

Large language models (LLMs) are rapidly emerging as transformative tools in patient care and clinical practice. Among these, ChatGPT (Chat Generative Pre-Trained Transformer) has achieved widespread popularity, with over 200 million active weekly users.1 The application of artificial intelligence (AI) to high-resolution esophageal manometry (HRM) is well suited as it can efficiently analyze large volumes of data and images with distinct, stereotypical patterns.2 Despite this potential, the application of ChatGPT to HRM has not been previously studied. We sought to evaluate the performance of ChatGPT-4o, an enhanced version capable of processing combined text and image inputs, in classifying HRM data according to the Chicago Classification v4.0 (CCv4.0) schema.3
HRM studies were selected from a prospectively enrolled cohort for an NIH-funded study (P01 DK117824) of adult patients (ages 18–89) evaluated for dysphagia at the Esophageal Center of Northwestern Memorial Hospital between 2019 and 2022. HRM studies were stratified by CCv4.0 diagnosis and ten studies were selected at random from each diagnostic group. Exceptions were for distal esophageal spasm (DES) and hypercontractile esophagus (HE), where fewer patients necessitated the inclusion of all available cases. Patients with a history of foregut surgery, mechanical obstruction, or conditions such as esophageal stricture, eosinophilic esophagitis, severe reflux esophagitis (Los Angeles classification C or D), or hiatal hernia >3 cm were excluded. Written informed consent was obtained from all participants for maintenance of data. All identifying information was removed, and only topographic plots and HRM-metrics (e.g., integrated relaxation pressure [IRP], panesophageal pressurization, distal contractile integral) were applied for analysis of this minimal-risk study under a waiver of informed consent (study protocol was approved by Northwestern University IRB).
Performance of ChatGPT-4o for identifying CCv4.0 diagnoses was evaluated across five distinct prompts. Prompt 1 provided a single image containing 10 supine swallows, 5 upright swallows, and the rapid drink challenge without metrics. Prompt 2 added thumbnails illustrating representative topographic patterns for each CCv4.0 diagnosis. Prompt 3 further included mean IRP values, study references, and panesophageal pressurization details. Prompt 4 entailed standard HRM reports with summary metrics for individual swallows, excluding CCv4.0 diagnoses. Finally, Prompt 5 provided a spreadsheet summarizing all key metrics while omitting diagnoses; Table S1. To mitigate bias from prior inputs, the chat session was reset before each HRM plot was submitted
Performance metrics included accuracy and Cohen’s kappa, calculated for each prompt and stratified by CCv4.0 diagnosis. Confusion matrices were constructed to elucidate error patterns. Analyses were performed using R version 4.4.0.
A total of 85 HRM studies were identified, with 10 representative studies for each CCv4.0 diagnosis, except for DES (6 studies) and HE (9 studies). Results revealed consistently poor performance across all prompts, with incremental improvement as additional structured information was provided. Accuracy and kappa values for Prompts 1 through 5 were 0.09/0.20, 0.07/0.18, 0.11/0.21, 0.33/0.41, and 0.35/0.41, respectively; Figure 1. Confusion matrices revealed a strong bias toward type II achalasia and ineffective esophageal motility (IEM), particularly for Prompt 3; Figure S1.
Figure 1 – ChatGPT Accuracy and Kappa Statistic by Prompt.
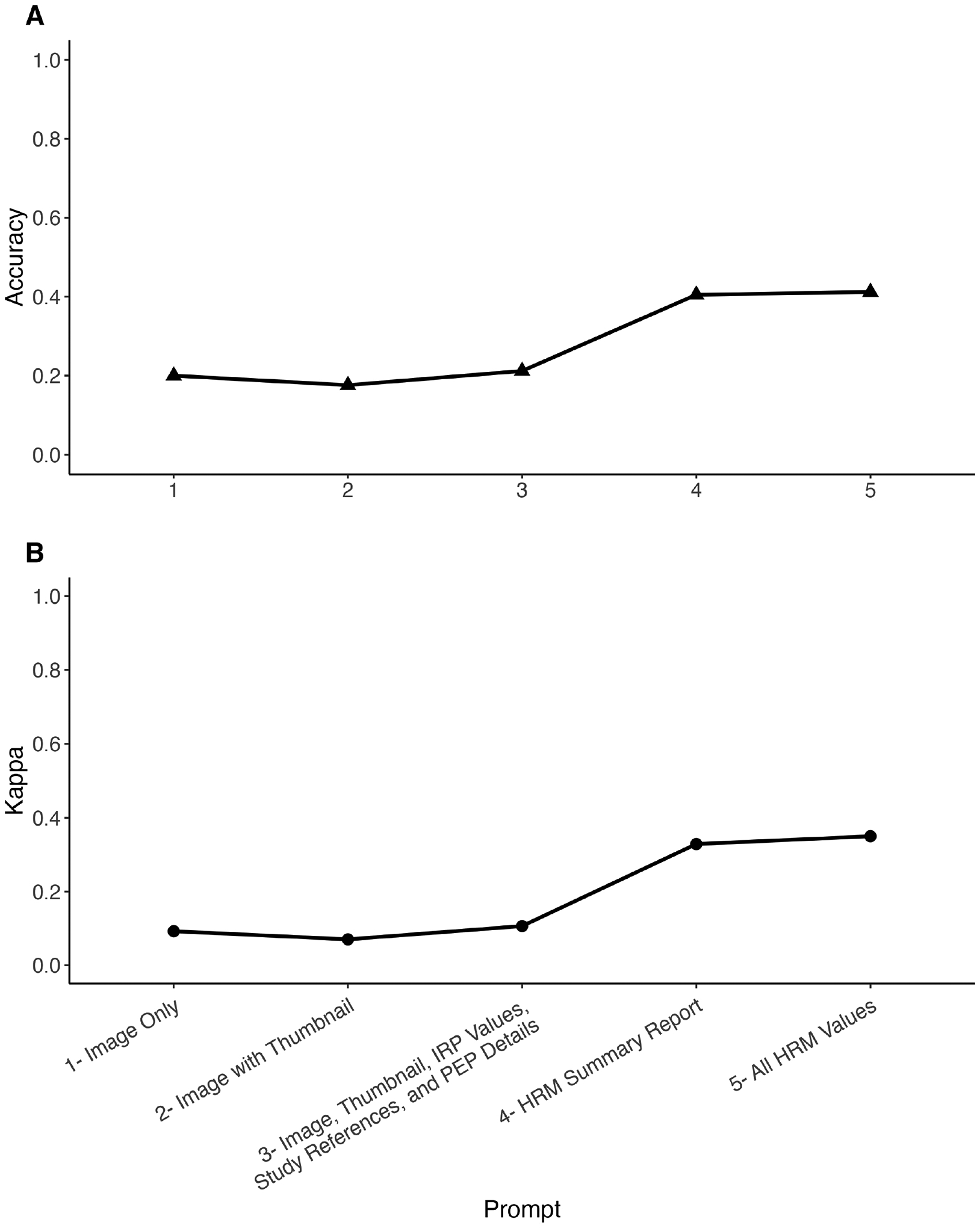
1A: Accuracy of ChatGPT-4o in classifying high-resolution esophageal manometry data across five prompts of increasing complexity. 1B: Cohen’s kappa measuring agreement between ChatGPT-4o classifications and high-resolution esophageal manometry (CCv4.0) diagnoses.
Both metrics show an upward trend, with accuracy increasing from 0.09 for Prompt 1 to 0.35 for Prompt 5, and kappa values rising from 0.20 to 0.41. Agreement levels based on kappa values: 0–0.2 (poor), 0.2–0.4 (fair), 0.4–0.6 (moderate), 0.6–0.8 (good), and 0.8–1.0 (excellent).
This bias likely stems from data that type II achalasia and IEM are the most common CCv4.0 diagnoses among disorders of esophagogastric junction (EGJ) outflow and peristalsis respectively.4,5 Despite this, the model struggled to accurately identify “normal” motility, the most common manometric pattern, likely due to its underrepresentation in the medical literature.
Providing more information, as seen in the progression from Prompts 1 to 5, numerically improved performance. Text-based prompts consistently outperformed image-based ones, highlighting ChatGPT’s limitations in interpreting medical images. Even with complete metrics, the model failed to reliably apply the CCv4.0 scheme. Performance was further undermined by a tendency to overestimate IRP values and significant response instability, with identical prompts often producing inconsistent classifications.
This study’s findings align with prior reports of LLM limitations in medical image analysis. One recent study assessed the accuracy of ChatGPT-4 in identifying colorectal adenomas from histopathologic images revealing a sensitivity of 74%, but poor specificity of 36% and low diagnostic consistency, with kappa values ranging from 0.06 to 0.11.6 Similarly, in another study evaluating Chat-GPT’s performance in diagnosing liver diseases from computed tomography images, sensitivity was found to be 20% and specificity 30%.7 Although the addition of textual context to images has been shown to improve ChatGPT’s accuracy, overall diagnostic performance remains suboptimal.8 These limitations are not surprising given that ChatGPT is optimized for language processing. AI platforms designed specifically for medical image classification, equipped with domain-specific neural network architectures, may yield superior results. LLMs like ChatGPT are trained on large, unstructured datasets that include conflicting and sometimes inaccurate information, reflecting the inconsistencies of “world knowledge” rather than the rigor of domain-specific guidelines such as CCv4.0.9 Consequently, these models are prone to generating factually inconsistent “hallucinations”.
While the findings from this study highlight the significant limitations of ChatGPT for HRM interpretation, they should not detract from the promising advancements being made with dedicated AI systems in this field. Models have been developed using specialized algorithms trained on specific, high-quality HRM datasets with architectures optimized for pattern recognition in manometric data.10 These purpose-built systems have demonstrated considerable promise and represent the appropriate direction for AI implementation in esophageal motility diagnostics. Future research should continue to refine these specialized approaches rather than attempting to repurpose general-purpose LLMs for clinical diagnoses.
These findings underscore the necessity for caution when considering LLMs for clinical applications. Until more refined and dedicated systems are developed, reliance on ChatGPT for HRM interpretation should be avoided, as it risks introducing significant errors into patient care. This serves as a cautionary tale for esophagologists seeking to leverage AI to streamline their workload. While LLMs hold tremendous potential, their current limitations preclude their use as standalone diagnostic tools in esophageal motility disorders.
Supplementary Material
Financial support/Source of funding:
This work was supported by P01 DK117824 (JEP) and R01 DK137775 (JEP and DAC) from the Public Health service.
Footnotes
Publisher's Disclaimer: This is a PDF file of an article that has undergone enhancements after acceptance, such as the addition of a cover page and metadata, and formatting for readability, but it is not yet the definitive version of record. This version will undergo additional copyediting, typesetting and review before it is published in its final form, but we are providing this version to give early visibility of the article. Please note that, during the production process, errors may be discovered which could affect the content, and all legal disclaimers that apply to the journal pertain.
Potential competing interests/Disclosures:
JEP: Sandhill Scientific/Diversatek (Consulting, Grant), Takeda (Speaking), Astra Zeneca (Speaking), Medtronic (Speaking, Consulting, Patent, License), Torax/Ethicon (Speaking, Consulting), EndoGastric Solutions (Advisory Board), Phathom (Speaking, Consulting) DAC: Medtronic (Speaking, Consulting, License); Diversatek (Consulting); Braintree (Consulting); Medpace (Consulting); Phathom Pharmaceuticals (Speaking; Consulting); Regeneron/Sanofi (Speaking)
Other authors have no conflicts to disclose.
References
- 1.OpenAI says ChatGPT’s weekly users have grown to 200 million. Reuters. https://www.reuters.com/technology/artificial-intelligence/openai-says-chatgpts-weekly-users-have-grown-200-million-2024-08-29/. August 29, 2024. Accessed January 13, 2025. [Google Scholar]
- 2.Fass O, Rogers BD, Gyawali CP. Artificial Intelligence Tools for Improving Manometric Diagnosis of Esophageal Dysmotility. Curr Gastroenterol Rep. 2024;26(4):115–123. doi: 10.1007/s11894-024-00921-z [DOI] [PMC free article] [PubMed] [Google Scholar]
- 3.Yadlapati R, Kahrilas PJ, Fox MR, et al. Esophageal motility disorders on high-resolution manometry: Chicago classification version 4.0©. Neurogastroenterol Motil. 2021;33(1):e14058. doi: 10.1111/nmo.14058 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 4.Zhou MJ, Kamal A, Freedberg DE, Markowitz D, Clarke JO, Jodorkovsky D. Type II Achalasia Is Increasing in Prevalence. Dig Dis Sci. 2021;66(10):3490–3494. doi: 10.1007/s10620-020-06668-7 [DOI] [PubMed] [Google Scholar]
- 5.Alani M, Al-Jashaami L, Mills M, Guha S, Ratuapli SK. Prevalence of Esophageal Motility Disorders in an Open Access Hybrid “Academic - Community Setting” Patient Population: 325. Official journal of the American College of Gastroenterology | ACG. 2018;113:S180. [Google Scholar]
- 6.Laohawetwanit T, Namboonlue C, Apornvirat S. Accuracy of GPT-4 in histopathological image detection and classification of colorectal adenomas. J Clin Pathol. 2025;78(3):202–207. doi: 10.1136/jcp-2023-209304 [DOI] [PubMed] [Google Scholar]
- 7.Zhang Y, Wu L, Wang Y, et al. Unexpectedly low accuracy of GPT-4 in identifying common liver diseases from CT scan images. Dig Liver Dis. 2024;56(4):718–720. doi: 10.1016/j.dld.2024.01.191 [DOI] [PubMed] [Google Scholar]
- 8.Ueda D, Mitsuyama Y, Takita H, et al. ChatGPT’s Diagnostic Performance from Patient History and Imaging Findings on the Diagnosis Please Quizzes. Radiology. 2023;308(1):e231040. doi: 10.1148/radiol.231040 [DOI] [PubMed] [Google Scholar]
- 9.Giuffrè M, Shung DL. Scrutinizing ChatGPT Applications in Gastroenterology: A Call for Methodological Rigor to Define Accuracy and Preserve Privacy. Clin Gastroenterol Hepatol. 2024;22(10):2156–2157. doi: 10.1016/j.cgh.2024.01.024 [DOI] [PubMed] [Google Scholar]
- 10.Kou W, Carlson DA, Baumann AJ, et al. A multi-stage machine learning model for diagnosis of esophageal manometry. Artificial intelligence in medicine. 2022;124:102233. [DOI] [PMC free article] [PubMed] [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.