

ABSTRACT
Viral load (VL) in the respiratory tract is the leading proxy for assessing infectiousness potential. Understanding the dynamics of disease‐related VL within the host is of great importance, as it helps to determine different policies and health recommendations. However, normally the VL is measured on individuals only once, in order to confirm infection, and furthermore, the infection date is unknown. It is therefore necessary to develop statistical approaches to estimate the typical VL trajectory. We show here that, under plausible parametric assumptions, two measures of VL on infected individuals can be used to accurately estimate the VL mean function. Specifically, we consider a discrete‐time likelihood‐based approach to modeling and estimating partial observed longitudinal samples. We study a multivariate normal model for a function of the VL that accounts for possible correlation between measurements within individuals. We derive an expectation‐maximization (EM) algorithm which treats the unknown time origins and the missing measurements as latent variables. Our main motivation is the reconstruction of the daily mean VL, given measurements on patients whose VLs were measured multiple times on different days. Such data should and can be obtained at the beginning of a pandemic with the specific goal of estimating the VL dynamics. For demonstration purposes, the method is applied to SARS‐Cov‐2 cycle‐threshold‐value data collected in Israel.
Keywords: Ct‐value, EM algorithm, multivariate normal distribution, SARS‐Cov‐2
1. Introduction
The Viral load (VL) is the amount of viral nucleic acid within the host, expressed as the number of viral particles in a given volume. The typical measure unit is the cycle‐threshold‐value (Ct‐value). In SARS‐Cov‐2, the typical Ct‐value for a positive sample is between 15 and 40, representing the number of duplications required for the amount of viral genetic material to reach a certain detectable fluorescence threshold. It is inversely correlated to the VL, with a lower Ct‐value indicating a higher VL. Sampling is done by taking a nasal swab conducted in testing centers or medical clinics, after which the sample is transferred to one of several special labs for analysis.
VL typically increases exponentially after infection, until reaching a peak after which it starts to decline exponentially as a result of the host's immune response [1]. Understanding the VL trajectory is of great importance, as it affects the rate of infectiousness, generation time and disease duration [2]. Real‐time estimates of quantitative viral shedding dynamics will enable better evidence‐based public health interventions, such as lock‐downs, length of quarantine, mask‐wearing and other health‐related policies. Most VL studies are based on longitudinal data, making them difficult and expensive to conduct [3, 4, 5]. A second difficulty stems from the fact that for most cases the exact day of infection is unknown or uncertain, due to the study design which follows participants only after diagnosis [3, 5]. As a practical solution, the time‐origin can be defined as the study‐entry time, which mostly coincides with symptom appearance. However, this approach is biased as the time‐origin clearly precedes the symptoms' appearance.
Our main goal is to provide basic practical guidelines for data collection and VL curve reconstruction that can be used in future outbreaks. Specifically, the approach can be applied to a semi‐controlled experiment where a sample of infected individuals is followed and provides a second VL measurement several days after the first positive test. Such data are logistically much simpler to collect compared to a full longitudinal study, yet, as we show here, can provide important information about the mean VL trajectory, even when the infection day is unknown.
Several studies addressed the problem of unknown time‐origin in the context of HIV infections, since initial infection time is typically unknown (the time scale since infection until detection in HIV is months or years while for pandemics, such as SARS‐Cov‐2, it takes only several days). Berman [6] studied the T4 level trajectory from infection, using a stochastic process with exponential damping function, treating the time from infection to diagnosis as a latent variable. A similar approach was used in [7] to estimate the time from infection. Other models use empirical Bayes approaches [8], or biology‐based dynamical models [9] to investigate the progression of various biomarkers from initial infection. A recent paper [10] proposed a likelihood‐based estimation method for longitudinal trajectory estimation, which can be incorporated into survival models. This model can be applied to a wider range of datasets, as demonstrated on cervical dilation and medfly data.
In this paper, we study a discrete‐time longitudinal trajectory estimation method. Similar to [10], our method is based on maximum likelihood estimation (MLE). However, here we consider the discrete‐time scenario with only a few measurements given for each individual (we mainly consider the case of two measurements per individual). Our main goal is to make use of data collected in a designed experiment and estimate the mean population trajectory; that is, the mean Ct at each time point, if all individual trajectories were aligned up, starting from a common time‐origin representing the infection time. We incorporate in our model a covariance matrix which accounts for possible within‐individual correlation, as in longitudinal data analysis or in linear mixed‐effects models [11]. Overall, the unknown parameters included in the likelihood function are the daily means, the covariance matrix, and the discrete distribution of the onset time. Using a Gaussian model for the measured values, we derive an EM algorithm for estimation, which treats the unknown time‐origin and the unknown measurements as latent variables. Owing to the discrete‐time approach and the multivariate normal model, the EM procedure mostly involves closed form calculations and standard quadratic function minimizations. The model is flexible and various constraints can be imposed on the parameters, such as unimodality and structured covariance matrices. We show that under mild conditions, the model is identifiable in all of its parameters.
Our model formulation is motivated by the SARS‐Cov‐2 pandemic. In order to apply the approach on real data, we use a dataset on numerous PCR tests and VL measurements conducted by a major Israeli lab between January to June 2022. Many individuals had their VL measured twice or more on different days. We show that although the day of infection is unknown, the large number of samples enables reconstructing the population's VL trajectory using our model formulation and assumptions. We compare our results to known results in the literature.
The paper is organized as follows. Section 2 formulates the model, the missing data‐generating process, and derives the likelihood function. Section 3 proves that under certain mild conditions, the parameters are identifiable. Section 4 develops an EM algorithm with and without structural constraints on the model's parameters. Section 5 reports results of numerical simulations, while Section 6 applies the method on SARS‐Cov‐2 data. Section 7 summarizes the paper and discusses limitations, and future directions.
2. Model
Let be an integer denoting the day following the time‐origin, and let be the outcome of interest as measured on day . We assume a model of the form , where are fixed parameters, and are zero‐mean random variables which are possibly correlated; the use of vectors of length will be explained in the sequel. We concentrate on the multivariate normal case , where is a covariance matrix. The parameters and are unknown, and should be estimated using incomplete data, as described below.
For statistically independent samples , parameter estimation by maximum likelihood is straightforward. Suppose now that only components from each vector are observed, but their indexing is unknown. Concretely, the data comprise of vectors of observations where . However, instead of fully observing the indices , we assume that and that only the difference between the indices are available:
for . For our motivating example, the assumptions state that the first observation is during the “infection” period that lasts for about days, but the exact day post infection is unknown, therefore only the differences between measurement times are exactly observed. If we formally define . Otherwise, since the 's are integers, 's are also positive integers satisfying . The goal is to estimate and based on .
The model considers possible time points during which the infection is “active”. However, in practice is often unknown, and the latest observation time might be larger than . In fact, as and are both possible, can be as large as . In typical settings, such as that of VL, it is reasonable to assume a “steady state” after time , so we propose the following convention: The means and standard deviations from time onward are all equal, that is, and for . The assumption of a complete viral clearance after days is also used by [12] and serves as an approximation for small VL levels. As we will see in the numerical simulations, selecting a proper is important for the estimate's accuracy.
We illustrate the settings described above with a simple example. Consider three persons with daily Ct‐values shown in the following table, starting in their infection day indexed as 1. Here , so that .

The observed Ct‐values are marked with squares, so these are on days 3 and 5 post infection for the first subject, days 4 and 7 for the second subject, and days 1, 4 and 8 for the third subject. While we observe the time differences between samples, , their times relative to infection (relative to day 1) are unknown. For person 1, for instance, we observe a pair of Ct‐values , and the time difference days between samples, but we do not know that these are on days 3 and 5 from infection. All possible infection days should be considered as candidates for the first observed Ct‐value.
To construct the likelihood, let () be the probability function of the first observed time . Assume a non‐informative selection mechanism in a sense that given , the observed data follows the model as described above (i.e., there is no selection bias). While this assumption might be considered strong, it holds in a controlled experiment, which should be conducted during a pandemic in order to support policy decisions.
For ease of notation, we use a single index to denote the variance parameters (i.e., the diagonal values of ), such that:
| (1) |
For the off‐diagonal covariance terms, we use two indices: . Given , the vector has an ‐variate normal distribution with mean and covariance
| (2) |
As is not observed, the likelihood is a mixture of normal densities:
| (3) |
Direct maximization of (3) is difficult. Treating and the unobserved components within as latent variables, we derive an EM algorithm [13] that maximizes the likelihood.
3. Model Identification
In this section, we focus on the case where only pairs of samples are given, together with the difference . We prove that under certain uniqueness conditions, the model is identifiable even for paired data. As a matter of convenience, we consider and omit the indices, and use the notation to mark the marginal bivariate Normal p.d.f with given parameters. Thus, for a given , the joint mixture distribution is
| (4) |
The mean and covariance are defined in Section 2 (see (2) and the discussion above it). To prove model identifiability, we show that if for all and , then , , and .
Without any constraints, the model is not identifiable. For example, if then clearly and are not identifiable. Similarly, if with probability 1 for some , then the () elements of are not identifiable. However, the model can be partially identifiable if we assume the following reasonable conditions:
Condition 1. The pairs are unique.
Condition 2. The mixing probabilities are positive for all .
The proof uses results on identifiability of finite mixture models [14, 15]. Specifically, [15] proved that an ‐dimensional Gaussian mixture model (GMM) is identifiable up to permutations of indices. Taking the special 2‐dimensional case, [15] shows that if a GMM p.d.f with different Gaussian components is identical to another, such that
then a permutation exists satisfying , and .
Our model does not fall into the GMM framework, as only bivariate marginals of the dimensional normal distribution are observed. Nevertheless, we can use the identifiability result of GMM to prove identification in our setting.
Proposition 1
Suppose that for . Under Conditions 1 and 2, the model ( 4 ) is identifiable in and .
For , we observe the mixture
(5) By identifiability of GMM models, the bivariate distributions in (5) and the mixing probabilities are all identifiable up to an indices permutation. By the first condition, the pair appears only in one of the mixtures, which identifies the first index. This also identifies , , and via the identification of Once is identified, and are identified via the identification of Continuing with the same reasoning shows identifiability of the mixing probabilities and all means, variances and single‐lag correlations. Repeating the same arguments for () establishes identification of the ‐lag correlations.
For a single Ct‐value, the model is not identifiable, as there is no information for estimating correlations. However, under Conditions 1 and 2 above, the means and variances are identifiable up to permutation of indices. While this is of limited use for most practical purposes, single observations can still identify interesting quantities such as the largest and smallest mean values.
4. An EM Algorithm
4.1. The Unconstrained Model
In terms of an EM algorithm, we define the complete likelihood to be of the time‐origin and all measurements of individual . Since are independent, the complete likelihood simply becomes:
| (6) |
where indicates the event . The conditional expectation of is calculated in the E‐step, which is then maximized over the unknown parameters in the M‐step. These steps are repeated until convergence.
E‐step. Denote by the set of estimated parameters obtained at the ‐th iteration, which contains the mean vector , the covariance , and the prior probability parameters . For ease of notation, we use to mark the observed data on subject , that is, , and the boldface letter to mark the entire observed data.
The negative log of (6), without constant terms, can be written as:
| (7) |
Computing the conditional expectation of (7) requires the calculation of and for a linear and a quadratic function . Denoting the former as , we have:
The expectation is readily obtained by recalling that has a normal distribution with mean and covariance matrix ; see (2) and the discussion above it.
For the second expectation, , we have:
The expectation involves calculation of the first two moments of conditionally on the event , which can be obtained using known properties of multivariate normal distributions. The details are deferred to Appendix I, see Supporting Information.
M‐step. The M‐step should minimize for , and the expression
| (8) |
where
| (9) |
and and are defined in Appendix I, see Supporting Information. Without any constraint, the minimum points and of (8) over and are similar to the sample mean and covariance. To see that, note that the ‐th partial derivative of (8) over , in a trace form, is:
where is the ‐th unit basis vector. It can be shown that the gradient becomes zero at the point
| (10) |
As for the covariance, the derivative of (8) over is:
which becomes zero at
Lastly, the updated probability parameters are the sample proportions:
4.2. Model Constraints
Since the model has many unknown parameters, it is helpful to specify structural constraints that are based on prior knowledge and are relevant to the problem's domain. We discuss several constraints that are relevant to our motivation problem of VL reconstruction.
Means. First note from (8) and (9) that estimating requires solving the following quadratic program:
| (11) |
We have already made a structural constraint in the model formulation (Section 2), by assuming all means for are equal to . This reflects the fact that VL stabilizes after recovery. A natural assumption is a unimodal model, as the VL is expected to increase initially until reaching a maximal point, and then to decrease over time. Concretely, assuming a peak at time , we impose the linear constraints and . If is unknown, we propose to run the EM‐algorithm for every and select the estimate with the largest likelihood value.
To further reduce the number of parameters, a parametric model can be used [12] assumes a piece‐wise constant model for the mean trajectory. While it is easy to adapt such a model here, we prefer a smoother model and focus on a family of unimodal functions specified by three parameters :
| (12) |
and for . These unimodal functions, which we refer to as the unimodal Gamma (due to their similarity to the Gamma function), can smoothly capture the exponential growth, followed by an exponential decline rate, which characterizes most Ct‐value and VL trajectories [4]. In that case, minimization of (11) can be carried out using a grid search over and .
Covariance. Within individual dependence should be taken into account when samples contain longitudinal measurements per individual. It is natural to assume a model of the form , where is the variance and the correlation matrix. Various models for the covariance matrix have been suggested, see for example Chapter 7 of [16]. Since correlation tends to vanish as time difference increases, we choose to focus on a parsimonious first‐order autoregressive model where . The M‐step now involves the minimization of (8) over under the constraint , which leads to:
For a fixed , simple differentiation shows that
minimizes the above function. A line search procedure can be applied in order to find the minimum point by calculating in a grid over , and selecting the point that gives the smallest objective value.
Another family of covariance matrices of interest has the linear form
| (13) |
where () are known symmetric matrices. An example is the heteroskedastic model in which . Here for is a matrix with 1 in the entry of the diagonal and 0 in all other entries. If in addition depends on the lag between observations, matrices having 1 in entries and 0 otherwise can be added to (13). A fixed point procedure for estimating the coefficient vector of a linear covariance model was proposed in [17]; we briefly describe the implementation of this algorithm to our problem in Appendix II, see Supporting Information.
4.3. Technical Remarks
Since the Ct‐value is inversely correlated to the VL, and it is upper bounded by 40, we use the negative linear transformation , where is the Ct‐value of subject measured on day . The values are highly variable and, together with non‐convexity of the likelihood, can lead to poor estimation. Reducing the number of parameters by using prior knowledge on the expected Ct curve, and specifically focusing on the family of unimodal functions (12), helps solving the problem to some extent.
To further deal with the non‐convexity of the likelihood, we apply the following procedure. First, we run the algorithm several times, starting from a random realization of all parameters. Second, for each set of initial values, instead of directly estimating the parameters under model (12), we found it better to first estimate under a unimodal constraint, as discussed in Section 4.2, and use the results as initial values after fitting the function (12) to the estimated means. Specifically, we generated five sets of estimates of using the EM‐algorithm under a unimodal constraint on assuming for , which is its expected range, and then use the results as initial values for the EM algorithm to the unimodal Gamma model (12), choosing the estimate that gives the largest likelihood value. The final estimate is the one that maximizes the likelihood over all replications.
5. Numerical Simulations
5.1. Performance of the Method
Hay et al. [5] measured the Ct‐values daily on a group of NBA players, providing a small sample of real‐world Ct data. We use this dataset as a baseline for our simulation study. For our first simulation setting, we approximated the sample mean of the daily Ct‐value by fitting (12). We constructed an AR(1) covariance matrix by setting and ; see discussion about covariance in Section 4.1. Lastly, we defined a vector of decreasing values in the simplex. We set these parameters as the ground truth when generating the samples and calculating the performance of the method. The parameters and that were used in the simulation are shown as the solid red lines in Figure 1a,c, respectively.
FIGURE 1.

Top row: Ct‐value plotted against day after infection. Blue dots are samples generated synthetically (a) and semi‐synthetically (b). Solid red lines represent the daily mean Ct‐values. (c): Synthetic sample parameters: (red line) and (histogram). (d): Histograms of the Ct‐values as provided in [5] with the density estimation of the corresponding semi‐synthetic Ct‐value distributions (solid red lines), on days 1, 3, 6, and 9.
The choice of is important for the performance of the estimator, and can be determined by policy makers in future pandemic‐like scenarios. We assume only paired data ( for all ), as logistically it will be easier to design experiments in which infected individuals are sampled only twice. We compare three distributions for the values: Uniformly distributed over , uniformly distributed over , and a decreasing distribution as shown by the histogram in Figure 1c. To generate a sample, we randomly select integer using , and sample according to its distribution. We then generate from a bivariate normal distribution parameterized by the corresponding means in and the sub‐covariance of . A scatter plot of the samples is shown in Figure 1a.
In order to better mimic the real world Ct‐values and to study the performance of the estimator when the assumptions do not hold, we conducted an additional set of simulations, this time sampling directly from the data provided by [5]. As mentioned before, the viral load of each participant was monitored on a daily basis, so information on the day of infection for each infected participant is quite accurate, and the Ct‐values on almost all days following infection are known. As the number of NBA players participating in the study was small, basing the simulation on the individuals' data was impractical. Instead, we sampled independent Ct‐values for 20 days using the marginal empirical distributions of the Ct‐value data and added a subject‐specific random number to the whole vector in order to add within individual correlations. To further deal with the small sample size, we added for each individual an additional noise for each coordinate using independent random numbers. The empirical distributions of the Ct‐values on days 1,3,6, and 9, as well as the corresponding marginal distributions used in the simulation, are shown in Figure 1d. After sampling the whole vector, we randomly select two entries from the distribution of presented in Figure 1c. Figure 1b is the equivalence of Figure 1a presenting the mean and the sampled data for this scenario. Of course, when estimating the parameters, only the data are used.
We quantify the estimates' accuracy using the normalized mean‐square error (NMSE):
We found that the homoscedastic AR(1) structure for the covariance matrix does not hold. Indeed, simulations showed no consistency of the estimate when assuming that structure. We therefore chose to use the linear covariance model (13), where the main diagonal can have different values, thus accounting for heteroscedasticity. To account for within‐individual correlation we set the two closest off‐diagonal entries in to be non‐zero with a unique value for each off‐diagonal ( if , if , if , and if ).
The NMSE results versus the number of samples are shown in Figure 2. Each NMSE value is calculated as the average of 200 trials. Figure 2a–c show NMSE results for , and respectively, in the three different settings of . Figure 2d displays all estimates of from the 200 trials for and (green lines). As expected, the variance is lower when . The average of 200 estimates coincide with the true (solid lines), which suggests the estimate is approximately unbiased. Estimation of is more challenging as the values have a smaller scale (between 0 and 1). Interestingly, the estimates of all parameters perform better when .
FIGURE 2.
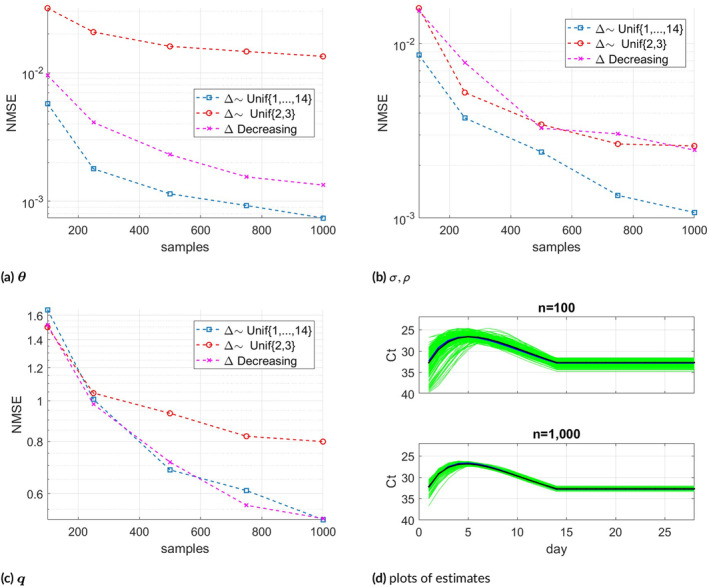
Synthetic sample NMSE for the following estimates: (a) , (b) in , (c) , and (d): Plots of estimates of 200 trials (green lines) for and , together with their averages and true (solid lines).
Figure 3a shows the semi‐synthetic samples' NMSE results for all three parameters. The NMSE results were averaged over 100 trials, a sufficient number to produce smooth curves in this case. Here has a linear covariance structure, so the NMSE is computed via the Frobenius norm. As previously, estimate is more accurate in terms of NMSE compared to , which is more difficult to estimate. Figure 3b shows 200 estimates of together with their average and true , for and .
FIGURE 3.

(a): Semi‐synthetic sample NMSE for the following , in and . (b): Plots of estimates of 200 trials (green lines) for and , together with their averages and true (solid lines).
5.2. Choice of
The latest day that limits the day after infection on which the first measurement was taken is somewhat arbitrary, reflecting a day on which the VL is low and individuals can be regarded as “recovered”. In this part, we examine how the choice of affects the estimate's accuracy. We use the same setting as in the first simulation model, using a uniform distribution of over . Generating 100 samples in each trial, we perform parameter estimation assuming various values: , and 20, where is the ground‐truth.
Panel (a) of Figure 4 shows the average results of the four estimates of compared to the ground‐truth under model (12), and panel (b) shows the same for a unimodal‐constrained model. The estimate coincides with the true in the early days, while towards the end the estimates differ. In general, the model is more sensitive to values smaller than the true . The value on which the VL is maximal, which is an important parameter, seems quite stable to the value of , especially under the unimodal constraint.
FIGURE 4.

(a): Plots of estimates for , and 20 assuming the unimodal Gamma function in (12). (b): Plots of estimates assuming a general unimodal function.
6. Viral Load Data
To lower the risk of sampling bias, the approach should be applied to controlled data, where is determined by the researcher. While such data are not available to us, we apply the method to purely observational data and compare the results to that of [5].
The data contains Nucleocapsid gene (‐gene) Ct‐values, measured by a major lab in Israel, on swab samples taken from patients who were tested positive for SARS‐Cov‐2. The samples were taken between January and June, 2022, during which the SARS‐Cov‐2 infections were most likely caused by the Omicron variant. The data contains records on patients whose Ct‐value was measured once, twice, or multiple times on different days. Specifically, out of 222 668 records, about records contain a single Ct‐measurement, while about , and respectively contain pairs, triples, and quadruples of Ct‐values measured on different days. These amount to over 6000 pairs, 580 triples, and 89 quadruples of Ct‐values.
Since the Ct‐values are documented only on patients who were tested positive, the estimate should be interpreted as the daily mean Ct‐value of all infected persons; more formally, the expectation of the Ct‐value conditioned on Ct‐value less than 40. This is different from the mean Ct‐value trajectory which includes deceased and recovered persons. The latter is usually the focus of viral load studies, such as [3, 5]. Nevertheless, because the probability of recovery (i.e., for the Ct‐value to reach 40) is low on the early days following infection, these two trajectories most likely coincide on these days. In any case, the last day should be chosen carefully and the estimate should be interpreted accordingly. Regarding deaths, during our follow‐up period the proportion of deceased patients among all confirmed cases is negligible (, [18]). Thus, we believe that excluding the Ct‐value documents of deceased patients will introduce a very little bias when considering the population Ct‐value.
Figure 5a shows a histogram of the first Ct‐value of individuals whose Ct‐value was measured multiple times on different days (6653 samples). This histogram is similar to that of the Ct‐value of individuals who were measured only once (Figure 5b, with 216 015 samples). We also notice that although samples with Ct‐value of 40 are not included, the tails decrease smoothly, without a sudden truncation at Ct‐value of 40. Figure 5c shows a histogram of the second Ct‐value of individuals whose Ct‐value was measured multiple times. The distribution is shifted more to the right, showing an average increase in Ct‐value between the tests. As a larger Ct‐value represents a smaller VL, this suggests that the second measurements were typically taken after the infection's peak. Figure 5d shows the distribution of ‐the difference in days between the first and second measurements (samples with were excluded; the number of such samples is negligible accounting for of all samples). Most of the values are between 1 and 7 days, which constitute about of all samples.
FIGURE 5.

Top row: Distribution of first Ct‐value measurement among: Persons who were tested multiple times (a), and persons who were tested once (b). Number of samples is given at the bottom. (c): Distribution of second Ct‐value measurement. (d): Histogram of time difference in days between the first and second measurement.
We included all pairs, triples, and quadruples of Ct‐values in estimation. We used the structural assumptions set in the semi‐synthetic simulation, namely the Gamma parametric class of and the linear covariance structure (due to possible heteroscedasticity). Although the maximum value of is 13, the maximum number of days after infection, , that best fits the data is unknown. A natural choice is ; however, we also examine and 20. For each , we follow the same procedure as described previously, running the EM algorithm several times using different random initializations, and selecting the one that gives the largest likelihood value. Since the number of samples is quite large, we use 1000 iterations as convergence might possibly be slower.
Figure 6a shows the daily Ct‐value estimation results for , and 20. Since gives the largest likelihood value we regard this as the estimate of choice and it is shown as a black solid line. The curve shows that the viral load reaches its peak during day 4 after infection (with Ct ), a result that is consistent with current knowledge [5]. The Ct‐value on day 10 reaches a value of 30, and it represents the average Ct‐value on day 10 and onward. Panel (b) of Figure 6 shows the daily Ct‐value estimates under unimodality constraints for various , which are quite similar to the parametric Gamma curves shown in (a).
FIGURE 6.
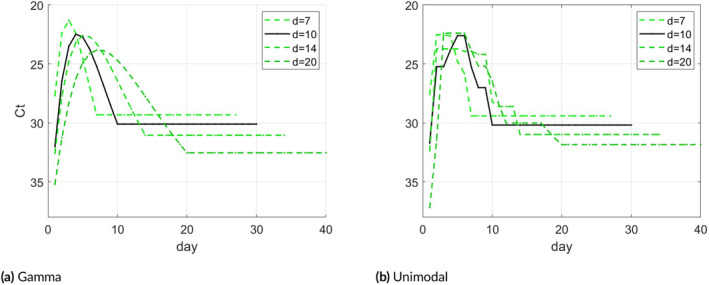
(a): Daily Ct‐value estimates for , and 20 based on the parametric model (12). (b): Daily Ct‐value estimates for , and 20 based on a unimodal constraint.
7. Discussion
In the midst of the COVID‐19 pandemic, crucial policy decisions have been made under the pressure of limited evidence. One such example is determining the appropriate length of quarantine for infected individuals – a decision that carries substantial economic and ethical consequences. In order to ensure responsible and effective policies, it is imperative to base these decisions on rapid and accurate information. Estimating viral load (VL) trajectories – a key factor in understanding infectiousness – traditionally requires resource‐intensive and complex longitudinal studies. These studies are not only time‐consuming but often involve substantial costs and logistical challenges. These led to delays in obtaining critical data needed for informed policy adjustments.
The method presented here requires much less resource (performing a second measure for a sample of infected individuals), is logistically much simpler than traditional methods, and can provide fast and important estimates for the parameters of interest. Importantly, the method's reliance on routine surveillance data makes it more adaptable and feasible for rapid implementation. In the face of emerging variants of concern, the ability to promptly evaluate data and adjust policies becomes even more vital. The current approach represents a significant advancement, offering the promise of faster decision‐making processes while maintaining scientific rigor. Although the method is based on strong modeling assumptions, it can provide good initial estimates that can be updated when more complete data are collected. From VL trajectory estimates one can derive other parameters of special interest to epidemiologists, such as the duration of viral shedding, given some VL threshold.
Using available observations data is often subject to selection bias that may affect the statistical results. As a referee commented, individuals who die, especially those who die immediately after infection, are under‐represented. We recommend conducting a semi‐controlled design in which a second test is performed to a sample of individuals who were found positive to the virus. The EM algorithm can deal with individuals who are included in the sample, but do not show up for their scheduled second test by using for these individuals. While this does not solve the selection bias problem, it may somewhat reduce it and can be used for sensitivity analysis under various assumptions regrading the expected VL trajectory for these partially‐observed individuals. For a pandemic with a low mortality rate, such as COVID‐19, this bias is expected to be small.
In the synthetic simulation, we examined how the distribution of the time difference between pairs of samples affects the accuracy of the estimate. We found that the uniformly distributed gave a stable and accurate estimate, which suggests using this approach when planning the design. A detailed analysis for finding the optimal distribution is a possible future research direction. Another important issue is the case where the samples greatly depart from the normal distribution. This includes, for instance, the bimodal distribution that can be relevant if recovered persons, whose VL becomes a fixed zero, are included in the samples.
Software
Matlab code for the EM‐algorithm and numerical simulations can be accessed at https://github.com/yonatan123/VL‐trajectory.
Conflicts of Interest
The authors declare no conflicts of interest.
Supporting information
Matlab code, Supporting Information
Acknowledgments
The authors would like to thank Arnona Ziv for providing the data.
Funding: This work was supported by the Israel Science Foundation, Grant No. 3663/19.
Data Availability Statement
Due to Israel Ministry of Health's regulations, individual Ct‐level data cannot be publicly shared.
References
- 1. Kissler S. M., Fauver J. R., Mack C., et al., “Viral Dynamics of Acute SARS‐CoV‐2 Infection and Applications to Diagnostic and Public Health Strategies,” PLoS Biology 19, no. 7 (2021): e3001333. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 2. Marks M., Millat‐Martinez P., Ouchi D., et al., “Transmission of COVID‐19 in 282 Clusters in Catalonia, Spain: A Cohort Study,” Lancet Infectious Diseases 21, no. 5 (2021): 629–636. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 3. Chia P. Y., Ong S. W. X., Chiew C. J., et al., “Virological and Serological Kinetics of SARS‐CoV‐2 Delta Variant Vaccine Breakthrough Infections: A Multicentre Cohort Study,” Clinical Microbiology and Infection 28, no. 4 (2022): 612. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 4. Ke R., Martinez P. P., Smith R. L., et al., “Daily Longitudinal Sampling of SARS‐CoV‐2 Infection Reveals Substantial Heterogeneity in Infectiousness,” Nature Microbiology 7, no. 5 (2022): 640–652. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 5. Hay J. A., Kissler S. M., Fauver J. R., et al., “Quantifying the Impact of Immune History and Variant on SARS‐CoV‐2 Viral Kinetics and Infection Rebound: A Retrospective Cohort Study,” eLife 11 (2022): e81849. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 6. Berman S. M., “A Stochastic Model for the Distribution of HIV Latency Time Based on T4 Counts,” Biometrika 77, no. 4 (1990): 733–741. [Google Scholar]
- 7. Dubin N., Berman S., Marmor M., Tindall B., Jarlais D. D., and Kim M., “Estimation of Time Since Infection Using Longitudinal Disease‐Marker Data,” Statistics in Medicine 13, no. 3 (1994): 231–244. [DOI] [PubMed] [Google Scholar]
- 8. Degruttola V., Lange N., and Dafni U., “Modeling the Progression of HIV Infection,” Journal of the American Statistical Association 86, no. 415 (1991): 569–577. [Google Scholar]
- 9. Drylewicz J., Guedj J., Commenges D., and Thiébaut R., “Modeling the Dynamics of Biomarkers During Primary HIV Infection Taking Into Account the Uncertainty of Infection Date,” Annals of Applied Statistics 4, no. 4 (2010): 1847–1870. [Google Scholar]
- 10. Wang T., Ratcliffe S. J., and Guo W., “Time‐To‐Event Analysis With Unknown Time Origins via Longitudinal Biomarker Registration,” Journal of the American Statistical Association 118, no. 543 (2022): 1–16. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 11. Myers R. H., Montgomery D. C., Vining G. G., and Robinson T. J., Generalized Linear Models: With Applications in Engineering and the Sciences (John Wiley & Sons, 2012). [Google Scholar]
- 12. Karita H. C. S., Dong T. Q., Johnston C., et al., “Trajectory of Viral RNA Load Among Persons With Incident SARS‐CoV‐2 G614 Infection (Wuhan Strain) in Association With COVID‐19 Symptom Onset and Severity,” JAMA Network Open 5, no. 1 (2022): e2142796. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 13. Dempster A. P., Laird N. M., and Rubin D. B., “Maximum Likelihood From Incomplete Data via the EM Algorithm,” Journal of the Royal Statistical Society: Series B 39, no. 1 (1977): 1–22. [Google Scholar]
- 14. Teicher H., “Identifiability of Finite Mixtures,” Annals of Mathematical Statistics 34, no. 4 (1963): 1265–1269. [Google Scholar]
- 15. Yakowitz S. J. and Spragins J. D., “On the Identifiability of Finite Mixtures,” Annals of Mathematical Statistics 39, no. 1 (1968): 209–214. [Google Scholar]
- 16. Fitzmaurice G. M., Laird N. M., and Ware J. H., Applied Longitudinal Analysis (John Wiley & Sons, 2012). [Google Scholar]
- 17. Anderson T. W., “Asymptotically Efficient Estimation of Covariance Matrices With Linear Structure,” Annals of Statistics 1, no. 1 (1973): 135–141. [Google Scholar]
- 18. Israel Ministry of Health Dashboard (Corona) , https://datadashboard.health.gov.il/portal/dashboard/health.
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.
Supplementary Materials
Matlab code, Supporting Information
Data Availability Statement
Due to Israel Ministry of Health's regulations, individual Ct‐level data cannot be publicly shared.