipped model of cross-modal data fusion, this paper aims to improve the adaptability and personalized feedback efficiency of flipped classroom in complex interactive scenes. It also aims to further promote the intelligence and interactivity of teaching process, and ensure that effective teaching support can still be provided in more complex teaching situations.
Research model
In this paper, a new model, VR-Flipped model, is designed, which combines the multimodal pre-training model based on CLIP with Transformer’s cross-modal attention mechanism. The core lies in optimizing the teaching process through cross-modal data fusion and intelligent feedback mechanism relying on VR technology. Specifically, the realization of VR-Flipped depends on the dynamic matching of real-time interactive data and teaching content in VR. Students interact with 3D teaching content in the virtual classroom, and the generated behavior data (such as sight, gestures, etc.) are captured by the CLIP model in real time and transformed into visual and text information21,22. CLIP model extracts rich semantic information from the virtual scene, and combines with the classroom explanation text to realize the deep fusion of multimodal data23–25. The cross-modal attention mechanism in Transformer automatically generates personalized learning feedback by analyzing the correlation between students’ virtual operation behavior and the content of the explanation, which helps students understand and master knowledge more efficiently26,27.
In the above realization process, firstly, the process of extracting visual feature 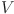 and text feature
and text feature 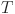 by CLIP is still the basis of multimodal feature fusion, and the visual feature
by CLIP is still the basis of multimodal feature fusion, and the visual feature 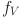 and text feature
and text feature 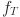 are defined as:
are defined as:
| 1 |
| 2 |
Equations (1) and (2) respectively represent the extraction process of visual mode and text mode features, in which the visual module of CLIP is used to encode the spatial semantics in the virtual scene, and the text module converts the text content in the course explanation into vector representation. This feature extraction ensures the efficient fusion of multimodal data at the semantic level.
Then, in order to measure the matching degree between visual and text features, cosine similarity is used to calculate the similarity score  between visual and text features.
between visual and text features.
| 3 |
Equation (3) is used to measure the vector similarity of visual and text features, capture the semantic consistency between students’ behavior and course content, and thus optimize the accuracy of cross-modal matching. Next, students’ learning behavior data 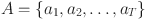 is defined, and the accumulation of learning behavior is represented by a recursive function
is defined, and the accumulation of learning behavior is represented by a recursive function 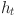 :
:
| 4 |
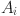 is the
is the 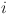 -th behavior of students. Equation (4) is used to capture the nonlinear relationship in time series behavior data, which considers the long-term and short-term influence of behavior dynamics on learning effect and provides a more comprehensive behavior context for cross-modal attention mechanism. The cross-modal attention mechanism is used to calculate the attention weight
-th behavior of students. Equation (4) is used to capture the nonlinear relationship in time series behavior data, which considers the long-term and short-term influence of behavior dynamics on learning effect and provides a more comprehensive behavior context for cross-modal attention mechanism. The cross-modal attention mechanism is used to calculate the attention weight 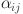 among different modes, and the equation is as follows:
among different modes, and the equation is as follows:
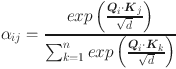 |
5 |
 and
and  are query vectors and key vectors respectively, and
are query vectors and key vectors respectively, and 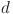 is the dimension scaling factor. Equation (5) is used to define the relationship between
is the dimension scaling factor. Equation (5) is used to define the relationship between 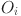 and
and 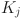 . Thus, the generation of weight distribution enables the model to focus on the most relevant part of multimodal features and improve the efficiency of data fusion.
. Thus, the generation of weight distribution enables the model to focus on the most relevant part of multimodal features and improve the efficiency of data fusion.
Attention output 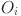 is calculated by weighted sum form:
is calculated by weighted sum form:
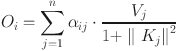 |
6 |
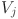 is the value vector, and the attention output
is the value vector, and the attention output 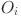 represents the weighted multimodal fusion result. In the process of personalized learning path generation, the model uses the prediction error to measure the difference between the real output
represents the weighted multimodal fusion result. In the process of personalized learning path generation, the model uses the prediction error to measure the difference between the real output  and the predicted output
and the predicted output 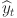 , and the loss function
, and the loss function  is defined as follows:
is defined as follows:
| 7 |
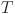 is the number of time steps. The deviation of knowledge imparting is measured by the matching degree between students’ behavior and curriculum goals, and the definition error
is the number of time steps. The deviation of knowledge imparting is measured by the matching degree between students’ behavior and curriculum goals, and the definition error  is as follows:
is as follows:
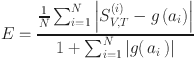 |
8 |
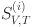 is the similarity score of the
is the similarity score of the 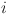 -th sample.
-th sample.  is the matching function between students’ interactive behavior and knowledge points. Emotional analysis module is used to capture students’ emotional response in VR28,29. Its feature
is the matching function between students’ interactive behavior and knowledge points. Emotional analysis module is used to capture students’ emotional response in VR28,29. Its feature  is extracted by the following equation:
is extracted by the following equation:
| 9 |
This equation combines visual mode  and text mode
and text mode 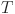 to extract emotional feature
to extract emotional feature 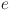 , and the relationship between emotional feature and personalized feedback generation is as follows:
, and the relationship between emotional feature and personalized feedback generation is as follows:
| 10 |
 is the feedback weight matrix, and personalized feedback
is the feedback weight matrix, and personalized feedback 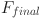 is generated by fusing attention output
is generated by fusing attention output 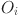 and emotional feature
and emotional feature  . In order to optimize the model, the regularization term is introduced into the final loss function
. In order to optimize the model, the regularization term is introduced into the final loss function 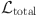 , which is defined as follows:
, which is defined as follows:
| 11 |
 and
and  are regularization weight factors.
are regularization weight factors. 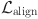 is multimodal alignment loss.
is multimodal alignment loss. 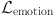 is emotional feature loss. Finally, the updating rules of model parameters are described as follows by gradient descent equation with fraction:
is emotional feature loss. Finally, the updating rules of model parameters are described as follows by gradient descent equation with fraction:
| 12 |
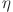 is the learning rate.
is the learning rate. 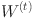 is the weight parameter of the
is the weight parameter of the 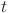 iteration. The gradient updating equation smoothes the parameter updating by considering the norm of the weight to ensure the stability of the optimization.
iteration. The gradient updating equation smoothes the parameter updating by considering the norm of the weight to ensure the stability of the optimization.
On the whole, VR-Flipped model fully captures the high-dimensional semantic relevance between different modes through the multi-modal embedded structure of multi-head attention layer. In each layer, Key, Value and Query are calculated in the form of embedded operation, and the weight distribution is dynamically adjusted through attention mechanism to strengthen semantic interaction between modes and reduce information loss. In addition, in order to ensure the consistency of time series data in the cross-modal embedding process, the model introduces the absolute Positional Encoding based on sine and cosine functions in the embedding layer, which gives the time dimension a clear sense of order, so as to better coordinate the time series matching between different modes. In the aspect of optimization strategy, the model chooses AdamW optimizer, whose weight attenuation mechanism effectively controls the risk of over-fitting, and ensures the convergence stability of gradient update by dynamically adjusting the learning rate. Finally, the organic combination of multi-head attention mechanism and optimization strategy is used to improve the performance of the model in semantic consistency and distribution stability of multimodal data to a certain extent, and provide reliable technical support for the deep integration and efficient delivery of teaching content.
Experimental design and performance evaluation
Datasets collection
Before the training and evaluation of VR-Flipped model, it is necessary to collect multimodal teaching materials such as text, images and audio from various public data sources. The research objects are divided into two kinds of curriculum resources: Small Private Online Courses (SPOC) and Massive Open Online Courses (MOOC). Chinese data are mainly dynamically crawled from the education platform through Scrapy and Selenium, and some restricted data are crawled after obtaining permissions through Application Programming Interface (API) interface. On the international platform, YouTube Data API, Twitter API and Instagram Graph API are used to collect educational videos and pictures. The data is formatted by ffmpeg tools, key frames are extracted by OpenCV to generate image sets, text data is segmented and cleaned by NLTK library, and image data is normalized by Pillow library. Finally, 164,875 data packets are retained and divided into 20 groups, of which 1–14 groups are used for training and 15–20 groups are used for inspection.
The basic situation of the 20 groups of data is shown in Table 1:
Table 1.
Basic situation of 20 groups of data.
| Datasets | Course duration (min) | Video frame rate (fps) | Audio length (min) | Text words | Audio bit rate (kbps) | Number of metadata fields |
|---|---|---|---|---|---|---|
| 1 | 11.835-104.805 | 22.316–59.990 | 7.570-55.673 | 543.460-4074.213 | 74.358-246.456 | 5.821–19.073 |
| 2 | 9.161–87.525 | 23.970-43.996 | 6.983–52.442 | 793.421-4490.879 | 80.244-223.028 | 8.326–17.615 |
| 3 | 11.955–94.134 | 21.921–58.012 | 9.312–58.990 | 715.830-3255.161 | 67.675-270.159 | 6.794–19.386 |
| 4 | 13.755–83.109 | 22.647–32.905 | 5.735–58.532 | 641.888-3726.165 | 73.236-266.398 | 6.962–19.083 |
| 5 | 19.616-119.448 | 19.055–28.650 | 7.461–45.165 | 822.959-4141.557 | 68.940-253.586 | 7.196–16.885 |
| 6 | 15.472-101.444 | 23.586–45.822 | 7.296–59.601 | 678.048-4973.030 | 81.043-198.633 | 7.313–16.507 |
| 7 | 9.643-112.552 | 17.058–48.181 | 7.463–46.575 | 802.887-3474.454 | 74.771-209.205 | 8.738–17.514 |
| 8 | 15.271–86.505 | 20.563–36.894 | 8.167–44.803 | 550.891-3305.718 | 66.028-318.715 | 6.161–19.498 |
| 9 | 18.664-112.901 | 16.022–48.177 | 5.379–42.578 | 622.979-3321.363 | 74.315-295.664 | 6.919–17.718 |
| 10 | 19.247-109.029 | 19.683–51.803 | 5.640-43.038 | 593.284-3570.190 | 72.149-279.232 | 9.532–18.121 |
| 11 | 14.201–96.730 | 19.681–54.679 | 5.694–52.817 | 586.687-4793.531 | 88.327-268.242 | 5.584–19.699 |
| 12 | 18.991-114.643 | 19.967–44.194 | 5.909–46.913 | 540.117-4049.023 | 79.090-244.716 | 8.139–16.675 |
| 13 | 5.678–81.055 | 22.890-38.525 | 9.484–49.479 | 705.198-4964.757 | 75.164–310.980 | 5.696–18.970 |
| 14 | 10.647-112.422 | 16.206–25.036 | 8.338–43.446 | 556.019-3795.711 | 90.580-315.523 | 8.100-17.667 |
| 15 | 19.809–86.017 | 21.796–46.331 | 5.961–40.817 | 984.735-4731.014 | 67.978-285.551 | 9.469–18.943 |
| 16 | 13.912–95.236 | 21.337–31.667 | 5.845–45.572 | 908.536-3515.806 | 94.027-215.198 | 5.758–16.559 |
| 17 | 19.549-113.685 | 16.227–24.524 | 5.885–41.774 | 585.444-4337.286 | 66.128-286.863 | 6.242–18.720 |
| 18 | 17.575–98.748 | 18.155–45.237 | 5.603–49.216 | 964.688-4113.526 | 82.383-299.754 | 5.168–17.849 |
| 19 | 11.222–90.936 | 18.530-39.749 | 6.032–47.285 | 785.806-3559.958 | 68.473-293.794 | 8.812–19.384 |
| 20 | 5.846-114.589 | 23.137–36.537 | 7.517–53.808 | 884.746-3374.087 | 70.452-212.948 | 6.710-19.106 |
Experimental environment
After sorting out, the relevant parameter ranges of 20 groups of data before the experiment are shown in Table 2:
Table 2.
Range of relevant parameters of 20 groups of data before the experiment.
| Datasets | Noise level (%) | Percentage of missing data (%) | Text compression ratio | Image compression ratio | Audio compression ratio |
|---|---|---|---|---|---|
| 1 | 0.014–0.092 | 0.020–0.045 | 1.127–2.750 | 1.389–2.856 | 1.156–2.335 |
| 2 | 0.015–0.070 | 0.011–0.048 | 1.184–2.898 | 1.432–2.397 | 1.494–2.026 |
| 3 | 0.042–0.057 | 0.019–0.036 | 1.182–2.191 | 1.367–2.205 | 1.169–1.772 |
| 4 | 0.019–0.086 | 0.016–0.032 | 1.115–2.472 | 1.217–2.896 | 1.107–2.414 |
| 5 | 0.039–0.082 | 0.011–0.030 | 1.326–2.066 | 1.105–2.086 | 1.147–2.077 |
| 6 | 0.038–0.077 | 0.018–0.020 | 1.410–2.453 | 1.183–2.027 | 1.210–2.054 |
| 7 | 0.020–0.067 | 0.013–0.032 | 1.310–2.441 | 1.173–2.583 | 1.361–2.330 |
| 8 | 0.017–0.095 | 0.015–0.048 | 1.260–2.560 | 1.269–2.893 | 1.183–1.511 |
| 9 | 0.033–0.070 | 0.013–0.030 | 1.162–2.182 | 1.427–2.342 | 1.155-2.400 |
| 10 | 0.028–0.097 | 0.017–0.034 | 1.445–2.946 | 1.204–2.380 | 1.450–2.097 |
| 11 | 0.016–0.079 | 0.012–0.034 | 1.249–2.271 | 1.336–2.268 | 1.340–2.165 |
| 12 | 0.030–0.081 | 0.011–0.025 | 1.358–2.409 | 1.350–2.409 | 1.170–2.414 |
| 13 | 0.011–0.094 | 0.015–0.033 | 1.110–2.156 | 1.321–2.436 | 1.268–1.883 |
| 14 | 0.047–0.078 | 0.019–0.031 | 1.386–2.659 | 1.218–2.948 | 1.308–1.547 |
| 15 | 0.038–0.096 | 0.016–0.039 | 1.111–2.222 | 1.405–2.140 | 1.167–2.238 |
| 16 | 0.038–0.058 | 0.010–0.040 | 1.192–2.672 | 1.447–2.487 | 1.133–2.103 |
| 17 | 0.033–0.080 | 0.012–0.049 | 1.108–2.104 | 1.458-2.800 | 1.198–1.889 |
| 18 | 0.027–0.087 | 0.011–0.032 | 1.420–2.179 | 1.270–2.022 | 1.215–1.856 |
| 19 | 0.047–0.096 | 0.011–0.050 | 1.361–2.238 | 1.207–2.542 | 1.388–1.797 |
| 20 | 0.028–0.056 | 0.015–0.038 | 1.140–2.243 | 1.353–2.258 | 1.327–1.976 |
In this paper, the verification of VR-Flipped model is verified through three levels:
(1) Accuracy verification of cross-modal data fusion: It is evaluated by cosine similarity analysis and Kullback–Leibler (KL) divergence. Cosine similarity analysis is used to measure the similarity of feature vectors among different modes (such as vision and text) and determine the semantic consistency after multimodal fusion30,31. On the other hand, KL divergence is used to evaluate the difference of modal data distribution before and after fusion, and the fusion effect of the model on cross-modal information is tested by quantifying the difference of distribution32.
(2) Automatic matching verification: The accuracy of feedback generated by the model is evaluated by matching the preset test label with the automatically generated feedback result33,34. Precision can be evaluated by the correctness of data labels, and combined with error analysis, the rationality of feedback generated by the model can be tested by Mean Squared Error (MSE), Root Mean Square Error (RMSE), Mean Absolute Error (MAE), Mean Absolute Percentage Error (MAPE) and other indicators to ensure that the feedback generated by the model can meet the expected teaching goals and contents.
In this process, different groups of data are scored for scene coherence, and the scoring equation is:
| 13 |
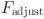 is the adjustment frequency.
is the adjustment frequency. 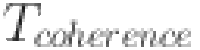 is the coherence retention time.
is the coherence retention time. 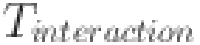 is the response time of interaction complexity.
is the response time of interaction complexity.  is the consistency value of teaching goals.
is the consistency value of teaching goals. 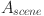 is the scene fitness.
is the scene fitness. 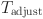 is the scene adjustment time.
is the scene adjustment time.  ,
, 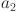 ,
, 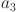 and
and 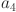 are the weight coefficients, which are used to adjust the influence of different factors on the score.
are the weight coefficients, which are used to adjust the influence of different factors on the score.
After adjusting the data of different groups, the score equation is:
| 14 |
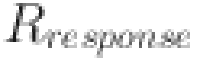 is the response time of the adaptive strategy.
is the response time of the adaptive strategy. 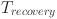 is the system recovery time.
is the system recovery time.  is the restored teaching coherence.
is the restored teaching coherence. 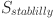 is system stability.
is system stability. 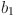 ,
,  and
and 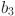 are the weight coefficients of different factors, which are used to adjust the score.
are the weight coefficients of different factors, which are used to adjust the score.
(3) Verification of dynamic adjustment ability: Dynamic scene adaptability test is used to analyze the adjustment frequency and consistency of the model in virtual scenes with different complexity to ensure that the model can still maintain the consistency between the scene and the teaching goals when dealing with complex interactions35. Secondly, the adaptive strategy evaluation is used to test whether the model can maintain a certain dynamic adjustment robustness by simulating unexpected events or abnormal operations in the scene.
Parameters setting
In order to meet more abundant teaching scenes, in the training and verification of VR-Flipped, the open classroom teaching videos are selected as input data. In the verification of dynamic adjustment capability, the parameters related to virtual scenes with different complexity and the unexpected events and abnormal operations in the scene are all automated script simulations, and extreme values are taken according to common ranges. The ranges of parameters related to virtual scenes with different complexity are shown in Table 3:
Table 3.
Parameter range of virtual scenes with different complexity.
| Number | Scene complexity (Level) | Number of scene objects | Number of interactive elements | Scene area (square meters) | Scene rendering time (ms) |
|---|---|---|---|---|---|
| A1 | 1.4–7.7 | 50.4-302.7 | 25.0-77.1 | 90.9-442.7 | 267.5-771.8 |
| A2 | 2.2–7.3 | 62.8-336.1 | 24.9–72.4 | 98.7-329.6 | 267.3-893.4 |
| A3 | 2.1–7.5 | 100.0-358.4 | 14.3–81.9 | 58.5-312.9 | 109.5-803.7 |
| A4 | 3.0–9.0 | 54.9-493.7 | 10.0-77.7 | 84.9-485.8 | 255.6–814.0 |
| A5 | 1.1–9.6 | 60.7-480.8 | 12.5–79.4 | 56.7-450.5 | 291.1-948.3 |
| A6 | 1.1–8.5 | 93.7-313.2 | 20.2–94.9 | 86.1-461.8 | 109.3-856.8 |
| A7 | 3.0-7.9 | 78.4-476.6 | 17.5–88.1 | 73.3-495.1 | 277.7-782.5 |
| A8 | 1.1–7.9 | 62.1–463.0 | 26.5–92.9 | 71.7–401.0 | 260.1-806.2 |
| A9 | 1.5–7.1 | 50.1-477.8 | 16.6–84.7 | 73.2-344.4 | 201.5-851.2 |
| A10 | 2.7–7.3 | 74.9-355.9 | 28.1–81.2 | 76.9-488.8 | 187.0-901.4 |
Regarding the calculation method of scene complexity level 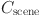 , the equation in this paper is:
, the equation in this paper is:
| 15 |
The first term 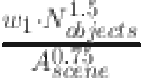 indicates the influence of the number of objects and the scene area on the complexity. The number of objects is increased by 1.5 power, while the scene area is reduced by 0.75 power. The second term
indicates the influence of the number of objects and the scene area on the complexity. The number of objects is increased by 1.5 power, while the scene area is reduced by 0.75 power. The second term 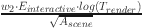 indicates the influence of the number of interactive elements and the rendering time. The rendering time is logarithmic, and considering the nonlinear growth of its influence, the area is reduced by the square root. The third item
indicates the influence of the number of interactive elements and the rendering time. The rendering time is logarithmic, and considering the nonlinear growth of its influence, the area is reduced by the square root. The third item 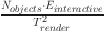 combines the influence of the number of objects and interactive elements on the rendering time, and the rendering time reduces the influence on the complexity by the square. The fourth term
combines the influence of the number of objects and interactive elements on the rendering time, and the rendering time reduces the influence on the complexity by the square. The fourth term 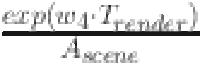 represents the increase of rendering time with exponential function, which is suitable for describing the significant impact on complexity when rendering time increases rapidly.
represents the increase of rendering time with exponential function, which is suitable for describing the significant impact on complexity when rendering time increases rapidly.
The range of parameters related to emergencies and abnormal operations in the scene is shown in Table 4:
Table 4.
Parameter range related to unexpected events and abnormal operations in the scene.
| Number | Event type | Event frequency (times/hour) | Event duration (s) | The system response time (s) | Event influence scope (square meters) | Event repair time (s) |
|---|---|---|---|---|---|---|
| B1 | Object disappears | 2.0-8.9 | 0.7–8.8 | 0.2–4.8 | 37.6-152.1 | 3.8–17.4 |
| B2 | Sudden power failure | 2.4–9.5 | 0.9–8.9 | 0.3–4.5 | 12.5-195.8 | 2.4–16.5 |
| B3 | Operation lag | 2.2–9.8 | 1.4–9.2 | 0.8–4.6 | 18.1-169.5 | 3.3–19.2 |
| B4 | UI failure | 2.4–8.4 | 1.4–9.4 | 0.4–4.9 | 13.5-161.1 | 4.5–19.0 |
| B5 | UI failure | 1.9–8.7 | 0.8–8.5 | 1.0-4.1 | 15.3-189.1 | 1.0-16.9 |
| B6 | Sudden power failure | 2.5–9.2 | 0.6–8.2 | 1.0-4.9 | 33.7-170.5 | 1.1–17.1 |
| B7 | Sudden power failure | 2.6–10.0 | 0.9–9.2 | 0.4-5.0 | 16.4-151.6 | 1.4–19.4 |
| B8 | Operation Lag | 3.0-9.1 | 1.6–8.8 | 0.6–4.6 | 38.9-177.4 | 2.6–15.6 |
| B9 | Sudden power failure | 1.2–8.8 | 0.6–8.3 | 0.9–4.2 | 18.9-167.7 | 2.2–18.9 |
| B10 | Object disappears | 1.6–8.6 | 0.6-9.0 | 0.3–4.5 | 38.6-174.6 | 2.9–15.2 |
Performance evaluation
Accuracy verification of cross-modal data fusion
The cosine similarity analysis results of cross-modal data fusion of VR-Flipped model are shown in Fig. 1:
Fig. 1.

Cosine similarity analysis of VR-Flipped cross-modal data fusion (a) Video-Text (b) Image-Text (c) Video-Image (d) Video-Text-Image.
In Fig. 1, among the six groups of test data, the average similarity of the model in the video-text mode is 0.85, the average similarity of the video-image mode is 0.89, and the similarity of the other two modes is almost close to 1, which shows that the feature vectors of different modes maintain high consistency after fusion. Modal data such as video and image effectively capture the semantic association through fusion, so that the fused information can achieve consistent understanding in multimodal interaction. The high similarity verifies the ability of VR-Flipped model in multimodal data fusion. Even when dealing with complex interactions in VR, it can maintain the synchronization and consistency of multimodal data, which is helpful to improve the efficiency of information transmission in teaching.
The KL divergence analysis results of cross-modal data fusion of VR-Flipped model are shown in Fig. 2:
Fig. 2.

KL divergence analysis of VR-Flipped cross-modal data fusion (a) Modal distribution performance (b) KL divergence results.
In Fig. 2, the KL divergence of visual-text is 0.49 and below, and the lowest is 0.19. The KL divergence of video-image is at least 0.12. The KL divergence value of text-image remains at [0.28, 0.40], and the small difference shows that the distribution of each mode remains relatively stable after fusion. Compared with cosine similarity, KL divergence analysis highlights the accuracy of the model in dealing with different modal data distribution, ensuring that multimodal fusion is not only semantically consistent, but also has no significant deviation in data distribution level. This is very important for optimizing the accuracy of teaching content, which shows that the model can effectively avoid information loss in cross-modal fusion and ensure deep collaboration between different modes.
Automated matching verification
The verification result of automatic matching degree of VR-Flipped model is shown in Fig. 3:
Fig. 3.

VR-Flipped automatic matching verification (a) Accuracy analysis (b) Error analysis.
In Fig. 3, VR-Flipped shows high superiority in the accuracy of automatically generating feedback. The correctness of preset labels of six groups of test datasets has reached more than 80%, and the accuracy of automatically generating feedback has reached 93.72%. This shows that VR-Flipped can efficiently match multi-modal data, greatly reducing the need for manual intervention and improving the efficiency of feedback generation. The lower MSE and MAE values in the error analysis show that VR-Flipped maintains stability when dealing with complex scenes, ensuring a small feedback error, which proves its robustness advantage in real-time teaching scenes. This makes the VR-Flipped model provide fast and accurate personalized feedback for the classroom and optimize the teaching process.
Dynamic adjustment capability verification
The verification result of the dynamic adjustment capability of VR-Flipped model is shown in Fig. 4:
Fig. 4.

Verification of VR-Flipped dynamic adjustment capability (a) Dynamic scene adaptability test and analysis (b) Sudden problem adaptability test and analysis.
In Fig. 4, VR-Flipped shows high adaptability in different complexity virtual scenes of A1-A10, the adjustment frequency is stable at about 2.5 times/minute, and the scene consistency score remains above 8.6, which proves that the model can still maintain a high degree of consistency with the teaching objectives in complex interaction. This shows that VR-Flipped can quickly respond to scene changes and ensure the consistency and consistency of the learning experience. In the emergency test of B1-B10, the average response time of the adaptive strategy is 3.43 s at most, and the teaching coherence remains at about 85.4% after recovery, which shows that VR-Flipped is robust in dealing with emergencies. Combined with these results, VR-Flipped has a strong adaptability to dynamic adjustment, which can not only cope with complex scenes, but also recover quickly in unexpected situations to ensure the achievement of teaching objectives.
Discussion
By designing and verifying the VR-Flipped model, this paper deeply discusses its application effect in complex interactive scenes. The research results show that VR-Flipped has obvious advantages in multimodal information integration and scene adaptability, especially in video-text and video-image modes. The high similarity and low KL divergence further prove the effective fusion and semantic consistency of the model for multimodal data. This data fusion not only enhances the accuracy of information transmission, but also ensures the consistency of teaching content in VR environment. More crucially, VR-Flipped can respond to learners’ operational behavior in real time through the adaptive feedback mechanism, which effectively reduces the time delay in the process of knowledge internalization and strengthens the teaching effect. The high accuracy of automatically generated feedback also reflects the robustness of the model in personalized learning feedback, ensuring its important position in the intelligent teaching process.
From the perspective of scene use, the experimental design of VR-Flipped fully considers the integration of diverse curriculum resources. Data crawling based on SPOC and MOOC platforms covers theoretical subjects and practical courses, which provides solid empirical support for the multi-modal adaptability of the model. The universality of this data source makes the model particularly outstanding in dynamic adjustment ability and semantic integration consistency, which provides a reliable guarantee for teaching coherence in complex scenes. In addition, the potential application of intelligent feedback and cross-modal analysis ability of VR-Flipped model in large-scale online courses and professional skills training shows its excellent adaptability. For example, in the MOOC environment, the model can effectively meet the complex needs of large-scale learning scenarios by real-time dynamic adjustment and optimization of personalized feedback. In STEM or art courses, its deep integration ability helps to improve the efficiency of mastering complex skills. Although the experimental data has not completely covered all disciplines, the design logic and verification results of the model show that it has a wide range of applicability and provides an important reference for promoting technological innovation and practice in diverse educational scenarios.
Conclusion
Research contribution
Before the final summary, the paper searches the framework of flipped classroom education model based on VR and AI in the frontier research at this stage, and compared it with the research in this paper. The arrangement of frontier achievements is shown in Table 5:
Table 5.
The framework of flipped classroom education model based on VR and AI in frontier research at the present stage.
| Researcher | Model/educational framework | Datasets/methods used in the paper | Conclusion |
|---|---|---|---|
| Lin et al.36 | Flip learning model based on VR | Comparison of 39 students in the experimental group and 37 students in the control group in the lumbar puncture course | The flip learning model based on virtual reality has significantly improved complex medical skills, self-efficacy and learning motivation. Suggestions on integrating VR technology into medical training are put forward. [36]. |
| Diningrat et al.37 | Extended flipped classroom mode | 112 students participated in the 2 × 2 factor design to analyze the interaction between extended flip classroom and memory capacity. | Expanding flip class can significantly improve primary school students’ reading comprehension ability, especially for students with high working memory capacity [37]. |
| Liao and Wu38 | Learning model based on video clickstream data analysis | 47,044 video viewing data of 47 graduate students, combined with click stream dynamic analysis. | This paper reveals the dynamic development mechanism of learning motivation through video interactive behavior, and suggests providing on-demand teaching materials to support learning autonomy [38]. |
| Zhang39 | Teaching and evaluation model of English as a Foreign Language (EFL) writing flip based on MOOC and AI | Three EFL teachers and 66 students triangulated the data of their pre-and post-test papers and questionnaires. | The model significantly improves EFL writing performance, and the growth trend of teachers’ knowledge of technology teaching content is of reference value to technology integration education [39]. |
| Wong et al.40 | Virtual and Augmented Reality Technology-Enhanced Learning Environment (VARTeL) | 156 mechanical engineering students, three VR games combined with pre-test and post-test and Technology-Rich Outcomes-Focused Learning Environment Inventory (TROFLEI) scale analysis. | VARTeL flipped classroom significantly improves the effect of engineering education, and the post-test increases by 24.8%, which verifies the potential of VR in complex technology learning [40]. |
| Gutiérrez-González et al.41 | Video lecture model based on Edpuzzle platform | Analysis of viewing data and retention rate of 51 videos of 109 medical students in neurosurgery courses for two consecutive years. | Short videos can attract students’ participation, and the viewing rate of early uploaded videos is higher. Design strategies are emphasized to improve learners’ participation [41]. |
From Table 5 above, the current cutting-edge research shows that VR and AI technologies have become the key driving forces for the optimization of the flipped classroom education model. Whether it is to improve the learning effect, optimize the interaction mode, or achieve more accurate personalized learning support, various studies are exploring how these technologies can better integrate with educational practice. In the general direction, these studies show a consistent trend, that is, using VR to provide an immersive learning environment and optimizing the learning experience through the feedback mechanism generated by AI. However, the differences between the studies are mainly reflected in the specific implementation methods and the design of application scenarios. For example, Lin et al.’ focused on the complex training of medical skills, emphasizing the enhancement of VR to repeated practice opportunities and immediate feedback. Diningrat et al. discussed the efficiency of extended flipped classroom model in language understanding, and combined the influence of working memory capacity on learning performance. In addition, Wong et al. enhanced the effect of engineering education through interactive VR games, further highlighting the advantages of VR technology in dynamic learning situations.
Compared with the above research, the designed VR-Flipped model shows unique advantages in multi-modal data fusion, intelligent feedback generation and dynamic scene adaptability. Its core lies in the deep integration of vision, text and interactive behavior through the combination of CLIP model and Transformer cross-modal attention mechanism, which provides more accurate personalized learning support. Different from the research that only focuses on specific subjects, VR-Flipped model has wider adaptability, and can dynamically adjust teaching strategies in high-frequency interactive virtual classroom scenes to ensure the accurate matching of learning paths and goals. In addition, the model significantly improves the semantic consistency and distribution stability of multimodal fusion through data-driven feedback mechanism, which is verified by KL divergence and similarity analysis.
Generally speaking, VR-Flipped not only analyzes students’ real-time performance through the cross-modal attention mechanism, but also makes intelligent adjustments according to their behaviors, provides targeted suggestions, and improves the effect of autonomous learning. VR technology provides students with an immersive learning scene, which makes autonomous learning before class and classroom interaction more efficient, and breaks the lag and singleness of feedback in the traditional flipped classroom. Through the in-depth analysis of video data, the model reduces the dependence on students’ real-time data, ensures the adaptability and objectivity in different teaching scenarios, and helps teachers optimize the structure and content of flipped classrooms. On the technical level, schools need to deploy high-performance computing equipment to support real-time cross-modal data processing, and be equipped with hardware facilities supporting virtual reality, such as VR head-mounted display and interactive equipment. In addition, in order to ensure the smooth operation of the system, it is necessary to build a distributed architecture based on cloud computing to deal with large-scale data input and feedback generation. On the financial level, the initial deployment of the system may require high investment, especially in hardware procurement and software development. However, through large-scale application and gradual upgrading of equipment, the cost can be significantly shared and the benefits can be maximized for a long time. In order to reduce the burden on schools, it is suggested to develop a shared resource platform through the support of government education funds or cooperation with technology companies, thus laying the foundation for the wide promotion of the system in practical scenes.
Based on this, in experiments-intensive and hands-on disciplines, such as engineering design, physical experiments, medical simulation and other courses, the application of VR-Flipped can better analyze students’ performance in VR in real time through the cross-modal attention mechanism, and make intelligent adjustments according to students’ learning behaviors in different modes. Students can learn interactively in the virtual laboratory or virtual classroom, and complete tasks such as experimental operation and project design. At the same time, teachers can get in-depth analysis of video data through the model and optimize the classroom structure and content. By reducing the dependence on real-time student feedback, teachers can adjust teaching strategies more effectively, enhance the flexibility and accuracy in the teaching process, and ensure the efficiency of students’ autonomous learning and classroom interaction.
Future works and research limitations
Although this paper provides a new perspective for the intelligence and dynamic adaptability of flipped classroom, there are still limitations. Firstly, the research mainly focuses on visual and text modes, and it needs to be extended to multi-sensory interaction such as audio and touch in the future to improve the perceptual accuracy and feedback diversity of VR-Flipped. In addition, although dynamically adjusting the frequency ensures the continuity of the scene, the influence on learners’ cognitive load in complex scenes has not been fully verified. For high-order cognitive tasks, such as critical thinking training, further large-scale experimental verification and algorithm optimization are needed. Compared with the dynamic clickstream analysis of Liao and Wu (2023), VR-Flipped’s deep-seated mining of students’ long-term learning behavior still needs to be further improved. In addition, due to the bottleneck of computing resources in multimodal data processing, the real-time performance of the model in ultra-complex scenes still needs to be optimized.
The future research will focus on the higher-level multimodal data fusion and feedback mechanism, and combine the cutting-edge theories of brain science and cognitive psychology to deeply analyze learners’ cognitive state and its dynamic changing law in the VR environment. By introducing neurophysiological signal acquisition techniques, such as EEG and functional near infrared spectroscopy, the neural response mechanism of learners under different cognitive loads is explored to optimize the personalized design of multimodal feedback. In addition, the research will further expand the deep interaction ability of the model in audio, tactile and virtual reality, and explore the synergy and gain effect of these modes in different learning scenarios. In order to meet the high demand for computing resources in ultra-complex scenes, distributed computing and lightweight algorithm optimization strategies will be introduced in the future to improve the real-time and scalability of the model and ensure its stable performance in high-complexity and diverse educational environments.
Author contributions
Wenxia Dai: Conceptualization, methodology, software, validation, formal analysis, investigation, resources, data curation, writing—original draft preparation Qinqing Kang: writing—review and editing, visualization, supervision, project administration, funding acquisition.
Funding
This work was supported by project on teaching reform of teaching reform of higher education insitution and universities in Hunan province (No.XJT202401000025).
Data availability
The datasets used and/or analyzed during the current study are available from the corresponding author Wenxia Dai on reasonable request via e-mail hydd119@126.com.
Declarations
Competing interests
The authors declare no competing interests.
Ethics statement
This article does not contain any studies with human participants or animals performed by any of the authors. All methods were performed in accordance with relevant guidelines and regulations.
Footnotes
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
References
- 1.Baig, M. I. & Yadegaridehkordi, E. Flipped classroom in higher education: A systematic literature review and research challenges. Int. J. Educ. Technol. High. Educ.20 (1), 61 (2023). [Google Scholar]
- 2.Vitta, J. P. & Al-Hoorie, A. H. The flipped classroom in second language learning: A meta-analysis. Lang. Teach. Res.27 (5), 1268–1292 (2023). [Google Scholar]
- 3.Li, C. et al. Research on the big data analysis of MOOCs in a flipped classroom based on attention mechanism in deep learning model. Comput. Appl. Eng. Educ.31 (6), 1867–1882 (2023). [Google Scholar]
- 4.Grassini, S. Shaping the future of education: eExploring the potential and consequences of AI and ChatGPT in educational settings. Educ. Sci.13 (7), 692 (2023). [Google Scholar]
- 5.Rengers, T. A., Thiels, C. A. & Salehinejad, H. Academic surgery in the era of large Language models: A review. JAMA Surg.159 (4), 445–450 (2024). [DOI] [PubMed] [Google Scholar]
- 6.Cueva, A. & Inga, E. Information and communication technologies for education considering the flipped learning model. Educ. Sci.12 (3), 207 (2022). [Google Scholar]
- 7.Cevikbas, M. & Kaiser, G. Promoting personalized learning in flipped classrooms: A systematic review study. Sustainability14 (18), 11393 (2022). [Google Scholar]
- 8.Bruno, S. & Nizar, H. A. Flipped learning effect on classroom engagement and outcomes in university information systems class. Educ. Inf. Technol.27 (3), 3341–3359 (2022). [Google Scholar]
- 9.Oliván-Blázquez, B. et al. Comparing the use of flipped classroom in combination with problem-based learning or with case-based learning for improving academic performance and satisfaction. Act. Learn. High Educ.24 (3), 373–388 (2023). [Google Scholar]
- 10.Zhao, Q. & Wu, G. Auxiliary feature extractor and dual attention-based image captioning. Signal. Image Video Process.18 (4), 3615–3626 (2024). [Google Scholar]
- 11.Jung, M. J., Han, S. D. & Kim, J. Re-scoring using image-language similarity for few-shot object detection. Comput. Vis. Image Underst.241 (7), 103956 (2024). [Google Scholar]
- 12.Arya, G. et al. Multimodal hate speech detection in memes using contrastive language-image pre-training. IEEE Access.12 (14), 22359–22375 (2024). [Google Scholar]
- 13.Sánchez-Muñoz, R. et al. A hybrid strategy to develop real-life competences combining flipped classroom, jigsaw method and project-based learning. J. Biol. Educ.56 (5), 540–551 (2022). [Google Scholar]
- 14.Fidan, M. The effects of microlearning-supported flipped classroom on pre-service teachers’ learning performance, motivation and engagement. Educ. Inf. Technol.28 (10), 12687–12714 (2023). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 15.Shen, D. & Chang, C. S. Implementation of the flipped classroom approach for promoting college students’ deeper learning. Educ. Technol. Res. Dev.71 (3), 1323–1347 (2023). [Google Scholar]
- 16.Al-Said, K. et al. Distance learning: Studying the efficiency of implementing flipped classroom technology in the educational system. Educ. Inf. Technol.28 (10), 13689–13712 (2023). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 17.Huang, A. Y. Q., Lu, O. H. T. & Yang, S. J. H. Effects of artificial intelligence–enabled personalized recommendations on learners’ learning engagement, motivation, and outcomes in a flipped classroom. Comput. Educ.194 (7), 104684 (2023). [Google Scholar]
- 18.Gong, J., Cai, S. & Cheng, M. Exploring the effectiveness of flipped classroom on STEM student achievement: A meta-analysis. Technol. Knowl. Learn.29 (2), 1129–1150 (2024). [Google Scholar]
- 19.Solissa, E. M. et al. The Effect of flipped Classroom size on students’ critical thinking abilities. Edumaspul J. Pendidik.. 7 (2), 5073–5081 (2023). [Google Scholar]
- 20.Zhu, Z., Xu, Z. & Liu, J. Flipped classroom supported by music combined with deep learning applied in physical education. Appl. Soft Comput.137 (24), 110039 (2023). [Google Scholar]
- 21.Egara, F. O. & Mosimege, M. Effect of flipped classroom learning approach on mathematics achievement and interest among secondary school students. Educ. Inf. Technol.29 (7), 8131–8150 (2024). [Google Scholar]
- 22.Chen, T. et al. The role of pre-class and in-class behaviors in predicting learning performance and experience in flipped classrooms. Heliyon9 (4), 158–164 (2023). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 23.Samaila, K. & Al-Samarraie, H. Reinventing teaching pedagogy: The benefits of quiz-enhanced flipped classroom model on students’ learning outcomes and engagement. J. Appl. Res. High. Educ.16 (4), 1214–1227 (2024). [Google Scholar]
- 24.Syafruddin, S. et al. The effectiveness of IoT-based flipped classroom model on students’ critical thinking skills: A meta-analysis. J. Penelit. Pendidik. IPA. 9 (10), 883–891 (2023). [Google Scholar]
- 25.Domu, I., Pinontoan, K. F. & Mangelep, N. O. Problem-based learning in the online flipped classroom: Its impact on statistical literacy skills. J. Educ. e-Learn. Res.10 (2), 336–343 (2023). [Google Scholar]
- 26.Buhl-Wiggers, J. et al. Investigating effects of teachers in flipped classroom: A randomized controlled trial study of classroom level heterogeneity. Int. J. Educ. Technol. High. Educ.20 (1), 26 (2023). [Google Scholar]
- 27.Daneshfar, F., Bartani, A. & Lotfi, P. Image captioning by diffusion models: A survey. Eng. Appl. Artif. Intell.138 (22), 109288 (2024). [Google Scholar]
- 28.Sointu, E. et al. Preliminary evidence of key factors in successful flipping: Predicting positive student experiences in flipped classrooms. High. Educ.85 (3), 503–520 (2023). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 29.Pratiwi, D. I. et al. Flipped classroom with gamified technology and paper-based method for teaching vocabulary. Asian-Pac. J. Second Foreign Lang. Educ.9 (1), 1 (2024). [Google Scholar]
- 30.Candel, E. C., de-la-Peña, C. & Yuste, B. C. Pre-service teachers’ perception of active learning methodologies in history: Flipped classroom and gamification in an e-learning environment. Educ. Inf. Technol.29 (3), 3365–3387 (2024). [Google Scholar]
- 31.Leão, P. et al. Flipped classroom goes sideways: Reflections on active learning methodologies. Rev. Gest.30 (2), 207–220 (2023). [Google Scholar]
- 32.Inayah, S. et al. The impact of flipped classroom implementation in mathematics learning at schools. Syst. Lit. Rev. J. Anal.. 9 (1), 59–73 (2023). [Google Scholar]
- 33.Pertuz, S. et al. MOOC-based flipped classroom for on-campus teaching in undergraduate engineering courses. IEEE Trans. Educ.66 (5), 468–478 (2023). [Google Scholar]
- 34.Kömür, İ. A., Kilinç, H. & Okur, M. R. The rotation model in blended learning. Asian J. Distance Educ.18 (2), 63–74 (2023). [Google Scholar]
- 35.Ozyurt, O. Empirical research of emerging trends and patterns across the flipped classroom studies using topic modeling. Educ. Inform. Technol.28 (4), 4335–4362 (2023). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 36.Lin, H. C. et al. Fostering complex professional skills with interactive simulation technology: A virtual reality-based flipped learning approach. Br. J. Edu. Technol.54 (2), 622–641 (2023). [Google Scholar]
- 37.Diningrat, S. W. M. et al. The effect of an extended flipped classroom model for fully online learning and its interaction with working memory capacity on students’ reading comprehension. J. New. Approaches Educ. Res.12 (1), 77–99 (2023). [Google Scholar]
- 38.Liao, C. H. & Wu, J. Y. Learning analytics on video-viewing engagement in a flipped statistics course: Relating external video-viewing patterns to internal motivational dynamics and performance. Comput. Educ.197 (22), 104754 (2023). [Google Scholar]
- 39.Zhang, Y. A lesson study on a MOOC-based and AI-powered flipped teaching and assessment of EFL writing model: Teachers’ and students’ growth. Int. J. Lesson Learn. Stud.13 (1), 28–40 (2024). [Google Scholar]
- 40.Wong, J. Y. et al. Evaluations of virtual and augmented reality technology-enhanced learning for higher education. Electronics13 (8), 1549 (2024). [Google Scholar]
- 41.Gutiérrez-González, R., Zamarron, A. & Royuela, A. Video-based lecture engagement in a flipped classroom environment. BMC Med. Educ.24 (1), 1218 (2024). [DOI] [PMC free article] [PubMed] [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.
Data Availability Statement
The datasets used and/or analyzed during the current study are available from the corresponding author Wenxia Dai on reasonable request via e-mail hydd119@126.com.