

Abstract
This paper focuses on discrete representation learning for multivariate time series with Gaussian processes. To overcome the challenges inherent in incorporating discrete latent variables into deep learning models, our approach uses a Gumbel-softmax reparameterization trick to address non-differentiability, enabling joint clustering and embedding through learnable discretization of the latent space. The proposed architecture thus enhances interpretability both by estimating a low-dimensional embedding for high dimensional time series and by simultaneously discovering discrete latent states. Empirical assessments on synthetic and real-world fMRI data validate the model’s efficacy, showing improved classification results using our representation.
Index Terms—: Interpretable discrete representation, Gaussian process, Bayesian inference, multivariate time series
I. Introduction
Interpretable representation learning for multivariate time series aims to reveal explainable latent structures within complex dynamical systems (e.g., biomedical time series data). Often unsupervised methods in such scenarios rely on oversimplified assumptions, such as treating the data as independently and identically distributed (i.i.d.) or assuming a continuous latent representation (assumptions which often do not hold in the context of multivariate time series, in particular when discrete states occur in the generating process [1]). As an illustrative example, consider an experiment in which an individual engages in a sequence of discrete predefined tasks during noninvasive neuroimaging with functional magnetic resonance imaging (fMRI) leading to a series of stateful, task-induced changes in the observed brain hemodynamics. Such data consists of high dimensional autocorrelated time series with underlying low-dimensional dynamics involving discrete brain states driven by the different tasks.
Although learning representations with continuous features has been the focus of much important prior work, we here concentrate on discrete representations as they are a more natural fit for problems like our illustrative example where latent dynamics are expected to be stateful (i.e., where the underlying neurophysiology is believed to involve dynamic transitions between distinct brain states). While using discrete latent variables in deep learning has proven challenging, powerful autoregressive models have recently been developed for modeling distributions over discrete variables. Such discrete representations can make more effective use of the latent space, successfully modeling and compressing signal that spans many dimensions in the ambient data space to more efficiently represent low dimensional signal while yielding explainable results.
Importantly, the learned representation in the lower-dimensional space is inherently temporal and can be used to summarize dynamic behavior over time. In recent years, there has been an increasing integration of such techniques with generative modeling [2]–[5]. However, the learned representations from these models [6] are often difficult to interpret. While a number of recent efforts have been dedicated to enhancing interpretability in such models, these efforts have exclusively concentrated on continuous representations, leaving discrete representations largely unexplored.
In this paper, we introduce a novel deep architecture designed to estimate topologically interpretable discrete representations in a probabilistic manner. To address the non-differentiability inherent in discrete representation learning architectures, we incorporate a Gumbel-Softmax reparameterization trick [7], [8]. We then substantiate our model’s efficacy through empirical assessments of synthetic and real-world medical fMRI data.
Our main contributions are to
Formulate an innovative framework for discrete representation learning on time series, emphasizing interpretability.
Demonstrate the enhancement of clustering and interpretability in time series representations through the incorporation of a latent probabilistic model within the representation learning architecture.
Evaluate the model’s performance on real-world fMRI brain imaging, showing its effectiveness in facilitating downstream tasks.
The remaining sections of the paper are structured as follows: Section II offers an overview of related work in representation learning for time series data. In Section III, we provide the technical background necessary for our model, which is detailed in Section IV. Section V outlines the experimental setup, datasets utilized, and implementation specifics, and presents results and discussions. Lastly, Section VI provides a conclusion, summarizing our contributions and suggesting avenues for future research.
II. Related Work
Using discrete variables in deep learning has proven challenging, as evidenced by the widespread use of continuous latent variable models even when the underlying data modality is inherently discrete. However, there have been considerable recent efforts in certain domains to address this challenge and explore the potential of discrete representations. The NVIL estimator [9] employs a single-sample objective to optimize the variational lower bound and utilizes various variance-reduction techniques to expedite training. VIMCO [10] optimizes a multi-sample objective, accelerating convergence by leveraging multiple samples from the inference network. VQ-VAE [11] extends the line of research that incorporates autoregressive distributions in the decoder of VAEs and/or in the prior. It utilizes vector quantization to represent the discrete latent space. Recently, some authors have proposed the adoption of a novel continuous reparameterization technique based on the Concrete [7] or Gumbel-Softmax [8] distribution. This distribution is continuous and includes a temperature parameter that can be annealed during training to converge to a discrete distribution in the limit. Initially, during training, the gradients exhibit low variance but are biased. As training progresses, the variance of the gradients increases, becoming unbiased towards the end of the training process [7], [8].
III. Background
A. Variational Inference
In Bayesian inference, the predictive distribution for a new test point is given by
| (1) |
where represents the output of interest, is a test input, and denote training input and output data, respectively, and is a vector of model parameters, which are unknown. The distribution typically cannot be evaluated analytically. Instead, an approximating variational distribution whose structure is easy to evaluate is defined. We want our approximation distribution to be close to the posterior distribution. We, therefore, minimize the Kullback-Leibler (KL) divergence, a measure of similarity between two distributions [12], and in our case between and , i.e.,
| (2) |
resulting in the approximate predictive distribution
| (3) |
Minimizing the KL divergence is equivalent to maximizing the log evidence lower bound (ELBO) given by
| (4) |
with respect to the variational parameters that define . We reiterate that the KL divergence in the last equation is between the approximate posterior and the true posterior over . Maximizing this objective will result in a variational distribution that explains the data well while still being close to the prior and preventing the model from over-fitting.
B. Approximation of Gaussian Processes
In the proposed method, we rely on Gaussian processes, more precisely, on an approximation of Gaussian processes defined in functional spaces. We briefly explain the approximation. We use Bochner’s theorem to reformulate the covariance function of a Gaussian process in terms of its frequencies [13]. If the covariance function is stationary, it can be represented as for all . According to the theorem, can be represented as the Fourier transform of some finite measure where is proportional to the power spectral density of the kernel, i.e.,
| (5) |
where and is a scaling parameter that controls the amplitude of the Gaussian process. It determines the overall magnitude of the variations in the function values modeled by the Gaussian process. The second equality holds because the covariance function is real-valued. The above integration can be approximately computed by the Monte Carlo method as a finite sum with terms according to
| (6) |
with and being dimensional vectors for that act as inducing inputs. We rewrite the above terms for every as
| (7) |
This integral can again be approximated as a finite sum using Monte Carlo integration similar as in [14]. To keep the computation cost low, we approximate the integral with a single sample for every . Then we can write
| (8) |
where is uniformly sampled from the interval , i.e., . In summary, with (8) we define our approximation of the covariance function .
We refer to as inducing frequencies and to as phases, and we denote . If we use as the covariance function of the GP, we obtain the following generative model:
| (9) |
| (10) |
Clearly, we can condition this model on the finite set of random variables . With our assumptions, the model depends on these variables alone, making them sufficient statistics for the model.
C. Gumbel-Softmax Reparameterization
Many applications in deep learning involve categorical or discrete latent processes. However, sampling from the distribution of these processes is not a differentiable operation, making it infeasible when trying to optimize for the model parameters. The Gumbel-Softmax [8] and the Concrete Distribution [7] were simultaneously proposed to address this problem. For i.i.d samples drawn from with , the Gumbel-softmax generates sample vectors based on inputs (that can be the output of previous layers) and a temperature hyperparameter according to
| (11) |
In contrast to prior work, we aim to discover dynamic discrete representations by employing the Gumbel softmax reparameterization trick to address non-differentiability, and by using sparse spectrum approximation to handle GP intractability. This allows us to perform joint clustering and emebbing within the Gaussian Process (GP) framework.
IV. The Model
A. The generative model
Assume a multivariate times series dataset , where is a vector observed at time . We are especially interested in cases where each is a high-dimensional vector. Therefore, we assume the existence of a low-dimensional process that governs the generation of the data.
We define a categorical variable with categories. Firstly, for each category , we model a latent process using Gaussian processes (GPs) [15] with mean zero and covariance function , where and represent time indices. These latent processes are then normalized using the softmax function to obtain probabilities , ensuring that the sum across all categories equals one at each time point. Next, we sample latent variables from a distribution , where represents the probabilities of each category. Furthermore, we model intermediate latent processes as draws from Gaussian process priors with mean zero and covariance function . Finally, we model the latent function values for different outputs as draws from another GP. The model is characterized by the following equations:
| (12) |
| (13) |
| (14) |
| (15) |
| (16) |
| (17) |
The graphical representation of the generative model is illustrated in Fig. 1. It shows the relationships between the latent variable , the unobserved variable , and the observed output . This model captures the dynamic relationships between latent variables, unobserved states, and observed outputs, providing a comprehensive framework for understanding the sequential generation processes. The variable represents an auto-regressive variable and is also auto-regressive with the same orders. This structure reflects the temporal dependencies inherent in the latent variable .
Fig. 1:
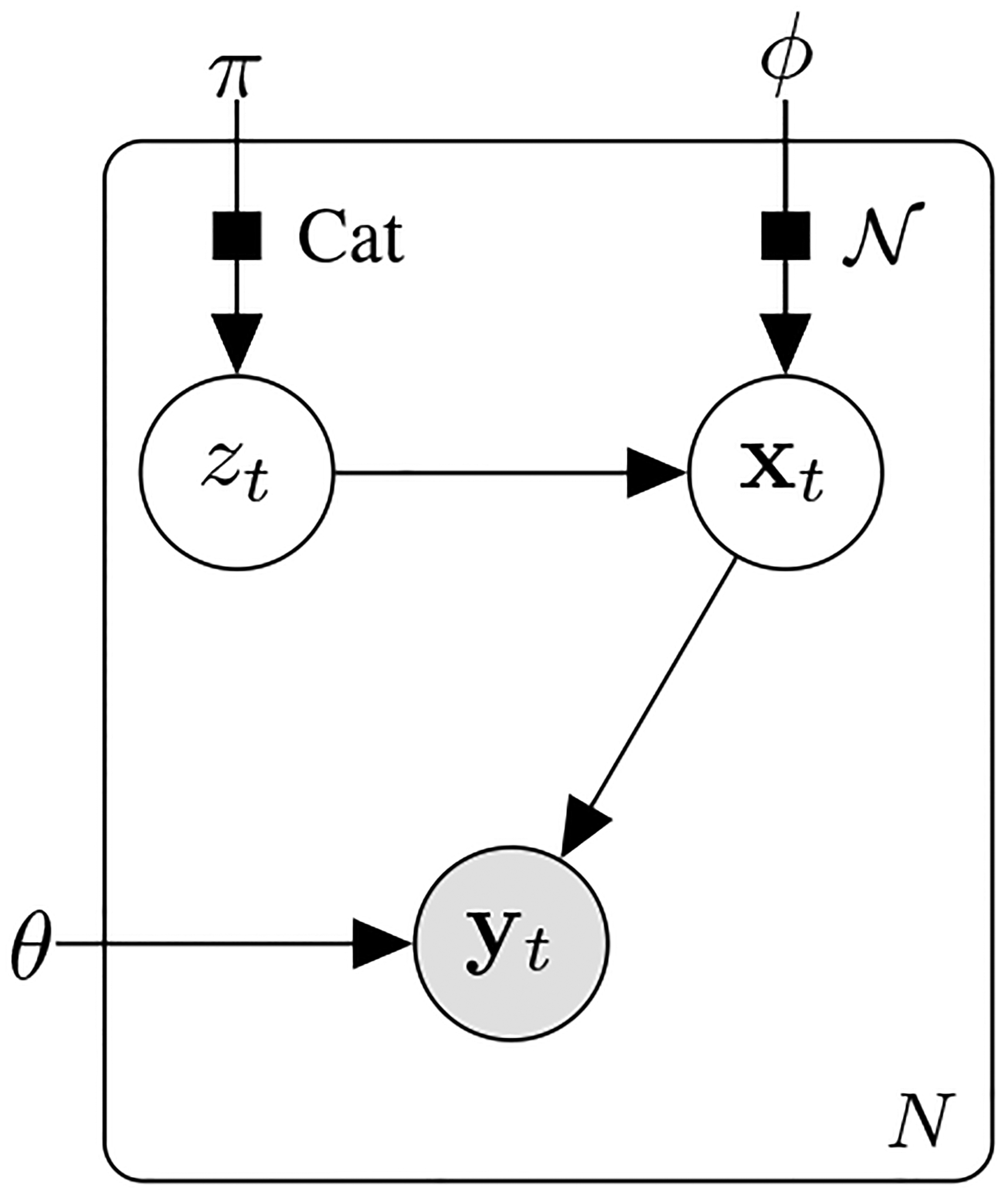
Graphical representation of the generative model.
B. The Inference
The matrix will collectively denote all observed data so that its -th column corresponds to the data point . Similarly, the matrix will denote the mapping latent variables, i.e., is associated with the observations . Analogously, and will store all low dimensional and intermediate latent variables. Further, we will refer to the rows of these matrices by the vectors , and . Given the latent variables, we assume independence over the data features, and given time, we assume independence over the latent dimensions. With these assumptions, we can write
| (18) |
| (19) |
We use a sparse spectrum approximation [16] of the Gaussian process introduced in the previous section. Common inference methods for Gaussian processes [12] become infeasible due to the non-differentiable sampling of the discrete variable . To optimize the latent variable , we therefore employ the Gumbel-Softmax relaxation technique. This method allows for differentiable sampling from a categorical distribution, enabling end-to-end training of the model using gradient-based optimization algorithms. The Gumbel-Softmax distribution approximates the categorical distribution by introducing noise from the Gumbel distribution and applying the softmax function to obtain a continuous relaxation.
V. Experiments and Results
A. Synthetic Data
We generate synthetic data using a Gaussian process framework, where the latent probabilities are drawn from a Gaussian process prior with mean zero and a covariance kernel . These latent probabilities are then normalized to obtain the probabilities [17]. The latent process is then sampled from a categorical distribution with parameter , forming a discrete representation of the data. Subsequently, the latent processes are generated from another Gaussian process with a covariance kernel composed of the temporal covariance and . Finally, the output is obtained by applying a function to , with additive noise . In summary,
| (20) |
| (21) |
| (22) |
| (23) |
| (24) |
| (25) |
The dimension of the categorical variable in this example is one, with . The dimension of is three () and the number of observed time series is 30 . All kernels are RBF with different hyperparameters. We assumed we knew the onset of the categorical variable and attempted to predict the corresponding task, using only the inferred , to evaluate how much the model was able to compress the information in . The accuracy of the task prediction was 82.3%. It is clear that this discrete latent variable was able to obtain the information about the task from the generated time series in a fully unsupervised fashion.
B. Real Data
To assess the effectiveness of our model on real data, we employed functional Magnetic Resonance Imaging (fMRI) data acquired from 35 individuals diagnosed with major depressive disorder. The dataset comprises multivariate time series extracted from Regions of Interest (ROIs) known to be implicated in depression.
The data were collected during the execution of diverse cognitive tasks, capturing subjects’ neural activity during both an anticipation phase (Anti) and a feedback phase (FB). The feedback stimuli presented images depicting expressions of happiness (Happy), neutrality (Neutral), or sadness (Sad) on the faces of familiar therapists.
In total, the dataset includes six distinct categorical variables and 375 ROIs. This comprehensive dataset enables a detailed exploration of neural dynamics in response to varied cognitive tasks and emotional stimuli, facilitating a robust assessment of our model’s performance in real-world scenarios. Figure 3 depicts how the read dataset looks like. We attempt to predict the underlying task using both latent processes and the discrete latent process . The confusion matrices of these classifications are depicted in Fig. 4 (a) and (b). The dimensionality of is 10, and the dimensionality of is one. We observe that the model successfully extracts information from the high-dimensional time series and summarizes them in and . However, it’s worth noting that the accuracy using alone will likely be lower, as the model is forced to compress the information into such a low dimension. Nevertheless, this low dimensionality is valuable for interpretability purposes. To further interpret the results, we selected one patient with high accuracy and plotted the probability of each task when , for . Figure 5 illustrates these probabilities, demonstrating how the model has compressed the information about each task into the latent variable .”
Fig. 3:

Real Data: The dataset comprises 375 time series. Only five are visualized here.
Fig. 4:
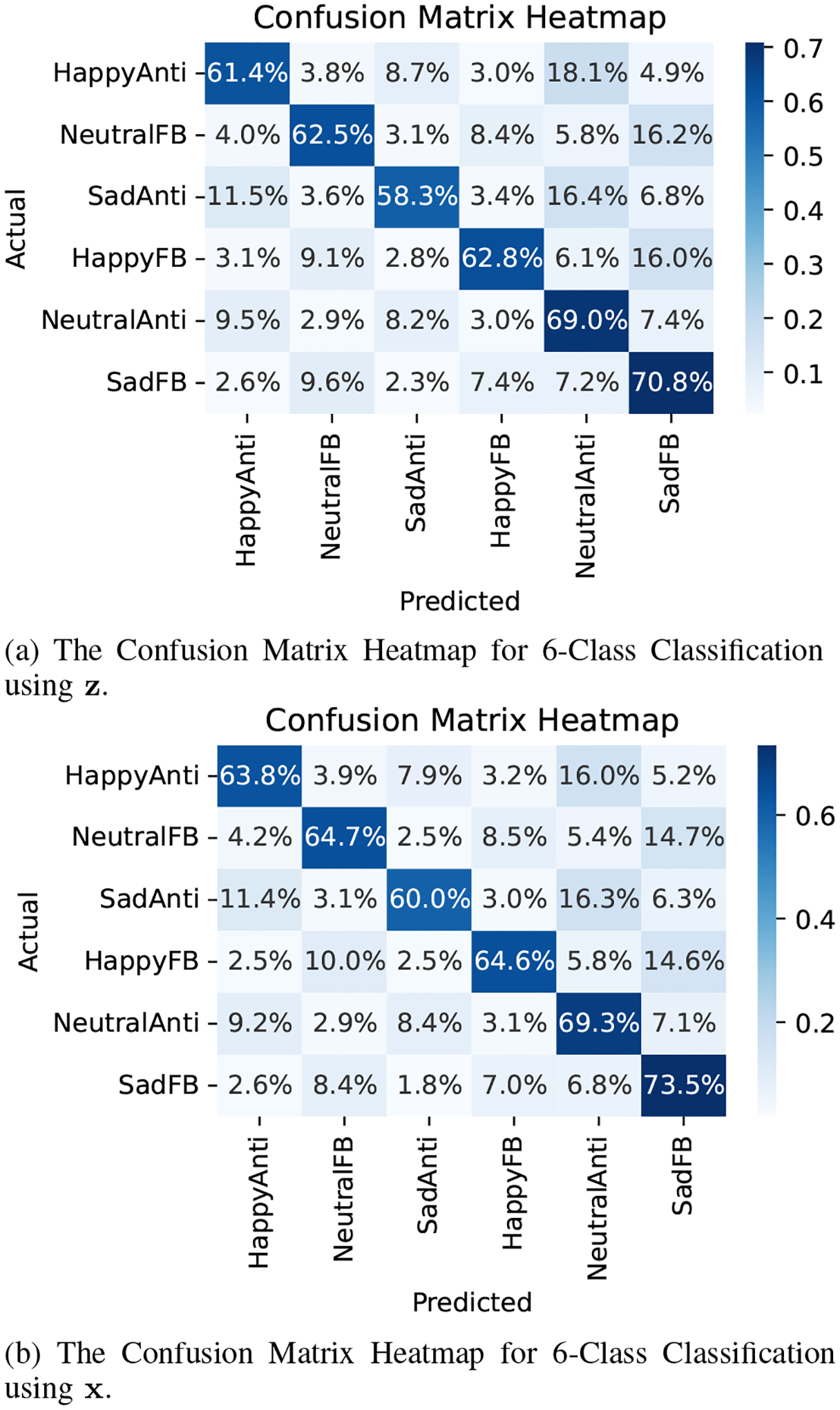
Downstream task using the learnt representation.
Fig. 5:

Task information embedded in for a single selected patient.
VI. Conclusion
In this study, we introduced a novel deep architecture for interpretable representation learning in multivariate time series, particularly focusing on fMRI data analysis. Our approach effectively captures significant features while maintaining interpretability, as demonstrated through empirical assessments on synthetic and real-world fMRI data. By emphasizing the importance of interpretability and presenting the model’s efficacy, we contribute to advancing the field of discrete representation learning for complex time series. Future research can explore higher dimensional fMRI data as well as broader applications beyond fMRI analysis.
Fig. 2:
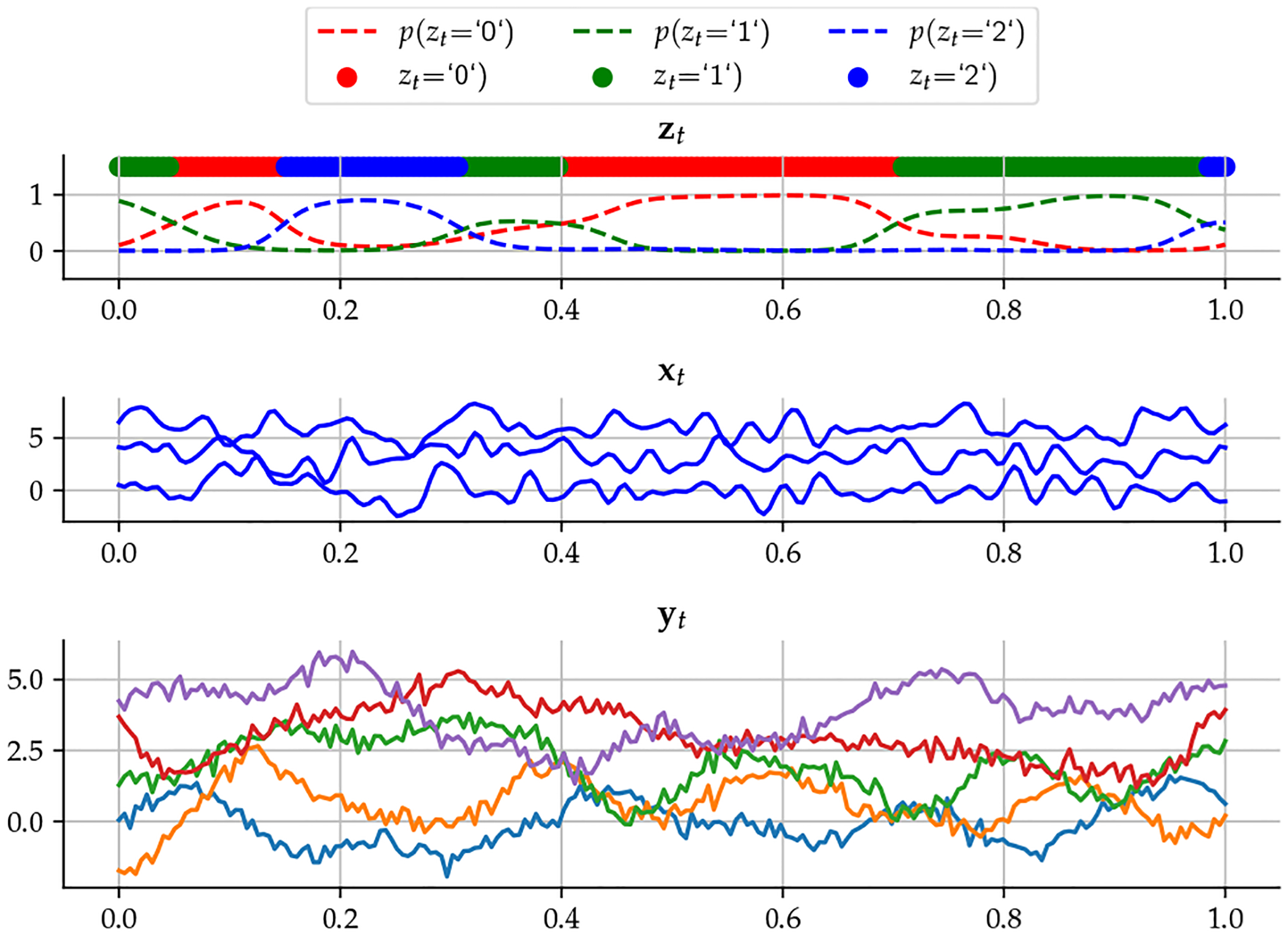
Synthetic data and latent variables and .
References
- [1].Ajirak Marzieh, Liu Yuhao, and Djurić Petar M, “Filtering of high-dimensional data for sequential classification,” in 27th International Conference on Information Fusion. IEEE, 2024. [Google Scholar]
- [2].Gal Yarin, Chen Yutian, and Ghahramani Zoubin, “Latent Gaussian processes for distribution estimation of multivariate categorical data,” in International Conference on Machine Learning, 2015, pp. 645–654. [Google Scholar]
- [3].Liu Yuhao, Ajirak Marzieh, and Djurić Petar M, “Sequential estimation of Gaussian process-based deep state-space models,” IEEE Transactions on Signal Processing, 2023. [Google Scholar]
- [4].Ajirak Marzieh and Djurić Petar M, “A Gaussian latent variable model for incomplete mixed type data,” in ICASSP 2023–2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2023, pp. 1–5. [Google Scholar]
- [5].Ajirak Marzieh, Liu Yuhao, and Djurić Petar M, “Ensembles of Gaussian process latent variable models,” in 2022 European Signal Processing Conference (EUSIPCO), 2022. [Google Scholar]
- [6].Ajirak Marzieh, Heidi Preis, Lobel Marci, and Djurić Petar M, “Learning from heterogeneous data with deep Gaussian processes,” in International Workshop on Computational Advances in Multi-Sensor Adaptive Processing (CAMSAP). IEEE, 2023. [Google Scholar]
- [7].Maddison Chris J, Mnih Andriy, and Teh Yee Whye, “The concrete distribution: A continuous relaxation of discrete random variables,” arXiv preprint arXiv:1611.00712, 2016. [Google Scholar]
- [8].Jang Eric, Gu Shixiang, and Poole Ben, “Categorical reparameterization with gumbel-softmax,” arXiv preprint arXiv:1611.01144, 2016. [Google Scholar]
- [9].Mnih Andriy and Gregor Karol, “Neural variational inference and learning in belief networks,” in International Conference on Machine Learning. PMLR, 2014, pp. 1791–1799. [Google Scholar]
- [10].Mnih Andriy and Rezende Danilo J, “Variational inference for monte carlo objectives,” arXiv preprint arXiv:1602.06725, 2016. [Google Scholar]
- [11].Van Den Oord Aaron, Vinyals Oriol, et al. , “Neural discrete representation learning,” Advances in neural information processing systems, vol. 30, 2017. [Google Scholar]
- [12].Blei David M, Kucukelbir Alp, and McAuliffe Jon D, “Variational inference: A review for statisticians,” Journal of the American statistical Association, vol. 112, no. 518, pp. 859–877, 2017. [Google Scholar]
- [13].Rahimi Ali and Recht Benjamin, “Random features for large-scale kernel machines,” Advances in Neural Information Processing Systems, vol. 20, 2007. [Google Scholar]
- [14].Liu Yuhao, Ajirak Marzieh, and Djurić Petar M., “Sequential estimation of Gaussian process-based deep state-space models,” IEEE Transactions on Signal Processing, pp. 1–14, 2023. [Google Scholar]
- [15].Rasmussen Carl Edward, “Gaussian processes in machine learning,” in Summer School on Machine Learning. Springer, 2003, pp. 63–71. [Google Scholar]
- [16].Quiñonero-Candela Joaquin and Rasmussen Carl Edward, “A unifying view of sparse approximate gaussian process regression,” Journal of Machine Learning Research, vol. 6, no. Dec, pp. 1939–1959, 2005. [Google Scholar]
- [17].Damianou Andreas, Titsias Michalis, and Lawrence Neil, “Variational gaussian process dynamical systems,” Advances in neural information processing systems, vol. 24, 2011. [Google Scholar]