

Abstract
The statistical study of human memory requires large-scale experiments, involving many stimulus conditions and test subjects. While this approach has proven to be quite fruitful for meaningless material such as random lists of words, naturalistic stimuli, like narratives, have until now resisted such a large-scale study, due to the quantity of manual labor required to design and analyze such experiments. In this work, we develop a pipeline that uses large language models (LLMs) both to design naturalistic narrative stimuli for large-scale recall and recognition memory experiments, as well as to analyze the results. We performed online memory experiments with a large number of participants and collected recognition and recall data for narratives of different sizes. We found that both recall and recognition performance scale linearly with narrative length; however, for longer narratives, people tend to summarize the content rather than recalling precise details. To investigate the role of narrative comprehension in memory, we repeated these experiments using scrambled versions of the narratives. Although recall performance declined significantly, recognition remained largely unaffected. Recalls in this condition seem to follow the original narrative order rather than the actual scrambled presentation, pointing to a contextual reconstruction of the story in memory. Finally, using LLM text embeddings, we construct a simple measure for each clause based on semantic similarity to the whole narrative, that shows a strong correlation with recall probability. Overall, our work demonstrates the power of LLMs in accessing new regimes in the study of human memory, as well as suggesting novel psychologically informed benchmarks for LLM performance.
In the classical paradigm for studying human memory, participants are presented with randomly assembled lists of words and then perform memory tasks such as recognition and recall (for review, see Kahana 2020). A wealth of results has been obtained in these studies. For instance, it has been found that words at the end and the beginning of the list have a higher chance of being recalled (recency and primacy effects, respectively), and there is a tendency to recall words close to each other in the list (contiguity, Kahana 1996). Moreover, it was found that when the presented lists grow in length, even though the average number of recalled words (R) is increasing, a progressively smaller fraction of the words is recalled (Murdock 1962). Several authors have addressed the issue of the mathematical form of the dependence of R on list length and found that the best description for this dependence is provided by power-law relations, , with exponents α generally below one (Murray et al. 1976). It is well known that recall also depends on multiple experimental factors such as, e.g., the presentation rate of words, the age of the participants, etc. However, in recent work, some of the authors discovered that if recall performance is analyzed as a function of a number of retained (M), rather than presented words, the relation becomes universal and is described by the analytical form: (Naim et al. 2020). Moreover, this relation follows from a simple deterministic model where words are retrieved one by one according to a random symmetric matrix of “similarities” reflecting their long-term encoding in memory, until the process enters a cycle and no more words can be recalled. The number of words retained in memory M, itself can be predicted by the retrograde interference model that assumes that each new word erases some of the previously presented words according to the “valence” or “importance” of each word (Georgiou et al. 2021, 2023).
While it is remarkable that human memory for random material can be described with universal mathematical relations, it is of course much more important and exciting to try to understand how people remember more natural, meaningful information. After the pioneering work of Bartlett (1932), many studies considered recalls of narratives. As opposed to random lists, narratives convey meaning, and hence have structure on multiple levels, which influences recall, as was confirmed in many previous publications (see section “Previous work”). The first challenge in understanding narrative recall is the fact that people tend not to recall the narrative verbatim. Rather, they remember what the narrative is about and retell it in their own words (Gomulicki 1956; Fillenbaum 1966; Sachs 1967). Counting correctly recalled words is therefore not a good score of recall, and the better score used in many studies, that we also adopt in our work, is a count of recalled “ideas,” or “clauses” (see, e.g., Bransford and Johnson 1972). Using this method, however, requires a human level of understanding of narratives and recalls, making collecting large amounts of data difficult and extremely time-consuming to analyze. In our study, we develop a way to overcome this and other difficulties by using large language models (LLMs) to assist in the analysis and design of experiments, as described later. In particular, we use LLMs to generate new narratives of a particular type and length, and to score human recalls obtained in multiple experiments performed over the internet. In addition to recall, we also performed recognition experiments (where people are requested to indicate whether a specific clause was in the presented story or not) in order to estimate how many clauses people remember after reading the narrative. To this end, we use LLMs to generate plausible lures, i.e., novel clauses that could have potentially appeared in the narrative.
Inspired by our previous results, we wanted to understand how recognition and recall performance scale up with narrative length as it increases and what the relation between them is. To this end, we performed a large number of experiments over the internet using the Prolific platform (www.prolific.com). We also compared the recall and recognition performance of original narratives with their scrambled versions in order to elucidate the effects of comprehension on different aspects of memory. Since there are different types of narratives that could potentially be more or less difficult for people to remember and recall, we decided to focus on one particular type of narrative first studied in the famous paper by Labov and Waletzky (1966) that established the field of narratology, namely the oral retelling of personal experience, told by real people, and the variants of those generated by LLMs (see later). While being collected in a research setting, these spoken recollections of dramatic personal episodes are close to the natural way people share their experiences in real life and therefore are of special interest for studying human memory.
Results
LLM-assisted recall and recognition experiments
For the purpose of this study, we have chosen several narratives of different lengths from Labov (2013) and Labov and Waletzky (1966). As part of the analysis in these publications, narratives were segmented into an ordered set of clauses, which are “the smallest unit of linguistic expression which defines the functions of narrative” (Labov and Waletzky 1966). In other words, they are the smallest meaningful pieces that still serve some function in communicating a narrative. Since these are spontaneous narratives spoken in local dialect, they are characterized by a number of features that are awkward to transcribe (pauses, repetition, gestures) as well as nonstandard (and sometimes outdated) English vernacular. These factors complicate comprehension when participants have to read narratives on the computer screen. We therefore instructed LLMs to generate new narratives modeled on the original ones, i.e., exhibiting a similar type of an event sequence and the overall length in terms of the total number of clauses. In particular, the LLM-generated narratives inherited the segmentation from the original story, i.e., the number of clauses was the same and the information contained in the corresponding clauses had a similar role in their respective narrative (see Methods section for details of narrative generation, and some examples in Supplemental Appendix A.2.1). Eight narratives were selected for subsequent memory experiments, ranging from 18 to 130 clauses in length. We presented each narrative to a large number of participants (∼200), who then performed either recall or recognition tasks. In the subsequent analysis, we treated clauses as the basic units that together communicate the meaningful information contained in the narrative. In particular, we quantified each individual recall by identifying which of the clauses in the narrative were recalled, determining this by whether information contained in this clause is present in the recall. We simplify the analysis by considering each clause as being either recalled or not. This scoring of recalls is traditionally performed by human evaluators and is very time-consuming. We, therefore, prompted an LLM to define which of the clauses of the original narrative were recalled and in which order. Here, we utilized the remarkable ability of modern LLMs to respond to instructions, provided as prompts written in standard English (as opposed to a programming language), to perform novel tasks without any additional training (known as zero-shot prompting or in-context learning [Brown et al. 2020], see Supplemental Appendix A.2 for more details).
To test the ability of the LLM to adequately score human recall (with appropriate prompting as described in the Methods section and Supplemental Appendix A.2), we performed an additional set of recall experiments with a specially LLM-generated narrative and compared the LLM-performed recall scoring to the one conducted manually by the authors (see Methods section for details). To this end, we calculated the fraction of participants who recalled each particular clause, i.e., the clause’s recall probability (Prec), as judged by the LLM and by the authors. For nearly all of our analysis, the LLM we used was OpenAI’s GPT-4 (see Supplemental Appendix B.1.2 for comparison between different LLMs). As shown in Figure 1, GPT-4 scoring of recalls results in recall probabilities close to ones obtained by human evaluations for a great majority of the clauses. Moreover, the variability of scoring is comparable between GPT-4 and human evaluators (compare Fig. 1B,C). Interestingly, the LLM has a greater correlation with the mean human scoring (r = 0.94) than with any individual scoring (r = 0.92, 0.90, 0.90) (see Table 3 in Appendix B.1; cf. Michelmann et al. 2023).
Figure 1.

Reliability of LLM scoring of recalls. Three authors and GPT-4 (OpenAI API model gpt-4-0613) performed scoring of 30 recalls by answering the question of whether the information present in each particular clause is present in each individual recall. (A) Comparison between recall probabilities Prec for each clause, as calculated from GPT-4 scores (orange) and average human scores (dashed blue). The full range of human scores is given by the shaded blue region. (B) A strong correlation between human and GPT-4 scores across clauses, with a correlation coefficient (r-value) of 0.94. (C) Correlations between individual human scores show overall a strong agreement between human scorers.
We also performed recognition experiments in order to estimate the average number of clauses that participants remember after the presentation. As we explain below, this analysis requires a large number of plausible lures, i.e., novel clauses that could have possibly been in the narrative and hence cannot be easily distinguished from the true clauses using context and style. Generating these lures is highly nontrivial as it requires an understanding of the narrative. This makes manually generating lures very challenging and time-consuming, which is why we utilized LLMs for this purpose (see Supplemental Appendix A.2.2 for prompts and example output). Using the LLM, for each story, we obtained the same number of lures as true clauses (denoted L for a given story), and sampled 10 clauses from this entire pool of 2L clauses uniformly and randomly for the testing phase. Participants would then see one clause at a time, and were asked whether the clause was in the presented narrative or not. We checked that presenting several clauses for recognition does not result in systematic drift in performance, i.e., no output interference was detected in our experiments (Criss et al. 2011; see Supplemental Appendix B.3). We then estimated the number of clauses retained in memory after the presentation of the narrative (M) from the fraction of “hits,” i.e., correct recognitions of the true clauses (Ph) and the fraction of “false alarms,” i.e., reporting lures as true clauses (Pf). We assume that if the participant remembers a given clause, they always recognize it as being part of the narrative; otherwise, they still give a positive answer with some guessing probability Pg. The guessing probability is the probability that they respond “yes” to a clause they did not retain, conditioned on having just read the narrative. We approximate this by the false alarm probability Pf, which is the probability that a participant responds “yes” to a clause that was not in the story, also conditioned on having just read the story. For this approximation to make sense, the lures must appear as if they could have been in the story, thus making the performance on a lure appear as close as possible to the performance on a true clause that was just not encoded. Therefore, using Pg ≈ Pf, the total probability of a correct recognition is given by
| (1) |
from which we obtain
| (2) |
This equation emphasizes the importance of using lures in recognition experiments, since without them we have no way of estimating the “guessing correction” to the hit probability.
Definition of mathematical variables
Here for convenience, we provide a summary of the main mathematical variables used in our analysis:
R—total number of clauses from a narrative recalled by an individual, averaged over all subjects.
L—total number of clauses in a narrative.
Prec(c)—recall probability of clause c, determined by the number of subjects who recalled clause c, divided by the total number of subjects in the experiment. Often the argument is not explicitly written.
Ph—hit probability, computed from yes/no recognition experiments as the ratio of the total number of hits H (over all subjects) divided by H plus the total number of misses M, i.e., Ph = H/(M + H).
Pf —false alarm probability, computed from yes/no recognition experiments as the ratio of the total number of false alarms FA (i.e., false positive) divided by FA plus the total number of correct rejections CR (true negative), i.e., Pf = FA/(FA + CR).
M—estimate of the total number of clauses retained in memory, averaged over all subjects. This is estimated from Ph and Pf using Equation 2.
Scaling of recall and memory
Having each narrative seen by roughly 200 participants, half of them doing recall and another half recognition, we were able to determine the average number of clauses retained in memory (M) and recalled clauses (R). As expected, both M and R grow with the length of the narrative presented, as measured by the number of clauses in the narrative and denoted by L (see Fig. 2A,B). Moreover, both M and R appear to grow linearly with L for the range of narrative lengths we explored, and hence when we plot R versus M, we also get an approximately linear relationship (see Fig. 2C). This scaling behavior is very different from what we observed with random lists of words with a characteristic square root scaling, i.e., unsurprisingly, recall of meaningful material is better than for random ones of the same size, even if we discount for better memorization. We should point out however that for the longest narrative in our set, some of the participants “summarized” several clauses in the narrative into a single clause of recall (see also Discussion). Scoring of these instances is ambiguous, and the LLM often judged summarized clauses as all being recalled, resulting in the average number of recalled clauses (R) being substantially larger than the average number of clauses in recalls of this narrative (C; green crosses in Fig. 2C, see also Supplemental Appendix B.2, Fig. 7A). If we apply a more conservative scoring and use C instead of R as a measure of recall, linear scaling of recall will not persist when the longest narrative is included (Fig. 2C; Supplemental Appendix B.2, Fig. 7B; see also Discussion).
Figure 2.

Human performance in recall and recognition experiments for narratives of different length. (A) Estimated number of retained clauses (M) is plotted as a function of the number of clauses in the narrative (L) measured in recognition experiment. Surprisingly, M has similar values in intact and scrambled narrative. (B) Average number of recalled clauses (R) for narratives of different length. In contrast to the M, R drops substantially for scrambled narratives. Also plotted are the average number of clauses used in the recall (green crosses), which drops significantly below R for the longest narrative, indicating the tendency of subjects to summarize. (C) Average number of recalled clauses versus number of retained clauses from the same story. As expected from (A) and (B) the number of retrieved clauses in scrambled narrative is substantially smaller that in intact narrative for the same number of retained clauses. For comparison, we presented the theoretical prediction for the random list of words, which was shown to describe data well (Naim et al. 2020). It is clear that there are more clauses recalled in intact narratives than words in lists of random words. Surprisingly, retrieval of scrambled stories is significantly worse than random lists, suggesting an active suppression of items in service of generating a coherent recall (participants were implicitly instructed to recall story). Finally, we show the mean number of clauses in a recall (green crosses), which is insensitive to the content of the clause and just measures the length of a participant’s recall. For R, we report standard error in total recall length over the entire population of subjects; for M, we calculate error using bootstrap.
One of the factors that apparently leads to better recall of narratives is the temporal ordering of recall. When people recall narratives, recall mostly proceeds in the forward direction (see Fig. 3A), probably reflecting the natural order of events in the narrative that cannot be inverted without affecting its coherence. This contrasts with the case of random lists, when recall proceeds in both directions with similar probability (see Fig. 3B), which, according to a model proposed in Naim et al. (2020) results in the process entering a cycle preventing many words from being recalled.
Figure 3.

Recall order. Color-coded order of clauses or words for different conditions is shown in all panels. Recalled clauses or words are stacked together vertically (with the first recalled clause at the bottom of a column, and the last recalled clause at the top). The height of the column represents the total number of clauses or words recalled in a given trial. In A, B, and D, color code represents serial position of presentation of clauses or words, from early (red) to later (blue) in presentation position. Panel (C) is the only exception, in which the color code reflects the serial position of clauses in the original (intact) story. Panel (A) shows that recall of coherent stories largely preserves presentation order. (B) Recall of random word lists does not preserve presentation order. (C) As with random lists, the recall of a scrambled story does not preserve presentation order, but rather appears to reconstruct the original order of the story, as seen from the color gradients in (B). Apparently, random words and scrambled stories are recalled in random order considering their presentation order, but people perform some unscrambling of the scrambled stories as can be seen in (C)—there is tendency of recalled clauses being in the order of original unscrambled narrative. The participants construct a mental representation of the scrambled narrative, which is evidently close to its original form. Recall consequently does not reflect input sequence, but rather the original sequence of the clauses.
Meaning and memory
As we mentioned above, people’s recall is strongly influenced by narrative comprehension, such that clauses that are most important in communicating the summary of the narrative are the ones that are recalled by most of the participants. We found however that recognition is not so strongly affected by meaning. This can be observed by evenly dividing all the clauses used in our experiments into subsequent bins according to their recall probabilities, and calculating the average recognition performance for all the clauses in each bin. Surprisingly, there is very little increase of recognition with recall probability across the clauses, such that clauses with highest and lowest average Prec only differ in their Ph by <0.15 (see Fig. 4; cf. Thorndyke and Yekovich 1980; Yekovich and Thorndyke 1981).
Figure 4.
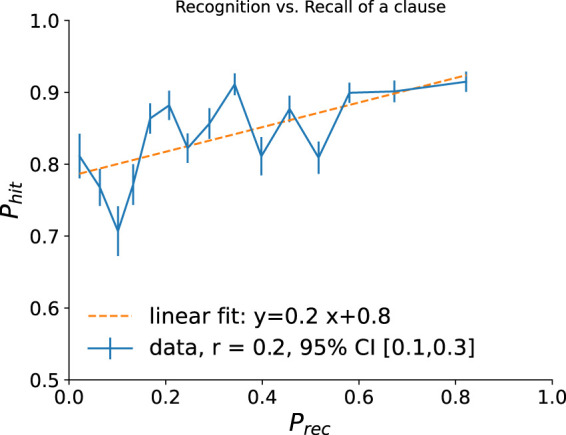
Recognition versus recall performance across different clauses. Clauses from all the narratives used in this study were divided evenly into 15 bins according to their Prec, and the average Ph for the clauses in each bin was computed and plotted against the center of the corresponding bin. Error bars show standard error within a bin. We show a linear fit (orange dashed) to the binned data (solid blue). The correlation coefficient r is computed using the unbinned cloud of data points, with the 95% confidence interval calculated using bootstrap with 3000 samples.
To further elucidate the role of meaning in memory, we repeated our experiments with another group of participants after randomly scrambling the order of clauses, thus making comprehension much more difficult if not impossible. We found that, unsurprisingly, recall of scrambled narratives is much poorer than the original ones (Fig. 2B,C). Recognition performance for scrambled narratives however is practically the same (Fig. 2A). This result indicates that memory encoding of clauses is not significantly affected by the structure and meaning of the narrative. Interestingly, the order in which people tend to recall clauses from a scrambled narrative corresponds much better to the order of these clauses in the original narrative than in the presented, scrambled one (see Fig. 3C,D), indicating that even in this situation people are trying to comprehend the meaning of the narrative rather than processing the input as a random list of unconnected clauses. This might explain why recall of scrambled narratives appears to be worse than recall of random word lists of the same size.
How can recognition remain so strong even when recall is suppressed? We observe even for coherent narratives in Figure 4 that recognition is generally quite high, even for Prec approaching zero. These observations appear to be consistent with the dual-process model of recognition (Yonelinas 2002), wherein familiarity judgments can be used to perform recognition even in the absence of explicit recollection (low recallability).
Semantic similarity predicts recall
One prominent feature seen in Figure 1A is a wide range of recall probabilities for different clauses. In other words, while some clauses are recalled by most of the participants, other clauses are not. Such a wide distribution of Prec’s across the clauses was observed in recalls of all the narratives and contrasts sharply with corresponding results for random lists of words where Prec’s are rather uniform except for the ones in the beginning and the end of the list (see Supplemental Appendix B.4). This wide distribution of Prec’s is apparently due to the fact that not all clauses have similar importance for communicating the narrative. Indeed, if we select the clauses with high enough Prec, we usually get a good summary of the narrative (see Supplemental Appendix B.6 for examples).
Can the recallability of a clause be predicted directly from a narrative? There is good reason to believe this is possible. Anecdotally, we know that highly skilled storytellers are often able to construct very memorable narratives, suggesting at least an intuitive understanding of the interplay between story structure and memory. Previous work has explored various methods to quantify this relationship. Most germane to our approach is Lee and Chen (2022), which introduces “semantic centrality,” a network measure of how semantically connected an event is to other events in a narrative. This was shown to correlate well with the probability to recall an event after watching a short video. Here, we introduce a simpler metric that directly computes the semantic similarity between a single clause and the entire narrative. This is motivated in part by the above-mentioned observation that the most highly recalled clauses, when read together in isolation, tend to make good summaries of the narrative (cf. Supplemental Appendix B.6). This suggests that these clauses are more important for determining the meaning of the narrative as a whole, and should therefore score higher under any metric of semantic similarity to the entire narrative.
We test this hypothesis using LLM text-to-vector embeddings. The semantic similarity is taken to be the cosine similarity between the vector representation, or embedding, of a single clause and the vector embedding of the entire narrative (including the clause) (for details, see Supplemental Appendix B.5).
For each narrative of length L, we compute L scores for each clause, which we subsequently compare to the recall probabilities. The main results of this analysis are presented in Figure 5, with a more thorough analysis saved for Supplemental Appendix B.5. We find a very strong relationship between our semantic similarity score and the recall probability for a majority of narratives. Figure 5A,B shows two examples for a shorter and longer story, while Figure S7 in Supplemental Appendix B.5 shows the same data for all of the narratives we used in our study. Figure 5C shows that for individual narratives, the similarity score shows a statistically significant correlation with Prec in a majority of the narratives we tested. There is, however, a general trend of correlations getting lower with story length. We speculate that this is due to the general trend of subjects to resort to summarization with longer narratives, thus potentially making such a clause-level analysis of similarity an overall weaker predictor of recall performance.
Figure 5.

Semantic similarity correlates with recall probability. (A) Scatter plot of recall probability Prec versus cosine similarity score (described in text) for each clause in a narrative with L = 19 clauses. Plotted in orange is the mean Prec and standard error per bin, for 5 bins, with the horizontal coordinate taken at the midpoint of the bin. The correlation coefficient (r-value) is 0.8 and statistically significant (p << 0.001). (B) Same as (A) with a story of length L = 32, and a statistically significant correlation of r = 0.58. Error bars are computed using standard error within each bin. (C) shows the correlation coefficient between Prec and similarity scores computed for each story, plotted here as a function of story length. The significance level is indicated in the legend, with green circles indicating P-value p < 0.001 (***), blue squares p < 0.01 (**), and orange triangles p < 0.05 (*), while empty circles indicate no statistically significant correlation (p > 0.05). P-values are computed using two-sided Wald test. 95% confidence intervals are computed using bootstrap with 1000 samples, and indicated with capped error bars in the figure. Text embeddings for this figure were obtained using OpenAI’s text-embedding-3-small model.
In Supplemental Appendix B.5, we also compare different embedding models and their ability to predict recall via our similarity score. The embedding models that we study have varying success in predicting recall. This suggests a novel benchmark for text embeddings that directly reflects how humans process and ascribe significance or importance to parts of a text.
Previous work
The experimental study of memory for narratives can be traced back to the highly influential descriptive work of Bartlett (1932). This and follow-up work introduced the idea that the encoding of memory for narratives is a process of abstraction (Gomulicki 1956), and that subsequent recall is in large part a generative process driven by a participant’s prior knowledge and biases. This line of thought was formalized much later in theories of narrative structure involving schemas, scripts, frames, and story grammars (Rumelhart 1975; Alba and Hasher 1983). By now, there is ample support for an abstracting process for memory encoding, and the existence of schematic structures that guide recall (Baldassano et al. 2018).
A parallel line of research into narrative structure originated in the field of sociolinguistics by Labov and Waletzky (1966). In carrying out linguistic fieldwork to analyze spoken dialects of English, the authors found that personal narratives of emotionally charged events tended to elicit the best examples of local dialect. Furthermore, the resulting narratives, which were produced spontaneously and by nonexpert storytellers, tended to be very regular in their structural properties. Of particular significance to us was the observation that stories were typically told in the order in which they were experienced by the speaker, which Labov encapsulates in his “egocentric principle” and “no flashback” constraint (Labov 2013). This lends some support to the strong iconicity assumption (Zwaan 1996), which states that readers (or listeners) will interpret the order in which events are reported as reflecting the actual chronological order in which they occurred.
However, serial order alone likely cannot explain the rich structure we observe in narrative recall. Indeed, temporal order provides just a single axis along which events in a narrative are organized. In addition to simple serial order, events or clauses can have causal relations (e.g., A causes B) (Trabasso and van den Broek 1985; Trabasso and Sperry 1985; Lee and Chen 2022), inferential relations (e.g., A implies B), and superordinate or constituency relations (e.g., A consists of B) (Black and Bower 1979). These relations conspire to give narratives hierarchical structure (Kintsch 1998). Story grammars provide one natural mechanism whereby the hierarchical structure arises, and served as early inspiration for studying structure dependence in narrative recall and recognition.
In this direction, Yekovich and Thorndyke (1981) and Thorndyke and Yekovich (1980) performed recall and recognition experiments to test how encoding and processing depend on hierarchical structure. Their recognition experiments included only old, paraphrase, and false statements in the test phase. The false statements tested were appropriate (invoking the appropriate agents or actions), but inconsistent with or contradictory to the story. They observed that recognition is very weakly correlated with recall, and the correlation is not significantly different from zero (Table 3 of Yekovich and Thorndyke 1981). Furthermore, whereas recall was argued to be sensitive to the structure of a narrative, recognition appeared to have no such sensitivity.
In another experiment seeking to isolate the structure sensitivity of narrative processing, Kintsch et al. (1977) tested the processing of scrambled narratives, in which paragraphs of a text were presented to participants in random order. Participants were able to produce coherent summaries of such scrambled text, which were indistinguishable from summaries produced by participants reading the coherent text. It is possible that scrambling larger units (paragraphs in this case, versus clauses in our experiments) produced an overall more comprehensible text, making descrambling easier. Nevertheless, we still observe descrambling, but of lower quality (see Fig. 3C).
There have been many efforts to uncover what features of an event in a narrative make it more or less memorable than other events. Trabasso and Sperry (1985) showed that the strongest predictor for recall was causal connectedness, in which more memorable clauses have more causal links to other clauses in the narrative. Some recent support for this observation was presented in Lee and Chen (2022), in which subjects performed immediate recall after watching short video clips. They showed that, in addition to causal centrality, a measure of semantic centrality was predictive of whether an event from the movie was later recalled. Crucially, semantic content was accessed using vector embeddings of text.
Semantic vector embeddings have been used in psychological modeling since the introduction of latent semantic analysis (LSA) (Deerwester et al. 1990), a technique that obtains embeddings from a low-rank approximation of a matrix of word-document occurrences in a corpus. The psychological relevance of the resulting embeddings has been demonstrated in many settings, including semantic proximity effects in free recall (Howard and Kahana 1999), and similarity judgments (Bhatia et al. 2019), just to name a few. The hypothesis of distributional semantics, which states that the meaning of a word can be captured by its statistical properties in a text, has been pushed to extremes with modern deep learning, given the availability of huge data sets and computational power. The resulting semantic embeddings have displayed surprising properties, such as linear structure that allows analogies to be solved by vector algebra (Mikolov et al. 2013). These approaches have culminated recently in deep neural networks that can effectively embed entire chunks of text, opening up new avenues to study semantic structure of memory and free recall in narratives. For instance, Heusser et al. (2021) utilize text embeddings to study the trajectories of story recall in semantic space, showing how gross structure of a trajectory can remain stable across participants, with high-frequency deviations from this path indicating selective omission of details.
Scaling laws for memory have been observed for random unstructured lists (pictures, words, etc.) (Standing 1973; Murray et al. 1976; Naim et al. 2020). Two important takeaways from these works are the following: memory typically exhibits power-law scaling with list length, and the retrieval process appears to be universal. Surprisingly, there is very little work that considers the scaling of narrative memory with story length, let alone attempts to quantify it. The only work we are aware of is Glenn (1978), which measured average recall as a function of story lengths of up to 83 “informational units,” which include clauses as well as noun and adjective phrases. The experimental design was motivated largely by questions about story grammars, and therefore the episodic structure of the narratives (in the story grammar sense developed by the authors) was kept constant while descriptive phrases and clauses (so-called “informational units”) were added to increase the length of the story. Therefore, the added statements are arguably a kind of filler, not contributing any significant additional meaning or structure to the underlying narrative. This might account for the seemingly sublinear scaling of their mean recall with story length, compared to our linear results (Fig. 2). There are other significant differences, including the test population (24 second grade schoolchildren), the stimulus input format (audio narratives), and the recall format (spoken recall).
The choice of “informational units” in Glenn (1978) also differs from our choice of clauses, and is similar to segmentations that use propositional analysis (Kintsch and van Dijk 1978), or pausal breaks (Johnson 1970). An important feature of these different units is that they provide a more fine-grained segmentation of a narrative—a clause can consist of many propositions or pausal breaks, but not the other way around. However, these smaller units would not have a narrative function in the Labovian sense. There is also evidence from experiments on immediate verbatim recall that clauses are recalled holistically and largely intact (Jarvella 1979). This suggests that beyond being a descriptive segmentation of text useful in the field of linguistics, clauses are psychologically processed as coherent units.
Indeed, it is generally believed that humans process continuous naturalistic stimuli via discrete segments. Radvansky and Zacks (2017) review theory and experimental evidence in favor of “events” as being the natural units of experience. In the Labovian classification, an event roughly corresponds to an episode, and so would constitute a more coarse-grained segmentation of a narrative (Bailey et al. 2017). Sargent et al. (2013) suggest that recall memory for a movie was correlated with an individual's “segmentation ability,” which measures how close their individual segmentation was to the average over a population. This natural tendency to segment stimuli, and its effects on recall memory, seems to give credence to our choice to measure memory for narratives in discrete units.
Discussion
In this contribution, we describe a new way to study human memory for meaningful narratives with the help of LLMs. Together with using internet platforms for performing experiments, this technology enables a quantitative leap in the amount of data one can collect and analyze. In particular, we describe the prompts that we used to make LLMs generate new narratives of a particular type and size, score multiple human recalls of these narratives by identifying which clauses were recalled, and generating plausible lures for recognition experiments. Having a large amount of data is important for memory research because, as opposed to, e.g., sensory processing that is believed to be largely uniform across people (Read 2015), the way people remember and recall meaningful material is highly variable. Hence, only through statistical analysis can some general patterns be uncovered. In particular, we considered how recognition and recall performance scale up for narratives of increasing length. We found that approximately the same fraction of narrative clauses are recognized and recalled when narratives become longer, in the range of 20–130 clauses that we considered for this analysis. We expect that as narratives become longer, this trend will not persist because people will start summarizing larger and larger chunks of the narrative into single sentences in their recalls, as indeed happened for some of the participants recalling the longest narrative in our pool (see Supplemental Appendix B.2). When summarizing happens, deciding whether individual narrative clauses in the chunk were recalled or not is ambiguous. In the extreme case, a short summary of the entire story can be scored as having recalled nothing, since no particular clause was recalled, when in fact there was a nontrivial recall but at a higher level of abstraction or organization. This in itself does not mean that studying recall for clauses is incorrect or uninformative, but rather that it must have some regimes of validity.
This discussion illustrates a fundamental limit in our analysis connected with the choice of linguistic clauses as the unit of recall and recognition. The basic issue at play is that the choice of segmentation imposes a natural scale onto the analysis, which will inevitably interact with other scales in the task, such as the total length of the narrative (experiment duration), working memory capacity, or even participant engagement. An important observation that follows from the discussion in the previous paragraph is that measuring recall at the scale of clauses will miss structure that emerges at a more coarse-grained scale, such as summaries. Capturing this structure might necessitate measuring larger units such as events, which is a standard choice in studies of memory for longer stimuli like movies or video clips, and which for text-based stimuli was shown to consist of many clauses (on the order of 10 as found in Bailey et al. 2017). It is also possible to resort to a more fine-grained analysis of text. Following previous work, we might consider a segmentation into propositions, which are abstract representations of the semantic content of a text. It has been argued, most persuasively by Kintsch (1998), that the structure of memory is semantic, and representations are propositional. While a clause itself is a proposition, consisting of a predicate with arguments, the arguments themselves can, in certain cases, be composed of multiple propositions. So a single clause could represent a (likely shallow) hierarchy of propositions. We expect that if we repeat our analysis for such finer-grained units, we will see a similar phenomenon to the one we observe for clauses: fine-grained propositions will be replaced with more coarse-grained units as the story length increases, but this transition will happen earlier (i.e., for shorter stories) than what we observe for clauses. There is therefore a need to develop techniques that are sensitive to this multiscale, hierarchical structure of recall, by automatically detecting higher-level units of meaning such as events and episodes, as well as possibly fine-grained units such as propositions.
We investigated the role of meaning in narrative memory by presenting the participants with the same clauses as in the original narrative but in a scrambled order. These “narratives” are much more difficult, if not impossible, to make sense of, and indeed their recall was very poor. However, the recognition of individual clauses was practically as good as in the original narrative. This surprising observation indicates that the encoding of clauses in memory is not very sensitive to the overall structure of the narrative, and only in the process of recall does the meaning of the narrative play a major role. This finding is consistent with the observations of Thorndyke and Yekovich (1980) and Yekovich and Thorndyke (1981). It also provides a striking confirmation of the generally held wisdom that while recall is structure sensitive, recognition need not be (Kintsch 1998). It is still possible, however, that these trends will change when longer narratives are considered. This will have to be investigated further.
Another interesting observation concerns the fact that as the narrative becomes longer, the range of recall probabilities for different clauses remains very wide, e.g., there are always some clauses that are recalled by most of the participants and others that are almost never recalled. In contrast, the probability to recall words from a random list of words decreases with the length of the list, with the exception of the last few words (due to the recency effect) (Murdock 1960).
An interesting theoretical question is to identify the factors that predict how well a given clause will be recalled in a given narrative. In this paper, we show that clauses that are semantically closest to the overall meaning of a narrative are best recalled. We accomplish this using semantic vector embeddings generated by LLMs. We show that the cosine similarity between a clause embedding and the whole-narrative embedding is a strong predictor of recall probability. Therefore, the geometry of LLM embeddings reflects in some way how humans process and assign importance to different clauses. Being a relatively new technology, there is still much work to be done in understanding and interpreting the structure of embeddings produced by these models. Our work implies that the geometry of embeddings has direct relevance to human cognitive processing of meaningful text.
We focused on first-person spoken stories. These were personal accounts of important events, shared naturally and informally. This way, they lacked the refinement of crafted stories, which may utilize tricks to improve memorability. It would be interesting to see how scaling of memory is affected by such expertly told or literary stories. Evidently, there is an impact, considering that many stories in the oral tradition endure over very long timescales (Rubin 1995; Nunn 2018). A striking example of this in a more controlled lab setting had participants trained to construct a narrative in which they embedded a random list of words (Bower and Clark 1969). This work found that employing such a mnemonic improved recall to nearly perfect for up to 12 consecutively learned lists.
While practice and rehearsal are necessary for preserving narratives in oral tradition, our results suggest that narratives are intrinsically quite memorable. We find that memory performance for narratives encountered only once, as measured by the scaling relations in Figure 2, are robustly superior to performance on unstructured lists.
The research conducted for this report relied crucially on a set of LLM input “prompts,” i.e., instructions, written in standard English, given to the LLM for carrying out various tasks. Roughly speaking, these appear as if they were instructions given to a human research assistant. Quite remarkably, the LLM completes the input string to provide a correct output without any additional training, a phenomenon known as “in-context” learning (Brown et al. 2020). Since this phenomenon is still not fully understood, we had to resort to a good amount of trial-and-error and fine-tuning in designing the prompts used in our analysis. We provide all of the prompts used in our experiments in Supplemental Appendix A.2. The specific model we utilize in most of the paper is OpenAI’s GPT-4. However, while we believe the capabilities necessary to carry out our experiments are not limited to this model, it is an open question whether the prompts we use can be transferred to different models.
In summary, using LLMs in conjunction with internet platforms for performing experiments is a powerful new tool that could bring significant new advances in understanding human memory.
Materials and Methods
With the aim of conducting a large-scale study on memory for natural continuous material (personal narratives in this case), we required an automated procedure that would facilitate measuring human recall memory performance, since manual scoring of recalls is very labor-intensive and thus limits the ability to analyze large data sets. We were able to achieve this through the use of LLMs and we assessed the reliability of our pipeline by comparing it to human scoring performed by the authors. Our data set was generated by conducting recall and recognition experiments online, recruiting participants through a crowd-sourcing platform. All segments of this study are detailed below.
Stimulus set: narrative pool
Nearly all of the stimuli we use are generated by LLMs and are based on first-person oral narratives taken from sociolinguistic interviews (Labov and Waletzky 1966; Labov 2013).1 The oral narratives are segmented into clauses in these references, and these are used as templates for the LLM narrative generation. The LLM output is a narrative of equal length (in number of clauses), with very similar narrative-syntactic structure, but involving different subject matters. Two stories were generated from each template for lengths L = 18, 32, and 54. Two additional narratives were directly taken from Labov and Waletzky (1966) and Labov (2013), one with L = 19 (“boyscout” Story 7) which was analyzed in Labov and Waletzky (1966), and the other with L = 130, which was minimally edited to remove punctuation due to speech breaks, in order to increase readability (story of Gloria Stein in Chapter 7 of Labov 2013, which we do not reproduce below). We tested with four scrambled narratives at lengths L = {19, 32, 54, 130}, by selecting a single story at each of these lengths, and randomly permuting the clauses. The resulting scrambled narratives then have an identical set of clauses to the original story, just presented in a random order. Some basic statistical features of the stories (including word and character counts) are summarized in Supplemental Appendix A.1.
More details of the narrative generation by LLMs can be found in Supplemental Appendix A.2.1, along with a sample narrative template in Argument 1 and examples of generated outputs in Completion 1. All but one of the narratives used as stimuli can be found in Supplemental Appendix A.3.
For the purpose of evaluating the reliability of recall scoring of LLMs and their similarity to human scoring, we generated and segmented a different narrative based on the “boyscout” story (Story 7, L = 19). This stage began before the rollout of gpt-4 and for this reason, we document the evaluation process separately in Supplemental Appendix A.5. The narrative generation step in this part produced variable length narratives in prose, which we had to subsequently segment using GPT-3. As a result, this narrative generation procedure did not keep the same number of clauses as the story it was based on (“boyscout”).
Experimental design
Participants were recruited online through the “Prolific” platform (www.prolific.com) and experiments were conducted on participant’s browser. For all experiments conducted in this study, ethics approval was obtained by the Institutional Review Board of the Weizmann Institute of Science, and each participant accepted an informed consent form before participation. Only candidates that indicated English as their first language were allowed to participate. No demographic information about the participants was collected. The trial was initiated by a button press. After a 3 sec counter, a narrative was presented in the form of rolling text (marquee) in black font in the middle of a white screen. All narratives were animated in constant speed of 250 pixels per second. The average character size was ∼22 px, leading to a rate of ∼12 characters per second. Once the marquee for the narrative has traversed outside the screen (all characters shown and disappeared), the testing phase was triggered automatically. This marquee style presentation was chosen because it allowed for comfortable reading while fixing the presentation duration for all participants and simultaneously preventing revisiting of already read material.
Free recall experiments
In the free recall experiments, subjects were first shown the following written description: “This is a recall task. You will be shown a small narrative in the form of rolling text and then you will be prompted to write it down as you remember it. Try to include as many details as possible.” The testing phase consisted of a textbox and a prompt to “Please recall the story.” Once participants finished typing their recall of the narrative, they submitted their response with a button press, and the experiment was concluded. The number of participants we ran for each free recall experiment can be found in Supplemental Appendix A.1.
Recognition experiments
In the recognition experiments, subjects were first shown the following written description: “This is a recognition task. You will be shown a small narrative in the form of rolling text and then you will be shown different clauses, one at a time and your task will be to choose whether it was shown in the text or not according to your memory.” This initial “learning phase” was identical to that for the free recall experiments. For the testing phase of the recognition experiment, 10 queries were sequentially presented. In each query, the participant was shown a single clause at random, either from the just presented narrative (old) or a lure (new). They were prompted to answer Yes or No to the question: “Was the following clause presented in the story?” The number of participants we ran for each recognition experiment can be found in Supplemental Appendix A.1.
We did not observe any signatures of output interference (Criss et al. 2011) (see Supplemental Appendix B.3) and therefore used all queries in the subsequent analysis. Lures were generated by asking the LLM to take a given narrative segmentation, and insert novel clauses between each existing clause. This ensures that the lures are distinct from the true clauses, but still fit within the overall context of the story. For instance, this avoids lures that might mention “dolphins” if the story is about boy scouts. The prompt used to generate lures and an example completion by gpt-4 are given in Supplemental Appendix A.2.2.
The recall and recognition experiments appeared on Prolific as separate experiments, and we generally got no overlap in participants (who were identified only by a unique hash string assigned by Prolific) for recall and recognition of the same story. However, for the L = 32 stories, there was nonnegligible overlap in participants. Excluding the participants who performed the recognition experiments after the recall experiments for the same story (or vice versa), we found marginal changes in the summary statistics (e.g., R and M) reported in the manuscript. Therefore, for the data reported in the figures, we use data from every participant in every experiment.
Analysis
Analysis was conducted through custom Python scripts. For recognition memory, in order to estimate total encoded memory M from Equation 2, we used population and test trial averaged hit rate (true positive probability Ph) and false alarm rate (false positive probability Pf). Standard error was computed using statistical bootstrap (Efron and Tibshirani 1994).
Recall scoring was done using the OpenAI model gpt-4-0613 (a GPT-4 model that receives no updates) based on the clause segmentation of the narratives. For each participant’s recall, gpt-4-0613 was instructed to loop through each clause of the given narrative (as presented) and examine whether the information that this clause provided was present in some form in the participant’s recall and the corresponding passage. The numbers of all clauses evaluated as being recalled were given at the end of the output in the form of a list. The full prompt we use for scoring recalls is given in Prompt 3, which takes three arguments: the narrative stimulus in prose (e.g., Argument 2), the numbered clause segmentation of the narrative stimulus (e.g., Argument 3), and the participant’s recall (e.g., Argument 4). A sample completion is provided in Completion 3.
Separately, to evaluate the similarity of recall scoring between humans and LLMs, three authors performed manual scoring of 30 recalls of Argument 5 using the same procedure, evaluating whether each clause was present in the recall or not. The data were collected under the free recall experimental protocol described above.
For vector embeddings of text in section “Semantic similarity predicts recall,” we used OpenAI’s embedding model text-embedding-3-small. Comparisons with other embedding models are given in Supplemental Appendix B.5.
Random list of nouns experiment
In addition to the experiments that used narrative stimuli, we also performed an experiment with a fixed list of 32 nouns (see Supplemental Appendix A.4) that were randomly selected from the pool of nouns used in Naim et al. (2020). The experimental protocol was exactly the same as in that work with presentation speed 1.5 sec per word. In total, 105 participants were recruited using the Prolific online platform, with each participant accepting informed consent prior to the beginning of a trial.
Data and code availability
Experimental data as well as code for the online experiments and the analysis presented above can be found in https://github.com/mkatkov/llm-narrative-analysis.
Supplementary Material
Acknowledgments
A.G. is supported by the Martin A. and Helen Chooljian Member in Biology Fund and the Charles L. Brown Member in Biology Fund. T.C. acknowledges the support of the Eric and Wendy Schmidt Membership in Biology, the Simons Foundation, and the Starr Foundation Member Fund in Biology at the Institute for Advanced Study, where this work was completed. M.T. is supported by the MBZUAI-WIS Joint Program for Artificial Intelligence Research, the Simons Foundation, and Foundation Adelis. M.K. is supported in part by a grant from Fran Morris Rosman and Richard Rosman. We thank Omri Barak, Danqi Chen, Michael Douglas, Ariel Goldstein, and Weishun Zhong for helpful conversations. We thank Stefanos Gkouveris for helpful comments on Javascript development. M.T. thanks Yadin Dudai for bringing the studies of spoken narratives by William Labov to his attention.
Author contributions: All authors designed the experiments. A.G. ran experiments. A.G. and T.C. developed the LLM pipeline for experimental design and data analysis. All authors wrote the manuscript.
Footnotes
The narratives “boyscout” and “stein” are taken directly from these references. The rest are generated using templates.
[Supplemental material is available for this article.]
Article is online at http://www.learnmem.org/cgi/doi/10.1101/lm.054043.124.
Freely available online through the Learning & Memory Open Access option.
References
- Alba JW, Hasher L. 1983. Is memory schematic? Psychol Bull 93: 203. 10.1037/0033-2909.93.2.203 [DOI] [Google Scholar]
- Bailey HR, Kurby CA, Sargent JQ, Zacks JM. 2017. Attentional focus affects how events are segmented and updated in narrative reading. Mem Cognit 45: 940–955. 10.3758/s13421-017-0707-2 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Baldassano C, Hasson U, Norman KA. 2018. Representation of real-world event schemas during narrative perception. J Neurosci 38: 9689–9699. 10.1523/JNEUROSCI.0251-18.2018 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Bartlett FC. 1932. Remembering: A study in experimental and social psychology. Cambridge University Press, Cambridge, UK. [Google Scholar]
- Bhatia S, Richie R, Zou W. 2019. Distributed semantic representations for modeling human judgment. Curr Opin Behav Sci 29: 31–36. 10.1016/j.cobeha.2019.01.020 [DOI] [Google Scholar]
- Black JB, Bower GH. 1979. Episodes as chunks in narrative memory. J Verbal Learning Verbal Behav 18: 309–318. 10.1016/S0022-5371(79)90173-7 [DOI] [Google Scholar]
- Bower GH, Clark MC. 1969. Narrative stories as mediators for serial learning. Psychon Sci 14: 181–182. 10.3758/BF03332778 [DOI] [Google Scholar]
- Bransford JD, Johnson MK. 1972. Contextual prerequisites for understanding: some investigations of comprehension and recall. J Verbal Learning Verbal Behav 11: 717–726. 10.1016/S0022-5371(72)80006-9 [DOI] [Google Scholar]
- Brown TB, Mann B, Ryder N, Subbiah M, Kaplan J, Dhariwal P, Neelakantan A, Shyam P, Sastry G, Askell A, et al. 2020. Language models are few-shot learners. Adv Neural Inf Process Syst 33: 1877–1901. [Google Scholar]
- Criss AH, Malmberg KJ, Shiffrin RM. 2011. Output interference in recognition memory. J Mem Lang 64: 316–326. 10.1016/j.jml.2011.02.003 [DOI] [Google Scholar]
- Deerwester S, Dumais ST, Furnas GW, Landauer TK, Harshman R. 1990. Indexing by latent semantic analysis. J Am Soc Inf Sci 41: 391–407. 10.1002/(ISSN)1097-4571 [DOI] [Google Scholar]
- Efron B, Tibshirani RJ. 1994. An introduction to the bootstrap. CRC Press, Boca Raton, FL. [Google Scholar]
- Fillenbaum S. 1966. Memory for Gist: Some Relevant Variables. Lang Speech 9: 217–227. 10.1177/002383096600900403 [DOI] [PubMed] [Google Scholar]
- Georgiou A, Katkov M, Tsodyks M. 2021. Retroactive interference model of forgetting. J Math Neurosci 11: 4. 10.1186/s13408-021-00102-6 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Georgiou A, Katkov M, Tsodyks M. 2023. Forgetting dynamics for items of different categories. Learn Mem 30: 43–47. 10.1101/lm.053713.122 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Glenn CG. 1978. The role of episodic structure and of story length in children’s recall of simple stories. J Verbal Learning Verbal Behav 17: 229–247. 10.1016/S0022-5371(78)90164-0 [DOI] [Google Scholar]
- Gomulicki BR. 1956. Recall as an abstractive process. Acta Psychol 12: 77–94. 10.1016/0001-6918(56)90009-9 [DOI] [Google Scholar]
- Heusser AC, Fitzpatrick PC, Manning JR. 2021. Geometric models reveal behavioural and neural signatures of transforming experiences into memories. Nat Hum Behav 5: 905–919. 10.1038/s41562-021-01051-6 [DOI] [PubMed] [Google Scholar]
- Howard MW, Kahana MJ. 1999. Contextual variability and serial position effects in free recall. J Exp Psychol: Learn Mem Cogn 25: 923–941. [DOI] [PubMed] [Google Scholar]
- Jarvella RJ. 1979. Immediate memory and discourse processing. In Psychology of learning and motivation (ed. Bower G), Vol. 13, pp. 379–421. Elsevier, San Diego, CA. [Google Scholar]
- Johnson RE. 1970. Recall of prose as a function of the structural importance of the linguistic units. J Verbal Learning Verbal Behav 9: 12–20. 10.1016/S0022-5371(70)80003-2 [DOI] [Google Scholar]
- Kahana MJ. 1996. Associative retrieval processes in free recall. Mem Cognit 24: 103–109. 10.3758/BF03197276 [DOI] [PubMed] [Google Scholar]
- Kahana MJ. 2020. Computational models of memory search. Annu Rev Psychol 71: 107–138. 10.1146/psych.2020.71.issue-1 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Kintsch W. 1998. Comprehension: A paradigm for cognition. Cambridge University Press, Cambridge, UK. [Google Scholar]
- Kintsch W, Mandel TS, Kozminsky E. 1977. Summarizing scrambled stories. Mem Cognit 5: 547–552. 10.3758/BF03197399 [DOI] [PubMed] [Google Scholar]
- Kintsch W, van Dijk TA. 1978. Toward a model of text comprehension and production. Psychol Rev 85: 363–394. 10.1037/0033-295X.85.5.363 [DOI] [Google Scholar]
- Labov W. 2013. The language of life and death: The transformation of experience in oral narrative. Cambridge University Press, Cambridge, UK. [Google Scholar]
- Labov W, Waletzky J. 1966. Narrative analysis: Oral versions of personal experience. In Essays on the verbal and visual arts: Proceedings of the 1966 annual spring meeting of the American ethnological society (ed. Helm J), pp. 12–44. University of Washington Press, Seattle, WA. [Google Scholar]
- Lee H, Chen J. 2022. Predicting memory from the network structure of naturalistic events. Nat Commun 13: 1–14. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Michelmann S, Kumar M, Norman KA, Toneva M. 2023. Large language models can segment narrative events similarly to humans. arXiv:2301.10297. [DOI] [PMC free article] [PubMed]
- Mikolov T, Sutskever I, Chen K, Corrado GS, Dean J. 2013. Distributed representations of words and phrases and their compositionality. In Advances in neural information processing systems, pp. 3111–3119. Curran Associates, Red Hook, NY. [Google Scholar]
- Murdock BB Jr. 1960. The immediate retention of unrelated words. J Exp Psychol 60: 222. 10.1037/h0045145 [DOI] [PubMed] [Google Scholar]
- Murdock BB Jr. 1962. The serial position effect of free recall. J Exp Psychol 64: 482. 10.1037/h0045106 [DOI] [Google Scholar]
- Murray DG, Pye C, Hockley WE. 1976. Standing’s power function in long-term memory. Psychol Res 38: 319–331. 10.1007/BF00309039 [DOI] [Google Scholar]
- Naim M, Katkov M, Romani S, Tsodyks M. 2020. Fundamental law of memory recall. Phys Rev Lett 124: 018101. 10.1103/PhysRevLett.124.018101 [DOI] [PubMed] [Google Scholar]
- Nunn P. 2018. The edge of memory: ancient stories, oral tradition and the post-glacial world. Bloomsbury Publishing, London, UK. [Google Scholar]
- Radvansky GA, Zacks JM. 2017. Event boundaries in memory and cognition. Curr Opin Behav Sci 17: 133–140. 10.1016/j.cobeha.2017.08.006 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Read J. 2015. The place of human psychophysics in modern neuroscience. Neuroscience 296: 116–129. 10.1016/j.neuroscience.2014.05.036 [DOI] [PubMed] [Google Scholar]
- Rubin DC. 1995. Memory in oral traditions: The cognitive psychology of epic, ballads, and counting-out rhymes. Oxford University Press, USA. [Google Scholar]
- Rumelhart DE. 1975. Notes on a schema for stories. In Representation and understanding (ed. Bobrow DG, Collins A), pp. 211–236. Academic Press, New York. [Google Scholar]
- Sachs JS. 1967. Recognition memory for syntactic and semantic aspects of connected discourse. Percept Psychophys 2: 437–442. 10.3758/BF03208784 [DOI] [Google Scholar]
- Sargent JQ, Zacks JM, Hambrick DZ, Zacks RT, Kurby CA, Bailey HR, Eisenberg ML, Beck TM. 2013. Event segmentation ability uniquely predicts event memory. Cognition 129: 241–255. 10.1016/j.cognition.2013.07.002 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Standing L. 1973. Learning 10,000 pictures. Q J Exp Psychol 25: 207–222. 10.1080/14640747308400340 [DOI] [PubMed] [Google Scholar]
- Thorndyke PW, Yekovich FR. 1980. A critique of schema-based theories of human story memory. Poetics 9: 23–49. 10.1016/0304-422X(80)90011-X [DOI] [Google Scholar]
- Trabasso T, Sperry L. 1985. Causal relatedness and the importance of narrative events. J Mem Lang 24: 595–611. 10.1016/0749-596X(85)90048-8 [DOI] [Google Scholar]
- Trabasso T, van den Broek P. 1985. Causal thinking and the representation of narrative events. J Mem Lang 24: 612–630. 10.1016/0749-596X(85)90049-X [DOI] [Google Scholar]
- Yekovich FR, Thorndyke PW. 1981. An evaluation of alternative functional models of narrative schemata. J Verbal Learning Verbal Behav 20: 454–469. 10.1016/S0022-5371(81)90560-0 [DOI] [Google Scholar]
- Yonelinas AP. 2002. The nature of recollection and familiarity: a review of 30 years of research. J Mem Lang 46: 441–517. 10.1006/jmla.2002.2864 [DOI] [Google Scholar]
- Zwaan RA. 1996. Processing narrative time shifts. J Exp Psychol: Learn Mem Cogn 22: 1196–1207. [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.
Supplementary Materials
Data Availability Statement
Experimental data as well as code for the online experiments and the analysis presented above can be found in https://github.com/mkatkov/llm-narrative-analysis.