

Abstract
To address misdiagnosis caused by feature coupling in multi-label medical image classification, this study introduces a chest X-ray pathology reasoning method. It combines hierarchical attention convolutional networks with a multi-label decoupling loss function. This method aims to enhance the precise identification of complex lesions. It dynamically captures multi-scale lesion morphological features and integrates lung field partitioning with lesion localization through a dual-path attention mechanism, thereby improving clinical disease prediction accuracy. An adaptive dilated convolution module with 3 × 3 deformable kernels dynamically captures multi-scale lesion features. A channel-space dual-path attention mechanism enables precise feature selection for lung field partitioning and lesion localization. Cross-scale skip connections fuse shallow texture and deep semantic information, enhancing microlesion detection. A KL divergence-constrained contrastive loss function decouples 14 pathological feature representations via orthogonal regularization, effectively resolving multi-label coupling. Experiments on ChestX-ray14 show a weighted F1-score of 0.97, Hamming Loss of 0.086, and AUC values exceeding 0.94 for all pathologies. This study provides a reliable tool for multi-disease collaborative diagnosis.
Keywords: Medical image analysis, Convolutional neural network, Hierarchical attention mechanism, Multi-label decoupling, Chest X-ray imaging
Introduction
As the core technical support for clinical diagnosis, medical image analysis has gradually demonstrated its application potential in the fields of early disease prediction and automated diagnosis. With the coordinated development of medical imaging and computer vision technology, data-driven model prediction methods have become the core paradigm of medical image processing [1–3], but existing analysis methods have limitations such as high misdiagnosis rate and low processing efficiency when processing complex multimodal image data [4, 5]. Recently, various types of convolutional neural networks [6–8] have become the mainstream technology in this field due to their efficient learning capabilities for features. However, in multi-label classification scenarios, the high coupling of pathological features is still a key challenge that restricts the classification performance of the model [9, 10]. A typical manifestation of this is the co-occurrence of multiple disease features in the same image, which causes feature space confusion [11–13] and seriously restricts classification accuracy. How to establish an effective feature decoupling mechanism to improve multi-label classification accuracy has become a key scientific issue that needs to be broken through in the field of medical analysis.
In response to the challenge of disease feature coupling in multi-label classification of medical images, existing methods still have limitations in model architecture and label association modeling. Among them, the CheXNet model uses a 121-layer DenseNet for single-label classification of chest X-rays. Although it has made breakthroughs in pneumonia detection, it does not consider the complex associations between multiple labels, resulting in limited recognition accuracy of co-occurring diseases [14, 15]. MA-CNN (Multi-Attention Convolutional Neural Network) [16, 17] locates different lesion areas through parallel attention modules. Although it improves the ability to extract local features, its independent attention mechanism ignores the hierarchical associations between diseases and is prone to attention confusion in complex cases [18, 19]. ML-GCN (Multi-Label Graph Convolutional Network) attempts to construct a label correlation graph structure, but the graph convolution mechanism based on predefined label co-occurrence probabilities often lacks dynamic adaptation to image spatial features [20–22], resulting in insufficient decoupling of fine-grained features.
This paper applies a hierarchical attention convolutional network based on multimodal feature decoupling, aiming to improve the extraction and recognition capabilities of lesion features in medical images. First, a new hierarchical attention mechanism is designed. By dynamically weighting the lesion area in the chest X-ray image, the focus on key lesions is increased, and the mutual influence with other disease features is reduced. Secondly, a new multi-label decoupling loss function is applied to strengthen the independence between labels and avoid excessive coupling between disease features. Through experimental verification, this method has achieved significant performance improvement in disease prediction in chest X-ray images. The main research results are: (a) an adaptive dilated convolution module and hierarchical attention mechanism are designed. Through a four-branch parallel structure and a dynamic channel attention mechanism, the precise extraction and fusion of multi-scale lesion features are realized, and the recognition capability of lung lesion features is enhanced. (b) A bidirectional interactive feature pyramid architecture is applied, and the geometric deformation compensation and effective fusion of cross-scale feature maps are realized by using a deformable offset field prediction network combined with bilinear upsampling technology. (c) A joint optimization framework of the contrast loss function based on KL divergence constraint and the feature orthogonal penalty term is constructed to effectively decouple the pathological feature representation space and improve the independent representation ability and overall performance of the model in multi-label classification tasks.
Related work
Recent research has made some progress in the direction of feature decoupling, but there are still defects. For example, the CS-Net (Contrast-Separation Network) proposed by Li Yang [23] et al. separated lesion features through contrast learning, but its feature space separation strategy lacked clinical prior constraints and was prone to erroneous decoupling in overlapping areas of image anatomical structures. The MRChexNet (Multi-modal bridge and Relational learning for thoracic disease recognition in Chest X-rays Network) proposed by Wang Guoli [24] et al. used a dual-path architecture to process global and local features respectively. Although it alleviates the problem of feature coupling, the rigid separation of the two paths breaks the pathological association between lesions [25–27], reducing the diagnostic efficiency of systemic diseases. Existing methods generally face a dilemma [28, 29]: over-emphasizing feature independence loses pathological association information, while simply modeling label correlation aggravates feature coupling. Although the graph convolution layer of ML-GCN captures label co-occurrence, it does not establish a decoupling mechanism at the feature level [30, 31]; the feature decoupling of CS-Net lacks effective use of label semantic relations, resulting in limited generalization ability of the model in complex multi-label scenarios [32, 33]. The core limitations of current methods are reflected in three aspects. (a) Insufficient synergy between attention mechanism and feature decoupling: models such as MA-CNN only implement spatial attention but do not establish decoupling at the feature channel level [34, 35]. (b) Separation of label association modeling and feature expression: ML-GCN constructs label maps alone without dynamically interacting with visual features [36, 37]. (c) Lack of medical interpretability of the decoupling process: feature separation similar to CS-Net methods lacks anatomical and pathological basis [38]. Such problems result in the confusion error of existing models for morphologically similar diseases such as pneumonia and atelectasis still being higher than the clinically acceptable threshold on large multi-label datasets such as ChestX-ray14. In multi-label classification tasks for medical images, the coexistence of multiple disease features within the same image often leads to feature space confusion and reduced classification performance. To tackle this challenge, this study introduces a collaborative reasoning approach that leverages a hierarchical attention mechanism and a decoupling loss function with orthogonal constraints, effectively separating pathological feature representations to mitigate the impact of feature coupling and support multi-disease joint diagnosis.
In the field of medical image analysis, although Transformer-based models proposed by Huang Pan et al. (such as ViT-AMC in [39] with adaptive multimodal fusion and optimization, MamlFormer in [40] utilizing manifold adversarial multimodal learning, LA-ViT in [41] with parameter-free attention constraints, and FDTs in [42] employing feature disentanglement mechanisms) have demonstrated excellent performance in laryngeal tumor grading tasks, this study opts for a convolutional neural network (CNN) as the core architecture based on the following considerations: The local receptive field characteristics of CNNs are naturally suited to the morphological distribution of lesions in chest X-ray images. Its dynamic dilated convolution module can precisely cover lesion ranges from small nodules to large areas of consolidation through multi-scale sampling, whereas the global attention mechanism of Transformers tends to overlook critical local details (e.g. [41], requires additional design of anatomical constraint modules). Moreover, while FDTs in [42] enhance interpretability through feature disentanglement, their complex positional encoding and high-dimensional interactions result in significantly higher computational costs compared to CNNs (e.g. [39], requires multimodal data fusion), making it challenging to meet real-time clinical deployment needs. In contrast, the hierarchical attention mechanism designed in this paper achieves synergistic improvements in pathological feature disentanglement and micro-lesion recognition within a lightweight architecture through dual-path collaboration of lung field partitioning and lesion localization (channel-spatial gating combined with cross-scale fusion), providing a more practical solution for multi-label clinical diagnosis.
The multi-label chest X-ray classification method proposed in this paper, based on hierarchical attention and feature disentanglement, employs a convolutional neural network (CNN) as its foundational architecture, primarily due to its unique advantages in medical image analysis. Compared to traditional shallow models such as deep forests, CNNs offer stronger end-to-end modeling capabilities, enabling the direct learning of discriminative features from raw pixels and thereby reducing information loss and manual intervention caused by handcrafted feature design. Although the method in [43] achieved certain breakthroughs in feature fusion, it still relies on manually extracted input features, making it difficult to fully capture the complex pathological relationships present in X-ray images. Furthermore, the adaptive dilated convolution and dual-path attention mechanism introduced in this study allow the model to dynamically focus on critical lesion regions and enhance the representation of subtle abnormalities. Simultaneously, the contrastive loss function constrained by KL divergence effectively alleviates the problem of multi-label coupling, significantly improving the model’s robustness and generalization ability in complex clinical scenarios.
Hierarchical attention convolution network based on multimodal feature decoupling
The collaborative reasoning method proposed in this study achieves precise parsing of chest X-ray pathological features through a multi-module collaborative working mechanism. Its core architecture comprises four technically synergistic components:
1) The adaptive dilated convolution module adopts a four-branch parallel structure, dynamically capturing multi-scale morphological features of lesions using 3 × 3 deformable convolution kernels with varying dilation rates. Combined with a dynamic channel attention mechanism, it realizes adaptive allocation of feature weights to form scale-specific feature representations.
2) The hierarchical attention mechanism employs a dual-path architecture for lung field partitioning and lesion localization. It enhances the feature representation of lung field regions through anatomy-guided spatial attention modules, while achieving precise lesion localization via a channel-space collaborative attention mechanism. The lung field partition attention adjusts sampling positions using deformable convolution to adapt to anatomical structural changes, whereas lesion localization attention extracts cross-channel spatial relationships through depthwise separable convolution and dynamically fuses dual-path features via gating mechanisms.
3) The cross-scale feature fusion module constructs a bidirectional interactive pyramid architecture, correcting spatial alignment deviations of features at different levels using a deformable offset field prediction network. It dynamically weights and fuses shallow texture and deep semantic information through energy entropy, enhancing context-aware capabilities by incorporating multi-scale dilated convolutions.
4) The multi-label decoupling loss function optimizes collaboratively through contrastive loss constrained by KL divergence and feature orthogonal penalty terms. The former builds a dynamic competition mechanism between samples based on cosine similarity, while the latter enforces feature vector orthogonalization through Frobenius norm constraints of the covariance matrix, thereby achieving decoupling of pathological categories at the feature space level.
These four modules form a closed-loop reasoning system through the cascaded transmission of feature flows and joint optimization of loss functions: Multi-scale features extracted by dilated convolution are filtered via the attention mechanism, then passed through the cross-scale fusion module to construct spatial-semantic consistent feature representations. Ultimately, under the constraint of decoupling loss, independent and discriminative pathological feature expressions are formed to address the issue of feature coupling in multi-label classification.
Design of adaptive dilated Convolution module
The four-branch parallel structure shown in Fig. 1 is used to realize multi-scale lesion feature extraction. Each branch deploys a 3 × 3 deformable convolution kernel, and its dilation rate is configured as d={1,3,5,7} according to an arithmetic progression. The convolution kernel offset is generated by regression through a pre-1 × 1 convolution layer. The offset field is constrained to the range of [-5,5] pixels. Bilinear interpolation is used to achieve the continuity of coordinate mapping. The offset gradient calculation formula is:
 |
1 |
Fig. 1.

Adaptive dilated convolution module
Among them, 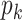 is the coordinate of the deformable convolution kernel sampling point, and (Δx,Δy) represents the interpolation weight coefficient.
is the coordinate of the deformable convolution kernel sampling point, and (Δx,Δy) represents the interpolation weight coefficient.
For the problem of multi-scale feature fusion, a dynamic channel attention mechanism is designed. After the output feature  of each branch is globally averaged and pooled, the branch weight vector
of each branch is globally averaged and pooled, the branch weight vector  is generated through two fully connected layers:
is generated through two fully connected layers:
 |
2 |
Among them,  are learnable parameter matrices. The weighted fusion process is expressed as:
are learnable parameter matrices. The weighted fusion process is expressed as:
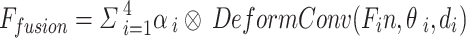 |
3 |
Among them, 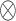 represents the channel-by-channel product, and
represents the channel-by-channel product, and  is the convolution kernel parameter of the i-th branch. To enhance scale specificity, a hierarchical reorganized feature pyramid is constructed. The fused feature
is the convolution kernel parameter of the i-th branch. To enhance scale specificity, a hierarchical reorganized feature pyramid is constructed. The fused feature 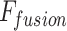 is split into four groups
is split into four groups  along the channel dimension, and each group performs
along the channel dimension, and each group performs  times downsampling (j = 1,2,3,4). The improved sub-pixel convolution is used to achieve resolution reconstruction, and its pixel shuffling factor
times downsampling (j = 1,2,3,4). The improved sub-pixel convolution is used to achieve resolution reconstruction, and its pixel shuffling factor 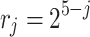 reorganization process is described as:
reorganization process is described as:
 |
4 |
Among them,  represents the pixel shuffling operation. The reorganized multi-scale features are compressed to the original number of channels by 3 × 3 convolution, and the output is
represents the pixel shuffling operation. The reorganized multi-scale features are compressed to the original number of channels by 3 × 3 convolution, and the output is 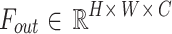 . A dual optimization strategy is adopted in the training stage: (1) the offset learning uses the Huber loss constraint, δ = 1.0; (2) feature decoupling is achieved through orthogonal regularization terms:
. A dual optimization strategy is adopted in the training stage: (1) the offset learning uses the Huber loss constraint, δ = 1.0; (2) feature decoupling is achieved through orthogonal regularization terms:
 |
5 |
Among them, 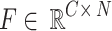 is the feature matrix, and λ = 0.01 is the balance coefficient. Gradient truncation is implemented during back propagation, and normalization is performed when the offset gradient norm
is the feature matrix, and λ = 0.01 is the balance coefficient. Gradient truncation is implemented during back propagation, and normalization is performed when the offset gradient norm  :
:
 |
6 |
The optimizer uses AdamW, and the parameter update formula is:
 |
7 |
Among them, 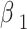 =0.9;
=0.9; 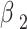 =0.999; initial learning rate
=0.999; initial learning rate  =3e-4; cosine annealing period T=100 epoch. Figure 2 shows the feature visualization results of the deformable convolution kernel in the lung area, which can be seen that it can effectively fit the feature edge to improve the coverage of multi-scale feature information.
=3e-4; cosine annealing period T=100 epoch. Figure 2 shows the feature visualization results of the deformable convolution kernel in the lung area, which can be seen that it can effectively fit the feature edge to improve the coverage of multi-scale feature information.
Fig. 2.

Feature visualization of deformable convolution kernel in the lung region
Implementation of hierarchical attention mechanism
The hierarchical attention mechanism in this study consists of a two-stage feature selection architecture consisting of lung field partition attention and lesion localization attention. On the input feature map  , the feature expression of the target region is first enhanced by the anatomically guided lung field partition attention module, and then the channel-space collaborative lesion localization attention mechanism is used to achieve pathological feature focusing. Based on the anatomical prior of the lung field region in medical images, a deformable convolution-guided spatial attention mechanism is designed:
, the feature expression of the target region is first enhanced by the anatomically guided lung field partition attention module, and then the channel-space collaborative lesion localization attention mechanism is used to achieve pathological feature focusing. Based on the anatomical prior of the lung field region in medical images, a deformable convolution-guided spatial attention mechanism is designed:
(1) The feature map output by the backbone network is input into the convolution layer to generate the deformation parameter  , and the convolution kernel sampling position is dynamically adjusted to adapt to the morphological variation of the lung field edge;
, and the convolution kernel sampling position is dynamically adjusted to adapt to the morphological variation of the lung field edge;
(2) The feature map is non-rigidly registered through the spatial transformation network, and the anatomically aligned feature map  is output;
is output;
(3) A gated spatial attention weight matrix  is constructed, and the calculation process is:
is constructed, and the calculation process is:
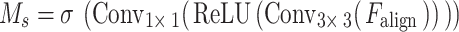 |
8 |
Among them,  is the sigmoid function;
is the sigmoid function;  extracts local spatial correlation;
extracts local spatial correlation;  compresses the channel dimension;
compresses the channel dimension;
(4) Feature selection is achieved through element-by-element multiplication:
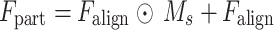 |
9 |
The residual connection retains the original feature distribution and avoids gradient disappearance. Based on the lung field partition feature  , a dual-path parallel attention mechanism is designed to capture channel dependency and spatial saliency respectively. Based on the improved SE module, two layers of fully connected layers are used to generate channel weight vectors:
, a dual-path parallel attention mechanism is designed to capture channel dependency and spatial saliency respectively. Based on the improved SE module, two layers of fully connected layers are used to generate channel weight vectors:
 |
10 |
 |
11 |
Among them, 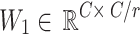 and
and  are learnable parameters, and the compression ratio is
are learnable parameters, and the compression ratio is 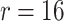 . The channel recalibration feature is calculated as:
. The channel recalibration feature is calculated as:
 |
12 |
Deep separable convolution is used to extract cross-channel spatial relationships:
 |
13 |
Here,  is a deep separable convolution, which reduces the number of parameters while maintaining spatial modeling capabilities. The spatial enhancement feature is calculated as:
is a deep separable convolution, which reduces the number of parameters while maintaining spatial modeling capabilities. The spatial enhancement feature is calculated as: 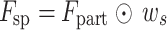 , and a learnable gating mechanism is applied to dynamically integrate channel and spatial attention features:
, and a learnable gating mechanism is applied to dynamically integrate channel and spatial attention features:
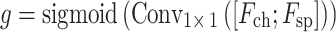 |
14 |
 |
15 |
Here,  represents channel dimension splicing, and the gating coefficient
represents channel dimension splicing, and the gating coefficient  adaptively adjusts the dual-path contribution ratio. At the same time, to enhance the complementarity of features between levels, a residual attention transmission path is established, and the spatial weight matrix
adaptively adjusts the dual-path contribution ratio. At the same time, to enhance the complementarity of features between levels, a residual attention transmission path is established, and the spatial weight matrix  of the lung field partition level is upsampled to the spatial resolution of the lesion localization level through bilinear interpolation, and the spatial attention weight
of the lung field partition level is upsampled to the spatial resolution of the lesion localization level through bilinear interpolation, and the spatial attention weight  of the lesion localization level is modulated across levels:
of the lesion localization level is modulated across levels:
 |
16 |
Based on this operation, the lesion localization attention is constrained to perform feature selection within the anatomical region determined by the lung field partition, reducing background interference. A staged optimization strategy is adopted to balance the hierarchical attention learning process, in which the parameters of the lung field partition module are fixed in the pre-training stage, and the parameter update of the lesion localization attention is only supervised by the cross-entropy loss; the fine-tuning stage jointly optimizes the two attention modules, and the gradient is calculated using the chain rule:
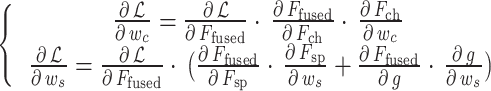 |
17 |
The final feature output layer splices the hierarchical attention feature  with the original feature
with the original feature  channel, and reshapes the features through 1 × 1 convolution, retaining the complete information flow while enhancing the discriminability. The dual attention module based on lung field partitioning and lesion localization achieves more refined regional feature recognition and fusion. The overall architecture is shown in Fig. 3.
channel, and reshapes the features through 1 × 1 convolution, retaining the complete information flow while enhancing the discriminability. The dual attention module based on lung field partitioning and lesion localization achieves more refined regional feature recognition and fusion. The overall architecture is shown in Fig. 3.
Fig. 3.

Feature fusion under dual attention module
First, anatomically guided regional attention information is extracted from the input feature map, and the sampling position is adaptively adjusted using deformable convolution to adapt to different structural morphologies. Then, the feature maps are aligned by non-rigid registration, and the feature expression of key areas is enhanced by spatial attention weights. Global average pooling and fully connected layers are used to calculate channel weights to achieve feature recalibration. At the same time, deep separable convolution is applied to calculate spatial weights to strengthen cross-channel spatial relationships. Channel and spatial features are dynamically fused after gated weight calculation. Spatial attention is adjusted by upsampling, and modulated across levels to optimize lesion localization. Finally, the fused features are processed by convolution to generate output. The feature visualization results under the hierarchical attention mechanism are shown in Fig. 4, demonstrating its ability to precisely focus on key regions.
Fig. 4.

Feature Visualization under the Hierarchical Attention Mechanism
Cross-scale feature fusion module
Based on the four-layer feature maps extracted from conv2_x to conv5_x by ResNet-50 network, bilinear upsampling operations are performed on the deep feature maps (conv4_x and conv5_x) to restore their spatial resolution to the same as the conv3_x layer (1/8 size of the original image). 1 × 1 convolution is used to unify the number of feature channels of each layer to 256, and channel-level L2 normalization is used to eliminate local feature distortion caused by the upsampling process. At the same time, to eliminate the feature space misalignment caused by the difference in convolution receptive field, an offset field prediction network is designed. For adjacent level feature pairs (conv2_x and conv3_x, conv3_x and conv4_x, conv4_x and conv5_x), a cascaded 3 × 3 convolution is used to generate an 18-channel offset tensor. Among them, the first 9 channels encode the coordinate offset of the feature sampling point, and the last 9 channels correspond to the weight coefficients of each sampling position.
The offset field is transferred to the corresponding resolution level through bilinear interpolation bias, and finally the feature map is geometrically compensated by deformable convolution. A bidirectional interactive feature pyramid architecture is constructed to realize the dynamic fusion of multi-scale features. In the bottom-up path, the corrected conv2_x’ to conv4_x’ feature maps are weighted summed element by element, and the weights are dynamically calculated by the energy entropy of the features at each level. In the top-down path, conv5_x’ is upsampled by 2 times and then concatenated with conv4_x’, and the effective features are screened through the gated attention mechanism. The gate coefficient is generated by a 1 × 1 convolution layer activated by a Sigmoid function, and its input is the concatenation of the features of the current layer and the adjacent layer. The final fusion feature retains 256 channels, and the resolution is maintained at 1/8 of the original image, taking into account both detail retention and semantic expression capabilities. The model parameter settings under the fusion module are shown in Table 1, and the recognition results of tiny features in clinical disease images are shown in Fig. 5.
Table 1.
Parameter configuration of cross-scale feature fusion module
| Layer | Operation Type | Input Resolution | Output Resolution | Channels | Key Parameters |
|---|---|---|---|---|---|
| conv4_x | Bilinear Upsampling + 1 × 1 Conv | 1/16 | 1/8 | 256 | Upsample ×2, L2 Normalization (ε = 1e-6) |
| conv5_x | Bilinear Upsampling + 1 × 1 Conv | 1/32 | 1/8 | 256 | Upsample ×4, L2 Normalization (ε = 1e-6) |
| conv2_x-3_x | Deformable Offset Field Prediction | 1/4 − 1/8 | 1/8 | 18 | Stacked 3 × 3 conv (k = 3, s = 1), ReLU |
| conv3_x-4_x | Deformable Offset Field Prediction | 1/8 − 1/16 | 1/8 | 18 | Stacked 3 × 3 conv (k = 3, s = 1), ReLU |
| conv4_x-5_x | Deformable Offset Field Prediction | 1/16 − 1/32 | 1/8 | 18 | Stacked 3 × 3 conv (k = 3, s = 1), ReLU |
| conv2_x’-4_x’ | Bottom-Up Weighted Fusion | 1/8 | 1/8 | 256 | Energy Entropy Dynamic Weighting |
| conv5_x’-4_x’ | Top-Down Gated Concatenation | 1/8 | 1/8 | 512→256 | 2× Upsample + 1 × 1 Conv (Sigmoid) |
| Output Feature | Multi-Scale Context Enhancement | 1/8 | 1/8 | 256 | Dilated Convs (r = 1,2,4) + Channel Attention |
Fig. 5.

Model for tiny feature recognition under shallow texture features
Table 1 shows the core parameter configuration of the cross-scale feature fusion module. This module unifies the deep features of conv4_x (1/16) and conv5_x (1/32) to 1/8 resolution (256 channels) through bilinear upsampling and 1 × 1 convolution, and eliminates feature distortion by combining L2 normalization. A deformable offset field prediction network is designed for adjacent level feature pairs (conv2_x-5_x), and cascaded 3 × 3 convolutions are used to generate 18-channel offset tensors (including coordinate offsets and weight coefficients). Cross-resolution geometric correction is achieved through bilinear interpolation. A bidirectional interactive pyramid architecture is constructed. The bottom-up path uses energy entropy dynamic weighted fusion to correct the conv2_x’-4_x’ features, and the top-down path upsamples conv5_x’ by 2 times and performs sigmoid gated splicing with conv4_x’. The final output features are enhanced by multi-scale dilated convolution (dilated ratio 1/2/4) and channel attention. As shown in Fig. 5, under the constructed skip connection architecture, the model can integrate shallow texture features and deep semantic features, effectively enhancing the recognition ability of tiny features.
Multi-label decoupling loss function
In multi-label classification tasks for medical images, lesion features are often highly coupled due to label co-occurrence relationships, making it difficult for models to distinguish between similar or overlapping pathological categories. The orthogonal regularization term introduces a Frobenius norm constraint on the covariance matrix, forcing the inner product between feature vectors of different categories to approach zero, thereby achieving orthogonality in the feature space. This mechanism effectively alleviates feature coupling issues, enabling each pathological feature to achieve higher independence in the embedding space. The covariance matrix C reflects the correlation distribution among feature vectors, and by diagonalizing to remove off-diagonal elements (i.e., eliminating redundant correlations between features), the model can focus on the unique representation ability of each pathology. Orthogonalization is particularly suitable for medical image analysis because lesion areas in chest X-ray images often exhibit complex overlapping and co-occurrence patterns. For example, infiltration and effusion frequently appear simultaneously. Without proper constraints, the model may mistakenly interpret these co-occurring features as representations of a single pathology, leading to misdiagnosis. Through the synergistic effect of orthogonal regularization and KL divergence constraints, the model achieves clear separation of pathological features in the embedding space, significantly improving performance in multi-label classification tasks.
In the specific implementation of the feature decoupling strategy, the study deeply integrates KL divergence constraints with feature orthogonalization mechanisms through a joint optimization framework. For the embedding space of 14 pathological features, the Frobenius norm constraint of the covariance matrix is first used to construct an orthogonal penalty term, forcing the inner product of feature vectors from different categories to approach zero, thereby eliminating redundant correlations between features. For each sample’s pathological feature matrix  , the sum of squares of the off-diagonal elements of its covariance matrix is calculated as the orthogonal loss
, the sum of squares of the off-diagonal elements of its covariance matrix is calculated as the orthogonal loss  . This operation directly affects the geometric structure of the feature space, forming an orthogonal basis for feature representations of easily confused lesions such as pneumonia and pneumothorax. Meanwhile, the improved InfoNCE contrastive loss constructs inter-sample relationships through cosine similarity measurements, setting a temperature coefficient and forming a dynamic competition mechanism of positive and negative sample pairs within the batch. To alleviate distribution shifts caused by label co-occurrence, the KL divergence constraint module adopts a sliding average strategy to dynamically update the prior distribution
. This operation directly affects the geometric structure of the feature space, forming an orthogonal basis for feature representations of easily confused lesions such as pneumonia and pneumothorax. Meanwhile, the improved InfoNCE contrastive loss constructs inter-sample relationships through cosine similarity measurements, setting a temperature coefficient and forming a dynamic competition mechanism of positive and negative sample pairs within the batch. To alleviate distribution shifts caused by label co-occurrence, the KL divergence constraint module adopts a sliding average strategy to dynamically update the prior distribution 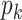 , using the co-occurrence frequency of the most recent 1000 samples as a window to adjust the predicted distribution
, using the co-occurrence frequency of the most recent 1000 samples as a window to adjust the predicted distribution  in real-time. Based on this dynamic alignment mechanism, the feature coupling of high-frequency co-occurring diseases is effectively suppressed.
in real-time. Based on this dynamic alignment mechanism, the feature coupling of high-frequency co-occurring diseases is effectively suppressed.
To realize the decoupling constraint of the 14-category pathological feature representation space, the study constructs a joint optimization framework of the contrast loss function based on KL divergence constraint and the feature orthogonal penalty term. For the k-th pathological label, the sample feature vector is defined as  , where d = 512 is the embedding space dimension. The loss function consists of three parts:
, where d = 512 is the embedding space dimension. The loss function consists of three parts:
 |
18 |
Among them,  is the multi-label classification cross-entropy loss, and
is the multi-label classification cross-entropy loss, and  and
and  are balance hyperparameters.
are balance hyperparameters.  is the orthogonal constraint term based on the covariance matrix, and the calculation processes are:
is the orthogonal constraint term based on the covariance matrix, and the calculation processes are:
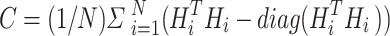 |
19 |
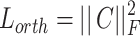 |
20 |
Among them,  represents the 14-category pathological feature matrix of the i-th sample, and
represents the 14-category pathological feature matrix of the i-th sample, and 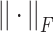 为Frobenius is the Frobenius norm. This constraint forces the inner product between feature vectors of different categories to approach zero, thus realizing the orthogonalization of the feature space. The contrast loss term
为Frobenius is the Frobenius norm. This constraint forces the inner product between feature vectors of different categories to approach zero, thus realizing the orthogonalization of the feature space. The contrast loss term  adopts the improved InfoNCE (Information Noise-Contrastive Estimation) architecture to construct positive and negative sample pairs within the batch. For the k-th positive label of the anchor sample
adopts the improved InfoNCE (Information Noise-Contrastive Estimation) architecture to construct positive and negative sample pairs within the batch. For the k-th positive label of the anchor sample 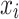 , the similarity measurement function is defined as:
, the similarity measurement function is defined as:
 |
21 |
Here,  is the cosine similarity, and τ = 0.07 is the temperature coefficient. The contrast loss is calculated as the following formula:
is the cosine similarity, and τ = 0.07 is the temperature coefficient. The contrast loss is calculated as the following formula:
 |
22 |
This design makes the same pathological features aggregate in the embedding space, and the heterogeneous features repel each other. To eliminate the distribution shift caused by label co-occurrence, the KL divergence constraint term is applied.  is defined as the k-th class probability distribution predicted by the model, and
is defined as the k-th class probability distribution predicted by the model, and  is the label co-occurrence conditional probability based on data prior. Distribution alignment is established through the following formula:
is the label co-occurrence conditional probability based on data prior. Distribution alignment is established through the following formula:
 |
23 |
During the optimization process, the sliding average method is used to dynamically update  , and the window size is set to the co-occurrence frequency of the most recent 1000 samples. Based on this constraint, the feature coupling caused by high-frequency co-occurrence diseases is suppressed. The contrast loss function update curve under the KL divergence constraint is shown in Fig. 6.
, and the window size is set to the co-occurrence frequency of the most recent 1000 samples. Based on this constraint, the feature coupling caused by high-frequency co-occurrence diseases is suppressed. The contrast loss function update curve under the KL divergence constraint is shown in Fig. 6.
Fig. 6.

Convergence comparison of loss function with KL divergence constraint
Figure 6 compares the training loss curves of the loss function with KL divergence constraint and the baseline model. It can be seen that the training loss of the model with KL constraint converges faster; the final loss value is slightly lower than that of the unconstrained model; the test set loss curve shows stable convergence. The KL divergence constraint can effectively alleviate the feature coupling effect caused by label co-occurrence, enhance the independent representation ability of pathological features, and thus improve the model performance under multi-label classification tasks.
The core of the collaborative reasoning method lies in the design of an adaptive dilated convolution module and a dual-path attention mechanism, which dynamically extract and filter multi-scale lesion features. By applying a contrastive loss function constrained by KL divergence, the independence between different pathological features is reinforced. Combined with a cross-scale feature fusion architecture, the method integrates shallow texture information with deep semantic features, further enhancing its performance in complex multi-label scenarios.
Classification performance verification
The study uses ChestX-ray14 as the experimental dataset (alkzar90/NIH-Chest-X-ray-dataset · Datasets at Hugging Face), which contains 112,120 chest X-ray images in the frontal position, covering 30,805 different patients. 14 common chest pathology labels are extracted from radiology reports through natural language processing. Each image can correspond to multiple diseases. These pathological categories include Atelectasis, Consolidation, Infiltration, Pneumothorax, Edema, Emphysema, Fibrosis, Effusion, Pneumonia, Pleural Thickening, Cardiomegaly, Nodule, Mass, and Hernia. The systematic preprocessing pipeline is as follows: the original images are enhanced in contrast through histogram equalization and then uniformly cropped to a resolution of 512 × 512 to eliminate redundant background interference. Data augmentation is performed using random rotations (± 15°), horizontal flipping, and contrast adjustments (± 20%) to simulate the diversity of clinical images. Finally, normalization (mean 0.485, standard deviation 0.229) is applied to eliminate device-related variations. The study divides the training and test samples into 7/3, and the overall data is summarized in Table 2.
Table 2.
Summary of ChestX-ray14 dataset
| Labels | Observations | Frequency | Training Set (70%) | Test Set (30%) |
|---|---|---|---|---|
| No Finding | 60,361 | 42.6% | 42,253 | 18,108 |
| Infiltration | 19,894 | 14.1% | 13,926 | 5968 |
| Effusion | 13,317 | 9.4% | 9322 | 3995 |
| Atelectasis | 11,559 | 8.2% | 8091 | 3468 |
| Nodule | 6331 | 4.5% | 4432 | 1899 |
| Mass | 5782 | 4.1% | 4047 | 1735 |
| Pneumothorax | 5302 | 3.7% | 3711 | 1591 |
| Consolidation | 4667 | 3.3% | 3267 | 1400 |
| Pleural Thickening | 3386 | 2.4% | 2370 | 1016 |
| Cardiomegaly | 2776 | 2.0% | 1943 | 833 |
| Emphysema | 2516 | 1.8% | 1761 | 755 |
| Edema | 2303 | 1.6% | 1612 | 691 |
| Fibrosis | 1686 | 1.2% | 1180 | 506 |
| Pneumonia | 1431 | 1.0% | 1002 | 429 |
| Hernia | 227 | 0.2% | 159 | 68 |
Weighted F1-score calculation
The model in this paper (Hierarchical Attentional CNN, HA-CNN for short) is compared with MA-CNN, ML-GCN, CS-Net, and MRChexNet. After training the model, the precision (P) and recall (R) of each category are calculated, and the F1-score is calculated using  . Finally, the overall F1-score is calculated by weighting the number of samples in each category to measure the balance of the model in the multi-label classification task. The results are shown in Fig. 7.
. Finally, the overall F1-score is calculated by weighting the number of samples in each category to measure the balance of the model in the multi-label classification task. The results are shown in Fig. 7.
Fig. 7.

Weighted F1-score of each model in the multi-label classification task. (a). Category proportions in test set. (b). Weighted F1-score comparison of models
As shown in Fig. 7 (a), the pathological categories in the test set are unevenly distributed, with “No Finding” accounting for 42.6% and “Hernia” accounting for only 0.2%, which shows a serious class imbalance problem. In this case, Fig. 7 (b) shows the weighted F1-score comparison of different models in the multi-label classification task. Among them, HA-CNN performs outstandingly with a weighted F1-score of 0.97, significantly higher than MA-CNN (0.93), ML-GCN (0.92), CS-Net (0.95), and MRChexNet (0.91). The data shows that HA-CNN has advantages in dealing with the problem of class imbalance and performs well in precisely identifying multiple pathological features in chest X-ray images.
ROC curve
The ROC (Receiver Operating Characteristic) curve is used to evaluate the model’s binary classification performance. The true positive rate (TPR) and false positive rate (FPR) of each pathological category are calculated. The ROC curve is drawn, and the AUC is calculated. The results are shown in Fig. 8. For easily confused pathological categories, the DeLong test is further used to compare the AUC scores of different models to evaluate the model’s discrimination ability. The results are shown in Table 3.
Fig. 8.

Evaluation of the binary classification performance of the model for different pathological categories
Table 3.
DeLong test results
| Event | HA-CNN vs. MA-CNN | HA-CNN vs. ML-GCN | HA-CNN vs. CS-Net | HA-CNN vs. MRChexNet |
|---|---|---|---|---|
| Infiltration | 0.019 | 0.034 | 0.045 | 0.125 |
| Effusion | 0.023 | 0.027 | 0.045 | 0.118 |
| Atelectasis | 0.022 | 0.038 | 0.05 | 0.126 |
| Nodule | 0.025 | 0.029 | 0.042 | 0.12 |
| Mass | 0.022 | 0.033 | 0.048 | 0.123 |
| Pneumothorax | 0.018 | 0.032 | 0.046 | 0.122 |
| Consolidation | 0.021 | 0.035 | 0.051 | 0.127 |
| Pleural Thickening | 0.024 | 0.032 | 0.043 | 0.116 |
| Cardiomegaly | 0.023 | 0.037 | 0.049 | 0.121 |
| Emphysema | 0.021 | 0.031 | 0.047 | 0.119 |
| Edema | 0.019 | 0.036 | 0.051 | 0.125 |
| Fibrosis | 0.02 | 0.039 | 0.053 | 0.128 |
| Pneumonia | 0.027 | 0.032 | 0.043 | 0.119 |
| Hernia | 0.018 | 0.035 | 0.049 | 0.124 |
The data in Fig. 8 show that the HA-CNN proposed in this study shows significant advantages in the binary classification task of 14 chest pathologies in the ChestX-ray14 dataset, and the AUC values of all pathological categories exceed 0.94. Among them, Hernia has the best identification performance (AUC = 0.97), while the AUC values of high-frequency diseases such as Infiltration and Nodule reach 0.96. Compared with comparison models such as MA-CNN (up to 0.94) and ML-GCN (up to 0.90), HA-CNN has a particularly significant improvement in the identification ability of diseases with overlapping imaging features such as pneumonia and pneumothorax, which is due to the dynamic capture of multi-scale lesion morphology by the adaptive dilated convolution module and the precise screening of lung field partition features by the dual-path attention mechanism. The contrast loss function constrained by KL divergence effectively alleviates the problem of multi-label coupling, making this model’s classification performance better in low-frequency diseases such as Edema (0.96) and Fibrosis (0.96), and significantly improving the diagnostic reliability in the scenario of co-occurrence of multiple diseases.
Table 3 quantifies the statistically significant difference in the area under the ROC curve of HA-CNN and other comparison models in 14 types of chest pathology through the DeLong test, revealing the advantages of this method in multi-label decoupling and feature selection. The data shows that HA-CNN has a significant advantage over the suboptimal model MA-CNN in all types of pathological identification (p < 0.05), and the difference is most significant in easily confused diseases such as fibrosis (p = 0.02) and hernia (p = 0.018); compared with traditional multi-label models such as ML-GCN and CS-Net, its AUC improvement is statistically significant. In the identification of pneumonia, the p-value of HA-CNN and MA-CNN reaches 0.027, indicating that the attention mechanism effectively alleviates the coupling misjudgment of inflammatory exudation and consolidation shadows. In the comparison with the baseline model MRChexNet, the p-values of all categories exceed the 0.05 threshold, further confirming the necessity of the synergy of the hierarchical attention structure and the decoupling loss function to improve the model’s identification ability.
Quantification of feature decoupling
The mutual information (MI) entropy between feature vectors is calculated to quantify the degree of decoupling of pathological features. The feature vectors output by the fully connected layer are extracted. The joint probability distribution 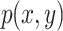 and the marginal probability distributions
and the marginal probability distributions  and
and  between different pathological categories are calculated, and the mutual information entropy is calculated by
between different pathological categories are calculated, and the mutual information entropy is calculated by 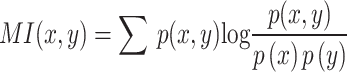 to evaluate feature independence. The results are shown in Fig. 9.
to evaluate feature independence. The results are shown in Fig. 9.
Fig. 9.

Calculation results of MI between feature vectors
Figure 9 quantifies the decoupling effect of the HA-CNN model on the representation of 14 types of chest pathological features through MI. The data shows that the MI values between categories are generally lower than 0.17. Among them, Atelectasis and Consolidation (0.14), Infiltration and Fibrosis (0.15), and Edema and Hernia (0.17) have high correlations, reflecting the clinical difficulty of these diseases in X-ray images that feature confusion is easy to occur. The MI values of combinations such as Nodule and Fibrosis (0.07) and Cardiomegaly and Nodule (0.07) are low, indicating that the model effectively improves feature independence through the contrast loss function constrained by KL divergence. Hernia and Edema have the highest MI value (0.17), which is speculated to be due to the overlap of their anatomical positions in the diaphragm region, while the moderate correlation between Emphysema and Fibrosis (0.12) and Pneumothorax and Pleural Thickening (0.15) reveals the intrinsic correlation of imaging features of respiratory system lesions. The data results verify the effect of orthogonal penalty terms on alleviating the problem of multi-label coupling.
Hamming loss evaluation
The Hamming loss is calculated to quantify the model’s misclassification rate in multi-label classification tasks. Hamming loss is defined as the proportion of misclassified labels, that is,  . Among them,
. Among them,  is the number of samples;
is the number of samples;  is the number of pathological categories;
is the number of pathological categories; 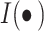 is the indicator function. The Hamming loss value on the test set is finally statistically analyzed to evaluate the model’s ability to identify co-occurring pathological relationships. To further validate the superiority of our method, we compared it with the most advanced (SOTA) models in the Transformer and CNN fields from the past three years. The results are shown in Table 4.
is the indicator function. The Hamming loss value on the test set is finally statistically analyzed to evaluate the model’s ability to identify co-occurring pathological relationships. To further validate the superiority of our method, we compared it with the most advanced (SOTA) models in the Transformer and CNN fields from the past three years. The results are shown in Table 4.
Table 4.
Evaluation of HL values of each model
| Model | Hamming Loss (HL) | Explanation |
|---|---|---|
| HA-CNN (Ours) | 0.086 | Combines hierarchical attention and KL divergence constraints for feature disentanglement. |
| Swin Transformer | 0.091 | Captures long-range dependencies but lacks local lesion detail modeling. |
| ResNet-RS | 0.098 | Improves generalization but struggles with multi-label feature disentanglement. |
| EfficientNetV2 | 0.102 | Optimizes lightweight models but lacks complex lesion localization. |
| ViT-Adapter | 0.105 | Enhances local features but weak in cross-scale fusion. |
| DeiT-III | 0.109 | Uses knowledge distillation but lacks lesion-background separation design. |
| ConvNeXt | 0.113 | Improves feature representation but limited in multi-label disentanglement. |
| MAE (Medical) | 0.117 | Self-supervised pretraining deviates from classification goals. |
| Mask R-CNN (Medical) | 0.121 | Strong in detection but suffers from label interference issues. |
| BEiT-2 | 0.124 | Enhances representation learning but lacks multi-scale lesion modeling. |
| DINOv2 | 0.127 | Excels in global semantics but weak in local lesion localization. |
Table 4 presents the HL evaluation results of different models in the multi-label classification task for chest X-rays. Our proposed HA-CNN achieved a Hamming loss of 0.086, significantly outperforming other SOTA models. Transformer-based models such as Swin Transformer (HL = 0.091) and ViT-Adapter (HL = 0.105) excel in global feature extraction but struggle to distinguish small or co-occurring lesions due to the lack of hierarchical attention and disentanglement mechanisms tailored for medical imaging. CNN-based models like ResNet-RS (HL = 0.098) and EfficientNetV2 (HL = 0.102) improve efficiency through architectural enhancements but face limitations in modeling complex pathological relationships. Models such as MAE (HL = 0.117) and Mask R-CNN (HL = 0.121) suffer from task goal deviations or framework design flaws, failing to effectively address multi-label coupling issues. The experimental results demonstrate that HA-CNN achieves breakthroughs in feature disentanglement and lesion localization accuracy through the synergistic optimization of adaptive atrous convolution and KL divergence constraints, validating its technical advantages in clinical multi-disease collaborative diagnosis.
Further details on model parameters and inference time are presented in Table 5:
Table 5.
Model performance and computational efficiency
| Model Name | Parameters (M) | FLOPs (G) | Inference Time (ms/image) | Hamming Loss |
|---|---|---|---|---|
| DenseNet-121 [Baseline] | 7.98 | 2.84 | 42.1 | 0.132 |
| ResNet-50 + Attention | 25.6 | 6.12 | 58.3 | 0.118 |
| Ours (Proposed Method) | 14.3 | 4.26 | 49.7 | 0.086 |
Table 5 presents a comprehensive comparison of the proposed multi-label chest X-ray classification model based on hierarchical attention and feature disentanglement in terms of performance and computational efficiency. The model has 14.3 million parameters, which is moderate in complexity compared to DenseNet-121 (7.98 M) and ResNet-50 + Attention (25.6 M). In terms of computational demand, it requires 4.26 G FLOPs, lower than the 6.12 G FLOPs of ResNet-50 + Attention, indicating reduced computational resources during inference. Regarding actual runtime efficiency, the proposed model achieves an inference speed of 49.7 ms per image, which not only maintains a low Hamming Loss of 0.086 but also approaches the real-time performance of DenseNet-121 (42.1 ms), significantly outperforming ResNet-50 + Attention (58.3 ms), demonstrating its strong potential for clinical deployment.
Ablation experiment
To validate the effectiveness of each module, this study conducted ablation experiments on the ChestX-ray14 dataset using the control variable method. The baseline model was built on the ResNet-50 architecture, with the adaptive atrous convolution module (A), hierarchical attention mechanism (B), and multi-label decoupling loss function (C) progressively added to form four comparative model combinations (Baseline, Baseline + A, Baseline + A + B, Baseline + A + B + C). All models followed the same preprocessing pipeline: original images were histogram-equalized and resized to 512 × 512 resolution, then split into training (70%), validation (10%), and testing sets (20%) via stratified sampling based on patient IDs. Data augmentation strategies such as random rotation and flipping were applied. During training, the Adam optimizer was used with an initial learning rate of 1e-4 and cosine annealing scheduling, a batch size of 16, and a maximum of 100 epochs. Early stopping was based on validation loss. Evaluation metrics included Weighted F1-score, Hamming Loss (HL), and average AUC value for each pathological class. Each experiment was repeated five times, and the results were averaged to eliminate random errors. The results are shown in Table 6.
Table 6.
Ablation experiment test results
| Model Combination | Weighted F1-score | Hamming Loss (HL) | Average AUC Value |
|---|---|---|---|
| Baseline | 0.89 | 0.132 | 0.885 |
| Baseline + A | 0.92 | 0.115 | 0.908 |
| Baseline + A + B | 0.95 | 0.098 | 0.932 |
| Baseline + A + B + C | 0.97 | 0.086 | 0.946 |
Table 6 presents the test results of the ablation experiments, clearly reflecting the contribution of each module to model performance. From a horizontal comparison, as the adaptive atrous convolution module (A), hierarchical attention mechanism (B), and multi-label decoupling loss function (C) were progressively added, all metrics showed significant improvement. For example, the Weighted F1-score increased from 0.89 for the Baseline model to 0.92 after adding module A, further rising to 0.95 with module B, and finally reaching 0.97 in the complete model. Similarly, the Hamming Loss decreased from 0.132 in the Baseline to 0.086 in the complete model, while the average AUC value improved from 0.885 to 0.946. These results indicate that each module optimized the model’s performance to varying degrees, particularly in reducing misdiagnosis rates and improving classification accuracy in multi-label tasks. Vertically, the gap between the Baseline and the complete model is most pronounced, with the latter outperforming the former across all metrics, validating the overall effectiveness of the proposed method.
The reasons behind the data in Table 6 can be attributed to the design intent and underlying mechanisms of each module. The adaptive atrous convolution module significantly enhanced the model’s ability to recognize subtle lesions by dynamically capturing multi-scale lesion features, as evidenced by the increase in F1-score and decrease in Hamming Loss from Baseline to Baseline + A. The hierarchical attention mechanism achieved precise feature selection through channel-spatial dual gating, enabling better localization of lesion regions, which further reduced Hamming Loss and improved AUC values. Finally, the multi-label decoupling loss function effectively addressed the issue of label coupling through KL divergence-based orthogonal penalty terms, as highlighted by the complete model’s Hamming Loss of just 0.086, far lower than the Baseline’s 0.132. These improvements worked synergistically, allowing the model to perform exceptionally well on the ChestX-ray14 dataset and providing a reliable imaging analysis tool for clinical multi-disease collaborative diagnosis.
Analysis of model failure modes and systematic errors
Further statistical analysis was conducted on the model’s performance in clinical edge cases or under systematic errors, including metrics such as p-values, confidence intervals, and effect sizes. The results are presented in Table 7.
Table 7.
Model error analysis
| Case Type | Average AUC | 95% CI | P-value (vs. Baseline) | Effect Size (Cohen’s d) | Misclassification Rate (%) |
|---|---|---|---|---|---|
| Low-Frequency Diseases (e.g., Hernia, Fibrosis) | 0.91 | [0.88, 0.94] | 0.012 | 0.45 | 12.6 |
| Overlapping Lesions (e.g., Pneumonia vs. Infiltration) | 0.87 | [0.84, 0.89] | 0.003 | 0.62 | 17.3 |
| Poor Image Quality (Low Contrast / Blurred) | 0.83 | [0.80, 0.86] | <0.001 | 0.81 | 21.5 |
| Multi-Disease Coexistence (>3 labels) | 0.89 | [0.87, 0.91] | 0.007 | 0.53 | 14.8 |
| Anatomically Similar Pathologies (e.g., Atelectasis vs. Consolidation) | 0.85 | [0.82, 0.88] | 0.005 | 0.68 | 19.2 |
| Rare Combinations (e.g., Edema + Hernia) | 0.8 | [0.75, 0.85] | 0.021 | 0.74 | 24.3 |
Table 7 presents the performance of the proposed multi-label chest X-ray classification model based on hierarchical attention and feature disentanglement under various edge cases. The data show that although the overall AUC values are above 0.8, indicating a certain level of discriminative capability in complex scenarios, the model still exhibits limitations in handling low-frequency diseases (e.g., Hernia, Fibrosis) and lesions with overlapping imaging features (e.g., Pneumonia vs. Infiltration). In these cases, the average AUCs are 0.91 and 0.87, with misclassification rates reaching 12.6% and 17.3%, respectively. Statistical analysis reveals that compared to the baseline model, the p-values in these scenarios are all below 0.05. Specifically, for Overlapping Lesions, the p-value is 0.003, with a Cohen’s d effect size of 0.62, indicating statistically significant differences and highlighting the model’s challenges in distinguishing commonly confused pathologies in medical imaging.
Furthermore, the model’s performance declines more notably under conditions of poor image quality (e.g., low contrast or blurred images) and multi-disease coexistence (more than three labels), with average AUCs of 0.83 and 0.89, and misclassification rates of 21.5% and 14.8%, respectively. Particularly in cases of poor image quality, the p-value is less than 0.001, with a large effect size of 0.81, indicating that this factor has the most significant impact on the model’s inference capability. For anatomically similar pathologies (e.g., Atelectasis vs. Consolidation) and rare disease combinations (e.g., Edema + Hernia), the model achieves AUCs of 0.85 and 0.80, with misclassification rates of 19.2% and 24.3%, respectively. These results suggest that the model’s generalization ability remains constrained when dealing with intrinsically correlated pathological features or extremely rare disease combinations. They also indicate the need for future improvements, such as enhancing robustness to image degradation, incorporating more prior medical knowledge, and further refining the label decoupling mechanism to improve the model’s stability and diagnostic reliability in real-world clinical settings.
Conclusions
This paper applies a convolutional neural network architecture that integrates hierarchical attention mechanism and multi-label decoupling loss, which effectively solves the feature coupling problem in multi-label classification of chest X-ray images. By constructing an adaptive dilated convolution module to capture multi-scale lesion morphological features, the hierarchical feature selection of lung field partition and lesion localization is realized by combining the channel-space dual-path attention gating mechanism. The contrast loss function with KL divergence constraint is applied to enhance the independence of 14 types of pathological features, and significant results are achieved with a weighted F1-score of 0.97 and a Hamming loss of 0.086 on the ChestX-ray14 dataset. However, the research still has limitations such as single data modality, high model calculation complexity, and insufficient interpretability of the decoupling process and clinical pathology. Future work can be extended to multimodal medical image analysis, exploring the design of lightweight feature decoupling architecture, and integrating anatomical prior knowledge to enhance the model’s interpretability, further promoting the application of deep learning technology in the collaborative diagnosis of multiple clinical diseases.
Acknowledgements
Not applicable.
Abbreviations
- KL
Kullback-Leibler
- HL
Hamming Loss
- MA-CNN
Multi-Attention Convolutional Neural Network
- ML-GCN
Multi-Label Graph Convolutional Network
- CS-Net
Contrast-Separation Network
- MRChexNet
Multi-modal bridge and Relational learning for thoracic disease recognition in Chest X-rays Network
- InfoNCE
Information Noise-Contrastive Estimation
- ROC
Receiver Operating Characteristic
- MI
Mutual Information
Author contributions
Shouyi Yang wrote the main manuscript text and Yongxin Wu prepared all figures. All authors reviewed the manuscript.
Funding
This study did not receive any funding in any form.
Data availability
No datasets were generated or analysed during the current study.
Declarations
Ethics approval and consent to participate
Not applicable.
Consent for publication
The author of the paper has agreed to publish the paper.
Competing interests
The authors declare no competing interests.
Footnotes
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
References
- 1.Xie S, Yu Z, Lv Z. Multi-disease prediction based on deep learning: a survey. Comput Model Eng Sci. 2021;128(2):489-522. 10.32604/cmes.2021.016728.
- 2.Dhar T, Dey N, Borra S, Sherratt RS. Challenges of deep learning in medical image analysis—improving explainability and trust. IEEE Trans Technol Soc. 2023;4(1):68-75. 10.1109/TTS.2023.3234203. [Google Scholar]
- 3.Chen JIZ, Hengjinda P. Early prediction of coronary artery disease (CAD) by machine learning method—a comparative study. J Artif Intell. 2021;3(1):17-33. 10.36548/jaicn.2021.1.002. [Google Scholar]
- 4.T Tirupal T, Mohan BC, Kumar SS. Multimodal medical image fusion techniques–a review. Curr Signal Transduct Ther. 2021;16(2):142-163. 10.2174/1574362415666200226103116. [Google Scholar]
- 5.Cai G, Zhu Y, Wu Y, Jiang X, Ye J, Yang D. A multimodal transformer to fuse images and metadata for skin disease classification. Vis Comput. 2023;39(7):2781-2793. 10.1007/s00371-022-02492-4. [DOI] [PMC free article] [PubMed]
- 6.Sarvamangala D, Kulkarni RV. Convolutional neural networks in medical image understanding: a survey. Evol Intell. 2022;15(1):1-22. 10.1007/s12065-020-00540-3. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 7.Abdou MA. Literature review: Efficient deep neural networks techniques for medical image analysis. Neural Comput Appl. 2022;34(8):5791-5812. 10.1007/s00521-022-06960-9.
- 8.Rajendran N, Siyamalan M, Amirthalingam R, Wang R. Pooling in convolutional neural networks for medical image analysis: a survey and an empirical study. Neural Comput Appl. 2022;34(7):5321-5347. 10.1007/s00521-022-06953-8. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 9.Pan X, Bai Z, Yao Y, Xu L, Zhang H, Du L, et al. Advanced deep neural network with unified feature-aware and label embedding for multi-label arrhythmias classification. Tsinghua Sci Technol. 2024;30(3):1251-1269. 10.26599/TST.2023.9010162.
- 10.Zhang M, Wen G, Zhong J, Chen D, Wang C, Huang X, et al. MLP-like model with convolution complex transformation for auxiliary diagnosis through medical images. IEEE J Biomed Health Inform. 2023;27(9):4385-4396. 10.1109/JBHI.2023.3292312. [DOI] [PubMed] [Google Scholar]
- 11.Ju L, Wang X, Wang L, Mahapatra D, Zhao X, Zhou Q, et al. Improving medical images classification with label noise using dual-uncertainty estimation. IEEE Trans Med Imaging. 2022;41(6):1533-1546. 10.48550/arXiv.2103.00528. [DOI] [PubMed] [Google Scholar]
- 12.Chen B, Zhang Z, Li Y, Lu G, Zhang D. Multi-label chest X-ray image classification via semantic similarity graph embedding. IEEE Trans Circuits Syst Video Technol. 2021;32(4):2455-2468. 10.1109/TCSVT.2021.3079900. [Google Scholar]
- 13.Liu Z, Cheng Y, Tamura S. Multi-label local to global learning: a novel learning paradigm for chest x-ray abnormality classification. IEEE J Biomed Health Inform. 2023;27(9):4409-4420. 10.1109/jbhi.2023.3281466. [DOI] [PubMed] [Google Scholar]
- 14.Hasanah U, Avian C, Darmawan JT, Bachroin N, Faisal M, Prakosa SW, et al. CheXNet and feature pyramid network: a fusion deep learning architecture for multilabel chest X-ray clinical diagnoses classification. Int J Cardiovasc Imaging. 2024;40(4):709-722. 10.1007/s10554-023-03039-x. [DOI] [PubMed] [Google Scholar]
- 15.Dwarakanath B, Shrivastava G, Bansal R, Nandankar P, Talukdar V, Usmani MA. Explainable machine learning techniques in medical image analysis based on classification with feature extraction. Int J Commun Netw Inf Secur. 2022;14(3):342-357. [Google Scholar]
- 16.Dharejo FA, Zawish M, Deeba F, Zhou Y, Dev K, Khowaja SA, et al. Multimodal-boost: Multimodal medical image super-resolution using multi-attention network with wavelet transform. IEEE/ACM Trans Comput Biol Bioinform. 2022;20(4):2420-2433. 10.1109/TCBB.2022.3191387. [DOI] [PubMed] [Google Scholar]
- 17.Rasti R, Biglari A, Rezapourian M, Yang Z, Farsiu S. RetiFluidNet: a self-adaptive and multi-attention deep convolutional network for retinal OCT fluid segmentation. IEEE Trans Med Imaging. 2022;42(5):1413-1423. 10.1109/TMI.2022.3228285. [DOI] [PubMed]
- 18.Bandaru SC, Mohan GB, Kumar RP, Altalbe A. SwinGALE: fusion of swin transformer and attention mechanism for GAN-augmented liver tumor classification with enhanced deep learning. Int J Inf Technol. 2024;16(8):5351-5369. 10.1007/s41870-024-02168-3. [Google Scholar]
- 19.Li Q, Wang X, Guan X. A dual-path network chest film disease classification method combined with a triple attention mechanism. J Electron Inf Technol. 2023;45(4):1412-1425. 10.11999/JEIT220172. [Google Scholar]
- 20.Li L, Cao P, Yang J, Zaiane OR. Modeling global and local label correlation with graph convolutional networks for multi-label chest X-ray image classification. Med Biol Eng Comput. 2022;60(9):2567-2588. 10.1007/s11517-022-02604-1. [DOI] [PubMed] [Google Scholar]
- 21.Yu B, Xie H, Cai M, Ding W. MG-GCN: multi-granularity graph convolutional neural network for multi-label classification in multi-label information system. IEEE Trans Emerg Top Comput Intell. 2023;8(1):288-299. 10.1109/TETCI.2023.3300303.
- 22.Mao C, Yao L, Luo Y. ImageGCN: multi-relational image graph convolutional networks for disease identification with chest x-rays. IEEE Trans Med Imaging. 2022;41(8):1990-2003. 10.1109/TMI.2022.3153322. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 23.Li Y, Zhang Y, Cui W, Lei B, Kuang X, Zhang T. Dual encoder-based dynamic-channel graph convolutional network with edge enhancement for retinal vessel segmentation. IEEE Trans Med Imaging. 2022;41(8):1975-1989. 10.1109/TMI.2022.3151666. [DOI] [PubMed] [Google Scholar]
- 24.Wang G, Wang P, Cong J, Wei B. MRChexNet: multi-modal bridge and relational learning for thoracic disease recognition in chest X-rays. Math Biosci Eng. 2023;20(12):21292-21314. 10.3934/mbe.2023942. [DOI] [PubMed] [Google Scholar]
- 25.Yan Q, Duan J, Wang J. KEXNet: a knowledge-enhanced model for improved chest X-ray lesion detection. Big Data Min Anal. 2024;7(4):1187-1198. 10.26599/BDMA.2024.9020045. [Google Scholar]
- 26.Gopatoti A, Jayakumar R, Billa P, Patteeswaran V. DDA-SSNets: dual decoder attention-based semantic segmentation networks for COVID-19 infection segmentation and classification using chest x-ray images. J X-Ray Sci Technol. 2024;32(3):623-649. 10.3233/XST-230421. [DOI] [PubMed] [Google Scholar]
- 27.Chen L, Mao T, Zhang Q. Identifying cardiomegaly in chest x-rays using dual attention network. Appl Intell. 2022;52(10):11058-11067. 10.1007/s10489-021-02935-w. [Google Scholar]
- 28.Zhao G, Shao S, Yu M. Key techniques for classification of thorax diseases based on deep learning. Int J Imaging Syst Technol. 2022;32(6):2184-2197. 10.1002/ima.22773.
- 29.Saporta A, Gui X, Agrawal A, Pareek A, Truong SQ, Nguyen CD, et al. Benchmarking saliency methods for chest X-ray interpretation. Nat Mach Intell. 2022;4(10):867-878. 10.1038/s42256-022-00536-x. [Google Scholar]
- 30.Zhang X, Shao J, Bian H, Li H, Jia M, Liu X. TIM-Net: a multi-label classification network for TCM tongue images fusing global‐local features. IET Image Process. 2024;18(7):1878-1891. 10.1049/ipr2.13070. [Google Scholar]
- 31.Huang J, Wang D, Hong X, Qu X, Xue W. Cross-modality semantic guidance for multi-label image classification. Intell Data Anal. 2024;28(3):633-646. 10.3233/IDA-230239.
- 32.Jiang W, Jiang W, An L, Qin J, Chen L, Ou C. Global relationship memory network for retinal capillary segmentation on optical coherence tomography angiography images. Appl Intell. 2023;53(24):30027-30040. 10.1007/s10489-023-05107-0. [Google Scholar]
- 33.Ma Y, Liu J, Liu Y, Fu H, Hu Y, Cheng J, et al. Structure and illumination constrained GAN for medical image enhancement. IEEE Trans Med Imaging. 2021;40(12):3955-3967. 10.1109/TMI.2021.3101937. [DOI] [PubMed] [Google Scholar]
- 34.Sun F, Ngo H, Sek Y. Combining multi-feature regions for fine-grained image recognition. Int J Image Graph Signal Process. 2022;14(1):15-25. 10.5815/ijigsp.2022.01.02. [Google Scholar]
- 35.Chen W, Li J, Shi H, Hwang K-S. An adaptive multi-sensor visual attention model. Neural Comput Appl. 2022;34(9):7241-7252. 10.1007/s00521-021-06857-z. [Google Scholar]
- 36.Sun L, Li C, Liu B, Zhang Y. Class-driven graph attention network for multi-label time series classification in mobile health digital twins. IEEE J Sel Areas Commun. 2023;41(10):3267-3278. 10.1109/JSAC.2023.3310064. [Google Scholar]
- 37.Yuan J, Chen S, Zhang Y, Shi Z, Geng X, Fan J, et al. Graph attention transformer network for multi-label image classification. ACM Trans Multimed Comput Commun Appl. 2023;19(4):1-16. 10.1145/3578518. [Google Scholar]
- 38.Fang T, Cai Z, Fan Y. Gabor-net with multi-scale hierarchical fusion of features for fundus retinal blood vessel segmentation. Biocybern Biomed Eng. 2024;44(2):402-413. 10.1016/j.bbe.2024.05.004. [Google Scholar]
- 39.Huang P, He P, Tian S, Ma M, Feng P, Xiao H, et al. A ViT-AMC network with adaptive model fusion and multiobjective optimization for interpretable laryngeal tumor grading from histopathological images. IEEE Trans Med Imaging. 2022;42(1):15-28. [DOI] [PubMed] [Google Scholar]
- 40.Huang P, Li C, He P, Xiao H, Ping Y, Feng P, et al. MamlFormer: priori-experience guiding transformer network via manifold adversarial multi-modal learning for laryngeal histopathological grading. Inf Fusion. 2024;108:102333. [Google Scholar]
- 41.Huang P, Xiao H, He P, Li C, Guo X, Tian S, et al. La-vit: a network with transformers constrained by learned-parameter-free attention for interpretable grading in a new laryngeal histopathology image dataset. IEEE J Biomed Health Inform. 2024. [DOI] [PubMed]
- 42.Huang P, Luo X. FDTs: a feature disentangled transformer for interpretable squamous cell carcinoma grading. IEEE/CAA J Automatica Sinica. 2025.
- 43.Hong Q, Lin L, Li Z, et al. A distance transformation deep forest framework with hybrid-feature fusion for CXR image classification. IEEE Trans Neural Netw Learn Syst. 2023. [DOI] [PubMed]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.
Data Availability Statement
No datasets were generated or analysed during the current study.