

Abstract
Based on natural language specification unmanned aerial vehicle tracking mission goal is to automatically and continuously track the target in subsequent frames by natural language descriptions. Existing tracking methods typically handle this problem through two separate steps: visual grounding and object tracking. However, this independent solution would result in ignoring the relationship between visual grounding and object tracking, e.g., natural language can provide semantic information about the target, and this solution would also result in an inability to train end-to-end. Therefore, we propose a framework based on natural language specification that integrates visual grounding and object tracking, redefining it as a unified task. This framework can track the object based on a given natural language reference. First, the proposed triangular integration effectively establishes the relationship between natural language and images (template image and search image). Then in order to accomplish multi-scale learning and global receptive field, and effectively improve the flexibility of the method to the visual characteristics of the tracking target, we designed a new lightweight concentrated multi-scale linear attention. Additionally, to reduce computational complexity, we introduced residuals. Finally, experiments conducted on six UAV tracking datasets showed that our tracker achieved accuracy, success rate, and average speed of 0.819, 0.654, and 61 FPS, respectively, outperforming other state-of-the-art trackers.
Keywords: Natural language specification, Unmanned aerial vehicle tracking, Triangular integration, Concentrated multi-scale linear attention
Subject terms: Image processing, Computer science
Introduction
Natural language specification tracking can continuously track a target based on natural language descriptions1,2. Unlike traditional tracking tasks3 that select the object bounding box in the first frame, natural language specification tracking offers an innovative human-computer collaboration method for object tracking. Consequently, integrating natural language specification tracking into unmanned aerial vehicles (UAV) has become popular, aiding humans in advanced application scenarios4. In recent years, UAV object tracking has become a key research focus in intelligent transportation scenarios, significantly simplifying the execution of practical tasks such as path tracking, disaster rescue, and agricultural supervision5–7. At the same time, natural language specification tracking differs from traditional bounding box tracking in the following ways: First, natural language can describe the target in a continuous state, whereas bounding box-based tracking can only provide a static representation of the target. Second, bounding boxes lack a definition of the target compared to natural language, making them prone to ambiguity. Natural language, on the other hand, can accurately track the target with a clear definition. Despite significant progress in some natural language specification tracking methods, there are still numerous challenges in real-time UAV tracking scenarios.
As shown in Fig. 1b, the existing method8 solves the problem by dividing it into the following steps: (a) Localize the tracking target to the initial frame through natural language representation, i.e., visual grounding. (b) Target localization for the predicted target state of the initial frame and continuous tracking in subsequent video sequences, i.e., performing object tracking. Some algorithms9 are inspired by the grounding and tracking blocks and combine the two. In these algorithms, the grounding block is responsible for modeling the relationship between natural language and visual to find the target location, while the tracking block models cross-attention between the template and search area to determine target positioning. However, this framework has certain shortcomings, which are as follows: (a) The grounding block and tracking block operate independently, without establishing a close connection between them. (b) Many algorithms10 simply choose existing grounding blocks or tracking blocks as the basis for their framework, resulting in a tracking framework that lacks the capability for end-to-end training.
Fig. 1.

Comparison of the popular architecture for visual tracking.
Generally, tracking block predict the target position in subsequent frames based only on the template from the initial frame, without considering the impact of natural language specifications on tracking. However, tracking methods that integrate visual and natural language specifications to predict the target position show significant improvement. This approach requires the model to simultaneously establish relational models for the template-search area and the language-visual relationship. Inspired by this tracking approach, we propose a new framework that accomplishes the modeling of both relationships. Our framework naturally connects visual and natural language inputs for UAV tracking and supports end-to-end training, as shown in Fig. 1(c).
To this end, we propose a new framework based on natural language specification that integrates visual grounding and object tracking (named TCMLTrack). Our perspective is to unify and redefine these two tasks by using the given language-visual input to accomplish target tracking. In terms of language, the reference information is presented in natural language. Within the context of visual tracking, the reference information consists of the prior target patch (known as the template) and the search region (or search image). Therefore, the key to the unification task is how to establish multi-source relationships among the provided natural language descriptions and the images, including cross-modal (visual and language) relationships and cross-temporal (prior images and present search images) relationships. To address this problem, a triangular integration multi-source relationship modeling approach is proposed. This approach is adaptable to accommodate the various references of visual grounding and object tracking, thereby effectively modeling these relationships. It helps our method to facilitate the transition between visual grounding and object tracking based on varying inputs.
Additionally, the linear attention in transformers captures local information weakly and fails to produce distinctly focused attention maps. To mitigate this issue, we present a efficient concentrated multi-scale linear attention (CMLatten), which achieves global receptive field and multi-scale learning. This attention mechanism primarily focuses on concentration ability and feature diversity, addressing the limitations of linear attention and enhancing expressive ability. Additionally, to reduce computational cost, we introduced residuals.
To summarize, our main contributions can be outlined as listed below.
We introduce a clean and novel framework for joint visual grounding and object tracking based on natural language specification that unifies the two into a single task and can adapt to different input information (natural language and images).
We propose a new CMLatten mechanism that enhances the expressiveness of linear attention, ultimately improving adaptability to changes in target appearance.
In order to improve the real-time performance of the tracking method, residuals are also introduced, and the amount of computation is thus reduced.
Our method is evaluated on six UAV tracking datasets and two general tracking datasets, and compared against state-of-the-art (SOTA) tracking methods. Extensive experimental results demonstrate the performance of our approach.
Related work
UAV tracking paradigms
The task of UAV tracking is to predict the position and scale of the tracked target in video sequences captured by onboard cameras and other relevant equipment. In the early stages, UAV tracking methods based on siamese networks11 achieved impressive results. These methods typically utilize a two-stage approach to extract features from the template and search regions, as shown in Fig. 1a. Then, fusion is performed through specially designed correlation modules (often using cross-correlation). Most siamese trackers12 commonly use neural networks (such as ResNet-50) as backbones. Recently, because of the high representational capacity of transformer-based trackers, they have gradually been applied to many real-time UAV tracking scenarios.
In order to enhance the interaction capability between features at a deeper level, previous research13 has made multiple attempts, focusing on modeling the internal relationships within the backbone. Some recent works14 have connected search and template tokens to jointly perform self-relationship modeling and cross-relationship modeling. For example, JLST15 propose a real-time UAV object tracking algorithm with adaptive spatial-temporal attention, where spatial and temporal attention filters are introduced to enhance tracking accuracy. The spatial filter suppresses background noise, while the temporal filter focuses on target continuity, improving robustness against occlusions and deformations. BACTrack16 introduces a robust tracking framework that dynamically builds and updates multiple target templates online. It leverages a Mixed-Temporal Transformer for efficient multi-template matching and an appearance discriminator for adaptive template updates, enhancing tracking performance by handling rapid target appearance changes and background interference. However, the training time is relatively long and requires the integration of other generative models or the adjustment of model architecture. Both one-stage and two-stage methods commonly interact with the template and each part of the search region separately, considering the search region in its entirety. When the feature extraction capability is insufficient or the modeling of mutual relationships is poor, this may result in difficulty distinguishing the target from the background, leading to tracking failures. To address this issue, we propose a novel framework that integrates visual grounding and object tracking based on natural language specification. The experimental results prove that our proposed framework outperforms prior approaches.
Tracking with natural language specification
TNLP17 was inspired by visual tracking and natural language, proposing a tracking method based on natural language specification. GTI18 decomposes the tracking problem into three sub-problems tracking, grounding and integration respectively and handles these sub-problems through three separate modules. Wang19 proposed a platform for natural language specification of tracking tasks and released a new natural language based tracking benchmark TNL2K. This benchmark contains two baselines, natural language initialization with bounding boxes and natural language initialization. VOT-NLP20 uses the tracking-by-detection framework to generate global proposals over video sequences via natural language specification to successfully track targets. GRM21 locates and tracks the target based on a given natural language reference. MMPT22 can effectively integrate visual and textual cues into various encoders, improving the extraction and alignment of cross modal features. CT-NLP23 uses a proposed object retrieval block to lock onto the object, which can also automatically select the object to initialize the tracker. Existing studies typically utilize existing visual grounding blocks24, or use special grounding25 to track targets, resulting in forced independence of visual grounding and object tracking. However, within our method, we introduce an integrated framework for visual grounding and object tracking for natural language specification tracking tasks. This framework can perform target tracking based on different input references.
Tracking with vision transformer
Given the input consisting of N tokens  , the self-attention in each head is represented by
, the self-attention in each head is represented by  , where
, where  are learnable linear projection matrices corresponding to Q, K, and V respectively.
are learnable linear projection matrices corresponding to Q, K, and V respectively.  denotes the i-th row of matrix O. Sim(.,.) is the similarity function. Currently, most mainstream transformer models are based on softmax attention, where the similarity function is
denotes the i-th row of matrix O. Sim(.,.) is the similarity function. Currently, most mainstream transformer models are based on softmax attention, where the similarity function is  . By this method, the similarity between all query-key pairs is computed to get the the attention map, with complexity
. By this method, the similarity between all query-key pairs is computed to get the the attention map, with complexity  . As a result of the impact of quadratic computation, it is challenging to use global receptive field self-attention alone, which inevitably increases computational costs. Some methods reduce computational load by using smaller attention windows26 and sparse global attention27. While these approaches improve efficiency to some extent, they also sacrifice the ability to model long-term dependencies.
. As a result of the impact of quadratic computation, it is challenging to use global receptive field self-attention alone, which inevitably increases computational costs. Some methods reduce computational load by using smaller attention windows26 and sparse global attention27. While these approaches improve efficiency to some extent, they also sacrifice the ability to model long-term dependencies.
In contrast, there exists a linear attention method that addresses the drawbacks of softmax attention, reducing computational complexity to  . Specifically, this is achieved by introducing a designed kernel function to serve as the original similarity function. Therefore, the expression of the self-attention is
. Specifically, this is achieved by introducing a designed kernel function to serve as the original similarity function. Therefore, the expression of the self-attention is  , where the order of computation is changed (transitioning from
, where the order of computation is changed (transitioning from  to
to  ) according to the laws related to matrix multiplication. As a result, the computational complexity of tokens is reduced to
) according to the laws related to matrix multiplication. As a result, the computational complexity of tokens is reduced to  .
.
However, linear attention also faces two challenges: model expressiveness and complexity. On one hand, using the ReLU activation function28 for similarity expression may lead to decreased performance due to being too loose. On the other hand, matrix decomposition or redesigning the kernel function29 can result in excessive computational load. Therefore, there are still significant gaps in both linear attention and softmax attention. Previous work30 demonstrated that simply using linear attention instead of softmax attention leads to performance degradation with high probability. TransT31 employs a feature fusion network that feeds the fused features into both bounding box regression and target classification. This fusion network consists of cross-attention and multiple self-attention modules. TrDiMP32 improves the DiMP tracker by using the output features of the encoder as training samples to generate weights. Then, the tracking block calculates the score map using these model weights, while TrDiMP utilizes IoUNet for target regression.
Unlike the above trackers, STARK33 is influenced by the transformer architecture of MDETR, where test and training features are combined and jointly handled throughout the entire model. Next, the target query is generated with the transformer encoder features fused to input to the decoder, for which the location of the target is directly predicted. HiFT34 introduced a multi-level feature mechanism for tracking. This tracker inputs the similarity map between the hierarchical levels to the feature transformer in order to realize the cross-fertilization of semantics (deep layers) and spatial (shallow layers). This strategy not only improves the global contextual information, but also has strong discriminative tracking features. However, targets are usually accompanied by significant scale variations. To alleviate this problem, most of the existing tracking algorithms use additional multi-scale computation time. Therefore, we propose a new light weight CMLatten, which avoids complex structures and efficient hardware requirements. The method analyses both concentration ability and feature diversity, and is able to improve both efficiency and performance.
Methods
Unified grounding and tracking framework
Our proposed framework consists of language and visual encoders, triangular integration, CMLatten35, target decoder, and localization head, respectively, named TCMLTrack, as shown in Fig. 2. Specifically, by inputting natural language and images, the language and visual encoders respectively process them to embed them into the feature space, generating token embeddings for words and image patches. Then, through the proposed triangular integration, the relationship between NL and images is modeled, adaptively selecting significant channels and filtering out redundant information. To reduce the number of learnable parameters and increase the speed, we introduce residuals. By freezing the cache model, only an additional set of lightweight category residuals and cache scores are trained. Finally, CMLatten is proposed to achieve multi-scale learning to further enhance the representation of the objective and computational efficiency.
Fig. 2.

Overview of TCMLTrack.
Our proposed framework is based on natural language specification of the tracking task and can be summarized as follows: (a) Given an initial frame, TCMLTrack assembles natural language specification and test images as inputs for target localization, and then extracts target templates based on the localization results. (b) In the subsequent tracking process, we use natural language specification, test image (i.e., search image) and target template as inputs for natural language-based visual tracking.
Triangular integration
For target tracking, the extracted features contain domain-specific and redundant information along the channel dimension. Where domain-specific information is more appropriate for target tracking, while redundant information represents general visual semantic features. Therefore, important feature channels are adaptively filtered based on two proposed criteria, i.e., inter-class similarity and inter-class variance.
-
Inter-class similarity. The inter-class similarity aims at extracting classification channels with strong discriminatory properties, i.e., minimized by selecting inter-class similarity. In target tracking, the first extracted features are denoted as
 , where D represents the total number of channels. The goal is to select Q feature channels from the total number of channels. Then, let masks
, where D represents the total number of channels. The goal is to select Q feature channels from the total number of channels. Then, let masks  and
and  denote the selection of the k-th element
denote the selection of the k-th element  , along with
, along with  . Finally, the optimalis B obtained so that the maximum inter-class divergence can be selected for the target tracking.For the tracking dataset with C categories, the category-averaged similarity S of all training samples is computed by the cosine similarity
. Finally, the optimalis B obtained so that the maximum inter-class divergence can be selected for the target tracking.For the tracking dataset with C categories, the category-averaged similarity S of all training samples is computed by the cosine similarity , calculated as
, calculated as
where
1  ,
,  are the total number of training samples.
are the total number of training samples.  ,
, are two categories of prior probability.
are two categories of prior probability.  and
and  are two classes.However, the cost of computing the class average similarity S across all training samples is very high, even when the number of frames is small. From contrastive pre-training, it was found that vision-language alignment is effective, and textual features can be considered as visual prototypes36,37. These prototypes can approximately represent the cluster centers of different category visual features in the embedding space. Then a simple template is used to put all the category names into [CLASS] as input to get the textual features, i.e., the textual features of the category are denoted as
are two classes.However, the cost of computing the class average similarity S across all training samples is very high, even when the number of frames is small. From contrastive pre-training, it was found that vision-language alignment is effective, and textual features can be considered as visual prototypes36,37. These prototypes can approximately represent the cluster centers of different category visual features in the embedding space. Then a simple template is used to put all the category names into [CLASS] as input to get the textual features, i.e., the textual features of the category are denoted as , where
, where  . Thus, the image features for each category are replaced by these textual features, which determine
. Thus, the image features for each category are replaced by these textual features, which determine  . In an open-world setting, assume
. In an open-world setting, assume  , the formula for minimizing inter-class similarity is as follows:
, the formula for minimizing inter-class similarity is as follows:
where
2  represents element-wise multiplication.
represents element-wise multiplication.  represents the selection of the most relevant feature channels to the target. So, by simplifying the cosine similarity the formula is as follows:
represents the selection of the most relevant feature channels to the target. So, by simplifying the cosine similarity the formula is as follows:
where
3  is the index of the feature channel selected when
is the index of the feature channel selected when  .
.  is the average inter-class similarity across the k-th channel.
is the average inter-class similarity across the k-th channel.In summary, after the above optimization, it is equivalent to selecting the Q elements with the lowest average similarity. In other words, by sorting the average similarity of the D elements and then selecting the Q smallest elements in front of them. This process allows us to generate the mask B, which ultimately yields the most discriminative feature channel for subsequent tracking.
- Inter-class variance. Additionally, we eliminate feature channels with small variations through inter-class variance. These redundant feature channels show no differences between different categories and have minimal impact on the classification task. We continue to use category textual features
 to improve efficiency (
to improve efficiency ( ). The formula for calculating the inter-class variance of the k-th feature channel is as follows:
). The formula for calculating the inter-class variance of the k-th feature channel is as follows:
where
4  represents the average variance of the k-th channel. The top Q channels with the highest variance can be selected, considering inter-class similarity as a sorting problem. This method helps to effectively filter out less informative or redundant channels. Finally, the three factors (i.e., balancing factor
represents the average variance of the k-th channel. The top Q channels with the highest variance can be selected, considering inter-class similarity as a sorting problem. This method helps to effectively filter out less informative or redundant channels. Finally, the three factors (i.e., balancing factor  , variance criteria, and similarity) are integrated to obtain the final result. The k-th feature channel is represented as follows:
, variance criteria, and similarity) are integrated to obtain the final result. The k-th feature channel is represented as follows:
where
5  . By selecting the top Q smallest, we designate them as the ultimate corrected feature channels, denoted as
. By selecting the top Q smallest, we designate them as the ultimate corrected feature channels, denoted as  . It can provide accurate target features during the subsequent tracking process.
. It can provide accurate target features during the subsequent tracking process. -
Residual. Specifically, a set of learnable embeddings C is used to complete the residual. Each embedding corresponds to a target, aiming to optimize finer feature channels Q for each target during few-shot training. Additionally, we apply residuals to the training-set
 feature and textual feature W to maintain the correspondence between vision and language.We obtain the L2-normalized features from the template image, text, and search region, referred to as
feature and textual feature W to maintain the correspondence between vision and language.We obtain the L2-normalized features from the template image, text, and search region, referred to as ,
,  , and
, and  , respectively. Subsequently, through the proposed inter-class similarity and inter-class variance, we obtain the Q most informative channels from the three features, denoted as
, respectively. Subsequently, through the proposed inter-class similarity and inter-class variance, we obtain the Q most informative channels from the three features, denoted as  ,
,  , and
, and  , respectively. On one hand, it filters out redundant information from the pre-training. On the other hand, it reduces the computational load of the cache model during inference. We fill Q the channel Res, where the excess channel index is set to zero, and also fill it into the D channel to form W. Finally, we perform element-wise addition by adding the padded Res to W to update the prediction in an optimized textual feature manner. This process is expressed by the formula:
, respectively. On one hand, it filters out redundant information from the pre-training. On the other hand, it reduces the computational load of the cache model during inference. We fill Q the channel Res, where the excess channel index is set to zero, and also fill it into the D channel to form W. Finally, we perform element-wise addition by adding the padded Res to W to update the prediction in an optimized textual feature manner. This process is expressed by the formula:
Next, we perform an association operation between
6  and
and  . By replicating the residuals across each category, we broadcast the residual of the C-embedding to CK, resulting in
. By replicating the residuals across each category, we broadcast the residual of the C-embedding to CK, resulting in  . Then, the expanded Res is element-wise added to
. Then, the expanded Res is element-wise added to  with the aim of optimizing the training set features, thus enhancing the few-shot prediction of the cache model. This process is expressed as follows:
with the aim of optimizing the training set features, thus enhancing the few-shot prediction of the cache model. This process is expressed as follows:
where
7  is a modulation scalar. Based on previous methods38, this modulation scalar reflects the similarity between images in the cache model.Additionally, considering the relationship between
is a modulation scalar. Based on previous methods38, this modulation scalar reflects the similarity between images in the cache model.Additionally, considering the relationship between and
and  , let
, let  represent the cosine similarity between them, which indicates the prediction for the few-shot training data. Calculate the KL-divergence
represent the cosine similarity between them, which indicates the prediction for the few-shot training data. Calculate the KL-divergence  to measure the difference between the predictions and their labels L, aiming to evaluate the subsequent target tracking. Through this operation, our method can adaptively select the most contributive cache scores, learning from different training sets. The specific expression is as follows:
to measure the difference between the predictions and their labels L, aiming to evaluate the subsequent target tracking. Through this operation, our method can adaptively select the most contributive cache scores, learning from different training sets. The specific expression is as follows:
where
8  is a smoothing parameter.
is a smoothing parameter.  represents the scores of the training features in the cache model, reflecting their accuracy and the degree of influence on the final prediction.Finally, according to the relationship between the three
represents the scores of the training features in the cache model, reflecting their accuracy and the degree of influence on the final prediction.Finally, according to the relationship between the three ,
,  ,
,  , we have the classification losits formula as (13).
, we have the classification losits formula as (13).
where
9  denotes diagonalization. The
denotes diagonalization. The  is a balance parameter.
is a balance parameter.  denotes few-shot predictions, which contain pretrained prior knowledge. The
denotes few-shot predictions, which contain pretrained prior knowledge. The  represents the few-shot predictions of the cache model, optimized through reweighting of feature channels and
represents the few-shot predictions of the cache model, optimized through reweighting of feature channels and  . So, through the analysis of three-way relationships and residuals, our proposed triangular integration module, trained with a smaller set of parameters, can avoid the costly adjustment of the cache model. By optimizing the refined features of this module, we achieve excellent performance, as shown in Fig. 3.
. So, through the analysis of three-way relationships and residuals, our proposed triangular integration module, trained with a smaller set of parameters, can avoid the costly adjustment of the cache model. By optimizing the refined features of this module, we achieve excellent performance, as shown in Fig. 3.
Fig. 3.
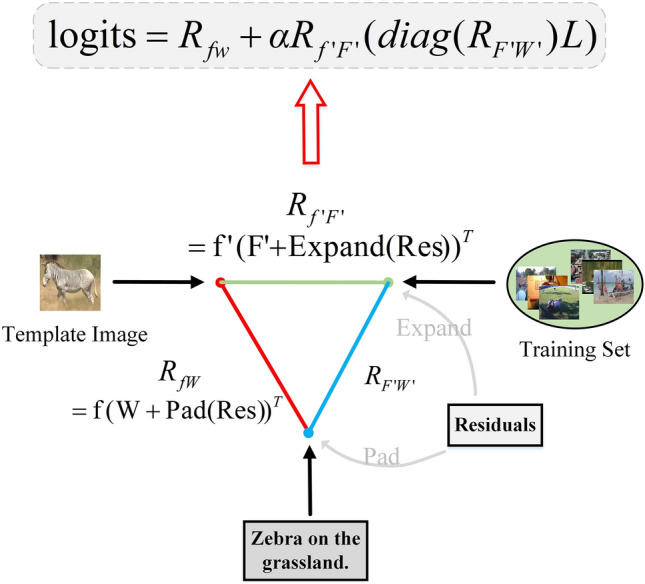
Triangular integration structure with residual.
Generate concentrated multi-scale linear attention
Due to the limited capacity of simple linear attention models, to enhance global attention in multi-scale learning, we propose aggregating information from nearby query, key, and value tokens to obtain multi-scale tokens. In each head, the process of aggregation of query, key, and value is independent, as shown in Fig. 4. To improve efficiency, a convolution with a smaller kernel is used for aggregation. In practice, since GPU execution of the aggregation operation is time-consuming, group convolution (GC) is employed to reduce the number of operations and computational load. Specifically, all  convolutions and all depthwise convolution (DWC) are first combined into a
convolutions and all depthwise convolution (DWC) are first combined into a  group convolution and a DWC, respectively, as shown in Fig. 2 (concentrated multi-scale linear attention). Then, after obtaining the multi-scale tokens, global attention is applied to derive global features. Finally, the features of different scales are concatenated according to the head dimension and input to the target decoder. Unlike previous methods, our multi-scale linear attention simultaneously accomplishes a global receptive field and multi-scale learning.
group convolution and a DWC, respectively, as shown in Fig. 2 (concentrated multi-scale linear attention). Then, after obtaining the multi-scale tokens, global attention is applied to derive global features. Finally, the features of different scales are concatenated according to the head dimension and input to the target decoder. Unlike previous methods, our multi-scale linear attention simultaneously accomplishes a global receptive field and multi-scale learning.
Concentrated multi-scale linear attention. As shown in Fig. 5, there are differences between the attention maps of softmax and linear attention mechanisms. Linear attention lacks a nonlinear similarity function, resulting in weaker local information capture and an inability to produce focused attention maps. To mitigate this limitation, we further propose CMLatten. First, we analyze the disadvantages of linear attention from two aspects: concentration ability and feature diversity. Then, we introduce our proposed CMLatten, which addresses this issue while striking a good balance between two key metrics in object tracking tasks: speed and accuracy. For tracking, both global receptive field and multi-scale learning are crucial. Previous SOTA trackers have made improvements in global receptive field and multi-scale learning to enhance accuracy to some extent, but there has been limited improvement in speed.
- Concentration ability. As shown in Fig. 5, softmax attention focuses on certain areas, specifically foreground objects. This is primarily because softmax attention uses a nonlinear reweighting method to emphasize important features. However, linear attention distributes attention more evenly, resulting in an inability to focus on the target area. To address this issue, we propose a simple yet effective method. Specifically, we begin by aligning the direction of each query and key to bring similar pairs closer and push dissimilar pairs further apart. Consequently, by introducing a mapping function called the concentrated function
 :
:
where
10  ,
,  denotes element-wise power p of x. To ensure the validity and non-negativity of the denominator in (14), we first apply the ReLU function as described in the aforementioned linear attention. It is evident that after mapping, the norm of the features is preserved, meaning only the feature direction is adjusted (
denotes element-wise power p of x. To ensure the validity and non-negativity of the denominator in (14), we first apply the ReLU function as described in the aforementioned linear attention. It is evident that after mapping, the norm of the features is preserved, meaning only the feature direction is adjusted ( ).
).
Fig. 4.

A depiction of the aggregation method for producing multi-scale tokens.
Fig. 5.

The distributions of linear, softmax, and our concentrated linear approaches.
To demonstrate that the proposed concentrated function can impact the attention distribution.
Proposition 1 (  Adjusting the feature direction)
Adjusting the feature direction)
Assuming
 . x
and
y
each have a maximum value of
. x
and
y
each have a maximum value of
 and
and
 , respectively. Considering a pair of features
, respectively. Considering a pair of features
 when the equality of
m
and
n
is satisfied:
when the equality of
m
and
n
is satisfied:
 |
11 |
A pair of features
 when
when
 :
:
 |
12 |
Therefore, at a suitable p, our concentrated function
 can amplify the difference between dissimilar query-key pairs (15) and similar query-key pairs (16). The goal is to ensure the initial sharp attention distribution of softmax attention.
can amplify the difference between dissimilar query-key pairs (15) and similar query-key pairs (16). The goal is to ensure the initial sharp attention distribution of softmax attention.
For clarity, the impact of  on the vectors is shown in the Fig. 6. It can move each vector toward its closest axis, with p controlling the degree of this shift. In this way,
on the vectors is shown in the Fig. 6. It can move each vector toward its closest axis, with p controlling the degree of this shift. In this way,  helps to partition the features into multiple groups, increasing the intra-group similarity while decreasing the inter-group similarity. This visualization result is consistent with our previous analysis. Therefore, with an appropriate parameter p, our concentrated function
helps to partition the features into multiple groups, increasing the intra-group similarity while decreasing the inter-group similarity. This visualization result is consistent with our previous analysis. Therefore, with an appropriate parameter p, our concentrated function  effectively attains a more distinct contrast between similar query-key pairs (15) and dissimilar query-key pairs (16), reinstating the sharp attention distribution similar to the original softmax function.
effectively attains a more distinct contrast between similar query-key pairs (15) and dissimilar query-key pairs (16), reinstating the sharp attention distribution similar to the original softmax function.
Fig. 6.

The  assists in directing each vector towards its closest axis, facilitating linear attention to concentrate on similar features.
assists in directing each vector towards its closest axis, facilitating linear attention to concentrate on similar features.
-
(3)Feature diversity. Feature diversity is one of the important factors affecting the expression of linear attention. A potential reason may be related to the rank of the attention matrix39, which indicates the diversity during feature aggregation. However, achieving this in the context of linear attention is quite challenging. In the linear attention mechanism, the rank of the attention matrix is affected by the channel dimension d and the number of tokens N in each head.
In most vision transformers, N is often greater than d, for example,
13  and
and  in DeiT, and
in DeiT, and  and
and  in Swin Transformer40. Due to the limitation imposed by the lower proportion on the rank of the attention matrix, numerous rows within the attention map exhibit significant homogenization. At the same time, the output of self-attention is the weighted sum of the same set of V, resulting in homogeneous attention weights that also contribute to the similarity of aggregated features. To address this limitation of linear attention, we propose a simple and efficient method. By introducing depthwise convolution (DWC), we redefine the output as follows:
in Swin Transformer40. Due to the limitation imposed by the lower proportion on the rank of the attention matrix, numerous rows within the attention map exhibit significant homogenization. At the same time, the output of self-attention is the weighted sum of the same set of V, resulting in homogeneous attention weights that also contribute to the similarity of aggregated features. To address this limitation of linear attention, we propose a simple and efficient method. By introducing depthwise convolution (DWC), we redefine the output as follows:
For a deeper insight into the role of DWC, it can be viewed as a special mechanism where each query does not attend to all features V, but only to adjacent features. On one hand, due to the locality characteristic, even if two queries have the same linear attention values, they can still obtain different local features corresponding to different outputs, thereby maintaining feature diversity. On the other hand, from the perspective of matrix rank, we can also explain the impact of DWC. According to (18), we have the following:
14
where
15  denotes equivalent full attention map and
denotes equivalent full attention map and  denotes the sparse matrix corresponding to the depthwise convolution function.
denotes the sparse matrix corresponding to the depthwise convolution function.  is a full-rank matrix, so it effectively increases the upper bound of the attention matrix rank, which to some extent can reduce computational complexity and also improve the performance of linear attention.
is a full-rank matrix, so it effectively increases the upper bound of the attention matrix rank, which to some extent can reduce computational complexity and also improve the performance of linear attention.
In summary, we propose a new CMLatten module that enhances expressive capability while reducing computational complexity. First, a new concentrated function is designed to simulate the sharp distribution of the original softmax attention. Then, to address the low-rank issue of linear attention, we employ a straightforward depthwise convolution method to reintroduce feature diversity. Finally, our new module combines the advantages of low linear complexity and strong expressiveness of softmax attention, as expressed by the following equation:
 |
16 |
Additionally, our designed CMLatten can adapt to larger receptive fields and different models, such as PVT41 and CSWin Transformer42. Most transformer models are based on softmax attention and utilize key-value pairs, resulting in computational complexity quadratic with respect to the number of tokens. However, our designed method has the advantage of lower linear complexity. With the same computational cost, it can extend to a larger receptive field while still benefiting from long-range dependencies. CMLatten can serve as a plugin module that can be easily applied to other transformer-based tracking methods. For specific experimental proof, refer to Section 4.7.
Target decoder and localization head
Target decoder. Influenced by the work of MPTrack43, we use a target decoder to improve the target information. Our decoder consists of CMLatten, Add & Norm, and a feed-forward network (FFN). The input to the target decoder can be either a target query or the target information from a particular frame, allowing for online updates. From visual grounding analysis, the target query contains potential information about the target. From visual tracking analysis, online updated target information can be added to the target decoder to obtain real-time target information.
Localization head. Our method predicts the target position using a shared localization head, with the aim of unifying grounding and tracking. Here, we utilize the localization head proposed in STARK, which offers a good balance between performance and speed.
Experiments
Experimental setup
(1) Implementation details. Swin Transformer-Base was initially pre-trained with ImageNet as the visual encoder. The language encoder was then used with the basic BERT44. For the vision input, we use the adjusted grounding with its long edge set to 320. Notably, to prevent disrupting the relationship between the visual and language signals, we do not apply rotation or cropping. The dimensions of the search image are set to 320  320, while those of the template image are 128
320, while those of the template image are 128  128.
128.
We train the TCMLTrack model with the training datasets of GOT-10K45 and LaSOT46. We trained it for 300 epochs. The language encoder and visual encoder increased linearly by  and
and  in the first 30 epochs, respectively. Starting from 200 epochs, the learning rate decreases tenfold every 50 epochs. Our TCMLTrack method was tested on NVDIA Titan RTX GPUs, equipped with 24GB of video memory, the CPU is Intel i9-10900K. The Pytorch version is 1.10.1. It took approximately six days to train the TCMLTrack model.
in the first 30 epochs, respectively. Starting from 200 epochs, the learning rate decreases tenfold every 50 epochs. Our TCMLTrack method was tested on NVDIA Titan RTX GPUs, equipped with 24GB of video memory, the CPU is Intel i9-10900K. The Pytorch version is 1.10.1. It took approximately six days to train the TCMLTrack model.
(2) Datasets and metrics. In this section, we evaluate our proposed TCMLTrack on six authoritative UAV tracking benchmarks47–50 (DTB70, UAV123, UAV123@10fps, VisDrone2018, UAV20L, and UAVTrack- 112L) and two general object tracking datasets (LaSOT and GOT-10K). These UAV tracking datasets include a total of over 480 sequences and more than 300K frames. To provide a comprehensive and objective analysis, we introduced recent SOTA trackers15,21,51–62, such as JVGT, MACF, SiamOBR, and MixFormer. For comparison with siamese network-based trackers, we used the AlexNet backbone. We evaluated the experiments using the one-pass evaluation tracking method and analyzed the test results using success rate (Suc) and precision (Pre). The Precision is calculated by estimating the proportion of frames where the target is within a specific distance threshold. We define the pixel threshold to 20 for ranking the experimental results. The success rate is determined by the proportion of frames where the intersection over union between the predicted bounding box and the ground truth exceeds a threshold from 0 to 1. We rank the experimental results using the area under the success rate curve (AUC). Additionally, to validate the design and performance of TCMLTrack, we conducted further ablation experiments and visualizations.
Quantitative results
Results on UAV123. The UAV123 dataset comprises 123 video sequences recorded by low-altitude UAV, totaling approximately more than 100,000 frames. Many sequences in the dataset display common characteristics of aerial video, such as low-resolution motion blur. As shown in Fig. 7a, TCMLTrack achieves 82.2% precision and 62.1% success rate, ranking first in both metrics.
Results on DTB70. It is a comprehensive benchmark video dataset comprising 70 videos recorded by UAV, containing various actions such as different sizes, viewpoint changes, and occlusions. As shown in Fig. 7b, despite these challenges, TCMLTrack achieves an accuracy of 83.1% and a success rate of 66.2%, which are 2 and 4.6 percentage points higher than those of MMF-Net, respectively. This result demonstrates the effectiveness of our proposed CMLatten, particularly in dealing with numerous viewpoint changes in the DTB70 dataset.
Results on VisDrone2018. It comprises 35 video sequences totaling over 30,000 frames collected from real-world scenarios in approximately 14 different cities using various drone platforms. As shown in Fig. 7c, our tracking approach achieves the best performance in accuracy and success rate, with 84.3% and 70.1%, respectively, demonstrating the robustness and accuracy of our proposed TCMLTrack.
Results on UAV123@10fps. It comprises 123 sequences where the targets exhibit significant inter-frame displacements, increasing the difficulty of the tracking task. As shown in Fig. 7d, TCMLTrack demonstrates significant advantages, with accuracy and success rates of 79.9% and 64.2%, respectively. Moreover, TCMLTrack outperforms other SOTA methods. This is attributed to the proposed triangular integration module, which possesses the capability to handle large displacements between adjacent frames and sudden changes in the tracked target, challenges commonly encountered in UAV scenarios.
Results on UAV20L. The UAV20L dataset comprises 20 long-term tracking sequences with a total of over 58,000 frames, averaging 2,934 frames per sequence. We use this dataset to measure the performance of TCMLTrack in real long-term aerial tracking scenarios. As shown in Fig. 7e, our tracker outperforms other SOTA trackers in terms of performance. Specifically, TCMLTrack achieves an accuracy of 82.2%, surpassing MixFormer and MMF-Net by 8.1 and 13.5 percentage points, respectively. Similarly, TCMLTrack achieves a success rate of 69.8%, outperforming MixFormer at 61.6% and MAT at 58.5%. These results demonstrate the effectiveness of TCMLTrack in long-term aerial tracking scenarios.
Results on UAVTrack112L. The UAVTrack112L dataset consists of 112 video sequences with a total of over 60,000 frames, making it the largest-scale aerial tracking dataset over an extended period. TCMLTrack demonstrates good accuracy and robustness relative to other SOTA methods, as shown in Fig. 7f. It achieves an accuracy of 79.5% and a success rate of 60.1%. The experimental results demonstrate that TCMLTrack, by leveraging natural language descriptions, can update the appearance of tracked targets and maintain continuous tracking in long-term video sequences.
Fig. 7.

The overall performance of TCMLTrack and other SOTA trackers across multiple datasets including UAV123, DTB70, VisDrone2018, UAV123@10fps, UAV20L, and UAVTrack112L.
Qualitative results
For a more evident demonstration of the effectiveness of the TCMLTrack method, we visualize qualitative results compared to several other SOTA trackers, as shown in Fig. 8. In challenging scenarios involving scale variations, partial occlusions, and fast motions, TCMLTrack consistently exhibits good accuracy and robustness. Specifically, in the five video sequences in Fig. 8, the targets face challenges such as cluttered backgrounds and scale variations during motion. Additionally, in the fourth row, the targets exhibit low resolution. In the first row (#147, #670) and second row (#30, #120), there are significant scale changes accompanied by similar backgrounds. In the third row (#483, #649), fourth row (#311, #577), and fifth row (#199, #212), the targets experience partial occlusions and are relatively small in size. Due to these issues in the video sequences, many methods fail or exhibit instability during tracking. However, our approach demonstrates consistent tracking with good accuracy, highlighting the robustness of TCMLTrack.
Fig. 8.

Qualitative analysis of the proposed TCMLTrack with other three SOTA methods on different attribute scenarios.
Visualization of CMLatten maps
As shown in Fig. 9, both softmax and linear attention struggle to consistently focus on the tracking target, whereas our method maintains focus on the target even under various challenges. For example, in the first row, the target is moving rapidly. In the second and third rows, there is low resolution. In the fourth row, the target is occluded while in motion. Linear attention differs from softmax attention in that it lacks a nonlinear similarity function, resulting in its inability to focus on the target and weaker capability to capture local information. Softmax attention is weaker regarding computational complexity and hardware latency. Our method aims to enhance the multi-scale learning expression of linear attention by aggregating information from surrounding Q/K/V (Query/Key/Value) tokens to obtain multi-scale tokens. Ultimately, we can focus on the target itself rather than distractions and background, demonstrating the effectiveness of the proposed CMLatten.
Fig. 9.

Visual analysis of different attention mechanisms.
Onboard tests
Apart from outstanding tracking performance, onboard adaptability is also a crucial indicator for evaluating UAV tracking methods. Therefore, our method has been experimentally verified on a UAV platform (Intel NUC8iHVK with a single i7-8809G CPU) to demonstrate the stability and practicality of the approach.
As shown in Fig. 10, our tracking method is compared with GRM in terms of tracking accuracy at each frame overlap. In the ship sequence, when the tracked target (ship) undergoes significant scale changes, the GRM fails to adapt to these changes, resulting in tracking drift. After frame 700, the center position gradually changes. Compared to our method, the GRM response map around frame 300 becomes smoother and contains more noise. The main reason is that around frame 300, due to background interference with the tracked target, GRM exhibits significant amplitude changes in overlap. However, our method can better handle background interference, demonstrating the robustness of the proposed approach.
Fig. 10.
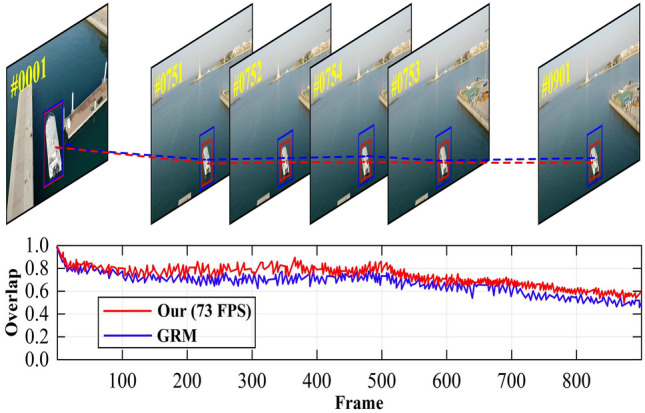
Overlap of Our and GRM on the sequence ship.
As shown in Fig. 11, we demonstrate the tracking accuracy at each frame overlap for our method and GRM on the person sequence. Despite the tree obstructing parts of the human body in the video sequence, we can still successfully track the target when it reappears. When the person is completely obscured by the tree and then reappears (#266), GRM fails to track and misidentifies the tree as the tracking target. The main reason is the bias introduced into the model during training with GRM.However, our proposed triangular integration mechanism can. without the need for continuously updating learning rates for appearance models. Thus, our method can still successfully track the target even after a short-term occlusion by the tree.
Fig. 11.
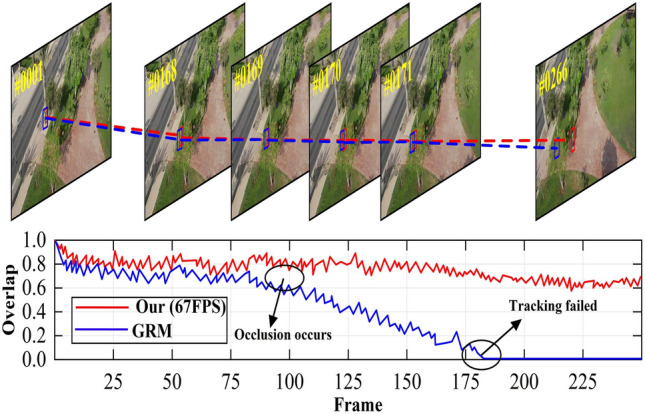
Overlap of Our and GRM on the sequence person.
Ablation study
To validate the effectiveness of each component in TCMLTrack, we isolated and analyzed three functional modules: the triangular integration module, CMLatten, and residual. Comprehensive ablation studies were conducted on these three modules to ensure fair experimentation, following identical training and parameter settings, with variations applied only to the proposed modules. The experimental results from Tables 1, 2, 3, 4, 5 and Fig. 13 demonstrate the contribution of each module to performance enhancement, which will be further analyzed below.
Table 1.
Ablation study.
| Components | Pre (%) | Params (M) | Speed (FPS) | |
|---|---|---|---|---|
| Multi-scale | Global attn | |||
| 78.1 | 48M | 48 | ||
 |
82.2 | 48M | 57 | |
 |
81.5 | 48M | 54 | |
 |
 |
83.9 | 48M | 62 |
Significant values are in bold.
Table 2.
Ablation on each block based on MixFormer.
| FLOPs (G) | Param (M) | Pre (%) | Diff | |
|---|---|---|---|---|
| Vanilla Linear Att | 1.5G | 6.1M | 79.5 | – 8.6 |
| + Concentrated Function | 1.5G | 6.1M | 82.2 | – 5.9 |
| + DWC | 1.5G | 6.6M | 88.1 | – |
| MixFormer | 1.7G | 6.1M | 85.7 | – 2.4 |
Significant values are in bold.
Table 3.
Ablation on concentrated factor.
| Concentrated Factor p | 2 | 3 | 4 | 8 | 32 |
|---|---|---|---|---|---|
| Pre | 82.71 | 83.01 | 82.62 | 82.75 | 82.86 |
Significant values are in bold.
Table 4.
Comparison of different attention on MixFormer and SwinTrack structures.
| Categories of Attention | FLOPs (G) | #Param (M) | Pre (%) |
|---|---|---|---|
| (a) Evaluation on MixFormer setting | |||
| Softmax Attn | 23.1G | 42.2M | 76.3 |
| Linear angular Attn | 23.1G | 42.2M | 72.4 |
| Hydra Attn | 23.1G | 42.2M | 77.5 |
| Efficient Attn | 23.1G | 42.2M | 77.1 |
| Enhanced linear Attn | 23.1G | 42.5M | 75.9 |
| Our | 23.1G | 42.5M | 79.8 |
| (b) Evaluation on SwinTrack setting | |||
| Softmax Attn | 13.3G | 22.7M | 70.6 |
| Linear angular Attn | 13.3G | 22.7M | 68.1 |
| Hydra Attn | 13.3G | 22.7M | 73.3 |
| Efficient Attn | 13.3G | 22.7M | 69.2 |
| Enhanced linear Attn | 13.3G | 22.9M | 69.6 |
| Our | 23.1G | 42.5M | 74.9 |
Significant values are in bold.
Table 5.
Ablation on window size based on CMLatten-SwinTrack.
| Window | FLOPs (G) | #Param (M) | Pre (%) | Diff | |
|---|---|---|---|---|---|
|
CMLatten- SwinTrack |
 |
5.1G | 32M | 88.2 |  |
 |
5.1G | 32M | 88.6 |  |
|
 |
5.1G | 32M | 89.0 |  |
|

|
5.1G | 32M | 90.1 | – | |
| SwinTrack |  |
5.1G | 32M | 82.6 |  |
Significant values are in bold.
Fig. 13.

Ablation study.
Similarity vs. variance criteria. As shown in Fig. 12a, we demonstrate how the two improvements (inter-class similarity and variance) on the tracking separately, along with our overall method tracking results. We can find that the lack of either similarity or variance has an impact on the tracking accuracy. In addition, we find that inter-class similarity is in most cases a little bit less accurate than variance for tracking, indicating that variance is better able to select more discriminative channels from it.
Decomposition of triangular integration. As shown in Fig. 12b, by decomposing the proposed triangular integration, we illustrate its roles. For only
 , the average tracking accuracy across multiple datasets is 78.84%. Then, adding
, the average tracking accuracy across multiple datasets is 78.84%. Then, adding  , the cache model with prior refinement can yield higher tracking results at 80.39%. Finally, the tripartite relationship (NL, template image and test image) is considered to form our proposed TCMLTrack framework, and the results show that our triangular integration can effectively improve the tracking accuracy.
, the cache model with prior refinement can yield higher tracking results at 80.39%. Finally, the tripartite relationship (NL, template image and test image) is considered to form our proposed TCMLTrack framework, and the results show that our triangular integration can effectively improve the tracking accuracy.With vs. without residual unit. As shown in Fig. 12c, we analyzed the impact of the residual module on tracking results, specifically including visual category
 , text category W, residual category Res, and cache score
, text category W, residual category Res, and cache score  . We can see that each learnable component contributes to improving the tracking performance of TCMLTrack. Additionally, optimizing the feature channels in W proves to be more effective compared to adjusting those in
. We can see that each learnable component contributes to improving the tracking performance of TCMLTrack. Additionally, optimizing the feature channels in W proves to be more effective compared to adjusting those in  . This is because the original pre-training goal of the model lies in visual-language contrast.
. This is because the original pre-training goal of the model lies in visual-language contrast.Effectiveness of multi-scale and global attention. We conducted ablation experiments on the GOT-10K dataset to analyze the effectiveness of the CMLatten mechanism, i.e. multi-scale and global attention capabilities. Furthermore, to reduce the impact of initial training on the experiments, we randomly initialized the model during training. The absence of either multi-scale or global attention reduces tracking accuracy, making it crucial to balance accuracy and efficiency, as shown in Table 1.
Concentrated function
 and different p. As shown in Table 2, we conducted experiments to confirm the performance of the proposed concentrated function
and different p. As shown in Table 2, we conducted experiments to confirm the performance of the proposed concentrated function  . From the experiments, it can be observed that the concentrated function improves tracking accuracy by 2.7 points. It enhances the expressive capability of linear attention, allowing our proposed CMLatten to achieve better tracking accuracy compared to softmax attention-based methods. As shown in Table 3, different concentrated factor p shave some impact on tracking performance. When p is between 2 and 32, the tracking accuracy does not vary significantly, indicating that our proposed method is robust to this parameter. Therefore, we choose
. From the experiments, it can be observed that the concentrated function improves tracking accuracy by 2.7 points. It enhances the expressive capability of linear attention, allowing our proposed CMLatten to achieve better tracking accuracy compared to softmax attention-based methods. As shown in Table 3, different concentrated factor p shave some impact on tracking performance. When p is between 2 and 32, the tracking accuracy does not vary significantly, indicating that our proposed method is robust to this parameter. Therefore, we choose  as the final choice.
as the final choice.Comparison with other attention. To compare our method with other attention mechanisms, we selected two representative Transformer-based methods (Mixformer and SwinTrack). Based on these two methods, we compared our approach with other popular attention mechanisms, namely linear angular attention63, hydra attention64, efficient attention65, and enhanced linear attention66, among others. Our designed attention mechanism considerably outperforms the other methods, as shown in Table 4. This demonstrates that our proposed method can enhance target representation capability without sacrificing a significant amount of computational time and retains portability.
Receptive Field. In addition we investigate the effect of CMLatten-based receptive field on target tracking, as shown in Table 5. As the window size expands, our method consistently achieves higher tracking accuracy. This experimental result demonstrates that our CMLatten can achieve a larger receptive field with equivalent computational cost and can be easily integrated into other systems.
Fig. 12.

A study of the impact of ambiguous natural language.
Discussion
In this subsection, we analyze some limitations of the algorithm. Since natural language-based tracking methods heavily rely on language descriptions to track targets, to some extent, this type of method is sensitive to the clarity of natural language descriptions. As shown in Fig. 13a, for ambiguous language descriptions (e.g., “sheep on the grassland”), which do not clearly specify the tracking target, our method may fail to select the correct target in the initial frame, resulting in tracking the wrong target. Currently, the solution to this problem is to provide as precise a natural language description of the object as possible. As shown in Fig. 13b, our method successfully selects the target and maintains stable tracking, which is achieved under the premise of providing clear natural language descriptions. Another alternative strategy that can be used to achieve disambiguation is to provide a bounding box in the initial frame in Fig. 13c. With the additional bounding box being able to correct the target, ultimately our method is still able to track the target correctly.
Conclusion
We successfully unify two tasks (i.e. visual grounding and object tracking) by relationally modeling natural language and images through the proposed triangular integration module. To achieve global receptive field and multi-scale learning, we introduce a lightweight CMLatten mechanism. This attention mechanism primarily addresses concentration ability and feature diversity, overcoming the limitations of linear attention while possessing strong expressive power. In addition, on this basis we introduce residuals, which greatly reduces the computational cost. Therefore, our proposed TCMLTrack exhibits significant advantages in both expressive power and computational efficiency. Extensive experiments validate the effectiveness of our proposed tracking framework, demonstrating strong competitiveness compared to SOTA tracking methods.
Although we reduce computational costs by introducing a lightweight CMLatten attention mechanism and using residual structures, the computational overhead may still be high for high-resolution images or large-scale datasets, such as long sequence videos or multi-target scenes. On the other hand, although we have effectively established multi-source relationships, there are still modeling challenges across modalities and time. Especially when the information in natural language descriptions is incomplete or ambiguous, how the model understands and correctly maps it to visual information remains a challenge. In terms of computational cost in the future, we can further optimize the computational efficiency of the CMLatten attention mechanism by combining pruning, quantization, or other lightweight techniques to reduce the computational complexity of the model. When natural language has ambiguity, more advanced cross modal learning techniques are introduced to improve the accuracy of the model. Ultimately, this enables the model to dynamically adjust its understanding of the target based on context, enhancing its ability to handle vague or incomplete language descriptions. At the same time, the edge computing and efficient communication of multi robot vision inertial SLAM proposed by Liu et al67. will help us further improve the performance of our method, especially in the robustness and adaptability in complex scenes.
Acknowledgements
This work was supported by the China National Key Research and Development Program (2021YFB2802100), Xinjiang Uygur Autonomous Region “Tianshan Talents” Science and Technology Innovation Leading Talent Program Project (2023TSYCLJ0025) and the China National Science Foundation under Grant (61862061, 62061045, 62266044).
Author contributions
G.D.: Conceptualization, Formal Analysis, Investigation, Methodology, Software, Validation, Visualization, Writing - Original Draft, P.Z.: Formal Analysis, Resources, N.Y.: Project administration, Software, A.A.: Formal Analysis, Resources, Data Curation, K.U.: Writing - Review & Editing, Funding acquisition, Resources, Supervision, Project administration.
Data availability
The data that support the findings of this study are available from the first author upon reasonable request.
Declarations
Competing interests
The authors declare no competing interests.
Footnotes
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
References
- 1.Wang, R. et al. Unified transformer with isomorphic branches for natural language tracking. IEEE Trans. Circuits Syst. Video Technol.33, 4529–4541 (2023). [Google Scholar]
- 2.Wen, S., Gong, S., Zhang, Z., Yu, F. R. & Wang, Z. Vision-and-language navigation based on history-aware cross-modal feature fusion in indoor environment. Knowl.-Based Syst.. 10.1016/j.knosys.2024.112610 (2024).
- 3.Liu, S., Xu, X., Zhang, Y., Muhammad, K. & Fu, W. A reliable sample selection strategy for weakly supervised visual tracking. IEEE Trans. Reliabil.72, 15–26 (2023). [Google Scholar]
- 4.Huang, F., Wu, P., Li, X., Li, J. & Zhao, R. Adaptive event-triggered pseudolinear consensus filter for multi-UAVs bearings-only target tracking. Neurocomputing571, 127127. 10.1016/j.neucom.2023.127127 (2024). [Google Scholar]
- 5.Zhou, Z., Sun, Q., Li, H., Li, C. & Ren, Z. Regression-selective feature-adaptive tracker for visual object tracking. IEEE Trans. Multimed.25, 5444–5457 (2023). [Google Scholar]
- 6.Yang, J., Gao, S., Li, Z., Zheng, F. & Leonardis, A. Resource-efficient RGBD aerial tracking. In 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). 13374–13383 (2023).
- 7.Yan, L. et al. Radiance field learners as UAV first-person viewers (2024). arXiv:2408.05533.
- 8.Jiao, L., Wang, D., Bai, Y., Chen, P. & Liu, F. Deep learning in visual tracking: A review. IEEE Trans. Neural Netw. Learn. Syst.34, 5497–5516 (2023). [DOI] [PubMed] [Google Scholar]
- 9.Xu, H., Ling, Z., Yuan, X. & Wang, Y. A video object detector with spatio-temporal attention module for micro UAV detection. Neurocomputing597, 127973. 10.1016/j.neucom.2024.127973 (2024). [Google Scholar]
- 10.Yang, Z., Kumar, T., Chen, T., Su, J. & Luo, J. Grounding-tracking-integration. IEEE Trans. Circuits Syst. Video Technol.31, 3433–3443 (2021). [Google Scholar]
- 11.Barrientos R., D. J., C. Medina, M. C., T. Fernandes, B. J. & A. Barros, P. V. The use of reinforcement learning algorithms in object tracking: A systematic literature review. Neurocomputing596, 127954. 10.1016/j.neucom.2024.127954 (2024).
- 12.Fan, C. et al. Siamon: Siamese occlusion-aware network for visual tracking. IEEE Trans. Circuits Syst. Video Technol.33, 186–199 (2023). [Google Scholar]
- 13.Hui, T. et al. Bridging search region interaction with template for rgb-t tracking. In 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). 13630–13639 (2023).
- 14.Lin, L., Fan, H., Zhang, Z., Xu, Y. & Ling, H. Swintrack: A simple and strong baseline for transformer tracking. Adv. Neural Inf. Process. Syst.35, 16743–16754 (2022). [Google Scholar]
- 15.Zhao, B., Ma, S., Zhao, Z., Zhang, L. & Hou, Z. Joint learning spatial-temporal attention correlation filters for aerial tracking. IEEE Signal Process. Lett.31, 686–690 (2024). [Google Scholar]
- 16.Liu, X. et al. Bactrack: Building appearance collection for aerial tracking. IEEE Trans. Circuits Syst. Video Technol.34, 5002–5017. 10.1109/TCSVT.2023.3340372 (2024). [Google Scholar]
- 17.Li, Z., Tao, R., Gavves, E., Snoek, C. G. M. & Smeulders, A. W. M. Tracking by natural language specification. In 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). 7350–7358 (2017).
- 18.Yang, Z., Kumar, T., Chen, T., Su, J. & Luo, J. Grounding-tracking-integration. IEEE Trans. Circuits Syst. Video Technol.31, 3433–3443 (2021). [Google Scholar]
- 19.Wang, X. et al. Towards more flexible and accurate object tracking with natural language: Algorithms and benchmark. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 13763–13773 (2021).
- 20.Zhang, S., Zhang, D. & Zou, Q. Mimtracking: Masked image modeling enhanced vision transformer for visual object tracking. Neurocomputing606, 128415. 10.1016/j.neucom.2024.128415 (2024). [Google Scholar]
- 21.Gao, S., Zhou, C. & Zhang, J. Generalized relation modeling for transformer tracking. In 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). 18686–18695 (2023).
-
22.Wang, T. et al. M
 pt: Multimodal prompt tuning for zero-shot instruction learning (2024). arXiv:2409.15657.
pt: Multimodal prompt tuning for zero-shot instruction learning (2024). arXiv:2409.15657.
- 23.Li, Y., Yu, J., Cai, Z. & Pan, Y. Cross-modal target retrieval for tracking by natural language. In 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW). 4927–4936 (2022).
- 24.Yang, Z. et al. A fast and accurate one-stage approach to visual grounding. In 2019 IEEE/CVF International Conference on Computer Vision (ICCV). 4682–4692 (2019).
- 25.Feng, Q., Ablavsky, V., Bai, Q. & Sclaroff, S. Siamese natural language tracker: Tracking by natural language descriptions with siamese trackers. In 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). 5847–5856 (2021).
- 26.Dong, X. et al. Cswin transformer: A general vision transformer backbone with cross-shaped windows. In 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). 12114–12124 (2022).
- 27.Xia, Z., Pan, X., Song, S., Li, L. E. & Huang, G. Vision transformer with deformable attention. In 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). 4784–4793 (2022).
- 28.Choromanski, K. et al. Rethinking attention with performers. arXiv preprintarXiv:2009.14794 (2020).
- 29.Xiong, Y. et al. Nyströmformer: A nyström-based algorithm for approximating self-attention. Proc. AAAI Conf. Artif. Intell.35, 14138–14148 (2021). [PMC free article] [PubMed] [Google Scholar]
- 30.Qin, Z. et al. cosformer: Rethinking softmax in attention. arXiv preprintarXiv:2202.08791 (2022).
- 31.Chen, X. et al. Transformer tracking. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 8126–8135 (2021).
- 32.Wang, N., Zhou, W., Wang, J. & Li, H. Transformer meets tracker: Exploiting temporal context for robust visual tracking. In 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). 1571–1580 (2021).
- 33.Yan, B., Peng, H., Fu, J., Wang, D. & Lu, H. Learning spatio-temporal transformer for visual tracking. In 2021 IEEE/CVF International Conference on Computer Vision (ICCV). 10428–10437 (2021).
- 34.Cao, Z., Fu, C., Ye, J., Li, B. & Li, Y. Hift: Hierarchical feature transformer for aerial tracking. In 2021 IEEE/CVF International Conference on Computer Vision (ICCV). 15437–15446 (2021).
- 35.Han, D., Pan, X., Han, Y., Song, S. & Huang, G. Flatten transformer: Vision transformer using focused linear attention. In 2023 IEEE/CVF International Conference on Computer Vision (ICCV). 5938–5948. 10.1109/ICCV51070.2023.00548 (2023).
- 36.Chen, J. et al. Apanet: Adaptive prototypes alignment network for few-shot semantic segmentation. IEEE Trans. Multimed.25, 4361–4373 (2023). [Google Scholar]
- 37.Lin, G., Xu, Y., Lai, H. & Yin, J. Revisiting few-shot learning from a causal perspective. IEEE Trans. Knowl. Data Eng. 1–13 (2024).
- 38.Udandarao, V., Gupta, A. & Albanie, S. Sus-x: Training-free name-only transfer of vision-language models. In 2023 IEEE/CVF International Conference on Computer Vision (ICCV). 2725–2736 (2023).
- 39.Yu, T., Khalitov, R., Cheng, L. & Yang, Z. Paramixer: Parameterizing mixing links in sparse factors works better than dot-product self-attention. In 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). 681–690 (2022).
- 40.Liu, Z. et al. Swin transformer: Hierarchical vision transformer using shifted windows. In 2021 IEEE/CVF International Conference on Computer Vision (ICCV). 9992–10002 (2021).
- 41.Wang, W. et al. Pvt v2: Improved baselines with pyramid vision transformer. Comput. Vis. Med.8, 415–424 (2022). [Google Scholar]
- 42.Dong, X. et al. Cswin transformer: A general vision transformer backbone with cross-shaped windows. In 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). 12114–12124 (2022).
- 43.Xu, T., Wu, X.-J., Zhu, X. & Kittler, J. Memory prompt for spatio-temporal transformer visual object tracking. IEEE Trans. Artif. Intell. 1–6 (2024).
- 44.He, D., Lv, X., Zhu, S., Chan, S. & Choo, K.-K.R. A method for detecting phishing websites based on tiny-bert stacking. IEEE Internet Things J.11, 2236–2243 (2024). [Google Scholar]
- 45.Huang, L., Zhao, X. & Huang, K. Got-10k: A large high-diversity benchmark for generic object tracking in the wild. IEEE Trans. Pattern Anal. Mach. Intell.43, 1562–1577 (2021). [DOI] [PubMed] [Google Scholar]
- 46.Fan, H. et al. Lasot: A high-quality benchmark for large-scale single object tracking. In 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). 5369–5378 (2019).
- 47.Li, S. & Yeung, D.-Y. Visual object tracking for unmanned aerial vehicles: A benchmark and new motion models. In Proceedings of the AAAI Conference on Artificial Intelligence. Vol. 31 (2017).
- 48.Du, D. et al. The unmanned aerial vehicle benchmark: Object detection and tracking. In Proceedings of the European Conference on Computer Vision (ECCV). 370–386 (2018).
- 49.Du, D., Zhu, P., Wen, L. & Bian, X. Visdrone-sot2019: The vision meets drone single object tracking challenge results. In 2019 IEEE/CVF International Conference on Computer Vision Workshop (ICCVW). 199–212 (2019).
- 50.Fu, C., Cao, Z., Li, Y., Ye, J. & Feng, C. Onboard real-time aerial tracking with efficient siamese anchor proposal network. IEEE Trans. Geosci. Remote Sens.60, 1–13 (2022). [Google Scholar]
- 51.Chen, X., Peng, H., Wang, D., Lu, H. & Hu, H. Seqtrack: Sequence to sequence learning for visual object tracking. In 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). 14572–14581 (2023).
- 52.Zhou, L., Zhou, Z., Mao, K. & He, Z. Joint visual grounding and tracking with natural language specification. In 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). 23151–23160 (2023).
- 53.Wu, Q. et al. Dropmae: Masked autoencoders with spatial-attention dropout for tracking tasks. In 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). 14561–14571 (2023).
- 54.Zhang, J. et al. Frame-event alignment and fusion network for high frame rate tracking. In 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). 9781–9790 (2023).
- 55.Zhao, H., Wang, D. & Lu, H. Representation learning for visual object tracking by masked appearance transfer. In 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). 18696–18705 (2023).
- 56.Yang, J., Gao, S., Li, Z., Zheng, F. & Leonardis, A. Resource-efficient rgbd aerial tracking. In 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). 13374–13383 (2023).
- 57.Zhu, J., Lai, S., Chen, X., Wang, D. & Lu, H. Visual prompt multi-modal tracking. In 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). 9516–9526 (2023).
- 58.Zhong, Y., Fang, X. & Shu, M. Online background discriminative learning for satellite video object tracking. IEEE Trans. Geosci. Remote Sens.62, 1–15 (2024). [Google Scholar]
- 59.Lin, B. et al. Motion-aware correlation filter-based object tracking in satellite videos. IEEE Trans. Geosci. Remote Sens.62, 1–13 (2024). [Google Scholar]
- 60.Gao, J. et al. Recursive least-squares estimator-aided online learning for visual tracking. IEEE Trans. Pattern Anal. Mach. Intell.46, 1881–1897 (2024). [DOI] [PubMed] [Google Scholar]
- 61.Chen, Z. et al. Siamban: Target-aware tracking with siamese box adaptive network. IEEE Trans. Pattern Anal. Mach. Intell.45, 5158–5173 (2023). [DOI] [PubMed] [Google Scholar]
- 62.Yang, K. et al. Siamcorners: Siamese corner networks for visual tracking. IEEE Trans. Multimed.24, 1956–1967 (2022). [Google Scholar]
- 63.You, H. et al. Castling-vit: Compressing self-attention via switching towards linear-angular attention at vision transformer inference. In 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). 14431–14442 (2023).
- 64.Bolya, D., Fu, C.-Y., Dai, X., Zhang, P. & Hoffman, J. Hydra attention: Efficient attention with many heads. In European Conference on Computer Vision. 35–49 (Springer, 2022).
- 65.Zhuoran, S., Mingyuan, Z., Haiyu, Z., Shuai, Y. & Hongsheng, L. Efficient attention: Attention with linear complexities. In 2021 IEEE Winter Conference on Applications of Computer Vision (WACV). 3530–3538 (2021).
- 66.Cai, H., Gan, C. & Han, S. Efficientvit: Enhanced linear attention for high-resolution low-computation visual recognition. arxiv 2022. arXiv preprintarXiv:2205.14756 (2022).
- 67.Liu, X., Wen, S., Zhao, J., Qiu, T. Z. & Zhang, H. Edge-assisted multi-robot visual-inertial slam with efficient communication. IEEE Trans. Autom. Sci. Eng. 10.1109/TASE.2024.3376427 (2024).
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.
Data Availability Statement
The data that support the findings of this study are available from the first author upon reasonable request.