

Abstract
Building heating, ventilation, and air conditioning (HVAC) systems account for nearly half of building energy consumption and 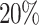 of total energy consumption in the US. Their operation is also crucial for ensuring the physical and mental health of building occupants. Compared with traditional model-based HVAC control methods, the recent model-free deep reinforcement learning (DRL) based methods have shown good performance while do not require the development of detailed and costly physical models. However, these model-free DRL approaches often suffer from long training time to reach a good performance, which is a major obstacle for their practical deployment. In this work, we present a systematic approach to accelerate online reinforcement learning for HVAC control by taking full advantage of the knowledge from domain experts in various forms. Specifically, the algorithm stages include learning expert functions from existing abstract physical models and from historical data via offline reinforcement learning, integrating the expert functions with rule-based guidelines, conducting training guided by the integrated expert function and performing policy initialization from distilled expert function. Moreover, to ensure that the learned DRL-based HVAC controller can effectively keep room temperature within the comfortable range for occupants, we design a runtime shielding framework to reduce the temperature violation rate and incorporate the learned controller into it. Experimental results demonstrate up to 8.8X speedup in DRL training from our approach over previous methods, with low temperature violation rate.
of total energy consumption in the US. Their operation is also crucial for ensuring the physical and mental health of building occupants. Compared with traditional model-based HVAC control methods, the recent model-free deep reinforcement learning (DRL) based methods have shown good performance while do not require the development of detailed and costly physical models. However, these model-free DRL approaches often suffer from long training time to reach a good performance, which is a major obstacle for their practical deployment. In this work, we present a systematic approach to accelerate online reinforcement learning for HVAC control by taking full advantage of the knowledge from domain experts in various forms. Specifically, the algorithm stages include learning expert functions from existing abstract physical models and from historical data via offline reinforcement learning, integrating the expert functions with rule-based guidelines, conducting training guided by the integrated expert function and performing policy initialization from distilled expert function. Moreover, to ensure that the learned DRL-based HVAC controller can effectively keep room temperature within the comfortable range for occupants, we design a runtime shielding framework to reduce the temperature violation rate and incorporate the learned controller into it. Experimental results demonstrate up to 8.8X speedup in DRL training from our approach over previous methods, with low temperature violation rate.
Keywords: HVAC control, Reinforcement learning, Deep learning
Subject terms: Electrical and electronic engineering, Mechanical engineering
Introduction
Buildings account for around 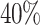 of the energy consumption in the United States, of which nearly half is by the heating, ventilation, and air conditioning (HVAC) systems1. In addition, the operation of HVAC systems significantly affects the physical and mental health of building occupants, as people spend around
of the energy consumption in the United States, of which nearly half is by the heating, ventilation, and air conditioning (HVAC) systems1. In addition, the operation of HVAC systems significantly affects the physical and mental health of building occupants, as people spend around 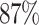 of their time indoors2,3, and even higher during the COVID-19 pandemic in recent years4. It is thus a critical task to develop effective HVAC control strategies that can maintain a comfortable indoor environment while reducing energy cost5–7.
of their time indoors2,3, and even higher during the COVID-19 pandemic in recent years4. It is thus a critical task to develop effective HVAC control strategies that can maintain a comfortable indoor environment while reducing energy cost5–7.
In the literature, there are extensive works of developing model-based approaches for HVAC control. For instance, Maasoumy et al.8 use RC-networks to model the building thermal dynamics and applies the linear quadratic regulator (LQR) method for controlling the HVAC system. The work from Toub et al.designs a model predictive control (MPC) method to minimize the energy consumption and cost of the building HVAC system combined with a solar power unit. Some other works on model-based approaches can be found in papers9–12. However, to achieve good performance, these model-based approaches require the development of detailed and accurate physical models, which are often difficult and costly in practice. Thus, there has been significant interest in developing learning-based, model-free approaches for HVAC control, in particular those based on deep reinforcement learning (DRL). For example, the work from Wei et al.13utilizes the deep Q-learning method for controlling the indoor air flow rate and leverages the EnergyPlus platform14for simulation-based training. Various other techniques have also been applied for DRL-based building HVAC control, including Deep Deterministic Policy Gradient (DDPG)15, Proximal Policy Optimization (PPO)16, Asynchronous Advantage Actor-Critic (A3C)17, etc.
However, a major difficulty in adopting DRL-based methods to building HVAC control is that it could take a long time to train the RL agent in practice during building operation – note that in this case, the agent training is part of its live deployment. For instance, it may take more than 100 months of training to reach convergence for the Q-learning based methods13,18, and around 500 months of training for the DDPG algorithm to converge on a laboratory building model19. In Yu et al.’s work20, DDPG is used for temperature control and energy management, and it takes around 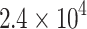 months to reach the best performance. Yu et al.21 present the method whose training time is almost
months to reach the best performance. Yu et al.21 present the method whose training time is almost 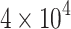 months in a multi-zone building environment. Clearly, such long training time would make it impossible to adopt DRL in practice for building control. While developing a detailed simulation model (e.g., in EnergyPlus) and conducting the training via simulation may help avoid this issue, the development of the simulation model itself is difficult and costly (in terms of both time and expertise), just as in the model-based methods.
months in a multi-zone building environment. Clearly, such long training time would make it impossible to adopt DRL in practice for building control. While developing a detailed simulation model (e.g., in EnergyPlus) and conducting the training via simulation may help avoid this issue, the development of the simulation model itself is difficult and costly (in terms of both time and expertise), just as in the model-based methods.
Thus, recently researchers have been trying to improve the training efficiency for DRL-based building HVAC control. Xu et al.3 present a transfer learning approach to extract and transfer the building-agnostic knowledge from an existing DRL controller of a source building to a new DRL controller of a target building, and only re-train the building-specific components for the new DRL controller. The work from Lissa et al.22also leverages transfer learning, but for heat pump control in microgrid. However, the effectiveness of the transfer learning-based methods strongly relies on the similarity between the existing building target building and the transferred building, and may not be feasible when they are not similar3. There are also a few studies on the application of offline reinforcement learning for building HVAC control, where historical data on existing controllers are leveraged to train new RL-based controllers. For instance, the work from Schepers et al.23conducts conservative Q-learning (CQL) to train controllers for maintaining the room temperature setpoint. The problem of such offline RL methods, however, is that the learned agents’ performance strong depends on the quality of the historical data. And they tend to perform poorly due to the distributional shift between the historical data and the learned policy, and may have limited improvement even with fine tuning via online training24.
In this work, to address the above challenge in DRL training efficiency, we propose a unified framework that leverages the knowledge from domain experts in various forms to accelerate online RL for building HVAC control. This is motivated by the observation that in established domains such as building control, there is extensive domain expertise, represented in various forms such as 1) abstract physical models(e.g., RC-networks25or ARX models26) of building thermal dynamics – they are not accurate enough for enabling training DRL or designing model-based methods with good performance, but nevertheless contain valuable information of building dynamics, 2) historical data collected from existing controllers – they may not be able to train DRL controllers with good performance due to distribution shift, but also contain useful information on building behavior, and 3) expert rules that reflect basic policies. We believe that leveraging these domain expertise can help accelerate the online RL process. In particular, our framework first learns expert functions from existing abstract physical models and from historical data via offline RL, and then combines those with expert rules to generate an integrated expert function, which will then be used to drive online RL with prior-guided learning and policy initialization from expert function distillation. In experiments, our framework is able to significantly reduce the convergence time for DRL training by up to 8.8X, while maintaining similar performance (in terms temperature violation rate and energy cost).
Moreover, to further improve the learned DRL-based controller’s capability in keeping room temperature within the comfortable range, we propose a novel runtime shielding framework with an expert model. Instead of combining the temperature violation and the energy cost as the optimization objective (like during the DRL training), the framework considers the comfortable temperature range as constraints and tries to adjust the DRL-based controller’s output for meeting the temperature constraints during runtime. More specifically, the expert model takes the system state as input and predicts the next-step indoor temperature and worst-case indoor temperature in the next few steps. Based on such prediction, the framework iteratively adjusts the controller output for meeting the temperature constraints. The runtime framework provides a general design for reducing temperature violation rate, where various controllers can be incorporated. In this case, when our proposed DRL-based controller is incorporated into it, significant reduction in temperature violation rate can be observed in experiments.
To summarize, our work makes the following contributions:
We propose a novel training framework to accelerate online RL for building HVAC control with heterogeneous expert guidances, including abstract physical models, historical data, and expert rules. These various guidances are unified in our framework via the expert functions.
We propose a novel runtime shielding framework with an expert model that can further reduce the temperature violation rate when applying on our learned DRL-based controller.
We conducted a series of experiments for evaluating the effectiveness of our framework. The results demonstrate that our approach can effectively reduce the DRL training time while maintaining low energy cost and temperature violation rate.
The rest of the paper is organized as follows. The second section discusses the related literature. The third section presents our approach, including the online DRL training framework with heterogeneous expert guidances and the runtime shielding framework. The fourth section presents the experimental results, and the last section concludes the paper.
Related works
Reinforcement learning for HVAC control
Building HVAC control is a critical and challenging problem as it significantly affects both building energy efficiency and occupants’ physical and mental health. In traditional model-based approaches, detailed and accurate physical models are needed for control optimization, but are often difficult and costly to develop and slow to run. Such limitations have motivated the exploration of model-free approaches in recent years, particularly those based on deep reinforcement learning3,13,17,27. These DRL-based HVAC control approaches leverage a variety of RL algorithms including DQN13, A3C17, DDPG15, PPO16, etc. For instance, Wei et al.13 convert the building HVAC control into a Markov decision process (MDP) problem and leverage the DQN method to intelligently learn the operation strategy based on offline simulations. Gao et al.15 adopt the neural network to predict occupants’ thermal comfort for part of their reward function design, and then apply the standard DDPG algorithm to learn from their building simulation environment. Abrazeh et al.16 develop a real-time digital twin with a PPO-based backstepping controller to maintain the relative humidity and temperature in buildings. However, a major obstacle in applying these DRL-based control algorithms is that they often require dozens of months or morefor training to reach the desired performance15,18,19. Such long time is clearly not feasible for direct training during real building operation (i.e., sensing the real building environment and sending the actuation signals to HVAC equipment). It may be possible to avoid this by developing accurate and detailed building models and conducting training via simulations on tools such as EnergyPlus and Modelica28-based tools18, however, this again requires the development of those detailed and costly physical models and somewhat defeats the original purpose of using model-free approaches. Thus, it is critical to improve the efficiency of online RL for HVAC control without the development of detailed physical models.
Transfer learning for HVAC control
One way to speed up RL is to transfer the learned policy between different buildings. For instance, the work from Xu et al.3 reduces the DRL training time by re-designing the learning objective and decomposing the neural network to a building-agnostic sub-network and a building-specific sub-network. The building-agnostic sub-network can be directly transferred from an existing DRL controller of a source building, and only the building-specific sub-network needs to be (re)-trained on the target building. This can reduce the DRL training time from months/years to weeks. Lissa et al.22 utilize the direct policy transfer between different houses with the same state/action space for heat pump control in microgrids. Zhang et al.29applies the transfer learning to a PPO-based controller for smart home to reduce the training cost. The main obstacles the current transfer learning-based methods face include the requirements for the source and target models to share the same learning objective, action space, and input space, and for the source and target buildings to be similar in their ambient conditions such as weather patterns. These requirements significantly limit the practical applicability of transfer learning-based methods, often resulting in poor performance when the target building is not similar to the source building or operates in a different environment3. In contrast, our approach presented in this paper provides an effective and efficient method to learn a policy with only expert knowledge on the building of interest. These two types of methods can be complementary in their usage scenarios.
Offline reinforcement learning
Another way to accelerate online RL is through offline RL, by leveraging historical data collected under existing control policies. Recent offline RL works focus on two aspects: offline policy optimization, and offline policy evaluation. The former aims to learn an optimal policy for maximizing a notion of cumulative reward, while the latter is intended to evaluate the accumulated reward (or the value function) of a given policy. For offline policy optimization in particular, a major challenge is that the agent cannot directly explore the environment. And the error (called extrapolation error30) that is caused by selected actions not contained in the historical dataset could occur and propagate during the training. This is one of the reasons that limits the effectiveness of existing offline RL approaches for building HVAC control23. The approaches that address this challenge mainly utilize regularization or constraint-based methods to help the policy stay near to the existing actions in the historical dataset. For instance, the batch-constrained Q-learning (BCQ) approach30 restricts its action space to make the learned behavior similar to the actions in the historical dataset. Jaques et al.31 penalize divergence between the prior learned from the historical dataset and the Q-network policy using KL-control. The approach from Wang et al.32learns the policy by filtered behavioral cloning, which utilizes critic-regularized regression to filter out low-quality actions. And other related investigations can be found in papers33–38. From the prior experiments, we notice that not all offline RL algorithms can be chosen for building the expert function. The method like TD3+BC38 may not always provide a good value estimation for the given states, as it only aims to make the learned policy closer to the behavior in the offline dataset and tend to overestimate the Q-value. So in this work, we use historical data as one of the expert guidance and conduct offline RL to build an expert function. We leverage the idea from Kumar et al.39 to estimate the value function from historical dataset because of its effectiveness, by directly setting regularization on the Q-function and generating the Q-value estimation in a conservative way to reduce overestimation.
Shielding methods for learning-based systems
Shielding methods typically first check a pre-defined shield and then adjust the control action accordingly by looking one step or a few steps ahead. For instance, to ensure safety, model predictive shielding40,41leverages a backup control policy to override the learning policy when unsafe scenarios are predicted to happen. In the Simplex architecture42, the high-assurance controller acts as a shield to the high-performance controller for improved system safety and performance. However, most shielding-based approaches rely on a fully-known environment model to synthesize a shield, which does not apply to our problem setting here where we focus on model-free building HVAC control. Moreover, shielding methods may also degrade the overall performance43. In this paper, we propose a novel runtime model-free shielding framework for the learned DRL-based controller. The framework does not require knowing the system dynamics, does not affect the training stage, is agnostic to the learned controller design, and as experiments show, can effectively reduce temperature violation rate while maintaining low energy cost.
Our proposed approach
System model
We use the building model with the fan-coil system from paper18, which is extended from a single-zone commercial building with manipulable internal thermal mass. The internal air is conditioned by an idealized fan coil unit (FCU) system, and the fan airflow rate is chosen from multiple discrete levels 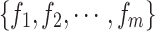 (which can be viewed as m control actions;
(which can be viewed as m control actions; 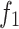 is to turn off the cooling system, and
is to turn off the cooling system, and 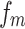 is to run it at full speed.). There are two different working modes in this system: the occupied time (daily from 7 am to 7 pm), and the unoccupied time (rest of the day). The HVAC system will run in a low-power mode during the unoccupied time for the energy-saving purpose (with the cooling system almost turned off). And the setting of comfortable temperature bound is different in these two modes. The system conducts control with a period of
is to run it at full speed.). There are two different working modes in this system: the occupied time (daily from 7 am to 7 pm), and the unoccupied time (rest of the day). The HVAC system will run in a low-power mode during the unoccupied time for the energy-saving purpose (with the cooling system almost turned off). And the setting of comfortable temperature bound is different in these two modes. The system conducts control with a period of 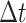 . Each training episode contains two days of data, so there are
. Each training episode contains two days of data, so there are 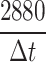 control steps in each episode. Other experiment-related settings can be found in experimental results section. The system state contains the following elements:
control steps in each episode. Other experiment-related settings can be found in experimental results section. The system state contains the following elements:
Current physical time t,
Indoor air temperature
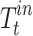 ,
,Outdoor air temperature
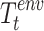 ,
,Solar irradiance intensity
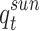 ,
,Power consumption during the current control interval
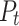 ,
,Outdoor air temperature forecast in the next three control steps
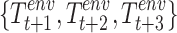 , and
, andSolar irradiance intensity forecast in the next three control steps
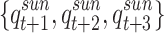 .
.
One thing to note is that we add one additional variable in the implementation to the system state design, which is the remainder after dividing the current physical time t by 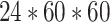 . This is to help the RL agent figure out the time position within one day (morning, noon, afternoon, etc.), and may help it reach better performance as observed in our preliminary experiments.
. This is to help the RL agent figure out the time position within one day (morning, noon, afternoon, etc.), and may help it reach better performance as observed in our preliminary experiments.
Our online DRL training framework with heterogeneous expert guidances
As stated in introduction section, to accelerate online DRL for HVAC control, we propose a unified framework that leverages heterogeneous expert guidances including abstract physical models, historical data, and expert rules. Figure 1 shows the overview of our framework design. Specifically, the framework includes the following major components:
An expert function
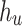 learned from an expert model. The expert model could be an abstract physical model developed by domain experts (commonly exists in building domain), or in case such physical model is not available, a neural network with its parameters determined from historical data (but different from offline RL; more details later).
learned from an expert model. The expert model could be an abstract physical model developed by domain experts (commonly exists in building domain), or in case such physical model is not available, a neural network with its parameters determined from historical data (but different from offline RL; more details later).Another expert function
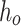 learned via offline RL on historical data that was collected using existing controllers.
learned via offline RL on historical data that was collected using existing controllers.An integrated expert function h by combining
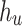 and
and 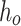 as well as expert rules.
as well as expert rules.Application of prior-guided learning and policy initialization from expert function distillation based on h.
The detailed flow of our approach is in Algorithm 1. Next, we will first explain the underlying DRL algorithm we use, and then introduce the details of each component in our approach to improve DRL efficiency with heterogeneous expert guidance.
Fig. 1.

Overview of our online DRL training framework with heterogeneous expert guidances. The framework includes the following major components: (1) An expert function 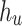 learned from an expert model, which can be an abstract physical model or a neural network with its parameters determined from a static historical dataset. (2) Another expert function
learned from an expert model, which can be an abstract physical model or a neural network with its parameters determined from a static historical dataset. (2) Another expert function 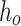 learned from offline RL based on historical data. (3) An integrated expert function h generated by combining
learned from offline RL based on historical data. (3) An integrated expert function h generated by combining 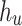 and
and 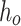 as well as expert rules. (4) Application of prior-guided learning and policy initialization from expert function distillation based on h.
as well as expert rules. (4) Application of prior-guided learning and policy initialization from expert function distillation based on h.
Algorithm 1.

Our Online DRL Training Framework with Heterogeneous Expert Guidances
Underlying DRL algorithm
Similarly as in recent works3,13,18, we utilize double Deep Q-learning (DDQN)44 as the underlying DRL algorithm for our framework and also the baseline method for comparison in our experiments. We choose DDQN mainly for its convenience in leveraging the value function and the good performance it has shown for HVAC control in those recent works, but our expert-guidance approach can also be applied to improve the efficiency for other DRL algorithms.
We assume that the next state of the building HVAC system only relies on the current system state, and thus HVAC control can be treated as a Markov decision process (MDP). As stated in system model section, the state 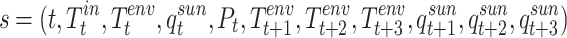 . The discrete action space
. The discrete action space 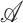 contains the normalized air flow rate (0 to 1) with
contains the normalized air flow rate (0 to 1) with 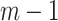 intervals. The reward is designed with consideration of indoor temperature violation and energy cost, as shown below:
intervals. The reward is designed with consideration of indoor temperature violation and energy cost, as shown below:
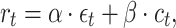 |
1 |
where 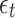 represents the temperature violation for the current time step,
represents the temperature violation for the current time step, 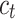 is the energy cost for the current time step, and
is the energy cost for the current time step, and 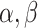 are the scaling factors. More specifically,
are the scaling factors. More specifically, 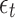 is defined as:
is defined as:
 |
2 |
where 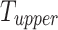 is the upper bound of a given comfortable temperature range (which could be based on standards such as ASHRAE45or OSHA46) and
is the upper bound of a given comfortable temperature range (which could be based on standards such as ASHRAE45or OSHA46) and 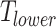 is the lower bound. Moreover:
is the lower bound. Moreover:
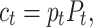 |
3 |
where 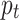 is the energy price at time t, and
is the energy price at time t, and 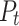 is the power consumption during the current control interval at time t.
is the power consumption during the current control interval at time t.
The goal of the DRL is to minimize total energy cost while maintaining indoor temperature within the comfortable temperature range. The loss function 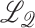 for updating the Q-network is:
for updating the Q-network is:
 |
4 |
where  ,
, 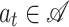 , Q is the Q network and
, Q is the Q network and 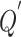 is the target Q network. Then, the components introduced in the rest of this section will generate expert functions to provide prior guidance and policy initialization for this underlying DRL algorithm.
is the target Q network. Then, the components introduced in the rest of this section will generate expert functions to provide prior guidance and policy initialization for this underlying DRL algorithm.
Learning expert function 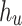 from expert model
from expert model
An expert function 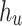 can be learned through an expert model. In many cases, such expert model already exists in the form of an abstract physical model for the building thermal dynamics, e.g., an ARX or RC-networks model. While these abstract models are typically not accurate enough to enable good performance for DRL or model-based methods, they can be effectively leveraged to generate an expert function.
can be learned through an expert model. In many cases, such expert model already exists in the form of an abstract physical model for the building thermal dynamics, e.g., an ARX or RC-networks model. While these abstract models are typically not accurate enough to enable good performance for DRL or model-based methods, they can be effectively leveraged to generate an expert function.
If an abstract physical model is not available, we can build a neural network as the expert model, with its parameters decided from a static historical dataset collected under existing control policy, as shown in Algorithm 2 (Line 5 in Algorithm 1) and described below.
Algorithm 2.

Learning Expert Function from Expert Model
We denote the historical dataset as 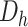 , with n data samples. For each data sample
, with n data samples. For each data sample 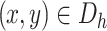 , let input
, let input 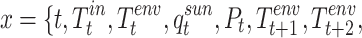
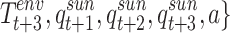 as defined in system model section and
as defined in system model section and 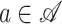 , and let output label
, and let output label 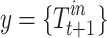 . The neural network-based expert model consists of
. The neural network-based expert model consists of 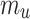 fully-connected layers. All hidden layers are followed by a GELU activation function47, and are sequentially connected (the detailed layer setting will be specified later in Table 1 of experimental results section). Note that we choose this relatively simple MLP (multilayer perceptron) architecture because the network input is low-dimensional and the design already shows good performance in experiments. For large and complex multi-zone commercial buildings, RNNs (recurrent neural networks) or transformers could be promising architectures to explore in future work..
fully-connected layers. All hidden layers are followed by a GELU activation function47, and are sequentially connected (the detailed layer setting will be specified later in Table 1 of experimental results section). Note that we choose this relatively simple MLP (multilayer perceptron) architecture because the network input is low-dimensional and the design already shows good performance in experiments. For large and complex multi-zone commercial buildings, RNNs (recurrent neural networks) or transformers could be promising architectures to explore in future work..
Table 1.
Hyper-parameters used in our experiments.
| Parameter | Value | Parameter | Value |
|---|---|---|---|
|
Expert- model |
[ 256,256,256, 256,256,256,2] |
Deep Q- network |
[ 256, 256, 256, 256, 51] |
| m | 51 |
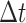
|
15 mins |
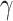
|
0.99 |
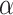
|
1.0 |
|
(occupied) |
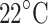
|
(occupied) |
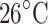
|
|
(unoccupied) |
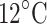
|
(unoccupied) |
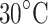
|
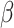
|
100.0 |

|
7 |
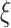
|
1.0 | n | 5760 |
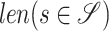
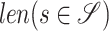
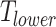

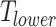
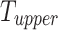
As different variables may not be in the same order of magnitude (e.g., t can be 1000 times larger than 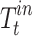 ), we normalize the input x and the output label y. The preprocessed input and output can be written as
), we normalize the input x and the output label y. The preprocessed input and output can be written as 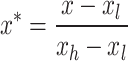 ,
, 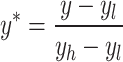 , where
, where 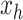 and
and 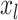 are the upper bound and lower bound of the variable x, and
are the upper bound and lower bound of the variable x, and 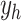 and
and 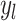 are the upper and lower bound of the variable y. We then train the expert model with a mean square error loss function
are the upper and lower bound of the variable y. We then train the expert model with a mean square error loss function
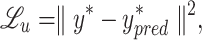 |
5 |
where 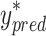 is the network prediction for the normalized y. When we apply this expert model after model training, we obtain the prediction of y by reversing the operation of previously-mentioned normalization step. It may not be necessary to predict the entire system state, e.g., the environment temperature
is the network prediction for the normalized y. When we apply this expert model after model training, we obtain the prediction of y by reversing the operation of previously-mentioned normalization step. It may not be necessary to predict the entire system state, e.g., the environment temperature 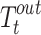 and solar irradiance
and solar irradiance 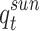 may be obtained from weather forecast.
may be obtained from weather forecast.
Once we have the expert model, either in the form of an abstract physical model or a neural network, the expert function 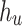 can be viewed as a prior guess of the optimal value function in the building HVAC control task and can be learned via DRL. More specifically, we define an MDP problem
can be viewed as a prior guess of the optimal value function in the building HVAC control task and can be learned via DRL. More specifically, we define an MDP problem 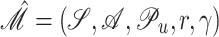 where the definitions of state
where the definitions of state 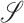 , action space
, action space 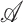 and reward function r are the same as defined at the beginning of underlying DRL algorithm section .
and reward function r are the same as defined at the beginning of underlying DRL algorithm section . 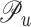 is from the expert model. We then apply DDQN on
is from the expert model. We then apply DDQN on 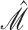 and obtain a trained Q-network Q. And the expert function
and obtain a trained Q-network Q. And the expert function 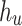 can be set up as:
can be set up as:
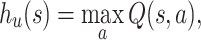 |
6 |
where s is the state and a is the control action.
Learning expert function 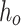 from offline RL
from offline RL
Another type of expert function 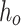 can be learned from the historical data via offline RL, as shown in Algorithm 3 (Line 6 in Algorithm 1). We leverage some of the techniques from conservative Q-learning (CQL)39 because of its effectiveness in reducing a large number of hyper-parameters.
can be learned from the historical data via offline RL, as shown in Algorithm 3 (Line 6 in Algorithm 1). We leverage some of the techniques from conservative Q-learning (CQL)39 because of its effectiveness in reducing a large number of hyper-parameters.
Algorithm 3.

Learning Expert Function from Offline RL
First, we build an offline RL model based on DDQN, but with different Q-network updating rules as the DRL presented in the beginning of underlying DRL algorithm section. Compared with Equation (4), we add an extra regularization term:
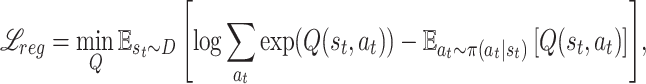 |
7 |
where 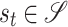 and
and 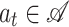 . Q is the Q-network, and D is the dataset produced by the behaviour policy
. Q is the Q-network, and D is the dataset produced by the behaviour policy 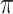 . In the equation, the first part
. In the equation, the first part 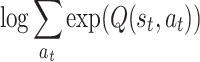 describes a penalty term for minimizing the Q-value of the action produced by current policy on the states in the historical dataset. It helps learn a smaller and more conservative Q-value estimator. The second term
describes a penalty term for minimizing the Q-value of the action produced by current policy on the states in the historical dataset. It helps learn a smaller and more conservative Q-value estimator. The second term 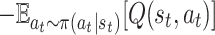 counts average Q-value in the state-action pairs in the historical dataset and maximizes it to push the current learned policy closer to the behavior policy in the historical dataset.
counts average Q-value in the state-action pairs in the historical dataset and maximizes it to push the current learned policy closer to the behavior policy in the historical dataset.
Then the policy updating is changed as follows:
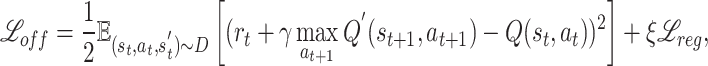 |
8 |
where 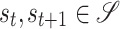 ,
, 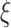 is a mixing coefficient, and
is a mixing coefficient, and 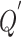 is the target Q-network. With enough training iterations, the offline RL agent can provide a good expert function
is the target Q-network. With enough training iterations, the offline RL agent can provide a good expert function 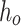 following the same procedure as in Equation (6).
following the same procedure as in Equation (6).
Note that we observe that not all offline RL algorithms can be a suitable choice for our framework. For example, approaches like TD3+BC38 may not always provide a good value estimation for the given states. We suspect that this may be due to two factors. One is related to the reward design, as the value function estimation in some offline RL algorithms is sensitive to the scale of the accumulated reward. The other is that because algorithms like TD3+BC only add regularization on the actor updating and do not set constraints on the Q function, which could enlarge the error in estimating the (Q-)value function when combined with possible numerical issues.
Generating integrated expert function h from 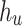 ,
, 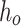 and expert rules
and expert rules
The expert function 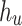 learned from the expert model and the expert function
learned from the expert model and the expert function 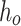 learned via offline RL tend to perform differently because of the complexity of the system dynamic and the sufficiency of the data. Moreover, the accuracy of their Q-value estimation can vary at different states depending on the data distribution within the historical dataset. Thus, it is a natural thought to form an ensemble of the two. And the ensemble of multiple expert functions calculated in different ways can further reduce the overestimation of Q-values through a conservative way, which we will introduce in this section later.
learned via offline RL tend to perform differently because of the complexity of the system dynamic and the sufficiency of the data. Moreover, the accuracy of their Q-value estimation can vary at different states depending on the data distribution within the historical dataset. Thus, it is a natural thought to form an ensemble of the two. And the ensemble of multiple expert functions calculated in different ways can further reduce the overestimation of Q-values through a conservative way, which we will introduce in this section later.
To begin with, after having 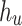 and
and 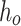 , we can combine them with expert rules to generate an integrated expert function h. The expert rules are often set by domain experts or building operators based on past experience and domain expertise. They do not provide an optimized control action for a given state, but instead offer suggestions that could be viewed as guidance or soft constraints – e.g., not turning on the cooling system when the indoor temperature is below the lower bound of the comfortable temperature range by certain threshold. Formally, we define that the expert rules
, we can combine them with expert rules to generate an integrated expert function h. The expert rules are often set by domain experts or building operators based on past experience and domain expertise. They do not provide an optimized control action for a given state, but instead offer suggestions that could be viewed as guidance or soft constraints – e.g., not turning on the cooling system when the indoor temperature is below the lower bound of the comfortable temperature range by certain threshold. Formally, we define that the expert rules 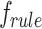 can generate an action candidate set
can generate an action candidate set 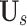 for each state:
for each state:
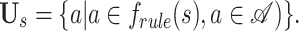 |
9 |
We can then generated an integrated expert function h based on 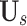 ,
, 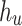 and
and 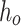 (Line 7 in Algorithm 1). Specifically, we apply a pessimistic ensemble strategy for selecting the value function estimation among different expert functions, and only choose corresponding actions from the expert rules’ action candidate set
(Line 7 in Algorithm 1). Specifically, we apply a pessimistic ensemble strategy for selecting the value function estimation among different expert functions, and only choose corresponding actions from the expert rules’ action candidate set 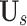 . Thus, the integrated expert function h can be formulated as:
. Thus, the integrated expert function h can be formulated as:
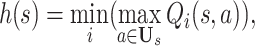 |
10 |
where 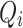 is the Q-value estimation from expert functions i. Note that this is a general formulation that can unify multiple expert functions – e.g., we may have more than one abstract physical models that provide multiple
is the Q-value estimation from expert functions i. Note that this is a general formulation that can unify multiple expert functions – e.g., we may have more than one abstract physical models that provide multiple 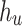 expert functions.
expert functions.
Prior-guided learning
Once we have the integrated expert function h, we can use it to guide the underlying DRL with prior-guided learning. There are several algorithms that could guide online RL with a single prior policy, such as HuRL48and JSRL49. Our framework is flexible in choosing those and we select HuRL48 in our implementation. In the original HuRL, the Q-value estimation in the RL agent is guided by a simple heuristic function that is learned from the Monte-Carlo regression. In our work, we instead leverage the integrated expert function h from above. By dynamically changing a mixing coefficient 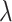 that controls the trade-off between the bias from the expert function h and the complexity of a reshaped MDP, we are able to accelerate the DRL training with a shortened MDP horizon. Specifically, given the state space
that controls the trade-off between the bias from the expert function h and the complexity of a reshaped MDP, we are able to accelerate the DRL training with a shortened MDP horizon. Specifically, given the state space 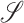 , action space
, action space 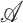 , reward function r that are mentioned at the beginning of underlying DRL algorithm section , as well as the transition dynamics of the building HVAC system
, reward function r that are mentioned at the beginning of underlying DRL algorithm section , as well as the transition dynamics of the building HVAC system 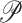 and a discount factor
and a discount factor 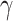 , we consider an MDP
, we consider an MDP 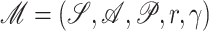 . We use the learned integrated expert function h as a prior guess for the optimal value function of
. We use the learned integrated expert function h as a prior guess for the optimal value function of 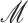 . Thus our online DRL can be described as a reshaped MDP
. Thus our online DRL can be described as a reshaped MDP 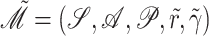 , where
, where 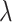 is a mixing coefficient,
is a mixing coefficient,
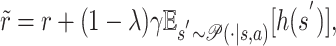 |
11 |
and
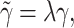 |
12 |
which is shown at Line 16 in Algorithm 1.
Policy initialization from expert function distillation
In the above section, we use the integrated expert function h to reshape the reward function and shorten the MDP horizon. In addition, we can also speed up the DRL training through better initialization, by leveraging the expert functions for determining the initial policy (Lines 8 and 9 in Algorithm 1).
Specifically, we initialize the deep Q-network through knowledge distillation50 on the expert functions. The first step is to extract the knowledge from multiple expert functions (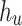 and
and 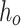 in our case) to a dataset
in our case) to a dataset 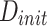 . We set the input dataset as
. We set the input dataset as 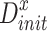 and the corresponding label set as
and the corresponding label set as 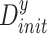 . In setting
. In setting 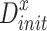 , we utilize all the unlabeled historical data, which only contain the system state. And the corresponding labels are calculated in a way that is similar to the strategy introduced earlier for integrating expert functions. That is, suppose we have
, we utilize all the unlabeled historical data, which only contain the system state. And the corresponding labels are calculated in a way that is similar to the strategy introduced earlier for integrating expert functions. That is, suppose we have  expert functions, then
expert functions, then
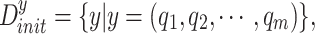 |
13 |
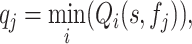 |
14 |
where 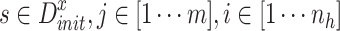 . As the expert functions we utilize are not as accurate as of the optimal (Q-) value function, we further add two mixing coefficients
. As the expert functions we utilize are not as accurate as of the optimal (Q-) value function, we further add two mixing coefficients 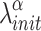 ,
, 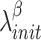 for balancing the relative size of the Q value from different actions. So the new definition of
for balancing the relative size of the Q value from different actions. So the new definition of 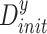 is
is
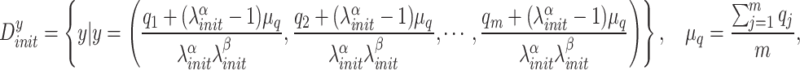 |
15 |
where the definition of 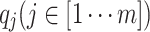 remains the same. Then the next step is to train the deep Q-network of our DRL agent by using the obtained dataset
remains the same. Then the next step is to train the deep Q-network of our DRL agent by using the obtained dataset 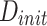 . As we consider a regression task, we apply the mean square error as the loss function
. As we consider a regression task, we apply the mean square error as the loss function
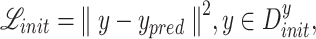 |
16 |
where 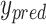 is the deep Q-network prediction. We obtain the network weight initialization by training for
is the deep Q-network prediction. We obtain the network weight initialization by training for 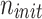 epochs. Moreover, with such policy initialization, we can use a smaller learning rate to tune the deep Q-network in the later DRL stages.
epochs. Moreover, with such policy initialization, we can use a smaller learning rate to tune the deep Q-network in the later DRL stages.
Runtime shielding framework
As shown in the previous sections, while the training of our DRL agent considers both the temperature violation and the energy cost in the reward function design, there is no explicit enforcing of the constraints on comfortable temperature range. Similarly for many other learning-based (and model-based) controllers, there is no explicit enforcing of the temperature constraints on the control actions, which may lead to constant temperature violations. Thus, in this work, we propose a novel runtime shielding framework to help HVAC controllers meet temperature constraints. The framework does not affect the controller training process and is agnostic to the controller design.
Figure 2 shows the overview of our runtime shielding framework, which integrates the HVAC controller – in this case, the DRL-based controller trained by our proposed online framework under heterogeneous expert guidances – with an expert model that predicts future indoor temperature based on the system states and the control input. The expert model is trained from the historical data collected from the building environment, similarly as the one used in our online training framework but with different goal and output. More specifically, during runtime, the learned DRL agent proposes a control action 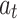 for the current time t. The expert model for temperature prediction takes the proposed control action
for the current time t. The expert model for temperature prediction takes the proposed control action 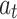 from the DRL agent and the system states
from the DRL agent and the system states 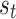 as input, and outputs the indoor temperature prediction that includes not only the temperature prediction for the next time step
as input, and outputs the indoor temperature prediction that includes not only the temperature prediction for the next time step 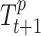 but also the worst-case temperature prediction from time
but also the worst-case temperature prediction from time 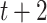 to
to 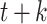 , named as
, named as 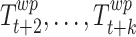 .
.
Fig. 2.

Overview of our runtime shielding framework for reducing temperature violation rate. The framework includes two major components: 1) the learned DRL agent (by our online DRL training framework as introduced earlier) that produces the control action based on the current system state, and 2) an expert model for predicting indoor temperature in future steps, based on a neural network with its parameters determined from historical data. More specifically, the expert model takes the current system states and proposed action from the DRL agent as input, and predicts the indoor temperature for the next step and the worse-case indoor temperature for the next few steps. Based on such predictions, the control action may be adjusted iteratively to meet the temperature constraints.
In particular, at time 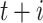 (
(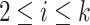 ), the expert model predicts the worst cases regarding both the temperature upper bound and the temperature lower bound as follows: (1) Based on the predicted temperature at time
), the expert model predicts the worst cases regarding both the temperature upper bound and the temperature lower bound as follows: (1) Based on the predicted temperature at time  and the worst-case control action for temperature lower bound at time
and the worst-case control action for temperature lower bound at time 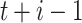 , which is
, which is 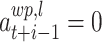 , the expert model will predict the indoor temperature at time
, the expert model will predict the indoor temperature at time 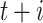 , named
, named 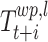 . This is a worst-case prediction of the temperature lower bound, i.e.,
. This is a worst-case prediction of the temperature lower bound, i.e., 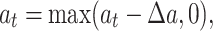 if
if 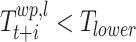 . (2) On the other hand, based on the predicted temperature at time
. (2) On the other hand, based on the predicted temperature at time 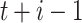 and the worst-case control action for temperature upper bound at time
and the worst-case control action for temperature upper bound at time 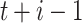 , which is
, which is 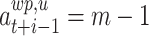 , the expert model will predict the indoor temperature at time
, the expert model will predict the indoor temperature at time 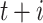 , named
, named 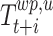 . This is the worst-case prediction of the temperature upper bound, i.e.,
. This is the worst-case prediction of the temperature upper bound, i.e., 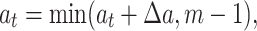 if
if 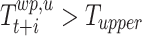 . Then, the comfortable temperature range will serve as the constraints against which these temperature predictions are checked. If the predictions are out of the range, the current proposed control action
. Then, the comfortable temperature range will serve as the constraints against which these temperature predictions are checked. If the predictions are out of the range, the current proposed control action 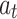 will be iteratively adjusted until the temperature constraints are met or the iteration number reaches p. Moreover, if such change for the proposed control action based on the prediction of time
will be iteratively adjusted until the temperature constraints are met or the iteration number reaches p. Moreover, if such change for the proposed control action based on the prediction of time 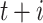 makes the previous temperature predictions (i.e.,
makes the previous temperature predictions (i.e., 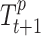 ,
, 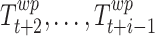 ) violate the temperature constraints, we will discard the result, stop next worst-case predictions, and use the results from time
) violate the temperature constraints, we will discard the result, stop next worst-case predictions, and use the results from time  .
.
Experimental results
Experiment settings
We conduct our experiments on a Ubuntu 20.04 OS server equipped with NVIDIA RTX A5000 GPU cards. Docker51is utilized for the environment configuration, with Python 3.7.9 and learning framework Pytorch 1.9.0. All neural networks are optimized through the Adam optimizer52.
We use the building simulation tool in paper18to simulate the behavior of single-zone commercial buildings, with an OpenAI-Gym53interface. We model two buildings as defined in the Building Energy Simulation Test validation suite54: one is with a lightweight construction (known as Case600FF) and the other is with a heavyweight construction (known as case900FF). Both buildings have the same model settings except that the wall and floor construction have either light or heavy materials. The floor dimensions are 6m-by-8m and the floor-to-ceiling height is 2.7m. There are four exterior walls facing the cardinal directions and a flat roof. The walls facing east-west have the short dimension. The south wall contains two windows, each 3m wide and 2mtall. The use of the building is assumed to be a two-person office with a light load density. The lightweight building is assumed to be located at Riverside, California, USA, and the heavyweight building is assumed to be located at Chicago, Illinois, USA. The weather data for different locations are obtained from the Typical Meteorological Year 3 database55. In addition, the various parameters and hyper-parameters mentioned in the previous sections are listed in Table 1.
Evaluation of our online DRL training framework and comparison with standard DDQN
We first apply our proposed online RL framework with heterogeneous expert guidances to building HVAC control and demonstrate its effectiveness in accelerating the DRL training, in particular the standard DDQN algorithm. We repeat each experiment 4 times and show the average results.
Comparison with standard DDQN on training efficiency
Figure 3demonstrates the temperature violation rate of the trained controller under different approaches for the lightweight building with weather data from Riverside. Temperature violation rate is one of the main objectives for DRL. It is defined as the percentage of the time the indoor temperature is outside of the comfortable temperature zone, similarly as used in works3,6,13,18.
Fig. 3.

Figure 3a to Figure 3f show the comparison between our online DRL training framework (in different settings with various techniques included) and the standard DDQN method on the lightweight building. The weather data is from Riverside, CA, USA. The x-axis shows the training episodes. The y-axis shows the temperature violation rate. Figure 3a shows the training process under the standard DDQN method. About 212 episodes are needed to reach a violation rate of 0.2. Figure 3b, Figure 3c, Figure 3d, and Figure 3e show the results when we gradually add an expert model that generates expert function  , offline RL that generates expert function
, offline RL that generates expert function  , an expert rule, and policy initialization based on expert functions, respectively. And we can observe the improvement on the required episodes step by step. Figure 3f shows the training process when we apply all of our techniques. In this case, only 24 episodes are needed to reach the violation rate of 0.2, an 8.8X improvement over standard DDQN. Then, Figure 3g and Figure 3h show the comparison between our approach with all techniques included (right) and the standard DDQN baseline (left) on the heavyweight building with larger thermal capacity under the weather data from Chicago, IL, USA. The green bar in each sub-figure shows the target temperature violation rate, depending on the building type. The number of training episodes is chosen to ensure that the violation rate has reached around or below the target level and it has relatively plateaued.
, an expert rule, and policy initialization based on expert functions, respectively. And we can observe the improvement on the required episodes step by step. Figure 3f shows the training process when we apply all of our techniques. In this case, only 24 episodes are needed to reach the violation rate of 0.2, an 8.8X improvement over standard DDQN. Then, Figure 3g and Figure 3h show the comparison between our approach with all techniques included (right) and the standard DDQN baseline (left) on the heavyweight building with larger thermal capacity under the weather data from Chicago, IL, USA. The green bar in each sub-figure shows the target temperature violation rate, depending on the building type. The number of training episodes is chosen to ensure that the violation rate has reached around or below the target level and it has relatively plateaued.
Figure 3a shows the training process of the standard DDQN, and the model needs about 212 episodes to reach a violation rate at around 20%for this building from18 ( may seem high, but it is due to the limitation of this particular building and its cooling-only HVAC system; more explanation on this later with Figure 5). Figure 3b shows the training process when we add a neural network-based expert model that generates the expert function
may seem high, but it is due to the limitation of this particular building and its cooling-only HVAC system; more explanation on this later with Figure 5). Figure 3b shows the training process when we add a neural network-based expert model that generates the expert function  . About 68 episodes are needed to reach the same violation rate. Figure 3c shows the training process when we add offline RL that generates the expert function
. About 68 episodes are needed to reach the same violation rate. Figure 3c shows the training process when we add offline RL that generates the expert function 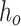 , and about 78 episodes are needed to reach the violation rate of
, and about 78 episodes are needed to reach the violation rate of 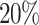 . Figure 3d shows the results when we apply both expert functions
. Figure 3d shows the results when we apply both expert functions 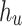 and
and 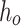 , but without the expert rules. We can see that about 40 episodes are needed. Figure 3e shows the results when we integrate the two expert functions
, but without the expert rules. We can see that about 40 episodes are needed. Figure 3e shows the results when we integrate the two expert functions 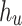 and
and 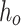 , as well as an expert rule f using the method introduced in Equation 10 . f is defined as follows: when the indoor temperature is below
, as well as an expert rule f using the method introduced in Equation 10 . f is defined as follows: when the indoor temperature is below 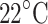 , the control action is suggested to be set within the set of
, the control action is suggested to be set within the set of 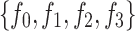 ; if the indoor temperature is above
; if the indoor temperature is above 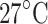 , the control action is suggested to be set within the set of
, the control action is suggested to be set within the set of 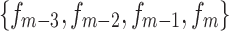 . We can see that the number of episodes needed is about 36. Finally, Figure 3f shows the training process when we apply all of our proposed techniques, including integrating the expert functions from expert model and offline RL as well as the expert rules, using the integrated expert function to guide DRL training, and conducting policy initialization with the expert functions. We can see that now only 24 episodes are needed to reach the same violation rate as the standard DDQN, an 8.8X reduction in training time. Table 2 summarizes the above number of episodes required to reach the violation rate of 0.2 for the standard DDQN baseline and our approach with various techniques included.
. We can see that the number of episodes needed is about 36. Finally, Figure 3f shows the training process when we apply all of our proposed techniques, including integrating the expert functions from expert model and offline RL as well as the expert rules, using the integrated expert function to guide DRL training, and conducting policy initialization with the expert functions. We can see that now only 24 episodes are needed to reach the same violation rate as the standard DDQN, an 8.8X reduction in training time. Table 2 summarizes the above number of episodes required to reach the violation rate of 0.2 for the standard DDQN baseline and our approach with various techniques included.
Fig. 5.
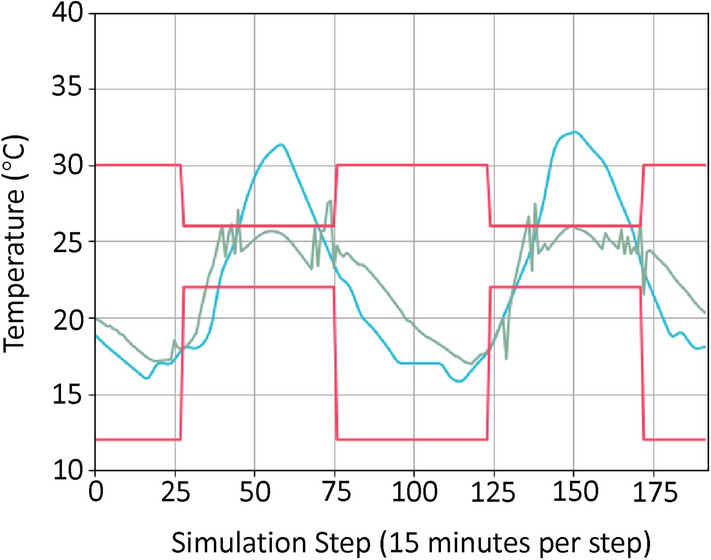
An illustration of the lightweight building temperature over 2 days under the controller learned from our approach with all techniques included. The red lines bound the comfortable temperature range. The blue line is the outdoor temperature in Riverside, CA. The green line is the indoor temperature under the learned controller.
Table 2.
Number of episodes required on the lightweight building to first reach the violation rate of 0.2 for the standard DDQN baseline and our online DRL training framework with various techniques included, corresponding to the results in Figure 3a to Figure 3f (the last line being our approach with all techniques in Algorithm 1).
| Method | Number of Episodes |
|---|---|
| DDQN | 212 |
| DDQN+Expert Model | 68 |
| DDQN+Offline RL | 78 |
| DDQN+Expert Model+Offline RL | 40 |
| DDQN+Expert Model+Offline RL | 36 |
| +Expert Rules | |
| DDQN+Expert Model+Offline RL | 24 |
| +Expert Rules+Init |
For further evaluation, we also conduct experiments on the heavyweight building with weather data from Chicago. In this set of experiments, the major change of the parameters is that the scaling factor 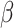 is set to 1.0 in Equation (1). This is because that the average energy consumption of this HVAC system is much higher than that of the previous building, and we need to re-balance the energy cost and the temperature violation in the reward design. Figure 3g and Figure 3h shows the comparison between our approach and the standard DDQN. And the experiments show that the number of episodes needed to first reach a violation rate of
is set to 1.0 in Equation (1). This is because that the average energy consumption of this HVAC system is much higher than that of the previous building, and we need to re-balance the energy cost and the temperature violation in the reward design. Figure 3g and Figure 3h shows the comparison between our approach and the standard DDQN. And the experiments show that the number of episodes needed to first reach a violation rate of 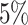 is reduced from around 160, as shown in Figure 3g, to around 80 in Figure 3h. The improvement, while still significant, is much less than the lightweight building. We suspect that this may be due to the quality of the historical data and plan to investigate it further in future work.
is reduced from around 160, as shown in Figure 3g, to around 80 in Figure 3h. The improvement, while still significant, is much less than the lightweight building. We suspect that this may be due to the quality of the historical data and plan to investigate it further in future work.
Energy cost and other details
Besides temperature violation rate and the number of episodes for reaching the goal of violation rate below 0.2 (i.e., training efficiency), we also assess the energy cost of the learned controllers during our experiments. We observed that different methods, including the standard DDQN baseline and our approach with various techniques included, achieve very similar energy cost for the learned controllers – in fact within 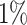 for both the lightweight building and the heavyweight building we tested.
for both the lightweight building and the heavyweight building we tested.
Figure 4 shows the normalized energy cost of our approach with all techniques included for the lightweight building with weather data from Riverside. We can observe that the energy cost quickly decreases to a lower value within 5 to 10 epochs and slightly fluctuates in the later training epochs.
Fig. 4.

Normalized energy cost during training for our approach with all techniques included for the lightweight building with weather data from Riverside.
Figure 5 illustrates the building temperature over 2 days, under the controller learned with our approach with all techniques included, for the lightweight building with weather data from Riverside. We can see that the temperature violation rate is around 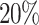 . It is relatively high because some violations are very hard to avoid for this particular building. Specifically, the HVAC system is set to only work during the occupied hours (from 7am to 7pm) and the comfortable temperature range is much more strict during that time (
. It is relatively high because some violations are very hard to avoid for this particular building. Specifically, the HVAC system is set to only work during the occupied hours (from 7am to 7pm) and the comfortable temperature range is much more strict during that time (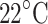 to
to 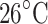 ) compared to during the unoccupied time (
) compared to during the unoccupied time (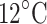 to
to 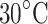 )18. This makes it almost impossible to meet the comfortable temperature range early in the morning since the HVAC system only provides cooling. We can see that after the early morning hours, the temperature is controlled well within the comfortable range by our controller.
)18. This makes it almost impossible to meet the comfortable temperature range early in the morning since the HVAC system only provides cooling. We can see that after the early morning hours, the temperature is controlled well within the comfortable range by our controller.
Ablation studies
Impact of the historical data quantity
We are interested in knowing how the quantity of the historical data may affect the performance of our approach. We conduct a series of experiments that have the quantity of the historical data chosen from 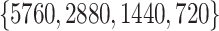 (i.e., from 2 months of data to 7.5 days of data). The results are shown in Table 3. We can observe that the training becomes faster as the quantity of the historical data becomes larger, as what we would expect.
(i.e., from 2 months of data to 7.5 days of data). The results are shown in Table 3. We can observe that the training becomes faster as the quantity of the historical data becomes larger, as what we would expect.
Table 3.
The number of epochs needed by our approach (with all techniques included) for reaching the violation rate of 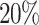 for the lightweight building, under different quantity of the historical data.
for the lightweight building, under different quantity of the historical data.
| #Samples | 720 | 1440 | 2880 | 5760 |
| #Episodes | 116 | 78 | 62 | 24 |
Impact of the control quality of historical data
We also study the performance of our approach under different levels of control quality of the historical data. Previously we directly use the historical data collected from an existing controller on the target building. To study different control quality of such historical data, we choose to take random actions with a probability of p – intuitively, higher p values implies more random control and hence worse quality. Table 4 shows the results. Our approach performs better with a smaller p, i.e., when our approach learns from historical data based on more reasonable control actions.
Table 4.
The number of epochs needed by our approach (with all techniques included) for reaching the violation rate of 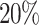 for the lightweight building, under different control quality of the historical data.
for the lightweight building, under different control quality of the historical data.
| p | 1.0 | 0.8 | 0.4 | 0.2 | 0.0 |
| #Episodes | 110 | 104 | 88 | 60 | 24 |
The usage of abstract physical model
In addition, we also try to utilize an abstract physical model, i.e., the ARX model from6, as the expert model to generate  , instead of learning a neural network. The training process is shown in Figure 6. About 64 episodes are needed to reach the same violation rate, more than the case where the expert model is a neural network learned from historical data. We think that this is due to the simplicity of the ARX model, and plan to investigate the performance of other abstract physical models in future. Nevertheless, it still provides considerable improvement over the standard DDQN.
, instead of learning a neural network. The training process is shown in Figure 6. About 64 episodes are needed to reach the same violation rate, more than the case where the expert model is a neural network learned from historical data. We think that this is due to the simplicity of the ARX model, and plan to investigate the performance of other abstract physical models in future. Nevertheless, it still provides considerable improvement over the standard DDQN.
Fig. 6.
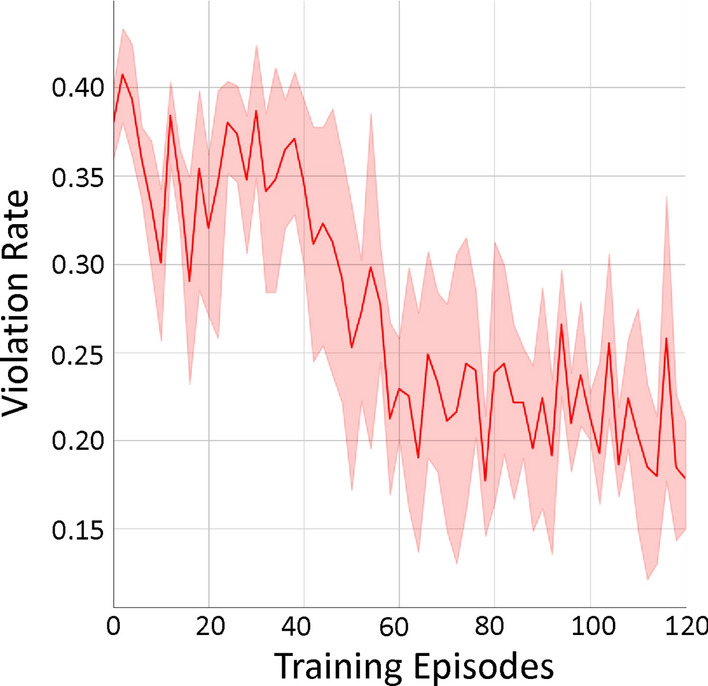
Training result for the lightweight building when the expert model in our approach (with all techniques included) is constructed from an abstract physical model.
Evaluation of our runtime shielding framework
For evaluating our proposed runtime shielding framework, in particular its capability in further reducing the temperature violation rate for our learned DDQN-based DRL controller, we conduct experiments on the heavyweight building. The expert model predicts the indoor temperature for the next step and the worst-case indoor temperature for another step ahead. We consider two DDQN agents – agent 1 is coarsely trained and agent 2 is the final model after additional training (the same one shown in Figure 3h).
From the results shown in Table 5, we can observe that while the temperature violation rate of agent 1 is initially quite high as it is coarsely trained, our runtime shielding framework can significantly decrease the violation rate by more than 3X (from 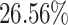 to
to 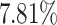 ), with only slight increase in energy cost. For agent 2, which has a much lower temperature violation rate than agent 1 given the additional training, our runtime shielding framework can still reduce the violation rate substantially, from
), with only slight increase in energy cost. For agent 2, which has a much lower temperature violation rate than agent 1 given the additional training, our runtime shielding framework can still reduce the violation rate substantially, from 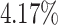 to
to 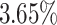 , with slight reduction on energy cost as well (Note that further reduction on temperature violation rate for this particular system is very challenging, due to the cooling-only nature of its HVAC system. As stated before, there is always a short period in the early morning when the indoor temperature is below the desired lower bound and the HVAC system has just started, as shown in Figure 5. Thus, without adding heating, there will be at least 2%−3% temperature violation rate for the system.). Overall, these results for agent 1 and agent 2 demonstrate the effectiveness of our shielding framework in reducing temperature violation rate while keeping similar energy cost, for controllers that have been trained to different degrees and have varying qualities.
, with slight reduction on energy cost as well (Note that further reduction on temperature violation rate for this particular system is very challenging, due to the cooling-only nature of its HVAC system. As stated before, there is always a short period in the early morning when the indoor temperature is below the desired lower bound and the HVAC system has just started, as shown in Figure 5. Thus, without adding heating, there will be at least 2%−3% temperature violation rate for the system.). Overall, these results for agent 1 and agent 2 demonstrate the effectiveness of our shielding framework in reducing temperature violation rate while keeping similar energy cost, for controllers that have been trained to different degrees and have varying qualities.
Table 5.
Comparison between two DDQN agents (trained by our online DRL training framework to different degrees) and when they are incorporated into our runtime shielding framework, in both temperature violation rate and energy cost.
| Method | Temperature Violation Rate (%) | Energy Cost |
|---|---|---|
| DDQN agent 1 | 26.56 | 1.60 |
| DDQN agent 1 + Runtime Shielding | 7.81 | 1.68 |
| DDQN agent 2 | 4.17 | 2.07 |
| DDQN agent 2 + Runtime Shielding | 3.65 | 1.94 |
Experiments in other domains
We believe that our approach of leveraging existing domain expertise in DRL training may be extended to other domains of cyber-physical systems. Thus, we conduct initial exploration outside of the building domain, on a few examples from the Gym56 environment, to assess our approach’s general applicability. Figure 7 shows the comparison between our approach and the standard DDQN baseline. We observe that our approach is able to significantly improve the learning efficiency and/or performance on some examples (particularly CartPole) but not others (Pendulum in particular). We think that in these cases the final results can be significantly affected by the quality of the generated expert functions. First, the offline data collected can affect the quality of both the expert model and the offline RL component. Since the task environment is different, the difficulty of constructing a good expert model from the historical data is also an important factor. Compared with the accuracy of predicted system states, the accuracy of the terminate condition in each step can also have a significant impact in some tasks. However, the terminate condition is always fixed in building HVAC control (run for certain steps) and we can even utilize the prior knowledge from the building domain combined with the offline data to help construct the expert model. These factors make the building HVAC control an ideal application for our approach.
Fig. 7.

Results on examples from the Gym environments.
Conclusions
In this paper, we present a systematic, unified framework to accelerate online RL for building HVAC control with heterogeneous expert guidances, including abstract physical models, historical data, and expert rules. These guidances are unified through the learning of expert functions, which are then used to accelerate DRL with prior-guided learning and policy initialization. Moreover, we propose a runtime shielding framework for further reducing the temperature violation. A series of experiments demonstrate that our approach can significantly reduce the training time over previous DRL methods while maintaining the indoor temperature within the comfortable temperature range. We believe that our approach not only addresses a critical challenge in applying DRL to building domain, but also has the potential in other domains where existing expertise could be leveraged in improving learning efficiency and performance. We plan to investigate this further in future work.
Acknowledgements
We gratefully acknowledge the support from Department of Energy (DOE) award DE-EE0009150 and National Science Foundation (NSF) awards 1834701 and 2038853.
Author contributions
S.X., Z.W., and Z.Y. designed the methods, S.X., and Y.F. conceived and conducted the experiments, S.X., Z.O., and Q.Z. analysed the results, S.X., Y.F., Y.W., C.H., and Q.Z. wrote and reviewed the manuscript.
Data availability statement
All the data we used are generated from the building simulation platform18, which is publicly available in https://github.com/YangyangFu/mpc-drl-tl.
Declarations
Competing interests
S.X., Y.F., Y.W., Z.Y., C.H., Z.O., Z.W., and Q.Z. declare no potential conflict of interest.
Footnotes
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Contributor Information
Shichao Xu, Email: shichaoxu2023@u.northwestern.edu.
Qi Zhu, Email: qzhu@northwestern.edu.
References
- 1.DoE, U. et al. Buildings energy data book. Energy Efficiency & Renewable Energy Department 286 (2011).
- 2.Klepeis, N. E. et al. The national human activity pattern survey (nhaps): a resource for assessing exposure to environmental pollutants. Journal of Exposure Science & Environmental Epidemiology11, 231–252 (2001). [DOI] [PubMed] [Google Scholar]
- 3.Xu, S., Wang, Y., Wang, Y., O’Neill, Z. & Zhu, Q. One for many: Transfer learning for building HVAC control. In Proceedings of the 7th ACM international conference on systems for energy-efficient buildings, cities, and transportation, 230–239 (2020).
- 4.Huang, B. et al. The analysis of isolation measures for epidemic control of covid-19. Applied Intelligence51, 3074–3085 (2021). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 5.Wei, T., Zhu, Q. & Yu, N. Proactive demand participation of smart buildings in smart grid. IEEE Transactions on Computers65, 1392–1406 (2015). [Google Scholar]
- 6.Xu, S., Fu, Y., Wang, Y., O’Neill, Z. & Zhu, Q. Learning-based framework for sensor fault-tolerant building HVAC control with model-assisted learning. In Proceedings of the 8th ACM International Conference on Systems for Energy-Efficient Buildings, Cities, and Transportation, 1–10 (2021).
- 7.Naug, A., Ahmed, I. & Biswas, G. Online energy management in commercial buildings using deep reinforcement learning. In 2019 IEEE SMARTCOMP, 249–257 (IEEE, 2019).
- 8.Maasoumy, M., Pinto, A. & Sangiovanni-Vincentelli, A. Model-based hierarchical optimal control design for HVAC systems. In Dynamic Systems and Control Conference54754, 271–278 (2011). [Google Scholar]
- 9.Ma, Y. et al. Model predictive control for the operation of building cooling systems. IEEE Transactions on Control Systems Technology20, 796–803 (2012). [Google Scholar]
- 10.Maasoumy, M., Razmara, M., Shahbakhti, M. & Vincentelli, A. S. Handling model uncertainty in model predictive control for energy efficient buildings. Energy and Buildings77, 377–392 (2014). [Google Scholar]
- 11.Energy modeling and optimal control. Salakij, S., Yu, N., Paolucci, S. & Antsaklis, P. Model-based predictive control for building energy management. i. Energy and Buildings133, 345–358 (2016). [Google Scholar]
- 12.Xu, Q. & Dubljevic, S. Model predictive control of solar thermal system with borehole seasonal storage. Computers & Chemical Engineering101, 59–72 (2017). [Google Scholar]
- 13.Wei, T., Wang, Y. & Zhu, Q. Deep reinforcement learning for building HVAC control. In 54th Annual Design Automation Conference (2017).
- 14.Crawley, D. B., Lawrie, L. K., Pedersen, C. O. & Winkelmann, F. C. Energy plus: energy simulation program. ASHRAE journal42, 49–56 (2000). [Google Scholar]
- 15.Gao, G., Li, J. & Wen, Y. Energy-efficient thermal comfort control in smart buildings via deep reinforcement learning. arXiv preprint arXiv:1901.04693 (2019).
- 16.Abrazeh, S. et al. Virtual hardware-in-the-loop fmu co-simulation based digital twins for heating, ventilation, and air-conditioning (HVAC) systems. IEEE Transactions on Emerging Topics in Computational Intelligence (2022).
- 17.Zhang, Z., Chong, A., Pan, Y., Zhang, C. & Lam, K. P. Whole building energy model for HVAC optimal control: A practical framework based on deep reinforcement learning. Energy Buildings199, 472–490 (2019). [Google Scholar]
- 18.Fu, Y., Xu, S., Zhu, Q. & O’Neill, Z. Containerized framework for building control performance comparisons: model predictive control vs deep reinforcement learning control. In Proceedings of the 8th ACM International Conference on Systems for Energy-Efficient Buildings, Cities, and Transportation, 276–280 (2021).
- 19.Gao, G., Li, J. & Wen, Y. Deepcomfort: Energy-efficient thermal comfort control in buildings via reinforcement learning. IEEE Internet of Things Journal7, 8472–8484 (2020). [Google Scholar]
- 20.Yu, L. et al. Deep reinforcement learning for smart home energy management. IEEE Internet of Things Journal7, 2751–2762 (2019). [Google Scholar]
- 21.Yu, L. et al. Multi-agent deep reinforcement learning for HVAC control in commercial buildings. IEEE Trans. Smart Grid.12, 407–419 (2020). [Google Scholar]
- 22.Lissa, P., Schukat, M., Keane, M. & Barrett, E. Transfer learning applied to drl-based heat pump control to leverage microgrid energy efficiency. Smart Energy3, 100044 (2021). [Google Scholar]
- 23.Schepers, J. et al. Autonomous building control using offline reinforcement learning. In International Conference on P2P, Parallel, Grid, Cloud and Internet Computing, 246–255 (Springer, 2021).
- 24.Nair, A., Dalal, M., Gupta, A. & Levine, S. Accelerating online reinforcement learning with offline datasets. arXiv preprint arXiv:2006.09359 (2020).
- 25.Lombard, C. & Mathews, E. Efficient, steady state solution of a time variable rc network, for building thermal analysis. Building and Environment27, 279–287 (1992). [Google Scholar]
- 26.Yun, K., Luck, R., Mago, P. J. & Cho, H. Building hourly thermal load prediction using an indexed arx model. In Energy and Buildings (2012).
- 27.Zhang, Z. et al. A deep reinforcement learning approach to using whole building energy model for HVAC optimal control. In 2018 Building Performance Analysis Conference and SimBuild, vol. 3, 22–23 (2018).
- 28.Mattsson, S. E., Elmqvist, H. & Otter, M. Physical system modeling with modelica. Control Engineering Practice6, 501–510 (1998). [Google Scholar]
- 29.Zhang, X. et al. Transferable reinforcement learning for smart homes. In Proceedings of the 1st International Workshop on Reinforcement Learning for Energy Management in Buildings & Cities, 43–47 (2020).
- 30.Fujimoto, S., Meger, D. & Precup, D. Off-policy deep reinforcement learning without exploration. In International Conference on Machine Learning, 2052–2062 (PMLR, 2019).
- 31.Jaques, N. et al. Way off-policy batch deep reinforcement learning of implicit human preferences in dialog. arXiv preprint arXiv:1907.00456 (2019).
- 32.Wang, Z. et al. Critic regularized regression. Advances in Neural Information Processing Systems33, 7768–7778 (2020). [Google Scholar]
- 33.Guo, Y. et al. Batch reinforcement learning through continuation method. In International Conference on Learning Representations (2020).
- 34.Chen, X. et al. Bail: Best-action imitation learning for batch deep reinforcement learning. Advances in Neural Information Processing Systems33, 18353–18363 (2020). [Google Scholar]
- 35.Fujimoto, S., Conti, E., Ghavamzadeh, M. & Pineau, J. Benchmarking batch deep reinforcement learning algorithms. arXiv preprint arXiv:1910.01708 (2019).
- 36.Agarwal, R., Schuurmans, D. & Norouzi, M. An optimistic perspective on offline reinforcement learning. In ICML (PMLR, 2020).
- 37.Levine, S., Kumar, A., Tucker, G. & Fu, J. Offline reinforcement learning: Tutorial, review, and perspectives on open problems. arXiv preprint arXiv:2005.01643 (2020).
- 38.Fujimoto, S. & Gu, S. S. A minimalist approach to offline reinforcement learning. NeurIPS (2021).
- 39.Kumar, A., Zhou, A., Tucker, G. & Levine, S. Conservative q-learning for offline reinforcement learning. Advances in Neural Information Processing Systems33, 1179–1191 (2020). [Google Scholar]
- 40.Li, S. & Bastani, O. Robust model predictive shielding for safe reinforcement learning with stochastic dynamics. In 2020 IEEE International Conference on Robotics and Automation (ICRA), 7166–7172 (IEEE, 2020).
- 41.Bastani, O., Li, S. & Xu, A. Safe reinforcement learning via statistical model predictive shielding. In Robotics: Science and Systems, 1–13 (2021).
- 42.Phan, D. T. et al. Neural simplex architecture. In NASA Formal Methods: 12th International Symposium, NFM 2020, Moffett Field, CA, USA, May 11–15, 2020, Proceedings 12, 97–114 (Springer, 2020).
- 43.Wang, Y., Zhan, S., Wang, Z., Huang, C., Wang, Z., Yang, Z. & Zhu, Q. Joint differentiable optimization and verification for certified reinforcement learning. In 14th International Conference on Cyber-Physical Systems (ICCPS) (2023).
- 44.Van Hasselt, H., Guez, A. & Silver, D. Deep reinforcement learning with double q-learning. In AAAI 2016 (2016).
- 45.Olesen, B. W. & Brager, G. S. A better way to predict comfort: The new ashrae standard 55-2004 (2004).
- 46.of Labor, U. S. D. Osha technical manual (otm) section iii: Chapter 2 (2021).
- 47.Hendrycks, D. & Gimpel, K. Gaussian error linear units (gelus). arXiv preprint arXiv:1606.08415 (2016).
- 48.Cheng, C.-A., Kolobov, A. & Swaminathan, A. Heuristic-guided reinforcement learning. NeurIPS (2021).
- 49.Uchendu, I. et al. Jump-start reinforcement learning. arXiv preprint arXiv:2204.02372 (2022).
- 50.Hinton, G., Vinyals, O., Dean, J. et al. Distilling the knowledge in a neural network. arXiv preprint arXiv:1503.025312 (2015).
- 51.Merkel, D. Docker: lightweight linux containers for consistent development and deployment. Linux journal2014, 2 (2014). [Google Scholar]
- 52.Kingma, D. P. & Ba, J. Adam: A method for stochastic optimization. arXiv preprint arXiv:1412.6980 (2014).
- 53.Brockman, G. et al. Openai gym. arXiv preprint arXiv:1606.01540 (2016).
- 54.Judkoff, R. & Neymark, J. International energy agency building energy simulation test (bestest) and diagnostic method. Tech. Rep., National Renewable Energy Lab.(NREL), Golden, CO (United States) (1995).
- 55.Wilcox, S. & Marion, W. Users manual for tmy3 data sets (2008).
- 56.Brockman, G. et al. Openai gym (2016). arXiv:1606.01540.
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.
Data Availability Statement
All the data we used are generated from the building simulation platform18, which is publicly available in https://github.com/YangyangFu/mpc-drl-tl.