

Abstract
Large language models (LLMs) have become powerful tools for biomedical applications, offering potential to transform healthcare and medical research. Since the release of ChatGPT in 2022, there has been a surge in LLMs for diverse biomedical applications. This review examines the landscape of text-based biomedical LLM development, analyzing model characteristics (e.g., architecture), development processes (e.g., training strategy), and applications (e.g., chatbots). Following PRISMA guidelines, 82 articles were selected out of 5,512 articles since 2022 that met our rigorous criteria, including the requirement of using biomedical data when training LLMs. Findings highlight the predominant use of decoder-only architectures such as Llama 7B, prevalence of task-specific fine-tuning, and reliance on biomedical literature for training. Challenges persist in balancing data openness with privacy concerns and detailing model development, including computational resources used. Future efforts would benefit from multimodal integration, LLMs for specialized medical applications, and improved data sharing and model accessibility.
Keywords: large language models, clinical NLP, biomedical applications, healthcare AI
1. INTRODUCTION
The field of artificial intelligence (AI) is undergoing a rapid transformation, driven by the advent of large language models (LLMs). These models have demonstrated remarkable capabilities on general-domain applications (1–6) and are being successfully applied to biomedical applications as well (7–12). This shift has also been propelled by the increasing digitization of healthcare data, including electronic health records (EHRs) and vast repositories of biomedical literature. The potential of LLMs to generate human-like text has opened new avenues to assist in tasks ranging from enhanced literature review and clinical documentation to diagnosis support and treatment planning (13–17).
Over the past few decades, AI-powered chatbots have found increasing applications in healthcare and life science, with companies leveraging these technologies for various specialized tasks, including personal health assistance, diagnostic support, and symptom checking (18–20). This trend has laid the groundwork for more advanced AI systems in the biomedical domain, setting the stage for the emergence of LLMs in this field. Given that prior research indicates general-purpose models like ChatGPT may generate inaccurate or partially correct content (21), particularly in specialized domains such as biomedicine, the need for domain-specific LLMs has become clear. Consequently, numerous efforts have focused on developing tailored models for biomedical applications, such as Med-PaLM (11), BiomedGPT (22), and GatorTronGPT (17).
The development of such models has also highlighted several challenges that need to be addressed to balance the power of AI with the nuanced complexities of medical practice. Medical data can be inherently biased due to factors like demographics and access to healthcare, which can be reflected in LLMs’ outputs if not carefully addressed during training. Additionally, data are highly sensitive, and ensuring the protection of privacy is crucial when training biomedical LLMs. Inappropriate application of biomedical LLMs could lead to incorrect diagnoses, unsuitable treatment recommendations, or patient harm, necessitating clear ethical guidelines for development and deployment. Understanding why an LLM generates a particular response is critical in healthcare, but this can be difficult due to complexities in model architectures, development, and evaluation of biomedical LLMs. As such, there is a need to comprehensively review and analyze the current landscape of biomedical LLMs, their development strategies, and their real-world applications and impact. By synthesizing existing research, such a review provides researchers insights into effective model development practices and aids in the establishment of guidelines for reporting standards, thereby promoting transparency and reproducibility in research outcomes. It can also identify research gaps, highlight areas for improvement, and contribute toward responsible advancement of biomedical LLMs.
This work aims to provide a comprehensive review of the literature on text-based biomedical LLM development, addressing the following research questions:
What is the current landscape of biomedical LLMs? We intend to generate a list of existing text-based LLMs that are trained using biomedical data and provide details about model characteristics such as architecture, parameter size, hyperparameters, and accessibility.
How are those biomedical LLMs being developed and evaluated? We collect information on the training of biomedical LLMs, such as training strategy, data used for training and evaluation, associated computational costs, and performance reporting metrics.
What are the main applications of biomedical LLMs? We gather data on various application domains and intended user groups, aiming to analyze the distribution of LLMs across clinical tasks.
To address these questions and uncover additional insights, our study analyzes relevant literature, encompassing peer-reviewed articles and preprints published between January 2022 and July 2024. We examine various aspects of biomedical LLMs, including their architecture, training data, fine-tuning approaches, evaluation methodologies, and real-world applications. This review aims to provide researchers and healthcare professionals with a comprehensive understanding of the current state of biomedical LLMs. By understanding the current environment and highlighting challenges and opportunities, we seek to inform future research directions and guide the responsible development and integration of these powerful tools in healthcare settings.
1.1. Background on LLMs
Language models (23) are probabilistic models that learn statistical patterns from large text corpora to predict and generate human language; they have been used to facilitate various natural language processing (NLP) tasks. The introduction of the transformer (24) revolutionized language model pretraining by utilizing self-attention mechanisms to effectively manage long-range dependencies and bidirectional context, as exemplified by models like BERT (Bidirectional Encoder Representations from Transformers) (25). LLMs are language models that are pretrained using very large corpora. While there is no universally accepted definition of the size of LLMs, they are generally characterized by their substantially larger scale in terms of model parameters and training data. Some studies suggest that LLMs typically feature tens to hundreds of billions of parameters and are trained on massive datasets ranging from many gigabytes to terabytes (26). This shift in scale has accompanied a progression in the biomedical domain from domain-specific pretrained models like PubMedBERT (27) and BioClinicalBERT (28) to more expansive models such as Med-PaLM (11) and GatorTronGPT (17). The earlier domain-specific BERT-based models, which have been extensively reviewed in previous literature (29–31), typically contained hundreds of millions of parameters. For example, PubMedBERT (27) and ClinicalBERT (28) are initialized from BERT-base (25) and have around 110 million parameters. In contrast, the newer generation of biomedical LLMs represents a significant leap in model size and capability. For example, GatorTronGPT (17) incorporates 20 billion (B) parameters, while Med-PaLM (11) represents a significant leap with 540B parameters. To maintain a focused scope in this review and to reflect this evolutionary trend in the field, we have chosen to concentrate on LLMs with more than 1B parameters, thereby capturing the most recent and advanced developments in biomedical language modeling.
Several prominent LLMs exemplify the advancements in this field:
The GPT (generative pretrained transformer) series developed by OpenAI, especially the GPT-3 (1), a 175B parameter decoder-only model, demonstrated how scaling model size and training data could enhance language understanding and generation. Building on this foundation, ChatGPT was optimized for conversational tasks using reinforcement learning from human feedback (RLHF) (32), excelling in maintaining dialogue context and reasoning through complex inquiries. GPT-4 supports multimodal inputs, allowing it to process both text and images, advancing the capabilities of its predecessors for broader applications.
Llama (4–6) is a series of open-source LLMs developed by Meta AI, ranging from 7B to 405B parameters. Despite their relatively modest scale compared to proprietary models, Llama models achieve competitive performance by training on extensive, high-quality datasets. These models have gained widespread attention due to their openness and efficiency, making advanced language modeling more accessible to the research community.
1.1.1. Model architecture.
LLMs predominantly use the transformer architecture, leveraging self-attention for efficient sequential data processing. They are classified into three main types: encoder-only models, such as BERT, operate bidirectionally, considering context from both preceding and following words simultaneously to generate representations; decoder-only models, like the GPT series, generate text in an autoregressive manner; and encoder–decoder models, such as BART (Bidirectional and Auto-Regressive Transformers) (33), handle tasks with differing input and output sequences, like translation. Most recent LLMs favor decoder-only architectures for their scalability in handling large datasets and parameters, which is ideal for extensive generative tasks. In addition, state space models like Mamba have gained attention for their ability to model complex dependencies in time-series data such as patient monitoring and dynamic treatment data (34).
1.1.2. Training strategy.
LLM training generally involves two phases: pretraining, where the model learns from large, diverse text corpora in a self-supervised manner using techniques like masked or autoregressive modeling, and fine-tuning, where the model adapts to specific tasks or domains using targeted datasets. Techniques such as instruction tuning (35) and RLHF (32) enhance the model’s task generalization and align its outputs with human preferences. Beyond medical text, multimodal LLMs may require more specialized training strategies, such as pre-training each modality individually before aligning them or using contrastive learning to learn multiple modalities simultaneously (36, 37).
General-purpose LLMs often underperform on medical texts due to limited medical-specific training data. Three key strategies improve their medical effectiveness: (a) Training from scratch on extensive medical texts builds a model grounded in medical language but requires significant resources; (b) continued pretraining on medical datasets refines an existing LLM for better handling of medical terminology and context, with moderate computational demands; and (c) instruction tuning fine-tunes the model on biomedical tasks, enhancing response accuracy based on quality task-specific data. In addition, LLMs can be extended to multimodal applications, such as aligning vision encoders with LLMs to create vision–language models (38).
1.2. Related Studies
The rapidly evolving landscape of LLMs has spurred the development of numerous review articles. Several reviews (39–41) have primarily focused on the application of LLMs within the biomedical domain such as in healthcare, medicine, and health informatics. Other studies (42–44) have taken a more targeted approach, examining the deployment of LLMs in specific clinical subdisciplines. Nassiri & Akhloufi (45) provide an overview of architectures of prominent LLMs (e.g., ChatGPT, PaLM, and Llama) and their clinical applications. Despite the usefulness of current reviews, none of them has systematically analyzed studies that are focused on developing domain-specific LLMs using biomedical data. To address this gap, we aim to provide a current and comprehensive analysis of biomedical LLMs development. We employ rigorous inclusion and exclusion criteria and ensure a thorough examination of relevant models encompassing not only the applications and technical details of these models but also their development strategies, data sources, evaluation methods, and required resources in terms of computational cost and time. By concentrating on these aspects, our analysis helps advance the state of the art in biomedical LLM development, accelerating progress by identifying current limitations and promising directions, thereby guiding future research efforts and fostering innovation in biomedical AI.
2. MATERIALS AND METHODS
We focus our analysis on LLMs that are specifically trained using domain-specific biomedical data. We consider a range of training strategies including models trained from scratch on biomedical corpora, those that undergo continual pretraining on domain-specific data utilizing an existing LLM, and models that are fine-tuned on biomedical tasks. However, it is important to note that we exclude models that rely solely on in-context learning strategies, such as few-shot learning. This decision is based on our aim to focus on models that have undergone substantial adaptation to the biomedical domain, rather than those that attempt to perform biomedical tasks through general language understanding alone. This review is conducted to compile and analyze a comprehensive body of literature that addresses our research questions and objectives. While committed to a rigorous and structured approach, closely adhering to the Preferred Reporting Items for Systematic Reviews and Meta-Analyses (PRISMA) guidelines (46), we acknowledge that our review does not fully conform to all aspects of these guidelines. The overall workflow of our review process is illustrated in Figure 1 and described in detail in the following sections.
Figure 1.

PRISMA flowchart showing the review process and reasons for exclusion. Abbreviations: B, billion; PRISMA, Preferred Reporting Items for Systematic Reviews and Meta-Analyses. Figure adapted from flowchart created with PRISMA 2020 (https://www.prisma-statement.org) (CC BY 4.0).
2.1. Search Strategy
The search to find relevant literature was conducted for the period between January 1, 2022, and July 31, 2024. We selected three databases based on their popularity, credibility, recognition, and accessibility, to conduct our search: PubMed, Scopus, and Embase. Our search query targeted research on LLMs in the biomedical and healthcare domains, also focusing on LLM architectures and biomedical subfields, while excluding review articles, systematic reviews, clinical trials, case reports, and meta-analyses to focus on primary research studies. The search query used is as follows:
(“large language model*” OR LLM OR “language model*” OR “foundation* model*” OR GPT OR ChatGPT OR LLaMA OR PaLM OR Gemini OR Mistral OR Falcon) AND (biomedical OR medical OR clinical OR health OR biomedicine OR healthcare OR medicine OR diagnosis OR patient OR biology OR genomics OR multilingual OR multimodal) AND (pretrain* OR pre-train* OR finetun* OR fine-tun*OR “instruction tun*” OR train*) AND (2022/01/01:2024/07/31[dp]) NOT review[pt] NOT systematic[sb] NOT clinical trial[pt] NOT case reports[pt] NOT meta-analysis[pt]
2.2. Study Selection Criteria and Screening
Our initial literature search yielded a substantial corpus of 7,963 articles. To ensure comprehensive coverage, we supplemented this collection with 2 additional articles from other sources, inviting all coauthors to recommend relevant publications that aligned with our research objectives. Following the removal of duplicate entries, we refined our selection to 5,512 articles. This collection then underwent a rigorous screening process to assess each article’s suitability for inclusion in our final analysis. We list in Table 1 the criteria for inclusion and exclusion.
Table 1.
Criteria for including/excluding articles
| Aspect | Criteria |
|---|---|
| Domain | Articles must focus on the biomedical domain with applications pertaining to clinical or biomedical tasks. |
| Model architecture | Any model architecture is permissible, with the only condition that the parameter size must exceed 1B parameters. |
| Model training | Inclusion: models trained from scratch, continual pretraining, or fine-tuning utilizing biomedical data Exclusion: models relying solely on prompt engineering strategies including in-context learning |
| Modality | Single or multimodal models with text data as one modality |
2.2.1. Title and abstract screening.
During the screening stage, two coauthors independently evaluated the articles based on their titles and abstracts. The articles were filtered based on the inclusion and exclusion criteria mentioned above. The independent screening process yielded a Cohen’s kappa score of 0.805, indicating strong inter-rater agreement. There were 82 articles on which the two raters disagreed; these were resolved through mutual discussion.
2.2.2. Full-text screening.
In the full-text review phase, a team of 11 coauthors carefully evaluated 158 papers. Most abstracts did not explicitly mention model parameter sizes or training strategies, which were crucial information for our selection criteria. These details were uncovered only during the full-text examination. As a result, 76 articles that did not meet the criteria were consequently excluded from further analysis.
2.3. Data Collection
The data extraction process involved a collaborative effort among the same 11 coauthors, who analyzed the 82 articles that met the inclusion criteria. Using a standardized data collection form, as presented in Table 2, the team extracted a comprehensive set of 35 variables from each article. To maintain high standards of accuracy and consistency, all collected data underwent a validation process, with multiple coauthors reviewing and confirming the extracted information.
Table 2.
Information extracted from the articles
| 1. What is the current landscape of biomedical LLMs? | |||
|---|---|---|---|
| Feature | Example of value | Feature | Example of value |
| Architecture | Decoder | Number of layers | 32 |
| Release date | 2024.04 | Hidden units | 2,560 |
| Backbone | Llama | Epochs | 10 |
| Modality | Text | Batch size | 8 |
| Number of parameters | 10.7B | Sequence length | 1,024 |
| Tokenizer | BERT tokenizer | Learning rate | 2e-6/5e-6 |
| Number of attention heads | 20 | ||
| 2. How are those biomedical LLMs being developed and evaluated? | |||
| Feature | Example of value | Feature | Example of value |
| Training strategy | From scratch | Training objective | MLM, SOP |
| Pretraining included? | No | Number of tokens | 300B tokens |
| Instruction tuning included? | Yes | Train time | ~6.25 days |
| Task-specific fine-tuning included? | Yes | GPUs used | 128 A100–40GB |
| Corpus | MedQA, MedMCQA | Evaluation task | Text generation |
| Corpus type | EHR | Evaluation metric | Perplexity, BLEU, GLEU |
| 3. What are the main applications of biomedical LLMs? | |||
| Feature | Example of value | Feature | Example of value |
| NLP task | Question answering | Institution | Google Research |
| Clinical application | Patient diagnosis | Language | English |
| Target user | Patient, caregiver | Data status | Proprietary |
| Carbon footprint | 539 tCO2eq | Model status | Open source |
| Journal | JAMIA, NeurIPS | License | MIT |
Abbreviations: EHR, electronic health record; LLM, large language model; NLP, natural language processing; tCO2eq, tons of carbon dioxide equivalent.
3. RESULTS
3.1. Model Characteristics Review
Biomedical LLMs exhibit diverse architectural and accessibility characteristics that shape their utility across various applications. This section provides a structured review of key model features, including architecture types, hyperparameters, and the degree of public accessibility.
3.1.1. Model architecture.
Table 3 exhibits the architectural landscape of biomedical LLMs. Notably, our inclusion criteria resulted in the incorporation of 91 models from 82 articles, with multiple models occasionally proposed in a single article. Among these, decoder-only architectures (n = 71, 78%) emerged as the most prevalent type. Defined by their autoregressive nature, these models find extensive utility in tasks necessitating text generation and completion. The second-most prevalent, encoder–decoder architectures (n = 13, 14.3%), were primarily employed in tasks that required both understanding and generation. Finally, multimodal models accounted for 7.7% (n = 7) of the architectures, with vision encoders integrated with LLMs.
Table 3.
Architectural details of all models (n = 91) from all 82 articles included in the study
| Backbone model | Architecture | Number of models | Model size | Number of models | Variants as backbone | Number of models |
|---|---|---|---|---|---|---|
| Llama (7, 8, 14, 15, 62–91) | Decoder-only | 36 (39.6%) | 7B | 17 (47.2%) | Llama-base | 28 (77.8%) |
| 13B | 14 (38.9%) | Alpaca | 3 (8.3%) | |||
| 70B | 2 (5.6%) | Vicuna | 2 (5.6%) | |||
| 33B | 2 (5.6%) | AlpaCare | 1 (2.8%) | |||
| 65B | 1 (2.8%) | Orca | 1 (2.8%) | |||
| Ziya | 1 (2.8%) | |||||
| GPT (17, 73, 74, 84, 92–104) | Decoder-only | 16 (17.6%) | 1.5B | 8 (50.0%) | GPT-base | 14 (87.5%) |
| 175B | 2 (12.5%) | BioGPT | 2 (12.5%) | |||
| 6.7B | 2 (12.5%) | |||||
| 2.7B | 1 (6.3%) | |||||
| 20B | 1 (6.3%) | |||||
| 6B | 1 (6.3%) | |||||
| 1.3B | 1 (6.3%) | |||||
| ChatGLM (105–111) | Encoder–decoder | 7 (7.7%) | 6B | 7 (100.0%) | ChatGLM-base | 7 (100.0%) |
| T5 (88, 112–116) | Encoder–decoder | 6 (6.6%) | 11B | 4 (66.7%) | Flan-T5 | 3 (50.0%) |
| 3B | 2 (33.3%) | T5-base | 1 (16.7%) | |||
| mt5 | 1 (16.7%) | |||||
| ProtT5 | 1 (16.7%) | |||||
| Baichuan (75, 117–121) | Decoder-only | 6 (6.6%) | 7B | 4 (66.7%) | Baichuan-base | 6 (100.0%) |
| 13B | 2 (33.3%) | |||||
| From scratch (122–124) | Decoder-only | 3 (3.3%) | 6.4B | 1 (33.3%) | ProGen | 1 (33.3%) |
| 2.5B | 1 (33.3%) | ProGen2 | 1 (33.3%) | |||
| 1.2B | 1 (33.3%) | Nucleotide Transformer | 1 (33.3%) | |||
| BLOOM (125–127) | Decoder-only | 3 (3.3%) | 7B | 2 (66.7%) | BLOOM-base | 3 (100.0%) |
| 1B | 1 (33.3%) | |||||
| Qwen (9, 128) | Decoder-only | 2 (2.2%) | 14B | 1 (50.0%) | Qwen-base | 2 (100.0%) |
| 7B | 1 (50.0%) | |||||
| PaLM (11, 129) | Decoder-only | 2 (2.2%) | 540B | 1 (50.0%) | PaLM-base | 2 (100.0%) |
| 340B | 1 (50.0%) | |||||
| LongNet (130) | Decoder-only | 1 (1.1%) | 1B | 1 (100.0%) | LongNet-base | 1 (100.0%) |
| GenSLM (131) | Decoder-only | 1 (1.1%) | 25B | 1 (100.0%) | GenSLM-base | 1 (100.0%) |
| Henya (132) | Decoder-only | 1 (1.1%) | 7B | 1 (100.0%) | StripedHyena | 1 (100.0%) |
| Multimodal (14, 87, 91, 96, 130, 133, 134) | Mixed | 7 (7.7%) | NA | NA | ViT | 4 (57.1%) |
| BLIP | 1 (14.3%) | |||||
| CLIP | 1 (14.3%) | |||||
| LLaVA | 1 (14.3%) |
Abbreviation: NA, not applicable.
Regarding backbone models, a considerable proportion of the models (n = 36, 39.6%) employed the Llama backbone, featuring model sizes spanning from 7B to 70B parameters. The prevalence of Llama-based models could be due to several factors including their resource efficiency, open-source availability, and capability for local deployment ensuring data privacy and compliance with regulations such as the Health Insurance Portability and Accountability Act (HIPAA), making them a favored choice for biomedical and clinical applications. Notably, the 7B and 13B parameter models stood out as the most commonly utilized (n = 17, 47.2%; n = 14, 38.9%). While larger models like the 33B, 65B, and 70B variants were also present, their representation was relatively limited, hinting at a potential trade-off between computational overhead and model performance gains. The fine-tuned versions of Llama, including Alpaca (n = 3, 8.3%), Vicuna (n = 2, 5.6%), AlpaCare (n = 1, 2.8%), and Orca (n = 1, 2.8%), and their continual pre-trained version, including Ziya (n = 1, 2.8%), also served as backbones. This distribution suggests a focused but diverse approach to model customization based on the downstream application supported. Moreover, a striking observation is the dominance of the base model of Llama (n = 28, 77.8%) among Llama variants. The lower adoption rates of fine-tuned models like Vicuna and AlpaCare may reflect the trade-offs associated with specialization, where fine-tuning is selectively utilized for niche applications demanding heightened domain specificity.
Another proportion of the decoder-only models comprises GPT-based models (n = 16, 17.6%), with model sizes ranging from 1.3B to 175B. Within the GPT family, the majority directly used the GPT-base model (n = 14, 87.5%), while two models (n = 2, 12.5%) opt for its variant, BioGPT, as the backbone.
Encoder–decoder architectures, represented by ChatGLM (n = 7, 7.7%) and T5 (n = 6, 6.6%), collectively contribute to 14.3% of our study’s focus. ChatGLM’s architecture is particularly notable for its ability to handle complex dialogue scenarios in patient interaction systems, while T5’s adaptability, facilitated through fine-tuning, supports a diverse array of text-based clinical tasks. Interestingly, in contrast to Llama, the variants of T5, FLAN-T5, mT5, etc. (n = 5, 83.3%), see prevalent usage compared to the T5-base model (n = 1, 16.7%).
Multimodal capabilities (n = 7, 7.7%) are also emerging as a significant factor in model development, as they incorporate inputs beyond text, such as radiological images or genomic data. They are often used by merging a modality encoder [e.g., vision encoder in LLaVA (47)] with a decoder-based LLM. We note that we have considered only those multimodal LLMs that have text as one modality.
3.1.2. Hyperparameters.
The reproducibility of the models significantly relies on the transparency of model configuration and training details. Our analysis specifically focused on two parameter categories: model hyperparameters and training hyperparameters. Model hyperparameters are configurations that define the architecture of the model itself and are set before the model starts learning from the data; they include the number of attention heads, number of layers, size of hidden units, and sequence length. On the other hand, training hyperparameters relate to the settings used during the training process of the model, which include number of epochs, batch size, and learning rates.
It was observed that 27 articles (33%) comprehensively reported model hyperparameters. This level of detail is crucial for replicating study results and validating model performance. In contrast, 51 articles (62.2%) lacked sufficient detail on model hyperparameters, raising concerns regarding the reproducibility of these studies. A smaller subset of articles (4.8%) only partially disclosed these details, offering some insight but leaving gaps that hinder full reproducibility. This low reporting might be due to the assumption that the base models, which are used for fine-tuning, have model hyperparameters that are already documented in the articles discussing those models.
Conversely, training hyperparameters were more frequently documented. Fifty-two articles (63.4%) reported complete details on training parameters, facilitating the learning process and ensuring replicability of model performance. However, 16 articles (19.5%) omitted reporting on training hyperparameters, complicating efforts to replicate the training process and validating outcomes. Partial disclosure was noted in 14 articles (17.1%), indicating a moderate level of transparency that could still hinder exact replication efforts. Incomplete hyperparameter reporting in research studies can result from several factors such as the absence of standard guidelines, oversight, space constraints, and assumptions of common knowledge.
3.1.3. Accessibility.
Our analysis indicated that out of the reviewed articles, 26 (31.7%) provide models that are directly downloadable. Furthermore, models in 3 articles (3.7%) are accessible only through a data use agreement (DUA). Additionally, 11 articles (13.4%) offer codes but do not facilitate direct model downloads. Conversely, a large proportion of articles (36, 43.9%) describe models that are closed source. This limitation may often stem from privacy concerns, data ownership, proprietary interests, or regulatory restrictions, which are particularly prevalent in the biomedical domain where patient privacy protection is critical. Our findings also show that 5 articles (6.1%) claim that their models are open source. However, they were not available as claimed at the time we conducted the full-text review.
The analysis of training data availability across 82 articles reveals the use of 198 datasets. A significant portion of these datasets, specifically 73 (36.9%), are readily accessible through direct download links. In contrast, access to 24 datasets (12.1%) is restricted and requires a DUA. Additionally, 30 datasets (15.2%) are entirely private, predominantly comprising proprietary clinical notes that are not publicly accessible. Notably, 71 datasets (35.9%) are ad hoc compilations, specifically curated to meet the unique requirements of the respective models. While these datasets themselves are not directly provided, their sources are publicly available, though they require specific processing to be usable for research purposes. This distribution of data accessibility highlights varied data governance practices in the field, reflecting a balance between open data principles and the protection of sensitive information.
The distribution of 191 testing datasets indicates a notable variance in accessibility and availability compared to training data. Analysis shows that a substantial portion of the testing datasets, specifically 107 (56.0%), are readily accessible through direct download links. In contrast, 38 datasets (19.9%), while not directly provided, originate from public sources that require additional processing to be utilized effectively. Furthermore, 26 datasets (13.6%) are classified as private, restricting access to potentially sensitive or proprietary data. Additionally, access to 20 datasets (10.5%) is contingent upon securing a DUA. This distribution pattern indicates that while more specialized datasets are often curated for training to tailor the models to specific tasks or clinical scenarios, testing data tend to be more universally accessible. This trend might reflect a preference within the community to use more accessible datasets for testing purposes, aiming to demonstrate model capabilities in a more transparent and reproducible manner.
3.2. Biomedical LLM Training and Evaluation
The performance and applicability of biomedical LLMs heavily depend on their training and evaluation methodologies. This section examines the strategies used for model training, the sources of biomedical data leveraged for learning, and the computational resources required for effective model development. Additionally, we review the evaluation techniques employed to benchmark these models, highlighting the key metrics that gauge their effectiveness in real-world biomedical tasks.
3.2.1. Model training strategy.
Our analysis reveals that pretraining is not universally adopted in biomedical LLM development; only 32 models (35.2%) incorporated pretraining, either from scratch (n = 6) or continual pretraining (n = 26). Fifty-nine models (64.8%) explicitly did not use pretraining techniques. The absence of pretraining in a large number of studies could stem from limitations related to data availability, powerful computational infrastructure, or the comprehensive engineering skills needed for massive training tasks.
Training models from scratch is a relatively uncommon practice, with only 6 models (6.6%) using this approach. Among these models, 4 (4.4%) were developed independently without leveraging preexisting architectures or weights, while 2 (2.2%) were built on existing architectures with uninitialized weights. Training models from scratch poses unique challenges in biomedical applications due to data complexity and resource demands, potentially explaining its limited prevalence in this domain.
Fine-tuning is overwhelmingly prevalent, with 87 models (95.6%) indicating its use, compared to only 4 models (4.4%) that did not include this technique. Fine-tuning allows for the adaptation of pretrained models to specific tasks by training on task-relevant data, enhancing the model’s performance on particular biomedical applications. The high adoption rate suggests that fine-tuning is recognized as a critical step for achieving optimal model performance in biomedical domains.
3.2.2. Source of training data.
Regarding the source of training data for model development, biomedical literature emerged as the most prevalent, accounting for 36 articles (43.4%) examined, as illustrated in Figure 2a. This high percentage underscores the vast potential of biomedical literature as a fundamental source of knowledge and training data for models designed to extract, process, and synthesize biomedical information. Following closely is the adoption of EHR data (both unstructured clinical notes and structured data) in 30 articles (36.1%), highlighting their pivotal role in training models aimed toward comprehending and predicting clinical outcomes and managing patient data.
Figure 2.

Analysis of training corpora and domains. (a) Number of articles utilizing different types of training data. Note that percentages are calculated based on 82 articles; multiple corpora usage in individual papers means the total does not sum to 100%.
(b) Subcategorization of textual training data. Abbreviation: EHR, electronic health record.
A notable trend is the prevalent use of proprietary datasets in 30 articles (36.6%). These datasets are often curated ad hoc for specific research purposes, enabling tailored model training that is closely aligned with unique project goals. Such customization allows researchers to address specific biomedical questions with high precision. Meanwhile, publicly accessible resources like PubMed and MIMIC datasets (48–50) [e.g., clinical notes from MIMIC-III (48) and MIMIC-IV (49), MIMIC-CXR (50), etc.] are also widely utilized, with 12 (14.6%) and 9 (10.8%) mentions, respectively. PubMed serves as a rich source of biomedical literature, providing expansive, high-quality content that is ideal for training models on a wide array of biomedical topics. MIMIC, a large database of deidentified EHR data, is crucial for models that deal with clinical scenarios and patient data analysis. Additionally, Wikipedia, which appears 7 times (8.4%), although less specialized, provides valuable supplementary information that helps in broadening the knowledge base of biomedical LLMs, particularly in models designed to understand general context or nonexpert explanations within the medical domain. Other commonly used training and testing datasets are detailed in Table 4. We note that while PubMed articles and clinical notes from the MIMIC database are utilized for pretraining models, other benchmark datasets [e.g., BioASQ (51), MedMCQA (52), PubMedQA (53)] are employed for task-specific fine-tuning.
Table 4.
Examples of the most frequently used training (pretraining/fine-tuning) and testing datasets
| Training dataset | Count | Testing dataset | Count |
|---|---|---|---|
| PubMed articles | 6 | PubMedQA (53) | 8 |
| MedMCQA (52) | 4 | BC5CDR (135) | 7 |
| MIMIC-III (48) | 4 | MedMCQA (52) | 7 |
| PubMedQA (53) | 4 | MedQA (136) | 6 |
| MedQA (136) | 3 | BioASQ (51) | 4 |
| MIMIC-CXR (50) | 3 | DDI (137) | 4 |
| MIMIC-IV (49) | 3 | National Center for Biotechnology Information disease (138) | 4 |
| HiTZ/multilingual (113) | 3 | MIMIC-CXR (50) | 3 |
| PromptCBLUE (139) | 3 | MIMIC-III (48) | 3 |
Figure 2b illustrates the domain-specific distribution of data sources, which further delineates the focal areas of current biomedical LLM research. General biomedical applications dominate, with 57.8% of the models targeting a broad range of biomedical tasks, suggesting a trend toward developing versatile models capable of performing multiple tasks across the biomedical spectrum. Disease-specific applications, which constitute 15.7% of the models developed, highlight the ongoing efforts to tailor LLMs for targeted disease detection, prognosis, and treatment options, offering a more personalized approach to healthcare. Smaller yet significant percentages are dedicated to more specialized domains such as genome/protein analysis, mental health, and radiology, each reflecting niche areas where LLMs can provide substantial advancements in understanding complex biological data and improving diagnostic accuracies.
3.2.3. Computational resources.
Table 5 details the computational resources used while training the models. It appears that the graphics processing unit (GPU) type and the number of GPUs are commonly reported metrics, with 60 (73.2%) and 59 (72.0%) of articles, respectively, disclosing this information. However, less frequently reported are the details about the GPU memory and the training time, with only 38 (46.3%) and 28 (34.1%) of articles including these data points.
Table 5.
Computational resources (n = 82)
| Reporting of computational resources | ||
|---|---|---|
| Reported | Not reported | |
| GPU type | 60 (73.2%) | 22 (26.8%) |
| Number of GPUs | 59 (72.0%) | 23 (28.0%) |
| GPU memory | 38 (46.3%) | 44 (53.7%) |
| Train time | 28 (34.1%) | 54 (65.9%) |
| Overview of GPU type | ||
| GPU type | Count | Proportion |
| A100 | 39 | 65.00% |
| V100 | 7 | 11.67% |
| A40 | 3 | 5.00% |
| RTX3090 | 2 | 3.30% |
| A5000 | 2 | 3.30% |
| A4000 | 2 | 3.30% |
| Cloud TPU v3 | 2 | 3.30% |
| AI bridging cloud infrastructure GPUs | 1 | 1.70% |
| A6000 | 1 | 1.70% |
| RTX 3090 Ti | 1 | 1.70% |
| RTX 3080 Ti | 1 | 1.70% |
Abbreviation: GPU, graphics processing unit.
The NVIDIA A100 (39 articles, 65.0%) is the most common GPU reported, showcasing its advanced capabilities for complex computational tasks. The NVIDIA V100 (7 articles, 11.67%) remains relevant in research, while other GPUs like the NVIDIA A40, A4000, A5000, and RTX 3080/3090 series are used less often, likely chosen for specific task requirements or based on availability at corresponding research institutes. Notably, the NVIDIA H100, though released in 2022, was not mentioned in any of the reviewed papers, which could be attributed to the academic community’s delayed adoption of the latest GPU technologies. This delay might stem from factors such as limited accessibility, cost and other resource constraints, or the need for time to integrate and optimize these new hardware platforms within existing research infrastructure.
Understanding GPU memory size utilization is important for understanding and optimizing computational resources. As shown in Figure 3a, the data reveal a strong preference for 80GB GPUs (25 articles, 64.1%), indicating the need for substantial memory resources to manage the computational workload in model training. Smaller GPU memory sizes, such as 32GB and 48GB, are primarily used in less-demanding scenarios (12 articles, 30.8%), with a minor utilization of 24GB GPUs (2 articles, 5.26%) for smaller model sizes and training datasets.
Figure 3.
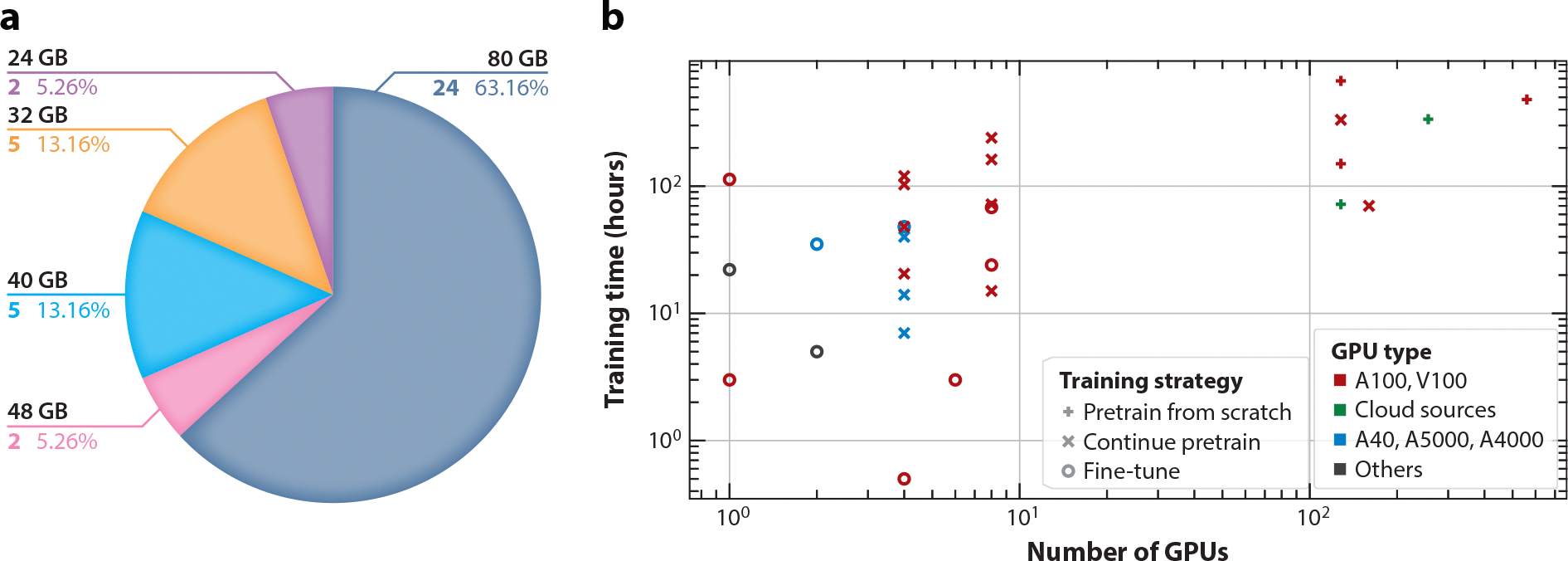
Analysis of computational resources. (a) Allocation of GPU memory sizes utilized in model training. (b) Distribution of training resources by training time and number of GPUs. Different colors represent different GPU types, and different shapes represent different training strategies. Abbreviation: GPU, graphics processing unit.
In Figure 3b, various training strategies for biomedical LLMs are highlighted along with the training time and number of GPUs required by the models utilizing those strategies. Notably, 54 articles did not report both training time and numbers of GPUs, resulting in only 28 included data points. A key observation from the analysis is the significant resource consumption variability. Models trained from scratch exhibit high computational demands, as shown in the plot’s upper right corner, indicating intensive resource requirements due to the complexity and size of biomedical datasets and the necessity to learn features and patterns from the ground up. Continual pretraining shows a dual pattern. It can mirror the resource usage of training from scratch for complex tasks, needing substantial model modifications and using very large biomedical datasets. Alternatively, it can align with fine-tuning, indicating lower resource demands when the model is already somewhat specialized, needing only moderate adjustments. Fine-tuning, primarily in the lower left quadrant, requires fewer GPUs and less time. Leveraging transfer learning, it adapts a pretrained model to a specific biomedical task efficiently. High-performance GPUs like the A100 and V100 are favored for intensive computational tasks like full model training or extensive pretraining. On the other hand, GPUs like the A40, A5000, and A4000 offer versatility and cost-effective performance, making them suitable for less-demanding fine-tuning processes.
3.2.4. Model evaluation.
In evaluating the performance of domain-specific LLMs across various biomedical tasks, our review identifies a diverse set of metrics employed to measure the efficacy of models in real-world scenarios. Predominantly, the evaluation metrics employed include the F1 score (24 articles, 29.3%), precision (11 articles, 13.4%), recall (12 articles, 14.6%), accuracy (27 articles, 32.9%), ROUGE (20 articles, 24.4%), BLEU (14 articles, 17.1%), ROC-AUC (receiver operating characteristic–area under curve) (5 articles, 6.1%), and METEOR (3 articles, 3.7%). Notably, 11 studies (13.4%) incorporated human evaluation to assess model performance, underscoring the importance of subjective assessment in model validation.
This breadth of metrics underscores the complexity of accurately gauging the capabilities of domain-specific LLMs for different biomedical applications. For medical question answering, metrics such as accuracy, precision, recall, F1 score, BLEU, ROUGE, GLEU, Distinct, and a clinical evaluation score are utilized to assess both the linguistic quality and clinical relevance of the generated responses. In text generation tasks, models are primarily evaluated through metrics like BLEU, METEOR, ROUGE, F1 score, and perplexity, which together help in determining the fluency, relevance, and cohesiveness of the generated text. For classification tasks within the biomedical domain, accuracy, F1 score, precision, recall, and ROC-AUC are critical metrics, offering a comprehensive view of the models’ ability to accurately categorize and predict clinical and nonclinical outcomes. This assortment of metrics highlights the complex and multifaceted nature of assessing LLMs tailored for specific biomedical applications, reflecting both their linguistic competency and their practical utility in a clinical context.
3.3. Applications of Biomedical LLMs
Table 6 outlines a wide array of NLP tasks to which biomedical LLMs have been applied, highlighting the versatility of generative models across diverse tasks. Predominantly, the focus lies on medical question answering (34 articles, 41.4%) and text generation (28 articles, 34.1%), crucial for real-time decision support and optimizing medical documentation. These applications not only boost healthcare delivery efficiency but also enhance the precision and customization of patient care, showcasing LLMs’ ability to flexibly operate in various contexts. Moreover, there is a strong focus on processing biomedical texts, evident from the significant number of articles focusing on classification (15 articles, 18.3%) and information extraction (16 articles, 19.5%). These tasks form essential building blocks in complex workflows for integrating clinical data effectively in real-world applications. Other tasks, though less frequent, such as prediction (6 articles, 7.3%), inference (4 articles, 4.9%), summarization (3 articles, 3.7%), and retrieval (2 articles, 2.4%), indicate a burgeoning interest in predictive analytics and efficient information synthesis. These models help forecast patient outcomes and extract actionable insights, which are critical in a data-driven healthcare environment, showing the growing interconnectedness of LLM applications in enhancing both the reach and depth of medical research and practice.
Table 6.
Categories of natural language processing tasks for which biomedical large language models are utilized (n = 82)
| Task | Count | Proportion |
|---|---|---|
| Medical question answering | 34 | 41.4% |
| Text generation | 28 | 34.1% |
| Classification | 15 | 18.3% |
| Information extraction | 16 | 19.5% |
| Prediction | 6 | 7.3% |
| Inference | 4 | 4.9% |
| Summarization | 3 | 3.7% |
| Retrieval | 2 | 2.4% |
Table 7 illustrates the clinical applications for each article. The analysis of 82 articles reveals a diverse spectrum of applications. The most frequent application (30 articles, 36.6%) is evaluating general biomedical NLP tasks, suggesting that the field is still in a relatively early stage, where establishing strong baseline performance on fundamental NLP tasks is crucial before moving on to more specialized or complex applications. The second most common applications, each appearing in 16 articles (19.5%), are medical chatbots and patient diagnosis or treatment outcome predictions. This reflects the increasing focus on leveraging LLMs to improve patient engagement and enhance clinical decision-making processes. Generating medical reports (e.g., case reports, radiology reports) and genomic tasks (e.g., protein structure prediction) account for 9 articles (11.0%) and 8 articles (9.8%), respectively, indicating significant, though lesser, utilization in creating medical documentation and understanding biological functions providing insights into the molecular basis of life processes. Last, the least represented category is medical education (3 articles, 3.7%), pointing to its nascent stage but potential for future growth in training medical professionals using AI-driven tools. Collectively, these distributions not only reflect the broad applicability and impact of LLMs in the biomedical domain but also suggest areas for future research and development, particularly in less explored fields that could benefit from further technological enhancements.
Table 7.
Categories of clinical applications mentioned in the papers (n = 82)
| Category | Count | Proportion |
|---|---|---|
| Evaluating general biomedical natural language processing tasks | 30 | 36.60% |
| Medical chatbots | 16 | 19.50% |
| Patient diagnosis/treatment outcomes | 16 | 19.50% |
| Generating medical reports | 9 | 11.00% |
| Genomic tasks | 8 | 9.80% |
| Medical education | 3 | 3.70% |
4. DISCUSSION
Our comprehensive review of LLMs in the biomedical domain reveals a rapidly evolving landscape with active development of biomedical LLMs using domain-specific data. By focusing on the technical aspects of model development, including architectural design strategies, hyperparameters, and training data, we have identified several trends and challenges that warrant further discussion.
4.1. Model Characteristics
The findings highlight a balance between model size and computational requirements, with a notable trend toward moderate-sized open-source models gaining more traction in the research community. This preference also indicates the computing resource constraints within the medical AI community, potentially limiting the development and evaluation of larger models that could offer enhanced capabilities. Particularly, the adoption of the Llama backbone with 7B parameters stands out within this domain. While this preference could be attributed to the open-source nature of Llama, enabling accessibility while also striking a balance between computational efficiency and performance, it could also be a result of the limitation of our study design, constraining to pretrained and fine-tuned models.
Model and data accessibility in biomedical LLM research presents a mixed landscape. While about one-third of the models are directly downloadable, a significant portion remain closed source. These accessibility challenges are uniquely complicated by the sensitive nature of medical data and the need for regulatory compliance. Unlike general-purpose LLMs, biomedical models often require careful consideration of patient privacy, clinical data protection, and healthcare regulations. This has created a need for standardized frameworks and guidelines specifically tailored to sharing biomedical LLMs, balancing open science principles with privacy concerns and regulatory requirements. The establishment of such regulations could help streamline the sharing process while ensuring appropriate safeguards.
4.2. Model Training and Evaluation
The development of medical LLMs relies heavily on biomedical literature, with many models trained on such corpora, likely influenced by the ease of access to PubMed articles. However, the scale of available training data remains limited compared to open-domain models. As mentioned above and highlighted by Wornow et al. (54), most existing models rely heavily on either narrowly scoped clinical datasets like MIMIC-III (48) or broad public biomedical corpora such as PubMed, failing to capture the full complexity of healthcare data. Moreover, the evaluation methods often fail to provide meaningful insights into the models’ practical value for health systems. To address these foundational challenges, emerging approaches like federated learning (55–57) offer promising solutions for expanding the training data landscape while maintaining privacy and regulatory compliance.
The evaluation also reveals concerning gaps in reporting practices, with inconsistent documentation of training procedures, evaluation metrics, and model limitations. Multiple documentation frameworks, such as model cards for model reporting (58) and datasheets for datasets (59), have emerged as essential tools for promoting transparency and accountability in AI systems, yet their adoption and utilization in the biomedical LLM community remain limited. These documentation frameworks aim to enable informed decision-making about model and dataset usage and encourage responsible development and deployment of AI systems, particularly crucial in sensitive domains like healthcare. Findings from systematic reviews on reporting guidelines (60) have also stressed the critical need for standardized reporting guidelines in clinical AI research, as current variations and gaps in documentation practices hinder the field’s progress.
4.3. Applications
The predominance of studies evaluating general biomedical NLP tasks suggests that the field is currently focused on developing versatile models with broad applicability across the biomedical domain. This trend indicates an emphasis on establishing strong baseline performance for fundamental NLP tasks, facilitating easier comparison between models, and creating a foundation for more specialized applications. While this approach allows for comprehensive benchmarking and potential transfer learning, it also highlights opportunities for future research to explore more specialized clinical applications of biomedical LLMs.
In summary, this review underscores the rapidly growing importance and potential of biomedical LLMs. We observed that open-source models of moderate size tend to gain more traction and adoption within the research community, likely due to their accessibility and computational feasibility. The diversity in training data, ranging from readily available to private datasets, can be a bottleneck in biomedical language modeling research, reflecting challenges in balancing data openness with privacy concerns. Reporting issues when releasing LLM models is another concern that needs to be addressed. Additionally, a significant portion of the models remains closed source. In the future, more emphasis on multimodal models (61) that integrate text with other modalities like images may offer promising opportunities for more comprehensive AI applications in healthcare. Expanding applications into specialized medical domains is an area that requires further exploration. To advance biomedical AI, the research community should strive for increased collaboration with domain experts, improved data-sharing mechanisms, standardized reporting practices, and improved model accessibility.
While this review provides valuable insights into the landscape of biomedical and clinical LLMs, several key limitations should be acknowledged. Our review primarily focused on LLMs dealing with medical text data, with limited coverage of multimodal approaches incorporating medical imaging, videos, etc. This scope limitation reflects the current state of the field but may not fully capture emerging trends in multimodal medical AI. Future work will address these limitations by expanding the scope to include all multimodal medical LLMs and not just those with text as a modality. Additionally, given the rapid pace of development in this domain, some recent models may not be included, and the proprietary nature of commercial medical LLMs means some developments may be underrepresented. As mentioned previously, another limitation of the study is the focus on pretrained and fine-tuned models, excluding prompt engineering of existing open- and closed-source LLMs. Future work will also focus on reviewing models including those employing prompt engineering strategies to provide a more comprehensive understanding of the overall landscape.
ACKNOWLEDGMENTS
This study is supported by multiple grants: RF1AG072799, R01AG080429, R01AG078154, and 1R01LM014604. The funders played no role in the study design, data collection, analysis and interpretation of data, or the writing of this manuscript.
Footnotes
DISCLOSURE STATEMENT
The authors are not aware of any affiliations, memberships, funding, or financial holdings that might be perceived as affecting the objectivity of this review.
LITERATURE CITED
- 1.Brown TB, Mann B, Ryder N, Subbiah M, Kaplan J, et al. 2020. Language models are few-shot learners. Preprint, arXiv:2005.14165v4 [cs.CL] [Google Scholar]
- 2.Achiam J, Adler S, Agarwal S, Ahmad L, Akkaya I, et al. 2024. GPT-4 technical report. Preprint, arXiv:2303.08774v6 [cs.CL] [Google Scholar]
- 3.GLM T, Zeng A, Xu B, Wang B, Zhang C, et al. 2024. ChatGLM: a family of large language models from GLM-130B to GLM-4 all tools. Preprint, arXiv:2406.12793v2 [cs.CL] [Google Scholar]
- 4.Touvron H, Lavril T, Izacard G, Martinet X, Lachaux M-A, et al. 2023. LLaMA: open and efficient foundation language models. Preprint, arXiv:2302.13971v1 [cs.CL] [Google Scholar]
- 5.Touvron H, Martin L, Stone K, Albert P, Almahairi A, et al. 2023. Llama 2: OPEN foundation and fine-tuned chat models. Preprint, arXiv:2307.09288v2 [cs.CL] [Google Scholar]
- 6.Grattafiori A, Dubey A, Jauhri A, Pandey A, Kadian A, et al. 2024. The Llama 3 herd of models. Preprint, arXiv:2407.21783v3 [cs.AI] [Google Scholar]
- 7.Xie Q, Chen Q, Chen A, Peng C, Hu Y, et al. 2024. Me LLaMA: foundation large language models for medical applications. Preprint, arXiv:2402.12749v5 [cs.CL] [Google Scholar]
- 8.Chen Z, Cano AH, Romanou A, Bonnet A, Matoba K, et al. 2023. MEDITRON-70B: scaling medical pretraining for large language models. Preprint, arXiv:2311.16079v1 [cs.CL] [Google Scholar]
- 9.Luo L, Ning J, Zhao Y, Wang Z, Ding Z, et al. 2024. Taiyi: a bilingual fine-tuned large language model for diverse biomedical tasks. J. Am. Med. Inf. Assoc. 31:1865–74 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 10.Yang X, Chen A, PourNejatian N, Shin HC, Smith KE, et al. 2022. A large language model for electronic health records. NPJ Digit. Med. 5:194. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 11.Singhal K, Azizi S, Tu T, Mahdavi SS, Wei J, et al. 2023. Large language models encode clinical knowledge. Nature 620:172–80 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 12.Saab K, Tu T, Weng W-H, Tanno R, Stutz D, et al. 2024. Capabilities of Gemini models in medicine. Preprint, arXiv:2404.18416v2 [cs.AI] [Google Scholar]
- 13.McDuff D, Schaekermann M, Tu T, Palepu A, Wang A, et al. 2023. Towards accurate differential diagnosis with large language models. Preprint, arXiv:2312.00164v1 [cs.CY] [DOI] [PMC free article] [PubMed] [Google Scholar]
- 14.Zhou J, He X, Sun L, Xu J, Chen X, et al. 2024. Pre-trained multimodal large language model enhances dermatological diagnosis using SkinGPT-4. Nat. Commun. 15:5649. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 15.Li Y, Li Z, Zhang K, Dan R, Jiang S, Zhang Y. 2023. ChatDoctor: a medical chat model fine-tuned on a large language model Meta-AI (LLaMA) using medical domain knowledge. Cureus 15:e40895. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 16.Oami T, Okada Y, Nakada T-A. 2024. Performance of a large language model in screening citations. JAMA Netw. Open 7:e2420496–e96 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 17.Peng C, Yang X, Chen A, Smith KE, PourNejatian N, et al. 2023. A study of generative large language model for medical research and healthcare. NPJ Digit. Med. 6:210. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 18.Caldarini G, Jaf S, McGarry K. 2022. A literature survey of recent advances in chatbots. Information 13:41 [Google Scholar]
- 19.Jovanović M, Baez M, Casati F. 2020. Chatbots as conversational healthcare services. IEEE Internet. Comput. 25:44–51 [Google Scholar]
- 20.Reis L, Maier C, Mattke J, Weitzel T. 2020. Chatbots in healthcare: status quo, application scenarios for physicians and patients and future directions. In Proceedings of the 28th European Conference on Information Systems (ECIS). https://aisel.aisnet.org/ecis2020_rp/163 [Google Scholar]
- 21.Wang Y, Pan Y, Yan M, Su Z, Luan TH. 2023. A survey on ChatGPT: AI-generated contents, challenges, and solutions. IEEE Open J. Comput. Soc. 4: 280–302 [Google Scholar]
- 22.Zhang K, Yu J, Yan Z, Liu Y, Adhikarla E, et al. 2024. BiomedGPT: a unified and generalist biomedical generative pre-trained transformer for vision, language, and multimodal tasks. Preprint, arXiv:2305.17100v4 [cs.CL] [Google Scholar]
- 23.Bengio Y, Ducharme R, Vincent P. 2000. A neural probabilistic language model. In Advances in Neural Information Processing Systems, Vol. 13, MIT Press [Google Scholar]
- 24.Vaswani A, Shazeer N, Parmar N, Uszkoreit J, Jones L, et al. 2017. Attention is all you need. In Advances in Neural Information Processing Systems, Vol. 30, ed. Guyon I, von Luxburg U, Bengio S, Wallach H, Fergus R, et al. Curran Associates [Google Scholar]
- 25.Devlin J, Chang M-W, Lee Kenton, Toutanova K. 2019. BERT: pre-training of deep bidirectional transformers for language understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers). Association for Computational Linguistics [Google Scholar]
- 26.Naveed H, Khan AU, Qiu S, Saqib M, Anwar S, et al. 2024. A comprehensive overview of large language models. Preprint, arXiv:2307.06435v10 [cs.CL] [Google Scholar]
- 27.Gu Y, Tinn R, Cheng H, Lucas M, Usuyama N, et al. 2021. Domain-specific language model pretraining for biomedical natural language processing. ACM Trans. Comput. Healthc. 3:2 [Google Scholar]
- 28.Alsentzer E, Murphy JR, Boag W, Weng W-H, Jin D, et al. 2019. Publicly available clinical BERT embeddings. Preprint, arXiv:1904.03323v3 [cs.CL] [Google Scholar]
- 29.Li L, Zhou J, Gao Z, Hua W, Fan L, et al. 2024. A scoping review of using large language models (LLMs) to investigate electronic health records (EHRs). Preprint, arXiv:2405.03066v2 [cs.ET] [Google Scholar]
- 30.Neveditsin N, Lingras P, Mago V. 2024. Clinical insights: a comprehensive review of language models in medicine. Preprint, arXiv:2408.11735v1 [cs.AI] [DOI] [PMC free article] [PubMed] [Google Scholar]
- 31.Rehana H, Çam NB, Basmaci M, Zheng J, Jemiyo C, et al. 2023. Evaluation of GPT and BERT-based models on identifying protein-protein interactions in biomedical text. Preprint, arXiv:2303.17728v2 [cs.CL] [Google Scholar]
- 32.Ouyang L, Wu J, Jiang X, Almeida D, Wainwright C, et al. 2022. Training language models to follow instructions with human feedback. In Advances in Neural Information Processing Systems, Vol. 35, ed. Koyejo S, Mohamed S, Agarwal A, Belgrave D, Cho K, Oh A. Curran Associates [Google Scholar]
- 33.Lewis M, Liu Y, Goyal N, Ghazvininejad M, Mohamed A, et al. 2019. BART: denoising sequence-to-sequence pre-training for natural language generation, translation, and comprehension. Preprint, arXiv:1910.13461v1 [cs.CL] [Google Scholar]
- 34.Gu A, Dao T. 2024. Mamba: linear-time sequence modeling with selective state spaces. Preprint, arXiv:2312.00752v2 [cs.LG] [Google Scholar]
- 35.Longpre S, Hou L, Vu T, Webson A, Chung HW, et al. 2023. The flan collection: designing data and methods for effective instruction tuning. In Proceedings of the 40th International Conference on Machine Learning, ed. Krause A, Brunskill E, Cho K, Engelhardt B, Sabato S, Scarlett J. Association for Computing Machinery [Google Scholar]
- 36.Song S, Li X, Li S, Zhao S, Yu J, et al. 2023. How to bridge the gap between modalities: a comprehensive survey on multimodal large language model. Preprint, arXiv:2311.07594v2 [cs.CL] [Google Scholar]
- 37.Wang J, Jiang H, Liu Y, Ma C, Zhang X, et al. 2024. A comprehensive review of multimodal large language models: Performance and challenges across different tasks. Preprint, arXiv:2408.01319v1 [cs.AI] [Google Scholar]
- 38.Liu Q, Zhu J, Yang Y, Dai Q, Du Z, et al. 2024. Multimodal pretraining, adaptation, and generation for recommendation: a survey. In Proceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining. Association for Computing Machinery [Google Scholar]
- 39.Meng X, Yan X, Zhang K, Liu D, Cui X, et al. 2024. The application of large language models in medicine: a scoping review. iScience 27:109713. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 40.Yu H, Fan L, Li L, Zhou J, Ma Z, et al. 2024. Large language models in biomedical and health informatics: a bibliometric review. Preprint, arXiv:2403.16303v4 [cs.DL] [DOI] [PMC free article] [PubMed] [Google Scholar]
- 41.Bedi S, Liu Y, Orr-Ewing L, Dash D, Koyejo S, et al. 2024. Testing and evaluation of health care applications of large language models: a systematic review. JAMA 333:319–28 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 42.Busch F, Hoffmann L, Rueger C, van Dijk EH, Kader R, et al. 2024. Systematic review of large language models for patient care: current applications and challenges. Preprint, medRxiv. https://www.medrxiv.org/content/10.1101/2024.03.04.24303733v1 [DOI] [PMC free article] [PubMed]
- 43.Loor-Torres R, Duran M, Toro-Tobon D, Chavez MM, Ponce O, et al. 2024. A systematic review of natural language processing methods and applications in thyroidology. Mayo Clin. Proc. Digit. Health 2:270–79 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 44.Guo Z, Lai A, Thygesen JH, Farrington J, Keen T, Li K. 2024. Large language model for mental health: a systematic review. Preprint, arXiv:2403.15401v3 [cs.CY] [DOI] [PMC free article] [PubMed] [Google Scholar]
- 45.Nassiri K, Akhloufi MA. 2024. Recent advances in large language models for healthcare. BioMedInformatics 4:1097–143 [Google Scholar]
- 46.Moher D, Liberati A, Tetzlaff J, Altman DG, Group P. 2010. Preferred reporting items for systematic reviews and meta-analyses: the PRISMA statement. Int. J. Surg. 8:336–41 [DOI] [PubMed] [Google Scholar]
- 47.Liu H, Li C, Wu Q, Lee YJ. 2024. Visual instruction tuning. In Advances in Neural Information Processing Systems, Vol. 36, ed. Oh A, Naumann T, Globerson A, Saenko K, Hardt M, Levine S. Curran Associates [Google Scholar]
- 48.Johnson AEW, Pollard TJ, Shen L, Lehman L-WH, Feng M, et al. 2016. MIMIC-III, a freely accessible critical care database. Sci. Data 3:160035. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 49.Johnson A, Bulgarelli L, Pollard T, Horng S, Celi LA, Mark R. 2020. MIMIC-IV. PhysioNet. https://physionet.org/content/mimiciv/1.0 [Google Scholar]
- 50.Johnson AE, Pollard TJ, Berkowitz SJ, Greenbaum NR, Lungren MP, et al. 2019. MIMIC-CXR, a de-identified publicly available database of chest radiographs with free-text reports. Sci. Data 6:317. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 51.Tsatsaronis G, Balikas G, Malakasiotis P, Partalas I, Zschunke M, et al. 2015. An overview of the BIOASQ large-scale biomedical semantic indexing and question answering competition. BMC Bioinf. 16:138. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 52.Pal A, Umapathi LK, Sankarasubbu M. 2022. MedMCQA: a large-scale multi-subject multi-choice dataset for medical domain question answering. Proc. Mach. Learn. Res. 174:248–60 [Google Scholar]
- 53.Jin Q, Dhingra B, Liu Z, Cohen WW, Lu X. 2019. PubMedQA: a dataset for biomedical research question answering. Preprint, arXiv:1909.06146v1 [cs.CL] [Google Scholar]
- 54.Wornow M, Xu Y, Thapa R, Patel B, Steinberg E, et al. 2023. The shaky foundations of large language models and foundation models for electronic health records. NPJ Digit. Med. 6:135. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 55.Kuang W, Qian B, Li Z, Chen D, Gao D, et al. 2024. FederatedScope-LLM: a comprehensive package for fine-tuning large language models in federated learning. In Proceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining. Association for Computing Machinery [Google Scholar]
- 56.Fan T, Kang Y, Ma G, Chen W, Wei W, et al. 2023. FATE-LLM: a industrial grade federated learning framework for large language models. Preprint, arXiv:2310.10049v1 [cs.LG] [Google Scholar]
- 57.Wu F, Li Z, Li Y, Ding B, Gao J. 2024. FedBiOT: LLM local fine-tuning in federated learning without full model. In Proceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining. Association for Computing Machinery [Google Scholar]
- 58.Mitchell M, Wu S, Zaldivar A, Barnes P, Vasserman L, et al. 2019. Model cards for model reporting. In FAT* ‘19: Proceedings of the Conference on Fairness, Accountability, and Transparency. Association for Computing Machinery [Google Scholar]
- 59.Gebru T, Morgenstern J, Vecchione B, Vaughan JW, Wallach H, et al. 2021. Datasheets for datasets. Commun. ACM 64:86–92 [Google Scholar]
- 60.Kolbinger FR, Veldhuizen GP, Zhu J, Truhn D, Kather JN. 2024. Reporting guidelines in medical artificial intelligence: a systematic review and meta-analysis. Commun. Med. 4:71. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 61.Wang X, Zhao J, Marostica E, Yuan W, Jin J, et al. 2024. A pathology foundation model for cancer diagnosis and prognosis prediction. Nature 634:970–78 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 62.Luo R, Sun L, Xia Y, Qin T, Zhang S, et al. 2022. BioGPT: generative pre-trained transformer for biomedical text generation and mining. Brief. Bioinf. 23:bbac409. [DOI] [PubMed] [Google Scholar]
- 63.Yang S, Zhao H, Zhu S, Zhou G, Xu H, et al. 2024. Zhongjing: enhancing the Chinese medical capabilities of large language model through expert feedback and real-world multi-turn dialogue. In Proceedings of the Thirty-Eighth AAAI Conference on Artificial Intelligence and Thirty-Sixth Conference on Innovative Applications of Artificial Intelligence and Fourteenth Symposium on Educational Advances in Artificial Intelligence. AAAI Press [Google Scholar]
- 64.Wu C, Lin W, Zhang X, Zhang Y, Xie W, Wang Y. 2024. PMC-LLaMA: toward building open-source language models for medicine. J. Am. Med. Inf. Assoc. 31:1833–43 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 65.Han T, Adams LC, Papaioannou J-M, Grundmann P, Oberhauser T, et al. 2023. MedAlpaca – an open-source collection of medical conversational AI models and training data. Preprint, arXiv:2304.08247v2 [cs.CL] [Google Scholar]
- 66.Wang H, Gao C, Dantona C, Hull B, Sun J. 2024. DRG-LLaMA: tuning LLaMA model to predict diagnosis-related group for hospitalized patients. NPJ Digit. Med. 7:16. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 67.Haghighi T, Gholami S, Sokol JT, Kishnani E, Ahsaniyan A, et al. 2024. EYE-Llama, an in-domain large language model for ophthalmology. Preprint, bioRxiv. https://www.biorxiv.org/content/10.1101/2024.04.26.591355v1 [DOI] [PMC free article] [PubMed]
- 68.Chieh-Ju Chao M, Banerjee I, Andrew Tseng M, Kane GC, Chao C-J. 2024. EchoGPT: a large language model for echocardiography report summarization. Preprint, medRxiv. https://www.medrxiv.org/content/10.1101/2024.01.18.24301503v1
- 69.Shen X, Li X. 2024. OmniNA: a foundation model for nucleotide sequences. Preprint, bioRxiv. https://www.biorxiv.org/content/10.1101/2024.01.14.575543v1
- 70.Wang A, Liu C, Yang J, Weng C. 2024. Fine-tuning large language models for rare disease concept normalization. J. Am. Med. Inf. Assoc. 31:2076–83 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 71.Keloth VK, Selek S, Chen Q, Gilman C, Fu S, et al. 2024. Large language models for social determinants of health information extraction from clinical notes – a generalizable approach across institutions. Preprint, medRxiv. https://www.medrxiv.org/content/10.1101/2024.05.21.24307726v1 [DOI] [PMC free article] [PubMed]
- 72.Keloth VK, Hu Y, Xie Q, Peng X, Wang Y, et al. 2024. Advancing entity recognition in biomedicine via instruction tuning of large language models. Bioinformatics 40:btae163. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 73.Li Y, Li J, He J, Tao C. 2024. AE-GPT: using large language models to extract adverse events from surveillance reports-a use case with influenza vaccine adverse events. PLOS ONE 19:e0300919. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 74.Luu RK, Buehler MJ. 2024. BioinspiredLLM: conversational large language model for the mechanics of biological and bio-inspired materials. Adv. Sci. 11:2306724. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 75.Zhang H, Chen J, Jiang F, Yu F, Chen Z, et al. 2023. HuatuoGPT, towards taming language model to be a doctor. Preprint, arXiv:2305.15075v1 [cs.CL] [Google Scholar]
- 76.Wang R, Duan Y, Lam C, Chen J, Xu J, et al. 2023. IvyGPT: interactive Chinese pathway language model in medical domain. In Artificial Intelligence: Third CAAI International Conference, CICAI 2023, Fuzhou, China, July 22–23, 2023, Revised Selected Papers, Part II. Springer [Google Scholar]
- 77.Liu S, McCoy AB, Wright AP, Carew B, Genkins JZ, et al. 2024. Leveraging large language models for generating responses to patient messages—a subjective analysis. J. Am. Med. Inf. Assoc. 31:1367–79 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 78.Li R, Wang X, Yu H. 2024. LlamaCare: an instruction fine-tuned large language model for clinical NLP. In Proceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation (LREC-COLING 2024). ELRA and ICCL [Google Scholar]
- 79.Yang K, Zhang T, Kuang Z, Xie Q, Huang J, Ananiadou S. 2024. MentaLLaMA: interpretable mental health analysis on social media with large language models. In Proceedings of the ACM Web Conference 2024. Association for Computing Machinery [Google Scholar]
- 80.Sun Y, Zhu C, Zheng S, Zhang K, Sun L, et al. 2024. PathAsst: a generative foundation AI assistant towards artificial general intelligence of pathology. In Proceedings of the AAAI Conference on Artificial Intelligence and Thirty-Sixth Conference on Innovative Applications of Artificial Intelligence and Fourteenth Symposium on Educational Advances in Artificial Intelligence. AAAI Press [Google Scholar]
- 81.Guthrie E, Levy D, Del Carmen G. 2024. The Operating and Anesthetic Reference Assistant (OARA): a fine-tuned large language model for resident teaching. Am. J. Surg. 234:28–34 [DOI] [PubMed] [Google Scholar]
- 82.Ghosh M, Mukherjee S, Ganguly A, Basuchowdhuri P, Naskar SK, Ganguly D. 2024. AlpaPICO: extraction of PICO frames from clinical trial documents using LLMs. Methods 226:78–88 [DOI] [PubMed] [Google Scholar]
- 83.Tran H, Yang Z, Yao Z, Yu H. 2024. BioInstruct: instruction tuning of large language models for biomedical natural language processing. J. Am. Med. Inf. Assoc. 31:1821–32 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 84.Akhondi-Asl A, Yang Y, Luchette M, Burns JP, Mehta NM, Geva A. 2024. Comparing the quality of domain-specific versus general language models for artificial intelligence-generated differential diagnoses in PICU patients. Pediatr. Crit. Care Med. 25:e273–82 [DOI] [PubMed] [Google Scholar]
- 85.Kim J-h. 2023. Fine-tuning the Llama2 large language model using books on the diagnosis and treatment of musculoskeletal system in physical therapy. Preprint, medRxiv. https://www.medrxiv.org/content/10.1101/2023.11.23.23298943v2
- 86.Zhou W, Miller TA. 2024. Generalizable clinical note section identification with large language models. JAMIA Open 7:ooae075. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 87.Moor M, Huang Q, Wu S, Yasunaga M, Dalmia Y, et al. 2023. Med-Flamingo: a multimodal medical few-shot learner. Proc. Mach. Learn. Res. 225:353–67 [Google Scholar]
- 88.Xu X, Yao B, Dong Y, Gabriel S, Yu H, et al. 2024. Mental-LLM: leveraging large language models for mental health prediction via online text data. Proc. ACM Interact. Mob. Wearable Ubiquitous Technol. 8:31. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 89.Liu Z, Zhong A, Li Y, Yang L, Ju C, et al. 2023. Tailoring large language models to radiology: a preliminary approach to LLM adaptation for a highly specialized domain. In Machine Learning in Medical Imaging: 14th International Workshop, MLMI 2023, Held in Conjunction with MICCAI 2023, Vancouver, BC, Canada, October 8, 2023, Proceedings, Part I. Springer [Google Scholar]
- 90.Jiang Y, Irvin JA, Ng AY, Zou J. 2023. VetLLM: large language model for predicting diagnosis from veterinary notes. Pac. Symp. Biocomput. 29:120–33 [PubMed] [Google Scholar]
- 91.Li J, Guan Z, Wang J, Cheung CY, Zheng Y, et al. 2024. Integrated image-based deep learning and language models for primary diabetes care. Nat. Med. 30:2886–96 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 92.Bolton E, Venigalla A, Yasunaga M, Hall D, Xiong B, et al. 2024. Biomedlm: a 2.7B parameter language model trained on biomedical text. Preprint, arXiv:2403.18421v1 [cs.CL] [Google Scholar]
- 93.Trieu H-L, Miwa M, Ananiadou S. 2022. BioVAE: a pre-trained latent variable language model for biomedical text mining. Bioinformatics 38:872–74 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 94.Zagirova D, Pushkov S, Leung GHD, Liu BHM, Urban A, et al. 2023. Biomedical generative pre-trained based transformer language model for age-related disease target discovery. Aging 15:9293. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 95.Chung P, Boodoo M, Doboli S. 2023. Case scenario generators for trauma surgery simulation utilizing autoregressive language models. Artif. Intell. Med. 144:102635. [DOI] [PubMed] [Google Scholar]
- 96.Li C, Wong C, Zhang S, Usuyama N, Liu H, et al. 2024. LlaVA-Med: training a large language-and-vision assistant for biomedicine in one day. In Advances in Neural Information Processing Systems, Vol. 36, ed. Oh A, Naumann T, Globerson A, Saenko K, Hardt M, Levine S. Curran Associates [Google Scholar]
- 97.Swanson K, He S, Calvano J, Chen D, Telvizian T, et al. 2024. Biomedical text readability after hypernym substitution with fine-tuned large language models. PLOS Digit. Health 3:e0000489. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 98.Biswas MR, Islam A, Shah Z, Zaghouani W, Belhaouari SB. 2023. Can ChatGPT be your personal medical assistant? In 2023 Tenth International Conference on Social Networks Analysis, Management and Security (SNAMS). IEEE [Google Scholar]
- 99.Nawab K, Fernbach M, Atreya S, Asfandiyar S, Khan G, et al. 2024. Fine-tuning for accuracy: evaluation of Generative Pretrained Transformer (GPT) for automatic assignment of International Classification of Disease (ICD) codes to clinical documentation. J. Med. Artif. Intell. 7. 10.21037/jmai-24-60 [DOI] [Google Scholar]
- 100.Bousselham H, Mourhir A. 2024. Fine-tuning GPT on biomedical NLP tasks: an empirical evaluation. In 2024 International Conference on Computer, Electrical & Communication Engineering (ICCECE). IEEE [Google Scholar]
- 101.Ni Y, Ding R, Chen Y, Hou H, Ni S. 2023. Focusing on needs: a chatbot-based emotion regulation tool for adolescents. In 2023 IEEE International Conference on Systems, Man, and Cybernetics (SMC). IEEE [Google Scholar]
- 102.Mazumdar H, Chakraborty C, Sathvik M, Panigrahi PK. 2023. GPTFX: a novel GPT-3 based framework for mental health detection and explanations. IEEE J. Biomed. Health Inform. 10.1109/JBHI.2023.3328350 [DOI] [PubMed] [Google Scholar]
- 103.Sirrianni J, Sezgin E, Claman D, Linwood SL. 2022. Medical text prediction and suggestion using generative pretrained transformer models with dental medical notes. Methods Inf. Med. 61:195–200 [DOI] [PubMed] [Google Scholar]
- 104.Adornetto C, Guzzo A, Vasile A. 2023. Automatic medical report generation via latent space conditioning and transformers. In 2023 IEEE Intl Conf on Dependable, Autonomic and Secure Computing, Intl Conf on Pervasive Intelligence and Computing, Intl Conf on Cloud and Big Data Computing, Intl Conf on Cyber Science and Technology Congress (DASC/PiCom/CBDCom/CyberSciTech). IEEE [Google Scholar]
- 105.Liu C, Sun K, Zhou Q, Duan Y, Shu J, et al. 2024. CPMI-ChatGLM: parameter-efficient fine-tuning ChatGLM with Chinese patent medicine instructions. Sci. Rep. 14:6403. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 106.Zheng C, Ye H, Guo J, Yang J, Fei P, et al. 2024. Development and evaluation of a large language model of ophthalmology in Chinese. Br. J. Ophthalmol. 108:1390–97 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 107.Dou Y, Zhao X, Zou H, Xiao J, Xi P, Peng S. 2023. ShennongGPT: a tuning Chinese LLM for medication guidance. In 2023 IEEE International Conference on Medical Artificial Intelligence (MedAI). IEEE [Google Scholar]
- 108.Wu C, Lin Z, Fang W, Huang Y. 2023. A medical diagnostic assistant based on LLM. In Health Information Processing. Evaluation Track Papers. CHIP 2023. Springer. https://link.springer.com/chapter/10.1007/978-981-97-1717-0_12 [Google Scholar]
- 109.Fan L, Liu X, Wang Y, Yang G, Du Z, Wang G. 2023. Enhancing medical language understanding: adapting LLMs to the medical domain through hybrid granularity mask learning. In 2023 IEEE International Conference on Bioinformatics and Biomedicine (BIBM). IEEE [Google Scholar]
- 110.Yang H, Li J, Liu S, Du L, Liu X, et al. 2023. Exploring the potential of large language models in personalized diabetes treatment strategies. Preprint, medRxiv. https://www.medrxiv.org/content/10.1101/2023.06.30.23292034v1
- 111.Yang B, Raza A, Zou Y, Zhang T. 2023. PCLmed at ImageCLEFmedical 2023: customizing general-purpose foundation models for medical report generation. In CLEF -WN 2023: Working Notes of the Conference and Labs of the Evaluation Forum. CEUR-WS Workshop Proceedings [Google Scholar]
- 112.Heinzinger M, Weissenow K, Sanchez JG, Henkel A, Mirdita M, et al. 2023. Bilingual language model for protein sequence and structure. Preprint, bioRxiv. https://www.biorxiv.org/content/10.1101/2023.07.23.550085v2 [DOI] [PMC free article] [PubMed]
- 113.García-Ferrero I, Agerri R, Salazar AA, Cabrio E, de la Iglesia I, et al. 2024. Medical mT5: an open-source multilingual text-to-text LLM for the medical domain. Preprint, arXiv:2404.07613v1 [cs.CL] [Google Scholar]
- 114.Zekaoui NE, Yousfi S, Mikram M, Rhanoui M. 2023. Enhancing large language models’ utility for medical question-answering: a patient health question summarization approach. In 2023 14th International Conference on Intelligent Systems: Theories and Applications (SITA). IEEE [Google Scholar]
- 115.Schlegel V, Li H, Wu Y, Subramanian A, Nguyen T-T, et al. 2023. PULSAR at MEDIQA-Sum 2023: large language models augmented by synthetic dialogue convert patient dialogues to medical records. Preprint, arXiv:2307.02006v1 [cs.CL] [Google Scholar]
- 116.Kanakarajan KR, Sankarasubbu M. 2023. Saama AI research at SemEval-2023 Task 7: exploring the capabilities of Flan-T5 for multi-evidence natural language inference in clinical trial data. In Proceedings of the 17th International Workshop on Semantic Evaluation (SemEval-2023). Association for Computational Linguistics [Google Scholar]
- 117.Na H 2024. CBT-LLM: a Chinese large language model for cognitive behavioral therapy-based mental health question answering. Preprint, arXiv:2403.16008v1 [cs.CL] [Google Scholar]
- 118.Li W, Yu L, Wu M, Liu J, Hao M, Li Y. 2023. DoctorGPT: a large language model with chinese medical question-answering capabilities. In 2023 International Conference on High Performance Big Data and Intelligent Systems (HDIS). IEEE [Google Scholar]
- 119.Tan Y, Zhang Z, Li M, Pan F, Duan H, et al. 2024. MedChatZH: a tuning LLM for traditional Chinese medicine consultations. Comput. Biol. Med. 172:108290. [DOI] [PubMed] [Google Scholar]
- 120.Ge C, Ling H, Quan F, Zeng J. 2023. Chinese diabetes question classification using large language models and transfer learning. In Health Information Processing. Evaluation Track Papers. CHIP 2023. Springer. https://link.springer.com/chapter/10.1007/978-981-97-1717-0_19 [Google Scholar]
- 121.Ren X, Song Y, Yan C, Xiong Y, Kong F, Fu X. 2023. CMed-Baichuan: task explanation-enhanced prompt method on PromptCBLUE benchmark. In Health Information Processing. Evaluation Track Papers. CHIP 2023. Springer. https://link.springer.com/chapter/10.1007/978-981-97-1717-0_3 [Google Scholar]
- 122.Madani A, Krause B, Greene ER, Subramanian S, Mohr BP, et al. 2023. Large language models generate functional protein sequences across diverse families. Nat. Biotechnol. 41:1099–106 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 123.Dalla-Torre H, Gonzalez L, Mendoza-Revilla J, Carranza NL, Grzywaczewski AH, et al. 2023. The Nucleotide Transformer: building and evaluating robust foundation models for human genomics. Preprint, bioRxiv. https://www.biorxiv.org/content/10.1101/2023.01.11.523679v3 [DOI] [PMC free article] [PubMed]
- 124.Nijkamp E, Ruffolo JA, Weinstein EN, Naik N, Madani A. 2023. Progen2: exploring the boundaries of protein language models. Cell Syst. 14:968–78.e3 [DOI] [PubMed] [Google Scholar]
- 125.Yang G, Liu X, Shi J, Wang Z, Wang G. 2024. TCM-GPT: efficient pre-training of large language models for domain adaptation in Traditional Chinese Medicine. Comput. Methods Programs Biomed. Update 6:100158 [Google Scholar]
- 126.Liu J, Zhang Z, Xiao J, Jin Z, Zhang X, et al. 2023. Large language model locally fine-tuning (LLMLF) on Chinese medical imaging reports. In Proceedings of the 2023 6th International Conference on Big Data Technologies. Association for Computing Machinery [Google Scholar]
- 127.Karn SK, Ghosh R, Farri O. 2023. shs-nlp at RadSum23: domain-adaptive pre-training of instruction-tuned LLMs for radiology report impression generation. Preprint, arXiv:2306.03264v1 [cs.CL] [Google Scholar]
- 128.Meng X, J-m Ji, Yan X, Xu H, gao J, et al. 2024. Real-world performance of large language models in emergency department chest pain triage. Preprint, medRxiv. https://www.medrxiv.org/content/10.1101/2024.04.24.24306264v1
- 129.Singhal K, Tu T, Gottweis J, Sayres R, Wulczyn E, et al. 2023. Towards expert-level medical question answering with large language models. Preprint, arXiv:2305.09617v1 [cs.CL] [DOI] [PMC free article] [PubMed] [Google Scholar]
- 130.Xu H, Usuyama N, Bagga J, Zhang S, Rao R, et al. 2024. A whole-slide foundation model for digital pathology from real-world data. Nature 630:181–88 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 131.Zvyagin M, Brace A, Hippe K, Deng Y, Zhang B, et al. 2023. GenSLMs: genome-scale language models reveal SARS-CoV-2 evolutionary dynamics. Int. J. High Perform. Comput. Appl. 37:683–705 [Google Scholar]
- 132.Nguyen E, Poli M, Durrant MG, Thomas AW, Kang B, et al. 2024. Sequence modeling and design from molecular to genome scale with Evo. Preprint, bioRxiv. https://www.biorxiv.org/content/10.1101/2024.02.27.582234v2 [DOI] [PMC free article] [PubMed]
- 133.Prabhakar V, Liu K. 2023. VLIB: Unveiling insights through visual and linguistic integration of Biorxiv data relevant to cancer via multimodal large language model. Preprint, bioRxiv. https://www.biorxiv.org/content/10.1101/2023.10.31.565037v1
- 134.Ji J, Hou Y, Chen X, Pan Y, Xiang Y. 2024. Vision-language model for generating textual descriptions from clinical images: model development and validation study. JMIR Formative Res. 8:e32690. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 135.Li J, Sun Y, Johnson RJ, Sciaky D, Wei C-H, et al. 2016. BioCreative V CDR task corpus: a resource for chemical disease relation extraction. Database 2016:baw068. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 136.Jin D, Pan E, Oufattole N, Weng W-H, Fang H, Szolovits P. 2021. What disease does this patient have? A large-scale open domain question answering dataset from medical exams. Appl. Sci. 11:6421 [Google Scholar]
- 137.Segura-Bedmar I, Martínez P, Herrero-Zazo M. 2013. SemEval-2013 task 9: extraction of drug-drug interactions from biomedical texts (DDIExtraction 2013). In Second Joint Conference on Lexical and Computational Semantics (*SEM), Volume 2: Proceedings of the Seventh International Workshop on Semantic Evaluation (SemEval 2013). Association for Computational Linguistics [Google Scholar]
- 138.Doğan RI, Leaman R, Lu Z. 2014. NCBI disease corpus: a resource for disease name recognition and concept normalization. J. Biomed. Inform. 47:1–10 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 139.Zhu W, Wang X, Zheng H, Chen M, Tang B. 2023. PromptCBLUE: a Chinese prompt tuning benchmark for the medical domain. Preprint, arXiv:2310.14151v1 [cs.CL] [Google Scholar]