

Abstract
Aberrant responses (e.g., careless responses, miskeyed items, etc.) often contaminate psychological assessments and surveys. Previous robust estimators for dichotomous IRT models have produced more accurate latent trait estimates with data containing response disturbances. However, for widely used Likert-type items with three or more response categories, a robust estimator for estimating latent traits does not exist. We propose a robust estimator for the graded response model (GRM) that can be applied to Likert-type items. Two weighting mechanisms for downweighting “suspicious” responses are considered: the Huber and the bisquare weight functions. Simulations reveal the estimator reduces bias for various test lengths, numbers of response categories, and types of response disturbances. The reduction in bias and stable standard errors suggests that the robust estimator for the GRM is effective in counteracting the harmful effects of response disturbances and providing more accurate scores on psychological assessments. The robust estimator is then applied to data from the Big Five Inventory-2 (Ober et al., 2021) to demonstrate its use. Potential applications and implications are discussed.
Keywords: Robust estimation, Graded response model (GRM), Item response theory, Aberrant responses
Introduction
Likert-type items are commonly used in psychological and educational assessments (exams, tests, surveys, etc.). Item response theory (IRT) models such as the graded response model (GRM) have been developed to model the probability that a subject responds in a certain category on these items (Samejima, 1969). Given a subject’s response vector and the item parameters, one can estimate their latent trait, via methods such as maximum likelihood (ML) estimation. However, responses to these items may not follow the assumed IRT model if the respondent exhibits one or more types of aberrant behaviors.
In the context of high-stakes testing, a variety of aberrant behaviors can plague a subject’s responses on such assessments, such as the six examples outlined by Meijer (1996). A subject may exhibit sleeping or warm up behavior, giving less effort to or being less focused on early items but paying greater attention to items appearing later in the test. Guessing occurs when a subject of low ability guesses blindly to items of higher difficulty or items towards the end of an assessment under time pressure. Cheating can occur when a subject with low ability copies answers from a subject of high ability. Plodding describes a subject who responds very slowly and carefully to each item. Alignment errors may occur when the response on the answer sheet does not match the intended response. Finally, some subjects of high ability may be extremely creative, reinterpreting easy items and responding incorrectly to them. In the low-stakes assessment context, aberrant behaviors such as careless or insufficient effort (C/IE) responding have also received a lot of attention, in which the subject responds with reduced attention to the item (Curran, 2016; Hong et al., 2020). C/IE responding can be nonrandom (e.g., endorsing the same response category) or random (Meade & Craig, 2012).
When a response vector contains even just some aberrant responses, traditional methods such as ML estimation result in biased estimates of the latent trait (De Ayala et al., 2000; Mislevy & Bock, 1982). Spuriously high or spuriously low assessment scores may yield undesirable consequences, such as giving opportunities to subjects who are not qualified, or failing to identify subjects who need further attention in clinical settings. Beyond latent trait estimates, other statistical properties of the test may be compromised, such as decreased scale reliability (Huang et al., 2012), poor factor model fit (Woods, 2006), lower predictive validity (Hong & Cheng, 2019a), and biased structural parameters (Oshima, 1994; Wise et al., 2004). If the aberrant subjects are known, steps can be taken (e.g., retesting or removing these subjects from the data) in order to eliminate the bias produced by the response disturbances. However, the identity of aberrant subjects is often unknown. Therefore, in order to minimize the bias, it is important to detect aberrant responses and then reduce or eliminate their negative impact.
Several methods have been developed in order to address aberrant responses to polytomous items. However, much of the previous literature focuses on fully removing cases marked as aberrant. Given the controversy of data removal, and to avoid losing information, we seek to downweight responses according to their degree of aberrancy instead of removing them. Hence, a robust estimator for the GRM will be derived to obtain more accurate latent trait estimates. With two examples of aberrant behavior, we aim to demonstrate that these robust estimates are less biased than the maximum likelihood estimates (MLE) in the presence of response disturbances.
Statistical methods to handle response disturbances
In the IRT literature, which focuses more on achievement or ability testing, a variety of methods have been developed as well to address the issue of aberrant responses. These methods generally handle response disturbances in one of two ways: modeling aberrant behavior or detecting aberrant behavior. In the former approach, traditional IRT models (e.g., the 1-PL, 2-PL, and 3-PL IRT models) are replaced with other models that accommodate the aberrant behavior. For example, speededness may be modeled as a reduction in ability, either abruptly (Yamamoto, 1982, 1995) or gradually (Goegebeur et al., 2008). Or, the dimension representing ability may be accompanied by another dimension to represent the aberrant behavior, such as an auxiliary dimension to represent speededness (Van Der Linden et al., 1999; Van Der Linden & Xiong, 2013), or an additional factor representing careless response styles (Wetzel & Carstensen, 2017). In some cases, careless response behaviors have been modeled through a sequential decision-making process (Böckenholt, 2017) and flexible item parameter estimates (Falk & Cai, 2016). When the data contain both normal and aberrant responses, mixture models can be used to account for a combination of “solution” or normal response behavior and aberrant response behaviors, including speeding (Bolt et al., 2002; Wang & Xu, 2015) or cheating (Wang et al., 2018).
However, modeling aberrant behaviors requires the researcher to know which aberrant behavior occurs in the data and by the mechanism in which it manifests, an unrealistic assumption in practice since the nature of the aberrant response is rarely known (Meade & Craig, 2012). On the other hand, if the solution or normal behavior is known, any type of behavior that deviate from the known pattern can be detected, regardless of the type or mechanism. This process is the approach to “detect” instead of “model” aberrant responses. Many statistical methods have been proposed to detect potential response disturbances in low-stakes assessments. For instance, Mahalanobis distance can detect aberrant response vectors whose patterns deviate from the centroid of data (Mahalanobis, 1936). Longstring analysis identifies individuals with the longest consecutive string of the same response, repeatedly endorsed (Huang et al., 2012; Costa Jr. & McCrae, 2008; Johnson, 2005). Previous articles provide a thorough review of best practices for using these and other methods (e.g., intra-individual response variability, psychometric synonyms, and psychometric antonyms) of aberrant response detection (Curran, 2016; Hong et al., 2020; Meade & Craig, 2012; Niessen et al., 2016). These methods typically do not involve latent variable modeling.
There are also many statistical methods to detect aberrant responses that are based on a latent variable model and residuals, which quantify how responses deviate from the main model for normal or solution behavior. Such residuals include person-fit statistics that are used to detect misfit between a subject’s test performance and their true latent trait. Typically, person-fit statistics compare an observed item response with an expected item response for a test item (Meijer & Sijtsma, 2001). Various aberrant behaviors can be identified, given that they deviate from the expected behavior of the subject according to the assumed model. Working under the IRT framework, we can leverage the item properties by considering the “appropriateness” of the subject response respective to the IRT model. A person-fit statistic that indicates that the response is atypical given the IRT model suggests that the response may be aberrant. A variety of person-fit statistics have been developed to detect unusual response vectors, such as appropriateness measures (e.g., and M), residual-based statistics (e.g., U and W), and standardized extended caution indices such as ECI1 and ECI2 (Drasgow et al., 1985, 1987, 1991; Levine & Rubin, 1979; Levine & Drasgow, 1988; Molenaar & Hoijtink, 1990; Tatsuoka, 1984; Trabin & Weiss, 1983; Wright & Stone, 1979; Wright & Masters, 1982). Karabatsos (2003) demonstrates the relative power of these and other person-fit statistics in detecting various aberrant responses across different test designs. A commonly used IRT-based person-fit statistic is which compares the standardized log-likelihood of a response vector against the standard normal distribution (Drasgow et al., 1985). Previous studies have shown the promising ability of to detect C/IE and other types of aberrant responses (Hong et al., 2020; Meijer & Sijtsma, 2001; Niessen et al., 2016).
Responses that are flagged as aberrant by these statistical methods are often removed from the data set. Fully removing cases of aberrant data has been practiced for many decades. For instance, Cronbach (1950) argues that full removal is more appropriate than considering the aberrant responses as valid as other responses. Full removal continues to be a conventional albeit controversial method for handling response disturbances (Hong et al., 2020; Meijer & Sijtsma, 2001).
More recently, other methods stemming from the statistical quality control literature have also been developed to detect aberrant response patterns, such as change-point analyses (CPA) and cumulative sum (CUSUM) chart. In addition to indicating the presence of aberrant responses, these methods also try to determine when a certain response pattern starts deviating from the expected response pattern (Shao et al., 2016; Sinharay, 2016). For example, one CPA procedure detects if back random responding (BRR, which refers to random responding towards the end of an assessment, potentially due to fatigue or loss of interest) occurs and, if yes, when it begins (Yu & Cheng, 2019). Compared to the aforementioned methods, CPA enables partial removal of data, instead of complete removal. For example, when BRR is detected and a change point is identified, all responses after the change point would be excluded from the latent trait estimation.
Likewise, CUSUM procedures, proposed by Page (1954), identify fluctuations in the mean of the variable of interest. Instead of identifying a sharp change in responding during a test, CUSUM can detect a change in the quality of responses based on gradual shifts in the estimated latent trait. For instance, Meijer (2002) demonstrates, with an empirical certification test, how a positive CUSUM trend can indicate “warm-up” behavior (i.e., the respondent answers more items correctly as the test continues) while a negative CUSUM trend can indicate fatigue or guessing due to time constraints. Yu and Cheng (2022) outline a number of CUSUM statistics used to detect aberrant response patterns such as those developed by Armstrong and Shi (2009), Bradlow et al. (1998) and Van Krimpen-Stoop and Meijer (2000, 2001).
However, both CPA and CUSUM procedures still make a strong assumption about respondent behavior and are inflexible. For instance, a respondent could resort to random responding when they encounter a set of challenging questions but later returns to normal responding. Removing all responses beyond a certain point would not be appropriate in that case.
Robust estimation is a procedure where all data are leveraged to the extent possible while counteracting aberrant behavior. The type of robust estimation applied in this paper follows Huber’s M-estimation, a procedure in which data points further away from the centroid of the data receive a smaller weight (Huber, 1981). Accordingly, extreme cases have a smaller impact.
The idea of robust estimation has been applied to counteract aberrant responses. An advantage to using robust estimation is that it downweights data according to the degree to which each observation is aberrant. A more “suspicious” observation receives less weight, such that it will contribute less to the overall parameter estimation than a less “suspicious” observation. Thus, robust estimation accounts for partially aberrant responses, instead of removing data according to a binary standard. In the context of latent variable modeling, robust estimation has been employed in a number of applications. For example, in the context of IRT models, Hong and Cheng (2019b) proposed a robust marginal maximum likelihood estimator for estimating item parameters (or structural parameters) for Likert-scale items that follow the GRM.
This paper will focus on the maximum likelihood estimate (MLE) of the latent trait in the IRT framework. Some approaches to counteract bias in the MLE include Warm (1989) weighted maximum likelihood estimation (WLE). Although similar to the robust MLE in that the likelihood function is adjusted, WLE addresses bias inherent in the MLE (e.g., due to short test length) rather than bias due to aberrant responding. To address bias in the latent trait due to aberrant responding, one proposed solution is to weigh item responses linearly based on their position on a test. Items appearing later on an assessment are weighed less in ability estimation than the earlier items when performance decline is of concern, and vice versa when performance increase is of concern (Wise et al., 2023). However, this method solely pertains to strict performance decline/incline, and cannot be generalized to a wider range of response disturbances. The weights are also arbitrarily determined by item position, instead of being data-driven.
More general and systematic robust ML estimators for unidimensional IRT (UIRT) and multidimensional IRT (MIRT) models with dichotomous data have been developed for estimating the latent trait (Filonczuk et al., 2022; Mislevy & Bock, 1982; Schuster & Yuan, 2011). These robust estimators are designed to mitigate the effects of response disturbances, on the basis that outlying cases indicate more aberrant behavior. Item responses that poorly fit the IRT model are downweighted such that they contribute less to the estimation of the respondent’s ability. The estimators are able to target a variety of response disturbances and are not restricted to specific aberrant behavior. Both Huber and bisquare weight functions (Huber, 1981; Mosteller & Tukey, 1977) are utilized, which are described later in more detail.
However, these robust IRT developments have been limited to dichotomous data. No robust estimator has been developed for estimating latent traits from polytomously scored Likert-scale items. Given the wide application of Likert-scale items in psychological and educational assessments, we propose a robust estimator using the GRM.
Methods
According to the GRM, the probability that a subject i responds in or above a category k for item j is
| 1 |
Embretson and Reise (2000), where is the item discrimination parameter applied to all category boundary functions for item j. D is a constant fixed to 1.7, commonly applied in order to scale the item parameters to that of a normal ogive model. Suppose there are K categories and threshold parameters (), where the location parameter separates response category k and (). The probability of endorsing exactly category k is therefore:
| 2 |
where and
The probability that a response falls in a category k for an individual with latent trait is
where is an indicator variable:
| 3 |
We assume the number of categories remains constant for all J items on the assessment. In ML estimation, we estimate the latent trait by first finding the likelihood of given the response vector
| 4 |
The log-likelihood,
| 5 |
is maximized by setting its first derivative equal to 0 and solving for .
In robust ML estimation, the likelihood of the item response function is weighted by a function , resulting in the weighted likelihood :
| 6 |
(Hu, 1994). The resulting weighted log-likelihood (Eq. 7) demonstrates how each item has a unique weighted contribution when determining the overall score:
| 7 |
Assigning an item a weight of zero is the equivalent of removing the response from estimation. Setting equal for all J items for a subject gives a weighted log-likelihood equivalent to that in ML estimation (Eq. 5) for finding the most likely .
The Newton–Raphson method is then used to estimate iteratively with
| 8 |
where t is the iteration. The first and second derivatives of the weighted log-likelihood with respect to are found as follows:
| 9 |
and
| 10 |
As suggested by Schuster and Yuan (2011), the MLE is used as a starting value for in the robustified Newton–Raphson algorithm. In our simulation and applied analyses, convergence was deemed reached when the log-likelihoods between consecutive iterations of the Newton-Raphson algorithm fell within a difference of 0.01. If a trait estimate converged outside the interval [-3.0, 3.0], the estimate was fixed to the endpoint closer in value (i.e., an estimate less than -3.0 was replaced with -3.0, and an estimate greater than 3.0 was replaced with 3.0), consistent with common practice in IRT research (Patton et al., 2014). Both of these practices were used for both ML and robust estimation in our simulations and applied example.
Standard errors of each estimate were obtained using the Huber-White sandwich estimator, a technique for estimating the variance of the MLE under a misspecified model (Huber, 1967; White, 1980). In the case of aberrant responses, the main IRT model is misspecified for them. Hence, the Huber–White SE is more appropriate than the usual Fisher-information-based SE for the MLE. The standard error (SE) of for subject i is estimated as where
is the second derivative of the weighted log-likelihood with respect to (Eq. 10) evaluated at
| 11 |
Using Eq. 9, is estimated as
| 12 |
If the model is correct, should equal B, and simplifies to the inverse of . 95% confidence intervals were calculated with the following expressions
| 13 |
Coverage rates were then computed as the proportion of subjects whose true lays within the 95% confidence interval, over all replications.
Weighting mechanisms
It is essential to have a systematic and data-driven way to properly assign weights. Oftentimes the weight is a function of a residual , which indicates the “deviation” of an observation from normal or expected behavior. In the IRT literature, is largely determined by the misfit between observed and expected (or model-based) responses, assuming that the IRT model fits well regular response data. The goal of the weighting function is to downweight contributions of items with large residuals. Previous residuals for robust estimation of ability with dichotomous data have drawn on item information to detect misfitting item responses when little information is to be expected from a subject on an item (Filonczuk et al., 2022; Mislevy & Bock, 1982; Schuster & Yuan, 2011). Previous residuals for responses on the GRM have been defined as a function of the difference between the observed response and expected score , such as used in CUSUM procedures to evaluate person-fit (Van Krimpen-Stoop & Meijer, 2002). Although a variety of residuals could be used, we propose using the standardized residual
| 14 |
The residual is standardized by where
| 15 |
The resulting standardized residual follow asymptotically the standard normal distribution, which allows for easy interpretation.
Given properly defined residuals that characterize how “suspicious” or misfitting a response is, a weight can be assigned to each response. In this study, two commonly used weight functions are considered: bisquare (Mosteller & Tukey, 1977),
| 16 |
and Huber (Huber, 1981),
| 17 |
where B and H are tuning parameters that regulate the proportion of item responses and the extent to which they are downweighted. Prior studies have incorporated these weight functions when robustly estimating latent traits, so both are considered in our study (Mislevy & Bock, 1982; Schuster & Yuan, 2011). Figure 1 illustrates the weight functions across different residuals with different values for the tuning parameters, B and H. A greater absolute residual indicates a greater misfit. Therefore, we wish to downweight these cases more. As the residual increases in absolute value, less weight is given, while residuals close to 0.0 are given weights close to 1.0. Tuning parameters H and B regulate the proportion and degree of the item responses being downweighted. A higher tuning parameter leads to less downweighting. For example, when we use in comparison to (the dashed black line in comparison to the solid black line in Fig. 1), item responses with residuals greater in magnitude receive higher weights; thus, such observations are downweighted less. The same effect occurs when we increase the Huber tuning parameter from to , shifting from the grey solid line to the grey dashed line.
Fig. 1.
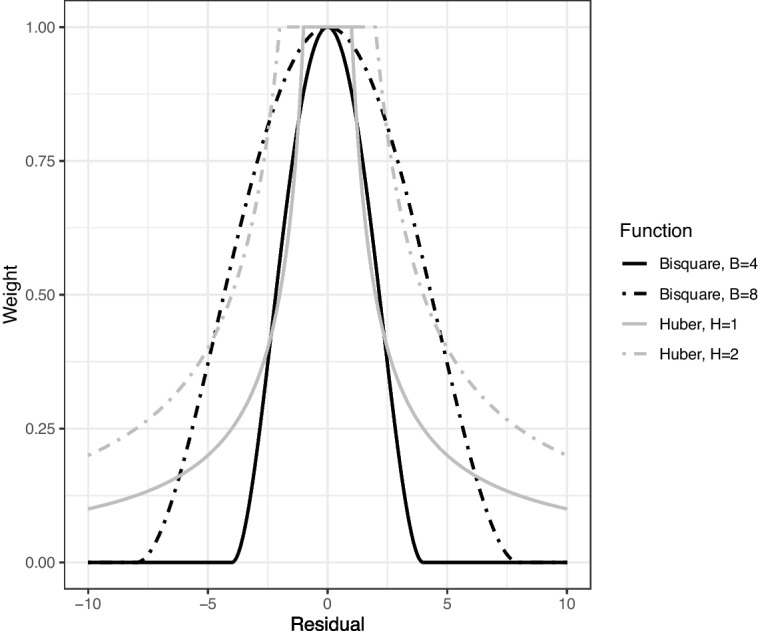
Weights as a function of the residual (black = bisquare weights, grey = Huber weights). Solid lines represent the tuning parameters used in the study (B=4.0 and H=1.0). Dashed lines represent weights when using higher tuning parameters (B=8.0 and H=2.0)
To sum up, our robust estimation procedure operates as follows. First, we find the MLE for each respondent. Second, we calculate the residuals on all items for each respondent, identifying the degree of mismatch between the expected and observed item responses. Third, a weighting mechanism is chosen, and a weight is assigned to each item response as a function of the residual. Fourth, the robust estimate for each individual is updated incorporating these weights. Steps two through four are repeated, calculating the residual as a function of the latest updated latent trait estimate, until the Newton–Raphson algorithm converges.
Simulation study
While this estimation procedure is capable of counteracting a wide variety of response disturbances, our main simulation examines two examples of commonly observed aberrant responses in low-stakes assessments: back random responding (BRR) and overlooking reverse-coded statements. BRR occurs when respondents initially respond to items according to their true latent trait, then switch to a careless response pattern, which is continued for the remaining items. Previous studies have reported that careless responding primarily occurs on the latter items of an assessment, particularly when motivation is low for taking the assessment (Clark et al., 2003). Because of its prevalence, we chose to model BRR as a response disturbance in our simulations.
Furthermore, reverse-coded items are worded in a sentiment opposite from the scale (i.e., negatively worded), but are assumed to measure the same underlying construct (Hughes, 2009). An example item is “I feel unhappy” in a scale that measures happiness. A greater score on a reverse-coded item indicates a lower level of the latent trait measured by the item, and vice versa. They are often included to provoke the subject to pay more attention and process item content individually instead of forming response sets (i.e., responding according to general attitudes towards the test as a whole; Weems et al., 2003). In addition, adding reverse-coded items may help avoid biased responding that can result if all items are worded in a socially desirable direction (Weems et al., 2006). When including these items, it is assumed that subjects will respond to negatively worded items in a manner opposite to the positively worded items. However, subjects and researchers may both violate this assumption when encountering reverse-coded items. First, subjects may be inattentive and overlook reverse-coded items, responding erroneously (Hughes, 2009). Reading and interpreting reverse-coded items may require more mental effort and be more difficult for subjects, resulting in an aberrant response (Marsh, 1986; Williams & Swanson, 2001) as well. Second, researchers who perform secondary data analysis may be unaware of negatively worded items, due to carelessness on their end or unfamiliarity with the data set. Then, these items may not be properly reverse-coded prior to analysis. These aberrant behaviors violate the IRT model, since the response does not reflect the subject’s true latent trait when calculating the score. Thus, we use robust estimation in lieu of ML estimation to provide more accurate latent trait scores.
In our simulation study, we varied the following properties of a test: the number of categories on each Likert-type item, the test length, the severity, or proportion of items that are disturbed in each response vector, and the type of aberrant response: BRR or overlooked reverse coding.
Likert-type scales are commonly developed with either three, five, or seven categories, where each number of categories has its respective advantages (Aybek & Toraman, 2022). Therefore, we simulated tests with three, five, and seven categories, keeping the number of categories constant for all items within each test (e.g., a test could not have some items with three categories and some items with five categories).
Tests were generated with lengths of 10, 30, 50, and 70 items. Although multidimensional psychological inventories can include hundreds of items, such as the 567-item MMPI-2 (Sellbom & Anderson, 2013), we are concerned with unidimensional scales, so in this study the maximum test length was set at 70.
The robust estimation is most successful when the subject exhibits some behavior true to their latent trait and not all responses are aberrant, otherwise complete data removal would be sufficient. Previous studies have set the severity, or proportion of aberrant items, between 10%-50% (Meade & Craig, 2012). Therefore, we examined two severity conditions: 10% and 30%.
In effect, under back random responding, random guessing began after 90% or 70% (severities of 0.10 and 0.30, respectively) of the test. At this change point, each response category had an equal probability (e.g., 1/K) of being selected according to the discrete uniform distribution U[1, K], for an item with K categories.
In the neglected reverse coded simulations (i.e., subjects are inattentive to the negatively worded items), 10% or 30% of randomly selected items from each test were designated as negatively worded. Aberrant responses to these items were generated as follows. First, the item response was generated based on the subject’s probabilities of endorsing each category according to their true ability. The response was then disturbed by being reversed in value, such that
where is the new response to replace . For example, on a 5-pt Likert scale ranging from 1 to 5, consider a subject with a high latent trait who is likely to respond 1 to the negatively worded item. After reverse coding, the response will be coded as 5, reflecting the subject’s true latent trait. However, if the subject fails to recognize it’s a negatively worded item, their response would be 5. After reverse coding, the response would be 1, which indicates a low latent trait and not their true latent trait.
In total, we generated a simulation design, incorporating three levels of item response categories, four test lengths, two severity levels, and two types of aberrant responses. For item parameter generation, we follow Dodd et al. (1989), who suggest generating s at random uniformly across the latent trait continuum, while varying the characteristics of the category threshold parameters within each item. In our study, we simulated to generate values, one value for each threshold parameter, for each item j. Within each item, these values were sorted in ascending order such that the highest value corresponded with the greatest threshold. Item discrimination parameters s have been previously simulated according to Unif(0.90, 2.15) (Dodd et al., 1989). Therefore, our items used values from [0.90, 2.15] with equal increments between each value; e.g., for a 10-item assessment, the 10 s would be (0.900, 0.943, 0.986, ..., 2.106, 2.150). All item parameters were treated as fixed across all replications for each of the 24 conditions.
True s from [-2.0, 2.0] in increments of 0.25 were used to generate data from each of the tests. Six hundred replications of each were used, forming 600 response vectors given the item parameters based on the following steps. Probabilities of responding in each category were generated for each of these true s according to the item parameters and the item response function (Eq. 2). Polytomous data was generated through sampling, using these probabilities as the probability of landing in each category.
Three trait estimates were obtained: the MLE, the bisquare-weighted robust estimate, and the Huber-weighted robust estimate. The same response vector was used for all three estimators. Initial values of zero were used in the Newton–Raphson algorithm to estimate the MLE. Following past practices in robust IRT literature, the MLE was then used as the initial value to estimate the robust estimate, using zero in cases where the MLE did not converge. The average bias and MSE were evaluated for the three latent trait estimates. If the estimate did not converge within 30 iterations or approached infinity, the estimate was considered missing and removed from our calculation of bias and MSE. If more than 30% of the estimates for a trait level on a certain test design did not converge, we did not report the bias and MSE for the trait level on that test design.
Tuning parameters and were used for the bisquare and Huber weight functions, respectively, in all simulations. These values were chosen through a series of pilot simulations in which B and H were each varied, and the optimal result was the value that produced the most reduced bias and MSE across the test conditions in our main simulations. For brevity, we omit these results from the paper but can provide them upon request. Although we used a limited number of conditions to come up with these values, the parameter values and are also consistent with the tuning parameters suggested in previous robust estimation of latent traits (Mislevy & Bock, 1982; Schuster & Yuan, 2011). However, for data with low degrees of aberrant responses (e.g., a severity of 10%) generated from tests with few categories (e.g., ), greater tuning parameters, such as and , tend to optimize the bias and MSE. Using and in this situation results in a minor overcorrection of the data (i.e., for a MLE with a negative bias, the robust estimate may produce positive bias). Since increasing the tuning parameter decreases the amount of downweighting applied to the data, these results appear consistent: with fewer response disturbances, less downweighting should be applied to the data.
Results
Similar patterns were observed for both back random responding and neglected reverse coding, so our findings are generalized to both types of aberrant responding. Due to a large number of simulation conditions, tables from the simulations with neglected reverse coding were omitted from this paper but are available on OSF (https://osf.io/jku4d/).
When an estimation method led to 30% or greater nonconvergence for a certain true trait and test design, the bias and average standard error were not reported. Instead, the nonconvergence rate is reported in parentheses with the results (Tables 1, 2, 3 and 4). This incident occurred predominantly in ML estimation for extreme traits (e.g., or even more extreme). However, the robust procedures both tend to result in much lower nonconvergence rates, suggesting that, when the ML estimation fails in convergence, robust estimation may be able to provide a converging estimate.
Table 1.
Bias using maximum likelihood (ML), biweight (BI, B = 4), and Huber (HU, H = 1) estimation of the latent trait when there is back random responding in the data at a severity of 10%. (Nonconvergence rates higher than 30% displayed in parentheses)
| K | J | −2 | −1.5 | −1 | −0.5 | 0 | 0.5 | 1 | 1.5 | 2 | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| ML | 3 | 10 | (79.5%) | (43.3%) | 0.18 | 0.08 | −0.05 | −0.18 | −0.28 | (67.5%) | (89.5%) |
| 30 | 0.42 | 0.37 | 0.28 | 0.17 | 0.06 | −0.01 | −0.09 | −0.15 | −0.21 | ||
| 50 | 0.23 | 0.12 | 0.02 | −0.04 | −0.08 | −0.14 | −0.24 | −0.30 | −0.31 | ||
| 70 | 0.31 | 0.23 | 0.15 | 0.07 | −0.01 | −0.08 | −0.16 | −0.19 | −0.25 | ||
| 5 | 10 | (66.8%) | 0.15 | −0.03 | −0.17 | −0.27 | −0.30 | −0.24 | (35.5%) | (80.8%) | |
| 30 | (33.7%) | 0.18 | 0.12 | 0.03 | −0.02 | −0.07 | −0.10 | −0.17 | −0.22 | ||
| 50 | (48.8%) | 0.16 | 0.10 | 0.05 | 0.00 | −0.05 | −0.11 | −0.17 | −0.31 | ||
| 70 | 0.24 | 0.17 | 0.13 | 0.09 | 0.04 | −0.02 | −0.09 | −0.15 | (33.2%) | ||
| 7 | 10 | (78.7%) | 0.29 | 0.20 | 0.17 | 0.11 | 0.01 | −0.06 | −0.20 | (44.0%) | |
| 30 | (89.8%) | 0.15 | 0.05 | 0.02 | −0.01 | −0.06 | −0.09 | −0.15 | (70.3%) | ||
| 50 | (80.3%) | 0.11 | 0.07 | 0.04 | −0.01 | −0.04 | −0.09 | −0.15 | (84.0%) | ||
| 70 | (91.0%) | 0.14 | 0.10 | 0.07 | 0.03 | −0.02 | −0.06 | −0.13 | (88.0%) | ||
| HU | 3 | 10 | −0.08 | −0.05 | 0.13 | 0.10 | −0.03 | −0.12 | −0.08 | 0.04 | 0.05 |
| 30 | −0.10 | 0.02 | 0.07 | 0.05 | 0.02 | −0.01 | −0.02 | −0.03 | 0.07 | ||
| 50 | −0.08 | −0.04 | −0.08 | −0.02 | 0.01 | 0.02 | −0.07 | −0.11 | 0.06 | ||
| 70 | −0.01 | 0.01 | −0.02 | 0.01 | 0.04 | 0.01 | −0.02 | −0.04 | 0.02 | ||
| 5 | 10 | 0.01 | −0.04 | −0.05 | −0.10 | −0.13 | −0.12 | −0.04 | 0.09 | 0.21 | |
| 30 | −0.06 | 0.04 | 0.03 | −0.04 | −0.02 | −0.03 | 0.02 | 0.05 | 0.07 | ||
| 50 | −0.04 | 0.03 | 0.02 | 0.01 | 0.03 | 0.00 | −0.03 | −0.01 | 0.02 | ||
| 70 | 0.00 | 0.03 | 0.01 | 0.03 | 0.05 | 0.00 | −0.04 | −0.04 | 0.02 | ||
| 7 | 10 | −0.15 | 0.02 | 0.09 | 0.10 | 0.09 | 0.02 | −0.04 | −0.08 | −0.06 | |
| 30 | −0.04 | 0.01 | 0.03 | 0.02 | 0.00 | −0.03 | −0.03 | −0.01 | 0.02 | ||
| 50 | −0.02 | 0.01 | 0.03 | 0.01 | −0.01 | −0.03 | −0.02 | −0.03 | 0.00 | ||
| 70 | −0.04 | 0.04 | 0.05 | 0.02 | 0.02 | −0.01 | −0.03 | −0.04 | −0.02 | ||
| BI | 3 | 10 | −0.33 | −0.12 | 0.12 | 0.09 | −0.02 | −0.12 | −0.08 | 0.09 | 0.11 |
| 30 | −0.13 | −0.03 | 0.00 | 0.02 | 0.00 | −0.03 | 0.00 | 0.00 | 0.09 | ||
| 50 | −0.13 | −0.09 | −0.10 | −0.02 | 0.03 | 0.05 | −0.04 | −0.06 | 0.07 | ||
| 70 | −0.05 | −0.04 | −0.06 | 0.01 | 0.03 | 0.02 | 0.01 | 0.00 | 0.05 | ||
| 5 | 10 | −0.09 | −0.05 | −0.04 | −0.08 | −0.10 | −0.09 | −0.02 | 0.07 | (35.0%) | |
| 30 | −0.11 | 0.00 | 0.00 | −0.05 | −0.03 | 0.00 | 0.04 | 0.07 | 0.08 | ||
| 50 | −0.07 | −0.01 | 0.00 | 0.00 | 0.02 | 0.01 | −0.01 | 0.02 | 0.08 | ||
| 70 | −0.04 | −0.01 | −0.02 | 0.02 | 0.03 | 0.01 | −0.02 | −0.01 | 0.08 | ||
| 7 | 10 | −0.29 | −0.06 | 0.06 | 0.08 | 0.07 | 0.01 | −0.03 | −0.05 | −0.03 | |
| 30 | −0.08 | −0.01 | 0.02 | 0.01 | 0.00 | −0.01 | −0.01 | 0.02 | 0.05 | ||
| 50 | −0.05 | −0.01 | 0.01 | 0.01 | −0.02 | −0.01 | 0.00 | −0.01 | 0.03 | ||
| 70 | −0.07 | 0.00 | 0.02 | 0.01 | 0.01 | 0.00 | −0.02 | −0.01 | 0.01 | ||
Table 2.
Bias using maximum likelihood (ML), biweight (BI, B = 4), and Huber (HU, H = 1) estimation of the latent trait when there is back random responding in the data at a severity of 30%. (Nonconvergence rates higher than 30% displayed in parentheses)
| K | J | −2 | −1.5 | −1 | −0.5 | 0 | 0.5 | 1 | 1.5 | 2 | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| ML | 3 | 10 | (58.2%) | (30.2%) | 0.62 | 0.50 | 0.29 | 0.01 | −0.26 | (48.0%) | (65.7%) |
| 30 | 0.95 | 0.71 | 0.44 | 0.22 | 0.01 | −0.19 | −0.36 | −0.55 | −0.71 | ||
| 50 | 0.82 | 0.57 | 0.35 | 0.16 | −0.01 | −0.21 | −0.41 | −0.58 | −0.74 | ||
| 70 | 0.71 | 0.50 | 0.30 | 0.12 | −0.08 | −0.29 | −0.49 | −0.66 | −0.78 | ||
| 5 | 10 | (38.3%) | 0.35 | 0.07 | −0.13 | −0.25 | −0.37 | −0.47 | −0.70 | (33.8%) | |
| 30 | 0.72 | 0.53 | 0.33 | 0.13 | −0.07 | −0.23 | −0.41 | −0.55 | −0.74 | ||
| 50 | 0.63 | 0.45 | 0.26 | 0.10 | −0.05 | −0.18 | −0.34 | −0.52 | −0.75 | ||
| 70 | 0.62 | 0.48 | 0.34 | 0.24 | 0.11 | −0.06 | −0.21 | −0.36 | −0.58 | ||
| 7 | 10 | 0.94 | 0.70 | 0.56 | 0.43 | 0.31 | 0.15 | 0.00 | −0.30 | −0.63 | |
| 30 | 0.60 | 0.37 | 0.21 | 0.10 | −0.05 | −0.19 | −0.36 | −0.50 | −0.65 | ||
| 50 | 0.58 | 0.44 | 0.31 | 0.17 | 0.02 | −0.12 | −0.26 | −0.43 | −0.60 | ||
| 70 | 0.59 | 0.44 | 0.32 | 0.18 | 0.02 | −0.12 | −0.25 | −0.39 | −0.57 | ||
| HU | 3 | 10 | −0.08 | −0.07 | 0.16 | 0.25 | 0.19 | 0.14 | 0.11 | −0.09 | −0.36 |
| 30 | 0.01 | 0.09 | 0.18 | 0.13 | −0.01 | −0.10 | −0.12 | −0.14 | −0.07 | ||
| 50 | 0.12 | 0.09 | 0.10 | 0.05 | 0.03 | −0.03 | −0.14 | −0.19 | −0.11 | ||
| 70 | 0.06 | 0.07 | 0.04 | 0.07 | 0.01 | −0.09 | −0.15 | −0.15 | −0.09 | ||
| 5 | 10 | 0.12 | −0.01 | −0.11 | −0.14 | −0.15 | −0.12 | −0.04 | −0.13 | −0.20 | |
| 30 | 0.20 | 0.25 | 0.18 | 0.05 | −0.08 | −0.16 | −0.15 | −0.05 | −0.03 | ||
| 50 | 0.13 | 0.14 | 0.08 | 0.01 | −0.02 | −0.04 | −0.10 | −0.16 | −0.19 | ||
| 70 | 0.09 | 0.11 | 0.09 | 0.09 | 0.09 | 0.00 | −0.07 | −0.11 | −0.18 | ||
| 7 | 10 | 0.08 | 0.13 | 0.20 | 0.19 | 0.20 | 0.15 | 0.05 | −0.10 | −0.28 | |
| 30 | 0.14 | 0.12 | 0.07 | 0.05 | −0.01 | −0.08 | −0.15 | −0.17 | −0.13 | ||
| 50 | 0.14 | 0.16 | 0.13 | 0.09 | 0.00 | −0.05 | −0.08 | −0.16 | −0.18 | ||
| 70 | 0.15 | 0.16 | 0.14 | 0.06 | −0.01 | −0.06 | −0.08 | −0.14 | −0.17 | ||
| BI | 3 | 10 | −0.41 | −0.18 | 0.14 | 0.25 | 0.17 | 0.15 | 0.15 | −0.02 | −0.26 |
| 30 | −0.14 | −0.12 | 0.04 | 0.08 | −0.03 | −0.10 | −0.05 | −0.02 | 0.00 | ||
| 50 | −0.05 | −0.05 | 0.01 | 0.00 | 0.03 | 0.01 | −0.07 | −0.06 | 0.01 | ||
| 70 | −0.08 | −0.07 | −0.05 | 0.04 | 0.02 | −0.06 | −0.04 | −0.01 | 0.03 | ||
| 5 | 10 | 0.00 | −0.06 | −0.15 | −0.15 | −0.13 | −0.08 | 0.02 | −0.09 | −0.19 | |
| 30 | 0.04 | 0.11 | 0.11 | 0.03 | −0.07 | −0.11 | −0.07 | 0.06 | 0.07 | ||
| 50 | 0.00 | 0.01 | 0.01 | 0.00 | −0.02 | 0.00 | −0.03 | −0.06 | −0.04 | ||
| 70 | −0.04 | −0.02 | 0.02 | 0.05 | 0.06 | 0.02 | −0.02 | −0.01 | −0.02 | ||
| 7 | 10 | −0.11 | −0.02 | 0.08 | 0.11 | 0.16 | 0.14 | 0.04 | −0.07 | −0.23 | |
| 30 | 0.03 | 0.03 | 0.02 | 0.02 | 0.00 | −0.02 | −0.06 | −0.06 | −0.01 | ||
| 50 | 0.03 | 0.06 | 0.05 | 0.05 | −0.01 | −0.01 | −0.01 | −0.06 | −0.05 | ||
| 70 | 0.02 | 0.04 | 0.06 | 0.03 | −0.02 | −0.02 | −0.03 | −0.05 | −0.05 | ||
Table 3.
Sandwich standard error using maximum likelihood (ML), biweight (BI, B = 4), and Huber (HU, H = 1) estimation of the latent trait when there is back random responding in the data at a severity of 10%. (Nonconvergence rates higher than 30% displayed in parentheses)
| K | J | −2 | −1.5 | −1 | −0.5 | 0 | 0.5 | 1 | 1.5 | 2 | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| ML | 3 | 10 | (79.5%) | (43.3%) | 0.71 | 0.76 | 0.77 | 0.72 | 0.59 | (67.5%) | (89.5%) |
| 30 | 0.62 | 0.47 | 0.32 | 0.21 | 0.21 | 0.28 | 0.34 | 0.34 | 0.36 | ||
| 50 | 0.39 | 0.30 | 0.22 | 0.17 | 0.18 | 0.23 | 0.26 | 0.29 | 0.32 | ||
| 70 | 0.28 | 0.23 | 0.18 | 0.14 | 0.14 | 0.19 | 0.25 | 0.28 | 0.29 | ||
| 5 | 10 | (66.8%) | 0.47 | 0.42 | 0.40 | 0.42 | 0.46 | 0.46 | (35.5%) | (80.8%) | |
| 30 | (33.7%) | 0.31 | 0.23 | 0.17 | 0.17 | 0.21 | 0.28 | 0.38 | 0.53 | ||
| 50 | (48.8%) | 0.24 | 0.17 | 0.13 | 0.15 | 0.18 | 0.20 | 0.25 | 0.34 | ||
| 70 | 0.27 | 0.23 | 0.18 | 0.13 | 0.12 | 0.13 | 0.14 | 0.18 | (33.2%) | ||
| 7 | 10 | (78.7%) | 0.59 | 0.44 | 0.34 | 0.33 | 0.36 | 0.40 | 0.46 | (44.0%) | |
| 30 | (89.8%) | 0.25 | 0.20 | 0.17 | 0.17 | 0.19 | 0.23 | 0.30 | (70.3%) | ||
| 50 | (80.3%) | 0.22 | 0.19 | 0.17 | 0.15 | 0.15 | 0.17 | 0.21 | (84.0%) | ||
| 70 | (91.0%) | 0.19 | 0.15 | 0.12 | 0.11 | 0.12 | 0.14 | 0.18 | (88.0%) | ||
| HU | 3 | 10 | 1.11 | 0.74 | 0.79 | 0.95 | 1.01 | 0.86 | 0.60 | 0.58 | 1.14 |
| 30 | 0.96 | 0.57 | 0.39 | 0.25 | 0.22 | 0.30 | 0.35 | 0.36 | 0.50 | ||
| 50 | 0.62 | 0.35 | 0.25 | 0.18 | 0.19 | 0.25 | 0.28 | 0.31 | 0.39 | ||
| 70 | 0.35 | 0.26 | 0.20 | 0.15 | 0.15 | 0.21 | 0.27 | 0.29 | 0.34 | ||
| 5 | 10 | 0.74 | 0.53 | 0.46 | 0.42 | 0.40 | 0.37 | 0.40 | 0.76 | 2.51 | |
| 30 | 0.64 | 0.35 | 0.25 | 0.18 | 0.17 | 0.21 | 0.30 | 0.45 | 0.69 | ||
| 50 | 0.39 | 0.26 | 0.18 | 0.14 | 0.16 | 0.19 | 0.21 | 0.29 | 0.51 | ||
| 70 | 0.31 | 0.24 | 0.18 | 0.13 | 0.13 | 0.13 | 0.15 | 0.20 | 0.32 | ||
| 7 | 10 | 1.65 | 0.67 | 0.44 | 0.35 | 0.35 | 0.38 | 0.43 | 0.54 | 0.75 | |
| 30 | 0.46 | 0.28 | 0.21 | 0.18 | 0.17 | 0.19 | 0.24 | 0.35 | 0.53 | ||
| 50 | 0.37 | 0.24 | 0.20 | 0.18 | 0.16 | 0.15 | 0.17 | 0.22 | 0.34 | ||
| 70 | 0.33 | 0.20 | 0.16 | 0.13 | 0.12 | 0.13 | 0.15 | 0.20 | 0.29 | ||
| BI | 3 | 10 | 2.66 | 1.26 | 0.84 | 0.95 | 1.00 | 0.87 | 0.61 | 0.65 | 1.29 |
| 30 | 1.08 | 0.61 | 0.42 | 0.26 | 0.22 | 0.30 | 0.36 | 0.37 | 0.53 | ||
| 50 | 0.75 | 0.37 | 0.26 | 0.18 | 0.20 | 0.25 | 0.29 | 0.31 | 0.39 | ||
| 70 | 0.38 | 0.27 | 0.21 | 0.15 | 0.15 | 0.22 | 0.28 | 0.30 | 0.37 | ||
| 5 | 10 | 1.19 | 0.61 | 0.47 | 0.42 | 0.40 | 0.37 | 0.44 | 0.76 | (35.0%) | |
| 30 | 0.72 | 0.37 | 0.26 | 0.18 | 0.17 | 0.22 | 0.31 | 0.47 | 0.70 | ||
| 50 | 0.42 | 0.26 | 0.19 | 0.14 | 0.16 | 0.19 | 0.21 | 0.31 | 0.57 | ||
| 70 | 0.33 | 0.25 | 0.19 | 0.13 | 0.13 | 0.14 | 0.16 | 0.21 | 0.35 | ||
| 7 | 10 | 2.49 | 0.89 | 0.47 | 0.35 | 0.35 | 0.38 | 0.44 | 0.56 | 0.76 | |
| 30 | 0.55 | 0.29 | 0.22 | 0.18 | 0.18 | 0.20 | 0.25 | 0.36 | 0.56 | ||
| 50 | 0.39 | 0.24 | 0.20 | 0.18 | 0.16 | 0.15 | 0.17 | 0.23 | 0.35 | ||
| 70 | 0.35 | 0.21 | 0.16 | 0.13 | 0.12 | 0.13 | 0.15 | 0.20 | 0.32 | ||
Table 4.
Sandwich standard error using maximum likelihood (ML), biweight (BI, B = 4), and Huber (HU, H = 1) estimation of the latent trait when there is back random responding in the data at a severity of 30%. (Nonconvergence rates higher than 30% displayed in parentheses)
| K | J | −2 | −1.5 | −1 | −0.5 | 0 | 0.5 | 1 | 1.5 | 2 | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| ML | 3 | 10 | (58.2%) | (30.2%) | 0.73 | 0.72 | 0.69 | 0.64 | 0.57 | (48.0%) | (65.7%) |
| 30 | 0.44 | 0.35 | 0.27 | 0.22 | 0.21 | 0.25 | 0.30 | 0.33 | 0.34 | ||
| 50 | 0.26 | 0.21 | 0.18 | 0.17 | 0.19 | 0.22 | 0.25 | 0.27 | 0.29 | ||
| 70 | 0.23 | 0.20 | 0.17 | 0.14 | 0.14 | 0.16 | 0.20 | 0.24 | 0.27 | ||
| 5 | 10 | (38.3%) | 0.45 | 0.43 | 0.42 | 0.43 | 0.45 | 0.46 | 0.46 | (33.8%) | |
| 30 | 0.30 | 0.25 | 0.20 | 0.17 | 0.17 | 0.20 | 0.24 | 0.29 | 0.36 | ||
| 50 | 0.24 | 0.19 | 0.15 | 0.13 | 0.15 | 0.18 | 0.19 | 0.21 | 0.23 | ||
| 70 | 0.23 | 0.19 | 0.15 | 0.13 | 0.12 | 0.13 | 0.14 | 0.16 | 0.19 | ||
| 7 | 10 | 0.54 | 0.45 | 0.38 | 0.35 | 0.35 | 0.38 | 0.41 | 0.45 | 0.50 | |
| 30 | 0.26 | 0.22 | 0.19 | 0.17 | 0.17 | 0.18 | 0.20 | 0.24 | 0.31 | ||
| 50 | 0.22 | 0.20 | 0.18 | 0.16 | 0.15 | 0.15 | 0.16 | 0.18 | 0.21 | ||
| 70 | 0.19 | 0.17 | 0.14 | 0.12 | 0.11 | 0.12 | 0.13 | 0.15 | 0.18 | ||
| HU | 3 | 10 | 1.06 | 0.75 | 0.67 | 0.77 | 0.80 | 0.70 | 0.54 | 0.49 | 0.60 |
| 30 | 0.91 | 0.56 | 0.36 | 0.24 | 0.22 | 0.27 | 0.33 | 0.35 | 0.47 | ||
| 50 | 0.46 | 0.30 | 0.20 | 0.17 | 0.20 | 0.24 | 0.27 | 0.30 | 0.36 | ||
| 70 | 0.34 | 0.24 | 0.19 | 0.15 | 0.15 | 0.19 | 0.25 | 0.28 | 0.32 | ||
| 5 | 10 | 0.77 | 0.57 | 0.48 | 0.44 | 0.42 | 0.40 | 0.43 | 0.61 | 1.33 | |
| 30 | 0.46 | 0.30 | 0.23 | 0.18 | 0.17 | 0.19 | 0.25 | 0.38 | 0.63 | ||
| 50 | 0.32 | 0.23 | 0.17 | 0.13 | 0.15 | 0.18 | 0.20 | 0.25 | 0.38 | ||
| 70 | 0.29 | 0.23 | 0.17 | 0.12 | 0.13 | 0.14 | 0.15 | 0.20 | 0.29 | ||
| 7 | 10 | 1.14 | 0.60 | 0.39 | 0.33 | 0.35 | 0.40 | 0.47 | 0.58 | 0.73 | |
| 30 | 0.40 | 0.27 | 0.21 | 0.17 | 0.17 | 0.19 | 0.22 | 0.29 | 0.45 | ||
| 50 | 0.30 | 0.21 | 0.19 | 0.17 | 0.16 | 0.16 | 0.17 | 0.21 | 0.30 | ||
| 70 | 0.27 | 0.19 | 0.15 | 0.13 | 0.12 | 0.12 | 0.14 | 0.18 | 0.25 | ||
| BI | 3 | 10 | 2.74 | 1.31 | 0.78 | 0.76 | 0.81 | 0.72 | 0.56 | 0.56 | 0.79 |
| 30 | 1.22 | 0.71 | 0.43 | 0.25 | 0.22 | 0.28 | 0.34 | 0.37 | 0.50 | ||
| 50 | 0.62 | 0.34 | 0.23 | 0.18 | 0.20 | 0.25 | 0.28 | 0.31 | 0.39 | ||
| 70 | 0.43 | 0.28 | 0.21 | 0.15 | 0.15 | 0.20 | 0.26 | 0.29 | 0.35 | ||
| 5 | 10 | 1.28 | 0.65 | 0.51 | 0.46 | 0.43 | 0.41 | 0.47 | 0.65 | 1.27 | |
| 30 | 0.59 | 0.33 | 0.24 | 0.18 | 0.17 | 0.20 | 0.26 | 0.44 | 0.71 | ||
| 50 | 0.39 | 0.25 | 0.18 | 0.14 | 0.15 | 0.18 | 0.21 | 0.28 | 0.47 | ||
| 70 | 0.34 | 0.25 | 0.18 | 0.13 | 0.13 | 0.14 | 0.16 | 0.22 | 0.37 | ||
| 7 | 10 | 1.72 | 0.85 | 0.45 | 0.34 | 0.35 | 0.40 | 0.48 | 0.61 | 0.80 | |
| 30 | 0.49 | 0.29 | 0.22 | 0.18 | 0.18 | 0.20 | 0.24 | 0.33 | 0.53 | ||
| 50 | 0.35 | 0.23 | 0.20 | 0.18 | 0.16 | 0.16 | 0.18 | 0.23 | 0.35 | ||
| 70 | 0.32 | 0.21 | 0.16 | 0.13 | 0.12 | 0.13 | 0.15 | 0.19 | 0.29 | ||
Overall, the bisquare- and Huber-weighted robust estimates resulted in less bias compared to the MLE. Tables 3 and 4 display the average bias for each of the three estimates (ML, Huber-weighted, and bisquare-weighted estimation) over each test design. For conciseness, a subset of true latent traits from the full simulation is shown ( -2.0, -1.5, -1.0, -0.5, 0.0, 0.5, 1.0, 1.5, and 2.0). Although both estimators were typically effective in reducing the bias, the bisquare weight function tended to produce the smaller bias of the two robust methods. For example, when the severity is 0.10, , , and , gives a bias of , while and give and 0.00, respectively. While the bisquare procedure does not always eliminate the bias, it typically is closer to zero than the Huber-weighted estimate. When K increases, the MLE tends to produce smaller bias, but not to the extent of elimination. Likewise, the Huber-and bisquare-weighted estimates provide smaller bias as K increases, to the point where the bisquare-weighted estimate almost reaches a negligible bias when .
Furthermore, when the severity is lower (Table 1), the bias is less in the MLE compared to instances of greater severity (Table 2). This pattern aligns with our expectations that, as more aberrant responses are present, the estimates will produce more bias. As the severity, number of categories, and test length all decrease, a slight overcorrection tends to appear in the bias by the robust estimators. For example, when , severity is 0.10, , and , the bias for is positive, 0.40, while that of and is -0.13 and -0.16, respectively. Beyond (with greater K and severity) the test length does not have much of an impact on the bias.
Therefore, the robust estimation works best with assessments with more than ten items and/or more than three categories. For such assessments with fewer items and categories, we recommend using robust estimation with caution, though the overcorrection that occurs in shorter tests can be mitigated with a larger tuning parameter.
Average sandwich standard errors for the latent trait estimates can be found in Tables 3 and 4. Standard errors are slightly larger for the robust estimates compared to MLE in some cases of extreme latent traits (e.g., ) or cases of short test lengths (e.g., ), but is otherwise negligible. Previous studies have reported increases in standard error consistent with these results when using robust estimation in general (Carroll & Pederson, 1993) and more precisely in item response models (Schuster & Yuan, 2011). When evaluating estimation procedures, the bias-variance trade-off must be considered: reducing the bias risks an increase in variance. However, the standard error does not increase substantially with the robust estimation in our study, compared to that of the MLE. Therefore, we achieve a desirable bias-variance balance, and the total error is not inflated with robust estimation.
Our findings are consistent with the robust literature. Overall, the robust estimates resulted in less bias along with comparable standard errors, compared to the MLEs. We find that the bisquare-weighted estimate performs better than the Huber-weighted estimate in most cases. This finding contradicts the findings of Schuster and Yuan (2011), which suggested the Huber-weighted estimate outperforms the bisquare-weighted estimate due to a high incidence of infinite estimates with the bisquare weight. Because our study pertains to Likert-type data, as opposed to dichotomous data studied by Schuster and Yuan (2011), less nonconvergence occurs since it is less likely that all responses fall in the lowest/highest response category (similar to all zeros or all 1’s in dichotomous data). Therefore, the issue of infinite estimates does not impact our bisquare estimation here in polytomous items as much as in dichotomous items, and the bisquare weight indeed tends to outperform the Huber weight in the robust estimation.
The Huber weight outperforms the bisquare weight in very few instances, such as when there is both low severity and smaller K. Here, the bisquare weight function results in a greater degree of overcorrection than the Huber weight function. Moreover, the Huber weight tends to result in a smaller standard error in short test lengths with more extreme traits. In all other cases, the bisquare weight tends to result in less bias and standard errors comparable to the Huber weight function.
Tables 5 and 6 display the coverage rates for BRR at severities of 0.1 and 0.3, respectively. Across all conditions, the coverage rates for the robust estimates are greater than those of the MLE. While the coverage rates for the MLE decrease with increasing severity, those for the robust estimate remain relatively similar. Thus, for higher severities, the advantage of the robust estimation on the coverage rates is more prominent, as it is able to mitigate the effects of increased aberrant behavior.
Table 5.
Coverage rates for the sandwich standard error using maximum likelihood (ML), biweight (BI, B = 4), and Huber (HU, H = 1) estimation of the latent trait when there is back random responding in the data at a severity of 10%. (Nonconvergence rates higher than 30% displayed in parentheses)
| K | J | −2 | −1.5 | −1 | −0.5 | 0 | 0.5 | 1 | 1.5 | 2 | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| ML | 3 | 10 | (79.5%) | (43.3%) | 0.97 | 0.95 | 0.91 | 0.92 | 0.98 | (67.5%) | (89.5%) |
| 30 | 0.95 | 0.89 | 0.84 | 0.84 | 0.99 | 0.94 | 0.95 | 0.98 | 0.98 | ||
| 50 | 0.97 | 0.96 | 0.97 | 0.98 | 0.91 | 0.89 | 0.88 | 0.88 | 0.92 | ||
| 70 | 0.86 | 0.87 | 0.87 | 0.94 | 0.96 | 0.92 | 0.90 | 0.95 | 0.96 | ||
| 5 | 10 | (66.8%) | 0.97 | 1.00 | 0.99 | 0.92 | 0.92 | 0.96 | (35.5%) | (80.8%) | |
| 30 | (33.7%) | 0.95 | 0.92 | 0.95 | 0.92 | 0.94 | 0.96 | 0.96 | 0.98 | ||
| 50 | (48.8%) | 0.95 | 0.90 | 0.94 | 0.95 | 0.97 | 0.97 | 0.97 | 0.95 | ||
| 70 | 0.98 | 0.97 | 0.90 | 0.87 | 0.91 | 0.93 | 0.90 | 0.92 | (33.2%) | ||
| 7 | 10 | (78.7%) | 0.98 | 0.95 | 0.94 | 0.98 | 0.97 | 0.97 | 0.96 | (44.0%) | |
| 30 | (89.8%) | 0.96 | 0.93 | 0.92 | 0.92 | 0.93 | 0.94 | 0.97 | (70.3%) | ||
| 50 | (80.3%) | 0.99 | 0.98 | 0.96 | 0.98 | 0.97 | 0.95 | 0.95 | (84.0%) | ||
| 70 | (91.0%) | 0.96 | 0.91 | 0.88 | 0.93 | 0.94 | 0.95 | 0.96 | (88.0%) | ||
| HU | 3 | 10 | 1.00 | 1.00 | 1.00 | 0.99 | 0.98 | 0.97 | 1.00 | 1.00 | 0.98 |
| 30 | 1.00 | 0.99 | 0.96 | 0.91 | 0.97 | 0.95 | 0.97 | 1.00 | 1.00 | ||
| 50 | 1.00 | 1.00 | 0.99 | 0.96 | 0.96 | 0.98 | 0.99 | 0.98 | 1.00 | ||
| 70 | 1.00 | 0.99 | 0.97 | 0.94 | 0.96 | 0.99 | 1.00 | 1.00 | 1.00 | ||
| 5 | 10 | 0.98 | 0.99 | 0.99 | 0.98 | 0.93 | 0.94 | 0.94 | 0.98 | 0.99 | |
| 30 | 1.00 | 0.99 | 0.98 | 0.97 | 0.92 | 0.96 | 0.98 | 0.99 | 1.00 | ||
| 50 | 1.00 | 1.00 | 0.98 | 0.95 | 0.97 | 0.98 | 0.99 | 0.99 | 1.00 | ||
| 70 | 1.00 | 1.00 | 0.99 | 0.94 | 0.93 | 0.95 | 0.96 | 0.97 | 1.00 | ||
| 7 | 10 | 1.00 | 0.98 | 0.96 | 0.95 | 0.96 | 0.97 | 0.98 | 0.98 | 0.99 | |
| 30 | 1.00 | 0.99 | 0.96 | 0.96 | 0.97 | 0.97 | 0.98 | 0.99 | 1.00 | ||
| 50 | 1.00 | 1.00 | 0.99 | 0.98 | 0.98 | 0.97 | 0.98 | 0.99 | 1.00 | ||
| 70 | 1.00 | 0.99 | 0.98 | 0.96 | 0.95 | 0.97 | 0.98 | 0.99 | 1.00 | ||
| BI | 3 | 10 | 1.00 | 1.00 | 1.00 | 1.00 | 0.99 | 0.96 | 1.00 | 1.00 | 0.98 |
| 30 | 1.00 | 0.99 | 0.97 | 0.94 | 0.97 | 0.94 | 0.96 | 1.00 | 1.00 | ||
| 50 | 1.00 | 1.00 | 0.99 | 0.95 | 0.96 | 0.98 | 1.00 | 0.99 | 1.00 | ||
| 70 | 1.00 | 1.00 | 0.98 | 0.94 | 0.96 | 0.98 | 1.00 | 1.00 | 1.00 | ||
| 5 | 10 | 0.98 | 0.98 | 0.99 | 0.97 | 0.92 | 0.94 | 0.95 | 0.99 | (35.0%) | |
| 30 | 1.00 | 0.99 | 0.98 | 0.96 | 0.90 | 0.96 | 0.98 | 0.99 | 1.00 | ||
| 50 | 1.00 | 1.00 | 0.97 | 0.96 | 0.97 | 0.98 | 1.00 | 0.99 | 1.00 | ||
| 70 | 1.00 | 1.00 | 0.98 | 0.95 | 0.92 | 0.94 | 0.97 | 0.99 | 1.00 | ||
| 7 | 10 | 1.00 | 0.99 | 0.96 | 0.96 | 0.96 | 0.96 | 0.98 | 0.97 | 0.99 | |
| 30 | 1.00 | 0.99 | 0.98 | 0.95 | 0.96 | 0.96 | 0.99 | 0.99 | 1.00 | ||
| 50 | 1.00 | 1.00 | 0.99 | 0.99 | 0.97 | 0.96 | 0.98 | 0.99 | 1.00 | ||
| 70 | 1.00 | 1.00 | 0.98 | 0.96 | 0.95 | 0.97 | 0.99 | 0.99 | 1.00 | ||
Table 6.
Coverage rates for the sandwich standard error using maximum likelihood (ML), biweight (BI, B = 4), and Huber (HU, H = 1) estimation of the latent trait when there is back random responding in the data at a severity of 30%. (Nonconvergence rates higher than 30% displayed in parentheses)
| K | J | −2 | −1.5 | −1 | −0.5 | 0 | 0.5 | 1 | 1.5 | 2 | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| ML | 3 | 10 | (58.2%) | (30.2%) | 0.84 | 0.76 | 0.77 | 0.85 | 0.97 | (48.0%) | (65.7%) |
| 30 | 0.43 | 0.42 | 0.50 | 0.71 | 0.94 | 0.75 | 0.68 | 0.63 | 0.49 | ||
| 50 | 0.16 | 0.28 | 0.49 | 0.78 | 0.88 | 0.77 | 0.62 | 0.45 | 0.29 | ||
| 70 | 0.17 | 0.31 | 0.54 | 0.77 | 0.85 | 0.53 | 0.34 | 0.29 | 0.20 | ||
| 5 | 10 | (38.3%) | 0.79 | 0.95 | 0.91 | 0.80 | 0.76 | 0.80 | 0.75 | (33.8%) | |
| 30 | 0.37 | 0.44 | 0.54 | 0.78 | 0.84 | 0.68 | 0.58 | 0.49 | 0.43 | ||
| 50 | 0.26 | 0.39 | 0.55 | 0.80 | 0.80 | 0.75 | 0.58 | 0.30 | 0.09 | ||
| 70 | 0.22 | 0.34 | 0.41 | 0.50 | 0.68 | 0.82 | 0.60 | 0.39 | 0.17 | ||
| 7 | 10 | 0.63 | 0.60 | 0.57 | 0.69 | 0.80 | 0.91 | 0.95 | 0.87 | 0.72 | |
| 30 | 0.36 | 0.59 | 0.71 | 0.72 | 0.78 | 0.69 | 0.54 | 0.45 | 0.44 | ||
| 50 | 0.24 | 0.43 | 0.55 | 0.73 | 0.85 | 0.78 | 0.59 | 0.37 | 0.19 | ||
| 70 | 0.13 | 0.30 | 0.39 | 0.60 | 0.79 | 0.72 | 0.53 | 0.32 | 0.13 | ||
| HU | 3 | 10 | 0.98 | 0.98 | 0.95 | 0.90 | 0.84 | 0.76 | 0.98 | 1.00 | 0.87 |
| 30 | 0.98 | 0.85 | 0.79 | 0.80 | 0.92 | 0.82 | 0.87 | 0.95 | 0.94 | ||
| 50 | 0.95 | 0.88 | 0.82 | 0.83 | 0.88 | 0.91 | 0.90 | 0.88 | 0.93 | ||
| 70 | 0.95 | 0.92 | 0.87 | 0.80 | 0.87 | 0.87 | 0.85 | 0.94 | 0.95 | ||
| 5 | 10 | 0.94 | 0.96 | 0.96 | 0.91 | 0.83 | 0.87 | 0.93 | 0.94 | 0.94 | |
| 30 | 0.89 | 0.79 | 0.78 | 0.87 | 0.83 | 0.73 | 0.80 | 0.94 | 0.98 | ||
| 50 | 0.95 | 0.90 | 0.88 | 0.86 | 0.80 | 0.87 | 0.88 | 0.90 | 0.90 | ||
| 70 | 0.98 | 0.94 | 0.88 | 0.80 | 0.77 | 0.90 | 0.87 | 0.91 | 0.91 | ||
| 7 | 10 | 0.95 | 0.91 | 0.82 | 0.86 | 0.82 | 0.89 | 0.97 | 0.95 | 0.89 | |
| 30 | 0.95 | 0.89 | 0.87 | 0.82 | 0.84 | 0.85 | 0.82 | 0.89 | 0.96 | ||
| 50 | 0.93 | 0.87 | 0.85 | 0.87 | 0.92 | 0.86 | 0.88 | 0.86 | 0.92 | ||
| 70 | 0.96 | 0.86 | 0.79 | 0.85 | 0.83 | 0.81 | 0.86 | 0.88 | 0.92 | ||
| BI | 3 | 10 | 0.99 | 0.98 | 0.94 | 0.88 | 0.84 | 0.78 | 1.00 | 1.00 | 0.92 |
| 30 | 0.99 | 0.93 | 0.83 | 0.85 | 0.91 | 0.79 | 0.85 | 0.97 | 0.97 | ||
| 50 | 0.98 | 0.94 | 0.87 | 0.85 | 0.85 | 0.90 | 0.93 | 0.93 | 0.98 | ||
| 70 | 0.99 | 0.98 | 0.89 | 0.79 | 0.87 | 0.87 | 0.93 | 0.98 | 0.99 | ||
| 5 | 10 | 0.95 | 0.95 | 0.94 | 0.89 | 0.83 | 0.88 | 0.96 | 0.94 | 0.94 | |
| 30 | 0.95 | 0.88 | 0.80 | 0.88 | 0.80 | 0.77 | 0.86 | 0.97 | 0.99 | ||
| 50 | 0.98 | 0.96 | 0.91 | 0.85 | 0.78 | 0.85 | 0.93 | 0.95 | 0.97 | ||
| 70 | 1.00 | 0.98 | 0.93 | 0.83 | 0.78 | 0.88 | 0.91 | 0.95 | 0.97 | ||
| 7 | 10 | 0.98 | 0.95 | 0.88 | 0.88 | 0.83 | 0.87 | 0.95 | 0.94 | 0.89 | |
| 30 | 0.99 | 0.93 | 0.88 | 0.81 | 0.80 | 0.85 | 0.91 | 0.95 | 0.98 | ||
| 50 | 0.98 | 0.95 | 0.91 | 0.88 | 0.89 | 0.84 | 0.91 | 0.93 | 0.97 | ||
| 70 | 0.99 | 0.96 | 0.87 | 0.86 | 0.80 | 0.82 | 0.92 | 0.94 | 0.98 | ||
Applied analysis
We applied our robust estimation procedure to data from the Big Five Inventory-2 (BFI-2) administered to adolescents ages 14 to 17 (Ober et al., 2021). The sample size of contained no missing responses. The scale consists of items on a five-point Likert scale, with 12 items loading onto each of the five personality factors. However, because we are concerned with the unidimensional GRM, we focused on one personality dimension, neuroticism, which is measured by 12 items. Six of these items (50%) were negatively worded such that they should be reverse coded before analysis. Item parameters were estimated using the properly reverse coded data for all 838 subjects.
160 respondents were randomly chosen to be aberrant (20% prevalence). For these subjects, aberrant responses were created such that four negatively worded items had responses opposite to the true intended responses (33% severity). In doing so, we tried to mimic a scenario where subjects were being inattentive and overlooked the negative wording, for example, missing a “NOT” in the question. Discrepancies between the MLE () and robust estimates ( when the bisquare weight is used and when the Huber weight is used) were compared between the aberrant and the nonaberrant, or undisturbed, responders. It is important to note that there may be other response disturbances that occur in the data (e.g., other types of careless responding), because they frequently plague real data. Therefore, our “nonaberrant” group data may not be entirely undisturbed. However, it is still presumably much less undisturbed than our artificially aberrant data. Likewise, the aberrant group may contain additional response disturbances beyond those artificially created.
Focusing first on the nonaberrant group in Fig. 2 (gray data points), the robust estimates are approximately the same as the MLEs for both the Huber- and bisquare-weighted cases, as most gray points fall close to the identity line, especially for the Huber-weighted cases. However, when we consider the aberrant respondents (black points), a different pattern emerges. For aberrant respondents with small , the corresponding and tend to fall below the identity line; whereas aberrant respondents whose are large tend to have and that fall above the identity line. In other words, the robust estimate for a subject tends to be pulled to the extremes (e.g., -2.0 or 2.0), while their MLE tends to be approximately average (i.e., near 0.0). We expect to see this pattern when a respondent misses some negatively worded items, as the mix of some high responses with some low responses will bias the MLE towards 0.
Fig. 2.

Comparing the MLE of each latent trait with its robust estimate. The figure on the left is the bisquare-weighted robust estimate and the figure on the right is the Huber-weighted robust estimate. Points in black represent the 20% of subjects with aberrant data, where 33% of their responses are oppositely coded. Points in gray represent subjects with “nonaberrant” data. Subjects were not plotted if their MLE or robust estimate did not converge
Table 7 provides the s for three example aberrant subjects based on their responses for the 12 items labeled 1 through 12, with “R” indicating one of the four negatively worded items that a respondent might miss. Consider, for example, the response vector for Subject 212. Their responses to regular items mostly consist of 1s and 2s, indicating low neuroticism. Neglecting negatively worded items, their responses to these items remained low, resulting in 5s on these items after reverse coding, which misled the MLE to produce higher estimates. The MLE is biased towards zero, as the aberrant items are increasing the score: a mix of high and low responses leads to an average trait estimate. However, when robust estimation is employed, the trait estimate is much lower ( and ), indicative of the subject’s actual low neuroticism. This estimate more closely reflects the subject’s true latent trait as suggested by the undisturbed responses. The discrepancy between the robust estimates and the MLE is much greater for Subject 212 in Fig. 2a and b than the non-aberrant subjects in this sample, as it falls further away from the identity line.
Table 7.
ML, Huber-weighted, and bisquare-weighted estimates (, , and , respectively) of neuroticism for three subjects alongside their responses. Note: Aberrant (mistreated reverse coded) items are marked with “R”. Values marked with “” did not converge
| ID | 1R | 2R | 3 | 4 | 5R | 6R | 7 | 8 | 9 | 10 | 11 | 12 | |||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 212 | −0.18 | −2.37 | −2.88 | 5 | 5 | 1 | 2 | 5 | 5 | 2 | 1 | 1 | 4 | 2 | 1 |
| 343 | 1.05 | 1.63 | 2.87 | 2 | 4 | 4 | 4 | 2 | 2 | 5 | 5 | 2 | 2 | 5 | 5 |
| 650 | − | 2.85 | 3.00 | 1 | 4 | 4 | 5 | 2 | 1 | 5 | 5 | 4 | 5 | 5 | 5 |
Likewise, the response vector for Subject 343 in Table 7 consists of mostly 4s and 5s, indicating a high level of neuroticism. The aberrant responses on the four negatively worded items then wrongfully indicate a lower level of neuroticism, and reduce the MLE. However, the robust procedure properly recovers the trait estimate to the high level of neuroticism ( and ). Subject 343 falls above the identity line in Fig. 2a and b, demonstrating how their robust estimate increased from the MLE.
Moreover, the trait estimates for Subject 650 demonstrate a common phenomenon in this robust estimation. Oftentimes, the MLE for a subject will not converge while the robust estimates will converge. The robust estimates ( and ) then reflect the high ability as suggested by the undisturbed responses. Thus, robust estimation can be used to overcome nonconverging MLEs. Because the MLE did not converge, this subject was neither plotted in Fig. 2a nor Fig. 2b. Note that did converge to a value greater than 3.00, so the estimate was truncated to 3.00.
Discussion
We have proposed a general robust estimation procedure for estimating latent traits with the GRM. We have found that the robust estimation proposed in this paper succeeds in reducing bias for data with various types of disturbances, without substantially increasing the standard error. The estimation is effective at various test lengths and number of response categories.
Both the Huber and bisquare weight functions are effective in reducing the bias in most cases, while providing the same or comparable standard error with respect to the MLE. The choice of either weighting mechanism is left to the researcher. Schuster and Yuan (2011) suggest that the Huber weight should be used over the bisquare weight in cases where nonconvergence may be an issue. Potential nonconverging cases may be identified by examining the data for response vectors which contain all, or predominantly all, responses in the same response category. However, given no concern about nonconvergence, the bisquare weight should be used if reduced bias is preferred. Indeed, in our simulations, we find that bias tends to be slightly reduced for the bisquare weight over the Huber weight, except in some conditions.
Although most differences between the results of the Huber and bisquare weight mechanisms are trivial, the decision of using one over the other may also be influenced by some observable characteristics of the data (e.g., short test lengths and/or few response categories). For data contaminated with a small proportion of aberrant responses (i.e., low severity), in cases of smaller K, the bisquare weight function may lead to a greater degree of overcorrection. In this case, the Huber weight function may be preferred. This discrepancy is negligible for greater K, where the bisquare weight function tends to reduce the bias more than the Huber weight function. Typically, the bisquare and Huber weights tend to produce very similar average standard errors. However, the Huber weight tends to give a smaller standard error than the bisquare weight for short test lengths (), especially for more extreme traits (e.g., , etc.).
Although we recommend using the tuning parameters and for the Huber and bisquare weight functions, respectively, it is ultimately up to the researcher to choose a tuning parameter. For a greater degree of downweighting, the tuning parameter can be decreased, while a lesser degree of downweighting can be accomplished with a greater tuning parameter. When the number of categories is low (e.g., ), the robust estimation is more sensitive to the choice of tuning parameters. For high degrees of aberrant behavior (e.g., 30% severity), using and operates well; however, for lesser degrees of aberrant behavior (e.g., 10% severity), a greater tuning parameter such as and may be more optimal in order to avoid overcorrection when items have few categories. However, in our preliminary analysis of H and B, we found that, generally, and are the most robust across different test conditions and response behaviors. These values are consistent with the recommendations in the literature as well. Therefore, they are suggested as a rule of thumb.
While the study has demonstrated the advantage of the robust estimator for polytomous items, it can be extended in multiple ways. First, the study is limited to the specific type of residual and weight functions we chose. Different residuals and weighting mechanisms with the same objectives of detecting misfit and downweighting large misfit can be substituted. Future studies may compare this robust estimation with other weighting mechanisms that target aberrant responding, such as those proposed by Wise et al. (2023). In addition, it may be of interest to compare the robust estimation in this analysis to the WLE instead of the MLE, particularly when the test is short, such as ten items (Warm, 1989). Although bias due to aberrant responding is typically more severe, the MLE may contain bias due to short test lengths, and the WLE may be a stronger benchmark in such conditions.
Second, this study is limited by the assumption that the item parameters are known. This assumption is practical given that many IRT-based testing programs use item parameters calibrated from pretesting. However, the true item parameters are never exactly known and are not exempt from misestimations due to aberrant data in the calibration sample (Patton et al., 2019; Tsutakawa & Johnson, 1990). Future studies should investigate these limitations with regards to robust estimation.
Lastly, the analyses in this study are limited to unidimensional data. Future investigations with this estimator could extend to multidimensional polytomous models, such as the multidimensional graded response model (Muraki & Carlson, 1995). It is also important to consider mixed-format assessments, where dichotomous and polytomous items both exist (Hong et al., 2021). A general solution that subsumes multiple item types and underlying latent dimensions will be very desirable. Moreover, robust estimation has been applied to improve estimates of subjects’ working speed under the response time model (Hong et al., 2021), and both item responses and response times information have been used in person fit analysis (Gorney et al., 2024) and detection of rapid guessing behavior (Lu et al., 2020). It is therefore potentially plausible and useful to develop robust estimators for joint models of item responses and response times.
Funding
The work is supported by NSF SES-1853166.
Availability of data and materials
The example data in the applied data analysis can be found at https://osf.io/fmz74 with additional details on the page https://osf.io/j2s73/.
Code availability
The materials and code for the simulation study and applied data analysis are available at https://osf.io/jku4d/. The study was not preregistered.
Declarations
Ethics approval
Not applicable.
Consent to participate
Not applicable.
Consent for publication
Not applicable.
Conflicts of interest/Competing interests
The authors have no competing interests to declare that are relevant to the content of this article.
Footnotes
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
References
- Armstrong, R. D., & Shi, M. (2009). Model-Free CUSUM Methods for Person Fit. Journal of Educational Measurement,46(4), 408–428. 10.1111/j.1745-3984.2009.00090.x [Google Scholar]
- Aybek, E. C., & Toraman, C. (2022). How many response categories are sufficient for Likert type scales? An empirical study based on the Item Response Theory. International Journal of Assessment Tools in Education,9, 534–54. 10.21449/ijate.1132931 [Google Scholar]
- Böckenholt, U. (2017). Measuring response styles in Likert items. Psychological Methods,22(1), 69–83. 10.1037/met0000106 [DOI] [PubMed] [Google Scholar]
- Bolt, D. M., Cohen, A. S., & Wollack, J. A. (2002). Item Parameter Estimation Under Conditions of Test Speededness: Application of a Mixture Rasch Model With Ordinal Constraints. Journal of Educational Measurement,39(4), 331–348. 10.1111/j.1745-3984.2002.tb01146.x [Google Scholar]
- Bradlow, E. T., Weiss, R. E., & Cho, M. (1998). Bayesian Identification of Outliers in Computerized Adaptive Tests. Journal of the American Statistical Association,93(443), 910–919. 10.1080/01621459.1998.10473747 [Google Scholar]
- Carroll, R. J., & Pederson, S. (1993). On Robustness in the Logistic Regression Model. Journal of the Royal Statistical Society: Series B (Methodological),55(3), 693–706. 10.1111/j.2517-6161.1993.tb01934.x [Google Scholar]
- Clark, M. E., Gironda, R. J., & Young, R. W. (2003). Detection of back random responding: Effectiveness of MMPI-2 and Personality Assessment Inventory validity indices. Psychological Assessment,15(2), 223–234. 10.1037/1040-3590.15.2.223 [DOI] [PubMed] [Google Scholar]
- Costa Jr., P.T., & McCrae, R. R. (2008). The Revised NEO Personality Inventory (NEO-PI-R). The SAGE Handbook of Personality Theory and Assessment: Volume 2 — Personality Measurement and Testing (pp. 179–198). 1 Oliver’s Yard, 55 City Road, London EC1Y 1SP United Kingdom: SAGE Publications Ltd.
- Cronbach, L. J. (1950). Further Evidence on Response Sets and Test Design. Educational and Psychological Measurement,10(1), 3–31. 10.1177/001316445001000101 [Google Scholar]
- Curran, P.G. (2016). Methods for the detection of carelessly invalid responses in survey data. Journal of Experimental Social Psychology, 66, 4–19 Retrieved 2021-12-20. https://linkinghub.elsevier.com/retrieve/pii/S002210311500093110.1016/j.jesp.2015.07.006
- De Ayala, R.J., Plake, B.S., Impara, J.C., Kozmicky, M. (2000). The Effect of Omitted Responses on Ability Estimation in IRT.
- Dodd, B. G., Koch, W. R., & De Ayala, R. J. (1989). Operational Characteristics of Adaptive Testing Procedures Using the Graded Response Model. Applied Psychological Measurement,13(2), 129–143. 10.1177/014662168901300202 [Google Scholar]
- Drasgow, F., Levine, M. V., & McLaughlin, M. E. (1987). Detecting Inappropriate Test Scores with Optimal and Practical Appropriateness Indices. Applied Psychological Measurement,11(1), 59–79. 10.1177/014662168701100105 [Google Scholar]
- Drasgow, F., Levine, M. V., & McLaughlin, M. E. (1991). Appropriateness Measurement for Some Multidimensional Test Batteries. Applied Psychological Measurement,15(2), 171–191. 10.1177/014662169101500207 [Google Scholar]
- Drasgow, F., Levine, M. V., & Williams, E. A. (1985). Appropriateness measurement with polychotomous item response models and standardized indices. British Journal of Mathematical and Statistical Psychology,38(1), 67–86. 10.1111/j.2044-8317.1985.tb00817.x [Google Scholar]
- Embretson, S. E., & Reise, S. P. (2000). Item response theory for psychologists. Mahwah, N.J: L. Erlbaum Associates. [Google Scholar]
- Falk, C. F., & Cai, L. (2016). A flexible full-information approach to the modeling of response styles. Psychological Methods,21(3), 328–347. 10.1037/met0000059 [DOI] [PubMed] [Google Scholar]
- Filonczuk, A., Hong, M., Cheng, Y. (2022). Robust Estimation of Ability in Multidimensional Item Response Theory [Unpublished].
- Goegebeur, Y., De Boeck, P., Wollack, J. A., & Cohen, A. S. (2008). A Speeded Item Response Model with Gradual Process Change. Psychometrika, 73(1), 65–87, Retrieved 2024-09-16, http://link.springer.com/10.1007/s11336-007-9031-2 (Publisher: Springer Science and Business Media LLC). 10.1007/s11336-007-9031-2 [DOI]
- Gorney, K., Sinharay, S., & Liu, X. (2024). Using item scores and response times in person-fit assessment. British Journal of Mathematical and Statistical Psychology,77(1), 151–168. 10.1111/bmsp.12320 [DOI] [PubMed] [Google Scholar]
- Hong, M., & Cheng, Y. (2019). Clarifying the Effect of Test Speededness. Applied Psychological Measurement,43(8), 611–623. 10.1177/0146621618817783 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Hong, M., & Cheng, Y. (2019). Robust maximum marginal likelihood (RMML) estimation for item response theory models. Behavior Research Methods,51(2), 573–588. 10.3758/s13428-018-1150-4 [DOI] [PubMed] [Google Scholar]
- Hong, M., Lin, L., & Cheng, Y. (2021). Asymptotically Corrected Person Fit Statistics for Multidimensional Constructs with Simple Structure and Mixed Item Types. Psychometrika,86(2), 464–488. 10.1007/s11336-021-09756-3 [DOI] [PubMed] [Google Scholar]
- Hong, M., Rebouças, D. A., & Cheng, Y. (2021). Robust Estimation for Response Time Modeling. Journal of Educational Measurement,58(2), 262–280. 10.1111/jedm.12286 [Google Scholar]
- Hong, M., Steedle, J. T., & Cheng, Y. (2020). Methods of Detecting Insufficient Effort Responding: Comparisons and Practical Recommendations. Educational and Psychological Measurement,80(2), 312–345. 10.1177/0013164419865316 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Hu, F. (1994). Relevance Weighted Smoothing and a New Bootstrap Method (Unpublished doctoral dissertation). The University of British Columbia.
- Huang, J. L., Curran, P. G., Keeney, J., Poposki, E. M., & DeShon, R. P. (2012). Detecting and Deterring Insufficient Effort Responding to Surveys. Journal of Business and Psychology,27(1), 99–114. 10.1007/s10869-011-9231-8 [Google Scholar]
- Huber, P. J. (1967). The Behavior of Maximum Likelihood Estimates Under Nonstandard Conditions. Proceedings of the Fifth Berkeley Symposium on Mathematical Statistics and Probability,1, 221–233. [Google Scholar]
- Huber, P.J. (1981). Robust Statistics: Huber/Robust Statistics. Hoboken, NJ, USA: John Wiley & Sons, Inc. Retrieved 2023-01-14, http://doi.wiley.com/10.1002/0471725250
- Hughes, G. D. (2009). The Impact of Incorrect Responses to Reverse-Coded Survey Items. Research in the Schools, 14,
- Johnson, J.A. (2005). Ascertaining the validity of individual protocols from Web-based personality inventories. Journal of Research in Personality, 39(1), 103–129, Retrieved 2023-05-17 https://linkinghub.elsevier.com/retrieve/pii/S0092656604000856.10.1016/j.jrp.2004.09.009
- Karabatsos, G. (2003). Comparing the Aberrant Response Detection Performance of Thirty-Six Person-Fit Statistics. Applied Measurement in Education,16(4), 277–298. 10.1207/S15324818AME1604 [Google Scholar]
- Levine, M. V., & Drasgow, F. (1988). Optimal appropriateness measurement. Psychometrika,53(2), 161–176. 10.1007/BF02294130
- Levine, M. V., & Rubin, D. B. (1979). Measuring the Appropriateness of Multiple-Choice Test Scores. Journal of Educational Statistics,4(4), 269–290. 10.3102/10769986004004269 [Google Scholar]
- Lu, J., Wang, C., Zhang, J., & Tao, J. (2020). A mixture model for responses and response times with a higher-order ability structure to detect rapid guessing behaviour. British Journal of Mathematical and Statistical Psychology,73(2), 261–288. 10.1111/bmsp.12175 [DOI] [PubMed] [Google Scholar]
- Mahalanobis, P. C. (1936). On the Generalised Distance in Statistics. Sankhya A,80(S1), 1–7. 10.1007/s13171-019-00164-5 [Google Scholar]
- Marsh, H. W. (1986). Negative item bias in ratings scales for preadolescent children: A cognitive-developmental phenomenon. Developmental Psychology,22(1), 37–49. 10.1037/0012-1649.22.1.37 [Google Scholar]
- Meade, A. W., & Craig, S. B. (2012). Identifying careless responses in survey data. Psychological Methods,17(3), 437–455. 10.1037/a0028085 [DOI] [PubMed] [Google Scholar]
- Meijer, R. R. (1996). Person-Fit Research: An Introduction. Applied Measurement in Education,9(1), 3–8. 10.1207/s15324818ame0901 [Google Scholar]
- Meijer, R. R. (2002). Outlier Detection in High-Stakes Certification Testing. Journal of Educational Measurement,39(3), 219–233. 10.1111/j.1745-3984.2002.tb01175.x [Google Scholar]
- Meijer, R. R., & Sijtsma, K. (2001). Methodology Review: Evaluating Person Fit. Applied Psychological Measurement,25(2), 107–135. 10.1177/01466210122031957 [Google Scholar]
- Mislevy, R. J., & Bock, R. D. (1982). Biweight Estimates of Latent Ability. Educational and Psychological Measurement,42(3), 725–737. 10.1177/001316448204200302 [Google Scholar]
- Molenaar, I. W., & Hoijtink, H. (1990). The many null distributions of person fit indices. Psychometrika,55(1), 75–106. 10.1007/BF02294745 [Google Scholar]
- Mosteller, F., & Tukey, J. W. (1977). Data Analysis and Regression: A Second Course in Statistics. Reading, Mass.: Addison-Wesley Publishing Company. [Google Scholar]
- Muraki, E., & Carlson, J. E. (1995). Full-Information Factor Analysis for Polytomous Item Responses. Applied Psychological Measurement,19(1), 73–90. 10.1177/014662169501900109 [Google Scholar]
- Niessen, A. S. M., Meijer, R. R., & Tendeiro, J. N. (2016). Detecting careless respondents in web-based questionnaires: Which method to use? Journal of Research in Personality, 63, 1–11, Retrieved 2023-06-07, https://linkinghub.elsevier.com/retrieve/pii/S0092656616300344. 10.1016/j.jrp.2016.04.010 [DOI]
- Ober, T. M., Cheng, Y., Jacobucci, R., & Whitney, B. M. (2021). Examining the factor structure of the Big Five Inventory-2 personality domains with an adolescent sample. Psychological Assessment,33(1), 14–28. 10.1037/pas0000962 [DOI] [PubMed] [Google Scholar]
- Oshima, T.C. (1994). The Effect of Speededness on Parameter Estimation in Item Response Theory. Journal of Educational Measurement, 31(3), 200–219, Retrieved 2024-03-22, from https://www.jstor.org/stable/1435266 (Publisher: [National Council on Measurement in Education, Wiley])
- Page, E. S. (1954). Continuous Inspection Schemes. Biometrika,41(1–2), 100–115. 10.1093/biomet/41.1-2.100 [Google Scholar]
- Patton, J. M., Cheng, Y., Hong, M., & Diao, Q. (2019). Detection and Treatment of Careless Responses to Improve Item Parameter Estimation. Journal of Educational and Behavioral Statistics,44(3), 309–341. 10.3102/1076998618825116 [Google Scholar]
- Patton, J.M., Cheng, Y., Yuan, K.- H., Diao, Q. (2014). Bootstrap Standard Errors for Maximum Likelihood Ability Estimates When Item Parameters Are Unknown. Educational and Psychological Measurement, 74(4), 697–712, Retrieved 2024-01-11, 10.1177/0013164413511083 (Publisher: SAGE Publications Inc).
- Samejima, F. (1969). Estimation of latent ability using a response pattern of graded scores. Psychometrika Monograph Supplement, 34(4, Pt. 2), 100–100,
- Schuster, C., & Yuan, K.- H. (2011). Robust Estimation of Latent Ability in Item Response Models. Journal of Educational and Behavioral Statistics,36(6), 720–735. 10.3102/1076998610396890
- Sellbom, M., & Anderson, J. L. (2013). The Minnesota Multiphasic Personality Inventory-2. R. P. Archer & E. M. A. Wheeler (Eds.), Forensic uses of clinical assessment instruments (pp. 21–62). Abingdon: Routledge/Taylor & Francis Group.
- Shao, C., Li, J., & Cheng, Y. (2016). Detection of Test Speededness Using Change-Point Analysis. Psychometrika,81(4), 1118–1141. 10.1007/s11336-015-9476-7 [DOI] [PubMed] [Google Scholar]
- Sinharay, S. (2016). Person Fit Analysis in Computerized Adaptive Testing Using Tests for a Change Point. Journal of Educational and Behavioral Statistics,41(5), 521–549. 10.3102/1076998616658331 [Google Scholar]
- Tatsuoka, K. K. (1984). Caution indices based on item response theory. Pshychometrika,49(1), 95–110. [Google Scholar]
- Trabin, T.E., & Weiss, D.J. (1983). The Person Response Curve: Fit of Individuals to Item Response Theory Models. New Horizons in Testing (pp. 83–108). Elsevier. Retrieved 2021-12-20, from https://linkinghub.elsevier.com/retrieve/pii/B9780127427805500147.
- Tsutakawa, R. K., & Johnson, J. C. (1990). The effect of uncertainty of item parameter estimation on ability estimates. Psychometrika,55(2), 371–390. 10.1007/BF02295293 [Google Scholar]
- Van Der Linden, W. J., Scrams, D. J., & Schnipke, D. L. (1999). Using Response-Time Constraints to Control for Differential Speededness in Computerized Adaptive Testing. Applied Psychological Measurement,23(3), 195–210. 10.1177/01466219922031329 [Google Scholar]
- Van Der Linden, W. J., & Xiong, X. (2013). Speededness and Adaptive Testing. Journal of Educational and Behavioral Statistics,38(4), 418–438. 10.3102/1076998612466143 [Google Scholar]
- Van Krimpen-Stoop, E. M., & Meijer, R. R. (2000). Detecting Person Misfit in Adaptive Testing Using Statistical Process Control Techniques. W.J. Van Der Linden and G.A. Glas (Eds.), Computerized Adaptive Testing: Theory and Practice (pp. 201–219). Dordrecht: Springer Netherlands.
- Van Krimpen-Stoop, E. M., & Meijer, R. R. (2001). CUSUM-Based Person-Fit Statistics for Adaptive Testing. Journal of Educational and Behavioral Statistics,26(2), 199–217. 10.3102/10769986026002199
- Van Krimpen-Stoop, E. M., & Meijer, R. R. (2002). Detection of Person Misfit in Computerized Adaptive Tests with Polytomous Items. Applied Psychological Measurement,26(2), 164–180. 10.1177/01421602026002004 [Google Scholar]
- Wang, C., & Xu, G. (2015). A mixture hierarchical model for response times and response accuracy. British Journal of Mathematical and Statistical Psychology,68(3), 456–477. 10.1111/bmsp.12054 [DOI] [PubMed] [Google Scholar]
- Wang, C., Xu, G., Shang, Z., & Kuncel, N. (2018). Detecting Aberrant Behavior and Item Preknowledge: A Comparison of Mixture Modeling Method and Residual Method. Journal of Educational and Behavioral Statistics,43(4), 469–501. 10.3102/1076998618767123 [Google Scholar]
- Warm, T. A. (1989). Weighted likelihood estimation of ability in item response theory. Psychometrika,54(3), 427–450. 10.1007/BF02294627 [Google Scholar]
- Weems, G. H., Onwuegbuzie, A. J., & Collins, K. M. (2006). The Role of Reading Comprehension in Responses to Positively and Negatively Worded Items on Rating Scales. Evaluation & Research in Education,19(1), 3–20. 10.1080/09500790608668322 [Google Scholar]
- Weems, G. H., Onwuegbuzie, A. J., Schreiber, J. B., & Eggers, S. J. (2003). Characteristics of respondents who respond differently to positively and negatively worded items on rating scales. Assessment & Evaluation in Higher Education,28(6), 587–606. 10.1080/0260293032000130234 [Google Scholar]
- Wetzel, E., & Carstensen, C. H. (2017). Multidimensional Modeling of Traits and Response Styles. European Journal of Psychological Assessment,33(5), 352–364. 10.1027/1015-5759/a000291 [Google Scholar]
- White, H. (1980). A Heteroskedasticity-Consistent Covariance Matrix Estimator and a Direct Test for Heteroskedasticity. Econometrica, 48(4), 817, Retrieved 2024-10-13, from https://www.jstor.org/stable/1912934?origin=crossref. 10.2307/1912934 [DOI]
- Williams, S. A., & Swanson, M. S. (2001). The Effect of Reading Ability and Response Formats on Patients’ Abilities to Respond to a Patient Satisfaction Scale. The Journal of Continuing Education in Nursing,32(2), 60–67. 10.3928/0022-0124-20010301-05 [DOI] [PubMed] [Google Scholar]
- Wise, S. L., Kingsbury, G. G., & Langi, M. L. (2023). Change in Engagement During Test Events: An Argument for Weighted Scoring? Applied Measurement in Education,36(4), 340–354. 10.1080/08957347.2023.2274568 [Google Scholar]
- Wise, S. L., Kingsbury, G. G., Thomason, J., & Kong, X. (2004). An Investigation of Motivation Filtering in a Statewide Achievement Testing Program. CA: San Diego. [Google Scholar]
- Woods, C. M. (2006). Careless Responding to Reverse-Worded Items: Implications for Confirmatory Factor Analysis. Journal of Psychopathology and Behavioral Assessment,28(3), 186–191. 10.1007/s10862-005-9004-7 [Google Scholar]
- Wright, B. D., & Masters, G. N. (1982). Rating scale analysis: rasch measurement. Chicago, Ill: Mesa Pr. [Google Scholar]
- Wright, B. D., & Stone, M. H. (1979). Best Test Design. Rasch Measurement. Chicago, IL: Mesa Press. [Google Scholar]
- Yamamoto, K. (1982). HYBRID Model of IRT and Latent Class Models. ETS Research Report Series, 1982(2), , 10.1002/j.2333-8504.1982.tb01326.x
- Yamamoto, K. (1995). Estimating the Effects of Test Length and Test Time on Parameter Estimation Using the HYBRID Model. ETS Research Report Series, 1995(1), , 10.1002/j.2333-8504.1995.tb01637.x
- Yu, X., & Cheng, Y. (2019). A change-point analysis procedure based on weighted residuals to detect back random responding. Psychological Methods,24(5), 658–674. 10.1037/met0000212 [DOI] [PubMed] [Google Scholar]
- Yu, X., & Cheng, Y. (2022). A Comprehensive Review and Comparison of CUSUM and Change-Point-Analysis Methods to Detect Test Speededness. Multivariate Behavioral Research,57(1), 112–133. 10.1080/00273171.2020.1809981 [DOI] [PubMed]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.
Data Availability Statement
The example data in the applied data analysis can be found at https://osf.io/fmz74 with additional details on the page https://osf.io/j2s73/.
The materials and code for the simulation study and applied data analysis are available at https://osf.io/jku4d/. The study was not preregistered.