

Abstract
With the rapid development of smart devices and their applications, using mobile devices for human–computer interaction has become important. Recent work uses ultrasound to perceive gestures. However, it is difficult to represent the time and frequency information of gestures, and, they are often classified as combined actions in continuous multiple gestures. We propose the Doppler Object Detection Algorithm (DODA) to decouple the information from each gesture’s time and frequency domain in continuous gestures and output the gesture classifications. DODA thus maps the feature information of multiple gestures from Doppler frequency shift images to information about real gesture actions. We present time domain Intersection over Union (Tiou), which computes the Tiou between each adjacent gesture to obtain more accurate prediction fields. We use the static exception eliminate algorithm (SEEA) to eliminate the effects of frame activity anomalies and use the mapping relationship of the DODA algorithm for data enhancement. We design an UltraWX to deploy on any mobile device. Our experimental results show that UltraWX can effectively segment and recognize continuous gestures, and output the start and end time of each gesture, and UltraWX can achieve 93.6% recognition accuracy for continuous gestures in complex environments.
Keywords: Sensor network, Continuous multi-gesture recognition, Human–computer interaction, Tiou, DODA
Subject terms: Software, Information technology
Introduction
With the proliferation of mobile devices, human–machine interaction technologies are advancing rapidly, so the idea of remote devices being controlled by nearby mobile devices without physical contact is gradually becoming a reality. Non-contact gesture recognition plays a crucial role in human–machine interaction, as the direct use of hands is the most natural and instinctive way for people to communicate. Moreover, the use of ubiquitous mobile devices to perceive simple gestures for real-time human–machine interaction can greatly advance the progress of human–machine interaction. Imagine that you could use a simple gesture nearby a phone at your office to open or close your smart home devices on your schedule, or use a pad in a classroom to remotely control lab equipment at a specific time. You could even get responsive feedback based on real-time stock prediction data generated by artificial intelligence through simple hand gestures, or determine users’ emotions based on the amplitude and speed of their gestures. You could also set up a set of commands on a mobile device with a few simple gestures to interact with devices for seamless human–machine communication. Existing RF-based technologies require specialized hardware, which is expensive, and prohibits wide deployment. Recent acoustic sensing can develop on smartphones1–3, which only need speakers and microphones to submit and receive an ultrasound4–7. SoundWrite8 is able to measure the feature of MFCC to output gesture classification. Sonicasl[9]use earphone to sign language, which is continuous multiple gestures. LoEar10 uses Channel Frequency Response (CFR) to sense the information of heartbeat based on ultrasound. EarHear11 innovates by integrating a Vision Transformer for Sign Language Recognition. These non-contact systems provide an immersive user experience and support various innovative applications in gaming, real-time interaction, and education. As gesture recognition becomes more commercialized, user requirements for gesture recognition are gradually shifting toward practicality, especially concerning real-time gesture recognition and multiple gesture classification12. Gesture recognition should not be limited to providing information about the classification of a gesture. It should also take into account the time and frequency domain characteristics of gestures, incorporating computational resources. Furthermore, it should aim to output as much gesture information as possible with minimal gesture input. Another practical challenge arises from the lack of sufficient training data, especially high-quality, systematic, and diverse ultrasound gesture data from different scenarios 13,14. To improve the accuracy of model recognition and ensure the robustness of gesture recognition, neural networks require a large amount of training data covering various changes in gestures in different real-world scenarios. In practice, collecting enough training data directly from users is cumbersome and sometimes impractical. To address these issues, this article proposes the Doppler-based Object Detection Algorithm (DODA), a highly versatile algorithm that uses mobile devices to capture and analyze real-time Doppler frequency domain images to extract information about gestures. This algorithm outputs both the temporal and spectral information of gestures as well as the gesture category and associates these details with real actions. In addition, the algorithm simplifies the model output by calculating the time domain overlap over unity (TIOU), which increases the model’s practicality.
Based on the algorithm, a WeChat Mini program15 has been developed that demonstrates high recognition accuracy for continuous multi-gesture scenarios across various usage contexts. The program recognizes five standardized gestures, as depicted in Fig. 1, and can identify continuous gestures composed of these five gestures in real-time. This results in (5^n) potential continuous gesture combinations within a range of 80 cm, where n represents the number of gestures. To facilitate human–machine interaction tasks, we utilize a WeChat mini program called UltraWX. UltraWX emits ultrasonic waves and samples the echo signals, which are then processed to generate Doppler frequency shift images. However, due to variations in different usage scenarios, such as the start time of gesture actions, different gesture speeds, distance to the transceiver, interference from other gesture actions, and ambient noise, the collected echo signals exhibit differences. To address these differences, this paper applies a set of selective data enhancement techniques to enhance the two-dimensional information of the Doppler frequency shift images in terms of their real-world meaning. The enhanced data is then used for model training to improve the robustness and versatility of UltraWX. In this paper, we propose the Doppler Object Detection Algorithm (DODA) to decouple the two-dimensional information in Doppler frequency shift images into one-dimensional time and frequency domain information. This is achieved by feeding the Doppler frequency shift images into an object recognition model for regression and classification, and then using DODA to decouple the information within the regression boxes into time and frequency domain information. The object recognition model outputs both the gesture action category and the time and frequency domain information, which is further processed by the DODA algorithm to obtain meaningful temporal information and gesture categories.
Fig. 1.

Shows the schematic representations of 5 types of gestures and their corresponding Doppler effects.
This article introduces an innovative method for optimizing models and reducing system consumption in the field of gesture recognition. To achieve this, a metric called "Joint Time Domain Intersection" (Tiou) is proposed, which calculates the intersection area between two different prediction boxes. Based on Tiou, a classifier is developed to filter and remove inefficient prediction boxes, improving the accuracy of the model and reducing the pressure caused by irrelevant information output of gesture actions.
The article presents four key innovative technologies:
A DODA algorithm is proposed to decouple the two-dimensional information in Doppler frequency shifted images into one-dimensional time-domain and frequency-domain information, enhancing gesture recognition ability and effectively segmenting continuous gestures to solve the challenge of recognizing continuous gestures.
A metric called "Joint Time Intersection" (Tiou) is introduced to optimize the model output and reduce the pressure of outputting irrelevant gesture action information. Based on this metric, a Tiou classifier is developed to filter and remove inefficient prediction boxes, improving the accuracy of the model and reducing unnecessary outputs.
Selective data augmentation techniques are adopted to enhance the collected ultrasound echo data, helping the model better adapt to different real-world conditions and improve its robustness and generality.
A static anomaly elimination algorithm (SEEA) is proposed to eliminate frame activity anomalies and locally enhance the information reflected in Doppler images. SEEA removes abnormal frame regions and normalizes the signal to make gesture action features more prominent.
Related work
Gesture recognition has become an essential aspect of human–computer interaction, facilitating natural and intuitive communication between users and devices. This chapter reviews the existing work in gesture recognition, with a focus on acoustic, radio frequency (RF) based, and vision-based approaches. As shown in Table 1.
Table 1.
The results of training set and verification set are compared under different training conditions
| Approach | Example System | Key Features | Limitations |
|---|---|---|---|
| Acoustic | SoundWrite 8 | Utilizes MFCC for classification | Challenges in representing time and frequency information |
| Sonicasl 9 | Recognizes sign language gestures via earphones | Difficulty in handling continuous multi-gestures | |
| LoEar 10 | Detects heartbeat based on ultrasound CFR | Limited application to general gesture recognition | |
| EarHear 11 | Utilizes Differential-Doppler for noise reduction and Vision Transformer for gesture recognition | May be sensitive to very high levels of environmental interference; data collection requires specialized equipment | |
| RF | HandGest 16 | Analyzes dynamic phase vector and motion rotation | Requires specialized hardware, limiting widespread deployment |
| ThuMouse 17 | Tracks finger movements using FMCW radar | High cost of specialized hardware | |
| Vision-Based | 3D CNN 19 | High accuracy using laptop cameras | Resource-intensive, sensitive to lighting conditions and occlusions |
| IPN Hand 18 | Real-time continuous gesture recognition | - |
Acoustic gesture recognition systems primarily employ sound waves, specifically ultrasonic signals, to detect and interpret hand gestures. Some notable systems include SoundWrite8, which utilizes Mel Frequency Cepstral Coefficients (MFCC) to extract stable features from different gestures for classification. However, it faces challenges in accurately representing the time and frequency information of gestures. Another system is Sonicasl9, which leverages earphones to recognize sign language gestures and effectively handles continuous multiple gestures. Nevertheless, it still struggles with accurately classifying complex, overlapping gestures. LoEar10 is another system that uses Channel Frequency Response (CFR) based on ultrasound to detect heartbeat information, demonstrating the versatility of acoustic sensing. More recent advancements, including EarHear11, have pushed the boundaries of acoustic gesture recognition. EarHear innovates by integrating a Vision Transformer for Sign Language Recognition, effectively distinguishing between similar gestures and translating sign language into natural language sequences. However, its application to general gesture recognition remains limited. Despite these challenges, these acoustic systems provide immersive user experiences and support various applications in gaming, real-time interaction, and education.
RF-based gesture recognition systems employ wireless signals to capture hand movements. Some key systems in this area are HandGest16 and ThuMouse17. HandGest analyzes dynamic phase vector and motion rotation variable to recognize hand gestures, showcasing the potential of RF signals in gesture detection. However, the requirement for specialized hardware increases costs and limits widespread deployment. ThuMouse, on the other hand, utilizes Frequency Modulated Continuous Wave (FMCW) radar to track finger movements, enabling cursor control through micro-gestures. Similar to HandGest, the high cost of specialized hardware remains a barrier to broader adoption of RF-based gesture recognition systems.
Vision-based gesture recognition relies on cameras to capture and analyze hand movements. Examples of such systems include 3D Convolutional Neural Networks19 and IPN Hand18. 3D Convolutional Neural Networks, employed on laptop cameras, demonstrate high accuracy in dynamic hand gesture recognition. However, vision-based methods are resource-intensive and sensitive to lighting conditions and occlusions. IPN Hand, on the other hand, focuses on real-time continuous gesture recognition and emphasizes computational efficiency. Despite its advantages, it shares the same limitations as other vision-based systems, including sensitivity to lighting conditions and occlusions.
Despite the progress made in gesture recognition, several challenges and limitations remain. Acoustic and RF-based approaches have difficulties accurately representing the time and frequency information of gestures, especially in continuous multi-gesture scenarios. Vision-based methods, while highly accurate, require significant computational resources and can be impacted by environmental factors such as lighting and occlusions. Additionally, the lack of sufficient and diverse training data, particularly for ultrasound gestures across various scenarios, hinders the development of robust recognition models. To address these issues, recent research has explored innovative techniques such as Doppler shift analysis and data augmentation strategies. Our work builds upon these foundations, proposing the Doppler Object Detection Algorithm (DODA) and a suite of enhancements to enable real-time, continuous gesture recognition on ubiquitous mobile devices.
System overview
Overview
As shown in Fig. 2, the system proposed in this article consists of four main modules, which are the transceiver, signal processing, gesture detection of DODA, and interaction implementation. In the transceiver module, the speaker plays ultrasonic waves for gesture recognition. At the same time, the microphone collects and samples the echoed ultrasonic waves during gesture movements. The echoed signals along with temporal domain labels, are then fed into the signal processing module along with temporal labels. In the signal processing module, the collected ultrasound echoes are converted into Doppler frequency shift images. To enrich the dataset and increase robustness, the dataset is selectively and meaningfully augmented based on the DODA algorithm (see Sect. 3.4 for details). In gesture recognition by DODA, the augmented data is fed into the YOLOv7-Tiny21,22 object recognition network, which outputs feature maps of predicted bounding boxes and time–frequency domain information, as well as class information related to gesture occurrence. The feature maps of predicted bounding boxes and temporal-frequency domain information of gesture occurrence are used for TIOU (Temporal Intersection over Union) and other computations. The TIOU classifier is used to remove duplicate predicted boxes. During the interaction phase, the real-time output of single or continuous multiple gestures along with their time and frequency information and class information is provided based on the server’s real-time information such as the current time.
Fig. 2.

Overview of UltraWX.
Signal processing
We modulated a tone ultrasound signal at 20 kHz, as shown in Fig. 3. The signal was emitted from the transducer speaker after passing through a bandpass filter19. At the same time, the microphone of the transceiver received the ultrasonic echo generated by the gesture. The received signal was then filtered with a bandpass filter to remove noise outside the gesture frequency band. In addition, a band-stop filter was applied to eliminate the channel detection carrier within the gesture frequency band. Subsequently, we addressed frame activity local anomalies caused by hardware power amplification, removed the highlighted portion on the far left of the X-axis, and enhanced the visibility of gesture features. Gaussian smoothing and normalization techniques were used to make the gesture motion features clearer and brighter. The processed ultrasonic echo signal was subjected to a short-time Fourier transform (STFT) to transform it into a three-dimensional thermal heat map representing the time domain, frequency domain, and amplitude. By applying the Doppler frequency shift formula, the signal was further transformed into a Doppler frequency shift image. Finally, we obtained the label for the gesture, including the information about the time–frequency domain and the gesture category, and a clear and low-noise Doppler image.
Fig. 3.

Design of transceiver.
We present the design of a WeChat mini program called UltraWX, which can be used on mobile devices to emit ultrasound and receive the echo of ultrasound while performing gestures. We use the WeChat Mini Program to control the speaker of the mobile device to emit modulated ultrasound and simultaneously record the sound using a microphone to collect the ultrasound echo. Signal filtering smooths and eliminates exception frame activity We set the speaker to emit a single 20-kHz audio signal. First, we apply a Butterworth bandpass filter to remove background noise outside the frequency range of 19,000 Hz to 21,000 Hz 23–25. Then, we apply a band-stop filter to eliminate the carrier of the ultrasonic detection carrier within the range of 19,985 Hz to 20,015 Hz. We use a Gaussian filter to adjust the signal matrix, remove outliers, and obtain a smoother spectrogram. Based on this, we calculate the difference between the current value and the minimum value and then divide it by the maximum difference within the range of values to obtain a linear mapping within the range [0, 1], which completes the normalization process.
In the unprocessed Doppler shift image, there is an anomaly present on the far left side of the image, as shown in Fig. 4(a)(c)(e). We have extracted the waveform of the signal and calculated the variance of each sampling frame. By calculating the variance of each frame, we can characterize the stability of the signal values in each sample, which is called frame activity. Based on this analysis, frames within the 0–0.5 s time frame were found to have abnormal activity, even in the absence of noise. We propose the SEEA algorithm to eliminate the frame activity anomalies. First, we use differential calculation to find the frame FA corresponding to the highest value of the variance graph used to calculate the frame activity. At this frame, the activity is the highest and at the same time the least stable. Then, starting from the time point corresponding to FA, we perform differential calculations backward. As the sign of the differential calculation changes between adjacent frames, we identify the earliest time variable that represents recovery from the effects of hardware-induced frame activity anomalies, denoted. Since each  is almost the same but with slight differences, in order to accurately eliminate the effects of frame activity anomalies while simplifying model training, we average the obtained
is almost the same but with slight differences, in order to accurately eliminate the effects of frame activity anomalies while simplifying model training, we average the obtained 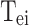 values using Eq. (1) to obtain
values using Eq. (1) to obtain 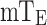 , which represents the average frame activity anomaly time.
, which represents the average frame activity anomaly time.
Fig. 4.

Data processed by SEEA.
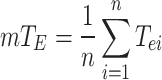 |
1 |
We removed the first 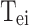 seconds from the ultrasound echoes, as shown in Fig. 4(b)(d)(f), and plotted the corresponding waveform and variance plots. We found that the waveform tends to stabilize within the first 48,672 sampling frames, and the frame activity reflected in the variance is much lower compared to the gesture feature part.
seconds from the ultrasound echoes, as shown in Fig. 4(b)(d)(f), and plotted the corresponding waveform and variance plots. We found that the waveform tends to stabilize within the first 48,672 sampling frames, and the frame activity reflected in the variance is much lower compared to the gesture feature part.
Data augmentation based on doppler image features
When using gesture recognition systems, there is often a decrease in recognition accuracy due to non-standard operations 20. We analyzed the non-standard factors such as the speed of the gesture, the distance to the microphone, the angle of arrival, and the time required for the entire gesture, and performed appropriate data augmentation of the Doppler image features. We also overlaid two gesture images that do not overlap in time to enrich the data set and recover the Doppler shift images of the real gestures as much as possible. This approach aims to improve the robustness of the system in continuous multi-gesture scenarios.
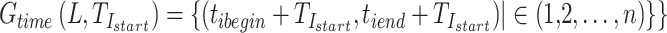 |
2 |
Equation (2) represents the 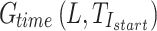 function for processing gesture timing information. Here, L refers to the temporal scale value in the label that indicates the relative time of each gesture occurrence within the signal, while
function for processing gesture timing information. Here, L refers to the temporal scale value in the label that indicates the relative time of each gesture occurrence within the signal, while 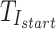 denotes the real time at which the gesture action occurs.
denotes the real time at which the gesture action occurs.
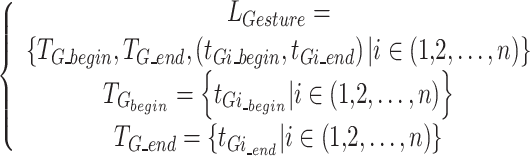 |
3 |
Equation (3) shows the function used to calculate the label 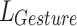 . In this context,
. In this context, 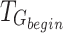 represents the start time of different actions,
represents the start time of different actions, 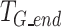 represents the end time of different actions,
represents the end time of different actions, 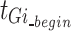 represents the start time of a single action, and
represents the start time of a single action, and 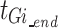 represents the end time of a single action.
represents the end time of a single action.
Different angles: to evaluate the effects of angle of arrival angles on Doppler frequency shift in mobile devices, gesture collectors performed gestures at different angles within a range of 20 cm from the transceiver. In this study, the range from 0° to 180° in front of the mobile device was divided into three 60° sectors (i.e., 0° to 60°, 60° to 120°, and 120° to 180°), and several trials with five different gestures were performed in each sector. Due to the significant influence of the arrival angles on the device, simple transformations to improve the measurements at different angles cannot be used in this work.
Different times for gesture occurrence: to evaluate the effects of different time ranges on Doppler images for the same gestures, the gesture collector performed the same gestures at different time intervals within the 20 cm and 40 cm ranges. The study found that due to the different times of gesture occurrence, there is a shift in the image features along the x-axis. In other words, by applying translation operations, we can enrich the dataset with gestures performed at different times.
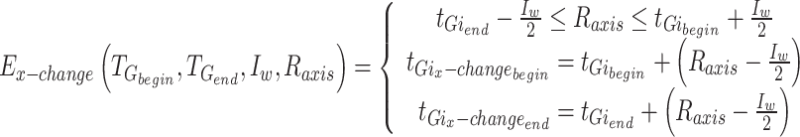 |
4 |
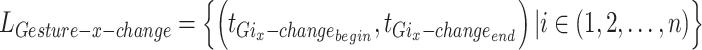 |
5 |
In Eq. (4), 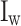 stands for the image width,
stands for the image width, 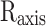 for the centre axis of the image,
for the centre axis of the image, 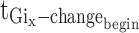 for the translated start time of the gesture, and
for the translated start time of the gesture, and 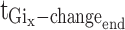 for the translated end time of the gesture. In Eq. (5),
for the translated end time of the gesture. In Eq. (5), 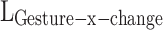 stands for the label for the gesture action after enhancement along the x-axis,
stands for the label for the gesture action after enhancement along the x-axis, 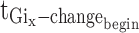 for the start time of the gesture action, and
for the start time of the gesture action, and 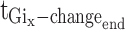 for the end time of the gesture action after enhancement.
for the end time of the gesture action after enhancement.
Continuous multiple gestures: In the experiment, we collected data for continuous multi-gestures, and the experimental results are shown in Fig. 5. In these images, the values of the gesture regions vary along the x-axis, and the interval distances are relatively large. In the real world, this can be interpreted as different completion times for gesture actions with substantial intervals. We determined whether two images with gestures overlapped along the x-axis. If there was no overlap, the Doppler images of the different gestures were superimposed. This approach shortened the distance between different gestures without affecting the target regions of the gesture actions. In the real world, this method can simulate continuous multiple gestures.
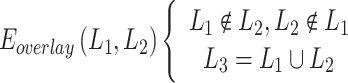 |
6 |
Fig. 5.

The new Doppler image after stretching, translating and superimposing the original Doppler image.
In Eq. (6),  represents one gesture feature and
represents one gesture feature and 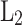 represents another gesture feature. When there is no inclusion relationship between
represents another gesture feature. When there is no inclusion relationship between  and
and 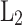 in terms of scale, the two images are superimposed to obtain the continuous multi-gesture feature,
in terms of scale, the two images are superimposed to obtain the continuous multi-gesture feature, 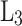 .
.
As shown in Fig. 5, we observed that the speed of gestures, the distance between gestures and the mobile device receiver, and the different completion times for gesture actions can affect the mapping of Doppler frequency shifts. Therefore, we conducted experiments and corresponding data enhancements to address the effects of these three factors and other related experimental manipulations. We perform x-axis translation on the collected data to generate Doppler feature images of ultrasonic gestures with different start and end times within an 8-s audio clip. We then apply x-axis stretching for different fast and slow gestures to create Doppler feature images of ultrasound gestures with varying speeds within the same 8-s audio clip. Finally, based on the above two augmentation methods and the original dataset, we perform gesture time range superposition discrimination. By overlaying one image onto the idle region of another image where no gesture features are present, we generate images of continuous multiple gestures.
DODA and object detection model
DODA We propose a Doppler shift image object detection algorithm (DODA) consisting of two parts. On the one hand, it uses an object recognition algorithm to extract classification and position features from gestures. On the other hand, the gesture features are mapped from the Doppler-shifted image to obtain time, frequency, and classification information about the gestures. As shown in Fig. 6, the trained object detection model can feed back the anchor boxes of the target features to the 2D image as needed. The anchor boxes output by the object detection represents the predicted bounding box information using a set of four variables (x, y, w, h), where (x, y) denote the coordinates of the upper left corner of the bounding box in the image and (w, h) denote the width and height of the box, which represent the position and size of the target object in the image. Based on these values, the position and size of the target object in the image can be determined for object classification and localization. Based on these values, the predicted bounding box of the output object contains information about the position of object on the 2D image.
Fig. 6.

Mapping relationship of DODA.
The temporal information is represented by the x-axis of the Doppler image, and the frequency domain information is represented by the y-axis of the Doppler image. Therefore, the DODA algorithm can map the two-dimensional Doppler image into a one-dimensional signal with practical meaning. It assigns the x-axis of the Doppler image to the relative time within 0–8 s, representing the hand movement’s start and end time. At the same time, the y-axis of the Doppler image is mapped to the frequency changes of the ultrasound in response to the hand movements during the gesture. Subsequently, the above information is mapped to the real duration of the hand gesture and the ultrasound frequency range corresponding to the hand movements, thereby achieving real-time decoupling of the original ultrasound echo signal in both the frequency and time domains.
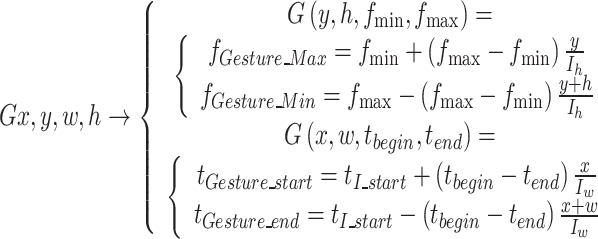 |
7 |
As per Eq. (7), the DODA transforms the collected ultrasound echo signals into Doppler images and employs an object detection model to train and regress four variables: x, y, w, and h. These variables are subsequently mapped to the entire real-world process of hand gesture actions, encompassing changes in frequency. Thus, in practical terms, the DODA algorithm can determine the relative start time (x) of a gesture and the cut-off frequency (y) of the hand gesture’s motion. It also provides information on the gesture’s duration (w) and the frequency bandwidth (h). From these values, one can infer the relative end time of the gesture (x + w) and the lowest frequency of the gesture (y-h).
We choose the YOLOv7-Tiny model, a first-stage object detection model, as the network for gesture recognition, as shown in Fig. 7. YOLO consists of a backbone network, head network, and neck network.
Fig. 7.

Network structure of YOLOv7-tiny.
The backbone network of the YOLO model is used to extract features from the input image. These features are used to predict the positions and classification of objects. The YOLOv7 backbone network consists of a total of 50 layers. First, there are 4 convolutional layers, which mainly consist of Conv + BN + SiLU. This is followed by three 5-layer pooling layers MP (max-pooling) and 8-layer ELAN (Enhanced Light-Weight Attention Network) pooling layers, resulting in eight-fold, 16-fold, and thirty-two-fold reduced feature maps.
The head network of the YOLO model is responsible for the regression and classification of targets based on the information from the feature maps of the backbone network. It uses the C5 convolutional model to map multiple grids onto three different sized feature maps. Using forward and backward calculations within each grid, the model performs regression to predict bounding boxes and classification for each classification and outputs the category labels, position information, and confidence scores.
The neck network of the YOLO model is based on the idea of feature pyramid network (FPN), which combines high-level features with low-level features to simultaneously exploit the high resolution of low-level features and the rich semantic information of high-level features. It independently predicts multi-level features, resulting in a significant improvement in small object detection. The loss function formula for YOLOv7 is as follows: Loss = Confidence loss * 0.1 + Classification loss * 0.125 + Localization loss * 0.05. The classification loss determines whether the recognized gestures accurately reflect the actual gestures, the localization loss measures the difference between predicted and actual bounding boxes, and the confidence loss evaluates the degree of missed recognitions in the predicted bounding boxes.
The evaluation metric used to evaluate the classification and prediction performance of the object detection model is “MAP” (Mean Average Precision). “MAP” is a commonly used evaluation metric for object detection tasks, which comprehensively evaluates the performance of the algorithm in various classifications. It is of great importance for algorithm improvement and comparison. The object detection model uses the Non-Maximum Suppression (NMS) method when calculating average precision. First, the NMS algorithm scores the confidence of the targets in the predicted bounding boxes based on the confidence scores in YOLO. Then, it ranks the bounding boxes in descending order of confidence and selects the box with the highest confidence as the candidate box. Then, it calculates the Intersection over Union (IOU) of the candidate box with other remaining boxes, and an IOU threshold is set. Boxes whose IOU is below this threshold are removed. NMS helps filter out redundant detection boxes, retaining only the most representative results. However, relying solely on confidence as a criterion may not be specific to handling Doppler frequency shift images. Removing duplicate boxes using NMS can lead to overlapping false detections, high error prediction rates, and situations where true detections with low confidence scores are lost, resulting in some degree of missed detections and false detections.
To achieve accurate recognition results and meaningful classification of gestures on Doppler frequency shift images, we integrate a specially developed interference-resistant classifier integrated into the model to replace the original mAP evaluation metric. The goal is to enhance the actual recognition accuracy for multiple gestures, continuous gestures, and similar gestures.
The classifier is equipped with four hyperparameters: Time length, frequency range, the ratio of overlap ranges, and confidence threshold for the model outputs. These hyperparameters correspond to the x-axis and y-axis of the Doppler images, the overlap range of the different gesture prediction fields, and the tolerance value for the detection probability of the model. They were developed to optimize the performance of the classifier in dealing with the unique characteristics of Doppler frequency shift images and to improve the overall accuracy of gesture recognition.
The pseudo-code of Algorithm 1 is as follow, First detection boxes that meet the conditions: Height of the box <  , Width of the box <
, Width of the box < 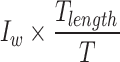 and
and 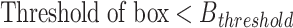 , will be included in the collection list L.If the current check box overlaps with a predicted box,
, will be included in the collection list L.If the current check box overlaps with a predicted box, 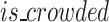 is set to 1 and
is set to 1 and 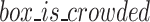 is set to 0. If
is set to 0. If 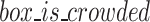 is 1, the TIOU (Time domain Intersection over Union)
is 1, the TIOU (Time domain Intersection over Union) 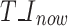 of the overlapping boxes is calculated.If
of the overlapping boxes is calculated.If 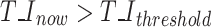 , the score of the box is added to the score set L_score.If
, the score of the box is added to the score set L_score.If 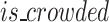 = 0, the current prediction box is added to the final collection
= 0, the current prediction box is added to the final collection  .If
.If  = 1 and the score of the current prediction box is the highest in the score set L_score, then the current prediction box is added to the final collection
= 1 and the score of the current prediction box is the highest in the score set L_score, then the current prediction box is added to the final collection 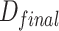 .
.

Algorithm 1 Tiou classifier
Experimental setup and evaluation
Experimental setting and evaluation index
Overall design of experiment
Data collection: We conducted two months of data collection on Huawei p30pro, Redmi k50 and OnePlus 9plus smart phone devices. The experimental results demonstrate the efficacy of the proposed algorithm in achieving real-time response to gesture manipulation using ultrasound on mobile devices. A total of twenty volunteers (ten male and ten female) from diverse age groups were invited to perform five distinct gestures, with the start and end times of each gesture recorded to within 0.1 s. Multiple repetitions of a single gesture were conducted within an 8-s period.
The user is required to stand or sit within a distance of 0.4 m to 1 m from the device, with the torso remaining relatively still within a detection range of 0.8 m. Gestures and hand movements are then carried out. As the start and end times of the gestures are annotated during the data set collection process, it is redundant to consider the impact of the non-gesture occurrence time environment, particularly the interference of hand raising and hand stopping. This reduces the discomfort associated with data collection and significantly enhances the reliability of the gesture data set.In our model training dataset, the gesture collector completes gestures at two different speeds, fast and slow, and collects gesture data at an angle of arrival of 0° centred on the phone’s central axis, with the gesture action less than or equal to 0.4 m from the phone. As shown in Fig. 8.
Fig. 8.

Data collection situation.
In our robustness experimental dataset, we designed the non-canonical operation robustness experimental dataset and the different collection conditions robustness experimental dataset respectively. In the non-canonical operation robustness experimental dataset, we collected gesture data at different reach angles from 0° to 180°, gesture data at a gesture distance of 0.6–0.8 m from the phone, and gesture data when the phone volume is not at its maximum value, respectively. In the experimental dataset of robustness to different collection conditions, we invited two other volunteers, one male and one female, who were not among the collection candidates in the model training dataset to collect the gesture data of different people, and chose the Xiaomi 11 and the Iphone 13, two other collection devices that were not among the original collection device models, to collect the gesture data. We collected a total of 5787 real gesture audio samples, of which a total of 16,609 target frames containing various gestures.
Training environment: We use paddlepaddle, an artificial intelligence framework developed by Baidu, as the basis to build the DODA algorithm model, and we also use two different versions of the YOLOv6 and YOLOv7 target detection models to build the recognition module of the DODA algorithm and train it, which is used to compare the effect of the model on different versions of the same backbone model. In order to maximize the accuracy, we use four nvidiaV100 32 GB graphics cards for training. Each set of model training experiments was performed for 400 iterations with a time length of 80 s per iteration.
Deployment environment: We deploy the DODA algorithm model to a local server with (I7-8750 h CPU, 16 GB RAM, 2 T hard disk space, and gtx1060ti graphics card), we send the wav files of ultrasonic echoes obtained by our WeChat applet UltraWX to the server and use the server to process the ultrasonic files in data for We send the wav files of ultrasonic echoes obtained by our WeChat app UltraWX to the server, and use the server to classify and predict the ultrasonic files after data processing and send the classification and prediction results back to the WeChat app in real time to complete the human–computer interaction of gesture recognition. In the process of interaction, the server can output and return data to the applet in parallel, and process multiple data at the same time, so as to improve the user experience.
Evaluation index
Since the map for target detection cannot make Doppler shift imaging and DODA algorithms for gesture movements reflect the real recognition information, several sets of covariates are defined in this paper to reflect the actual performance of the model. One is a class of parameters based on real samples, whose purpose is to represent the model’s detection performance compared with the real situation. Parameters based on samples include detection rate, missing rate and total error rate. The detection rate includes the positive detection rate and the negative detection rate. The detection rate is the number of samples divided by the number of samples, and the positive detection rate is the number of correct samples divided by the number of samples. The negative detection rate is the number of errors detected divided by the number of samples. The missed detection rate is the number of samples minus the number of detections divided by the number of samples, which is complementary to the detection rate. The total negative rate is the negative detection rate plus the lost detection rate. The other category is the parameters based on the number of prediction frames, which are intended to represent the performance of the model detection and model prediction situations compared to the number of prediction frames, the parameters based on the number of prediction frames are the missed prediction rate and the detection rate, where the detection rate contains the detection positive rate and the detection negative rate. The meaning of mTIOU is the average of the TIOU of multiple experimental results. Also this paper defines the overall accuracy, which is used to measure the correct detection of the model in all cases, the overall accuracy is defined as the number of correct detections divided by the total number of predictions when the number of predictions is greater than the number of samples, and when the total number of predictions is less than the number of samples, it is defined as the number of correct detections divided by the number of samples. The overall accuracy is shown in Eq. (7).
 |
8 |
Comparison and evaluation of overall model performance
In this experiment, we compare the performance of the same model for augmented data, and the performance of different models for augmented data, to judge and select the best performing target detection model for outputting the category and real-time information of the user’s input gesture, and use the selected model as the basis for implementing DODA.
Comparison and analysis of overall model performance for different training conditions
Impact of data enhancement: In this paper, we use the method mentioned above to augment the experimental data with data, in this experiment this paper compares the original data without data augmentation with the augmented data after data augmentation after the training of the YOLOv7 target detection model, for the Mean Average Precision (mAP) which represents the comprehensive performance of the model, as well as the optimal accuracy which represents the final result of different trainings.
As shown in Fig. 9(a)(c) we compare the confusion matrices of the unenhanced dataset and the enhanced dataset on the recognition accuracy of the five gestures movement test set. As shown in Table 2, we compare the overall accuracy, detection rate, predict rate, and mTIOU of the unenhanced dataset and the enhanced dataset on the training and validation sets .As shown in Fig. 10a, compared to the data without data enhancement, although the enhanced data performs slightly worse on the training set, the map of the training and validation sets are not significantly different, which proves that using the data enhanced data to train the model avoids the overfitting problem to a greater extent.
Fig. 9.

Confusion matrix of test sets of models under different training conditions.
Table 2.
The results of training set and verification set are compared under different training conditions
| Model Result | Overall accuracy | Detection rate | Predict rate | mTIOU |
|---|---|---|---|---|
| Raw data train | 98.81% | 98.79% | 98.81% | 0.9712 |
| Raw data val | 98.24% | 98.24% | 98.24% | 0.9171 |
| Yolov6 train | 98.55% | 98.45% | 98.36% | 0.9448 |
| Yolov6 val | 98.20% | 98.10% | 98.11% | 0.9159 |
|
Yolov7 train (Enhanced data train) |
99.70% | 99.81% | 99.70% | 0.9659 |
|
Yolov7 val (Enhanced data val) |
99.63% | 99.66% | 99.66% | 0.9585 |
Fig. 10.

Comparison of result indexes of models under different training conditions.
It is also found that the variance of the maps of different gestures with data enhancement processing is smaller than that of the maps of different gestures without data enhancement processing, which proves that the probability of misrecognition decreases, the overall accuracy of the model increases, and the model recognition results are more stable after data enhancement processing. As shown in Fig. 9(c), compared to the data without data enhancement, we find that the enhanced data has the largest increase in flip action accuracy by 18.65% on the test set, mTiou becomes smaller, and the optimal accuracy, detection rate, and prediction rate become larger. The experimental results show that the data enhancement technique in this experiment does provide the target detection model with data that has very high correlation with the original data and improves the positive detection rate and detection rate of the model, which increases the accuracy of the model while decreasing the overhead of the model, which helps to train a better model.
Comparison between different YOLO models: We chose the YOLO model with strong real-time performance and performed a model comparison between the YOLOv6 and YOLOv7 models. As in Fig. 10a, c we compare the confusion matrices of the recognition accuracy of the dataset augmented with the YOLOv7 model training and the dataset augmented with the YOLOv6 model training for the five gesture action test set. As shown in Table 2, this paper compares the best_ACC, detection rate, predict rate, and mTIOU of YOLOv6 and YOLOv7-Tiny on the training and validation sets.As shown in Fig. 10b, d, the map of the five gestures in the training set and validation set of YOLOv6 is higher than that of YOLOv7-Tiny, but the test set accuracy and overall accuracy, detection rate, predict rate, mTIOU and training set of each gesture in YOLOv6 have a large difference, with the Rowing gesture MAP has a difference of 30% while YOLOv7-Tiny has a more stable performance compared to YOLOv6 for each gesture action, best_ACC, detection rate, predict rate, and mTIOU have a smaller relative difference compared to the training set and the test set except for mTiou which has an average difference of 16%. So it is concluded that YOLOv6 has the risk of model overfitting compared to YOLOv7, which is not conducive to model generalization. Therefore using YOLOv7 model can output more accurate real-time information about gesture categorization for the test set data.
Comparison and analysis of overall model performance for different training conditions
Because the classification calculation of target detection involves the calibration of the prediction frame, and the results are screened only based on the output confidence threshold, the overall screening method is single, and cannot properly deal with the situation of overlapping recognition frames, and the effective recognition results are poor, and because the overall accuracy is only one parameter of the output confidence threshold, the stability of the method is poor, and the generalization is not good, and the fluctuation of the recognition accuracy is obvious when faced with different scenarios, so its classification does not represent the real recognition accuracy of multiple gestures, consecutive gestures, and similar gestures, so we have autonomously improved the classification of target detection, and have increased a classifier to exclusively apply the classification results of the output gestures.
We set four hyperparameters for the innovative classifier at the same time, and conduct a comprehensive screening of these four hyperparameters, by adjusting the values of the above four hyperparameters in the model of the training to fit a classifier model with stronger generalization, higher recognition accuracy and less fluctuation in the overall stability of the recognition accuracy, as shown in Fig. 11 The experiments show that, after integrating and increasing the classifiers that we proposed, the total correctness and leakage rate of the model are higher after convergence of hyperparameters in the target detection model for multiple complex greatly gestures than the original one, as compared with the original one. classification of the target detection model set for any situation with a single parameter, DODA in the face of multiple complex gestures, the total correct rate and missed detection rate of the model after the hyperparameter convergence of a larger scale rise and fall, so our innovative classifier, improve the classification accuracy of gesture recognition while reducing the model in the regression of the preselected boxes of the overhead, to achieve the purpose of optimizing the overall performance of the model.
Fig. 11.

The training progress of whether to use a classifier. (a) no classifier, (b) Tiou classifier.
We have identified the relationship between the ratio of the number of prediction frames divided by the total number of samples and the total accuracy obtained by DODA based on the Tiou classifier and no classifier respectively, and have drawn scatter plots as shown in Fig. 11, the total accuracy reaches a peak when the ratio of the number of prediction frames divided by the total number of samples is close to 1. This is because at this point the number of prediction frames corresponds to exactly the real samples of gesture action features. As the number of prediction frames increases, the total accuracy becomes lower, as shown in Fig. 12(a) we characterize this phenomenon with a linear function, reflecting this trend can be seen in the presence of the TIOU classifier, the total prediction rate of the model decreases at a slower rate. As in Fig. 12(b) we fitted the independent and dependent variables with a quadratic function can see that the total prediction rate of the model is more stable in the presence of the TIOU classifier.
Fig. 12.

The result of whether to use a classifier. (a) First-order function, (b) Quadratic function.
Robustness experiments
In order to verify that DODA can still accurately get the results we want in complex environments, we designed a series of robustness experiments to verify our conjectures, and we will explore the robustness from two aspects in the following.
Non-independent robustness experiments with different devices and users
Figure 13a, b Gesture experiment collection by the same experimenter using different devices (iphone13, Xiaomi 11). Figure 13c, d shows the acquisition experimental results of gesture experiments we let different gesture collectors (male and female) use the same device for gesture experiments Reality The average call dataset device difference for each gesture action of different cell phones is 10%, and the average call dataset device difference for each gesture action of different USERS is 10%, and the OVERALL ACCURACY, detection rate, predict rate, and mTIOU differ by 8%. Figure 13 shows that even under the conditions of different data collectors and different data collection devices DODA can still recognize most of the gestures correctly and detect the time-domain and frequency-domain features of the gestures correctly, and the detection accuracy is not significantly reduced.
Fig. 13.

Results of independent robustness experiments on different devices and users. (a) Results for different devices, (b) System performance of different, (c) The results of different personnel, (d) System performance for different.
Experiments on the robustness of the system to non-standardized operations
As shown in Fig. 14(a)(d) by the same experimenter gesturing at a distance of 60 cm and 80 cm from the transceiver, the worst fluctuation in accuracy at the furthest distance of 80 cm can still achieve more than 80% accuracy. Figure 14(b)(e) shows gestures made by the same experimenter at orientations of 0°, 60°, 120°, and 180° with respect to the transceiver. The poorest precision finger-double action at the furthest 60° still achieves about 85% accuracy.
Fig. 14.

The results of the robustness test of the system against non-standard operation. (a) Remote robustness experiment, (b) The results of Remote robustness experiment, (c) Multi-angle robustness experiment, (d) The results of Multi-angle robustness experiment, (e) Robustness experiment with different volume sizes, (f) The results of robustness experiments with different volume sizes.
The experiments proved to be related to whether the mobile device is an omni-directional speaker and microphone or not, but can still effectively recognize gestures at multiple angles. Figure 14(c)(f) shows that the ultrasound was not played at full volume, and the experiment shows that the worst-precision stroke action can still achieve more than 80% accuracy without full volume playback. Figure 14 shows that even under irregular operation the algorithm proposed in this paper is still able to recognize most of the gestures correctly, and the detection accuracy is not significantly reduced.
Model comparison system performance
As demonstrated in Table 3, this paper undertakes a comparative analysis of disparate models for behavioural recognition that utilise ultrasonic signals, as referenced in the extant literature. It is evident that all of the aforementioned systems utilise ultrasound as a means of behaviour recognition. A notable distinction emerges in the signal processing of sensory data, with UltraWX and EarHear employing the D-Doppler method, while SoundWrite and LoEar resort to the MFCC and CFR methods, respectively. With respect to the devices utilised, UltraWX demonstrates a remarkable versatility by supporting a range of acoustic sensing devices for gesture recognition. These devices encompass smartphones, smart speakers, and smartphones. UltraWX supports a variety of acoustic sensing devices for gesture recognition, including smartphones, smart speakers, and other smart IoT devices, whereas the other three models do not support behavioural sensing in the environment through multiple devices at the same time, because they mainly support data collection and recognition from smartphones. In terms of the behavioural recognition model, UltraWX is different from the CNN + LSTM approach for behavioural recognition that is used by the three models. UltraWX is distinguished from the CNN + LSTM approach employed by the other three models in that it employs the Tiou DODA algorithm for behaviour recognition, which effectively decouples the data in the time and frequency domains, and accurately anchors the behaviours perceived by each acoustic perception node at each time period. With regard to the recognition accuracy of the model, since the other three models are unable to recognise gestures through multiple devices, it does not support simultaneous perception of behaviour in the environment through multiple devices. With regard to the recognition accuracy of the model, given that the other three models are incapable of recognizing gestures across multiple devices, the present study primarily compares the accuracy of the aforementioned models when employing smartphones. Notably, UltraWX demonstrates the capacity to recognize gestures across multiple devices, resulting in the final recognition accuracy being the average of the results obtained from multiple devices.
Table 3.
Comparison of different acoustic gesture recognition models
| Technologies | UltraWX | EarHear | SoundWrite | LoEar |
|---|---|---|---|---|
| Signal | Acoustic | Acoustic | Acoustic | Acoustic |
| Method | D-Doppler | D-Doppler | MFCC | CFR |
| Devices | Smartphone, Smartspeaker and AIOT devices et | Smartphone | Smartphone | Smartphone |
| Multidevice | Yes | No | No | No |
| Algorithm | Tiou DODA | CNN + LSTM | CNN + LSTM | CNN + LSTM |
| Accuracy | 95.6% | 93.9% | 91.2% | 93.5% |
System performance
Execution Time: In this paper, the execution time of 20,000 actions is measured and the mean execution time is calculated. Throughout the D-Doppler processing phase, time monitoring is performed each time before anti-interference filtering and SEEA, which take about 13 ms and 2.2 ms, respectively. The Tiou DODA model trained in this paper can handle an average of one D-Doppler data every 23 ms on a high-end server. The current implementation of UltraWX in this paper focuses on the generalisability of acoustic perception networks. In order to reduce the computational overhead on the mobile device side, we move the computationally intensive tasks involved in gesture recognition to a high-end server. Research progress in running deep neural network models on mobile devices has yielded significant results through model compression, cloud-free DSPs, and system optimisation. We plan to support lightweight, resource-constrained smart devices in future work. The time cost of each stage of the data processing and classification phase is shown in Table 4.
Table 4.
The running time of UltraWX
| D-Doppler measurements calculation | Action Recognition | ||
|---|---|---|---|
| Filtering of interference | SEEA | Data Enhancement | Tiou DODA |
| 13 ms | 2.2 ms | 4.8 ms | 23 ms |
Operating distance: UltraWX is designed to perceive behaviour within a 40 cm range, and a decrease in detection and recognition accuracy is observed when the operating distance exceeds 60 cm.
Power Consumption: the power consumption of UltraWX is also acceptable. In our experiments, a fully charged Huawei P30 Pro mobile phone can continuously transmit and record ultrasound for about 7 h. It is possible to reduce power consumption further by setting the system to run idle at a low frame rate until an activated gesture is detected; however, this is a topic to be explored in future research.
Conclusion
This paper proposes DODA, a ubiquitous continuous gesture information, to overcome the limitations of existing gesture recognition systems. Among other things, DODA focuses on outputting the time–frequency domain information of each gesture in real time, and maps the start and end time of the gesture to its meaning in the real world. The model classifier is improved by computing the proposed Temporal Intersection of Unions (TIOU) metric, which reduces model consumption while improving accuracy and stability. In addition, SEEA eliminates local frame The graphical signal correspondences proposed in DODA are used to perform data enhancement on the original dataset. Experimental results show that DODA’s UltraWX real-time output provides time–frequency domain information and gesture categories with real-world meaning for each consecutive gesture. It demonstrated 95.6% recognition accuracy on a variety of mobile devices, while maintaining 88.6% recognition accuracy in complex scenarios tested with different people.
Acknowledgements
This work was supported by the National Natural Science Foundation of China (Grant 62262061, Grant 62162056, Grant 62261050), Major Science and Technology Projects of Gansu(23ZDGA009), Science and Technology Commissioner Special Project of Gansu(23CXGA0086), Lanzhou City Talent Innovation and Entrepreneurship Project (2020-RC-116, 2021-RC-81), and Gansu Pro-vincial Department of Education: Industry Support Program Project (2022CYZC-12).
Author contributions
Z.Z.: Methodology, Conceptualization, Validation, Software, Formal Analysis, Writing—Manuscript Preparation, Visualization, Writing—Review Editing. Z.J.: Methodology, resources, writing—review editing, visualization, supervision. M.L.: Methodology, concepts, investigations, software, resources, writing—manuscript preparation.
Data availability
The datasets generated during and/or analyzed during the current study are not publicly available due to [Data and processing information related to product development] but are available from the corresponding author on reasonable request.
Declarations
Competing interests
The authors declare no competing interests.
Institutional review board statement
The study was conducted in accordance with the guidelines of the Declaration of Helsinki and approved by the Ethics Committee of Northwest Normal University in China. Informed consent has been obtained from all subjects participating in the study.
Footnotes
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
References
- 1.Adhikari, A., & Sur, S. Argosleep: Monitoring Sleep Posture from Commodity Millimeter-Wave Devices. In Proceedings IEEE INFOCOM. (2023).
- 2.Adhikari, A., Avula, S., & Sur, S. MatGAN: Sleep Posture Imaging using Millimeter-Wave Devices. In Proceedings IEEE INFOCOM. (2023).
- 3.Zhong, M. et al. Beluga whale acoustic signal classification using deep learning neural network models. J. Acoust. Soc. Am.147(3), 1834–1841 (2020). [DOI] [PubMed] [Google Scholar]
- 4.Serrurier, A. & Neuschaefer-Rube, C. Morphological and acoustic modeling of the vocal tract. J. Acoust. Soc. Am.153(3), 1867–1886 (2023). [DOI] [PubMed] [Google Scholar]
- 5.Palo, P., & Lulich, S. M. Improving signal-to-noise ratio in ultrasound video pixel difference. The Journal of the Acoustical Society of America, 153(3_supplement), A373-A373. (2023).
- 6.Liu, J., Li, W., Gu, T., Gao, R., Chen, B., Zhang, F., ... & Zhang, D. (2023). Towards a Dynamic Fresnel Zone Model to WiFi-based Human Activity Recognition. Proceedings of the ACM on Interactive, Mobile, Wearable and Ubiquitous Technologies, 7(2), 1–24.
- 7.Siddiqui, N. & Chan, R. H. Hand gesture recognition using multiple acoustic measurements at wrist. IEEE Trans. Hum.-Mach. Syst.51(1), 56–62 (2020). [Google Scholar]
- 8.Luo, G., Chen, M., Li, P., Zhang, M., & Yang, P. SoundWrite II: Ambient acoustic sensing for noise tolerant device-free gesture recognition. In 2017 IEEE 23rd International Conference on Parallel and Distributed Systems (ICPADS) (pp. 121–126). IEEE. (2017).
- 9.Jin, Y., Gao, Y., Zhu, Y., Wang, W., Li, J., Choi, S., & Jin, Z. Sonicasl: An acoustic-based sign language gesture recognizer using earphones. Proceedings of the ACM on Interactive, Mobile, Wearable and Ubiquitous Technologies, 5(2), 1–30. (2021).
- 10.Wang, L. et al. Loear: Push the range limit of acoustic sensing for vital sign monitoring. Proc. ACM Interactive Mobile Wearable Ubiquitous Technol.6(3), 1–24 (2022). [Google Scholar]
- 11.Hao, Z., Wang, Y., Zhang, Z., & Dang, X. EarHear: Enabling the Deaf to Hear the World via Smartphone Speakers and Microphones. IEEE Internet of Things Journal. (2023).
- 12.Jiang, W., Miao, C., Ma, F., Yao, S., Wang, Y., Yuan, Y., Su, L. Towards environment independent device free human activity recognition. In Proceedings of the 24th annual international conference on mobile computing and networking (pp. 289–304). (2018).
- 13.Yang, K. et al. cDeepArch: A compact deep neural network architecture for mobile sensing. IEEE/ACM Trans. Netw.27(5), 2043–2055 (2019). [Google Scholar]
- 14.Ling, K. et al. Ultragesture: Fine-grained gesture sensing and recognition. IEEE Trans. Mob. Comput.21(7), 2620–2636 (2020). [Google Scholar]
- 15.Lye, K. P. (2019). WeChat mini program development for travel guide services and user statistical analysis for Kampar tourism (Doctoral dissertation, UTAR).
- 16.Zhang, J. et al. HandGest: Hierarchical sensing for robust-in-the-air handwriting recognition with commodity WiFi devices. IEEE Internet Things J.9(19), 19529–19544 (2022). [Google Scholar]
- 17.Li, Z., Lei, Z., Yan, A., Solovey, E., & Pahlavan, K. ThuMouse: A micro-gesture cursor input through mmWave radar-based interaction. In 2020 IEEE International Conference on Consumer Electronics (ICCE) (pp. 1–9). IEEE. (2020).
- 18.Mao, W., Wang, M., & Qiu, L. Aim: Acoustic imaging on a mobile. In Proceedings of the 16th Annual International Conference on Mobile Systems, Applications, and Services (pp. 468–481). (2018).
- 19.Zhang, W., & Wang, J. Dynamic hand gesture recognition based on 3D convolutional neural network models. In 2019 IEEE 16th International Conference on Networking, Sensing and Control (ICNSC) (pp. 224–229). IEEE. (2019).
- 20.Tran, T., Pham, T., Carneiro, G., Palmer, L., & Reid, I. A bayesian data augmentation approach for learning deep models. Advances in neural information processing systems, 30. (2017).
- 21.Wang, C. Y., Bochkovskiy, A., & Liao, H. Y. M. YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (pp. 7464–7475). (2023).
- 22.Li, C., Li, L., Jiang, H., Weng, K., Geng, Y., Li, L., Wei, X. YOLOv6: A single-stage object detection framework for industrial applications. arXiv preprint arXiv:2209.02976. (2022).
- 23.Hao, Z., Wang, Y., Zhang, D., & Dang, X. UltrasonicG: Highly Robust Gesture Recognition on Ultrasonic Devices. In International Conference on Wireless Algorithms, Systems, and Applications (pp. 267–278). Cham: Springer Nature Switzerland. (2022).
- 24.Wang, Y., Hao, Z., Dang, X., Zhang, Z. & Li, M. UltrasonicGS: A Highly Robust Gesture and Sign Language Recognition Method Based on Ultrasonic Signals. Sensors23(4), 1790 (2023). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 25.Wang, Y., Shen, J. & Zheng, Y. Push the limit of acoustic gesture recognition. IEEE Trans. Mobile Comput.21(5), 1798–1811 (2020). [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.
Data Availability Statement
The datasets generated during and/or analyzed during the current study are not publicly available due to [Data and processing information related to product development] but are available from the corresponding author on reasonable request.