

ABSTRACT
Multistate models allow for the study of scenarios where individuals experience different events over time. While effective for descriptive and predictive purposes, multistate models are not typically used for causal inference. We propose an estimator that combines a multistate model with g‐computation to estimate the causal effect of treatment delay strategies. In particular, we estimate the impact of strategies such as awaiting natural recovery for 3 months, on the marginal probability of recovery. We use an illness–death model, where illness and death represent, respectively, treatment and recovery. We formulate the causal assumptions needed for identification and the modeling assumptions needed to estimate the quantities of interest. In a simulation study, we present scenarios where the proposed method can make more efficient use of data compared to an alternative approach using cloning–censoring–reweighting. We then showcase the proposed methodology on real data by estimating the effect of treatment delay on a cohort of 1896 couples with unexplained subfertility who seek intrauterine insemination.
Keywords: causal inference, g‐computation, multistate model, observational data, survival analysis
1. Introduction
Multistate models have gathered considerable attention in medical statistics, offering a pivotal extension of survival analysis methodology to settings where individuals may experience multiple different events over time [1, 2, 3]. Multistate models are primarily used for descriptive and predictive purposes, for example, describing the likelihood of a specific event occurring in the presence of intermediate or competing events or gaining insight into the association between prognostic factors and different transition probabilities. Transitions in the multistate model represent those observed in the data. Thus, when used on observational data, multistate models are not targeted toward answering causal questions that aim to estimate outcomes under “what if” scenarios resulting from potential interventions that change certain transitions in the model.
The value of estimating transition rates under hypothetical changes in event distributions was heavily debated in the survival analysis literature, as identification requires additional assumptions [4, 5, 6, 7, 8, 9]. In particular, survival in a hypothetical world where one competing cause of death is removed is identifiable under the assumptions that a realization of the latent failure times is unchanged by cause removal and that latent failure times are independent of one another [4, 5, 8]. Formulating these assumptions necessitates a comprehensive understanding of the mechanism under study and demands careful consideration of the setting in which the data were collected. This led many researchers to advocate for “sticking to this world” and methodological extensions of the multistate framework predominantly followed this advice by restricting to observable quantities rather than latent failure times [4, 5, 8, 10, 11].
It is nowadays increasingly recognized that when the research question is intrinsically causal, the analysis should reflect this, with careful description and assessment of the assumptions [12]. Some recent works applied a causal approach in a multistate setting. Gran et al. [13] investigated the effect of hypothetical interventions on return‐to‐work for a cohort of work rehabilitation participants, showing how multistate models can be employed to address causal questions: by including treatment/exposure as one of the states, by modeling treatment/exposure as a covariate that has an effect on some of the transitions or by reweighting the population to estimate the transition intensities in a different population. Valeri et al. [14] recently examined how inequities in access to healthcare contribute to racial disparities in the survival of cancer patients by employing a multistate model for the hypothetical scenario where a black person would have the same access to healthcare as a white person. Young et al. [15] formulated a causal framework for classical statistical estimands in failure time settings with competing events for contexts where treatment is assigned at baseline. Erdmann et al. [16] used multistate models to estimate treatment effects in the hypothetical scenario of a clinical trial where the treatment was never interrupted due to patients no longer being allowed to receive the investigational drug.
In this paper, we propose the use of an illness–death model, a specific type of multistate model, to estimate the causal effect of treatment delay from observational data in the presence of baseline confounders. In the proposed illness–death model, treatment and recovery represent, respectively, the analogue to illness and death. We provide estimands for when hypothetical modifications to the transition from the starting state to the treatment state are of interest. Investigating the impact of treatment delay has clear medical relevance, as it may help to prevent potentially expensive and invasive treatments for patients who stand a reasonable chance of recovering without intervention. However, the optimal delay of treatment initiation, often referred to as a “wait‐and‐see” or “expectant management” periods, remains largely unknown. Our multistate formulation shares similarities to that of Valeri et al. [14]. However, the estimands of interest and the formulation differ, as they approach their problem from a mediation analysis standpoint [14].
The rest of the paper is set up as follows: In Section 2, we provide a formal definition of the recovery probabilities in the hypothetical scenario of a fixed delay of treatment initiation, outline the assumptions required to identify this quantity from observational data in the presence of baseline confounding, and introduce our proposed estimation approach; in Section 3, we present a simulation study to assess the performance of our proposed method in small‐sample scenarios and compare it to the clone–censor–reweighting method [17, 18]; in Section 4, we apply our method to a cohort of couples with unexplained subfertility, studying the timing of intrauterine insemination (IUI). In Section 5, we discuss our findings.
2. Methods
2.1. Setting
We consider the situation outlined in Figure 1. Initially, all patients are untreated at time 0 (starting state), which may correspond to diagnosis or, more generally, the moment when patients consult a doctor for guidance on whether and when to initiate treatment. At this point, doctor and patient choose their treatment strategy: some patients start treatment right away, while others choose to delay treatment initiation to first see if recovery without treatment occurs. In this context, patients may transition between three states: starting state (state 1), treatment (state 2), and recovery (state 3). Some move directly from the starting state to recovery, while others first transition from the starting state to treatment. Not all patients necessarily reach the recovery state: some may never leave the starting state, and some may never leave the treatment state. This setting is known as an irreversible illness–death model in multistate literature [2]. This paper focuses on studying treatment strategies of the form “if not recovered by a certain time, then initiate treatment.” We refer to the waiting time before treatment initiation as “treatment delay.”
FIGURE 1.
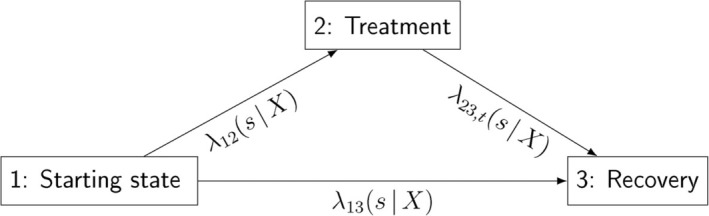
The illness–death setting: The three states (starting state, treatment, and recovery) are connected by arrows that represent the possible transitions between them. The respective transition intensities between states are depicted.
2.2. Notation and Estimand
Let denote the time since entry on the starting state (). We let be the time from baseline to recovery. Some patients transition directly from the starting state to recovery, while others first receive treatment. We let be the time to first event (so either recovery if the patient recovers untreated or treatment if the patient receives treatment first). Following a competing risks notation, we define the indicator that takes value 1 if the patient is treated and takes value 2 if the patient recovers without treatment. We then let be time from baseline to censoring. We let be the observed recovery time, with status indicator that takes value 1 if we observe the recovery and 0 if the patient is censored before recovery. We let be the observed first event with indicator that takes value 1 if the patient is treated, takes value 2 if the patient recovers without treatment, and takes value 0 if the patient is censored before either treatment or recovery. Times and depend on , a vector of baseline covariates that confound the relation between treatment time and recovery.
We let be a treatment strategy of the form “if not yet recovered by time , then initiate treatment at .” The strategy “never assign treatment” corresponds to . We define as the potential recovery time under treatment strategy . Our estimand of interest is , the marginal, that is, population averaged, recovery probability by a fixed time point under treatment strategy .
2.3. Multistate Model
We define the (observable) hazard rates, also known as transition intensities [2], for the three transitions as
| (1) |
We define the cumulative hazard function for the transitions as
| (2) |
and the functions , and as
| (3) |
where indicates the product taken over the infinitesimally small intervals . We remark that the functions (), while they can be estimated, cannot in general be interpreted as survival distributions. Only when the competing events (and the censoring process) are independent conditionally on can these functions be interpreted as the survival distribution in the situation that the competing event does not occur. We refer to literature [2] for further background.
2.4. Identification of Causal Effects for Multistate Models
In the following, we demonstrate how our quantity of interest is identifiable under four identifiability conditions: consistency and, conditional on a set of baseline covariates , positivity, exchangeability, and independent censoring. These conditions, delineated in this section, represent an adapted version of the standard identifiability conditions used in causal inference for time‐to‐event outcomes [19], to match our setting of interest. Under these assumptions, the following identification formula holds:
| (4) |
We will now formulate in detail the four identifiability conditions and prove Equation (4) under these conditions.
Let be the time‐dependent treatment indicator that takes the value 0 if the patient is still untreated at time and 1 otherwise and let be the treatment history up to : . Similarly, let be the time‐dependent censoring indicator that takes the value 0 if the patient is uncensored at time and 1 otherwise, and let be the censoring history up to : . Under this notation, the identifiability conditions are
Consistency: if and ) if . This means that the counterfactual outcome is equal to the outcome on those subjects who actually follow the treatment strategy .
-
Positivity: .
In other words, the treatment rate at time given for subjects who have not yet recovered, have not yet been treated, and are not yet censored is larger than 0 for every treatment strategy of interest and for all observed values of . This also implies that there are still subjects at risk for transitions and at time .
- Conditional Exchangeability: for ,
In other words, within each level of , the probability of being treated during the interval is independent of the outcome under treatment strategy in that same interval for all . The conditional exchangeability assumption requires that, within each level of the baseline confounder , treated and untreated patients are comparable at each treatment time, meaning those who receive treatment are representative of those who do not (and vice versa). This assumption holds when the decision to initiate treatment is made based on baseline characteristics only, as outlined in Section 2.1. If the decision to initiate treatment is based on time‐varying confounders, this assumption is not met. -
Independent Censoring: for :
- ;
- for , .
In other words, and the observed treatment strategy are independent of the censoring mechanism conditionally on . Similarly to the conditional exchangeability assumption, the independent censoring assumption requires that, within each level of , the patients who remain uncensored at each censoring time are representative of those who were censored.
Let us now denote by the counterfactual hazard rate of recovery under treatment strategy :
| (5) |
Under this notation
| (6) |
where the first equality is due to the law of total expectation and the second follows by splitting the interval into infinitesimally small sub‐intervals. By assuming consistency, positivity, and conditional exchangeability, for , we have
| (7) |
Conditional exchangeability (C.E.) ensures the first equality as it allows us to condition on patients who are still untreated just before time . Consistency (Co.) ensures the second equality as it allows us to switch from the condition to , which combined with yields the condition . Conditional exchangeability ensures the third equality of Equation (7) as it allows restricting to patients who remain untreated during the next short amount of time and, together with consistency, it ensures we can switch from the counterfactual to the factual . Points (a) and (b) of the independent censoring (I.C.) assumption ensure that , and are mutually independent and, therefore, that we can condition on patients who are still uncensored (and untreated) just before time (fourth equality of Equation (7)). Points (a) and (b) of the independent censoring assumption (I.C.) ensure, together with , the fifth equality of Equation (7), as they allow restricting to patients who remain uncensored (and untreated) during the next short amount of time . Positivity ensures that there are subjects at risk for transition for all , ensuring that exists for all . This would not happen if, for example, patients with certain values all received treatment before time . Similarly, for :
Conditional exchangeability ensures the first equality as it allows us to condition on patients who were treated at time . Consistency ensures the second equality as it allows us to switch from the condition to . The independent censoring assumption ensures, together with , the equality of the quantities at lines 3 and 4. Positivity ensures that there are subjects that did transition from state 1 to state 2 at time , ensuring that exists.
This means that when the identifiability conditions hold, the transition intensities and remain unchanged after the modification of transition . It follows that we can replace the quantity in Equation (6) by for and by for , yielding Equation (4).
2.5. Estimation
We propose a semi‐parametric g‐computation, which relies on the correct specification of the outcome model, that is, of transition hazards and . We model and using a Cox‐type model with a clock‐reset at the time of treatment initiation:
| (8) |
where and represent baseline hazards for and , respectively; is the (possibly time‐dependent) parameter vector for the effect of on recovery without treatment; is the (possibly time‐dependent) parameter vector for the effect of on recovery after treatment; is the parameter vector for the effect of treatment delay on recovery after treatment; and and are functions representing the (possibly time‐dependent) multiplication factor on the log scale for the hazards of transitions and , respectively, for an individual with covariate values . With the proposed semi‐parametric multistate method, we are less concerned about random violations of the positivity assumption. Unlike non‐parametric estimation of (4), this method allows us to borrow information across treatment strategies and levels of , so it is not necessary to observe each treatment strategy for the every level of . Resetting the clock is helpful for treatment strategies where is close to 0. As all individuals start untreated, data may be insufficient for the correct estimation of with a clock‐forward approach. The flexibility in borrowing information comes at the expense of further assumptions, that is, the correct specification of and . A simple choice for these hazards would be using Cox proportional hazards models: and , where the parameter vectors , and do not vary over time. This version of the hazards can be used if the assumptions of linearity and proportional hazards hold. Under this simple choice, the following estimator of (4) can be used:
| (9) |
where the cumulative baseline hazards and can be estimated by means of the Breslow estimator and indicates that we average over the empirical distribution of in the sample. Interactions can be included in the covariate set if needed for correct model specification. If the linearity or the proportional hazard assumptions fail for a covariate, an alternative functional form of that covariate or an interaction of that covariate with an appropriate function of time could be employed. We refer to the literature [20] for further details on model selection.
3. Simulation
We report our simulation setup and results according to the ADEMP (Aims, Data generating mechanisms, Estimands, Methods, Performance measures) structure [21].
3.1. Simulation Setup
Aim
The aim of this simulation is to evaluate the small‐sample performance of our proposed method and, secondly, to compare accuracy and efficiency to clone–censor–reweighting, an existing method, based on inverse probability weighting, that could alternatively be used for the estimation of the effect of treatment delay from observational data [17, 18, 22].
Data Generating Mechanism
We generated four different scenarios. Scenario 1 is the base scenario. Each subsequent scenario differs from the base scenario by introducing one single modification in the data generating mechanism. In all presented scenarios, we generated the data in such a way that the assumptions of consistency, conditional exchangeability, and positivity, conditional on the covariate , hold. Parameter choices are loosely based on the data application presented in Section 4. To allow for clearer interpretation of the results, each scenario presented here assumes constant baseline hazards, modeled with an exponential distribution. For comparison, results from the same four scenarios using time‐varying baseline hazards from a Weibull distribution are provided in Appendix A.
Scenario 1—Base: We generated data representing patients. We generated one continuous baseline covariate , which influences both time‐to‐treatment and time‐to‐recovery. We then generated:
A latent time of recovery without treatment with hazard ;
A latent time of treatment , drawn from a discrete distribution with and discrete hazard at times ; if no treatment time is drawn, we assume the patient remains untreated until the end of follow‐up;
A latent post‐treatment time of recovery with hazard , so that the hazard of recovery decreases if treatment is started later;
A latent censoring time with hazard .
The choice to generate discrete treatment times, and not continuous, for our base scenario was motivated by wanting to ensure practical positivity for all treatment strategies that we wished to study, which is especially needed for clone–censor–reweight approach. The observed final data set was made up of the following covariates: (i) the covariate ; (ii) time of first event with treatment status indicator ; and (iii) time of recovery if and if .
The remaining scenarios challenge different assumptions regarding the correct model specification. We modify the data generating mechanism for transition to challenge our proposed multistate approach, which requires the correct specification of the outcome model, and we modify the transition to challenge the clone–censor–reweight method, which requires the correct specification of the time‐to‐treatment model. The generating mechanism for transition remains unchanged across all scenarios, as modifying transition is enough to challenge models that require the correct specification of the outcome model.
Scenario 2—Continuous Treatment Times: Time of treatment was drawn from a continuous distribution with exponential hazard function .
Scenario 3—Non‐proportional Effect of in Transition : The effect of on the log hazard for was modeled by separate baseline hazards, one for each discrete treatment time . The new hazard function of transition followed a Weibull distribution, with the shape parameter that depends on . This makes the proportional hazard assumption fail for transition with respect to the variable . We chose the shape parameter , yielding the hazard at time . This choice regarding the shape parameter was made to obtain recovery rates that are similar to the base scenario, to make it easier to compare results across scenarios.
Scenario 4—Non‐proportional Effect of in Transition : Instead of a constant effect () of on the discrete hazard of transition , as in the base scenario, we used a time‐dependent effect , which varies quadratically over time. This makes the proportional hazard assumption fail for transition with respect to the covariate .
Estimand
The estimand of interest was , for , with a given treatment initiation strategy. In this simulation, we compared the following strategies: initiating treatment right away (), at , at , at and not initiating treatment before time 1.5 (we will refer to this strategy as the “Never” strategy).
Methods
We compared the proposed multistate method to the clone–censor–reweight method [17, 18]. To gain deeper insight from this comparison, we considered two variants of each method: one variant assumes that treatment delay is a continuous variable and has a linear effect on the log hazard of the outcome model, while the other categorizes treatment delay and stratifies hazards by treatment delay. All methods rely on the causal identifiability conditions presented in Section 2.4.
Multistate Continuous: We fitted the multistate model using Cox proportional hazards models, with hazards and as specified in Equation (8). Treatment delay was included as a continuous variable in the model for the log hazard for the transition from treatment to recovery, assuming linearity. Recovery probabilities under different treatment strategies were then estimated as presented in Equation (9). For this method, we need correct specification of and .
Multistate Categorical: We modeled , stratifying the baseline hazard by treatment delay . In scenario 2 where time to treatment is continuous, treatment delay was categorized into , with levels , , , , , . Patients who received treatment after 1.5 (time horizon) were censored at the time of treatment to avoid creating baseline hazards based on too few or too incomparable individuals (which are unnecessary for estimating our target estimand). The choice of intervals was aimed at obtaining similar results to scenario 1. This method also relies on the correct specification of and .
Clone–Censor–Reweight Categorical: We performed the following: (i) cloning: each individual was assigned to one or more treatment strategies at time zero by creating clones, one for each treatment strategy that was compatible with their observed data at time zero; (ii) censoring: clones were artificially censored when they deviated from their assigned strategy; and (iii) reweighting: inverse probability weighting was used to address the dependent censoring we introduced in the data. For the estimation of the weights, a time‐to‐treatment Cox model was used, assuming a linear and proportional effect of . In the simulation runs where infinite weights were produced, weights were trimmed to the 97.5 percentile. After cloning, censoring, and reweighting, we estimated the recovery probabilities by means of a (reweighted) Kaplan–Meier estimator. In scenario 2, where time to treatment was continuous, we introduced grace windows spanning 0.125 before and after the target treatment delay, effectively changing the estimand slightly. For example, treatment strategy “start at 0” became “start before time 0.125” and treatment strategy “start at 0.5” became “start between 0.375 and 0.625.” This method relies on the correct specification of the time‐to‐treatment model.
Clone–Censor–Reweight Continuous: After cloning, censoring, and reweighting the observational data as described in the previous method, the recovery probabilities were estimated via a (reweighted) Cox model. In the Cox model, the baseline hazard was stratified by treatment yes/no and treatment delay was included linearly as a single continuous variable for the stratum “treatment = yes.” Time was reset after treatment initiation. For scenario 2, grace windows spanning 0.125 before and after the target treatment delay were used for cloning, censoring, and reweighting. In the estimation of the reweighted Cox model, the treatment delay variable took the value associated with the treatment strategy of each clone (e.g., for clones who are consistent with the “start before 0.125” grace period, we used treatment delay equal to 0; for clones consistent with “start between 0.375 and 0.625” strategy, we used treatment delay equal to 0.5). Unlike the categorical method, this approach did not change the estimand, as we used the Cox model to estimate the probability of recovery for specific point values of treatment delay. This approach relies on the correct specification of both the time‐to‐treatment model and the Cox model and assumes that individuals who start treatment within the grace window can be combined together into a single group.
Performance Measures
Performance of the four methods was assessed numerically through bias and root‐mean‐square error (RMSE) at time horizon (1.5) and visually by comparing the true and estimated recovery probabilities along a fine grid of time horizons between 0 and 1.5. The truth was computed as the numerical integral , where is the underlying probability density function of used in the data generation. We used the hazard as the true latent post‐treatment hazard of recovery under treatment strategy .
3.2. Software
All analyses were conducted using the statistical software R (version 4.3.1) [23] using the packages mstate [24], survival [25], tidyverse [26], and matrixStats [27]. Our simulation code is available at https://github.com/survival‐lumc/CausalMultistate.
3.3. Simulation Results
We ran our simulation 200 times. Table 1 provides numerical assessment of bias and RMSE at time horizon 1.5 for all four scenarios. Figure 2 provides a visual representation of the simulation results for the base scenario (scenario 1). Figures for the other scenarios can be found in Appendix A.
TABLE 1.
Simulation results.
| Multistate continuous | Multistate categorical | CCR continuous | CCR categorical | ||||||
|---|---|---|---|---|---|---|---|---|---|
| Scenario | Strategy | Bias | RMSE | Bias | RMSE | Bias | RMSE | Bias | RMSE |
| 1‐Base: Correctly | 0 months | 0.00 | 0.03 | −0.01 | 0.05 | 0.00 | 0.03 | 0.00 | 0.05 |
| specified models | 3 months | 0.00 | 0.02 | −0.01 | 0.03 | 0.00 | 0.02 | 0.00 | 0.03 |
| 6 months | 0.00 | 0.02 | −0.01 | 0.04 | 0.00 | 0.02 | 0.00 | 0.03 | |
| 9 months | 0.00 | 0.01 | −0.01 | 0.04 | 0.00 | 0.02 | 0.00 | 0.04 | |
| 1 year | 0.00 | 0.02 | 0.00 | 0.03 | 0.00 | 0.02 | 0.00 | 0.03 | |
| Never | 0.00 | 0.01 | 0.00 | 0.01 | 0.00 | 0.01 | 0.00 | 0.01 | |
| 2‐Continuous | 0 months | 0.00 | 0.02 | −0.01 | 0.05 | −0.01 | 0.03 | −0.02 | 0.05 |
| treatment times | 3 months | 0.00 | 0.02 | 0.00 | 0.03 | 0.00 | 0.03 | −0.01 | 0.04 |
| 6 months | 0.00 | 0.02 | 0.00 | 0.04 | 0.00 | 0.02 | −0.01 | 0.04 | |
| 9 months | 0.00 | 0.01 | 0.00 | 0.03 | 0.00 | 0.02 | −0.01 | 0.04 | |
| 1 year | 0.00 | 0.01 | 0.00 | 0.03 | 0.00 | 0.02 | −0.01 | 0.03 | |
| Never | 0.00 | 0.01 | 0.00 | 0.01 | 0.00 | 0.01 | 0.00 | 0.01 | |
| 3‐Non‐proportional | 0 months | 0.01 | 0.02 | −0.01 | 0.04 | −0.01 | 0.03 | 0.00 | 0.05 |
| effect of in | 3 months | 0.00 | 0.02 | −0.01 | 0.03 | −0.01 | 0.02 | 0.00 | 0.03 |
| transition | 6 months | 0.00 | 0.02 | 0.00 | 0.04 | 0.00 | 0.02 | 0.00 | 0.04 |
| 9 months | 0.01 | 0.02 | 0.00 | 0.03 | 0.01 | 0.02 | 0.00 | 0.03 | |
| 1 year | 0.02 | 0.03 | 0.00 | 0.03 | 0.04 | 0.04 | 0.00 | 0.03 | |
| Never | 0.00 | 0.01 | 0.00 | 0.01 | 0.00 | 0.01 | 0.00 | 0.01 | |
| 4‐Non‐proportional | 0 months | 0.00 | 0.02 | −0.01 | 0.05 | 0.03 | 0.04 | −0.01 | 0.05 |
| effect of in | 3 months | 0.00 | 0.02 | 0.00 | 0.03 | 0.01 | 0.02 | 0.03 | 0.04 |
| transition | 6 months | 0.00 | 0.01 | 0.00 | 0.03 | 0.00 | 0.02 | 0.02 | 0.04 |
| 9 months | 0.00 | 0.01 | 0.00 | 0.03 | −0.02 | 0.02 | −0.01 | 0.04 | |
| 1 year | 0.00 | 0.01 | 0.00 | 0.02 | −0.02 | 0.03 | −0.03 | 0.04 | |
| Never | 0.00 | 0.01 | 0.00 | 0.01 | −0.01 | 0.01 | −0.01 | 0.01 | |
Note: Bias and root‐mean‐squared error (RMSE) averaged over 200 simulation runs for the estimates of the cumulative recovery probabilities at time 1.5 under six treatment strategies: initiate immediately, delayed at 0.25, delayed at 0.5, delayed at 0.75, delayed at 1, and never initiate (before 1.5). Four estimation approaches are reported: (i) Multistate continuous; (ii) Multistate categorical; (iii) Clone–censor–reweight (CCR) continuous; (iv) CCR categorical. Four scenarios are presented: (1) assumptions needed for all estimation approaches are met; (2) time of treatment is generated continuously; (3) the effect of treatment delay on time‐to‐recovery is non‐proportional; and (4) the effect of the covariate on time‐to‐treatment is non‐proportional. Standard errors (SEs) of the simulation can be derived using the relation RMSE = SE
= SE + Bias
+ Bias .
.
FIGURE 2.
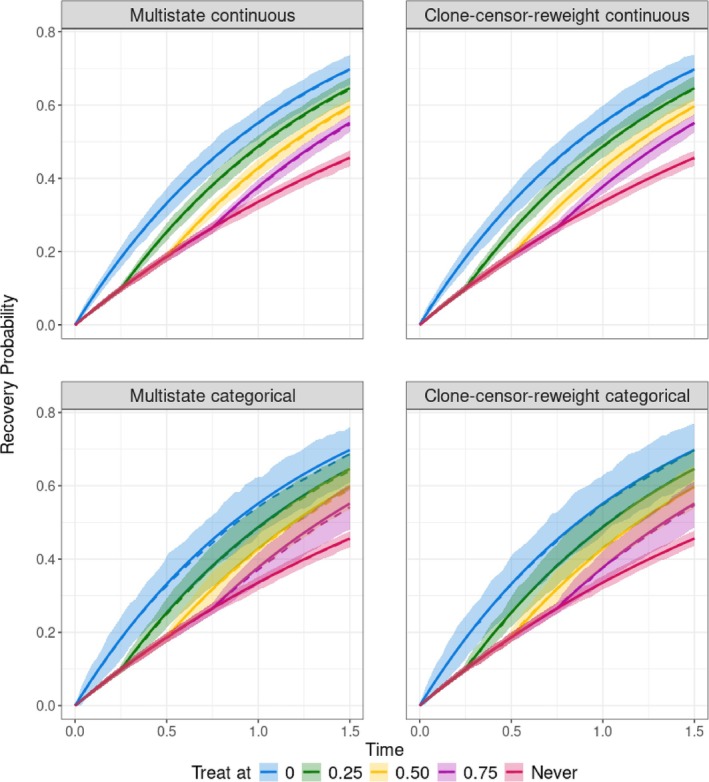
Visual representation of the simulation results for scenario 1, where assumptions needed for all estimation approaches are met. Cumulative recovery probabilities until time 1.5 are plotted under five treatment strategies: initiate immediately, delayed at 0.25, delayed at 0.5, delayed at 0.75, and never initiate. Four estimation approaches are reported: (i) Multistate continuous; (ii) Multistate categorical; (iii) Clone–censor–reweight continuous; (iv) Clone–censor–reweight categorical. The solid lines represent the true values, the dotted line represents the mean of the estimates, and the shaded area represents the [5th–95th] percentile of the estimates.
In the base scenario (scenario 1), all methods performed well. This was expected, as data were generated in a way such that assumptions needed for all four estimation approaches were met. The multistate continuous model showed the smallest [5th–95th] percentile range of the estimates in Figure 2 and smallest RMSEs in Table 1. The clone–censor–reweight continuous ranked second in terms of RMSE.
In scenario 2, where treatment initiation was generated continuously, the multistate continuous yielded the smallest bias and RMSE, while the clone–censor–reweight categorical method presented bias for strategies where treatment was initiated (see Table 1 and Figure 4 in Appendix A). This is consistent with the fact that this method targeted a slightly different estimand. In 47 out of the 200 scenarios examined, the clone–censor–reweight method produced infinite weights, which were trimmed. This observation aligns with clone–censor–reweighting being more susceptible to random violations to positivity, which is common when treatment initiation is a continuous variable.
In scenario 3, where treatment delay influenced the log hazard of the recovery chances non‐proportionally, the multistate continuous and the clone–censor–reweight continuous showed bias due to incorrect model specification (see Table 1 and Figure 5 in Appendix A). For these methods, the RMSEs at 1.5 increased compared to scenario 1. For the other two methods, the RMSEs remained unchanged from scenario 1.
In the fourth scenario, where the covariate influenced the log hazard of the recovery chances non‐proportionally, the two clone–censor–reweight approaches showed increased bias and RMSE compared to the base scenario as the model for the weights was not correctly specified.
4. Data Application
We applied the proposed method to estimate the probability of getting pregnant within 1.5 years after workup completion under different treatment delay strategies for patients with unexplained subfertility, defined as having tried to conceive naturally for over a year without success [28, 29] despite having parameters of infertility within normal ranges. The interest in determining whether and for how long to delay treatment initiation stems from the fact that while treatment usually increases the pregnancy probabilities [30, 31, 32], it also carries potential negative side effects associated with IUI, such as the potential risks of the hormonal therapy accompanying IUI and the financial and psychological burden on the couple.
We used data from a prospective cohort that was recruited across 38 hospitals in The Netherlands between January 2000 and October 2005. A more detailed description of the protocol and of the clinical definitions and setting can be found elsewhere [33, 34]. For the current study, we included couples with unexplained subfertility from seven (out of 38) centers that additionally collected data on IUI. These centers included 1896 couples, with at most 4 years of follow‐up. Of these couples, 569 became pregnant without treatment and 863 received IUI treatment. Cumulative probabilities over the time of pregnancy without treatment and of IUI treatment can be found in Appendix B. Of the 863 couples who received treatment, 163 became pregnant after treatment.
We set time 0 at the completion of workup, marking the start of “expectant management” (starting state, state 1). Some couples successfully achieved pregnancy (recovery, state 3) within 1.5 years, whereas others remained in either state 1 (they did not start treatment and did not conceive within 1.5 years) or 2 (they started treatment but did not conceive within 1.5 years). Treatment initiation could occur at any time during follow‐up, making it a continuous variable.
The estimands of interest were the probability of getting pregnant by 1.5 years if treatment was (i) initiated at 0 months; (ii) initiated at 6 months; and (iii) not initiated within 1.5 years. We included in the model the baseline covariates that were tested during the couples' workup and which may influence the future pregnancy probability as well as the choice to start IUI quickly or delay its initiation. These covariates are female age, subfertility duration, gynecologist referral (yes/no), infertility type (primary = no pregnancies before/secondary = lasting pregnancy before), fallopian tubal blockage (no blockage, one‐sided blockage, no test), and percentage of progressive sperm count. The covariate age and progressive sperm count were centered and standardized for the analysis.
We modeled the two outcome transitions and by means of a Cox proportional hazards model, assuming proportional hazards and linearity. Confidence intervals were obtained by bootstrapping.
We relied on the assumptions of consistency, positivity, conditional exchangeability, conditional independent censoring, and correct model specification. While the assumptions of consistency and conditional exchangeability are not testable, they were plausible in our context. The well‐defined delay periods supported the assumption of consistency, and the fact that no further evaluations were performed on these couples after workup completion supported the assumption of conditional exchangeability. We evaluated the validity of the positivity assumption in the data. Details can be found in Appendix B. The assumption of a conditionally independent censoring mechanism, although it could not be checked in the data, also appeared plausible. In our analysis, couples were mainly censored to start in vitro fertilization (IVF). The decision to start with IVF was largely influenced by the covariates in the dataset, and thus conditional independence seemed plausible to assume [35]. For the correct model specification assumption in the multistate model, we checked the assumptions of linearity (by plotting Martingale residuals) and proportional hazards (by testing the Schoenfeld residuals) for both transitions and . Based on the linearity checks, subfertility duration and treatment delay were log‐transformed before being used as covariates. No notable violations of the proportional hazards assumption were found. We assessed the completeness of follow‐up for the study population over 1.5 years for both transitions and by means of a reverse Kaplan–Meier to ensure that we had an adequate number of individuals in the at‐risk set to at all time points. Figures and further details can be found in Appendix B.
Figure 3 shows the results of our analysis. Our findings suggest that, on average, initiating treatment directly or delaying treatment for 6 months yields similar pregnancy probabilities at 1.5 years post‐workup. This implies that delaying treatment does not significantly diminish the likelihood of pregnancy at 1.5 years while reducing the number of couples undergoing treatment. Not initiating IUI treatment before 1.5 years leads to lower pregnancy probabilities at 1.5 years. However, the wide confidence intervals prevent us from firm conclusions. For the “treat at 0 months” strategy, confidence intervals are particularly wide: this aligns with transition having only a few subjects that were followed up for 1.5 years.
FIGURE 3.
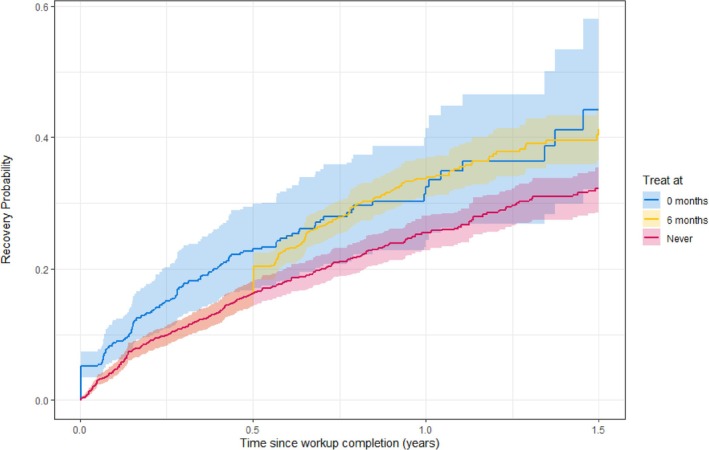
Estimated cumulative pregnancy probability for unexplained subfertile couples if they are assigned different treatment strategies.
5. Discussion
In this paper, we propose an illness–death model combined with g‐computation that allows estimating the impact of treatment delay in observational data where all patients commence without treatment, and the intended treatment delay remains unobserved for patients who recover before starting treatment. Illness–death modeling provides a natural framework for this semi‐competing risk problem. The strength of our work lies in the careful formulation of the set of assumptions under which it is possible to use an illness–death model to draw causal conclusions on the effect of treatment delay. As a key finding, we demonstrated that the identifiability conditions commonly used in causal inference—consistency, positivity, and conditional exchangeability—imply, in the presented illness–death model, that other transition rates remain unchanged after modifying the transition to treatment. While survival analysis experts, as noted in the introduction, often caution against assuming that other transition rates are unaffected by such modifications, we formally show that, under these identifiability conditions, the transition rates for and indeed remain unchanged when the transition is modified, as detailed in Section 2.4. The identifiability conditions provide a more intuitive framework compared to directly assuming that transition rates remain unchanged.
In our proposed estimation approach, we reset the clock after treatment and include treatment delay as a covariate. When using illness–death models, researchers can generally choose between a clock‐forward or clock‐reset approach, corresponding to Markov and Markov renewal models, respectively, and decide whether to include the time of arrival in the state as a covariate, which further relaxes the Markov (renewal) assumption. As remarked in the paper by Putter et al. [2], these modeling choices should primarily be informed by the clinical context. Our modeling choice was motivated by two main considerations. First, in our data application, the more relevant time scale after treatment is time since treatment. Second, data may be insufficient for a correct estimation of the hazard of transition with a clock‐forward approach, as noted in Section 2.5. It is important to highlight that transition is the only transition for which these modeling choices require careful evaluation. The other two transitions, which create a competing risk scenario, are always Markovian due to the absence of prior event history [2].
With simulations, we compared the performance of our proposed method to the clone–censor–reweight method. Both approaches are expected to provide asymptotically unbiased estimates of the probability of recovery under different treatment strategies when their respective assumptions are met. We evaluated scenarios in which the modeling assumptions for both methods held, as well as cases where these assumptions were violated, illustrating where and how each method may fail in limited sample sizes. Our proposed method may fail when either one (or both) of the transitions to the outcome is misspecified, whereas the clone–censor–reweight method may fail when the time‐to‐treatment model for the weights is misspecified. In the scenarios where the modeling assumptions for both methods hold, our multistate model exhibits greater efficiency (smaller variance) in utilizing data compared to the clone–censor–reweight approach, as it borrows information across different delay strategies for both the effect of the covariates and the effect of treatment delay. This finding is consistent with the existing literature, where g‐computation typically outperforms inverse probability weighting methods in terms of efficiency [36, 37, 38]. Double robust methods are able to provide consistent estimates when either the model for the weights or the outcome model is correctly specified. Exploring double‐robust methods for estimating treatment delay could be a promising avenue for future research.
A limitation of our method is that it does not account for time‐varying confounding, which occurs in situations where treatment decisions are influenced by prognostic factors beyond baseline characteristics. This happens, for instance, if patients are monitored regularly and treatment decisions are made based on their current health status. Our data application provided an ideal setting to demonstrate our methodology, as treatment initiation decisions were made using only baseline information. Exploring extensions of the current methodology to incorporate time‐varying confounders could be a potentially valuable direction for future research.
A second limitation is that our method does not account for competing events, which are relevant when patients can reach a state where treatment is no longer an option. For example, if treatment time was initially planned but the patient later developed conditions preventing them from receiving it, the current approach would need adaptation. In our data application, no such events occurred. While death and treatment ineligibility could in principle be competing events, their probability within our target population (couples trying to conceive with unexplained subfertility) was negligible, with no occurrences in our dataset. A possible extension of our approach could involve defining a new treatment strategy of interest, such as “treat at if not yet recovered and no competing event has occurred”, with the cumulative incidence of recovery if everyone followed treatment strategy as the estimand. Extending identifiability conditions to this scenario warrants further exploration.
Conflicts of Interest
The authors declare no conflicts of interest.
Supporting information
Data S1. Supplement Materials.
Data S1. Data Files.
Acknowledgments
We would like to thank Rik van Eekelen, Kristine Openshaw, and Matea Skypala for their contribution in this project. We also thank the CECERM study group (Collaborative Effort for Clinical Evaluation in Reproductive Medicine) who collected the data with grant support from ZonMw, The Netherlands Organization for Health Research and Development, The Hague, The Netherlands, grant 945/12/002. Finally, we would like to thank the anonymous reviewers and the associate editor for their comments and suggestions.
References
- 1. Meira‐Machado L., de Uña‐Álvarez J., Cadarso‐Suárez C., and Andersen P. K., “Multi‐State Models for the Analysis of Time‐To‐Event Data,” Statistical Methods in Medical Research 18, no. 2 (2009): 195–222. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 2. Putter H., Fiocco M., and Geskus R. B., “Tutorial in Biostatistics: Competing Risks and Multi‐State Models,” Statistics in Medicine 26, no. 11 (2007): 2389–2430. [DOI] [PubMed] [Google Scholar]
- 3. Andersen P. K. and Pohar P. M., “Inference for Outcome Probabilities in Multi‐State Models,” Lifetime Data Analysis 14, no. 4 (2008): 405–431. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 4. Tsiatis A., “A Nonidentifiability Aspect of the Problem of Competing Risks,” National Academy of Sciences of the United States of America 72, no. 1 (1975): 20–22. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 5. Prentice R. L., Kalbfleisch J. D., Peterson A. V., Flournoy N., Farewell V. T., and Breslow N. E., “The Analysis of Failure Times in the Presence of Competing Risks,” Biometrics 34, no. 4 (1978): 541. [PubMed] [Google Scholar]
- 6. Cox D. R., “The Analysis of Exponentially Distributed Life‐Times With Two Types of Failure,” Journal of the Royal Statistical Society, Series B 21, no. 2 (1959): 411–421. [Google Scholar]
- 7. Moeschberger M. L. and David H. A., “Life Tests Under Competing Causes of Failure and the Theory of Competing Risks,” Biometrics 27, no. 4 (1971): 909–933. [Google Scholar]
- 8. Gail M., “A Review and Critique of Some Models Used in Competing Risk Analysis,” Biometrics 31, no. 1 (1975): 209–222. [PubMed] [Google Scholar]
- 9. Keiding N., Klein J. P., and Horowitz M. M., “Multi‐State Models and Outcome Prediction in Bone Marrow Transplantation,” Statistics in Medicine 20, no. 12 (2001): 1871–1885. [DOI] [PubMed] [Google Scholar]
- 10. Pepe M. S. and Mori M., “Kaplan—Meier, Marginal or Conditional Probability Curves in Summarizing Competing Risks Failure Time Data?,” Statistics in Medicine 12, no. 8 (1993): 737–751. [DOI] [PubMed] [Google Scholar]
- 11. Andersen P. K. and Keiding N., “Interpretability and Importance of Functionals in Competing Risks and Multistate Models,” Statistics in Medicine 31, no. 11–12 (2012): 1074–1088. [DOI] [PubMed] [Google Scholar]
- 12. Hernán M. A., “The C‐Word: Scientific Euphemisms Do Not Improve Causal Inference From Observational Data,” American Journal of Public Health 108, no. 5 (2018): 616–619. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 13. Gran J. M., Lie S. A., Øyeflaten I., Borgan Ø., and Aalen O. O., “Causal Inference in Multi‐State Models–Sickness Absence and Work for 1145 Participants After Work Rehabilitation,” BMC Public Health 15, no. 1 (2015): 1082. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 14. Valeri L., Proust‐Lima C., Fan W., Chen J. T., and Jacqmin‐Gadda H., “A Multistate Approach for the Study of Interventions on an Intermediate Time‐To‐Event in Health Disparities Research,” Statistical Methods in Medical Research 32, no. 8 (2023): 1445–1460. [DOI] [PubMed] [Google Scholar]
- 15. Young J. G., Stensrud M. J., Tchetgen E. J. T., and Hernán M. A., “A Causal Framework for Classical Statistical Estimands in Failure Time Settings With Competing Events,” Statistics in Medicine 39, no. 8 (2020): 1199–1236. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 16. Erdmann A., Loos A., and Beyersmann J., “A Connection Between Survival Multistate Models and Causal Inference for External Treatment Interruptions,” Statistical Methods in Medical Research 32, no. 2 (2023): 267–286. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 17. Hernán M. A., “How to Estimate the Effect of Treatment Duration on Survival Outcomes Using Observational Data,” BMJ 360 (2018): k182. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 18. Maringe C., Benitez Majano S., Exarchakou A., et al., “Reflection on Modern Methods: Trial Emulation in the Presence of Immortal‐Time Bias. Assessing the Benefit of Major Surgery for Elderly Lung Cancer Patients Using Observational Data,” International Journal of Epidemiology 49, no. 5 (2020): 1719–1729. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 19. Hernán M. and Robins J. M., Causal Inference (Chapman & Hall/CRC, 2023). [Google Scholar]
- 20. Klein J. P. and Moeschberger M. L., Survival Analysis: Techniques for Censored and Truncated Data (Springer, 2005). [Google Scholar]
- 21. Morris T. P., White I. R., and Crowther M. J., “Using Simulation Studies to Evaluate Statistical Methods,” Statistics in Medicine 38, no. 11 (2019): 2074–2102. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 22. Gaber C. E., Hanson K. A., Kim S., Lund J. L., Lee T. A., and Murray E. J., “The Clone‐Censor‐Weight Method in Pharmacoepidemiologic Research: Foundations and Methodological Implementation,” Current Epidemiology Reports 11 (2024): 164–174. [Google Scholar]
- 23. RStudio Team , “RStudio: Integrated Development Environment for R,” in RStudio (PBC, 2020). [Google Scholar]
- 24. de Wreede L. C., Fiocco M., and Putter H., “The Mstate Package for Estimation and Prediction in Non‐ and Semi‐Parametric Multi‐State and Competing Risks Models,” Computer Methods and Programs in Biomedicine 99, no. 3 (2010): 261–274. [DOI] [PubMed] [Google Scholar]
- 25. Therneau T. M., “A Package for Survival Analysis in R,” 2023. R Package Version 3.5‐7.
- 26. Wickham H., Averick M., Bryan J., et al., “Welcome to the Tidyverse,” Journal of Open Source Software 4, no. 43 (2019): 1686. [Google Scholar]
- 27. Bengtsson H., “Matrixstats: Functions That Apply to Rows and Columns of Matrices (and to Vectors),” 2023. R Package Version 1.0.0.
- 28. Habbema J. D. F., Collins J., Leridon H., Evers J. L. H., Lunenfeld B., and te Velde E. R., “Towards Less Confusing Terminology in Reproductive Medicine: A Proposal,” Human Reproduction 19, no. 7 (2004): 1497–1501. [DOI] [PubMed] [Google Scholar]
- 29. Gnoth C., Godehardt E., Frank‐Herrmann P., Friol K., Tigges J., and Freundl G., “Definition and Prevalence of Subfertility and Infertility,” Human Reproduction 20, no. 5 (2005): 1144–1147. [DOI] [PubMed] [Google Scholar]
- 30. Farquhar C. M., Liu E., Armstrong S., Arroll N., Lensen S., and Brown J., “Intrauterine Insemination With Ovarian Stimulation Versus Expectant Management for Unexplained Infertility (TUI): A Pragmatic, Open‐Label, Randomised, Controlled two‐Centre Trial,” Lancet 391, no. 10119 (2018): 441–450. [DOI] [PubMed] [Google Scholar]
- 31. Farhi J. and Orvieto R., “Cumulative Clinical Pregnancy Rates After COH and IUI in Subfertile Couples,” Gynecological Endocrinology 26, no. 7 (2010): 500–504. [DOI] [PubMed] [Google Scholar]
- 32. van Eekelen R., van Geloven N., van Wely M., et al., “Is IUI With Ovarian Stimulation Effective in Couples With Unexplained Subfertility?,” Human Reproduction 34, no. 1 (2019): 84–91. [DOI] [PubMed] [Google Scholar]
- 33. van der Steeg J., Steures P., Eijkemans M., et al., “Pregnancy Is Predictable: A Large‐Scale Prospective External Validation of the Prediction of Spontaneous Pregnancy in Subfertile Couples,” Human Reproduction 22, no. 2 (2007): 536–542. [DOI] [PubMed] [Google Scholar]
- 34. Custers I. M., Steures P., van der Steeg J. W., et al., “External Validation of a Prediction Model for an Ongoing Pregnancy After Intrauterine Insemination,” Fertility and Sterility 88, no. 2 (2007): 425–431. [DOI] [PubMed] [Google Scholar]
- 35. van Geloven N., Geskus R. B., Mol B. W., and Zwinderman A. H., “Correcting for the Dependent Competing Risk of Treatment Using Inverse Probability of Censoring Weighting and Copulas in the Estimation of Natural Conception Chances,” Statistics in Medicine 33, no. 26 (2014): 4671–4680. [DOI] [PubMed] [Google Scholar]
- 36. Goetghebeur E., le Cessie S., De Stavola B., Moodie E. E., and Waernbaum I., “Formulating Causal Questions and Principled Statistical Answers,” Statistics in Medicine 39, no. 30 (2020): 4922–4948. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 37. Denz R., Klaaßen‐Mielke R., and Timmesfeld N., “A Comparison of Different Methods to Adjust Survival Curves for Confounders,” Statistics in Medicine 42, no. 10 (2023): 1461–1479. [DOI] [PubMed] [Google Scholar]
- 38. Ren J., Cislo P., Cappelleri J. C., Hlavacek P., and DiBonaventura M., “Comparing G‐Computation, Propensity Score‐Based Weighting, and Targeted Maximum Likelihood Estimation for Analyzing Externally Controlled Trials With Both Measured and Unmeasured Confounders: A Simulation Study,” BMC Medical Research Methodology 23, no. 1 (2023): 18. [DOI] [PMC free article] [PubMed] [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.
Supplementary Materials
Data S1. Supplement Materials.
Data S1. Data Files.