

Abstract
Purpose
This study investigates the feasibility of using complex‐valued neural networks (NNs) to estimate quantitative transmit magnetic RF field (B1 +) maps from multi‐slice localizer scans with different slice orientations in the human head at 7T, aiming to accelerate subject‐specific B1 +‐calibration using parallel transmission (pTx).
Methods
Datasets containing channel‐wise B1 +‐maps and corresponding multi‐slice localizers were acquired in axial, sagittal, and coronal orientation in 15 healthy subjects utilizing an eight‐channel pTx transceiver head coil. Training included five‐fold cross‐validation for four network configurations: used transversal, sagittal, coronal data, and was trained on all slice orientations. The resulting maps were compared to B1 +‐reference scans using different quality metrics. The proposed network was applied in‐vivo at 7T in two unseen test subjects using dynamic kt‐point pulses.
Results
Predicted B1 +‐maps demonstrated a high similarity with measured B1 +‐maps across multiple orientations. The estimation matched the reference with a mean relative error in the magnitude of (2.70 ± 2.86)% and mean absolute phase difference of (6.70 ± 1.99)° for transversal, (1.82 ± 0.69)% and (4.25 ± 1.62)° for sagittal (), as well as (1.33 ± 0.27)% and (2.66 ± 0.60)° for coronal slices () considering brain tissue. trained on all orientations enables a robust prediction of B1 +‐maps across different orientations. Achieving a homogenous excitation over the whole brain for an in‐vivo application displayed the approach's feasibility.
Conclusion
This study demonstrates the feasibility of utilizing complex‐valued NNs to estimate multi‐slice B1 +‐maps in different slice orientations from localizer scans in the human brain at 7T.
Keywords: 7 tesla, B1 +‐mapping, brain, deep learning, parallel transmission
1. INTRODUCTION
Ultra‐high field (UHF; ≥7T) MRI allows for increased spectral, spatial, and/or temporal resolution and, in many cases, improved contrast compared to lower field strengths. 1 However, a fundamental problem at UHF is the spatial heterogeneity of the transmit (Tx) magnetic RF field (B1 +) required to excite or manipulate the magnetization, yielding spatially heterogeneous flip‐angles (FAs) and, thus, heterogeneous signals and contrast. 2 , 3 One effective solution is parallel transmission (pTx). Here, channel‐independent static or dynamic RF pulses 2 , 3 , 4 , 5 are used for multi‐Tx‐channel coils. However, even for identical feeding voltages at the coil elements, the resulting B1 +‐field distributions can vary among subjects and even within the same measurement due to respiratory motion. 6 , 7 , 8 Therefore, subject‐tailored pTx pulses are commonly calculated at the beginning of each session based on measured B1 +‐maps. This calibration process is often time‐consuming, requiring up to 15 min, 9 particularly when focusing on the human body.
Different approaches have been pursued to accelerate this calibration process. Gras et al. 11 introduced universal pulses: B1 +‐maps are acquired in different subjects before the actual study for a given pTx coil. Based on these datasets, an RF pulse approximating the desired FA pattern across all subjects is calculated offline. Such one‐fits‐all pulses also perform well in unseen subjects and have been applied in various studies in the brain, 10 , 11 , 12 heart, 13 and spinal cord 14 at UHF.
Alternatively, rapid B1 +‐mapping procedures, 15 , 16 , 17 , 18 , 19 , 20 such as DREAM 15 or presaturation‐based B1 +‐mapping, 18 , 19 , 20 can expedite the calibration process. These methods allow channel‐wise acquisitions of 3D or 2D multi‐slice B1 +‐maps of the entire brain within a minute or less. For example, Kent et al. 20 reduced the acquisition time for 3D B1 +‐maps to under 20 s with eight Tx‐channels utilizing a sandwiched presaturation TurboFLASH sequence.
Both approaches have distinct merits and limitations. Universal pulses eliminate the calibration process within the session, while subject‐tailored techniques typically achieve a better FA homogeneity. 13 , 16 , 21 However, the performance of subject‐specific RF pulses depends on the B1 +‐maps's accuracy. Fast B1 +‐mapping methods often yield less accurate results and/or lower dynamic ranges. 22 , 23 , 24 Furthermore, high acceleration factors may require long reconstruction times, and increasing the resolution or the number of Tx‐channels from eight to 16 or 32 25 , 26 extends calibration times to several minutes, even for the human brain.
Recent works applied deep learning (DL) to calibration techniques in UHF MRI, 27 , 28 , 29 , 30 , 31 , 32 , 33 , 34 , 35 , 36 particularly to acquire B1 +‐fields more rapidly. 34 , 35 , 36 Eberhardt et al. 36 accelerated channel‐wise B1 +‐mapping for the brain at 7 T, acquiring data for only a fraction of Tx‐channels, while the remaining channels were estimated using DL. Furthermore, a novel DL‐based method for the thorax 37 approximates relative, complex B1 +‐maps for eight Tx‐channels based on localizers obtained with multiple receive (Rx) channels using a real‐valued neural network (NN). This technique does not add calibration time for B1 +‐mapping, as localizers are acquired by default at the beginning of each session. Yet, in that work, B1 +‐maps were estimated only for transversal 2D slices, and changing the slice orientation requires new training data. Most importantly, although B1 +‐fields are complex‐valued quantities, all introduced DL‐based techniques so far consider solely real‐valued NNs. Achieving high performances for complex‐valued data with real‐valued NNs might be plausible, for example, for magnitude image reconstruction. 38 , 39 However, for phase‐sensitive applications, such as B1 +‐mapping, complex‐valued NNs might enhance the learning process 40 , 41 by incorporating mathematically consistent complex operations. 42 , 43
This work investigates the benefits of using complex‐valued NNs to estimate channel‐wise multi‐slice B1 +‐maps from single localizer images obtained in a CP+ ‐transmission mode for different orientations in the human brain at 7T using an eight‐channel pTx transceiver head‐coil. The proposed complex‐valued NNs are compared to corresponding real‐valued architectures and the recently presented DL‐based approach. 37 The impact of the localizer's orientation on the resulting B1 +‐maps is analyzed, and the performance of four different NNs trained on transversal, sagittal, and coronal slices, as well as on a combined dataset containing all orientations, is evaluated. The accuracy of the predicted (PR) B1 +‐maps is investigated concerning acquired B1 +‐reference scans as ground truth (GT). A subject‐specific calibration pipeline using dynamic 3D kt‐point pTx pulses is investigated by Bloch simulations, and an in‐vivo application is demonstrated.
2. METHODS
A custom‐built 8Tx/8Rx‐channel transceiver head‐coil 44 is used to acquire CP+ ‐like localizers as input to the NNs (c.f. Figure S1), and absolute, Tx‐channel‐wise, multi‐slice B1 +‐maps 45 (c.f. Supporting Information S1) as unbiased B1 +‐reference (46) in different orientations. Subject‐specific static 37 , 47 and dynamic pTx pulses 48 based on the estimated whole‐brain B1 +‐maps are designed (c.f. Supporting Information S2) to assess the impact of the PR quality on the pulse design. The approach's feasibility is demonstrated in‐vivo (c.f. Supporting Information S3).
2.1. NNs and cross‐validation
All NNs transform complex‐valued, Rx‐channel‐wise localizers and the sum‐of‐squares localizer magnitude as the complex input into Tx‐channel‐wise B1 +‐maps for the complex output (c.f. Figure S1). Using complex‐valued NNs preserves the correlation between real and imaginary parts of complex‐valued quantities for both linear (e.g., multiplication) and non‐linear operations (activation function). 41 Complex convolutions, activations, loss functions, and common network layers, for example, pooling, are redefined for the complex plane. 41 , 42 , 43 , 49 The architecture of the complex‐valued NNs (termed ) is derived from the recently presented NN (termed ) for the thorax 37 and implemented in Python 3.8.5 using Tensorflow 2.2.0 50 trained on a 24GB NVIDIA Titan RTX.
The eight Rx‐channels of the complex‐valued localizers and one corresponding sum‐of‐squares magnitude image lead to an input size of 128×96×9. The output size of 128×96×8 is based on the B1 +‐maps for eight Tx‐channels. Multi‐slice input and output with whole‐brain coverage are processed slice‐wise, generating 2D sets of B1 +‐maps for eight Tx‐channels for each 2D localizer input to the NN. contains four encoding and decoding stages, each with two sequential (3×3) complex convolutions with (1,1) strides for feature extraction and an additional (3×3) (up‐) convolution using (2,2) strides for up‐ or down‐sampling. A modified rectified linear unit (ModReLU) 43 , 51 with Glorot‐uniform‐initialization 52 is utilized as the complex non‐linear activation function:
| (1) |
Here, represents any arbitrary complex number and a real‐valued, learnable bias parameter to shift the magnitude with respect to the origin. The number of feature maps is 16 in the first and last encoding/decoding stages and in/decreased two‐fold per stage. Skip connections and dropout layers 49 are incorporated at the end of each stage. Unlike the original model , the architectures of use convolutions for downsampling aiming for improved feature extraction and additional head layers in each Tx‐channel for adaption, consisting of four convolutions with decreasing feature maps.
The complex‐valued encoder‐decoder models proposed in this study are trained by minimizing an unbiased ⊥ + L2 loss. 53 An adaptive moment estimation optimizer 54 is used for optimization, with a learning rate starting at 10−4, decaying by 0.19% per epoch. Training includes a batch size of 1 for 1000 epochs. The source code and an exemplary dataset are provided: https://github.com/felixkrueger90/ComplexB1.
Four complex NNs are trained with different slice orientations to investigate the impact of the localizer's orientation on the resulting B1 +‐maps. is trained on transversal data (164 slices), on sagittal (184 slices), and on coronal data (222 slices) from 15 subjects. is trained on a combined library of all orientations (570 slices). A five‐fold split ratio and cross‐validation for all four NNs evaluate the approach's generalization capability. Datasets of 15 subjects containing transversal, sagittal, and coronal Rx‐channel‐wise localizers and corresponding Tx‐channel‐wise B1 +‐maps are randomly divided into five subsets, each containing data with all orientations from three subjects. Each fold uses one subset as test data and the other four for training, repeated five times for all NN configurations ( to ) with consistent subject partitioning. is compared to corresponding real‐valued networks with increasing numbers of trainable parameters (: 7.8 M, : 15.9 M, : 30.5 M) (c.f. Figure S2A), the architecture for the thorax (), and a modified version () for the brain (c.f. Figure S2B) to examine the impact of the complex‐valued architecture. The data procession and optimization parameters for the real‐valued NNs can be found in. 37
Analysis of the quality of the PR (B1 + PR) compared to the reference (B1 + GT) involves the absolute differences of the complex‐valued quantities B1 + PR and B1 + GT considered for the magnitude and phase , root‐mean‐squared error (RMSE) of the magnitude and complex quantities, and structural similarity index measure (SSIM) for the magnitude, phase, and complex values.
3. RESULTS
3.1. Network architecture and image quality
Figure 1 compares the prediction performance assessed by the SSIM for the magnitude (Figure 1A), phase (Figure 1B), and the complex quantity (Figure 1C) of the complex‐valued network , corresponding real‐valued networks ( to ) with an increasing number of trainable parameters, the network for the thorax (), and the modified version for the brain () for 32 unseen transversal slices. In general, the quality metrics indicated an inferior prediction quality for the architecture constructed for the thorax. The results improved when going to real‐valued NNs, but the number of trainable parameters did not notably influence the results. Furthermore, the prediction quality did not significantly improve for the complex‐valued compared to the best real‐valued network . Furthermore, an evaluation regarding the quantitative agreement (Figure S4) revealed a similar prediction quality for the magnitudes but a trend toward a better prediction quality for the phase for the complex‐valued .
FIGURE 1.
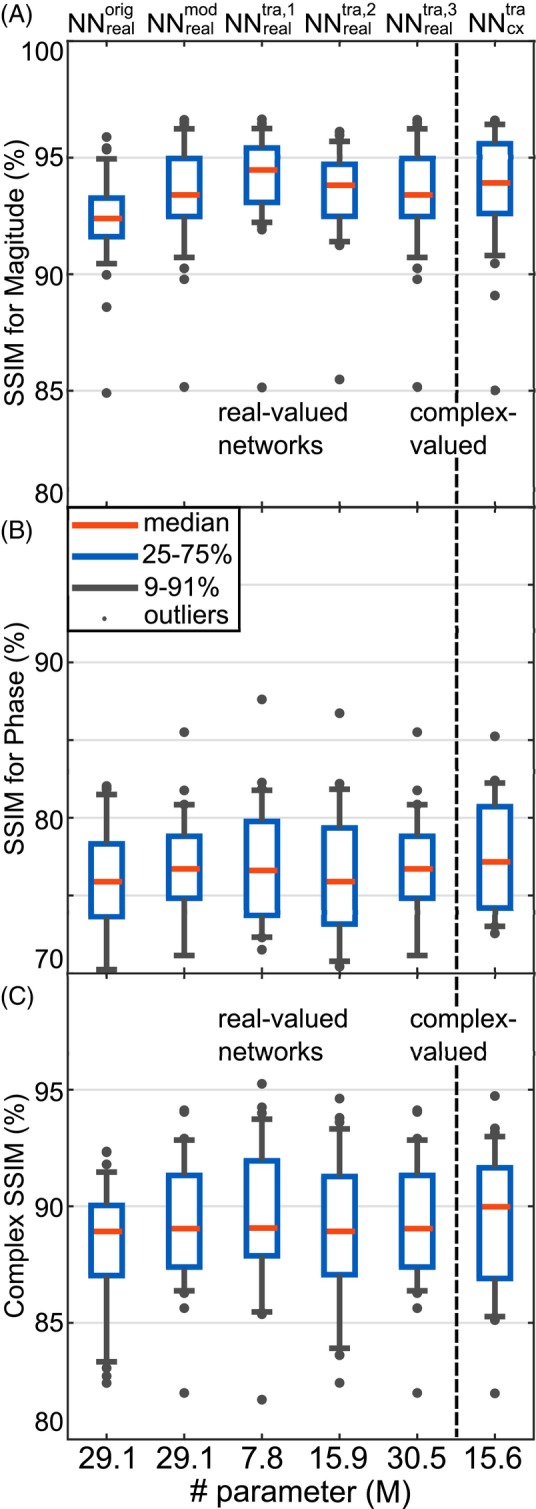
Comparison of the prediction quality assessed by the structure similarity index measure (SSIM) for the magnitude (A), phase (B), and the complex quantity (C) between the complex‐valued network , corresponding real‐valued networks ( to ), the previously introduced network for the human thorax (), and a modified version for the introduced use case (). The networks were tested for 32 transversal slices from three unseen subjects. Note the different axis intervals for the phase.
Figure 2 shows the channel‐wise B1 +‐maps for one slice, comparing the PR of to real‐valued networks to , , and with the GT. The PR data of all NN matches the GT data, not only for the magnitude but particularly in the phase distributions. Yet, phase differences in regions of low magnitudes, c.f. Tx‐channels 1, 3, and 6 and deviations in the magnitude at high levels between PR and GT are evident.
FIGURE 2.
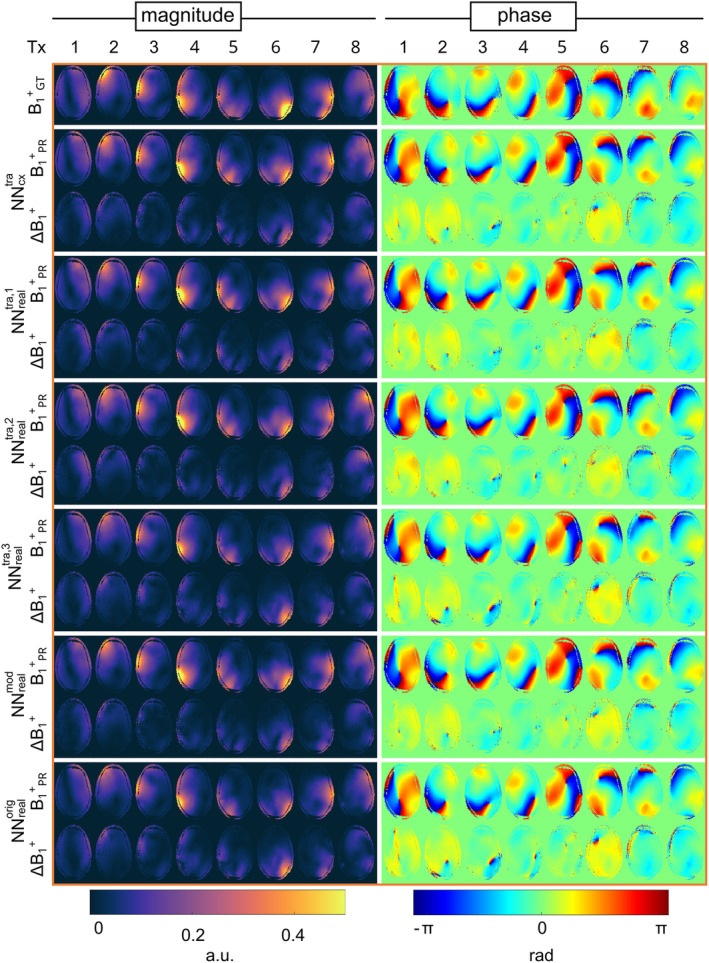
Channel‐wise B1 +‐maps considering the magnitude and phase for the prediction B1 + PR of the complex‐valued network , corresponding real‐valued networks ( to ) with an increasing number of real‐valued parameters, the previously introduced network for the human thorax () and a modified version for the introduced use case (). The results are compared to the B1 +‐reference B1 + GT, displayed by the absolute error ΔB1 + of the magnitude Δ|B1 +| = | B1 + PR − B1 + GT | and phase ∠B1 + = ∠(B1 + PR / B1 + GT) for one exemplary transversal slice of one unseen subject.
Further assessment of to regarding the five‐fold cross‐validation (Tables S1–S4) and prediction quality (Figures S5–S11) is provided.
3.2. Effect of B1 +‐quality on RF pulse design for dynamic pTx
Figure 3 illustrates the FA results of four kt‐point pulses optimized based on PR maps of and B1 +‐reference data to improve the FA homogeneity for three unseen test subjects. The dynamic pTx pulses improve the homogeneity of the excitation profile and produce smooth FA distributions over multiple slices when applied to the GT. Residual, low‐frequency variation can be seen in lower and upper slices, where the coil has less transmit sensitivity. The CV values calculated over all slices for the three test subjects improved from 27.4%, 28.7%, and 25.1% for the CP+ ‐like mode of the GT data to 13.7%, 16.3%, and 9.7% using four kt‐point pulses calculated on the PR maps of , indicating a low FA heterogeneity. In comparison, when relying on the acquired B1 +‐reference data for the optimization process, the CV values reduce to 8.2%, 8.9%, and 7.1%. The effect of the B1 +‐quality of the PR data on RF pulse design for static pTx is provided (Supporting Information S5).
FIGURE 3.
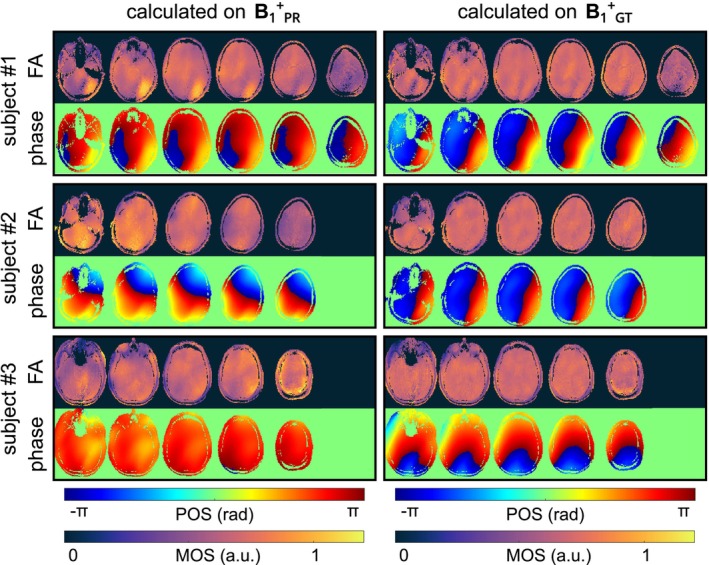
FA and phase prediction of dynamic four kt‐point pulses designed based on the predicted multi‐slice B1 +‐maps (B1 + PR) using and the B1 +‐reference (B1 + GT) data for every second slice of all three unseen datasets of subset #2. Using Bloch simulation, the calculated pulses are applied to the B1 + GT data. The dynamic pulses produce smooth FA distributions over the whole‐brain volume for all unseen subjects. Note the varying numbers of slices due to different head sizes.
3.3. Predicting B1 + for different slice orientations
Figure 4A shows the Tx‐channel‐combined B1 +‐magnitude for transversal and coronal slices, comparing the B1 +‐reference to the PR of , , and . and successfully estimated their trained orientations, failing on the other orientations. accurately predicted all orientations, highlighting the importance of including all orientations in the training process. Figure 4B compares the prediction quality using the SSIM for network configurations , , and . For axial slices, yields a mean SSIM of 89.3% (range = 82.8%–94.3%), while leads to lower mean values of 70.0% (range = 65.6%–90.7%). In contrast, for coronal slices, results in lower mean values of 88.7% (range = 85.7%–91.3%), while tends to higher values of 95.6% (range = 93.3%–97.2%). showed comparable accuracy across all orientations with mean SSIM values of 88.5% (range = 81.1%–93.8%) for axial and 95.7% (range = 93.8%–96.9%) for coronal slices. Similar results can be shown for sagittal slices (Figure S13).
FIGURE 4.
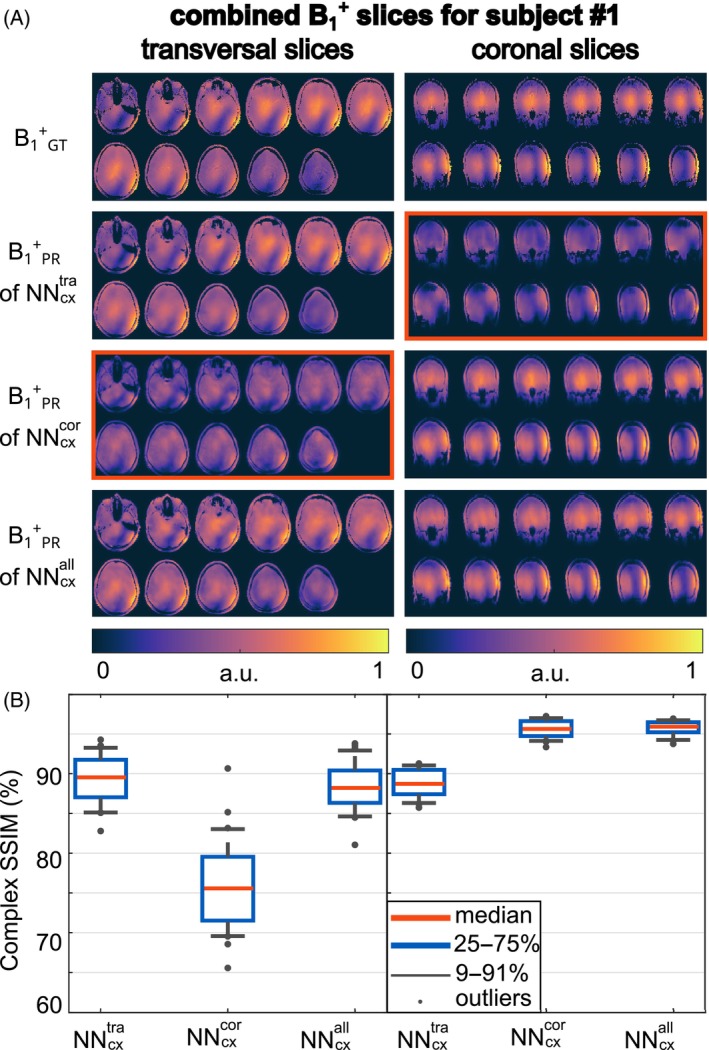
(A) Combined B1 +‐magnitude for the ground truth (GT) B1 + GT compared to the prediction (B1 + PR) of different neural networks regarding transversal and coronal slices. was trained on axial slices and was trained on coronal slices. In contrast, was trained on axial, sagittal, and coronal slices. Note that the displayed data is not masked. The red boxes indicate a failure to predict the B1 +‐maps. (B) SSIM for the complex‐valued data of the prediction compared to the GT for network configurations , , and .
3.4. In‐vivo application
Figure 5A compares the PR and GT channel‐combined B1 +‐data to a multi‐slice GRE measurement for all slice orientations in in‐vivo test subject #1. Qualitatively, a close match between PR, GT channel‐combined B1 +‐data, and GRE images is observed. Note that the receive profiles of the RF coil bias the GRE images. For Figure 5B, the PR transversal B1 +‐data were used to calculate four kt‐point RF pulses for a subsequent high‐resolution GRE measurement. Achieving homogeneous FAs for the whole brain volume demonstrated the feasibility of the suggested DL approach. In comparison, the high‐resolution GRE results are shown when calculating the four kt‐point pulses on the GT. The results for the application in in‐vivo test subject #2 are provided (Figure S14).
FIGURE 5.
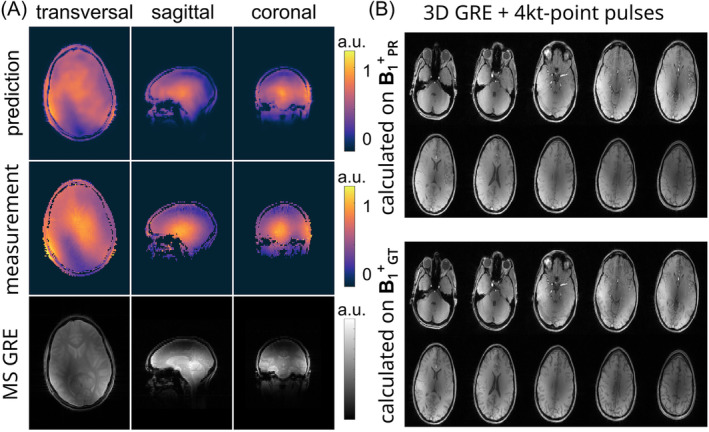
(A) Predicted and measured channel‐combined B1 +‐data compared to the multi‐slice gradient echo (GRE) measurement for all slice orientations for in‐vivo test subject #1. The NN was trained on data of all slice orientations of all 15 subjects. (B) The predicted transversal B1 +‐data was used to calculate four kt‐pulses for a subsequent high‐resolution GRE measurement compared to a high‐resolution GRE acquired with four kt‐pulses calculated on the measured B1 +‐data.
4. DISCUSSION
This study explored the advantages of employing complex‐valued NNs to estimate B1 +‐maps for eight Tx‐channels based on localizer images acquired in a CP+ ‐mode at 7T. The DL model efficiently predicted multi‐slice B1 +‐maps of the entire brain volume slice‐by‐slice with a computation time of under 1 s per subject. Extending the model to 16 or 32 Tx‐channels increases the computation time approximately linearly with the channel count. Multiple slice orientations were considered during training and ensured a robust PR of B1 +‐maps in different orientations.
Even though B1 +‐data are complex‐valued, most DL‐based approaches in UHF imaging do not support complex representation. For example, Eberhardt et al. 36 or Kilic et al. 33 split the complex data into real and imaginary components for two independent real‐valued channels. Plumley et al. 35 used two separate NNs for magnitude and phase distributions to represent the complex nature of the B1 +‐fields. Other work focused solely on the B1 +‐magnitudes. 29 , 34
Our results indicate that complex‐valued NNs can accurately approximate both magnitude and phase data from the localizer images. Localized deviations compared to the GT were only visible for high magnitudes and regions with low SNR or locations with rapidly changing B1 +‐phases. Comparing the complex‐valued , to real‐valued networks for the same test data revealed comparable prediction quality for the magnitude, indicating a trend toward better prediction quality for the phase (c.f. Figures 1 and S4). However, statistical significance for this trend using the Wilcoxon rank‐sum test investigating the null hypothesis by comparing the prediction quality of the complex‐valued and the corresponding real‐valued networks could not be established, and further investigations are needed.
The feasibility of the DL‐based B1 +‐mapping approach in the context of a subject‐specific pTx was investigated by improving the excitation homogeneity in the human brain using dynamic pTx pulses calculated on the estimated whole‐brain B1 +‐maps. Applying the pulses calculated on the PR to the GT achieved acceptable homogeneous excitation (c.f. Figure 3). However, the CV values were generally higher for pTx pulses calculated on the PR than for pulses calculated on the GT, likely due to residual deviations between PR and GT.
The impact of the slice orientation was analyzed by training NNs on different slice orientations. , , and estimated B1 +‐maps for their trained orientations with high accuracy but failed for others (c.f. Figures 4 and S13), likely due to varying relative positions of the coil elements. Considering all orientations during training for enabled accurate prediction of transversal, sagittal, and coronal B1 +‐slices. Further investigations are needed to determine if this applies to any orientations, including double‐oblique orientations.
Limitations include the deliberate use of a custom‐built eight‐channel Tx/Rx transceiver head volume coil, where transmission and receiving are performed using identical coil elements. Thus, B1 − and B1 +‐profiles were expected to show resembling distributions, possibly enhancing the prediction performance. The impact of a non‐transceiver head coil, for example, the ‘standard’ 8Tx/32Rx 7T head coil from Nova Medical, on the approach's performance is under investigation. Furthermore, the target B1 +‐maps and, thus, the PR were normalized to speed up the learningprocess and to account for changes in the MR system. A conversion to absolute B1 +‐maps is only feasible if identical acquisition conditions are maintained for all training and test datasets; however, additional research is required. Nevertheless, the hybrid B1 +‐mapping technique utilized for data acquisition is unbiased regarding T1 relaxation and proton density variations. 37
Further investigation is necessary to compare the suggested method to rapid acquisition techniques like DREAM. Additionally, the performance of the excitation pulses calculated on DL‐based B1 +‐maps needs to be compared to calibration‐free counterparts like universal pulses. The FA error introduced by the estimated B1 +‐data into subject‐tailored pulses is currently more pronounced than the excitation error of universal pulses in unseen subjects. 13 , 21 However, the performance of the presented technique is expected to improve with a larger training library. Compared to the previous work on the human body, 37 we were able to use less training data, which may be related to the higher SNR, the lack of respiratory motion, similar shapes between subjects, and other factors. Applying the presented approach to the body requires more training data to account for inter‐subject variations and avoid overfitting. Furthermore, patients may need to be included to account for geometrical anomalies.
Combining this work with other DL‐based approaches, for example, for pTx pulse design 30 , 33 or physics‐informed DL‐approaches exploiting prior knowledge about the underlying physics, 55 , 56 could create a robust RF calibration pipeline for UHF MRI entirely based on DL.
5. CONCLUSIONS
In conclusion, this work presents a DL‐based approach to estimate multi‐slice B1 +‐maps from localizers in the human head at 7T. The complex‐valued networks accurately predict B1 +‐distributions in multiple orientations with sufficient quality for dynamic pTx. Although the prediction quality did not improve significantly compared to real‐valued networks, phase‐sensitive applications might benefit from complex‐valued networks due to a trend to an enhanced phase prediction.
Supporting information
Figure S1. Network architecture of the complex‐valued, convolutional neural networks . Each encoder and decoder stage includes layers with complex convolutions (Conv) with K feature maps and modified rectified linear unit (ModReLU) activations for feature extraction and up−/ down‐sampling. The decoder pipelines are split up per transmission (Tx) channel.
Figure S2. (A) Corresponding real‐valued networks (, , ) to the introduced complex‐valued network () with increasing trainable parameters by modifying the number of feature maps. The real‐valued networks employ two sequential (3 × 3) convolutions with (1,1) strides for feature extraction, along with an additional (3 × 3) (up‐) convolution using (2,2) strides for up‐ or down‐sampling with rectified linear units (ReLU) as activation functions in each stage. For data processing, the real and imaginary parts of the channel‐wise localizers and B1 +‐maps were separated and concatenated, leading to 128 × 96 × 17 for the input with 8 real, 8 imaginary localizers and one root‐sum‐of‐squares magnitude image and 128 × 96 × 16 for the output with 8 transmission channels. (B) Network architecture () based on the recently introduced real‐valued, convolutional neural network for the thorax applied to the human head. Each encoder and decoder stage includes a max pool layer, two 3 × 3 convolutions with K = 32 feature maps, a batch norm (BN), and a leaky ReLU activation function. The architecture is modified () omitting the batch norm and using a ReLU activation function for every convolution layer.
Figure S3. Schematical overview of the hybrid approach. Multi‐slice, whole‐brain gradient echo (GRE) localizer images are acquired for different slice orientations with all Tx‐channels transmitting. The acquisition is repeated eight times depending on slice orientation, with only a single Tx‐channel active for each measurement. The Tx‐channel‐wise, orientation‐dependent GRE measurements are merged with a 3D actual flip imaging (AFI) data set obtained for all Tx‐coils active. This results in Tx‐channel‐wise, multi‐slice B1 +‐maps with different slice orientations.
Figure S4. Comparison of the prediction quality assessed by the mean deviation for the phase (A), the root mean squared error (RMSE) for the magnitude (B), and complex quantity (C) between the complex‐valued network , corresponding real‐valued networks ( to ), the previously introduced network for the human thorax () and a modified version for the introduced use case (). The networks were tested for 32 transversal slices from three unseen subjects. predicted magnitudes with a similar mean relative error of (2.70 ± 2.86)% to with (2.68 ± 2.85)% (p‐value of 0.90), while indicating a trend towards better prediction quality for the phase with a mean absolute error of (6.70 ± 1.99)° compared to (6.90 ± 2.07)° (p‐value of 0.30).
Figure S5. Combined B1 +‐maps for subject #1 given for the magnitude and phase (A) and the real and imaginary parts (B) for . The predicted (B1 + PR) and the reference (B1 + GT) data are shown for the magnitude and phase of the complex summed‐up data. A mean difference in the phase of (1.90° ± 0.68°), a relative error for the magnitude of (0.94 ± 0.29)%, a relative error for the real part of (1.86 ± 1.84)%, and (1.89 ± 2.23)% for the imaginary part in the brain tissue can be calculated. The multi‐slice data is depicted with a static, phase‐only shim setting, calculated on the center slice of the predicted B1 +‐maps for an optimized efficiency set to a predefined value of 60% to avoid a zero‐phase of the summed‐up B1 +‐data. The best prediction quality (highlighted in blue) was seen for the top slices, whereas the worst performance was found in the bottom slices (marked in green). For subsequent analysis, a slice located in the middle has been selected.
Figure S6. Combined B1 +‐maps for unseen Subject #2 and Subject #3 for . The predicted (B1 + PR) and the reference (B1 + GT) data are shown for the magnitude and phase of the complex summed‐up data. The multi‐slice data is depicted with a static, phase‐only shim setting, calculated on the center slice of the predicted B1 +‐maps for an optimized efficiency set to a predefined value of 60% to avoid a vanishing phase distribution for the summed‐up data due to the common phase as a reference. for yields a PR with a mean relative error for the magnitude of (1.13 ± 0.15) % and (0.59 ± 0.12) % and a mean difference in the phase of (2.92° ± 0.92°) and (1.04° ± 0.35°) for the brain tissue.
Figure S7. Combined B1 +‐maps for the unseen subject #1 in a sagittal orientation predicted by and a coronal orientation predicted by . The predicted (B1 + PR) and the reference (B1 + GT) data are shown for the magnitude and phase of the complex summed‐up data. The multi‐slice data is depicted with a static, phase‐only shim setting, calculated on the center slice of the predicted B1 +‐maps for an optimized efficiency set to a predefined value of 0.60% to avoid a vanishing phase distribution for the summed‐up data due to the common phase as a reference.
Figure S8. Channel‐wise B1 +‐magnitude and phase maps for the prediction (PR) of network B1 + PR compared to the reference as the ground truth (GT) B1 + GT for the selected inferior slice of unseen subject #1. Only minor deviations are visible in the magnitude and phase for the absolute error ΔB1 + between PR and GT. Vertical and horizontal profiles through the channel‐wise magnitude maxima for the PR (black) and GT (red) B1 +‐maps are provided for all transmission (Tx) channels. Overall, the prediction qualitatively matches the GT for both the magnitude and the phase.
Figure S9. Channel‐wise B1 +‐magnitude and phase maps for the prediction (PR) of network B1 + PR compared to the reference as the ground truth (GT) B1 + GT for the exemplary slice of all three test subjects. Only minor deviations are visible in the magnitude and phase for the absolute error ΔB1 + between PR and GT for all depicted slices. The absolute error ΔB1 + considered for the magnitude Δ|B1 +| = | B1 + PR ‐ B1 + GT | and phase ∠B1 + = ∠(B1 + PR / B1 + GT), whereas B1 + PR and B1 + GT are complex quantities.
Figure S10. Pixel‐wise correlation between the predicted (PR) B1 +‐maps (B1 + PR) using and the reference as the ground truth (GT) B1 + GT for the magnitude |B1 +| (A) and the phase ∠B1 + (B) for all Tx‐channels regarding the brain tissue. The phase is unwrapped to avoid phase jumps greater than or equal to π radians. The correlation plots are illustrated for the shown example and the best and worst cases regarding the structure similarity index measure. The axes range between 0 and 1 for the relative magnitude (A) and 0 and 2π for phase (B). The Pearson coefficients ρ are given for every correlation plot. A linear correlation between PR and GT becomes evident, leading to mean Pearson coefficients of ρ = (0.966 ± 0.018) for the magnitude and ρ = (0.884 ± 0.142) for the phase. Tx‐channels 1, 2, 6, and 7 exhibit the most significant deviation from linear behavior, resulting in the lowest Pearson coefficients among the cases presented.
Figure S11. Combined B1 +‐maps for unseen subject #1 of Fold #3 given for the magnitude and phase for . The predicted (B1 + PR) and the reference (B1 + GT) data are shown for the magnitude and phase of the complex summed‐up data. The multi‐slice data is depicted with a static, phase‐only shim setting, calculated on the center slice of the predicted B1 +‐maps for an optimized efficiency set to a predefined value of 60% to avoid a zero‐phase of the summed‐up B1 +‐data. The best prediction quality (highlighted in blue) was seen for the top slices, whereas the worst performance was found in the bottom slices (marked in green). For subsequent analysis, a slice located in the middle has been selected.
Figure S12. (A) B1 +‐shimming results for the example slice, best and worst case of unseen subject #1. The shim setting b CP+ for transmission in a CP+ ‐mode is compared to the homogeneous shim b Hom calculated on the prediction B1 + PR of network and ground truth B1 + GT and subsequently applied the ground truth. The magnitude of the complex sum (MOS) and phase of the complex sum (POS) over the eight transmission channels are shown. The zero‐phase in the POS in the default case is due to the calculation relative to the phase of the superimposed complex‐valued B1 +‐maps of all Tx‐channels. Optimizing the Tx‐phase by considering the CV as a cost function improves homogeneity in the selected ROI at the expense of a lower magnitude level. (B) Coefficient of variation (CV) in the brain for b CP+ and b Hom, independently optimized on the reference data and the predicted B1 +‐maps of the complex () and real‐valued networks ( to ) and applied to the B1 + GT data of all unseen 32 2D B1 +‐slices of subset #2. Applying b Hom to B1 + GT improves the mean CV for all introduced cases calculated on B1 + PR, but the CV values are generally higher than applying a b Hom optimized on B1 + GT.
Figure S13. (A) Combined B1 +‐magnitude for the reference (GT) B1 + GT compared to the prediction (B1 + PR) of different neural networks regarding sagittal slices. was trained on axial slices and was trained on sagittal slices. In contrast, was trained on axial, sagittal, and coronal slices. Note that the displayed data is not masked. The red box indicates a failure to predict the B1 +‐ maps. (B) Structure similarity index measure (SSIM) of the predicted data compared to the GT for network configurations , , and .
Figure S14. (A) Predicted and measured channel‐combined B1 +‐data compared to the multi‐slice gradient echo (GRE) measurement for all slice orientations in in‐vivo test case #2. The neural network was trained on all slice orientations of all 15 subjects. (B) The predicted transversal B1 +‐data was used to calculate 4 kt‐pulses for a subsequent high‐resolution GRE measurement compared to a high‐resolution GRE acquired with 4 kt‐pulses calculated on the measured B1 +‐data.
Table S1. Predicted image quality of trained and tested on transversal slices during a 5‐fold cross‐validation. The image quality is assessed using the mean over the fold of the root mean squared error (RMSE) for the magnitude, the mean deviation of the phase, and the structural similarity index measure (SSIM) averaged real and imaginary parts. Fold #2, tested on subset #2, was utilized for further evaluation.
Table S2. Predicted image quality of trained and tested on sagittal slices during a 5‐fold cross‐validation. The image quality is assessed using the mean over the fold of the root mean squared error (RMSE) for the magnitude, the mean deviation of the phase, and the structural similarity index measure (SSIM) averaged real and imaginary parts. Fold #2, tested on subset #2, was utilized for further evaluation.
Table S3. Predicted image quality of trained and tested on coronal slices during a 5‐fold cross‐validation. The image quality is assessed using the mean over the fold of the root mean squared error (RMSE) for the magnitude, the mean deviation of the phase, and the structural similarity index measure (SSIM) averaged real and imaginary parts. Fold #2, tested on subset #2, was utilized for further evaluation.
Table S4. Predicted image quality of trained and tested on all slice orientations during a 5‐fold cross‐validation. The image quality is assessed using the mean over the fold of the root mean squared error (RMSE) for the magnitude, the mean deviation of the phase, and the structural similarity index measure (SSIM) averaged real and imaginary parts. Fold #2, tested on subset #2, was utilized for further evaluation.
ACKNOWLEDGMENTS
We gratefully acknowledge funding by the Deutsche Forschungsgemeinschaft (DFG, German Research Foundation)–SCHM 2677/4‐1, SCHM 2677/5‐1, and GRK2260, BIOQIC.
Krueger F, Aigner CS, Lutz M, et al. Deep learning‐based whole‐brain B1 +‐mapping at 7T . Magn Reson Med. 2025;93:1700‐1711. doi: 10.1002/mrm.30359
Parts of this work have been presented at the 2023 Annual Meeting of the International Society for Magnetic Resonance in Medicine.
DATA AVAILABILITY STATEMENT
The source code, the used neural networks, and an exemplary dataset are provided: https://github.com/felixkrueger90/ComplexB1.
REFERENCES
- 1. Ladd ME, Bachert P, Meyerspeer M, et al. Pros and cons of ultra‐high‐field MRI/MRS for human application. Prog Nucl Magn Reson Spectrosc. 2018;109:1‐50. [DOI] [PubMed] [Google Scholar]
- 2. Padormo F, Beqiri A, Hajnal J, Malik S. Parallel transmission for ultrahigh‐field imaging. NMR Biomed. 2016;29:1145‐1161. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 3. Gras V, Wu X, Boulant N. Parallel transmission: physics background, pulse design, and applications in neuro MRI at ultra‐high field. Advances in Magnetic Resonance Technology and Applications. Academic Press; 2023:97‐123. [Google Scholar]
- 4. Zhu Y. Parallel excitation with an Array of transmit coils. Magn Reson Med. 2004;51:775‐784. [DOI] [PubMed] [Google Scholar]
- 5. Deniz CM. Parallel transmission for ultrahigh field MRI. Top Magn Reson Imaging. 2019;28:159‐171. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 6. Deniz CM, Vaidya MV, Sodickson DK, Lattanzi R. Radiofrequency energy deposition and radiofrequency power requirements in parallel transmission with increasing distance from the coil to the sample. Magn Reson Med. 2016;75:423‐432. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 7. De Greef M, Ipek O, Raaijmakers AJ, Crezee J, Van Den Berg CA. Specific absorption rate intersubject variability in 7T parallel transmit MRI of the head. Magn Reson Med. 2013;69:1476‐1485. [DOI] [PubMed] [Google Scholar]
- 8. Schoen N, Seifert F, Petzold J, et al. The impact of respiratory motion on electromagnetic fields and specific absorption rate in cardiac imaging at 7T. Magn Reson Med. 2022;88:2645‐2661. [DOI] [PubMed] [Google Scholar]
- 9. Aigner CS, Dietrich S, Schmitter S. Three‐dimensional static and dynamic parallel transmission of the human heart at 7 T. NMR Biomed. 2021;34:1‐15. [DOI] [PubMed] [Google Scholar]
- 10. Gras V, Mauconduit F, Vignaud A, et al. Design of universal parallel‐transmit refocusing kT‐point pulses and application to 3D T2‐weighted imaging at 7T. Magn Reson Med. 2018;80:53‐65. [DOI] [PubMed] [Google Scholar]
- 11. Oliveira ÍAF, Roos T, Dumoulin SO, Siero JCW, van der Zwaag W. Can 7T MPRAGE match MP2RAGE for gray‐white matter contrast? Neuroimage. 2021;240:118384. [DOI] [PubMed] [Google Scholar]
- 12. Van Damme L, Mauconduit F, Chambrion T, Boulant N, Gras V. Universal nonselective excitation and refocusing pulses with improved robustness to off‐resonance for magnetic resonance imaging at 7 tesla with parallel transmission. Magn Reson Med. 2021;85:678‐693. [DOI] [PubMed] [Google Scholar]
- 13. Aigner CS, Dietrich S, Schaeffter T, Schmitter S. Calibration‐free pTx of the human heart at 7T via 3D universal pulses. Magn Reson Med. 2022;87:70‐84. [DOI] [PubMed] [Google Scholar]
- 14. Aigner CS, Alarcon MFS, D'Astous A, Alonso‐Ortiz E, Cohen‐Adad J, Schmitter S. Calibration‐free pTx of the cervical, thoracic, and lumbar spinal cord at 7T. Paper presented at: Proceedings of the 33th Annual Meet ISMRM; 2024; Singapur, Singapur: Abstract 2570.
- 15. Nehrke K, Versluis MJ, Webb A, Börnert P. Volumetric B1 + mapping of the brain at 7T using DREAM. Magn Reson Med. 2014;71:246‐256. [DOI] [PubMed] [Google Scholar]
- 16. Herrler J, Liebig P, Gumbrecht R, et al. Fast online‐customized (FOCUS) parallel transmission pulses: a combination of universal pulses and individual optimization. Magn Reson Med. 2021;85:3140‐3153. [DOI] [PubMed] [Google Scholar]
- 17. Sacolick LI, Wiesinger F, Hancu I, Vogel MW. B1 mapping by Bloch‐Siegert shift. Magn Reson Med. 2010;63:1315‐1322. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 18. Chung S, Kim D, Breton E, Axel L. Rapid B1 + mapping using a preconditioning RF pulse with turboFLASH readout. Magn Reson Med. 2010;64:439‐446. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 19. Amadon A, Boulant N, Cloos MA, et al. B1 mapping of an 8‐channel TX‐array over a human‐head‐like volume in less than 2 minutes: the XEP sequence. Paper presented at: Proceedings of the 18th Annual Meet ISMRM; 2010; Stockholm, Sweden: Abstract 2828.
- 20. Kent JL, Dragonu I, Valkovič L, Hess AT. Rapid 3D absolute B1 + mapping using a sandwiched train presaturated TurboFLASH sequence at 7 T for the brain and heart. Magn Reson Med. 2023;89:964‐976. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 21. Gras V, Vignaud A, Amadon A, Le Bihan D, Boulant N. Universal pulses: a new concept for calibration‐free parallel transmission. Magn Reson Med. 2017;77:635‐643. [DOI] [PubMed] [Google Scholar]
- 22. Pohmann R, Scheffler K. A theoretical and experimental comparison of different techniques for B1 mapping at very high fields. NMR Biomed. 2013;26:265‐275. [DOI] [PubMed] [Google Scholar]
- 23. Bosch D, Bause J, Geldschläger O, Scheffler K. Optimized ultrahigh field parallel transmission workflow using rapid presaturated TurboFLASH transmit field mapping with a three‐dimensional centric single‐shot readout. Magn Reson Med. 2023;89:322‐330. [DOI] [PubMed] [Google Scholar]
- 24. Gavazzi S, van den Berg CAT, Sbrizzi A, et al. Accuracy and precision of electrical permittivity mapping at 3T: the impact of three B1 + mapping techniques. Magn Reson Med. 2019;81:3628‐3642. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 25. Schmitter S, Wu X, Auerbach EJ, et al. Seven‐tesla time‐of‐flight angiography using a 16‐channel parallel transmit system with power‐constrained 3‐dimensional spoke. Invest Radiol. 2014;49:314‐325. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 26. Orzada S, Solbach K, Gratz M, et al. A 32‐channel parallel transmit system add‐on for 7T MRI. PLoS One. 2019;14:1‐20. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 27. Meliadò EF, Raaijmakers AJE, Sbrizzi A, et al. A deep learning method for image‐based subject‐specific local SAR assessment. Magn Reson Med. 2020;83:695‐711. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 28. Gokyar S, Zhao C, Ma SJ, Wang DJJ. Deep learning‐based local SAR prediction using B1 maps and structural MRI of the head for parallel transmission at 7 T. Magn Reson Med. 2023;1–15:2524‐2538. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 29. Brink WM, Yousefi S, Bhatnagar P, Remis RF, Staring M, Webb AG. Personalized local SAR prediction for parallel transmit neuroimaging at 7T from a single T1‐weighted dataset. Magn Reson Med. 2022;88:464‐475. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 30. Vinding MS, Aigner CS, Schmitter S, Lund TE. DeepControl: 2DRF pulses facilitating B1 + inhomogeneity and B0 off‐resonance compensation in vivo at 7 T. Magn Reson Med. 2021;85:3308‐3317. [DOI] [PubMed] [Google Scholar]
- 31. Ianni JD, Cao Z, Grissom WA. Machine learning RF shimming: prediction by iteratively projected ridge regression. Magn Reson Med. 2018;80:1871‐1881. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 32. Ma X, Uğurbil K, Wu X. Mitigating transmit‐B1 artifacts by predicting parallel transmission images with deep learning: a feasibility study using high‐resolution whole‐brain diffusion at 7 tesla. Magn Reson Med. 2022;88:727‐741. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 33. Kilic T, Liebig P, Demirel OB, et al. Unsupervised deep learning with convolutional neural networks for static parallel transmit design: a retrospective study. Magn Reson Med. 2024;91:2498‐2507. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 34. Abbasi‐Rad S, O'Brien K, Kelly S, et al. Improving FLAIR SAR efficiency at 7T by adaptive tailoring of adiabatic pulse power through deep learning B1 + estimation. Magn Reson Med. 2021;85:2462‐2476. [DOI] [PubMed] [Google Scholar]
- 35. Plumley A, Watkins L, Treder M, Liebig P, Murphy K, Kopanoglu E. Rigid motion‐resolved B1 + prediction using deep learning for real‐time parallel‐transmission pulse design. Magn Reson Med. 2021;87:2254‐2270. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 36. Eberhardt B, Poser BA, Shah NJ, Felder J. B1 field map synthesis with generative deep learning used in the design of parallel‐transmit RF pulses for ultra‐high field MRI. Z Med Phys. 2022;32:334‐345. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 37. Krueger F, Aigner CS, Hammernik K, et al. Rapid estimation of 2D relative B1 +‐maps from localizers in the human heart at 7T using deep learning. Magn Reson Med. 2022;89:1002‐1015. [DOI] [PubMed] [Google Scholar]
- 38. Kofler A, Dewey M, Schaeffter T, Wald C, Kolbitsch C. Spatio‐temporal deep learning‐based Undersampling artefact reduction for 2D radial cine MRI with limited training data. IEEE Trans Med Imaging. 2020;39:703‐717. [DOI] [PubMed] [Google Scholar]
- 39. Jin KH, Mccann MT. Deep convolutional neural network for inverse problems in imaging. IEEE Trans Image Process. 2017;26:4509‐4522. [DOI] [PubMed] [Google Scholar]
- 40. Cole E, Cheng J, Pauly J, Vasanawala S. Analysis of deep complex‐valued convolutional neural networks for MRI reconstruction and phase‐focused applications. Magn Reson Med. 2021;86:1093‐1109. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 41. Virtue P. Complex‐Valued Deep Learning with Applications to Magnetic Resonance Image Synthesis. Univ. California; 2019. [Google Scholar]
- 42. Hammernik K, Küstner T. Machine enhanced reconstruction learning and interpretation networks (MERLIN). Paper presented at: Proceedings of the 31th Annual Meet ISMRM; 2022; London, United Kingdom: Abstract 1051.
- 43. Hammernik K, Küstner T, Rueckert D. Machine learning for MRI reconstruction. Machine Learning for MRI Reconstruction. Academic Press; 2022:281‐323. [Google Scholar]
- 44. Seifert F, Pfeiffer H, Mekle R, Waxmann P, Ittermann B. 7T 8‐channel PTx head coil with high B1 + efficiency optimized for MRS. Paper presented at: roceedings of the 24th Annual Meet ISMRM; 2016; Singapur, Singapur: Abstract 3545.
- 45. Van de Moortele PF, Snyder C, DelaBarre L, Adriany G, Vaughan T, Ugurbil K. Calibration Tools for RF Shim at Very High Field with Multiple Element RF Coils: from Ultra Fast Local Relative Phase to Absolute Magnitude B1 + Mapping. Paper presented at: Proceedings of the 15th Annual Meeting of ISMRM; 2007; Berlin, Germany: Abstract 1676.
- 46. Dietrich S, Aigner CS, Kolbitsch C, et al. 3D free‐breathing multichannel absolute B1 + mapping in the human body at 7T. Magn Reson Med. 2021;85:2552‐2567. [DOI] [PubMed] [Google Scholar]
- 47. Cao Z, Yan X, Grissom WA. Array‐compressed parallel transmit pulse design. Magn Reson Med. 2016;76:1158‐1169. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 48. Grissom WA, Khalighi MM, Sacolick LI, Rutt BK, Vogel MW. Small‐tip‐angle spokes pulse design using interleaved greedy and local optimization methods. Magn Reson Med. 2012;68:1553‐1562. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 49. Trabelsi C, Bilaniuk O, Zhang Y, et al. Deep complex networks. Paper presented at: The Sixth International Conference on Learning Representations (ICLR 2018); 2018.
- 50. Abadi M, Agarwal A, Barham P, et al. TensorFlow: large‐scale machine learning on heterogeneous distributed systems. arXiv Prepr arXiv 2016;1603.04467.
- 51. Arjovsky M, Shah A, Bengio Y. Unitary evolution recurrent neural networks. Paper presented at: Proceedings of the 33rd International Conference on Machine Learning; 2016; New York, USA.
- 52. Glorot X, Bengio Y. Understanding the difficulty of training deep feedforward neural networks. Paper presented at: Proceedings of the Thirteenth International Conference on Artificial Intelligence and Statistics; 2010; Sardinia, Italy; pp. 249–256.
- 53. Terpstra ML, Maspero M, Sbrizzi A, van den Berg CAT. ⊥−loss: a symmetric loss function for magnetic resonance imaging reconstruction and image registration with deep learning. Med Image Anal. 2022;80:102509. [DOI] [PubMed] [Google Scholar]
- 54. Kingma DP, Ba JL. Adam: a method for stochastic optimization. arXiv:1412.6980v9 2017.
- 55. Zimmermann FF, Kolbitsch C, Schuenke P, Kofler A. PINQI: an end‐to‐end physics‐informed approach to learned quantitative MRI reconstruction. arXiv Prepr. arXiv 2023;2306.11023.
- 56. Schote D, Winter L, Kolbitsch C, Rose G, Speck O, Kofler A. Joint B0 and image reconstruction in low‐field MRI by physics‐informed deep‐learning. IEEE Trans Biomed Eng. 2024:1–12;71:2842‐2853. doi: 10.1109/TBME.2024.3396223 [DOI] [PubMed] [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.
Supplementary Materials
Figure S1. Network architecture of the complex‐valued, convolutional neural networks . Each encoder and decoder stage includes layers with complex convolutions (Conv) with K feature maps and modified rectified linear unit (ModReLU) activations for feature extraction and up−/ down‐sampling. The decoder pipelines are split up per transmission (Tx) channel.
Figure S2. (A) Corresponding real‐valued networks (, , ) to the introduced complex‐valued network () with increasing trainable parameters by modifying the number of feature maps. The real‐valued networks employ two sequential (3 × 3) convolutions with (1,1) strides for feature extraction, along with an additional (3 × 3) (up‐) convolution using (2,2) strides for up‐ or down‐sampling with rectified linear units (ReLU) as activation functions in each stage. For data processing, the real and imaginary parts of the channel‐wise localizers and B1 +‐maps were separated and concatenated, leading to 128 × 96 × 17 for the input with 8 real, 8 imaginary localizers and one root‐sum‐of‐squares magnitude image and 128 × 96 × 16 for the output with 8 transmission channels. (B) Network architecture () based on the recently introduced real‐valued, convolutional neural network for the thorax applied to the human head. Each encoder and decoder stage includes a max pool layer, two 3 × 3 convolutions with K = 32 feature maps, a batch norm (BN), and a leaky ReLU activation function. The architecture is modified () omitting the batch norm and using a ReLU activation function for every convolution layer.
Figure S3. Schematical overview of the hybrid approach. Multi‐slice, whole‐brain gradient echo (GRE) localizer images are acquired for different slice orientations with all Tx‐channels transmitting. The acquisition is repeated eight times depending on slice orientation, with only a single Tx‐channel active for each measurement. The Tx‐channel‐wise, orientation‐dependent GRE measurements are merged with a 3D actual flip imaging (AFI) data set obtained for all Tx‐coils active. This results in Tx‐channel‐wise, multi‐slice B1 +‐maps with different slice orientations.
Figure S4. Comparison of the prediction quality assessed by the mean deviation for the phase (A), the root mean squared error (RMSE) for the magnitude (B), and complex quantity (C) between the complex‐valued network , corresponding real‐valued networks ( to ), the previously introduced network for the human thorax () and a modified version for the introduced use case (). The networks were tested for 32 transversal slices from three unseen subjects. predicted magnitudes with a similar mean relative error of (2.70 ± 2.86)% to with (2.68 ± 2.85)% (p‐value of 0.90), while indicating a trend towards better prediction quality for the phase with a mean absolute error of (6.70 ± 1.99)° compared to (6.90 ± 2.07)° (p‐value of 0.30).
Figure S5. Combined B1 +‐maps for subject #1 given for the magnitude and phase (A) and the real and imaginary parts (B) for . The predicted (B1 + PR) and the reference (B1 + GT) data are shown for the magnitude and phase of the complex summed‐up data. A mean difference in the phase of (1.90° ± 0.68°), a relative error for the magnitude of (0.94 ± 0.29)%, a relative error for the real part of (1.86 ± 1.84)%, and (1.89 ± 2.23)% for the imaginary part in the brain tissue can be calculated. The multi‐slice data is depicted with a static, phase‐only shim setting, calculated on the center slice of the predicted B1 +‐maps for an optimized efficiency set to a predefined value of 60% to avoid a zero‐phase of the summed‐up B1 +‐data. The best prediction quality (highlighted in blue) was seen for the top slices, whereas the worst performance was found in the bottom slices (marked in green). For subsequent analysis, a slice located in the middle has been selected.
Figure S6. Combined B1 +‐maps for unseen Subject #2 and Subject #3 for . The predicted (B1 + PR) and the reference (B1 + GT) data are shown for the magnitude and phase of the complex summed‐up data. The multi‐slice data is depicted with a static, phase‐only shim setting, calculated on the center slice of the predicted B1 +‐maps for an optimized efficiency set to a predefined value of 60% to avoid a vanishing phase distribution for the summed‐up data due to the common phase as a reference. for yields a PR with a mean relative error for the magnitude of (1.13 ± 0.15) % and (0.59 ± 0.12) % and a mean difference in the phase of (2.92° ± 0.92°) and (1.04° ± 0.35°) for the brain tissue.
Figure S7. Combined B1 +‐maps for the unseen subject #1 in a sagittal orientation predicted by and a coronal orientation predicted by . The predicted (B1 + PR) and the reference (B1 + GT) data are shown for the magnitude and phase of the complex summed‐up data. The multi‐slice data is depicted with a static, phase‐only shim setting, calculated on the center slice of the predicted B1 +‐maps for an optimized efficiency set to a predefined value of 0.60% to avoid a vanishing phase distribution for the summed‐up data due to the common phase as a reference.
Figure S8. Channel‐wise B1 +‐magnitude and phase maps for the prediction (PR) of network B1 + PR compared to the reference as the ground truth (GT) B1 + GT for the selected inferior slice of unseen subject #1. Only minor deviations are visible in the magnitude and phase for the absolute error ΔB1 + between PR and GT. Vertical and horizontal profiles through the channel‐wise magnitude maxima for the PR (black) and GT (red) B1 +‐maps are provided for all transmission (Tx) channels. Overall, the prediction qualitatively matches the GT for both the magnitude and the phase.
Figure S9. Channel‐wise B1 +‐magnitude and phase maps for the prediction (PR) of network B1 + PR compared to the reference as the ground truth (GT) B1 + GT for the exemplary slice of all three test subjects. Only minor deviations are visible in the magnitude and phase for the absolute error ΔB1 + between PR and GT for all depicted slices. The absolute error ΔB1 + considered for the magnitude Δ|B1 +| = | B1 + PR ‐ B1 + GT | and phase ∠B1 + = ∠(B1 + PR / B1 + GT), whereas B1 + PR and B1 + GT are complex quantities.
Figure S10. Pixel‐wise correlation between the predicted (PR) B1 +‐maps (B1 + PR) using and the reference as the ground truth (GT) B1 + GT for the magnitude |B1 +| (A) and the phase ∠B1 + (B) for all Tx‐channels regarding the brain tissue. The phase is unwrapped to avoid phase jumps greater than or equal to π radians. The correlation plots are illustrated for the shown example and the best and worst cases regarding the structure similarity index measure. The axes range between 0 and 1 for the relative magnitude (A) and 0 and 2π for phase (B). The Pearson coefficients ρ are given for every correlation plot. A linear correlation between PR and GT becomes evident, leading to mean Pearson coefficients of ρ = (0.966 ± 0.018) for the magnitude and ρ = (0.884 ± 0.142) for the phase. Tx‐channels 1, 2, 6, and 7 exhibit the most significant deviation from linear behavior, resulting in the lowest Pearson coefficients among the cases presented.
Figure S11. Combined B1 +‐maps for unseen subject #1 of Fold #3 given for the magnitude and phase for . The predicted (B1 + PR) and the reference (B1 + GT) data are shown for the magnitude and phase of the complex summed‐up data. The multi‐slice data is depicted with a static, phase‐only shim setting, calculated on the center slice of the predicted B1 +‐maps for an optimized efficiency set to a predefined value of 60% to avoid a zero‐phase of the summed‐up B1 +‐data. The best prediction quality (highlighted in blue) was seen for the top slices, whereas the worst performance was found in the bottom slices (marked in green). For subsequent analysis, a slice located in the middle has been selected.
Figure S12. (A) B1 +‐shimming results for the example slice, best and worst case of unseen subject #1. The shim setting b CP+ for transmission in a CP+ ‐mode is compared to the homogeneous shim b Hom calculated on the prediction B1 + PR of network and ground truth B1 + GT and subsequently applied the ground truth. The magnitude of the complex sum (MOS) and phase of the complex sum (POS) over the eight transmission channels are shown. The zero‐phase in the POS in the default case is due to the calculation relative to the phase of the superimposed complex‐valued B1 +‐maps of all Tx‐channels. Optimizing the Tx‐phase by considering the CV as a cost function improves homogeneity in the selected ROI at the expense of a lower magnitude level. (B) Coefficient of variation (CV) in the brain for b CP+ and b Hom, independently optimized on the reference data and the predicted B1 +‐maps of the complex () and real‐valued networks ( to ) and applied to the B1 + GT data of all unseen 32 2D B1 +‐slices of subset #2. Applying b Hom to B1 + GT improves the mean CV for all introduced cases calculated on B1 + PR, but the CV values are generally higher than applying a b Hom optimized on B1 + GT.
Figure S13. (A) Combined B1 +‐magnitude for the reference (GT) B1 + GT compared to the prediction (B1 + PR) of different neural networks regarding sagittal slices. was trained on axial slices and was trained on sagittal slices. In contrast, was trained on axial, sagittal, and coronal slices. Note that the displayed data is not masked. The red box indicates a failure to predict the B1 +‐ maps. (B) Structure similarity index measure (SSIM) of the predicted data compared to the GT for network configurations , , and .
Figure S14. (A) Predicted and measured channel‐combined B1 +‐data compared to the multi‐slice gradient echo (GRE) measurement for all slice orientations in in‐vivo test case #2. The neural network was trained on all slice orientations of all 15 subjects. (B) The predicted transversal B1 +‐data was used to calculate 4 kt‐pulses for a subsequent high‐resolution GRE measurement compared to a high‐resolution GRE acquired with 4 kt‐pulses calculated on the measured B1 +‐data.
Table S1. Predicted image quality of trained and tested on transversal slices during a 5‐fold cross‐validation. The image quality is assessed using the mean over the fold of the root mean squared error (RMSE) for the magnitude, the mean deviation of the phase, and the structural similarity index measure (SSIM) averaged real and imaginary parts. Fold #2, tested on subset #2, was utilized for further evaluation.
Table S2. Predicted image quality of trained and tested on sagittal slices during a 5‐fold cross‐validation. The image quality is assessed using the mean over the fold of the root mean squared error (RMSE) for the magnitude, the mean deviation of the phase, and the structural similarity index measure (SSIM) averaged real and imaginary parts. Fold #2, tested on subset #2, was utilized for further evaluation.
Table S3. Predicted image quality of trained and tested on coronal slices during a 5‐fold cross‐validation. The image quality is assessed using the mean over the fold of the root mean squared error (RMSE) for the magnitude, the mean deviation of the phase, and the structural similarity index measure (SSIM) averaged real and imaginary parts. Fold #2, tested on subset #2, was utilized for further evaluation.
Table S4. Predicted image quality of trained and tested on all slice orientations during a 5‐fold cross‐validation. The image quality is assessed using the mean over the fold of the root mean squared error (RMSE) for the magnitude, the mean deviation of the phase, and the structural similarity index measure (SSIM) averaged real and imaginary parts. Fold #2, tested on subset #2, was utilized for further evaluation.
Data Availability Statement
The source code, the used neural networks, and an exemplary dataset are provided: https://github.com/felixkrueger90/ComplexB1.