

Abstract
Many biological systems perform close to their physical limits, but promoting this optimality to a general principle seems to require implausibly fine tuning of parameters. Using examples from a wide range of systems, we show that this intuition is wrong. Near an optimum, functional performance depends on parameters in a “sloppy” way, with some combinations of parameters being only weakly constrained. Absent any other constraints, this predicts that we should observe widely varying parameters, and we make this precise: the entropy in parameter space can be extensive even if performance on average is very close to optimal. This removes a major objection to optimization as a general principle, and rationalizes the observed variability.
Humans can count single photons on a dark night [1], insects see the world with a resolution close to the limits set by diffraction through the lenses of the compound eye [2, 3], and bacteria navigate chemical gradients with a precision limited by random arrival of molecules at their surface receptors [4]. In these and other examples, living systems approach fundamental physical limits to their performance, and in this sense are close to optimal. In many different contexts it has been suggested that this sort of optimization should be elevated to a principle from which the behavior and underlying mechanisms of these complex systems can be derived [5, 6]. In contrast, others have argued that evolution cannot find optimal solutions, and emphasize examples in which the assignment of complex structures and mechanisms to functional behavior is misleading [7]. One important observation is that the parameters of biological systems, from the copy numbers of proteins in single cells to the strengths of synapses between neurons, can be highly variable [8–10], and this seems to be direct evidence against the idea that these parameters have been tuned to optimal values.
Intuitions about the ability of evolution to find optima and about the significance of parameter variations both depend on hypotheses about the landscape for optimization. If optima are small, sharply defined regions in a rugged terrain [11, 12], then plausible dynamics for the exploration of high dimensional parameter spaces are unlikely to find the optimum; similarly, even small variations in parameters would drive the system far from optimality. We will see that this picture of the landscape is wrong in many cases. Instead, the dependence of functional performance on the underlying parameters is very gentle or “soft,” so that at least some combinations of parameters can vary substantially with very little effect. As a result, many of the arguments against optimization lose their force. In particular, in the absence of any other constraints, a theory of systems that are very close to optimal predicts that we should observe widely varying parameters. We try to make this precise, exploring several different biological systems as well as biologically inspired model neural networks.
Our analysis is inspired in part by the idea of sloppy models [13]. When we fit multi–parameter models to the observed behavior of complex systems, we often find that some combinations of parameters are determined precisely, and others are not [14, 15]. Sethna and colleagues have argued that this is generic [16]; that the smoothness of models implies that the sensitivity to parameters is distributed more or less uniformly on a logarithmic scale, so that the fit is orders of magnitude more sensitive to some combinations of parameters than to others [17]; and that this behavior provides a path to model simplification [18].
To address the issue of optimization in living systems, we consider not the quality of a model’s fit to data, but the functional performance of the organism at some task essential for its survival. The parameters are not something we choose, but rather the physical properties of the organism’s internal mechanisms—concentrations of molecules, binding constants, positions of cells, strengths of synapses—that are adjusted through adaptation, learning, and evolution. Sloppiness or the existence of soft modes then means that organisms can be very close to optimal performance while its physical properties can vary along many dimensions.
It is tempting to think that soft modes appear just because there are many parameters feeding in to a single functional output, so that there is a kind of redundancy. While this plays a role, we will see that soft modes appear in addition to any true redundancies. We also will see that these modes emerge in part from the structure of the problem that needs to be solved by the biological system rather than being generic features of the underlying mechanisms.
In analyzing complex models, sloppiness suggests a path to simplification. Similarly, it might seem that mechanisms with parameters that have little effect on functional performance are somehow inefficient, but this notion of parameter efficiency then is something we should have added to the performance measure from the start. We also will see that soft modes in parameter space generally are not aligned with the microscopic components; for example, sloppiness of a genetic network crucial for fly development does not mean that we can knock out genes and maintain the same level of functional performance, even after readjustment of all other parameters [19]. These and other considerations mean that soft modes or sloppiness have consequences for the organism, not just for our models.
Evolution, learning, and adaptation allow organisms to explore their parameter spaces. A natural hypothesis is that this exploration ranges as widely as possible while maintaining, on average, some high level of performance. Our results on the spectrum of soft modes allows us to turn this hypothesis into quantitative predictions about observable variations in parameters, especially in the limit that parameter spaces are very high–dimensional. Quantitatively, we argue that the entropy of the allowed variations in parameter space can be extensive even if performance is on average arbitrarily close to optimal. Thus variability is not a retreat from optimization to a weaker notion of being “good enough;” rather it is a feature of these systems that optimization and variability coexist.
FORMULATING THE PROBLEM
In different biological systems, the relevant measure of functional performance is different. If we can think about the organism as a whole in the context of evolution, then by definition the relevant measure is fitness. In many cases we want to think more explicitly about particular systems within the organism to which we can ascribe less abstract goals. In a neural circuit that generates a rhythm what might be important is the frequency of the rhythm; in a developing embryo what might matter is the ability of cells to adopt fates that are appropriate to their positions; for an array of receptor cells the measure of performance might be the amount of sensory information that these cells can capture from the outside world. In the same spirit, the underlying parameters of different systems are different. The dynamics of a neural circuit are determined by the number of each different kind of ion channel in each cell and by the strengths of the synapses between cells; the ability of a genetic network to read out positional information in the embryo is determined in part by the thresholds at which different genes are activated or repressed; the information gathered by receptor arrays depends on the positions of the cells in the sensory epithelium. We want to address these different problems in a common language.
We will write the measure of functional performance as , where larger means better performance. We write the parameters of the underlying mechanism in a vector , where the number of parameters may be quite large. There is some function that determines how performance depends on parameters, and there is some parameter setting that maximizes performance. In the neighborhood of the optimum we can write
| (1) |
where the Hessian matrix
| (2) |
The eigenvectors of the Hessian define combinations of parameters that have independent effects on the performance, and the corresponding eigenvalues measure the strength of these effects. If we think of the (negative) performance as an energy function then the eigenvalues measure the stiffness of springs that hold the parameters to their optimal setting; small eigenvalues correspond to soft springs. Our goal is to understand the spectrum of spring constants that arise in different systems, using the examples summarized in Table I.
TABLE I:
Summary of the systems used to explore how optimizing a performance function, which we can think of as a surrogate for fitness, impacts variation in system parameters. Each of the five examples show variation near their optima, but in different ways across a wide range of problems and solutions.
| system | performance | parameters |
|---|---|---|
| photoreceptor array | information about visual input | receptor positions |
| transcription factors in fly embryo | positional information | readout thresholds |
| small neural circuit (STG) | match to desired period or duty cycle | channel protein copy numbers |
| recurrent neural network | match to desired filter | synaptic strengths |
| deep artificial network | image classification performance | synaptic strengths |
SAMPLING THE VISUAL WORLD
The lenses of the insect compound eye have a nearly crystalline arrangement, as seen in Fig 1A, and this structure is repeated through several layers of visual processing circuitry [20]. It is an old idea that this structure optimizes the image forming or information gathering capacity of the eye [2, 3]. More generally, we expect that regular sampling will maximize the capture of information, which suggests that the retinae of humans and other vertebrates—with rather random packing of photoreceptor cells, as in Fig 1B [21–24] —must be far from optimal. Perhaps surprisingly, this is not true.
FIG. 1:
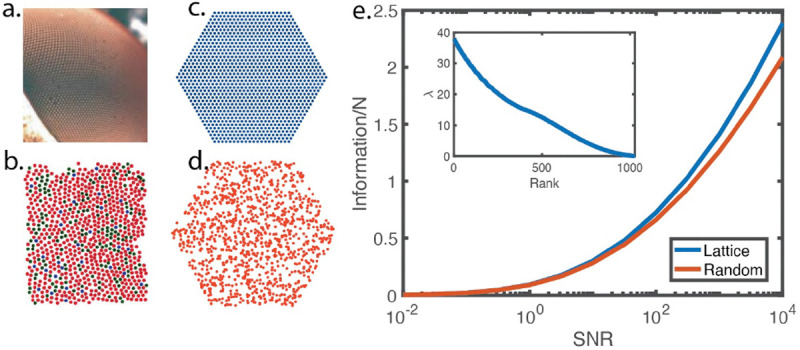
Sampling the visual world. (a) A segment of the fly’s eye showing the regular lattice of lenses, which is echoed by a regular lattice of receptors and processing circuitry [25]. (b) Photoreceptor array in a human retina, with cells colored by their spectral sensitivity; note the more random arrangement [21]. (c) Array of receptors on a regular lattice. (d) The same number of receptors scattered at random. (e) Functional performance—here, information per cell—from Eqs (5, 6), as a function of the signal–to–noise ratio for individual cells in the regular (blue) or random (red) arrangements. The range of SNR is chosen to match estimates for human cones in moderate daylight [26]. Inset shows the spectrum of eigenvalues of the Hessian of the functional performance, from Eq (2).
In this problem, we will take the functional measure of performance to be the information that the array of receptor responses convey about the visual input, normalized by the number of cells, so that . The parameters are the positions of the cells on the retina, , so the dimensionality of the parameter space . To calculate we need to describe the statistics of the visual input and the nature of cells’ responses. As explained in Box 1, we assume that receptors respond linearly to the light intensity as seen through an optical blurring function, and that input images are described by the power spectrum of spatial fluctuations in contrast measured in natural scenes [26].
Box 1: Information in a receptor array.
The retina samples the image intensity or contrast , which varies across position , with receptors centered at locations . This sampling involves local spatial averaging, at a minimum from the optics of the eye’s lens(es), and the receptor response will be noisy, so we can write
| (3) |
For simplicity we will assume that both signal and noise are Gaussian, with the noise independent in each receptor, , and the image statistics described by their power spectrum . Measurements on natural scenes show that the spectrum is scale invariant [26], with
| (4) |
and . We treat the spatial averaging as Gaussian, , and assume that the width of this blur is matched to the overall density of receptors . In this setting we find that the mutual information between the set of responses and the image is
| (5) |
and the matrix has elements
| (6) |
where is a Bessel function and . We can choose as the unit of distance, so the only free parameter is a dimensionless signal–to–noise ratio . A natural performance measure is the information per receptor cell, .
In Figure 1 we see an array of receptors arranged in a regular lattice (Fig 1C) or completely at random (Fig 1D) across the same area. The resulting information per cell is shown as a function of SNR in Fig 1E. The lattice solution outperforms all random solutions; however, it does so only narrowly across all signal–to–noise ratios. This implies that the space of near-optimal retinal arrays is enormous and is on a scale similar to the entire volume of the configuration space.
Figure 1E provides a global view of the space available for parameter variation with rather small changes in the functional performance of the system. We can give a local analysis, computing the Hessian as in Eq (2), with the spectrum of eigenvalues shown in the inset to Fig 1E, around the optimal crystalline arrangement. The eigenvectors of the Hessian are waves of receptor displacements across the array, as expected from translation invariance with corrections for the boundaries. The eigenvalues scale roughly as for long wavelengths , giving a finite density of soft modes, close to , for parameter variation. This means that performance is only a weakly varying function of the parameters, consistent with the result in Fig 1E that even random parameter choices are not so far from optimal.
These results allow us to understand how the human retina can provide near optimal gathering of visual information while being disordered, allowing different instantiations of disorder in different individuals. In this precise sense, optimality and variability can coexist. In the compound eye, the size of the lens is the distance between receptors; formally this would be described in Eq (3) by having a different blurring function for each cell, with a width related to the distances to neighboring cells. But changing the size of the lens has a large effect on the degree of blur at each point in the retina [2, 3], so that disorder in the receptor lattice would drive each lens away from its optimal size. Because of these local constraints on the optics, optimality and variability cannot coexist in compound eyes the way they do in vertebrate eyes, and correspondingly we see near crystalline structures.
INFORMATION AND TRANSCRIPTIONAL REGULATION
Levels of gene expression provide information about variables relevant in the life of the organism. In a developing embryo, for example, it is an old idea that concentrations of crucial “morphogen” molecules carry information about position, driving cell fate decisions that are appropriate to their locations [27], and this can be made precise [28–30]. In the fruit fly all of the relevant molecules have been identified [31, 32], and the concentrations of just four “gap gene” products are sufficient to determine position with an accuracy of ~ 1%, comparable to the precision of downstream events [28, 33].
There is a classical view of gap gene expression as occurring in domains that are essentially on or off [34]. If we interpret the expression levels in this way, as binary variables, then much of the information about position is lost, which means that cells must “measure” intermediate levels [28]. But any realistic mechanism for cells to respond to gap gene expression will be noisy. This points to an optimization problem: Given a limited capacity to measure the concentrations of the relevant molecules, how can cells use this capacity to best capture information about position [35, 36]?
We can think of a limited capacity as being equivalent to discretization, mapping continuous gene expression values into a small set of alternatives . The functional performance measure is the information that this discrete variable provides about a cell’s position in the embryo, , and the parameters are the locations of the thresholds or boundaries that define these discrete alternatives. Importantly, if we have enough samples from the joint distribution of and then we can compute directly from data. In Figure 2 we do this for the genes hunchback and Krüppel in the early fruit fly embryo; for this pair of genes we know that this simple discretization is a very good approximation to a more general problem of preserving positional information through limited capacity measurements of the gene expression levels (Box 2).
FIG. 2:
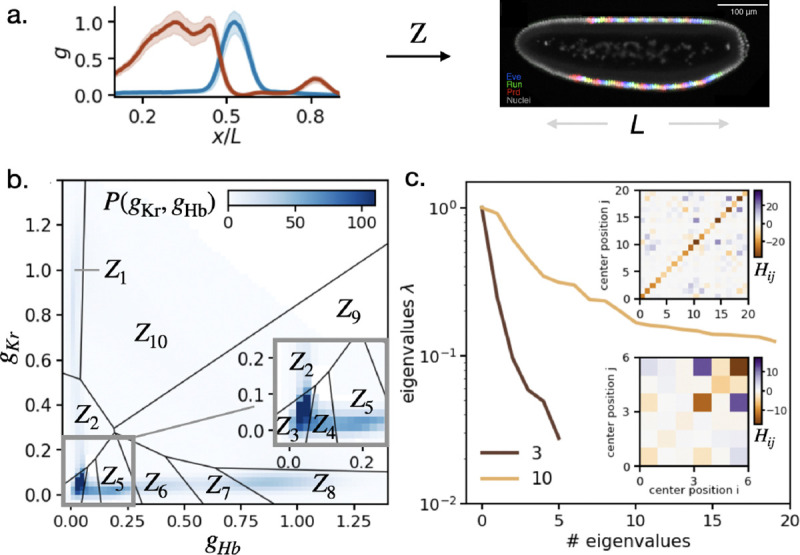
Optimizing the response to morphogens. (a) (left) Expression levels of Hb (red) and Kr (blue) as a function of position along the anterior–posterior axis of the embryo [33]. Solid lines are means over many embryos, and shaded regions show the standard deviation at each position. Expression of each gene is normalized so that , and position is measured in units of the embryo length . (right) An image of three “pair–rule” genes [37], whose expression depends on enhancers reading information from all gap genes and hence on the (hypothetical) compressed variable . (b) Discretizing combinations of expression levels. This is the optimal solution for , with regions bounded by solid lines. Grey levels illustrate the probability density across all embryos and all positions. (c) Hessian matrices (insets), from Eq (2), and their eigenvalues for and . The peak is normalized to 1.
Box 2: Compression of expression levels.
Cells in the fly embryo respond to the proteins encoded by hunchback and Krüppel as they bind to enhancer elements along the genome, and these in turn interact with promoters to influence the expression of other genes [38]. We can think of this abstractly as a mapping from concentrations into some internal variable , which might represent the occupancy of enhancer binding sites or the resulting activity of the promoter [35, 39]. Noise and limited dynamic range in the cellular response imply that this variable captures only limited information . For each value of this information there is a maximum information that can be represented about the position of the cell, , and this is determined by the structure of expression profiles and their variability. Formally this problem can be phrased as
| (7) |
where is a Lagrange multiplier and in general the mapping can be probabilistic; this is an instance of the information bottleneck problem [40]. We have solved this optimization problem [35], and a very good approximation is to divide the space of expression levels into Vornoi polygons, deterministically (Fig 2B). The Vornoi construction is parameterized by the positions of the central points
| (8) |
each is a vector with two components, one for hunchback and one for Krüppel, so that has dimensions. Capturing more information defines a more reliable and complex body plan [6], so we take as a measure of functional performance.
Figure 2A shows the spatial profiles of hunchback and Krüppel in a small time window 40−45min into the fourteenth cycle of nuclear division in the embryo. Figure 2B shows the optimal discretization into regions. Figure 2C shows the eigenvalues of the Hessian in the neighborhood of this optimum, both for and 10. We see that these eigenvalues are distributed over a decade or more. We emphasize that this emerges directly from the expression level data—mean spatial profiles and the (co)variances of fluctuations around these means—and thus represents a feature of the problem faced by the organism, not a model.
ELECTRICAL DYNAMICS OF SINGLE NEURONS
The electrical dynamics of neurons are determined by the molecular dynamics of ion channels in the cell membrane [41, 42]. A typical neuron expresses several kinds of channels, chosen from roughly one hundred possibilities encoded in the genome. Channels interact with one another through the voltage across the membrane, and these are the protein networks for which we have the most precise mathematical descriptions. The models of these networks predict that stabilizing even the qualitative behavior of neurons requires feedback from electrical activity to channel copy number [43], and these feedback mechanisms now are well established. Here we consider a small network of neurons that generate a rhythm in the crab stomatogastric ganglion, as schematized in Figs 3A and B [9]; these coordinated oscillations create crucial feeding patterns in the crab. A description of the channel dynamics in the simplest three cell network requires twenty parameters that define the number of each type of channel, and we measure functional performance by the closeness of the period and duty cycle to target values (Box 3).
FIG. 3:

Ion channel copy numbers in a small neural circuit. (a) Schematic of the core rhythm generating network in the crab stomatogastric ganglion [9], showing the anterior burster and pyloric dilator neurons (AB/PD), the lateral pyloric neuron (LP) and the pyloric neurons (PY), as well as their synaptic connections. (b) Voltage vs time for the three neurons, from the model described in Box 3. (c) Eigenvalues of the Hessian in Eq (2), where the functional performance is measured by the fractional closeness of the rhythm period (black) or duty cycle of the individual neurons (blue, green, yellow) and the parameters are the copy numbers of the different channel types in each cell.
Box 3: Ion channel dynamics.
Electrical dynamics in single neurons are described by generalized Hodgkin–Huxley equations [44]:
| (9) |
| (10) |
| (11) |
The variable is the voltage across the membrane of cell and is its capacitance. There are many types of ion channel proteins that can insert into the cell membranes, and these are labeled by and are the “activation” and “inactivation” variables, respectively, for these channels, reflecting the states of the proteins. Given the ionic selectivity of each channel type and the chemical potential differences of the ions across each cell membrane, current through channels of type reverses at a voltage in cell . If these channels are fully open the maximal conductance is , proportional to the number of copies of that protein in the membrane. When the voltage across the membrane is , the equilibrium values of the activation and inactivation variables are and , respectively, and relaxation toward these equilibrium values occurs with time constants and ; these voltage dependencies are well characterized for each channel type [41]. Each cell has a “leak” conductance that pulls the voltage back toward zero. Current is injected into each cell by synapses from other neurons,
| (12) |
| (13) |
The input current to the postsynaptic neuron depends on the momentary activation of the synapse from cell , the maximal synapse strength , and the difference between the membrane potential of the postsynaptic neuron and the reversal potential of the synapse, . The activation of the synapse relaxes on a timescale toward a steady state . The functions and are modeled as in Ref [45], with taking the form of a sigmoid In small circuits as in Fig 3 we find solutions to Eqs (9–13) that are periodic, so that . One measure of fitness is the (fractional) approach of this period to some desired value, . During the period each neuron spends part of the cycle in firing state and part of the cycle not firing. We can define a duty cycle for each neuron by first inferring the timing of each of the firing events within a single burst of firing, and then finding the length of the firing burst. Finally, we can define the duty cycle as . Then, we define a fitness as the fractional approach of this duty cycle to a desired value for each cell . We take the parameters to be the channel protein copy numbers or maximal conductances, . Hessians were estimated through numerical simulation using the Xolotl package [46], using the “example pyloric network” to define and .
Figure 3C shows the eigenvalues of the Hessian, from Eq (2). Whether we focus on the period of the oscillation or the duty cycles of individual neurons, the results are strikingly similar, and show that eigenvalues are distributed almost uniformly on a logarithmic scale. The dynamic range is ~ 1010, which means that some combinations of parameters can vary by one hundred thousand times as much as others while having the same effect on the performance. Said another way, to hold all parameters fixed would require that variations of ~ 10−10 are significant.
A RECURRENT NETWORK
Going beyond single neurons to explore the dynamics of networks we can see more examples of these ideas. We consider first a network with recurrent internal connections and a linear readout (Fig 4A). Nonlinear versions of these networks have been widely discussed as generators of complex outputs , as in motor control [47–49]. A much simpler case is where the dynamics are linear and there is a single input (Box 4), in which case the output is a linearly filtered version of this signal,
| (14) |
FIG. 4:

A linear recurrent network of neurons. (a) Schematic network architecture (left). A network with internal connections , is driven by a signal via an input weight vector , and the output is a weighted sum of network activity via the readout weights . Visualization of the network filter (right), from Eq (14). (b) Hessian eigenvalues of the cost function, Eq (16), for a random filter when perturbing the readout weights ; different values of in colors. (c) As in (B) when perturbing the recurrent connectivity weights .
Box 4: A linear network.
We consider a linear network of neurons in which the activity of each neuron is described by a variable . This activity relaxes to its resting state on time scale , and measures the strength of the connection from neuron to neuron . There is a single input that drives each neuron with a fixed weight , so the full dynamics are
| (15) |
The output of the network is some linear combination of activities, . Linearity of the dynamics implies that is a linearly filtered version of , as in Eq (14). We measure functional performance as the similarity of this filter to some target,
| (16) |
We can make a generic choice of the target by drawing each synaptic strength independently from a Gaussian distribution with zero mean and , and similarly picking weights from zero mean unit variance Gaussians. In the large limit, the eigenvalues of are uniformly distributed on a disc centered at the origin of the complex plane, with radius . Through Equation (15) this means that when the network dynamics have increasingly longer timescales, and when the dynamics destabilize.
We can take as a measure of functional behavior the closeness of this filter to some desired target . The parameters are the strengths of internal synapses and the readout weight, .
We can make a generic choice of the target filter by setting all the parameters to random values. Note that as we increase the variance of the synaptic strengths ( from Box 4), the network has access to a wider range of time scales and these will be reflected in . We can gain some insight by first varying only the readout weights . We find the eigenvalues of the Hessian matrix shown in Fig 4B, illustrating once again the tendency for these values to be equally spaced on a logarithmic axis. At larger , and hence a wider range of time scales, we find a larger number of eigenvalues that are significantly nonzero, but at all values of there is a range of more than ten orders of magnitude. Indeed, as the spectrum becomes almost perfectly uniform across this range.
When we change the synaptic strengths we find the eigenvalues of the Hessian shown in Fig 4C. To understand this result we can think not about the individual elements of the synaptic matrix but about the eigenvalues and eigenvectors of this matrix. If perturbations to the network parameters change only the eigenvectors, then we can compensate by adjusting the readout weights. But this means that there are parameters of the synaptic matrix that are effectively redundant, so we see only significantly nonzero eigenvalues. Beyond true redundancy or over–parameterization, even the nonzero eigenvalues are widely distributed (Fig 4C). These eigenvalues span roughly five orders of magnitude, and except for a few they are distributed uniformly on a logarithmic axis, as in our other examples.
A DEEP NETWORK
Modern artificial neural networks began as schematic models for networks of real neurons. While not faithful to the details of the brain’s dynamics, they capture important functional behaviors that are at the heart of the current revolution in artificial intelligence. Although it often is emphasized these networks have very large numbers of parameters, networks of real neurons have even more. Here we use deep networks [50] as a controlled test case to further explore the interplay of optimization and variability.
Networks that are trained on classification tasks are models for a conditional distribution , where is the class, is the –dimensional input such as an image, and are the (many) parameters. The inputs themselves are drawn from a distribution . The performance of the model can be measured by the average (log) probability that the model can explain the data we have seen,
| (17) |
where is the class to which the input belongs. As usual in neural networks the parameters are the connection weights and biases for activation of individual units. Note that our distinction between functional performance and model fit becomes blurred in this example.
Because the network implements a probabilistic model, and the model is large enough to achieve perfect performance, the Hessian matrix of is equal to the Fisher information matrix [51] at the optimum, but the Fisher matrix is well defined and positive definite even away from the optimum. This allows us to ask, for example, how the soft modes emerge over the course of learning.
In most modern applications of neural networks, and perhaps in the brain itself, there are more parameters than examples from which to learn, and so we expect that some combinations of parameters are completely unconstrained, generating true zero eigenvalues in the Hessian matrix. But there are hints in the literature that beyond these genuinely undetermined parameters there is a near continuum soft modes [52]. To explore this further we consider ResNet20, a twenty layer network [53, 54], that is trained to 100% accuracy—and hence the absolute maximum —on the CIFAR–10 task, in which 32 × 32 color images must be assigned to classes [55]. A schematic of the network is shown in Fig 5A, and Fig 5B shows that learning indeed reaches the optimum, with perfect classification of the training data. This network has parameters, and the Hessian matrix is . As explained in Box 5, we have developed finite rank approximations to the Fisher information matrix that involve a direct average over samples.
FIG. 5:

Eigenvalue spectrum of the Fisher information matrix for a network that learns the CIFAR–10 task. (a) Schematic of the network. (b) Performance of the network as function of time (“epoch”) during training. Training reaches a true optimum—zero loss—both for the natural task and for an artificial task in which the labels on images are randomized. (c) Eigenvalues of the Fisher information matrix estimated from as in Eq (24). These estimates are based on samples, probing the spectrum at different stages in the learning process. The distribution of eigenvalues converges as we increase , especially in the tail of small eigenvalues.
Box 5: The Hessian in large networks.
As before we are interested in the Hessian
| (18) |
At large we can replace the average over samples with an average over the true distribution . But in modern deep networks, the very large number of parameters makes it possible to achieve perfect classification on the set of training examples, so that . When this is true, the Hessian at the optimum is the Fisher information matrix,
| (19) |
| (20) |
| (21) |
We note that the Fisher information matrix is a property of the model and not of the training data, except insofar as the training drives us to a particular set of parameters . Because is an expectation value we can approximate it by drawing examples out of the true distribution (not necessarily examples used for training). Concretely we can construct
| (22) |
| (23) |
This is a rank approximation to the true matrix and the eigenvalues of are the same as the nonzero eigenvalues of
| (24) |
Handling the matrix is a manageable task for reasonably large , so long as . The eigenvalues of approach those of as increases, and we can find these eigenvalues by diagonalizing . If the eigenvalue spectrum of stabilizes as becomes large, then we are finding a good approximation to the spectrum of itself.
We see in Figure 5C that the Hessian has just a handful of large eigenvalues; as noted previously the number of these “stiff” directions is equal to the number of classes [52, 56]. As learning progresses, the density of moderate eigenvalues is depleted and added to the tail at small eigenvalues, which becomes nearly scale invariant so that the spectrum is barely integrable; there is no obvious limit to how soft these modes can be. Importantly, the spectrum we see converges rapidly as we increase the rank of our approximation.
The classical examples of sloppy models involve eigenvalues that are distributed almost uniformly on a logarithmic scale, which is equivalent to the scale invariant distribution that we see here. It is striking that we see this not only across many decades in , but across many thousands of dimensions. We emphasize that this uniform distribution across scales is not a property of the generic deep network, but emerges during training, as we can see by comparing different colors in Fig 5C. More subtly, if we change the task by randomly permuting the labels we can still reach optimal performance (Fig 5B), but in Fig 5C we see that the density of moderate and large eigenvalues now grows over the course of training at the expense of the very smallest eigenvalues.
SYNTHESIS
Across all of the systems highlighted here, we observe a large number of soft modes in parameter space. This describes quantitatively the flexibility of parameter choices that allow equivalent and very nearly optimal performance. As parameter spaces expand, the scaling of the eigenvalues that we observe admits yet more soft modes. Our framework allows us to see the generality of these relationships across vastly different biological substrates and cost functions.
In thinking about the possibility of parameter variation it is useful to imagine a population of cells, networks, or organisms that choose their underlying parameters at random from a distribution . This population will exhibit an average performance or fitness ,
| (25) |
Environmental and evolutionary pressures will push for this average to reach some characteristic level. Unless there is some mechanistic or historical constraint beyond the fitness itself, we expect that the parameters will be as variable as possible while obeying the mean value in Eq (25).
The only consistent way to make “as variable as possible” mathematically precise is to ask for the distribution that has the maximum entropy consistent with the constraint on [57, 58]. This maximum entropy distribution has the form
| (26) |
where is a parameter that must be set so that Eq (25) is satisfied and enforces the normalization of the distribution. We recognize this as the Boltzmann distribution with the performance measure playing the role of the (negative) energy and the temperature.
A seemingly different view of the problem is that there is some added cost in controlling the parameters, and this competes with the fitness advantage that can be gained by tuning towards an optimum. If the cost is proportional to the information, in bits, that is used to specify the parameters, then achieving a certain mean fitness at minimal cost means that the distribution of parameters will again be drawn from Eq (26). In this picture the effective temperature measures the relative cost of the information needed for control vs the gain in fitness.
If the evolutionary pressure is strong enough to keep the mean performance close to its maximum, then we can use the expansion in Eq (1), and in agreement with the equipartition theorem, we find
| (27) |
independent of the details of the eigenvalue spectrum. We can explicitly insert our knowledge of the eigenvalue spectrum into the expression for the entropy of the distribution,
| (28) |
If we have a sloppy spectrum with
| (29) |
then
| (30) |
In this way, we can relate the entropy to the temperature and dimensionality, , of the system. Solving for and inserting the expression into Eq (27), we can also probe the scaling of the cost function with dimensionality. Putting things together we have
| (31) |
This implies that if the the dimensionality of the parameter space is large () we can get arbitrarily close to optimal performance, on average, even though the variability corresponds to a finite entropy per parameter.
It is useful to think about the case where parameter spaces are so large that the discrete Hessian eigenvalues are drawn from a nearly continuous distribution with normalized density , as in Fig 5. Then the analog of Eq (31) is
| (32) |
The condition to have finite entropy per parameter at vanishing fitness cost is that the dynamic range of grow with the dimensionality of the parameter space. This growth is linear if the sloppy spectrum in Eq (29) is exact, but this can happen in a wider range of systems.
Similar considerations appear in many examples beyond those discussed here. In some of these problems the parameters are discrete, as for the mapping of amino acid sequences into protein structure and function, but the principles are the same. The fact that proteins form families is a hint that the mapping from sequence to structure is many–to–one [59–61], and this observation is at the root of a large literature that builds statistical physics models for the distribution of sequences consistent with a given structure [62–66]. Within these models one can estimate the entropy of sequence variations at fixed structure, analogous to the entropy at fixed mean performance discussed here; again this entropy appears to be extensive in the number of amino acids [67]. This is not a generic feature of proteins, and it has been suggested that evolution selects for structures that are the stable folded states of many sequences, in effect maximizing the entropy in parameter space [68, 69]. Direct experimental explorations of sequence space also suggest that the landscape may be more easily navigable than previously expected [70, 71].
On a higher level of organization, many cognitive tasks can be thought of as sequential decision making, leading to a natural discrete parameterization of the space of strategies. There is a regime in which tasks are complex enough to be interesting but small enough that this space can be explored exhaustively. For foraging tasks, this enumeration reveals a broad swath of strategies that differ significantly in form but have negligible loss in performance, very much analogous to the results above [72].
CONCLUSION
Contrary to a widely held intuition, near–optimal performance of biological systems does not require fine tuning of parameters. We have seen this in examples across scales, from the control of gene expression to the dynamics of large neural networks. This is not a generic feature of high–dimensional, “over–parameterized” systems, but rather emerges from an interplay between the underlying mechanistic architecture and the structure of the problem that the system is selected to solve. Nor is the tolerance for parameter variation a retreat from optimality to “good enough” solutions; rather it is a feature of the landscape for optimization itself. Optimization principles for the function of living systems thus predict that there should be substantial variation in the underlying parameters. We should not be surprised by optimality, but rather only by those rare cases where microscopic parameters are controlled beyond what seems necessary for function.
ACKNOWLEDGMENTS
Portions of this work were presented at the NITMB workshop on Biological Systems that Learn, and we thank our colleagues there for helpful discussions, especially M Holmes–Cerfon. This work was supported in part by the National Science Foundation through the Center for the Physics of Biological Function (PHY–1734030) and a Graduate Research Fellowship (to CMH); by the National Institutes of Health through the BRAIN initiative (1R01EB026943) and Grant R01NS104899; by Fellowships from the Simons Foundation and the John Simon Guggenheim Memorial Foundation (WB); by a Polymath Fellowship from the Schmidt Sciences Foundation (SEP); by a Jane Coffins Childs Memorial Fund Fellowship (CMH); and by NWO Talent/VIDI grant NWO/VI.Vidi.223.169 (MB). WB also thanks colleagues at Rockefeller University for their hospitality during a portion of this work.
References
- [1].Rieke F. & Baylor D. A. Single photon detection by rod cells of the retina. Reviews of Modern Physics 70, 1027–1036 (1998). [Google Scholar]
- [2].Barlow H. B. The size of ommatidia in apposition eyes. Journal of Experimental Biology 29, 667–674 (1952). [Google Scholar]
- [3].Snyder A. W. Acuity of compound eyes: Physical limitations and design. Journal of Comparative Physiology 116, 161–182 (1977). [Google Scholar]
- [4].Berg H. C. & Purcell E. M. Physics of chemoreception. Biophysical Journal 20, 193–219 (1977). [DOI] [PMC free article] [PubMed] [Google Scholar]
- [5].Bialek W. Biophysics: Searching for Principles (Princeton University Press, Princeton NJ, 2012). [Google Scholar]
- [6].Bialek W. Ambitions for theory in the physics of life. In Bitbol A.-F., Mora T., Nemenman I. & Walczak A. M. (eds.) Les Houches Summer School Lecture Notes (SciPost Physics Lecture Notes 84, 2024). [Google Scholar]
- [7].Gould S. J. & Lewontin R. C. The spandrels of san marco and the panglossian paradigm: A critique of the adaptationist programme. Proceedings of the Royal Society B: Biological Sciences 205, 581–598 (1979). [DOI] [PubMed] [Google Scholar]
- [8].Spudich J. L. & Koshland D. E. Jr. Non-genetic individuality: Chance in the single cell. Nature 262, 467–471 (1976). [DOI] [PubMed] [Google Scholar]
- [9].Prinz A. A., Bucher D. & Marder E. Similar network activity from disparate circuit parameters. Nature Neuroscience 7, 1345–1352 (2004). [DOI] [PubMed] [Google Scholar]
- [10].Marder E. & Goaillard J. M. Variability, compensation and homeostasis in neuron and network function. Nature Reviews Neuroscience 7, 563–574 (2006). [DOI] [PubMed] [Google Scholar]
- [11].Wright S. The roles of mutation, inbreeding, crossbreeding and selection in evolution. In Jones D. F. (ed.) Proceedings of the Sixth International Congress of Genetics, vol I, 356–366 (Genetics Society of America, 1932). [Google Scholar]
- [12].Szendro I. G., Schenk M. F., Franke J., Krug J. & de Visser J. A. G. M. Quantitative analyses of empirical fitness landscapes. Journal of Statistical Mechanics P01005 (2013). [Google Scholar]
- [13].Transtrum M. K. et al. Perspective: Sloppiness and emergent theories in physics, biology, and beyond. Journal of Chemical Physics 143, 010901 (2015). [DOI] [PubMed] [Google Scholar]
- [14].Brown K. S. & Sethna J. P. Statistical mechanical approaches to models with many poorly known parameters. Physical Review E 68, 021904 (2003). [DOI] [PubMed] [Google Scholar]
- [15].Gutenkunst R. N. et al. Universally sloppy parameter sensitivities in systems biology models. PLoS Computational Biology 3, e189 (2007). [DOI] [PMC free article] [PubMed] [Google Scholar]
- [16].Waterfall J. J. et al. Sloppy–model universality class and the Vandermonde matrix. Physical Review Letters 97, 150601 (2006). [DOI] [PubMed] [Google Scholar]
- [17].Quinn K. N., Wilber H., Townsend A. & Sethna J. P. Chebyshev approximation and the global geometry of model predictions. Physical Review Letters 122, 158302 (2019). [DOI] [PubMed] [Google Scholar]
- [18].Quinn K. N., Abbott M. C., Transtrum M. K., Machta B. B. & Sethna J. P. Information geometry for multiparameter models: New perspectives on the origin of simplicity. Reports on Progress in Physics 86, 035901 (2022). [DOI] [PMC free article] [PubMed] [Google Scholar]
- [19].Sokolowski T. R., Gregor T., Bialek W. & Tkačik G. Deriving a genetic regulatory network from an optimization principle. Proceedings of the National Academy of Sciences (USA) 122, e2402925121 (2025). [DOI] [PMC free article] [PubMed] [Google Scholar]
- [20].Strausfeld N. Atlas of an Insect Brain. Verlag (Springer, Berlin, 1976). [Google Scholar]
- [21].Roorda A., Mehta A. B., Lennie P. & Williams D. R. Packing arrangement of the three cone classes in primate retina. Vision Research 41, 1291–1306 (2001). [DOI] [PubMed] [Google Scholar]
- [22].Szél Á., Röhlich P., Caffé A. R. & van Veen T. Distribution of cone photoreceptors in the mammalian retina. Microscopy Research and Technique 35, 445–462 (1996). [DOI] [PubMed] [Google Scholar]
- [23].Sherry D. M., Bui D. D. & Degrip W. J. Identification and distribution of photoreceptor subtypes in the neotenic tiger salamander retina. Visual Neuroscience 15, 1175–1187 (1998). [DOI] [PubMed] [Google Scholar]
- [24].Jiao Y. et al. Avian photoreceptor patterns represent a disordered hyperuniform solution to a multiscale packing problem. Physical Review E 89, 022721 (2014). [DOI] [PMC free article] [PubMed] [Google Scholar]
- [25].Leertouwer H. L. Cover photograph, June 28. Science 252 (1991). [Google Scholar]
- [26].Ruderman D. L. & Bialek W. Statistics of natural images: Scaling in the woods. Physical Review Letters 73, 814–817 (1994). [DOI] [PubMed] [Google Scholar]
- [27].Wolpert L. Positional information and the spatial pattern of cellular differentiation. Journal of Theoretical Biology 25, 1–47 (1969). [DOI] [PubMed] [Google Scholar]
- [28].Dubuis J. O., Tkačik G., Wieschaus E. F., Gregor T. & Bialek W. Positional information, in bits. Proceedings of the National Academy of Sciences (USA) 110, 16301–16308 (2013). [DOI] [PMC free article] [PubMed] [Google Scholar]
- [29].Tkačik G., Dubuis J. O., Petkova M. D. & Gregor T. Positional information, positional error, and read–out precision in morphogenesis: a mathematical framework. Genetics 199, 39–59 (2015). [DOI] [PMC free article] [PubMed] [Google Scholar]
- [30].Tkačik G. & Gregor T. The many bits of positional information. Development 148, dev176065 (2021). [DOI] [PMC free article] [PubMed] [Google Scholar]
- [31].Lawrence P. A. The Making of a Fly: The Genetics of Animal Design (Blackwell Scientific, Oxford, 1992). [Google Scholar]
- [32].Wieschaus E. & Nüsslein-Volhard C. The Heidelberg screen for pattern mutants of drosophila: A personal account. Annual Review of Cell and Developmental Biology 32, 1–46 (2016). [DOI] [PubMed] [Google Scholar]
- [33].Petkova M. D., Tkačik G., Bialek W., Wieschaus E. F. & Gregor T. Optimal decoding of cellular identities in a genetic network. Cell 176, 844–855 (2019). [DOI] [PMC free article] [PubMed] [Google Scholar]
- [34].Jaeger J. The gap gene network. Cellular and Molecular Life Sciences 68, 243–274 (2011). [DOI] [PMC free article] [PubMed] [Google Scholar]
- [35].Bauer M., Petkova M. D., Gregor T., Wieschaus E. F. & Bialek W. Trading bits in the readout from a genetic network. Proceedings of the National Academy of Sciences (USA) 118, e2109011118 (2021). [DOI] [PMC free article] [PubMed] [Google Scholar]
- [36].Bauer M. & Bialek W. Information bottleneck in molecular sensing. PRX Life 1, 023005 (2023). [Google Scholar]
- [37].McGough L. et al. Finding the last bits of positional information. PRX Life 2, 013016 (2024). [DOI] [PMC free article] [PubMed] [Google Scholar]
- [38].Furlong E. E. & Levine M. Developmental enhancers and chromosome topology. Science 361, 1341 (2018). [DOI] [PMC free article] [PubMed] [Google Scholar]
- [39].Bauer M., Petkova M. D., Gregor T., Wieschaus E. F. & Bialek W. Trading bits in the readout from a genetic network (2020). arXiv:2012.15817 [q-bio.MN]. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [40].Tishby N., Pereira F. C. & Bialek W. The information bottleneck method. In Hajek B. & Sreenivas R. S. (eds.) Proceedings of the 37th Annual Allerton Conference on Communication, Control and Computing, 368–377 (University of Illinois, 1999). arXiv:physics/0004057 [physics.data-an]. [Google Scholar]
- [41].Johnston D. & Wu S. M.-S. Foundations of Cellular Neurophysiology (MIT Press, Cambridge MA, 1994). [Google Scholar]
- [42].Bevan M. D. & Wilson C. J. Mechanisms underlying spontaneous oscillation and rhythmic firing in rat subthalamic neurons. Journal of Neuroscience 19, 7617–7628 (1999). [DOI] [PMC free article] [PubMed] [Google Scholar]
- [43].LeMasson G., Marder E. & Abbott L. F. Activity–dependent regulation of conductances in model neurons. Science 259, 1915–1917 (1993). [DOI] [PubMed] [Google Scholar]
- [44].Aidley D. J. The Physiology of Excitable Cells (Cambridge University Press, Sunderland MA and Cambridge UK, 1998). Third Edition (2001) Editor Hille B., Ion Channels of Excitable Membranes. [Google Scholar]
- [45].Abbott L. F. & Marder E. Modeling small networks (1998). [Google Scholar]
- [46].Gorur-Shandilya S., Hoyland A. & Marder E. Xolotl: an intuitive and approachable neuron and network simulator for research and teaching. Frontiers in neuroinformatics 12, 87 (2018). [DOI] [PMC free article] [PubMed] [Google Scholar]
- [47].Hennequin G., Vogels T. P. & Gerstner W. Optimal control of transient dynamics in balanced networks supports generation of complex movements. Neuron 82, 1394–1406 (2014). [DOI] [PMC free article] [PubMed] [Google Scholar]
- [48].Sussillo D., Churchland M. M., Kaufman M. T. & Shenoy K. V. A neural network that finds a naturalistic solution for the production of muscle activity. Nature Neuroscience 18, 1025–1033 (2015). [DOI] [PMC free article] [PubMed] [Google Scholar]
- [49].Susman L., Mastrogiuseppe F., Brenner N. & Barak O. Quality of internal representation shapes learning performance in feedback neural networks. Physical Review Research 3, 013176 (2021). [Google Scholar]
- [50].LeCun Y., Bengio Y. & Hinton G. Deep learning. Nature 521, 436–444 (2015). [DOI] [PubMed] [Google Scholar]
- [51].Thomas V. et al. On the interplay between noise and curvature and its effect on optimization and generalization. In Chiappa S. & Calandra R. (eds.) Proceedings of the Twenty Third International Conference on Artificial Intelligence and Statistics, vol. 108 of Proceedings of Machine Learning Research, 3503–3513 (PMLR, 2020). [Google Scholar]
- [52].Sagun L., Evci U., Güney V. U., Dauphin Y. N. & Bottou L. Empirical analysis of the hessian of over-parametrized neural networks. In 6th International Conference on Learning Representations, ICLR 2018, Vancouver, BC, Canada, April 30 - May 3, 2018, Workshop Track Proceedings (OpenReview.net, 2018). URL https://openreview.net/forum?id=rJO1\_M0Lf. [Google Scholar]
- [53].He K., Zhang X., Ren S. & Sun J. Deep residual learning for image recognition. arXiv:1512.03385 (2015). [cs.CV]. [Google Scholar]
- [54].Idelbayev Y. Proper ResNet implementation for CI-FAR10/CIFAR100 in PyTorch. https://github.com/akamaster/pytorch_resnet_cifar10 (2018).
- [55].Krishevsky A. Learning multiple layers of features from tiny images. https://www.cs.toronto.edu/~kriz/cifar.html (2009).
- [56].Gur-Ari G., Roberts D. A. & Dyer E. Gradient descent happens in a tiny subspace (2018). arXiv:1812.04754 [cs.LG]. [Google Scholar]
- [57].Shannon C. E. A mathematical theory of communication. Bell System Technical Journal 27, 379–423 (1948). & 623–656. [Google Scholar]
- [58].Jaynes E. T. Information theory and statistical mechanics. Physical Review 106, 620–630 (1957). [Google Scholar]
- [59].Stroud R. M. A family of protein cutting proteins. Scientific American 231, 74–88 (1974). [DOI] [PubMed] [Google Scholar]
- [60].Sonnhammer E. L. L., S. R. E. & Durbin R. Pfam: A comprehensive database of protein families based on seed alignments. Proteins 28, 405 (1997). [DOI] [PubMed] [Google Scholar]
- [61].Blum M. et al. The interpro protein families and domains database: 20 years on. Nucleic Acids Research 49, D344–D354 (2020). [DOI] [PMC free article] [PubMed] [Google Scholar]
- [62].Lapedes A., Giraud B. G., Liu L. C. & Stormo G. A maximum entropy formalism for disentangling chains of correlated sequence positions. LANL Report 98–1094 (1998). LA-UR. [Google Scholar]
- [63].Bialek W. & Ranganathan R. Rediscovering the power of pairwise interactions (2007). arXiv:0712.4397 [q-bio.QM]. [Google Scholar]
- [64].Weigt M., White R. A., Szurmant H., Hoch J. A. & Hwa T. Identification of direct residue contacts in protein–protein interaction by message passing. Proceedings of the National Academy of Sciences (USA) 106, 67–72 (2009). [DOI] [PMC free article] [PubMed] [Google Scholar]
- [65].Marks D. S. et al. Protein 3d structure computed from evolutionary sequence variation. PLoS One 6, e28766 (2011). [DOI] [PMC free article] [PubMed] [Google Scholar]
- [66].Russ W. P. et al. An evolution-based model for designing chorismate mutase enzymes. Science 369, 440–445 (2020). [DOI] [PubMed] [Google Scholar]
- [67].Barton J. P., Chakraborty A. K., Cocco S., Jacquin H. & Monasson R. On the entropy of protein families. Journal of Statistical Physics 162, 1267–1293 (2016). [Google Scholar]
- [68].Li H., Helling R., Tang C. & Wingreen N. Emergence of preferred structures in a simple model of protein folding. Science 273, 666–669 (1996). [DOI] [PubMed] [Google Scholar]
- [69].Li H., Tang C. & Wingreen N. S. Are protein folds atypical? Proceedings of the National Academy of Sciences (USA) 95, 4987–4990 (1998). [DOI] [PMC free article] [PubMed] [Google Scholar]
- [70].Carneiro M. & Hartl D. L. Adaptive landscapes and protein evolution. Proceedings of the National Academy of Sciences (USA) 107, 1747–1751 (2010). [DOI] [PMC free article] [PubMed] [Google Scholar]
- [71].Papkou A., Garcia-Pastor L., Escudero J. & Wagner A. A rugged yet easily navigable fitness landscape. Science 382, eadh3860 (2023). [DOI] [PubMed] [Google Scholar]
- [72].Ma T. & Hermundstad A. M. A vast space of compact strategies for effective decisions. Science Advances 10, eadj4064 (2024). [DOI] [PMC free article] [PubMed] [Google Scholar]