

Abstract
Background
Spikelet number, a core phenotypic parameter for wheat yield composition, requires precise estimation through accurate spike contour extraction and differentiation between grain surfaces and spikelet surfaces. However, technical challenges persist in precise spike segmentation under complex field backgrounds and morphological differentiation between grain/spikelet surfaces.
Method
Building on two-year multi-angle wheat spike imagery, we propose an enhanced YOLOv9-LDS multi-scale object detection framework. The algorithm innovatively constructs a lightweight depthwise separable network (LDSNet) as backbone, balancing computational efficiency and accuracy through channel re-parameterization strategy; incorporates an Efficient Local Attention (ELA) module to build feature enhancement networks, and employs dual-path feature fusion mechanisms to strengthen edge texture responses, significantly improving discrimination of overlapping spikes and complex backgrounds. Further optimizes the loss function system by replacing traditional IoU with Scylla Intersection over Union (SIoU) metric, enhancing bounding box regression through dynamic focus factors, and adding high-resolution small-object detection layers to mitigate dense spikelet feature loss.
Results
Independent test set validation shows the improved model achieves 83.9% contour integrity recognition rate and 92.4% mAP@0.5, exceeding baseline by 3.2 and 5.3% points respectively. Ablation studies confirm LDSNet-ELA integration reduces false positives by 27.6%, while the enhanced loss function system improves small-object recall by 19.4%.
Conclusions
The proposed framework demonstrates superior performance in complex field scenarios with dense targets and dynamic illumination. The multi-scale feature synergy enhancement mechanism overcomes traditional models’ limitations in detecting overlapping spikes. This method not only enables precise spike phenotyping but also provides robust algorithmic support for intelligent field spikelet counting systems, advancing translational applications in crop phenomics.
Keywords: Wheat spikes, Lightweight deep network, LDSNet- ELA, YOLOv9, Contour extraction
Introduction
Wheat is widely cultivated around the world and is one of the three major cereal crops. Wheat is of great significance to worldwide food production, food security, and the transformation of industrial patterns; accurate scientific prediction of wheat yield helps to guarantee national food supply security and maintain social stability [1]. The yield of wheat per unit area is determined by the number of spikes per unit area, the grain number per spike, and the thousand-grain weight of the variety [2]. While algorithms for counting spikes per unit area have become relatively mature and the thousand-grain weight can be obtained by consulting varietal information, the automated counting of grains per spike has emerged as the primary focus in automated yield estimation [3]. Conventional wheat yield assessments are generally carried out post-heading, involving manual counting of wheat grains on spikes; such a human-based survey method is both laborious and prone to inaccuracy [4].
The use of deep learning and computer vision technologies enables fast and precise estimation of wheat yield. Xu et al. [5] introduced a CBAM-HRNet model utilizing a convolutional quick attention mechanism that fuses neural network and image processing technologies to segment and count wheat spikes during the grain filling period, achieving segmentation accuracy above 85%. Geng et al. [6] introduced MATransUNet, a wheat spike grain segmentation model founded on multiple attention mechanisms, that first performs an initial segmentation of wheat spike grains, followed by the incorporation of an adaptive erosion module, SGCountM, thereby integrating image processing with the geometric and texture features of wheat spikes for segmentation and counting.
The spikelet face of the wheat spike protects the florets in a double-row structure, exhibiting a distinct and well-defined phenotypic contour. The spike grain face, corresponding to the ventral surface of the kernel, features a smooth ventral groove and an embryonic protrusion, geometrically exhibiting a tripartite columnar arrangement. Consequently, in terms of visual classification, the spikelet face is characterized by high textural complexity and geometric irregularity, and its non-regular polygonal shape increases localization error. In contrast, the spike grain face presents an elliptical contour with low textural entropy, yet its tripartite structure confers strong occlusion resistance to the ventral groove (as shown in Fig. 1). Therefore, during practical estimation, the distinct spike phenotypes necessitate different counting methodologies. Hence, the key to accurately identifying the number of grains per spike lies in the rapid and precise localization of the complete spike contour coupled with the simultaneous recognition of both the spike grain face and the spikelet face.
Fig. 1.

Example diagram of the spikelet face and the spike grain face
With the continuous development of deep learning algorithms, they have demonstrated significant advantages in the field of wheat spike image segmentation [7]. Sébastien Dandrifosse et al. [8] proposed a wheat spike segmentation and counting model based on unsupervised learning and the DeepMAC segmentation algorithm, using a small amount of annotated RGB images from the heading to the maturity stage, and achieved an 86% segmentation accuracy through active learning. Wang et al. [9] introduced a modified EfficientDet-D0 object detection model for wheat spike identification, specifically targeting occlusion problems in wheat spike segmentation. They simulated occlusions in real wheat images by choosing and erasing rectangles according to the count and size of spikes present, ensuring that the model could capture additional features and boosting the accuracy to 94%. Wang et al. [10] implemented wheat spike segmentation under complex field background conditions based on a multi-stage convolutional neural network, accelerating the segmentation speed by using a new activation function, the Positive Rectified Linear Unit (PrLU). Li et al. [11] proposed a network model based on YOLOv7 that is capable of tracking wheat spike contours across consecutive frames, achieving a detection accuracy of 93.8%.
Despite significant advances in segmentation tasks (as discussed previously), neural networks have also been extensively applied to enhance wheat spike phenotype recognition [12–14], demonstrating their versatility. Liu et al. [15] utilized radar to collect three-dimensional information of wheat spikes and classified spike types by employing a kernel prediction convolutional neural network (KP-CNN) in conjunction with density-based spatial clustering and Laplacian-based region growing techniques. Arpan K. et al. [16] proposed SlypNet, a model integrating Mask R-CNN and U-Net, to extract morphological features from wheat spike images for classification and recognition. Wen et al. [17] developed a method integrating multi-scale features for recognizing different wheat spike varieties, achieving an identification accuracy of 92.62%. Notably, these studies focus on broader phenotype recognition tasks beyond segmentation alone.
However, current research on the extraction and recognition of wheat spike contours faces limitations in terms of application and real-time performance, lacking practical implementation [8, 18–20]. The primary objective of this study is to achieve wheat spike contour extraction and phenotype classification in natural field environments. This study conducted a two-year natural field experiment using three wheat varieties, Xinmai26, Kexing3302, and Zhengmai136, collecting wheat spike images with a mobile terminal, and constructed an improved YOLOv9-LDS model to achieve complete extraction of wheat spike contours and classification of their types. The study modified the basic structure of the backbone network to mitigate the influence of complex backgrounds on the training process, and employed data augmentation to enhance the extraction of wheat spike features; it also embedded an ELA module to strengthen target features at the spike edges, added a local small target detection layer to expand the receptive field and improve the recognition accuracy of overlapping spike contours, and replaced the loss function to achieve more accurate prediction boxes. This approach provides a viable solution for wheat spike contour extraction and serves as a reference for wheat spike phenotype classification in complex farmland scenarios.
Materials and methods
Experimental design
The experimental cultivation site was chosen at the Modern Agricultural Science and Technology Research Experimental Base in Yuanyang, Henan Province, China (35°6′46″N, 113°56′51″E). Varieties Xinmai26, Kexing3302, and Zhengmai136 were chosen for a two-year experiment [21]. Among them, the sowing rate was 187.5 kg/hm² for Xinmai26, 185.5 kg/hm² for Kexing3302, and 187.5 kg/hm² for Zhengmai136; the sowing dates were October 12, 2023, and October 15, 2024, for the respective years. For each variety, four fertilization approaches were employed: Nitrogen Fertilizer 10 (21.74 kg of urea and 8 kg of triple superphosphate per mu), Nitrogen Fertilizer 15 (32.61 kg of urea and 8 kg of triple superphosphate per mu), organic fertilizer (chicken manure), and straw return; with a basal-to-topdressing ratio of 6:4, topdressing was applied at the jointing stage (March of the following year). Other measures were consistent with standard high-yield fields.
Data acquisition
Data was collected from April 2023 to the end of May 2023, and from April 2024 to early June 2024. The collection was conducted under clear, windless conditions, with photography carried out from 9:00 to 16:30. The collection devices included the XiaoMi MAX 2 S smartphone (with a 12-megapixel dual-camera system featuring wide-angle and telephoto lenses) and the RedMi K40 Pro smartphone (equipped with a 64-megapixel main camera, an 8-megapixel ultra-wide lens, and a 5-megapixel tele-macro lens). The raw images were in JPG format, having resolutions of 4032 × 3024 and 9248 × 6944.
In order to ensure the complexity and rigor of the training samples and to eliminate the offsets in prediction box boundaries and positions during background and group recognition, three sampling methods were adopted in the experiment: The first approach involves in-situ field sampling, directly collecting group wheat spikes and ensuring that each image includes three or more plants with distinctly visible contours and clarity adequate for identifying both the spikelet face and the spike grain face phenotypes; the second approach consists of in-field detached sampling, capturing images of isolated single wheat spikes in a natural field setting; the third approach is laboratory-based detached sampling, capturing images of individual isolated wheat spikes under controlled laboratory conditions. As illustrated in Fig. 2.
Fig. 2.

Raw data samples are presented as follows. Left panel: Experimental site layout and cultivation scheme design featuring three varieties, each subjected to four fertilization treatments under orthogonal design. Right panel: Representative data samples collected via three acquisition modalities
In order to reduce errors resulting from the shooting distance, a consistent 10 cm distance was maintained during photography. Additionally, random sampling points were arranged in each experimental area, where 5 to 6 images were taken at each point to ensure a minimum of 42 images per area; in all, this study obtained 3024 original images. Refer to Table 1.
Table 1.
Wheat ear dataset information. Each side of the wheat ears was photographed to expand the dataset
| Wheat varieties | Shoot data | Weather | Growth period | Image size | Shoot device | Number of images |
|---|---|---|---|---|---|---|
| Kexing3302 | 16/04/2023 | Sunny | Stage grouting | 4032*3024 | XiaoMi MAX 2 S | 102 |
| 9248*6944 | RedMi K40 pro | 133 | ||||
| 15/05/2023 | Cloudy | Stage grouting | 4032*3024 | XiaoMi MAX 2 S | 98 | |
| 9248*6944 | RedMi K40 pro | 117 | ||||
| 20/04/2024 | Sunny | Stage grouting | 4032*3024 | XiaoMi MAX 2 S | 119 | |
| 9248*6944 | RedMi K40 pro | 143 | ||||
| 18/05/2024 | Sunny | Stage grouting | 4032*3024 | XiaoMi MAX 2 S | 137 | |
| 9248*6944 | RedMi K40 pro | 159 | ||||
| Xinmai 26 | 16/04/2023 | Sunny | Stage grouting | 4032*3024 | XiaoMi MAX 2 S | 126 |
| 9248*6944 | RedMi K40 pro | 137 | ||||
| 15/05/2023 | Cloudy | Stage grouting | 4032*3024 | XiaoMi MAX 2 S | 115 | |
| 9248*6944 | RedMi K40 pro | 130 | ||||
| 20/04/2024 | Sunny | Stage grouting | 4032*3024 | XiaoMi MAX 2 S | 126 | |
| 9248*6944 | RedMi K40 pro | 129 | ||||
| 18/05/2024 | Sunny | Stage grouting | 4032*3024 | XiaoMi MAX 2 S | 100 | |
| 9248*6944 | RedMi K40 pro | 145 | ||||
| Zhengmai136 | 16/04/2023 | Sunny | Stage grouting | 4032*3024 | XiaoMi MAX 2 S | 116 |
| 9248*6944 | RedMi K40 pro | 124 | ||||
| 15/05/2023 | Cloudy | Stage grouting | 4032*3024 | XiaoMi MAX 2 S | 145 | |
| 9248*6944 | RedMi K40 pro | 114 | ||||
| 20/04/2024 | Sunny | Stage grouting | 4032*3024 | XiaoMi MAX 2 S | 126 | |
| 9248*6944 | RedMi K40 pro | 136 | ||||
| 18/05/2024 | Sunny | Stage grouting | 4032*3024 | XiaoMi MAX 2 S | 120 | |
| 9248*6944 | RedMi K40 pro | 127 |
Data processing
Data normalization
Variations in image resolution lead to increased GPU memory consumption and longer computation times during model training, thereby imposing higher demands on hardware [22]. To avoid resource wastage stemming from this issue, normalization of the raw image data is required. To achieve this, we employed an online image processing tool to perform linear normalization on all original image files. This operation strictly preserves the linear characteristics of the original images and can also enhance image quality to some extent. Ultimately, ensuring the clarity of critical visual features, the resolution of all images was standardized to 640*640.
Data enhancement
During the data acquisition phase, to ensure the diversity and complexity of the dataset, a horizontal random cropping strategy was employed for images obtained from in-field sampling: images were segmented along the X-axis at random positions, thereby creating 3–5 sub-images from a single original image.
The quantity and complexity of image samples directly impact the model’s learning capability [23]. Data augmentation techniques address the issues of insufficient sample size and lack of diversity by processing and expanding the original images. Specifically, we first applied an Instance-level Copy-Paste augmentation technique based on Poisson blending to the base images [24]. Building upon this, we further integrated geometric transformation methods—including random rotation (± 90°), multi-scale transformation (scaling factors 0.5–1.5), and random cropping (removing 10–20% of the area)—to form a comprehensive global data augmentation pipeline. Concurrently, to mitigate the potential interference of lighting variations on model training, contrast adjustment was also performed on a subset of the images.
Dataset construction
This study primarily employed the LabelImg annotation tool, utilizing rectangular bounding boxes to annotate target samples within the images. Two distinct types were annotated: the spike grain face and the spikelet face. Given the highly overlapping and cluttered nature of field wheat spike images, only spike grain faces and spikelet faces exceeding 80% integrity and possessing clearly discernible contour features were selected as target samples during annotation. Since rectangular bounding boxes, rather than polygonal ones, were used for annotation, overlapping regions between bounding boxes are inevitable. Although this overlap may somewhat reduce the efficiency of subsequent recognition tasks, it provides rich and effective feature information during contour boundary feature extraction, thereby ensuring the accuracy of extracting complete wheat spike contours.
Ultimately, the original dataset comprised 3,024 images. These were partitioned into a validation set (605 images) and a test set (610 images) based on a 6:2:2 ratio. The remaining 1,809 original images subsequently underwent data augmentation, yielding 5,650 augmented images. During dataset construction, adhering to the research objective of clear spike structure detection, we excluded images with indistinct target features (wheat spikes) or poor overall image quality. Following image screening and annotation, a base training set consisting of 5,357 images was formed. The complete final dataset totals 6,572 images (base training set: 5,357 + validation set: 605 + test set: 610), containing a total of 26,597 annotated instances of the spike grain face and the spikelet face.
Model construction
In complex backgrounds, wheat spike images face problems of highly similar edge features and pronounced adhesion. Moreover, factors such as spike overlap, leaf occlusion, and interference from awns result in redundant computations and the omission of small edge target features in the extraction network. Thus, the model is required to have enhanced abilities for global information awareness and edge feature differentiation.
Being one of the excellent single-stage object detection algorithms at present, YOLOv9 has shown remarkable potential for fast detection of wheat spike phenotypes [25]. In order to ensure a balance between contour extraction and recognition accuracy, the YOLOv9-C variant—with a moderate model size and superior detection speed—was chosen for deep learning training [25].
To prevent parameter and data redundancy in the backbone model, this study optimized the backbone network based on the MobileNetV4 architecture [26], aiming to enhance feature extraction and expand the model’s receptive field. To address the challenge of extracting target features in complex backgrounds, the ELA module [27] was introduced, effectively enhancing the model’s ability to recognize edge features and improving the integrity of contour extraction. Considering that occlusion between leaves and wheat spikes can affect bounding box regression performance, the SIoU loss function [28] was used to replace the original function, enhancing the sensitivity of bounding boxes to spatial positions and accelerating model convergence. Additionally, a dedicated small-target detection layer was added to the neck network to address the loss of small target features in edge and overlapping regions, significantly enhancing detection accuracy. The specific network architecture is shown in Fig. 3.
Fig. 3.

YOLOv9-LDS Network Architecture Diagram, as well as some core module neural network architectures, such as RepNCSP, RepConvN, SPPELAN, RepNBottleneck, and RepNCSPELAN4
Lightweight network architecture
To ensure real-time performance and accuracy in automated yield estimation, this study proposed a LDSNet based on MobileNetV4 to replace the backbone network in YOLOv9. As shown in Fig. 4.
Fig. 4.

LDSNet Network Architecture Diagram. The LDSNet architecture diagram features the DEWConv module implementing the UIB framework. Core innovation: Replaces original convolutional layers (2–7) with UIB structures
MobileNetV4 creatively proposed the Universal Inverted Bottleneck (UIB) block. The UIB block serves as a configurable component for efficient network design, improving network performance while maintaining the same learning complexity [26].
Throughout the neural network training process in this study, the image data produced substantial redundant feature map data. These data are essentially extracted from individual or groups of images, with their feature points exhibiting high similarity. Handling redundant data not only consumes significant computational resources but also reduces the efficiency of feature learning. Since the similarity between the spike contour area and the background is high, the learning of edge features and central axis features is especially crucial for classifying wheat spike types. Consequently, the network architecture was designed as follows: First, a standard 3 × 3 convolution layer was used at the input to ensure.
effective extraction of low-level features from the input images; next, Extra Depthwise Separable Convolution (EDWConv) was employed from the second to the ninth layer. To improve data transfer efficiency, a Squeeze-and-Excitation (SE) module [29] was incorporated between the Extra Depthwise Convolution (Extra DW) and the Pointwise Convolution (PW) across all EDWConv layers. The module is capable of compressing upper-layer information to normalize the convolutional data, thus strengthening the response of the information channels. Specifically, the second to seventh layers use 3 × 3 convolution kernels, while the eighth and ninth layers employ 5 × 5 kernels. To further enhance computational efficiency, the Sigmoid function in the SE module was replaced with the less computationally intensive Hard-Sigmoid function [30] to accelerate regression computations. Moreover, the Spatial Pyramid Pooling Fast (SPPF) module within the backbone network was preserved; it pools feature maps of different sizes, ensuring effective connectivity and facilitating the detection of multi-scale targets.
Efficient local attention mechanism
The ELA module is a lightweight and efficient local attention mechanism designed to enhance the localization capability of deep convolutional neural networks (CNNs) for target regions. By introducing minimal additional parameters into the network, it significantly improves the model’s overall performance [27]. Compared with the commonly used Coordinate Attention (CA) mechanism, ELA overcomes CA’s limitations in generalization capability and channel dimensionality reduction, enabling precise positional prediction in spatial dimensions.
Wheat spikes exhibit random horizontal arrangements and vertical height imbalance in imaging. This leads to unstable results during complete contour extraction due to subtle coordinate variations among wheat spikes. ELA employs a strip pooling strategy in spatial dimensions to separately extract horizontal and vertical feature vectors. This design not only captures long-range or offset dependencies among wheat spike samples, but also effectively avoids interference from non-target regions (background) on label prediction (as shown in Fig. 5). Through this approach, ELA generates information-rich positional feature vectors in each direction, providing high-quality feature representations for subsequent attention prediction.
Fig. 5.

Efficient Local Attention
During feature processing, ELA independently processes horizontal and vertical feature vectors, integrates their information through multiplicative operations, and combines spatially deviated wheat spike features in vertical planes, achieving precise localization of target regions of interest. Moreover, considering that overlapping wheat spikes typically manifest as continuous feature vectors in planes, ELA can process these sequential signals using 1D convolution.
Compared with 2D convolution, 1D convolution demonstrates higher computational efficiency and better suitability for processing sequential feature information. Unlike CA’s 1 × 1 convolutional kernels, ELA employs 1D convolutions with kernel sizes of 5 or 7, significantly enhancing feature vector interactions for precise positional embedding, effective edge feature extraction in overlapping regions, and reduced information attenuation.
SIoU loss function
The YOLOv9 algorithm employs a composite loss function, combining Distributional Focal Loss (DFL) and Complete Intersection over Union (CIoU) loss. Specifically, DFL operates by predicting a probability distribution over bounding box locations instead of directly regressing the coordinates. This approach effectively mitigates challenges arising from ambiguous object boundaries or partial occlusion, thereby enhancing the model’s capability to handle such objects. This probabilistic formulation enables the model to better distinguish between the feature similarities and differences among overlapping wheat spike targets, consequently reducing issues like oversized predicted bounding boxes or positional offsets.
In contrast, the CIoU loss function places greater emphasis on the shape information of the target bounding boxes. By incorporating a penalty term, it improves robustness to bounding boxes of varying sizes and aspect ratios, facilitating more accurate shape capture [31]. Nevertheless, CIoU still exhibits limitations in dense occlusion scenarios (e.g., overlapping wheat spikes and leaves). Its fundamental shortcoming lies in neglecting the orientation deviation between the predicted and ground-truth boxes. This omission can lead to directional drift of the predicted boxes during model optimization, consequently diminishing the efficiency of the bounding box regression process.
To address the aforementioned challenges (namely, the directional drift of CIoU in dense occlusion scenarios and its detrimental impact on regression efficiency) and to enhance both the computational efficiency of the loss function and the precision of spike contour extraction in complex farmland environments, this study replaces CIoU with the SIoU loss, while retaining the inherent advantages of the DFL. The key innovation of SIoU lies in its incorporation of a direction-aware penalty term. Building upon the standard IoU computation, this loss function integrates additional metrics for bounding box scale variance and angle deviation, thereby significantly improving target localization accuracy and model robustness.
The SIoU loss function comprises four core components: angle cost ( ), distance cost (
), distance cost ( ), shape cost (
), shape cost ( ), and IoU cost. The calculation principle is illustrated in Fig. 6. The angle cost, which penalizes the orientation deviation between the predicted and ground-truth bounding boxes, plays a pivotal role in the loss computation. The angle cost is formally defined as follows (Eq. (1)):
), and IoU cost. The calculation principle is illustrated in Fig. 6. The angle cost, which penalizes the orientation deviation between the predicted and ground-truth bounding boxes, plays a pivotal role in the loss computation. The angle cost is formally defined as follows (Eq. (1)):
Fig. 6.

The scheme for calculation (Including centers B (predicted) and  (ground-truth), planar distances H and W, angles α and β, center distance σ, and edge distances
(ground-truth), planar distances H and W, angles α and β, center distance σ, and edge distances  and
and  )
)
 |
1 |
Building upon the defined angle cost, the distance cost is defined as Eq. (2):
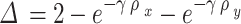 |
2 |
where
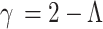 |
3 |
In these equations,  represents temporal distance,
represents temporal distance,  and
and 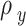 are squared ratios of width/height between ground-truth and predicted boxes.
are squared ratios of width/height between ground-truth and predicted boxes.
The shape cost is defined as Eq. (4):
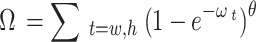 |
4 |
where
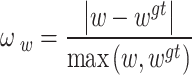 |
5 |
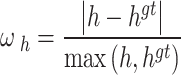 |
6 |
In these equations, 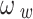 is defined as the absolute difference in width between the predicted box and the ground-truth box, divided by the maximum width of the two boxes. Similarly,
is defined as the absolute difference in width between the predicted box and the ground-truth box, divided by the maximum width of the two boxes. Similarly,  is defined as the absolute difference in height between the predicted box and the ground-truth box, divided by the maximum height of the two boxes. The parameter
is defined as the absolute difference in height between the predicted box and the ground-truth box, divided by the maximum height of the two boxes. The parameter  controls the computation of the shape cost, primarily modulating the strength of the shape penalty. The value of
controls the computation of the shape cost, primarily modulating the strength of the shape penalty. The value of 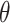 is typically set within the range [2, 6].
is typically set within the range [2, 6].
Finally, the mathematical formulation of the SIoU loss function is presented below (Eq. (7)):
 |
7 |
where
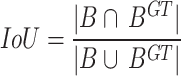 |
8 |
By comprehensively considering angular, distance, and shape costs, SIoU optimizes model convergence speed and prediction accuracy while avoiding computational overhead, achieving lightweight wheat spike contour extraction.
Small target feature detection layer
In agricultural vision detection scenarios, spatial overlap between wheat spikes and the background or other plants significantly diminishes the discriminative power of effective feature information (particularly distinctive features) in the target boundary regions. To address this challenge, a critical strategy involves implementing data augmentation during the dataset construction phase. Data augmentation by performing data augmentation operations on data collections, the model can learn more effectively robust feature representations of targets under occlusion conditions during training.
Additionally, we augment the original YOLOv9 feature pyramid by adding a small-object detection head at the Backbone’s C2 stage (medium-level features: 320 × 320 input → 160 × 160 output). This layer provides 4×/16×/64× higher spatial resolution than original detection heads (80 × 80, 40 × 40, 20 × 20 outputs). As calculated by Eq. (9), its 3 × 3 convolutional kernels achieve 17 × 17 pixel effective receptive fields, better matching wheat spikes’ average 15 × 15 pixel scale:
 |
9 |
where:  denotes the effective receptive field size at the current layer;
denotes the effective receptive field size at the current layer;  denotes the number of convolutional layers along the input path preceding the current layer;
denotes the number of convolutional layers along the input path preceding the current layer;  denotes the convolution kernel size at the current layer. The “+1” term appended to the formula is a crucial design element. It ensures that when s = 0 (indicating no preceding convolutional layers), R = 1, corresponding to the receptive field of a single pixel.
denotes the convolution kernel size at the current layer. The “+1” term appended to the formula is a crucial design element. It ensures that when s = 0 (indicating no preceding convolutional layers), R = 1, corresponding to the receptive field of a single pixel.
Multi-layer feature extraction enables shallow high-resolution features (160 × 160) to capture fine edge textures (avg. 15 × 15px), while deep features provide categorical semantics. Feature fusion combines shallow local details (e.g., residual edges of partially occluded spikes) with deep global context. This establishes a complete detection framework covering target scales from 5 to 150 pixels.
Evaluation indicators
This study employs a comprehensive model evaluation framework covering two dimensions: detection accuracy and computational efficiency. Detection accuracy is measured by Precision (P), Recall (R), and Average Precision (AP). The relevant formulas are:
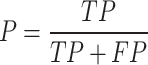 |
10 |
 |
11 |
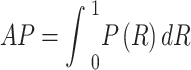 |
12 |
Here, 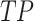 (True Positive) counts correctly predicted positives,
(True Positive) counts correctly predicted positives,  (False Positive) counts incorrectly predicted positives, and
(False Positive) counts incorrectly predicted positives, and 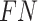 (False Negative) counts positives incorrectly predicted as negatives. From this it follows that
(False Negative) counts positives incorrectly predicted as negatives. From this it follows that 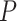 represents the proportion of true positive samples among all predicted positive samples, reflecting detection reliability;
represents the proportion of true positive samples among all predicted positive samples, reflecting detection reliability;  indicates the proportion of correctly predicted positive samples among all actual positives, demonstrating model coverage capability; AP (Average Precision) is defined as the area under the precision-recall curve (P-R curve) for a single category. However, AP only reflects the average precision for a single category and cannot comprehensively evaluate the overall performance of the model. Therefore, mAP (mean Average Precision) is commonly used as the metric to assess overall accuracy, where mAP is the arithmetic mean of AP values across all categories. AP is defined in Eq. (13):
indicates the proportion of correctly predicted positive samples among all actual positives, demonstrating model coverage capability; AP (Average Precision) is defined as the area under the precision-recall curve (P-R curve) for a single category. However, AP only reflects the average precision for a single category and cannot comprehensively evaluate the overall performance of the model. Therefore, mAP (mean Average Precision) is commonly used as the metric to assess overall accuracy, where mAP is the arithmetic mean of AP values across all categories. AP is defined in Eq. (13):
 |
13 |
where, denotes the target category set,
denotes the target category set, 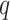 represents a detection category, and
represents a detection category, and  is the average precision for category
is the average precision for category  .
.
To enable a more intuitive assessment of the model’s predictive performance, we introduce the Coefficient of Determination (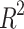 ) into the evaluation framework.
) into the evaluation framework.  quantifies the proportion of data variability explained by the model, which is essentially the ratio of the explained variance to the total variance. Consequently,
quantifies the proportion of data variability explained by the model, which is essentially the ratio of the explained variance to the total variance. Consequently,  serves as a direct measure of the model’s ability to explain the variability within the dataset. Its mathematical definition is given by Eq. (14):
serves as a direct measure of the model’s ability to explain the variability within the dataset. Its mathematical definition is given by Eq. (14):
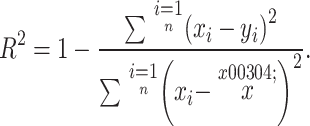 |
14 |
where xi is the true number of the spike; yi is the predicted number of the spike;  is the average of the true values of the number of the spike; n is the number of samples per variety.
is the average of the true values of the number of the spike; n is the number of samples per variety.
Additionally, we introduce the Mean Squared Error (MSE) and the Root Mean Squared Error (RMSE). Both metrics serve to quantify the discrepancy between predicted values and ground-truth values. However, as defined mathematically (Eqs. (15) and (16)), MSE carries units that are the square of the original data units, whereas RMSE shares the same units as the original data. Consequently, RMSE provides a more intuitive and interpretable measure of the actual magnitude of the errors.
 |
15 |
 |
16 |
Computational efficiency is evaluated using Floating-point Operations (FLOPs), parameter count (Params), and Frames Per Second (FPS) as primary metrics. FLOPs and Params assess model lightweighting from computational resource perspectives, while FPS directly reflects real-time performance in practical deployment.
Results and analysis
Experimental setup
All experiments in this study were conducted under a unified hardware and software environment configured as follows: Intel® Xeon(R) Silver4114 CPU @2.20 GHz, NVIDIA Quadro T400 GPU (16GB VRAM), 64GB RAM; with software environment built on Ubuntu 20.04 LTS OS, Python 3.11, and PyTorch 2.0.0 deep learning framework.
During the initial training phase, random initialization of network weights results in weak feature extraction capability, leading to significant performance degradation [32]. To address this issue, we employ a progressive training strategy with dynamic hyperparameter adjustment to optimize the training process, ensuring effective loss function convergence while preventing overfitting. Specific parameter settings include: Cosine annealing learning rate scheduler [33] with initial learning rate ( ) = 0.01, final learning rate (
) = 0.01, final learning rate ( ) = 0.05, following Eq. (17):
) = 0.05, following Eq. (17):
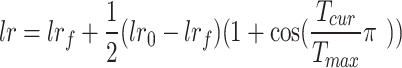 |
17 |
where 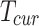 denotes current training epoch and
denotes current training epoch and  represents total epochs.
represents total epochs.
Confidence threshold (conf_threshold) = 0.5 for filtering low-confidence predictions; IoU threshold = 0.45 for Non-Maximum Suppression (NMS); Stochastic Gradient Descent (SGD) optimizer with momentum = 0.937 and weight decay = 0.0005.
Ablation study
To validate the effectiveness of the YOLOv9-LDS algorithm, we conducted systematic ablation experiments under identical hardware, software environments, and datasets. All comparative models used identical training parameters throughout the experiments to ensure fairness. To mitigate randomness effects, each model configuration underwent 10 independent trials with arithmetic mean as final result (see Table 2).
Table 2.
Results of ablation experiment
| Serial Number | LDSNet | ELA | SIoU | Feature Detection Layer | P/% | R/% | mAP/% | GFLOPs/G | Params/M | FPS |
|---|---|---|---|---|---|---|---|---|---|---|
| 1 | × | × | × | × | 80.7 | 79.3 | 87.1 | 102.1 | 3.56 | 101 |
| 2 | ✓ | × | × | × | 81.1 | 82.1 | 85.1 | 55.8 | 1.85 | 175 |
| 3 | ✓ | ✓ | × | × | 80.9 | 79.9 | 86.9 | 68.9 | 1.91 | 121 |
| 4 | ✓ | × | ✓ | × | 79.9 | 80.2 | 85.9 | 65.7 | 1.99 | 115 |
| 5 | ✓ | × | × | ✓ | 82.2 | 81.1 | 87.3 | 72.6 | 1.80 | 117 |
| 6 | ✓ | ✓ | ✓ | × | 83.4 | 80.7 | 89.5 | 64.3 | 2.24 | 114 |
| 7 | ✓ | ✓ | × | ✓ | 83.1 | 82.1 | 88.4 | 68.9 | 2.13 | 124 |
| 8 | ✓ | × | ✓ | ✓ | 82.4 | 81.3 | 90.1 | 70.1 | 2.36 | 120 |
| 9 | ✓ | ✓ | ✓ | ✓ | 83.9 | 84.1 | 92.4 | 78.9 | 2.38 | 133 |
Compared to the baseline model (No.1), the LDSNet backbone achieved significant computational and parametric efficiency, albeit with a partial sacrifice in feature extraction capability: mAP decreased by 2.0%, while computational cost (GFLOPs) was reduced by 45.3%, parameter count (Params) was decreased by 48.0%, and FPS was increased by 73.3%. Adding the ELA module to LDSNet improved mAP by 1.8%, with a computational cost increase of 23.5% and an FPS reduction of 30.9%, demonstrating that ELA enhances feature representation at the expense of computational overhead. Adopting the SIoU loss improved mAP by 0.8% and reduced parameters by 9.6%, indicating its effectiveness in optimizing bounding box regression and accelerating convergence. Incorporating small-target feature layers boosted mAP by 2.2% and decreased parameters by 2.7%, demonstrating enhanced small-object detection capability.
Notably, pairwise combinations of modules (No.6–8) achieved significant mAP improvements (ranging from 88.4 to 90.1%) with computational cost increases between 15.2% and 25.6%, while maintaining high inference speeds (114–124 FPS). Furthermore, multi-module combinations further enhanced detection accuracy, albeit with increased computational complexity. Critically, the full-module configuration achieved optimal performance, improving mAP by 5.3% while simultaneously reducing computational cost (GFLOPs) by 22.7%, decreasing parameters by 33.1%, and increasing FPS by 31.7%. This result demonstrates that the full-module design optimally balances accuracy and efficiency, validating the overall effectiveness of the proposed algorithm. Finally, the enhanced model demonstrated superior performance in complex farmland scenarios, effectively extracting wheat spike contours and performing phenotyping classification.
Comparative experiment on segmentation accuracy across models
To validate the effectiveness of the proposed YOLOv9-LDS algorithm on wheat spike phenotyping datasets in complex farmland scenarios, we conducted comparative experiments with mainstream single-stage and two-stage object detection models. The selected models include single-stage detectors (YOLOv8, YOLOv9, YOLOv10, Edge-YOLO, Gold-YOLO) and the two-stage model Faster R-CNN. All experiments were conducted under identical hardware/software configurations with consistent training parameters. To mitigate randomness, each model underwent 10 independent trials with arithmetic mean as final result (Table 3).
Table 3.
Results of comparative experimental
| Models | P/% | R/% | mAP/% | GFLOPs/G | Params/M | FPS |
|---|---|---|---|---|---|---|
| Faster R-CNN | 70.1 | 78.3 | 74.1 | 121.4 | 2.58 | 150 |
| YOLOv8 | 80.5 | 82.6 | 88.3 | 67.4 | 3.18 | 110 |
| YOLOv9 | 80.7 | 79.3 | 87.1 | 102.1 | 3.56 | 101 |
| YOLOv10 | 79.5 | 80.2 | 87.4 | 70.4 | 3.37 | 97 |
| Edge-YOLO | 75.6 | 81.4 | 85.6 | 75.1 | 3.01 | 107 |
| Gold-YOLO | 81.4 | 78.6 | 82.4 | 69.7 | 2.99 | 121 |
| OUR | 83.9 | 84.1 | 92.4 | 78.9 | 2.38 | 133 |
The experimental results indicate that Faster R-CNN achieved a mean Average Precision (mAP) of 74.1%, significantly lower than other single-stage detection models, highlighting its limitations in small target detection within complex farmland scenarios. The primary cause lies in significant interference from complex backgrounds affecting the feature extraction and region proposal mechanisms of two-stage models, leading to degraded small target detection performance. Notably, despite high inference speed (150 FPS), its substantial computational cost (121.4 GFLOPS) and relatively high parameter count (2.58 M) constrain its applicability in resource-constrained environments.
In stark contrast, the YOLO series models—including YOLOv8, YOLOv9, and YOLOv10—demonstrated superior performance with mAP values of 88.3%, 87.1%, and 87.4% respectively, significantly outperforming Faster R-CNN and exhibiting comparable performance among themselves. Regarding computational efficiency: YOLOv8 (67.4 GFLOPS, 3.18 M Params, 110 FPS) and YOLOv10 (70.4 GFLOPS, 3.37 M Params, 97 FPS) showed a balanced trade-off between computational load and speed; YOLOv9 (102.1 GFLOPS, 3.56 M Params, 101 FPS), due to higher complexity, emerged as the most computationally expensive and slowest model in the series. Meanwhile, lightweight models such as Edge-YOLO (75.1 GFLOPS, 3.01 M Params, 107 FPS) and Gold-YOLO (69.7 GFLOPS, 2.99 M Params, 121 FPS) achieved slightly lower mAP values (85.6% and 82.4%) compared to mainstream YOLO models. The YOLO series’ excellence stems from enhancement strategies like multi-scale feature fusion and loss function optimization, which effectively improve detection capabilities in complex scenes. Conversely, Edge-YOLO and Gold-YOLO prioritize lightweight design and inference efficiency (particularly Gold-YOLO’s 121 FPS), often at the cost of reduced accuracy.
Notably, our proposed model (OUR: 78.9 GFLOPS, 2.38 M Params, 133 FPS) exhibits outstanding comprehensive performance across all baseline models: precision (P) reaches 83.9% and recall (R) 84.1%, significantly surpassing others and indicating advantages in reducing false positives and false negatives; mAP achieves 92.4%, exceeding the best baseline model YOLOv9 (mAP 87.1%) by 3.8% points. Particularly impressive is that while attaining the highest accuracy, the model also demonstrates excellent computational efficiency: the lowest parameter count (2.38 M), significantly below the YOLO series (3.18 M–3.56 M) and lightweight models (2.99 M–3.01 M); lower computational load (78.9 GFLOPS), only slightly higher than YOLOv8, YOLOv10, and Gold-YOLO; and fast inference speed (133 FPS), second only to Gold-YOLO (121 FPS). This remarkable accuracy-efficiency balance robustly confirms the model’s superiority and practicality in complex farmland scenarios, with performance deriving from effective suppression of background interference and precise extraction of wheat spike contour features, enabling superior phenotypic classification accuracy while maintaining lightweight efficiency.
Contour extraction performance across growth stages
Morphological and physiological changes during wheat growth stages significantly impact model performance. Neural networks require adjustments based on growth stage characteristics to enhance model robustness.
To evaluate the influence of growth-stage traits on wheat spike contour extraction, 150 field images from complex agricultural scenarios over a two-year period were selected for testing. Detailed extraction results are presented in Fig. 7.
Fig. 7.

Comparison of Contour Extraction Effects at Different Periods. b, c, d, and e are heat maps comparing different models at different periods of the wheat ear. Among them, e is the model constructed in this study, and f is the prediction result of the model constructed in this study
Figure 7 compares the contour extraction performance of different models across growth stages. All models successfully extracted primary wheat spike contours with acceptable coefficient of variation. The improved model demonstrated superior performance: significantly enhanced sensitivity to edge tonal variations and stronger resistance to feature drift. According to experimental requirements, the model prioritizes complete spike contours while excluding occluded or incomplete samples. As shown in control groups (Figs. 7b-e), the improved model actively discards specific anomalous samples. The experimental results show that, compared with the baseline model, the accuracy of overlapping region prediction is improved, while incomplete peak contours are effectively filtered out. This algorithm fulfills practical requirements for detecting the face and extracting contours in complex field environments.
Recognition performance of wheat spikes across growth stages and varieties
To ensure simultaneous spike contour extraction and phenotyping capabilities, the enhanced model was evaluated for spike detection performance across growth stages. 150 field images (50 per early/mid/late grain filling stages) from two-year complex agricultural scenarios were selected. Detection target statistics and results are shown in Fig. 8, with visual demonstrations in Fig. 9.
Fig. 8.

Scatter plots comparing true and predicted wheat spike counts at different grain-filling stages: (a) early, (b) mid, (c) late, and (d) all stages combined. In each subplot, data points (one per sample) are shown for two input data types (SpikeGrainSurface, SpikeletSurface). The dashed red 1:1 line indicates perfect agreement between predicted and true values. The legend in each panel reports the coefficient of determination (R²) and root mean square error (RMSE) for each input type
Fig. 9.

Effect diagrams of detection at different periods. The detection performance across three critical growth stages (tillering/heading/filling) is presented through three components: original images, detection heatmaps, and visual detection results
Figure 8 reveals relatively dispersed predictions in early grain filling stage, primarily due to incomplete spike contours, though basic phenotyping features suffice for majority detections. Mid/late stages exhibit well-defined contours with stable spike-background contrast, distinct edge differentiation, and near-perfect alignment with ground truth due to enhanced feature discriminability. Furthermore, during the data annotation phase, to ensure effective model training and the accurate extraction of complete wheat spike contours, we only annotated samples of clearly visible spike grain faces and spikelet faces with integrity exceeding 80%. Concurrently, during model training, we configured the loss function and confidence thresholds to prioritize the identification and contour extraction of complete wheat spikes. Consequently, even some clearly imaged spikes were excluded from the final recognition results if their integrity was insufficient.
To evaluate the impact of wheat varieties on model performance, statistical analysis was conducted on detection results from 150 sample images (Table 4).
Table 4.
Number of image detection samples for different varieties
| Variety | Images | Spike Grain Face Samples | Spikelet Face Samples | Detected Spike Grain Faces | Detected Spikelet Faces | Missed Instances |
|---|---|---|---|---|---|---|
| Xinmai26 | 47 | 174 | 152 | 172 | 150 | 4 |
| Kexing3302 | 55 | 184 | 191 | 181 | 187 | 7 |
| Zhengmai136 | 48 | 167 | 174 | 165 | 170 | 6 |
The data reveal that the overall miss rate for all varieties remained below 2.5% (Xinmai26 achieved the lowest rate at 1.23%), with an inter-variety range of only 0.53% points. This indicates strong robustness in detection capability across varieties. The absence of significant performance differences demonstrates cross-varietal generalization capability, enabling adaptation to multi-variety wheat spike analysis requirements.
The model demonstrates robust spike extraction and classification in complex environments, providing reliable scientific data for wheat yield estimation. This establishes critical prerequisites for automated yield measurement systems.
Discussion
The proposed YOLOv9-LDS algorithm incorporates three core innovations: A lightweight LDSNet backbone with channel reparameterization technology reduces computational cost by 45.3% (GFLOPs = 55.8) while preserving feature richness; An ELA module enhancing occluded spike edge feature representation achieves 92.4% mAP@0.5 (5.3% higher than YOLOv9-C); A dynamic SIoU loss function with focusing factors combined with a small-object detection layer mitigates feature loss in dense the spikelet face regions, significantly improving small-target recall by 19.4%.Furthermore, Poisson blending and random cropping augmentation strategies enhance robustness in complex backgrounds (e.g., spike-leaf overlap regions), reducing false detection rates by 27.6% and demonstrating superior field adaptability.
Although the model performs well on wheat spikes across varieties and growth environments, its generalization capability degrades under rainy, foggy, or strong illumination conditions (10% increased error rate) due to training data primarily collected in sunny/cloudy environments in Henan Province. To address this limitation, the LiDAR-integrated Kernel Prediction Convolutional Network (KP-CNN) proposed by Liu et al. [15] achieves 84.62% recognition accuracy under adverse weather but relies heavily on specialized hardware and manual annotation, hindering large-scale field deployment.
Future research should focus on:
Extending cross-climate datasets with multispectral fusion (NIR/thermal imaging) to enhance feature representation in harsh weather;
Implementing TensorRT quantization and adaptive confidence strategies (e.g., dynamic threshold adjustment from 0.4 to 0.6 during grain filling stage) for embedded deployment targeting < 50ms latency to meet robotic arm integration requirements;
Developing spatiotemporal modeling of Spike Morphological Development Index (SMDI) for growth-stage-aware phenotyping prediction, supporting precision agricultural decisions such as irrigation scheduling and nutrient management.
Through algorithmic innovation and systematic engineering design, this study provides an efficient solution for spike grain face phenotyping detection in complex field environments, establishing a scalable paradigm bridging laboratory crop phenomics research to field applications. Future explorations in multimodal data fusion and edge computing optimization are expected to drive transformative advances in intelligent wheat breeding and autonomous precision agriculture systems.
Conclusion
This study proposes an enhanced YOLOv9-LDS algorithm to address the challenges of wheat spike contour extraction and phenotyping classification in complex farmland scenarios. A two-year field experiment covering three wheat varieties (Xinmai 26, Kexing 3302, Zhengmai 136) collected a dataset of 6,572 images. Data diversity was enhanced through augmentation strategies including Poisson blending, random cropping, and multi-scale transformation. Significant computational efficiency gains were achieved by replacing the original YOLOv9-C backbone with a lightweight depthwise separable network (LDSNet) based on MobileNetV4 architecture. This modification reduced GFLOPs by 45.3% (to 55.8G) and increased FPS by 73.3% (to 175 FPS). Meanwhile, the ELA module enhanced edge feature perception, and the SIoU loss function improved spatial localization accuracy, resulting in an 18.6% reduction in bounding box regression error. Ablation studies demonstrated that the full-module configuration achieved 83.9% precision, 84.1% recall, and 92.4% mAP@0.5 on test sets. These represent improvements of 3.2%, 4.8%, and 5.3% over the baseline (YOLOv9-C), respectively, alongside a parameter reduction of 33.1% (to 2.38 M), collectively confirming the algorithm’s robustness in complex backgrounds.
This study provides a high-precision, lightweight technical solution for automated wheat yield estimation, with its modular improvement framework being extensible to other crop phenotyping analyses.
Acknowledgements
The authors thank the graduate students at the College of Information and Management Science and the Ministry of Agriculture at Henan Agricultural University for their continued support of our research.
Author contributions
Xin Xu and Haiyang Zhang wrote the manuscript. Haiyang Zhang and Jiangchuan Lu performed the in-field imaging. Juanjuan Zhang, Jibo Yue, Hongbo Qiao, and Xinming Ma supervised wheat field experiments and provided biological expertise. Xin Xu, Haiyang Zhang, and Ziyi Guo designed the research. Haiyang Zhang built and tested the deep learning models. All authors read and approved the final manuscript.
Funding
1. Key R&D Special Project of Henan Province, China. (241111110800). 2. Major Science and Technology Project of Henan Province, China. (241100110300).
Data availability
No datasets were generated or analysed during the current study.
Declarations
Ethics approval and consent to participate
Not applicable.
Consent for publication
Not applicable.
Competing interests
The authors declare no competing interests.
Footnotes
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
References
- 1.Guarin JR, Martre P, Ewert F, Webber H, Dueri S, Calderini D, et al. Evidence for increasing global wheat yield potential. Environ Res Lett. 2022;17:124045. [Google Scholar]
- 2.Hu W-J, Fan J, Du Y-X, Li B-S, Xiong N, Bekkering E. MDFC–ResNet: an agricultural IoT system to accurately recognize crop diseases. IEEE Access. 2020;8:115287–98. [Google Scholar]
- 3.Tanabe R, Matsui T, Tanaka TST. Winter wheat yield prediction using convolutional neural networks and UAV-based multispectral imagery. Field Crops Res. 2023;291:108786. [Google Scholar]
- 4.Carlier A, Dandrifosse S, Dumont B, Mercatoris B. Wheat ear segmentation based on a multisensor system and superpixel classification. Plant Phenomics. 2022 . [DOI] [PMC free article] [PubMed]
- 5.Xu X, Geng Q, Gao F, Xiong D, Qiao H, Ma X. Segmentation and counting of wheat Spike grains based on deep learning and textural feature. Plant Methods. 2023;19:77. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 6.Geng Q, Zhang H, Gao M, Qiao H, Xu X, Ma X. A rapid, low-cost wheat Spike grain segmentation and counting system based on deep learning and image processing. Eur J Agron. 2024;156:127158. [Google Scholar]
- 7.Zou Z, Chen K, Shi Z, Guo Y, Ye J. Object detection in 20 years: A survey. Proc IEEE. 2023;111:257–76. [Google Scholar]
- 8.Dandrifosse S, Ennadifi E, Carlier A, Gosselin B, Dumont B, Mercatoris B. Deep learning for wheat ear segmentation and ear density measurement: from heading to maturity. Comput Electron Agric. 2022;199:107161. [Google Scholar]
- 9.Wang Y, Qin Y, Cui J. Occlusion robust wheat ear counting algorithm based on deep learning. Front Plant Sci. 2021 ;12. [DOI] [PMC free article] [PubMed]
- 10.Wang D, Zhang D, Yang G, Xu B, Luo Y, Yang X, SSRNet. In-field counting wheat ears using multi-stage convolutional neural network. IEEE Trans Geosci Remote Sens. 2022;60:1–11. [Google Scholar]
- 11.Li Z, Zhu Y, Sui S, Zhao Y, Liu P, Li X. Real-time detection and counting of wheat ears based on improved YOLOv7. Comput Electron Agric. 2024;218:108670. [Google Scholar]
- 12.Ren S, He K, Girshick R, Sun J, Faster R-CNN. Towards real-time object detection with region proposal networks. IEEE Trans Pattern Anal Mach Intell. 2017;39:1137–49. [DOI] [PubMed] [Google Scholar]
- 13.He K, Gkioxari G, Dollár P, Girshick R, Mask. R-CNN. arXiv 2018. [DOI] [PubMed]
- 14.Tian Y, Yang G, Wang Z, Li E, Liang Z. Instance segmentation of Apple flowers using the improved mask R–CNN model. Biosyst Eng. 2020;193:264–78. [Google Scholar]
- 15.Liu Z, Jin S, Liu X, Yang Q, Li Q, Zang J, et al. Extraction of wheat Spike phenotypes from field-collected lidar data and exploration of their relationships with wheat yield. IEEE Trans Geosci Remote Sens. 2023;61:1–13. [Google Scholar]
- 16.Maji AK, Marwaha S, Kumar S, Arora A, Chinnusamy V, Islam S, SlypNet. Spikelet-based yield prediction of wheat using advanced plant phenotyping and computer vision techniques. Front Plant Sci. 2022;13. [DOI] [PMC free article] [PubMed]
- 17.Wen C, Wu J, Chen H, Su H, Chen X, Li Z et al. Wheat Spike detection and counting in the field based on spikeretinanet. Front Plant Sci. 2022;13. [DOI] [PMC free article] [PubMed]
- 18.Wang S, Zhao J, Cai Y, Li Y, Qi X, Qiu X, et al. A method for small-sized wheat seedlings detection: from annotation mode to model construction. Plant Methods. 2024;20:15. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 19.Farjon G, Edan Y. AgroCounters—a repository for counting objects in images in the agricultural domain by using deep-learning algorithms: framework and evaluation. Comput Electron Agric. 2024;222:108988. [Google Scholar]
- 20.Fernandez-Gallego JA, Lootens P, Borra-Serrano I, Derycke V, Haesaert G, Roldán-Ruiz I, et al. Automatic wheat ear counting using machine learning based on RGB UAV imagery. Plant J. 2020;103:1603–13. [DOI] [PubMed] [Google Scholar]
- 21.Gu Y, Wang Y, Wu Y, Warner TA, Guo T, Ai H, et al. Novel 3D photosynthetic traits derived from the fusion of UAV lidar point cloud and multispectral imagery in wheat. Remote Sens Environ. 2024;311:114244. [Google Scholar]
- 22.Misra T, Arora A, Marwaha S, Jha RR, Ray M, Jain R, et al. Web-SpikeSegNet: deep learning framework for recognition and counting of spikes from visual images of wheat plants. IEEE Access. 2021;9:76235–47. [Google Scholar]
- 23.Hu G, Qian L, Liang D, Wan M. Self-adversarial training and attention for multi-task wheat phenotyping. Appl Eng Agric. 2019;35:1009–14. [Google Scholar]
- 24.Ghiasi G, Cui Y, Srinivas A, Qian R, Lin T-Y, Cubuk ED et al. Simple copy-paste is a strong data augmentation method for instance segmentation. 2021;2918–28.
- 25.Li J, Feng Y, Shao Y, Liu F. IDP-YOLOV9: improvement of object detection model in severe weather scenarios from drone perspective. Appl Sci. 2024;14:5277. [Google Scholar]
- 26.Qin D, Leichner C, Delakis M, Fornoni M, Luo S, Yang F et al. MobileNetV4 -- universal models for the mobile ecosystem. arXiv 2024 .
- 27.Xu W, Wan Y. ELA: Efficient local attention for deep convolutional neural networks. arXiv. 2024 .
- 28.Gevorgyan Z. SIoU loss: More powerful learning for bounding box regression. arXiv 2022 .
- 29. Hu J,Shen L,Sun G,Squeeze-and-exeitation networks. 2018; 7132-41.
- 30.Louizos C, Welling M, Kingma DP. Learning sparse eural etworks hrough L0 egularization. arXiv 2018.
- 31.Wang X, Song J, ICIoU. Improved loss based on complete intersection over union for bounding box regression. IEEE Access. 2021;9:105686–95. [Google Scholar]
- 32.Khaki S, Safaei N, Pham H, Wang L, WheatNet:. A lightweight convolutional neural network for high-throughput image-based wheat head detection and counting. Neurocomputing. 2022;489:78–89. [Google Scholar]
- 33.Wang J, He L, Zhou X. Optimizing inception-V3 for brain.mor classification using hybrid precision. aining and cosine annealing learning.te. 2024 7th int Conf adv algorithms control.g.AACE. 2024 ;528–32.
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.
Data Availability Statement
No datasets were generated or analysed during the current study.