

Abstract
The complexity of the outdoor orchard environment, especially the changes in light intensity and the shadows generated by fruit clusters, present challenges in the identification and classification of mature fruits. To solve these problems, this paper proposes an innovative fruit recognition model, HAT-YOLOV8, aiming to combine the advantages of Hybrid Attention Transformer (HAT) and YOLOV8 deep learning algorithm. This model improves the ability to capture complex dependencies by integrating the Shuffle Attention (SA) module while maintaining low computational complexity. In addition, during the feature fusion stage, the Hybrid Attention Transformer (HAT) module is integrated into TopDownLayer2 to enhance the capture of long-term dependencies and the recovery of detailed information in the input data. To more accurately evaluate the similarity between the prediction box and the real bounding box, this paper uses the EIoU loss function instead of CIoU, thereby improving detection accuracy and accelerating model convergence. In terms of evaluation, this study was experimented on a dataset containing five fruit varieties, each of which was classified into three different maturity levels. The results show that the HAT-YOLOV8 model improved mAP by 11%, 10.2%, 7.6% and 7.8% on the test set, and the overall mAP reached 88.9% respectively. In addition, the HAT-YOLOV8 model demonstrates excellent generalization capabilities, indicating its potential for application in the fields of fruit recognition, maturity assessment and fruit picking automation.
Supplementary Information
The online version contains supplementary material available at 10.1038/s41598-025-04184-0.
Keywords: Fruit ripeness detection, Hybrid attention transformer, YOLOV8s, Shuffle attention, EIoU
Subject terms: Computational science, Mechanical engineering
Introduction
The world is increasingly emphasising agricultural efficiency and sustainable development, and the detection of ripeness plays a key role in the automatic harvesting and sorting of fruit. The ripeness of the fruit is often closely related to the colour of the peel, which allows the fruit ripeness to be determined visually. As global fruit production increases, together with increasing labour costs and labour shortages, there is a growing demand for effective technology for fruit ripening. Retention of fruit ripeness is a problem in object detection. In natural environments1, problems such as overlapping, occlusion and variations in lighting during photography prevent accurate identification.
In particular, the development of object detection involves two phases: traditional and deep learning based on convolutional neural networks (CNN). With the advent of convolutional networks, models such as AlexNet2, VGG3, GoogleNet4–6, and ResNet7,8 have received wide-spread attention. Deep learning technologies have seen rapid progress in recent years. Fruit ripening has therefore become a research hot spot, and methods can usually be divided into two types: Region Detection Methods (RDM) and Image Detection Methods (IDM).
Region Detection Methods (RDM) involve extracting and analyzing regions of interest (ROIs) from input images, using Deep Convolutional Neural Networks (DCNNs) for feature extraction, and employing Region Proposal Networks (RPN) to detect fruit ripeness. The Faster R-CNN algorithm is a representative example, significantly improving detection speed and accuracy, outperforming traditional techniques in detecting fruits against complex backgrounds9,10. Li et al.11 introduced a model named Strawberry R-CNN, specifically designed for intelligent identification and counting of strawberries in natural environments, achieving a mean Average Precision (mAP) of 0.8733. Shiu et al.12 utilized Faster R-CNN to detect the number of mature pineapple plants in high-resolution images captured by unmanned aerial vehicles (UAVs), achieving an Average Precision (AP) of 0.739.
Image-based detection techniques require a direct analysis of the entire visual image and the processing of large amounts of visual data to extract the discriminating features. Neural computing and Fully Convolutional Networks (FCNs) have made considerable progress in this area13. The YOLO algorithm is a typical representative one, which demonstrates excellent speed and accuracy in identifying fruit, which is appropriate for agricultural scenarios requiring rapid response14,15. Yang et al.16 proposed a new algorithm called You Only Look Once-SDW (YOLO-SDW), based on the YOLOv5 algorithm. YOLO-SDW introduces spatial depth-shift transform convolution to the backbone network of the original YOLOv5 algorithm, replacing traditional strided convolutions by SPD-Conv. This improvement resulted in an improvement in mean Average Precision (mAP) compared to the original YOLOv5 algorithm, which was 83.5 percent. Chen et al.17 introduced a novel enhanced pyramid module for multi-scale feature fusion to optimize the YOLOv8 architecture, resulting in the proposed PMF-YOLOv8 framework. This enhancement specifically targets the challenge of missed detections in dense remote sensing ship scenarios. By incorporating shallow feature fusion into the neck component of YOLOv8, the algorithm employs adaptive spatial feature fusion combined with a path-based aggregation network to process hierarchical features from the backbone. Experimental evaluations demonstrate that PMF-YOLOv8 achieves significant performance improvements over the baseline YOLOv8, with absolute gains of 3.7%, 4.1%, 5.7%, and 2.5% in mean average precision at IoU=0.5 (mAP@0.5), mAP across IoU thresholds from 0.5 to 0.95 (mAP@0.5:0.95), recall, and classification accuracy, respectively. In18, a novel computational framework for leaf disease detection, termed the VM-space-based Multi-scale Feature-fusion Single-shot Multi-array Detector (VMF-SSD), is introduced to enhance multi-scale image representation capabilities for capturing leaf lesions of varying sizes. By integrating feature fusion mechanisms across VM-space dimensions, the method enables adaptive scaling of lesion patterns. Experimental evaluations demonstrate that the VMF-SSD framework achieves a mean error rate of 83.19% in classification tasks, providing a quantitative baseline for future comparisons in precision agriculture applications.
The Transformer architecture has had a profound impact on computer vision19. Carion et al.20 proposed an end-to-end object detection method based on the Transformer, revealing its potential in visual performance. Alexeyev et al.21 introduced the Vision Transformer (ViT), demonstrating that it can compete with traditional CNNs and has the potential to replace them. ViT splits an image into several fixed-size patches and treats these patches as sequence data, which is then fed into the Transformer. It is particularly suitable for computer vision tasks, especially image classification. Subsequently, Alshawabkeh et al.22 proposed a hybrid method that combines the R-CNN mask and the Vision Transformer (ViT) model for detecting sidewalk cracks. Xue et al.23 integrated CNNs and Transformers for facial expression recognition.
Despite its successes, ViT has drawbacks such as computational inefficiency and poor small object detection. The widget separates images into slices, but the relationship between the complexity and the size of the slices prevents the sliceness of the slices from being captured. Inspired by ViT, Swin Transformer performs calculations in the Shift window, uses fine-grained image representation to perform demanding tasks, and achieves excellent results in object detection and image segmentation24–26.
In order to improve the accuracy of fruit ripening detection and to address the algorithmic complexity while at the same time improving the model’s generalisation capability, this paper proposes the HAT-YOLOV8 fruit ripening model, which incorporates the Transformer and YOLOV8. The primary contributions of this research include:
The integration of the Shuffle Attention (SA) module into the backbone enables more precise and comprehensive extraction of core features while reducing computational complexity.
The incorporation of the Hybrid Attention Transformer (HAT) module in the feature fusion stage within the TopDown Layer2, enabling the capture of long-term dependencies in the input data while restoring more detailed features.
The substitution of the loss function CIoU with EIoU, which more accurately reflects the similarity between the predicted bounding box and the ground truth bounding box, thereby improving the precision of object detection while accelerating model convergence.
The utilization of a mixed fruit dataset comprising five different types of fruits, each categorized into three levels of ripeness, to validate the model’s generalization capability.
The remainder of the paper is organized as follows. Section "Related work" reviews the current works related to fruit maturity detection. Section "Methods" provides an in-depth explanation of the methodology and details of the proposed model. Section "Experiments" presents experimental comparison results between representative models and the proposed model on a mixed fruit dataset. Finally, Sect. "Conclusion" concludes the paper.
Related work
A large number of studies have been devoted to solving the problem of fruit ripening, mainly using deep learning techniques. These methods can be classified into three types: brainstorming. The RPN methods use differential modelling techniques to generate candidate regions for ranking and ranking of the fruit variety. Ren et al.27 introduced Faster R-CNN, which improves the speed and accuracy of object detection by RPNs by sharing folded functions, reducing computational burden and accurately locating fruit. Lin et al.28 proposed an FPN architecture that integrates features from different scales to improve fruit recognition and location performance and has demonstrated good results in different datasets, particularly for small fruits and dense images. Chen et al.29 Integrating contextual information into FPNs to optimise the representation of features and the accuracy of recognition in complex environments. Shardless methods of attention (SA) introduce attention mechanisms for focusing on prominent features.
The Transformer architecture, renowned for its prowess in capturing long-range dependencies and contextual information, has seen increasing applications in scenarios such as natural language processing and computer vision. Graph Transformer effectively integrates Graph Neural Networks (GNNs) with the self-attention mechanism of Transformers, enabling the processing of relationships between nodes in graph-structured data and efficient capture of long-range dependencies. Li et al.30 introduced HGGEP, a hypergraph neural network model designed for predicting gene expression from histology images. By incorporating a gradient enhancement module and a hypergraph association module, this model overcomes the limitations of existing methods, adeptly capturing cell morphology and higher-order feature associations. Testing on HER2+ breast tumor and cSCC datasets demonstrates that HGGEP outperforms state-of-the-art models, showcasing exceptional accuracy and robust performance in gene expression prediction. Liu et al.31 proposed DrugFormer, a graph-augmented language model for single-cell level drug resistance prediction. Integrating gene tokens and knowledge graphs, this model achieves high precision in predicting drug responses. Leveraging single-cell RNA sequencing data, DrugFormer identifies drug-resistant cells, uncovers molecular mechanisms, and proposes potential therapeutic targets such as COX8A. This research significantly advances drug resistance prediction, providing valuable insights for personalized treatment strategies. Graph Transformer is particularly well-suited for tasks involving graph-structured data (e.g., social networks, knowledge graphs, chemical molecules), with a primary focus on modeling relationships between nodes and edges.
Following the groundwork laid by Vision Transformers (ViT)32, which have demonstrated comparability with and potential to replace traditional Convolutional Neural Networks (CNN), some progress has been made in solving specific problems in fruit recognition tasks. Li et al.33 proposed an improved method for detecting underwater objects combining transformer with multiple-scale focus-stream fusion.A new transformer based on the Coordinate Decomposition Window (CDW) is also introduced to extract spatial positioning information more precisely. Xiao et al.34 examined the benefits of three models - Vision Transformer (ViT), Swin Transformer and Multilayer Perceptron (MLP) - in the accurate analysis of ripening fruit. The Swin transformer achieved more significant results than the Vision transformer when compared to the standardized standardized one for pears and apples.
The Hybrid Attention Transformer (HAT), inspired by the Vision Transformer (ViT) architecture, has been developed to address these limitations. By integrating channel-centric and window-oriented self-attention mechanisms, the HAT adeptly strikes the balance between global statistical information and robust local target identification. This integrative approach is particularly advantageous for fruit classification tasks, where the detection of nuanced details such as nuanced color shifts, intricate texture patterns, and subtle morphological variations is crucial for precise assessment of fruit ripeness.
In the context of fruit recognition, the use of HAT facilitates a more accurate extraction of characteristics, which allows the model to detect subtle differences between mature and immature fruit. By integrating channel-based attention, HAT can focus on the most informative features in different channels, while the window-based self-monitoring mechanism allows for effective capture of local dependencies in specific areas of the image. This double-checking mechanism increases the model’s generalisation capacity to different fruit types and environmental conditions, and is a promising solution for fruit ripening and quality assessment.
In our research on the detection of ripeness, challenges such as lighting conditions, fruit occlusion, and color variations have been encountered. These issues require the ability to capture fine details in images, an area where traditional Convolutional Neural Networks (CNNs) are less effective. A Hybrid Attention Transformer (HAT) has been introduced for its advantages in retrieving subtle details and semantic relationships. To address the need for fast processing in automated harvesting, the Shuffle Attention (SA) module has been integrated into the YOLOV8 backbone network and combined with the Hybrid Attention Transformer (HAT) module during the TopDown Layer2 feature fusion phase. Additionally, to enhance the accuracy of localization, the original CIoU loss function has been replaced with the EIoU loss function.
Methods
Overall structure of HAT-YOLOv8
The network structure diagram of HAT-YOLOV8 is illustrated in Fig. 1, featuring three primary components: the Shuffle Attention (SA) module, the Hybrid Attention Transformer (HAT) module, and the EIoU module. The SA module is integrated into the YOLOv8 backbone network, generating richer feature representations by grouping and processing input feature maps; this enhancement, enriched with contextual information, allows for more precise identification of fruit characteristics while significantly reducing parameters and computational overhead, thus improving detection efficiency. The incorporation of the HAT module at the component fusion phase of TopDown Layer 2 is notable, as the Overlapping Cross-Attention Block (OCAB) promotes interaction among adjacent window elements, addressing information isolation issues typical of traditional transformer models. This results in a more nuanced understanding of the relationships among various fruit parts, thereby increasing detection accuracy and reliability. Additionally, the HAT module has shown exceptional performance in super-resolution tasks, effectively recovering clearer feature details. Lastly, the regression loss function in the EIoU has been refined to further boost prediction accuracy35.
Fig. 1.

HAT-YOLOV8 network structure. The proposed framework comprises three key components: the SA module embedded in the YOLOv8 backbone, which achieves lightweight feature extraction via channel grouping to reduce model parameters while enhancing fruit characteristic recognition; the HAT module at TopDown Layer 2, enabling cross-window interactions to capture subtle relationships between fruit parts and recover fine-grained details; and the EIoU module, which refines the regression loss for precise bounding box alignment. Collectively, these components boost detection accuracy and efficiency.
Shuffle attention (SA) module
As shown in Fig. 2, the Shuffle Attention module systematically divides the input feature map into multiple clusters and utilizes the Shuffle unit to integrate both channel-wise and spatial attention within each block of these clusters. The derived sub-features are then aggregated, with the “Channel Attention” operator facilitating the transfer of information between the distinct sub-features.
Fig. 2.

Network structure of the Shuffle Attention module. Shows the network structure of the Shuffle Attention module, which combines channel shuffling and attention mechanisms to boost feature representation and cross-channel interaction, thereby enhancing model performance.
The Spatial Attention (SA) mechanism initially subdivides the feature map, denoted as 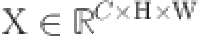 , into G discrete clusters along the channel dimension, where C represents the total number of channels and H , W signify the spatial dimensions of height and width, respectively. This segmentation is articulated as:
, into G discrete clusters along the channel dimension, where C represents the total number of channels and H , W signify the spatial dimensions of height and width, respectively. This segmentation is articulated as:
| 1 |
where  with
with  denoting the k-th subgroup. Each subgroup
denoting the k-th subgroup. Each subgroup  is further split into two branches for channel and spatial attention, each containing
is further split into two branches for channel and spatial attention, each containing 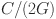 channels:
channels:
| 2 |
where  and
and  are dedicated to modeling channel-wise dependencies and spatial relationships, respectively.
are dedicated to modeling channel-wise dependencies and spatial relationships, respectively.
For the channel attention branch, global average pooling (GAP) is applied to to embed global spatial information, generating channel statistics  via:
via:
| 3 |
where  denotes the global average pooling operation. The channel statistics are then passed through a linear transformation
denotes the global average pooling operation. The channel statistics are then passed through a linear transformation 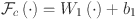 followed by a sigmoid activation
followed by a sigmoid activation 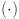 , which normalizes outputs to the range (0,1) to produce attention coefficients. The output of the channel attention module is:
, which normalizes outputs to the range (0,1) to produce attention coefficients. The output of the channel attention module is:
| 4 |
where  and
and  are learnable parameters, and
are learnable parameters, and  represents the sigmoid activation function.
represents the sigmoid activation function.
For the spatial attention branch, the input first undergoes Group Normalization (GN) to stabilize spatial statistics. A linear transformation 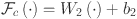 is then applied to the normalized features, followed by sigmoid activation to generate spatial attention weights. The output is:
is then applied to the normalized features, followed by sigmoid activation to generate spatial attention weights. The output is:
| 5 |
where  and
and  are learnable parameters, and
are learnable parameters, and  denotes a fully connected layer with linear transformation.
denotes a fully connected layer with linear transformation.
The outputs of the two branches, 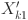 and
and  each with channels, are concatenated along the channel dimension to reconstruct the subgroup feature with the original
each with channels, are concatenated along the channel dimension to reconstruct the subgroup feature with the original  channels:
channels:
| 6 |
ensuring the channel count matches the input subgroup .
To clarify notation: k is the subgroup index ranging from 1 to G, indicating the k-th channel cluster; and are the two sub-branches of the k-th subgroup for channel and spatial attention, respectively; is the sigmoid activation function  used to generate attention coefficients; and represents a linear transformation with learnable weights and biases applied in both attention modules. This ensures all parameters are explicitly defined within the narrative flow, addressing concerns about unclear notation while maintaining the original mathematical structure and format.
used to generate attention coefficients; and represents a linear transformation with learnable weights and biases applied in both attention modules. This ensures all parameters are explicitly defined within the narrative flow, addressing concerns about unclear notation while maintaining the original mathematical structure and format.
Hybrid attention transformer (HAT) module
As shown in Fig. 3 (Network Structure of the Hybrid Attention Transformer (HAT) Module), the Hybrid Attention Transformer (HAT) integrates channel attention and self-attention to comprehensively leverage global information processing capabilities and core feature extraction abilities. Additionally, it introduces the Overlapping Cross-Attention Block (OCAB) module, which enables more direct interactions between adjacent window features, thereby activating more pixels for reconstruction and achieving significant performance improvements. The network consists of three components: shallow feature extraction, deep feature extraction, and image reconstruction, an architectural design widely adopted in previous studies36,37. Specifically, for a given low-resolution (LR) input 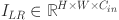 , a convolutional layer first extracts shallow features
, a convolutional layer first extracts shallow features  , where
, where  and
and  denote the input channel number and the intermediate feature channel number, respectively. Subsequently, a series of Residual Hybrid Attention Group (RHAG) and a 3 × 3 convolutional layer HConv(⋅) are employed for deep feature extraction. A global residual connection is then added to fuse the shallow features
denote the input channel number and the intermediate feature channel number, respectively. Subsequently, a series of Residual Hybrid Attention Group (RHAG) and a 3 × 3 convolutional layer HConv(⋅) are employed for deep feature extraction. A global residual connection is then added to fuse the shallow features 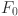 and deep features
and deep features  , which are subsequently fed into the reconstruction module to generate high-resolution results. Each RHAG comprises multiple Hybrid Attention Blocks (HABs), one Overlapping Cross-Attention Block (OCAB), and a 3 × 3 convolutional layer with residual connections. In the reconstruction module, the pixel shuffle method is adopted to upsample the fused features. The L1 loss is straightforwardly utilized for optimizing network parameters during training.
, which are subsequently fed into the reconstruction module to generate high-resolution results. Each RHAG comprises multiple Hybrid Attention Blocks (HABs), one Overlapping Cross-Attention Block (OCAB), and a 3 × 3 convolutional layer with residual connections. In the reconstruction module, the pixel shuffle method is adopted to upsample the fused features. The L1 loss is straightforwardly utilized for optimizing network parameters during training.
Fig. 3.

Network structure of the Hybrid Attention Transformer (HAT) module. Depicts the network structure of the Hybrid Attention Transformer (HAT) module, designed to integrate multi-head attention and spatial–temporal feature interaction for capturing complex contextual relationships and improving feature discrimination in target detection tasks.
Channel attention activates a greater number of pixels by leveraging global information for weight computation, thereby enhancing visual representations and optimization capabilities inherent in Transformers38–40. To improve the representational capacity of the network, a convolutional block utilizing channel attention has been integrated into the standard Transformer block. As illustrated in Fig. 4, a Channel Attention Block (CAB) is incorporated in parallel after the first Layer Normalization (LN) layer within the Swin Transformer block, alongside the Window-based Multi-head Self-Attention (W-MSA) module. Moreover, similar to the approaches detailed in41,42, Shifted Window Multi-head Self-Attention (SW-MSA) is applied between consecutive Hybrid Attention Blocks (HABs). To mitigate potential conflicts between CAB and MSA in terms of optimization and visual representation, the output of CAB is scaled by a small constant, α. The entire computation process of HAB for a given input feature (X) can be succinctly described as follows:
| 7 |
Fig. 4.

Mixed Fruit Dataset. Shows the Mixed Fruit Dataset, which comprises images of grape, strawberry, apple, persimmon, and banana, providing diverse samples for fruit detection and classification research.
where 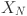 and
and  denote intermediate features, with
denote intermediate features, with  representing the output of HAB. Specifically, each pixel is treated as a token for embedding43 (the patch size is set to 1 for patch embedding). MLP stands for Multi-Layer Perceptron. For the computation of the self-attention module, given input features of size
representing the output of HAB. Specifically, each pixel is treated as a token for embedding43 (the patch size is set to 1 for patch embedding). MLP stands for Multi-Layer Perceptron. For the computation of the self-attention module, given input features of size  , they are first divided into
, they are first divided into  local windows of size
local windows of size 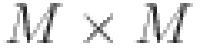 , and then self-attention is computed within each window. For the local window feature
, and then self-attention is computed within each window. For the local window feature  , the query, key, and value matrices Q, K, and V are obtained through linear projections. The window-based self-attention can then be expressed as follows:
, the query, key, and value matrices Q, K, and V are obtained through linear projections. The window-based self-attention can then be expressed as follows:
| 8 |
where d denotes the dimension of query/key. B represents relative positional encoding. To establish connections between adjacent non-overlapping windows, a shifted window partitioning approach42 is adopted, with the shift size set to half of the window size. CAB consists of two standard convolutional layers with GELU activation functions and a channel attention (CA) module. Therefore, the number of channels in the output features of the first convolutional layer is compressed by a constant factor β. For input features with C channels, the number of channels in the output features after the first convolutional layer is reduced to Cβ, and then the features are expanded back to C channels through the second layer. Subsequently, a standard CA module37 is utilized to adaptively readjust the weights of the channel features.
The Overlapping Cross-Attention Block (OCAB) is introduced to directly establish cross-window connections and enhance the representational capacity of window-based self-attention. The OCAB comprises an Overlapping Cross-Attention (OCA) layer and an MLP layer, similar to the standard Swin Transformer block42. However, in the context of OCA, different window sizes are utilized for partitioning the projected features. Specifically,  of the input feature X,
of the input feature X, 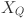 is divided into non-overlapping windows of size , whereas
is divided into non-overlapping windows of size , whereas 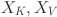 is expanded into
is expanded into  overlapping windows of size
overlapping windows of size  . The computation of the OCAB is detailed as follows:
. The computation of the OCAB is detailed as follows:
| 9 |
where  is a constant that controls the degree of overlap. The standard window partitioning can be regarded as a sliding partition with both the kernel size and stride equal to the window size
is a constant that controls the degree of overlap. The standard window partitioning can be regarded as a sliding partition with both the kernel size and stride equal to the window size  . In contrast, overlapping window partitioning can be viewed as a sliding partition where the kernel size is
. In contrast, overlapping window partitioning can be viewed as a sliding partition where the kernel size is  , while the stride remains . To ensure consistent window sizes in overlapping partitions, zero-padding of size
, while the stride remains . To ensure consistent window sizes in overlapping partitions, zero-padding of size  is employed. Unlike Window Self-Attention (WSA), where the query, key, and value are computed from the same window feature, the Overlapping Cross-Attention (OCA) module computes the key/value from a larger field, which can provide more useful information for the query.
is employed. Unlike Window Self-Attention (WSA), where the query, key, and value are computed from the same window feature, the Overlapping Cross-Attention (OCA) module computes the key/value from a larger field, which can provide more useful information for the query.
EIoU model
The precise localization of fruit specimens is a pivotal determinant in the accuracy of fruit ripeness detection; within the YOLOV8 algorithmic framework, the regression loss is computed utilizing the CIoU metric, and its mathematical formulation is expressed as follows:
| 10 |
in the context where A and B denote the respective bounding boxes,  and
and 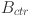 signify the central midpoints of A and B. Consequently, the initial two components of the
signify the central midpoints of A and B. Consequently, the initial two components of the  metric are congruent with the
metric are congruent with the  metric, resulting in the loss function denoted as
metric, resulting in the loss function denoted as  . The sole parameter that undergoes augmentation is the
. The sole parameter that undergoes augmentation is the  coefficient, appended to the posterior, which serves as an indicator of the aspect ratio variance.
coefficient, appended to the posterior, which serves as an indicator of the aspect ratio variance.
Nevertheless, the metric exhibits two significant inadequacies: firstly, even when the aspect ratios of the predicted bounding boxes correspond precisely with those of the ground truth boxes, the penalty associated with the aspect ratio is perpetually null; secondly, within the framework, the gradients pertaining to width and height are inversely proportional to the velocity, which precludes concurrent augmentation or reduction.
In evaluating the congruence of bounding box alignment,  metric takes into account both the extent of overlapping area and the proximity of central points, in contradistinction to the which is predicated exclusively on the area of intersection. Consequently, provides a more holistic assessment of similarity by incorporating the distance between central points, thereby accurately delineating positional correlations and facilitating the learning of precise spatial locations by object detection models. In juxtaposition with , introduces additional parameters, thereby augmenting its sensitivity to diminutive targets. This refinement is instrumental in enhancing the discriminative power and regression performance, culminating in improved accuracy and robustness in object detection tasks, as evidenced by references44,45. Our proposed HAT-YOLOV8 architecture harnesses the metric in lieu of the , optimizing the model’s performance in this regard.
metric takes into account both the extent of overlapping area and the proximity of central points, in contradistinction to the which is predicated exclusively on the area of intersection. Consequently, provides a more holistic assessment of similarity by incorporating the distance between central points, thereby accurately delineating positional correlations and facilitating the learning of precise spatial locations by object detection models. In juxtaposition with , introduces additional parameters, thereby augmenting its sensitivity to diminutive targets. This refinement is instrumental in enhancing the discriminative power and regression performance, culminating in improved accuracy and robustness in object detection tasks, as evidenced by references44,45. Our proposed HAT-YOLOV8 architecture harnesses the metric in lieu of the , optimizing the model’s performance in this regard.
refines the penalty structure of by disentangling the aspect ratio dependency between the predicted and actual bounding boxes, and by calculating their dimensions—length and width—autonomously. This method of decoupling mitigates the intrinsic challenges pertinent to , as documented in reference46. The metric is constituted of three pivotal constituents: the  loss, the centroid distance loss, and the height-width ratio loss, each pertaining to the degree of overlap, the separation of centroids, and the aspect ratio, respectively. The precise mathematical articulation of is delineated as follows:
loss, the centroid distance loss, and the height-width ratio loss, each pertaining to the degree of overlap, the separation of centroids, and the aspect ratio, respectively. The precise mathematical articulation of is delineated as follows:
| 11 |
where  and
and 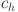 signify the dimensions, specifically the width and height, respectively, of the smallest enclosing rectangle that encapsulates both the predicted bounding box and the actual bounding box.
signify the dimensions, specifically the width and height, respectively, of the smallest enclosing rectangle that encapsulates both the predicted bounding box and the actual bounding box.  denotes the Euclidean distance separating two points.
denotes the Euclidean distance separating two points.
Experiments
Experimental environment and datasets
All experiments were conducted on a Windows 11 workstation equipped with an Intel® Core™ i9-13900K processor, 64.0 GB RAM, and an NVIDIA GeForce GTX 4080 GPU (16 GB dedicated memory). The deep learning environment was configured using Python 3.11.7, PyTorch 2.2.1, and CUDA 11.8. The neural network training model adopted a fixed input image size of 640×640 pixels, a batch size of 8, a momentum value of 0.94, an initial learning rate of 0.01 (with a cyclic learning rate scheduling strategy), a weight decay coefficient of 0.0005, and was trained for a total of 100 iterations.
As shown in Fig. 4, the dataset comprises 2,212 high-quality images covering five fruit varieties: grape, strawberry, apple, persimmon, and banana. Each fruit variety is classified into three maturity stages: ripe (H), medium (M), and unripe (L). Apples are further subdivided into apple H, apple M, and apple L to capture spectral-textural variations during the ripening process. Images were annotated using LabelImg and rigorously validated to ensure they accurately represent real-world variability in color evolution and environmental conditions.
The dataset was divided into training and test sets using a stratified sampling method to maintain consistent distributions of fruit varieties and maturity stages in both sets. The split ratio was 8:2, with 80% of the images allocated for training and 20% for testing. To enhance evaluation rigor, five random seeds were used during the splitting process according to the fruit categories in the mixed fruit dataset. This approach minimizes potential biases and enables a more reliable assessment of model performance through averaging results across different dataset splits, ensuring robust generalization capabilities.
Model evaluation metrics
The primary metric for evaluating fruit ripeness detection performance is the mean Average Precision (mAP) computed on the test dataset. This metric synthesizes Precision (P) and Recall (R) to quantify model accuracy across varying operational thresholds.
Precision (P) measures the proportion of correctly identified positive samples among all samples classified as positive:
| 11 |
where True Positives (TP) refers to correctly identified positive instances, and False Positives (FP) corresponds to negative samples erroneously classified as positive.
Recall (R) quantifies the proportion of actual positives correctly identified:
| 12 |
where False Negatives (FN) indicates missed true positives.
Average Precision (AP) evaluates single-category detection performance by integrating precision-recall trade-offs. For object detection tasks, AP is calculated as the area under the Precision-Recall (PR) curve, generated by discretely sampling precision values across descending confidence thresholds. The discrete formulation is preferred for practical implementation:
| 13 |
where  denotes the number of unique confidence thresholds evaluated, and
denotes the number of unique confidence thresholds evaluated, and  represents precision at the k-th threshold.
represents precision at the k-th threshold.
Mean Average Precision (mAP) generalizes AP to multi-category scenarios by averaging per-class AP scores:
| 14 |
where  is the total number of fruit categories. This metric provides a holistic assessment of model strengths and limitations across diverse phenotypic variations.
is the total number of fruit categories. This metric provides a holistic assessment of model strengths and limitations across diverse phenotypic variations.
Comparison and analysis of the performance of different models
This method is compared with other representative methods and analyzes the performance of each model. The quantitative results are summarized in Table 1. The upper part is the CNN model (SSD, FasterR-CNN and YOLOV8), and the lower part is the Transformer model (ViT).
Table 1.
Performance comparison between our HAT-YOLOV8 method and state-of-the-art methods on the dataset.
| Methos | Backbone | mAP (%) | FPS (640 × 640) | FLOPs (G) |
|---|---|---|---|---|
| SSD | VGG-16 | 77.9 | 45 | 32.6 |
| Faster R-CNN | ResNet-101 | 78.7 | 18 | 85.2 |
| YOLOV8s | CSPNet | 81.3 | 280 | 26.5 |
| ViT | ViT-B_16 | 81.1 | 120 | 54.8 |
| HAT-YOLOV8 | SwinIR + CSPNet | 88.9 | 220 | 35.7 |
Table 1 shows that the integration of FPN, LSTM and CNN architectures in YOLOV8 makes it easier to extract features at different scales and to merge complementary fragment information in the image. This collaborative approach increases the model’s adaptability to complex scenarios and shows better results in CNN scenarios. However, despite careful design, the optimal performance of the CNN method is only slightly better than that of the pure transformer method, with YOLOV8 improving only by 0.2 percentage points compared to the Vision Transformer (ViT) in the dataset. By contrast, the HAT-YOLOV8 model using the SwinIR+ CSPNet architecture shows an improvement in performance of 11, 10.2 and 7.6 percent when compared to the CNN-based methods. These findings confirm the usefulness of our proposed template. Compared to previous approaches, our model boasts accuracy rate of 88.9 percent.
In terms of inference efficiency and computational complexity, the models exhibit distinct characteristics, as summarized in Table 1. Among CNN-based methods, SSD (VGG-16) achieves a moderate performance with 45 FPS and 32.6 G FLOPs, while Faster R-CNN (ResNet-101) significantly lags at 18 FPS and 85.2 G FLOPs due to its two-stage architecture and region proposal mechanism. YOLOv8s (CSPNet) stands out with the highest efficiency, attaining 280 FPS and the lowest FLOPs at 26.5 G, enabling real-time inference crucial for dynamic agricultural scenarios. The pure Transformer model, ViT (ViT-B_16), demonstrates moderate efficiency at 120 FPS and 54.8 G FLOPs, reflecting the computational cost associated with its global self-attention mechanisms, which limits its applicability on resource-constrained edge devices. The proposed HAT-YOLOV8 model effectively balances accuracy and efficiency, achieving 220 FPS and 35.7 G FLOPs—surpassing ViT by 83% in FPS while reducing FLOPs by 35%. It maintains a reasonable computational overhead compared to YOLOv8s, with only a 35% increase in FLOPs for an 8.1% gain in mean Average Precision (mAP). This efficiency is attributed to the lightweight Shuffle Attention (SA) module in the backbone, which minimizes parameter increments while enhancing feature discriminability, as well as the Hybrid Attention Transformer (HAT) module, which employs overlapping window mechanisms to reduce the complexity of self-attention. Consequently, HAT-YOLOV8 outperforms CNN-based methods in accuracy without compromising speed, and it surpasses pure Transformers in computational efficiency, making it ideally suited for real-time applications in agricultural automation, such as robotic harvesting, where low latency and energy-efficient inference are essential.
As shown in Fig. 5, a comparison is made among the HAT-YOLOV8 model, the YOLOV8s model with the highest accuracy among CNN, and the Transformer (ViT) model using the mixed fruit dataset. The HAT-YOLOV8 (our method) also demonstrates the strongest detection capability.
Fig. 5.

Visualization of Detection Performance Comparison Among YOLOv8s, VIT, and HAT-YOLOv8 on Mixed Fruit Dataset. Shows a visualization of the detection performance of three models: YOLOv8s (CNN-based), VIT (Transformer-based), and the proposed HAT-YOLOv8. The subplots display representative detection results, including bounding boxes with confidence scores. HAT-YOLOv8 demonstrates exceptional detection capabilities, achieving tighter bounding box alignment with fruit contours compared to YOLOv8s and VIT, along with higher confidence scores for correctly classified instances and fewer false negatives and positives.
As illustrated in Fig. 6, the fluctuations of the loss function and accuracy function during the model training process are compared. Additionally, the three methods that demonstrate the best performance (YOLOV8s, ViT, and HAT-YOLOV8) are selected for a comparative analysis over 100 training epochs. The results indicate that HAT-YOLOV8 outperforms the other methods.
Fig. 6.

Comparison of Convergence, Loss, and Accuracy Across Models. Shows that our HAT-YOLOV8 model surpasses the other models in convergence, loss function, and accuracy. Notably, the Transformer-based methods ViT and HAT-YOLOV8 are closer in box loss.
Confusion matrix analysis
The confusion matrix reflects the degree of confusion and mispredictions by the algorithm on similar classes. In this experiment, five different types of fruits (grape, strawberry, apple, persimmon, and banana) were selected. Each type of fruit was further categorized into three maturity levels (high, medium, and low), resulting in 15 distinct classes. Among the comparison methods, which include three CNN-based approaches (SSD, Faster R-CNN, and YOLOV8s), YOLOV8s, which exhibited the best performance, was chosen for comparative analysis alongside the transformer-based method ViT and the proposed method. As shown in Fig. 7, darker colors indicate a higher percentage of predictions for the corresponding class. The true labels are placed on the x-axis, while the predicted labels are on the y-axis. It is observed that CNN-based methods (Fig. 7a) tend to have more misclassified predictions compared with transformer-based methods (Fig. 7b-c). Among all methods, the proposed method (Fig. 7c) demonstrates the best predictive capability.
Fig. 7.

Confusion Matrices of Ripeness Levels for Five Fruits Across Models. Confusion matrices for the ripeness levels of five different fruits are presented as follows: (a) YOLOv8s model, (b) ViT model, and (c) HAT-YOLOv8 model. H, M, and L denote ripe, medium, and unripe.
Ablation study
An ablation study was conducted on the HAT-YOLOV8 model. The HAT-YOLOV8 model utilizes YOLOV8s as its baseline and consists of the Shuffle Attention (SA) module, Hybrid Attention Transformer (HAT) module, and EIoU module. In the ablation study, each component was systematically examined individually, with the performance of each module assessed using the mean Average Precision (mAP) as the evaluation metric. The results of the ablation experiments are presented in Table 2.
Table 2.
Each module ablation study.
| Methods | Baseline | SA | HAT | EIoU | mAP (%) |
|---|---|---|---|---|---|
| YOLOV8s | ✓ | 81.3 | |||
| YOLOV8 + SA | ✓ | ✓ | 86.5 | ||
| YOLOV8 + HAT | ✓ | ✓ | 87.8 | ||
| YOLOV8 + EIoU | ✓ | ✓ | 83.6 | ||
| HAT-YOLOV8 | ✓ | ✓ | ✓ | ✓ | 88.9 |
Experimental results reveal that, in terms of their impact on enhancing model accuracy, the modules can be ranked in descending order of significance as follows: the Hybrid Attention Transformer (HAT) module, the Shuffle Attention (SA) module, and the EIoU module. This finding is in alignment with our initial expectations. The Hybrid Attention Transformer (HAT) module serves predominantly as a backbone for feature extraction, proficiently capturing consistent and core information during fruit ripeness image recognition. This is achieved by employing a shifted window approach to delve deeply into the intricate semantic relationships embedded within fruit images. Consequently, it effectively extracts invariant core features of fruit ripeness images while concurrently enhancing the super-resolution performance of the images. This underscores the advantageous integration of YOLOV8s with the Hybrid Attention Transformer (HAT), a conclusion that is further corroborated by ablation experimental results.
Furthermore, the integration of the Shuffle Attention (SA) module into the backbone network effectively combines spatial and channel attention mechanisms. These two attention mechanisms are utilized to capture pixel-level pairwise relationships and channel dependencies, respectively. By concurrently focusing on feature dependencies in both spatial and channel dimensions, the SA module is capable of comprehensively capturing the feature information present in the input data.
Lastly, the EIoU module also demonstrated its efficacy in boosting model accuracy. In comparison to the YOLOV8s baseline model, the inclusion of the three modules in our proposed model resulted in an improvement in accuracy by 5.2%, 6.5%, and 2.3% for the fruit ripeness dataset, respectively. Ultimately, the HAT-YOLOv8 model achieved an impressive accuracy of 88.9%.
Visualization
To enhance the comprehensibility of the HAT-YOLOV8 algorithm, a visualization initiative was undertaken. By employing ScoreCAM47, the nuanced intricacies of the neural network were elucidated. Figure 8 illustrates the ScoreCAM heatmap visualizations, which delineate the salient regions of interest within the input imagery. A selection of five distinct fruits (grape, strawberry, apple, persimmon, and banana) was curated, with each fruit accompanied by a corresponding heatmap and object detection outcome for comparative analysis. The evaluation encompassed four methodologies: YOLOV8s, ViT, and HAT-YOLOV8 (the proposed method).
Fig. 8.

Heatmap Comparison of Representative Methods for Fruit Detection. Heatmap comparison among several representative methods is presented, showcasing the results of three distinct approaches: YOLOv8s, ViT, and HAT-YOLOv8 (our method).
In Fig. 8, a comparative examination of the heatmaps and detection results elucidates that, with respect to the delineation of salient features, transformer-architected algorithms (ViT and HAT-YOLOV8) surpass their convolutional neural network (CNN) counterparts (YOLOV8s). The CNN-based methods (YOLOV8s) manifest a wider purview of feature detection, yet they display diminished proficiency in the precise localization of essential features. Conversely, transformer-based approaches, by refining the detection perimeter, augment the discernment of pivotal features, with HAT-YOLOV8 exhibiting a higher degree of accuracy in this domain compared to ViT. Notably, HAT-YOLOV8 excels in the identification of the apical, median, basal, and marginal regions of fruits as critical features. Among the methodologies assessed, HAT-YOLOV8 stands out for its superior capability in feature identification, boasting a detection accuracy that surpasses that of other techniques.
Conclusion
This work presents a novel algorithm called HAT-YOLOV8 for fruit ripening detection, which consists of three modules: the Shuffle Attention (SA) module, the Hybrid Attention Transformer (HAT) module, and the EIoU module. The SA module is designed to capture information on characteristics more comprehensively from the input data. The HAT module utilizes a shifted window scheme to achieve the capability of capturing constant and essential information, delving deeply into the large semantic relationships present in fruit ripening images, while simultaneously enhancing the super-resolution performance of the images. To further optimize the effectiveness of detection, the EIoU module serves as a regression loss function.
To evaluate the validity and generalization of the HAT-YOLOV8 model, a dataset of mixed fruit maturity levels was employed. The experimental results demonstrate the remarkable ability of this method to detect invariant features in fruit samples and highlight its significant advantage in achieving accurate localization. Given the impressive results obtained by HAT-YOLOV8, it is suggested that invariant-based learning methods possess a unique competitive advantage and considerable potential for further development in the field of fruit ripening. Future plans include the development of lightweight and video versions of the algorithm to enhance its effectiveness in practical scenarios, thereby supporting the widespread adoption and advancement of fruit ripening technology.
Electronic supplementary material
Below is the link to the electronic supplementary material.
Acknowledgements
The authors would like to thank the editors and reviewers for their valuable work.
Author contributions
Jianyin Tang: Conceptualization, Methodology, Software, Writing—original draft. Zhenglin Yu: Supervision, Writing—review & editing. Changshun Sao: Data curation, Visualization. All authors reviewed the results and approved the final version of the manuscript.
Funding
The Basic Research Project of Science and Technology Department of Jilin Province, China under the Grant no 202002044JC.
Data availability
Data is provided within the manuscript or supplementary information files.
Declaration
Competing interests
The authors declare no competing interests.
Footnotes
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
References
- 1.Zhang, Y., Li, X., Wang, J. & Liu, H. Deep learning-based fruit ripeness detection using color and texture features under natural conditions. Comput. Electron. Agric.214, 107823. 10.1016/j.compag.2023.107823 (2023).
- 2.Chen, H. C. et al. AlexNet convolutional neural network for disease detection and classification of tomato leaf. Electronics11, 17. 10.3390/electronics11060951 (2022). [Google Scholar]
- 3.Thakur, P. S., Sheorey, T. & Ojha, A. VGG-ICNN: A Lightweight CNN model for crop disease identification. Multim. Tool Appl.82, 497–520. 10.1007/s11042-022-13144-z (2023). [Google Scholar]
- 4.Yang, L. et al. GoogLeNet based on residual network and attention mechanism identification of rice leaf diseases. Comput. Electron. Agric.204, 11. 10.1016/j.compag.2022.107543 (2023). [Google Scholar]
- 5.Yang, N., Zhang, Z. K., Yang, J. H., Hong, Z. L. & Shi, J. A Convolutional Neural Network of GoogLeNet Applied in Mineral Prospectivity Prediction Based on Multi-source Geoinformation. Nat. Resour. Res.30, 3905–3923. 10.1007/s11053-021-09934-1 (2021). [Google Scholar]
- 6.Zhu, X. H. et al. Automatic detection and classification of dead nematode-infested pine wood in stages based on YOLO v4 and GoogLeNet. Forests14, 19. 10.3390/f14030601 (2023). [Google Scholar]
- 7.Shaheed, K. et al. EfficientRMT-net-an efficient ResNet-50 and vision transformers approach for classifying potato plant leaf diseases. Sensors23, 28. 10.3390/s23239516 (2023). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 8.Zhang, L. et al. AM-ResNet: Low-energy-consumption addition-multiplication hybrid ResNet for pest recognition. Comput. Electron. Agric.202, 13. 10.1016/j.compag.2022.107357 (2022). [Google Scholar]
- 9.Girshick, R. & IEEE. Fast R-CNN. in IEEE International Conference on Computer Vision. pp 1440–1448. 10.1109/iccv.2015.169 (2015).
- 10.Qin, H. et al. An improved faster R-CNN method for landslide detection in remote sensing images. J. Geovisual. Spat. Anal.8, 17. 10.1007/s41651-023-00163-z (2024). [Google Scholar]
- 11.Li, J. J., Zhu, Z. F., Liu, H. X., Su, Y. R. & Deng, L. M. Strawberry R-CNN: Recognition and counting model of strawberry based on improved faster R-CNN. Eco. Inform.77, 15. 10.1016/j.ecoinf.2023.102210 (2023). [Google Scholar]
- 12.Shiu, Y. S., Lee, R. Y. & Chang, Y. C. Pineapples’ detection and segmentation based on faster and mask R-CNN in UAV imagery. Remote Sens.15, 20. 10.3390/rs15030814 (2023). [Google Scholar]
- 13.Firat, H., Asker, M. E., Bayindir, M. I. & Hanbay, D. Hybrid 3D/2D complete inception module and convolutional neural network for hyperspectral remote sensing image classification. Neural Process. Lett.55, 1087–1130. 10.1007/s11063-022-10929-z (2023). [Google Scholar]
- 14.Badgujar, C. M., Poulose, A. & Gan, H. Agricultural object detection with You Only Look Once (YOLO) Algorithm: A bibliometric and systematic literature review. Comput. Electron. Agric.223, 18. 10.1016/j.compag.2024.109090 (2024). [Google Scholar]
- 15.Li, R. J. et al. Lightweight network for corn leaf disease identification based on improved YOLO v8s. Agricult. -Basel14, 17. 10.3390/agriculture14020220 (2024). [Google Scholar]
- 16.Yang, H. et al. YOLO-SDW: A method for detecting infection in corn leaves. Energy Rep.12, 6102–6111. 10.1016/j.egyr.2024.11.072 (2024). [Google Scholar]
- 17.Chen, D., Zhao, H. D., Li, Y. Q., Zhang, Z. T. & Zhang, K. PMF-YOLOv8: Enhanced ship detection model in remote sensing images. Inform. Technol. Control53, 334. 10.5755/j01.itc.53.4.37003 (2024). [Google Scholar]
- 18.Tian, L. L. et al. VMF-SSD: A novel V-space based multi-scale feature fusion SSD for apple leaf disease detection. IEEE-ACM Trans. Comput. Biol. Bioinform.20, 2016–2028. 10.1109/tcbb.2022.3229114 (2023). [DOI] [PubMed] [Google Scholar]
- 19.Jiang, J. L., Xu, H. X., Xu, X. L., Cui, Y. & Wu, J. T. Transformer-based fused attention combined with CNNs for image classification. Neural Process. Lett.55, 11905–11919. 10.1007/s11063-023-11402-1 (2023). [Google Scholar]
- 20.Carion, N., F. Massa, G. Synnaeve, N. Usunier, A. Kirillov, & S. Zagoruyko. End-to-end object detection with transformers. in European conference on computer vision. pp 213–229. https://link.springer.com/chapter/10.1007/978-3-030-58452-8_13 (2020).
- 21.Dosovitskiy, A., L. Beyer, A. Kolesnikov, D. Weissenborn, X. Zhai, T. Unterthiner, M. Dehghani, M. Minderer, G. Heigold, and S. Gelly, (2020) An image is worth 16x16 words: Transformers for image recognition at scale. arXiv preprint arXiv:2010.11929. https://arxiv.org/pdf/2010.11929/1000
- 22.Alshawabkeh, S., Wu, L., Dong, D., Cheng, Y. & Li, L. A hybrid approach for pavement crack detection using mask R-CNN and vision transformer model. Comput, Mater Continua.10.32604/cmc.2024.057213 (2025). [Google Scholar]
- 23.Xue, F., Q. Wang, & G. Guo. Transfer: Learning relation-aware facial expression representations with transformers. in Proceedings of the IEEE/CVF International Conference on Computer Vision. pp 3601–3610. 10.1109/ICCV48922.2021.00358 (2021).
- 24.Liu, Z., Y. Lin, Y. Cao, H. Hu, Y. Wei, Z. Zhang, S. Lin, & B. Guo Swin transformer: Hierarchical vision transformer using shifted windows. in Proceedings of the IEEE/CVF international conference on computer vision. pp 10012–10022. 10.1109/ICCV48922.2021.00986 (2021).
- 25.Xu, X. et al. An improved swin transformer-based model for remote sensing object detection and instance segmentation. Remote Sens.13, 4779. 10.3390/rs13234779 (2021). [Google Scholar]
- 26.Pan, Z. et al. Picking point identification and localization method based on swin-transformer for high-quality tea. J. King Saud Univer. –Comput. Inform. Sci.36, 102262. 10.1016/j.jksuci.2024.102262 (2024). [Google Scholar]
- 27.Ren, S. Q., He, K. M., Girshick, R. & Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. IEEE Trans. Patt. Anal. Mach. Intell.39, 1137–1149. 10.1109/tpami.2016.2577031 (2017). [DOI] [PubMed] [Google Scholar]
- 28.Lin, T.-Y., P. Dollár, R. Girshick, K. He, B. Hariharan, & S. Belongie Feature pyramid networks for object detection. in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. pp 2117–2125 (2017).
- 29.Deng, C. F., Wang, M. M., Liu, L., Liu, Y. & Jiang, Y. L. Extended feature pyramid network for small object detection. IEEE Trans. Multim.24, 1968–1979. 10.1109/tmm.2021.3074273 (2022). [Google Scholar]
- 30.Li, B. et al. Gene expression prediction from histology images via hypergraph neural networks. Brief. Bioinform.25, 1500. 10.1093/bib/bbae500 (2024). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 31.Liu, X. et al. DrugFormer: Graph-enhanced language model to predict drug sensitivity. Adv. Sci.11, 2405861. 10.1002/advs.202405861 (2024). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 32.Chen, J. H., Wu, P., Zhang, X. M., Xu, R. J. & Liang, J. Add-Vit: CNN-Transformer hybrid architecture for small data paradigm processing. Neural Process. Lett.56, 17. 10.1007/s11063-024-11643-8 (2024). [Google Scholar]
- 33.Li, Z., Li, C. F., Guan, T. X. & Shang, S. P. Underwater object detection based on improved transformer and attentional supervised fusion. Inform. Technol. Control52, 397–415. 10.5755/j01.itc.52.2.33214 (2023). [Google Scholar]
- 34.Xiao, B. J., Nguyen, M. & Yan, W. Q. Fruit ripeness identification using transformers. Appl. Intell.53, 22488–22499. 10.1007/s10489-023-04799-8 (2023). [Google Scholar]
- 35.Loarca, J. et al. BerryPortraits: phenotyping of ripening traits cranberry (Vaccinium macrocarpon Ait) with YOLOv8. Plant Methods20, 19. 10.1186/s13007-024-01285-1 (2024). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 36.Niu, B., W. Wen, W. Ren, X. Zhang, L. Yang, S. Wang, K. Zhang, X. Cao, & H. Shen. Correction to: Single image super-resolution via a holistic attention network. in Computer Vision – ECCV 2020. pp C1-C1 (2020).
- 37.Zhang, K., Zuo, W. M. & Zhang, L. FFDNet: Toward a fast and flexible solution for CNN-Based image denoising. IEEE Trans. Image Process.27, 4608–4622. 10.1109/tip.2018.2839891 (2018). [DOI] [PubMed] [Google Scholar]
- 38.Shi, W., J. Caballero, F. Huszár, J. Totz, A.P. Aitken, R. Bishop, D. Rueckert, & Z. Wang Real-time single image and video super-resolution using an efficient sub-pixel convolutional neural network. in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. pp 1874–1883. 10.1109/CVPR.2016.207 (2016).
- 39.Wu, B., C. Xu, X. Dai, A. Wan, P. Zhang, Z. Yan, M. Tomizuka, J. Gonzalez, K. Keutzer, & Vajda, P. Visual transformers: Token-based image representation and processing for computer vision (2020). arXiv preprint arXiv:2006.03677. https://arxiv.org/abs/2006.03677 (2006).
- 40.Cao, H., Y. Wang, J. Chen, D. Jiang, X. Zhang, Q. Tian, and M. Wang,(2022) Swin-unet: Unet-like pure transformer for medical image segmentation. in European conference on computer vision. https://link.springer.com/chapter/10.1007/978-3-031-25066-8_9 pp 205–218
- 41.Zhang, Y., Tian, Y., Kong, Y., Zhong, B. & Y. Fu. Residual dense network for image super-resolution. in Proceedings of the IEEE conference on computer vision and pattern recognition. pp 2472–2481. 10.48550/arXiv.1802.08797 (2018).
- 42.Liu, D., B. Wen, Y. Fan, C.C. Loy, & T.S. Huang. Non-local recurrent network for image restoration. Advances in neural information processing systems 31 (2018).
- 43.Niu, B., Wen, W., Ren, W., Zhang, X., Yang, L., Wang, S., Zhang, K., Cao, X. & H. Shen. Single image super-resolution via a holistic attention network. in Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, August 23–28, Proceedings, Part XII 16. pp 191–207. 10.1007/978-3-030-58610-2_47 (2020).
- 44.Zhang, Y.-F. et al. Focal and efficient IOU loss for accurate bounding box regression. Neurocomputing506, 146–157. 10.1016/j.neucom.2022.07.042 (2022). [Google Scholar]
- 45.Qi, W., Chen, H., Ye, Y., & G. Yu. Indoor object recognition based on YOLOv5 with EIOU loss function. in Third International Conference on Advanced Algorithms and Signal Image Processing (AASIP 2023). pp 880–885. 10.1117/12.3005836 (2023).
- 46.Du, S., Zhang, B., Zhang, P., & P. Xiang. An improved bounding box regression loss function based on CIOU loss for multi-scale object detection. in 2021 IEEE 2nd International Conference on Pattern Recognition and Machine Learning (PRML). pp 92–98. 10.1109/PRML52754.2021.9520717 (2021).
- 47.Wang, H., Wang, Z., Du, M., Yang, F., Zhang, Z., Ding, S., Mardziel, P. & X. Hu. Score-CAM: Score-weighted visual explanations for convolutional neural networks. in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops. pp 24–25. 10.1109/CVPRW50498.2020.00020 (2020).
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.
Supplementary Materials
Data Availability Statement
Data is provided within the manuscript or supplementary information files.