

Abstract
In the information age, novel hardware solutions are urgently needed to efficiently store and process increasing amounts of data. In this scenario, memory devices must evolve significantly to provide the necessary bit capacity, performance, and energy efficiency needed in computation. In particular, novel computing paradigms have emerged to minimize data movement, which is known to contribute the largest amount of energy consumption in conventional computing systems based on the von Neumann architecture. In-memory computing (IMC) provides a means to compute within data with minimum data movement and excellent energy efficiency and performance. To meet these goals, resistive-switching random-access memory (RRAM) appears to be an ideal candidate thanks to its excellent scalability and nonvolatile storage. However, circuit implementations of modern artificial intelligence (AI) models require highly specialized device properties that need careful RRAM device engineering. This work addresses the RRAM concept from materials, device, circuit, and application viewpoints, focusing on the physical device properties and the requirements for storage and computing applications. Memory applications, such as embedded nonvolatile memory (eNVM) in novel microcontroller units (MCUs) and storage class memory (SCM), are highlighted. Applications in IMC, such as hardware accelerators of neural networks, data query, and algebra functions, are illustrated by referring to the reported demonstrators with RRAM technology, evidencing the remaining challenges for the development of a low-power, sustainable AI.


1. Introduction
According to the von Neumann architecture, a computer consists of two essential parts, namely, the central processing unit (CPU) and the memory. The latter must support both instructions and data for the computation, which is executed in the CPU. With the massive increase of data and the widespread use of artificial intelligence (AI) in our modern digital society, memory and computing demand have seen an exponential increase which dictates the introduction of novel memory technologies and computing paradigms. In particular, there is a need to introduce a novel memory concept that can provide a large density combined with a high performance in terms of data access time, thus unifying the properties of storage and memory modules. In addition, for modern AI and machine learning applications, the processing time and energy consumption become limited by the data movement between the memory and the CPU. Overcoming this fundamental gap of performance requires the introduction of novel computing paradigms, such as in-memory computing (IMC), capable of moving a large portion of the computation within the memory, thus alleviating the memory bottleneck. ,
In this scenario, memory technologies acquire paramount importance, as they must provide a broad scope of properties, including nonvolatile storage, low voltage/current operation, high scaling capability, compatibility with the CMOS process flow, and integration in the back end of the line (BEOL). The last 25 years have seen the introduction of several emerging nonvolatile memory (NVM) technologies, such as resistive switching random-access memory (RRAM), phase change memory (PCM), magnetic random-access memory (MRAM), and ferroelectric random-access memory (FeRAM). , Historically, these technologies have been known for a relatively long time due to pioneering research works on a variety of materials and devices, such as oxides or chalcogenides. Currently, these memory concepts can hardly replace existing established technologies, such as static random-access memory (SRAM), dynamic random-access memory (DRAM), and nonvolatile flash memory, due to insufficient performance and excessive cost. On the other hand, emerging memories can provide a unique solution for embedded memories, where a high-capacity memory needs to be integrated into the same chip of a computing system, such as a microcontroller unit (MCU) for edge computing. Emerging memories also provide an improved radiation hardness compared to conventional CMOS-based memories, such as Flash memories. In particular, RRAM has been shown to have excellent radiation hardness, which is crucial for radiation-tolerant systems in spaceborne applications. , Also, emerging memory devices combining nonvolatile storage and high density are a suitable platform for IMC circuits for AI applications.
Among the emerging NVM technologies, RRAM displays a simple device structure and fabrication process that are amenable to crossbar array (CBA) architecture and 3D integration to achieve extremely high density. The nonvolatile switching behavior ensures good retention even at elevated temperatures, while program/erase cycling shows strong endurance, making RRAM an ideal solution for embedded nonvolatile memory (eNVM). The properties of RRAM devices match well with the requirements of several computing applications, such as nonvolatile behavior, multilevel operation, good scaling capability, and high linearity. RRAM can also offer unconventional properties such as stochastic phenomena and short-term memory effects, which are useful in selected computing applications. All of these properties can be tuned and optimized by careful materials and device engineering as well as circuit design. Usually, computing application requirements are met by a detailed design/technology co-optimization (DTCO), where the most convenient solution is provided by a specific set of materials, stack, process steps, device geometry, and circuit design.
Overall, thanks to its simple structure and flexible concept, RRAM appears as a strong candidate for advanced memory technology and IMC. However, many challenges still need to be addressed, including the optimization of the programming precision, linearity, and endurance, as well as the feasibility and energy efficiency of the overall RRAM computing system, which also includes ancillary circuits such as the analog-digital converters, the programming periphery circuits, the select/unselect decoders, and the digital controller. To solve these fundamental challenges, a cross-disciplinary research approach is essential, where materials engineering, device technology, circuit design, conceptual architecture, and final application, including its requirements, are fully understood and carefully monitored.
To meet these goals, the purpose of this work is to provide a comprehensive overview of RRAM from materials, devices, circuits, systems, and applications viewpoints. The review is organized as follows. Section provides an overview of RRAM devices including device structure, characteristics, and operation. Section describes the RRAM cell and array structure for memory applications, including a summary of presented demonstrators in the literature. Section presents RRAM circuits for computing primitives, such as matrix-vector multiplication (MVM) and inverse matrix calculation. Section addresses RRAM-based computing applications, focusing on various AI, neural networks, and other popular machine learning tasks and highlighting the specific requirements which are essential for each computing task. Section provides a conclusion and a perspective on the open research challenges.
2. RRAM Devices
Resistive switching random-access memory (RRAM) is a memory device capable of changing its resistance upon the application of electrical pulses. − Most typically, the RRAM structure consists of a metal–insulator–metal (MIM) stack, where the insulating layer can be modified by the presence and growth of a conductive filament (CF) shunting the two metal electrodes. This is shown in Figure a, indicating the MIM where a CF connects the metal electrodes across the insulating layer. Modification of the CF leads to a resistance change of the MIM structure, which is thus responsible for the resistance switching effect. The CF is generally first introduced in the MIM structure by an electrical forming operation, also known as electroforming, which consists of a controlled voltage-induced breakdown operation of the insulating layer. Then, the CF can be activated or deactivated by generation of a depleted gap across the filament as shown in Figure b. Figure c shows the typical current–voltage (I–V) curve for a RRAM device, displaying the set transition for the switching from high to low resistance and the reset transition for the switching from high to low resistance. The type of switching displayed in Figure c is the unipolar switching of RRAM, where the set and reset transition can take place at the same voltage polarity. , Most relevant for the memory and computing applications of RRAM is the bipolar characteristic in Figure d, where the set and reset transitions take place at opposite polarities. The set transition generally shows a steep slope in the I–V curve from high to low resistance, which is attributed to the negative differential resistance (NDR) due to CF formation and the consequent growth of a low resistance path across the oxide. The reset transition instead shows a more gradual, continuous change in the I–V curve, as the CF is gradually disconnected or retracted in response to the electric field.
1.

Sketch of RRAM and its switching characteristics. (a, b) Sketch of the RRAM device, including the conductive filament (CF). (c) Schematic I–V curve for a unipolar switching RRAM device. (d) Schematic I–V curve for a bipolar switching RRAM device. Reproduced from ref . Copyright 2016 IOP Publishing Ltd. with Creative Commons Attribution 3.0 license https://creativecommons.org/licenses/by/3.0/.
In the case of unipolar switching, although set/reset operations occur at the same polarity, they differ by the current condition, in that the set operation requires a limitation in current known as the compliance current (CC) to prevent the destructive breakdown of the device. The CC is generally adopted for the set process of bipolar switching as well, to minimize degradation and enable tight control of the final resistive state. The two stable states of RRAM are known as the high resistance state (HRS) and the low resistance state (LRS), which are obtained after the reset and set transition, respectively.
Early reports about resistive switching (RS) have been published in the 1960s within studies of the reversible breakdown phenomena in thin metal oxides, such as SiO x , Al2O3, Ta2O5, ZrO2, and TiO2. In general, these layers displayed an NDR effect which was explained by a space-charge-limited current (SCLC) originating from the trapping of electrons in localized states. Studies in niobium oxide (Nb2O5) layers demonstrated bistable RS between two stable states. Figure shows one of the first reported I–V curves for RS, where the LRS (a) is first subject to a reset transition to the HRS at negative voltage (b), followed by a set transition back to the LRS at positive voltage (c). Both the HRS and LRS were found to be stable, thus supporting the possibility of conceiving a nonvolatile memory (NVM) from a RRAM device.
2.

Measured I–V curves of a MIM stack with a Nb2O5 insulating layer. Resistance switching is demonstrated where the application of a negative voltage (b) causes a reset transition from LRS (a) to HRS, and the application of a positive voltage (c) causes a set transition from HRS to LRS. Reproduced with permission from ref . Copyright 1965 American Institute of Physics.
Those early studies were mostly aimed at elucidating the fundamental transport properties of insulating layers, such as transition metal oxide. However, in the early 2000s interest in RS phenomena rose significantly for studying NVM applications. Similar to phase change memory (PCM), ferroelectric random access memory (FeRAM), and magnetic random access memory (MRAM), RRAM devices were extensively studied with the specific purpose of developing a new class of memory technology. In particular, research on these emerging memory concepts was aimed at assessing the scalability, density, performance, energy consumption, reliability, and cost of the technology, to be compared to conventional memories of complementary metal-oxide-semiconductor (CMOS) technology, such as static random access memory (SRAM), dynamic random access memory (DRAM) and Flash NVM. Given the excellent combination of speed, reliability, low voltage operation, and endurance, RRAM devices were even targeted as potential ‘universal’ memory, capable of satisfying the requirements of all major device technologies, from SRAM to Flash.
2.1. Unipolar Switching RRAM
Unipolar switching in NiO-based RRAM devices first attracted interest as a high-density NVM technology. Figure shows the measured I–V curve for polycrystalline NiO films deposited on Pt/Ti/SiO2/Si substrates, indicating unipolar switching for both positive and negative applied voltages, also referred to as nonpolar switching. Two types of switching are shown in Figure , namely, nonvolatile, or memory, switching (Figure a) and volatile, or threshold, switching (Figure b), where the set transition results in an unstable LRS, which spontaneously switches back to HRS within a short retention time. Memory and threshold switching in NiO were found for different ratios of Ni and O concentrations in the NiO film, which were Ni/O = 1.05 and 0.95 in Figure a and b, respectively. Memory switching took place under the same polarity by applying a proper k during the set transition. On the other hand, threshold switching leads to a transition from HRS to LRS with CC of 3 mA; however, the HRS was recovered as the voltage decreased below a characteristic holding voltage VH. Although not useful for NVM technology, threshold switching has a significant role in several applications for both storage, e.g. select devices in CBAs, and computing, such as short-term memory and oscillating circuits. Unipolar memory switching with RRAM was explored given the simplicity of the circuit integration, where not only a field-effect transistor (FET) but also unipolar diodes or bipolar junction transistors can be adopted for high-density NVM CBAs. Metal-oxide p–n diodes suitable for integration in the back-end of the line (BEOL) of the CMOS process flow were demonstrated as RRAM selectors, thus enabling 3D stackable high-density CBAs.
3.

Measured I–V curves for Pt/NiO/Pt RRAM devices with memory switching (a) and threshold switching (b) under either polarity, thus demonstrating nonpolar unipolar switching. The different behaviors are due to different Ni/O ratios in the switching layer, namely, 1.05 and 0.95 in (a) and (b), respectively. Reproduced with permission from ref . Copyright 2004 AIP Publishing.
2.2. Bipolar Switching RRAM
While advantageous from an integration viewpoint, unipolar switching RRAM devices showed poor reproducibility of switching mainly due to the lack of control of the CF size and resistance in the LRS. Unipolar switching is mainly explained by thermochemical oxidation and diffusion of the material locally at the CF as a result of Joule heating, which lacks directionality. Bipolar switching RRAM then attracted interest because of the improved ability to control the ionic migration responsible for CF growth and disconnection. Contrary to thermally induced oxidation and diffusion, field-induced migration can be directed toward either electrode side, thus enabling the controllable modulation of CF resistance. After the seminal works of the 1960s, studies on bipolar switching of metal oxides were revived by covering perovskite materials, such as SrZrO3, and binary metal oxides such as TiO2 and HfO2. ,, Among the latter materials, HfO2 raised considerable interest, mostly thanks to the relevance of this material as a high-k gate dielectric for the logic CMOS technology. ,
Figure a shows the measured I–V curves of HfO2-based RRAM, indicating bipolar switching with controllable LRS resistance via the CC. The bipolar switching effect can be understood by the directional migration of ionic species, such as oxygen vacancies responsible for the higher local conductivity in the CF. During reset, field- and temperature-induced ionic migration cause the opening of a depleted gap across the CF, thus bringing the device into an HRS. By increasing the time and/or the voltage of the reset operation, the gap length increases its length, thus resulting in a higher resistance and enabling tight control of the HRS resistance. During the set transition, the applied field causes the migration of ions in the opposite direction, thus replenishing the previously opened gap and restoring the LRS conductance. The CC plays a key role during the set transition by limiting the final resistance of the LRS to the value R = V C /I C , where V C is a critical voltage, characteristic of the microscopic ion-migration process, and I C is the CC. , The critical voltage V C represents the voltage value for the acceleration of the CF growth by ionic migration at the time scale characteristic of the experiment, e.g. about 1 s for a typical quasi-static experiment. Experimental results indicate that this voltage increases at decreasing times during the set transition. Due to the weak dependence of V C among different RRAM materials, the LRS resistance was found to follow a universal behavior when plotted as a function of the CC. Note that ionic migration is a directional process guided by the field, thus supporting the repeatability of the set-reset process at the basis of cycling endurance. Cycle-to-cycle variability is also strongly reduced compared to unipolar switching RRAM, as the same defects are consistently reused during bipolar set/reset processes, thus mitigating defect-number variation. HfO2-based RRAM also showed excellent switching speed and scaling in the 10 nm range, thus supporting this materials system as a promising solution for scalable RRAM.
4.

Measured I–V curves for bipolar switching RRAM devices, namely Ti/HfO2/Pt RRAM (a) and Cu/AlO x conductive-bridge random-access memory (CBRAM) device (b). Panel (a) is adapted with permission from ref . Copyright 2008 IEEE. Panel (b) is adapted with permission from ref . Copyright 2013 IEEE.
2.3. RRAM Stack Optimization
Despite the outstanding performance of HfO2-based RRAM, it was soon realized that RRAM optimization requires an overarching engineering effort aimed at the whole RRAM stack, including both metal oxide and metal electrodes, in terms of composition profile, material structure, and interfaces. Several RRAM stacks were then reported with the objective of optimizing the device behavior from various perspectives.
Figure b shows the I–V curve for a conductive-bridge random-access memory (CBRAM), also known as the electrochemical metallization (ECM) device. In CBRAM, the top electrode material is replaced by an active metal, such as Cu, ,− Ag, or CuTe. Application of a positive voltage to the top electrode causes the field-induced oxidation and migration of electrode cations across the insulating layer, also known as the electrolyte. The latter consists of a chalcogenide layer, such as GeSe or GeS2, or an oxide layer, such as Al2O3, ZrO x , SiO2 or GdO x . Compared to conventional oxide-based RRAM devices, CBRAMs display a larger resistance window, in a range of 104 compared to about 102 for the case of metal-oxide RRAM. The higher resistance window can be explained by the higher ionic mobility of Cu and Ag in CBRAM compared to oxygen vacancies and enables the design and integration in high-density memory arrays. The relatively high ionic mobility of Cu and Ag can be challenging due to thermally induced diffusion during the BEOL process at 400 °C. Process-induced Cu diffusion was reduced by diffusion barriers such as TiW inserted between the electrolyte and the Cu injecting electrode without compromising the memory performance. Thanks to the large resistance window, multilevel operation over a resistance range of 6 orders of magnitude of the LRS was demonstrated by CC-control of the set transition. Due to the high mobility of the cation species, especially in the case of Ag, the CF generally displays a short retention time, which enables short-term memory and other dynamic properties that become useful in neuromorphic computing (Section ).
Binary metal oxide layers also require careful design and engineering to improve the electrical performance. Figure a shows the transmission electron microscopy (TEM) image of the cross-section of a RRAM device with a TiN/Ti/HfO x /TiN stack. A thin Ti cap was introduced between TiN and HfO x to enable oxygen exchange according to the following reaction:
5.

Top electrode engineering for bipolar switching RRAM devices. (a) TEM image of a TiN/Ti/HfO x /TiN stack for a bipolar switching RRAM device. (b) XPS depth profile of a TiN/Ti/HfO2/TiN stack indicating the presence of the OEL. Panel (a) is adapted with permission from ref . Copyright 2008 IEEE. Panel (b) is adapted with permission from ref . Copyright 2009 IEEE.
| 1 |
thus resulting in an intermediate oxygen exchange layer (OEL) with a high concentration of oxygen vacancies. The OEL is clearly shown in Figure b, reporting the X-ray photoelectron spectroscopy (XPS) profile of the stack in Figure a and indicating a relatively wide transition region between the TiN and HfO x layers. The generation of oxygen vacancies provides an initial reservoir of defects available for migration during forming, set, and reset operation of the RRAM device, thus supporting good performance and reliability of the device. Similar cap layers to form the OEL were adopted in several RRAM reports, with the cap consisting of Ti, , Hf, or Ta. ,
To better assess the impact of the OEL on the device performance, Figure a shows the measured I–V curves for a HfO x -based RRAM device under forming, set, and reset operation. The forming voltage is critical for the device, since it dictates the size of the selector and decoder transistors, which must sustain part of the applied voltage soon after the forming event. The forming voltage is directly linked to the leakage current across the pristine device, as shown in Figure b. Here, the leakage was increased and the forming voltage was decreased by increasing the thickness of the Ti cap layer in the RRAM stack, resulting in a more extensive O exchange and, hence, a larger concentration of oxygen vacancies. Optimizing the metal cap and thermal annealing to activate the O exchange are essential to control and minimize the forming voltage. Forming-free RRAM devices have also been developed to mitigate the forming issue.
6.

Impact of OEL on forming. (a) Measured I–V curves showing set, reset and forming characteristics for a HfO x -based RRAM. (b) Measured I–V curves showing an increase of leakage current and a decrease of forming voltage for increasing thickness of the Ti cap layer. Panel (a) is adapted with permission from ref . Copyright 2011 IEEE. Panel (b) is adapted with permission from ref . Copyright 2013 IEEE.
Stack optimization is important not only for forming but also for set operation. A key issue of both forming and set is the abrupt transition to a lower resistance, which can result in a high-voltage degradation of the select transistor, as well as in current overshoot effects causing device overprogramming and excessive reset currents. To minimize the overshoot effects, a local series resistance can be integrated close to the RRAM device to accommodate part of the applied voltage at the set/forming transition. Such close integration of the switching device and the conductive device can be achieved by bilayer structures, where one layer acts as a series resistance while the other layer acts as the proper switching layer. This is the case for the Ta2O5/TaO x bilayer structures shown in Figure a, consisting of a relatively thick conductive TaO x layer and a relatively thin switching Ta2O5 layer. Figure b shows the cross-sectional TEM image of the RRAM stack, including the Pd top and bottom electrodes. As shown in Figure a, the CF extends across only the thin switching layer, whereas the conductive layer only serves as a series resistance to prevent excessive degradation to the select transistors and overshoot effects. The integration of the series resistance within the RRAM stack enables high scalability and low parasitic capacitances. Bilayer structures based on the TiN/TaO x /HfO2/TiN stack, where TaO x and HfO2 serve as conductive and switching layers, respectively, were recently reported to enable analog-type switching with improved control of the HRS and LRS states.
7.

Bilayer RRAM structures. (a) Sketch and (b) cross-sectional TEM image of a Ta2O5/TaO x bilayer, where Ta2O5 and TaO x layers serve as the switching and the conductive layers, respectively. (c) Cross-sectional TEM of a vertical RRAM device with TiO2/TaO x bilayers, with close-up images of the (d) top and (e) bottom device in the vertical structure. Panels (a) and (b) are reprinted from ref . Copyright 2014 ACS. Panels (c,d,e) are adapted with permission from ref . Copyright 2016 IEEE.
Similar RRAM structures consisting of TiO2/TaO x bilayers were reported to enable analog switching in vertical RRAM devices as shown in Figure c,d,e. ,− Atomic layer deposition (ALD) is generally adopted as a deposition tool to tightly control the thickness, uniformity, composition, and structure of each layer in the bilayer stack. Analog switching was optimized in bilayer stacks, such as HfO2/Al:TiO2 and TaO x /HfO2, to achieve high linearity, high symmetry and high endurance, which are essential in hardware accelerators for supervised training of neural networks (see Section ).
In addition to the top electrode and oxide layers, bottom electrode engineering is also essential, particularly for reliability optimization. Cycling endurance in bipolar RRAM devices was shown to be limited by the unwanted set transition occurring under negative polarity when the normal set process was expected under positive voltage. To prevent a negative set, the bottom electrode should be as chemically inert as possible. RRAM with bottom electrodes based on inert materials such as Pt, C, and Ru has been shown to display excellent retention, thanks to a reduced chemical ionization of the bottom electrode and reduced interaction with the oxide layer.
2.4. Nonfilamentary RRAM Devices
Although most of the RRAM implementation relies on the filamentary concept, RRAM devices based on uniform (or interface) switching were also reported. In these devices, resistance switching results from a change in the resistivity which extends uniformly across the active device area via an electrically induced change of the stack composition impacting the local conductivity. A possible physical mechanism for the uniform switching is illustrated in Figure , showing the density profile of oxygen vacancies in the LRS (a) and the HRS (b). First, oxygen vacancies are uniformly distributed in an OEL at the top-electrode side, thus resulting in relatively high conductivity across the RRAM oxide layer. The application of a negative voltage to the top electrode results in the migration of oxygen ions toward the OEL, thus causing the reoxidation of the OEL with a local increase of resistivity due to the formation of a Schottky barrier. The reoxidized layer is indicated as Oxide B in the figure, where reoxidation has taken place via partial depletion of oxygen from the Oxide A layer.
8.
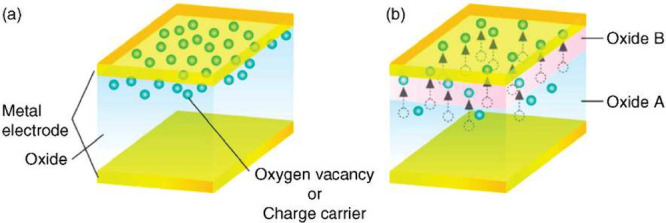
Uniform switching RRAM concept illustrating the defect distribution in the LRS (a) and HRS (b). Migration of oxygen vacancies from the top electrode side to the bottom electrode side under a negative applied bias in (b) causes the top electrode reoxidation of the OEL at the top electrode (oxide B in the figure), thus causing an enhanced Schottky barrier, and hence reduced carrier injection characterizing the HRS. Reproduced with permission from ref . Copyright 2008 IEEE.
The most typical materials showing uniform switching are perovskites, such as manganites, − where switching was shown to occur by oxygen transfer from the manganite layer to an active electrode, such as Al or Sm. Uniform switching can be generally recognized by the absence of an abrupt set transition and from the linearity of LRS and HRS resistance on the device area. Given the area-scaling property of the programming current, uniform switching RRAM has been considered for ultralow-power RRAM suitable in high-density 3D CBAs.
2.5. RRAM Area Scaling
Device scaling is among the most important properties of any memory concept, to support area scaling, bit-cost reduction, and competitiveness compared to conventional CMOS-based memory concepts, such as SRAM, DRAM, and Flash. RRAM scaling has been supported by several reports, evidencing the ability to reduce both the area and thickness scaling. Figure a shows a top-view SEM image of a RRAM device with a TiN/Hf/HfO x /TiN RRAM stack where the size of both the top and bottom electrodes was defined in the range of 10 nm. This is shown in Figure b and c, reporting the TEM cross-sectional images of the device along the top and bottom electrodes, respectively. A key concern of area downscaling was shown to be the forming voltage, which tends to increase according to the Poisson area scaling of time-dependent dielectric breakdown (TDDB). To compensate for such an area dependence, the switching layer thickness can be reduced and optimized by composition profiling. For optimized scaling behavior of the forming voltage, an amorphous structure of the oxide layer is preferred compared to a polycrystalline structure, where grain boundaries might induce local nonuniformities.
9.

Scaling of RRAM devices. (a) Top view SEM image of TiN/Hf/HfO x /TiN RRAM device with CBA structure. (b) Cross-sectional TEM image of the same device along the top electrode direction, exhibiting the 10 nm width of the bottom electrode. (c) Cross-sectional TEM image along the bottom electrode direction, exhibiting the 10 nm width of the Hf cap at the top electrode side. Reproduced with permission from ref . Copyright 2011 IEEE.
Sub-10 nm scaling of RRAM devices was shown by advanced techniques based on vertical film deposition and fin exposure. RRAM CBA circuits with a 2 nm width of the top and bottom electrodes were demonstrated, while a line pitch of about 12 nm was achieved, corresponding to a device density in the range of 4.5 terabits per square inch. The switching of the TiO2/HfO2 stack was shown to occur with a low current in the range of about 50 nA.
2.6. RRAM Based on 2D Materials
In addition to area and pitch scaling, thickness scaling is essential to enable a good aspect ratio of the device geometry and a low forming voltage. Toward this goal, RRAM with atomic thickness was demonstrated by adopting a 2D transitional metal dichalcogenide (TMD) monolayer as the switching layer. Various types of single-layer TMDs were demonstrated as switching layers, including MoS2, MoSe2, WS2, and WSe2 with Ag and Au electrodes. This device was dubbed ‘atomristor’ to highlight its ability for thickness miniaturization to the atomic scale. The TMD monolayer was deposited by chemical vapor deposition (CVD) or metal–organic CVD (MOCVD) and then transferred on the bottom electrode and completed with top electrode deposition and patterning. Figure a shows the sketch of the device while Figure b shows the cross-section of the RRAM devices, evidencing the atomically thin MoS2 monolayer between Au top and bottom electrodes. Figure c shows the crystalline atomic structure of the MoS2 layer, indicating the presence of S vacancies, which potentially influence the forming and switching behavior of the device.
10.

RRAM device with TMD switching layer. (a) Sketch of the device with CBA structure evidencing the TMD layer sandwiched between the top and the bottom electrodes. (b) TEM cross-sectional image illustrating the Au/MoS2/Au stack with monolayer thickness and atomic smoothness of the interface. (c) Scanning tunneling microscopy (STM) image of a monolayer MoS2 evidencing the S vacancy defects. Reprinted from ref . Copyright 2017 ACS.
Thickness scaling was further demonstrated in van der Waals (vdW) structures, where both the switching layer and the electrode consist of a 2D material. The vdW heterostructure graphene/MoS2–x O x /graphene was demonstrated in a RRAM device with switching endurance of up to 107 and with the possibility for deposition on flexible organic substrates. RRAM devices based on hexagonal boron nitride (hBN), an insulating 2D material, were demonstrated in combination with MoS2-based select transistors, thus supporting the feasibility of 2D-based one-transistor/one-resistor (1T1R) memory in the BEOL at relatively low temperature. Wafer-scale integration and full-CMOS integration at the 180 nm node were recently demonstrated for hBN-based RRAM devices.
2D semiconductors provide an attractive solution as active channel materials for scalable CMOS transistors, thanks to their atomic-scale thickness and their capability for 3D, BEOL integration. , Significant progress has been recently reported to support 2D semiconductors as a feasible technology to extend the Moore’s law of CMOS transistor scaling. −
Memory devices based on 2D semiconductors include not only RRAM but also charge-based concepts such as floating gate memories , and charge trap memories. , RRAM and transistor functionalities were merged in a new device named ‘memtransistor’, consisting of a 3-terminal device with a 2D-semiconductor channel controlled by a gate and contacted by source and drain. − The device can operate as a conventional transistor, where the gate voltage enables control of the channel conductivity. However, the application of a relatively large voltage across the drain and source can result in RS of the channel conductance, similar to RRAM operation. The switching mechanism in MoS2-based memtransistors has been explained by the field-induced dislocation migration in the polycrystalline MoS2 channel , or the modulation of the Schottky barrier at the metal–semiconductor contact.
Figure a shows a top-view SEM image of a memtransistor device based on a MoS2 channel with Ag source and drain separated by a 18 nm gap. The channel conduction was controlled by the gate voltage V G applied to the Si back gate, with a SiO2 layer of thickness 285 nm. To initiate the RS behavior, a forming operation was initially carried out by applying a voltage of 1.8 V across the source and drain. Figure b shows the I–V curves after formation, indicating a set transition at about V DS = 0.9 V from HRS to LRS, followed by a spontaneous decay from LRS to HRS as V DS is reduced below a characteristic holding voltage V hold of about 0.2 V. The volatile switching can be attributed to the formation of a conductive bridge shunting the source and drain as a result of voltage-induced Ag migration on the surface of the MoS2 channel. The decay of the Ag CF can be explained by its instability as a result of the large surface energy, which is minimized by collapsing the elongated CF shape into isolated nanoparticles, as already shown by in situ experimental results and simulations. More detailed time-resolved studies indicate a retention time in the range of about 100 ms. Figure c shows the measured V set and V hold as a function of V GS from Figure b, indicating that the set and holding voltage do not depend on the applied gate voltage, which only controls the channel leakage current in the HRS. Similar memtransistor devices were reported, although with an asymmetric structure of source and drain electrode materials. , Thanks to the controllability of the gate and the drain, memtransistors are a promising device technology for neuromorphic computing applications.
11.

MoS2-based memtransistor device. (a) Top-view SEM image of the back-gated MoS2-based transistor with a Ag source and drain. (b) I–V curves of the set transition at V set followed by a spontaneous collapse to the HRS at the characteristic holding voltage V hold . Changing the gate voltage affects only the HRS current without any impact on V set or LRS resistance, with the latter being controlled by the CC. (c) Measured V set and V hold as a function of V GS . Reproduced with permission from ref . Copyright 2022 Wiley VCH.
3. RRAM Cell and Array Structure
For memory and computing applications, the RRAM device element can be replicated several times to realize a device array arranged in rows and columns, usually referred to as word lines (WLs) and bit lines (BLs). Figure shows a summary of the various structures for the RRAM cell and the array, including one-resistor (1R) structure (a), one-selector/one-resistor (1S1R) structure (b), one-transistor/one-resistor (1T1R) structure (c), and one-capacitor (1C) structure (d). In the 1R structure, every RRAM device is connected between a row and a column of the array. While being particularly attractive from a density point of view, the 1R array, also referred to as passive CBA, is prone to disturb effects during set/reset programming and to sneakpath problems during readout.
12.

RRAM cell and array structure. (a) One-resistor (1R) array, where RRAM is connected between each row and column in the CBA. (b) One-selector/one-resistor (1S1R) array, where each RRAM element is combined with a selector device in series. (c) One-transistor/one-resistor (1T1R) array, where each RRAM element is combined with a transistor device requiring an additional line for connecting the transistor gates. (c) One-capacitor (1C) array, where the RRAM is operated as a capacitor and is connected between each row and column in the CBA. Reproduced from ref . Copyright 2023 AIP Publishing with Creative Commons Attribution 4.0 license https://creativecommons.org/licenses/.
3.1. 1S1R Arrays
To prevent the sneakpath current, a nonlinear selector element can be added in series to the device in the 1S1R structure. − Thanks to the nonlinear element, when a device is selected by applying a voltage to its row and column, all other devices are subject to a smaller voltage, which translates into an exponentially lower current.
The adoption of a two-terminal selector element, such as an antifuse element, a p-n diode, or an ovonic threshold switch (OTS) device, allows maintenance of a small cell area of only 4F, where F is the lithography feature of the technology.
The selector element must satisfy a number of challenging properties, including (i) a sufficient nonlinearity, to enable safe select/unselect bias schemes where the cumulated unselected device current is negligible compared to the selected device one, (ii) a sufficient on-state current, to support the programming current of the memory RRAM device in both set and reset processes, (iii) a sufficient endurance, to enable several set, reset, and read operations of the device, (iv) a low variation of threshold switching voltage and on/off-state currents, (v) a high speed to enable fast transition from select to unselect bias modes, and (vi) a bipolar operation, where the selector device can operate under both positive and negative voltage polarities to support set and reset of bipolar RRAM devices. Oxide-based p-n diodes generally display unipolar operation due to their p-n structure; thus, they are compatible only with the class of unipolar RRAM devices. Mixed ionic/electronic conduction (MIEC) devices have been shown to display a high nonlinearity combined with a bipolar operation, although their operating voltage is relatively low compared with that of typical RRAM devices. Similarly, tunneling-based selector devices with a barrier engineered stack of oxide layers show excellent bipolar characteristics with high nonlinearity, although dielectric breakdown may critically affect endurance at the high operating voltages needed to set/reset RRAM devices.
Selector devices with threshold switching characteristics have also been explored with a range of different materials, including reversible insulator–metal transition metal oxides such as VO2 and NbO2. These metal oxides display a reversible threshold switching from an off-state to an on-state, which can be used to select and unselect devices within a crosspoint array. However, the on/off current ratio is generally not sufficient to enable cell selection within a relatively large memory array. An on/off ratio of several orders of magnitude is offered by field-assisted superlinear threshold (FAST) devices and diffusive memristors consisting of a volatile RRAM device made of an Ag electrode and an oxide layer, such as SiO2. In this case, key concerns are the stochastic variation of the threshold voltage and the relatively long retention time for the transition from on-state to the off-state, which is generally limited by the rediffusion of cations to dissolve the conductive filament responsible for the on-state conduction. The OTS selector device shows excellent properties, including high on/off current ratio, high speed and high endurance, which must be sufficient for both the programming and the read operations. A relatively high on/off ratio is generally achieved by operating the device at a high threshold switching voltage, which, however, affects the power consumption and the design of the front-end transistors in the peripheral circuits. To improve the trade-off between threshold voltage and nonlinearity, low-voltage OTS devices were recently developed. Most recently, OTS device technology gained a renewed interest in selector-only memory (SOM) devices, where a nonlinear OTS layer can both serve as a selector and store memory states consisting of different threshold voltages. Up to 8 levels of different SOM threshold voltages were demonstrated, although the mechanism for the threshold voltage variation is still under debate. −
3.2. 1T1R Arrays
The drawbacks of the 1S1R devices are alleviated in the 1T1R structure, where the 2-terminal selector device is replaced by a 3-terminal MOS transistor as shown in Figure c. − The select transistor allows for better current control during the set transition as well as minimizing the leakage current from half-selected and unselected devices, at the expense of an additional line, usually called the WL, to access the gate terminal. Another limitation of the 1T1R structure is the need for a relatively large selector device to sustain the programming current of the device. As a result, the cell area is generally much larger than 4F, which prevents achievement of a large integration density. Figure d shows the 1C passive array, where the device memory bit is encoded in the capacitance instead of the device resistance, which is typical of ferroelectric materials and devices.
3.3. RRAM Array Demonstrators
Table reports a summary of RRAM technology demonstrators, namely prototypes of memory arrays with a density of at least 1 kb. ,− Prototypes are listed for increasing years of the report, between 2011 and 2023, evidencing a consistent decrease of the technology node from 180 nm to 12 nm. All demonstrators adopted a 1T1R structure, except for ref , where a 1S1R structure with a high capacity of 32 Gbit was reported.
1. Summary of RRAM Integrated Demonstrators ,− .
| Year | Node [nm] | Capacity | Institution | Stack | Ref |
|---|---|---|---|---|---|
| 2011 | 180 | 4 Mb | ITRI | TiN/Ti/HfO2/TiN | |
| 2011 | 130 | 384 kb | Adesto | Ag/GeS2 | |
| 2011 | 180 | 4 Mb | Sony | CuTe/GdO x | |
| 2012 | 180 | 8 Mb | Panasonic | TaN/TaO2/Ta2O5/Ir | |
| 2013 | 180 | 500 kb | Panasonic | TaN/TaO2/Ta2O5/Ir | |
| 2013 | 24 | 32 Gb | Sandisk/Toshiba | Metal Oxide | |
| 2014 | 28 | 1 Mb | TSMC | Metal Oxide | |
| 2014 | 27 | 16 Gb | Micron/Sony | Cu-based/oxide | |
| 2015 | 90 | 2 Mb | Renesas | Metal/Ta2O5/Ru | |
| 2017 | 90 | 500 kb | Winbond | TiN/HfO2/Ti/TiN | |
| 2018 | 40 | 11.3 Mb | TSMC | ||
| 2019 | 22 | 3.6 Mb | Intel | ||
| 2020 | 22 | 13.5 Mb | TSMC | ||
| 2020 | 28 | 500 kb | TSMC | ||
| 2020 | 28 | 1.5 Mb | TSMC/IMECAS | ||
| 2021 | 14 | 1 Mb | IMECAS | Cu-based/oxide | |
| 2022 | 28 | 800 kb | Infineon/TSMC | ||
| 2023 | 12 | 1 Mb | TSMC |
Figure shows the array capacity (a) and the technology node (b) as a function of the year of the demonstrator. In most cases, the prototypes in Table display relatively small capacity, aiming at the demonstration of eNVM capable of being integrated into the same chip as analog and digital circuits for sensing and processing, such as microcontroller units (MCUs). RRAM technology is among the most promising thanks to the BEOL integration requiring only metal and insulator layers for the active cell, while the CMOS select transistor can be integrated in the front-end of the line. This solution allows for overcoming the difficult integration of Flash devices in advanced CMOS nodes beyond the 28 nm node, where CMOS transistors adopt the high-k/metal-gate (HKMG) process.
13.

Summary of RRAM technology scaling according to Table . (a) Array capacity and (b) technology nodes of the reported RRAM demonstrators.
In just two cases, the capacity in Table exceeds the Gbit level, which evidences the effort to achieve RRAM arrays with high capacity approaching the typical range of Flash and DRAM. , This was possible thanks to an extremely small cell area of 4F for the 1S1R structure and 6F for the 1T1R structure.
This technological trend generally goes under the name of storage class memory (SCM), which identifies a memory technology capable of filling the gap in the memory hierarchy between volatile DRAM, characterized by relatively high performance and relatively large area, and nonvolatile Flash NAND storage, characterized by relatively small area, low cost and slow access times.
Figure a shows the TEM cross-section along the BL direction of the 1T1R array with 6F cell area in the 27 nm node. The cross-section evidences the V-shaped recess access transistors with elongated channels and buried WL and the RRAM devices sharing the same TE line, which minimizes the cell footprint along the BL direction. Figure b shows the cumulative distributions of the measured read current for the LRS and the HRS after 103 cycles for various cells, namely the integrated cell in Figure a, the intrinsic cell with larger RRAM active area and the scaled cell with larger pitch. The distributions show a similar shape and similar read window, suggesting that the integration process does not significantly affect the RRAM cell behavior. Note the relatively large statistical spread of the HRS read current, which makes the effective read window relatively small in the large array.
14.

1T1R RRAM array with 6F cell area. (a) TEM cross-section of the array along the bit line (BL), evidencing the select transistors with recess geometry and the RRAM devices sharing the TE. (b) Cumulative distributions of read current for the LRS and HRS for the intrinsic cell, integrated cell and scaled cell after 103 cycles. Reproduced with permission from ref . Copyright 2014 IEEE.
An even higher capacity was achieved by the 1S1R array in ref thanks to (i) the 2-terminal structure of the selector element thus enabling a CBA architecture and (ii) the 3D stacking, where two devices occupy the same cell area. This is the horizontal 3D approach evidenced in Figure a, where multiple CBAs are stacked on top of each other to minimize the effective cell area and, hence, maximize the bit density. A horizontal 3D RRAM array with 6 layers was demonstrated with a Cu/Ta/TaN/TaON/Cu stack in 28 nm HKMG CMOS technology. A similar horizontal 3D approach has been pursued in the 3DXP technology consisting of stacked 1S1R CBAs of a PCM element combined with an OTS selector. , However, horizontal stacking is prone to layer-to-layer variation due to thermal degradation during the fabrication process. Most importantly, the process yield decreases sharply with the number of stacked layers, due to the repetition of critical lithography masks, similar to the case of 3D flash NAND technology.
15.
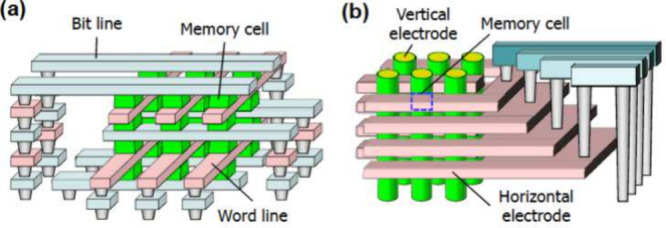
3D RRAM arrays. (a) Horizontal 3D RRAM array, where two or more CBAs are stacked to share the same area. (b) Vertical RRAM array, where the memory cells are obtained at the interface between vertical and horizontal electrodes. Reproduced with permission from ref . Copyright 2011 IEEE.
To maximize the bit density while maintaining a high process yield, the vertical 3D RRAM technology of Figure b was developed. Here, each bit cell is located at the crossing between a horizontal metal plane or electrode and a vertical electrode. The processing yield is maximized with this approach, since there is just one critical lithography mask to realize the vertical holes to be filled with the oxide/electrode stack. 3D vertical RRAM concepts were demonstrated with both filamentary-type HfO x -based RRAM and uniform-switching RRAM with TiO2/TaO x bilayers (see also Figure c,d,e ,, ). In all vertical 3D RRAM implementations, conformal deposition techniques such as ALD become critical for the deposition of the vertical oxide/electrode stack within holes or trenches with a high aspect ratio.
4. RRAM Circuits for Computing
RRAM has been initially developed for memory applications and identified as a promising technology for SCM and eNVM for consumer, industrial and automotive microcontrollers. Besides the pure memory application, RRAM can provide an enabling technology in computing applications, where the memory plays a crucial role within the von Neumann architecture. In fact, bringing the compute function near (or even inside) the memory can provide several advantages for data-intensive computing tasks. ,,, Such a memory- or data-centric approach, as opposed to the conventional compute-centric one, is a promising paradigm to accelerate modern computing tasks such as data search, data analytics, machine learning, and artificial intelligence (AI). This constitutes the so-called in-memory computing (IMC) concept, where computing in situ within the memory can alleviate or suppress the data movement which is responsible for most of the energy consumption and latency in conventional digital computing systems.
RRAM features several advantages for IMC, such as high density, scalability, low-power operation, nonvolatile storage, multilevel operation, and CMOS-compatible BEOL integration. Memory applications in computing generally rely on the ability to perform analog-domain operations with high parallelism within the RRAM array, typically exploiting Kirchhoff’s law for summation and Ohm’s law for multiplication. Several concepts for such physical computing within RRAM have been proposed in the literature, as summarized in Figure . The schematic I–V curve in Figure a highlights two potential regimes for IMC operation, namely (i) the static regime at low voltage, where RRAM can store a pretrained, preprogrammed parameter for computation (Figure b), and (ii) the dynamic regime at high voltage across the switching regime where the device can dynamically change its programmed state to mimic spike integration, learning, adaptation, and other linear or nonlinear functions (Figure c).
16.

Applications of RRAM Devices for in-memory computing (IMC). (a) Schematic I–V curve of a RRAM device with low-voltage and high-voltage regimes, corresponding to static and dynamic IMC, respectively. (b) Examples of static IMC, where pretrained parameters are stored in the memory to perform physical computation tasks, such as matrix-vector multiplication (MVM). (c) Examples of dynamic IMC, where pulses are applied in the switching regime to induce dynamic changes in the conductance for reproducing adaptation, learning, and other types of linear/nonlinear computing functions. Reproduced from ref . Copyright 2023 AIP Publishing with Creative Commons Attribution 4.0 license https://creativecommons.org/licenses/.
Among the static IMC functions, matrix-vector multiplication (MVM) is probably the most popular and explored, due to its implication in the deep neural network (DNN) for both the inference and the training processes. Similarly, a RRAM CBA can be used for inverse MVM, where a linear system is solved, thus facilitating the calculation of inverse, pseudoinverse matrices, eigenvectors and singular value decomposition. Other static functions include content addressable memory (CAM) for data search and query, , combinatorial optimization, , physical unclonable function (PUF) , and Bayesian inference.
Dynamic IMC aims at exploiting the programming property of the RRAM to reproduce dynamic functions, such as nonlinear neuron activation, stateful Boolean logic gates, , synaptic plasticity, , and learning in supervised/unsupervised neural networks. − Typically, the dynamic regime leverages controlled switching close to the set or reset voltage to modify the conductance of the RRAM device in response to the applied pulse width and amplitude. Randomized switching in the dynamic set/reset range can be used to develop circuits for true random number generation (TRNG). − Steep-slope logic devices have also been proposed based on the abrupt set transition in the dynamic regime of RRAM devices.
A key issue with dynamic RRAM computing is the limited set/reset endurance of RRAM devices as well as the energy consumption required by the set/reset operations. On the other hand, static IMC provides nonvolatile storage of computational weights for the execution of standardized tasks, such as neural network inference. Dynamic and static IMC can be generally combined in the same platform to provide energy-efficient processing capable of learning and adaptation. ,
4.1. RRAM Crossbar Arrays for Matrix-Vector Multiplication
The CBA circuit of RRAM devices has been widely used for accelerating MVM, or dot product, which, among various use cases, is one of the dominating bottlenecks in accelerating inference and training of neural network models. Figure a shows a circuit for performing MVM based on CBAs, namely a dot-product engine (DPE). The CBA can be a passive 1R array (Figure a) or a selected-memory CBA, such as the 1S1R array (Figure b) or the 1T1R array (Figure c). Thanks to the possibility of programming analog parameters into a RRAM device, the RRAM CBA can be adopted as a physical transcription of a matrix, where each RRAM cell serves as a matrix entry. A matrix is programmed in the CBA such that each RRAM conductance is given by G ij = A ij × G 0, where G 0 is a suitable unit conductance. An analog voltage vector is applied to the rows that are connected to the RRAM top electrodes. By connecting the M columns at ground, the resulting vector of currents i is given by
17.

Matrix-vector multiplication (MVM) with RRAM CBAs. (a) Circuit schematic of a dot-product engine (DPE) with RRAM devices. Input voltages are applied on the TE (rows), and currents are accumulated on the columns and sensed using a transimpedance amplifier (TIA). (b) I–V curves of the RRAM devices programmed in multiple conductance states, indicating both the multiple achievable states and the linear (ohmic) conduction for relatively high conductance. (c) Image of an integrated circuit including multiple 1T1R arrays of various sizes. (d) Correlation plot between the experimentally measured MVM with linear correction and the ideal MVM performed in software. (e) Equivalent MVM bit-precision as a function of memristor bit accuracy for multiple array sizes, i.e., the number of rows in the CBAs. (f) MVM throughput as a function of array size of DPE and digital ASIC. Panels (a,c,e,f) are adapted with permission from ref . Copyright 2016 Association for Computing Machinery. Panel (b) is adapted from ref . Copyright 2021 Nature Publishing Group with Creative Commons Attribution 4.0 license http://creativecommons.org/licenses/by/4.0/. Panel (d) is adapted with permission from ref . Copyright 2018 Wiley VCH.
| 2 |
which corresponds to a MVM or dot product. The output current i can be sensed by a transimpedance amplifier (TIA) which converts the current into a voltage, which can, in turn, be converted into a digital word with an analog-to-digital converter (ADC).
Figure b shows the current–voltage characteristic for several RRAM devices in the read (low-voltage) regime, with multiple stable conductance levels having ohmic, i.e. linear, conduction, which is essential for performing dot products without errors due to nonlinear parasitic effects. To avoid nonlinearity issues due to the non-ohmic behavior of RRAM devices for some states, a 1T1R structure can be used with the TE voltage fixed to a convenient voltage V read and the gate voltage equal to the logic binary input, while the summation current is accumulated along the column. After conversion of the current to a digital word, further summation can be achieved with the help of a shift-and-add operation in the digital domain. Such a binary-input approach also comes with the advantage of effectively eliminating the need for a digital-to-analog converter (DAC) at the CBA input rows, with benefits of reduced area and improved energy efficiency.
Figure c shows the physical implementation of multiple CBAs with a maximum size of N = 64 rows and M = 128 columns of 1T1R cells. The chip in the figure was used to demonstrate an on-chip MVM and to assess the impact of the array size on the accuracy of the dot-product operation. Figure d shows a correlation plot of the measured analog output as a function of the expected software output. A linear correction was applied to address the column-wise error due to IR-drop, and the results show a good agreement between the software and experiments. However, as the array size increases, the impact of the parasitic wire resistance of the TE and BE becomes increasingly relevant, thus limiting the effectiveness of linear correction. In fact, the array wire resistance causes a current resistance (IR) drop along the rows and columns. Considering the same current I flowing in each device, the voltage drop ΔV IR across the wire can be estimated by
| 3 |
where r is the cell-to-cell wire resistance. Considering, for instance, r = 1 Ω, I = 10 μA and N = 128, we obtain an estimate for the total IR drop along the line of ΔV IR ≈ 8 mV, which can contribute significantly to the dot-product error. By performing a dot product on arrays of different sizes and comparing it with the error obtained by performing a digital MVM with reduced precision, such as fixed-point INT8 or INT4, it is possible to correlate the array size with a given bit precision, as shown in Figure e. If only one value is programmed per column, the computational accuracy equals the RRAM accuracy (worst case); however, 7-bit computational precision can be reached for dense matrices of 6-bit RRAMs, given that noise is assumed uncorrelated among multiple devices. Computational accuracy saturates to 8-bit even for a large number of bits stored in the RRAM, due to the IR drop becoming the dominant factor compared to device noise. By properly modeling the IR drop, it is possible to introduce compensation techniques at both circuit level , and system level. Large arrays are desirable to maximize the equivalent throughput, defined as the number of operations (two in the case of multiply accumulate) performed in a unit of time. Figure f shows the throughput as a function of matrix size N for a RRAM-based DPE and a digital ASIC, demonstrating that DPE can reach a higher computing speed than a digital counterpart for N ≈ 128, and be 10 times faster for N > 512.
4.2. RRAM CBA Circuits with Analog Feedback for Inverse MVM
By modifying the analog peripherals of the CBA, it is possible to perform inverse linear algebra operations, such as computing the solution of linear systems, extracting the eigenvectors of a matrix, performing linear regression , and others. Figure a shows the circuit schematic of the CBA and its analog peripherals required for computing the solution of a linear system. The columns and rows of the CBA are connected to the input and output terminals of operational amplifiers, respectively, to provide a feedback loop. The conductance G ij values of the RRAM devices in the CBA are programmed with the coefficients of a positive-definite matrix A; then a current vector i is injected at the column terminals, which are kept at virtual ground potential by the feedback loop. The application of the input current pulse stimulates an analog output voltage vector v:
18.

Inverse MVM in CBAs with a feedback loop connection. (a) Circuit schematic of a closed-loop CBA for the solution of linear systems. The inset shows a programmed 3 × 3 matrix. (b) The conceptual schematic highlighting the difference with conventional circuits for the direct operation of CBAs. (c) Experimental and analytical output voltages for the solution of a linear system. (d) Output voltage as a function of the input parameters β with i in = βi ref . (e) Correlation plot of analytical and measured inverse matrix computation. Reproduced with permission from ref . Copyright 2019 National Academy of Sciences.
| 4 |
which is the same as eq but referred to the output voltage. Equation provides the solution of the linear system with matrix A = G and the known vector i.
Figure b shows the concept of this circuit and its relationship with the open-loop MVM of Section . While the MVM circuit is similar to the simple case of a voltage applied to a conductance, resulting in a scalar product I = GV, the inverse MVM case resembles the TIA circuit, where the applied current is converted to a voltage V = −G –1 I thanks to the concept of feedback loop enabled by the operational amplifiers.
Figure c shows an experimental demonstration of the concept, with the measured output of a linear system with 3 equations closely matching the analytical result. The result is confirmed for various inputs in Figure d, where parameter β provides the relative amplitude of the applied input current. The same circuit can be used for computing the inverse of a matrix by applying the vectors of an identity matrix as input and collecting the various obtained output voltage vectors to form the inverse matrix. Figure e shows the correlation plot comparing the elements of the inverse matrix computed with the analytical formula to those obtained from the experimental output voltage, indicating a good accuracy of the inverse matrix circuit. This circuit with the CBA in analog feedback can be used for various applications beyond the solutions of linear systems, as further illustrated in Section .
4.3. Content Addressable Memories
The content addressable memory (CAM) is a fundamental memory structure that operates in a complementary way with respect to the random access memory (RAM). As shown in Figure a, reading a RAM circuit consists of selecting an address as input and obtaining a data bit stored at the address location as output. On the other hand, reading a CAM requires that a content is presented as input, while the output yields the memory address where that specific content is stored. Figure b shows a ternary CAM (TCAM), where each cell verifies whether the input is equal to the stored value. A wildcard (‘X’, or don’t care) is added to match both 0s and 1s as input. If all of the TCAM cells in a row are matched, a match value is returned on the match line (ML), which can be then converted into the specific address.
19.

CAM architectures. (a) Conceptual circuit schematic of the RAM. (b) Conceptual circuit schematic of TCAM. (c) TCAM cell with 4T2M structure. (d) TCAM cell with 2T2M structure. (e) TCAM cell with 3T1M. (f,g,h) Search latency for 4T1M, 2T2M, and 3T1M cell structures, respectively. (i,j,k) Search margin for 4T1M, 2T2M and 3T1M cell structures, respectively. The RRAM resistive window ΔR was changed to assess its impact on the circuit performance. Adapted with permission from ref . Copyright 2019 IEEE.
TCAMs are ubiquitous in several applications, particularly in networking. , However, the broader use of TCAMs for computing has been hindered by the large area and power consumption of SRAM-based TCAMs, which require 16 transistors for storing and searching ternary values. From this viewpoint, RRAM-based TCAM implementation is attractive, as it enables a smaller cell area and hence a higher bit density. Various designs of RRAM-based TCAM cells have been proposed, including 4-transistors/2-memories (4T2M, Figure c), 2-transistors/2-memories (2T2M, Figure d), and 3-transistors/1-memory (3T1M, Figure e). In general, a TCAM circuit is operated by connecting all the input search line (SL) terminals along the column direction and all the output ML terminals along the row direction for creating the array in Figure b. For the TCAM search operation, the ML is initially precharged to a convenient potential, and then the input data are applied to the SL. If the input data match the value stored in the RRAM devices, the ML remains at the precharged potential; otherwise, a pull-down transistor is activated to discharge the ML. A sense amplifier connected to the ML is used for sensing and latching the output after a given search time.
In the case of the 4T2M TCAM in Figure d, two RRAM devices are programmed to represent a 0, 1, or X in [HRS,LRS], [LRS,HRS] or [LRS,LRS], respectively. As an example of the TCAM operation, when a ‘1’ is applied to the SL (and a ‘0’ on SLn), if a ‘0’ is stored, then a voltage divider between the two RRAMs activates the pull-down transistor, thus causing the discharge of the ML. A similar behavior can be derived for other cases such as search ‘1’ store ‘1’, search ‘0’ store ‘0’, and search ‘0’ store ‘1’. In the case of an ‘X’ stored, the voltage divider node is the mean voltage which is tuned to be below the pull-down threshold. In the case of the 2T2M cell, the encoding of the cell state into the RRAM device is the same; however, the input transistors act directly as pull-down transistors, thus avoiding the need for an additional transistor.
The 3T1M cell utilizes three RRAM states, namely, LRS, medium resistance state (MRS), and HRS to store 1, X, and 0, respectively. When a ‘1’ is searched, both data lines (DL) are kept at the ground, with only SLp at 1. If the cell stores a 0, most of the voltage drop is on the RRAM, thus activating the pull-down node and vice versa in the case where a 1 is stored. The conductance of the MRS is tuned such that the voltage drop on the RRAM device is not sufficient to activate the pull-down transistor. Note that TCAM operations can also be emulated by conventional CBAs, although this requires significant additional peripheral overhead.
Figure f,g,h shows the worst-case search latency as a function of array word length for 4T2M, 2T2M, and 3T1M simulated with the same technology node, i.e. CMOS 180 nm. The worst case is defined as a 1-bit mismatch since only one pull-down transistor is activated to remove the charge from the ML, thus resulting in a relatively long search time. Search time scales linearly with the word length since a drain-source parasitic capacitance on the ML is added for each cell on a row, increasing the overall ML capacitance. Figure i,j,k shows the read margin as a function of the word length for 4T2M, 2T2M, and 3T1M, respectively, under a similar simulation on the CMOS 180 nm technology node. The readout margin is defined as the difference between the voltage on the ML during the worst-case match (all ‘X’s) and the worst-case mismatch (1-bit). Longer columns have larger leakage, thus significantly reducing the read margin, due to the nonactivated pull-down transistors providing a parasitic contribution to the discharge of the ML.
While 2T2M has the most compact structure, it requires a large HRS (e.g. >1 MΩ) to minimize the parasitic discharge leakage and, hence, maximize the array size. On the other hand, the 3T1M architecture provides the fastest response, which comes at the cost of a relatively large static power consumption during search operation. The 4T2M cell design displays a larger area; however, it can provide a suitable trade-off between conductance window requirements, latency, and power consumption. The proposed RRAM-based TCAM cells have been demonstrated in various compute applications, including regular expression matching, genomics, and hyperdimensional computing. ,
By leveraging the analog operation of emerging NVMs, an analog CAM (Figure a) was recently proposed, where TCAM columns are merged in ranges, to return a match in a cell if the analog input is within the stored range. For this purpose, two RRAM devices can be used for the lower and upper bound, as shown in the circuit of Figure b with a 6-transistors/2-memories (6T2M) design. If the input voltage applied to the DL is high enough, T1 is turned on, effectively pulling down the gate of T2, which is switched off and thus plays no role in affecting the ML, which returns a match. Figure c,d shows the lower and upper bound circuits. The lower bound circuit operation is shown in Figure e with the voltage on the gate of the lower bound pull-down transistor as a function of the input voltage on the data line (DL) for multiple programmed conductances in M1. By increasing the M1 conductance, it is possible to move the lower bound to a higher value. Complementary to the lower bound, the upper bound is realized by adding an inverter between the voltage divider on M2 and the pull-down transistor. Figure f shows the voltage on the upper bound pull-down gate G2 and a function of the input voltages for multiple conductance values programmed on M2. Similarly, by increasing the conductance on M2, it is possible to extend the upper bound. Analog CAM has been demonstrated for the acceleration of multiple compute workloads, including tree-based machine learning, one-shot learning and query processing.
20.

Analog CAM concept. (a) Conceptual circuit schematic. (b) Circuit design of the 6T2M TCAM cell. (c) Lower bound subcell controlling the G1 pull-down transistor. (d) Upper bound subcell controlling the pull-down transistor G2. (e) Lower and (f) upper bound pull-down voltages as a function of input voltage V DL for multiple programmed conductance. Adapted from ref . Copyright 2020 Nature Publishing Group with Creative Commons Attribution 4.0 license http://creativecommons.org/licenses/by/4.0/.
5. Computing Applications
IMC is extremely promising for the execution of data processing tasks directly in the memory, thus reducing the energy consumption and taking advantage of the extreme parallelism and analog operation of the memory array circuit. Table summarizes the most relevant computing applications that have been explored for IMC. The mainstream applications attracting widespread interest are inference and training of AI models, such as DNNs and large language models (LLMs). Other computing applications include solving linear equations, linear regression problems, principal component analysis (PCA), decision trees, combinatorial optimization of complexes, multiple-variable problems, stochastic computing and spiking neural networks in neuromorphic computing. Each of these computing applications generally relies on a different IMC circuit primitive. For instance, DNN inference generally requires MVM to support the extensive weighted summation that takes place in each fully connected or convolutional layer. On the other hand, linear regression requires IMVM to support the pseudoinverse matrix calculation. Most importantly, each circuit/application combination may require a different set of properties of the RRAM device. The device requirements that should be fulfilled for each specific computing application are summarized in Table and include multilevel operation, data retention, endurance, linear conductance update, linear conduction, and short-term memory.
2. Summary of the Most Relevant Computing Applications and Corresponding RRAM Requirements.

5.1. Neural Network Inference
The DPE circuit for MVM can be used for accelerating neural network inference. In fact, each layer of a feedforward DNN performs the dot product of the i-th layer neurons with their corresponding synaptic weights, to be accumulated at the i+1-th layer neurons as input for the nonlinear activation function. Thus, each layer of a DNN can be mapped to one or more CBAs, whose outputs are then accumulated and sent to an activation function unit. Recently, multiple fully integrated DNN accelerators have been realized using RRAM-based CBAs. − Such accelerators generally include the CBA circuit, all of the sensing units required for operating it, and a bus or network-on-chip to control the data flow.
A notable example is NeuRRAM, consisting of 48 cores, each one of them able to realize multiplication of vectors with 256 × 256 stored matrices. Figure a illustrates the NeuRRAM circuit schematic of the core architecture. Each core consists of 16 × 16 corelets that share common bit-lines and word-lines along the rows and source-lines along the columns. Each corelet (Figure b) comprises a 16 × 16 RRAM CBA and one neuron circuit. CBAs in NeuRRAM can be connected in multiple configurations, including forward, where inputs are applied on the rows, for typical MVM, and backward, where input are applied on the column to perform the transposed MVM, which can be used for computing gradients during training. Compared to conventional DPE circuits performing MVM with current mode sensing (Figure c), NeuRRAM performs voltage mode sensing (Figure d) to reduce energy consumption. Accumulating the current of multiple devices can result in a large power consumption, thus requiring large TIAs. Also, as shown in Figure e, different DNN models, having different weight distributions, would result in strongly different current distributions to sense. By performing voltage mode sensing, the output is normalized by the total equivalent conductance seen by each neuron, resulting in a more uniform current distribution. Thanks to voltage-mode sensing, the energy-delay product in the NeuRRAM circuit outperforms other accelerators − despite being designed in a relatively old technology, as shown in Figure f. To improve the classification accuracy during inference, NeuRRAM employs several hardware-software codesign techniques, such as noise-aware training and on-chip fine-tuning.
21.

Illustration of DNN inference in NeuRRAM based on 1T1R arrays of RRAM devices. (a) Overall architecture and (b) individual corelet of the NeuRRAM chip. Each corelet of size 16 × 16 is connected to a neuron. 16 × 16 corelets are organized in a core, which has a resulting size of 256 × 256. (c) Illustration of current mode sensing and (d) voltage mode sensing. (e) Comparison of the distribution of output for current- and voltage-mode sensing. (f) Energy delay product as a function of bit-precision for multiple taped-out RRAM-based accelerators. (g) Distribution of programmed conductance during programming and (h) after 30 min for multiple programmed levels. (i) Classification accuracy for the data set of the Canadian Institute for Advanced Research with 10 classes (CIFAR-10) of NeuRRAM with various operation modes. (j) Layer-wise accuracy comparison with and without fine-tuning. Adapted from ref . Copyright 2022 Nature Publishing Group with Creative Commons Attribution 4.0 license http://creativecommons.org/licenses/by/4.0/.
Figure g shows the distribution of conductances programmed in 8 equally spaced levels, corresponding to 3 bits. The programming resolution is limited by several factors, including IR drops, capacitive coupling, and limited ADC range. Three bits are not enough to reach good classification accuracy, with most networks requiring 4 or even 8 bits for quantization for good enough results. Moreover, as shown in Figure h, after 30 min it is possible to observe a distribution broadening. To solve this issue, instead of quantizing a pretrained model or training a quantized network, which is equivalent to injecting uniformly distributed noise into weights, networks are trained with floating point precision with Gaussian distributed noise extracted from RRAM characterization. Figure i shows the simulated and experimentally verified result of such operation while performing inference on the CIFAR-10 data set, improving accuracy from 25.35% to 83.67%. Moreover, a fine-tuning training with chip-in-the-loop is performed to further increase the accuracy. Weights are programmed and finely adjusted in each layer while the network is undergoing training, to avoid multiple reprogramming while keeping hardware-awareness during the training operation. First, the model is trained completely offline. Then the first layer is programmed into the chip. Afterward, inference with the training set is performed by using experimental activations coming from the on-chip first layer and offline software activation for the other layers. The weights of all of the offline layers are adjusted to minimize the loss. The operation is repeated by programming the second layer on the chip, performing fine-tuning of all others, and so on until all of the model is programmed. The overall effect of such operation and noise injection is shown at the right-most bar in Figure i, resulting in an accuracy of 85.66%, with the layer-wise comparison between training with and without fine-tuning shown in Figure j.
A key advantage of using RRAM compared to traditional CMOS memories, such as SRAMs, for IMC is the multilevel programming capability, which results in improved computational efficiency per unit area and reduced complexity of the peripheral circuits. Multiple conductance states can be achieved by properly modulating the pulse parameters during the set operation or during a reset operation. Figure a shows the cumulative distribution function (CDF) of the conductance obtained after a set operation in a 1T1R RRAM device by changing the gate voltage of the select transistor at a fixed TE voltage, namely using an incremental gate pulse programming algorithm. Similarly, Figure b shows the CDF of conductance obtained after the reset operation, where the stop voltage was gradually increased during reset at a fixed gate voltage, which is referred to as the incremental reset pulse programming algorithm. These results demonstrate the ability to tune the average analog conductance via set or reset operations; however, the conductance variations are relatively large, which suggests that adoption of a closed-loop program-verify (PV) algorithm is advantageous.
22.

Multilevel programming of RRAM devices. (a) Cumulative distribution function (CDF) of the conductance obtained by modulating the set voltage. (b) Same as (a) but obtained by modulating the reset voltage. (c) CDF comparison for multiple program and verify algorithms. (d) Programming error standard deviation as a function of the median conductance. (e) Measured resistance as a function of time after programming, indicating fluctuations due to random walk (RW) and random telegraph noise (RTN). (f) Standard deviation of the programmed conductance as a function of time, indicating broadening of the programmed distributions. Panels (a,b) are adapted with permission from ref . Copyright 2021 IEEE. Panel (c) is adapted with permission from ref . Copyright 2021 IEEE. Panels (d,f) are adapted with permission from ref . Copyright 2023 IEEE. Panel (e) is adapted with permission from ref . Copyright 2015 IEEE.
Figure c shows the CDF of 5 conductance levels for different PV algorithms, namely incremental step pulse with verify algorithm (ISPVA) and incremental gate voltage with verify algorithm (IGVVA) based on 100 mV (IGVVA-100) and 10 mV (IGVVA-10) voltage steps. ISPVA consists of programming LRS in 5 different levels by keeping the gate voltage fixed at different levels, for example from 1 to 1.6 V with steps of 200 mV, and gradually increasing the TE voltage until the desired conductance is reached. In the case of IGVVA, the TE voltage is kept fixed, while the gate voltage is modulated with incremental steps until the desired conductance is reached. Results show that by using IGVVA with small steps of 10 mV, the conductance variation is significantly reduced. Hybrid PV algorithms with the modulation of both the TE and the gate voltages were also discussed and can achieve higher precision, although the hybrid algorithm might result in a relatively large number of pulses and, hence, a significant overhead. Figure d shows an example of the standard deviation of conductance as a function of conductance after a hybrid PV algorithm, showing essentially two regimes, one for HRS in which the standard deviation increases with the conductance and one for LRS, with an exponential decrease of the standard deviation with the conductance. Interestingly, the results indicate a trade-off between power consumption and precision.
Note that the multilevel operation is not a strict requirement for neural network training and inference, since, in principle, binary neural networks can be trained/inferred or multiple binary devices can be used to represent a multibit weight. However, without multilevel operation, RRAM-based accelerators might significantly underperform digital accelerators based on SRAMs. Typically, neural network layers require at least 4- to 8-bit precision, which is challenging to achieve with a single RRAM device. Multiple techniques for operating more than one device and increasing the precision have been presented. For instance, bit slicing is a technique where two or more devices are used to represent different slices of the weights, such as the two most significant and two least significant bits of a 4-bit weight. After the multiply operation, the output is reconstructed with a shift-and-add operation in the digital domain. Consider for example, a RRAM device that can efficiently store 4 levels, or equivalently 2 bits. If, for instance, x 10 = 11 has to be stored (where the subscript 10 denotes the decimal base), two RRAMs can be programmed to the most and least significant values, x 4 = 2 and x 4 = 3. The overall value can be reconstructed as x = 41 × 2 + 42 × 3 = 11. Interestingly, doubling the number of RRAMs results in an exponential increase in the number of levels (or doubles the number of bits).
A different approach is to program the RRAM with a floating-point value and encode the resulting error in a second RRAM device. , Given a target conductance G and a programmed conductance G p resulting in an error ϵ G = G – G p , a second RRAM is programmed with G ϵ = αϵ G , where α is a scaling factor to match the maximum error on a CBA column with the full-scale range, corresponding at the highest conductance to program. Consider, for example, the case of a CBA column. Initially, a first weight G 00 is programmed in a first, most significant, RRAM cell. After PV, the resulting conductance is G 00 = G 00 – G 00 where G 00 is the error resulting from the imprecise programming operation. The operation is repeated until all columns are programmed. At this point, the scaling factor of the column is calculated as
| 5 |
where max i (G i0 ) is the maximum error across the column and G FSR is the full-scale range of the RRAM conductance, namely G FSR = G max – G min. At this point, for the first weight, a second, least significant, RRAM device is programmed with the error conductance, namely:
| 6 |
where α0 is used as the scaling factor. After PV is performed, the programmed conductance is G 00 = G00 – G 00 . The scaling factor α0 is thus used as the attenuation of the second RRAM column. The resulting equivalent conductance of the most and least significant couple is thus given by
| 7 |
The error is thus reduced directly by a factor of α0, given that α0 is generally much smaller than 1.
In other computing primitives, such as CBAs with analog feedback for scientific computing (see Section ) and Ising machines with continuous time and continuous variables, the presented slicing techniques can hardly be adopted without a significant overhead. Similarly, for analog CAMs (see Section ), doubling the number of cells results in doubling the number of levels, rather than the number of bits, which results in an exponential overhead necessary to increase the precision.
In addition to the limited precision of programming multilevel conductances, RRAM devices can undergo significant conductance changes after programming. Figure e shows various two possible sources of conductance change after programming, namely random walk (RW) and random telegraph noise (RTN). RW is an abrupt change of conductance at a random time and amplitude, while RTN consists of a two-level fluctuation of the conductance. Figure f shows the standard deviation of conductance as a function of time for multiple conductance states of TaO x RRAM devices. For most analog computing applications, conductance stability, or retention, is a strict requirement. In the case of DNNs inference, knowledge about conductance noise and broadening can be embedded in the training algorithm. For instance, DNN model training optimization and fine-tuning for noise-resiliency have demonstrated an increase of accuracy by 8.4% for inference of the MNIST data set. A similar approach has shown significant improvement in the inference of decision trees in analog CAMs. Nevertheless, sometimes RRAMs experience abrupt changes that can significantly debilitate the accuracy performance. For some applications, such as linear algebra, it is not possible to train the problem with noise awareness. For such cases, the analog error correction code (A-ECC) has been presented. , Digital error correction codes (ECC) are ubiquitous both in memory and communication systems and use special features of the Boolean alphabet to recognize if an error occurs and eventually decode the correct output. In the case of A-ECC, the alphabet is considered an integer value, but the techniques can still be applied. By equipping the RRAM arrays with the required redundancy, it is possible to compute a syndrome which can determine if the result is correct by its parity. In case the computed dot product is wrong, a decoder matrix can be used to correct the wrong output. Experiments have shown accuracy recovery from 73.12% to 97.36% for the inference classification of the MNIST data set.
5.2. Inference in Attention-Based Models
With the growing interest in LLMs and their increasingly high energy consumption, LLM hardware accelerators based on RRAM have started to emerge. However, performing inference of LLMs and other attention-based models raises novel challenges to IMC accelerators. Figure shows the differences in performing inference of conventional DNNs or recurrent neural networks compared with attention-based ones. The programming operation is highlighted by the red arrows in the figure, while the inference (or read) operation is represented with black arrows. In conventional DNNs (Figure a), the inference operation in the i-th layer consists of two steps: (1) an MVM between the input x and the static weight matrix W i and (2) passing the output of the multiplication through an activation function and sending the result to the next layer. To accelerate the inference operation, the weights G W i of the i-th layer are programmed in the CBA only once (Figure b) and then reused for the whole lifetime of the model. As a result, inference can be viewed as a mere read operation on the CBA (Figure c).
23.

Architecture of a multihead attention unit in a transformer. (a) DNN structure and pipeline. (b) Programming and (c) performing inference of a DNN in a CBA. (d) Attention-based mechanism in transformers. (e) Programming and (f) performing inference of an attention layer in CBAs.
Transformer models, which are the foundational models for LLMs, are essentially heterogeneous neural network models that differ from conventional DNNs by the attention mechanism, which is capable of assessing the relationship between different tokens in the input sequence. Figure d illustrates the attention mechanism architecture. An input sequence X is multiplied by three matrices (W Q , W K , W V ) generating the query (Q), key (K), and value (V) matrices, respectively. The final attention matrix A is defined as
| 8 |
where the softmax function is given by , is a normalization factor and d is the size of the Q, K and V matrices. Note that all of the matrix multiplications in eq contain dynamic values that change at each new inference sequence. After initializing the CBAs with the query, key, and value weights (Figure e), an inference pipeline can be built by subsequent CBA read and write. A possible example of a three-step pipeline is shown in Figure f. In the first step, Q is computed by performing an MVM with input sequence X and query weights G W Q . At the same time, K is computed by performing an MVM with input sequence X and query weights G W K . A similar operation is performed for computing V as well. Then, in the second step, Q is written to a new CBA (G Q ) and multiplied by K. The product Q × K T is then passed through the activation function σ (representing the softmax), normalized, and programmed into a CBA G C . Finally, attention output A is obtained in step 3, where V is multiplied by G C .
Notably, the important difference between inference in DNNs and attention-based neural networks is that weights are static in the former case, while matrices are dynamic in the latter case and thus must be programmed in the CBA at each inference step, which dramatically reduces the performance, energy efficiency, and reliability of IMC accelerators. Accurately programming the matrix entries into RRAM CBA devices requires several iterations, thus limiting the inference speed and resulting in a significant increase in the latency. Also, given the limited endurance of RRAM devices, the lifetime of the accelerator might be significantly reduced. Assuming an optimistic endurance of 108 cycles, an open-loop single-pulse programming operation and a 1 ms latency for inference of a language model, we can anticipate that the chip would die after only 105 seconds, which is equivalent to approximately 1 day of operation.
From the previous analysis, the implementation of transformer accelerators with RRAM-based IMC circuits might be severely affected by endurance from the reliability viewpoint. Cycling endurance is an essential requirement not only for inference in transformer accelerators but also for computing applications leveraging the weight update as a basis for learning, such as neural network training and spiking neural networks where RRAM are used in I&F neurons and STDP synapses. For memory applications, endurance would support RRAM for reconfigurable NVM where data need to be continuously updated.
Endurance is generally evaluated as the number of set/reset cycles for which the RRAM device continues to display a minimum resistance window. For instance, Figure a shows the measured resistance after set and after reset for a HfO2-based RRAM device as a function of the number of cycles N C . The resistance window slightly increases with an increasing number of cycles thanks to a gradual lowering of the LRS resistance. However, after about 2.6 × 104 cycles, the device displays a sudden decrease of the resistance window, where both the LRS and HRS resistances converge to an intermediate value. Endurance strongly depends on the reset condition, namely, the stop voltage V stop at which the reset operation was conducted. Figure b shows the endurance cycles N C as a function of V stop , showing a steep exponential decrease of N C for increasing V stop . For relatively small V stop , the reset transition could not take place, thus leaving the device in a permanent (stuck) set state. The figure also shows data for various values of I C , which has a negligible role in controlling endurance. The fundamental mechanism for endurance failure was attributed to negative set, namely a dielectric breakdown effect taking place during the reset operation under negative voltage. Given the lack of a current limitation during the reset operation, a negative set can lead to uncontrolled filament growth. Even after reset, the resulting filamentary region shows a relatively low resistance, which accounts for the intermediate value after endurance failure in Figure a. Note that V stop also controls the resistance window, as the HRS resistance increases with V stop . These results thus indicate that there is an inherent trade-off between endurance and the resistance window, where an increasing resistance window generally comes at the expense of a smaller endurance. This general trend was also observed by comparing different device stacks and materials, as shown in Figure c. To improve the cycling endurance, the bottom electrode was optimized by selecting inert materials, such as C, Ir, Pt, and Ru, , resulting in relatively large endurance in the range of 1012 cycles. When the statistical tails of early failing bits are included, this endurance is not sufficient for the intensive cycling required by transformer accelerators and some neural network training applications. For these applications, CMOS volatile memory devices, such as SRAM and DRAM, seem to be most adequate.
24.

RRAM endurance. (a) Measured LRS and HRS resistances as a function of the number of cycles for a HfO2-based RRAM device, indicating an endurance of about 2.6 × 104 cycles. (b) Endurance as a function of V stop , namely the maximum negative voltage in the reset pulse. Endurance exponentially decreases with V stop due to the negative set effect. (c) Correlation between endurance and resistance window for oxide-based RRAM and CBRAM. Panel (a) is adapted with permission from ref . Copyright 2014 IEEE. Panel (b) is adapted with permission from ref . Copyright 2015 IEEE. Panel (c) is adapted with permission from ref . Copyright 2016 IEEE.
5.3. Neural Network Training
DNN training generally combines two major workloads, namely, forward propagation, to compute the error of the DNN, and backward propagation, or simply backpropagation, to enable the gradient descent to minimize the error function. While the first operation is similar to inference, the second one requires additional linear algebra operations. From the execution viewpoint, the radical difference between training and inference is that weights remain fixed for inference operation, while they need to be continuously updated during training at each epoch step, which thus requires extensive dynamic IMC as opposed to static IMC for DNN inference. Consider for example Figure a, which shows the last three layers of indices i, j and k, respectively, of a multilayer perceptron (MLP). Training consists of three main functions, namely (i) forward pass for computing activations, (ii) gradients computation, and (iii) weight update. Assuming an input vector y i at the i-th layer of a neural network with weights W ij between layer i and layer j, the output vector of the layer z j is given by
| 9 |
which must be submitted to a nonlinear activation function such as a sigmoid or a rectifying linear unit (ReLU). Equation can be readily mapped in a CBA as a conventional MVM reported in Section , while the activation function is usually implemented in a dedicated analog or a digital circuit, as shown in Figure b. Training the MLP involves back-propagation to compute the gradients of the loss function, with respect to the weights and biases. Gradients can be computed by deriving the loss function , which generally consists of the mean squared error for regression or the cross-entropy for classification, both assessing the error between the predicted output of the last layer y k and the true output ŷ provided by the label. Let δ k = y k – ŷ be the error term for the output layer k. After computing the error for the last layer, it is possible to backpropagate it to any other layer via the chain rule. For the layer j, the error term can be computed as
| 10 |
where σ′ is the derivative of the activation function and ⊙ is the element-wise product which is generally computed in the digital domain. Equation includes a transposed MVM, or M T VM, that can be implemented by applying the inputs to the columns, rather than the rows, of a CBA as shown in Figure c. Finally, the weights can be updated according to the gradient descent rule as W ij ← W ij – ηδ j , where η is the learning rate. To maximize the energy efficiency for weight update, one can implement the outer-product accumulate (OPA) in the CBA to update the conductance in the direction of the gradients as shown in Figure c. , The OPA approach consists of applying at the same time the input vector and the weight update vector ηδ j to the CBA rows and columns, respectively.
25.

Illustration of neural network training. (a) Example of feedforward neural network. (b) Mapping of the forward propagation on CBA. (c) Mapping backpropagation in CBAs. Adapted with permission from ref . Copyright 2016 IEEE.
However, significant device challenges arise during training, notably the nonlinearity and asymmetry of weight updates. The gradual set and reset operations in RRAM devices are inherently nonlinear and asymmetric. The conductance change generally depends on the conductance state; e.g., a positive voltage pulse might result in a strong increase in conductance for low conductance, while the same pulse might cause a minimum change at high conductance. Also, a positive pulse might cause a small change of conductance, while a negative pulse of the same amplitude and at the same initial conductance state might result in a large change of conductance.
It is important to note that the use of PV algorithms is impractical during training, as the programming operation must be rapid to expedite the overall training process, while PV would introduce an unacceptable energy/latency cost. Moreover, to maximize efficiency, it is not feasible to read each conductance state before updating; therefore, blind update pulses should be applied irrespective of the conductance state.
During blind updates, the asymmetric and nonlinear conductance as a function of the normalized update pulse number p can be described by ,
| 11 |
where G 0 is a constant given by G 0 = (G max – G min)/(1 – e –ν), while G min and G max represent the minimum and maximum conductance, respectively. The exponent ν in eq is a shape factor, or nonlinearity parameter, which provides a metric for the nonlinearity of the weight-update characteristic. Similarly, the conductance as a function of the negative update pulse number can be modeled by
| 12 |
where the same shape factor ν has been assumed for simplicity, although the nonlinearity might depend on the voltage polarity. Figure a shows the calculated conductance as a function of the pulse number for positive and negative change updates and various shape factors ν.
26.

Illustration of the weight update during training. (a) Conductance as a function of the number of update pulses for multiple shape factors ν for asymmetric characteristics. (b) Same as (a), but for symmetric characteristics. (c) Conductance windows as a function of ν for multiple device technologies. Panels (a,b) are adapted with permission from ref . Copyright 2016 IEEE. Panel (c) is adapted with permission from ref . Copyright 2022 IEEE.
Some devices, while showing a symmetric switching between positive and negative pulses, might display a nonlinear operation within the switching polarity. In that case, the conductance as a function of the pulse update can be modeled as
| 13 |
where parameters A and B are given by
| 14 |
| 15 |
Figure b shows calculations from eq as a function of the update pulse number for various shape factors ν.
The memory device technology can be engineered to achieve a low ν to optimize the update linearity. Ideally, a suitable device for training should display both a large conductance window, allowing for multiple updates without the need for refreshing the overall weights, and a low ν. Figure c shows the conductance window as a function of ν for multiple resistive memory device technologies, including RRAM with different stacks, such as AlO x /HfO x , Ag:a-Si, TaO x /TIO2, and Pr1–x Ca x MnO3 (PCMO). The figure also shows non-RRAM device technologies, such as MoS2/Ag charge-trap memory (CTM), MoS2/WO3 CTM, and WO3-based electrochemical random access memory (ECRAM).
Note that nonlinearity and asymmetry affect the training by changing the weight update characteristics depending on the conductance state. As a result, the hardware-operated weight update W ij ← W ij – ηδ j features an error, compared to the theoretical gradient descent behavior, due to the device asymmetry and nonlinear update operation. To compensate for such errors, a possible solution is to implement a dedicated device-aware training algorithm, such as the Tiki-Taka methodology. The Tiki-Taka algorithm mitigates update errors by adopting a coupled dynamical system that minimizes both the original objective function and the unintended cost term due to device asymmetry at the same time. According to the Tiki-Taka algorithm, the weight matrix W is first split into two matrices A and C such that
| 16 |
where γ is a convenient scaling factor. Then, as a one-time initial calibration, a symmetry point shifting technique is used to eliminate the asymmetry term in the weight update in matrix A. The symmetry point shifting technique consists of a sequence of alternating positive and negative update pulses which is applied to all devices in the CBA in parallel. Such a sequence is designed to enable the convergence of the device conductance to its symmetry point, namely, the conductance value where the conductance increment Δg ij and decrement Δg ij display the same amplitude. During training, the updates are accumulated on A, which exhibits symmetric behavior around zero, and are periodically transferred to C, ensuring the network weights converge to the optimal values despite device asymmetry. Simulation results show that the Tiki-Taka algorithm achieves a training accuracy that is comparable to that of ideal symmetric devices.
Recently a new RRAM device was developed for Tiki-Taka training algorithm requirements, by adopting a stack of TiN/conductive-TaO x /HfO2/TiN structure which enables relatively low voltage and low current operation, as well as symmetric potentiation/depression characteristics. Figure a shows the RRAM device characteristics for repeated potentiation and depression sequences with equal amplitude of updating pulses. The characterization technique consists of (i) the application of several voltage pulses of opposite polarity followed by (ii) the application of a sequence of alternated single pulses of positive and negative amplitude to reach the symmetry point. The number of states N states is defined as
| 17 |
where G max and G min are the maximum and minimum conductance averaged over 10 cycles, respectively, while ( is the standard deviation of the conductance during the final phase of single up/down pulse alternation (Figure a). The symmetry point skew SP skew , which should be ideally equal to 50%, was evaluated as
| 18 |
where is the average conductance during the single up/down train (Figure b). Finally, the noise-to-signal ratio NSR is computed as
| 19 |
which provides the relative standard deviation of conductance updates during the single up/down pulse train and ideally should be much smaller than one. Experimental results for multiple devices demonstrate median values of N states = 22, SP skew = 54% and generally NSR < 1, with a trade-off between NSR and N states . These results demonstrate the feasibility of the proposed RRAM device for Tiki-Taka training, with only a 0.7% drop in accuracy compared with digital hardware in training a three-layer network for MNIST classification. In addition to device engineering, the Tiki-Taka algorithm can be improved to mitigate device nonidealities, such as a high robustness against device noise.
27.

(a) Number of states, (b) symmetry point skew, and (c) noise to signal ratio as defined by the Tiki-Taka Algorithm. Reprinted from ref . Copyright 2024 ACS.
5.4. Other Machine-Learning Applications
The mainstream application of RRAM-based IMC accelerators is indeed the inference and training for deep learning and neural network primitives. However, other machine learning models such as regression, principal component analysis (PCA), and tree-based machine learning are characterized by higher robustness and explainability, and thus are preferred in sectors like healthcare, finance, and law, where decisions can significantly impact individuals’ lives. These models differ significantly in workload compared to neural networks, thus making it challenging for accelerators specialized for deep learning to efficiently run, e.g., a tree-based model. However, circuit primitives of Section can provide a useful platform for various types of RRAM-based accelerators tailored to these established machine-learning algorithms. In the following, IMC implementations of linear regression, PCA, and tree-based machine learning with RRAM-based accelerators are reviewed.
Linear regression is a widely used machine learning model with applications across various domains, including biology, social science, and economics. In a simple one-dimensional case, linear regression requires finding the line that best fits a set of data by minimizing a certain error. Solving a one-dimensional linear regression thus consists of finding the intercept and slope of the best-fitting line. More generally, linear regression involves finding the M-dimensional vector w in the overdetermined linear system:
| 20 |
where X is an N × M matrix representing the input data and y is an known N-dimensional vector. A possible way to solve eq is to minimize the least-squares error (LSE) given by ∥ϵ∥2 = ∥Xw – y∥2 by computing the Moore–Penrose inverse (or pseudoinverse) matrix X + given by
| 21 |
The equation can be solved in an IMC circuit obtained by a proper configuration of MVM (Section ) and IMVM circuits (Section ). Figure a shows the IMVM circuit consisting of two CBAs for computing linear regression through eq . A first CBA with conductance G X is used to map the independent variables X, and a current I is used to inject the dependent variable y on the CBA rows, which are kept at virtual ground. The CBA rows are connected to the low-impedance input of a TIA stage with a G TI gain, and its output is connected to the second CBA rows, which map again G X . The second CBA columns are kept at the virtual ground via operational amplifiers, whose output is then connected to the first CBA columns.
28.

Illustration of IMC Implementations of Regression and PCA. (a) CBA circuit with closed-loop analog feedback for linear regression computation. (b) Experimental demonstration of linear regression and (c) prediction using the circuit in (a). (d) CBAs with closed-loop analog feedback for PCA computation. (e) PCA accuracy as a function of the memory device precision. (f) Comparison between the data set projections computed by either 64-bit floating-point (FP64) precision or limited precision (IMC). Panels (a,b,c) are adapted from ref . Copyright 2024 American Association for the Advancement of Science with Creative Commons Attribution 4.0 license https://creativecommons.org/licenses/by-nc/4.0/. Panels (d,e,f) are adapted with permission from ref . Copyright 2023 IEEE.
The input currents in the TIA stage are then given by I T = G X V + I, where V is the output voltage of the high impedance amplification stage. The current i T is then divided by the TIA feedback conductance as V 0 = – I T /G TI . The high impedance stage forces the current flowing in the second CBA columns to be zero, which leads to
| 22 |
By solving this equation, it is possible to obtain V = −(G T G)−1 × G T i, which, apart from the sign, provides the solution to the linear regression problem of eq as the voltage at the columns of the left array in Figure a. Figure b shows an experimental verification of the circuit, where the experimentally obtained linear regression closely matches the analytical result. Finally, by programming an extra row with a new independent variable and keeping the input floating, it is possible to predict its regression by measuring the current flowing into it. Figure c correspondingly shows an experimental result, where the extra row was programmed with values of x*, allowing extraction of the predicted value y*.
The concept of combining multiple CBAs in a feedback loop to solve complicated algebraic equations can be further extended. An example of combining multiple CBAs and feedback circuits for solving multiterm equations is shown in Figure d for the case of principal component analysis (PCA). PCA is a technique aimed at reducing the dimensionality of a data set by computing the vector directions along which the data set variance is maximized. In particular, the i-th principal component corresponds to the i-th eigenvector of the data set covariance matrix C = m –1 D T D, where D is a matrix representing the data set and m the number of observations, namely the number of D rows. To reduce the dimensionality of the data set, only the PCs with eigenvalues larger than a threshold are used to create a basis P and a corresponding data set projection Y = DP. The principal eigenvector can be obtained by the circuit in Figure a modified by the removal of the external input signal generators, since the known term is zero in calculating the eigenvectors. However, for computing any eigenvector starting from its eigenvalue, a more complicated circuit is needed. Figure d shows the closed loop analog feedback circuit for the eigenvectors computation. Here, given a known matrix X and a tentative value for its eigenvalue λ, matrix X – λI is programmed in a total of four separate CBAs, interleaved by two stages of TIAs in two opposite directions, with gains f and δ, respectively. By following a similar approach as in the regression example, it is possible to compute the output of the operational amplifier as
| 23 |
which leads to
| 24 |
For fδ approaching zero, eq can be approximated to (X – λI)V out = 0, where V out thus provides an estimation of the eigenvector. Finally, by replacing X with a matrix–matrix multiply circuit for computing C = m –1 D T D, namely two CBAs mapping D interleaved by a TIA, all the operations of the PCA can be computed in the analog domain in one step.
Figure b shows the accuracy in computing the principal components (PC) as a function of the number of bits for representing the matrix values, namely, the RRAM memory bit precision, demonstrating the need for at least 4 bits for reaching good results. A graphical example is shown in Figure c comparing the two data set projections obtained by using 64-bit floating-point (FP64) precision on a digital processor and integer 4-bit precision using the proposed analog IMC circuit, demonstrating a good agreement. Results show that the IMC approaches significantly provide better performance than a graphical processing unit (GPU), having similar accuracy and throughput but up to 10000× improved energy efficiency.
Another approach to infer traditional machine learning models with IMC is the use of an analog CAM for accelerating tree-based machine learning. Decision trees are well-established machine learning models that are highly appreciated by the machine learning community thanks to their easiness to train, state-of-the-art performance for tabular and time-series data, and explainable decision process.
Figure a shows an example of a decision tree with four input features, three nodes, a depth D = 2, and L = 4 leaves. A node consists of a comparison of one of the input features with a trainable value resulting in a branching operation; for example, the first node performs the comparison f 1 ≤ 0.2 for the first feature with the trained value 0.2 taking either the left branch in case the condition is met or the right branch if the condition is not met. Conditional branching is performed until reaching the leaf which stores the model prediction, such as the predicted class. Ensembles of decision trees such as Random Forests and eXtreme Gradient Boosting (XGBoost) consist of multiple trees inferred in parallel and trained either by bagging, i.e., each tree is trained on a subsample of the data set, or boosting, i.e. the i-th tree is trained based on the errors of the i-1-th tree. The output of each tree is combined with the others through a reduction operation, such as a majority vote or a summation, followed by an activation function. Modern tree-based models consist of millions of nodes and thousands of trees that need to be run in parallel. Such large ensembles are not suitable for being accelerated with traditional hardware, such as CPUs and GPUs, due to the highly irregular memory access and unpredictable traverse time, given the presence of short and tall tree branches.
29.

Illustration of Analog CAM-based decision tree inference. (a) Example of decision tree and (b) its mapping into the analog CAM. (c) Accuracy for multiple data sets considering ideal and noisy devices/circuits. Adapted from ref . Copyright 2023 IEEE with Creative Commons Attribution 4.0 license https://creativecommons.org/licenses/by-nc-nd/4.0/.
Figure b shows the mapping of the decision tree in Figure a into an analog CAM. Root-to-leaf branches are mapped in the analog CAM rows in which each cell is performing the comparison corresponding to a node. The feature vector is applied at the input, resulting in a match for the predicted class, which can be retrieved in the adjacent memory. Large-scale simulations and benchmarks have shown tremendous improvement in the throughput and latency compared with other technologies, with up to 10,000× shorter latency. Such a large improvement is because the performance is essentially independent of the model size given the massively parallel inference operation. Interestingly, thanks to their ensembling behavior, tree-based models do not require high precision of the memory cell, given that even if an error is committed in one tree, it might be recovered by another in the ensemble. Figure c shows the accuracy for multiple data sets inference using ideal devices and circuits, injecting RRAM and DAC noise. Results demonstrate only a small impact in the case of regression problems, in which the Root Mean Square Error (RMSE) is considered, and no statistically significant degradation in the case of classification problems.
Both IMVM and analog CAM circuits rely on the multiplication taking place in the circuit as I = GV, thus requiring that the memory element in the CBA displays a highly linear, or ohmic, I–V curve. While in CBAs for MVM, typically inputs are applied digitally to the WL, and analog inputs are applied directly to the TE in the case of IMVM. Similarly in analog CAM, the voltage divider between the input transistor, which is activated with analog voltages representing the input, and the RRAM device effectively induces a different analog voltage applied to the RRAM device. However, RRAM devices generally display nonlinear I–V characteristics, which are correlated to the density of oxygen vacancies in the CF. Nonlinearity effects can be minimized by operating the device in a limited number of states, typically close to the LRS, in which the conduction appears more linear. In that case, simulations have shown a uniform CF independent of the CC, which allows better heat dissipation. However, this approach may significantly limit the available stable levels in the cell.
The RRAM device stack can be optimized to offer a better linearity. For example, the TE, or oxygen exchange layer, can affect oxygen availability during forming and switching, thus affecting the shape and uniformity of the CF and ultimately controlling the conduction linearity. Figure a shows the measured and simulated I–V characteristics for multiple CCs of a RRAM device with a Ti/Ta2O5–x stack. The curves indicate a significant nonlinearity at low CCs, which are attributed by simulations to the conical shape of the CF and the limited thermal conductivity of the switching material. Figure b shows the effect of replacing Ti with Ta as the TE material, resulting in a Ta/Ta2O5–x stack and largely contributing to improving the linearity of the I–V curve. Figure c shows a comparison between the Ti/Ta2O5–x and Ta/Ta2O5–x through the CDF of the nonlinearity parameter, defined as I(V read )/I(0.5V read ), where V read is the read voltage, after programming multiple devices for multiple cycles with I C = 100 μA The results suggest a nonlinearity of about 2, which corresponds to a perfectly ohmic behavior, for the quasi-metallic filament of the Ta-based RRAM, compared to a large spread of nonlinearity parameters with a median along 10 for the Ti-based RRAM.
30.

Linearity of the conduction characteristics of RRAM devices. (a) Measured and simulated I–V characteristics of Ti/Ta2O5–x . (b) Same except for Ta/Ta2O5–x . (c) CDF of the nonlinearity for the two stacks, including both device-to-device and cycle-to-cycle variability. Adapted with permission from ref . Copyright 2019 IEEE.
5.5. Combinatorial Optimization
Optimization problems, such as Boolean satisfiability, are at the core of many scientific, security, and machine-learning problems. Typically, optimization consists of finding a set of input values that satisfy a certain number of conditions, e.g. clauses. There are two classes of algorithms for solving optimization problems, namely exact and stochastic solvers. Exact solvers always lead to a solution, although they tend to be slow for classes of problems in which the structure is unknown or difficult to grasp. On the opposite side, stochastic solvers based, for example, on quadratic unconstrained binary optimization (QUBO) with simulated annealing (SA) can efficiently solve problems with random structures. Interestingly, such workloads can be mapped in computing primitives such as the Ising machine or the Hopfield neural network (HNN). The typical HNN operates in a recurrent, iterative mode, where, at each iteration, given a vector of spins s as input, the network computes the output v i defined as
| 25 |
where u i is the MVM operation, namely:
| 26 |
where W ij is a coupling matrix, representing the specific problem to be solved, while θ i represents a threshold. The HNN iteratively converges toward the minimum of its energy function given by
| 27 |
However, depending on the initial conditions and energy landscape defined by the coupling matrix W ij , the HNN can remain stuck at a local minimum. To prevent getting stuck at the local minima, noise can be added to u i , which is thus equivalent to implementing an SA algorithm.
The main computational complexity of the HNN consists of the MVM for computing u in eq ; thus, RRAM CBAs offer an efficient implementation of HNNs and Ising machines. ,,, Figure a shows the circuit schematic of an optimization solver based on an RRAM CBA. The circuit is very similar to a recurrent version of the DPE in Section , where the output is directly fed back to the input without any postprocessing. Also, input and output signals are digital according to eq , which is implemented by comparators in the circuit of Figure a. Note that the HNN circuit generally does not need power-hungry ADCs or any complicated digital periphery between inputs and outputs, thus making the circuit particularly energy efficient. Finally, the intrinsic noise of RRAM devices can be leveraged for performing a variety of annealing techniques.
31.

RRAM-based solution of combinatorial optimization problems. (a) Hopfield neural network (HNN). (b) Example of a 6-node weighted graph partitioning problem and (c) its corresponding synaptic weights mapped into a RRAM CBA. (d) Energy as a function of the number of epochs for multiple annealing schemes. Adapted with permission from ref . Copyright 2019 IEEE.
Figure b shows an example of a weighted graph partitioning problem that involves dividing the vertices of a graph into disjointed subsets while optimizing a specific criterion. Figure c shows the mapping of the graph partitioning problem into a CBA. In this example, multiple intrinsic annealing techniques, such as chaotic simulated annealing (CSA), stochastic simulated annealing (SSA), and exponential annealing (EA), have been tested and compared in terms of the performance and efficiency of the solution. Figure c shows the energy function during the circuit iterations, indicating different convergence speeds for the various annealing schemes. The annealing scheme can be controlled by effectively programming the CBA to inject random currents having different types of chaotic behavior. While HNNs can efficiently solve QUBO problems, practical industrially relevant optimization problems, such as Boolean satisfiability problems (SAT), show a higher number (i.e., >2) of interactions. Mapping SAT or in general polynomial unconstrained binary optimization (PUBO) can lead to a significant overhead, due to auxiliary variables making the problem more complex. Recently, higher-order optimization solvers based on RRAM have also been presented. ,
5.6. Stochastic Computing
While noise can be useful for SA and other optimization metaheuristics, it can also be used as a source of entropy or seed for stochastic computing. For example, in the case of Bayesian approaches, noise can be used in different ways; namely, it can be (i) tolerated, such as in the case of Bayesian machines, (ii) embraced, for example during inference Bayesian neural networks, or (iii) exploited for Bayesian learning.
Bayesian machines can be implemented in near-memory accelerators able to perform efficient Bayesian inference, namely, generating a posterior distribution p(Y = y|O i ) based on the prior distribution p(Y = y) and observations O i . Referring to the simple case of conditionally independent processes, the Bayesian inference consists of computing:
| 28 |
A RRAM-based Bayesian machine implements eq by encoding each likelihood factor, i.e. p(O i |Y m = y m ), in an independent RRAM array and performing multiplication, which in the case of stochastic computing consists of just an AND operation between stochastic streams of random bits, with a multiplier tree close to the memories. The observations O i are used as addresses for the memory arrays, selecting the corresponding likelihood value. Being that the operation is inherently stochastic and since the RRAM devices are programmed in binary states, RRAM-based Bayesian machines are highly resilient to noise and variations.
In Bayesian neural networks, the model weights are probability distributions that are sampled during inference; thus, noisy RRAM devices can naturally represent the network weights. The noise of RRAM devices in the LRS generally displays a normal probability distribution, where its standard deviation is tightly related to the mean value. Thus, by considering this relationship during training and without using the standard deviation as a free parameter, it is possible to implement the distribution of a model parameter with one or more RRAM devices. A Bayesian neural network layer can thus be mapped similarly to a conventional DNN, as shown in Section , where each computational layer consists of a dot product operation. Interestingly, Bayesian neural networks can provide a distribution of the outputs, leading to important insights for model explanation.
Finally, the stochastic properties of RRAM devices can be leveraged for Bayesian learning, for example in the case of training Metropolis-Hasting Monte Carlo Markov Chain (MCMC) models. Weights are sampled randomly from a Gaussian distribution whose mean was learned at the previous learning iteration step. Sampling can thus be directly obtained from RRAMs in LRS. The technique was used to train a Bayesian neural network with software equivalent accuracy.
5.7. Neuromorphic Computing
Neuromorphic computing refers to the ability of electronic circuits to emulate specific mechanisms of information processing taking place in the brain. The human brain is characterized by extremely low energy consumption in the range of 20 W, combined with high parallelism and a unique capability to adapt to the environment and learn from external stimulation. Compared to artificial computers based on the von Neumann architecture, where memory and processing functions take place in different modules within the computing system, the human brain is characterized by the memory and processing being colocated within the same biological network. Such in situ processing of information within memory has been a constant inspiration for the IMC field to maximize energy efficiency by minimizing data movement. Neuromorphic engineering and computing were introduced in the early 1990s and revived in the last 20 years as a response to the fast growth of interest in AI and the emergence of the hardware limitations to solve AI tasks. ,
A specific challenge of neuromorphic computing is the misalignment between the brain processes, including fundamental physiological, biochemical, and biophysical processes, and the conventional CMOS technology, including transistors, resistors, capacitors, and their constitutive electrical characteristics. For instance, the input/output characteristics, localization, connectivity, and time scales are different in the human brain and in a digital or analog computer. To fill this gap, it is essential to introduce a new technology platform of neuromorphic devices that can provide a realistic equivalent of the bioneurological processes within electronic hardware. ,, From this standpoint, RRAM devices have been the object of growing interest as a memristive technology capable of providing unique properties of dynamic and static learning. − In fact, RRAM and other emerging NVMs can provide a wide portfolio of device physical properties capable of mimicking the most important neurobiological processes occurring at the neuron soma, synapses and dendrites.
Figure shows an overview of the major neurobiological processing mechanisms and their possible emulation via emerging NVM such as RRAM and PCM. , Spikes are delivered from one neuron to the others to exchange information, inducing synaptic excitatory/inhibitory adaptation and dendritic processing. The summation of weighted spikes can be mimicked by the MVM operation taking place in RRAM CBAs, where input voltage signals are converted into currents by Ohm’s law, followed by current summation and collection by Kirchhoff’s law (see Section ). ,, Leaky integrate-and-fire (LIF) neuron dynamics can be emulated by pulse accumulation in various types of multilevel NVMs, such as PCM , and RRAM. , Other neuron mechanisms, such as stochastic spiking and homeostasis, have also been implemented in RRAM devices and circuits. Dendritic filtering has been reported via the use of volatile RRAM devices based on TaO x /AlOδ for the artificial dendrite and on NbO x for the artificial soma. Synaptic elements based on RRAM were demonstrated to display both long-term potentiation (LTP) ,,, and short-term potentiation (STP). ,
32.

Brain-inspired computing with RRAM device physics, including neuron summation, integration and fire, dendritic processing, and synaptic long- and short-term plasticity. Adapted with permission from ref . Copyright 2021 AIP Publishing LLC.
Neuromorphic computing aims at implementing a specific brain-inspired function, such as unsupervised learning, spatiotemporal pattern recognition, or in-sensor computing, via a specific combination of CMOS and RRAM circuits. Within this combination, the RRAM technology can provide a unique asset of device properties that would be impossible to achieve with CMOS-only devices. For instance, RRAM can provide long-term plasticity via the nonvolatile storage of a parameter, such as a weight or a membrane potential. Such a nonvolatile effect is essential for reproducing learning and adaptation in the human brain, thus motivating the need for RRAM technology for neuromorphic computing. Similarly, working memory for short-term plasticity in speech recognition and decision-making is characterized by a typically long time scale. These long-time constants require relatively large capacitors within a pure-CMOS circuit, which would negatively impact the cost of the neuromorphic chip. Finally, RRAM devices can provide multilevel storage of parameters with high density, which ensures high connectivity of the human brain, in the range of 104 synaptic connections per neuron.
Neuromorphic circuits displaying adaptive, unsupervised learning where RRAM devices play the role of synaptic elements sensitive to spikes have attracted strong attention. LTP in the human brain has been traditionally attributed to Hebbian learning, where synapses selectively display potentiation or depression depending on when they are subject to a large spiking activity or to a strong interaction of more spikes in time. Examples of Hebbian learning include paired-pulse facilitation (PPF), , spike-timing dependent plasticity (STDP), ,,, triplet-based LTP , and spike-rate dependent plasticity (SRDP) according to the Bienenstock–Cooper–Munro (BCM) rule. −
One of the most popular descriptions of Hebbian learning in the brain is STDP, where the synaptic potentiation or depression is the result of the occurrence of a pair of spikes originating at the presynaptic and postsynaptic neurons. ,,, In particular, according to the STDP rule, LTP takes place when the postsynaptic spike follows the presynaptic one, namely when the spiking delay time Δt is positive, or Δt = t post – t pre > 0, where t post and t pre are the postsynaptic and presynaptic time, respectively. On the other hand, depression takes place when the delay time is negative, namely Δt < 0. STDP can be achieved by careful engineering of the post-/presynaptic spikes so that the overlap between the spikes results in a pulse across the RRAM devices with a pulse width and/or amplitude that depends on the sign and magnitude of Δt. ,, Note that the pulses resulting from the spike overlap must fall in the programming regime in Figure , thus resulting in dynamic IMC that is necessary for permanent modification of the RRAM conductance.
Figure a shows the schematic circuit for an RRAM synapse with 1T1R structure capable of LTP via STDP. The presynaptic neuron drives the gate terminal of the 1T1R synapse, while the output current is injected to the postsynaptic neuron via the source terminal, ideally serving as a virtual ground terminal. When the postsynaptic neuron fires, a spike is applied to the TE terminal of the synapse, normally biased to a read voltage to sustain the synaptic readout current. The postsynaptic spike displays a positive pulse followed by a negative pulse exceeding the set and reset voltages, respectively, as shown in Figure b. Due to the particular shape of the postsynaptic spike, the overlap between pre- and postsynaptic spikes causes LTP and LTD for Δt > 0 and Δt < 0, respectively.
33.

Long-term potentiation (LTP) with RRAM devices. (a) Structure of a 1T1R artificial synapse for STDP. (b) Sketch of the overlapping presynaptic (gate) spike and postsynaptic (TE) spike for the case of synaptic potentiation (Δt > 0). (c) Sketch of STDP for second-order RRAM device where nonoverlapping spikes can lead to LTP or Ltd. (d) Single-layer perceptron (SLP) with STDP synapses capable of unsupervised learning of spatial visual patterns. (e) Measured synaptic conductance as a function of the number of epochs, namely the spike number, indicating that LTP and LTD take place in specific synaptic elements in (d) depending on their position with respect to the stimulating pattern. Panels (a,b) are adapted with permission from ref . Copyright 2016 IEEE. Panel (c) is adapted with permission from ref . Copyright 2015 ACS Publications. Panels (d,e) are adapted from ref . Copyright 2017 Nature Publishing Group with Creative Commons Attribution 4.0 International License https://creativecommons.org/licenses/by/4.0/.
The overlap concept for STDP can require relatively long pulses in the same range as the typical time delay in the STDP characteristic that must be implemented. Long pulse widths can also result in large energy consumption or occupation of shared interconnect lines for relatively long times, preventing massive parallelism of spike communication. These problems can be overcome by the nonoverlap STDP algorithm in Figure c, where the simple sequence of postsynaptic and postsynaptic spikes without overlap can result in delay-dependent LTP. This is possible in the so-called second-order memristor, consisting of a bilayer stack Ta2O5–x /TaO y , where PPF due to thermal or chemical interaction between successive pulses can lead to STDP with nonoverlapping spikes. ,
STDP provides the basis for unsupervised learning within the single-layer perceptron (SLP) circuit sketched in Figure d, where N input neurons are connected to a single output neuron via N synapses. The output neuron is set to operate according to an integrate-and-fire mode, where input spikes cause an increase in the local membrane potential V m , until V m reaches the threshold for fire. The application of an input spiking stimulation, such as a visual pattern, leads to selective LTP and LTD depending on the delay time Δt. Due to the correlation between input pattern spikes, the presentation of the input pattern leads to output neuron fire with Δt > 0, thus causing LTP. On the other hand, uncorrelated input noise spikes cause a fire with Δt < 0, thus causing Ltd. , Figure e shows the experimental evolution of the conductance within the SLP, indicating selective LTP and LTD taking place in synapses stimulated by the input pattern and by noise, respectively, as a result of the STDP in 1T1R synapses based on RRAM. The development of such multisynaptic circuits is extremely promising for developing perceptron-like networks capable of autonomous learning and adaptation.
In addition to LTP, neuromorphic computing takes advantage of short-term memory, which supports several functions in the human brain, such as speech/language understanding, problem-solving, decision-making, navigation, selective attention, mental arithmetic, and so on. Short-term memory can be implemented in RRAM devices by engineering the stack to achieve volatile switching, as opposed to the nonvolatile memory effect that is generally pursued for memory applications. Figure a shows the measured I–V curve for a volatile RRAM device based on Ag nanodots, where the Ag filament is not stable after switching, thus collapsing the device to an off state. Set transition is observed under both positive and negative voltages; however, the device switches back to the off state as the voltage is decreased below a minimum holding voltage V hold . − To better highlight the time scale of the on–off transition, Figure b shows the measured applied voltage and the current response as a function of time. After the applied spike is removed, the current response remains active under a small applied read voltage for a retention time on the order of 150 μs. The limited retention time can be attributed to the unstable Ag filament, where the tendency to minimize the free energy associated with the surface leads to the collapse of the filament toward the electrodes, or its breakdown into smaller nanocrystals. ,
34.

Neuromorphic computing with volatile RRAM devices with short-term memory. (a) I–V characteristics of an RRAM device with Ag nanocrystals displaying volatile switching to the LRS under both positive and negative voltage sweep. (b) Measured applied voltage and current response for an Ag-based volatile RRAM device, highlighting the retention time in the range of about 150 μs. (c) Spatiotemporal pattern recognition based on a differential circuit comparing the current response of excitatory and inhibitory synapses. (d) Measured excitatory postsynaptic current (EPSC) for a sequence A–B in (c), resulting in a positive EPSC. (e) Same as (d) but for sequence B–A, resulting in a negative EPSC. Panel (a) is adapted with permission from ref . Copyright 2020 Wiley VCH. Panel (b) is adapted with permission from ref . Copyright 2021 IEEE. Panels (c, d and e) are adapted from ref . Copyright 2021 Wiley VCH with Creative Commons Attribution 4.0 International License https://creativecommons.org/licenses/by/4.0/.
The volatile response of Ag-based RRAM devices can be used for emulating the excitatory postsynaptic current (EPSC) which takes place as a result of the spiking stimulation of a synapse causing the opening of ionic channels for a relatively short period of time. Figure c shows a differential circuit comparing the current response of an excitatory synapse and an inhibitory synapse, each stimulated by pulses of a sequence A-B (preferred) or B-A (nonpreferred). Each synapse in the figure consists of several RRAM devices, where the composition of several random rectangular responses results in an overall response with an almost exponential decay behavior. As shown in Figure d,e, due to the delay between the excitatory and inhibitory synaptic currents, the differential current I EPSC shows a positive or negative sign for the preferred and nonpreferred sequence, respectively, thus featuring spatiotemporal sequence recognition. Such a short-term EPSC effect enables the recognition of different directions of dynamic visual signals by mimicking the direction-selective ganglion cell in the human retina.
Figure a shows a volatile RRAM circuit for the brain-inspired processing of auditory signals. Here, several volatile RRAM devices are stimulated by voltage signals with linearly increasing amplitude close to the threshold voltage V set for the set transition. Due to the exponential voltage dependence of switching probability, the number of devices being activated by the input signal increases with the frequency of the signal. This is shown in Figure b,c,d, where the application of a train of rectangular pulses shows the activation of an increasing number of devices as the frequency increases from a relatively low value (b) to a relatively high value (d). Note that the number of activated devices can be probed by the current level due to the parallel connection in the circuit of Figure a, thus enabling a frequency to current conversion. Figure e shows the number N on of activated devices as a function of frequency, indicating a linear increase of N on with the logarithmic frequency, as a result of the exponential increase of the switching probability with voltage. These results are compared with the tonotopic characteristic of the cochlea, namely the depth location of stimulated cilia in the cochlea as a function of frequency. The ability to track the frequency on a logarithmic scale allows for bioinspired tonotopic processing of auditory signals by exploiting the unique exponential voltage response of RRAM switching probability.
35.

Tonotopic frequency detection in volatile RRAM devices with short-term memory. (a) Circuit for frequency-current conversion by exploiting the exponential dependence of switching probability on voltage. (b) Response of the circuit to a relatively low stimulating frequency of 632 Hz, resulting in just one device being activated. (c) Same as (b) but for a higher frequency, indicating the activation of 2 devices. (d) Same as (c), but with even higher frequency, causing 3 devices to be activated. (e) Measured number of activated devices as a function of frequency, indicating a linear increase of current on a logarithmic current, due to the exponential voltage dependence of switching probability. Results are compared with the cochlea tonotopic characteristic. Reproduced from ref . Copyright 2024 Nature Publishing Group with Creative Commons Attribution 4.0 International License https://creativecommons.org/licenses/by/4.0/.
An important methodology in neuromorphic computing is reservoir computing depicted in Figure a, where the input stimuli are processed by a dynamic reservoir layer, while a second readout layer is used for classification. , For the processing of a time-dependent sequence, the reservoir layer must contain dynamic elements, such as LIF neurons or short-term memory devices, with a typical time constant in the same range as the signal being processed. For this purpose, volatile RRAM can provide an ideal technology given the high density and the tunable retention time usually in the range between 1 ms and 1 s. This is illustrated in Figure b, showing the time sequence of input pulses and the corresponding internal state variable, e.g., the conductance of an RRAM device subjected to the input sequence of pulses in the range of the set voltage, thus inducing dynamic short-term potentiation. The reservoir approach is most suitable for the processing of electro-physiological signals, such as neuron spike sorting, speech recognition, and epileptic seizure prediction. However, not only spatiotemporal patterns but also purely spatial patterns, such as images, can be processed via reservoir computing by suitably converting the spatial pattern into one or more spatiotemporal patterns. This is shown in Figure c, where a visual pattern, namely the digit ‘2’ in Figure d, is converted into a spatiotemporal pattern consisting of a sequence of 4 pulses across 5 channels, each connected to the input of a RRAM device. The readout current of the RRAM subject to pulse-induced potentiation is then applied to the readout layer for classification. While the reservoir layer is usually untrained, the readout network is a fully connected network where the synaptic weights are pretrained for a specific task, e.g. the classification of digits based on the internal state variables in the reservoir.
36.

Reservoir computing concept. (a) Sketch of a reservoir computing network, including an input layer for delivering the input signals, a reservoir layer for dynamic processing, and an output layer for classification. (b) Sketch of input signals and internal state variables in the reservoir layer as a function of time. (c) Conversion of a spatial pattern into a spatiotemporal pattern, applied to an RRAM-based reservoir layer and finally classified by a pretrained fully connected read-out layer. (d) Conversion of an image into a spatiotemporal pattern for reservoir computing. Reproduced with permission from ref . Copyright 2017 Nature Publishing Group.
Similar reservoir computing demonstrations have been reported for other memory devices, such as MoS2-based charge-trap memory devices and spin-torque nano-oscillators. The dynamic layer in reservoir computing does not necessarily consist of a well-defined, top-down structured memory array; rather, it can also feature a random, bottom-up nanostructure, such as a network of nanowires or nanotubes. This is the so-called in-materia computing approach, where the reservoir layer consists of a material or structure where input signals are applied, while output signals are extracted to monitor the internal state variable, usually consisting of a localized chemical, physical or electrical property of the material. ,, Such in-materia computing is particularly promising given the extreme scalability, BEOL integration, and dynamic response with the same time scale of the electro-physiological signals that need to be processed in the neuromorphic system.
While STM is an essential requirement for neuromorphic computing, the typical decay time constant of STM should match the time scale of the signal to be processed. For instance, speech recognition via reservoir computing requires that the memory devices in the reservoir layer react to signal stimulations within the frequency range (from 0.1 to 20 kHz) of the audio signal to be processed. , Similarly, neuron spike sorting and classification requires that memory devices display an STM decay in the time scale between a few milliseconds to a few seconds. The STM time constant should also be statistically uniform for the same device operated in several cycles and for different devices within the same or different circuits, thus enabling the design of SNN circuits with predictable behavior.
To assess the time constant of the STM, RRAM devices are measured according to the experimental technique shown in Figure a. Here, a voltage pulse is applied to the RRAM device to induce the set transition; then the voltage is rapidly reduced to a relatively low value V read to enable readout without disturbing the device. The device, consisting of a MIM structure with Au electrodes and a dielectric layer of silk-Ag nanowires composite, was monitored by measuring the voltage across a low series resistance, typically of 50 Ω, by an oscilloscope (see inset). Figure b shows the RRAM conductance, measured as the response current divided by V read , for increasing I C . The conductance sharply drops after a variable retention time t R . As I C increases, both G and t R increase as a result of the larger cross-sectional area of the CF, thus resulting in a larger conductance and better stability with a longer retention time. The CF decay is attributed to the structural instability of the Ag CF, where the relatively large surface energy causes a spontaneous surface rediffusion of Ag atoms to minimize the surface-to-volume ratio.
37.

Characterization of STM behavior and time scale in volatile RRAM devices. (a) Voltage waveform for the characterization of the short-term memory effect in RRAM. The inset shows the electrical circuit connection to probe the current response of the RS element via a load resistor. (b) Measured conductance for RRAM devices at increasing I C . (c) Cumulative distributions of t T for increasing I C . (d) Cumulative distributions of t R for increasing V read . The STM time constant can be tuned by I C and V read , thus enabling reservoir computing with dynamic RRAM for various real-life applications. Panels (a,b) are adapted from ref . Copyright 2019 Nature Publishing Group with Creative Commons Attribution 4.0 International License https://creativecommons.org/licenses/by/4.0/. Panels (c,d) are adapted with permission from ref . Copyright 2021 IEEE.
Figure c shows the cumulative distributions of measured t R on a single RRAM with a Ag/SiO2/C stack. Data confirm the increase of t R with increasing I C , as a result of the improved stability with increasing size of the CF. Data also show that the t R scale can be tuned between approximately 0.1 and 50 ms by operating the device at different I C . This property is essential to enable neuromorphic applications for the processing of real-life data such as electrophysiological signals, speech and gesture, which generally display characteristic time and frequency over different time scales. Figure d shows the cumulative distributions of t R for increasing V read , where t R increases with V read due to the competition between field-induced ionic drift, sustaining the CF structural stability, and ionic rediffusion responsible for CF dissolution.
The results in Figure support the ability to tune the retention time, which is useful for applications requiring a large range of decay times for the processing of signals with multiple frequency components. The millisecond time scale of t R also supports three-factor learning, where the potentiation and depression of the synaptic RRAM is enabled within a limited time window. Note that t R is affected by a non-negligible cycle-to-cycle variation, which might be due to the stochastic shape and size of the CF, as well as the stochastic rediffusion processes, which might be sensitive to the local microstructure of defects and grain boundaries. Such a stochastic variation can impact the accuracy of a reservoir computing system for signal recognition. These variations can be mitigated by circuit design solutions, such as the use of several RRAM devices in parallel where the retention time is dictated by the decay of the summation of the RRAM currents.
6. Conclusions
This paper reviews the main applications and corresponding requirements for IMC with RRAM devices, as summarized in Table . RRAM development and understanding have made significant progress during the last 20 years. Thanks to the extensive efforts in device engineering, characterization, and modeling, RRAM is today a consolidated technology that has been extensively demonstrated in CMOS-compatible chips, for both stand-alone and embedded NVM, as well as for a number of technological demonstrations of IMC. RRAM appears as a unique technology capable of offering significant added value, in terms of nonvolatile storage, low-voltage/low-current operation, compatibility with the CMOS process flow, scalability, multilevel operation, and fast read. At the same time, to face the competition of conventional CMOS memories, such as DRAM and SRAM, and of other emerging NVM technologies, more work is needed to address some remaining challenges.
In particular, IMC poses significant challenges to RRAM given the diverse requirements for various computing algorithms. For instance, a key RRAM limitation for DNN inference accelerators is the stochastic variation and fluctuation of resistance, which affects the weight bit precision and the accuracy of IMC. More challenges arise with the inference of modern models, such as transformers where the attention mechanism plays a pivotal role. The attention matrices change for each input sequence; thus, CBAs have to be rewritten, making endurance an extra requirement. Endurance is also an essential requirement for DNN training due to the extensive weight update in the hardware back-propagation algorithm. DNN training also requires RRAM devices with highly linear weight updates to implement the back-propagation without significantly changing the learning rule. For inverse linear algebra operations such as the solution of linear equations, linear regression, and PCA, the main requirements are high endurance, to enable rapid and frequent reconfiguration, and highly linear I–V characteristics, in addition to high multilevel precision of the mapped weight with low variation and noise. Similar properties are needed for the implementation of optimization solvers accelerated with RRAM-based Ising machines and HNN. Note that high endurance and high retention are generally not required at the same time, since applications requiring fast/frequent reconfiguration, such as DNN training, generally do not require the persistency of the mapped parameters for a long time and high temperature.
In the case of stochastic computing, such as Bayesian learning, noise must be minimized to guarantee sampling without drift of the mean or standard deviation, whereas retention is a strong requirement. Tree-based ML circuits, specifically those relying on analog CAMs, require multilevel operation to represent different conditional branching without significant overhead in the circuit peripherals. In particular, compared with CBAs in which multiple devices can be used in parallel, slicing schemes in CAMs can result in exponential overhead. Linear I–V curves are also essential requirements for analog CAM. Finally, in the case of SNN, STM and good endurance are a strong requirement for implementing reservoir computing and neuromorphic learning and adaptation.
In conclusion, diverse RRAM requirements arise for diverse applications. Careful RRAM engineering is needed to meet these multiple requirements as much as possible within a single device technology. Alternatively, material stacks and algorithm optimization could be developed to match the specific requirements for any individual application, with the aid of specialized peripheral circuits and architecture improvements that can be used to mitigate RRAM nonidealities and assist the specialized RRAM algorithms, such as advanced PV methods. Hardware-software and device-to-system co-optimization routines tailored for the various applications, supported by novel automated design techniques, might enable RRAM technology for energy-efficient, high-performance, accurate IMC.
Acknowledgments
This work has received funding from the European Research Council (ERC) (grant agreement n° 101054098). The authors would like to thank D. Bridarolli, M. Farronato, A. Glukhov, G. Larelli, P. Mannocci, G. Panettieri, M. Porzani and S. Ricci for critical proofreading of the manuscript.
Glossary
List of Acronyms
- 1C
one-capacitor
- 1R
one-resistor
- 1S1R
one-selector/one-resistor
- 1T1R
one-transistor/one-resistor
- A-ECC
analog error correction code
- ADC
analog-digital converter
- AI
artificial intelligence
- ALD
atomic layer deposition
- BCM
Bienenstock–Cooper–Munro
- BEOL
back-end of the line
- BL
bitline
- CAM
content addressable memory
- CBA
crossbar array
- CBRAM
conductive-bridge random-access memory
- CC
compliance current
- CDF
cumulative distribution function
- CF
conductive filament
- CIFAR-10
Canadian Institute for Advanced Research with 10 classes
- CMOS
complementary metal-oxide-semiconductor
- CPU
central processing unit
- CSA
chaotic simulated annealing
- CTM
charge trap memory
- CVD
chemical vapor deposition
- DAC
digital-analog converter
- DL
Data line
- DNN
Deep neural network
- DPE
dot-product engine
- DRAM
dynamic random access memory
- DTCO
design/technology co-optimization
- EA
exponential annealing
- ECC
error correction code
- eNVM
embedded nonvolatile memory
- EPSC
excitatory postsynaptic current
- ECRAM
electrochemical random access memory
- FeRAM
ferroelectric random access memory
- FET
field-effect transistor
- FP64
floating point 64-bit
- FSR
full-scale range
- GPU
graphical processing unit
- HKMG
high-k/metal-gate
- HNN
Hopfield Neural Network
- HRS
high resistance state
- I–V
current–voltage
- IGVVA
incremental gate voltage with verify algorithm
- IMC
in-memory computing
- IMVM
inverse matrix vector multiplication
- ISPVA
incremental step pulse with verify algorithm
- LIF
leaky integrate-and-fire
- LLM
large language model
- LRS
low resistance state
- LSE
least-squares error
- LTD
long-term depression
- LTP
long-term potentiation
- MCMC
Monte Carlo Markov Chain
- MCU
microcontroller unit
- MIM
metal–insulator–metal
- ML
match line
- MLP
multilayer perceptron
- MNIST
Modified National Institute of Standards and Technology
- MOCVD
metal-organic chemical vapor deposition
- MRAM
magnetic random access memory
- MRS
medium resistance state
- MVM
matrix vector multiplication
- NDR
negative differential resistance
- NSR
noise-to-signal ratio
- NVM
nonvolatile memory
- OEL
oxygen exchange layer
- OPA
Outer Product Accumulate
- PC
principal component
- PCA
principal component analysis
- PCM
phase change memory
- PPF
paired-pulse facilitation
- PUBO
Polynomial Unconstrained Binary Optimization
- PUF
physical unclonable function
- PV
program verify
- QUBO
Quadratic Unconstrained Binary Optimization
- RAM
random access memory
- ReLU
rectifying linear unit
- RMSE
root mean square error
- RRAM
resistive switching random-access memory
- RS
resistive switching
- RTN
random telegraph noise
- RW
random walk
- SA
simulated annealing
- SAT
Boolean satisfiability problem
- SCLC
space-charge limited conduction
- SCM
storage class memory
- SLP
single-layer perceptron
- SOM
selector-only memory
- SRAM
static random access memory
- SRDP
spike-rate dependent plasticity
- SSA
stochastic simulated annealing
- STDP
spike-timing dependent plasticity
- STP
short-term potentiation
- TCAM
ternary CAM
- TDDB
time-dependent dielectric breakdown
- TIA
transimpedance amplifier
- TMD
transition metal dichalcogenide
- TRNG
true random number generator
- vdW
van der Waals
- WL
wordline
- XPS
X-ray photoelectron spectroscopy
Biographies
Daniele Ielmini is a Professor at the Dipartimento di Elettronica, Informazione e Bioingegneria, Politecnico di Milano, Italy. He received his Ph.D. from Politecnico di Milano in 2000. His research interests include nonvolatile memories, such as phase change memory (PCM) and resistive switching random-access memory (RRAM), and novel in-memory computing circuits. He authored/coauthored more than 20 book chapters, more than 400 papers published in international journals and presented at international conferences, and 10 patents. He is Associate Editor of IEEE Trans. Nanotechnology and Semiconductor Science and Technology. He received the Intel Outstanding Researcher Award, the Ovshinsky Award, the IEEE-EDS Paul Rappaport Award, the ERC Consolidator Grant and the ERC Advanced Grant. He is a Fellow of the IEEE.
Giacomo Pedretti is a Senior Research Scientist at the Artificial Intelligence Research Lab of Hewlett-Packard Laboratories in Milpitas (CA), where he leads the in-memory computing architectures and hardware software codesign research. He received his Ph.D. from Politecnico di Milano in 2020, and he spent one year in the same institution as a postdoctoral researcher before joining Hewlett-Packard Laboratories in 2021. He coauthored more than 60 papers in peer-reviewed journals and conferences, 4 book chapters, and 14 patents.
CRediT: Daniele Ielmini conceptualization, funding acquisition, methodology, writing - original draft, writing - review & editing; Giacomo Pedretti conceptualization, methodology, writing - original draft, writing - review & editing.
The authors declare no competing financial interest.
Published as part of Chemical Reviews special issue “Neuromorphic Materials”.
References
- Wong H.-S. P., Salahuddin S.. Memory leads the way to better computing. Nat. Nanotechnol. 2015;10:191–194. doi: 10.1038/nnano.2015.29. [DOI] [PubMed] [Google Scholar]
- Horowitz, M. 1.1 Computing’s energy problem (and what we can do about it). 2014 IEEE International Solid-State Circuits Conference Digest of Technical Papers (ISSCC). San Francisco, CA, USA, 2014; pp 10–14. [Google Scholar]
- Zidan M. A., Strachan J. P., Lu W. D.. The future of electronics based on memristive systems. Nature Electronics. 2018;1:22–29. doi: 10.1038/s41928-017-0006-8. [DOI] [Google Scholar]
- Ielmini D., Wong H.-S. P.. In-memory computing with resistive switching devices. Nature Electronics. 2018;1:333–343. doi: 10.1038/s41928-018-0092-2. [DOI] [Google Scholar]
- Ielmini D., Ambrogio S.. Emerging neuromorphic devices. Nanotechnology. 2020;31:092001. doi: 10.1088/1361-6528/ab554b. [DOI] [PubMed] [Google Scholar]
- Hickmott T.. Low-frequency negative resistance in thin anodic oxide films. J. Appl. Phys. 1962;33:2669–2682. doi: 10.1063/1.1702530. [DOI] [Google Scholar]
- Ovshinsky S. R.. Reversible Electrical Switching Phenomena in Disordered Structures. Phys. Rev. Lett. 1968;21:1450–1453. doi: 10.1103/PhysRevLett.21.1450. [DOI] [Google Scholar]
- Marinella M. J.. Radiation Effects in Advanced and Emerging Nonvolatile Memories. IEEE Trans. Nucl. Sci. 2021;68:546–572. doi: 10.1109/TNS.2021.3074139. [DOI] [Google Scholar]
- Prinzie J., Simanjuntak F. M., Leroux P., Prodromakis T.. Low-power electronic technologies for harsh radiation environments. Nature Electronics. 2021;4:243–253. doi: 10.1038/s41928-021-00562-4. [DOI] [Google Scholar]
- Mannocci P., Farronato M., Lepri N., Cattaneo L., Glukhov A., Sun Z., Ielmini D.. In-memory computing with emerging memory devices: Status and outlook. APL Machine Learning. 2023;1:010902. doi: 10.1063/5.0136403. [DOI] [Google Scholar]
- Waser R., Aono M.. Nanoionics-based resistive switching memories. Nature materials. 2007;6:833–840. doi: 10.1038/nmat2023. [DOI] [PubMed] [Google Scholar]
- Waser R., Dittmann R., Staikov G., Szot K.. Redox-Based Resistive Switching Memories-Nanoionic Mechanisms, Prospects, and Challenges. Advanced Materials (Deerfield Beach, Fla.) 2009;21:2632–2663. doi: 10.1002/adma.200900375. [DOI] [PubMed] [Google Scholar]
- Yang J. J., Strukov D. B., Stewart D. R.. Memristive devices for computing. Nat. Nanotechnol. 2013;8:13–24. doi: 10.1038/nnano.2012.240. [DOI] [PubMed] [Google Scholar]
- Ielmini D.. Resistive switching memories based on metal oxides: mechanisms, reliability and scaling. Semicond. Sci. Technol. 2016;31:063002. doi: 10.1088/0268-1242/31/6/063002. [DOI] [Google Scholar]
- Seo S., Lee M., Seo D., Jeoung E., Suh D.-S., Joung Y., Yoo I., Hwang I., Kim S., Byun I.. Reproducible resistance switching in polycrystalline NiO films. Appl. Phys. Lett. 2004;85:5655–5657. doi: 10.1063/1.1831560. [DOI] [Google Scholar]
- Baek, I. ; Lee, M. ; Seo, S. ; Lee, M. ; Seo, D. ; Suh, D.-S. ; Park, J. ; Park, S. ; Kim, H. ; Yoo, I. ; et al. Highly scalable nonvolatile resistive memory using simple binary oxide driven by asymmetric unipolar voltage pulses. IEDM Technical Digest. IEEE International Electron Devices Meeting, 2004; pp 587–590. [Google Scholar]
- Lee H., Chen P., Wu T., Chen Y., Wang C., Tzeng P., Lin C., Chen F., Lien C., Tsai M.-J.. Low power and high speed bipolar switching with a thin reactive Ti buffer layer in robust HfO2 based RRAM. 2008 IEEE International Electron Devices Meeting. 2008:1–4. [Google Scholar]
- Lampert M. A.. Simplified theory of space-charge-limited currents in an insulator with traps. Phys. Rev. 1956;103:1648. doi: 10.1103/PhysRev.103.1648. [DOI] [Google Scholar]
- Simmons J., Verderber R.. New conduction and reversible memory phenomena in thin film insulating films. Proc. R. Soc. A. 1967;301:77–102. doi: 10.1098/rspa.1967.0191. [DOI] [Google Scholar]
- Hiatt W. R., Hickmott T. W.. Bistable Switching in Niobium Oxide Diodes. Appl. Phys. Lett. 1965;6:106–108. doi: 10.1063/1.1754187. [DOI] [Google Scholar]
- Liu X., Sadaf S. M., Son M., Park J., Shin J., Lee W., Seo K., Lee D., Hwang H.. Co-Occurrence of Threshold Switching and Memory Switching in Pt/NbO x /Pt Cells for Crosspoint Memory Applications. IEEE Electron Device Lett. 2012;33:236–238. doi: 10.1109/LED.2011.2174452. [DOI] [Google Scholar]
- Wang, W. ; Covi, E. ; Milozzi, A. ; Farronato, M. ; Ricci, S. ; Sbandati, C. ; Pedretti, G. ; Ielmini, D. . Neuromorphic Motion Detection and Orientation Selectivity by Volatile Resistive Switching Memories. Advanced Intelligent Systems 2021, 3, 2000224, Publisher: John Wiley & Sons, Ltd. [Google Scholar]
- Núñez J., Avedillo M. J., Jiménez M., Quintana J. M., Todri-Sanial A., Corti E., Karg S., Linares-Barranco B.. Oscillatory neural networks using VO2 based phase encoded logic. Frontiers in Neuroscience. 2021;15:655823. doi: 10.3389/fnins.2021.655823. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Baek, I. ; Kim, D. ; Lee, M. ; Kim, H.-J. ; Yim, E. ; Lee, M. ; Lee, J. ; Ahn, S. ; Seo, S. ; Lee, J. ; et al. Multi-layer cross-point binary oxide resistive memory (OxRRAM) for post-NAND storage application. IEEE International Electron Devices Meeting. IEDM Technical Digest. 2005; pp 750–753. [Google Scholar]
- Lee M.-J., Park Y., Kang B.-S., Ahn S.-E., Lee C., Kim K., Xianyu W., Stefanovich G., Lee J.-H., Chung S.-J., Kim Y.-H., Lee C.-S., Park J.-B., Baek I.-G., Yoo I.-K.. 2-stack 1D-1R Cross-point Structure with Oxide Diodes as Switch Elements for High Density Resistance RAM Applications. 2007 IEEE International Electron Devices Meeting. 2007:771–774. [Google Scholar]
- Russo U., Ielmini D., Cagli C., Lacaita A. L.. Self-accelerated thermal dissolution model for reset programming in unipolar resistive-switching memory (RRAM) devices. IEEE Trans. Electron Devices. 2009;56:193–200. doi: 10.1109/TED.2008.2010584. [DOI] [Google Scholar]
- Larentis S., Nardi F., Balatti S., Gilmer D. C., Ielmini D.. Resistive switching by voltage-driven ion migration in bipolar RRAMPart II: Modeling. IEEE Trans. Electron Devices. 2012;59:2468–2475. doi: 10.1109/TED.2012.2202320. [DOI] [Google Scholar]
- Beck A., Bednorz J., Gerber C., Rossel C., Widmer D.. Reproducible switching effect in thin oxide films for memory applications. Appl. Phys. Lett. 2000;77:139–141. doi: 10.1063/1.126902. [DOI] [Google Scholar]
- Choi B., Jeong D. S., Kim S., Rohde C., Choi S., Oh J. H., Kim H., Hwang C., Szot K., Waser R., Reichenberg B., S T.. Resistive switching mechanism of TiO2 thin films grown by atomic-layer deposition. J. Appl. Phys. 2005;98:033715. doi: 10.1063/1.2001146. [DOI] [Google Scholar]
- Lee H., Chen Y., Chen P., Gu P., Hsu Y., Wang S., Liu W., Tsai C., Sheu S., Chiang P.. Evidence and solution of over-RESET problem for HfOx based resistive memory with sub-ns switching speed and high endurance. 2010 International Electron Devices Meeting. 2010:19–7. [Google Scholar]
- Nardi F., Larentis S., Balatti S., Gilmer D. C., Ielmini D.. Resistive switching by voltage-driven ion migration in bipolar RRAMPart I: Experimental study. IEEE Trans. Electron Devices. 2012;59:2461–2467. doi: 10.1109/TED.2012.2202319. [DOI] [Google Scholar]
- Brivio S., Spiga S., Ielmini D.. HfO2-based resistive switching memory devices for neuromorphic computing. Neuromorphic Computing and Engineering. 2022;2:042001. doi: 10.1088/2634-4386/ac9012. [DOI] [Google Scholar]
- Ielmini D.. Modeling the Universal Set/Reset Characteristics of Bipolar RRAM by Field- and Temperature-Driven Filament Growth. IEEE Trans. Electron Devices. 2011;58:4309–4317. doi: 10.1109/TED.2011.2167513. [DOI] [Google Scholar]
- Belmonte A., Kim W., Chan B. T., Heylen N., Fantini A., Houssa M., Jurczak M., Goux L.. A Thermally Stable and High-Performance 90-nm Al2O3/Cu-Based 1T1R CBRAM Cell. IEEE Trans. Electron Devices. 2013;60:3690–3695. doi: 10.1109/TED.2013.2282000. [DOI] [Google Scholar]
- Nardi F., Larentis S., Balatti S., Gilmer D. C., Ielmini D.. Resistive Switching by Voltage-Driven Ion Migration in Bipolar RRAMPart I: Experimental Study. IEEE Trans. Electron Devices. 2012;59:2461–2467. doi: 10.1109/TED.2012.2202319. [DOI] [Google Scholar]
- Kinoshita K., Tsunoda K., Sato Y., Noshiro H., Yagaki S., Aoki M., Sugiyama Y.. Reduction in the reset current in a resistive random access memory consisting of NiO x brought about by reducing a parasitic capacitance. Appl. Phys. Lett. 2008;93:033506. doi: 10.1063/1.2959065. [DOI] [Google Scholar]
- Ielmini D., Nardi F., Balatti S.. Evidence for Voltage-Driven Set/Reset Processes in Bipolar Switching RRAM. IEEE Trans. Electron Devices. 2012;59:2049–2056. doi: 10.1109/TED.2012.2199497. [DOI] [Google Scholar]
- Chen Y., Lee H., Chen P., Gu P., Chen C., Lin W., Liu W., Hsu Y., Sheu S., Chiang P.. Highly scalable hafnium oxide memory with improvements of resistive distribution and read disturb immunity. 2009 IEEE International Electron Devices Meeting (IEDM). 2009:1–4. [Google Scholar]
- Ielmini D.. Resistive switching memories based on metal oxides: mechanisms, reliability and scaling. Semicond. Sci. Technol. 2016;31:063002. doi: 10.1088/0268-1242/31/6/063002. [DOI] [Google Scholar]
- Govoreanu, B. ; et al. 10×10nm2 Hf/HfOx crossbar resistive RAM with excellent performance, reliability and low-energy operation. 2011 International Electron Devices Meeting. Washington, DC, USA, 2011; pp 31.6.1–31.6.4. [Google Scholar]
- Kund, M. ; Beitel, G. ; Pinnow, C.-U. ; Rohr, T. ; Schumann, J. ; Symanczyk, R. ; Ufert, K.-D. ; Muller, G. . Conductive bridging RAM (CBRAM): An emerging non-volatile memory technology scalable to sub 20nm. IEEE InternationalElectron Devices Meeting, 2005. IEDM Technical Digest. 2005; pp 754–757. [Google Scholar]
- Liu Q., Sun J., Lv H., Long S., Yin K., Wan N., Li Y., Sun L., Liu M.. Real-time observation on dynamic growth/dissolution of conductive filaments in oxide-electrolyte-based ReRAM. Adv. Mater. 2012;24:1844. doi: 10.1002/adma.201104104. [DOI] [PubMed] [Google Scholar]
- Schindler C., Weides M., Kozicki M., Waser R.. Low current resistive switching in Cu-SiO2 cells. Appl. Phys. Lett. 2008;92:122910. doi: 10.1063/1.2903707. [DOI] [Google Scholar]
- Gopalan C., Ma Y., Gallo T., Wang J., Runnion E., Saenz J., Koushan F., Blanchard P., Hollmer S.. Demonstration of conductive bridging random access memory (CBRAM) in logic CMOS process. Solid-State Electron. 2011;58:54–61. doi: 10.1016/j.sse.2010.11.024. [DOI] [Google Scholar]
- Aratani K., Ohba K., Mizuguchi T., Yasuda S., Shiimoto T., Tsushima T., Sone T., Endo K., Kouchiyama A., Sasaki S.. A novel resistance memory with high scalability and nanosecond switching. 2007 IEEE International Electron Devices Meeting. 2007:783–786. [Google Scholar]
- Calderoni A., Sills S., Cardon C., Faraoni E., Ramaswamy N.. Engineering ReRAM for high-density applications. Microelectron. Eng. 2015;147:145–150. doi: 10.1016/j.mee.2015.04.044. [DOI] [Google Scholar]
- Fackenthal, R. ; Kitagawa, M. ; Otsuka, W. ; Prall, K. ; Mills, D. ; Tsutsui, K. ; Javanifard, J. ; Tedrow, K. ; Tsushima, T. ; Shibahara, Y. ; et al. A 16Gb ReRAM with 200MB/s write and 1GB/s read in 27nm technology. 2014 IEEE International Solid-State Circuits Conference Digest of Technical Papers (ISSCC). 2014; pp 338–339. [Google Scholar]
- Ambrogio S., Balatti S., Choi S., Ielmini D.. Impact of the mechanical stress on switching characteristics of electrochemical resistive memory. Adv. Mater. 2014;26:3885–3892. doi: 10.1002/adma.201306250. [DOI] [PubMed] [Google Scholar]
- Lee M.-J., Lee C. B., Lee D., Lee S. R., Chang M., Hur J. H., Kim Y.-B., Kim C. J., Seo D. H., Seo S.. A fast, high-endurance and scalable non-volatile memory device made from asymmetric Ta2O5‑x /TaO2‑x bilayer structures. Nature materials. 2011;10:625–630. doi: 10.1038/nmat3070. [DOI] [PubMed] [Google Scholar]
- Torrezan A. C., Strachan J. P., Medeiros-Ribeiro G., Williams R. S.. Sub-nanosecond switching of a tantalum oxide memristor. Nanotechnology. 2011;22:485203. doi: 10.1088/0957-4484/22/48/485203. [DOI] [PubMed] [Google Scholar]
- Gilmer, D. ; Bersuker, G. ; Park, H.-Y. ; Park, C. ; Butcher, B. ; Wang, W. ; Kirsch, P. ; Jammy, R. . Effects of RRAM stack configuration on forming voltage and current overshoot. 2011 3rd IEEE International Memory Workshop (IMW). 2011. [Google Scholar]
- Young-Fisher K. G., Bersuker G., Butcher B., Padovani A., Larcher L., Veksler D., Gilmer D. C.. Leakage current-forming voltage relation and oxygen gettering in HfO x RRAM devices. IEEE Electron Device Lett. 2013;34:750–752. doi: 10.1109/LED.2013.2256101. [DOI] [Google Scholar]
- Ricci S., Mannocci P., Farronato M., Hashemkhani S., Ielmini D.. Forming-Free Resistive Switching Memory Crosspoint Arrays for In-Memory Machine Learning. Advanced Intelligent Systems. 2022;4:2200053. doi: 10.1002/aisy.202200053. [DOI] [Google Scholar]
- Kim S., Choi S., Lu W.. Comprehensive physical model of dynamic resistive switching in an oxide memristor. ACS Nano. 2014;8:2369–2376. doi: 10.1021/nn405827t. [DOI] [PubMed] [Google Scholar]
- Wang I.-T., Lin Y.-C., Wang Y.-F., Hsu C.-W., Hou T.-H.. 3D synaptic architecture with ultralow sub-10 fJ energy per spike for neuromorphic computation. 2014 IEEE international electron devices meeting. 2014:28–5. [Google Scholar]
- Stecconi T., Guido R., Berchialla L., La Porta A., Weiss J., Popoff Y., Halter M., Sousa M., Horst F., Dávila D.. Filamentary TaO x /HfO2 ReRAM Devices for Neural Networks Training with Analog In-Memory Computing. Advanced Electronic Materials. 2022;8:2200448. doi: 10.1002/aelm.202200448. [DOI] [Google Scholar]
- Hsu C.-W., Wan C.-C., Wang I.-T., Chen M.-C., Lo C.-L., Lee Y.-J., Jang W.-Y., Lin C.-H., Hou T.-H.. 3D vertical TaOx/TiO2 RRAM with over 103 self-rectifying ratio and sub-μA operating current. 2013 IEEE International Electron Devices Meeting. 2013:10.4.1–10.4.4. [Google Scholar]
- Wang Y.-F., Lin Y.-C., Wang I.-T., Lin T.-P., Hou T.-H.. Characterization and modeling of nonfilamentary Ta/TaO x /TiO2/Ti analog synaptic device. Sci. Rep. 2015;5:10150. doi: 10.1038/srep10150. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Wang I.-T., Chang C.-C., Chiu L.-W., Chou T., Hou T.-H.. 3D Ta/TaO x /TiO2/Ti synaptic array and linearity tuning of weight update for hardware neural network applications. Nanotechnology. 2016;27:365204. doi: 10.1088/0957-4484/27/36/365204. [DOI] [PubMed] [Google Scholar]
- Chang, C.-C. ; Liu, J.-C. ; Shen, Y.-L. ; Teyuh, C. ; Chen, P.-C. ; Wang, I.-T. ; Su, C.-C. ; Wu, M.-H. ; Hudec, B. ; Chang, C.-C. ; Tsai, C.-M. ; Chang, T.-S. ; Wong, H.-S. P. ; Hou, T.-H. . Challenges and Opportunities toward Online Training Acceleration using RRAM-based Hardware Neural Network. 2017 IEEE International Electron Devices Meeting (IEDM), San Francisco, CA, USA, 2017; pp 11.6.1–11.6.4. [Google Scholar]
- Chang C.-C., Liu J.-C., Shen Y.-L., Chou T., Chen P.-C., Wang I.-T., Su C.- C., Wu M.-H., Hudec B., Chang C.-C.. Challenges and opportunities toward online training acceleration using RRAM-based hardware neural network. 2017 IEEE International Electron Devices Meeting (IEDM). 2017:11–6. [Google Scholar]
- Stecconi T., Bragaglia V., Rasch M. J., Carta F., Horst F., Falcone D. F., Ten Kate S. C., Gong N., Ando T., Olziersky A.. Analog Resistive Switching Devices for Training Deep Neural Networks with the Novel Tiki-Taka Algorithm. Nano Lett. 2024;24:866–872. doi: 10.1021/acs.nanolett.3c03697. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Balatti S., Ambrogio S., Wang Z., Sills S., Calderoni A., Ramaswamy N., Ielmini D.. Voltage-Controlled Cycling Endurance of HfOx-Based Resistive-Switching Memory. IEEE Trans. Electron Devices. 2015;62:3365–3372. doi: 10.1109/TED.2015.2463104. [DOI] [Google Scholar]
- Yang J. J., Zhang M.-X., Strachan J. P., Miao F., Pickett M. D., Kelley R. D., Medeiros-Ribeiro G., Williams R. S.. High switching endurance in TaOx memristive devices. Appl. Phys. Lett. 2010;97:232102. doi: 10.1063/1.3524521. [DOI] [Google Scholar]
- Bricalli A., Ambrosi E., Laudato M., Maestro M., Rodriguez R., Ielmini D.. Resistive Switching Device Technology Based on Silicon Oxide for Improved ON-OFF RatioPart I: Memory Devices. IEEE Trans. Electron Devices. 2018;65:115–121. doi: 10.1109/TED.2017.2777986. [DOI] [Google Scholar]
- Chen C., Goux L., Fantini A., Redolfi A., Clima S., Degraeve R., Chen Y. Y., Groeseneken G., Jurczak M.. Understanding the impact of programming pulses and electrode materials on the endurance properties of scaled Ta 2 O 5 RRAM cells. 2014 IEEE International Electron Devices Meeting. 2014:14–2. [Google Scholar]
- Sawa A.. Resistive switching in transition metal oxides. Mater. Today. 2008;11:28–36. doi: 10.1016/S1369-7021(08)70119-6. [DOI] [Google Scholar]
- Sawa A., Fujii T., Kawasaki M., Tokura Y.. Hysteretic current-voltage characteristics and resistance switching at a rectifying Ti/Pr0. 7Ca0. 3MnO3 interface. Appl. Phys. Lett. 2004;85:4073–4075. doi: 10.1063/1.1812580. [DOI] [Google Scholar]
- Seong D.-j., Park J., Lee N., Hasan M., Jung S., Choi H., Lee J., Jo M., Lee W., Park S.. Effect of oxygen migration and interface engineering on resistance switching behavior of reactive metal/polycrystalline Pr0.7Ca0.3MnO3 device for nonvolatile memory applications. 2009 IEEE International Electron Devices Meeting (IEDM). 2009:1–4. [Google Scholar]
- Hasan M., Dong R., Choi H., Lee D., Seong D.-J., Pyun M., Hwang H.. Uniform resistive switching with a thin reactive metal interface layer in metal-La0.7Ca0.3MnO3-metal heterostructures. Appl. Phys. Lett. 2008;92:202102. doi: 10.1063/1.2932148. [DOI] [Google Scholar]
- Sim H., Choi H., Lee D., Chang M., Choi D., Son Y., Lee E.-H., Kim W., Park Y., Yoo I.-K.. et al. Excellent resistance switching characteristics of Pt/SrTiO3 Schottky junction for multi-bit nonvolatile memory application. IEEE InternationalElectron Devices Meeting, 2005. IEDM Technical Digest. 2005:758–761. [Google Scholar]
- Chevallier, C. J. ; Siau, C. H. ; Lim, S. F. ; Namala, S. R. ; Matsuoka, M. ; Bateman, B. L. ; Rinerson, D. . A 0.13 μm 64Mb multi-layered conductive metal-oxide memory. 2010 IEEE International Solid-State Circuits Conference-(ISSCC). 2010; pp 260–261. [Google Scholar]
- Palumbo F., Wen C., Lombardo S., Pazos S., Aguirre F., Eizenberg M., Hui F., Lanza M.. A review on dielectric breakdown in thin dielectrics: silicon dioxide, high-k, and layered dielectrics. Adv. Funct. Mater. 2020;30:1900657. doi: 10.1002/adfm.201900657. [DOI] [Google Scholar]
- Pi S., Li C., Jiang H., Xia W., Xin H., Yang J. J., Xia Q.. Memristor crossbar arrays with 6-nm half-pitch and 2-nm critical dimension. Nat. Nanotechnol. 2019;14:35–39. doi: 10.1038/s41565-018-0302-0. [DOI] [PubMed] [Google Scholar]
- Ge R., Wu X., Kim M., Shi J., Sonde S., Tao L., Zhang Y., Lee J. C., Akinwande D.. Atomristor: nonvolatile resistance switching in atomic sheets of transition metal dichalcogenides. Nano Lett. 2018;18:434–441. doi: 10.1021/acs.nanolett.7b04342. [DOI] [PubMed] [Google Scholar]
- Wang M., Cai S., Pan C., Wang C., Lian X., Zhuo Y., Xu K., Cao T., Pan X., Wang B.. et al. Robust memristors based on layered two-dimensional materials. Nature Electronics. 2018;1:130–136. doi: 10.1038/s41928-018-0021-4. [DOI] [Google Scholar]
- Wang C.-H., McClellan C., Shi Y., Zheng X., Chen V., Lanza M., Pop E., Wong H.-S. P.. 3D monolithic stacked 1T1R cells using monolayer MoS2 FET and hBN RRAM fabricated at low (150 C) temperature. 2018 IEEE International Electron Devices Meeting (IEDM). 2018:22–5. [Google Scholar]
- Chen S., Mahmoodi M. R., Shi Y., Mahata C., Yuan B., Liang X., Wen C., Hui F., Akinwande D., Strukov D. B.. et al. Wafer-scale integration of two-dimensional materials in high-density memristive crossbar arrays for artificial neural networks. Nature Electronics. 2020;3:638–645. doi: 10.1038/s41928-020-00473-w. [DOI] [Google Scholar]
- Zhu K., Pazos S., Aguirre F., Shen Y., Yuan Y., Zheng W., Alharbi O., Villena M. A., Fang B., Li X.. et al. Hybrid 2D-CMOS microchips for memristive applications. Nature. 2023;618:57–62. doi: 10.1038/s41586-023-05973-1. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Radisavljevic B., Radenovic A., Brivio J., Giacometti V., Kis A.. Single-layer MoS2 transistors. Nature Nanotechnol. 2011;6:147–150. doi: 10.1038/nnano.2010.279. [DOI] [PubMed] [Google Scholar]
- Fiori G., Bonaccorso F., Iannaccone G., Palacios T., Neumaier D., Seabaugh A., Banerjee S. K., Colombo L.. Electronics based on two-dimensional materials. Nature Nanotechnol. 2014;9:768–779. doi: 10.1038/nnano.2014.207. [DOI] [PubMed] [Google Scholar]
- Jayachandran D., Pendurthi R., Sadaf M. U. K., Sakib N. U., Pannone A., Chen C., Han Y., Trainor N., Kumari S., Mc Knight T. V.. et al. Three-dimensional integration of two-dimensional field-effect transistors. Nature. 2024;625:276–281. doi: 10.1038/s41586-023-06860-5. [DOI] [PubMed] [Google Scholar]
- Chung Y.-Y., Yun W.-S., Chou B.-J., Hsu C.-F., Yu S.-M., Arutchelvan G., Li M.-Y., Lee T.-E., Lin B.-J., Li C.-Y.. et al. Monolayer-MoS2 Stacked Nanosheet Channel with C-type Metal Contact. 2023 International Electron Devices Meeting (IEDM). 2023:1–4. [Google Scholar]
- Dorow C., Schram T., Smets Q., O’Brien K., Maxey K., Lin C.-C., Panarella L., Kaczer B., Arefin N., Roy A.. et al. Exploring manufacturability of novel 2D channel materials: 300 mm wafer-scale 2D NMOS & PMOS using MoS2, WS2, & WSe2 . 2023 International Electron Devices Meeting (IEDM). 2023:1–4. [Google Scholar]
- Bertolazzi S., Krasnozhon D., Kis A.. Nonvolatile memory cells based on MoS2/graphene heterostructures. ACS Nano. 2013;7:3246–3252. doi: 10.1021/nn3059136. [DOI] [PubMed] [Google Scholar]
- Migliato Marega G., Ji H. G., Wang Z., Pasquale G., Tripathi M., Radenovic A., Kis A.. A large-scale integrated vector-matrix multiplication processor based on monolayer molybdenum disulfide memories. Nature Electronics. 2023;6:991–998. doi: 10.1038/s41928-023-01064-1. [DOI] [Google Scholar]
- Zhang E., Wang W., Zhang C., Jin Y., Zhu G., Sun Q., Zhang D. W., Zhou P., Xiu F.. Tunable charge-trap memory based on few-layer MoS2 . ACS Nano. 2015;9:612–619. doi: 10.1021/nn5059419. [DOI] [PubMed] [Google Scholar]
- Farronato M., Mannocci P., Melegari M., Ricci S., Compagnoni C. M., Ielmini D.. Reservoir computing with charge-trap memory based on a MoS2 channel for neuromorphic engineering. Adv. Mater. 2023;35:2205381. doi: 10.1002/adma.202205381. [DOI] [PubMed] [Google Scholar]
- Sangwan V. K., Jariwala D., Kim I. S., Chen K.-S., Marks T. J., Lauhon L. J., Hersam M. C.. Gate-tunable memristive phenomena mediated by grain boundaries in single-layer MoS2 . Nat. Nanotechnol. 2015;10:403–406. doi: 10.1038/nnano.2015.56. [DOI] [PubMed] [Google Scholar]
- Sangwan V. K., Lee H.-S., Bergeron H., Balla I., Beck M. E., Chen K.-S., Hersam M. C.. Multi-terminal memtransistors from polycrystalline monolayer molybdenum disulfide. Nature. 2018;554:500–504. doi: 10.1038/nature25747. [DOI] [PubMed] [Google Scholar]
- Lee H.-S., Sangwan V. K., Rojas W. A. G., Bergeron H., Jeong H. Y., Yuan J., Su K., Hersam M. C.. Dual-gated MoS2 memtransistor crossbar array. Adv. Funct. Mater. 2020;30:2003683. doi: 10.1002/adfm.202003683. [DOI] [Google Scholar]
- Wang L., Liao W., Wong S. L., Yu Z. G., Li S., Lim Y.-F., Feng X., Tan W. C., Huang X., Chen L.. et al. Artificial synapses based on multiterminal memtransistors for neuromorphic application. Adv. Funct. Mater. 2019;29:1901106. doi: 10.1002/adfm.201901106. [DOI] [Google Scholar]
- Farronato M., Melegari M., Ricci S., Hashemkhani S., Bricalli A., Ielmini D.. Memtransistor devices based on MoS2 multilayers with volatile switching due to Ag cation migration. Advanced Electronic Materials. 2022;8:2101161. doi: 10.1002/aelm.202270037. [DOI] [Google Scholar]
- Wang Z.. et al. Memristors with diffusive dynamics as synaptic emulators for neuromorphic computing. Nat. Mater. 2017;16:101–108. doi: 10.1038/nmat4756. [DOI] [PubMed] [Google Scholar]
- Wang W., Wang M., Ambrosi E., Bricalli A., Laudato M., Sun Z., Chen X., Ielmini D.. Surface diffusion-limited lifetime of silver and copper nanofilaments in resistive switching devices. Nat. Commun. 2019;10:81. doi: 10.1038/s41467-018-07979-0. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Yin S., Luo Z., Li Q., Xiong C., Liu Y., Singh R., Zeng F., Zhong Y., Zhang X.. Emulation of learning and memory behaviors by memristor based on Ag migration on 2D MoS2 surface. physica status solidi (a) 2019;216:1900104. doi: 10.1002/pssa.201900104. [DOI] [Google Scholar]
- Hao S., Ji X., Zhong S., Pang K. Y., Lim K. G., Chong T. C., Zhao R.. A monolayer leaky integrate-and-fire neuron for 2D memristive neuromorphic networks. Advanced Electronic Materials. 2020;6:1901335. doi: 10.1002/aelm.201901335. [DOI] [Google Scholar]
- Flocke, A. ; Noll, T. G. . Fundamental analysis of resistive nano-crossbars for the use in hybrid Nano/CMOS-memory. ESSCIRC 2007–33rd European Solid-State Circuits Conference. 2007; pp 328–331. [Google Scholar]
- Li F., Yang X., Meeks A., Shearer J., Le K.. Evaluation of SiO2 Antifuse in a 3D-OTP Memory. IEEE Transactions on Device and Materials Reliability. 2004;4:416–421. doi: 10.1109/TDMR.2004.837118. [DOI] [Google Scholar]
- Burr G. W., Shenoy R. S., Virwani K., Narayanan P., Padilla A., Kurdi B., Hwang H.. Access devices for 3D crosspoint memory. Journal of Vacuum Science & Technology B, Nanotechnology and Microelectronics: Materials, Processing, Measurement, and Phenomena. 2014;32:040802. doi: 10.1116/1.4889999. [DOI] [Google Scholar]
- Lee M.-J., Lee D., Cho S.-H., Hur J.-H., Lee S.-M., Seo D. H., Kim D.-S., Yang M.-S., Lee S., Hwang E., Uddin M. R., Kim H., Chung U.-I., Park Y., Yoo I.-K.. A plasma-treated chalcogenide switch device for stackable scalable 3D nanoscale memory. Nat. Commun. 2013;4:2629. doi: 10.1038/ncomms3629. [DOI] [PubMed] [Google Scholar]
- Chen Y.-C., Chen C., Chen C., Yu J., Wu S., Lung S., Liu R., Lu C.-Y.. An access-transistor-free (0T/1R) non-volatile resistance random access memory (RRAM) using a novel threshold switching, self-rectifying chalcogenide device. IEEE International Electron Devices Meeting 2003. 2003:37–4. [Google Scholar]
- Kim K. H., Kang B. S., Lee M.-J., Ahn S.-E., Lee C. B., Stefanovich G., Xianyu W. X., Kim C. J., Park Y.. Multilevel programmable oxide diode for cross-point memory by electrical-pulse-induced resistance change. IEEE Electron Device Lett. 2009;30:1036–1038. doi: 10.1109/LED.2009.2029247. [DOI] [Google Scholar]
- Virwani K.. et al. Sub-30nm scaling and high-speed operation of fully-confined Access-Devices for 3D crosspoint memory based on mixed-ionic-electronic-conduction (MIEC) materials. 2012 International Electron Devices Meeting. 2012:2.7.1–2.7.4. [Google Scholar]
- Lee W., Park J., Kim S., Woo J., Shin J., Choi G., Park S., Lee D., Cha E., Lee B. H., Hwang H.. High Current Density and Nonlinearity Combination of Selection Device Based on TaOx/TiO2/TaOx Structure for One Selector-One Resistor Arrays. ACS Nano. 2012;6:8166–8172. doi: 10.1021/nn3028776. [DOI] [PubMed] [Google Scholar]
- Son M., Lee J., Park J., Shin J., Choi G., Jung S., Lee W., Kim S., Park S., Hwang H.. Excellent Selector Characteristics of Nanoscale VO2 for High-Density Bipolar ReRAM Applications. IEEE Electron Device Lett. 2011;32:1579–1581. doi: 10.1109/LED.2011.2163697. [DOI] [Google Scholar]
- Zhao X., Chen A., Ji J., Wu D., Gan Y., Wang C., Ma G., Lin C.-Y., Lin C.-C., Liu N., Wan H., Tao L., Wang B., Chang T.-C., Wang H.. Ultrahigh Uniformity and Stability in NbOx-Based Selector for 3-D Memory by Using Ru Electrode. IEEE Trans. Electron Devices. 2021;68:2255–2259. doi: 10.1109/TED.2021.3063327. [DOI] [Google Scholar]
- Jo S. H., Kumar T., Narayanan S., Lu W. D., Nazarian H.. 3D-stackable crossbar resistive memory based on Field Assisted Superlinear Threshold (FAST) selector. 2014 IEEE International Electron Devices Meeting. 2014:6.7.1–6.7.4. [Google Scholar]
- Midya R.. et al. Anatomy of Ag/Hafnia-Based Selectors with 10 10 Nonlinearity. Adv. Mater. 2017;29:1604457. doi: 10.1002/adma.201604457. [DOI] [PubMed] [Google Scholar]
- Wang W., Wang M., Ambrosi E., Bricalli A., Laudato M., Sun Z., Chen X., Ielmini D.. Surface diffusion-limited lifetime of silver and copper nanofilaments in resistive switching devices. Nat. Commun. 2019;10:81. doi: 10.1038/s41467-018-07979-0. [DOI] [PMC free article] [PubMed] [Google Scholar]
- DerChang, Kau ; et al. A stackable cross point Phase Change Memory. 2009 IEEE International Electron Devices Meeting (IEDM). Baltimore, MD, USA, 2009; pp 1–4. [Google Scholar]
- Ambrosi E., Wu C.-H., Lee H.-Y., Lee C.-M., Hsu C.-F., Chang C.-C., Lee T.-Y., Bao X.-Y.. Reliable Low Voltage Selector Device Technology Based on Robust SiNGeCTe Arsenic-Free Chalcogenide. IEEE Electron Device Lett. 2022;43:1673–1676. doi: 10.1109/LED.2022.3203146. [DOI] [Google Scholar]
- Hong S., Choi H., Park J., Bae Y., Kim K., Lee W., Lee S., Lee H., Cho S., Ahn J., Kim S., Kim T., Na M., Cha S.. Extremely high performance, high density 20nm self-selecting cross-point memory for Compute Express Link. 2022 International Electron Devices Meeting (IEDM). 2022:18.6.1–18.6.4. [Google Scholar]
- Jung L., Lee J., Seo Y., Hwang H.. Achieving 3-bit Operation in Selector-only-memory by Controlling Variability with Microwave Annealing and Bipolar Pulse Scheme. 2024 International Electron Devices Meeting (IEDM). 2024:1–4. [Google Scholar]
- Lee J., Seo Y., Ban S., Kim D. G., Park Y. B., Lee T. H., Hwang H.. Understanding Switching Mechanism of Selector-Only Memory Using Se-Based Ovonic Threshold Switch Device. IEEE Trans. Electron Devices. 2024;71:3351–3357. doi: 10.1109/TED.2024.3378221. [DOI] [Google Scholar]
- Clima S., Ducry F., Garbin D., Ravsher T., Degraeve R., Belmonte A., Kar G. S., Pourtois G.. Selector Only Memory: Exploring Atomic Mechanisms from First-Principles. 2024 IEEE International Electron Devices Meeting (IEDM). 2024:1–4. [Google Scholar]
- Fantini P., Ghetti A., Varesi E., Pirovano A., Baratella D., Ribaldone C., Campi D., Bernasconi M., Bez R.. VT Window Model of the Single-Chalcogenide Xpoint Memory (SXM) 2024 IEEE International Electron Devices Meeting (IEDM). 2024:1–4. [Google Scholar]
- Hu, M. ; Williams, R. S. ; Strachan, J. P. ; Li, Z. ; Grafals, E. M. ; Davila, N. ; Graves, C. ; Lam, S. ; Ge, N. ; Yang, J. J. . Dot-product engine for neuromorphic computing: programming 1T1M crossbar to accelerate matrix-vector multiplication. Proceedings of the 53rd Annual Design Automation Conference on - DAC ’16. Austin, TX, 2016; pp 1–6. [Google Scholar]
- Ielmini D., Nardi F., Cagli C.. Physical models of size-dependent nanofilament formation and rupture in NiO resistive switching memories. Nanotechnology. 2011;22:254022. doi: 10.1088/0957-4484/22/25/254022. [DOI] [PubMed] [Google Scholar]
- Milo V., Zambelli C., Olivo P., Pérez E., K Mahadevaiah M., G Ossorio O., Wenger C., Ielmini D.. Multilevel HfO2-based RRAM devices for low-power neuromorphic networks. APL Materials. 2019;7:081120. doi: 10.1063/1.5108650. [DOI] [Google Scholar]
- Yu S., Luo Y.-C., Kim T.-H., Phadke O.. Nonvolatile Capacitive Synapse: Device Candidates for Charge Domain Compute-In-Memory. IEEE Electron Devices Magazine. 2023;1:23–32. doi: 10.1109/MED.2023.3293060. [DOI] [Google Scholar]
- Sheu, S.-S. ; Chang, M.-F. ; Lin, K.-F. ; Wu, C.-W. ; Chen, Y.-S. ; Chiu, P.-F. ; Kuo, C.-C. ; Yang, Y.-S. ; Chiang, P.-C. ; Lin, W.-P. ; et al. A 4Mb embedded SLC resistive-RAM macro with 7.2 ns read-write random-access time and 160ns MLC-access capability. 2011 IEEE International Solid-State Circuits Conference. 2011; pp 200–202. [Google Scholar]
- Otsuka, W. ; Miyata, K. ; Kitagawa, M. ; Tsutsui, K. ; Tsushima, T. ; Yoshihara, H. ; Namise, T. ; Terao, Y. ; Ogata, K. . A 4Mb conductive-bridge resistive memory with 2.3 GB/s read-throughput and 216MB/s program-throughput. 2011 IEEE International Solid-State Circuits Conference. 2011; pp 210–211. [Google Scholar]
- Kawahara A., Azuma R., Ikeda Y., Kawai K., Katoh Y., Hayakawa Y., Tsuji K., Yoneda S., Himeno A., Shimakawa K.. et al. An 8 Mb multi-layered cross-point ReRAM macro with 443 MB/s write throughput. IEEE Journal of Solid-State Circuits. 2013;48:178–185. doi: 10.1109/JSSC.2012.2215121. [DOI] [Google Scholar]
- Kawahara A., Kawai K., Ikeda Y., Katoh Y., Azuma R., Yoshimoto Y., Tanabe K., Wei Z., Ninomiya T., Katayama K.. et al. Filament scaling forming technique and level-verify-write scheme with endurance over 107 cycles in ReRAM. 2013 IEEE International Solid-State Circuits Conference Digest of Technical Papers. 2013:220–221. [Google Scholar]
- Liu, T.-Y. ; et al. A 130.7mm2 2-layer 32Gb ReRAM memory device in 24nm technology. 2013 IEEE International Solid-State Circuits Conference Digest of Technical Papers. San Francisco, CA, 2013; pp 210–211. [Google Scholar]
- Chang M.-F., Wu J.-J., Chien T.-F., Liu Y.-C., Yang T.-C., Shen W.-C., King Y.-C., Lin C.-J., Lin K.-F., Chih Y.-D.. et al. 19.4 embedded 1Mb ReRAM in 28nm CMOS with 0.27-to-1V read using swing-sample-and-couple sense amplifier and self-boost-write-termination scheme. 2014 IEEE International Solid-State Circuits Conference Digest of Technical Papers (ISSCC). 2014:332–333. [Google Scholar]
- Zahurak J., Miyata K., Fischer M., Balakrishnan M., Chhajed S., Wells D., Li H., Torsi A., Lim J., Korber M.. et al. Process integration of a 27nm, 16Gb Cu ReRAM. 2014 IEEE International Electron Devices Meeting. 2014:6–2. [Google Scholar]
- Ueki M., Takeuchi K., Yamamoto T., Tanabe A., Ikarashi N., Saitoh M., Nagumo T., Sunamura H., Narihiro M., Uejima K.. et al. Low-power embedded ReRAM technology for IoT applications. 2015 symposium on VLSI technology (VLSI technology). 2015:T108–T109. [Google Scholar]
- Ho C., Chang S.-C., Huang C.-Y., Chuang Y.-C., Lim S.-F., Hsieh M.-H., Chang S.-C., Liao H.-H.. Integrated HfO 2-RRAM to achieve highly reliable, greener, faster, cost-effective, and scaled devices. 2017 IEEE International Electron Devices Meeting (IEDM). 2017:2–6. [Google Scholar]
- Chou, C.-C. ; Lin, Z.-J. ; Tseng, P.-L. ; Li, C.-F. ; Chang, C.-Y. ; Chen, W.-C. ; Chih, Y.-D. ; Chang, T.-Y. J. . An N40 256K× 44 embedded RRAM macro with SL-precharge SA and low-voltage current limiter to improve read and write performance. 2018 IEEE International Solid - State Circuits Conference - (ISSCC). San Francisco, CA, 2018; pp 478–480. [Google Scholar]
- Jain P., Arslan U., Sekhar M., Lin B. C., Wei L., Sahu T., Alzate-Vinasco J., Vangapaty A., Meterelliyoz M., Strutt N.. et al. 13.2 A 3.6 Mb 10.1 Mb/mm2 embedded non-volatile ReRAM macro in 22nm FinFET technology with adaptive forming/set/reset schemes yielding down to 0.5 V with sensing time of 5ns at 0.7 V. 2019 IEEE International Solid-State Circuits Conference-(ISSCC). 2019:212–214. [Google Scholar]
- Chou C.-C., Lin Z.-J., Lai C.-A., Su C.-I., Tseng P.-L., Chen W.-C., Tsai W.-C., Chu W.-T., Ong T.-C., Chuang H.. et al. A 22nm 96KX144 RRAM macro with a self-tracking reference and a low ripple charge pump to achieve a configurable read window and a wide operating voltage range. 2020 IEEE Symposium on VLSI Circuits. 2020:1–2. [Google Scholar]
- Yang C.-F., Wu C.-Y., Yang M.-H., Wang W., Yang M.-T., Chien T.-C., Fan V., Tsai S.-C., Lee Y.-H., Chu W.-T.. et al. Industrially applicable read disturb model and performance on mega-bit 28nm embedded RRAM. 2020 IEEE Symposium on VLSI Technology. 2020:1–2. [Google Scholar]
- Yang J., Xue X., Xu X., Wang Q., Jiang H., Yu J., Dong D., Zhang F., Lv H., Liu M.. 24.2 A 14nm-FinFET 1Mb embedded 1T1R RRAM with a 0.022 μm2 cell size using self-adaptive delayed termination and multi-cell reference. 2021 IEEE International Solid-State Circuits Conference (ISSCC). 2021:336–338. [Google Scholar]
- Peters C., Adler F., Hofmann K., Otterstedt J.. Reliability of 28nm embedded RRAM for consumer and industrial products. 2022 IEEE International Memory Workshop (IMW). 2022:1–3. [Google Scholar]
- Wu C.-Y., Yang C.-F., Lai C.-W., Wu Y.-T., Chien T.-C., Yang M.-H., Yang M.-T., Kao Y.-N., Cheng C.-L., Wang C.-Y.. et al. Emerging Memory RRAM Embedded in 12FFC FinFET Technology for industrial Applications. 2023 International Electron Devices Meeting (IEDM). 2023:1–4. [Google Scholar]
- Yang J., Xue X., Xu X., Lv H., Zhang F., Zeng X., Chang M.-F., Liu M.. A 28nm 1.5 Mb embedded 1T2R RRAM with 14.8 Mb/mm2 using sneaking current suppression and compensation techniques. 2020 IEEE Symposium on VLSI Circuits. 2020:1–2. [Google Scholar]
- Zuliani P., Varesi E., Palumbo E., Borghi M., Tortorelli I., Erbetta D., Libera G. D., Pessina N., Gandolfo A., Prelini C., Ravazzi L., Annunziata R.. Overcoming Temperature Limitations in Phase Change Memories With Optimized GexSbyTez . IEEE Trans. Electron Devices. 2013;60:4020–4026. doi: 10.1109/TED.2013.2285403. [DOI] [Google Scholar]
- Freitas R. F., Wilcke W. W.. Storage-class memory: The next storage system technology. IBM J. Res. Dev. 2008;52:439–447. doi: 10.1147/rd.524.0439. [DOI] [Google Scholar]
- Baek, I. G. ; et al. Realization of vertical resistive memory (VRRAM) using cost effective 3D process. 2011 International Electron Devices Meeting. Washington, DC, USA, 2011; pp 31.8.1–31.8.4. [Google Scholar]
- Hsieh M.-C., Liao Y.-C., Chin Y.-W., Lien C.-H., Chang T.-S., Chih Y.-D., Natarajan S., Tsai M.-J., King Y.-C., Lin C. J.. Ultra high density 3D via RRAM in pure 28nm CMOS process. 2013 IEEE International Electron Devices Meeting. 2013:10.3.1–10.3.4. [Google Scholar]
- Kau D., Tang S., Karpov I. V., Dodge R., Klehn B., Kalb J. A., Strand J., Diaz A., Leung N., Wu J.. et al. A stackable cross point phase change memory. 2009 IEEE International Electron Devices Meeting (IEDM). 2009:1–4. [Google Scholar]
- Fazio A.. Advanced Technology and Systems of Cross Point Memory. 2020 IEEE International Electron Devices Meeting (IEDM). 2020:24.1.1–24.1.4. [Google Scholar]
- Tanaka H., Kido M., Yahashi K., Oomura M., Katsumata R., Kito M., Fukuzumi Y., Sato M., Nagata Y., Matsuoka Y., Iwata Y., Aochi H., Nitayama A.. Bit Cost Scalable Technology with Punch and Plug Process for Ultra High Density Flash Memory. 2007 IEEE Symposium on VLSI Technology. 2007:14–15. [Google Scholar]
- Yu S., Chen H.-Y., Gao B., Kang J., Wong H.-S. P.. HfOx-Based Vertical Resistive Switching Random Access Memory Suitable for Bit-Cost-Effective Three-Dimensional Cross-Point Architecture. ACS Nano. 2013;7:2320–2325. doi: 10.1021/nn305510u. [DOI] [PubMed] [Google Scholar]
- Peters C., Adler F., Hofmann K., Otterstedt J.. Reliability of 28nm embedded RRAM for consumer and industrial products. 2022 IEEE International Memory Workshop (IMW). 2022:1–3. [Google Scholar]
- Grossi A., Coppetta M., Aresu S., Kux A., Kern T., Strenz R.. 28nm Data Memory with Embedded RRAM Technology in Automotive Microcontrollers. 2023 IEEE International Memory Workshop (IMW). 2023:1–4. [Google Scholar]
- Mutlu, O. ; Ghose, S. ; Gómez-Luna, J. ; Ausavarungnirun, R. In Emerging Computing: From Devices to Systems: Looking Beyond Moore and Von Neumann; Aly, M. M. S. ; Chattopadhyay, A. , Eds.; Springer Nature Singapore: Singapore, 2023; pp 171–243. [Google Scholar]
- Sun Z., Pedretti G., Ambrosi E., Bricalli A., Wang W., Ielmini D.. Solving matrix equations in one step with cross-point resistive arrays. Proc. Natl. Acad. Sci. U. S. A. 2019;116:4123–4128. doi: 10.1073/pnas.1815682116. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Chang M.-F., Lin C.-C., Lee A., Chiang Y.-N., Kuo C.-C., Yang G.-H., Tsai H.-J., Chen T.-F., Sheu S.-S.. A 3T1R Nonvolatile TCAM Using MLC ReRAM for Frequent-Off Instant-On Filters in IoT and Big-Data Processing. IEEE Journal of Solid-State Circuits. 2017;52:1664–1679. doi: 10.1109/JSSC.2017.2681458. [DOI] [Google Scholar]
- Graves C. E., Lam S.-T., Li X., Kiyama L., Foltin M., Hardy M. P., Strachan J. P., Li C., Sheng X., Ma W., Chalamalasetti S. R., Miller D., Ignowski J. S., Buchanan B., Zheng L.. Memristor TCAMs Accelerate Regular Expression Matching for Network Intrusion Detection. IEEE Transactions on Nanotechnology. 2019;18:963–970. doi: 10.1109/TNANO.2019.2936239. [DOI] [Google Scholar]
- Cai F., Kumar S., Van Vaerenbergh T., Sheng X., Liu R., Li C., Liu Z., Foltin M., Yu S., Xia Q., Yang J. J., Beausoleil R., Lu W. D., Strachan J. P.. Power-efficient combinatorial optimization using intrinsic noise in memristor Hopfield neural networks. Nature Electronics. 2020;3:409–418. doi: 10.1038/s41928-020-0436-6. [DOI] [Google Scholar]
- Mahmoodi M. R., Prezioso M., Strukov D. B.. Versatile stochastic dot product circuits based on nonvolatile memories for high performance neurocomputing and neurooptimization. Nat. Commun. 2019;10:5113. doi: 10.1038/s41467-019-13103-7. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Carboni R., Ielmini D.. Stochastic Memory Devices for Security and Computing. Advanced Electronic Materials. 2019;5:1900198. doi: 10.1002/aelm.201900198. [DOI] [Google Scholar]
- Chen B., Cai F., Zhou J., Ma W., Sheridan P., Lu W. D.. Efficient in-memory computing architecture based on crossbar arrays. 2015 IEEE International Electron Devices Meeting (IEDM) 2015:17.5.1–17.5.4. [Google Scholar]
- Dalgaty T., Esmanhotto E., Castellani N., Querlioz D., Vianello E.. Ex Situ Transfer of Bayesian Neural Networks to Resistive Memory-Based Inference Hardware. Advanced Intelligent Systems. 2021;3:2000103. doi: 10.1002/aisy.202000103. [DOI] [Google Scholar]
- Pedretti G., Milo V., Ambrogio S., Carboni R., Bianchi S., Calderoni A., Ramaswamy N., Spinelli A. S., Ielmini D.. Stochastic Learning in Neuromorphic Hardware via Spike Timing Dependent Plasticity With RRAM Synapses. IEEE Journal on Emerging and Selected Topics in Circuits and Systems. 2018;8:77–85. doi: 10.1109/JETCAS.2017.2773124. [DOI] [Google Scholar]
- Borghetti J., Snider G. S., Kuekes P. J., Yang J. J., Stewart D. R., Williams R. S.. ‘Memristive’ switches enable ‘stateful’ logic operations via material implication. Nature. 2010;464:873–876. doi: 10.1038/nature08940. [DOI] [PubMed] [Google Scholar]
- Sun Z., Ambrosi E., Bricalli A., Ielmini D.. Logic Computing with Stateful Neural Networks of Resistive Switches. Adv. Mater. 2018;30:1802554. doi: 10.1002/adma.201802554. [DOI] [PubMed] [Google Scholar]
- Yu S., Wu Y., Jeyasingh R., Kuzum D., Wong H.-S. P.. An Electronic Synapse Device Based on Metal Oxide Resistive Switching Memory for Neuromorphic Computation. IEEE Trans. Electron Devices. 2011;58:2729–2737. doi: 10.1109/TED.2011.2147791. [DOI] [Google Scholar]
- Pedretti G., Milo V., Ambrogio S., Carboni R., Bianchi S., Calderoni A., Ramaswamy N., Spinelli A. S., Ielmini D.. Memristive neural network for on-line learning and tracking with brain-inspired spike timing dependent plasticity. Sci. Rep. 2017;7:5288. doi: 10.1038/s41598-017-05480-0. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Burr G. W., Shelby R. M., Sidler S., di Nolfo C., Jang J., Boybat I., Shenoy R. S., Narayanan P., Virwani K., Giacometti E. U., Kurdi B. N., Hwang H.. Experimental Demonstration and Tolerancing of a Large-Scale Neural Network (165 000 Synapses) Using Phase-Change Memory as the Synaptic Weight Element. IEEE Trans. Electron Devices. 2015;62:3498–3507. doi: 10.1109/TED.2015.2439635. [DOI] [Google Scholar]
- Ambrogio S., Narayanan P., Tsai H., Shelby R. M., Boybat I., di Nolfo C., Sidler S., Giordano M., Bodini M., Farinha N. C. P., Killeen B., Cheng C., Jaoudi Y., Burr G. W.. Equivalent-accuracy accelerated neural-network training using analogue memory. Nature. 2018;558:60–67. doi: 10.1038/s41586-018-0180-5. [DOI] [PubMed] [Google Scholar]
- Prezioso M., Merrikh-Bayat F., Hoskins B. D., Adam G. C., Likharev K. K., Strukov D. B.. Training and operation of an integrated neuromorphic network based on metal-oxide memristors. Nature. 2015;521:61–64. doi: 10.1038/nature14441. [DOI] [PubMed] [Google Scholar]
- Gaba S., Sheridan P., Zhou J., Choi S., Lu W.. Stochastic memristive devices for computing and neuromorphic applications. Nanoscale. 2013;5:5872–5878. doi: 10.1039/c3nr01176c. [DOI] [PubMed] [Google Scholar]
- Balatti S., Ambrogio S., Wang Z., Ielmini D.. True Random Number Generation by Variability of Resistive Switching in Oxide-Based Devices. IEEE Journal on Emerging and Selected Topics in Circuits and Systems. 2015;5:214–221. doi: 10.1109/JETCAS.2015.2426492. [DOI] [Google Scholar]
- Balatti S., Ambrogio S., Carboni R., Milo V., Wang Z., Calderoni A., Ramaswamy N., Ielmini D.. Physical Unbiased Generation of Random Numbers With Coupled Resistive Switching Devices. IEEE Trans. Electron Devices. 2016;63:2029–2035. doi: 10.1109/TED.2016.2537792. [DOI] [Google Scholar]
- Shukla N., Thathachary A. V., Agrawal A., Paik H., Aziz A., Schlom D. G., Gupta S. K., Engel-Herbert R., Datta S.. A steep-slope transistor based on abrupt electronic phase transition. Nat. Commun. 2015;6:7812. doi: 10.1038/ncomms8812. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Li C.. et al. Analogue signal and image processing with large memristor crossbars. Nature Electronics. 2018;1:52–59. doi: 10.1038/s41928-017-0002-z. [DOI] [Google Scholar]
- Hu M., Graves C. E., Li C., Li Y., Ge N., Montgomery E., Davila N., Jiang H., Williams R. S., Yang J. J., Xia Q., Strachan J. P.. Memristor-Based Analog Computation and Neural Network Classification with a Dot Product Engine. Adv. Mater. 2018;30:1705914. doi: 10.1002/adma.201705914. [DOI] [PubMed] [Google Scholar]
- Gokmen, T. ; Vlasov, Y. . Acceleration of Deep Neural Network Training with Resistive Cross-Point Devices: Design Considerations. Frontiers in Neuroscience 2016, 10, 10.3389/fnins.2016.00333 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Lepri N., Baldo M., Mannocci P., Glukhov A., Milo V., Ielmini D.. Modeling and compensation of IR drop in crosspoint accelerators of neural networks. IEEE Trans. Electron Devices. 2022;69:1575–1581. doi: 10.1109/TED.2022.3141987. [DOI] [Google Scholar]
- Lepri N., Glukhov A., Mannocci P., Porzani M., Ielmini D.. Compact Modeling and Mitigation of Parasitics in Crosspoint Accelerators of Neural Networks. IEEE Trans. Electron Devices. 2024;71:1900–1906. doi: 10.1109/TED.2024.3360015. [DOI] [Google Scholar]
- Aguirre, F. L. ; Gomez, N. M. ; Pazos, S. M. ; Palumbo, F. ; Suñé, J. ; Miranda, E. . Minimization of the Line Resistance Impact on Memdiode-Based Simulations of Multilayer Perceptron Arrays Applied to Pattern Recognition. J. Low Power Electron. Appl. 2021, 11, 9 10.3390/jlpea11010009 [DOI] [Google Scholar]
- Hsu S. K., Agarwal A., Anders M. A., Mathew S. K., Kaul H., Sheikh F., Krishnamurthy R. K.. A 280 mV-to-1.1 V 256b reconfigurable SIMD vector permutation engine with 2-dimensional shuffle in 22 nm tri-gate CMOS. IEEE journal of solid-state circuits. 2013;48:118–127. doi: 10.1109/JSSC.2012.2222811. [DOI] [Google Scholar]
- Sun Z., Pedretti G., Ambrosi E., Bricalli A., Ielmini D.. In-Memory Eigenvector Computation in Time O (1) Advanced Intelligent Systems. 2020;2:2000042. doi: 10.1002/aisy.202000042. [DOI] [Google Scholar]
- Sun Z., Pedretti G., Bricalli A., Ielmini D.. One-step regression and classification with cross-point resistive memory arrays. Science Advances. 2020;6:eaay2378. doi: 10.1126/sciadv.aay2378. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Mannocci P., Melacarne E., Ielmini D.. An Analogue In-Memory Ridge Regression Circuit With Application to Massive MIMO Acceleration. IEEE Journal on Emerging and Selected Topics in Circuits and Systems. 2022;12:952–962. doi: 10.1109/JETCAS.2022.3221284. [DOI] [Google Scholar]
- Pagiamtzis K., Sheikholeslami A.. Content-Addressable Memory (CAM) Circuits and Architectures: A Tutorial and Survey. IEEE Journal of Solid-State Circuits. 2006;41:712–727. doi: 10.1109/JSSC.2005.864128. [DOI] [Google Scholar]
- Yu, F. ; Katz, R. ; Lakshman, T. . Gigabit rate packet pattern-matching using TCAM. Proceedings of the 12th IEEE International Conference on Network Protocols, 2004. ICNP 2004. 2004; pp 174–183. [Google Scholar]
- Meiners, C. R. ; Patel, J. ; Norige, E. ; Torng, E. ; Liu, A. X. . Fast Regular Expression Matching Using Small TCAMs for Network Intrusion Detection and Prevention Systems. Proceedings of the 19th USENIX Conference on Security. Washington, DC, USA, 2010; p 8. [Google Scholar]
- Li J., Montoye R., Ishii M., Stawiasz K., Nishida T., Maloney K., Ditlow G., Lewis S., Maffitt T., Jordan R.. et al. 1Mb 0.41 μm2 2T-2R cell nonvolatile TCAM with two-bit encoding and clocked self-referenced sensing. 2013 Symposium on VLSI Technology. 2013:C104–C105. [Google Scholar]
- Graves, C. E. ; Foltin, M. ; Strachan, J. P. ; Hardy, M. P. ; Ma, W. ; Sheng, X. ; Buchanan, B. ; Zheng, L. ; Lam, S.-T. ; Li, X. ; Chalamalasetti, S. R. ; Kiyama, L. . Regular Expression Matching with Memristor TCAMs for Network Security. Proceedings of the 14th IEEE/ACM International Symposium on Nanoscale Architectures - NANOARCH ’18. Athens, Greece, 2018; pp 65–71. [Google Scholar]
- Graves C. E., Li C., Sheng X., Miller D., Ignowski J., Kiyama L., Strachan J. P.. In-Memory Computing with Memristor Content Addressable Memories for Pattern Matching. Adv. Mater. 2020;32:2003437. doi: 10.1002/adma.202003437. [DOI] [PubMed] [Google Scholar]
- Imani M., Rahimi A., Kong D., Rosing T., Rabaey J. M.. Exploring Hyperdimensional Associative Memory. 2017 IEEE International Symposium on High Performance Computer Architecture (HPCA) 2017:445–456. [Google Scholar]
- Li H., Chen W.-C., Levy A., Wang C.-H., Wang H., Chen P.-H., Wan W., Khwa W.-S., Chuang H., Chih Y.-D., Chang M.-F., Wong H.-S. P., Raina P.. SAPIENS: A 64-kb RRAM-Based Non-Volatile Associative Memory for One-Shot Learning and Inference at the Edge. IEEE Trans. Electron Devices. 2021;68:6637–6643. doi: 10.1109/TED.2021.3110464. [DOI] [Google Scholar]
- Li C., Graves C. E., Sheng X., Miller D., Foltin M., Pedretti G., Strachan J. P.. Analog content-addressable memories with memristors. Nat. Commun. 2020;11:1638. doi: 10.1038/s41467-020-15254-4. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Pedretti G., Graves C. E., Serebryakov S., Mao R., Sheng X., Foltin M., Li C., Strachan J. P.. Tree-based machine learning performed in-memory with memristive analog CAM. Nat. Commun. 2021;12:5806. doi: 10.1038/s41467-021-25873-0. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Ni K., Yin X., Laguna A. F., Joshi S., Dünkel S., Trentzsch M., Müller J., Beyer S., Niemier M., Hu X. S., Datta S.. Ferroelectric ternary content-addressable memory for one-shot learning. Nature Electronics. 2019;2:521–529. doi: 10.1038/s41928-019-0321-3. [DOI] [Google Scholar]
- Li, C. ; Muller, F. ; Ali, T. ; Olivo, R. ; Imani, M. ; Deng, S. ; Zhuo, C. ; Kampfe, T. ; Yin, X. ; Ni, K. . A Scalable Design of Multi-Bit Ferroelectric Content Addressable Memory for Data-Centric Computing. 2020 IEEE International Electron Devices Meeting (IEDM). San Francisco, CA, USA, 2020; pp 29.3.1–29.3.4. [Google Scholar]
- Chen W.-H., Dou C., Li K.-X., Lin W.-Y., Li P.-Y., Huang J.-H., Wang J.-H., Wei W.-C., Xue C.-X., Chiu Y.-C.. et al. CMOS-integrated memristive non-volatile computing-in-memory for AI edge processors. Nature Electronics. 2019;2:420–428. doi: 10.1038/s41928-019-0288-0. [DOI] [Google Scholar]
- Yao P., Wu H., Gao B., Tang J., Zhang Q., Zhang W., Yang J. J., Qian H.. Fully hardware-implemented memristor convolutional neural network. Nature. 2020;577:641–646. doi: 10.1038/s41586-020-1942-4. [DOI] [PubMed] [Google Scholar]
- Wan W., Kubendran R., Schaefer C., Eryilmaz S. B., Zhang W., Wu D., Deiss S., Raina P., Qian H., Gao B., Joshi S., Wu H., Wong H.-S. P., Cauwenberghs G.. A compute-in-memory chip based on resistive random-access memory. Nature. 2022;608:504–512. doi: 10.1038/s41586-022-04992-8. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Mochida R., Kouno K., Hayata Y., Nakayama M., Ono T., Suwa H., Yasuhara R., Katayama K., Mikawa T., Gohou Y.. A 4M synapses integrated analog ReRAM based 66.5 TOPS/W neural-network processor with cell current controlled writing and flexible network architecture. 2018 IEEE Symposium on VLSI Technology. 2018:175–176. [Google Scholar]
- Xue, C.-X. ; Chen, W.-H. ; Liu, J.-S. ; Li, J.-F. ; Lin, W.-Y. ; Lin, W.-E. ; Wang, J.-H. ; Wei, W.-C. ; Chang, T.-W. ; Chang, T.-C. ; et al. 24.1 A 1Mb multibit ReRAM computing-in-memory macro with 14.6 ns parallel MAC computing time for CNN based AI edge processors. 2019 IEEE International Solid-State Circuits Conference-(ISSCC). 2019; pp 388–390. [Google Scholar]
- Cai F., Correll J. M., Lee S. H., Lim Y., Bothra V., Zhang Z., Flynn M. P., Lu W. D.. A fully integrated reprogrammable memristor-CMOS system for efficient multiply-accumulate operations. Nature electronics. 2019;2:290–299. doi: 10.1038/s41928-019-0270-x. [DOI] [Google Scholar]
- Xue, C.-X. ; Huang, T.-Y. ; Liu, J.-S. ; Chang, T.-W. ; Kao, H.-Y. ; Wang, J.-H. ; Liu, T.-W. ; Wei, S.-Y. ; Huang, S.-P. ; Wei, W.-C. ; et al. 15.4 A 22nm 2Mb ReRAM compute-in-memory macro with 121-28TOPS/W for multibit MAC computing for tiny AI edge devices. 2020 IEEE International Solid-State Circuits Conference-(ISSCC). 2020; pp 244–246. [Google Scholar]
- Ambrogio S., Balatti S., McCaffrey V., Wang D. C., Ielmini D.. Noise-Induced Resistance Broadening in Resistive Switching MemoryPart II: Array Statistics. IEEE Trans. Electron Devices. 2015;62:3812–3819. doi: 10.1109/TED.2015.2477135. [DOI] [Google Scholar]
- Zhang J., Wang Z., Verma N.. In-memory computation of a machine-learning classifier in a standard 6T SRAM array. IEEE Journal of Solid-State Circuits. 2017;52:915–924. doi: 10.1109/JSSC.2016.2642198. [DOI] [Google Scholar]
- Pedretti, G. ; Ambrosi, E. ; Ielmini, D. . Conductance variations and their impact on the precision of in-memory computing with resistive switching memory (RRAM). 2021 IEEE International Reliability Physics Symposium (IRPS). Monterey, CA, USA, 2021; pp 1–8. [Google Scholar]
- Milo V., Zambelli C., Olivo P., Pérez E., K. Mahadevaiah M., G. Ossorio O., Wenger C., Ielmini D.. Multilevel HfO2 -based RRAM devices for low-power neuromorphic networks. APL Materials. 2019;7:081120. doi: 10.1063/1.5108650. [DOI] [Google Scholar]
- Milo V., Anzalone F., Zambelli C., Pérez E., Mahadevaiah M. K., Ossorio Ó. G., Olivo P., Wenger C., Ielmini D.. Optimized programming algorithms for multilevel RRAM in hardware neural networks. 2021 IEEE International Reliability Physics Symposium (IRPS) 2021:1–6. [Google Scholar]
- Merced-Grafals E. J., Dávila N., Ge N., Williams R. S., Strachan J. P.. Repeatable, accurate, and high speed multi-level programming of memristor 1T1R arrays for power efficient analog computing applications. Nanotechnology. 2016;27:365202. doi: 10.1088/0957-4484/27/36/365202. [DOI] [PubMed] [Google Scholar]
- Mao R., Wen B., Jiang M., Chen J., Li C.. Experimentally-validated crossbar model for defect-aware training of neural networks. IEEE Transactions on Circuits and Systems II: Express Briefs. 2022;69:2468–2472. doi: 10.1109/TCSII.2022.3160591. [DOI] [Google Scholar]
- Yu, S. ; Li, Z. ; Chen, P.-Y. ; Wu, H. ; Gao, B. ; Wang, D. ; Wu, W. ; Qian, H. . Binary neural network with 16 Mb RRAM macro chip for classification and online training. 2016 IEEE International Electron Devices Meeting (IEDM). San Francisco, CA, USA, 2016; pp 16.2.1–16.2.4. [Google Scholar]
- Gupta, S. ; Agrawal, A. ; Gopalakrishnan, K. ; Narayanan, P. . Deep learning with limited numerical precision. International conference on machine learning. 2015; pp 1737–1746. [Google Scholar]
- Shafiee, A. ; Nag, A. ; Muralimanohar, N. ; Balasubramonian, R. ; Strachan, J. P. ; Hu, M. ; Williams, R. S. ; Srikumar, V. . ISAAC: A Convolutional Neural Network Accelerator with In-Situ Analog Arithmetic in Crossbars. 2016 ACM/IEEE 43rd Annual International Symposium on Computer Architecture (ISCA). Seoul, South Korea, 2016; pp 14–26. [Google Scholar]
- Pedretti G., Mannocci P., Li C., Sun Z., Strachan J. P., Ielmini D.. Redundancy and Analog Slicing for Precise In-Memory Machine Learning-Part II: Applications and Benchmark. IEEE Trans. Electron Devices. 2021;68:4379–4383. doi: 10.1109/TED.2021.3095430. [DOI] [Google Scholar]
- Song W., Rao M., Li Y., Li C., Zhuo Y., Cai F., Wu M., Yin W., Li Z., Wei Q.. et al. Programming memristor arrays with arbitrarily high precision for analog computing. Science. 2024;383:903–910. doi: 10.1126/science.adi9405. [DOI] [PubMed] [Google Scholar]
- Pedretti, G. ; Moon, J. ; Bruel, P. ; Serebryakov, S. ; Roth, R. M. ; Buonanno, L. ; Gajjar, A. ; Zhao, L. ; Ziegler, T. ; Xu, C. ; et al. X-TIME: accelerating large tree ensembles inference for tabular data with analog CAMs. IEEE Journal on Exploratory Solid-State Computational Devices and Circuits 2024, 10, 116. 10.1109/JXCDC.2024.3495634 [DOI] [Google Scholar]
- Ambrogio S., Balatti S., McCaffrey V., Wang D. C., Ielmini D.. Noise-induced resistance broadening in resistive switching memoryPart II: Array statistics. IEEE Trans. Electron Devices. 2015;62:3812–3819. doi: 10.1109/TED.2015.2477135. [DOI] [Google Scholar]
- Pedretti, G. ; Graves, C. E. ; Van Vaerenbergh, T. ; Serebryakov, S. ; Foltin, M. ; Sheng, X. ; Mao, R. ; Li, C. ; Strachan, J. P. . Differentiable Content Addressable Memory with Memristors. Adv Elect Materials 2022, 8, 9. 10.1002/aelm.202101198 [DOI] [Google Scholar]
- Feinberg B., Wang S., Ipek E.. Making memristive neural network accelerators reliable. 2018 IEEE International Symposium on High Performance Computer Architecture (HPCA) 2018:52–65. [Google Scholar]
- Roth R. M.. Analog error-correcting codes. IEEE Transactions on Information Theory. 2020;66:4075–4088. doi: 10.1109/TIT.2020.2977918. [DOI] [Google Scholar]
- Hamming R. W.. Error detecting and error correcting codes. Bell system technical journal. 1950;29:147–160. doi: 10.1002/j.1538-7305.1950.tb00463.x. [DOI] [Google Scholar]
- Li C., Roth R. M., Graves C., Sheng X., Strachan J. P.. Analog error correcting codes for defect tolerant matrix multiplication in crossbars. 2020 IEEE International Electron Devices Meeting (IEDM) 2020:36.6.1–36.6.4. [Google Scholar]
- Vaswani, A. ; Shazeer, N. ; Parmar, N. ; Uszkoreit, J. ; Jones, L. ; Gomez, A. N. ; Kaiser, Ł. ; Polosukhin, I. . Attention is all you need. Advances in neural information processing systems 2017, 30. [Google Scholar]
- Chen P., Liu F., Lin P., Li P., Xiao Y., Zhang B., Pan G.. Open-loop analog programmable electrochemical memory array. Nat. Commun. 2023;14:6184. doi: 10.1038/s41467-023-41958-4. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Burr G., Tsai H., Simon W., Boybat I., Ambrogio S., Ho C.-E., Liou Z.-W., Rasch M., Büchel J., Narayanan P.. et al. Design of Analog-AI Hardware Accelerators for Transformer-based Language Models. 2023 International Electron Devices Meeting (IEDM) 2023:1–4. [Google Scholar]
- Balatti S., Ambrogio S., Wang Z.-Q., Sills S., Calderoni A., Ramaswamy N., Ielmini D.. Pulsed cycling operation and endurance failure of metal-oxide resistive (RRAM) 2014 IEEE International Electron Devices Meeting. 2014:14.3.1–14.3.4. [Google Scholar]
- Nail C.. et al. Understanding RRAM endurance, retention and window margin trade-off using experimental results and simulations. 2016 IEEE International Electron Devices Meeting (IEDM) 2016:4.5.1–4.5.4. [Google Scholar]
- Kim Y.-B., Lee S. R., Lee D., Lee C. B., Chang M., Hur J. H., Lee M.-J., Park G.-S., Kim C. J., Chung U.-I., Yoo I.-K., Kim K.. Bi-layered RRAM with unlimited endurance and extremely uniform switching. 2011 Symposium on VLSI Technology - Digest of Technical Papers. 2011:52–53. [Google Scholar]
- Chen C., Goux L., Fantini A., Redolfi A., Clima S., Degraeve R., Chen Y., Groeseneken G., Jurczak M.. Understanding the impact of programming pulses and electrode materials on the endurance properties of scaled Ta2O5 RRAM cells. 2014 IEEE International Electron Devices Meeting. 2014:14.2.1–14.2.4. [Google Scholar]
- Lee M.-J., Lee C. B., Lee D., Lee S. R., Chang M., Hur J. H., Kim Y.-B., Kim C.-J., Seo D. H., Seo S., Chung U.-I., Yoo I.-K., Kim K.. A fast, high-endurance and scalable non-volatile memory device made from asymmetric Ta2O5-xTaO2-x bilayer structures. Nat. Mater. 2011;10:625. doi: 10.1038/nmat3070. [DOI] [PubMed] [Google Scholar]
- Agarwal, S. ; Plimpton, S. J. ; Hughart, D. R. ; Hsia, A. H. ; Richter, I. ; Cox, J. A. ; James, C. D. ; Marinella, M. J. . Resistive memory device requirements for a neural algorithm accelerator. 2016 International Joint Conference on Neural Networks (IJCNN). 2016; pp 929–938. [Google Scholar]
- Marinella M. J., Agarwal S., Hsia A., Richter I., Jacobs-Gedrim R., Niroula J., Plimpton S. J., Ipek E., James C. D.. Multiscale co-design analysis of energy, latency, area, and accuracy of a ReRAM analog neural training accelerator. IEEE Journal on Emerging and Selected Topics in Circuits and Systems. 2018;8:86–101. doi: 10.1109/JETCAS.2018.2796379. [DOI] [Google Scholar]
- Chen, P.-Y. ; Lin, B. ; Wang, I.-T. ; Hou, T.-H. ; Ye, J. ; Vrudhula, S. ; Seo, J.-s. ; Cao, Y. ; Yu, S. . Mitigating effects of non-ideal synaptic device characteristics for on-chip learning. 2015 IEEE/ACM International Conference on Computer-Aided Design (ICCAD). 2015; pp 194–199. [Google Scholar]
- Mahalanabis D., Barnaby H., Gonzalez-Velo Y., Kozicki M., Vrudhula S., Dandamudi P.. Incremental resistance programming of programmable metallization cells for use as electronic synapses. Solid-state electronics. 2014;100:39–44. doi: 10.1016/j.sse.2014.07.002. [DOI] [Google Scholar]
- Farronato, M. ; Melegari, M. ; Ricci, S. ; Hashemkani, S. ; Compagnoni, C. M. ; Ielmini, D. . Low-current, highly linear synaptic memory device based on MoS2 transistors for online training and inference. 2022 IEEE 4th International Conference on Artificial Intelligence Circuits and Systems (AICAS). 2022; pp 1–4. [Google Scholar]
- Woo J., Moon K., Song J., Lee S., Kwak M., Park J., Hwang H.. Improved Synaptic Behavior Under Identical Pulses Using AlOx/HfO2 Bilayer RRAM Array for Neuromorphic Systems. IEEE Electron Device Lett. 2016;37:994–997. doi: 10.1109/LED.2016.2582859. [DOI] [Google Scholar]
- Jo S. H., Chang T., Ebong I., Bhadviya B. B., Mazumder P., Lu W.. Nanoscale Memristor Device as Synapse in Neuromorphic Systems. Nano Lett. 2010;10:1297–1301. doi: 10.1021/nl904092h. [DOI] [PubMed] [Google Scholar]
- Jang J.-W., Park S., Burr G. W., Hwang H., Jeong Y.-H.. Optimization of Conductance Change in Pr1-xCaxMnO3-Based Synaptic Devices for Neuromorphic Systems. IEEE Electron Device Lett. 2015;36:457–459. doi: 10.1109/LED.2015.2418342. [DOI] [Google Scholar]
- Tang, J. ; Bishop, D. ; Kim, S. ; Copel, M. ; Gokmen, T. ; Todorov, T. ; Shin, S. ; Lee, K.-T. ; Solomon, P. ; Chan, K. ; Haensch, W. ; Rozen, J. . ECRAM as Scalable Synaptic Cell for High-Speed, Low-Power Neuromorphic Computing. 2018 IEEE International Electron Devices Meeting (IEDM). San Francisco, CA, 2018; pp 13.1.1–13.1.4. [Google Scholar]
- Gokmen T., Haensch W.. Algorithm for training neural networks on resistive device arrays. Frontiers in Neuroscience. 2020;14:103. doi: 10.3389/fnins.2020.00103. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Gokmen, T. Enabling Training of Neural Networks on Noisy Hardware. Frontiers in Artificial Intelligence 2021, 4, 10.3389/frai.2021.699148. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Kaggle, State of machine learning and data science 2020. https://www.kaggle.com/kaggle-survey-2020, 2020.
- Weisberg, S. Applied linear regression; John Wiley & Sons, 2005; Vol. 528. [Google Scholar]
- Penrose R.. A generalized inverse for matrices. Mathematical proceedings of the Cambridge philosophical society. 1955;51:406–413. doi: 10.1017/S0305004100030401. [DOI] [Google Scholar]
- Jolliffe, I. Principal component analysis. Encyclopedia of statistics in behavioral science; 2005. 10.1002/0470013192.bsa501 [DOI] [Google Scholar]
- Sun Z., Pedretti G., Ambrosi E., Bricalli A., Ielmini D.. In-Memory Eigenvector Computation in Time O(1) Advanced Intelligent Systems. 2020;2:2000042. doi: 10.1002/aisy.202000042. [DOI] [Google Scholar]
- Mannocci, P. ; Giannone, E. ; Ielmini, D. . In-Memory Principal Component Analysis by Analogue Closed-Loop Eigendecomposition. IEEE Transactions on Circuits and Systems II: Express Briefs 2024, 71, 1839. 10.1109/TCSII.2023.3334958 [DOI] [Google Scholar]
- Grinsztajn L., Oyallon E., Varoquaux G.. Why do tree-based models still outperform deep learning on typical tabular data? Advances in neural information processing systems. 2022;35:507–520. [Google Scholar]
- Lundberg S. M., Nair B., Vavilala M. S., Horibe M., Eisses M. J., Adams T., Liston D. E., Low D. K.-W., Newman S.-F., Kim J., Lee S.-I.. Explainable machine-learning predictions for the prevention of hypoxaemia during surgery. Nature Biomedical Engineering. 2018;2:749–760. doi: 10.1038/s41551-018-0304-0. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Biau G., Scornet E.. A random forest guided tour. TEST. 2016;25:197–227. doi: 10.1007/s11749-016-0481-7. [DOI] [Google Scholar]
- Chen, T. ; Guestrin, C. . XGBoost: A Scalable Tree Boosting System. Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. San Francisco California USA, 2016; pp 785–794. [Google Scholar]
- Xie, Z. ; Dong, W. ; Liu, J. ; Liu, H. ; Li, D. . Tahoe: tree structure-aware high performance inference engine for decision tree ensemble on GPU. Proceedings of the Sixteenth European Conference on Computer Systems. Online Event United Kingdom, 2021; pp 426–440. [Google Scholar]
- Degraeve R., Roussel P., Goux L., Wouters D., Kittl J., Altimime L., Jurczak M., Groeseneken G.. Generic learning of TDDB applied to RRAM for improved understanding of conduction and switching mechanism through multiple filaments. 2010 International Electron Devices Meeting. 2010:28–4. [Google Scholar]
- Sung C., Padovani A., Beltrando B., Lee D., Kwak M., Lim S., Larcher L., Della Marca V., Hwang H.. Investigation of IV linearity in TaOx-Based RRAM devices for neuromorphic applications. IEEE Journal of The Electron Devices Society. 2019;7:404–408. doi: 10.1109/JEDS.2019.2902653. [DOI] [Google Scholar]
- Lucas, A. Ising formulations of many NP problems. Frontiers in Physics 2014, 2, 10.3389/fphy.2014.00005 [DOI] [Google Scholar]
- Kirkpatrick S., Gelatt C., Vecchi M.. Optimization by Simulated Annealing. Science. 1983;220:671–680. doi: 10.1126/science.220.4598.671. [DOI] [PubMed] [Google Scholar]
- Mohseni N., McMahon P. L., Byrnes T.. Ising machines as hardware solvers of combinatorial optimization problems. Nature Reviews Physics. 2022;4:363–379. doi: 10.1038/s42254-022-00440-8. [DOI] [Google Scholar]
- Mahmoodi, M. R. ; Kim, H. ; Fahimi, Z. ; Nili, H. ; Sedov, L. ; Polishchuk, V. ; Strukov, D. B. . An Analog Neuro-Optimizer with Adaptable Annealing Based on 64 × 64 0T1R Crossbar Circuit. 2019 IEEE International Electron Devices Meeting (IEDM). San Francisco, CA, 2019; pp 14.7.1–14.7.4. [Google Scholar]
- Yang K., Duan Q., Wang Y., Zhang T., Yang Y., Huang R.. Transiently chaotic simulated annealing based on intrinsic nonlinearity of memristors for efficient solution of optimization problems. Science Advances. 2020;6:eaba9901. doi: 10.1126/sciadv.aba9901. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Dobrynin D., Renaudineau A., Hizzani M., Strukov D., Mohseni M., Strachan J. P.. Disconnectivity graphs for visualizing combinatorial optimization problems: challenges of embedding to Ising machines. arXiv. 2024:2403.01320. doi: 10.1103/PhysRevE.110.045308. [DOI] [PubMed] [Google Scholar]
- Pedretti G., Böhm F., Hizzani M., Bhattacharya T., Bruel P., Moon J., Serebryakov S., Strukov D., Strachan J., Ignowski J.. et al. Zeroth and higher-order logic with content addressable memories. 2023 International Electron Devices Meeting (IEDM). 2023:1–4. [Google Scholar]
- Bhattacharya T., Hutchinson G. H., Pedretti G., Sheng X., Ignowski J., Van Vaerenbergh T., Beausoleil R., Strachan J. P., Strukov D. B.. Computing High-Degree Polynomial Gradients in Memory. Nat. Commun. 2024;15:8211. doi: 10.1038/s41467-024-52488-y. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Turck C., Bonnet D., Harabi K.-E., Dalgaty T., Ballet T., Hirtzlin T., Pontlevy A., Renaudineau A., Esmanhotto E., Bessière P.. et al. Bayesian In-Memory Computing with Resistive Memories. 2023 International Electron Devices Meeting (IEDM) 2023:1–4. [Google Scholar]
- Harabi K.-E., Hirtzlin T., Turck C., Vianello E., Laurent R., Droulez J., Bessière P., Portal J.-M., Bocquet M., Querlioz D.. A memristor-based Bayesian machine. Nature Electronics. 2023;6:52–63. doi: 10.1038/s41928-022-00886-9. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Dalgaty T., Esmanhotto E., Castellani N., Querlioz D., Vianello E.. Ex situ transfer of bayesian neural networks to resistive memory-based inference hardware. Advanced Intelligent Systems. 2021;3:2000103. doi: 10.1002/aisy.202000103. [DOI] [Google Scholar]
- Dalgaty T., Castellani N., Turck C., Harabi K.-E., Querlioz D., Vianello E.. In situ learning using intrinsic memristor variability via Markov chain Monte Carlo sampling. Nature Electronics. 2021;4:151–161. doi: 10.1038/s41928-020-00523-3. [DOI] [Google Scholar]
- Mead C.. Neuromorphic electronic systems. Proceedings of the IEEE. 1990;78:1629–1636. doi: 10.1109/5.58356. [DOI] [Google Scholar]
- Indiveri G., Liu S.-C.. Memory and Information Processing in Neuromorphic Systems. Proceedings of the IEEE. 2015;103:1379–1397. doi: 10.1109/JPROC.2015.2444094. [DOI] [Google Scholar]
- Mehonic A., Kenyon A. J.. Brain-inspired computing needs a master plan. Nature. 2022;604:255–260. doi: 10.1038/s41586-021-04362-w. [DOI] [PubMed] [Google Scholar]
- Schuman C. D., Kulkarni S. R., Parsa M., Mitchell J. P., Date P., Kay B.. Opportunities for neuromorphic computing algorithms and applications. Nature Computational Science. 2022;2:10–19. doi: 10.1038/s43588-021-00184-y. [DOI] [PubMed] [Google Scholar]
- Marković D., Mizrahi A., Querlioz D., Grollier J.. Physics for neuromorphic computing. Nature Reviews Physics. 2020;2:499–510. doi: 10.1038/s42254-020-0208-2. [DOI] [Google Scholar]
- Ielmini D., Wang Z., Liu Y.. Brain-inspired computing via memory device physics. APL Materials. 2021;9:050702. doi: 10.1063/5.0047641. [DOI] [Google Scholar]
- Indiveri G., Linares-Barranco B., Legenstein R., Deligeorgis G., Prodromakis T.. Integration of nanoscale memristor synapses in neuromorphic computing architectures. Nanotechnology. 2013;24:384010. doi: 10.1088/0957-4484/24/38/384010. [DOI] [PubMed] [Google Scholar]
- Zamarreño-Ramos, C. ; Camuñas-Mesa, L. A. ; Pérez-Carrasco, J. A. ; Masquelier, T. ; Serrano-Gotarredona, T. ; Linares-Barranco, B. . On Spike-Timing-Dependent-Plasticity, Memristive Devices, and Building a Self-Learning Visual Cortex. Frontiers in Neuroscience 2011, 5, 10.3389/fnins.2011.00026 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Serrano-Gotarredona, T. ; Masquelier, T. ; Prodromakis, T. ; Indiveri, G. ; Linares-Barranco, B. . STDP and STDP variations with memristors for spiking neuromorphic learning systems. Frontiers in Neuroscience 2013, 7 10.3389/fnins.2013.00002 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Zhao Y. D., Kang J. F., Ielmini D.. Materials challenges and opportunities for brain-inspired computing. MRS Bull. 2021;46:978–986. doi: 10.1557/s43577-021-00205-1. [DOI] [Google Scholar]
- Tuma T., Pantazi A., Le Gallo M., Sebastian A., Eleftheriou E.. Stochastic phase-change neurons. Nat. Nanotechnol. 2016;11:693–699. doi: 10.1038/nnano.2016.70. [DOI] [PubMed] [Google Scholar]
- Lashkare S., Chouhan S., Chavan T., Bhat A., Kumbhare P., Ganguly U.. PCMO RRAM for Integrate-and-Fire Neuron in Spiking Neural Networks. IEEE Electron Device Lett. 2018;39:484–487. doi: 10.1109/LED.2018.2805822. [DOI] [Google Scholar]
- Dongre A., Trivedi G.. RRAM-Based Energy Efficient Scalable Integrate and Fire Neuron With Built-In Reset Circuit. IEEE Transactions on Circuits and Systems II: Express Briefs. 2023;70:909–913. doi: 10.1109/TCSII.2022.3219203. [DOI] [Google Scholar]
- Mehonic, A. ; Kenyon, A. J. . Emulating the Electrical Activity of the Neuron Using a Silicon Oxide RRAM Cell. Frontiers in Neuroscience 2016, 10, 10.3389/fnins.2016.00057 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Bianchi S., Muñoz-Martín I., Covi E., Bricalli A., Piccoloni G., Regev A., Molas G., Nodin J. F., Andrieu F., Ielmini D.. Combining Accuracy and Plasticity in Convolutional Neural Networks Based on Resistive Memory Arrays for Autonomous Learning. IEEE Journal on Exploratory Solid-State Computational Devices and Circuits. 2021;7:132–140. doi: 10.1109/JXCDC.2021.3118061. [DOI] [Google Scholar]
- Li X., Tang J., Zhang Q., Gao B., Yang J. J., Song S., Wu W., Zhang W., Yao P., Deng N., Deng L., Xie Y., Qian H., Wu H.. Power-efficient neural network with artificial dendrites. Nat. Nanotechnol. 2020;15:776–782. doi: 10.1038/s41565-020-0722-5. [DOI] [PubMed] [Google Scholar]
- Wang, Z. ; Ambrogio, S. ; Balatti, S. ; Ielmini, D. . A 2-transistor/1-resistor artificial synapse capable of communication and stochastic learning in neuromorphic systems. Frontiers in Neuroscience 2015, 8, 10.3389/fnins.2014.00438 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Ambrogio S., Balatti S., Milo V., Carboni R., Wang Z.-Q., Calderoni A., Ramaswamy N., Ielmini D.. Neuromorphic Learning and Recognition With One-Transistor-One-Resistor Synapses and Bistable Metal Oxide RRAM. IEEE Trans. Electron Devices. 2016;63:1508–1515. doi: 10.1109/TED.2016.2526647. [DOI] [Google Scholar]
- Covi, E. ; Ielmini, D. ; Lin, Y.-H. ; Wang, W. ; Stecconi, T. ; Milo, V. ; Bricalli, A. ; Ambrosi, E. ; Pedretti, G. ; Tseng, T.-Y. . A Volatile RRAM Synapse for Neuromorphic Computing. 2019 26th IEEE International Conference on Electronics, Circuits and Systems (ICECS). Genoa, Italy, 2019; pp 903–906. [Google Scholar]
- Ricci S., Kappel D., Tetzlaff C., Ielmini D., Covi E.. Tunable synaptic working memory with volatile memristive devices. Neuromorphic Computing and Engineering. 2023;3:044004. doi: 10.1088/2634-4386/ad01d6. [DOI] [Google Scholar]
- Hebb, D. O. The organization of behavior; a neuropsychological theory; Wiley, 1949. [Google Scholar]
- Ohno T., Hasegawa T., Tsuruoka T., Terabe K., Gimzewski J. K., Aono M.. Short-term plasticity and long-term potentiation mimicked in single inorganic synapses. Nat. Mater. 2011;10:591–595. doi: 10.1038/nmat3054. [DOI] [PubMed] [Google Scholar]
- Bi G.-q., Poo M.-m.. Synaptic Modifications in Cultured Hippocampal Neurons: Dependence on Spike Timing, Synaptic Strength, and Postsynaptic Cell Type. J. Neurosci. 1998;18:10464–10472. doi: 10.1523/JNEUROSCI.18-24-10464.1998. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Pfister J.-P., Gerstner W.. Triplets of Spikes in a Model of Spike Timing-Dependent Plasticity. J. Neurosci. 2006;26:9673–9682. doi: 10.1523/JNEUROSCI.1425-06.2006. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Gjorgjieva J., Clopath C., Audet J., Pfister J.-P.. A triplet spike-timing-dependent plasticity model generalizes the Bienenstock-Cooper-Munro rule to higher-order spatiotemporal correlations. Proc. Natl. Acad. Sci. U.S.A. 2011;108:19383–19388. doi: 10.1073/pnas.1105933108. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Bienenstock E., Cooper L., Munro P.. Theory for the development of neuron selectivity: orientation specificity and binocular interaction in visual cortex. J. Neurosci. 1982;2:32. doi: 10.1523/JNEUROSCI.02-01-00032.1982. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Wang Z., Zeng T., Ren Y., Lin Y., Xu H., Zhao X., Liu Y., Ielmini D.. Toward a generalized Bienenstock-Cooper-Munro rule for spatiotemporal learning via triplet-STDP in memristive devices. Nat. Commun. 2020;11:1510. doi: 10.1038/s41467-020-15158-3. [DOI] [PMC free article] [PubMed] [Google Scholar]
- John R. A., Milozzi A., Tsarev S., Brönnimann R., Boehme S. C., Wu E., Shorubalko I., Kovalenko M. V., Ielmini D.. Ionic-electronic halide perovskite memdiodes enabling neuromorphic computing with a second-order complexity. Science Advances. 2022;8:eade0072. doi: 10.1126/sciadv.ade0072. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Wu Y., Yu S., Wong H.-S. P., Chen Y.-S., Lee H.-Y., Wang S.-M., Gu P.-Y., Chen F., Tsai M.-J.. AlOx-Based Resistive Switching Device with Gradual Resistance Modulation for Neuromorphic Device Application. 2012 4th IEEE International Memory Workshop. 2012:1–4. [Google Scholar]
- Kuzum D., Jeyasingh R. G. D., Lee B., Wong H.-S. P.. Nanoelectronic Programmable Synapses Based on Phase Change Materials for Brain-Inspired Computing. Nano Lett. 2012;12:2179–2186. doi: 10.1021/nl201040y. [DOI] [PubMed] [Google Scholar]
- Kim S., Du C., Sheridan P., Ma W., Choi S., Lu W. D.. Experimental Demonstration of a Second-Order Memristor and Its Ability to Biorealistically Implement Synaptic Plasticity. Nano Lett. 2015;15:2203–2211. doi: 10.1021/acs.nanolett.5b00697. [DOI] [PubMed] [Google Scholar]
- Khanas A., Hebert C., Becerra L., Portier X., Jedrecy N.. Second-Order Memristor Based on All-Oxide Multiferroic Tunnel Junction for Biorealistic Emulation of Synapses. Advanced Electronic Materials. 2022;8:2200421. doi: 10.1002/aelm.202200421. [DOI] [Google Scholar]
- Li Y., Tang J., Gao B., Sun W., Hua Q., Zhang W., Li X., Zhang W., Qian H., Wu H.. High-Uniformity Threshold Switching HfO2-Based Selectors with Patterned Ag Nanodots. Advanced Science. 2020;7:2002251. doi: 10.1002/advs.202002251. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Covi E., Wang W., Lin Y.-H., Farronato M., Ambrosi E., Ielmini D.. Switching Dynamics of Ag-Based Filamentary Volatile Resistive Switching DevicesPart I: Experimental Characterization. IEEE Trans. Electron Devices. 2021;68:4335–4341. doi: 10.1109/TED.2021.3076029. [DOI] [Google Scholar]
- Wang W., Covi E., Lin Y.-H., Ambrosi E., Milozzi A., Sbandati C., Farronato M., Ielmini D.. Switching Dynamics of Ag-Based Filamentary Volatile Resistive Switching DevicesPart II: Mechanism and Modeling. IEEE Trans. Electron Devices. 2021;68:4342–4349. doi: 10.1109/TED.2021.3095033. [DOI] [Google Scholar]
- Lester R., Jahr C.. NMDA channel behavior depends on agonist affinity. J. Neurosci. 1992;12:635–643. doi: 10.1523/JNEUROSCI.12-02-00635.1992. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Milozzi A., Ricci S., Ielmini D.. Memristive tonotopic mapping with volatile resistive switching memory devices. Nat. Commun. 2024;15:2812. doi: 10.1038/s41467-024-47228-1. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Zwislocki J.. Theory of the acoustical action of the cochlea. J. Acoust. Soc. Am. 1950;22:778–784. doi: 10.1121/1.1906689. [DOI] [Google Scholar]
- Du C., Cai F., Zidan M. A., Ma W., Lee S. H., Lu W. D.. Reservoir computing using dynamic memristors for temporal information processing. Nat. Commun. 2017;8:2204. doi: 10.1038/s41467-017-02337-y. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Tanaka G., Yamane T., Héroux J. B., Nakane R., Kanazawa N., Takeda S., Numata H., Nakano D., Hirose A.. Recent advances in physical reservoir computing: A review. Neural Networks. 2019;115:100–123. doi: 10.1016/j.neunet.2019.03.005. [DOI] [PubMed] [Google Scholar]
- Zhu X., Wang Q., Lu W.. Memristor networks for real-time neural activity analysis. Nat. Commun. 2020;11:2439. doi: 10.1038/s41467-020-16261-1. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Zhong Y., Tang J., Li X., Gao B., Qian H., Wu H.. Dynamic memristor-based reservoir computing for high-efficiency temporal signal processing. Nat. Commun. 2021;12:408. doi: 10.1038/s41467-020-20692-1. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Liu Z., Tang J., Gao B., Li X., Yao P., Lin Y., Liu D., Hong B., Qian H., Wu H.. Multichannel parallel processing of neural signals in memristor arrays. Sci. Adv. 2020;6:41. doi: 10.1126/sciadv.abc4797. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Marković D., Leroux N., Riou M., Abreu Araujo F., Torrejon J., Querlioz D., Fukushima A., Yuasa S., Trastoy J., Bortolotti P., Grollier J.. Reservoir computing with the frequency, phase, and amplitude of spin-torque nano-oscillators. Appl. Phys. Lett. 2019;114:012409. doi: 10.1063/1.5079305. [DOI] [Google Scholar]
- Milano G., Pedretti G., Montano K., Ricci S., Hashemkhani S., Boarino L., Ielmini D., Ricciardi C.. In materia reservoir computing with a fully memristive architecture based on self-organizing nanowire networks. Nat. Mater. 2022;21:195–202. doi: 10.1038/s41563-021-01099-9. [DOI] [PubMed] [Google Scholar]
- Banerjee D., Kotooka T., Azhari S., Usami Y., Ogawa T., Gimzewski J. K., Tamukoh H., Tanaka H.. Emergence of In-Materio Intelligence from an Incidental Structure of a Single-Walled Carbon Nanotube-Porphyrin Polyoxometalate Random Network. Advanced Intelligent Systems. 2022;4:2100145. doi: 10.1002/aisy.202270014. [DOI] [Google Scholar]
- Fang R., Zhang W., Ren K., Zhang P., Xu X., Wang Z., Shang D.. In-materio reservoir computing based on nanowire networks: fundamental, progress, and perspective. Materials Futures. 2023;2:022701. doi: 10.1088/2752-5724/accd87. [DOI] [Google Scholar]
- Jaeger H., Noheda B., van der Wiel W.. Toward a formal theory for computing machines made out of whatever physics offers. Nat. Commun. 2023;14:4911. doi: 10.1038/s41467-023-40533-1. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Frémaux, N. ; Gerstner, W. . Neuromodulated Spike-Timing-Dependent Plasticity, and Theory of Three-Factor Learning Rules. Frontiers in Neural Circuits 2016, 9. 10.3389/fncir.2015.00085 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Wang Z., Wu H., Burr G. W., Hwang C. S., Wang K. L., Xia Q., Yang J. J.. Resistive switching materials for information processing. Nature Reviews Materials. 2020;5:173–195. doi: 10.1038/s41578-019-0159-3. [DOI] [Google Scholar]