

Abstract
多任务学习(MTL)在生理信号测量领域具有显著的优势,该方法使得模型在数据稀缺的环境下也能通过相似任务间的参数和特征共享提高模型的泛化能力。然而,传统的多任务生理信号测量方法面临着任务间特征冲突、任务不平衡和模型复杂度过高等问题,限制了其在复杂环境中的应用。因此,本文设计了一种基于欧拉视频放大(EVM)、超分辨率重建和卷积多层感知器的增强多尺度时空网络(EMSTN)模型。首先,本研究通过在网络的输入阶段引入EVM,放大视频中的细微颜色和运动变化,显著提高了模型对脉搏和呼吸信号的捕捉能力。此外,本文还在网络中加入超分辨率重建模块,提升了输入图像分辨率,从而增强了细节捕捉能力,提高了面部动作单元(AU)识别任务的准确性。然后,本文采用卷积多层感知器替代传统二维卷积,提高了特征提取的效率和灵活性,显著提升了心率和呼吸率测量任务的表现。最终,通过在宾汉姆顿匹兹堡四维自发面部表情数据集(BP4D+)上进行综合实验,实验结果充分验证了本文所提出方法在多任务生理信号测量中的有效性和优越性。
Keywords: 多任务学习, 远程光电容积脉搏波描记法信号测量, 面部动作单元
Abstract
Multi-task learning (MTL) has demonstrated significant advantages in the field of physiological signal measurement. This approach enhances the model's generalization ability by sharing parameters and features between similar tasks, even in data-scarce environments. However, traditional multi-task physiological signal measurement methods face challenges such as feature conflicts between tasks, task imbalance, and excessive model complexity, which limit their application in complex environments. To address these issues, this paper proposes an enhanced multi-scale spatiotemporal network (EMSTN) based on Eulerian video magnification (EVM), super-resolution reconstruction and convolutional multilayer perceptron. First, EVM is introduced in the input stage of the network to amplify subtle color and motion changes in the video, significantly improving the model's ability to capture pulse and respiratory signals. Additionally, a super-resolution reconstruction module is integrated into the network to enhance the image resolution, thereby improving detail capture and increasing the accuracy of facial action unit (AU) tasks. Then, convolutional multilayer perceptron is employed to replace traditional 2D convolutions, improving feature extraction efficiency and flexibility, which significantly boosts the performance of heart rate and respiratory rate measurements. Finally, comprehensive experiments on the Binghamton-Pittsburgh 4D Spontaneous Facial Expression Database (BP4D+) fully validate the effectiveness and superiority of the proposed method in multi-task physiological signal measurement.
Keywords: Multi-task learning, Remote photoplethysmography signal measurement, Facial action units
0. 引言
在现代医疗技术中,远程光电容积脉搏波描记(remote photoplethysmography,rPPG)技术因其非接触式特性,在心率监测中展现出显著优势[1]。rPPG技术可通过分析摄像头传感器捕捉到的皮肤颜色微小变化[2],从中提取脉搏波信号[3],为远程生理信号测量提供了一种便捷有效的途径[4]。然而,单一的心率监测往往无法提供足够的诊断信息,因此研究者们逐渐开发出多任务学习(multi-task learning,MTL)方法,致力于同步测量多种生理信号,从而推动生理信号测量技术的发展,以便更全面地实现人体健康状态远程诊疗。
尽管MTL方法能够有效地进行多个生理信号的同步测量,但其在实际应用中仍面临若干挑战,主要包括任务之间的梯度冲突、参数共享与特征专用等问题。在过去的几十年里,研究人员提出了多种方法,例如:Cipolla等[5]通过为每个任务设计不同的损失权重,在训练过程中动态调整每个任务对总损失的贡献。Sener等[6]提出的模型中使用MTL优化器实现任务独立更新,减少了任务之间的干扰。Yu等[7]提出“梯度修正”技术应对梯度冲突问题。尽管这些方法在一定程度上缓解了上述问题,但MTL仍有进一步优化的空间。
在MTL中,参数共享通常分为:① 参数硬共享机制;② 参数软共享机制。参数硬共享机制通过共享部分参数并为每个任务保留特定分支以实现MTL[8],如通用卷积神经网络(universal convolutional neural network,UberNet)[9]和多任务级联卷积网络(multi-task cascaded convolutional network,MT-CNN)[10]等。本文使用参数硬共享机制实现MTL方法。
对于生理测量领域,面部动作是发生在局部的肌肉运动[11],而rPPG信号几乎存在于所有皮肤组织中,并且具有高度的周期性。呼吸信号则介于上述两者之间,通常具有周期性,但有时是不规则的,并且只能从身体的某些部位(如胸部或腹部)测量。这表明,不同任务在空间和时间特征上的需求差异可能导致梯度更新时互相干扰。尽管如此,这些任务仍具有共同特性,它们都是由自主神经系统控制[12],且通过面部捕捉可以共享生理信息[13-14],这为生理测量精度的提升提供了可能。
自Verkruysse等[15]于2008年首次展示使用普通摄像机捕捉面部视频以测量rPPG信号的可行性以来,rPPG技术在生理信号测量领域取得了显著进展。近年来主流的基于rPPG的MTL网络架构有:多任务时空卷积注意力网络(multi-task temporal-spatial convolutional attention network,MTTS-CAN)[16]和大小分支(BigSmall)网络[17],虽然这些架构在多个生理信号测量任务中展现了良好的性能,但它们仍然存在一些不足之处。例如,MTTS-CAN通过引入时间移动模块(temporal shift module,TSM)[18]和注意力机制,提高了心率和呼吸频率测量的精度,但在面部动作单元(action units,AU)识别任务中的表现不佳。BigSmall网络结合高分辨率和低分辨率分支,优化了计算效率和任务性能,但在局部特征提取方面仍存在不足。
基于上述原因,本文探索将欧拉视频放大(Eulerian video magnification,EVM)技术与基于rPPG的MTL模型结合的可能性。这是由于EVM技术可通过放大视频中的微小颜色变化,有效捕捉与心率相关的信号;相关研究例如,Qiu等[19]提出EVM卷积神经网络(EVM convolutional neural network,EVM-CNN)模型,将卷积神经网络和EVM技术结合,用于测量rPPG信号。Jaiswal等[20]提出rPPG融合网络(rPPG fusion network,rPPG-FuseNet),使用EVM相关方法融合不同类型图像数据,提高心率测量的准确性。Zhang等[21]结合视频运动放大、全局特征提取模块,通过增强微表情特征实现更加精准的分类。
为了进一步提升MTL模型的局部特征提取能力,本文在网络中加入超分辨率重建模块。相关研究如:Dong等[22]提出超分辨率卷积神经网络,通过端到端学习实现了从低分辨率到高分辨率的映射,开创了深度学习在超分辨率领域的应用。Cao等[23]提出了一种基于生成对抗网络的新模型,用于进行面部图像的超分辨率特征重建,提升了面部细节的重建能力。Shi等[24]提出创新的卷积神经网络模型,通过次像素卷积优化了实时应用中的速度和准确性。与传统插值方法不同,本文直接在低分辨率空间进行超分辨率操作,提升了实时应用中的处理速度与精度。
基于以上这些因素,本文对现有的BigSmall网络模型进行改进,提出了能够测量多种人体生理信号的增强多尺度时空网络(enhanced multi-scale spatiotemporal network,EMSTN)模型,用于多种人体生理信号的同步测量。最终,本文期望通过增强超分辨率模块、EVM技术融合和MTL的优化,提升多种生理信号的测量精度和鲁棒性,为健康监测和智能医疗提供了一种潜在的有效技术手段。
1. 本文算法
本文的EMSTN模型专注于三个关键任务:rPPG监测、呼吸频率测量和面部AU识别任务。这些任务对视频输入的质量和处理有不同的需求。具体而言,rPPG监测要求对极细微的变化敏感,因为它需要从皮肤颜色的微小变动中提取脉搏波信号,是这三个任务中对分辨率和变化敏感度要求最高的任务;呼吸频率测量虽然也需要高分辨率来观察胸腔或腹部的细微运动,但相比rPPG监测,其对细节的敏感度略低;面部AU识别任务则主要依赖于高分辨率来捕捉面部表情中的细节变化,但相对于生理信号的微小变化,面部表情的变化幅度更大,对细微变化的敏感度需求最低。
尽管rPPG监测、呼吸频率测量和面部AU识别任务是MTL模型中的独立任务,但它们共享相同的底层网络架构,通过不同的分支处理各自的特定需求。最终,这些任务通过整合各自分支的输出,共同输出三个任务的结果。
为了提升模型性能和计算效率,本文提出若干优化措施,如图1所示。首先,引入EVM技术,对视频中的微小颜色变化进行放大,以增强生理信号的检测效果。随后,模型将输入数据分解为高、低分辨率两部分,针对低分辨率部分,采用亚像素卷积神经网络(efficient sub-pixel convolutional neural network,ESPCN)进行图像放大处理,提升初步细节重建效果。同时,该网络集成了卷积注意力模块和卷积多层感知器模块,形成双分支特征处理结构。其中,卷积注意力模块对当前帧进行特征提取,聚焦于图像中的关键细节区域;卷积多层感知器模块则通过对当前帧和下一帧的差值进行归一化处理,提取深层动态语义特征。最终,将两分支提取的特征进行融合,联合预测多任务结果,实现高效且精准的特征分析与重建。
图 1.

The overall network structure of the EMSTN model
EMSTN模型整体网络结构
在rPPG和呼吸频率检测任务中,为减少由非心脏跳动引起的运动干扰,本文采用了处理后的“归一化差值”作为输入。取C(t)和C(t + 1)分别表示当前帧t和下一帧t + 1的颜色或强度信息。分子C(t + 1)—C(t)是捕捉两帧之间的差异,突出时间上的变化,分母C(t + 1) + C(t) 用于对差异进行归一化,避免非周期性运动引起的幅度变化过大。分子与分母的比值则代表了相邻视频帧之间颜色变化的相对变化量,即颜色的变化相对于两帧的总和的比例。这种输入方法有效地突出与生理信号相关的动态信息,同时抑制其它无关运动变化。具体来说,心脏跳动引起的颜色变化是由血液流动导致皮肤表面反射光的微小变化,这些变化具有较高的时间周期性,并且幅度较小。而在视频中,由其它非周期性运动引起的像素变化(如头部运动、面部表情变化等)通常幅度较大且不具有与心跳信号一致的时间模式。因此,通过差帧处理,非周期性运动的影响能够在某种程度上被抑制,因为这些大幅度的瞬时运动变化不会在相邻帧之间保持稳定或周期性规律。而归一化操作进一步增强了与心率相关的微小波动,而削弱了幅度较大的无关运动噪声的影响。
此外,归一化差值对运动干扰的鲁棒性还体现在它将整个图像区域进行差分分析,而不是依赖于单个像素的绝对值变化。因此,即使存在轻微的整体运动,也能通过局部相对差异的保留来减少对心率和呼吸率信号提取的干扰。这种方法有效地放大了与生理信号相关的动态颜色变化,同时降低了因头部或背景移动、光照变化等因素引入的干扰,从而提高了rPPG信号的准确性和鲁棒性。
1.1. 欧拉视频放大技术
本文引入EVM技术的目的是放大视频中与心率相关的微小变化,从而增强生理信号的可视性。实验表明,先进行颜色放大处理可以减少超分辨率重建过程中可能引起的色彩失真,从而提高图像质量和实用性。EVM技术通过将视频分解为不同空间尺度,并对这些尺度进行带通滤波,以提取呼吸或心跳引起的频率变化。然后,对滤波后的信号进行放大,将放大的信号与原始图像重构,生成包含增强生理信号的视频输出。
1.2. 超分辨率图像重建
经过EVM处理后的视频包含放大的微小变化,为进一步提升分辨率,本文引入超分辨率重建模块,采用子像素卷积层实现从低分辨率到高分辨率的端到端映射。
首先,通过一系列卷积层从输入的低分辨率图像中提取特征,这些层通常采用线性整流函数(rectified linear unit,ReLU)以增加网络的非线性处理能力,具体操作如式(1)所示:
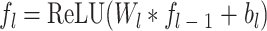 |
1 |
其中,fl表示第l层输入,fl-1表示第l-1层输入,Wl和bl分别是第l层的权重和偏置,“*”表示卷积操作,ReLU(∙)代表激活函数。
接着,通过子像素卷积层进行空间分辨率提升,即通过像素重排操作实现上采样,如式(2)所示:
 |
2 |
其中,fout是输出层的结果,fk − 1是前一层的输出特征图,Wk是子像素卷积层的权重,即低分辨率的图像特征,bk是子像素卷积层的偏置项,PS(∙)代表像素重排操作。
最终,通过端到端训练,超分辨率重建模块能够更好地映射低分辨率到高分辨率,生成的图像边缘更清晰,质量更高。
1.3. 基于卷积注意力模块的动作单元识别
在面部AU识别任务中,为了提高细微面部特征的提取能力,本文引入了基于卷积注意力模块的网络结构。如图2所示,卷积注意力模块包含6个二维卷积层,滤波器的深度依次为 [32, 32, 32, 64, 64, 64]。此外,该模块还包含3个平均池化层,每个池化层后均连接一个丢弃层,丢弃率设置为0.2。这种设计旨在有效提取关键特征,同时通过丢弃层防止过拟合,提升模型的泛化能力。尤其需强调的是,在第一个和第三个二维卷积层之后,本文添加了空间注意力模块。空间注意力模块通过计算特征图在空间维度上的重要性权重,有针对性地增强关键区域的响应,从而进一步提升模型对图像细节的捕获能力。结合卷积层的局部感知特性和空间注意力的全局特征选择,该模块能够更精准地聚焦于图像中的重要信息,为后续特征融合和任务预测提供更加丰富且有效的表征。
图 2.

Convolutional attention module
卷积注意力模块
空间注意力机制的数学表达可以简化表示为如式(3)所示:
 |
3 |
其中,A(x, y)表示空间注意力机制中的输出;X代表输入特征图;W是学习得到的权重,通常是一个卷积核或全连接层的权重,用来对输入特征图 X进行线性变换;“*”是卷积操作;b是偏置,用于对卷积结果进行平移调整。f(∙)表示操作函数,用于生成新的特征图。σ(∙)代表新生成的特征图经过逻辑函数,用于生成每个空间位置的注意力权重。
1.4. 基于卷积多层感知器模块的综合生理信号检测
在rPPG和呼吸频率检测任务中,为了减少由非心脏跳动引起的运动干扰,本文采用处理后的“归一化差值”作为输入,进一步聚焦于视频帧间由心脏跳动引起的微小颜色变化。这种输入方法有效突出了与生理信号相关的动态信息,同时抑制其它无关运动变化。接着,通过卷积多层感知器模块,网络能够精准捕捉这些微小动态特征并减少无关运动干扰带来的噪声。如图3所示,二维卷积在局部空间内提取特征,确保对心脏跳动引起的局部颜色变化进行高效建模;随后,深度可分离卷积进一步降低计算复杂度,同时强化对局部细节的提取能力,减少运动模糊对特征提取的影响。在此基础上,多层感知器模块通过全局通道建模,进一步突出与生理信号相关的全局动态变化,忽略无关运动干扰所带来的不相关信息。此外,通过下采样卷积逐步降低特征图的空间维度,网络实现了更大感受野的动态特征提取,聚焦于全局的关键动态模式。整体而言,卷积多层感知器模块结合卷积与多层感知器模块的优势对动态视频帧间的特征进行提取,旨在有效区分心脏跳动引起的颜色变化与其他无关运动信息,减少无关运动干扰对rPPG和呼吸频率任务的影响。
图 3.

Convolutional multilayer perceptron module
卷积多层感知器模块
2. 实验及分析
2.1. 数据集
本文数据来源于由宾汉姆顿大学和匹兹堡大学联合构建的公开多模态数据集——宾汉姆顿匹兹堡四维自发面部表情数据集(Binghamton Pittsburgh 4 dimensional spontaneous expression database,BP4D)的扩展集(BP4D+),本文在实验中使用了其中的多模态自发情绪语料库[25]。
BP4D+数据集专门用于面部表情识别和生理信号测量,包含了140名来自多种族和文化背景的参与者在10个不同任务场景下录制的视频,总计1 400个视频文件。参与者的年龄和性别覆盖范围广,确保了数据的多样性和广泛适用性。此外,BP4D + 包括丰富的面部表情标签,如8种基本情绪表情和其他复杂的面部行为。数据收集过程中,使用了三维面部成像技术和高速摄像机来捕捉面部动作,每个视频还包含详细的生理信号数据。
2.2. 参数设置
本研究实验训练轮数为10,批大小为128,学习率设置为0.001以平衡训练速度和模型收敛性,优化器采用自适应矩估计优化器,卷积层的激活函数使用ReLU函数,随机丢弃率设置为0.2以缓解过拟合问题。
2.3. 评价指标
(1)平均绝对误差(mean absolute error,MAE):衡量模型预测的心率值与实际心率值之间的平均差异,反映了心率预测的准确性。
(2)平均绝对百分比误差(mean absolute percentage error,MAPE):通过计算预测误差的绝对值与实际值的百分比,然后求取这些百分比的平均值来评估模型的准确性,反映心率预测的相对误差大小。
(3)皮尔逊相关系数(ρ):用于衡量预测心率与真实心率之间的线性相关程度,数值范围在− 1~1之间,数值越接近1表示预测值与真实值的线性关系越强。
(4)F1评分(F1 score):F1评分综合考虑了模型面部AU识别任务的正确性和完整性。F1评分数值越高,表示模型在平衡精确率和召回率方面表现越好,模型在处理正类样本时既准确又全面。
(5)准确率(accuracy,Acc):F1评分和Acc共同为面部AU识别任务提供了全面的性能评估,确保模型不仅能准确分类,还能在处理不平衡类别时保持稳定表现。
2.4. 模型性能对比
本文比较了EMSTN模型与几种代表性算法在rPPG、呼吸频率测量与面部AU识别任务上的性能优劣。这些算法包括两种传统算法:光电容积脉搏波氧饱和度法(photoplethysmogram oxygen saturation,POS)[26]和基于色彩空间算法(chrominance-based algorithm,CHROM)的脉搏波信号处理方法[27],以及四种神经网络方法:高效生理度量(efficient physiological measurement,EfficientPhy)网络[28]、MTTS-CAN、深度生理度量(deep physiological measurement,DeepPhys)网络[29]和BigSmall[25]。在面部AU识别任务中还与深度回归MTL网络(deep regression and MTL,DRML)[30]、亚历克斯网络(Alex network,AlexNet)[31]和BigSmall进行了对比。EMSTN与这些方法在BP4D + 数据集上的对比结果如表1和表2所示。
表 1. Quantitative evaluation table of heart rate and respiratory rate comparison on the BP4D+ dataset.
BP4D+数据集上对比心率与呼吸频率的定量数据评价表
| 方法 | rPPG | 呼吸频率 | ||||
| MAE | MAPE | ρ | MAE | MAPE | ρ | |
| POS | 10.40 | 9.73 | 0.41 | — | — | — |
| CHROM | 5.27 | 5.12 | 0.69 | — | — | — |
| EfficientPhy | 8.86 | 9.85 | 0.41 | — | — | — |
| MTTS-CAN | 2.86 | 3.27 | 0.85 | 3.88 | 18.88 | 0.11 |
| DeepPhys | 2.68 | 3.07 | 0.86 | 3.51 | 17.06 | 0.20 |
| BigSmall | 2.38 | 2.71 | 0.89 | 3.39 | 16.65 | 0.21 |
| EMSTN | 2.25 | 2.56 | 0.90 | 3.34 | 16.54 | 0.22 |
表 2. Quantitative evaluation table of facial AU comparison on the BP4D+ dataset.
BP4D+数据集上对比面部AU识别的定量数据评价表
| 方法 | 面部AU识别 | |
| F1 | Acc | |
| DRML | 44.00 | 74.90% |
| AlexNet | 44.20 | 63.10% |
| BigSmall | 43.30 | 67.40% |
| EMSTN | 44.68 | 67.23% |
如表1所示,EMSTN模型集成EVM技术、超分辨率重建模块以及卷积多层感知器模块,在BP4D + 数据集上的性能显著优于基线模型POS、CHROM、EfficientPhy。在rPPG与呼吸频率测量任务中,对比基准模型BigSmall,EMSTN模型在BP4D + 数据集上显示出以下指标的显著改进:MAE呈现明显下降,MAPE显著降低,ρ值也有提高。具体而言,EMSTN在这两个任务中的表现均优于BigSmall,表现出更强的精度和稳定性。如表2所示,加入空间注意力机制后,EMSTN在MTL任务中的性能提升显著,其F1评分达到44.68,较BigSmall模型的43.30有明显提高。
如图4和图5所示,虚线代表模型的预测值,实线代表真实值。图4、图5中两条曲线高度吻合,尤其在波峰与波谷部分,模型能够精准捕捉生理信号的周期性变化,表现出极高的预测精度和稳定性。在心率预测任务中,EMSTN模型有效还原了心脏跳动引起的微小颜色变化,误差极小;而在呼吸频率预测任务中,模型同样能够准确模拟呼吸信号的起伏趋势,避免了由非周期性噪声引起的干扰。整体来看,EMSTN模型在两项任务中均实现了最低的误差和最好的相关性,表明其在捕捉微小生理信号变化方面的优越性。
图 4.

Heart rate prediction curve
心率预测曲线
图 5.

Respiratory rate prediction curve
呼吸频率预测曲线
综上所述,详细的数据分析显示,尽管在面部AU识别任务中的Acc有所下降,改进后的EMSTN模型在MTL框架中取得了显著的性能提升。整体而言,该模型展现了更优的性能和更佳的任务平衡性。
2.5. 消融实验
为了进一步研究本文提出的方法在模型性能上的影响,进行了消融实验,结果如表3所示。
表 3. Ablation studies of EMSTN.
EMSTN消融实验
| 模型 | rPPG | 呼吸频率 | 面部AU识别 | |||||||
| MAE | MAPE | ρ | MAE | MAPE | ρ | F1 | Acc | |||
| 去除EVM | 3.16 | 7.38 | 0.64 | 3.43 | 16.84 | 0.21 | 46.59 | 71.33% | ||
| 去除超分辨率重建模块 | 2.89 | 6.21 | 0.85 | 3.75 | 17.12 | 0.19 | 41.55 | 67.83% | ||
| 去除EVM和超分辨率重建模块 | 3.41 | 7.52 | 0.81 | 4.02 | 18.21 | 0.16 | 44.25 | 68.97% | ||
| 去除空间注意力 | 2.36 | 3.07 | 0.87 | 3.45 | 16.99 | 0.21 | 42.38 | 66.12% | ||
| EMSTN | 2.25 | 2.56 | 0.90 | 3.34 | 16.54 | 0.22 | 44.68 | 67.23% | ||
如表3所示的数据,移除EVM技术后,模型在多个任务上的性能明显下降。特别是在rPPG测量任务中,去除EVM后,模型的MAE和MAPE显著增加,ρ值明显下降,这表明EVM对心率相关信号的增强至关重要。相比之下,呼吸频率测量任务的性能下降较小,MAE、MAPE和ρ值的变化较为温和,表明EVM对呼吸频率测量的影响相对较小。在面部AU识别任务中,去除EVM后F1评分和Acc反而略有提升,这可能是由于去除了EVM所引入的额外噪声。
去除超分辨率重建模块对所有任务的性能均产生了不利影响,尤其是在rPPG和呼吸频率预测上。MAE显著增加,证明高质量图像重建对于准确性的重要性。而,同时移除EVM和超分辨率重建模块导致rPPG和呼吸频率测量的准确度大幅降低,表明这两种技术能显著提升这两个生理测量任务的准确度。虽然面部AU识别任务也出现了性能下降,但下降程度较轻,表明该任务对EVM和超分辨率重建模块的依赖较低。
去除空间注意力模块虽对rPPG和呼吸频率的测量影响较小,但其对面部AU识别的F1评分和Acc造成明显下降,证实了空间注意力在提升面部特征识别中的重要性。
综上所述,EVM和超分辨率重建模块对于rPPG和呼吸频率的精确预测至关重要,而空间注意力则显著增强了面部表情识别的效果。尽管去除某些组件在特定任务中可能带来性能提升,但总体上,包含这些创新技术的模型表现出更高的准确性和鲁棒性。
3. 结论
本文提出了一种改进的多任务神经网络EMSTN,旨在并行测量rPPG、呼吸频率和面部AU识别。为了增强模型的测量能力,本文在架构中集成了三项关键创新:EVM技术、超分辨率重建模块以及卷积多层感知器模块。此外,引入空间注意力模块以增强特征提取的精度和效率。通过在BP4D+数据集上的广泛实验,本文验证了模型改进的有效性。实验结果表明,改进后的模型在rPPG测量任务中,MAE和MAPE降低,同时ρ值提高,显示出在心率测量任务中的优异表现。在呼吸频率测量任务中,MAE和MAPE的下降幅度较小,ρ值提高明显,表明该模型在呼吸频率测量中的优势。面部AU识别任务中,EMSTN模型的F1评分较基准模型BigSmall有小幅提升,尽管在Acc上略低于BigSmall,但整体性能依然表现出色。研究表明,本文提出的改进模型在多个生理信号测量任务中表现优越,验证了各个创新模块的有效性。
重要声明
利益冲突声明:本文全体作者均声明不存在利益冲突。
作者贡献声明:徐思源负责数据分析、数据收集、实验设计、代码设计、实验分析和论文写作;张孙杰负责提出研究的内容和意义、实验可行性分析、基金支持和论文修订。
Funding Statement
国家自然科学基金资助项目(61603255);上海市晨光计划项目(18CG52)
References
- 1.Prathosh A P, Praveena P, Mestha L K, et al Estimation of respiratory pattern from video using selective ensemble aggregation. IEEE Trans Signal Process. 2017;65(11):2902–2916. doi: 10.1109/TSP.2017.2664048. [DOI] [Google Scholar]
- 2.Song R, Zhang S, Cheng J, et al New insights on super-high resolution for video-based heart rate estimation with a semi-blind source separation method. Comput Biol Med. 2020;116:103535. doi: 10.1016/j.compbiomed.2019.103535. [DOI] [PubMed] [Google Scholar]
- 3.Jeon H J, Kim J D, Lim S J Pulse detection from PPG signal with motion artifact using independent component analysis and nonlinear auto-correlation. J Sens Sci Technol. 2016;25(1):71–78. doi: 10.5369/JSST.2016.25.1.71. [DOI] [Google Scholar]
- 4.曾梓琳, 胡志刚, 尚鹏, 等 基于面部视频的非接触式心率检测方法研究. 计算机科学. 2022;49(11A):211000182. doi: 10.11896/jsjkx.211000182. [DOI] [Google Scholar]
- 5.Cipolla R, Gal Y, Kendall A. Multi-task learning using uncertainty to weigh losses for scene geometry and semantics// 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City: IEEE, 2018: 7482-7491.
- 6.Sener O, Koltun V. Multi-task learning as multi-objective optimization. Adv Neural Inf Process Syst, 2018: 31.
- 7.Yu T, Kumar S, Gupta A, et al Gradient surgery for multi-task learning. Adv Neural Inf Process Syst. 2020;33:5824–5836. [Google Scholar]
- 8.Caruana R Multitask learning. Mach Learn. 1997;28:41–75. doi: 10.1023/A:1007379606734. [DOI] [Google Scholar]
- 9.Kokkinos I. Ubernet: Training a universal convolutional neural network for low-, mid-, and high-level vision using diverse datasets and limited memory//2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu: IEEE, 2017: 6129-6138.
- 10.Zhang K, Zhang Z, Li Z, et al Joint face detection and alignment using multitask cascaded convolutional networks. IEEE Signal Process Lett. 2016;23(10):1499–1503. doi: 10.1109/LSP.2016.2603342. [DOI] [Google Scholar]
- 11.刘正成. 基于人脸视频的非接触式心率检测方法研究. 长春: 东北师范大学, 2021.
- 12.Ekman P, Levenson R W, Friesen W V Autonomic nervous system activity distinguishes among emotions. Science. 1983;221(4616):1208–1210. doi: 10.1126/science.6612338. [DOI] [PubMed] [Google Scholar]
- 13.Martinez B, Valstar M F, Jiang B, et al Automatic analysis of facial actions: a survey. IEEE Trans Affective Comput. 2017;10(3):325–347. [Google Scholar]
- 14.McDuff D Camera measurement of physiological vital signs. ACM Comput Surv. 2023;55(9):176. [Google Scholar]
- 15.Verkruysse W, Svaasand L O, Nelson J S Remote plethysmographic imaging using ambient light. Opt Express. 2008;16(26):21434–21445. doi: 10.1364/OE.16.021434. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 16.Liu X, Fromm J, Patel S, et al Multi-task temporal shift attention networks for on-device contactless vitals measurement. Adv Neural Inf Process Syst. 2020;33:19400–19411. [Google Scholar]
- 17.Narayanswamy G, Liu Y, Yang Y, et al. BigSmall: efficient multi-task learning for disparate spatial and temporal physiological measurements//2024 IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), Waikoloa: IEEE, 2024: 7914-7924.
- 18.Lin J, Gan C, Han S. TSM: Temporal shift module for efficient video understanding//2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul: IEEE, 2019: 7083-7093.
- 19.Qiu Y, Liu Y, Arteaga-Falconi J, et al EVM-CNN: real-time contactless heart rate estimation from facial video. IEEE Trans Multimedia. 2019;21(7):1778–1787. doi: 10.1109/TMM.2018.2883866. [DOI] [Google Scholar]
- 20.Jaiswal K B, Meenpal T rPPG-FuseNet: non-contact heart rate estimation from facial video via RGB/MSR signal fusion. Biomed Signal Process Control. 2022;78:104002. doi: 10.1016/j.bspc.2022.104002. [DOI] [Google Scholar]
- 21.Zhang J, Yan B, Du X, et al Motion magnification multi-feature relation network for facial microexpression recognition. Complex Intell Syst. 2022;8(4):3363–3376. doi: 10.1007/s40747-022-00680-2. [DOI] [Google Scholar]
- 22.Dong C, Loy C C, He K, et al Image super-resolution using deep convolutional networks. IEEE Trans Pattern Anal Mach Intell. 2015;38(2):295–307. doi: 10.1109/TPAMI.2015.2439281. [DOI] [PubMed] [Google Scholar]
- 23.Cao M, Liu Z, Huang X, et al. Research for face image super-resolution reconstruction based on wavelet transform and SRGAN//2021 IEEE 5th Advanced Information Technology, Electronic and Automation Control Conference (IAEAC), Chongqing: IEEE, 2021, 5: 448-451.
- 24.Shi W, Caballero J, Huszár F, et al. Real-time single image and video super-resolution using an efficient sub-pixel convolutional neural network//2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas: IEEE, 2016: 1874-1883.
- 25.Zhang Z, Girard J M, Wu Y, et al. Multimodal spontaneous emotion corpus for human behavior analysis//2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas: IEEE, 2016: 3438-3446.
- 26.Wang W, den Brinker A C, Stuijk S, et al Algorithmic principles of remote PPG. IEEE Trans Biomed Eng. 2016;64(7):1479–1491. doi: 10.1109/TBME.2016.2609282. [DOI] [PubMed] [Google Scholar]
- 27.de Haan G, Jeanne V Robust pulse rate from chrominance-based rPPG. IEEE Trans Biomed Eng. 2013;60(10):2878–2886. doi: 10.1109/TBME.2013.2266196. [DOI] [PubMed] [Google Scholar]
- 28.Liu X, Hill B, Jiang Z, et al. EfficientPhys: enabling simple, fast and accurate camera-based cardiac measurement//2023 IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), Waikoloa: IEEE, 2023: 5008-5017.
- 29.Chen W, McDuff D. DeepPhys: Video-based physiological measurement using convolutional attention networks//Proceedings of the European Conference on Computer Vision (ECCV), Springer, 2018: 349-365.
- 30.Zhao K, Chu W S, Zhang H. Deep region and multi-label learning for facial action unit detection//2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas: IEEE, 2016: 3391-3399.
- 31.Krizhevsky A, Sutskever I, Hinton G E ImageNet classification with deep convolutional neural networks. Commun ACM. 2017;60(6):84–90. doi: 10.1145/3065386. [DOI] [Google Scholar]