

Abstract
Deep learning foundation models are becoming increasingly popular for their use in bioactivity prediction. Recently, Feng et al. (Nature Machine Intelligence 2024), developed ActFound, a bioactive foundation model that jointly uses pairwise learning and meta-learning. By utilizing these techniques, the model is capable of being fine-tuned to a more specific bioactivity task with only a small amount of new data. To investigate the generalizability of the model, we looked to fine-tune the foundation model on an antibacterial natural products (NPs) dataset. Large, labeled NPs datasets, which are needed to train traditional deep learning methods, are scarce. Therefore, the bioactivity prediction of NPs is an ideal task for foundation models. We studied the performance of ActFound on the NPs dataset using a range of few-shot settings. Additionally, we compared ActFound’s performance with those of other state-of-the-art models in the field. We found ActFound was unable to reach the same level of accuracy on the antibacterial NPs dataset as it did on other cross-domain tasks reported in the original publication. However, ActFound displayed comparable or better performance compared to the other models studied, especially at the low-shot settings. Our results establish ActFound as a useful foundation model for the bioactivity prediction of tasks with limited data. Especially for datasets that contain the bioactivities of similar compounds.
The bioactivity of compounds plays a key role in drug discovery. Bioactivity refers to the effect, either beneficial or adverse, a compound has on a biological process1. It encompasses the efficacy, potency, and selectivity of a compound and is important in the identification of hits in a drug campaign and subsequent lead optimization2. Deep learning (DL) approaches have shown promise in their ability to predict the bioactivity of compounds3,4,5,6,7. However, DL models require large, high-quality datasets in order to accurately identify patterns within the data8. Many bioactivity tasks do not have an adequate amount of labeled data sufficient for training. One solution is to use foundation models, which are pretrained on large, general datasets. These models serve as a ‘foundation’ which can be fine-tuned for more specific tasks9.
Recently, Feng et al. introduced ActFound10, a meta-learning foundation model trained to predict the bioactivity of compounds. To accomplish this, ActFound jointly utilizes meta-learning and pairwise learning. Meta-learning, or “learning to learn,” is a commonly used algorithm to develop foundation models11,12. Meta-learning models are trained on a variety of tasks with the intention of creating a model that can quickly adapt to new tasks from only a small amount of new data13. By using meta-learning, Feng et al. were able to pre-train their model on a wide range of diverse assays, leveraging the information to develop a general foundation model capable of few-shot learning. Pairwise learning was used to address the incompatibility of information within training assays differing in metrics, units, and value ranges. Instead of directly predicting the bioactivity of compounds, pairwise learning allows ActFound to predict the difference in bioactivity between two compounds within the same assay14.
During the fine-tuning stage, ActFound utilized the algorithm k-nearest neighbors MAML (kNN-MAML), which identifies assays within the training set that are similar to the fine-tuning assay. Leveraging information from similar assays allows for rapid fine-tuning to a new, unseen assay.
In this reusability report, we looked to study ActFound’s performance on a natural products (NPs) dataset that contains plant-derived compounds with antibacterial activity15. NPs are an abundant source of antibiotics, with many approved antibiotics being NPs or NP-derivatives16. However, antibacterial NPs have historically been plagued by the dereplication process, where known NPs are repeatedly rediscovered17. The lack of new antibiotics being identified has led to a rising interest in DL models for antibacterial prediction18,19,20,21. However, there is a lack of large, labeled bioactivity datasets in the NPs field22. This makes it an ideal task for a pairwise meta-learning model like ActFound. In this study, we fine-tuned both the ActFound model pre-trained on assays from ChEMBL23 as well as the model pre-trained on assays from BindingDB24. We investigated the use of the few-shot setting, fine-tuning the models on the NPs dataset in a range of shot-settings between 8 and 128 fine-tuning compounds (Fig. 1). We then compared the performance of the ActFound fine-tuned models with other conventional meta-learning models MAML and ProtoNet as well as transfer learning variants of ActFound and MAML13,25.
Figure 1. Overview of the fine-tuning procedure.

Growth inhibitory assays were used to fine-tune ActFound and create bacteria-specific models.
Fine-tuning ActFound on a Natural Products Dataset
To investigate ActFound’s ability to generalize to new domains not explored in the original publication, we fine-tuned the model on an antibacterial NPs dataset. This dataset was curated by Porras et al. in an extensive literature review spanning from 2012 to 2019 and contains the growth inhibitory activity of NPs against a range of bacteria. A t-Distributed Stochastic Neighbor Embedding (t-SNE) comparing the compounds within the NPs dataset and the ChEMBL training data shows overlap, indicating the two datasets likely contain similar compounds (Fig 2e). However, we did not attempt to identify any identical assays between the datasets or exclude molecules potentially seen during training. We acknowledge this could have caused data leakage that inflated the performance of the model pre-trained on ChEMBL assays. Given that this dataset was the result of manual literature curation, it is unlikely that the exact data in this dataset was deposited into ChEMBL. In addition, considering the NPs dataset only contained growth inhibitory assays, there should be no identical assays in the BindingDB training dataset.
Figure 2. Performance of ActFound on the NPs dataset.

a,b, Bar plots comparing ActFound and ActFound Transfer’s performance on the NPs dataset in terms of (a) r2 and (b) RMSE. Plot shows the mean value across each shot setting used to fine-tune the ChEMBL pre-trained models and the BindingDB pre-trained models. c,d, Bar plots comparing the models’ performances in terms of r2 at the (c) 8-, 16-, 32-, 64-, and 128-shot setting and when (d) 20, 40, 60, 75, and 80% of the assays were used for fine-tuning. (e) t-SNE plot comparing the molecules in the NPs dataset and a random selection of 50% of the ChEMBL training dataset.
When fine-tuning, we considered each bacteria strain to be its own assay and assessed the performance of ActFound across a range of shot settings. This included using 8 to 128 fine-tuning compounds as well as using 20 to 80% of the compounds within each assay for fine-tuning. Averaging the r2 value across all shot settings for ActFound and ActFound Transfer, a transfer learning variant of ActFound, showed that overall ActFound Transfer had a higher r2 value than ActFound on the NPs dataset (Fig 2a). However, ActFound was found to have the lowest RMSE value (Fig 2b). When looking at the performance for each shot setting, ActFound and ActFound Transfer performed the best in the 16-shot setting, with performance dropping as the shot setting increased (Fig 2c). This is in contrast with the original publication, where the performance of ActFound increased with the number of compounds used for fine-tuning. Since providing more compounds for fine-tuning should inherently improve performance, we investigated using a percentage of the assays for fine-tuning instead of supplying a specific shot setting. In this case, ActFound performed as expected, with the r2 values increasing as the percentage of compounds used for fine-tuning increased (Fig 2d). We attribute this behavior to the fact that only four assays had enough compounds to be used for fine-tuning in the 64- and 128-shot setting. When looking at the performance on each assay, the four largest assays (B. subtilis, E. coli, S. aureus, and S. aureus (MRSA)) were the four assays with the worst model performance (Fig 3a).
Figure 3. Performance of ActFound on each assay.

a, Bar plot comparing ActFound and ActFound Transfer’s performance on each assay in the NPs dataset in terms of r2. Plot shows the mean value across each shot setting used to fine-tune the ChEMBL pre-trained models and the BindingDB pre-trained models. b, Scatter plot comparing the first step loss and r2 value for every fine-tuning iteration for each assay for the ChEMBL pre-trained ActFound and the BindingDB pre-trained ActFound.
ActFound was found to have varying degrees of performance across the 14 assays, ranging from r2 values of 0.01 to 0.12. For reference, in the cross-domain setting, the original publication found two kinase inhibitor datasets to have average r2 values between 0.15 and 0.25, so the model performs only slightly worse on some of the NP antibacterial datasets and much worse on others. ActFound utilizes pairwise learning and works under the assumption that similar compounds will have similar bioactivities. This is typically advantageous, as many assay data sets are assembled to investigate structure-activity relationships (SAR) thus the compounds will be similar to one another. However, one disadvantage to this approach, and what we believe is causing such a range in performance for the NPs dataset, is that if the assay does not contain similar compounds, the pairwise learning function will cause large errors. In the original publication, Feng et al. removed what they called ‘orphan compounds’ from the assays. These orphan compounds are those which have a Tanimoto similarity less than 0.2 to the other compounds in the assay. When we performed the same procedure, none of the assays had enough compounds left for fine-tuning. This is likely due to how we defined our ‘assays.’ Although Porras et al. provided references in the NPs dataset, there were not enough bioactivities per bacteria in each reference to fine-tune the model. Therefore, we combined compounds from multiple references to treat each bacteria strain as its own assay, which likely led to many dissimilar compounds in each assay. Since removing the orphan compounds left only one assay available for fine-tuning, we decided not to remove them. We acknowledge that this decision likely played a part in how well ActFound was able to perform on the NPs dataset. However, it also reveals an important limitation of the ActFound method. NP datasets will often lack closely related pairs of compounds, as natural products are highly diverse26 and congeners of a primary product may be difficult to discover and isolate without the use of specialized techniques27. This limitation may also pose a problem for high throughput screening assay datasets that use compound libraries assembled for compound diversity over preliminary SAR, as is sometimes the case28.
The original paper found a correlation between a small loss value for the first optimization and a large r2 value. This was identified as a way to determine how well ActFound will perform on the fine-tuning assay since assays with small loss values will likely result in high r2 values. However, we did not find this correlation to hold on the NPs dataset. Although most of the assays had larger loss values, even the assays with small loss values had small r2 values (Fig 3b).
Evaluation against other state-of-the-art models
In addition to ActFound and ActFound Transfer, we also used the NPs dataset to fine-tune three other conventional models: MAML, ProtoNet, and TransferQSAR. MAML and ProtoNet are meta-learning models, while TransferQSAR is a transfer learning variant of MAML. However, none of the models incorporate pairwise learning to learn the relative bioactivities as ActFound does. ActFound Transfer outperformed all other models with both the ChEMBL and BindingDB versions (Fig 4a,b). Even though we found ActFound to perform worse on the NPs dataset compared to the results in the original publication, ActFound and ActFound Transfer tended to have a larger r2 value than the other three models when fewer compounds were used for fine-tuning (Fig 4c,d). This is indicative of ActFound’s ability to quickly adapt to new assays with only a small number of fine-tuning compounds. However, the meta-learning variant of ActFound did not perform better than the other three models when only 20% of the assays were used for fine-tuning. At this setting, the median number of compounds used for fine-tuning was 9, which is a smaller shot setting than was studied in the original paper. Although we identified disadvantages to using pairwise learning with our dataset, these results also indicate the effectiveness of utilizing pairwise learning to learn the relative bioactivity values. When the number of fine-tuning compounds is increased, both variants of ActFound perform on par with the other models, a trend that was also identified by Feng et al..
Figure 4. Performance of conventional models on the NPs dataset.
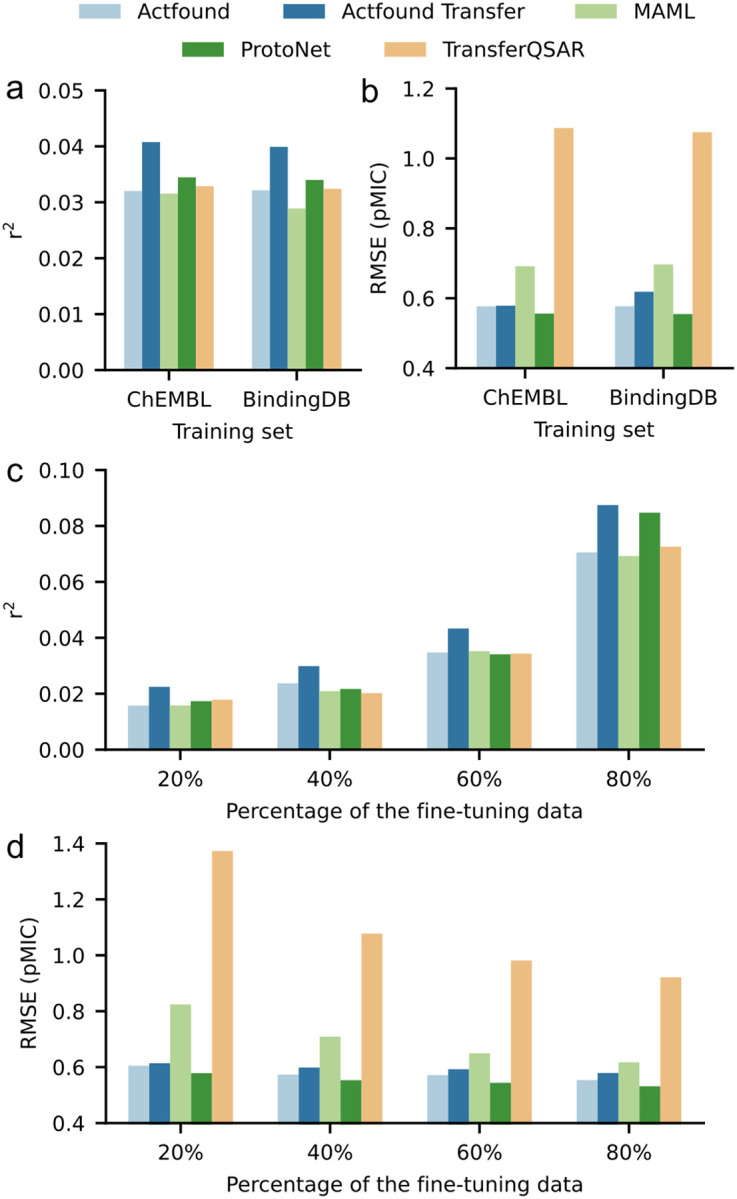
a,b, Bar plots comparing each model’s performance on the NPs dataset in terms of (a) r2 and (b) RMSE. Plot shows the mean value across each shot setting used to fine-tune the ChEMBL pre-trained models and the BindingDB pre-trained models. c,d, Bar plots comparing the models’ performances when 20, 40, 60, 75, and 80% of the assays were used for fine-tuning in terms of (c) r2 and (d) RMSE.
Discussion and Conclusion
To investigate ActFound’s reusability, we fine-tuned the model on an antibacterial NPs dataset, studying its performance on a range of shot settings. With the availability of Feng et al.’s Google Colab, we found ActFound to be easy to use and fine-tune on our dataset. In contrast to the results of the original publication, ActFound Transfer was found to perform better than the meta-learning variant of ActFound. We also found both variants of ActFound to have diminished performances compared to the cross-domain setting in the original paper. This was likely due to the incompatibility of ActFound to the NPs dataset as the assays in this dataset contained dissimilar compounds. This meant the pairwise learning function of ActFound was not able to be fully advantageous for our dataset. Another possible explanation for the relatively low accuracy, is that NPs have different chemical properties than synthetic compounds, which likely make up most of the training data. However, given that the t-SNE analysis shows that the chemical space of the NP dataset overlaps with the training set, we believe that the lack of suitable pairs of compounds for pairwise learning contributes more to lowering the accuracy. Despite the poorer performance on our chosen dataset, we found both variants of ActFound to perform better than other state-of-the-art models at the lower shot settings. Therefore, we believe ActFound to be a very useful framework for those who do not have enough labeled data to train a task-specific deep learning model. Especially for those whose datasets consist of structure-activity relationship studies as these datasets will contain the bioactivities of similar compounds which will increase the capabilities of the pairwise learning function.
Methods
Dataset Preparation
The NPs dataset used in this reusability report was obtained from the Porras et al. review paper15. To prepare the dataset for fine-tuning, we followed a similar pipeline as Feng et al. did when evaluating ActFound on two kinase inhibitor datasets, KIBA29 and Davis30. In this cross-domain setting, they considered each kinase to be its own assay. Similarly, we considered each bacteria strain as a separate assay. The NPs dataset contains 1439 growth inhibitory values of 472 unique compounds against 115 bacteria strains. We considered resistant strains and subspecies as separate assays from the original strain. Assays with fewer than 20 compounds were removed. If an assay contained duplicate compounds, the growth inhibitory values were averaged across the duplicated compounds. Additionally, we only considered compounds with MIC values and ug/mL units. This left us with 14 assays with an average of 64 compounds per assay.
Model Fine-tuning
All of the foundation models (ActFound, ActFound Transfer, MAML, ProtoNet, and TransferQSAR) trained by Feng et al. were obtained from their Figshare at https://figshare.com/articles/dataset/ActFound_data/24452680. We fine-tuned the models using the public code of ActFound from its GitHub repository at https://github.com/BFeng14/ActFound.git. During the fine-tuning process, the hyperparameters and architecture for each model were the same as used by Feng et al. The input for the models were 2,048-dimensional Morgan fingerprints, which were computed using RDKit31, and the negative log of the MIC values p(MIC) = −log10(MIC).
Each model was fine-tuned using the 8-, 16-, 32-, 64-, and 128-shot settings. Additionally, each model was fine-tuned on different proportions of the data. During this fine-tuning stage, we used 20%, 40%, 60%, and 80% of the assay data for fine-tuning. Each assay was randomly split 40 times into the fine-tuning and testing sets and the models were fine-tuned with each random split. The results of the models are an average across each iteration.
t-Distributed Stochastic Neighbor Embedding (t-SNE)
To study the similarities between the compounds in the ChEMBL training set and the NPs dataset, we performed a t-SNE analysis using scikit-learn’s t-Distributed Stochastic Neighbor Embedding32. A t-SNE reduces the dimensionality of the Morgan fingerprints from 2,048 to 2. We used the default values for each parameter except the distance metric which we set to ‘jaccard’. Since the Jaccard distance, or the Tanimoto distance, is equal to 1 – Tanimoto similarity, the distance between points is directly related to the similarity between compounds. The ChEMBL training set is large (1.4 million datapoints) and running a t-SNE on the entire dataset would be computationally expensive. Therefore, to speed up the computation, we opted to randomly select 50% of the training set to perform the t-SNE.
Acknowledgments
Research reported in this publication was supported by the National Institute of General Medical Sciences under award number R35GM146987. The content is solely the responsibility of the authors and does not necessarily represent the official views of the National Institutes of Health.
Footnotes
Department of Chemistry, Vanderbilt University, Nashville, TN, USA
Caitlin M. Butt & Allison S. Walker
Department of Biological Sciences, Vanderbilt University, Nashville, TN, USA
Allison S. Walker
Additional Declarations: There is NO Competing Interest.
Contributor Information
Allison Walker, Vanderbilt University.
Caitlin Butt, Vanderbilt University.
Data availability
The data used in this report are available in ref.15.
Code availability
The ActFound code is available at https://github.com/BFeng14/ActFound.git. All of the foundation model checkpoints are available at https://figshare.com/articles/dataset/ActFound_data/24452680.
References
- 1.Jackson C. M., Esnouf M. P., Winzor D. J. & Duewer D. L. Defining and measuring biological activity: applying the principles of metrology. Accred Qual Assur 12, 283–294 (2007). [Google Scholar]
- 2.Dougall I. G. & Unitt J. Chapter 2 - Evaluation of the Biological Activity of Compounds: Techniques and Mechanism of Action Studies. in The Practice of Medicinal Chemistry (Fourth Edition) (eds. Wermuth C. G., Aldous D., Raboisson P. & Rognan D.) 15–43 (Academic Press, San Diego, 2015). doi: 10.1016/B978-0-12-417205-0.00002-X. [DOI] [Google Scholar]
- 3.Wang S., Guo Y., Wang Y., Sun H. & Huang J. SMILES-BERT: Large Scale Unsupervised Pre-Training for Molecular Property Prediction. in Proceedings of the 10th ACM International Conference on Bioinformatics, Computational Biology and Health Informatics 429–436 (Association for Computing Machinery, New York, NY, USA, 2019). doi: 10.1145/3307339.3342186. [DOI] [Google Scholar]
- 4.Zhang Z., Liu Q., Wang H., Lu C. & Lee C.-K. Motif-based Graph Self-Supervised Learning for Molecular Property Prediction. in Advances in Neural Information Processing Systems vol. 34 15870–15882 (Curran Associates, Inc., 2021). [Google Scholar]
- 5.Fang X. et al. Geometry-enhanced molecular representation learning for property prediction. Nat Mach Intell 4, 127–134 (2022). [Google Scholar]
- 6.Rong Y. et al. Self-Supervised Graph Transformer on Large-Scale Molecular Data. Preprint at 10.48550/arXiv.2007.02835 (2020). [DOI] [Google Scholar]
- 7.Yang K. et al. Analyzing Learned Molecular Representations for Property Prediction. J. Chem. Inf. Model. 59, 3370–3388 (2019). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 8.Sun C., Shrivastava A., Singh S. & Gupta A. Revisiting Unreasonable Effectiveness of Data in Deep Learning Era. Preprint at 10.48550/arXiv.1707.02968 (2017). [DOI] [Google Scholar]
- 9.Zhou C. et al. A comprehensive survey on pretrained foundation models: a history from BERT to ChatGPT. Int. J. Mach. Learn. & Cyber. (2024) doi: 10.1007/s13042-024-02443-6. [DOI] [Google Scholar]
- 10.Feng B. et al. A bioactivity foundation model using pairwise meta-learning. Nat Mach Intell 6, 962–974 (2024). [Google Scholar]
- 11.Hospedales T., Antoniou A., Micaelli P. & Storkey A. Meta-Learning in Neural Networks: A Survey. IEEE Transactions on Pattern Analysis and Machine Intelligence 44, 5149–5169 (2022). [DOI] [PubMed] [Google Scholar]
- 12.Bommasani R. et al. On the Opportunities and Risks of Foundation Models. Preprint at 10.48550/arXiv.2108.07258 (2022). [DOI] [Google Scholar]
- 13.Finn C., Abbeel P. & Levine S. Model-Agnostic Meta-Learning for Fast Adaptation of Deep Networks. Preprint at 10.48550/arXiv.1703.03400 (2017). [DOI] [Google Scholar]
- 14.Koch G., Zemel R. & Salakhutdinov R. Siamese Neural Networks for One-shot Image Recognition. Proceedings of the 32nd International Conference on Machine Learning, Lille, France, JMLR: W&CP; volume 37 (2015). [Google Scholar]
- 15.Porras G. et al. Ethnobotany and the Role of Plant Natural Products in Antibiotic Drug Discovery. Chem Rev 121, 3495–3560 (2021). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 16.Rossiter S. E., Fletcher M. H. & Wuest W. M. Natural Products as Platforms To Overcome Antibiotic Resistance. Chem. Rev. 117, 12415–12474 (2017). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 17.Hutchings M. I., Truman A. W. & Wilkinson B. Antibiotics: past, present and future. Current Opinion in Microbiology 51, 72–80 (2019). [DOI] [PubMed] [Google Scholar]
- 18.Wong F., de la Fuente-Nunez C. & Collins J. J. Leveraging artificial intelligence in the fight against infectious diseases. Science 381, 164–170 (2023). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 19.Stokes J. M. et al. A Deep Learning Approach to Antibiotic Discovery. Cell 180, 688–702.e13 (2020). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 20.Wong F. et al. Discovery of a structural class of antibiotics with explainable deep learning. Nature 626, 177–185 (2024). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 21.Ma Y. et al. Identification of antimicrobial peptides from the human gut microbiome using deep learning. Nat Biotechnol 40, 921–931 (2022). [DOI] [PubMed] [Google Scholar]
- 22.Sorokina M. & Steinbeck C. Review on natural products databases: where to find data in 2020. J Cheminform 12, 20 (2020). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 23.Gaulton A. et al. ChEMBL: a large-scale bioactivity database for drug discovery. Nucleic Acids Research 40, D1100–D1107 (2012). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 24.Liu T., Lin Y., Wen X., Jorissen R. N. & Gilson M. K. BindingDB: a web-accessible database of experimentally determined protein–ligand binding affinities. Nucleic Acids Research 35, D198–D201 (2007). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 25.Snell J., Swersky K. & Zemel R. S. Prototypical Networks for Few-shot Learning. Preprint at 10.48550/arXiv.1703.05175 (2017). [DOI] [Google Scholar]
- 26.Hong J. Role of natural product diversity in chemical biology. Current Opinion in Chemical Biology 15, 350–354 (2011). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 27.Herath K. B. et al. Rapid, Selective, and Sensitive Method for Semitargeted Discovery of Congeneric Natural Products by Liquid Chromatography Tandem Mass Spectrometry. J. Nat. Prod. 84, 814–823 (2021). [DOI] [PubMed] [Google Scholar]
- 28.Dandapani S., Rosse G., Southall N., Salvino J. M. & Thomas C. J. Selecting, Acquiring, and Using Small Molecule Libraries for High-Throughput Screening. Curr Protoc Chem Biol 4, 177–191 (2012). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 29.Tang J. et al. Making Sense of Large-Scale Kinase Inhibitor Bioactivity Data Sets: A Comparative and Integrative Analysis. J. Chem. Inf. Model. 54, 735–743 (2014). [DOI] [PubMed] [Google Scholar]
- 30.Davis M. I. et al. Comprehensive analysis of kinase inhibitor selectivity. Nat Biotechnol 29, 1046–1051 (2011). [DOI] [PubMed] [Google Scholar]
- 31.RDKit: Open-source cheminformatics. https://www.rdkit.org
- 32.Pedregosa F. et al. Scikit-learn: Machine Learning in Python. J. Mach. Learn. Res. 12, 2825–2830 (2011). [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.
Data Availability Statement
The data used in this report are available in ref.15.
The ActFound code is available at https://github.com/BFeng14/ActFound.git. All of the foundation model checkpoints are available at https://figshare.com/articles/dataset/ActFound_data/24452680.