

Abstract
Self-supervised learning (SSL) is a potent method for leveraging unlabelled data. Nonetheless, EEG signals, characterised by their low signal-to-noise ratio and high-frequency attributes, often do not surpass fully-supervised techniques in cross-subject tasks such as Emotion Recognition. Therefore, this study introduces a hybrid SSL framework: Self-Supervised Enhancement for Multidimension Emotion Recognition using Graph Neural Networks (SS-EMERGE). This model enhances cross-subject EEG-based emotion recognition by incorporating Causal Convolutions for temporal feature extraction, Graph Attention Transformers (GAT) for spatial modelling, and Spectral Embedding for spectral domain analysis. The approach utilises meiosis-based contrastive learning for pretraining, followed by fine-tuning with minimal labelled data, thereby enriching dataset diversity and specificity. Evaluations on the widely-used Emotion recognition datasets, SEED and SEED-IV, reveal that SS-EMERGE achieves impressive Leave-One-Subject-Out (LOSO) accuracies of 92.35% and 81.51%, respectively. It also proposes a foundation model pre-trained on combined SEED and SEED-IV datasets, demonstrating performance comparable to individual models. These results emphasise the potential of SS-EMERGE in advancing EEG-based emotion recognition with high accuracy and minimal labelled data.
Keywords: EEG, Self-Supervised Learning, GNN, Constrastive Learning, Cross-Subject Emotion Recognition
Subject terms: Computer science, Neuroscience, Cognitive neuroscience
Introduction
The rapid advancement in data acquisition technologies and the exponential growth in data volume have made it increasingly inadequate to rely solely on supervised datasets to gain insights into environmental phenomena or understand the human brain’s complexities. Supervised learning paradigms require vast amounts of labelled data, often expensive,time-consuming, and limited scope. In fields such as Computer Vision (CV)1,2, Natural Language Processing (NLP)3,4, and Audio Processing5,6, recent progress has underscored the significance of leveraging extensive data available on the internet to develop foundation models. These models capture fundamental principles governing these modalities or their intermodal relationships, enabling robust performance even with limited labelled data.
Understanding brain dynamics through Electroencephalogram (EEG) signals provides crucial insights into neurological activities. These non-invasive signals are crucial in applications like emotion recognition, stress estimation, and sleep staging7–9. In the context of EEG-based emotion recognition, evaluations can be conducted in several ways to validate the robustness and generalizability of models:
Subject-Independent Evaluation (a.k.a. Cross-Subject or LOSO): This method tests the model’s ability to generalise across individuals. It involves training the model on data from a subset of subjects and testing it on data from entirely new subjects not included in the training set. This evaluation is crucial for applications where the model must perform well on new users without retraining.
Subject-Dependent Evaluation: This approach tests the model on the same subjects but on different sessions or instances than those used for training. It assesses how well the model performs when it has already been exposed to data from the test subjects during training. This type of evaluation might be less challenging than subject-independent tests since the model is already tuned to the characteristics of the specific subjects.
Subject-Mixed Evaluation (a.k.a. Trial-Level Random Split): In this evaluation, all EEG trials across subjects are pooled together and randomly split into training and testing sets (e.g., 80-20), without ensuring subject separation. As a result, trials from the same individual may appear in both training and test sets. While this setup facilitates rapid benchmarking of model architectures, it does not accurately reflect cross-subject generalization and may lead to inflated performance due to subject-specific feature leakage.
These evaluation strategies are essential for developing EEG-based systems that are both effective and adaptable to various real-world scenarios. However, unlike more straightforward data types encountered in Computer Vision (CV) or Natural Language Processing (NLP), EEG data collection is fraught with unique challenges. These challenges include variability in sensor types, data collection errors, and individual differences in demographics and health, all of which contribute to high noise levels and low signal. These issues are particularly pronounced in emotion recognition, where the relevant signals can be subtle and frequently masked by artifacts or unrelated physiological events. Representation learning isolates and enhances the informative components of EEG signals crucial for distinguishing between emotional states. It mitigates the need for extensive labelled datasets for each emotional state by leveraging the intrinsic properties of the data.
Self-supervised learning (SSL), a prominent method within representation learning, excels in extracting rich representations from unlabeled EEG data10–13. By learning from the inherent variability among individuals, SSL facilitates the development of models that are accurate and capable of generalising across diverse subjects14,15. Once trained, these models can be fine-tuned for specific downstream tasks, such as emotion classification, with only minimal labelled data. It represents a significant paradigm shift in machine learning, especially for applications with scarce or expensive labelled data. The SSL techniques can be broadly categorised into two main types:
Generative Models: These models aim to reconstruct their input data, thereby learning rich and detailed data representations. The process involves predicting missing parts of data or generating new data instances based on the observed data, which helps the model capture the underlying structure of the input distribution.
Contrastive Models: These models learn by comparing and contrasting different data instances. They typically work by distinguishing between similar (positive) and dissimilar (negative) pairs of data instances, which sharpens their ability to discern critical features that define the data.
Both approaches have proven effective across various domains, including image processing, natural language understanding, and audio recognition, by leveraging large amounts of unlabeled data to learn valuable representations without explicit annotations. Specifically, in the context of EEG signals, a survey by Rafiei et al.16 indicates that generative modelling-based SSL techniques excel with smaller datasets. In comparison, contrastive learning techniques benefit from larger datasets.
Recent advancements in Self-Supervised Learning (SSL) have significantly impacted emotion recognition using EEG signals17–20. Based on state-of-the-art research, the following summary illustrates diverse SSL techniques and their applications to EEG data analysis, as detailed in Table 1.
Table 1.
State of the art Emotion Recognition work done using SSL.
| Work | SSL Tech. | Model | Domains | SEED21 | SEED-IV22 | Limitations | ||
|---|---|---|---|---|---|---|---|---|
| Fully SL | SSL | Fully SL | SSL | |||||
| MV-SSTMA17 | Generative | Multi-Domain reconstruction (MAE) | Spectral, Spatial and Temporal | 95.32 | 83.49 | 92.82 | 82.55 | Doesn’t explore the Contrastive Learning |
| GMSS19 | Spatial Contrastive (SimCLR) | GNN | Spatial and Spectral | 86.52 | 76.04 | 86.67 | 65.31 | Cross-subject is decent across SEED21but poor on SEED-IV22 shows it lacks across different datasets. |
| DS-AGC20 | Contrastive (SimCLR) | GNN | Spatial and Spectral | 85.00 | 82.18 | 65.79 | 61.32 | SEED21numbers are good for cross-subject whereas SEED-IV22 fully-supervised numbers show that the model is not robust. |
| SGMC18 | Meiosis-based Contrastive Learning | ResNet(CNN) | Temporal | 94.04 | 89.83 | NA | NA | Only models in the temporal domain, without fully exploiting the potential of spatial interactions between channels. Also, it does not evaluate cross-subject evaluation. |
SL: Supervised Learning, SSL: Self Supervised Learning, Tech.: Technique.
Background and related work
The Multi-view Spectral-Spatial-Temporal Masked Autoencoder (MV-SSTMA)17employs a generative SSL approach to reconstruct signals across spectral, spatial, and temporal domains using the Masked AutoEncoder (MAE) technique, achieving high accuracy on the SEED dataset21. However, it shows a significant decrease in performance in self-supervised settings compared to fully-supervised ones. Additionally, MV-SSTMA’s17 reliance on multi-head attention for spatial modelling assumes all channels are interconnected, potentially leading to overfitting, as it does not consider the actual electrode placements.
Graph-based Multi-Space Self-Supervised (GMSS)19utilises a spatial contrastive approach via Simple Contrastive Learning (SimCLR)11within a Graph Neural Network (GNN). It models spatial and spectral domains, showing decent cross-subject performance on SEED21, but lacks robustness on the more challenging SEED-IV22 dataset, indicating limitations in model adaptability across datasets.
Differential Entropy-based Self-Attentive Graph Convolution (DS-AGC)20, which incorporates spatial contrastive learning with Simple Contrastive Learning (SimCLR)11and a Graph Neural Network (GNN) architecture, demonstrates good cross-subject performance on the SEED dataset21. However, it struggles with robustness on the SEED-IV dataset22 in both fully-supervised and self-supervised settings. It indicates that the model architecture may not be sufficiently adaptable or resilient, as it fails to perform effectively even in fully-supervised scenarios.
Self-Supervised Group Meiosis Contrastive Learning (SGMC)18implements a contrastive model using SimCLR11, over a group of subjects coming from the same stimuli while performing meiosis augmentation and contrastive loss for self-supervised learning with a Convolutional Neural Network (CNN) architecture, focusing on the temporal domain. It shows outstanding results on SEED21but does not evaluate its performance on SEED-IV22, nor fully utilises spatial interactions between EEG channels. Furthermore, it lacks evaluation across cross-subject variations. Enhancing contrastive learning with meiosis-based techniques improves model performance by creating more diverse negative samples.
The works summarised in Table 1 collectively highlight a recurrent theme: while SSL techniques have significantly advanced emotion recognition from EEG data, they still face challenges in maintaining robustness across diverse subjects and datasets. These limitations often stem from model architectures that focus predominantly on individual domains such as temporal, spatial, or spectral—without effectively integrating them.
Causal Convolutions, as employed in Temporal Convolutional Networks (TCNs), address temporal dependencies by ensuring that each time step is influenced only by the current and past inputs, preserving the causality intrinsic to EEG signals23–25. This feature is particularly beneficial for emotion recognition, where the sequence of brain activity reflects emotional transitions. Furthermore, dilated convolutions allow TCNs to capture long-range temporal dependencies without excessive computational overhead, providing an efficient alternative to recurrent networks.
Graph Attention Networks (GATs)dynamically enhance spatial domain modelling by assigning varying importance to interactions between EEG channels. Unlike static graph methods, GATs utilise an attention mechanism that identifies the most relevant electrode relationships for a given emotional or cognitive state, making them highly adaptable to the variability present in EEG data26,27. This capability is crucial for capturing spatial dependencies, as interactions between brain regions vary across subjects and tasks. GATs prioritise key spatial patterns, improving robustness in subject-dependent scenarios.
Spectral Embeddingsleverage frequency-domain features to encode EEG signals into a compact and meaningful vector space. Differential Entropy (DE), in particular, has been widely recognised as one of the most practical features for emotion recognition, as it captures variability across critical frequency bands (e.g., delta, theta, alpha, beta, and gamma)7,17. By deriving DE-based embeddings before modelling spatial and temporal aspects, SS-EMERGE ensures that frequency-domain information is preserved and seamlessly integrated into the overall representation.
The combination of these techniques—temporal modelling with Causal Convolutions, spatial relationship modelling with GATs, and frequency-domain encoding with Spectral Embeddings—offers a unified and holistic framework in SS-EMERGE. Each component contributes uniquely to addressing the inherent challenges of EEG-based emotion recognition. Temporal modelling captures the dynamic evolution of emotional states, spatial modelling identifies critical inter-channel relationships, and spectral embeddings provide robust frequency-domain features. Together, these techniques enable SS-EMERGE to achieve superior generalizability and performance across diverse datasets and subject variations, overcoming the limitations of methods that prioritise single-domain representations.
This work proposes a comprehensive approach to enhance EEG-based emotion recognition by integrating self-supervised learning with multidimension graph neural networks. The key innovations and contributions of this work are as follows:
- Proposal of SS-EMERGE model for SSL training for Emotion Recognition with main contributions as follows:
- Temporal, Spatial, and Spectral Integration: Combines causal convolutions for encoding temporal interactions, and using Graph Attention Transformer (GAT)28inspired by famous multivariate time series anomaly detection model, MTAD-GAT27for learning spatial channel interactions, and borrowing integration of spectral domain by using spectral embeddings from MV-SSTMA17. The multidimension integration ensures a holistic representation of EEG signals, capturing the intricate dynamics in different domains.
- Meiosis Augmentations Based Contrastive Learning: Integration of the meiosis-based contrastive learning technique proposed by SGMC18for EEG. It performs contrastive learning on groups of stimuli, such as video samples in SEED21and SEED-IV22, instead of individual subject samples. The augmentation technique cross-exchanges EEG segments within a video group, creating new augmented samples that facilitate contrastive learning and enhance the model’s ability to generalise across different subjects and emotional states.
This work introduces a novel SS-EMERGE model that integrates SSL and GNN for advanced emotion recognition from EEG data. It addresses key challenges, including the need for extensive labelled datasets and handling high noise and variability in EEG signals. The SS-EMERGE model achieves 95.05% accuracy on SEED21and 83.67% on SEED-IV22 with minimal labelled data for emotion recognition.
The structure of this paper is organised as follows: First, Section 2 defines the problem statement and details the proposed solution. Next, Section 4 showcases the experimental results obtained by applying the methodology described in Section 2. It is followed by a Section on Experimental Setup. Finally, Section 5 summarises the findings and discusses potential future research directions.
Methodology
This section details SS-EMERGE for emotion recognition using a comprehensive framework that integrates multiple domains of EEG data processing. The methodology includes a pretraining phase with Meiosis-based contrastive learning followed by a fine-tuning phase with labelled data. The system processes EEG data in spectral, spatial, and temporal domains, utilising specialised network components for each aspect.
Figure 1 describes the overall flow of SS-EMERGE that integrates a dual-phase approach to enhance the effectiveness of an EEG-based emotion recognition model. Phase-1 (pretraining) and Phase-2 (fine-tuning) followed by evaluation for the held-out subject, are briefly explained as follows:
Phase-1 (pretraining without labels): This phase learns the generalised features from a diverse EEG dataset using self-supervised contrastive learning. This phase employs components such as meiosis-based constrative learning without using the emotion labels of the sample. By leveraging data from all subjects except one (N-1 subjects), this phase captures broad patterns and features inherent in the entire dataset, promoting generalisation across different contexts and conditions29.
Phase-2 (Fine-tuning with labels): The fine-tuning phase aims to adapt the pre-trained model to the downstream emotion classification task. This phase involves fine-tuning the pre-trained model with a classifier head using Cross-Entropy Loss on the same N-1 subjects. It ensures that the model is specifically tailored to recognise the emotional states from the EEG data of the given subjects.
Prediction on the hold-out subject: Finally, the prediction happens on all the sessions of the hold-out subject (the Nth subject) for evaluation.
Fig. 1.

SS-EMERGE Flow Diagram.
Model architecture
The SS-EMERGE model architecture leverages a combination of advanced techniques to process EEG signals for emotion recognition effectively. This section explains each component in the model architecture, from input and initial processing, spectral, temporal, and spatial modelling to latent representation modelling. Figure 2 illustrates the SS-EMERGE backbone architecture that learns the latent representations in Phase-1 (pretraining), followed by Phase-2 (fine-tuning), which fine-tunes the pre-trained network adding the classification for downstream emotion recognition task.
Fig. 2.

SS-EMERGE backbone architecture for representation learning using SSL and fine-tuning for emotion classification label and associate with the text not clear.
Input and initial processing
The input to the model consists of raw EEG signals segmented into 1-second intervals. These short segments help capture the immediate brain responses associated with different emotional states. From these EEG signals, Differential Entropy (DE)9,30 features are extracted. DE features are robust in representing the spectral properties of EEG signals, making them particularly suitable for emotion recognition tasks.
Spectral domain modelling
SS-EMERGE leverages the Differential Entropy (DE) feature, which has demonstrated effectiveness in EEG-based emotion recognition tasks31. The model extracts DE features 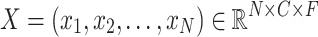 from EEG signals in the spectral domain and transforms them into samples
from EEG signals in the spectral domain and transforms them into samples  using an overlapping window of
using an overlapping window of  seconds, where
seconds, where 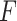 represents frequency bands (
represents frequency bands (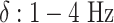 ,
,  ,
, 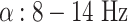 ,
,  , and
, and 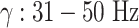 ) converted by a Short-Time Fourier transform (STFT) for each channel C. In the spectral embedding layer, SS-EMERGE projects the
) converted by a Short-Time Fourier transform (STFT) for each channel C. In the spectral embedding layer, SS-EMERGE projects the 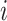 -th sample,
-th sample, 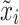 , which resides in
, which resides in 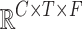 , into a
, into a  -dimensional space using a linear layer. This process embeds the spectral information of the EEG signals into
-dimensional space using a linear layer. This process embeds the spectral information of the EEG signals into 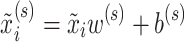 , where
, where  is the weight vector in
is the weight vector in  and
and 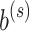 is the bias in
is the bias in 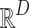 . It finally reshapes
. It finally reshapes 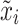 to
to 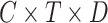 dimensional embedding shape. Later, Positional Encoding (PE)32 layer retains the temporal position of all channels C by adding sine-cosine encoding on each ith time step of signal with length T of every channel to facilitate later encoding.
dimensional embedding shape. Later, Positional Encoding (PE)32 layer retains the temporal position of all channels C by adding sine-cosine encoding on each ith time step of signal with length T of every channel to facilitate later encoding.
Spatial domain modelling
Inspired by the Multivariate Time-series Anomaly Detection via Graph Attention Network (MTAD-GAT)27, which first passes the time series through 1D Conv followed by two GAT networks. SS-EMERGE integrates two types of Graph Attention Transformers (GAT)26 to effectively capture spatial using Feature-Oriented GAT and temporal dependencies via Time Oriented GAT in the EEG signals.
Feature Oriented GAT: This layer constructs a graph where nodes represent different features simultaneously, and edges depict the relationships or interactions between these features. It effectively models the spatial relationships among various EEG features, enhancing the model’s ability to understand how different features interact at a given moment in time.
Time Oriented GAT: This layer constructs a graph where nodes represent the same feature across different time points, and edges represent the temporal dependencies between these nodes. It captures the temporal progression of individual EEG features over time, allowing the model to track changes and developments in feature values across the duration of the signal33.
Temporal domain modelling
In SS-EMERGE, sequential modelling is handled using a Temporal Convolutional Network (TCN) to capture temporal dependencies in EEG signals. Unlike recurrent architectures, TCN employs causal convolutions34, ensuring that each output at a given time step is influenced only by current and past inputs while preserving the chronological order of EEG sequences.
The TCN module processes spectrally and spatially enriched embeddings using stacked 1D convolutional layers with dilation, allowing the network to model long-range dependencies without the vanishing gradient problem of recurrent models. This makes it highly efficient for EEG-based emotion recognition.
As illustrated in Figure 2, sequential modelling in SS-EMERGE follows a structured pipeline:
Input Features: Spectral embeddings from the Spectral modelling module.
Feature-Oriented and Time-Oriented GAT: Extracts spatial relationships in EEG signals.
Temporal Convolutional Network (TCN): Models sequential dependencies over time.
Batch Normalisation and Dropout Layers: Prevent overfitting and stabilise learning.
Latent representation
Graph Attention Transformers (GATs) first process outputs through a series of Batch Normalization (BN) and Dropout Layers with a dropout rate of 0.2 before passing them to the Fully Connected (FC) layers. It starts with batch normalisation to stabilise the learning process and incorporates a dropout of 0.2 to prevent overfitting. Subsequent layers increase in neuron count from 1024 to 2048 and then 4096, each refining the features into a high-dimensional latent representation that encapsulates comprehensive EEG signal information.
Phase-1: SSL using Meiosis-based contrastive learning
Phase 1 (pretraining) learns the latent representation using Meiosis-based constrastive learning to the discriminative capabilities of a model by leveraging the augmented pairs created through Meiosis Data Augmentation. In the context of EEG data, constrastive learning learns distinct differences in brain responses that can signify various cognitive or emotional states in response to identical stimuli. Meiosis augmentation enhances EEG-based emotion recognition by cross-exchanging signal segments from different subjects within the same group. It creates augmented pairs, where positive samples come from subjects who watched the exact video (same stimuli), and negative samples come from different video groups (different stimuli). Meiosis-based Contrastive Learning helps the model to distinguish between similar and dissimilar stimuli, improving its ability to recognise emotions.
Meiosis data augmentation
Meiosis data augmentation aims to enhance EEG-based emotion recognition by augmenting one group sample to generate two groups that preserve the same stimuli-related features. It involves aligning stimuli in the EEG group to construct positive pairs, thereby increasing the meaningful difficulty of the model decoding EEG samples.
- Group Creation:
- Sampling EEG Data: Select
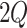 subjects EEG recordings
subjects EEG recordings 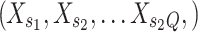 based on their exposure to specific video clips
based on their exposure to specific video clips  videos
videos 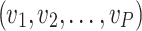 , where each clip serves as a unique stimulus.
, where each clip serves as a unique stimulus. - Group Formation: For each selected video clip
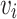 , form groups
, form groups  consisting of EEG samples from the
consisting of EEG samples from the  subjects. Thus, a group
subjects. Thus, a group  for video clip
for video clip 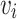 is defined as:
is defined as:
Each group
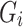 shares similar stimuli-related features among its samples.
shares similar stimuli-related features among its samples.
- Meiosis Data Augmentation:
- Individual Pairing: For an original group of EEG signals
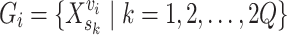 (corresponding to a video clip
(corresponding to a video clip  ), pair the signals randomly to form
), pair the signals randomly to form  pairs:
pairs: 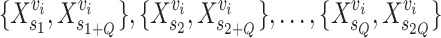 .
. - Crossover: Meiosis receives a randomly given split position
 (where
(where 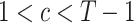 ) to perform the crossover transformation for each pair, exchanging data of the first
) to perform the crossover transformation for each pair, exchanging data of the first 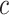 sampling points between the two signals. It results in augmented pairs
sampling points between the two signals. It results in augmented pairs 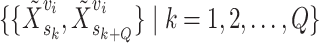 .
. - Separation: The transformed signals are then randomly divided into two groups. Paired transformed signals are placed in different groups X and Y, which results in two homologous groups of EEG
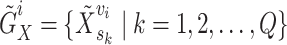 and
and  that share similar group-level stimuli-related features.
that share similar group-level stimuli-related features.
- Constructing the Minibatch:
- Equation 1 shows that for one minibatch of
 group samples
group samples  ,
,  group samples
group samples 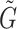 are obtained through the Meiosis augmentation process.
are obtained through the Meiosis augmentation process. 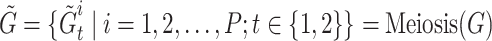
1 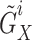 forms a positive pair with
forms a positive pair with 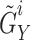 and forms negative pairs with any other
and forms negative pairs with any other  group samples.
group samples.
Contrastive learning setup
Contrastive learning uses meiosis-augmented pairs to train a model that learns to distinguish between pairs that share the same stimuli label (positive pairs) and pairs that come from different stimuli labels (negative pairs). Figure 2shows that the pretraining phase maximises the similarity between positive pairs and minimises the similarity between the negative pairs in the latent space5. The complete contrastive learning happens along with the Meiosis Augmentation as follows:
Augmentation: Meiosis augmentation generates pairs of EEG signals
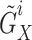 and
and 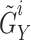 by cross-exchanging segments from different subjects within the same group. For instance,
by cross-exchanging segments from different subjects within the same group. For instance,  might contain segments from subject
might contain segments from subject 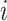 and
and 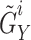 from subject
from subject 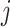 , both corresponding to the same stimuli.
, both corresponding to the same stimuli.Feature Extraction: SS-EMERGE extracts latent features
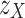 for the augmented pairs
for the augmented pairs 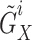 and
and 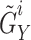 , generated by meosis augmentation35.
, generated by meosis augmentation35.-
Contrastive Loss:Finally, Phase-1 employs constrative loss to train the model using SimCLR11 loss function. The loss function penalises large deviations between the similarity scores and their expected values based on the temperature-scaled cross-entropy in Equation 3:
Here,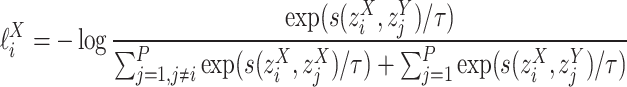
3  denotes the number of groups,
denotes the number of groups, 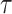 is the temperature parameter, and
is the temperature parameter, and  is an indicator function that equals 1 if
is an indicator function that equals 1 if 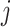 is not equal to
is not equal to 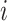 37.Equation 4 then calculates the combined loss across all the groups in a batch of Stochastic Gradient Descent.
37.Equation 4 then calculates the combined loss across all the groups in a batch of Stochastic Gradient Descent.
4
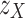
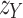
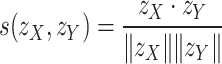
Algorithm 1 outlines the end-to-end Phase-1 pretraining using contrastive learning with meiosis augmentation. It starts by extracting group-level features and projecting them to latent space. It helps obtain group representations. The algorithm then minimises the distance between positive pairs and maximises amongst the negative pairs38.
Phase-2: fine-tune emotion classification model
In Phase-2 (fine-tuning), the pre-trained SS-EMERGE model generates the latent representation but further fine-tunes using the classification head seen in Figure 2 for emotion classification modelling. It only learns the parameters of the classification head without changing other model parameters.
Model Architecture and Training Procedures:
- Classifier Head: The classifier consists of additional fully connected layers that further process the latent representation of dimension D. These layers are followed by a softmax layer to produce the final emotion class probabilities (
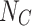 ).
). -
Fully Connected Layers: The layers with 1024, 256, and 128 neurons progressively transform and reduce the dimensionality of the latent representation.
Algorithm 1.
 Pretraining with Meiosis-Based Contrastive Learning
Pretraining with Meiosis-Based Contrastive Learning - Class Logits (FC (
 )): This layer outputs
)): This layer outputs 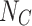 neurons, where
neurons, where 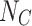 corresponds to the number of emotion classes.
corresponds to the number of emotion classes. - Softmax Layer: Converts the logits into class probabilities using Softmax.
-
- Training Procedure:
- Finally, Phase 2 fine-tunes the classifier head over the pre-trained model using labelled EEG data.
- The training process involves minimising a cross-entropy loss, which learns to discriminate different predicted class probabilities and the true emotion labels.
- It optimises the network using Stochastic Gradient Descent (SGD), with appropriate learning rate scheduling to ensure convergence shown in Table 2.
- It regularises the model training using a dropout of 0.5 and batch normalisation to prevent overfitting.

Table 2.
Hyperparameters of the SS-EMERGE Model.
| Phase | Parameter | Value |
|---|---|---|
| SSL Phase | Learning Rate | 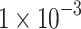 |
| Momentum | 0.1 | |
| Batch Size | 64 | |
| Epochs | 3288 | |
| Meiosis Augmentation - P | 16 (video clips per iteration) (SGMC18) | |
| Meiosis Augmentation - Q | 2 (samples per group) (SGMC18) | |
| Classification Phase | Learning Rate | 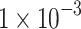 |
| Batch Size | 256 | |
| Epochs | 100 | |
| Optimization | Adam with learning rate scheduling | |
| Loss Function | Cross-entropy | |
| Dropout | 0.5 |
Experimental setup
Dataset
This work conducts experiments on the SEED21and SEED-IV22 datasets, known for their robust emotional state annotations and varying class distributions. These datasets provide a comprehensive and balanced foundation for evaluating the performance of emotion recognition models.
SEED-IV Dataset 21: Consists of EEG recordings from 15 subjects (7 males and 8 females) as they watched film clips designed to evoke specific emotions. Each subject contributed 45 samples, evenly distributed among three emotion labels: happy, sad, and neutral, resulting in a total of 675 samples21. The signals were recorded using a 62-channel ESI NeuroScan System, with a sampling rate of 1,000 Hz. To facilitate analysis, the signals were downsampled to 200 Hz and bandpass filtered between 0–75 Hz to remove unrelated artifacts.
SEED-IV Dataset 22: Includes data from the same 15 subjects, with each providing 72 samples distributed across four emotion labels: happy, sad, fear, and neutral, leading to a total of 1,080 samples22. The experimental setup and data processing methods were similar to those used in the SEED21 dataset. However, the bandpass frequency filter was set to 1–75 Hz for SEED-IV, and the DE features were normalised to ensure consistency across samples.
The balanced distribution of samples across subjects and emotion classes in both datasets ensures an unbiased training and evaluation process.
Data preparation
For both SEED21and SEED-IV22 datasets, each trial of EEG signal in each channel undergoes L2 normalisation to ensure that the data from different trials are on a similar scale. The movie videos are divided into 1-second windows. Given the varying lengths of the trial videos, adjacent windows are segmented from front to back according to the time axis until the coverage of windows exceeds the video range.
Evaluation strategy
To rigorously assess the generalisation capabilities and performance stability of the SS-EMERGE model, this work employs a robust evaluation strategy involving subject-mixed and subject-independent testing frameworks. The Leave-One-Subject-Out (LOSO) cross-validation scheme is utilised to ensure comprehensive evaluation:
- Subject-Independent / Cross-Subject Evaluation (LOSO):
- Fully-supervised Learning: For each cycle of LOSO, the model is trained on EEG data from
 subjects using all available labels. The model is then tested on the left-out subject, assessing its adaptability to new individual data unseen during the training phase.
subjects using all available labels. The model is then tested on the left-out subject, assessing its adaptability to new individual data unseen during the training phase. - Self-Supervised Learning: Begins with pretraining a base model on all subjects without labels to capture generalisable features. The model is then fine-tuned on minimal labelled data from the left-out subject, optimising the blend of learned representations with subject-specific adjustments.
- Subject-Mixed / Trial-Random Evaluation:
- Conducted using a random train-test split (80-20%) to evaluate the model’s architecture and ability to generalise across a random data selection, focusing not specifically on individual subject differences.
Training parameters for SSL and classification model
Phase-1 (pretraining) and Phase-2 (fine-tuning) select the hyperparameters used by SGMC18 along with the default settings of the optimiser. These settings yield good subject-independent and subject-dependent performance without the rigorous need for hyperparameter tuning. Table 2 lists all the hyperparameters with their corresponding default values during pretraining and fine-tuning of the Emotion Classification model.
Results and discussion
The results presented in this section evaluate the performance of SS-EMERGE in different experimental settings in the SEED21and SEED-IV22 datasets. The evaluation focuses on three key aspects as follows:
Experiment 1: Subject-Mixed and Cross-Subject Evaluation of Base-Model Architecture Using fully-supervised Learning
Experiment 2: Comparative Analysis of Self-Supervised vs Full-Supervised Learning for Cross-Subject Adaptation
Experiment 3: Foundational pretraining by combining SEED and SEED-IV.
Experiment 1: choosing a base model architecture
EEG-based emotion recognition is inherently challenging due to subject-specific variations. A cross-subject generalisation is particularly difficult, as models must adapt to significant intersubject variability. This experiment compares the ResNet used by SGMC18 with the proposed SS-EMERGE, a fully-supervised model trained for EEG emotion classification. The objective is to determine the most effective fully-supervised backbone model for emotion recognition for cross-subject.
Unlike previous studies that rely primarily on subject-independent evaluations, this work evaluates cross-subject, ensuring that the model is trained on 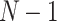 samples of a partial sample of subjects and tested on rest. This approach rigorously assesses cross-subject generalisation.
samples of a partial sample of subjects and tested on rest. This approach rigorously assesses cross-subject generalisation.
From Table 3, ResNet achieves 67.83% accuracy under the cross-subject evaluation, demonstrating its limited ability to generalise across subjects. In contrast, SS-EMERGE outperforms ResNet, achieving 84.13%, highlighting its effectiveness as a fully-supervised backbone model for EEG-based emotion recognition. Both models exhibit stronger performance in the random-split setting due to similarities in intra-subject training and testing data.
Table 3.
Performance of models on SEED21 dataset under subject-independent and cross-subject setups.
| Model | Setup | Positive (%) | Neutral (%) | Negative (%) | Average (%) |
|---|---|---|---|---|---|
| ResNet | Subject-Mixed | 89.7 | 90.0 | 89.8 | 89.83 |
| Cross-Subject | 68.5 | 69.8 | 65.2 | 67.83 | |
| SS-EMERGE | Subject-Mixed | 96.2 | 92.5 | 94.1 | 94.27 |
| Cross-Subject | 87.4 | 83.1 | 81.9 | 84.13 |
Experiment 2: cross-subject evaluation under self-supervised and fully-supervised learning
Having established SS-EMERGE as the superior fully-supervised backbone in Experiment 1, this experiment evaluates SS-EMERGE, a self-supervised learning (SSL) approach that combines contrastive learning with classification. SS-EMERGE is compared against SGMC, which also employs SSL, and SS-EMERGE, the strongest fully-supervised model from Experiment 1.
The SEED21and SEED-IV22 datasets are used to analyse how SSL compares with fully-supervised learning under cross-subject conditions. The model is fine-tuned using varying percentages of labelled data (10%, 50%, and 100%) to evaluate performance under different data availability scenarios.
From Table 4, SS-EMERGE consistently outperforms both SGMC and SS-EMERGE across all labelled data settings. Notably, when fine-tuned with only 10% labelled data, SS-EMERGE achieves 75.5% accuracy on SEED, compared to 74.12% for SS-EMERGE and 73.29% for SGMC. Also, when compared with fully-supervised counterpart, SEED21 achieves 84.13% cross-subject performance as compared to 92.35% of SSL.
Table 4.
Experiment 3: foundational pretraining using SEED and SEED-IV datasets
This experiment evaluates the impact of foundational pretraining using the combined datasets of SEED21and SEED-IV22. Given that both datasets share identical channel configurations, data integration during pretraining is streamlined. The distinct video stimuli in each dataset require a specialized approach for stimulus identification. To address this, a composite identifier that merges the dataset and video ID is used, ensuring accurate alignment with subject-specific emotional responses.
Baseline models
The baseline models for this study include:
Vanilla SGMC: This model operates solely in the temporal domain using a ResNet architecture, focusing on capturing dynamic temporal features.
SS-EMERGE: An advanced model that integrates features across temporal (T), spectral (F), and spatial (S) domains using a Graph Attention Transformer (GAT)28.
Ablation studies
Ablation studies are performed to assess the impact of each domain:
SS-EMERGE.FT: Focuses on the spectral and temporal domains, evaluating the models ability to utilize these features for emotion recognition.
SS-EMERGE.TS: Analyzes the integration of temporal and spatial domains, omitting spectral features to determine the importance of spatial information.
These models are evaluated on a subject-independent basis due to computational constraints, which also guide the domain-specific ablation studies.
The SEED21and SEED-IV22 datasets are processed under identical protocols to ensure uniformity, as detailed in subsection 3.2. Stimuli are uniquely tagged with dataset-specific prefixes, facilitating clear differentiation and integration into the SGMC model without modifications. Foundational pretraining employs contrastive loss to enhance feature discrimination across emotional stimuli without using labels.
In the fine-tuning phase, labels are reintroduced, tailoring the model to the distinct emotional patterns of each dataset. Performance is evaluated directly on the subjects from the training data, avoiding cross-subject validation.
As shown in Table 5, pretraining on the combined datasets significantly improves model accuracy 88.80% on SEED and 81.50% on SEED-IV21,22, demonstrating the efficacy of cross-domain pretraining. This approach represents the first attempt to merge and assess these datasets for cross-subject performance.
Table 5.
| #Samples | SGMC | SS-EMERGE.FT | SS-EMERGE.TS | SS-EMERGE |
|---|---|---|---|---|
| T | FT(Proposed) | TS(Proposed) | FTS(Proposed) | |
| SEED Dataset21 | ||||
| 10% | 73.29% | 73.82% | 73.51% | 74.11% |
| 50% | 83.71% | 84.02% | 83.84% | 84.42% |
| 100% | 83.04% | 85.56% | 85.12% | 88.87% |
| SEED-IV Dataset22 | ||||
| 10% | 58.33% | 56.81% | 55.53% | 57.92% |
| 50% | 66.44% | 62.32% | 61.02% | 63.54% |
| 100% | 77.64% | 76.31% | 75.08% | 82.75% |
Experiment 4: visualisation of underlying embedding
The t-Distributed Stochastic Neighbor Embedding (t-SNE) visualisations in Figures 3 and 4illustrate the feature representations from the SS-EMERGE on the SEED21and SEED-IV22 dataset. The t-SNE projections reduce the 4096-dimensional feature space to a 2-dimensional space for visualisation. The clustering of SS-EMERGE learnt features shows distinct and well-separated clusters. The more precise separation of clusters of the SS-EMERGE indicates that it enhances the model’s ability to capture the discriminative features due to its rich representation learning.
Fig. 3.

TSNE visualization of SEED21 embeddings.
Fig. 4.

TSNE visualization of SEED-IV21 embeddings.
Conclusion and future work
This study presents the SS-EMERGE model, a novel self-supervised learning approach using multidimension graph neural networks to enhance EEG-based emotion recognition. Evaluated on the SEED and SEED-IV datasets, SS-EMERGE consistently outperforms the SGMC baseline and fully-supervised models, particularly when labelled data is limited. The model shows substantial performance gains with just 10% and 50% labelled data and achieves its highest accuracy with full data utilisation, highlighting its potential for applications with scarce labelled resources.
Furthermore, SS-EMERGE demonstrates its capability as a foundational model for emotion recognition by efficiently leveraging combined datasets during pretraining. Future research could explore integrating additional diverse EEG datasets to improve model robustness further and investigate the efficacy of meiosis-based contrastive learning for enhanced group-level feature representation. This direction is promising for advancing emotion recognition technologies in real-world scenarios.
Author contributions
The authors confirm contribution to the paper: study conception and design: Chirag Ahuja; analysis and interpretation of results: Chirag Ahuja; draft manuscript preparation: Chirag Ahuja, Divyashikha Sethia. All authors reviewed the results and approved the final version of the manuscript.
Funding
The authors did not receive support from any organisation for the submitted work. No funding was received to assist with preparing this manuscript. No funding was received for conducting this study. No funds, grants, or other support was received.
Data availability and access
The data used in this study is available on SEED21and SEED-IV22. Access to the datasets can be requested through the following link: https://bcmi.sjtu.edu.cn/home/seed/.
Declaration
Competing interests
The authors have no relevant financial or non-financial interests to disclose. The authors have no conflicts of interest to declare relevant to this article’s content. All authors certify that they have no affiliations with or involvement in any organisation or entity with any financial or non-financial interest in the subject matter or materials discussed in this manuscript. The authors have no financial or proprietary interests in any material discussed in this article.
Footnotes
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
References
- 1.LeCun, Yann, Bengio, Yoshua & Hinton, Geoffrey. Deep Learning. Nature521(7553), 436–444 (2015). [DOI] [PubMed] [Google Scholar]
- 2.Multiple Authors: Self-Supervised Learning for Visual Understanding. Nature Reviews Methods Primers (2023)
- 3.Devlin, Jacob, Chang, Ming-Wei, Lee, Kenton, & Toutanova, Kristina. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 4171–4186 (2019).
- 4.Authors, Multiple. Natural Language Processing: State of the Art (Current Trends and Challenges, Multimedia Tools and Applications, 2023). [DOI] [PMC free article] [PubMed]
- 5.Oord, Aaron van den, Li, Yazhe, & Vinyals, Oriol. Representation Learning with Contrastive Predictive Coding. arXiv preprint arXiv:1807.03748 (2018).
- 6.Multiple Authors: Self-Supervised Learning in Audio. In: ICML 2023 Proceedings (2023). https://proceedings.mlr.press/v139.
- 7.Zheng, Wei-Long, & Lu, Bao-Liang. Investigating Critical Frequency Bands and Channels for EEG-Based Emotion Recognition with Deep Neural Networks. In: IEEE Transactions on Autonomous Mental Development (2015).
- 8.Li, Xin, Zhang, Xiangyu, Song, Xue, Li, Zhouyun, & Wu, Xiaohua Tony. Cross-Subject Emotion Recognition Using Deep Adaptation Networks. In: 2019 8th International Conference on Affective Computing and Intelligent Interaction (ACII), pp. 1–7 (2019). IEEE.
- 9.Zheng, Wei-Long., Liu, Jiahui & Lu, Bao-Liang. EmotionMeter: A Multimodal Framework for Recognizing Human Emotions. IEEE Transactions on Cybernetics49(3), 1110–1122 (2018). [DOI] [PubMed] [Google Scholar]
- 10.Hadsell, Raia, Chopra, Sumit, & LeCun, Yann. Dimensionality Reduction by Learning an Invariant Mapping. In: 2006 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’06), vol. 2, pp. 1735–1742 (2006). IEEE.
- 11.Chen, Ting, Kornblith, Simon, Norouzi, Mohammad, & Hinton, Geoffrey. A Simple Framework for Contrastive Learning of Visual Representations. In: International Conference on Machine Learning, pp. 1597–1607 (2020). PMLR.
- 12.Zheng, Wei-Long., Zhu, Jiangjiang & Lu, Bao-Liang. Multichannel EEG-Based Emotion Recognition via Group Sparse Canonical Correlation Analysis. IEEE Transactions on Cognitive and Developmental Systems9(3), 281–290 (2017). [Google Scholar]
- 13.Kostas, Dimitrios, & Rudzicz, Frank. Thinker Invariance: Enabling Deep Neural Networks for BCI Across More than 100 Subjects. arXiv preprint arXiv:1811.00928 (2018). [DOI] [PubMed]
- 14.Schirrmeister, Robin Tibor, Springenberg, Jost Tobias, Fiederer, Lukas, Dominique Josef, Glasstetter, Martin, Eggensperger, Katharina, Tangermann, Michael, Hutter, Frank, Burgard, Wolfram, Ball, Tonio. Deep Learning with Convolutional Neural Networks for EEG Decoding and Visualization. In: Human Brain Mapping, vol. 38, pp. 5391–5420 (2017). Wiley Online Library. [DOI] [PMC free article] [PubMed]
- 15.Bashivan, Pouya, Rish, Irina, Yeasin, Md, & Codella, Noel. Learning Representations from EEG with Deep Recurrent-Convolutional Neural Networks. In: International Conference on Learning Representations (2015).
- 16.Rafiei, M.H., Gauthier, L., Adeli, H., & Takabi, D. Self-supervised learning for electroencephalography. IEEE Transactions on Neural Networks and Learning Systems PP, 1–15 (2022) 10.1109/TNNLS.2022.3190448. [DOI] [PubMed]
- 17.Li, Rui, Wang, Yiting, Zheng, Wei-Long, & Lu, Bao-Liang. A Multi-View Spectral-Spatial-Temporal Masked Autoencoder for Decoding Emotions with Self-Supervised Learning. In: Proceedings of the 30th ACM International Conference on Multimedia, pp. 4002–4010 (2022). ACM.
- 18.Zheng, Wei-Long, Duan, Jun-Cheng, & Lu, Bao-Liang. Self-Supervised Group Meiosis Contrastive Learning for EEG-Based Emotion Recognition. In: 2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pp. 1335–1339 (2021). IEEE.
- 19.Li, R., Wang, Y., Zheng, W.-L., & Lu, B.-L. Graph-Based Multi-Space Self-Supervised Learning for EEG Representation Learning. In: Proceedings of the 29th ACM International Conference on Multimedia, pp. 1065–1073 (2021). ACM.
- 20.Song, Tinglei, Zheng, Wei-Long, Lu, Bao-Liang, Zong, Yixuan. EEG Emotion Recognition Using Dynamical Graph Convolutional Neural Networks. In: 2018 24th International Conference on Pattern Recognition (ICPR), pp. 3599–3604 (2018). IEEE.
- 21.Zheng, W. L. et al.: Investigating EEG-Based Emotion Recognition via Ensemble Learning. IEEE Transactions on Affective Computing (2015).
- 22.Zheng, Wei-Long., Zhu, Jia-Yi. & Lu, Bao-Liang. EmotionMeter: A Multimodal Framework for Recognizing Human Emotions. IEEE Transactions on Cybernetics49(3), 1110–1122 (2018). [DOI] [PubMed] [Google Scholar]
- 23.Oord, A., Dieleman, S., Zen, H., Simonyan, K., Vinyals, O., Graves, A., Kalchbrenner, N., Senior, A., & Kavukcuoglu, K. Wavenet: A generative model for raw audio. arXiv preprint arXiv:1609.03499 (2016).
- 24.Bai, S., Kolter, J.Z., & Koltun, V. An empirical evaluation of generic convolutional and recurrent networks for sequence modeling. arXiv preprint arXiv:1803.01271 (2018).
- 25.Ingolfsson, T.M., Wang, X., Hanna, G., Gugat, R., McAllister, J., & Frossard, P. Eeg-tcnet: An accurate temporal convolutional network for embedded motor-imagery brain-machine interfaces. arXiv preprint arXiv:2006.00622 (2020).
- 26.Velickovic, Petar, Cucurull, Guillem, Casanova, Arantxa, Romero, Adriana, Liò, Pietro, & Bengio, Yoshua. Graph Attention Networks. In: International Conference on Learning Representations (ICLR) (2018).
- 27.Hsu, T.-H., Tseng, Y.-C., & Chen, J.-J. Graph attention transformer for unsupervised multivariate time series anomaly detection. In: Proceedings of MACLEAN: MAChine Learning for EArth ObservatioN Workshop 2022, Co-located with the European Conference on Machine Learning and Principles and Practice of Knowledge Discovery in Databases (ECML/PKDD 2022), Grenoble, France (2022). https://ceur-ws.org/Vol-3343/paper3.pdf.
- 28.Gao, Z. et al.: Vital Signs Monitoring of Multiple People Using a FMCW Radar with Beamforming. IEEE Transactions on Microwave Theory and Techniques (2019).
- 29.Shen, Y. et al.: Comprehensive EEG-Based Emotion Recognition. IEEE Transactions on Affective Computing (2021).
- 30.Alarcao, Sergio M., & Fonseca, Manuel J. Emotions Recognition Using EEG Signals: A Survey. IEEE Transactions on Affective Computing 10(3), 374–393 (2017).
- 31.Duan, L. et al.: EEG Emotion Recognition Based on Deep Learning Techniques. Journal of Neural Engineering (2022).
- 32.Vaswani, A. et al.: Attention Is All You Need. In: NeurIPS (2017).
- 33.Brody, S. et al.: Attentive Temporal Graph Convolutional Networks for Dynamic Graphs. In: ICLR (2020).
- 34.Oord, A. V. D. et al.: WaveNet: A Generative Model for Raw Audio. arXiv preprint arXiv:1609.03499 (2016).
- 35.Misra, I. et al.: Self-Supervised Learning with Augmented Multiview Embeddings. In: NeurIPS (2020).
- 36.Grill, J. B. et al.: Bootstrap Your Own Latent: A New Approach to Self-Supervised Learning. In: NeurIPS (2020).
- 37.Chen, X. et al.: Improved Baselines with Momentum Contrastive Learning. arXiv preprint arXiv:2003.04297 (2020).
- 38.Tian, Y. et al.: Contrastive Multiview Coding. In: ECCV (2020).
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.
Data Availability Statement
The data used in this study is available on SEED21and SEED-IV22. Access to the datasets can be requested through the following link: https://bcmi.sjtu.edu.cn/home/seed/.