

Abstract
医学跨模态检索旨在实现不同模态间医疗案例的语义相似性搜索,如通过超声报告快速定位相关的超声图像,或利用超声图像反向检索匹配的超声报告。然而,现有医学跨模态哈希检索方法面临显著挑战,包括不同模态之间的语义差异、视觉差异及哈希算法在大规模数据下的可扩展性问题。为应对这些挑战,本文提出了一种基于Transformer语义对齐的医学图像跨模态哈希检索算法(MSACH)。该算法通过分段式训练策略,结合模态特征提取与哈希函数学习,有效提取包含重要语义信息的低维特征,并通过Transformer编码器进行跨模态语义学习。通过流形相似度约束、平衡约束和线性分类网络约束,增强了哈希码的可判别性。实验结果表明,MSACH 算法在两个数据集上的平均检索精度比传统方法分别提高了11.8%和12.8%。该算法在提升检索精度、处理大规模医学数据方面表现出色,具有较好的应用前景。
Keywords: 跨模态哈希, Transformer, 语义对齐, 分段式训练
Abstract
Medical cross-modal retrieval aims to achieve semantic similarity search between different modalities of medical cases, such as quickly locating relevant ultrasound images through ultrasound reports, or using ultrasound images to retrieve matching reports. However, existing medical cross-modal hash retrieval methods face significant challenges, including semantic and visual differences between modalities and the scalability issues of hash algorithms in handling large-scale data. To address these challenges, this paper proposes a Medical image Semantic Alignment Cross-modal Hashing based on Transformer (MSACH). The algorithm employed a segmented training strategy, combining modality feature extraction and hash function learning, effectively extracting low-dimensional features containing important semantic information. A Transformer encoder was used for cross-modal semantic learning. By introducing manifold similarity constraints, balance constraints, and a linear classification network constraint, the algorithm enhanced the discriminability of the hash codes. Experimental results demonstrated that the MSACH algorithm improved the mean average precision (MAP) by 11.8% and 12.8% on two datasets compared to traditional methods. The algorithm exhibits outstanding performance in enhancing retrieval accuracy and handling large-scale medical data, showing promising potential for practical applications.
Keywords: Cross-modal hash, Transformer, Semantic alignment, Segmented training
0. 引言
医学跨模态检索是医学信息检索领域的重要研究方向,旨在实现不同模态之间的数据关联,如通过医学图像检索诊断报告,或通过文本检索相关图像[1]。这种检索能力对提升医疗服务质量和效率至关重要,可帮助医生快速理解不同模态数据,为患者提供更精准的诊断和治疗方案[2]。近年来,跨模态哈希学习作为一种高效的检索方式,能够将高维特征压缩为紧凑的二进制哈希码,在大规模数据检索中表现出显著优势[3-5]。
在跨模态哈希学习领域,文献[6]作为首个将特征学习与哈希码学习结合在同一深度学习框架中的方法,为跨模态哈希检索奠定了基础。随后,Xu等[7]提出了一种多流形深度判别跨模态哈希方法,通过整合多流形相似性和判别正则化,不仅保留了数据的语义关系,还增强了学习到的哈希码的判别能力。然而,随着计算机视觉和医学影像技术的不断进步,医学图像数据量呈指数级增长[8]。数据的多样性和复杂性对检索技术提出了严峻挑战,不仅因为数据量的庞大,还因为不同模态数据间的异质性、图像质量的参差不齐,以及普遍存在的噪声和伪影等问题[9]。尽管现有的深度跨模态哈希方法在医学跨模态检索方面取得了一些进展,但仍存在以下不足:① 数据模态间的信息交互不足,导致特征提取效率受限;② 对大规模医学数据的处理能力有限;③ 对医学数据独特的语义差异和视觉复杂性缺乏深入挖掘。医生在进行跨模态数据检索时,常常因为检索效率低下而导致诊断和治疗过程的延迟,这在紧急情况下尤为严重[10]。此外,检索结果的准确性不足也可能导致误诊或漏诊,从而影响患者的治疗效果[11]。
文献[12-13]已充分验证,预训练任务在捕获模态的丰富特征信息方面表现出色。文献[14]利用对比、掩码和匹配任务进行了有效的特征提取并在多个下游任务上获得了出色的效果,证明了在多模态特征提取中的有效性。基于此,本文提出了一种基于Transformer[15]语义对齐的医学图像跨模态哈希检索算法(Medical image Semantic Alignment Cross-modal Hashing,MSACH)。该算法通过设计分段式训练策略和结合多种预训练任务,深度挖掘不同模态数据的语义特征;同时,引入流形相似度约束等机制,增强了哈希码的判别性和模型的检索效率。本文研究的核心目标是探索适用于医学数据的跨模态哈希检索方法,为临床场景提供高效、精准的技术支持。
1. MSACH模型整体流程
MSACH检索算法的架构如图1所示。MSACH模型包括预训练模型、哈希层和哈希约束。本文将医学图像与文本数据(如诊断报告、病例描述)视为不同模态,通过联合学习提取低维语义特征,并利用哈希函数将其转化为高质量哈希码。
图 1.

MSACH model architecture
MSACH模型架构
1.1. 符号描述
本文考虑了两种最常见的模态,即医学图像和诊断报告,以详细说明提出的MSACH。假设给定 个样本实例对的训练数据集
个样本实例对的训练数据集 ,其中
,其中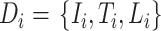 描述了第
描述了第 个实例。
个实例。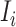 、
、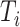 分别表示第
分别表示第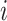 个医学图像和医学诊断报告文本,
个医学图像和医学诊断报告文本,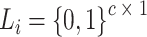 表示
表示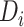 的标签向量,
的标签向量,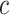 表示类别的个数。
表示类别的个数。
1.2. 模态特征提取
在模态特征提取阶段,采用三个预训练任务的联合学习策略,旨在将获取的模态低维特征与其他模态的丰富语义信息实现有效融合,从而增强特征表达的丰富性和准确性。
1.2.1. 特征提取模型架构
如图2所示,MSACH的特征提取模块由三部分组成:医学图像编码器、诊断报告文本编码器和图像文本跨模态编码器。医学图像编码器基于ImageNet-1k预训练的12层Vit-B/16[16]模型,输入图像 I转化为一系列嵌入 ,其中
,其中 为补丁序列的全局特征[CLS]。文本编码器采用BERT-base[17]模型的前6层,输入诊断报告
为补丁序列的全局特征[CLS]。文本编码器采用BERT-base[17]模型的前6层,输入诊断报告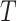 转化为
转化为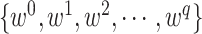 ,其中
,其中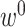 为文本序列的全局特征[CLS]。跨模态编码器采用BERT-base模型的后6层,通过注意力机制融合图像与文本特征,生成联合嵌入。其中
为文本序列的全局特征[CLS]。跨模态编码器采用BERT-base模型的后6层,通过注意力机制融合图像与文本特征,生成联合嵌入。其中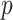 和
和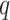 分别为医学图像和诊断报告的序列长度,
分别为医学图像和诊断报告的序列长度, 为序列的特征维度。
为序列的特征维度。
图 2.

Feature extraction module of MSACH
MSACH的特征提取模块
1.2.2. 预训练目标
在模态特征提取阶段采用了三个优化目标:医学图像编码器和诊断报告文本编码器上的图像-文本对比学习(Image-Text Contrastive,ITC),利用多模态编码器执行诊断报告的掩码语言建模(Masked Text Modeling,MTM),以及在多模态编码器上实现医学图像与诊断报告对的匹配学习任务(Image-Text Matching,ITM)。在训练阶段,通过在计算ITC损失时挖掘的硬负样本来改进ITM任务[14]。总训练目标函数如式(1)所示,具体损失函数内容参见附件1。
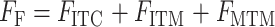 |
1 |
1.2.3. 实现细节
在预处理阶段,将医学图像分辨率统一为224 × 224 × 3,并通过随机裁剪和翻转进行数据增强以增加训练样本的多样性。在前向传播过程中,将医学图像和诊断报告数据各自复制三份,其中一份诊断报告会经过随机掩码处理。然后,分别计算ITC、MTM和ITM损失,并将它们相加进行反向传播以更新模型参数。训练过程中,采用AdamW[18]优化器,其权重衰减设置为0.02,批量大小设为256,初始学习率为0.01,并在1 000次迭代中采用每10次迭代平均衰减至0.000 1的策略。
1.3. 哈希函数学习
在哈希函数学习阶段,本文利用前一阶段提取到的模态特征来学习对应模态的哈希函数,以得到高质量的哈希码。具体来说,在第一阶段完成后,将医学图像编码器和诊断报告编码器产生的特征向量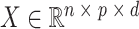 和
和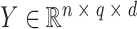 ,作为第二阶段哈希层的输入数据。
,作为第二阶段哈希层的输入数据。
1.3.1. 哈希约束
在哈希约束方面,本文通过构建不同模态流形相似矩阵来捕获不同模态间的异构关系,以增强哈希码的可判别性。具体流形相似矩阵的内容参见附件2。采用哈希码间的平衡约束和线性分类网络约束来学习哈希函数,最终提高哈希码的质量和哈希检索的精度。哈希函数目标包括流形相似约束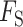 、哈希码间的比特平衡约束
、哈希码间的比特平衡约束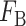 、哈希码与模型特征之间的2范数约束
、哈希码与模型特征之间的2范数约束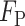 以及线性分类网络约束
以及线性分类网络约束 ,如式(2)所示。具体损失函数内容参见附件2。
,如式(2)所示。具体损失函数内容参见附件2。
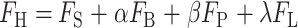 |
2 |
式中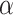 、
、 和
和 为引入的超参数,用于平衡约束之间的比重。
为引入的超参数,用于平衡约束之间的比重。
在构建哈希层时,本文设计了轻量化架构。如图1所示,哈希层包括自注意力层、残差归一化层、前馈网络层及双线性层。值得注意的是,本文将仅包含全局特征的[CLS],通过线性层获得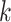 维特征向量,分别表示医学图像特征
维特征向量,分别表示医学图像特征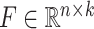 和诊断报告特征
和诊断报告特征 。最终通过符号函数转换为
。最终通过符号函数转换为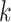 维哈希码:
维哈希码: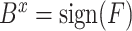 ,
,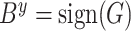 。
。
1.3.2. 哈希码函数训练
本文采用交替学习策略来学习医学图像模态的哈希函数 和诊断报告模态的哈希函数
和诊断报告模态的哈希函数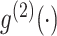 ,以及哈希码
,以及哈希码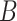 和分类网络参数
和分类网络参数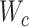 。通过哈希函数,可以获取对应的模态特征:
。通过哈希函数,可以获取对应的模态特征: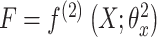 和
和 。在优化过程中,每次仅针对一个参数进行优化,固定其他参数不变,通过交替循环的方式更新每个网络的参数。算法1简要描述了MSACH的哈希函数学习算法。对于任何不在训练集中的样本实例,只需要通过它的一个模态就可以获得它的哈希码,具体样本外的扩展内容参见附件3。
。在优化过程中,每次仅针对一个参数进行优化,固定其他参数不变,通过交替循环的方式更新每个网络的参数。算法1简要描述了MSACH的哈希函数学习算法。对于任何不在训练集中的样本实例,只需要通过它的一个模态就可以获得它的哈希码,具体样本外的扩展内容参见附件3。
表 A1.
| 算法1 MSACH的哈希函数学习算法 |
输入:医学图像低纬特征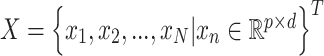 ,诊断报告低纬特征 ,诊断报告低纬特征 ,以及跨模态流形相似矩阵 ,以及跨模态流形相似矩阵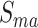 。哈希码长度 。哈希码长度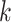 ,标签矩阵 ,标签矩阵
|
输出:医学图像哈希函数参数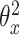 ,诊断报告哈希函数参数 ,诊断报告哈希函数参数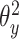 ,分类网络参数 ,分类网络参数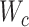 和二值哈希码 和二值哈希码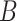
|
初始化:学习率: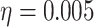 ;迭代次数: ;迭代次数: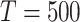 ;批量大小: ;批量大小: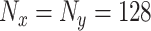 ;采样器: ;采样器: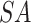
|
(1) 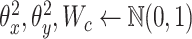 (正态分布初始化模型参数) (正态分布初始化模型参数) |
(2) 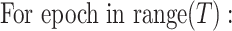
|
(3) 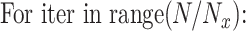
|
(4) 从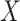 中随机抽取 中随机抽取 个点来构建一个小批量 个点来构建一个小批量 |
(5) 对于小批量中的每个采样点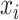 通过前向传播计算 通过前向传播计算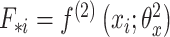
|
(6) 根据式(2)计算总损失,然后固定参数 、 、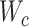 和哈希码 和哈希码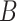 计算参数 计算参数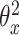 的梯度 的梯度 |
(7) 通过反向传播和随机梯度下降更新参数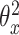
|
(8) 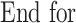
|
(9) 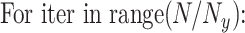
|
(10) 从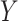 中随机抽取 中随机抽取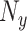 个点来构建一个小批量 个点来构建一个小批量 |
(11) 对于小批量中的每个采样点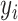 通过前向传播计算 通过前向传播计算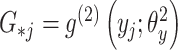
|
(12) 根据式(2)计算总损失,然后固定参数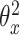 、 、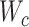 和哈希码 和哈希码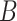 计算参数 计算参数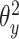 的梯度 的梯度 |
(13) 通过反向传播和随机梯度下降更新参数
|
(14) 
|
(15) 通过公式 和 和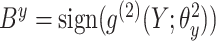 更新哈希码 更新哈希码
|
(16) 
|
(17) 从 中随机抽取 中随机抽取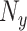 个点来构建一个小批量 个点来构建一个小批量 |
(18) 对于小批量中的每个采样点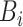 ,进行前向传播 ,进行前向传播 |
(19) 根据式(2)计算损失,然后固定参数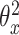 、 、 和哈希码 和哈希码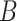 计算参数 计算参数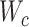 的梯度 的梯度 |
(20) 通过反向传播和随机梯度下降更新参数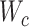
|
(21) 
|
(22) 
|
2. 实验
本研究在两个真实医学数据集上进行了广泛的实验,以验证MSACH的有效性。实验环境主要配置为Anaconda Navigator 2.4.0,Jupyter Notebook 6.5.4,Python 3.8.16。使用开源深度学习工具箱PyTorch在拥有三个计算节点、每个节点拥有8颗RTX 3090 GPU的BCM集群服务器上实现所有实验。
2.1. 数据集
本文在两个基准跨模态数据集ODIR和URBN上评估了提出的方法。其中ODIR为公开数据集,URBN为重庆医科大学附属第二医院收集的真实数据集。
ODIR:ODIR是一个包含5 000名患者的结构化眼科数据库,提供患者年龄、双眼彩色眼底照片及医生诊断关键词。患者被分为8个标签:正常(N)、糖尿病(D)、青光眼(G)、白内障(C)、AMD(A)、高血压(H)、近视(M)和其他异常(O)。本文对眼底照片进行黑边切除,并拼接左右眼照片形成图像数据集,同时将患者左右眼诊断关键词与信息按统一结构组成诊断描述。
URBN:URBN是一个乳腺结节超声报告数据集,来源于重庆医科大学附属第二医院的832例乳腺结节患者,包含2 261张超声图像及相应文本报告。患者按BI-RADS分级分为6类:2、3、4a、4b、4c、5。本研究仅纳入二维灰度图像以避免不同超声模式下的偏倚。文本报告从边界、边缘、方向、回声模式、后方回声特点及钙化等方面描述结节,同时记录其他判断结节性质的个性化描述。
图3展示了两个数据集的医学图像、诊断报告和标签示例。本文将数据集划分为查询(测试)集、检索集和训练集。ODIR数据集随机抽取350个实例为查询集,剩余为检索集,并从中随机选取2 275个实例作为训练集。URBN数据集取226个实例为查询集,剩余为检索集,并从中抽取1 831个实例作为训练集。
图 3.

Examples of images in the ODIR dataset and URBN dataset
ODIR数据集和URBN数据集中的图像示例
2.2. 实验设置和评估
模型设置中,所有线性层的隐藏层大小为3 072。在训练过程中,超参数α、β和λ在[0.01, 100]的范围内先进行粗细搜索,最终确定最优组合,具体超参数灵敏度分析的内容参见附件4。在实验中,本文进行了两种类型的跨模态哈希检索任务:① 医学图像检索诊断报告(Image to Text,I2T);② 诊断报告检索医学图像(Text to Image,T2I)。为评估哈希方法性能,采用Hamming排序和哈希查找两种协议,并通过平均检索精度(mean average precision,MAP)、Top-K精度(Precision-Top-K)曲线和精度-召回(Precision-Recall)曲线三个指标进行评价[19]。
本文将MSACH与七种经典的有监督深度跨模态哈希方法进行了比较,包括DCHUC[20]、BI_CMR[21]、DCMH[6]、SSAH[22]、CPAH[23]、GCH[24]和DCHMT[25]。其中,DCHUC和BI_CMR基于朴素网络相似性约束构建哈希函数;DCMH通过负对数似然约束将不同模态映射到同一汉明空间;SSAH和CPAH采用生成对抗网络生成哈希函数;GCH利用图卷积网络约束哈希码生成;DCHMT与MSACH均引入Transformer块进行模态特征提取。七种方法均使用开源代码,并根据作者建议方案调整参数,加载预训练参数,并重复实验三次取稳定结果参与对比。最后,为了深入探究哈希函数学习阶段各组件的性能表现,本文精心设计了MSACH的三种不同变体进行消融实验,具体消融实验的内容参见附件5。
2.3. 哈希检索结果
本文比较了MSACH与七种不同哈希方法的性能。如表1所示,它展示了MSACH和基线方法在数据集ODIR和URBN的MAP值,最好的结果进行加粗表示。通过观察可以得到:① 在两个检索任务中,本文方法在不同长度哈希码下均优于其他跨模态哈希方法。在ODIR数据集中,I2T和T2I任务的MAP平均增量分别为8.3%和15.3%;在URBN数据集中分别为14.5%和11.1%。② 分阶段学习模态特征和哈希函数能显著提升性能。特征提取阶段通过简单多任务联合学习即可获得良好的模态特征并包含跨模态信息,使哈希学习阶段更好地弥合模态间隙,减轻哈希学习负担。相比之下,DCHMT虽能共同学习统一哈希码和特定模式哈希函数,但其端到端训练方式增加了复杂度,仅依靠哈希约束学习模态特征,限制了性能表现。③ 本文方法在复杂数据特征中表现更优。如URBN数据集的二维灰度超声图像相比ODIR的彩色眼底照片,数据特征更复杂且模态差异小,但MSACH在URBN数据集上的MAP增量更高。
表 1. Comparison of MAP values in benchmark datasets.
基准数据集的MAP值对比
| 任务 | 模型 | ODIR | URBN | |||||
| 32 bits | 64 bits | 32 bits | 64 bits | 32 bits | 64 bits | |||
| 注:加粗数字表示最优结果 | ||||||||
| I2T | DCHUC | 0.633 | 0.656 | 0.633 | 0.656 | 0.633 | 0.656 | |
| BI_CMR | 0.639 | 0.657 | 0.639 | 0.657 | 0.639 | 0.657 | ||
| DCMH | 0.545 | 0.552 | 0.545 | 0.552 | 0.545 | 0.552 | ||
| SSAH | 0.587 | 0.615 | 0.587 | 0.615 | 0.587 | 0.615 | ||
| CPAH | 0.618 | 0.636 | 0.618 | 0.636 | 0.618 | 0.636 | ||
| GCH | 0.605 | 0.614 | 0.605 | 0.614 | 0.605 | 0.614 | ||
| DCHMT | 0.650 | 0.662 | 0.650 | 0.662 | 0.650 | 0.662 | ||
| MSACH | 0.665 | 0.669 | 0.665 | 0.669 | 0.665 | 0.669 | ||
| T2I | DCHUC | 0.785 | 0.797 | 0.785 | 0.797 | 0.785 | 0.797 | |
| BI_CMR | 0.817 | 0.835 | 0.817 | 0.835 | 0.817 | 0.835 | ||
| DCMH | 0.637 | 0.640 | 0.637 | 0.640 | 0.637 | 0.640 | ||
| SSAH | 0.744 | 0.762 | 0.744 | 0.762 | 0.744 | 0.762 | ||
| CPAH | 0.797 | 0.804 | 0.797 | 0.804 | 0.797 | 0.804 | ||
| GCH | 0.768 | 0.774 | 0.768 | 0.774 | 0.768 | 0.774 | ||
| DCHMT | 0.832 | 0.840 | 0.832 | 0.840 | 0.832 | 0.840 | ||
| MSACH | 0.888 | 0.889 | 0.888 | 0.889 | 0.888 | 0.889 | ||
为了进一步报告MSACH模型,本文还在Precision-Recall曲线和Precision-Top-K曲线下评估了MSACH。图4展示了在哈希码长度为64时,MSACH与七种经典跨模态哈希检索算法在Precision-Recall曲线上的比较。观察显示,PR曲线覆盖面积越大,模型检索性能越优,而MSACH的PR曲线始终高于其他方法,表明其性能显著优于现有基线模型。因此,MSACH能在更小汉明半径内生成更精准的哈希码,表现出显著优势。图5展示了哈希码长度为64时,MSACH与七种经典跨模态哈希方法在Precision-Top-K曲线上的比较。对于Top-K曲线,越靠近上方表示精度越高,模型综合性能越优。本文仅报告前1 000的检索精度值。结果显示,MSACH在ODIR和URBN数据集上均优于其他方法,且随着K增大,其精度保持得最稳定。
图 4.

Comparison results of PR curves of various algorithms
各种算法的PR曲线对比结果
图 5.

Comparison results of Top-K precision curves of various algorithms
各种算法的Top-K精度曲线对比结果
2.4. 检索可视化
为直观展示检索效果,本文在URBN数据集上进行了64位哈希的医学图像检索诊断报告及诊断报告检索医学图像任务的可视化对比。如图6所示,在两个检索任务中,将我们的模型分别与不同似然约束的哈希方法进行了检索实例对比,绿色表示分类和病理都相同的检索结果,黄色表示分类或者病理相似的检索结果,而红色表示是不相关的检索结果。可以看出,无论是基于朴素网络相似性约束的DCHUC还是引入Transformer块的DCHMT,MSACH的检索结果都包含了最多的高相关性实例。
图 6.

Visualization of retrieval on the URBN dataset
在URBN数据集上的检索可视化
3. 结论
本文提出了基于Transformer语义对齐的医学图像跨模态哈希检索算法——MSACH,旨在帮助医学专家高效检索所需数据,适用于病例回顾、诊断建议和医学教育等场景。MSACH采用分段式训练策略,结合模态特征提取与哈希函数学习,有效提取低维语义特征。通过Transformer编码器设计特征提取模块,并利用医学图像-诊断报告对的对比学习、匹配任务和掩码预测任务融合模态间语义信息,减少语义间隙,加速哈希函数收敛。在哈希学习阶段,引入模态内外相似度约束、哈希码平衡约束和线性分类网络约束,结合流形相似矩阵捕获异构关系,提升哈希码判别性与检索精度。实验结果表明,MSACH在两个医学数据集上均优于现有方法。但是,尽管MSACH表现出性能显著提升,但本研究数据集多样性和规模还有限。具体而言,ODIR为公开数据集,URBN来源单一机构,模态种类与语义复杂性不足以代表广泛临床应用。此外,方法主要针对图像与文本间的检索,未涵盖时序或视频数据等更复杂模态。未来研究将扩展数据集规模与类型,增加多模态和复杂医疗数据验证方法的适用性与鲁棒性。
重要声明
利益冲突声明:本文全体作者均声明不存在利益冲突。
作者贡献声明:吴钱林主要负责算法设计、仿真实现和原稿写作;唐伦主要负责算法构思、提供资源和原稿审阅;刘青海主要负责算法构思、写作指导、数据收集和撰写与编辑;徐黎明主要负责数据整理、数据分析、实验设计和写作审阅与编辑;陈前斌主要负责监督和项目管理。
本文附件见本刊网站的电子版本(biomedeng.cn)。
SUPPLEMENTARY DATA
Supplementary data to this article can be found online.
Funding Statement
国家自然科学基金(62071078);川渝联合实施重点研发项目(2021YFQ0053)
References
- 1.Huang S C, Pareek A, Seyyedi S, et al Fusion of medical imaging and electronic health records using deep learning: a systematic review and implementation guidelines. NPJ Digit Med. 2020;3(1):136. doi: 10.1038/s41746-020-00341-z. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 2.Das P, Neelima A An overview of approaches for content-based medical image retrieval. Int J Multim Inf Retr. 2017;6(4):271–280. doi: 10.1007/s13735-017-0135-x. [DOI] [Google Scholar]
- 3.Peng Y, Qi J, Huang X, et al CCL: Cross-modal correlation learning with multigrained fusion by hierarchical network. IEEE Trans on Mul. 2017;20(2):405–420. [Google Scholar]
- 4.苏海, 钟雨辰. 基于偏差抑制对比学习的无监督深度哈希图像检索. 计算机系统应用, 2025, 34(2): 165-173.
- 5.刘华咏, 徐明慧. 基于混合注意力与偏振非对称损失的哈希图像检索. 计算机科学, 2024: 1-12.
- 6.Jiang Q Y, Li W J. Deep cross-modal hashing// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Honolulu: IEEE, 2017: 3232-3240.
- 7.Xu L, Zeng X, Zheng B, et al Multi-manifold deep discriminative cross-modal hashing for medical image retrieval. IEEE Trans Image Process. 2022;31:3371–3385. doi: 10.1109/TIP.2022.3171081. [DOI] [PubMed] [Google Scholar]
- 8.Guan A, Liu L, Fu X, et al Precision medical image hash retrieval by interpretability and feature fusion. Comput Methods Programs Biomed. 2022;222:106945. doi: 10.1016/j.cmpb.2022.106945. [DOI] [PubMed] [Google Scholar]
- 9.Fang J, Fu H, Liu J Deep triplet hashing network for case-based medical image retrieval. Med Image Anal. 2021;69:101981. doi: 10.1016/j.media.2021.101981. [DOI] [PubMed] [Google Scholar]
- 10.Han J, Men A, Liu Y, et al IoT-V2E: an uncertainty-aware cross-modal hashing retrieval between infrared-videos and EEGs for automated sleep state analysis. IEEE Internet Things J. 2024;11(3):4551–4569. doi: 10.1109/JIOT.2023.3300891. [DOI] [Google Scholar]
- 11.Huang S C, Pareek A, Zamanian R, et al Multimodal fusion with deep neural networks for leveraging CT imaging and electronic health record: a case-study in pulmonary embolism detection. Sci Rep. 2020;10(1):22147. doi: 10.1038/s41598-020-78888-w. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 12.Li J, Li D, Xiong C, et al. Blip: Bootstrapping language-image pre-training for unified vision-language understanding and generation// International Conference on Machine Learning. PMLR, 2022: 12888-12900.
- 13.Bao H, Wang W, Dong L, et al VLMo: Unified vision-language pre-training with mixture-of-modality-experts. Adv Neural Inf Process Syst. 2022;35:32897–32912. [Google Scholar]
- 14.Li J, Selvaraju R, Gotmare A, et al Align before fuse: Vision and language representation learning with momentum distillation. Adv Neural Inf Process Syst. 2021;34:9694–9705. [Google Scholar]
- 15.Vaswani A, Shazeer N, Parmar N, et al. Attention is all you need// 31st Conference on Neural Information Processing Systems (NIPS2017). Long Beach: NIPS, 2017: 6000-6010.
- 16.Touvron H, Cord M, Douze M, et al. Training data-efficient image transformers & distillation through attention// International Conference on Machine Learning. PMLR, 2021: 10347-10357.
- 17.Devlin J, Chang M W, Lee K, et al. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv preprint arXiv, 2018: 1810.04805.
- 18.Loshchilov I, Hutter F. Decoupled weight decay regularization. arXiv preprint arXiv, 2017: 1711.05101.
- 19.Nie X, Wang B, Li J, et al Deep multiscale fusion hashing for cross-modal retrieval. IEEE Trans Circuits Syst Video Technol. 2020;31(1):401–410. [Google Scholar]
- 20.Tu R C, Mao X L, Ma B, et al Deep cross-modal hashing with hashing functions and unified hash codes jointly learning. IEEE Trans Knowl Data Eng. 2020;34(2):560–572. [Google Scholar]
- 21.Li T, Yang X, Wang B, et al Bi-CMR: Bidirectional reinforcement guided hashing for effective cross-modal retrieval// Proceedings of the AAAI Conference on Artificial Intelligence. Vancouver: AAAI. 2022;36(9):10275–10282. doi: 10.1609/aaai.v36i9.21268. [DOI] [Google Scholar]
- 22.Li C, Deng C, Li N, et al. Self-supervised adversarial hashing networks for cross-modal retrieval// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Salt Lake City: IEEE, 2018: 4242-4251.
- 23.Xie D, Deng C, Li C, et al Multi-task consistency-preserving adversarial hashing for cross-modal retrieval. IEEE Trans Image Process. 2020;29:3626–3637. doi: 10.1109/TIP.2020.2963957. [DOI] [PubMed] [Google Scholar]
- 24.Xu R, Li C, Yan J, et al Graph convolutional network hashing for cross-modal retrieval// Proceedings of the Twenty-Eighth International Joint Conference on Artificial Intelligence. Macao: IJCAI. 2019;2019:982–988. [Google Scholar]
- 25.Tu J, Liu X, Lin Z, et al. Differentiable cross-modal hashing via multimodal transformers// Proceedings of the 30th ACM International Conference on Multimedia. Lisboa: ACM, 2022: 453-461.
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.
Supplementary Materials
Supplementary data to this article can be found online.