

Abstract
Eye diseases can affect vision and well-being, so early, accurate diagnosis is crucial to prevent serious impairment. Deep learning models have shown promise for automating the diagnosis of eye diseases from images. However, current methods mostly use single-model architectures, including convolutional neural networks (CNNs), which might not adequately capture the long-range spatial correlations and local fine-grained features required for classification. To address these limitations, this study proposes a multi-stage framework for eye diseases (MST-EDS), including two stages: hybrid and stacking models in the categorization of eye illnesses across four classes: normal, diabetic_retinopathy, glaucoma, and cataract, utilizing a benchmark dataset from Kaggle. Hybrid models are developed based on Transformer models: Vision Transformer (ViT), Data-efficient Image Transformer (DeiT), and Swin Transformer are used to extract deep features from images, Principal Component Analysis (PCA) is used to reduce the complexity of extracted features, and Machine Learning (ML) models are used as classifiers to enhance performance. In the stacking model, the outputs of the best hybrid models are stacked, and they are used to train and evaluate meta-learners to improve classification performance. The experimental results show that the MST-EDS-RF model recorded the best performance compared to individual Transformer and hybrid models, with 97.163% accuracy.
Keywords: Image processing, Eye diseases, Diagnostic model, Vision transformer (ViT), Data-efficient image transformer (DeiT), Swin transformer, MST-EDS
Subject terms: Eye diseases, Diagnosis
Introduction
Early and precise diagnosis of eye diseases can save patients from vision loss and help in preventing blindness through taking timely treatment for irreversible vision loss caused by factors such as diabetic retinopathy, glaucoma, and age-related macular degeneration1. However, many eye conditions have few initial symptoms and can often go unnoticed until extensive screening is carried out2, revealing the need for an accurate examination. Unfortunately, diagnosis usually depends on complex imaging modalities such as OCT and fundus photography by highly trained professionals, which can result in delay and variability3,4.
In addition, techniques such as measuring intraocular pressure (IOP) are uncomfortable or invasive, making them unsuitable for large-scale screening where patient cooperation is critical, especially in glaucoma detection5. Furthermore, glaucoma detection does not address other eye diseases, which leads to incomplete screening without employing multiple methods6. Moreover, many traditional methods, such as optical coherence tomography (OCT) and fundus photography, require expensive and specialized equipment that may not be accessible in all healthcare settings. For this reason, the accurate evaluation of the optic nerve and interpretation of results requires trained ophthalmologists or optometrists, which is especially limiting in rural or underserved areas7.
Artificial Intelligence (AI) technology’s intervention in diagnosing eye diseases8–10, CNNs were used, but over time, many of its weaknesses became apparent. CNNs are affected by changes in imaging conditions like lighting, angle, and resolution11 and still cannot synthesize a high-order global context in images, which is conducive to analyzing complex relations in eye diseases12, making it challenging to incorporate the contextual information of patient leading to inconsistency in performance on various datasets13. While CNNs effectively capture spatial features, they struggle to model temporal changes in imaging data. In contrast, Transformers models use self-attention, hierarchical structure, and a shifted windowing mechanism that can capture long-range dependencies, contextual information, and local and global feature representations to significantly improve diagnostic performance in eye disease detection14.
In addition, transformer models include different types, such as ViT, DeiT, and Swin. ViT divides images into patches, processes them as sequences, and uses self-attention mechanisms to capture long-range dependencies15. Swin is built upon ViT architecture but introduces a hierarchical structure and shifted windowing mechanism to improve efficiency significantly. Swin enables better spatial modeling by capturing both local and global feature representations through the integration of non-overlapping and shifted windows. This design reduces computational complexity and memory consumption16. DeiT is designed to enhance the efficiency of ViT Transformer, particularly on smaller datasets, by incorporating knowledge distillation techniques, making it more accessible. Deit relies on self-attention to capture relationships between different parts of the image, allowing it to learn complex patterns17. In our model, MST-EDS, we used three types together to benefit from each one’s advantages by applying the stacking model. These transformer models serve as diverse and complementary feature extractors within the framework. Their integration enriches the feature space and improves the robustness and accuracy of eye disease classification.
The stacked model facilitates the integration of heterogeneous architectures and learning paradigms, enabling each constituent model to extract complementary patterns and insights from the data. By leveraging this ensemble approach, the overall system benefits from improved predictive performance and enhanced generalizability across diverse datasets18,19.
Existing research often focuses on applying pre-trained CNN, single transformer models, or hybrid models to classify eye disease; they do not apply different types of transformer or stacking models to make generalizations and enhance performance. For example, Aslam et al.20 applied five different pre-trained models, including VGG-16, VGG-19, Resnet-50, Resnet-152, and DenseNet-121. Wang et al.21 presented ViT based on the self-attention mechanism to enhance performance in medical image analysis. Abbas et al.22 introduced a hybrid ensemble model consisting of the AlexNet model, ReliefF as a feature selector, and ML as a classifier. This study aims to bridge this gap by proposing that MST-EDS be developed based on hybrid and stacking models to make generalizations and enhance performance. Advantages of this design: (1) Diversity in models: Different transformer models, such as ViT, DeiT, and Swin, can be applied to ensure varied feature representations. (2) To minimize dimensionality while retaining the most informative aspects of the data, we apply PCA after extracting feature vectors from multiple models. PCA effectively captures the most significant variance within the dataset, enabling us to reduce redundant and irrelevant features23. This alleviates the risk of overfitting and improves the model’s computational efficiency and overall predictive performance. (3) Stacking Ensemble: Improves generalization by combining the strengths of individual classifiers.
The study’s findings and insights can be distilled into the following key contributions:
Novel multi-stage framework for eye diseases: Developing MST-EDS consists of hybrid and stacking models. Hybrid models were developed based on transformer architecture (Swin, ViT, and DeiT), feature selection, and ML models as classifiers. The stacking model is trained and evaluated using the outputs of the best hybrid models in stacking training and stacking testing to enhance classification performance.
Evaluating performance across benchmark datasets: The proposed model is evaluated using a benchmark eye disease classification images dataset. MST-EDS achieves an exceptional accuracy of 97.163%, surpassing existing transformer and hybrid models in precision, recall, and F1-score.
Applying transformer model in medical image: Applying Swin transformer with framework records the significant performance; its architecture uses a hierarchical self-attention mechanism that can capture long and short contextual patterns.
Addressing computational efficiency of model: Through PCA feature selection, our approach maximizes the computational efficiency of transformer models, lowering processing overhead without sacrificing accuracy.
We demonstrate the effectiveness of using transformers in classifying eye illnesses by going beyond the techniques currently used in the literature.
This paper is structured as follows: “Literature reviews” provides an overview of existing research on eye diseases. “Materials and method” introduces our proposed framework, presenting its design and methodology. The experimental results are presented in “Experiments results”. “Limitation and future work” presents limitations and future work. Finally, “Conclusion” presents the essential findings and contributions of the study.
Literature reviews
Early fund screening can efficiently and cost-effectively reduce the risk of blindness from ophthalmic diseases. A manual diagnosis may delay the diagnosis due to a lack of medical resources. Researchers have achieved good results in eye diseases using deep learning and machine learning. Many researchers addressed the development models for classifying normal glaucoma, diabetic retinopathy, and contract eye diseases.
Aslam et al.20 applied five different pre-trained models, including VGG-16, VGG-19, Resnet-50, Resnet-152, and DenseNet-121, for classifying eye disease. According to the findings, VGG-19 had the best results. Albelaihi et al.24 proposed a model that integrates ResNet152V2 + Bidirectional GRU (Bi-GRU) to classify four classes of eye disease. Their proposed model recorded the best performance compared to other models, EfficientNetB0, VGG16, ResNet152V2, and ResNet152V2. They employed online and offline geometric augmentation methods to assess the accuracy of models. Wang et al.21 presented ViT based on the self-attention mechanism to enhance performance in medical image analysis. The results showed that ViT performed the best compared to other models, such as ResNet, VGG, DenseNet, and MobileNet, in classifying eye disease. In25, the authors proposed an R-CNN+LSTM model based on DL models (R-CNN and LSTM) to extract features, NCAR to select features, and SVM as a classifier to classify eight different ophthalmologic diseases using the ODIR dataset.
The authors applied models to classify four classes: cataract, diabetic retinopathy, and glaucoma, using the eye_diseases_classification (EDC) dataset collected from Kaggle. Babaqi26 et al. identified eye illnesses using CNN models and transfer learning. The results proved that transfer learning for multi-class classification recorded the highest accuracy compared to traditional CNN. Using the same dataset, Tasnim et al.27 proposed BayeSVM500 based on different stages. Firstly, Deep features were extracted from pre-trained CNN models, VGG16, VGG19, ResNet50, EfficientNet, and DenseNet, to extract deep features. Principal Component Analysis (PCA) was used to reduce feature dimensionality. Then, a Support Vector Machine classifier (SVM) was used as a classifier. They conducted different experiments to select the best-extracted features and recorded the best performance. Abdullah et al.28 proposed a weighted ensemble DL based on feature selection and a pre-trained CNN. Both models of Efficientb6 and Densnet169 were employed for the extracted features. PCA and Two-Dimensional Discrete Wavelet Transform (2D DWT) to optimize extracted features. Jessica Ryan et al.29 explored various pre-trained-CNN: VGG-16, VGG-19, ResNet-50, and ResNet-152v2 to identify the best model for detecting different types of eye diseases using ocular diseases. The results showed that ResNet-152v2 performed well compared to other models. Wahab Sait et al.30 proposed a model based on the DL technique to classify eye disease using advanced image pre-processing methods. Denoising autoencoders were used to remove noise from image datasets. The essential features are produced via the single-shot detection (SSD) method. The features are chosen using the whale optimization algorithm (WOA) and the Levy Flight and Wavelet search strategy. Babaqi et al.26 applied a custom CNN and EfficientNet to detect three eye diseases, i.e., cataracts, diabetic retinopathy, and glaucoma. The results showed that performance significantly increased with the CNN-pretrained model. The results showed that the proposed model recorded the highest performance. Abbas et al.22 introduced a hybrid ensemble model consisting of the AlexNet model as a feature extractor, ReliefF as a feature selector, and XgBoost as a classifier. Image feature extraction was conducted using the AlexNet model. Subsequently, the ReliefF method was employed to select the most crucial features. The XgBoost classifier was applied to the selected features for class identification.
The authors conducted experiments based on OCT images. Hemalakshmi et al.31 proposed a hybrid model (SViT) that combined the strengths of SqueezeNet and ViT to capture local and global features of images. SViT compared CNN-based and standalone transformer models and recorded the highest accuracy. Said et al.32 proposed Tokens-To-Token Vision Transformer (T2T-ViT) and Mobile Vision Transformer (Mobile-ViT). According to experimental results using ViT techniques, Mobile-ViT performs better than the others in terms of classification accuracy.
Table 1 compares the research studies related to the areas discussed. Some authors developed a model using the ODIR dataset, a subset of EDC; therefore, we conducted an experiment based on the EDC dataset in our research. Existing research employs single transformer models, hybrid models, or pre-trained CNNs to categorize eye diseases; it does not use several transformer models or stacking models to improve performance and make generalizations.
Table 1.
Comparing literature studies based on highlights and limitations.
| Papers | Datasets | Highlights | Limitations |
|---|---|---|---|
| Aslam et al.20 | ODIR | Applying different pre-trained CNN models |
It did not use transformer models It did not apply hybrid models |
| Albelaihi et al.24 | ODIR | Developing an integrated model ResNet152V2 + Bi-GRU | It did not use transformer models |
| Wang et al.21 | ODIR |
Applying ViT transformer Comparing ViT with pretrained models |
It did not apply hybrid model It did not apply ensemble learning |
| Hemalakshmi et al.31 | OCT | Developing a hybrid model (SViT) that combined the strengths of SqueezeNet and ViT |
It did not apply hybrid model It did not apply ensemble learning |
| Said et al.32 | OCT |
Developing hybrid model Mobile-ViT Applying ViT transformer |
It did not apply ensemble learning |
| Babaqi26 | EDC | Applying different pre-trained CNN models |
It did not use transformer models It did not apply hybrid models |
| Tasnim et al.27 | EDC | Proposing BayeSVM500 based on pretrained CNN model, PCA, and SVM |
It did not use transformer models It did not apply ensemble learning |
| Abdullah et al.28 | ODIR | Proposing a weighted ensemble DL based on pretrained CNN models and PCA | It did not use transformer models |
| Jessica Ryan et al.29 | ODIR | Applying different pre-trained CNN models |
It did not use transformer models It did not apply ensemble learning |
| Wahab Sait et al.30 | EDC |
Applying DL models Applying denoising autoencoders to remove noise from an image |
It did not use transformer models It did not apply stacking model |
| Babaqi et al.26 | ODIR |
Applying customize CNN model Applying pre-trained CNN model |
It did not use transformer models It did not apply ensemble learning |
| Abbas et al.22 | ODIR | Developing a hybrid ensemble model based on AlexNet, ReliefF, and XgBoost |
It did not use transformer models It did not apply stacking model |
Materials and method
The primary steps involved in classifying eye diseases are as follows: image data description, data augmentation, training models, and evaluation models, as shown in Fig. 1. Each step is described in the following.
Fig. 1.

The main steps of classifying eye diseases.
Image data descriptions
The performance of the models was assessed using a publicly available dataset obtained from Kaggle: Eye diseases classification images dataset (EDC)33. The EDC dataset was collected from various sources such as IDRiD, Ocular recognition, HRF, retinal_dataset, and DRIVE. The dataset is balanced, comprising 4217 images distributed across four classes: 1074 normal, 1098 diabetic retinopathy, 1007 glaucoma, and 1038 cataract cases as shown in Fig. 2.
In cataracts, the eye’s lens becomes cloudy and blurry, causing impaired vision. A cloudy lens can be replaced with an artificial one surgically to restore clear vision and quality of life.
Diabetic retinopathy is a complication of diabetes that affects the blood vessels in the retina. In severe cases, it may lead to blindness because of blurred or distorted vision. Preventing and managing diabetes requires early detection, regular eye examinations, and proper management.
A glaucoma is an eye disease characterized by damage to the optic nerve caused by increased fluid pressure in the eye. It gradually leads to vision loss, starting with peripheral vision and potentially progressing to complete blindness. Timely diagnosis, treatment, and ongoing monitoring are vital for preserving vision and preventing irreversible damage.
Fig. 2.

Eye-related diseases.
Image preprocessing and augmentation techniques
Image preprocessing is a crucial phase in numerous applications for computer vision since it boosts the performance and reliability of models34. Augmenting image data involves changes in original imaging to increase the diversity and variability of the training data artificially. These augmentations help enhance models’ generalization robustness and accuracy. The typical image preprocessing/augmentation techniques are:
Flipping is the process of rotating an image horizontally, reversing the left and right sides of the image, or vertically, reversing the top and bottom of the image35. Flipping may assist in expanding the array of the training data and improve the model’s generalizability by introducing novel viewpoints and mirrored copy images of the input images.
Resizing is frequently required since deep learning models usually need fixed-size inputs. Resizing can be accomplished via several interpolation approaches, notably nearest-neighbor, bilinear, and bicubic interpolation36.
Normalization is a method of scaling input data to guarantee that all features hold the same scale, thereby promoting the stability and convergence of the training process. Image data is commonly normalized using mean and standard deviation37.
Table 2 presents the values of augmentation techniques. Figure 3 presents the impact of each augmentation technique in the image.
Table 2.
The values of augmentation techniques.
| Augmentation techniques | Value |
|---|---|
| HorizontalFlip | 0.5 |
| VerticalFlip | 0.5 |
| Resize | 224x224 |
| Normlization | Mean and standardization |
Fig. 3.

The effect of each augmentation technique.
Transformer models
We used three Transformer models: Vision Transformer (ViT), Data-efficient Image Transformer (DeiT) and Swin as standalone to compare with proposed models.
Vision transformer (ViT)
ViT is a deep learning architecture that extends the transformer architecture from natural language processing (NLP) to computer vision38. This model got attention and performed well in image recognition39. ViT treats an image as a sequence of patches and uses self-attention to record their interactions. The model relies on transformer encoder and patch embedding38. ViT is a transformer-based architecture that interprets an image as a series of patches and processes them through the transformer architecture40. The source image is split into a grid of non-overlapping patches of 16 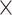 16 or 32
16 or 32 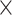 32 pixels and an embedding dimension (D) of 76840. The embedding dimension sets the size of the patch embeddings, which are vector representations of image patches. Expanding the embedding dimension can lead to a more expressive and powerful representation of input patches but also increases computational and memory requirements. The patch embedding sequence and positional encodings are included in the transformer encoder, which comprises 12 transformer blocks, each with a multi-head attention mechanism based on feedforward neural network FFN with 12 attention heads. FFN controls the number of parallel attention computations conducted in the Multi-Head Attention module. The FFN module applies a simple feedforward neural network of dimension 3072 for every patch separately in the ViT transformer blocks, offering more modeling capacity to learn deeper representations40. To prevent overfitting in neural networks, a dropout rate 0.1 controls the potential of activations dropping out with a weight decay of 0.1 during the training phase. To improve the model’s generalization efficiency, Attention Dropout with 0.1 was utilized to regularize the attention mechanism41. A unique classification token is added after the transformer encoder sequence to record the input image’s global representation while being processed by a fully connected layer that generates the final classification output41. Figure 4 shows the general architecture of ViT transformer.
32 pixels and an embedding dimension (D) of 76840. The embedding dimension sets the size of the patch embeddings, which are vector representations of image patches. Expanding the embedding dimension can lead to a more expressive and powerful representation of input patches but also increases computational and memory requirements. The patch embedding sequence and positional encodings are included in the transformer encoder, which comprises 12 transformer blocks, each with a multi-head attention mechanism based on feedforward neural network FFN with 12 attention heads. FFN controls the number of parallel attention computations conducted in the Multi-Head Attention module. The FFN module applies a simple feedforward neural network of dimension 3072 for every patch separately in the ViT transformer blocks, offering more modeling capacity to learn deeper representations40. To prevent overfitting in neural networks, a dropout rate 0.1 controls the potential of activations dropping out with a weight decay of 0.1 during the training phase. To improve the model’s generalization efficiency, Attention Dropout with 0.1 was utilized to regularize the attention mechanism41. A unique classification token is added after the transformer encoder sequence to record the input image’s global representation while being processed by a fully connected layer that generates the final classification output41. Figure 4 shows the general architecture of ViT transformer.
Fig. 4.

General architecture of ViT transformer.
Data-efficient image transformer (DeiT)
DeiT is a version of the ViT model that aims to achieve high accuracy on image classification tasks while being trained with far less training data than the original ViT. Distillation token from DeiT takes a different approach, which is capable of fast learning without relying heavily on large, labeled datasets that hinder the traditional transfer learning methods. This approach enables the possibility of fast convergence and enhanced performance. DeiT is built to be trained on smaller datasets without requiring large-scale pretraining42. DeiT uses optimization via a distillation token and a teacher model. It learns from a teacher’s predictions to allow the model to achieve superior results with less data. Similar to ViT, DeiT employs a pure transformer architecture for image classification. It divides an image into fixed-size patches, flattens them, and applies self-attention mechanisms to them. DeiT enhances performance by incorporating optimized training strategies, including data augmentation, regularization, and learning rate schedules42.
Swin transformer
The Swin transformer architecture introduces a hierarchical structure to model local and global dependencies efficiently, distinguishing it from the traditional Transformer. Swin Tiny is used to classify eye disease. The Swin tiny transformer applies the self-attention method to the entire image; the Swin Transformer separates the 4*4 input images onto non-overlapping 7-size windows and calculates self-attention within each window43. This minimizes the computational complexity and increases model effectiveness. The Transformer possesses a hierarchical architecture, increasing the number of layers as one proceeds further into the model44. A multi-head attention mechanism with heads was additionally employed, in which the self-attention computation is distributed between many attention heads to assist the model in capturing more diverse and complicated relationships in the input data44. Yet, it increases the model’s complexity and processing complexity.
The Multi-Layer Perceptron (MLP) Ratio is typically set to 4, implying that the hidden dimension in the MLP layer is four times the embedding dimension. To prevent overfitting, standard values for dropout rates in Swin Transformer models are 0.1 and weight decay is 0.05, while the learning rate, which primarily regulates the step size during the optimization process used to train the Swin Transformer model, should be 0.00145. Swin Transformer alters the window partitioning in the following layer to record interactions between neighboring windows, allowing the self-attention mechanism to function across window boundaries45. The Swin Transformer has a hierarchical architecture in which the number of windows and window sizes is gradually reduced in deeper layers, permitting the model to capture knowledge at various scales. The embedding dimension plays a vital role in establishing the representative capacity and performance of the Swin Transformer model46. The Embedding Dimension describes the number of channels or features within each transformer block’s output. Applying the Swin transform with an embedding size of 96 is preferable since higher embedding dimensions empower the model to capture more complex and detailed properties. However, they additionally increase the model’s computational and memory needs46. Figure 5 shows the general architecture of Swin transformer.
Fig. 5.

General architecture of Swin transformer.
The proposed model (MST-EDS)
Figure 6 illustrates a two-stage of the proposed model (MST-EDS) for eye disease classification using hybrid models and stacking models. Advantages of this design: (1) Diversity in models: Different transformer models, such as ViT, DeiT, and Swin, can be applied to ensure varied feature representations. (2) To minimize dimensionality while retaining the most informative aspects of the data, we apply PCA after extracting feature vectors from multiple models. PCA effectively captures the most significant variance within the dataset, enabling us to reduce redundant and irrelevant features23. This not only alleviates the risk of overfitting but also improves the model’s computational efficiency and overall predictive performance23. (3) Stacking ensemble: Improves generalization by combining the strengths of individual classifiers.
Fig. 6.

The main stages of the proposed model.
Stage 1: Hybrid models
This stage includes three parallel pipelines, each combining Transformer models, PCA for dimensionality reduction, and an ML classifier. Feature selection (FS) is crucial to transforming high-dimensional data into low-dimensional data47,48.
- Hybrid model 1 pipeline
- ViT model extracts high-dimensional features and global context from images using self-attention mechanisms.
- PCA reduces the high-dimensional features output by the ViT model. This minimizes redundancy and computational complexity while preserving variance.
- Classifier: The reduced feature set is fed into SVM, RF, and LR classifiers to generate the prediction output (P1).
- Hybrid model 2 pipeline
- DeiT is designed to enhance performance by incorporating knowledge distillation techniques, making it more accessible. DeiT relies on self-attention to capture relationships between different parts of the image, allowing it to learn complex patterns.
- PCA reduces dimensionality of the DeiT-extracted features.
- The reduced feature vectors are subsequently input to SVM, RF, LR classifiers to produce the prediction output, denoted as P2
- Hybrid model 3 pipeline
- Swin Transformers extracts local and global features using hierarchical structure and shifted windows.
- PCA as feature reduction is applied to Swin outputs.
- The reduced feature vectors are subsequently input to produces prediction P3.
Each pipeline outputs a prediction vector (P1, P2, P3) representing class probabilities.
Stage 2: Stacking model
This stage aggregates the individual predictions from the hybrid models to make a final classification. The stacking model is called stacked generalization, a type of ensemble learning that integrates various base models to enhance model performance49,50. Stacking consists of three hybrid models used as base models and meta-learning, including RF, SVM and LR. First, the outputs of the base models for the training set are combined into the stacking train, and the predictions of the base models for the testing set are incorporated into the stacking test. Second, the stacking training set is used to train the meta-model, while the stacking testing is used to evaluate the meta-model.
Evaluation models
The evaluation of classification models in machine learning is critically hinged on a suite of key metrics. It is defined as the ratio of true positives (TP) and true negatives (TN) to the total number of instances, including false positives (FP) and false negatives (FN)51,52.
- Accuracy: Represents the proportion of correctly classified instances.
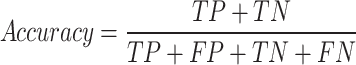
1 - Recall: Reflects the ability of the algorithm to correctly identify positive instances out of all actual positives.

2 - Precision: Indicates the proportion of correctly identified positive instances out of all instances predicted as positive.

3 - F1-score: Presents the harmonic mean of precision and recall, providing a balanced measure of a model’s performance.

4
Experiments results
Experimental setup
This study implemented models using Python, an NVIDIA RTX-3090 GPU, Windows 10 Professional, and an Intel i7 processor with 3.2 GHz. Swin, ViT, and DeiT were implemented using Monai, PyTorch, and Sklearn.
We conducted different experiments based on various approaches. The first approach is standalone transformer models (Swin, ViT, and DeiT). The second approach integrates transformer models, Swin, ViT, and Diet, as feature extraction with ML as a classifier. The second approach is based on Swin, ViT, and DieT, which are used for feature extraction; PCA is used for feature reduction to reduce the complexity of features; and ML models, including RF, SVM, and LR, are used as classifiers. The third approach is hybrid models based on Swin, ViT, and Diet, which are used for feature extraction; PCA is used for feature reduction to reduce the complexity of features; and ML models, including RF, SVM, and LR, are used as classifiers. The fourth approach is the proposed model MST-EDS, which is trained by stacking training that is stacked by the output predictions from the training set based on the best hybrid models, and evaluated by stacking testing that is stacked from the testing set based on the best hybrid models.
The PCA method is employed with a preserved variance of 95% to reduce the data’s dimensionality. It is applied to training features, and then the number of components is used to testing features, resulting in DeiT reducing from (2949, 37824) to (2949, 2757) with 2757 principal components, Swin reducing from (2949, 768) to (2949, 500) with 500 principal components (500), and ViT reducing from (2949, 768) to (2949, 580) with 580 principal components.
For the setting of ML, we stated that ML classifiers were trained using a 5-fold cross-validation strategy to ensure generalizability and avoid overfitting with key hyperparameters of RF (number of estimators = 100, max depth = 10, criterion = gini), LR (C = 1.0, max_iter = 100), and SVM (kernel = rbf, C = 1). The hyperparameters of Transformer models as shown in Table 3.
Table 3.
Setting of model parameters.
| Models | Parameters | Values |
|---|---|---|
| Swin-tiny | Embedding dimension | 96 |
| Number of layers | 4 Stages | |
| Window size | 7 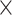 7 7 |
|
| Number of heads | (3, 6, 12, 24) | |
| MLP hidden dim | 4 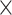 Embedding dim Embedding dim |
|
| Number of blocks | (2, 2, 6, 2) | |
| Input size | 224 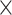 224 224 |
|
| Epoch | 70 with early stopping | |
| Batch size | 32 | |
| Optimizer | AdamW | |
| ViT-base | Embedding dimension (D) | 768 |
| Number of layers (L) | 12 | |
| Number of attention heads (H) | 12 | |
| MLP dimension (D MLP) | 3072 | |
| Input size | 224  224 224 |
|
| Epoch | 70 with early stopping | |
| Batch size | 32 | |
| Optimizer | AdamW | |
| DeiT-Small | Embedding dimension | 384 |
| Number of layers | 12 | |
| Number of attention heads | 6 | |
| Input size | 224 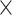 224 224 |
|
| Epoch | 70 with early stopping | |
| Batch size | 32 | |
| Optimizer | AdamW |
Data splitting
The models were trained using 70% of the total number of images, validated using 10%, and tested with 20%. The dataset is balanced and divided using stratified methods, which means the number of classes in training, testing, and validation sets is approximately nearby. Table 4 shows the number of images in each class.
Table 4.
The number of images in training, validation, and testing sets.
| Classes | Training | Validation | Testing | |
|---|---|---|---|---|
| Normal | 751 | 107 | 216 | 1074 |
| Diabetic_retinopathy | 768 | 110 | 220 | 1098 |
| Glaucoma | 704 | 101 | 202 | 1007 |
| Cataract | 726 | 104 | 208 | 1038 |
| Total | 2949 | 422 | 846 | 4217 |
The performance of models across all classes of eye disease
Tables 5 and 6 present the performance of different models for each class across three approaches: standalone models, hybrid models, and MST-EDS based on various evaluation matrices precision, recall, and F1-score. As shown in Tables, all models based on diabetic_retinopathy classes recorded the highest performance compared to glaucoma or cataracts because the features in diabetic_retinopathy, such as microaneurysms, hemorrhages, and exudates, are easy to detect by models. MST-EDS recorded the best performance across all classes, especially with RF, because Swin captures local and global features using hierarchical representation and attention mechanisms. RF provides insights into the importance of different features, which is useful in understanding the underlying relationships in the data.
Table 5.
The performance of models across all classes of eye disease.
| Approaches | Models | Classes | Precision | Recall | F1-score |
|---|---|---|---|---|---|
| Standalone models | ViT | Cataract | 90.640 | 88.462 | 89.538 |
| Diabetic_retinopathy | 94.787 | 90.909 | 92.807 | ||
| Glaucoma | 85.561 | 79.208 | 82.262 | ||
| Normal | 75.102 | 85.185 | 79.826 | ||
| DeiT | Cataract | 92.500 | 88.942 | 90.686 | |
| Diabetic_retinopathy | 94.860 | 92.273 | 93.548 | ||
| Glaucoma | 85.864 | 81.188 | 83.461 | ||
| Normal | 76.763 | 85.648 | 80.963 | ||
| Swin | Cataract | 94.175 | 93.269 | 93.720 | |
| Diabetic_retinopathy | 99.099 | 100.000 | 99.548 | ||
| Glaucoma | 83.945 | 90.594 | 87.143 | ||
| Normal | 90.500 | 83.796 | 87.019 | ||
| Models-ML | ViT-RF | Cataract | 92.893 | 87.981 | 90.370 |
| Diabetic_retinopathy | 96.875 | 98.636 | 97.748 | ||
| Glaucoma | 82.524 | 84.158 | 83.333 | ||
| Normal | 86.301 | 87.500 | 86.897 | ||
| ViT-LR | Cataract | 93.401 | 88.462 | 90.864 | |
| Diabetic_retinopathy | 96.429 | 98.182 | 97.297 | ||
| Glaucoma | 80.583 | 82.178 | 81.373 | ||
| Normal | 85.388 | 86.574 | 85.977 | ||
| ViT-SVM | Cataract | 91.327 | 86.058 | 88.614 | |
| Diabetic_retinopathy | 95.536 | 97.273 | 96.396 | ||
| Glaucoma | 79.126 | 80.693 | 79.902 | ||
| Normal | 84.545 | 86.111 | 85.321 | ||
| DieT-RF | Cataract | 94.872 | 88.942 | 91.811 | |
| Diabetic_retinopathy | 97.738 | 98.182 | 97.959 | ||
| Glaucoma | 84.466 | 86.139 | 85.294 | ||
| Normal | 87.500 | 90.741 | 89.091 | ||
| DieT-LR | Cataract | 93.000 | 89.423 | 91.176 | |
| Diabetic_retinopathy | 95.982 | 97.727 | 96.847 | ||
| Glaucoma | 83.333 | 84.158 | 83.744 | ||
| Normal | 86.239 | 87.037 | 86.636 | ||
| DeiT-SVM | Cataract | 92.040 | 88.942 | 90.465 | |
| Diabetic_retinopathy | 95.982 | 97.727 | 96.847 | ||
| Glaucoma | 81.818 | 80.198 | 81.000 | ||
| Normal | 84.305 | 87.037 | 85.649 | ||
| Swin-RF | Cataract | 94.231 | 94.231 | 94.231 | |
| Diabetic_retinopathy | 99.087 | 98.636 | 98.861 | ||
| Glaucoma | 88.095 | 91.584 | 89.806 | ||
| Normal | 90.909 | 87.963 | 89.412 | ||
| Swin-LR | Cataract | 94.634 | 93.269 | 93.947 | |
| Diabetic_retinopathy | 98.636 | 98.636 | 98.636 | ||
| Glaucoma | 87.500 | 88.099 | 88.780 | ||
| Normal | 89.202 | 87.963 | 88.578 | ||
| Swim-SVM | Cataract | 91.943 | 93.269 | 92.601 | |
| Diabetic_retinopathy | 98.074 | 97.273 | 98.165 | ||
| Glaucoma | 84.332 | 90.594 | 87.351 | ||
| Normal | 91.089 | 85.185 | 88.038 |
Table 6.
Continued the performance of models across all classes of eye disease.
| Approaches | Models | Classes | Precision | Recall | F1-score |
|---|---|---|---|---|---|
| Models-PCA-ML | ViT-PCA-RF | Cataract | 94.898 | 89.423 | 92.079 |
| Diabetic_retinopathy | 98.206 | 99.545 | 98.871 | ||
| Glaucoma | 83.575 | 85.644 | 84.597 | ||
| Normal | 87.273 | 88.889 | 88.073 | ||
| ViT-PCA-LR | Cataract | 93.939 | 89.423 | 91.626 | |
| Diabetic_retinopathy | 96.889 | 99.091 | 97.978 | ||
| Glaucoma | 82.843 | 83.663 | 83.251 | ||
| Normal | 86.301 | 87.500 | 86.897 | ||
| ViT-PCA-SVM | Cataract | 92.386 | 87.500 | 89.877 | |
| Diabetic_retinopathy | 96.444 | 98.636 | 97.528 | ||
| Glaucoma | 80.882 | 81.683 | 81.281 | ||
| Normal | 85.455 | 87.037 | 86.239 | ||
| DeiT-PCA-RF | Cataract | 95.918 | 90.385 | 93.069 | |
| Diabetic_retinopathy | 98.649 | 99.545 | 99.095 | ||
| Glaucoma | 85.507 | 87.624 | 86.553 | ||
| Normal | 88.688 | 90.741 | 89.703 | ||
| DeiT-PCA-LR | Cataract | 94.500 | 90.865 | 92.647 | |
| Diabetic_retinopathy | 97.321 | 99.091 | 98.198 | ||
| Glaucoma | 84.804 | 85.644 | 85.222 | ||
| Normal | 87.615 | 88.426 | 88.018 | ||
| DeiT-PCA-SVM | Cataract | 93.035 | 89.904 | 91.443 | |
| Diabetic_retinopathy | 96.875 | 98.636 | 97.748 | ||
| Glaucoma | 83.333 | 81.683 | 82.500 | ||
| Normal | 85.650 | 88.426 | 87.016 | ||
| Swin-PCA-RF | Cataract | 95.673 | 95.673 | 95.673 | |
| Diabetic_retinopathy | 100.000 | 100.000 | 100.000 | ||
| Glaucoma | 89.474 | 92.574 | 90.998 | ||
| Normal | 91.866 | 88.889 | 90.353 | ||
| Swin-PCA-LR | Cataract | 95.631 | 94.712 | 95.169 | |
| Diabetic_retinopathy | 99.548 | 100.000 | 99.773 | ||
| Glaucoma | 88.942 | 91.584 | 90.244 | ||
| Normal | 90.995 | 88.889 | 89.930 | ||
| Swin-PCA-SVM | Cataract | 93.810 | 94.712 | 94.258 | |
| Diabetic_retinopathy | 99.548 | 100.000 | 99.773 | ||
| Glaucoma | 86.667 | 90.099 | 88.350 | ||
| Normal | 91.220 | 86.574 | 88.836 | ||
| The proposed model | MST-EDS-RF | Cataract | 97.573 | 96.635 | 97.101 |
| Diabetic_retinopathy | 100.000 | 100.000 | 100.000 | ||
| Glaucoma | 95.588 | 96.535 | 96.059 | ||
| Normal | 95.370 | 95.370 | 95.370 | ||
| MST-EDS-LR | Cataract | 97.087 | 96.154 | 96.618 | |
| Diabetic_retinopathy | 100.000 | 100.000 | 100.000 | ||
| Glaucoma | 92.271 | 94.554 | 93.399 | ||
| Normal | 93.427 | 92.130 | 92.774 | ||
| MST-EDS-SVM | Cataract | 94.787 | 96.154 | 95.465 | |
| Diabetic_retinopathy | 100.000 | 100.000 | 100.000 | ||
| Glaucoma | 88.995 | 92.079 | 90.511 | ||
| Normal | 93.204 | 88.889 | 90.995 |
In standalone models, Swin models achieved the highest performance across all classes with 99.099 precision and 93.548 F1-score for diabetic_retinopathy. ViT scored the lowest across all classes with 75.102 precision and 79.826 F1-score for normal classes.
For integrating transformer models with ML, for ViT-ML models, ViT-RF achieved the highest recall, with a score of 98.636 for diabetic_retinopathy. Meanwhile, ViT-SVM with glaucoma had the lowest precision of 79.126. For DieT-ML, DeiT-RF had the highest recall for diabetic_retinopathy, scoring 98.182. and DeiT-SVM recorded the lowest recall with 80.198 for glaucoma. Swin-RF had the highest precision, recall, and F1 Score for Swin-PCA-ML models in every class, with a score of 99.087 for diabetic_retinopathy.
Similarly, combining transformer models with PCA and ML yields better results than combining transformer models with ML since PCA chooses the best features from the feature representation matrix. The integration of Swin-PCA-RF scored the highest because Swin captures local and global features. RF provides insights into the importance of different features, which is useful in understanding the underlying relationships in the data.
For ViT-PCA-ML models, ViT-PCA-RF scored the highest recall, with 99.545 for diabetic_retinopathy. It also had the highest precision and recall for glaucoma and normal, with 83.575 and 87.273, respectively. ViT-PCA-SVM scored the lowest recall, with 81.683 for glaucoma. It had the same recall for cataracts and normal, around 87. For DieT-PCA-ML, DeiT-PCA-RF had the highest recall for diabetic retinopathy, scoring 99.545. At 87.624 and 90.741, respectively, it likewise had the highest recall for glaucoma and normal. For Swin-PCA-ML models, Swin-PCA-RF recorded the highest precision, recall and F1 Score across all classes, with 100 for diabetic retinopathy and 95.673 for cataract. Swin-PCA-SVM scored the worst precision, with 86.667 for glaucoma and the same F1-score, round 88, for normal and glaucoma.
The proposed model (MST-EDS), MST-EDS-RF enhanced results and scored the best performance across all classes, with 100 precision for diabetic_retinopathy and 97.573 precision for cataract. MST-EDS-SVM recorded the lowest precision, at 88.995 and 90.511 F1-score for glaucoma.
Results of the average performance of the models
Table 7 presents the average of accuracy, precision, recall, and F1-score of different models for each class across approaches: standalone models, hybrid models, and MST-EDS.
Table 7.
Results of the average performance of the models.
| Approaches | Models | Accuracy | Precision | Recall | F1-score |
|---|---|---|---|---|---|
| Standalone models | Swin | 91.962 | 92.075 | 91.962 | 91.954 |
| ViT | 86.052 | 86.539 | 86.052 | 86.171 | |
| DeiT | 87.116 | 87.511 | 87.116 | 87.223 | |
| Model-ML | ViT-RF | 89.716 | 89.770 | 89.716 | 89.722 |
| ViT-LR | 89.007 | 89.082 | 89.007 | 89.023 | |
| ViT- SVM | 87.707 | 87.777 | 87.707 | 87.717 | |
| DeiT-RF | 91.135 | 91.250 | 91.135 | 91.159 | |
| DeiT-LR | 89.716 | 89.741 | 89.716 | 89.717 | |
| DeiT-SVM | 88.652 | 88.650 | 88.652 | 88.635 | |
| Swin-RF | 93.144 | 93.180 | 93.144 | 93.148 | |
| Swin-LR | 92.553 | 92.585 | 92.553 | 92.562 | |
| Swin-SVM | 91.608 | 91.762 | 91.608 | 91.630 | |
| Model-PCA-ML | ViT-PCA-RF | 91.017 | 91.108 | 91.017 | 91.036 |
| ViT-PCA-LR | 90.071 | 90.107 | 90.071 | 90.070 | |
| ViT-PCA-SVM | 88.889 | 88.925 | 88.889 | 88.885 | |
| DeiT-PCA-RF | 92.199 | 92.296 | 92.199 | 92.221 | |
| DeiT-PCA-LR | 91.135 | 91.161 | 91.135 | 91.136 | |
| DeiT-PCA-SVM | 89.835 | 89.832 | 89.835 | 89.817 | |
| Swin-PCA-RF | 94.799 | 94.797 | 94.799 | 94.793 | |
| Swin-PCA-LR | 94.326 | 94.346 | 94.326 | 94.324 | |
| Swin-PCA-SVM | 92.908 | 92.935 | 92.908 | 92.897 | |
| The proposed model | MST-EDS-RF | 97.163 | 97.168 | 97.163 | 97.164 |
| MST-EDS-LR | 95.745 | 95.760 | 95.745 | 95.747 | |
| MST-EDS-SVM | 94.326 | 94.355 | 94.326 | 94.320 |
As shown in Table 7, standalone transformer models were evaluated, where Swin achieved the highest performance with 91.962 accuracy, 92.075 precision, 91.962 recall, and 91.954 F1-score because Swin captures local and global features using hierarchical representation and attention mechanisms. While, ViT presented poorly with 87.116 accuracy, 87.511 precision, 87.116 recall, and 87.223 F1-score.
For integrating transformer models with ML, transformer models integrating with RF recorded the best performance because RF provides insights into the importance of different features, which helps understand the underlying relationships in the data. As a result, Swin-RF recorded the best performance at 93.144 accuracy, 93.180 precision, 93.144 recall, and 93.148 F1-score. Meanwhile, ViT-SVM recorded the lowest performance, with 87.707 accuracy and 87.717 F1-score.
In the same way, integrating transformer models with PCA and ML results in the best performance compared to integrating transformer models with ML because PCA selects the best features from the feature representation matrix, as shown in the Table 7. As a result, Swin-PCA-RF performed scientifically with 94.799 accuracy, 94.797 precision, 94.799 recall, and 94.793 F1-score, resulting in Swin using attention processes and hierarchical representation to capture both local and global features. While transformer models integrating with SVM scored the worst, due to SVM’s limitations with high-dimensional embeddings and difficulty handling large datasets, as a result, ViT-PCA-SVM registered the worst results with 88.889 accuracy, 88.925 precision, 88.889 recall, and 88.885 F1-score.
The proposed model (MST-EDS) enhanced performance by 2% compared to Swin-RF because stacking the outputs of Swin-PCA-RF, ViT-PCA-RF, and DeiT-PCA-RF with RF as a meta-learner effectively learns optimal feature combinations, enhancing generalization and performance. MST-EDS-RF records the best performances with 97.163 accuracy, 97.168 recall, 97.163 precision, and 97.164 F1-score compared to other models.
The experimental results showed that ML models improve the performance of the MST-EDS system by effectively leveraging deep, high-dimensional feature representations created by transformer models: ViT, Swin, and DeiT. Unlike the traditional SoftMax classifier, which applies a shallow, linear decision layer, ML models such as RF and SVM can capture complex, non-linear patterns within the reduced feature space by PCA, which reduces redundancy and highlights the most informative features. These models offer greater robustness and improved classification accuracy.
Overall, the combination of transformer model, feature fusion, and ensemble learning in the multi-stage framework provides a more complicated and effective method for eye disease classification, which can overcome the shortcomings of the traditional SoftMax classification methods.
Discussion
Looking at Fig. 7, it is clear that MST-EDS-RF recorded the highest performance because, by stacking the outputs of hybrid models with RF, optimal feature combinations are effectively learned, and generalization and performance are enhanced. This suggests that adopting sophisticated AI tools in the clinic might improve diagnostic accuracy in eye diseases. The experimental results of MST-EDS, which integrates advanced transformer-based models (Swin, ViT, and DeiT) along with dimensionality reduction (PCA) and ML classifiers, have several implications for the future development of AI tools in medical diagnostics, particularly for eye disease detection: (1) Multimodal and hybrid design potential: By integrating deep transformer architectures with ML, MST-EDS proves that the hybrid approach can improve performance and generalizability, especially when dealing with image medical data. (2) Scalable architecture: MST-EDS’s modularity promotes the method’s transferability by enabling future researchers and developers to modify the pipeline to other imaging modalities or medical areas outside of ophthalmology. (3) Clinical Value and decision support: MST-EDS has the potential to be a dependable decision support system that can help ophthalmologists detect diseases early and accurately, especially in areas with limited access to experts, thanks to its strong diagnostic performance and capacity to incorporate multi-input feature representation. These implications emphasize that MST-EDS advances technical performance and aligns with the practical needs of scalable, interpretable, and clinically deployable AI solutions.
Fig. 7.

Performance comparison of standalone, hybrid, and proposed models using accuracy, precision, recall, and F1-Score.
Figure 8 shows three confusion matrices for MST-EDS-RF, MST-EDS-LR, MST-EDS-SVM. Each confusion matrix evaluates the performance of a classification task involving four classes: cataract, diabetic retinopathy, glaucoma, and normal. All three models show high classification accuracy for diabetic retinopathy. Glaucoma appears to be the most challenging to classify accurately, with a higher number of misclassifications. The MST-EDS-RF model seems to have slightly better performance compared to LR and SVM in terms of lower misclassification rates.
Fig. 8.

Confusion matrixs of MST-EDS-RF, MST-EDS-LR and MST-EDS-SVM transformers for four classes blue color presents the percentage of True Positive (TP) and percentage of True Negative (TN) and white color presents percentage of False Positive (FP) and percentage of False Negatives.
Comparison with literature studies
Table 8 compares the proposed model and literature studies using EDC. The EDC dataset was collected from various sources such as IDRiD, Ocular recognition, HRF, retinal_dataset, and DRIVE. The MST-EDS-RF model improves performance by integrating the hybrid models as base models with a meta-model (RF), achieving the highest accuracy at 97.163. Advantages of this design: (1) Diversity in models: Different transformer models, such as ViT, DeiT, and Swin, can be applied to ensure varied feature representations. (2) PCA is applied to minimize dimensionality by selecting the most informative aspects of the data. (3) Stacking Ensemble to improve performance and make generalizations. While the proposed model offers high accuracy and reliability, its reliance on large labeled datasets and computational complexity poses challenges for real-time deployment. The table shows that MST-EDS-RF recorded the best performance compared to other studies using the EDC dataset. In26, the authors applied the EfficientNet and CNN models and achieved an accuracy of 94 and 84, respectively. In27, the authors applied BayeSVM500 and achieved an accuracy 95.33. An ensemble approach was deployed in the study by28, leading to an accuracy of 96.1, and they compared it with EfficientNetB6 and DenseNet169, which recorded 88.3 and 93.9 of accuracy, respectively. In53, EfficientNetB3 was utilized, yielding an accuracy 93.8.
Table 8.
Comparison with literature studies.
Limitation and future work
The proposed model recorded the best performance in eye disease classification, several limitations must be noted. First, the model was tested and evaluated using an annotated large dataset, which may not be readily available in all clinical settings. Second, further validation on diverse and external datasets is required to evaluate the generalizability and robustness of the proposed model. Third, the transformer-ensemble architecture’s computational complexity makes it difficult to deploy in situations with limited resources, especially for real-time applications. Lastly, our framework does not integrate explainability mechanisms, which are essential for supporting clinical decision-making and the trust of healthcare professionals. Future work may focus on reducing computational demands through model optimization techniques such as pruning and quantization. In addition, approaches like self-supervised learning and domain adaptation could improve performance in low-data scenarios. To support clinical adoption, integrating explainable AI methods may enhance transparency and foster trust among healthcare professionals.
Conclusion
This study proposed a multi-stage framework for eye diseases (MST-EDS) to classify eye illnesses across four classes: normal, diabetic, glaucoma, and cataract, utilizing a benchmark dataset from Kaggle. Our approach leverages transformer models, hybrid models, feature selection methods, and ML models, leading to robust decision-making. It aims to improve accuracy and generalization in complex medical image classification tasks compared to existing methods.
It is developed in two stages: hybrid and stacking models. In hybrid models, transformer models ViT, DeiT, and Swin extract deep features from images. PCA is used to reduce the complexity of the extracted features and select the best features. The resulting optimized features are then classified using ML models (RF, SVM, and LR). In the stacking stage, the best hybrid models are selected based on their performance and used to generate prediction outputs, which are then stacked into a stacking training set and a stacking testing set. Stacking training is used to train meta-learners (RF, SVM, and LR), and the stacking testing set is used to evaluate further and enhance overall classification performance. In addition, we conducted different experiments based on various approaches, including standalone transformers, hybrid models, and the proposed model MST-EDS. The experimental results indicated that the MST-EDS-RF model recorded the best results compared to individual transformer and hybrid models. It achieves 97.163 accuracy, 97.168 precision, 97.163 recall, and 97.164 F1-Score.
The results demonstrate the potential of integrating transformer-based models with ensemble learning techniques to enhance the classification of eye diseases. This approach may contribute to the development of advanced AI-assisted tools in medical diagnostics.
Author contributions
A.A. done conceptualization; data curation, formal analysis, funding acquisition, investigation, methodology, software, H.S.; Writing—original draft; Writing—review and editing. All authors have read and agreed to the published version of the manuscript.
Funding
No funding was received to conduct this study.
Data availability
The data that support the findings of this study are publicly available at the following URL: https://www.kaggle.com/datasets/gunavenkatdoddi/eye-diseases-classification
Declarations
Competing interests
The authors declare no competing interests.
Footnotes
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
References
- 1.Dar, M. A., Maqbool, M., Ara, I. & Qadrie, Z. Preserving sight: Managing and preventing diabetic retinopathy. Open Health4, 20230019 (2023). [Google Scholar]
- 2.Cassel, G. H. The Eye Book: A Complete Guide to Eye Disorders and Health (JHU Press, 2021).
- 3.Saleh, G. A. et al. The role of medical image modalities and ai in the early detection, diagnosis and grading of retinal diseases: a survey. Bioengineering9, 366 (2022). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 4.Yang, L., Li, J., Zhou, B. & Wang, Y. An injectable copolymer for in situ lubrication effectively relieves dry eye disease. ACS Mater. Lett.7, 884–890 (2025). [Google Scholar]
- 5.Kelly, S. Using large-scale visual field data to gain insights into management of patients with glaucoma. Ph.D. thesis, City, University of London (2019).
- 6.Thompson, A. C., Jammal, A. A. & Medeiros, F. A. A review of deep learning for screening, diagnosis, and detection of glaucoma progression. Transl. Vis. Sci. Technol.9, 42–42 (2020). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 7.Dolar-Szczasny, J., Barańska, A. & Rejdak, R. Evaluating the efficacy of teleophthalmology in delivering ophthalmic care to underserved populations: a literature review. J. Clin. Med.12, 3161 (2023). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 8.Singh, L. K. et al. An artificial intelligence-based smart system for early glaucoma recognition using oct images. Int. J. E-Health Med. Commun. IJEHMC12, 32–59 (2021). [Google Scholar]
- 9.Singh, L. K., Garg, H. et al. Detection of glaucoma in retinal fundus images using fast fuzzy c means clustering approach. In 2019 International Conference on Computing, Communication, and Intelligent Systems (ICCCIS), 397–403 (IEEE, 2019).
- 10.Zeng, Y. et al. Gccnet: A novel network leveraging gated cross-correlation for multi-view classification. IEEE Trans. Multimed. (2024).
- 11.Hu, C., Sapkota, B. B., Thomasson, J. A. & Bagavathiannan, M. V. Influence of image quality and light consistency on the performance of convolutional neural networks for weed mapping. Remote Sens.13, 2140 (2021). [Google Scholar]
- 12.Kumar, Y., Koul, A., Singla, R. & Ijaz, M. F. Artificial intelligence in disease diagnosis: a systematic literature review, synthesizing framework and future research agenda. J. Ambient. Intell. Humaniz. Comput.14, 8459–8486 (2023). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 13.Santos, C. F. G. D. & Papa, J. P. Avoiding overfitting: A survey on regularization methods for convolutional neural networks. ACM Comput. Surv. Csur54, 1–25 (2022). [Google Scholar]
- 14.Nerella, S. et al. Transformers in healthcare: A survey. arXiv preprintarXiv:2307.00067 (2023).
- 15.Chitty-Venkata, K. T., Mittal, S., Emani, M., Vishwanath, V. & Somani, A. K. A survey of techniques for optimizing transformer inference. J. Syst. Architect.144, 102990 (2023). [Google Scholar]
- 16.Liu, Z. et al. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision, 10012–10022 (2021).
- 17.Cord, M. Going deeper with image transformers. In IEEE/CVF International Conference on Computer Vision (ICCV) (2021).
- 18.Ganaie, M. A., Hu, M., Malik, A. K., Tanveer, M. & Suganthan, P. N. Ensemble deep learning: A review. Eng. Appl. Artif. Intell.115, 105151 (2022). [Google Scholar]
- 19.Matlock, K., De Niz, C., Rahman, R., Ghosh, S. & Pal, R. Investigation of model stacking for drug sensitivity prediction. BMC Bioinform.19, 21–33 (2018). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 20.Aslam, J., Arshed, M. A., Iqbal, S. & Hasnain, H. M. Deep learning based multi-class eye disease classification: Enhancing vision health diagnosis. Tech. J.29, 7–12 (2024). [Google Scholar]
- 21.Wang, D., Lian, J. & Jiao, W. Multi-label classification of retinal disease via a novel vision transformer model. Front. Neurosci.17, 1290803 (2024). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 22.Abbas, Q., Albathan, M., Altameem, A., Almakki, R. S. & Hussain, A. Deep-ocular: Improved transfer learning architecture using self-attention and dense layers for recognition of ocular diseases. Diagnostics13, 3165 (2023). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 23.Omuya, E. O., Okeyo, G. O. & Kimwele, M. W. Feature selection for classification using principal component analysis and information gain. Expert Syst. Appl.174, 114765 (2021). [Google Scholar]
- 24.Albelaihi, A. & Ibrahim, D. M. Deepdiabetic: An identification system of diabetic eye diseases using deep neural networks. IEEE Access. (2024).
- 25.Demir, F. & Taşcı, B. An effective and robust approach based on r-cnn+ lstm model and ncar feature selection for ophthalmological disease detection from fundus images. J. Pers. Med.11, 1276 (2021). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 26.Babaqi, T., Jaradat, M., Yildirim, A. E., Al-Nimer, S. H. & Won, D. Eye disease classification using deep learning techniques. arXiv preprintarXiv:2307.10501 (2023).
- 27.Zannah, T. B. et al. Bayesian optimized machine learning model for automated eye disease classification from fundus images. Computation12, 190 (2024). [Google Scholar]
- 28.Abdullah, A. A., Aldhahab, A. & Al Abboodi, H. M. Deep-ensemble learning models for the detection and classification of eye diseases based on engineering feature extraction with efficientb6 and densnet169. Int. J. Intell. Eng. Syst.17 (2024).
- 29.Ryan, J., Nathaniel, D. A., Purwanto, E. S. & Ario, M. K. Harnessing deep learning for ocular disease diagnosis. Proc. Comput. Sci.245, 914–923 (2024). [Google Scholar]
- 30.Wahab Sait, A. R. Artificial intelligence-driven eye disease classification model. Appl. Sci.13, 11437 (2023). [Google Scholar]
- 31.Hemalakshmi, G., Murugappan, M., Sikkandar, M. Y., Begum, S. S. & Prakash, N. Automated retinal disease classification using hybrid transformer model (svit) using optical coherence tomography images. Neural Comput. Appl. 1–18 (2024).
- 32.Akça, S., Garip, Z., Ekinci, E. & Atban, F. Automated classification of choroidal neovascularization, diabetic macular edema, and drusen from retinal oct images using vision transformers: a comparative study. Lasers Med. Sci.39, 140 (2024). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 33.Eye diseases classification. https://www.kaggle.com/datasets/gunavenkatdoddi/eye-diseases-classification (accessed 2024).
- 34.Vidal, M. & Amigo, J. M. Pre-processing of hyperspectral images. essential steps before image analysis. Chemom. Intell. Lab. Syst.117, 138–148 (2012). [Google Scholar]
- 35.Maharana, K., Mondal, S. & Nemade, B. A review: Data pre-processing and data augmentation techniques. Glob. Transit. Proc.3, 91–99 (2022). [Google Scholar]
- 36.Maitra, I. K., Nag, S. & Bandyopadhyay, S. K. Technique for preprocessing of digital mammogram. Comput. Methods Programs Biomed.107, 175–188 (2012). [DOI] [PubMed] [Google Scholar]
- 37.Huang, L. et al. Normalization techniques in training dnns: Methodology, analysis and application. IEEE Trans. Pattern Anal. Mach. Intell.45, 10173–10196 (2023). [DOI] [PubMed] [Google Scholar]
- 38.Dosovitskiy, A. et al. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv preprintarXiv:2010.11929 (2020).
- 39.Chen, C.-F. R., Fan, Q. & Panda, R. Crossvit: Cross-attention multi-scale vision transformer for image classification. In Proceedings of the IEEE/CVF International Conference on Computer Vision, 357–366 (2021).
- 40.Khan, S. et al. Transformers in vision: A survey. ACM Comput. Surv. CSUR.54, 1–41 (2022). [Google Scholar]
- 41.Chen, M., Peng, H., Fu, J. & Ling, H. Autoformer: Searching transformers for visual recognition. In Proceedings of the IEEE/CVF International Conference on Computer Vision, 12270–12280 (2021).
- 42.Jumphoo, T. et al. Exploiting data-efficient image transformer-based transfer learning for valvular heart diseases detection. IEEE Access12, 15845–15855 (2024). [Google Scholar]
- 43.Yoo, D. & Yoo, J. Fswin transformer: Feature-space window attention vision transformer for image classification. IEEE Access. (2024).
- 44.Liu, Y. et al. Vision transformers with hierarchical attention. Mach. Intell. Res. 1–14 (2024).
- 45.Park, N. & Kim, S. How do vision transformers work? arXiv preprintarXiv:2202.06709 (2022).
- 46.Liu, Z. et al. Video swin transformer. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 3202–3211 (2022).
- 47.Singh, L. K., Khanna, M., Thawkar, S. & Singh, R. A novel hybridized feature selection strategy for the effective prediction of glaucoma in retinal fundus images. Multimed. Tools Appl.83, 46087–46159 (2024). [Google Scholar]
- 48.Singh, L. K., Khanna, M. & Singh, R. Feature subset selection through nature inspired computing for efficient glaucoma classification from fundus images. Multimed. Tools Appl.83, 77873–77944 (2024). [Google Scholar]
- 49.Yin, R., Tran, V. H., Zhou, X., Zheng, J. & Kwoh, C. K. Predicting antigenic variants of h1n1 influenza virus based on epidemics and pandemics using a stacking model. PLoS One13, e0207777 (2018). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 50.Zhang, R. et al. Mvmrl: a multi-view molecular representation learning method for molecular property prediction. Brief. Bioinform.25, bbae298 (2024). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 51.Başaran, E. et al. Chronic tympanic membrane diagnosis based on deep convolutional neural network. In 2019 4th International Conference on Computer Science and Engineering (UBMK), 1–4 (IEEE, 2019).
- 52.Sertkaya, M. E., Ergen, B. & Togacar, M. Diagnosis of eye retinal diseases based on convolutional neural networks using optical coherence images. In 2019 23rd International Conference Electronics, 1–5 (IEEE, 2019).
- 53.Soni, T. Advanced eye disease classification using the efficientnetb3 deep learning model. In 2024 3rd International Conference on Automation, Computing and Renewable Systems (ICACRS), 875–879 (IEEE, 2024).
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.
Data Availability Statement
The data that support the findings of this study are publicly available at the following URL: https://www.kaggle.com/datasets/gunavenkatdoddi/eye-diseases-classification