

Abstract
Adapting large-scale pre-trained generative models in a parameter-efficient manner is gaining traction. Traditional methods like low rank adaptation achieve parameter efficiency by imposing constraints but may not be optimal for tasks requiring high representation capacity. We propose a novel spectrum-aware adaptation framework for generative models. Our method adjusts both singular values and their basis vectors of pretrained weights. Using the Kronecker product and efficient Stiefel optimizers, we achieve parameter-efficient adaptation of orthogonal matrices. Specifically, we introduce Spectral Orthogonal Decomposition Adaptation (SODA), which balances computational efficiency and representation capacity. Extensive evaluations on text-to-image diffusion models demonstrate SODA’s effectiveness, offering a spectrum-aware alternative to existing fine-tuning methods.
1. Introduction
Adapting large-scale pre-trained vision generative foundation models, such as Stable Diffusion [5, 10, 36], in a parameter-efficient manner, is increasingly gaining traction within the research community. These generative models, which have demonstrated remarkable capabilities in generating high-quality images, can be computationally intensive and require substantial memory resources. To make these models more accessible and adaptable to various applications [4, 20, 46, 49], researchers are focusing on methods that fine-tune these models efficiently without necessitating retraining the entire network. Parameter-efficient adaptation [8,29,44] not only reduces computational overhead but also enables quicker and more flexible model deployment across different tasks and datasets.
The potential for parameter-efficient fine-tuning has been highlighted through extensive validations, demonstrating the ability to adapt base models to various data, enabling enhancements and customizations tailored to specific tasks and user characteristics. These methods allow the underlying model architecture to remain largely unchanged while inserting or adjusting a small subset of parameters. This approach is advantageous because it preserves the pre-trained knowledge while introducing task-specific adjustments. The lightweight nature of the optimized parameters also facilitates their seamless integration, making it possible to achieve high performance without the computational costs associated with full model retraining.
The efficiency of these methods is generally achieved by introducing structures or constraints into the parameter space. For instance, Low Rank Adaptation (LoRA) [18] constrains parameter changes to be low-rank, while Kronecker Adapter (KronA) [9] constrains weight matrix changes to be a Kronecker product. By imposing these constraints, the adaptation process becomes more manageable and computationally efficient. LoRA, for example, operates under the assumption that the necessary adjustments to the model’s parameters are intrinsically low-dimensional, which simplifies the optimization process. However, this low-rank constraint might not always be optimal, especially for tasks requiring higher representation capacity, as it might limit the model’s ability to capture complex patterns in the data.
Despite the simplicity and effectiveness of LoRA, its low-rank constraint may not be optimal for tasks requiring high representation capacity. Specifically, for a rank approximation of a matrix , the optimal solution corresponds to the largest singular values and their associated singular vectors, which LoRA does not explicitly utilize. This limitation suggests that there are potentially valuable directions in the parameter space, represented by the singular vectors, that are not being exploited. Recognizing this gap, we propose to leverage the full spectral information of the pretrained weight matrices during the fine-tuning process, thereby enhancing the model’s adaptability and performance.
In this paper, we propose a novel approach for spectrum-aware adaptation of generative models. Our method leverages the spectral space of pretrained weights, adjusting both singular values and singular vectors during fine-tuning. By focusing on both the magnitude and direction of these spectral components, we can achieve a more nuanced and effective adaptation. To ensure parameter efficiency, we employ a Kronecker product to rotate the singular vectors, thus modifying both their magnitude and direction. This approach allows us to maintain a balance between computational efficiency and the ability to capture complex data representations, making our method particularly suitable for high-dimensional tasks. Our contributions are as follows:
We propose a fine-tuning framework for personalization of text-to-image diffusion models by utilizing the spectrum of the pretrained parameters.
We introduce SODA, Spectral Orthogonal Decomposition Adaptation, a parameter-efficient formulation of spectrum aware fine-tuning framework for generative models that leverages Kronecker product and jointly adjusts the magnitude and orientation of the parameter’s singular vectors during fine-tuning.
We conduct extensive evaluations for our method on customization of text-to-image diffusion models, and demonstrate it serves as an attractive alternative to traditional parameter-efficient fine-tuning methods that are not spectrum-aware.
2. Related Work
Diffusion personalization.
Diffusion [16,34,36,39,40,43] personalization [12,37] aims to learn or reproduce concepts or subjects using pre-trained diffusion models, given one or a few images. Some works [24, 25, 37] fine-tune the pre-trained diffusion models on images containing the desired concepts or subjects. DreamBooth [37] proposes fine-tuning the entire set of weights to represent the subjects or concepts as unique identifiers, which can be used for synthesizing images of different scenarios or styles. CustomDiffusion [24] suggests that fine-tuning only the cross-attention layers is sufficient to learn new concepts, leading to better performance on multiple-concept compositional generation. Lee et al. propose DCO [25], which fine-tunes the diffusion models without losing the composition ability of the pre-trained models by using implicit reward models. Another line of work [11, 12] focuses on optimizing the word embeddings. Specifically, Textual Inversion [12] proposes optimizing word embeddings to capture unique concepts while freezing the pre-trained diffusion model weights. Additionally, some works [2, 13, 45] combine the optimization of word embeddings and diffusion model weights. However, model fine-tuning methods typically involve a large number of parameters, which can be inefficient and prone to overfitting.
Parameter efficient fine-tuning.
The rapid development of foundation models, which contain a large number of parameters, has made fine-tuning these models on small datasets challenging due to the numerous parameters involved. To address the efficiency and overfitting issues in model fine-tuning, Parameter Efficient Fine-Tuning (PEFT) techniques have been proposed. One line of PEFT research focuses on Adapter tuning [6,19,35], which involves inserting trainable layers within the layers of pre-trained models. Another line of research explores Low-Rank Adaptation (LoRA) [7,15,18,23,50,51]. LoRA [18,38] proposes learning residual weights by constructing them through the multiplication of two low-rank matrices, thereby significantly reducing the number of learned parameters. Other methods have also been developed, such as SVDiff [14], which performs singular value decomposition on the pre-trained weight matrices and only fine-tunes the singular values, and OFT [26,33], which maintains the hyperspherical energy of the pre-trained model by multiplying a trainable orthogonal matrix. Additionally, KronA [9, 28] constructs the residual weight matrices using the Kronecker product of two small-size matrices. However, the aforementioned methods do not fully leverage the prior knowledge embedded in the pre-trained weights. In this work, we enhance existing PEFT methods by introducing Spectral Orthogonal Decomposition Adaptation. While a concurrent study [48] also employs a spectrum-aware approach, it differs from ours as it solely focuses on fine-tuning the top spectral space.
3. Methodology
3.1. Preliminary
Low-Rank Adaptation (LoRA).
Text-to-image diffusion models consist of numerous large pre-trained weights. We follow LoRA’s Stable Diffusion implementation [38] and only fine-tune the linear projection matrices in cross-attention layers, one of which is denoted as . The weight change during the fine-tuning process is denoted as . Low-Rank Adaptation (LoRA) assumes the low rank of the network’s weight increments and decomposes each increment matrix into the product of two low-rank matrices , where and . Therefore, we can derive the following:
| (1) |
where and respectively represent the output and input of .
Orthogonal Fine-Tuning (OFT).
Finetuning diffusion models usually requires efficiency and prior knowledge preservation. To enhance prior knowledge, OFT [33] proposes to retain hyperspherical energy in pairwise relational structure among neurons. In detail, it learns an orthogonal matrix to conduct the same transformation for all neurons in each layer, which keeps the angle among all neurons in each layer unchanged. The weight update is represented by
| (2) |
where is an orthogonal matrix and is the pre-trained weight. To decrease the number of trainable parameters, the original OFT uses a block-diagonal structure to make it parameter efficient, where and each is a small-size orthogonal matrix.
3.2. Optimization on Stiefel Manifold
A Stiefel manifold is the set of matrices with each column orthogonal to all other columns. Consider the optimization problem , which is to find a matrix that minimizes a given objective function subject to the constraint that lies on a Stiefel manifold. This optimization problem has plenty of applications, such as the OFT above. To make sure that the parameter being optimized stays on the Stiefel manifold, the original OFT use Cayley parameterization, where is a skew-symmetric matrix. Then is an orthogonal matrix and OFT only needs to optimize . Here we utilize the Stiefel optimizer introduced in [22], which preserves the manifold structure and keeps momentum in the cotangent space. Given an orthogonal matrix , we can use a Stiefel optimizer to keep it in the Stiefel manifold. However, directly optimizing is not parameter efficient. Here we utilize the following property:
Remark. If are orthogonal matrices, then their Kronecker product is also orthogonal.
Then, the Kronecker product of several small-size orthogonal matrices can generate a relatively large-size orthogonal matrix, so the number of parameters is reduced. Such formulation is more efficient than OFT, we call it Kronecker Orthogonal Fine-Tuning (KOFT). However, it is not always possible to find a Kronecker decomposition for any given orthogonal matrix. Thus, inspired by OFT, we learn a rotation matrix to adjust . Now, since is initialized as identity , we can always parameterize it using Kronecker product, . The shared block diagonal structure as adopted by the original OFT corresponds to . Comparing with ours, this is more sparse. So why do we want to consider optimizing in Stiefel manifold? On the one hand, orthogonal matrices naturally arise in numerical decomposition. On the other hand, previous works [1,3] have shown that imposing orthogonality on model parameters facilitates the learning by limiting the exploding/vanishing gradients and improves the robustness.
3.3. Spectrum Aware Fine-Tuning
LoRA and OFT have shown promising performance in adapting pre-trained models to downstream tasks. However, LoRA neglects the prior knowledge in the pre-trained weights, while OFT only utilizes the angle information among neurons, failing to explore the knowledge in the pre-trained weights fully. To better utilize the spectrum of pre-trained weights, we propose Spectral Orthogonal Decomposition Adaptation (SODA). We first decompose the pre-trained weight matrix in each layer into a spectral component and a basis matrix , formulated as . We then update the spectrum in the spectral component and the basis matrix separately. The spectrum in the spectral component is optimized using a gradient descent optimizer. As the basis matrix is always orthogonal, we could use a Stiefel optimizer to optimize it on the Stiefel manifold. However, directly optimizing would result in a number of trainable parameters as large as full-weight tuning. Considering that both the matrix product and Kronecker product of orthogonal matrices are also orthogonal, we construct an orthogonal matrix , where is a small-size orthogonal matrix. Then our updated weight can be formulated as:
| (3) |
where the parameters with underlin are trainable. denotes the incremental spectrum, where the operator represents the addition of the incremental spectrum to the spectrum in the spectral component matrix . The incremental spectrum is updated using a gradient descent optimizer, while each orthogonal matrix is updated using a Stiefel optimizer, which ensures that the orthogonality constraint is maintained during the optimization process. Here we consider two decomposition methods, SVD and LQ/QR decomposition:
Singular Value Decomposition (SVD).
If we decompose where is singular values and is an orthogonal matrix, SVDiff [14] proposes to fine-tune the singular values, or tuning the spectral shifts ,
| (4) |
We propose to fine-tune the singular vectors as well. However, directly tuning would not be parameter-efficient. We thus leverage Kronecker product ,
| (5) |
with
LQ/QR Decomposition (QR).
We can alternatively decompose , where is a lower triangle matrix and is an orthonormal matrix. Similar to SVD, the diagonal of are eigenvalues of and we propose to fine-tune both and ,
| (6) |
with
3.4. Analysis
Number of parameters.
A comparison of number of tunable parameters for different approaches is shown in Table 1. To simplify notation, here we assume and small rotation blocks are evenly divided ( for OFT, and for SODA). For KOFT and SODA, we can observe that the parameter count decreases drastically as grows (we use in our experiments).
Table 1.
Comparison of Parameter Counts for Different Methods.
| Method | LoRA | OFT | KOFT | SODA |
|---|---|---|---|---|
| Number of params | or (shared) |
Gradient of singular values.
Given a matrix and its singular value decomposition . If we denote the derivative of loss w.r.t. output as , then the gradient of equals to , and
| (7) |
| (8) |
where denotes inner product, and and are the -th column of and , respectively. As can be seen, the gradient of singular values is composed of two parts: a) “from left to right”, the gradient is projected onto columns of ; b) “from right to left”, the input is projected onto columns of and only the -th component influences .
If we consider the change of weight matrix after a small step as , then if we are only tuning singular values , we can compute the effective change of the weight matrix ,
| (9) |
| (10) |
We can observe that
| (11) |
| (12) |
| (13) |
The sign comes from the fact that the Hadamard product masks out non-diagonal elements thus shrinks the Frobenius norm. In fact, since we will mask out most of the elements, tends to be much smaller than and this is why we set a large learning rate to .
4. Experiments
We use Stable Diffusion XL (SDXL) [32] as the pretrained T2I diffusion model. We conduct experiments on subject personalization (Sec. 4.1), style personalization (Sec. 4.1), and ablation studies (Sec. 4.3). In all experiments, following [14, 24] we train the text encoders and UNet of the SDXL model by replacing all linear modules in the attention and cross-attention layers with corresponding PEFT. Detailed experiment settings and configurations can be found in the Appendix B.
4.1. Subject Personalization
Experimental setting.
For Subject Personalization, we fine-tuned the SDXL model on the DreamBooth dataset [37] following the Direct Consistency Optimization (DCO) framework [25]. For a fair comparison, we tuned the best learning rate for each method and tested each method with three different learning rates. This allows us to evaluate their performance comprehensively.
Baselines.
We compared our methods with strong baselines including LoRA [38] and OFT [33]. For a fair comparison and to keep the number of parameters approximately the same, we set rank for LoRA and for KOFT and SODA, i.e., . We will explain this choice of hyperparameter further in Appendix D.
Quantitative results.
We report Image-Text Similarity (↑, using SigLIP [47]) to measure the fidelity and Image Similarity (↑, using DINOv2 [31]) to measure the faithfulness or identity preservation. Detailed information on the evaluation prompts and metrics can be found in Appendix. We plot the Pareto curve consists of scores at varying learning rates. This curve illustrates the trade-off between the fidelity and faithfulness for the evaluated method. The upper right of the curve is ideal, indicating that the method can achieve prompt-aligned compositional generation while preserving the subject’s identity.
Fig. 3 shows comparison of LoRA (★), our methods, SODA-SVD (●) and SODA-QR (▲). Interestingly, LoRA cannot push the frontier to the upper right, indicating that LoRA tends to overfit to the subject and struggles to generate prompt-aligned images while preserving the subject identity. This suggests that jointly adjusting the magnitude and orientation of the decomposed pretrained weight can better utilize model priors when adapting to new concepts without overfitting. Compared to OFT (■), our methods SODA-SVD (●) and SODA-QR (▲) depict the upper-right frontier in both image-text similarity and image similarity, demonstrating their effectiveness. This suggests incorporating spectral tuning can further enhance performance. Interestingly, our methods, SODA-SVD (●) and SODA-QR (▲), overlap with each other, suggesting that tuning has a very similar effect to tuning the diagonal of R.
Figure 3.

Pareto curve between subject fidelity (image similarity) and compositionality (image-text similarity) on subject personalization task of T2I diffusion models. Scores of each point on the curve are measured with different learning rates.
Qualitative results.
In Fig. 4, we provide qualitative comparisons between our approaches (SODA-SVD and SODA-QR) and the baselines (OFT and LoRA). We observe that prompts involving background changes (f) or style changes (g) are handled well by all methods. These prompts are likely easier because they don’t require a deep understanding of the subject; even overfitting can still produce prompt-aligned images. However, for prompts requiring changes in shape (e) or texture (a-d), LoRA struggles with compositional generation due to overfitting the object. Our methods and OFT perform significantly better than LoRA on prompts requiring texture or shape changes. For example, in (a), (c), and (e), our methods demonstrate superior compositional generation. This suggests the benefit of leveraging the spectrum of the pretrained weights, not just adjusting the basis orthogonally. These observations are also supported by the quantitative results discussed above. Interestingly, with objects like dogs (d), LoRA sometimes succeeds in generating good compositional images that changes the subject’s texture. We hypothesize this is because pretrained models have a strong prior for such objects, making it easier for LoRA to find optimization points that represent the object well without overfitting. Moreover, we conduct a human evaluation in Appendix C which further validates the superiority of SODA.
Figure 4.

Results for Subject Personalization. Each subfigure consists of 3 samples: a large one on the left and two smaller ones on the right. The text under the input images indicates the class of the personalized subject, while the text prompt under the sample images is used for inference. Our observations indicate that SODA outperforms both LoRA and OFT in generating prompt-aligned images while preserving subject identities at a similar level.
4.2. Style Personalization
Experimental setting.
For style personalization we experiment on style images from StyleDrop dataset [41], we finetune all peft methods on 10 style reference images and generate comopositional images for the corresponded style. This result is displayed in Fig. 5, And we follow [41] to mix the personalized subject and style model to generate images of a personalized subject in a personalized style. we randomly picked 10 subjects from Dreambooth dataset [37] and merge their residual fine-tuned peft weight with the residual fine-tuned style peft weight . For merging, we use an arithmetic merge (Merge) [41], i.e., , result is displayed in Fig. 8. Other experiment settings follows Sec. 4.1.
Figure 5. Personalized style generation.

We show curated samples of ours (SODA-SVD, SODA-QR), SVDiff [14] (SVD), and LoRA [18]. Independently trained subject and style weights are merged without joint training. SVDiff tends to overfit to the subject and fail to preserve the style well.
Figure 8.

Comparison of my subject in my style.
Baselines.
We compared our methods with LoRA with rank , and SVDiff [14]. For LoRA and SVDiff, we can directly get the merged residual weight by merging the residual weight of the subject personalization model and the style model. For our Methods, we calculate the residual weight by subtracting the fine-tuned SVD or QR weight by the pre-trained weight and merge the residual weight.
Results.
Fig. 5 shows results comparisons between LoRA, SVDiff and Ours (SODA-SVD and SODA-QR). Our methods can generate prompt-aligned images in the reference style, while SVDiff observed over-fit to the images, and LoRA generates artifacts. Fig. 8 shows results of generated images by merging the subject model and the style model. Our models can generate style match images while preserving the identity of the personalized subject. However, SVDiff tends to overfit to the subject and fail to preserve the style well, and lora also overfit to the subject and generate artifact. Additionally, we show novel compositional generation of the combined subject and style in Fig. 6
Figure 6. Compositional generation of my subject in my style.

We show visual samples of my subject in my style with different actions or visual attributes specified by the text prompts. Independently trained subject and style weights are merged without joint training.
4.3. Ablation Study
We also conduct ablation studies on spectral awareness and optimization on Stiefel Manifold to validate our design and choice.
Spectral Awareness.
a) We study the effect of spectral tuning and orthogonal tuning. We select 10 subjects from the DreamBooth dataset [37] and compare our method (SODA-SVD), which combines spectral tuning and orthogonal tuning, and only spectral tuning (SVD), only orthogonal tuning (Kronecker orthogonal Adapter), and a residual version of SODA-SVD. Fig. 7a shows orthogonal only and spectral only have similar performance to each other while ours performs better. b) We also study the choice of spectral tuning method. In Fig. 7b, we compare the performance of spectral tuning using SVD and LQ/QR decomposition. The results demonstrate that SVD spectral tuning slightly outperforms LQ/QR. Fig. 9 visualizes the impact of different output constraint choices (no ReLU, softplus, and ReLU) on SVD spectral tuning. The results show that using ReLU achieves the best performance.
Figure 7.

Ablation studies on spectral awareness and optimization on Stiefel Manifold.
Figure 9.

Results for spectral tuning on SVD.
Optimization on the Stiefel manifold.
We conduct ablations on different optimization methods on the Stiefel Manifold. We compare the original OFT, KOFT (OFT with Kronecker product), KOFT-Cayley (OFT with Kronecker product and Cayley parameterization), and OFT-Stiefel (OFT with Stiefel optimizer). From Fig. 7c, we observe that the Stiefel optimizer [22] outperforms the other methods when using a small learning rate, while the other methods perform similarly to each other. This demonstrates that the Stiefel optimizer can achieve comparable performance to Cayley parameterization, with the added flexibility of allowing a non-square matrix. Furthermore, the Stiefel optimizer exhibits greater robustness, as it achieves better performance with smaller learning rates compared to the other methods and achieves comparable performance with larger learning rates.
5. Conclusion and Discussion
In this paper, we first identify the limitations of previous PEFT methods, which are not designed to fully utilize the prior knowledge in the pre-trained weights. To address this issue, we propose spectrum-aware parameter-efficient fine-tuning, a novel approach that leverages the spectrum of the pre-trained parameters. Specifically, we introduce Spectral Orthogonal Decomposition Adaptation (SODA), which jointly performs spectral and orthogonal tuning. Experiments on diffusion personalization demonstrate that our method outperforms previous PEFT methods. Furthermore, ablation studies validate the effectiveness of the individual components of our proposed SODA approach.
Figure 1.
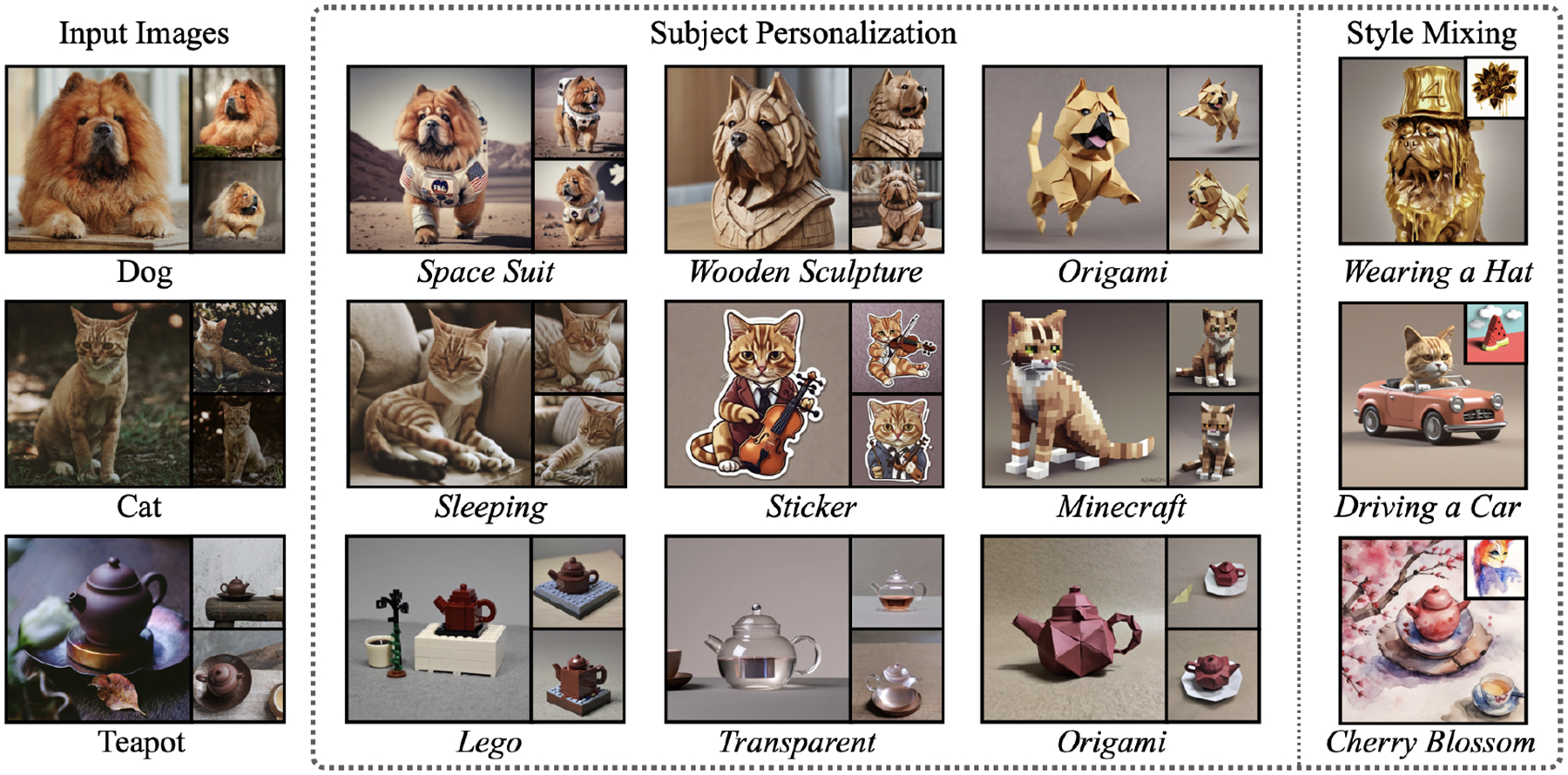
SODA achieves superior image quality and text alignment across diverse input images and prompts, such as changing the background, altering the texture, and synthesizing new poses. Additionally, SODA can generate prompt-aligned images in a given style specified by an input style image.
Figure 2.

Comparison of difference PEFT approaches. (■: frozen parameters; ■: tunable parameters; ■: zeros.)
Acknowledgement:
Research partially funded by research grants to Metaxas from NSF: 2310966, 2235405, 2212301, 2003874, 1951890, AFOSR 23RT0630 and NIH 2R01HL127661.
Appendix
A. Derivations
Remark. If are orthogonal matrices, then their Kronecker product is also orthogonal.
Proof. Without loss of generality, let’s assume and .
We begin by verify is orthogonal,
| (14) |
| (15) |
| (16) |
| (17) |
| (18) |
When both and are square matrices, similarly, we have . Also, the determinant .
The final result can be obtained by iteratively applying the above.
Derivation of gradient of gradients:
Gradient of singular values.
We have and . Then
| (19) |
| (20) |
| (21) |
| (22) |
| (23) |
| (24) |
| (25) |
Thus . Here means staking the rows of a matrix.
Frobenius norm of weight change.
| (26) |
| (27) |
| (28) |
| (29) |
| (30) |
| (31) |
| (32) |
| (33) |
| (34) |
B. Implementation Details
B.1. Dataset
For Subject Personalization, we fine-tuned the SDXL model on the DreamBooth dataset [37] following the Direct Consistency Optimization (DCO) framework [25]. The SDXL model was fine-tuned on 30 subjects, with each subject having 3–5 images and corresponding comprehensive captions generated by GPT-4 [30]. The model was trained with all PEFT methods for 1000 steps with a batch size of 1. For evaluation, we sampled 16 images for 10 prompts per subject. Seven of these prompts were designed to alter the texture of the original subject, such as “a [] [berry_bowl] made of lego.” These prompts were chosen because we observe that they present a significant challenge for personalization, requiring the fine-tuned model to learn new concepts without overfitting the subject.
Examples of input images and their corresponding captions generated by GPT-4 is provided in Fig. 10. And we use “pll” as the placeholder [] during subject personalization (e.g., An outdoor shot of a [] dog on a sandy path with green trees and a pond in the background.).
For style personalization, we fine-tuned the SDXL model on the Styledrop dataset [41], with a single reference image for 10 different styles.
B.2. Hyperparameters
Figure 12.

Parameters numbers for different methods
Budget.
We conducted all our experiments on a single GPU (e.g., A100) using a batch size of 1. We fine-tuned all the methods with 1000 optimization steps and evaluated each methods at this iteration count. To ensure fair comparisons, we hardcoded the architecture of OFT (shared orthogonal blocks) and our methods (with the orthogonal matrix constructed by the Kronecker Product of 3 small matrices). The parameter numbers for each method are detailed in Fig. 12.
Experiment Details.
In all experiments, we train each method for 1,000 steps with a batch size of 1 on a single A100 GPU. With all the training without orthogonal requirements, we use the AdamW [27] optimizer. For fair comparisons between experiments that require orthogonality, we use Adam Optimizer [21] for OFT and Stiefel optimizer [22] for our methods. For the DCO loss [25], we use . For SODA-SVD and SODA-QR, we found that they typically perform well when using the Stiefel optimizer with a learning rate of 5e-4, and a learning rate of 5e-3 for the AdamW optimizer. In both SODA methods, we simultaneously optimize the model using the Stiefel optimizer and the AdamW optimizer. For sampling, we use DDIM [42] scheduler with 50 steps, and use CFG guidance scale of 7.5 throughout experiments.
Figure 10.

Results for Examples of comprehensive captions generated by GPT-4. The class tokens are marked in bold (e.g., dog, duck_toy, monster_toy).
Figure 11.

Number of parameters for different methods.
Computation Efficiency.
Decomposing all the weight matrices in the linear modules replaced by SODA takes 2–3 minutes. However, this is a one-time computation that can be cached, as the initial weights of SDXL remain constant. In comparison, LoRA [18] and SVDiff [14] require approximately 10 minutes to train, while SODA and OFT [33] take around 20 minutes. Notably, there is no difference in inference time across all methods
Evaluation metric.
Following [25], we utilize the DINOV2 score [31], which is calculated as the mean cosine similarity between the embeddings of the reference and synthesized images. Additionally, we apply SigLip [47] to measure image-text similarity, which is defined as:
where and represent the normalized embeddings from the image and text encoders, respectively, and is a bias term optimized during pretraining.
Other Implementation Details.
While we adopt the DCO framework [25] in all our experiments, we identified and corrected a bug in their implementation. The correct DCO loss is defined as:
where represents the optimizing model and is the original pretrained model. In the original DCO implementation, they mistakenly used the optimizing model for . We have corrected this in our implementation.
C. Human Evaluation
Table 2.
Human preferences on image- and text-alignment.
| Learning Rate | SODA-SVD | OFT | LoRA |
|---|---|---|---|
| Large | 0.63 | 0.30 | 0.07 |
| Mid | 0.62 | 0.31 | 0.07 |
| Small | 0.80 | 0.17 | 0.03 |
Figure 13.

Example image for human evaluation.
Settings.
We conducted a structured human evaluation for the subject personalization task across three methods—LoRA, OFT, and SODA—involving 50 participants. For each method, we trained the models at three different learning rates in the subject personalization experiment (Section 4.1). After training, we randomly sampled one image generated from 10 unique text prompts, resulting in 300 learning rate-subject-prompt combinations. Participants were then asked to select the best image based on two criteria: which image best preserved the original identity of the subject (image alignment) or which best matched the given text description (text alignment). A sample of the evaluation question sample is provided in Fig. 13.
Results.
The results are presented in Tab. 2, showing the proportion of participants who selected each method based on image alignment and text alignment. It is evident that SODA is consistently preferred across all learning rates, indicating its robustness in generating both image-aligned and text-aligned outputs.
D. Additional Experiments
Table 3.
Performance comparison of SODA for different values of .
| Metric | |||
|---|---|---|---|
| Image-Text Similarity | 0.668 | 0.670 | 0.653 |
| Image Similarity | 0.548 | 0.549 | 0.550 |
D.1. Different for SODA
In Tab. 3, we present the performance of SODA in terms of image similarity and image-text similarity across different values of . Our experiments showed that varying did not significantly impact performance. However, increasing improved parameter efficiency, as the number of SODA parameters is (Tab. 1). We selected for our experiments, as it provided a good balance of performance and parameter efficiency, allowing us to match the number of parameters in SVDiff and ensure a fair comparison.
Table 4.
Performance comparison across methods with higher parameter counts.
| Metric | LoRA (rank=16) | Adapter (reduction factor=20) | OFT | SVD | SODA-SVD |
|---|---|---|---|---|---|
| Image-Text Similarity | 0.604 | 0.647 | 0.720 | 0.718 | 0.761 |
| Image Similarity | 0.546 | 0.530 | 0.519 | 0.526 | 0.520 |
Table 5.
Performance comparison across methods with lower parameter counts.
| Metric | LoRA (rank=1) | Adapter (reduction factor=300) | OFT | SVD | SODA-SVD |
|---|---|---|---|---|---|
| Image-Text Similarity | 0.564 | 0.542 | 0.719 | 0.718 | 0.726 |
| Image Similarity | 0.511 | 0.591 | 0.520 | 0.526 | 0.532 |
D.2. Adapter [17] Comparison
We conducted experiments using Adapter [17], an important PEFT baseline, for the subject personalization task. We compared all methods in two settings, differing only in parameter numbers of the PEFT modules—one similar to LoRA with rank=1 and the other with rank=16, except for SVD, which has a fixed parameter count. As shown in Tab. 4,5, SODA demonstrates superior compositional ability while preserving subject identity. In contrast, LoRA and Adapter perform comparably in maintaining subject identity but show weaker compositional performance, likely due to their limited use of spectral information. These methods tend to overfit both the object and background, reducing their effectiveness in complex compositional tasks, which is expected since LoRA functions as an adapter applied after all linear modules rather than directly after attention.
E. Additional Visual Results
We show additional visual results in Fig. 14 15 16 17.
Figure 14.

Results of Our Methods for the subject fancy_boot.
Figure 15.

Results of Our Methods for the subject monster_toy.
Figure 16.

Results of Our Methods for the subject cat.
Figure 17.

Results of Our Methods for the subject dog.
References
- [1].Achour El Mehdi, Malgouyres François, and Mamalet Franck. Existence, stability and scalability of orthogonal convolutional neural networks. Journal of Machine Learning Research, 23(347):1–56, 2022. [Google Scholar]
- [2].Avrahami Omri, Aberman Kfir, Fried Ohad, Cohen-Or Daniel, and Lischinski Dani. Break-a-scene: Extracting multiple concepts from a single image. In SIGGRAPH Asia 2023 Conference Papers, pages 1–12, 2023. [Google Scholar]
- [3].Bansal Nitin, Chen Xiaohan, and Wang Zhangyang. Can we gain more from orthogonality regularizations in training deep networks? Advances in Neural Information Processing Systems, 31, 2018. [Google Scholar]
- [4].Black Kevin, Janner Michael, Du Yilun, Kostrikov Ilya, and Levine Sergey. Training diffusion models with reinforcement learning. In ICML 2023 Workshop on Structured Probabilistic Inference {∖&} Generative Modeling, 2023. [Google Scholar]
- [5].Blattmann Andreas, Dockhorn Tim, Kulal Sumith, Mendelevitch Daniel, Kilian Maciej, Lorenz Dominik, Levi Yam, English Zion, Voleti Vikram, Letts Adam, et al. Stable video diffusion: Scaling latent video diffusion models to large datasets. arXiv preprint arXiv:2311.15127, 2023. [Google Scholar]
- [6].Chen Shoufa, Ge Chongjian, Tong Zhan, Wang Jiangliu, Song Yibing, Wang Jue, and Luo Ping. Adaptformer: Adapting vision transformers for scalable visual recognition. Advances in Neural Information Processing Systems, 35:16664–16678, 2022. [Google Scholar]
- [7].Dettmers Tim, Pagnoni Artidoro, Holtzman Ari, and Zettlemoyer Luke. Qlora: Efficient finetuning of quantized llms. Advances in Neural Information Processing Systems, 36, 2024. [Google Scholar]
- [8].Ding Ning, Qin Yujia, Yang Guang, Wei Fuchao, Yang Zonghan, Su Yusheng, Hu Shengding, Chen Yulin, Chan Chi-Min, Chen Weize, et al. Parameter-efficient fine-tuning of large-scale pre-trained language models. Nature Machine Intelligence, 5(3):220–235, 2023. [Google Scholar]
- [9].Edalati Ali, Tahaei Marzieh, Kobyzev Ivan, Partovi Nia Vahid, Clark James J, and Rezagholizadeh Mehdi. Krona: Parameter efficient tuning with kronecker adapter. arXiv preprint arXiv:2212.10650, 2022. [Google Scholar]
- [10].Esser Patrick, Kulal Sumith, Blattmann Andreas, Entezari Rahim, Müller Jonas, Saini Harry, Levi Yam, Lorenz Dominik, Sauer Axel, Boesel Frederic, et al. Scaling rectified flow transformers for high-resolution image synthesis. arXiv preprint arXiv:2403.03206, 2024. [Google Scholar]
- [11].Fei Zhengcong, Fan Mingyuan, and Huang Junshi. Gradient-free textual inversion. In Proceedings of the 31st ACM International Conference on Multimedia, pages 1364–1373, 2023. [Google Scholar]
- [12].Gal Rinon, Alaluf Yuval, Atzmon Yuval, Patashnik Or, Bermano Amit Haim, Chechik Gal, and Cohen-or Daniel. An image is worth one word: Personalizing text-to-image generation using textual inversion. In The Eleventh International Conference on Learning Representations, 2022. [Google Scholar]
- [13].Gal Rinon, Arar Moab, Atzmon Yuval, Bermano Amit H, Chechik Gal, and Cohen-Or Daniel. Encoder-based domain tuning for fast personalization of text-to-image models. ACM Transactions on Graphics (TOG), 42(4):1–13, 2023. [Google Scholar]
- [14].Han Ligong, Li Yinxiao, Zhang Han, Milanfar Peyman, Metaxas Dimitris, and Yang Feng. Svdiff: Compact parameter space for diffusion fine-tuning. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 7323–7334, 2023. [Google Scholar]
- [15].Hayou Soufiane, Ghosh Nikhil, and Yu Bin. Lora+: Efficient low rank adaptation of large models. arXiv preprint arXiv:2402.12354, 2024. [Google Scholar]
- [16].Ho Jonathan, Jain Ajay, and Abbeel Pieter. Denoising diffusion probabilistic models. Advances in Neural Information Processing Systems, 33:6840–6851, 2020. [Google Scholar]
- [17].Houlsby Neil, Giurgiu Andrei, Jastrzebski Stanislaw, Morrone Bruna, De Laroussilhe Quentin, Gesmundo Andrea, Attariyan Mona, and Gelly Sylvain. Parameter-efficient transfer learning for nlp. In International conference on machine learning, pages 2790–2799. PMLR, 2019. [Google Scholar]
- [18].Edward J Hu, Wallis Phillip, Allen-Zhu Zeyuan, Li Yuanzhi, Wang Shean, Wang Lu, Chen Weizhu, et al. Lora: Low-rank adaptation of large language models. In International Conference on Learning Representations, 2021. [Google Scholar]
- [19].Hu Zhiqiang, Wang Lei, Lan Yihuai, Xu Wanyu, Lim Ee-Peng, Bing Lidong, Xu Xing, Poria Soujanya, and Lee Roy Ka-Wei. Llm-adapters: An adapter family for parameter-efficient fine-tuning of large language models. In The 2023 Conference on Empirical Methods in Natural Language Processing, 2023. [Google Scholar]
- [20].Kawar Bahjat, Zada Shiran, Lang Oran, Tov Omer, Chang Huiwen, Dekel Tali, Mosseri Inbar, and Irani Michal. Imagic: Text-based real image editing with diffusion models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 6007–6017, 2023. [Google Scholar]
- [21].Kingma Diederik P. and Ba Jimmy. Adam: A method for stochastic optimization, 2017. [Google Scholar]
- [22].Kong Lingkai, Wang Yuqing, and Tao Molei. Momentum stiefel optimizer, with applications to suitably-orthogonal attention, and optimal transport. In The Eleventh International Conference on Learning Representations, 2022. [Google Scholar]
- [23].Kopiczko Dawid Jan, Blankevoort Tijmen, and Asano Yuki Markus. Vera: Vector-based random matrix adaptation. arXiv preprint arXiv:2310.11454, 2023. [Google Scholar]
- [24].Kumari Nupur, Zhang Bingliang, Zhang Richard, Shechtman Eli, and Zhu Jun-Yan. Multi-concept customization of text-to-image diffusion. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 1931–1941, 2023. [Google Scholar]
- [25].Lee Kyungmin, Kwak Sangkyung, Sohn Kihyuk, and Shin Jinwoo. Direct consistency optimization for compositional text-to-image personalization, 2024.
- [26].Liu Weiyang, Qiu Zeju, Feng Yao, Xiu Yuliang, Xue Yuxuan, Yu Longhui, Feng Haiwen, Liu Zhen, Heo Juyeon, Peng Songyou, et al. Parameter-efficient orthogonal finetuning via butterfly factorization. In The Twelfth International Conference on Learning Representations, 2023. [Google Scholar]
- [27].Loshchilov Ilya and Hutter Frank. Decoupled weight decay regularization, 2019.
- [28].Marjit Shyam, Singh Harshit, Mathur Nityanand, Paul Sayak, Yu Chia-Mu, and Chen Pin-Yu. Diffusekrona: A parameter efficient fine-tuning method for personalized diffusion model. arXiv preprint arXiv:2402.17412, 2024. [Google Scholar]
- [29].Mou Chong, Wang Xintao, Xie Liangbin, Wu Yanze, Zhang Jian, Qi Zhongang, and Shan Ying. T2i-adapter: Learning adapters to dig out more controllable ability for text-to-image diffusion models. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 38, pages 4296–4304, 2024. [Google Scholar]
- [30].OpenAI. Gpt-4 technical report, 2024.
- [31].Oquab Maxime, Darcet Timothée, Moutakanni Théo, Vo Huy, Szafraniec Marc, Khalidov Vasil, Fernandez Pierre, Haziza Daniel, Massa Francisco, El-Nouby Alaaeldin, et al. Dinov2: Learning robust visual features without supervision. arXiv preprint arXiv:2304.07193, 2023. [Google Scholar]
- [32].Podell Dustin, English Zion, Lacey Kyle, Blattmann Andreas, Dockhorn Tim, Müller Jonas, Penna Joe, and Rombach Robin. Sdxl: Improving latent diffusion models for high-resolution image synthesis, 2023.
- [33].Qiu Zeju, Liu Weiyang, Feng Haiwen, Xue Yuxuan, Feng Yao, Liu Zhen, Zhang Dan, Weller Adrian, and Schölkopf Bernhard. Controlling text-to-image diffusion by orthogonal finetuning. Advances in Neural Information Processing Systems, 36:79320–79362, 2023. [Google Scholar]
- [34].Ramesh Aditya, Dhariwal Prafulla, Nichol Alex, Chu Casey, and Chen Mark. Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:2204.06125, 2022. [Google Scholar]
- [35].Rebuffi Sylvestre-Alvise, Bilen Hakan, and Vedaldi Andrea. Learning multiple visual domains with residual adapters. Advances in neural information processing systems, 30, 2017. [Google Scholar]
- [36].Rombach Robin, Blattmann Andreas, Lorenz Dominik, Esser Patrick, and Ommer Björn. High-resolution image synthesis with latent diffusion models. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 10684–10695, 2022. [Google Scholar]
- [37].Ruiz Nataniel, Li Yuanzhen, Jampani Varun, Pritch Yael, Rubinstein Michael, and Aberman Kfir. Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation, 2023.
- [38].Ryu Simo. Low-rank adaptation for fast text-to-image diffusion fine-tuning. https://github.com/cloneofsimo/lora.
- [39].Saharia Chitwan, Chan William, Saxena Saurabh, Li Lala, Whang Jay, Denton Emily, Seyed Ghasemipour Seyed Kamyar, Karagol Ayan Burcu, Mahdavi S Sara, Gontijo Lopes Rapha, et al. Photorealistic text-to-image diffusion models with deep language understanding. arXiv preprint arXiv:2205.11487, 2022. [Google Scholar]
- [40].Sohl-Dickstein Jascha, Weiss Eric, Maheswaranathan Niru, and Ganguli Surya. Deep unsupervised learning using nonequilibrium thermodynamics. In International Conference on Machine Learning, pages 2256–2265. PMLR, 2015. [Google Scholar]
- [41].Sohn Kihyuk, Jiang Lu, Barber Jarred, Lee Kimin, Ruiz Nataniel, Krishnan Dilip, Chang Huiwen, Li Yuanzhen, Essa Irfan, Rubinstein Michael, et al. Styledrop: Text-to-image synthesis of any style. Advances in Neural Information Processing Systems, 36, 2024. [Google Scholar]
- [42].Song Jiaming, Meng Chenlin, and Ermon Stefano. Denoising diffusion implicit models. In International Conference on Learning Representations, 2021. [Google Scholar]
- [43].Song Yang, Sohl-Dickstein Jascha, Kingma Diederik P, Kumar Abhishek, Ermon Stefano, and Poole Ben. Score-based generative modeling through stochastic differential equations. arXiv preprint arXiv:2011.13456, 2020. [Google Scholar]
- [44].Sun Mingjie, Liu Zhuang, Bair Anna, and Kolter J Zico. A simple and effective pruning approach for large language models. In The Twelfth International Conference on Learning Representations, 2023. [Google Scholar]
- [45].Wei Yuxiang, Zhang Yabo, Ji Zhilong, Bai Jinfeng, Zhang Lei, and Zuo Wangmeng. Elite: Encoding visual concepts into textual embeddings for customized text-to-image generation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 15943–15953, 2023. [Google Scholar]
- [46].Xue Zeyue, Song Guanglu, Guo Qiushan, Liu Boxiao, Zong Zhuofan, Liu Yu, and Luo Ping. Raphael: Text-to-image generation via large mixture of diffusion paths. Advances in Neural Information Processing Systems, 36, 2024. [Google Scholar]
- [47].Zhai Xiaohua, Mustafa Basil, Kolesnikov Alexander, and Beyer Lucas. Sigmoid loss for language image pre-training. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 11975–11986, 2023. [Google Scholar]
- [48].Zhang Fangzhao and Pilanci Mert. Spectral adapter: Finetuning in spectral space. arXiv preprint arXiv:2405.13952, 2024. [Google Scholar]
- [49].Zhang Lvmin, Rao Anyi, and Agrawala Maneesh. Adding conditional control to text-to-image diffusion models. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 3836–3847, October 2023. [Google Scholar]
- [50].Zhang Qingru, Chen Minshuo, Bukharin Alexander, He Pengcheng, Cheng Yu, Chen Weizhu, and Zhao Tuo. Adaptive budget allocation for parameter-efficient finetuning. In The Eleventh International Conference on Learning Representations, 2023. [Google Scholar]
- [51].Zhu Jiacheng, Greenewald Kristjan, Nadjahi Kimia, Sáez de Ocáriz Borde Haitz, Gabrielsson Rickard Brüel, Choshen Leshem, Ghassemi Marzyeh, Yurochkin Mikhail, and Solomon Justin. Asymmetry in low-rank adapters of foundation models. arXiv preprint arXiv:2402.16842, 2024. [Google Scholar]