

Abstract
Medicine is one of the most sensitive fields in which artificial intelligence (AI) is extensively used, spanning from medical image analysis to clinical support. Specifically, in medicine, where every decision may severely affect human lives, the issue of ensuring that AI systems operate ethically and produce results that align with ethical considerations is of great importance. In this work, we investigate the combination of several key parameters on the performance of artificial neural networks (ANNs) used for medical image analysis in the presence of data corruption or errors. For this purpose, we examined five different ANN architectures (AlexNet, LeNet 5, VGG16, ResNet-50, and Vision Transformers - ViT), and for each architecture, we checked its performance under varying combinations of training dataset sizes and percentages of images that are corrupted through mislabeling. The image mislabeling simulates deliberate or nondeliberate changes to the dataset, which may cause the AI system to produce unreliable results. We found that the five ANN architectures produce different results for the same task, both for cases with and without dataset modification, which implies that the selection of which ANN architecture to implement may have ethical aspects that need to be considered. We also found that label corruption resulted in a mixture of performance metrics tendencies, indicating that it is difficult to conclude whether label corruption has occurred. Our findings demonstrate the relation between ethics in AI and ANN architecture implementation and AI computational parameters used therefor, and raise awareness of the need to find appropriate ways to determine whether label corruption has occurred.
Supplementary Information
The online version contains supplementary material available at 10.1038/s41598-025-15268-2.
Keywords: Ethics, Artificial neural network, Chest X-ray images, Label corruption, Dataset size
Subject terms: Health policy, Medical ethics, Medical imaging, Computer science, Information technology, Scientific data, Software
Introduction
At these times, it is evident that Artificial intelligence (AI) is being implemented in many aspects of our lives in an astonishing rapid manner, from gaming to finance, from law to agriculture to name but a few1–4.One of the fields that uses AI tools most extensively is image processing, where tasks such as image segmentation, recognition, and classification are constantly improved by AI-tools5. In particular, the analysis of medical images with AI tools has been used not only for disease diagnosis5,6, but also for real-time video surgical navigation7 and inference process auditing 8.
Along with the benefits provided and anticipated by AI systems and tools, there are concerns regarding ethical issues at all levels of creation and use of the AI systems and tools, including, inter alia, training, algorithms and models, and ways of using AI applications9–11. The ethical issues refer to bias, security, privacy, and many more12, and there is a great need to investigate further and cope with the aforementioned ethical issues to promise reliable AI-based image analysis13–23.
Here, the relation of ethics to AI is considered in terms of “labeling errors” in the training dataset, or specifically, intentionally-made label poisoning (rather than accidental error). In large datasets, it is common to encounter accidental labeling errors, which arise from various reasons, such as lack of expertise, carelessness, or technical glitches, and may include typos, missing data, duplicate entries, or incorrect formatting. If not detected and corrected in time, they can affect the accuracy and reliability of the predicted data and may lead to erroneous conclusions.
Intentionally-made errors can be inserted into AI systems by adversaries, which is why it is sometimes called label poisoning24,25. These errors may be caused by the adversaries intentionally mislabeling or inserting inaccurate and biased data, if the adversaries have hidden agendas (such as racism or political tendencies) that can lead them to insert such errors19. A hypothetical scenario that demonstrates deliberate insertion of errors is where an adversary can gather or corrupt a training dataset of healthy patients under a certain age based on a belief or intent to show that a disease cannot occur under that age. Such a dataset can lead to biased results, and the AI system trained on such data may not be able to detect the disease in patients who are younger than the age group values. Therefore, it is crucial to be vigilant and ensure that AI systems are trained on accurate and unbiased data to avoid unintended consequences.
This work aims to address the relation of ethics in AI to artificial neural network (ANN)-based medical image analysis. Specifically, we are addressing the issues of what happens if the dataset size is reduced, if labeling errors occur during training, and how different ANN architectures perform in the presence of different amounts of labeling errors and/or dataset sizes. The motivation of our research is to link ethics in AI and the effect of dataset reduction and label corruption conditions on different network architectures, and if some network architectures perform better or are less sensitive than others under such conditions, to flag a need to consider this as a further requirement when a network architecture is selected for implementation.
Research on the linkage between ethics and medical-AI is of great importance since, already today, many physicians use AI for clinical practice tasks and rely on its outputs (according to a recent survey that was done in the United Kingdom (UK) - one in five general practitioners admits using GenAI tools for clinical practice tasks26. A biased AI system against a specific sex or race (which is a known phenomenon in AI27, or if a group with a hidden agenda will build an AI model aimed to deliver results according to the group’s hidden agenda, can lead to catastrophic consequences such as incorrect diagnostics and faulty disease detection, which can affect certain populations.
Related works
In this work, we investigate two sources of possible performance accuracy corruption, analyze their effect on neural network (NN) performance, and describe how such corruption is connected to ethics in AI. The first possible source of corruption is a reduction in dataset size. Many studies investigated the effect of dataset size on the performance of NN, in many fields, such as medicine and geoscience28,31,29,30. For example, in28 the authors investigated the performance of 6 different classification models (only one of them is NN) on 20 different datasets with a reduction of 50% and 90% in medical dataset sizes, and revealed that some classifiers show good performances (in terms of recall and accuracy) even with small dataset sizes.
A similar conclusion was reported in29, using two segments of medical dataset size reduction (90% and 99%). Interestingly, an opposite conclusion was derived in30, where the authors used head-and-neck CT images with 10 segments size reduction (i.e., from 10 training images to 800 training images) imported to a single NN model (U-Net). It was found that the dataset size had major influence on the performance of the NN (in terms of dice-similarity-coefficient), but a small dataset size (~ 40) can be used for specific organ segmentation. The great influence of dataset size on NN performance was also observed in geoscience, for carbonate rock classification31, where the authors compared the performance of 9 different Convolutional Neural Network (CNN) architectures for three dataset sizes: 7,000, 42,000 and 104,000 training images. The authors recommended to use more than 100,000 training images in order to get accurate classification results, as opposed to most studies in the geoscience field that use a 90% smaller dataset size for the same classification tasks. In addition, the authors showed that the Inception-v3 and ResNet architectures produce high training accuracies (> 90%), but this does not always translate to high test accuracies.
The second possible source of corruption is label poisoning that stems from various reasons. One source of such label corruption is noise32,33, which reduces the classification accuracy with increasing noise fraction. An imbalance in medical imaging datasets20 can be considered as an error, which leads to a biased classification in medical diagnosis. Both sources of label poisoning may be related to accidental errors. Intentionally-made errors, such as the ones investigated in19, are also a source of label poisoning. In19, the authors introduced the balance-corruption method, suggesting that a reduction in classification accuracy may also be a result of an imbalanced dataset and not only due to label corruption.
Altogether, research in the field of ethics in AI for medicine is rapidly growing, and it includes various aspects of ethical issues, from bias to AI hallucinations34–46. For example, the work34 describes 13 types of biases found in AI for pathology image analysis, and in the work35 five sources of bias in AI were analyzed. Furthermore, new AI methods, like synthetic medical image generation (aimed to reduce labeling efforts)47,48 or transfer learning (aimed to overcome small-sized datasets)49 raise novel ethical issues such as imbalanced performances against race50 and propagated bias51.
The motivation and scope of this work are:
To investigate the effect of various combinations of dataset size changes, ANN architecture selections, and label corruption amounts on the performance of ANN classifiers;
If some network architectures perform better or are less sensitive than others under such conditions, to flag a need to consider this as a further requirement for network architecture selection.
To consider this issue concerning the effects on AI-ethics aspects.
A comparison of this work and related works in the field of ethics-in-AI for healthcare is presented in Table 1.
Table 1.
Comparison of related works describing ethical aspects in AI for healthcare and this work.
| Work | Key findings |
|---|---|
| Hanna, M. et al.34 | Reviews various types of biases found in pathology and describes ways to mitigate it. |
| Mennella, C et al.37 | Reviews general principles and guidelines to ethical concepts in AI for healthcare (beyond bias). |
| Kim, Y. et al.39 | Investigates the phenomenon of hallucinations found in medical data generated by an AI-based Foundation Model. |
| Larrazabal, A.J.,et al.20 | Discusses gender imbalance and shows a decrease in performance when two datasets are imbalanced (men vs. women) and evaluates three types of NNs. |
| Kaplan, S. et al.19 | Investigates the sensitivity of the performance of AI systems to labelling errors. |
| This work | Evaluates the response of five ANN architectures to dataset size reduction and deliberate dataset corruption with respect to ethics in AI. |
Methods
In the following paragraphs, we explain in detail the procedures in our investigation, including the selection of two databases and five ANN architectures.
Databases
We used two databases in this research. First, we chose to refer to a non-human labeled database named “ChestX-ray8” that was developed in52 and was taken from Kaggle (https://www.kaggle.com/datasets/nih-chest-xrays/data). This database comprises 108,948 frontal-view hospital-scale chest X-ray images of 32,717 patients, each labeled with eight thoracic disease classifications using text mining, with > 90% accuracy. Second, we used the Skin Cancer “MNIST: HAM10000” database that was also taken from Kaggle (https://www.kaggle.com/datasets/kmader/skin-cancer-mnist-ham10000). This database is a large collection of multi-source dermatoscopic images of pigmented skin lesions. It contains 10,015 images collected from different populations and acquired using various modalities.
The ChestX-ray8 database is the database for which the procedures is explained in detail below.
Database pre-processing
To facilitate simpler performance evaluation metrics, we first pre-processed the database. Since the database is both multi-class and multi-label (i.e., each data point can be assigned to more than one class), as well as highly imbalanced (i.e., there are significant differences in the number of data points across the different classes), we pre-processed the database according to the following steps:
Instead of 8 labels, we discarded all multi-labeled images and took only the 4 most represented classes, leaving us with 19,192 images. By selecting only single-labeled images and only the 4 most represented classes, we created, in fact, a new dataset, derived from the entire ChestX-ray8 database, and this new dataset became the source dataset on which we performed reduction and corruption operations. Selection of only the four most represented classes also enabled us to avoid the classes with very small numbers of images, which even under very small mislabeling percentages may result in complete class mislabeling and distort the analysis.
We resized all the images to 128 × 128 using the Lanczos resampling53 to maintain their quality while making them more manageable for further analysis. Compared to other methods for decimating and interpolating 2D image data, the Lanczos technique offers the best compromise for reducing aliasing, maintaining sharpness, and minimizing ringing54.
We standardized each X-ray image using the Mean-Variance-Softmax-Rescale (MVSR) algorithm55. Such a normalization process is crucial for enhancing the accuracy of ANN models. By normalizing the images, we prevent network layers from becoming saturated or deteriorated, which, in turn, helps maintain the stability and effectiveness of the models.
After implementing data pre-processing techniques, we achieved a perfectly balanced dataset with an equal distribution of diagnoses. This means that each diagnosis category was represented equally in the dataset. Figure 1 shows the distribution of the ChestX-ray8 database before our pre-processing. The distribution of the top four diagnoses from the original dataset is illustrated in Fig. 1a. It is evident that the dataset is highly imbalanced, with the most frequent diagnosis being ‘No Finding.’ An example of post-processed ChestX-ray8 images (for every diagnosis with high contrast) is depicted in Fig. 1b. Even though the information about patient’s sex is not explicitly received, such information can be retrieved from frontal Chest X-ray images themselves56. In Fig. 1c, the breakdown of patient sex and age for each diagnosis as a function of the relative number of diagnoses is displayed. The patient sex distribution is consistent across all age groups for each diagnosis, as depicted in the figure. The dotted lines represent the mean and standard deviation (SD).
Fig. 1.

(a) Dataset balance for top four single-label diagnoses, (b) Visual examples of top four thorax diagnoses after rebalancing, (c) Diagnosis distribution in the rebalanced dataset. The x-axis variable is the relative number of diagnoses. Our main purpose is to show that we have an equal number of images per patient sex and diagnosis, with roughly the same distribution across age. The dotted lines represent the mean and SD.
The MNIST: HAM10000 database was preprocessed using the same methods as the ChestX-ray8 database.
The corruption-reduction method
To examine the impact of biased label corruption and dataset size on the performance of neural networks, we made the following modifications:
We introduced corruption and reduction parameters to determine the relative percentage of mislabeled images and the number of removed images from a target dataset.
We created a deliberately biased dataset by making changes based on patient’s sex.
To create a biased representation of the data in the ChestX-ray8 derived dataset, we randomly selected images with the diagnoses of “Atelectasis,” “Effusion,” and “Infiltration” with uniform probability and marked them as “No Finding” for male patients only. This was done starting from 0% corruption, where no mislabeling occurs, up to 60% corruption in steps of 5%. For example, a corruption level of 25% with the target patient sex of “Male” meant that 25% of images with the source label of “Atelectasis,” “Effusion,” and “Infiltration” on male patients were marked as “No Finding.”
While it seems that two types of corruption occur simultaneously, i.e., incorrect diagnostics and incorrect gender determination, the patient’s sex remains unchanged, while diagnosing labeling can be corrupted. However, when the size of a specific patient group is reduced, itlowers the total number of images in the group, including incorrectly labeled images.
Similarly, we used a reduction parameter to represent the percentage of images removed from the dataset. Since we aimed to create an imbalanced, biased dataset, the reduction parameter was applied to the same patient sex as the corruption parameter. The reduction parameter ranges from 0 to 100%. A reduction of 0% means that all images from the source dataset are present in the target dataset. In comparison, a reduction of 100% means that no images of the selected patient group exist in the target dataset. The step size for the reduction parameter was the same as that for the corruption parameter, namely 5%.
The use of these parameter changes simulates possible cases of biased diagnoses of groups, such as minority groups, and inadequate dataset size selection, which in turn may also contribute to such bias. The bias may occur due to various reasons such as hidden agendas, racism, or political interests. Such biased diagnoses can lead to inaccurate treatment and negative consequences for the affected individuals. Therefore, addressing and eliminating any biases in the diagnostic process is essential to ensure that everyone receives fair and equitable healthcare, regardless of race, ethnicity, or sex.
Artificial neural network architectures
We used the following well-known ANN architectures: AlexNet, LeNet 5, VGG16, ResNet-50, and Vision Transformers (ViT). The architecture of each ANN and its parameters are described in the Supporting Information section.
We used Python as the primary programming language to train all neural networks with the PyTorch framework in a Linux environment. We utilized the advanced capabilities of an AMD RX 7900 XTX graphics processing unit (GPU) to accelerate the training process.
Training process
To evaluate the performance of our neural network models with biased datasets, we chose 50 images from each patient group and diagnosis. These images were set aside for testing and were not included in the training dataset. The remaining images were split with a 4:1 ratio for training and validation. The number of training and validation images was reduced to achieve the effect of dataset size reduction on accuracy and/or a portion of the training images was corrupted to achieve the effect of bias on the obtained results. The validation images were used to monitor performance during training and optimize hyper-parameters such as the learning rate.
During our research, we encountered a potential issue with overfitting in the neural network. This was due to the significant reduction of the dataset and the injection of corrupted labels. To address this issue, we implemented an early stop technique57. This technique enables the network to stop training once it reaches a certain level of loss on the validation data, thereby preventing overfitting and improving the model’s generalization ability. By utilizing this technique, we ensured that our neural network performed optimally and produced accurate results. The flow chart of the Early-Stop is in the Supporting Information.
Performance analysis
We have opted to utilize precision and recall as our evaluation metrics and not accuracy, since the last parameter is less appropriate to imbalanced data distribution. As is well known55precision is a measure that tells how well the model predicts positive classes, and it is given by the formula:
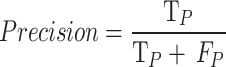 |
1 |
While recall is a measure that tells how well the model predicts positive classes out of all real positive classes, and it is given by the formula:
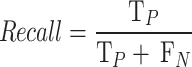 |
2 |
where 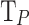 is a True Positive,
is a True Positive, 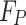 is a False Positive example, and
is a False Positive example, and  is a False Negative example for a specific class.
is a False Negative example for a specific class.
We also used a score, F1 score, which combines precision and recall using their harmonic mean, which means that maximizing F1 score implies simultaneously maximizing both precision and recall according to:
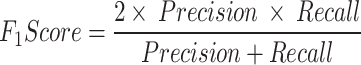 |
3 |
Lastly, we calculated the macro-averaged precision and recall scores upon obtaining each class’s precision and recall values. This was done by taking the mean of the precision and recall values across all classes. This approach provides equal weighting to each class, regardless of its size or frequency in the dataset:
 |
4 |
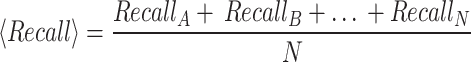 |
5 |
Where  is macro average.
is macro average.
Computing the macro-averaged precision and recall scores can evaluate the model’s overall performance across all classes. This metric is particularly useful when the goal is to assess the model’s average performance rather than its performance for a specific class. Additionally, it can help identify potential imbalances in the model’s performance across different classes, indicating that further adjustments to the model are needed or recommended.
To understand how system performance changes, we need to examine precision and recall in relation to each other. Due to fundamental limitations, it is very difficult to achieve perfect precision and recall on real-life datasets. There will ultimately be a trade-off between these two measures.
Improving precision, which means reducing the proportion of false positives, is likely to decrease true positives—thus affecting recall negatively. Similarly, to enhance recall by reducing the proportion of false negatives may increase the percentage of false positives, which would adversely impact precision.
Reduce learning rate on plateau
Instead of using a fixed learning rate, we implemented an adaptive one with faster convergence and better performance. This enables the network to quickly adapt to changes in the loss function and avoid getting stuck in local minima. Hence, we used the Reduce Learning Rate on Plateau method58 which reduces the learning rate when the specified metric stops improving for an extended period. A description of this algorithm appears in the Supporting Information.
Results
The results below are presented separately for the ChestX-ray8 and the MNIST: HAM10000 databases.
ChestX-ray8
We examined the effect of dataset size reduction and label corruption on the performance of each of the five different ANN architectures mentioned above. Throughout our studies, we meticulously recorded all performance metrics for each process step, considering all three dataset intended segments: training, validation, and testing. To ensure no interference exists between the neural network’s weight and the optimizer’s parameters, we adopted a rigorous approach of recreating and initializing the neural network from scratch for each step. This helped us maintain a consistent baseline and ensure accurate and reliable results at every stage.
We used the ANN architectures “as is”, namely without any optimization because these are the network architectures that users usually take as starting points, even though they did not show good enough performance in advance. This means that the network is not optimized for this image set (x-ray chest images) – it can be pre-trained and optimized on other datasets.
Utilizing pre-trained and optimized networks is often beneficial to ensure efficient and speedy development of research processes. To facilitate this, we maintained the original network architecture as closely as possible despite the potential impact on overall performance.
Figures 2, 3, 4, 5 and 6 show precision heatmaps of the ANN architectures ResNet-50, AlexNet, VGG-16, LeNet-5, and ViT, respectively, each representing the results for various dataset sizes and label corruption. All the precision heatmaps were obtained from the utilization of the same new dataset mentioned above, which was derived from the entire ChestX-ray8 database.
Fig. 2.

ResNet-50 precision heatmap based on dataset size and label corruption, analyzing male patients only, female patients only, and combined data per diagnosis.
Fig. 3.

AlexNet precision heatmap based on dataset size and label corruption, analyzing male patients only, female patients only, and combined data per diagnosis.
Fig. 4.

VGG-16 precision heatmap based on dataset size and label corruption, analyzing male patients only, female patients only, and combined data per diagnosis.
Fig. 5.

LeNet-5 precision heatmap based on dataset size and label corruption, analyzing male patients only, female patients only, and combined data per diagnosis.
Fig. 6.

ViT precision heatmap based on dataset size and label corruption, analyzing male patients only, female patients only, and combined data per diagnosis.
Just from looking at the differences in colors between corresponding areas in the heatmaps of Figs. 2, 3, 4, 5 and 6, it can easily be noticed that the results obtained for various dataset sizes and label corruptions are different when different network architectures are used, even though the utilized dataset is the same. This means that the above-mentioned ANN architectures do not provide the same results for the same task of chest X-ray diagnosis. Additionally, the different network architectures also have different sensitivities to dataset reduction and label corruption. Figures 7 and 8 show specific examples of such differences between results obtained by two different ANN architectures for the same task.
Fig. 7.

Precision and recall metrics for ResNet-50 for each diagnosis and patient sex (a) without dataset modification, and (b) under 35% label corruption.
Fig. 8.

Precision and recall metrics for AlexNet for each diagnosis and patient sex (a) without dataset modification, and (b) under 35% label corruption.
Figures 7 and 8 respectively show precision and recall metrics for ResNet-50 and AlexNet for each diagnosis and patient sex without dataset modification (Figs. 7a and 8a), and under 35% label corruption (Figs. 7b and 8b). It is clear that the diagnostic results with and without corruption obtained with the two different ANN architecture are different. It is also interesting to note that for certain diagnosis results, label corruption has increased precision and reduced recall (e.g., Fig. 7, infiltration diagnosis and Fig. 8, atelectasis diagnosis), and for some other diagnosis results label corruption has reduced precision and increased recall.
(e.g., Figs. 7 and 8, “no finding” diagnosis – in Fig. 8 increased recall for “no finding” was obtained for female patients only).
A combination of increased precision with reduced recall (with respect to the no dataset modification case) indicates that a classifier operating under such combination is very cautious or skeptical in its predictions. It is confident about the few positive instances it identifies but may overlook many actual positives. For example, in an application of detecting fraudulent transactions, high precision and low recall mean that the transactions flagged as fraudulent are likely to be accurate. However, many actual fraudulent transactions may be missed.
A combination of reduced precision with increased recall (with respect to the no dataset modification case) indicates that a classifier operating under such combination catches many actual positive cases. However, it also identifies many false positives. For example, in detecting fraudulent transactions, this means that many transactions get flagged, but many of those might be legitimate.
Accordingly, label corruption that generates the combination of increased precision with reduced recall or the combination of reduced precision with increased recall makes the results obtained using an ANN architecture in which these combinations occur unreliable.
Figures 9 and 10 show two additional specific examples of the results obtained by two different ANN architectures. Figure 9 shows precision and recall metrics for VGG-16 for each diagnosis and patient sex (a) without dataset modification and (b) under 35% label corruption with 60% dataset reduction. Figure 10 shows precision and recall metrics for LeNet-5 for each diagnosis and patient sex (a) without dataset modification and (b) under 50% dataset reduction.
Fig. 9.

Precision and recall metrics for VGG-16 for each diagnosis and patient sex (a) without dataset modification and (b) under 35% label corruption with 60% dataset reduction.
Fig. 10.

Precision and recall metrics for LeNet-5 for each diagnosis and patient sex (a) without dataset modification and (b) under 50% dataset reduction.
Figure 9 shows a drop in precision under 35% label corruption with 60% dataset reduction for all diagnosis results, except for the “Effusion” diagnosis for male patients, with respect to the case where there is no dataset modification. A drop is also shown for the recall, with respect to the case where there is no dataset modification, for all diagnosis results except for the “No Finding” diagnosis for male patients.
Figure 10 shows that with respect to the case where there is no dataset modification, the effect of a 50% dataset reduction alone is relatively small or moderate.
MNIST: HAM10000
Figures 11 and 12 show precision heatmaps of the ANN architectures ResNet-50 and AlexNet, respectively, each representing the results for various dataset sizes and label corruption for the diagnoses of BCC (Basal Cell Carcinoma), BKL (Benign Keratosis-like Lesions), Mel (Melanoma), and Nv (Melanocytic Lesions). Looking at the differences in colors between corresponding areas in the precision heatmaps, the results for Bcc and NV clearly show that precision increases as corruption increases both for male and female patients and both for ResNet-50 and AlexNet. Also, in certain instances, for example, with respect to Mel and NV, ResNet-50 and AlexNet provide different results both for male and female patients.
Fig. 11.

ResNet-50 precision heatmap based on dataset size and label corruption, analyzing male patients only, female patients only, and combined data per diagnosis.
Fig. 12.

AlexNet precision heatmap based on dataset size and label corruption, analyzing male patients only, female patients only, and combined data per diagnosis.
Figure 13 shows a specific example of the results obtained by ResNet-50 architecture. Here, the ResNet-50 model shows increased recall and decreased precision for patients diagnosed with melanoma (Mel) when encountering label corruption, compared to its performance on an unmodified dataset. As mentioned above with respect to Figs. 11 and 12, there are conflicting cases where precision increases as corruption increases. This means that label corruption results in a mixture of performance metrics tendencies.
Fig. 13.

Precision and recall metrics for ResNet-50 for each diagnosis and patient sex (a) without dataset modification and (b) under 35% dataset corruption.
Discussion
This work deals with investigation of some parameters related to datasets used for training neural networks and their effect on the performance of the neural networks, and for this purpose an AI-based task of chest X-ray diagnosis was selected and examined using different ANN architectures and an AI-based task of dermatoscopic image analysis was examined using some of the different ANN architectures. The parameters examined in respect of these tasks and for each of the different ANN architectures included dataset size reduction and label corruption, which may lead to undesired results in terms of ethical perspectives.
Referring to the task of chest X-ray diagnosis, one outcome of this work is that for the same utilized dataset and for the same task of chest X-ray diagnosis, the five ANN architectures mentioned above do not provide the same results, even in the absence of dataset modification. This means that these five different network architectures differ both in performance and in sensitivity to dataset size reduction and label corruption.
Another outcome is that, when examining precision and recall for the task, label corruption results in a mixture of performance metrics tendencies. For example, in Fig. 7, label corruption of 35% increased precision for Atelectasis and Infiltration diagnoses both for male and female patients, increased precision for Effusion diagnosis for male patients but decreased precision for Effusion diagnosis for female patients, and decreased precision for “No Finding” diagnosis both for male and female patients. As for recall, the label corruption of 35% decreased recall for Atelectasis diagnosis for male patients but increased recall for Atelectasis diagnosis for female patients, decreased recall for Effusion and Infiltration diagnoses both for male and female patients, and increased recall for “No Finding” diagnosis both for male and female patients. Other mixtures of performance metrics tendencies are apparent from Fig. 8.
While some of the tendencies for precision and recall for the “No Finding” diagnosis may be explained by that the mislabeling was carried out by changing, for male patients only, the labeling of some selected images with the diagnoses Atelectasis, Effusion, and Infiltration to the “No Finding” diagnosis, explanation for other tendencies is not straightforward.
The outcomes mentioned above raise problematic issues with possible ethical implications. A first issue refers to the selection of an ANN architecture for actual use. If different network architectures produce different results, then which ANN architecture should be selected? This question is of great importance with respect to ethical perspectives, particularly for medical diagnosis applications.
We suggest that care should be taken to select an ANN architecture that enables obtaining both adequate performance and low sensitivity to dataset size and the amount of data errors or data corruption anticipated. We also suggest that the selection process include a comparison of results from the use of a group of ANN architectures from which selection is to be made on a benchmark case. In this respect, it is to be noted that both performance and sensitivity may depend on the AI task to be performed.
A second issue is that it appears that the precision-recall trade-off alone is not sufficient for determining that data corruption has occurred. The mixtures of performance metrics tendencies mentioned above cannot clearly indicate that corruption has occurred because improvement of some metrics when corruption occurs may cause confusion. However, as mentioned above, accuracy alone may also not be sufficient as the evaluation metrics for a multi-class dataset with a single dominant class. Therefore, we expect that a determination that data corruption has occurred will require a more complex approach in which a combination of parameters will be considered, including precision, recall, accuracy, and possibly additional parameters. The possibility of determining the occurrence of data corruption is important from an ethical point of view in order to make sure that AI systems are competent and reliable. It is to be noted that the lack of consideration of the issues mentioned above may affect reliability of medical diagnosis results obtained using AI systems, as well as the reliability of other medical-related results obtained using AI systems. This may affect the willingness of patients and physicians to rely on or otherwise use AI systems for clinical applications, and hence affect AI adoption in the medical field.
Examination of the task of dermatoscopic image analysis shows complying outcomes. As mentioned above with respect to Figs. 11 and 12, in certain instances, for example with respect to Mel and Nv, ResNet-50 and AlexNet provide different results both for male and female patients. This complies with the first one of the two outcomes mentioned above. Further with respect to Figs. 11 and 12, there are cases where the precision increases as corruption increases and cases where the precision decreases as corruption increases (and similarly with respect to recall as can be seen from Fig. 13), which means that label corruption results in a mixture of performance metrics tendencies. This complies with the second one of the two outcomes mentioned above. We therefore conclude that the examination in respect of the MNIST: HAM10000 database verifies the tendencies found in respect of the ChestX-ray8 database.
Future research directions
This work exemplifies the ethical aspects associated with the performance of ANNs in the presence of data errors/corruption and with the sensitivity of different ANNs to dataset size and the amount of data errors/corruption. As such, future research topics in which other examples of used parameters will be explored may be beneficial in attempting to cope with these problematic issues:
Datasets: In the present work, we investigated two datasets, derived from the ChestX-ray8 database and the MNIST: HAM10000 database. Investigation of other medical datasets, or datasets from fields other than medicine, may be a future topic of research.
Task: In the present work, only tasks of diagnosis were investigated. Investigation of other tasks, such as disease progression or disease forecast tasks, may be a future topic of research.
Mislabeling pattern: In this work, the biased representation of the data in the dataset was created by random selection, with uniform probability, of images with different diagnoses. A future topic of research in this respect is the use of other mislabeling patterns, such as a systematic pattern in which one in a fixed number of images is mislabeled or a pattern in which mislabeling selection is made in accordance with a Gaussian distribution.
Demographic bias: The analysis in this work refers to bias with respect to male patients only. Future topics of research in this respect are bias with respect to female patients and bias with respect to both male and female patients, and also the use of other types of demographic bias, such as bias based on race or age.
ANN model: The analysis in the present work refers to five ANNs. A future topic of research in this respect is use of other models, such as transformers beyond ViT and diffusion models.
Use of multi-label images: In the present work multi-label images were discarded so as not to obscure the results and complicate the analysis. A future topic of research in this respect is use of multi-label images with combinations in which labeling of some, all, or none of the multi-label images are corrupted or combinations in which single-label parts of multi-label images are corrupted.
A very important future research direction is systematic development of ways to mitigate bias and increase the reliability of the results obtained by the AI systems, for example, according to the FAIR (findability, accessibility, interoperability, reusability) principles34 and other fairness metrics, such as equalized odds and demographic parity46. It is worth mentioning that one strategy for increasing ethical reliability in AI, and specifically in medical image analysis, includes explainable AI (XAI)59,60, which may increase fairness and trustworthiness of AI-based systems. Furthermore, recently developed bias detection algorithms, such as adversarial debiasing61, Learning from Failure (LfF)62, and Individual-Group-Debiasing (IGD) Post-Processing63 are all aimed to mitigate biased AI systems during different stages of AI development46. In connection with this, we view the issue of finding appropriate ways to determine whether data corruption actually occurs as part of this important future research direction.
Conclusions
This work connects ethics in AI with empirical parameters of AI, such as dataset size, ANN architectures, and labeling. It specifically investigates how dataset size reduction and label corruption affect five different ANN architectures within an ethical context. We found that, for the same chest X-ray diagnosis task, the five ANN architectures yielded different results both with and without dataset modifications. Additionally, we found that label corruption resulted in a mixture of performance metrics tendencies. We confirmed these findings by examining another task: dermatoscopic image analysis using a database of images of pigmented skin lesions. We conclude that choosing an ANN architecture should be done carefully, while examining performance and sensitivity to dataset size and the amount of data errors/corruption anticipated. We recommend that the selection process involve comparing results from a group of ANN architectures on a benchmark case.
Supplementary Information
Below is the link to the electronic supplementary material.
Author contributions
A.H., M.O., and D.H. performed the research, wrote the main manuscript text and prepared the figures. All authors reviewed the manuscript.
Data availability
The datasets used and/or analysed during the current study available from the corresponding author on reasonable request.
Declarations
Competing interests
The authors declare no competing interests.
Footnotes
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
These authors equally contributed to this work: Michael Okunev and Doron Handelman.
References
- 1.Arya, K. V., Rodriguez, C., Singh, S. & Singhal, A. Artificial Intelligence and Machine Learning Techniques in Image Processing and Computer Vision. (2024).
- 2.Hilpisch. Y. J. Artificial Intelligence in Finance: A Python-Based Guide (2020).
- 3.Millington, I. AI for Games (Crc Press, Taylor & Francis Group, 2019).
- 4.Custers, B. & Fosch-Villaronga, E. Law and Artificial Intelligence: Regulating AI and Applying AI in Legal Practice (T.M.C. Asser, 2022).
- 5.Zgallai, W. A. & Dilber U. O. Artificial Intelligence and Image Processing in Medical Imaging, (2024).
- 6.Wang, G. et al. A deep-learning pipeline for the diagnosis and discrimination of viral, non-viral and COVID-19 pneumonia from chest X-ray images. Nat. Biomed. Eng.5, 509–521 (2021). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 7.Ryu, S. et al. Real-time artificial intelligence Navigation-Assisted anatomical recognition in laparoscopic colorectal surgery. J. Gastrointest. Surg.27, 3080–3082 (2023). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 8.DeGrave, A.J., Cai, Z.R., Janizek, J.D., Daneshjou, R. & Lee, S. I. Auditing the inference processes of medical-image classifiers by leveraging generative AI and the expertise of physicians. Nat. Biomed. Eng9, 294–306 (2025). [DOI] [PubMed]
- 9.Alvarez, J. M. et al. Policy advice and best practices on bias and fairness in AI. Ethics Inform. Technology26, 1–26 (2024).
- 10.Yang, Y., Zhang, H., Gichoya, J. W., Katabi, D. & Ghassemi, M. The limits of fair medical imaging AI in real-world generalization. Nat. Med.30, 2838–2848 (2024). [DOI] [PMC free article] [PubMed]
- 11.Ziller, A. et al. Reconciling privacy and accuracy in AI for medical imaging. Nat. Mach. Intell.6, 764–774 (2024).
- 12.Huang, C., Zhang, Z., Mao, B. & Yao, X. An overview of artificial intelligence ethics. IEEE Trans. Artif. Intell.4, 1–21 (2022). [Google Scholar]
- 13.Bleher, H. & Braun, M. Reflections on putting AI ethics into practice: how three AI ethics approaches conceptualize theory and practice. Science Eng. Ethics29, 1–23, (2023). [DOI] [PMC free article] [PubMed]
- 14.Buijsman, S. Transparency for AI systems: a value-based approach. Ethics Inform. Technology26, 1–11 (2024).
- 15.Challen, R. et al. Artificial intelligence, bias and clinical safety. BMJ Qual. Saf.28, 231–237 (2019). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 16.Di Nucci, E. Should we be afraid of medical AI? J. Med. Ethics. 45, 556–558 (2019). [DOI] [PubMed] [Google Scholar]
- 17.Grote, T. Randomised controlled trials in medical AI: ethical considerations. J. Med. Ethics. 48, 899–906 (2022). [DOI] [PubMed]
- 18.Hespel Adrien-Maxence et al. Comparison of error rates between four pretrained densenet convolutional neural network models and 13 board-certified veterinary radiologists when evaluating 15 labels of canine thoracic radiographs. Vet. Radiol. Ultrasound. 63, 456–468 (2022). [DOI] [PubMed] [Google Scholar]
- 19.Kaplan, S., Handelman, D. & Handelman, A. Sensitivity of neural networks to corruption of image classification. AI and Ethics, 1, 425–434 (2021). [DOI] [PMC free article] [PubMed]
- 20.Larrazabal, A. J., Nieto, N., Peterson, V., Milone, D. H. & Ferrante, E. Gender imbalance in medical imaging datasets produces biased classifiers for computer-aided diagnosis. Proc. Natl. Acad. Sci.117, 12592–12594 (2020). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 21.Maier-Hein, L. et al. Metrics reloaded: recommendations for image analysis validation. Nat. Methods. 21, 195–212 (2024). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 22.Milka Nyariro, Emami, E. Pascale Caidor & Samira Abbasgholizadeh rahimi. Integrating equity, diversity and inclusion throughout the lifecycle of AI within healthcare: a scoping review protocol. BMJ Open.13, e072069–e072069 (2023). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 23.Ossa, L. A. et al. Integrating ethics in AI development: a qualitative study. BMC Med. Ethics25, 1–11 (2024). [DOI] [PMC free article] [PubMed]
- 24.Jha, R. D., Hayase, J. & Oh, S. Label Poisoning is All You Need. arXiv.org (2023). https://arxiv.org/abs/2310.18933
- 25.Tavallali, P., Behzadan, V., Tavallali, P. & Singhalet M. Adversarial Label-Poisoning Attacks and Defense for General Multi-Class Models Based on Synthetic Reduced Nearest Neighbor. 10.48550/arXiv.2102.05867 (2021).
- 26.Blease, C. R., Locher, C., Gaab, J., Hägglund, M. & Mandl, K. D. Generative artificial intelligence in primary care: an online survey of UK general practitioners. BMJ Health Care Inf.31, e101102–e101102 (2024). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 27.Etgar S., Oestreicher-Singer G., & Yahav I. Implicit bias in LLMs: Bias in financial advice based on implied gender. 10.2139/ssrn.4880335 (2024).
- 28.Althnian, A. et al. Impact of dataset size on classification performance: an empirical evaluation in the medical domain. Appl. Sci.11, 796 (2021). [Google Scholar]
- 29.Bailly, A. et al. Effects of dataset size and interactions on the prediction performance of logistic regression and deep learning models. Comput. Methods Programs Biomed.213, 106504 (2021). [DOI] [PubMed] [Google Scholar]
- 30.Fang, Y. et al. The impact of training sample size on deep learning-based organ auto-segmentation for head-and-neck patients. Phys. Med. Biol.66, 185012–185012 (2021). [DOI] [PubMed] [Google Scholar]
- 31.Dawson, H. L., Dubrule, O. & John, C. M. Impact of dataset size and convolutional neural network architecture on transfer learning for carbonate rock classification. Comput. Geosci.171, 105284 (2023). [Google Scholar]
- 32.Bekker A. J. & Goldberger, J. Training deep neural-networks based on unreliable labels. (2016). 10.1109/icassp.2016.7472164
- 33.Song, H., Kim, M., Park, D., Shin, Y. & Lee, J. G. Learning from noisy labels with deep neural networks: A survey. IEEE Trans. Neural Networks Learn. Systems, 34(11), 8135–8153 (2022). [DOI] [PubMed]
- 34.Hanna, M. G. et al. Ethical and bias considerations in artificial intelligence (AI)/Machine learning. Modern Pathology38, 1–13 (2024). [DOI] [PubMed]
- 35.Yang, Y. et al. A survey of recent methods for addressing AI fairness and bias in biomedicine. J. Biomed. Inform.154, 104646–104646 (2024). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 36.Dehdashtian, S. et al. Fairness and bias mitigation in computer vision: A survey. ArXiv Org. https://arxiv.org/abs/2408.02464 (2024).
- 37.Mennella, C., Maniscalco, U., Pietro, G. D. & Esposito, M. Ethical and regulatory challenges of AI technologies in healthcare: A narrative review. Heliyon10, e26297–e26297 (2024). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 38.Pesapane, F., Volonté, C., Codari, M. & Sardanelli, F. Artificial intelligence as a medical device in radiology: ethical and regulatory issues in Europe and the united States. Insights into Imaging. 9, 745–753 (2018). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 39.Kim, Y. et al. Medical hallucination in foundation models and their impact on healthcare. MedRxiv (Cold Spring Harbor Laboratory). 10.1101/2025.02.28.25323115 (2025). [Google Scholar]
- 40.Cross, J. L., Choma, M. A. & Onofrey, J. A. Bias in medical AI: implications for clinical decision-making. PLOS Digit. Health. 3, e0000651 (2024). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 41.Liu, M. et al. A translational perspective towards clinical AI fairness. npj Digit. Medicine6(1), 172 (2023). [DOI] [PMC free article] [PubMed]
- 42.McCradden, M. D., Joshi, S., Mazwi, M. & Anderson, J. A. Ethical limitations of algorithmic fairness solutions in health care machine learning. Lancet Digit. Health. 2, e221–e223 (2020). [DOI] [PubMed] [Google Scholar]
- 43.Burak et al. Bias in artificial intelligence for medical imaging: fundamentals, detection, avoidance, mitigation, challenges, ethics, and prospects. Diagn. Interventional Radiol.10.4274/dir.2024.242854 (2024). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 44.Johnson, J. M. & Khoshgoftaar, T. M. Survey on deep learning with class imbalance. J. Big Data6, 1–54 (2019).
- 45.Liu, H. et al. Does gender matter?? Towards fairness in dialogue systems. Int. Conf. Comput. Linguistics. 10.18653/v1/2020.coling-main.390 (2020). [Google Scholar]
- 46.Fereshteh et al. Bias recognition and mitigation strategies in artificial intelligence healthcare applications. Npj Digit. Medicine8, (2025). [DOI] [PMC free article] [PubMed]
- 47.Khosravi, B. et al. Synthetically enhanced: unveiling synthetic data’s potential in medical imaging research. EBioMedicine104, 105174 (2024). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 48.Pezoulas, V. C. et al. Synthetic data generation methods in healthcare: A review on open-source tools and methods. Comput. Struct. Biotechnol. J.23, 2892–2910 (2024). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 49.Yazar, S. A comparative study on classification performance of emphysema with transfer learning methods in deep convolutional neural networks. Comput. Sci. J. Moldova. 30, 259–278 (2022). [Google Scholar]
- 50.Du, X., Yu, X., Liu, J., Dai, B. & Xu, F. Ethics-aware face recognition aided by synthetic face images. Neurocomputing600, 128129 (2024). [Google Scholar]
- 51.Li, A. S., Iyengar, A., Kundu, A. & Bertino, E. Transfer Learning for Security: Challenges and Future Directions. arXiv.org (2024). https://arxiv.org/abs/2403.00935
- 52.Wang, X. et al. ChestX-Ray8: Hospital-Scale chest X-Ray database and benchmarks on Weakly-Supervised classification and localization of common thorax diseases. 2017 IEEE Conf. Comput. Vis. Pattern Recognit. (CVPR). 10.1109/cvpr.2017.369 (2017). [Google Scholar]
- 53.Sales, V. et al. Evaluation of resampling techniques to provide better synthesized input data to Super-Resolution deep learning model training. IGARSS 2023 - 2023 IEEE International Geoscience and Remote Sensing Symposium, Pasadena, CA, USA, 7368–7371 (2023).
- 54.Duchon, C. E. Lanczos filtering in one and two dimensions. J. Appl. Meteorol.18, 1016–1022 (1979). [Google Scholar]
- 55.Yaman, S., Karakaya, B. & Erol, Y. A novel normalization algorithm to facilitate pre-assessment of Covid-19 disease by improving accuracy of CNN and its FPGA implementation. Evol. Syst. 14, 581–591 (2023) [DOI] [PMC free article] [PubMed] [Google Scholar]
- 56.Z, X., LR, S. K. A. & GR, T. L. Using deep learning for detecting gender in adult chest radiographs. SPIE Medical Imaging (2018).
- 57.Bai, Y. et al. Understanding and Improving Early Stopping for Learning with Noisy Labels. arXiv:2106.15853 [cs] (2021).
- 58.Raff, E. Inside Deep Learning (Simon and Schuster, 2022).
- 59.Khan, A. R. & Saba, T. Explainable Artificial Intelligence in Medical Imaging (CRC, 2025).
- 60.Barredo Arrieta, A. et al. Explainable artificial intelligence (XAI): concepts, taxonomies, opportunities and challenges toward responsible AI. Inform. Fusion. 58, 82–115 (2020). [Google Scholar]
- 61.Ehsan et al. Representation learning with statistical independence to mitigate bias. PubMed Cent.10.1109/wacv48630.2021.00256 (2021). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 62.Nam, J., Cha, H., Ahn, S., Lee, J. & Shin, J. Learning from Failure: Training Debiased Classifier from Biased Classifier. arXiv.org (2020). https://arxiv.org/abs/2007.02561
- 63.Lohia, P. K. et al. Bias mitigation Post-processing for individual and group fairness. ICASSP 2019 - 2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton, UK, 2847–2851 (2019).
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.
Supplementary Materials
Data Availability Statement
The datasets used and/or analysed during the current study available from the corresponding author on reasonable request.