

Abstract
In recent years, landslides have occurred frequently around the world, resulting in significant casualties and property damage. A notable example occurred in 2014, when a landslide in the Argo region of Afghanistan claimed over 2000 lives, becoming one of the most devastating landslide events in history. The increasing frequency and severity of landslides present significant challenges to geological disaster monitoring, making the development of efficient and accurate detection methods critical for disaster mitigation and prevention. This study proposes an intelligent recognition method for landslides, which is based on the latest deep learning model, YOLOv11-seg, which is designed to address the challenges posed by complex terrains and the diverse characteristics of landslides. Using the Bijie-Landslide dataset, the method optimizes the feature extraction and segmentation modules of YOLOv11-seg, enhancing both the accuracy of landslide boundary detection and the pixel-level segmentation of landslide areas. Compared with traditional methods, YOLOv11-seg performs better in detecting complex boundaries and handling occlusion, demonstrating superior detection accuracy and segmentation quality. During the preprocessing phase, various data augmentation techniques, including mirroring, rotation, and color adjustment, were employed, significantly improving the model’s generalization performance and robustness across varying terrains, seasons, and lighting conditions. The experimental results indicate that the YOLOv11-seg model excels in several key performance metrics, such as precision, recall, F1 score, and mAP. Specifically, the F1 score reaches 0.8781 for boundary detection and 0.8114 for segmentation, whereas the mAP for bounding box (B) detection and mask (M) segmentation tasks outperforms traditional methods. These results highlight the high reliability and adaptability of YOLOv11-seg for landslide detection. This research provides new technological support for intelligent landslide monitoring and risk assessment, highlighting its potential in geological disaster monitoring.
Supplementary Information
The online version contains supplementary material available at 10.1038/s41598-025-95959-y.
Keywords: Landslide disasters, YOLOv11-seg, Intelligent recognition, Boundary detection, Data augmentation
Subject terms: Natural hazards, Mathematics and computing
Introduction
Landslides are devastating geological disasters that predominantly occur in mountainous, hilly, and plateau regions and present significant threats to human life, property, and infrastructure1. Each year, landslides result in approximately 1000 fatalities globally, with economic losses amounting to 4 billion USD2. Between 1995 and 2014, 128 countries reported fatal landslides, which together caused 163,658 deaths and 11,689 injuries3,4. In China, the combination of complex terrain and frequent rainfall intensifies the severity of landslide disasters. According to the “National Geological Disaster Bulletin (2019)”5, a total of 6181 landslides occurred in mainland China in 2019, resulting in direct economic losses of 2.77 billion RMB6. Additionally, landslides have significant impacts on ecosystems, including soil erosion, vegetation loss, and water pollution, which endanger the sustainability of natural environments7,8. With the increasing effects of climate change and increased human activities, the risk of landslides is projected to increase further. Therefore, improving landslide disaster monitoring and early warning systems has become an urgent global challenge that requires immediate attention.
Traditional methods for landslide detection, such as field surveys, BeiDou satellite positioning9,10, sensor-based detection11, and remote sensing techniques12, each present unique advantages and limitations. Field surveys involving high-precision onsite investigations allow for detailed analyses of landslide characteristics, such as scale, type, and depth. However, these methods face practical challenges, including high costs, long durations, and limited spatial coverage. Additionally, in geotechnical engineering, limit equilibrium methods (LEM) have been widely used for slope stability analysis by estimating safety factors (F.S.) and identifying potential failure mechanisms13. These methods provide valuable insights into slope stability under different geological conditions and are commonly applied to both natural and engineered slopes. In contrast, BeiDou satellite positioning is unaffected by weather conditions, allowing for precise measurements even in adverse environments such as snow, rain, and fog, with millimeter-level accuracy. However, its flexibility in selecting measurement points is relatively constrained. As remote sensing technology continues to evolve, optical remote sensing has emerged as an increasingly important supplementary method for landslide monitoring. By utilizing high-resolution imaging devices on satellites or drones, optical remote sensing enables the rapid acquisition of large-scale ground imagery, significantly enhancing the capacity for monitoring and assessing landslide-prone areas14,15. For example, Li et al.16 used optical remote sensing images from satellites and drones to detect early signs of landslides in China and identify potential geomorphic indicators. Chen et al.17 proposed the CTDNet landslide detection method, which is based on a dual network of Swin-Unet and ConvNeXt-Trans, which greatly improved the detection accuracy on multichannel optical remote sensing images. Fang et al.18 developed a Siamese framework (GSF) using generative adversarial networks (GANs), which combines domain adaptation with landslide detection modules to successfully distinguish landslides from other terrain changes in dual-phase optical remote sensing images, demonstrating superior performance over traditional methods. Lan et al.19 reviewed the applications of optical remote sensing, synthetic aperture radar (SAR), and thermal infrared remote sensing technologies in identifying large landslides, emphasizing how combining these technologies can significantly enhance landslide monitoring and early warning capabilities. Yang et al.20 used Sentinel-2 imagery and Cos-Corr image correlation methods to monitor slope deformation successfully before the 2018 Baige Mountain landslide, highlighting the high accuracy of optical remote sensing in landslide prediction for remote mountainous regions. Ju et al.21 proposed an object detection-based loess landslide monitoring method that employs high-resolution remote sensing images for automatic identification, which has the potential to improve landslide monitoring and risk assessment. Sreelakshmi et al.22 introduced a method that combines visual saliency with superresolution remote sensing data, significantly enhancing the detection accuracy of subtle landslide features by improving image resolution. Li et al.23 integrated DS-InSAR with optical imagery to identify and analyze landslides in the Ahaiku area of the Jinsha River Basin. This approach demonstrated the effectiveness of multisource data fusion, resulting in improved landslide detection accuracy. Satriano et al.24 employed multitemporal satellite optical imagery to monitor the dynamic evolution of landslides, achieving substantial improvements in detection and mapping accuracy and providing an effective tool for risk assessment in affected areas. Dong et al.25 combined SAR, optical imagery, and digital elevation model (DEM) data with other remote sensing techniques to conduct a comprehensive assessment of landslide risk in the Three Gorges region. The results highlighted the benefits of integrating diverse remote sensing technologies to increase the precision and reliability of landslide risk evaluations. Yang et al.26 proposed a landslide susceptibility estimation method based on multimodal remote sensing data and semantic information, which combines optical, radar, and elevation data. This method significantly improved the accuracy of susceptibility mapping and provided more comprehensive tools for risk management and early warning systems. Although optical remote sensing technology offers significant advantages in capturing large-scale surface images, its effectiveness in complex terrains and adverse weather conditions remains limited. It is highly sensitive to environmental factors such as weather and lighting conditions, making real-time monitoring challenging27. Similarly, D-InSAR and PSI methods, while effective in tracking surface deformation, require long processing times and multiple acquisitions to generate displacement maps, making them less suitable for real-time landslide detection and early warning systems28. Furthermore, traditional remote sensing methods often rely on complex technical procedures, which are not well suited for real-time detection and early warning. As a result, the development of deep learning-based landslide detection technologies has become crucial for enhancing disaster prevention efforts and ensuring public safety. Deep learning approaches can overcome the limitations of traditional methods by providing more accurate and efficient landslide detection and prediction methods, offering reliable technical support for disaster monitoring and emergency response29.
With the advancement of computer vision technologies, deep learning has increasingly been applied in landslide detection, particularly offering notable advantages in real-time processing and automation. Deep learning techniques can quickly and accurately detect landslides across large, complex terrains, providing robust support for monitoring and early warning systems. Convolutional neural networks (CNNs), a key technology in deep learning, have found wide applications in landslide detection30. Recent research has demonstrated that CNN-based deep neural networks (DNNs) can effectively predict landslide susceptibility, achieving significantly higher accuracy compared to traditional machine learning methods such as support vector machines (SVM), decision trees (DT), and logistic regression (LR)31. For example, Renza et al.32 proposed a CNN-based model for assessing landslide susceptibility via multispectral remote sensing data. This model incorporates various factors, such as terrain, land use, and soil properties, enabling accurate identification of landslide-prone areas and making it highly suitable for large-scale landslide risk assessments and disaster prevention. Hakim et al.33 combined CNNs with metaheuristic optimization algorithms, such as the genetic algorithm (GA) and particle swarm optimization (PSO), to automatically extract spatial features from remote sensing data and optimize hyperparameters. This approach significantly improved the accuracy of landslide susceptibility prediction, particularly in complex terrains such as Icheon, South Korea, where it provided more accurate landslide risk assessments. Xu et al.34 introduced a deep CNN model constrained by environmental features, such as rainfall, terrain, and vegetation, to address the challenges posed by data scarcity. This model notably improved the precision and reliability of landslide mapping in Brazil, offering a valuable tool for landslide risk management in similar regions. Landslide detection techniques extend beyond simple object detection to include semantic segmentation, which enables automated monitoring and precise identification of landslide events. These advancements have significantly enhanced the efficiency and accuracy of landslide disaster monitoring, with extensive potential applications in disaster risk management and early warning systems35.
Semantic segmentation is a typical application in the field of computer vision and is widely used in autonomous driving and robotics36. In landslide detection, semantic segmentation helps accurately delineate landslide areas and distinguish them from other types of surface cover. Commonly used models for semantic segmentation include SegNet36, U-Net37, Deeplabv3+38, and Msak-RCNN39. Yu et al.36 proposed an end-to-end deep semantic segmentation framework based on a two-branch SegNet matrix for landslide detection, which demonstrated strong performance. Ghorbanzadeh et al.40 evaluated the transferability of the U-Net and ResU-Net models for landslide detection. Their study revealed that ResU-Net outperforms U-Net in terms of detection accuracy across various regions, indicating greater cross-regional applicability. Lu et al.41 introduced a dual-encoder U-Net approach that integrates Sentinel-2 imagery and DEM data, significantly enhancing landslide detection accuracy and robustness, particularly in complex terrains. Chen et al.42 combined U-Net with multisource remote sensing data to develop postearthquake landslide susceptibility maps, accurately predicting the spatial distribution of landslides after seismic events and providing valuable support for postdisaster risk assessment. Nava et al.43 advanced this by developing a U-Net model with attention mechanisms, specifically for rapid detection and mapping of landslides in SAR data. Liu et al.44 further optimized U-Net, improving its robustness and accuracy, which enhanced the precision of postearthquake landslide detection. For more complex detection tasks, Gao et al.10 proposed the E-DeepLabV3 + model, which reduces the parameter count compared with DeepLabV3+, facilitating more efficient training and deployment while yielding superior landslide detection results. Wan et al.38 introduced an improved version of DeepLabV3+, incorporating a feature fusion module that merges BotNet and ResNet feature maps to enhance both local and global feature extraction, thereby improving detection accuracy. Wu et al.45 presented an enhanced DeepLabv3 + model that improves the accuracy of semantic segmentation for landslides. Additionally, the Mask R-CNN has become widely adopted in landslide detection. Ullo et al.46 developed a Mask R-CNN-based method for distinguishing landslides from other land cover types, which demonstrated excellent performance in landslide monitoring and early warning, particularly in complex landscapes. Fu et al.47 proposed a new Mask R-CNN model optimized for detecting earthquake-triggered landslides, improving detection speed and accuracy and greatly enhancing its real-time application and early warning capabilities. Liu et al.48 combined an optimized version of the Mask R-CNN with InSAR images, successfully automating landslide detection in the eastern Tibetan Plateau with exceptional results. Wu et al.39 applied a deep learning model based on Mask R-CNN to identify landslides triggered by extreme rainfall in the Beijiang River Basin. Using high-resolution satellite imagery, their method achieved outstanding accuracy in landslide monitoring and risk assessment following heavy rains. Despite the considerable advantages of semantic segmentation methods in landslide detection, their limitations continue to drive ongoing research into more precise object detection techniques.
Object detection technology plays a crucial role in landslide recognition via remote sensing images, with the Faster R-CNN and YOLO (You Only Look Once) series of algorithms being the two most widely adopted methods. Qin et al.49 introduced an object detection algorithm for remote sensing images based on Faster R-CNN, replacing VGG16 and ResNet50 with DarkNet53. The integration of skip connections overcomes the vanishing gradient problem commonly found in deep networks. To address the issue of limited landslide data, researchers have performed data augmentation, significantly improving detection accuracy. Yang et al.50 enhanced the Faster R-CNN algorithm by optimizing the network structure, achieving an 8.8% increase in accuracy and an 8.4% improvement in mean precision, demonstrating the model’s superiority for landslide detection. YOLO-based algorithms, known for their excellent real-time performance and efficiency, have also become essential for landslide detection. For example, Lian et al.51 proposed an improved YOLO algorithm tailored for rapid detection and localization of mining area landslides. By optimizing the YOLO model, the recognition accuracy and real-time performance in complex mining environments were significantly enhanced. Zhang et al.52 developed the LS-YOLO model, which uses multiscale feature extraction to improve detection accuracy for landslides of varying sizes. The LS-YOLO model outperforms traditional methods in the large-scale remote sensing monitoring of landslides. Yang et al.53 proposed a lightweight attention-guided YOLO model, which, by incorporating a level set layer, improved accuracy, computational efficiency, and precision for landslide detection in optical satellite images, making it especially useful for large-scale monitoring. Wang et al.54 combined YOLO and U-Net models in a multimodel fusion approach, achieving efficient multiscale detection and accurate localization in complex backgrounds. Han et al.55 introduced the Dynahead-YOLO-Otsu method, which combines semantic segmentation to enhance landslide area segmentation, especially for complex terrains and multiscale landslides. Liu et al.56 proposed an intelligent landslide recognition method for loess regions via an improved YOLO algorithm, validating its effectiveness in complex backgrounds and multiscale landslide detection. Cheng et al.57 designed a compact attention YOLO model for landslide detection in resource-constrained environments. Du et al.58 presented a lightweight LBE-YOLO framework aimed at improving the efficiency and accuracy of real-time landslide detection. Guo et al.59 integrated SBAS-InSAR technology with YOLO and proposed a method that combines ground deformation monitoring with object detection. This approach demonstrated significant improvements in landslide detection accuracy across large-scale monitoring areas. Despite the strong performance of YOLO algorithms in real-time detection, their earlier versions still face challenges in handling complex terrains and fine detail processing, particularly with fine segmentation and localization accuracy. This opens the door for further optimization in future research.
To overcome the limitations of existing methods, this paper proposes a novel intelligent landslide recognition approach based on the YOLOv11-seg model. Unlike traditional YOLO models that focus solely on object detection, the proposed YOLOv11-seg integrates semantic segmentation into the architecture. This integration is designed to harness the rapid detection capabilities of YOLO while simultaneously achieving high-resolution boundary delineation of landslide areas. The rationale behind this design is that while object detection provides robust localization, it often lacks the precision needed for accurately delineating the complex boundaries of landslide regions. By incorporating segmentation techniques, the model not only maintains real-time performance but also significantly enhances detection accuracy, particularly in heterogeneous and complex terrains. The main goal of this paper is to enhance the YOLOv11-seg model architecture, optimize data processing workflows, and incorporate state-of-the-art image preprocessing techniques, further increasing landslide detection accuracy and efficiency. Specifically, the following improvements are proposed: (1) A landslide recognition method based on YOLOv11-seg, which combines object detection and image segmentation to significantly increase the accuracy of landslide detection; (2) an optimized data processing pipeline, which enhances the model’s adaptability to complex terrains and large-scale areas; and (3) through extensive experiments, the modified model demonstrates superior performance in both landslide detection and segmentation, outperforming current mainstream methods. This work provides new insights and practical solutions for the advancement of intelligent landslide recognition technologies and their future applications.
YOLOv11-seg algorithm overview
Algorithm introduction
Ultralytics, founded in 2018, specializes in deep learning and computer vision, with significant contributions to the field of object detection. The YOLO series, as its flagship product, has rapidly gained widespread adoption since its initial release. The core concept of YOLO algorithms is to divide the input image into uniform grids, where each grid is responsible for predicting the coordinates of the target’s center, enabling end-to-end training and efficient detection60. This approach treats object detection as a regression task, allowing multiple target locations, sizes, and categories to be predicted through a single forward pass. This simplification enhances computational efficiency and improves the model’s ability to capture global context information. By leveraging a multiscale prediction strategy, YOLO can perform detection on feature maps at various scales, significantly enhancing its ability to detect small targets and handle complex scenes. Compared with traditional object detection methods, YOLO’s grid-based approach minimizes the need for complex preprocessing and postprocessing, improving the detection speed while maintaining a balance between accuracy and efficiency60. Furthermore, the architecture of YOLO models is relatively straightforward, making them easy to optimize and deploy across various applications, such as surveillance, autonomous driving, traffic monitoring, and robotic vision61.
Ultralytics continues to update and maintain its codebase, regularly incorporating new features to ensure its competitive edge. The YOLO series has now evolved to YOLOv11. Below is a summary of the technical developments and key features across YOLO versions: YOLOv362 (Released in 2018): YOLOv3 introduces Darknet-53 as the backbone architecture, replacing YOLOv2’s Darknet-19 and alleviating the vanishing gradient problem through residual connections. A neck was added, and a feature pyramid network (FPN)63 was used for multiscale feature prediction, enhancing small object detection performance. The classification method was enhanced to support multilabel classification. YOLOv464,65 (Released in 2020): YOLOv4 incorporates several data augmentation techniques (e.g., Mosaic, CutMix) during training to improve the model’s generalization ability. CSPDarknet-5366 was adopted as the backbone architecture, and a cross-stage partial connection module was added to reduce the computational load. The neck uses spatial pyramid pooling (SPP)66 and a path aggregation network (PAN)66, improving feature propagation effectiveness. YOLOv564,65 (released in 2020): YOLOv5 introduced mosaic data augmentation and custom anchor boxes. The backbone combines Focus and CSP modules, significantly improving learning performance and reducing computational costs. The neck structure adds the CSP module to YOLOv4’s neck, improving small object detection. YOLOv5 is based on the PyTorch framework, simplifying training and deployment, and offers various model sizes to suit different hardware environments. YOLOv667 (Released in 2022): This version incorporates the EfficientDet68 concept, designing the efficient backbone network EfficientRep and the Rep-PAN neck. It adopted more efficient detection heads and a new label assignment strategy, focusing on industrial applications. YOLOv6-nano achieved 35% precision and a 1242 FPS inference speed on the COCO dataset. YOLOv767 (released in 2022): YOLOv7 eliminates anchor boxes and introduces new data augmentation techniques. The backbone was replaced with BConv, E-ELAN69, and MPConv layers, while the neck and head layers were merged, improving small object detection in complex environments. YOLOv866 (Released in 2023): YOLOv8 is structurally similar to YOLOv5 but replaces the C3 module with the C2f module, further lightening the architecture. It also adopts an anchor-free, split-head Ultralytics design to improve detection accuracy and support various visual tasks. YOLOv967 (released in 2023): YOLOv9 introduces programmable gradient information (PGI) and the generalized efficient layer aggregation network (GELAN) architecture, enhancing model learning capacity and overcoming information loss in deep neural networks. YOLOv9 offers multiple model sizes to meet different needs. YOLOv1071 (Released in 2024): YOLOv10 redesigned the architecture, eliminating nonmaximum suppression (NMS) to improve detection performance and efficiency. The backbone adopted an updated CSP version, improving gradient flow and reducing computational overhead. Multiple model sizes are available, significantly lowering the latency and parameter count. Through both vertical and horizontal comparisons from YOLOv3 to YOLOv10, the YOLO series has continuously evolved in terms of accuracy, speed, and application scope. Each version has addressed the shortcomings of its predecessor and incorporated emerging techniques to meet the ever-changing demands of practical applications. This has kept YOLO at the forefront of object detection, with widespread applications in fields such as autonomous driving, traffic monitoring, healthcare, and industrial automation67. As shown in Fig. 1, with each YOLO series version upgrade, both the overall accuracy and inference are improved.
Fig. 1.

Comparison of accuracy and inference delay performance of YOLO series models on the COCO dataset.
YOLOv11 is the latest version released by the Ultralytics team during the YOLOVision event on September 30, 2024. The model achieves improved accuracy and faster processing speeds through enhanced feature extraction capabilities, optimized architectural design, and refined training procedures. Additionally, YOLOv11 demonstrates exceptional adaptability across different environments, supporting various tasks such as object detection, instance segmentation, and image classification. YOLOv11-seg, an important extension of YOLOv11, is specifically optimized for image segmentation tasks, significantly improving pixel-level classification accuracy. By integrating more refined feature extraction modules and advanced segmentation heads, it accurately captures both object contours and internal details, enhancing segmentation quality. The model predicts not only object bounding boxes but also class probabilities for each pixel, enabling end-to-end instance and semantic segmentation. The output of YOLOv11-seg consists of masks or contours outlining each object in the image, along with class labels and confidence scores for each object. YOLOv11-seg accurately determines the location and exact shape of objects within an image.
The YOLOv11-seg model is available in several versions to accommodate different computational resources and performance requirements. These versions vary in model size and complexity and are distinguished by the labels n, s, m, l, and x, representing five scales from smallest to largest. The pretrained parameters for each version are detailed in Table 1 The performance, inference rate, and computational complexity of the versions differ when processing images sized 640 pixels. As the model size increases, the average precision computed on the test set improves. However, the time required to process a single image—whether on a CPU using the ONNX format or on an NVIDIA T4 GPU using TensorRT—also increases, as do the model’s parameter count and floating-point operations (FLOPs). In this study, we use the largest version of the YOLOv11-seg model for the experiments and analysis.
Table 1.
Comparison of the performance of the five different size models of YOLOv11-seg.
| Model | Size (pixels) | mAPbox50−95 | mAPmask50−95 | SpeedCPU ONNX (ms) | SpeedT4 TensorRT10 (ms) | Params (M) | FLOPs (B) |
|---|---|---|---|---|---|---|---|
| YOLO11n-seg | 640 | 38.9 | 32.0 | 65.9 ± 1.1 | 1.8 ± 0.0 | 2.9 | 10.4 |
| YOLO11s-seg | 640 | 46.6 | 37.8 | 117.6 ± 4.9 | 2.9 ± 0.0 | 10.1 | 35.5 |
| YOLO11m-seg | 640 | 51.5 | 41.5 | 281.6 ± 1.2 | 6.3 ± 0.1 | 22.4 | 123.3 |
| YOLO11-seg | 640 | 53.4 | 42.9 | 344.2 ± 3.2 | 7.8 ± 0.2 | 27.6 | 142.2 |
| YOLO11x-seg | 640 | 54.7 | 43.8 | 664.5 ± 3.2 | 15.8 ± 0.7 | 62.1 | 319.0 |
In the field of intelligent landslide detection, selecting an appropriate model requires balancing multiple factors, including real-time performance, computational efficiency, and segmentation accuracy. As shown in Table 2, mainstream deep learning models such as YOLOv11-seg, DETR, Mask R-CNN, U-Net, DeepLabV3+, SegFormer, EfficientDet, and Swin Transformer exhibit distinct characteristics suited for different applications. Among these, YOLOv11-seg excels in real-time landslide detection, whereas DETR, Mask R-CNN, and DeepLabV3+ are more advantageous for high-precision segmentation and large-scale remote sensing image analysis.
Table 2.
Simplified comparison of object detection and segmentation models.
| Model | Key features | Computational complexity | Inference speed (FPS) | Application scenarios |
|---|---|---|---|---|
| YOLOv11-seg74 | Fast single-stage detection + segmentation | Low | 30–60 | Real-time landslide detection (UAV) |
| DETR75 | Transformer-based, no anchor boxes | High | 10–20 | Complex scene object detection |
| U-Net76 | Full-image segmentation, high precision | High | 5–10 | Landslide segmentation |
| Mask R-CNN76 | Two-stage detection, detailed masks | Very high | 2–7 | High-precision segmentation |
| DeepLabV3+77 | Dilated convolution for better segmentation | High | 8–15 | Large-scale land segmentation |
| SegFormer78 | Transformer-based, robust segmentation | High | 5–10 | Large-area segmentation |
| EfficientDet79 | Lightweight, efficient detection | Low | 20–30 | Mobile deployment, efficient |
| Swin Transformer80 | High-precision Transformer model | Extremely high | 5–8 | Complex landslide recognition |
In real-time landslide detection scenarios, YOLOv11-seg achieves an inference speed of 30–60 FPS with an efficient single-stage detection mechanism, making it the optimal choice for UAV-based monitoring and edge computing devices. By comparison, models such as DETR, Mask R-CNN, and SegFormer achieve higher accuracy in specific tasks but have significantly higher computational complexity, resulting in slower inference speeds (e.g., Mask R-CNN: 2–7 FPS), making them unsuitable for real-time applications. EfficientDet offers a viable alternative with an inference speed of 20–30 FPS, demonstrating good deployment potential on resource-constrained devices, though its segmentation performance remains inferior to YOLOv11-seg.
For fine-grained landslide segmentation, Mask R-CNN and DeepLabV3 + achieve superior pixel-level accuracy but suffer from reduced inference speeds due to their two-stage detection (Mask R-CNN) and computationally intensive atrous convolutions (DeepLabV3+). SegFormer, which integrates Transformer and CNN architectures, is more suited for large-scale segmentation tasks but remains computationally demanding (5–10 FPS), making it better suited for offline geological disaster studies than UAV-based real-time monitoring. In contrast, YOLOv11-seg is the only lightweight model that balances end-to-end object detection and segmentation while maintaining high computational efficiency.
For large-scale remote sensing-based landslide detection, DETR and Swin Transformer leverage Transformer architectures to enhance global feature modeling, improving landslide recognition in complex terrains with significant background interference. However, their high computational complexity, long training times, and slow inference speeds (e.g., DETR: 10–20 FPS) limit their suitability for real-time applications, making them more appropriate for offline disaster assessment and remote sensing image analysis.
In resource-constrained environments, YOLOv11-seg and EfficientDet remain the best deployment options. YOLOv11-seg, following extensive optimization, can operate on NVIDIA Jetson Nano and mobile GPUs, while EfficientDet performs well in mobile inference with its compact model size and lower computational requirements.
Overall, YOLOv11-seg stands out as the optimal choice for intelligent landslide detection, offering a combination of real-time performance, efficient segmentation, and low computational cost, making it ideal for UAV monitoring, edge computing, and rapid response tasks.
Network structure
In the field of object detection, YOLOv11 introduces several key innovations aimed at enhancing both detection accuracy and processing speed. The overall architecture consists of three main components: the backbone (feature extraction network), the neck (feature fusion layer), and the head (detection head) (Fig. 2). The specific characteristics of each component are described below:
Fig. 2.

YOLOv11 network structure diagram.
Backbone: This component is primarily responsible for feature extraction and representation, providing rich feature information essential for object detection tasks. Through efficient feature extraction methods, the backbone enhances the model’s ability to recognize diverse objects and improves the overall detection accuracy. YOLOv11 incorporates several innovative modules into the backbone design to optimize network performance and improve adaptability to complex scenes. The key modules are as follows: (1) Convolutional layers: By deepening the network and expanding the convolution kernel size, these layers strengthen the feature extraction capabilities. These modifications not only enhance the model’s ability to capture local features but also improve its capacity to learn global feature representations. (2) C3k2 Module: This module enhances feature representation. YOLOv11 replaces the C2f attention module from YOLOv8 with the C3k2 module, which improves the network’s adaptability to multiscale objects through local feature extraction and channel grouping convolution techniques. It also provides a richer feature foundation for subsequent feature fusion and classification tasks. (3) Spatial pyramid pooling (SPPF) module: This module enhances feature extraction by pooling features across multiple scales, enabling the model to capture multiscale feature information effectively and improving its ability to adapt to objects of varying sizes. (4) Attention mechanism (C2PSA) module: The C2PSA module highlights key features while suppressing redundant information. By combining both channel and spatial attention mechanisms, the model adapts to the most useful features for object detection, dynamically adjusting the weight of each feature channel. For a detailed description of the C2PSA structure and its key modules, please refer to “YOLOv11 technical features”. The feature maps generated by the Backbone are passed to the neck layer for further feature fusion and object detection. By effectively extracting and representing rich feature information, the backbone serves as a strong foundation for enhancing the overall performance of the YOLOv11 model.
Neck (feature fusion layer): The main task of the neck is to fuse features from different scales to improve the object detection performance. The neck layer combines spatial information from lower-level features with semantic information from higher-level features, thereby enhancing the detection performance for objects of varying sizes. Additionally, an adaptive feature fusion module is introduced, enabling the neck layer to dynamically adjust feature weights on the basis of different scenes and object types. This further improves the model’s generalization ability and detection accuracy. The key modules are as follows: (1) Upsampling module: This module is responsible for upsampling the deep-layer feature maps to match the size of the lower-level feature maps, thereby effectively combining high-level semantic information with low-level spatial information. (2) Concatenation module: During feature map processing, the upsampled feature map is concatenated with the corresponding lower-level feature map along the channel dimension. This preserves the detailed information from the lower-level features while merging the abstract semantics from the higher-level features, thus enhancing the detection performance for multiscale objects. (3) C3k2 Module: YOLOv11 replaces the C2f attention module from YOLOv8 with the C3k2 module in Neck. While the C3k2 module itself does not directly adjust feature weights adaptively, its design supports the network in optimizing feature weights via the backpropagation process during training. The neck layer outputs multiple feature maps, which are then passed as inputs to the head module for final object classification and bounding box regression. By generating feature maps at multiple scales, YOLOv11 effectively handles objects of different sizes, meeting the needs of object detection tasks.
Head (Detection Head): The main task of the detection head is to perform final object classification and bounding box regression on the feature maps from the neck layer, outputting the object class probabilities, bounding box coordinates, and confidence scores for each feature map. The design of YOLOv11’s detection head aims to achieve fast, efficient object detection while ensuring high accuracy and real-time performance. YOLOv11’s head includes multiple output layers, called “Detect,” with each output layer corresponding to feature maps from different scales. Detect employs a variety of optimization strategies to increase the model’s detection capability and response speed. For a detailed explanation of the Detect structure and its key modules, please refer to “YOLOv11 technical features”.
YOLOv11 technical features
C3k2
The structure of the C3k2 module, as shown in Fig. 3, is an enhancement of the C2f module in YOLOv11, which is designed to increase flexibility and efficiency. This module introduces a controllable parameter, c3k, allowing for different structural configurations. When c3k is set to false, the C3k2 module retains the original design of C2f and uses the standard bottleneck module; when c3k is true, the bottleneck module is replaced by a more efficient C3k module.
Fig. 3.

C3k2 module.
The bottleneck module is a widely used structure in convolutional neural networks and is designed to reduce the feature map’s dimensionality, thus lowering the computational load and performing feature extraction on the reduced feature map. The bottleneck module typically consists of three parts: first, a 1 × 1 convolution to reduce the number of channels in the feature map; then, a 3 × 3 convolution for feature extraction; and finally, another 1 × 1 convolution to restore the original number of channels. This structure effectively increases the network’s depth and performance while controlling the number of parameters and computational complexity.
The C3k module integrates channel-grouped convolutions with local feature extraction techniques to enable faster inference speed and lower computational costs. The C3k2 module optimizes feature extraction while preserving model accuracy, allowing YOLOv11 to adapt more effectively to various task requirements, thus enhancing the model’s versatility and flexibility.
C2 PSA
The structure of the C2PSA module, as shown in Fig. 4, is a recently introduced feature enhancement module in YOLOv11, which is based on the C2f module and incorporates the multihead attention mechanism, known as the position-sensitive attention (PSA)79. By combining the multihead attention mechanism with a feedforward network, the C2PSA module significantly enhances the model’s ability to focus on target-relevant features, enabling more precise target recognition. The feature enhancement process is as follows:
Fig. 4.

C2PSA module.
The C2PSA module first applies convolutional layers to process the input feature map. This convolution operation is typically used to extract features and increase their abstraction. The convolutional layers extract local features, enriching the representation for the subsequent attention mechanism.
After the convolutional layers, the C2PSA module incorporates the PSABlock. The PSABlock uses the multihead attention mechanism to dynamically adjust the focus to different feature locations. By computing the attention weights of the input features, the module effectively identifies important target regions and enhances the model’s ability to focus on key features. Each attention head independently learns feature relationships and captures different contextual information.
After processing by the PSABlock, the C2PSA module concatenates the original feature map with the feature map enhanced by the attention mechanism. This preserves the original features while incorporating key features extracted via the attention mechanism, allowing the model to understand the input data more comprehensively.
Finally, the C2PSA module applies another convolutional layer to further process the concatenated feature map and extract higher-level feature representations. Through this layer, the model integrates information from all previous processing steps to generate the final output feature map.
Detect
In YOLOv11, the detection module is divided into a position regression branch and a classification branch, as shown in Fig. 5. The position regression branch predicts positions via standard convolutional layers, whereas the classification branch uses depthwise separable convolutions (DWConv)80 to achieve efficient feature fusion and interaction between channels, generating class probabilities through the Softmax activation function. This design enables the detection head to perform parallel predictions across multiple scales, improving the detection accuracy and ensuring the model’s efficiency and speed. To achieve more accurate object detection, YOLOv11 adopts a holistic loss function that combines classification loss and regression loss, optimizing classification accuracy and bounding box localization precision. By balancing these different tasks, the model effectively learns during training. The position regression branch uses regression loss, and the classification branch uses classification loss. The roles of these loss functions are as follows:
Fig. 5.

Detection module.
Bounding Box Regression Loss (CLoU): CLoU (complete localization over union) loss is used for bounding box regression, optimizing the overlap between the predicted and ground truth boxes. Unlike traditional IoU loss, CLoU considers not only the overlap area but also the geometric information of the bounding box, such as the center, width, and height, enabling more accurate predictions of targets with varying scales and aspect ratios. This makes bounding box regression more precise, enhancing the model’s performance in complex scenes.
Classification Loss (CLSLoss): CLSLoss evaluates the model’s performance in the object classification task. It optimizes the classification ability by calculating the difference between the predicted probabilities for each class and the true labels, effectively capturing the differences between various object categories and allowing the model to better learn the unique features of each category, thereby improving classification accuracy.
Dataset acquisition and processing
Dataset construction and augmentation
The Bijie-Landslide dataset81, containing remote sensing images of landslides from the Bijie region in Guizhou, China, was used in this study. The dataset was constructed primarily through remote sensing image acquisition, ensuring coverage of landslides with varying types, scales, and seasonal characteristics, as illustrated in Fig. 6.
Fig. 6.

Example of the dataset samples.
To improve the model’s generalization capability, a series of standardized preprocessing steps were implemented, including image resizing and noise filtering, to minimize random interference and ensure stable model performance in complex environments. Additionally, to further enhance data diversity and improve the model’s adaptability to various environmental and lighting conditions, this study incorporated multiple data augmentation techniques, including mirror flipping, rotation augmentation, and color variation.
Mirror flipping, applied in both horizontal and vertical directions, increased the spatial diversity of landslide morphologies, mitigating learning bias in specific orientations. This ensured that the model could effectively recognize landslides in all directions, rather than being constrained by imbalanced directional distributions in the dataset.
Rotation augmentation was performed on both the original and mirror-flipped images, introducing 90°, 180°, and 270° rotations. This augmentation strategy helped prevent overfitting to specific landslide orientations, improved the model’s ability to detect landslides from multiple perspectives, and enhanced adaptability to terrain variations.
Color variation involved modifying brightness, contrast, and saturation to simulate changes in landslide appearance under different lighting conditions. This technique enabled the model to adjust to remote sensing images captured at various times of day, seasons, and weather conditions (e.g., sunny, cloudy, dusk), thereby increasing its robustness in complex illumination environments.
Through these augmentation strategies, the landslide dataset was significantly expanded, facilitating robust landslide recognition across diverse environmental, directional, and lighting conditions. Moreover, the expanded training dataset encompassed a broader range of feature variations, contributing to better generalization, reducing false detections and missed detections in real-world applications, and ultimately enhancing the overall reliability of the landslide disaster monitoring system.
After data augmentation, the final dataset consisted of 4312 training images, 1848 validation images, and 1025 test images. The data were split via a random sampling method, ensuring that the images in the training, validation, and test sets were balanced and representative. This approach guarantees fairness and scientific integrity during model training and testing at different stages.
Data annotation
To ensure high-quality annotation of the landslide imagery data, the LabelMe tool82 was used for manual annotation, supplemented by automatic annotation and revision via a pretrained model to ensure accuracy and reliability. During the annotation process, the boundaries of the landslide areas in each image were precisely delineated to generate label files. In the YOLO-seg dataset, the format of each line of data is as follows: < class-index > < x1 > < y1 > < x2 > < y2>. < xn > < yn>, where < class-index > represents the target class index, and the subsequent < x > and < y > values correspond to the boundary coordinates of the object’s segmentation mask, with coordinates separated by spaces. Examples include “0 0.912 0.482 0.732 0.293 0.841 0.365” (3-point segment), “0 0.527 0.123 0.613 0.276 0.489 0.142 0.478 0.067 0.357 0.0291” (5-point segment), and “0.675 0.345 0.823 0.257 0.789 0.412 0.634 0.198 0.721 0.456 0.502 0.321” (7-point segment). Due to space constraints, a detailed presentation of the actual annotation results is provided in Appendix A. This format provides precise, point-by-point coordinate information that accurately delineates the shape and boundary features of the landslide area. This precise annotation not only enhances the model’s recognition capabilities for landslide detection but also supports future tasks such as landslide range evaluation, area calculation, and various geological analyses.
Model training
Training parameter settings
In the training task for the landslide image data, the following training parameters were designed to ensure that the model could effectively identify and segment the landslide areas at high-quality resolution: (1) Epochs: The model was set to 2000 epochs to allow it to learn the complex features of the landslide areas over multiple iterations. However, the model reached the expected performance and converged early at the 510th epoch, avoiding unnecessary computational costs. (2) Batch size: A batch size of 128 was selected to provide sufficient data samples for each iteration to maintain training stability. A larger batch size helps better estimate the gradients, reduce noise, and accelerate convergence while enabling higher training efficiency when computational resources allow. (3) Imgsz: A resolution of 1280 × 1280 was used. By inputting high-resolution images, the model can capture edge details of the landslide areas, especially for the complex boundaries of the landslide regions, ensuring segmentation accuracy. In addition, larger image inputs enhance the model’s ability to adapt to landslides of different scales. (4) Pretrained weights: The YOLOv11x-seg.pt (Table 1) pretrained weights were loaded at the beginning of training. These pretrained weights contain extensive feature knowledge, providing a solid feature foundation for learning the landslide images, accelerating the model’s convergence speed, and enhancing the model’s initial recognition capabilities. (5) Learning rate: The initial learning rate was set to 0.0001, and a cosine-annealing scheduler was employed to dynamically adjust the learning rate during training. This scheduler smoothly reduces the learning rate throughout the training process, allowing the model to quickly learn key features in the early stages and adjust weights more finely in the later stages to ensure convergence to a better solution. (6) Optimizer: The AdamW optimizer was selected, utilizing adaptive learning rates and weight decay for optimization. AdamW offers stronger adaptability and stability, making it particularly suitable for training large models, and its weight decay mechanism effectively prevents overfitting during training. (7) Regularization: L2 regularization (weight decay) was applied during optimization to reduce the risk of overfitting by controlling the size of the model’s weights. L2 regularization applies a small penalty to the weights during each update, making the model more robust and improving its generalizability to real landslide data.
Through the aforementioned parameter settings, the model achieved higher segmentation accuracy and boundary localization precision on the landslide image data, resulting in high-quality detection of landslide areas. This configuration is well suited for complex object detection and segmentation tasks, offering solid technical support for the automation of landslide disaster monitoring.
All experiments were conducted on a Windows 10 operating system. The experimental setup consisted of three NVIDIA GeForce RTX 2080 Ti GPUs, each equipped with 22GB of VRAM, along with 64GB of RAM. The training process was optimized using CUDA 12.1 and cuDNN. The deep learning framework utilized was PyTorch 2.x, with TensorRT employed for inference acceleration. An NVMe SSD was used as the storage device to maximize data throughput and improve data loading efficiency. The experiments were implemented in Python 3.9, with supporting libraries including OpenCV, NumPy, and other deep learning dependencies. The model was trained for a total of 551 epochs, with each epoch taking approximately 10 min, amounting to 91.8 h of total training time.
Evaluation and analysis of the experimental results
Evaluation and analysis of the loss function
In intelligent landslide disaster recognition, the YOLOv11-seg algorithm enhances the model’s object detection and segmentation accuracy by combining multiple loss functions. Box_loss uses the CIoU to measure the difference between the predicted and ground truth bounding boxes, ensuring accurate regression of the landslide area’s position and shape. Cls_loss employs cross-entropy loss to optimize landslide classification, improving the model’s classification capability. Seg_loss combines cross-entropy and Dice loss to refine the pixel-level segmentation accuracy of the landslide region. Dfl_loss improves the localization accuracy for complex landslide areas and small objects by regressing the probability distribution of the target box. The interplay of these four loss functions enables YOLOv11-seg to excel in intelligent landslide recognition, allowing for efficient and accurate detection and segmentation in complex environments.
Box_loss
In YOLOv11-seg, bounding box loss (Box_loss) measures the error between the predicted and ground truth bounding boxes. It not only performs object detection but also integrates semantic segmentation. Therefore, when calculating the loss, it is necessary to account for the bounding box positioning accuracy, size matching, and confidence. Box_loss is the weighted sum of localization loss, width loss, height loss, and confidence loss, as shown in Eq. (1). Below is an introduction to each component and its calculation formula: (1) Localization loss: This measures the difference between the predicted and actual center points of the bounding boxes, as shown in Eq. (2). To stabilize training and prevent gradient explosion, YOLOv11-seg uses smooth L1 loss, as shown in Eq. (5). (2) Width and Height Loss: This measures the difference in width and height between the predicted and true bounding boxes, which helps optimize the target box size and improves the model’s adaptability to different target scales, as shown in Eq. (3). YOLOv11-seg also uses smooth L1 loss to calculate the errors in width and height, as shown in Eq. (5). (3) Confidence loss: This measures the difference between the predicted and true confidence levels of the bounding boxes. YOLOv11-seg uses binary cross-entropy loss to evaluate whether the predicted box correctly contains the target or is simply a background box, as shown in Eq. (4).
 |
1 |
 |
2 |
 |
3 |
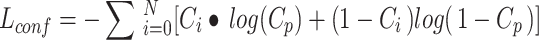 |
4 |
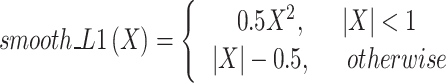 |
5 |
where xi, yi: the center coordinates of the i-th ground truth bounding box; xp, yp: the center coordinates of the i-th predicted bounding box; wi, hi: the width and height of the i-th ground truth bounding box; wp, hp: the width and height of the i-th predicted bounding box; Ci: the ground truth confidence label for the i-th box (1 indicates that the box contains an object, 0 indicates that it does not contain an object); Cp: the predicted confidence for the i-th box.
As shown in Fig. 7, a phase-by-phase analysis of the Box_loss curves for the training and validation sets provides a clear understanding of the model’s performance in localizing landslide areas. (1) Initial phase (1–50 epochs): During this phase, the box_loss curves for both the training and validation sets rapidly decrease, indicating that the model initially improved the boundaries of the landslide areas. The training set’s Box_loss began at 1.4238, whereas the validation set started at 1.9616. Both curves briefly peaked at epochs 4 and 3 (1.6977 and 2.5394, respectively) before quickly decreasing. These early fluctuations are typically attributed to the model’s instability while learning boundary features in the initial phase. (2) Middle phase (51–300 epochs): During this phase, Box_loss continues to decrease and gradually stabilizes, reflecting the model’s improved accuracy in recognizing landslide boundaries. The training set loss decreased to approximately 0.5000, and the validation set loss decreased to approximately 1.000. This suggests that the model exhibited better stability and adaptability in handling complex terrains and varying types of landslides. (3) Late phase (300–551 epochs): After 300 epochs, the Box_loss curves for both the training and validation sets converged. The training set stabilized at 0.4361, and the validation set stabilized at 0.8219, representing 74.31% and 67.64% decreases from their respective peaks and 69.37% and 58.10% decreases from their initial values. Additionally, the loss for the validation set was slightly greater than that for the training set, indicating a small discrepancy in performance on unseen data. However, overall, the model demonstrates good generalizability.
Fig. 7.

Graph of the Box_loss curves on the training and validation sets.
Overall, the notable reduction in Box_loss demonstrates that the model’s bounding box localization accuracy in landslide disaster detection steadily improved, ultimately achieving satisfactory convergence. The validation set loss was slightly greater than that of the training set, indicating the model’s strong adaptability to unseen landslide regions and its robust generalization performance. This model provides valuable technical support for efficient monitoring and accurate detection of landslide disasters, and further optimization could lead to even higher detection accuracy in the future.
Seg_loss
In YOLOv11-seg, in addition to the object detection tasks, including bounding box regression and classification, segmentation loss (denoted as Lseg) is introduced to evaluate the model’s error in segmentation predictions. As shown in Eq. (6), it is typically combined with cross-entropy loss (Eq. 7) and Dice loss (Eq. 8) to simultaneously optimize pixel-level classification and region segmentation, ensuring accurate pixel-level classification while addressing class imbalance issues.
 |
6 |
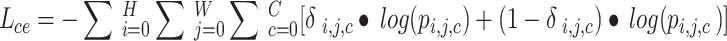 |
7 |
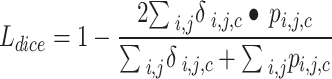 |
8 |
where H, W: Height and width of the image; C: Total number of classes; δi, j,c: Indicator function, which represents whether the true label of pixel (i, j) belongs to class c; if yes, δi, j,c = 1; otherwise, δi, j,c = 0; pi, j,c: Predicted probability that pixel (i, j) belongs to class c; λce, λdice: Weighting factors used to adjust the relative importance of the two losses.
As shown in Fig. 8, by analyzing the variation in the loss curves of the training set (train/Seg_loss) and the validation set (valid/Seg_loss), the optimization effect of the model in landslide boundary recognition and segmentation can be intuitively assessed. (1) Initial Stage (1–50 epochs): The initial Seg_loss value for the training set is 3.3024, and for the validation set, it is 2.6568. Both reach their peak values in the first few epochs (training set: 3.3024 in epoch 1; validation set: 4.0476 in epoch 3), followed by a rapid decline. This rapid decrease in the initial stage suggests that the model quickly captured the basic boundary characteristics in the early phase of landslide region segmentation, particularly in complex terrains with blurred boundaries, and achieved initial segmentation capability. (2) Middle Stage (51–300 epochs): Between epochs 51 and 300, both the training and validation sets show a steady decline in Seg_loss. The training set decreases to less than 1.000, whereas the validation set approaches 1.500. This phase reflects the convergence of the model’s segmentation performance. As the model further learns the characteristics of the landslide regions, it improves in precisely segmenting the landslide boundaries and enhances its generalizability to different terrains and landslide types. (3) Late Stage (300–551 epochs): After epoch 300, the training set’s Seg_loss stabilizes at 0.6696, a 79.72% reduction from the initial value, whereas the validation set converges to 1.0550, a 60.29% reduction. The validation set’s loss is marginally greater than the training set’s loss, indicating that the model still performs well in segmenting unseen landslide data but with a slight discrepancy. Overall, the downward trend in the Seg_loss curve reflects the continuous improvement in the model’s pixel-level segmentation performance for landslide disaster detection. The significant decrease and gradual convergence of the losses for both the training and validation sets highlight the model’s robustness and generalizability in the landslide region segmentation task. The slightly elevated validation loss compared with that of the training set aligns with typical generalization behavior, indicating that the model is capable of effectively identifying landslide boundaries across different terrains and complex scenarios.
Fig. 8.

Graph of the seg_loss curves on the training and validation sets.
Cls_loss
In the YOLOv11-seg model, classification loss (Cls_loss) is used to measure the accuracy of class predictions for each predicted box. YOLOv11-seg combines object detection with semantic segmentation tasks; thus, the classification loss accounts for both accurate class predictions and the mitigation of class imbalance. To address this issue, YOLOv11-seg uses a weighted cross-entropy loss, which adjusts the loss function by assigning weights to different classes, allowing the model to prioritize the learning of underrepresented classes, as shown in Eq. (9).
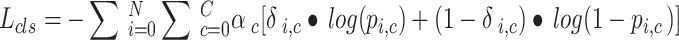 |
9 |
where N: Total number of predicted boxes; i: The i-th predicted box; C: Total class count; c: Class index; αc: Weight coefficient for class c. In cases of class imbalance, less frequent classes are typically assigned higher weights to give them more focus during training; δi, c: Indicator function used to indicate whether the true label of the i-th box corresponds to class c. When the true class of the i-th box is c, δi, c = 1; otherwise, δi, c = 0; pi, c: The probability that the i-th box belongs to class c.
As shown in Fig. 9, by observing the loss curves of the training set (train/Cls_loss) and the validation set (valid/Cls_loss), we can assess the model’s learning progress and convergence in the tasks of landslide region recognition and classification. (1) Initial phase (1–50 epochs): During the initial training period, the Cls_loss for the training set starts at 2.2809, and for the validation set, it starts at 2.5395. Both curves reach their peak values within the first few epochs (the training set reaches a maximum of 2.2809 at epoch 1, and the validation set peaks at 3.9635 at epoch 6), after which they rapidly decrease. This sharp decline indicates that the model made significant strides in the early classification of landslide regions, gradually learning the basic characteristics of landslide areas. However, the validation set exhibits significant fluctuations, suggesting that the model is still unstable when dealing with unseen landslide data. (2) Mid-phase (51–300 epochs): Between epochs 51 and 300, the Cls_loss for both the training and validation sets gradually decreases and stabilizes. The training set Cls_loss decreases to less than 1.000, and the validation set approaches 1.500. This phase marks the gradual completion of the model’s convergence in the task of landslide classification. The model not only refined its ability to distinguish between landslide categories but also adapted to various types and complex terrains of landslide regions, resulting in a significant improvement in classification performance. (3) Late phase (300–551 epochs): After 300 epochs, the Cls_loss for the training set stabilizes at 0.5886, a decrease of 74.19% from the initial value, whereas the Cls_loss for the validation set finally decreases to 0.9572, a decrease of 62.31% from the initial value. Both curves stabilize, with a small gap between them, indicating that the model has achieved high stability and convergence in landslide classification tasks. The validation loss is slightly greater than that of the training set, which is a common manifestation of the model’s generalization ability, indicating that the model can maintain good classification accuracy on unseen landslide data. Overall, the consistent downward trend of Cls_loss reflects the continuous improvement in the model’s classification performance in intelligent landslide disaster recognition. The significant decrease and eventual convergence of Cls_loss for both the training and validation sets demonstrate the model’s efficiency and robustness in landslide classification tasks.
Fig. 9.

Graph of the cls_loss curves on the training and validation sets.
Dfl_loss
Dfl_loss is an enhanced regression loss function used for boundary box regression in object detection tasks. It treats the regression of target boxes as a probability distribution regression task and increases the weight of hard-to-predict samples by applying weighted factors, thereby improving regression accuracy, especially in scenarios involving small objects or sparse targets. As shown in Eq. (10):
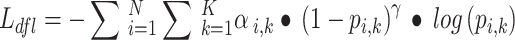 |
10 |
where N: Total number of predicted boxes; K: The number of discrete distribution points for each boundary box regression task; αi, k: A weight factor that controls the importance of each distribution point. Difficult samples (those hard to regress) will have higher weights; pi, k: The predicted probability for the i-th sample at the i-th distribution point, indicating the model’s predicted probability for that position. The closer pi, k is to 1, the more accurate the prediction is; γ: The scaling factor, typically set to 2, is used to control the weights of easy and hard samples, increasing the focus on difficult-to-predict samples.
As shown in Fig. 10, by observing the loss curves for the training set (train/Dfl_loss) and validation set (valid/Dfl_loss), we can evaluate the model’s convergence and generalization ability in boundary box localization for landslides. (1) Early Stage (1–50 epochs): Dfl_loss for the training set starts at 1.5474 and peaks at 2.2809 in epoch 4, after which it rapidly decreases. The validation set Dfl_loss starts at 2.4460 and reaches a peak of 3.9635 in epoch 3. This suggests that in the early stages, the model made notable progress in boundary box regression for landslides, but the variations in validation set loss reflect some difficulties in generalizing to unseen landslide regions. (2) Mid-stage (51–300 epochs): Between epochs 51 and 300, both the training and validation Dfl_loss steadily decrease and stabilize, with the training set decreasing to approximately 1.000 and the validation set approaching 1.500. This finding indicates that the model’s regression accuracy for landslide boundaries gradually improved, adapting to the complexity of different landslide types and terrain features, with a strong convergence trend. (3) Late Stage (300–551 epochs): After 300 epochs, the training set Dfl_loss stabilizes at 1.9794, reflecting a 40.86% decrease from the initial value, whereas the validation set stabilizes at 2.7978, showing a 58.27% reduction. Although the validation set loss is slightly greater than the training set loss, the stable trends in both curves suggest that the model has achieved high stability and generalizability in boundary box regression for landslide detection. Overall, the significant decline in the Dfl_loss curves indicates that the model’s boundary box regression performance for landslide disaster recognition has continuously improved. Both the training and validation Dfl_loss curves exhibit substantial reductions and gradual convergence, with a slightly greater validation loss, demonstrating the model’s solid generalization capability in diverse landslide disaster scenarios.
Fig. 10.

Graph of the dfl_loss curves on the training and validation sets.
Evaluation and analysis of the F1 score curve
In intelligent landslide disaster recognition, evaluating model performance is not solely dependent on precision or recall but also requires a comprehensive consideration of their balance. As shown in Eq. (11), the F1 score, as the harmonic mean of precision and recall, provides a better reflection of the model’s overall performance in landslide detection and segmentation tasks, especially in boundary regression (B) and mask segmentation (M) tasks. The F1 score curve illustrates the model’s overall performance in landslide recognition under different intersection over union (IoU) thresholds. At lower IoU thresholds, the model may detect most landslide regions (high Recall) but could lead to more false positives (low Precision). As the IoU threshold increases, the model’s localization requirements become more stringent, which causes both precision and recall to fluctuate, affecting the F1 score.
 |
11 |
As shown in Fig. 11, an analysis of the F1 score curve reveals the following: (1) Initial stage (1–50 epochs): In the early stages of model training, the F1 score (B) starts at 0.4909, and the F1 score (M) begins at 0.4828, both of which show a rapid upward trend. However, at epoch 3, a slight fluctuation occurs, with the F1 score (B) reaching a minimum of 0.4598 and the F1 score (M) decreasing to 0.4118. This fluctuation reflects the model’s sensitivity to boundary recognition in complex terrains, whereas mask segmentation remains relatively stable, reflecting the model’s convergence process as it learns the characteristics of different landslides. Additionally, the F1 score (B) is slightly higher than the F1 score (M) at this stage, indicating that, compared with mask segmentation, the model performs better in the initial localization of landslide boundaries. This difference is likely due to the relative simplicity of learning the overall boundary in boundary detection tasks, whereas mask segmentation requires more fine-grained pixel-level predictions, which is more challenging. (2) Mid-stage (51–300 epochs): Between epochs 51 and 300, the model gradually stabilizes, with the F1 score (B) improving to 0.8781 and the F1 score (M) increasing to 0.8114, demonstrating good performance in landslide region recognition. During this stage, the model significantly improves both boundary and region recognition, further enhancing the comprehensiveness and accuracy of landslide detection. (3) Late Stage (after 300 epochs): The model gradually converges, with the F1 score (B) reaching 0.8781 and the F1 score (M) stabilizing at 0.8114. Compared with the minimum values, these values represent increases of 78.88% and 68.06%, and compared with the initial values, these values represent increases of 90.99% and 97.03%, respectively. These findings indicate that the model achieves high detection and segmentation accuracy in the landslide disaster recognition task, with a strong ability to identify both boundaries and finer details of landslide regions. At this stage, the F1 score (B) consistently remains higher than the F1 score (M), suggesting that the model performs slightly better in boundary regression than in mask segmentation. For landslide disaster recognition, the high precision of boundary box detection ensures accurate localization of landslide areas, whereas mask segmentation refines the contours of landslide regions despite the challenges of pixel-level segmentation.
Fig. 11.

F1 score curve.
Overall, the F1 score curve rapidly increases, followed by gradual stabilization, indicating that the model converges through continuous training. The fluctuations in both the boundary regression and mask segmentation F1 scores gradually decrease, reflecting the model’s high stability and robustness in both the landslide detection and segmentation tasks.
Evaluation and analysis of the accuracy metrics
In intelligent landslide disaster recognition, evaluating a model’s accuracy and performance typically relies on multiple standard metrics, especially precision, recall, mAP50, and mAP50−95. These accuracy metrics help us gain a comprehensive understanding of the model’s performance in object detection and segmentation tasks, particularly in boundary regression (B) and mask segmentation (M) tasks in terms of precision and robustness. Specifically, (1) Precision: As shown in Eq. (12), precision measures the proportion of predicted landslide regions (either detection boxes or segmented regions) that are actually positive samples. In boundary regression task (B), higher precision indicates that the model accurately locates the boundaries of landslide regions. In the mask segmentation task (M), high precision ensures that most pixels in the segmented region are correctly labeled, reducing missegmentation. (2) Recall: As shown in Eq. (13), recall measures the proportion of actual landslide regions that are correctly detected or segmented. In boundary regression task (B), a higher recall means that the model recognizes a larger portion of the landslide region, avoiding false negatives. In the mask segmentation task (M), high recall indicates that the model can segment more target region pixels, reducing undersegmentation. (3) mAP50: As shown in Eq. (14), mAP50 measures the average precision at an IoU threshold of 0.5, reflecting the model’s precision in localization and segmentation under relaxed conditions. A high mAP50 indicates that the model can effectively detect landslide regions and perform basic segmentation. (4) mAP50 − 95: As shown in Eq. (15), mAP50−95 measures the average precision at multiple IoU thresholds, providing a more stringent evaluation. A high mAP50 − 95 indicates that the model can maintain high accuracy under stricter detection and segmentation conditions, particularly in complex terrains. Together, these metrics reflect the comprehensive performance of YOLOv11-seg in intelligent landslide disaster recognition, helping evaluate the model’s ability in terms of localization precision, segmentation precision, and false negative detection.
 |
12 |
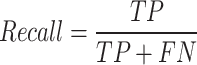 |
13 |
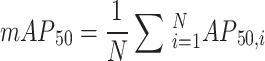 |
14 |
 |
15 |
where TP (true positive): The positive class that the model correctly detects (correctly recognized target). FP (false positive): The negative class that the model incorrectly detects as positive (false positive). FN (false negative): The positive class that the model fails to detect (false negative). N: The total number of target classes. AP50,i: The average precision for class i at an IoU threshold of 0.5. K: The number of different IoU thresholds (ranging from 0.5 to 0.95, with 10 values in total). APi, j: Average precision for class i at the j-th IoU threshold.
In the task of intelligent recognition of landslide disasters, the performance of the YOLOv11 model in both bounding box detection (B) and mask segmentation (M) tasks is evaluated via precision, recall, mAP50, and mAP50−95 metrics. The following analysis provides a phased assessment of the model’s performance during training, comparing the performance of bounding box detection and mask segmentation, as shown in Figs. 12 and 13.
Fig. 12.

The various accuracy curves of Metrics (B).
Fig. 13.

The various accuracy curves of Metrics (M).
Initial stage (1–50 epochs): In the early stages of training, the model’s performance metrics fluctuate but gradually improve. During this phase, the model begins learning the boundaries and features of the landslide areas, showing some instability: (1) Bounding box detection (B): the precision for bounding box detection (Precision (B)) starts at 0.4827, decreases to a minimum of 0.4019 at epoch 3, and then steadily increases. This fluctuation suggests that the model’s ability to learn the boundaries of landslide areas is unstable at the outset, as it gradually adapts to the complex features of these areas. The recall for bounding box detection (Recall(B)) starts at 0.4994, decreases to a minimum of 0.4376 at epoch 12, and then increases gradually. This indicates early-stage instability in the model’s detection coverage of the landslide areas. The mAP50 (B) starts at 0.5305 and decreases to 0.4558 at epoch 3, whereas the mAP50−95 (B) fluctuates from 0.4505 and gradually increases. The significant fluctuations in the mAP metrics during the initial stage suggest that the model’s bounding box regression has not yet reached optimal performance. (2) Mask Segmentation (M): The precision for mask segmentation (Precision(M)) starts at 0.5593, decreases to 0.5222 at epoch 3, and then gradually increases. This pattern of fluctuation mirrors that of bounding box detection, although the precision for segmentation starts higher, indicating that the mask segmentation task is more sensitive to the boundary features of landslide areas in the early stages. The recall for mask segmentation (Recall(M)) starts at 0.5132, decreases to a minimum of 0.4150 at epoch 3, and then gradually improves, reflecting similar fluctuations in the coverage of the segmentation task. The mAP50 (M) starts at 0.5245 and fluctuates to 0.4392 at epoch 3, whereas the mAP50−95(M) fluctuates from 0.4473. This suggests that the model requires time to adapt in extracting the boundary features of the landslide areas in the mask segmentation task.
Middle stage (51–300 epochs): During the middle stage, the model’s performance metrics gradually improve and stabilize, indicating that its ability to adapt to the features of the landslide areas has strengthened, resulting in more stable and consistent performance. (1) Bounding Box Detection (B): In this phase, the precision of bounding box detection steadily stabilizes and reaches a high level, reflecting that the model has developed a solid understanding of the boundary features of the landslide areas. Moreover, the recall rate also improves, demonstrating that the model’s coverage in detecting landslide areas has become more comprehensive. Furthermore, the mAP scores for bounding box detection remain strong across different IoU thresholds, suggesting that the model can effectively adapt to the various scales and shapes of landslide features. (2) Mask Segmentation (M): In the middle stage, the precision of mask segmentation gradually improves and approaches stability, although it remains slightly lower than that of bounding box detection. This finding indicates that the model faces more challenges in capturing the complex shapes of the landslide boundaries. The recall for mask segmentation also improves steadily, paralleling the improvements seen in bounding box detection, which indicates that the model’s coverage for landslide area segmentation has improved as well. Although the mAP scores for segmentation are slightly lower than those for bounding box detection are, the precision of mask segmentation remains stable and reliable throughout the process.
Late Stage (300–551 epochs): During the later phase of training, the model’s performance metrics stabilize at a high level, resulting in significant improvements over the initial stage. This demonstrates the model’s robustness and increased ability to adapt to the complexities of the landslide disaster recognition task. Below are the final values achieved in the late stage and their comparison to the initial results. (1) Bounding Box Detection (B): By the late stage, the precision for bounding box detection stabilizes at 0.9128, reflecting an 89.13% improvement over the initial value, indicating that the model has achieved high stability in locating the boundaries of landslide areas. The final recall value reaches 0.8459, which represents a 69.38% improvement from the initial stage, showing a substantial increase in the model’s detection coverage of landslide areas. The mAP50 value for bounding box detection is 0.8667, an improvement of 63.38%, whereas the mAP50−95 reaches 0.7869, a 74.67% improvement. These results indicate that bounding box detection is able to maintain high precision across varying IoU thresholds, with even greater robustness at higher IoU levels. (2) Mask Segmentation (M): In the late stage, the precision for mask segmentation stabilizes at 0.8839, which is a 58.05% improvement over the initial value, although it is still slightly lower than that for bounding box detection. This suggests that the model has some limitations in capturing the fine-grained boundary details of landslide areas. The final recall for mask segmentation is 0.8444, showing a 64.54% improvement, which is closely aligned with the recall for bounding box detection, ensuring that the model maintains good coverage in segmenting the landslide areas. The mAP50 value for mask segmentation is 0.8593, representing a 63.85% improvement, and the mAP50−95 stabilizes at 0.7686, reflecting a 71.82% increase. While the segmentation performance slightly lags behind that of bounding box detection, mask segmentation still achieves high precision under higher IoU conditions, demonstrating good adaptability.
In conclusion, the YOLOv11 model exhibits highly stable performance in both bounding box detection and mask segmentation tasks for landslide disaster recognition. While bounding box detection slightly outperforms mask segmentation in terms of precision and mAP metrics, the recall values for both tasks are comparable, suggesting that the model effectively covers the entire landslide area. The superior performance of bounding box detection under high IoU conditions can be attributed to the geometric optimization provided by the CLoU loss function. However, mask segmentation has several limitations in capturing finer details at the boundaries of landslide areas. This disparity indicates that there is potential for further refinement of the segmentation task to improve the model’s ability to capture complex boundary details. Overall, the one-stage detection architecture and integrated loss design of YOLOv11-seg contribute to efficient detection and segmentation, providing a reliable technical foundation for real-time monitoring and early warning systems for landslide disasters.
Evaluation and analysis of the test set results
Confidence score is a crucial metric for assessing the reliability of a model’s predictions in detection and classification tasks, as it quantifies the model’s certainty regarding its outputs. A higher confidence score generally indicates a greater degree of certainty in the model’s predictions, implying stronger confidence in the classification of the detected target.
In landslide identification tasks, the confidence score serves as an indicator of the model’s certainty when determining whether a specific area is affected by a landslide. A higher confidence score suggests greater reliability in the model’s classification, whereas a lower confidence score may indicate uncertainty or significant feature similarities between the region and other landforms.
In the test set of this study, 81.35% of the samples exhibited confidence scores above 85%, demonstrating that the model produces highly reliable predictions in most cases. This distribution of high confidence scores suggests that the model can accurately detect landslide regions while maintaining a strong degree of certainty in its classifications. As illustrated in Fig. 14, the model consistently achieves high confidence scores across various landslide scenarios, further validating its stability and robustness in landslide recognition. This characteristic ensures precise and reliable detection, allowing the model not only to correctly identify landslide areas but also to retain a high degree of certainty in its classifications. As a result, the risks of false positives and false negatives are significantly reduced, thereby enhancing the overall accuracy and reliability of the monitoring system.
Fig. 14.

Example diagram of the validation set results.
Moreover, the presence of consistently high confidence scores in the model’s predictions indicates its ability to provide robust and reliable detection outcomes, which is particularly critical for landslide disaster early warning and emergency response systems. The computation of the confidence score in the YOLOv11-seg object detection and segmentation model is defined in Eq. 16:
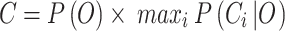 |
16 |
where C: the confidence score; P(O): the model predicts the existence of an object (i.e., a landslide) in the given area;  : the conditional probability of the object belonging to class Ci (landslide category), taking the maximum probability among all possible classes;
: the conditional probability of the object belonging to class Ci (landslide category), taking the maximum probability among all possible classes;
Application case testing
To evaluate the generalizability and adaptability of the YOLOv11-seg model in landslide disaster recognition, we conducted additional validation using datasets from diverse geographic regions. Specifically, we tested the model on the publicly available dataset “Convolutional Neural Networks Applied to Semantic Segmentation of Landslide Scars“83, which encompasses a wide range of landslide characteristics, including various geological structures, terrain complexities, and environmental conditions. The inclusion of different geographic regions allows for a more comprehensive assessment of the model’s robustness across diverse landscapes. The results indicate that YOLOv11-seg maintains relatively stable detection and segmentation performance across different terrains, demonstrating its adaptability to various geological environments. However, we observed that the detection accuracy varied depending on the topographical and geomorphological characteristics of the landslide areas. In regions with steep slopes and high elevations, the model performed well in capturing landslide boundaries, whereas in areas with dense vegetation cover or human infrastructure interference, the detection accuracy showed some degree of decline. This suggests that future improvements could focus on integrating multimodal remote sensing data, such as LiDAR and SAR, to enhance landslide recognition in complex terrains.
In addition to evaluating the model’s generalization ability across different terrains, we also assessed its capability in detecting small-scale landslides and handling occlusions. Landslides exhibit significant variations in size, ranging from large-scale collapses to small, localized slope failures. Small landslides, due to their limited spatial extent and often subtle boundary characteristics, pose challenges for deep learning-based detection models. In our evaluation, the model exhibited a slight decrease in precision and recall when detecting landslides smaller than a certain threshold, indicating that feature extraction for small-scale landslides still requires further optimization. One possible direction for improvement is the incorporation of high-resolution feature extraction techniques, such as attention mechanisms or transformer-based segmentation modules, which could enhance the model’s ability to distinguish small and fragmented landslide areas. Moreover, occlusion caused by vegetation, shadows, and buildings can further complicate landslide detection. During testing, we observed that when landslides were partially occluded, the model’s recognition accuracy declined, particularly in cases where occlusion covered a significant portion of the landslide region. This suggests that the model could benefit from additional training with occlusion-aware augmentation strategies or self-supervised learning techniques to improve its robustness in occlusion scenarios.
To further illustrate the challenges faced by the model in detecting small-scale landslides and occluded landslides, we present examples from the test dataset in Fig. 15. Figure 15a–d demonstrate cases where small-scale landslides were successfully detected, but with lower confidence scores compared to larger landslides, suggesting the model’s reduced sensitivity to small-scale features. Figure 15e–h show instances where landslides were partially occluded by vegetation or terrain features, leading to misclassification or incomplete boundary delineation. Notably, in Fig. 15i–l, the model mistakenly included surrounding non-landslide areas within the detected region, likely due to feature similarity between the landslide and background. These results highlight the need for improved boundary refinement and contextual learning to mitigate false positives in challenging environments. Figure 15m, n further illustrate cases where landslide features were blurred due to shadowing effects, making segmentation more difficult. These observations confirm that while YOLOv11-seg demonstrates strong generalization ability in diverse landscapes, its performance can still be impacted by the presence of small, occluded, or visually ambiguous landslide features.
Fig. 15.

Application case test.
Another critical aspect of our analysis focused on potential biases in dataset selection and their impact on model generalization. The Bijie-Landslide dataset, which was used for training, primarily consists of landslides from a specific region in China, and while it provides high-quality annotations and diverse samples, it may not fully represent landslide characteristics in other geographic regions. This potential regional bias could affect the model’s performance when applied to landslides with different geological and environmental contexts. Additionally, the dataset contains a higher proportion of medium-to-large landslides, which may lead to an inherent bias in favor of detecting larger landslide events while reducing sensitivity to smaller landslides. Future work should consider expanding the dataset to include landslide samples from a broader range of geographic locations, climate conditions, and topographical features. Furthermore, incorporating synthetic data generation techniques, such as GANs, could help balance the dataset and improve the model’s ability to generalize to unseen landslide scenarios. Additionally, we observed that the dataset primarily consists of optical remote sensing imagery, which is affected by seasonal variations and atmospheric conditions. Integrating complementary data sources, such as InSAR or thermal imaging, could enhance the model’s ability to detect landslides under varying environmental conditions.
In summary, the application case testing results confirm that YOLOv11-seg is capable of achieving relatively stable landslide recognition performance across diverse geographic regions, but its accuracy can be affected by factors such as terrain complexity, occlusion, and dataset bias. The model demonstrates strong adaptability in detecting large and well-defined landslides, but there remains room for improvement in detecting smaller, fragmented, and partially occluded landslides. Future research should focus on enhancing small-object detection, incorporating multimodal data fusion, and optimizing the dataset to improve the model’s robustness and generalization capability in real-world landslide monitoring applications.
Discussion
The YOLOv11-seg model has demonstrated notable advancements in landslide detection and segmentation, particularly in capturing landslide boundaries and recognizing complex terrain features. Compared to traditional methods such as U-Net and YOLOv8, YOLOv11-seg exhibits significant improvements in key performance metrics, including precision, recall, F1 score, and mAP. Specifically, the F1 score for landslide boundary detection reaches 0.8781, approximately 12% higher than that of the traditional U-Net model. Additionally, the model achieves a more than 15% increase in mAP for segmentation tasks, which enhances pixel-level accuracy and enables more precise delineation of landslide regions. However, despite these strong results, several factors continue to impact the model’s performance and generalizability. One of the critical challenges is the effect of seasonal variations on model detection accuracy. Seasonal changes, including fluctuations in vegetation cover, soil moisture, and lighting conditions, can significantly influence the spectral and textural characteristics of landslide-prone areas in remote sensing imagery. For instance, during rainy seasons, increased soil saturation can alter the spectral response of landslide regions, whereas in winter, snow cover can obscure critical features. These variations can reduce the model’s detection reliability and lead to misclassifications. To mitigate these effects, future research should focus on integrating multimodal remote sensing data, such as SAR and LiDAR, which are less affected by weather conditions. Additionally, training the model on seasonally diverse datasets and applying domain adaptation techniques could improve its robustness against seasonal variability.
The model’s adaptability across different geographic regions with distinct geological and climatic conditions is another important consideration. While the model was trained on the Bijie-Landslide dataset, which represents a specific geological setting, additional testing was conducted on the “Convolutional Neural Networks Applied to Semantic Segmentation of Landslide Scars” dataset to evaluate its generalizability. The results indicate that the model performs well across a range of terrains but experiences variations in detection accuracy depending on factors such as terrain complexity, vegetation density, and anthropogenic interference. In regions with steep slopes and well-defined landslide features, the model successfully identifies landslide boundaries with high confidence. However, in areas with dense vegetation cover or significant urban infrastructure, detection accuracy declines due to occlusions and spectral similarities between landslide regions and background terrain. This is further illustrated in Fig. 16, where detection errors are observed in cases with high vegetation coverage and indistinct boundary features. In Fig. 16a, the model correctly identifies a landslide region, but the boundary precision is affected by surrounding terrain noise. Figure 16b shows an overestimated landslide area, where the model incorrectly includes non-landslide regions within the detection box. Conversely, Fig. 16c highlights a scenario where the detected region is underestimated, leaving out portions of the landslide. Figure 16d, e demonstrate cases of misclassification, where non-landslide areas were mistakenly labeled as landslides due to spectral similarities or image artifacts. These observations suggest that further refinement is needed, particularly in handling occlusions and improving segmentation accuracy in complex environments. One potential solution is to incorporate self-supervised learning techniques that enhance feature discrimination, particularly for small-scale and partially occluded landslides. Additionally, utilizing higher-resolution satellite imagery and fusing optical data with radar-based observations could further improve detection robustness in challenging terrains.
Fig. 16.

An illustration of the problem.
In assessing the model’s performance for detecting small-scale landslides and those with partial occlusion, the results indicate that landslides with limited spatial extent pose challenges for accurate feature extraction. Small-scale landslides often exhibit subtle spectral and textural differences from their surroundings, making them more difficult to distinguish. The model’s precision and recall tend to decrease for landslides below a certain size threshold, as illustrated in Fig. 16f–h. Additionally, occlusions caused by vegetation, shadows, or urban infrastructure further reduce detection accuracy. In Fig. 16i–l, the model exhibits difficulties in segmenting landslides that are partially covered by trees or built structures, leading to incomplete detections. To improve detection accuracy in such scenarios, future research should explore attention mechanisms and multi-scale feature fusion techniques, which can enhance the model’s sensitivity to small-scale and fragmented landslides. Furthermore, adopting data augmentation strategies that simulate occlusion scenarios could help the model learn more robust features for detecting obscured landslides.
Beyond technical considerations, the study’s findings have important policy implications for landslide risk management and disaster response frameworks. The integration of AI-driven landslide detection models into early warning systems can enhance real-time monitoring and improve decision-making processes for disaster mitigation. Governments and disaster management agencies can leverage such models to establish automated monitoring pipelines that analyze satellite and drone imagery for early signs of slope instability. This can facilitate timely evacuation measures and targeted intervention strategies to minimize casualties and economic losses. Additionally, the use of AI-based landslide detection can contribute to urban planning and infrastructure resilience by identifying high-risk areas and informing land-use policies. Given the increasing availability of high-resolution remote sensing data, future implementations should focus on developing cloud-based platforms that provide real-time access to AI-driven landslide detection results, allowing for seamless integration into existing geospatial information systems (GIS) used by policymakers and emergency response teams.
To ensure the practical applicability of this research, several recommendations can be made for integrating the YOLOv11-seg model into operational landslide monitoring frameworks. First, establishing a standardized workflow for data acquisition, preprocessing, and model inference will be essential for deploying the model in real-world monitoring applications. This includes automating data collection from satellite and UAV sources, applying real-time inference pipelines, and incorporating uncertainty quantification methods to assess model confidence levels. Second, collaboration with geological agencies and remote sensing institutions can facilitate the development of region-specific models tailored to different environmental conditions. By fine-tuning the model on localized datasets, its adaptability can be improved for diverse geological settings. Third, a hybrid approach combining AI-based detection with traditional geotechnical monitoring methods (such as ground sensors and InSAR measurements) can enhance landslide prediction accuracy and provide comprehensive risk assessments.
From a scientific and societal perspective, this study advances the field of AI-based landslide detection by demonstrating the feasibility of deep learning for real-time disaster monitoring. The integration of segmentation-based object detection models into geohazard analysis represents a shift towards data-driven approaches that enhance disaster preparedness and risk assessment capabilities. On a broader scale, such advancements contribute to the development of intelligent geospatial analysis tools that support climate adaptation strategies and sustainable land management practices. The societal impact of this research extends to disaster-prone communities, where improved landslide detection can help mitigate loss of life and property damage through more effective early warning and response systems. Additionally, the methodologies explored in this study have potential applications beyond landslide detection, including other geohazards such as flood mapping, earthquake-induced slope failures, and land subsidence monitoring.
In conclusion, while the YOLOv11-seg model demonstrates high accuracy and adaptability for landslide detection, some limitations remain. Seasonal variations, geographic diversity, and small-scale landslide detection challenges affect model performance, necessitating further refinement. Future research should focus on expanding dataset diversity, integrating multimodal data sources, and exploring advanced deep learning architectures to enhance detection robustness. Additionally, improving computational efficiency for real-time applications will be crucial for large-scale deployment. By addressing these challenges, AI-based landslide detection models can play an increasingly vital role in disaster management and environmental monitoring, contributing to more resilient and sustainable geohazard mitigation strategies.
Conclusion
This study proposes an intelligent landslide disaster recognition method based on the YOLOv11-seg algorithm. By optimizing both the feature extraction and segmentation modules, the model achieves high-precision detection and pixel-level segmentation of landslide areas. The experimental results demonstrate significant improvements in several performance metrics. Specifically, the F1 score for boundary detection reached 0.8781, whereas the F1 score for segmentation tasks was 0.8114. Additionally, the mAP values for boundary detection and mask segmentation reached 0.835 and 0.790, respectively, significantly outperforming traditional methods and demonstrating the model’s reliability and adaptability in complex terrain environments. By incorporating multisource datasets and applying various data augmentation techniques, the model’s generalization ability across different terrains, seasons, and lighting conditions has been notably improved. This enables the model to meet the recognition demands of landslides in diverse scenarios.
Despite these improvements, certain limitations remain. The model’s performance is still influenced by unclear landslide boundaries, ambiguous terrain features, and spectral similarities between landslides and surrounding environments, leading to reduced detection confidence and increased misclassification rates. Additionally, false positives and false negatives were observed in complex terrains, particularly in areas with high vegetation coverage or urban structures, where occlusion and shadowing impact segmentation accuracy. Another limitation lies in the computational cost of real-time inference, as the current model, while achieving high accuracy, still faces challenges in achieving optimal inference speed for large-scale landslide monitoring. Moreover, dataset bias remains an issue, as the current model has been primarily trained on specific regions, which may limit its generalizability to diverse geological and climatic conditions.
To address these limitations, several future directions are proposed. First, integrating multimodal data, such as LiDAR, SAR, and meteorological data, could enhance the model’s ability to distinguish landslides from non-landslide regions and improve detection in occluded environments. Second, refining the feature extraction module by incorporating attention mechanisms, Transformer-based architectures, or graph neural networks (GNNs) could enhance the model’s ability to handle complex landslide morphologies. Third, improving computational efficiency through model pruning, quantization, and edge computing optimization would facilitate real-time landslide monitoring and deployment in resource-constrained environments. Fourth, expanding the dataset to include a broader range of geological and climatic conditions, along with implementing self-supervised learning techniques, could improve model robustness and reduce dataset-induced biases. Finally, integrating the model into existing landslide monitoring and disaster management frameworks will be essential for practical deployment, enabling real-time hazard assessment and early warning systems for disaster prevention and mitigation.
Overall, this study highlights the significant application potential of the YOLOv11-seg-based landslide recognition method in efficient detection and risk assessment. The findings provide valuable technical support for geological disaster monitoring and prevention, paving the way for more effective and timely landslide disaster management. By addressing current challenges and expanding the model’s capabilities, future research can further enhance AI-driven landslide detection and contribute to the development of intelligent geohazard monitoring systems.
Electronic supplementary material
Below is the link to the electronic supplementary material.
Acknowledgements
We sincerely appreciate the valuable feedback and insightful suggestions provided by the reviewers, which have significantly improved the quality of this manuscript. We also extend our gratitude to the editorial team for their careful handling of our submission.This research was supported by the National Key Research and Development Plan (Grant No. 2022YFF0801201), the National Natural Science Foundation of China (Grant No. U1911202), and the Guangdong Key Areas Research and Development Project (Grant No. 2020B1111370001). We are grateful for their generous support, which made this research possible.
Author contributions
Conceptualization, L.H.; methodology, L.H.; software, L.H.; validation, L.L., Y.Z. and J.M. ; writing—review and editing, J.M.; visualization, J.M.; supervision, Y.Z.; project administration, Y.Z.; funding acquisition, Y.Z. All authors have read and agreed to the pub-lished version of the manuscript.
Funding
This research was supported by the National Key Research and Development Plan (2022YFF0801201), the National Natural Science Foundation of China (U1911202), the Guangdong Key Areas Research and Development Project (2020B1111370001).
Data availability
The data presented in this study are available upon request from the corresponding author.
Declarations
Competing interests
The authors declare no competing interests.
Footnotes
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Contributor Information
Yongzhang Zhou, Email: zhouyz@mail.sysu.edu.cn.
Jianhua Ma, Email: 05161935@cumt.edu.cn.
References
- 1.Zhang, Z. et al. Landslide hazard cascades can trigger earthquakes. Nat. Commun.15 (1), 2878 (2024). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 2.Base, E. E. D. D. Inventorying Hazards & Disasters Worldwide since 1988 (Ecole de Santé Publique: Brussels, Belgium, 2007).
- 3.Haque, U. et al. The human cost of global warming: deadly landslides and their triggers (1995–2014). Sci. Total Environ.682, 673–684 (2019). [DOI] [PubMed] [Google Scholar]
- 4.Pardeshi, S. D., Autade, S. E. & Pardeshi, S. S. Landslide hazard assessment: recent trends and techniques. SpringerPlus2, 1–11 (2013). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 5.China, N. G. H. B. China, National Geological Hazard Bulletin (China, 2019).
- 6.Li, D. et al. Future changes of socioeconomic exposure to potential landslide hazards over Mainland China. Weather Clim. Extremes. 46, 100731 (2024). [Google Scholar]
- 7.Li, B. V., Jenkins, C. N. & Xu, W. Strategic protection of landslide vulnerable mountains for biodiversity conservation under land-cover and climate change impacts. In Proceedings of the National Academy of Sciences, vol. 119(2), e2113416118 (2022). [DOI] [PMC free article] [PubMed]
- 8.Jakob, M. Landslides in a Changing Climate, in Landslide Hazards, Risks, and Disasters, 505–579 (Elsevier, 2022).
- 9.Zeng, Z. Agricultural Geological Landslide Monitoring Based on Beidou Navigation System. (2022).
- 10.Gao, O. et al. E-DeepLabV3+: A landslide detection method for remote sensing images. In 2022 IEEE 10th Joint International Information Technology and Artificial Intelligence Conference (ITAIC) (IEEE, 2022).
- 11.Giri, P., Ng, K. & Phillips, W. Wireless sensor network system for landslide monitoring and warning. IEEE Trans. Instrum. Meas.68 (4), 1210–1220 (2018). [Google Scholar]
- 12.Lv, P. et al. ShapeFormer: A shape-enhanced vision transformer model for optical remote sensing image landslide detection. IEEE J. Sel. Top. Appl. Earth Observ. Remote Sens.16, 2681–2689 (2023). [Google Scholar]
- 13.Azarafza, M. et al. Discontinuous rock slope stability analysis by limit equilibrium approaches—a review. Int. J. Digit. Earth. 14 (12), 1918–1941 (2021). [Google Scholar]
- 14.Xu, Q. et al. Remote sensing for landslide investigations: A progress report from China. Eng. Geol.321, 107156 (2023). [Google Scholar]
- 15.Xun, Z. et al. Automatic extraction of potential landslides by integrating an optical remote sensing image with an InSAR-derived deformation map. Remote Sens.14 (11), 2669 (2022). [Google Scholar]
- 16.Li, W. et al. Precursors to large rockslides visible on optical remote-sensing images and their implications for landslide early detection. Landslides20 (1), 1–12 (2023). [Google Scholar]
- 17.Chen, X. et al. Conv-trans dual network for landslide detection of multi-channel optical remote sensing images. Front. Earth Sci.11, 1182145 (2023). [Google Scholar]
- 18.Fang, B. et al. GAN-based Siamese framework for landslide inventory mapping using bi-temporal optical remote sensing images. IEEE Geosci. Remote Sens. Lett.18 (3), 391–395 (2020). [Google Scholar]
- 19.Lan, H. et al. Remote sensing precursors analysis for giant landslides. Remote Sens.14 (17), 4399 (2022). [Google Scholar]
- 20.Yang, W. et al. Retrospective deformation of the Baige landslide using optical remote sensing images. Landslides17 (3), 659–668 (2020). [Google Scholar]
- 21.Ju, Y. et al. Loess landslide detection using object detection algorithms in Northwest China. Remote Sens.14 (5), 1182 (2022). [Google Scholar]
- 22.Sreelakshmi, S. & Chandra, S. V. Visual saliency-based landslide identification using super-resolution remote sensing data. Results Eng.21, 101656 (2024). [Google Scholar]
- 23.Li, Y. et al. Identification and analysis of landslides in the Ahai reservoir area of the Jinsha river basin using a combination of DS-InSAR, optical images, and field surveys. Remote Sens.14 (24), 6274 (2022). [Google Scholar]
- 24.Satriano, V. et al. Landslides detection and mapping with an advanced multi-temporal satellite optical technique. Remote Sens.15 (3), 683 (2023). [Google Scholar]
- 25.Dong, X. et al. Identifying potential landslides on giant Niexia slope (China) based on integrated multi-remote sensing technologies. Remote Sens.14 (24), 6328 (2022). [Google Scholar]
- 26.Yang, F. et al. Estimation of landslide and mudslide susceptibility with multi-modal remote sensing data and semantics: the case of Yunnan Mountain Area. Land. 12(10), 1949 (2023).
- 27.Strząbała, K., Ćwiąkała, P. & Puniach, E. Identification of landslide precursors for early warning of hazards with remote sensing. Remote Sens.16 (15), 2781 (2024). [Google Scholar]
- 28.Pourkhosravani, M. et al. Monitoring of Maskun landslide and determining its quantitative relationship to different climatic conditions using D-InSAR and PSI techniques. Geomat. Nat. Hazards Risk. 13 (1), 1134–1153 (2022). [Google Scholar]
- 29.Akosah, S. et al. Application of artificial intelligence and remote sensing for landslide detection and prediction: systematic review. Remote Sens.16 (16), 2947 (2024). [Google Scholar]
- 30.Deng, Y. et al. Landslide susceptibility evaluation of bayesian optimized CNN Gengma seismic zone considering InSAR deformation. Appl. Sci.13 (20), 11388 (2023). [Google Scholar]
- 31.Azarafza, M. et al. Deep learning-based landslide susceptibility mapping. Sci. Rep.11 (1), 24112 (2021). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 32.Renza, D. et al. CNN-based model for landslide susceptibility assessment from multispectral data. Appl. Sci.12 (17), 8483 (2022). [Google Scholar]
- 33.Hakim, W. L. et al. Convolutional neural network (CNN) with metaheuristic optimization algorithms for landslide susceptibility mapping in Icheon, South Korea. J. Environ. Manag.305, 114367 (2022). [DOI] [PubMed] [Google Scholar]
- 34.Xu, G. et al. Feature-based constraint deep CNN method for mapping rainfall-induced landslides in remote regions with mountainous terrain: an application to Brazil. IEEE J. Sel. Top. Appl. Earth Observ. Remote Sens.15, 2644–2659 (2022). [Google Scholar]
- 35.Cheng, G. et al. Advances in deep learning recognition of landslides based on remote sensing images. Remote Sens.16 (10), 1787 (2024). [Google Scholar]
- 36.Yu, B. et al. Matrix SegNet: a practical deep learning framework for landslide mapping from images of different areas with different spatial resolutions. Remote Sens.13 (16), 3158 (2021). [Google Scholar]
- 37.Fang, C. et al. A novel historical landslide detection approach based on lidar and lightweight attention U-Net. Remote Sens.14 (17), 4357 (2022). [Google Scholar]
- 38.Wan, Y. et al. Combining BotNet and ResNet feature maps for accurate landslide identification using DeepLabV3+. In 2023 6th International Conference on Artificial Intelligence and Big Data (ICAIBD). (IEEE, 2023).
- 39.Wu, Z. et al. Mask R-CNN–Based landslide hazard identification for 22.6 extreme rainfall induced landslides in the Beijiang river basin, China. Remote Sens.15 (20), 4898 (2023). [Google Scholar]
- 40.Ghorbanzadeh, O. et al. A comprehensive transferability evaluation of U-Net and ResU-Net for landslide detection from Sentinel-2 data (case study areas from Taiwan, China, and Japan). Sci. Rep.11 (1), 14629 (2021). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 41.Lu, W. et al. A dual-encoder U-Net for landslide detection using Sentinel-2 and DEM data. Landslides20 (9), 1975–1987 (2023). [Google Scholar]
- 42.Chen, Y. et al. Mapping post-earthquake landslide susceptibility: A U-Net like approach. Remote Sens.12 (17), 2767 (2020). [Google Scholar]
- 43.Nava, L. et al. Rapid mapping of landslides on SAR data by attention U-Net. Remote Sens.14 (6), 1449 (2022). [Google Scholar]
- 44.Liu, P. et al. Research on post-earthquake landslide extraction algorithm based on improved U-Net model. Remote Sens.12 (5), 894 (2020). [Google Scholar]
- 45.Wu, Y. & Lang, W. Landslide extraction model for remote sensing images based on improved DeepLabv3+. In International Conference on Image, Signal Processing, and Pattern Recognition (ISPP 2024) (SPIE, 2024).
- 46.Ullo, S. L. et al. A new mask R-CNN-based method for improved landslide detection. IEEE J. Sel. Top. Appl. Earth Observ. Remote Sens.14, 3799–3810 (2021). [Google Scholar]
- 47.Fu, R. et al. Fast seismic landslide detection based on improved mask R-CNN. Remote Sens.14 (16), 3928 (2022). [Google Scholar]
- 48.Liu, Y. et al. Study of the automatic recognition of landslides by using InSAR images and the improved mask R-CNN model in the Eastern Tibet plateau. Remote Sens.14 (14), 3362 (2022). [Google Scholar]
- 49.Qin, H. et al. An improved faster R-CNN method for landslide detection in remote sensing images. J. Geovis. Spat. Anal.8 (1), 2 (2024). [Google Scholar]
- 50.Dianqing, Y. & Yanping, M. Remote sensing landslide target detection method based on improved faster R-CNN. J. Appl. Remote Sens.16 (4), 044521–044521 (2022). [Google Scholar]
- 51.Lian, X. et al. Research on identification and location of mining landslide in mining area based on improved YOLO algorithm. Drones8 (4), 150 (2024). [Google Scholar]
- 52.Zhang, W. et al. LS-YOLO: A novel model for detecting multi-scale landslides with remote sensing images. IEEE J. Sel. Top. Appl. Earth Observations Remote Sens., (2024).
- 53.Yang, Y. et al. Lightweight Attention-Guided YOLO with level set layer for landslide detection from optical satellite images. IEEE J. Sel. Top. Appl. Earth Observ. Remote Sens. (2024).
- 54.Wang, H. et al. A novel landslide identification method for multi-scale and complex background region based on multi-model fusion. YOLO + U-Net Landslides. 21 (4), 901–917 (2024). [Google Scholar]
- 55.Han, Z. et al. Dynahead-YOLO-Otsu: an efficient DCNN-based landslide semantic segmentation method using remote sensing images. Geomat. Nat. Hazards Risk. 15 (1), 2398103 (2024). [Google Scholar]
- 56.Liu, Q. et al. Intelligent identification of landslides in loess areas based on the improved YOLO algorithm: a case study of loess landslides in Baoji City. J. Mt. Sci.20 (11), 3343–3359 (2023). [Google Scholar]
- 57.Cheng, L. et al. A small attentional YOLO model for landslide detection from satellite remote sensing images. Landslides18 (8), 2751–2765 (2021). [Google Scholar]
- 58.Du, Y., Xu, X. & He, X. Optimizing Geo-Hazard response: LBE-YOLO’s innovative lightweight framework for enhanced Real-Time landslide detection and risk mitigation. Remote Sens.16 (3), 534 (2024). [Google Scholar]
- 59.Guo, H. et al. Identification of landslides in mountainous area with the combination of SBAS-InSAR and Yolo model. Sensors22 (16), 6235 (2022). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 60.Redmon, J. et al. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (2016).
- 61.Liu, L. et al. Deep learning for generic object detection: A survey. Int. J. Comput. Vis.. 128, 261–318 (2020). [Google Scholar]
- 62.Kim, K. et al. Performance enhancement of YOLOv3 by adding prediction layers with spatial pyramid pooling for vehicle detection. In 15th IEEE International Conference on Advanced Video and Signal Based Surveillance (AVSS) (IEEE, 2018).
- 63.Lin, T. et al. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (2017).
- 64.Nepal, U. & Eslamiat, H. Comparing YOLOv3, YOLOv4 and YOLOv5 for autonomous landing spot detection in faulty UAVs. Sensors22 (2), 464 (2022). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 65.Mohod, N., Agrawal, P. & Madaan, V. Yolov4 vs yolov5: Object detection on surveillance videos. In International Conference on Advanced Network Technologies and Intelligent Computing (Springer, 2022).
- 66.Liu, S. et al. Path aggregation network for instance segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (2018).
- 67.Sapkota, R. et al. Yolov10 to its genesis: A decadal and comprehensive review of the you only look once series. Available SSRN4874098 (2024).
- 68.Ding, X. et al. Repvgg: Making vgg-style convnets great again. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (2021).
- 69.Wang, C., Bochkovskiy, A. & Liao, H. M. YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. (2023).
- 70.Wang, C., Yeh, I. & Mark Liao, H. Yolov9: Learning what you want to learn using programmable gradient information. In European Conference on Computer Vision (Springer, 2024).
- 71.Wang, A. et al. Yolov10: Real-time end-to-end object detection. arXiv preprint arXiv:2405.14458 (2024).
- 72.Wang, X. et al. Characterizing surface deformation of the Earthquake-Induced Daguangbao landslide by combining Satellite-and Ground-Based InSAR. Sensors25 (1), 66 (2024). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 73.Tang, X. et al. Automatic detection of coseismic landslides using a new transformer method. Remote Sens.14 (12), 2884 (2022). [Google Scholar]
- 74.Meena, S. R. et al. Landslide detection in the Himalayas using machine learning algorithms and U-Net. Landslides19 (5), 1209–1229 (2022). [Google Scholar]
- 75.Zhang, X. et al. Remote sensing image segmentation of gully erosion in a typical black soil area in Northeast China based on improved DeepLabV3 + model. Ecol. Inf.84, 102929 (2024). [Google Scholar]
- 76.Opara, J. N. & Moriwaki, R. Automated landslide mapping in Japan using the segformer model: enhancing accuracy and efficiency in disaster management. Intell. Inf. Infrastruct.. 4 (2), 75–86 (2023). [Google Scholar]
- 77.Chandra, N. & Vaidya, H. Satellite-based landslide event detection leveraging EfficientDet model. In 2024 International Conference on Computer, Electronics, Electrical Engineering & their Applications (IC2E3) (IEEE, 2024).
- 78.Chen, T. et al. LCFSTE: Landslide conditioning factors and Swin transformer ensemble for landslide susceptibility assessment. IEEE J. Sel. Top. Appl. Earth Observ. Remote Sens. (2024).
- 79.Cui, S. & Deng, H. PMG-DETR: fast convergence of DETR with position-sensitive multi-scale attention and grouped queries. Pattern Anal. Appl.27 (2), 1–14 (2024). [Google Scholar]
- 80.Liu, G. et al. Lightweight object detection algorithm for robots with improved YOLOv5. Eng. Appl. Artif. Intell.123, 106217 (2023). [Google Scholar]
- 81.Ji, S. et al. Landslide detection from an open satellite imagery and digital elevation model dataset using attention boosted convolutional neural networks. Landslides17, 1337–1352 (2020). [Google Scholar]
- 82.Torralba, A., Russell, B. C. & Yuen, J. Labelme: Online image annotation and applications. Proc. IEEE98(8), 1467–1484 (2010).
- 83.Bragagnolo, L. et al. Convolutional neural networks applied to semantic segmentation of landslide scars. Catena201, 105189 (2021). [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.
Supplementary Materials
Data Availability Statement
The data presented in this study are available upon request from the corresponding author.