

Abstract
Face Verification (FV) systems have exhibited remarkable performance in verification tasks and have consequently garnered extensive adoption across various applications, from identity duplication to authentication in mobile payments. However, the surge in popularity of face verification has raised concerns about potential vulnerabilities in the face of adversarial attacks. These concerns originate from the fact that advanced FV systems, which rely on deep neural networks, have recently demonstrated susceptibility to crafted input samples known as adversarial examples. Although imperceptible to human observers, adversarial examples can deceive deep neural networks during the testing and deployment phases. These vulnerabilities raised significant concerns about the deployment of deep neural networks in safety-critical contexts, prompting extensive investigations into adversarial attacks and corresponding defense strategies. This comprehensive survey provides a comprehensive overview of recent advances in deep face verification, encompassing a broad spectrum of topics such as algorithmic designs, database utilization, protocols, and application scenarios. Furthermore, we conduct an in-depth examination of state-of-the-art algorithms to generate adversarial examples and the defense mechanisms devised to mitigate such adversarial threats.
Keywords: Face verification, Deep neural network, Adversarial attacks, Adversarial perturbation, Defense techniques
Subject terms: Computational science, Information technology, Scientific data
Introduction
Face verification (FV) is an active research topic in computer vision. It has been involved in various applications such as active authentication1–4, driving licenses, and airport security due to the growing size of face databases and the high accuracy of the FV system. Different organizations around the world have widely adopted FV.
The key to face verification is extracting a discriminative set of features from face images using Deep Convolutional Neural Networks (DCNNs). With recent advances in DCNNs5,6, face verification reached impressive performances and highly accurate results over the past years7–10. For instance, the accuracy of Labeled Faces in the Wild (LFW) benchmark dataset11 has been boosted from 97% to above 99.8%, and Youtube Faces (YTF) dataset12 has been increased from 91.4% to above 98%. Moreover, DCNN frameworks enable end-to-end learning, i.e., learning a mapping from the input image space to the target label space.
In the last few years, researchers have discovered that FV systems are susceptible to attacks that introduce data variations, which can deceive classifiers. These attacks can be accomplished either via (i) Spoof attacks: artifacts in the physical domain (i.e., 3D masks, eyeglasses, replaying videos)13, (ii) Adversarial perturbation attacks: imperceptible noises added to probes for evading FV systems, and (iii) Digital manipulation attacks: entirely or partially modified photo-realistic faces using generative models14.
Among the various attacks, adversarial attacks are the most dangerous because they generally target Deep Neural Networks (DNNs) and focus on Convolutional Neural Networks (CNNs), which are based on the latest FV models. Figure 1 demonstrates the attractiveness of this type of attack and the explosive growth in the number of papers published each year in generating adversarial examples. Therefore, DCNNs are fragile and can be easily attacked by adversarial examples resulting from adding small perturbations15–17. These amounts of perturbations are imperceptible to the human eye. The goal is to mislead the classifier to provide wrong prediction outputs because the synthesized images look almost the same as the original ones. Adversarial attacks on FV systems are generated in a manner that humans cannot notice the adversarial perturbations, but the perturbations cause the FV system to misclassify an image, as shown in Fig. 2. Therefore , it is essential to gain a deeper understanding of how these models are susceptible to these attacks.
Fig. 1.

The cumulative number of adversarial example papers published in the last years (Image Credit:18).
Fig. 2.

The face verification (FV)system misclassifies the two images belonging to the same person.
Several known methods for crafting adversarial examples vary significantly in terms of their challenges, complexity, computational cost, and the objectives of the attacks. The level of information available to the attacker is classified into three categories (i) White-box attack19, (ii) Black-box attack20, and (iii) Semi-white box attack21. Depending on the attacker’s objective, creating adverse face images can be seen as a security threat. In addition to the apparent security risk of identity theft, this poses an ethical justification to conduct face testing22. Another reason to study adversarial attacks on face verification is from the perspective of the machine learning researcher18. Identifying new modes of attacks has shown that training on the perturbed instances can help negate the very same line of attacks23. Thus, to build robust models, it is necessary to break them up and then adversarially retrain the previously weak model to make it more robust.
Due to the users’ privacy issues related to spoofed systems, the requirement to prevent face attacks is becoming increasingly critical. Due to the extensive use of automated face verification systems for border control, failing to detect face attacks might pose a significant security risk. With the introduction of smartphones, we now all have automated facial recognition algorithms integrated into our pockets. Face recognition on our phones makes it easier to (i) unlock the device, (ii) execute financial transactions, and (iii) access privileged content stored on the device.
As a result, considerable literature on defending deep neural networks against adversarial cases has emerged. As indicated in Fig. 3, there are two types of defenses against adversarial attacks. First, Robust Optimization (i.e., Adversarial Training) is the most popular defense method, which modifies the net training procedures or architectures and aims to improve the classifier’s robustness17,23–26. Although these algorithms are safe against specific attacks, these defenses are still vulnerable to attacks from other mechanisms. However, because online adversarial example generation requires additional computation, adversarial training takes longer than training on clean images alone. Second, the pre-processing strategy leaves the training procedure and architecture unchanged but modifies the data by aiming to detect, remove, or purify the images. For example, in the case of adversarial examples detection, which involves training a binary classifier to distinguish between real and adversarial ones27–33. In the case of removing adversarial noise34,35, which aims to remove the adversarial perturbation by applying transformations as a preprocessing on the input data and then sending these inputs to the target models. But in the case of the purification, it is removed from the input adversarial images only36 to avoid purifying the real images and consequently avoid the high false reject rates.
Fig. 3.

Defense strategies in literature.
The main contributions of this survey are as follows:
Highlighting the major shortcomings and key areas in facial verification, we present a comparison and analysis of publicly available databases that are vital for both model training and testing.
Analyzing the state-of-the-art adversarial attacks on FV systems to give an overview of the main techniques and contributions to adversarial attacks.
Analyzing major defense methods commonly used in the literature and summarizing the most recent related work concerned with detection challenges of Adversarial face images.
The subsequent sections of this paper are structured as follows: Section "Terms and Definitions" introduces pivotal definitions and concepts commonly applied in the realm of adversarial attacks and their corresponding defenses within the framework of the FV system. Section “Face Verification” provides an in-depth examination of the Face Verification system, including diverse network architectures, loss functions, and a comprehensive overview of facial processing algorithms and datasets. Sections "FV Systems Vulnerabilities and Defense" are dedicated to scrutinizing adversarial attack generation methodologies designed to subvert the FV mission and exploring various defensive strategies. The paper concludes in Section “Conclusion”.
Terms and definitions
In this section, we provide a concise overview of the fundamental elements concerning model attacks and defenses within the context of the FV system. Precise terminology definitions play a pivotal role in facilitating comprehension of the primary aspects explored in prior research about adversarial attacks and their corresponding countermeasures. The subsequent sections of this scholarly work consistently adhere to the established definitions of these terms.
General terms
Adversarial example/image: A deliberately altered variant of the original image, achieved through the introduction of perturbations such as noise, with the objective of misleading deep convolutional neural networks (DCNN) and machine learning models (ML), including (FV) models.
Adversarial perturbation: A form of interference is introduced into the clean image to transform it into an adversarial example.
Adversarial training: A model training procedure incorporating adversarial images in conjunction with unaltered ones.
Transferability: The capacity of a perturbed example to influence models other than those employed in its creation.
Specific terms
We can talk about attacks from several aspects, namely: (i) the objective of the attacks and (ii) the information available to the attacker through which the attacks are classified into three categories: (i) White-box attack, (ii) Black-box attack, and (iii) Semi-white box attack.
Objective of the attacks
Poisoning Attack vs Evasion Attack. Evasion37 is the most common attack performed during production. It refers to designing an input, which seems normal for a human but is wrongly classified by deep learning models.
A poisoning attack38 happens when the adversary can inject poisoned data into your model’s training, hence getting it to learn something it shouldn’t. This attack frequently appears when the adversary has access to the training database.
Target Attack vs Non-Target Attack: Indeed, targeted attacks are more complicated than non-targeted ones. The purpose of the non-target attack is to make the model misclassify the adversarial image. In contrast, the targeted attack makes the model classify the adversarial image as a specific target class, which is different from the true class.
Obfuscation Attack vs Impersonation Attack: Obfuscation Attacks (OA) and Impersonation Attacks (IA) are frauds. In OA, the attacker seeks to avoid being verified by the FV system, but in IA, the attacker seeks to be incorrectly verified as a different legitimate user by the FV system. In both cases, the fraud process is done by adding an imperceptible perturbation to probe the image. This amount of perturbation is imperceptible to the human eye and differs from one person to another.
Attacker’s information
White-Box Attack : In a white-box setting, the attacker has full information about the deep learning models, such as parameters, architecture, defense methods, and gradients . Then, it uses this information to add a small imperceptible perturbation to an inquiry image17,23. Perhaps this is not available in the real world for two reasons. First, the attacker cannot access the model because model designers usually do not open their model parameters for special reasons. Second, the model may have been trained in this type of attack, so the model will have the ability to detect this type of attack. As a result of the popularity of the white-box type of attack, designers are creating a robustness model that cannot be deceived by these attacks.
Black-Box Attack : In a Black-box setting, the attacker does not know the details of target models such as architectures, parameters, and defense methods. They use different models to generate adversarial images, hoping these will transfer to the target model. Additionally, the adversary may have only partial knowledge about (i) the classifier’s data domain, for example, handwritten digits, photographs, and human faces, and (ii) the architecture of the classifier, such as CNNs and RNNs.
Semi-white Box Attack : In a semi-white box attack setting, the attacker trains a generative model for producing adversarial examples in a white-box setting. Once the generative model is trained, the attacker does not need the victim model anymore and can craft adversarial examples in a black-box setting.
Face verification
Biometrics encompasses technologies designed to authenticate or identify individuals based on physiological attributes or behavioral characteristics. Physiological attributes, such as the iris, fingerprints, and facial features, are generally considered more reliable than behavioral traits like voice patterns, typing style, or walking gait. The domain of deep learning, essential for developing robust verification algorithms, necessitates substantial training data. Obtaining facial images from online sources is notably more straightforward than collecting iris or fingerprint data, primarily due to the widespread availability of digital cameras in affordable smartphones. In contrast, specialized hardware sensors are required for fingerprint and iris recognition. Consequently, the advancement of deep learning techniques has significantly improved face verification performance.
FV technologies are presently deployed in numerous critical commercial and governmental applications. FV plays a pivotal role in preventing identity card duplication, thwarting individuals from obtaining multiple identification documents, such as driver’s licenses and passports, under different aliases. Despite the accomplishments of FV systems in the scenarios above, their performance remains constrained, particularly under unconstrained conditions.
As depicted in Fig. 4, factors like varying poses, lighting conditions, facial expressions, age, and obstructions can significantly distort the appearance of an individual’s face, highlighting the need to reduce intra-personal variations while accentuating inter-personal distinctions as a central focus in face verification. Moreover, face attacks have materialized in physical realms, such as 3D face masks, and digital domains, encompassing adversarial and digitally manipulated facial images. Malicious actors, called attackers, are increasingly challenging the security of FV pipelines utilized for government services, access control, and financial transactions, often bypassing human operator verification of the legitimacy of facial image acquisition. This section provides an essential foundation for comprehending deep face verification and offers an overview of relevant research in this domain.
Fig. 4.

Sources of intra-personal variations: (a) pose, (b) illumination, (c) expression, and (d) Occlusion. Each row shows intra-personal variations for the same individual (Image Credit: Google Images).
In Face Recognition (FR), two primary categories exist: Face Identification (FI), denoted as one-to-many face recognition, and face verification (FV), referred to as one-to-one face recognition. FI is concerned with classifying a face image into a specific identity. At the same time, FV is tasked with ascertaining whether or not two given face images correspond to the same identity. It is important to note that a more efficient FV system directly contributes to the overall efficiency of the FR system. Consequently, face verification can be conceptualized as evaluating the degree of similarity between a pair of facial images.
Face verification pipeline
Face verification can be simplified as the problem of comparing the similarity between a pair of face images. The whole deep FV system pipeline consists of (i) Input Image (Images or Image Frames), (ii) Face Detector, which localizes faces in images, (iii) Alignment, aligned to normalized canonical coordinates, (iv) Face processing to handle intra-personal variations, (v) Feature Extraction, and (vi) Face Matching. The verification pipeline is shown in Figure 5. The following subsections provide a detailed description of each component of the pipeline.
Fig. 5.

The end-to-end pipeline of the deep FV system.
Face detector
One of the most formidable challenges within the field of computer vision pertains to face detection, primarily attributable to the substantial intra-class variability inherent in facial appearances. This variability encompasses factors like skin complexion, background interference, facial orientation, and lighting conditions. Face detection (FD) assumes critical importance within Facial Verification (FV) systems, as it involves precisely localizing and isolating the facial region within an image. FD, in essence, encompasses the capability to identify and delineate one or more faces within a photograph, irrespective of their spatial orientation, lighting variations, attire, accessories, hair color, presence of facial hair, application of makeup, and age of the individuals. In this context, the localization phase involves the placement of a bounding box around the facial region’s spatial coordinates within the image. In contrast, the location phase pertains to the precise determination of these coordinates. It is worth noting that classical feature-based methods, exemplified by the “Haar Cascade classifier,” have historically provided a reasonably effective solution to this challenge, and such approaches remain popular for face detection39. However, recent years have witnessed significant advancements in face detection techniques, with deep learning methodologies emerging as the forefront contenders for achieving state-of-the-art results on established benchmark datasets. Noteworthy examples in this domain include the Multi-task Cascaded Convolutional Neural Network (MTCNN)40 and RetinaFace41, which have garnered recognition as leading approaches in the realm of face detection.
Alignment
Face alignment entails identifying correspondences among facial features, relying on landmark fiducial points, including the eyes, nose, mouth, and jaw. This phase assumes critical importance in the context of face verification. As an illustrative example, Schroff et al.9 underscored the significance of face alignment following face detection, demonstrating an enhancement in the FaceNet model’s accuracy from 98.87% to 99.63%. The simplest approach to alignment involves the application of a basic 2D rigid affine transformation to align the eyes, accounting for variations in facial size and head rotation9,42. More advanced techniques employ 3D modeling methods to achieve frontal face alignment. Nevertheless, it is worth noting that 3D face alignment methods are often associated with heightened computational complexity and cost implications.
Face processing
The preprocessing stage is frequently regarded as a pivotal phase in constructing machine learning models. Preceding the training and testing phases, it addresses inherent intra-personal variations, encompassing poses, illuminations, expressions, and occlusions. Research conducted by Ghazi et al.43 conclusively demonstrates that these diverse conditions continue to exert a discernible impact on the efficacy of deep face verification systems. Face-processing methodologies are classified into two distinct categories, namely, (i) one-to-many and (ii) many-to-one approaches.
One-to-many approaches: These encompass methodologies such as data augmentation, 3D modeling, autoencoder modeling, and GAN modeling44–46. Their primary function is to generate multiple patches or images that encapsulate pose variations derived from a single image. This facilitates the training of deep neural networks in acquiring pose-invariant representations. These strategies address the challenges associated with data acquisition by augmenting training data and expanding the gallery of test data.
Many-to-one approaches: These include techniques like autoencoder modeling, CNN modeling, and GAN modeling47–49. They are designed to transform facial images, specifically by producing frontal views and reducing the variability in appearance within the test data. The objective is to standardize facial alignment and enhance comparability, simplifying face-matching.
Feature extraction
In developing an FV system, a critical phase involves extracting a numerical value set referred to as a feature vector or representation. It is imperative to meticulously design the feature vector to prevent the inclusion of superfluous and potentially redundant features, as this can adversely affect verification rates. In recent years, FV systems have been categorized into three distinct approaches for facial representation: (i) holistic, (ii) local, and (iii) shallow and deep learning methods.
The Holistic Face Representations methodology entails utilizing all pixels present in the input facial image to construct a low-dimensional representation, guided by specific distribution assumptions like the linear subspace50,51 and sparse representation52,53. Nonetheless, it is widely recognized that these theoretically sound, holistic approaches demonstrate limited generalizability when applied to datasets that were not part of their training regimen.
To build local face representations, face features can also be retrieved from overlapping patches in the face image at several sizes. Local features can be concatenated into a final feature vector summarizing the input face image to add holistic information. The final face representation is usually over-complete, with redundant data and excessive dimensionality. Feature selection, boosting, and dimensionality reduction techniques such as PCA and LDA are utilized to build a more compact face representation. Ahonen et al.54 proposed Local Binary Patterns (LBP) for face recognition. They divide the face image into a grid to exploit local and global facial features. A histogram of LBP characteristics is generated for each cell in the grid, and the resulting face representation is concatenated.
-
In facial verification, Convolutional Neural Networks (CNNs) have outperformed human capabilities on various benchmark assessments10. The proliferation of extensive facial datasets and improved computational resources, notably Graphics Processing Units (GPUs), has led to a notable surge in interest over the past few years in automatic feature extraction techniques centered around Convolutional Neural Networks (CNNs)10, as evidenced by the data in Table 1. Diverse architectural configurations and loss functions have been employed to extract distinguishing identity attributes from facial images through the utilization of Deep Convolutional Neural Networks (DCNNs). This has been achieved by carefully designing loss functions to augment discriminative capacity during the training process55.
One of the primary challenges faced by the facial verification (FV) research community was the one-shot learning problem. This challenge involved the development of FV systems capable of verifying a person’s identity using just a single example of their face. Historically, deep learning algorithms struggled with this scenario, as discussed in reference56—however, DeepFace10 successfully addressed this issue and achieved an impressive accuracy rate of 97.35% on the Labeled Faces in the Wild (LFW) benchmark dataset, approaching human-level performance. Additionally, it significantly reduced the error rate of the YouTube Face database by more than 50%. This achievement was accomplished by training a nine-layer deep neural network (CNN) with over 120 million parameters on a dataset containing four million facial images with 3D alignment for face processing.
Furthermore, an end-to-end metric learning approach was tested using a Siamese neural network replicated twice during training. This network takes two images as input and outputs the degree of difference between their features, followed by a top fully connected layer that maps this information into a single logistic unit. Schroff et al.9 introduced FaceNet, which utilized a triplet loss function to learn a Euclidean distance metric for measuring face similarity. This approach achieved remarkable accuracies of 99.63%±0.09 with additional face alignment, 98.87%±0.15 when using a fixed center crop on LFW, and 95.12% on the YouTube Faces dataset.
Notably, these methods emphasize end-to-end learning, representing the entire system directly from facial pixels rather than relying on engineered features. They also require minimal alignment, typically focusing on a tight crop around the facial region9.
Table 1.
Face verification methods evaluated on LFW and YTF datasets.
| Method | Loss | Architecture | Training Set | LFW | YTF |
|---|---|---|---|---|---|
| DeepFace10 | Softmax | AlexNet | Facebook SFC (4.4M, 4K) | 97.35% | 91.4% |
| FaceNet9 | Triplet | Inception | Google (200M, 8M) | 99.63% | 95.12% |
| VGGFace57 | Softmax | VGG-16 | VGGFace (2.6M, 2.6K) | 98.95% | 97.3% |
| SphereFace7 | A-Softmax | ResNet-64 | CASIA-WebFace (0.49M, 10K) | 99.42% | 95.0% |
| ArcFace8 | ArcFace | ResNet-100 | MS1M (5.8M, 85K) | 99.83% | 98.02% |
| Gate-FV58 | Angular | MDCNN | CASIA-WebFace (0.49M, 10K) | 99.38% | 94.3% |
Face matching
In the context of facial feature extraction, the primary objective of an FV system is to determine the degree of similarity between these extracted features. This is achieved by applying similarity measurement techniques, with commonly used methods including cosine similarity8 and Euclidean distance9. While Euclidean distance is a straightforward choice for comparing feature vectors, other distance metrics such as cosine similarity, Manhattan distance, histogram intersection, log-likelihood statistics, and chi-square statistics have been explored to enhance face verification performance.
Benchmark dataset
In recent years, a discernible pattern has arisen, characterized by a transition from small-scale to large-scale experimentation, a shift from reliance on single sources to incorporating diverse sources, and a progression from laboratory-controlled settings to unconstrained real-world conditions. Table 2 presents a comprehensive compilation of data about a collection of benchmark datasets utilized within the academic literature. This compilation encompasses various elements, including database size quantified by the number of images, the presence of identifiable faces, and the intended applications.
Faces in the Wild (LFW)11 stands as one of the pioneering databases specifically tailored for the investigation of uncontrolled, “in-the-wild” face verification scenarios. This repository encompasses a considerably larger volume of images, which serve as essential evaluative material for algorithms designed for practical, real-world applications. Within the domain of face verification, LFW continues to hold its status as a key benchmark. The inception of this dataset dates back to its initial release in 200711, and subsequently, it underwent updates in 201465. It comprises 13,233 facial images, each sized at 250x250 pixels, representing 5,749 distinct individuals, with 4,069 of these individuals featuring in only a single image.
YouTube Faces (YTF)12 The YTF dataset was curated to investigate unconstrained videos featuring matched background similarities. Comprising 3,425 videos drawn from 1,595 distinct subjects, the dataset exhibits an average of 2.15 videos per subject. Notably, video durations within the dataset range from 48 frames for the shortest clip to 6,070 frames for the longest, with an average video clip length of 181.3 frames.
IARPA Janus Benchmark A (IJB-A)60 encompasses a heterogeneous collection of visual data, including both images and videos, originating from a pool of 500 subjects captured in diverse real-world scenarios. Notably, for each subject included in the dataset, a minimum of five images and one video is available. The IJB-A dataset comprises 5,712 images and 2,085 videos, translating to an average of 11.4 images and 4.2 videos per subject. At the granularity of individual subjects, the dataset is structured into ten distinct, randomly generated training and testing splits, each encompassing all 500 subjects in IJB-A. For each of these splits, a subset of 333 subjects is randomly allocated to the training set, serving as a foundation for algorithmic model development and acquiring insights into facial variations germane to the Janus challenge. The remaining 167 individuals are assigned to the testing set for evaluation and validation.
Cross-Pose LFW (CPLFW)63 database represents a revitalized iteration of the Labeled Faces in the Wild (LFW) dataset, which serves as the prevailing benchmark for evaluating unconstrained face verification algorithms. Within the LFW framework, ten distinct sets of image pairs have been meticulously constructed for cross-validation, each containing 300 positive and negative pairs. These subsets are organized based on unique subject identities, ensuring each identity is exclusively featured in a single subgroup. In contrast, the CPLFW dataset employs an analogous partitioning approach, creating ten partitions or “folds,” mirroring the identity distributions found in the original LFW folds. Notably, each individual within the CPLFW dataset is represented by a set of two to three images.
MegaFace61 stands as a substantial publicly available face recognition training dataset that has established itself as an industry benchmark. Within MegaFace, a comprehensive compilation of 4,753,320 facial images is available , representing a diverse pool of 672,057 distinct identities sourced from a repository of 3,311,471 photographs from the personal albums of 48,383 users on the Flickr platform. Notably, while the photos featured in MegaFace predominantly possessed Creative Commons licenses, most did not permit commercial usage.
CASIA-Webface59 dataset is a valuable resource for addressing face verification and recognition challenges. Comprising a collection of 500,000 facial images featuring 10,575 distinct celebrities, these images were sourced from publicly available online sources, capturing subjects in uncontrolled, real-world settings, thus characterizing the “in the wild” nature of the dataset acquisition process.
VGGFace262 consists of 3.3 million facial images of celebrities drawn from a pool of 9,000 unique identities, with an average of 362 images available per subject, the creators of the dataset prioritized the meticulous reduction of label inaccuracies, alongside the deliberate inclusion of a wide spectrum of facial poses and age groups. These meticulous efforts have rendered the VGGFace2 dataset an optimal selection for training advanced deep-learning models designed to excel in tasks related to facial analysis.
VGGface57 dataset comprises an extensive compilation of 2.6 million facial images, encompassing 2,622 unique identities. Each identity is accompanied by an associated text file with image URLs and corresponding facial detection information.
Table 2.
Common face verification datasets
| Database Name | # Images | # Identities | Availability | Type |
|---|---|---|---|---|
| LFW11 | 13,233 | 5,749 | Public | Test |
| YTF12 | 3,425 videos | 1,595 | Public | Test |
| Facebook10 | 4.4M | 4K | Private | Train |
| CASIA-WebFace59 | 494,414 | 10,575 | Public | Train |
| Google-FaceNet9 | 200M | 8M | Private | Train |
| VGGFace57 | 2.6M | 2.6K | Public | Train |
| IJB-A60 | 5,712 | 500 | Public | Test |
| MegaFace61 | 4.7M | 672,057 | Public | Train |
| VGGFace262 | 3.31M | 9,131 | Public | Train |
| CPLFW63 | 11,652 | 3,968 | Public | Test |
| WebFace260M64 | 260M | 4M | Public | Train |
Evaluation metrics
The facial matching procedure involves the computation of the dissimilarity measure between a given pair of facial images, which is subsequently compared to a predefined threshold. When the calculated dissimilarity measure falls below this threshold, the pair of faces is classified as belonging to the same individual; otherwise, they are deemed to represent distinct individuals. This categorization identifies correctly matched pairs as either true positives (indicating same-person pairs) or true negatives (indicating different-person pairs). Within this context, two types of errors may occur: (i) false positives, also known as false acceptances, correspond to instances where different individuals are erroneously identified as the same person, and (ii) false negatives, or false rejections, occur when the same individual is mistakenly categorized as distinct individuals. The assessment of facial verification performance relies on the evaluation of these two error types, with the utilization of the subsequent metrics:
Accuracy represents the percentage of truly recognized pairs, both positive and negative.
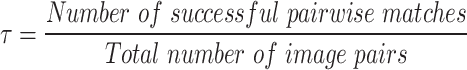 |
1 |
where the numerator represents the Number of sucessful pairwise matches and the denominator represents the Total number of image pairs. Verification Accuracy (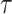 ) represents the acceptance threshold and is determined using cross-validation.
) represents the acceptance threshold and is determined using cross-validation.
We also report the True Accept Rate at a pre-determined False Accept Rate. The  is determined via a Receiver Operating Characteristic (ROC) curve. Formally,
is determined via a Receiver Operating Characteristic (ROC) curve. Formally,
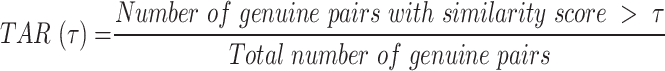 |
2 |
 |
3 |
Equal Error Rate (EER) is the error when false positive rate (FPR) and false negative rate (FNR) are the same, which is found by varying the threshold. Receiver Operating Characteristic (ROC) is the curve of true positive rate (TPR) against false positive rate (FPR) that is calculated by varying the threshold.
FV systems vulnerabilities
Despite the impressive verification performance achieved using deep learning models, the FV systems remain vulnerable to the growing threat of face attacks, such as face spoofing and adversarial perturbations, in both the physical and digital domains. For example, an attacker can hide his identity by using a printed photograph, a worn mask66, or even an image displayed on another electronic device to present a fake face to the biometric sensor, or intruders can assume a victim’s identity by digitally swapping their face with the victim’s face image14.
There are three types of facial attacks depicted in Fig. 6: (i) Spoofing attacks: physical domain artifacts such as 3D masks, eyeglasses, and replaying videos13, (ii) Adversarial perturbation attacks: imperceptible noises added to probes to evade FV systems, and (iii) Digital manipulation attacks: entirely or partially modified photo-realistic faces using generative models14. There are various attack types in each of these categories. For example, 13 common types of spoofing attacks13. Similarly, in adversarial and digital manipulation attacks, each attack model is designed with unique objectives and losses and can be regarded as one attack type.
Fig. 6.

The broad categorization of facial attack types aimed to deceive the FV systems.
Several face-attack defense approaches have been proposed to protect FV systems from these attacks. Because the exact type of face attack may not be known a priori, a generalizable defense that can defend an FV system against any of the three attack categories is critical.
-
Spoof Attacks: are presentation attacks targeting facial recognition systems, as illustrated in Fig. 7, encompass various physical counterfeiting techniques necessitating active engagement by actors. These methods encompass the utilization of tangible counterfeits like 3D printed masks, printed images on paper, or digital tools such as video replays on mobile devices, all of which enable the impersonation of an individual’s identity or the concealing of the attacker’s identity. The ease with which an assailant can employ these tactics, such as displaying videos featuring the victim’s visage or submitting printed representations of the victim to a Facial Verification (FV) system67.
Even if a countermeasure system were in place, leveraging depth sensors to detect face presentation attacks, it would still be susceptible to more advanced subterfuge techniques. Attackers may resort to using 3D masks68, cosmetic disguises, or even virtual reality simulations69, thereby enabling the execution of more intricate and sophisticated attacks.
-
Adversarial Perturbation Attacks: Most facial verification (FV) models are predominantly constructed using Deep Convolutional Neural Networks (DCNNs) and have consistently demonstrated impressive performance and high accuracy in recent years. Nonetheless, DCNNs exhibit susceptibility to adversarial examples, which are generated through minor perturbations introduced into input samples15–17. Adversarial perturbations, exemplified in Fig. 8, can be defined as minimal alterations represented by
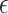 , where the addition of this perturbation to the input image x, denoted as (x +
, where the addition of this perturbation to the input image x, denoted as (x + 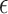 ), results in the misclassification of the input by deep learning models. Despite the imperceptibility of the perturbation to the human eye, it constitutes an adversarial example in image classification, capable of causing CNNs to misclassify the image. According to certain seminal works, such as70, the emergence of adversarial examples can be attributed to the limited generalization capabilities of DNN models, possibly stemming from the high complexity of their architectural design. The investigation into the existence of adversarial examples holds significance, as it can provide valuable insights for designing more robust models and enhancing our comprehension of existing deep learning frameworks.
), results in the misclassification of the input by deep learning models. Despite the imperceptibility of the perturbation to the human eye, it constitutes an adversarial example in image classification, capable of causing CNNs to misclassify the image. According to certain seminal works, such as70, the emergence of adversarial examples can be attributed to the limited generalization capabilities of DNN models, possibly stemming from the high complexity of their architectural design. The investigation into the existence of adversarial examples holds significance, as it can provide valuable insights for designing more robust models and enhancing our comprehension of existing deep learning frameworks.Malicious actors can manipulate their facial images to deceive FV systems, leading to two primary types of attacks: impersonation attacks, where the attacker aims to be recognized as a target victim, and obfuscation attacks, where the attacker seeks to be matched with a different identity within the system. However, the adversarial facial image generated by such attacks should appear legitimate to human observers. In contrast, face presentation attacks, as depicted in Fig. 7, involve the attacker physically presenting a fake face as the target identity to the FV system. These attacks are typically more conspicuous to human observers, especially in situations involving human operators, such as those in airports.
Notably, adversarial examples possess the characteristic of transferability, meaning that adversarial examples created to target one specific victim model are also highly likely to mislead other models. This property of transferability is often exploited in black-box attack techniques71. If attackers obscure the model’s parameters, they can resort to attacking alternative models, thereby leveraging the portability of the generated adversarial samples. Defense methods also harness the property of portability, as demonstrated in72, by utilizing adversarial training with samples created to perturb one type of model to bolster the defense of another type of model.
In this section, our primary focus is on exploring adversarial perturbations, as detailed in Section 4.1.
Digital Manipulation Attacks: is the process of affording the capacity to comprehensively or partially alter genuine facial images using Variational Auto Encoders (VAEs) and Generative Adversarial Networks (GANs)14. Figure 9 shows different face presentation attacks based on digital manipulation. These digital manipulation attacks may be categorized into distinct types, as outlined below:
Fig. 7.

Face presentation attacks require a physical artifact. (a) real face, from (b-d) represents three types of face presentation attacks: (b) printed photograph, (c) replaying the targeted person’s video on a smartphone, and (d) a 3D mask of the target’s face (Image Credit: Google Images).
Fig. 8.

Image samples for probe face images and their corresponding synthesized ones. (a) gallery enrolled images and (b) probed images for the same person (c) FGSM (d) PGD (e) AdvFaces. Euclidean distance scores were obtained by comparing (b-e) to the enrolled images.
Fig. 9.

Examples of digitally manipulated faces from different sources such as FFHQ, CelebA, FaceForensics++, FaceAPP and StarGAN, PGGAN, StyleGAN datasets (Image Credit:14).
Identity Swapping:
These methods replace one person’s face with another person’s face digitally. For example, FaceSwap73 contains well-known actors in movie scenes in which they have never been featured before. DeepFakes also uses deep learning algorithms to produce face swaps.
Expression Swapping:
These methods exchange expressions in real time using only RGB cameras. Expressions in the facial image can be digitally and artificially replaced by others74.
Attribute Manipulation:
studies like StarGAN75 and STGAN76 use the latest GANs to manipulate attributes by changing single or multiple traits in a facial image, such as gender, age, skin color, hair, and glasses.
Entire Face Synthesis:
An attacker can easily synthesize entire facial images of unknown identities, which are so realistic that even humans have difficulty assessing whether they are authentic or manipulated77. Due to the advent of GANs and large-scale, high-resolution facial data sets.
Adversarial example generation
In the realm of computer vision, a multitude of techniques for generating adversarial examples have been developed. These methodologies aim to introduce subtle perturbations into specific images, thereby inducing erroneous classifications by machine learning models17,78. To formalize the concept of adversarial examples, we introduce the following notation: let x represent an input that is accurately classified as y, and f(x) denote the classification decision made by the machine learning model. An adversarial example, denoted as 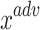 = x +
= x + 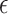 , is formed through the addition of a perturbation
, is formed through the addition of a perturbation 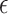 , satisfying the condition:
, satisfying the condition:
 |
4 |
Generating adversarial examples ultimately involves identifying perturbations in input data that remain imperceptible to human observers yet lead to misclassifications by vulnerable machine learning models. Additionally, researchers have demonstrated the creation of a general perturbation applied to a dataset, resulting in the high likelihood of misclassification for numerous normal images16. Szegedy et al.70 unveiled the existence of adversarial examples and introduced the first algorithm capable of reliably detecting adversarial perturbations. The Fast Gradient Sign Method (FGSM), proposed by Goodfellow et al.17 and illustrated in Fig. 10, forms the basis of this algorithm. Kurakin et al.25 extended the FGSM method to generate larger quantities of adversarial examples, enhance the quality of the generated adversarial models, and enable the execution of targeted attacks. However, it is worth noting that some of these extensions come at the expense of increased computational resources.
Fig. 10.

By adding small perturbations (distortions) to the original image, which results in the model labeling this image as a gibbon, with high confidence (Image Credit:17).
Moosavi-Dezfooli et al.16 introduced Deepfool, designed initially for untargeted attacks with a focus on improving perturbations in the L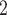 norm but adaptable to any L
norm but adaptable to any L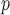 norm. Their approach is highly effective and can discover smaller perturbations compared to Szegedy et al.’s L-BFGS approach70. The fundamental idea behind their proposed algorithm is an iterative approximation of the hyperplanes that separate distinct classes and the distances between perturbed inputs and decision boundaries, estimated through orthogonal projections. While Deepfool cannot guarantee the discovery of the optimal solution with the minimal perturbation for a given input, the authors assert that the resulting perturbation approximates the minimal perturbation effectively.
norm. Their approach is highly effective and can discover smaller perturbations compared to Szegedy et al.’s L-BFGS approach70. The fundamental idea behind their proposed algorithm is an iterative approximation of the hyperplanes that separate distinct classes and the distances between perturbed inputs and decision boundaries, estimated through orthogonal projections. While Deepfool cannot guarantee the discovery of the optimal solution with the minimal perturbation for a given input, the authors assert that the resulting perturbation approximates the minimal perturbation effectively.
Papernot et al.79 introduced the Jacobian-based Saliency Map Attack (JSMA), optimized for the L0 distance metric. This method leverages the gradients of the records or softmax units with respect to the input image to compute a saliency map, which approximates the impact of each pixel on the image’s classification. JSMA perturbs the most significant pixels until a targeted attack succeeds or the number of perturbed pixels exceeds a predefined threshold.
Carlini and Wagner80 proposed three algorithmic models for generating optimized adversarial examples with L , L
, L or L
or L norms. All three variants can perform targeted attacks by minimizing the respective objective functions, which can also govern prediction confidence. Finally, Sabbour et al.81 focus on directly manipulating deep representations through imperceptibly small perturbations instead of inducing explicit misclassifications. While the previously mentioned methods aim to create adversarial models leading to misclassified labels, this approach seeks to transform the internal representations of an image to closely resemble those of an image from a different category with imperceptible perturbations.
norms. All three variants can perform targeted attacks by minimizing the respective objective functions, which can also govern prediction confidence. Finally, Sabbour et al.81 focus on directly manipulating deep representations through imperceptibly small perturbations instead of inducing explicit misclassifications. While the previously mentioned methods aim to create adversarial models leading to misclassified labels, this approach seeks to transform the internal representations of an image to closely resemble those of an image from a different category with imperceptible perturbations.
Recent methods have focused on improving the transferability of adversarial examples, ensuring effectiveness even when attackers have no direct knowledge of the target model. Zhou et al.82 introduced the Diverse Parameters Augmentation (DPA) method, which diversifies surrogate models by training multiple intermediate checkpoints with varied parameter initializations, significantly enhancing adversarial transferability for face recognition tasks. Complementarily, research by Yu et al.83 has shown that embedding carefully designed triggers within adversarial examples (trigger activation techniques) can effectively evade traditional defensive mechanisms, further increasing the robustness and transferability of generated adversarial examples.
Adversarial attacks on image classification
In image classification, adversarial examples refer to intentionally crafted images that closely resemble their original counterparts but can elicit erroneous predictions from the classifier. These adversarial perturbations must be imperceptible to human observers. Therefore, the investigation of adversarial examples within the domain of images holds significant importance for two primary reasons: (a) the perceptual similarity between counterfeit and genuine images is readily discernible to human observers, and (b) the structural simplicity of both image data and image classifiers, in contrast to other domains such as graphs or audio, has led to numerous studies treating image classifiers as a standard case.
Many adversarial example generation methods have been proposed in recent years, as documented in Table 3. As evidenced in previous research, many of these attack methods can be categorized into intensity-based attacks17 and geometry-based attacks84,85. For instance, Goodfellow et al.17 introduced a white-box attack named the Fast Gradient Sign method (FGSM), which introduces subtle perturbations to various regions of the original image via back-propagation through the target model, causing the model to confidently misclassify the adversarial image into another category, as illustrated in Fig. 10. However, their approach is associated with several drawbacks, such as the excessive computational time required for generating adversarial examples and the resultant degradation in the perceptual quality of the generated images. Additionally, it relies on the white-box attack paradigm, which proves impractical in real-world scenarios. Moreover, the requirement of applying perturbations to all regions of the image and relying on softmax probabilities for evading an image classifier is not viable, especially in cases like the FV system, where the classifier does not employ a fixed set of classes (identities). Moosavi-Dezfooli et al.16 proposed image-agnostic adversarial attacks, which entail the generation of universal perturbations capable of deceiving the classifier across a wide range of image types and models. Recent work also shows that backdoor-style triggers, e.g., universal ‘master-key’ patterns, can force a network to verify an impostor as the genuine user86.
Table 3.
Comparison of different adversarial attack methods.
| Attack Method | Attack Settings | Similarity Metric | Scope | Domain | Attack Objectives |
|---|---|---|---|---|---|
| FGSM17 | White-Box |
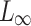 , , 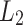
|
Universal | Classification | Obfuscation |
| Face Recognition19 | White-Box | Physical | Image-specific | Recognition | Impersonation |
| PGD23 | White-Box |  |
Universal | Classification | Obfuscation |
| A3GN84 | White-Box | Cosine | Image-specific | Recognition | Impersonation |
| Evolutionary Optimization20 | Black-Box | – | Image-specific | Recognition | Impersonation |
| GFLM85 | White-Box | – | Image-specific | Recognition | Obfuscation |
| AdvFaces21 | Semi-White-Box | 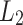 |
Image-specific | Recognition | Both |
| GAP++88 | White-Box |
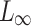 , , 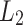 , , 
|
Universal | – | Obfuscation |
In image classification scenarios, adversarial threats have evolved towards more stealthy and practical black-box attack strategies. For instance, Park et al.87 proposed the Mind the Gap technique, which analyzes incremental query updates to systematically craft adversarial images under black-box conditions. This approach demonstrates how iterative query strategies can bypass detection mechanisms, underscoring the growing complexity and sophistication of adversarial attacks on image classification models.
Adversarial attacks on face verification (FV) systems
Utilizing deep learning models, the Facial Verification (FV) system can attain a noteworthy True Accept Rate (TAR) of 99.27% while maintaining an impressively low False Accept Rate (FAR) of 0.001% with genuine face pairs when leveraging FaceNet9. This level of performance is attributed to the ample availability of extensive facial datasets for training these models and the incorporation of Convolutional Neural Network (CNN) architectures, as illustrated in Table 1. However, it should be noted that CNN models are susceptible to adversarial perturbations, as elucidated in Table 3. Even minute imperceptible perturbations, undetectable to the human eye, can lead to misclassification by the CNN70.
Notwithstanding their commendable verification capabilities, mainstream FV systems are still exposed to an escalating risk posed by adversarial examples, as depicted in Figure 8. To compromise the FV system, an adversary can intentionally manipulate their facial image to deceive the FV system into incorrectly identifying them as the intended target (impersonation attack) or as a different individual (obfuscation attack). Crucially, the manipulated facial image must convincingly appear as a legitimate representation of the adversary to human observers, as illustrated in Fig. 11.
Fig. 11.

Examples of adversarial Attacks: (a) AdvFaces, (b) FGSM, (c) PGD.
However, it is essential to note that in the context of adversarial faces, the adversary need not actively engage in the authentication process when comparing their probe and gallery images. Conversely, in scenarios involving presentation attacks, such as the use of masks or the replay of images/videos of genuine individuals, the adversary must actively participate. Such active participation may be discernible in situations involving human operators. Hence, it is imperative to thoroughly investigate the spectrum of attacks to which CNN models are susceptible to comprehensively assess their vulnerabilities and limitations. This understanding should inform the design and modification of CNN models by developers in the future.
Recently, a prominent area of research has emerged in the field of face verification, focusing on the generation of adversarial examples. Researchers such as Bose et al.89 have pursued this inquiry by employing constrained optimization techniques to create adversarial examples that elude face detection systems. Similarly, Dong et al.20 have introduced an evolutionary optimization approach for generating adversarial faces, particularly in black-box scenarios. Nevertheless, this method necessitates a substantial number of queries to yield satisfactory results.
Song et al.84 have contributed to this discourse by proposing an attention-driven adversarial attack generative network (A3GN) tailored for producing counterfeit face images within a white-box framework, emphasizing impersonation attacks. However, their method exhibits certain limitations, including a requirement for access to gallery-enrolled face images, which may be impractical in real-world settings. Furthermore, it mandates at least five images of the target individual for training and is confined to targeting a single subject. The image generation process is characterized by low-quality and time-consuming operations.
Many of these shortcomings have been addressed by Deb et al.21, who introduced a semi-white box attack known as ’Advfaces.’ This method generates adversarial examples by feeding the network and necessitates only a single face image of the target subject for both training and inference. Importantly, Advfaces produces adversarial images of high quality and perceptual realism , posing no discernible threat to the human eye. Its efficacy is demonstrated by its ability to outperform state-of-the-art face matches, achieving an impressive attack success rate of 97.22% in obfuscation attacks. Moreover, Advfaces exhibits the property of transferability, wherein adversarial examples designed to target one victim model have a high likelihood of confounding other models.
We provide a succinct overview of the three popular obfuscation adversarial attacks FGSM17, PGD23, and Advfaces 21, on face verification systems, elucidating the process by which the magnitude of perturbation is precisely determined.
- Fast Gradient Sign Method (FGSM)17: FGSM is a fast method to generate an adversarial perturbation. It computes the gradient of the loss function J of the model concerning the image vector x to get the direction of pixel change and generates adversarial examples
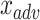 by minimizing the probability of the true class. FGSM perturbations can be computed by minimizing either the L1, L2 or L
by minimizing the probability of the true class. FGSM perturbations can be computed by minimizing either the L1, L2 or L norms according to the following equations17:
norms according to the following equations17:
, where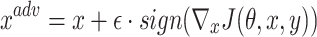
 controls the perturbation magnitude and
controls the perturbation magnitude and 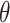 is the model parameters.
is the model parameters. - Projected Gradient Descent (PGD)23: PGD is an improved version of FGSM by applying it multiple times with a small step size
 . The adversarial examples were generated in multiple iterations by the following equation:
. The adversarial examples were generated in multiple iterations by the following equation:
, where Clip
5 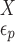 (
( ) clips updated images to constrain it within the
) clips updated images to constrain it within the 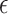 -ball of X (i.e.,limits the change of the generated adversarial image in each iteration). The initial perturbation was a random point within the allowed
-ball of X (i.e.,limits the change of the generated adversarial image in each iteration). The initial perturbation was a random point within the allowed 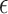 -ball, and the search was repeated multiple times to avoid falling into the local minimum.
-ball, and the search was repeated multiple times to avoid falling into the local minimum. - AdvFaces21: is a neural network model developed by Debayan et al. to generate perturbations in the silent regions of the face images without reducing the image quality. It consists of three components: a generator, a discriminator, and a face matcher. For the generator G, which takes an input image x and generates an adversarial image,
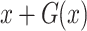 , by adding an adversarial mask G(x) with minimal perturbation that is similar to the original image, using the following
, by adding an adversarial mask G(x) with minimal perturbation that is similar to the original image, using the following 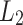 norm function:
norm function:
, where
6 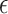 represents the minimum amount of perturbation. During the training process, AdvFace used a face matcher, F, to supervise the training process. AdvFace minimizes the cosine similarity between the original image and the generated perturbed one using the following identity loss function:
represents the minimum amount of perturbation. During the training process, AdvFace used a face matcher, F, to supervise the training process. AdvFace minimizes the cosine similarity between the original image and the generated perturbed one using the following identity loss function:
As the goal of the obfuscation attack is to reject the claimed identity, the attack model uses a discriminator, D, that distinguishes between the probed image and the generated adversarial one by using the following GAN loss function: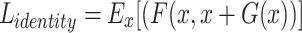
7
Consequently, the whole picture of the AdvFaces attack model is working based on the following objective loss function: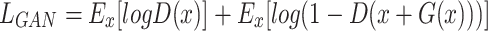
8 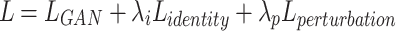
9
Generation of Perturbation Figure 12 illustrates the synthesis of adversarial facial images using three distinct attack methods: FGSM, PGD, and AdvFace. Each row in the figure corresponds to adversarial images with their respective perturbation values denoted as 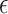 . Both FGSM and PGD rely on the gradients of the loss function and apply perturbations to every pixel in the facial image, resulting in low-quality adversarial images. In contrast, AdvFaces21 autonomously learns to perturb specific regions of the face, such as the eyes, nose, and mouth, which are generally considered non-distracting or “silent.” Consequently, AdvFaces produces higher-quality adversarial images than those generated by the FGSM and PGD attack methods.
. Both FGSM and PGD rely on the gradients of the loss function and apply perturbations to every pixel in the facial image, resulting in low-quality adversarial images. In contrast, AdvFaces21 autonomously learns to perturb specific regions of the face, such as the eyes, nose, and mouth, which are generally considered non-distracting or “silent.” Consequently, AdvFaces produces higher-quality adversarial images than those generated by the FGSM and PGD attack methods.
Fig. 12.

(Upper Row) Adversarial face images synthesized via three attacks: FGSM, PGD, and AdvFace. (Lower Row) Corresponding adversarial perturbations. FaceNet Euclidean distance scores between the adversarial and unaltered gallery images (not shown). A score above 1.1 indicates dissimilar subjects. (Image Credit:90).
Adversarial attacks on large vision-language models (VLMs)
As face verification systems increasingly integrate vision-language models (VLMs), they have become significantly more powerful due to their ability to jointly interpret visual and textual cues. Yet, this integration has inadvertently broadened their vulnerability to sophisticated adversarial attacks. Unlike traditional face verification methods, VLM-based systems process multimodal information, which not only enriches their performance but also creates new attack surfaces that adversaries can exploit. Understanding these novel threats is essential for both researchers and practitioners to build more trustworthy verification systems.
For instance, AnyAttack91 revealed that adversarial images crafted through self-supervised methods can deceive VLMs even without predefined labels or textual prompts. This approach, which leverages large-scale multimodal datasets, has demonstrated remarkable effectiveness and transferability across numerous commercial models. Such findings demonstrate that attackers no longer need intimate knowledge of the target systems; instead, they can exploit common embedding structures to launch potent impersonation attacks. This exposes an urgent need for defenses focusing not only on detecting adversarial patterns but also on fortifying the multimodal embeddings themselves. In addition to digital attacks, the physical world also presents surprising avenues for adversaries. The ProjAttacker method92 exemplifies how subtle, dynamic projections of adversarial patterns onto faces can deceive verification systems, circumventing traditional defenses such as liveness detection. This attack notably shifts the adversarial paradigm from physically intrusive methods (such as masks or makeup) to subtle, environmental manipulations. Thus, attackers have become less conspicuous, prompting the need for systems that recognize subtle environmental tampering rather than overt spoofing methods.
Further complicating matters, adversaries have begun to exploit generative AI in novel ways. Adv-CPG93, for instance, incorporates adversarial perturbations directly into generative portrait models. By embedding identity-masking mechanisms at the point of image generation, adversaries can effectively block unauthorized facial recognition, thus undermining the reliability of verification systems. This proactive integration of adversarial intent into generative processes marks a significant shift, highlighting how the boundary between data creation and attack execution is becoming increasingly blurred.
Moreover, new strategies like the DPA Attack82 illustrate the ingenuity of adversaries who now diversify surrogate models, rather than inputs alone, to enhance attack transferability across unknown systems. Simultaneously, methods such as Cross-Modal Adversarial Patches94 exploit the very interactions between image and text, strategically placing patches that disrupt multimodal associations while remaining visually plausible. Such developments underscore that adversaries are effectively leveraging the strengths of multimodal models against them, emphasizing that security solutions must now anticipate threats at the intersection of different modalities rather than within individual modalities alone.
Recent studies have extended adversarial research to transformer-based and multimodal face-verification systems. Kong et al.95 demonstrates that multimodal architectures, which combine visual and auxiliary sensor inputs, can still be vulnerable to adversarial perturbations targeting individual modalities, exposing weaknesses in cross-modal fusion. Cai et al.96 further show that Vision Transformers, a core component in many large vision-language models, can be adapted for face anti-spoofing but remain susceptible to adversarial triggers due to the high-dimensional token interactions. Complementing these findings, Digital and Physical Face Attacks97 provides a systematic review of recent digital and real-world attack strategies, highlighting the emerging risks posed by advanced transformer- and multimodal-based face-verification pipelines.
Collectively, these insights highlight a critical shift in the landscape of adversarial attacks targeting VLM-based face verification systems. As attacks become increasingly subtle, sophisticated, and multimodal, defenders face the growing challenge of maintaining user trust and system reliability.
Defense
Face verification systems have achieved widespread adoption, ubiquitously integrated into our smartphones. These systems facilitate various functions, including device unlocking, financial transactions, and access to premium content stored on the device. In this context, the robustness of face verification systems has emerged as a critical consideration to ensure their reliability. The failure to detect adversarial smartphone attacks poses a significant risk to confidential information, encompassing emails, bank records, social media content, and personal photos. Consequently, the presence of such adversarial examples has spurred research efforts among academic and industry groups and social media platforms to develop generalizable defenses against ever-evolving adversarial attacks. As a result, the urgency of countering face attacks has intensified, driven by mounting concerns regarding user privacy. The failure to detect such attacks poses a substantial security threat, particularly given the widespread use of face verification systems in contexts such as border control. Despite the remarkable performance exhibited by face verification systems, attributed to advances in deep learning and the availability of extensive datasets, these systems remain susceptible to the increasing menace of adversarial attacks, as indicated by various studies13,17,21,23,98. Attackers invest significant time and effort into manipulating faces through physical13,98 and digital14 means, with the objective of evading face verification systems. It has been demonstrated that these systems are vulnerable to adversarial attacks stemming from perturbations introduced to the images under scrutiny20,21,85. Notably, even when such perturbations are imperceptible to the human eye, they can undermine the performance of face verification. In the literature focusing on defense strategies against adversarial examples, these strategies primarily fall within two main categories: robust optimization and pre-processing techniques, as illustrated in Fig. 3. Robust optimization, a widely employed defense approach, involves altering the training procedures or architectures of neural networks to enhance their resistance to adversarial perturbations17,23–26. While these algorithms offer some protection against specific attack methods, they remain susceptible to other adversarial mechanisms. It is essential to note that adversarial training, a component of robust optimization, requires more time and computational resources than training models solely on clean images, as it necessitates additional computations for generating online adversarial examples . Conversely, pre-processing strategies maintain the core training procedures and network architectures unchanged and instead focus on identifying, eliminating, or purifying adversarial elements. For instance, in the context of detecting adversarial examples, this involves training a binary classifier to distinguish between genuine and adversarial instances27–33. In the case of removing adversarial noise34,35, the objective is to eliminate adversarial perturbations by applying preprocessing transformations to input data before feeding it to target models. Conversely, in the context of purification, the perturbations are exclusively removed from input images containing adversarial elements36, preventing the inadvertent alteration of genuine images and the associated high false rejection rates. Securing resilient face verification systems against adversarial examples represents a complex and ongoing challenge. A multitude of adversarial defense mechanisms have been employed to safeguard FV systems from such threats. The current body of academic literature concerning defense strategies can be categorized into two primary domains: robust optimization and preprocessing. This survey offers an overview of prior research pertinent to our investigations in adversarial defenses, with a particular emphasis on preprocessing techniques. Specifically, our research centers on perturbation removal and detection strategies. Table 4 lists common benchmark methods for each defense strategy in the literature.
Table 4.
Common methods for each defense strategy in the literature.
| Defense Strategy | Authors | Method | Datasets | Attacks |
|---|---|---|---|---|
| Robustness | Kurakin et al.25 | Adversarial training with FGSM | ImageNet101 | FGSM17 |
| Jang et al.26 | Training with adversarial examples | MNIST105, CIFAR-10106 | FGSM17, C&W80, PGD23 | |
| Transformations | Guo et al.35 | Quilting, TVM, cropping, rescaling | ImageNet101 | DeepFool78, FGSM17, C&W80, I-FGSM25 |
| Shaham et al.34 | PCA, wavelet, JPEG compression | NIPS 2017 competition | FGSM17, C&W80, I-FGSM25 | |
| Detection | Gong et al.29 | Binary CNN | MNIST105, CIFAR-10106, SVHN | FGSM17, TGSM107, JSMA79 |
| Massoli et al.27 | MLP/LSTM on AFR filters | VGGFace262 | FGSM17, C&W80, BIM107 | |
| Goel et al.28 | Adaptive noise detection | Yale Face108 | DeepFool78, FGSM17, EAD109 | |
| Goswami et al.110 | SVM on AFR filters | MEDS111, PaSC112, MBGC113 | EAD109 | |
| Agarwal et al.30 | PCA + SVM | PaSC112, MEDS111, Multi-PIE114 | Universal Perturbation16, Fast Feature Fool115 | |
| Awany et al.116 | Detection framework | CASIA-WebFace59, LFW11 | FGSM17, PGD23, AdvFaces21 | |
| Purification | Debayan et al.36 | Generator + detector + purifier | CASIA-WebFace59, LFW11, CelebA117, FFHQ118 | FGSM17, PGD23, DeepFool78, AdvFaces21, GFLM85, Semantic 119 |
Perturbation removing
This type of defense aims to remove adversarial perturbations by applying transformations, such as preprocessing the input data and then sending these inputs to the target models. As Guo et al.35 applied image transformations, such as total variance minimization99, image quilting100, image cropping and rescaling, and bit-depth reduction to smooth input images. Applied on ImageNet101 dataset and shown that these defenses can be surprisingly effective against existing three attacks, they are as follows, (i) countering the (iterative) fast gradient sign method25, (ii) Deepfool78, and (iii) Carlini-Wagner attack80 in particular, when the convolutional network is trained on the images on which these transformations are performed. Dziugaite et al.102 and Das et al.103 suggested applying JPEG compression to insert images before feeding them over the network. Hendrycks et al.72; and Li et al.31, proposed defense methods based on principal component analysis (PCA). Liu et al. proposed the DNN-favorable JPEG compression, namely “feature distillation,” by redesigning the standard JPEG compression algorithm to maximize the defense efficiency while assuring the DNN testing accuracy104. As a result of the good performance of these methods on an ImageNet101 dataset in35.
Perturbation detection
Another strategic direction that defends against adversarial attacks on the FV system is detecting adversarial examples. Adversarial detection techniques have recently gained attention within the scientific community, and many adversarial detection mechanisms are deployed as a preprocessing step. The attacks addressed in this study120–122 were initially suggested in object recognition and often fail to detect attacks in a feature extraction network setting, such as in face verification. Therefore, prevalent detectors against hostile faces have only been effective in a highly restricted environment where the number of people is limited and constant during training and testing27,28,30. Defending against adversarial attacks by detection involves creating robust systems that consist of a weak model and a detection system that indicates the occurrence of attacks. Detecting subsystems are often implemented as binary detectors that discriminate between authentic and adversarial inputs. For instance, Gong et al.29 proposed to train an additional binary classifier that decides whether the input image is pure or adversarial. Grosse et al.123 adopted statistical tests in pixel space to prove that adversarial images could be distinguished and suggested introducing the “adversarial” category in the original category trained according to the model. Similarly, Metzen et al.32 proposed a detection subnetwork based on intermediate representations generated by the model at the time of inference. However, it has been shown that many detection schemes can be bypassed120. Guo et al.124 propose CCA-UD, a universal backdoor-detection framework that first partitions the training data with density-based clustering and then applies a centroid-shift test. Representative features of each cluster are superimposed on benign images; a cluster is deemed poisoned when these composites consistently induce misclassification. Because the method exploits a trigger-agnostic property—general misclassification under feature overlay—it remains effective across clean-label and dirty-label attacks and with global, local, sample-specific, and source-specific triggers, achieving superior detection rates compared with prior defences.
Adversarial training for CNN-based face verification
Conventional CNN-based face verification models, including ArcFace8 and CosFace125, have seen notable improvements in robustness via adversarial fine-tuning using techniques such as Projected Gradient Descent (PGD) and Fast Gradient Sign Method (FGSM)17,23 . However, integrating adversarial perturbations directly into training has often induced a noticeable trade-off, enhancing robustness but simultaneously diminishing accuracy on clean images due to distortions in the model’s embedding space. To mitigate these negative side effects, regularization strategies like TRADES126 have been explored to strike a balance, aiming to preserve discriminative capabilities critical for facial recognition tasks. An alternative approach involves auxiliary defense mechanisms, exemplified by FaceGuard36, which deploys a self-supervised purification and detection module without modifying the verification model itself. Such modular defenses have demonstrated high efficacy, achieving a high detection accuracy of adversarial perturbations and maintaining original accuracy for legitimate users. Nonetheless, while auxiliary modules show promise in isolating adversarial perturbations, their effectiveness relies heavily on accurately modeling diverse attack patterns, highlighting an ongoing challenge of overfitting to specific adversarial strategies and underscoring the need for continually adaptive defenses. Recent extensions, such as Adversarial Weight Perturbation and Feature-Denoising FaceNet, further improve robustness while reducing the drop in clean accuracy, indicating a move toward parameter-efficient and embedding-aware training strategies.
Adversarial training in large vision-language models (VLMs)
Adversarial training in Vision–Language Models (VLMs) presents unique challenges due to their joint multimodal embedding spaces127. Early supervised adversarial fine-tuning of CLIP-like models improved robustness but often degraded zero-shot generalization when trained on fixed-label datasets128.
Recent approaches focus on maintaining robustness while preserving generalization. Robust CLIP129 adversarially fine-tunes the vision encoder while freezing the text encoder, leading to significant robustness improvements without compromising zero-shot capabilities. Anchor-RFT130 constrains fine-tuning to anchor points in the joint vision–text space, which helps preserve out-of-distribution accuracy while enhancing robustness against PGD-style and Auto-Attack perturbations. Hyper-AT131 employs a hyper-network to generate adversarial perturbations dynamically during training, reducing computational overhead while improving robust accuracy.
Beyond adversarial training, multimodal approaches have emerged as promising solutions to enhance face-verification robustness. Kong et al.97 proposed Echo-FAS, an acoustic-based face anti-spoofing system that relies only on a speaker and microphone for liveness detection. Although Echo-FAS does not directly employ adversarial training, it illustrates how incorporating auxiliary modalities can mitigate spoofing attacks and can complement adversarially trained multimodal architectures such as M3FA95. Similarly, methods that detect manipulated facial regions using combined semantic and noise-level features, such as the framework by Kong et al.132, provide complementary defences that can be integrated with transformer-based models to improve resilience to face forgeries.
Parameter-efficient strategies, including adversarial prompt tuning133 and low-rank adaptation131, further support robust fine-tuning by maintaining clean accuracy and zero-shot performance while requiring minimal parameter updates. Transformer-based models such as S-adapter96 and multimodal fusion systems like M3FAS demonstrate the benefits of combining adversarial training with auxiliary defences and multiple modalities. Collectively, these developments reflect a clear trend toward modular, scalable, and attack-agnostic approaches that enhance the robustness of VLM-based face-verification systems while mitigating the trade-off with generalization ability.
Conclusion
In conclusion, this survey has examined recent developments in face verification systems. While advancements in recent years have enhanced accuracy and efficiency, particularly through the integration of deep learning, the path forward requires a keen awareness of the human element. Challenges surrounding privacy, ethical considerations, and the persistent issue of bias in datasets and algorithms demand our continued attention.
Future research must strive for greater technical sophistication in handling variations like pose, illumination, and aging, and prioritize the development of systems that are fair, transparent, and respectful of individual rights. By focusing on creating more diverse and representative datasets, establishing robust ethical guidelines, and ensuring accountability in deployment, we can harness the power of face verification technology for societal good while safeguarding fundamental human values.
Acknowledgements
We would like to thank our colleagues for their feedback on the earlier version of this survey.
Author contributions
All authors contributed to the study conception and design. Sohair Kilany: Conceptualization, methodology, data collection, investigation, visualization, writing original draft, review and editing. Ahmed Mahfouz: Conceptualization, methodology, investigation, validation, supervision, writing review an editing.
Funding
Open access funding provided by The Science, Technology & Innovation Funding Authority (STDF) in cooperation with The Egyptian Knowledge Bank (EKB).
Data availability
The datasets used and/or analysed during the current study are available from the corresponding author on reasonable request.
Declarations
Competing interests
The authors declare no competing interests.
Consent for publication
The article was submitted with the consent of all authors and institutions for publication.
Footnotes
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Contributor Information
Sohair Kilany, Email: sohair_kilany@mu.edu.eg.
Ahmed Mahfouz, Email: ahmed.m@aou.edu.om.
References
- 1.Fathy, M. E., Patel, V. M., & Chellappa, R. Face-based active authentication on mobile devices. In Acoustics, Speech and Signal Processing (ICASSP), 2015 IEEE International Conference On, pp. 1687–1691 (2015). 10.1109/ICASSP.2015.7178258
- 2.Crouse, D., Han, H., Chandra, D., Barbello, B., & Jain, A. K. Continuous authentication of mobile user: Fusion of face image and inertial measurement unit data. In 2015 International Conference on Biometrics (ICB), pp. 135–142 (2015). 10.1109/ICB.2015.7139043
- 3.Samangouei, P., & Chellappa, R. Convolutional neural networks for attribute-based active authentication on mobile devices. In 2016 IEEE 8th International Conference on Biometrics Theory, Applications and Systems (BTAS), pp. 1–8 (2016). 10.1109/BTAS.2016.7791163
- 4.Acien, A., Morales, A., Vera-Rodriguez, R., Fierrez, J., & Tolosana, R. Multilock: Mobile active authentication based on multiple biometric and behavioral patterns. In ACM Intl. Conf. on Multimedia, Workshop on Multimodal Understanding and Learning for Embodied Applications (MULEA), pp. 53–59 (2019). 10.1145/3347450.3357663
- 5.Huang, G., Liu, Z., Van Der Maaten, L., & Weinberger, K. Q. Densely connected convolutional networks. In 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pp. 2261–2269 (2017). 10.1109/CVPR.2017.243
- 6.He, K., Zhang, X., Ren, S., & Sun, J. Deep residual learning for image recognition. In 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pp. 770–778. IEEE, (2016). 10.1109/CVPR.2016.90
- 7.Liu, W., Wen, Y., Yu, Z., Li, M., Raj, B., & Song, L. Sphereface: Deep hypersphere embedding for face recognition. CoRR arXiv:1704.08063 (2017).
- 8.Deng, J., Guo, J., Xue, N., & Zafeiriou, S. Arcface: Additive angular margin loss for deep face recognition, 4690–4699 (2019). [DOI] [PubMed]
- 9.Schroff, F., Kalenichenko, D., & Philbin, J. Facenet: A unified embedding for face recognition and clustering. In 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pp. 815–823 (2015). 10.1109/CVPR.2015.7298682
- 10.Taigman, Y., Yang, M., Ranzato, M., & Wolf, L. Deepface: Closing the gap to human-level performance in face verification. In 2014 IEEE Conference on Computer Vision and Pattern Recognition, pp. 1701–1708 (2014). 10.1109/CVPR.2014.220
- 11.Huang, G. B., Mattar, M., Berg, T., & Learned-Miller, E. Labeled faces in the wild: A database forstudying face recognition in unconstrained environments. In Workshop on Faces in’Real-Life’Images: Detection, Alignment, and Recognition (2008)
- 12.Wolf, L., Hassner, T., & Maoz, I. Face recognition in unconstrained videos with matched background similarity, pp. 529–534 (2011). 10.1109/CVPR.2011.5995566
- 13.Liu, Y., Stehouwer, J., Jourabloo, A., & Liu, X. Deep tree learning for zero-shot face anti-spoofing. In In Proceeding of IEEE Computer Vision and Pattern Recognition, pp. 4680–4689. IEEE, (2019). 10.1109/CVPR.2019.00481
- 14.Dang, H., Liu, F., Stehouwer, J., Liu, X., & Jain, A. On the detection of digital face manipulation. In In Proceeding of IEEE Computer Vision and Pattern Recognition, Seattle, WA (2020)
- 15.Dong, Y., Liao, F., Pang, T., Hu, X., & Zhu, J. Discovering adversarial examples with momentum. CoRR arXiv:1710.06081 (2017).
- 16.Moosavi-Dezfooli, S., Fawzi, A., Fawzi, O., & Frossard, P. Universal adversarial perturbations. CoRR arXiv:1610.08401 (2016).
- 17.Goodfellow, I. J., Shlens, J., & Szegedy, C. Explaining and harnessing adversarial examples. arXiv preprint arXiv:1412.6572 (2014)
- 18.Carlini, N. A complete list of all (arxiv) adversarial example papers. (2019). https://nicholas.carlini.com/writing/2019/all-adversarial-example-papers.html
- 19.Sharif, M., Bhagavatula, S., Bauer, L., & Reiter, M. K. Accessorize to a crime: Real and stealthy attacks on state-of-the-art face recognition. In Proceedings of the 2016 ACM SIGSAC Conference on Computer and Communications Security, pp. 1528–1540. Association for Computing Machinery, New York, NY, USA (2016). 10.1145/2976749.2978392 .
- 20.Dong, Y., Su, H., Wu, B., Li, Z., Liu, W., Zhang, T., & Zhu, J. Efficient decision-based black-box adversarial attacks on face recognition. In 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pp. 7706–7714 (2019). 10.1109/CVPR.2019.00790 . IEEE
- 21.Deb, D., Zhang, J., & Jain, A. K. Advfaces: Adversarial face synthesis. CoRR arXiv:1908.05008 (2019)
- 22.Fastpass- a harmonized, modular reference system for all european automated bordercrossing points. https://www.fastpass-project.eu
- 23.Madry, A., Makelov, A., Schmidt, L., Tsipras, D., & Vladu, A. Towards deep learning models resistant to adversarial attacks. In 6th International Conference on Learning Representations, ICLR 2018, Vancouver, BC, Canada, April 30 - May 3, 2018, Conference Track Proceedings. OpenReview.net, (2018). https://openreview.net/forum?id=rJzIBfZAb
- 24.Tramèr, F. et al. Ensemble Adversarial Training: Attacks and Defenses (2020).
- 25.Kurakin, A., Goodfellow, I., & Bengio, S. Adversarial Machine Learning at Scale (2017)
- 26.Jang, Y., Zhao, T., Hong, S., & Lee, H. Adversarial defense via learning to generate diverse attacks. In 2019 IEEE/CVF International Conference on Computer Vision (ICCV), pp. 2740–2749 (2019). 10.1109/ICCV.2019.00283
- 27.Massoli, F. V., Carrara, F., Amato, G. & Falchi, F. Detection of face recognition adversarial attacks. Computer Vision and Image Understanding202, 103103 (2021). [Google Scholar]
- 28.Goel, A., Singh, A., Agarwal, A., Vatsa, M., & Singh, R. Smartbox: Benchmarking adversarial detection and mitigation algorithms for face recognition. In 2018 IEEE 9th International Conference on Biometrics Theory, Applications and Systems (BTAS), pp. 1–7 (2018). 10.1109/BTAS.2018.8698567
- 29.Gong, Z., Wang, W., & Ku, W.-S. Adversarial and clean data are not twins. arXiv preprint arXiv:1704.04960 (2017).
- 30.Agarwal, A., Singh, R., Vatsa, M., & Ratha, N. Are image-agnostic universal adversarial perturbations for face recognition difficult to detect? In 2018 IEEE 9th International Conference on Biometrics Theory, Applications and Systems (BTAS), pp. 1–7 (2018). 10.1109/BTAS.2018.8698548
- 31.Li, X., & Li, F. Adversarial examples detection in deep networks with convolutional filter statistics. In 2017 IEEE International Conference on Computer Vision (ICCV), pp. 5775–5783 (2017). 10.1109/ICCV.2017.615
- 32.Metzen, J. H., Genewein, T., Fischer, V., & Bischoff, B. On Detecting Adversarial Perturbations (2017).
- 33.Zantedeschi, V., Nicolae, M.-I., & Rawat, A. Efficient Defenses Against Adversarial Attacks, pp. 39–49. Association for Computing Machinery, (2017). 10.1145/3128572.3140449
- 34.Shaham, U. et al. Defending against Adversarial Images using Basis Functions Transformations (2018). https://api.semanticscholar.org/CorpusID:4549456
- 35.Guo, C., Rana, M., Cisse, M., & Maaten, L. Countering adversarial images using input transformations. In International Conference on Learning Representations (2018). https://openreview.net/forum?id=SyJ7ClWCb
- 36.Deb, D., Liu, X., & Jain, A. K. FaceGuard: A Self-Supervised Defense Against Adversarial Face Images. IEEE Computer Society, Los Alamitos, CA, USA (2023). 10.1109/FG57933.2023.10042617 .
- 37.Evtimov, I. et al. Robust physical-world attacks on machine learning models. CoRR arXiv:1707.08945 (2017).
- 38.Zügner, D., Akbarnejad, A., & Günnemann, S. Adversarial attacks on neural networks for graph data. In Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, pp. 2847–2856 (2018).
- 39.Viola, P., & Jones, M. Rapid object detection using a boosted cascade of simple features. In Proceedings of the 2001 IEEE Computer Society Conference on Computer Vision and Pattern Recognition. CVPR 2001, vol. 1, p. (2001). 10.1109/CVPR.2001.990517
- 40.Zhang, K., Zhang, Z., Li, Z. & Qiao, Y. Joint face detection and alignment using multitask cascaded convolutional networks. IEEE Signal Process. Lett.23, 1499–1503 (2016). [Google Scholar]
- 41.Deng, J., Guo, J., Ververas, E., Kotsia, I., & Zafeiriou, S. Retinaface: Single-shot multi-level face localisation in the wild. In 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pp. 5202–5211 (2020). 10.1109/CVPR42600.2020.00525
- 42.Wang, D., Otto, C. & Jain, A. K. Face search at scale. IEEE Transactions on Pattern Analysis and Machine Intelligence39(6), 1122–1136. 10.1109/TPAMI.2016.2582166 (2017). [DOI] [PubMed] [Google Scholar]
- 43.Ghazi, M. M., & Ekenel, H. K. A Comprehensive Analysis of Deep Learning Based Representation for Face Recognition (2016).
- 44.Dou, P., Shah, S. K., & Kakadiaris, I. A. End-to-end 3D face reconstruction with deep neural networks (2017).
- 45.Zhao, J. et al. Dual-agent gans for photorealistic and identity preserving profile face synthesis. In Guyon, I., Luxburg, U. V., Bengio, S., Wallach, H., Fergus, R., Vishwanathan, S., Garnett, R. (eds.) Advances in Neural Information Processing Systems, vol. 30. Curran Associates, Inc., (2017). https://proceedings.neurips.cc/paper/2017/file/7cbbc409ec990f19c78c75bd1e06f215-Paper.pdf
- 46.Sun, Y., Wang, X., & Tang, X. Sparsifying Neural Network Connections for Face Recognition (2016).
- 47.Yang, J., Reed, S., Yang, M.-H. & Lee, H. Weakly-supervised Disentangling with Recurrent Transformations for 3D View Synthesis (MIT Press, 2015). [Google Scholar]
- 48.Zhou, E., Cao, Z., & Sun, J. GridFace: Face Rectification via Learning Local Homography Transformations (2018). arXiv:1808.06210
- 49.Deng, J., Cheng, S., Xue, N., Zhou, Y., & Zafeiriou, S. UV-GAN: Adversarial Facial UV Map Completion for Pose-invariant Face Recognition (2018).
- 50.Belhumeur, P. N., Hespanha, J. P. & Kriegman, D. J. Eigenfaces vs. fisherfaces: Recognition using class specific linear projection. IEEE Trans. Pattern Anal. Mach. Intell.19(7), 711–720 (1997). [Google Scholar]
- 51.Deng, W., Hu, J., Lu, J. & Guo, J. Transform-invariant pca: A unified approach to fully automatic facealignment, representation, and recognition. IEEE Transactions on Pattern Analysis and Machine Intelligence36(06), 1275–1284. 10.1109/TPAMI.2013.194 (2014). [DOI] [PubMed] [Google Scholar]
- 52.Deng, W., Guo, J. & Hu, J. Extended src: Undersampled face recognition via intraclass variant dictionary. IEEE Transactions on Pattern Analysis and Machine Intelligence34(09), 1864–1870. 10.1109/TPAMI.2012.30 (2012). [DOI] [PubMed] [Google Scholar]
- 53.Wright, J., Yang, A. Y., Ganesh, A., Sastry, S. S. & Ma, Y. Robust face recognition via sparse representation. IEEE Transactions on Pattern Analysis and Machine Intelligence31(2), 210–227. 10.1109/TPAMI.2008.79 (2009). [DOI] [PubMed] [Google Scholar]
- 54.Ahonen, T., Hadid, A. & Pietikäinen, M. Face recognition with local binary patterns. In Computer Vision - ECCV 2004 (eds Pajdla, T. & Matas, J.) 469–481 (Springer, Berlin, Heidelberg, 2004). [Google Scholar]
- 55.Wen, Y., Zhang, K., Li, Z., & Qiao, Y. A discriminative feature learning approach for deep face recognition. In Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, October 11–14, 2016, Proceedings, Part VII 14, pp. 499–515 (2016). Springer
- 56.Chopra, S., Hadsell, R., & LeCun, Y. Learning a similarity metric discriminatively, with application to face verification. In 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’05), vol. 1, pp. 539–5461 (2005). 10.1109/CVPR.2005.202
- 57.Parkhi, O. M., Vedaldi, A., & Zisserman, A. Deep face recognition. In Proceedings of the British Machine Vision Conference (BMVC), pp. 41–14112. BMVA Press, (2015). 10.5244/C.29.41
- 58.Huang, X. et al. Face verification based on deep learning for person tracking in hazardous goods factories. Processes10(2), 380. 10.3390/pr10020380 (2022). [Google Scholar]
- 59.Yi, D., Lei, Z., Liao, S., & Li, S. Z. Learning face representation from scratch. CoRR arXiv:1411.7923 (2014).
- 60.Klare, B. F. et al. Pushing the frontiers of unconstrained face detection and recognition: Iarpa janus benchmark a. In 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pp. 1931–1939 (2015). 10.1109/CVPR.2015.7298803
- 61.Miller, D., Kemelmacher-Shlizerman, I., & Seitz, S. M. Megaface: A million faces for recognition at scale. CoRR arXiv:1505.02108 (2015).
- 62.Cao, Q., Shen, L., Xie, W., Parkhi, O. M., & Zisserman, A. Vggface2: A dataset for recognising faces across pose and age. In 2018 13th IEEE International Conference on Automatic Face Gesture Recognition (FG 2018), pp. 67–74 (2018). 10.1109/FG.2018.00020 . IEEE
- 63.Zheng, T., & Deng, W. Cross-pose lfw: A database for studying cross-pose face recognition in unconstrained environments. Technical Report 18-01, Beijing University of Posts and Telecommunications (2018).
- 64.Zhu, Z. et al. Masked face recognition challenge: The webface260m track report. CoRR arXiv:2108.07189 (2021).
- 65.Learned-Miller, G. B. H. E. Labeled faces in the wild: Updates and new reporting procedures. Technical Report UM-CS-2014-003, University of Massachusetts, Amherst (2014).
- 66.Jia, S., Guo, G. & Xu, Z. A survey on 3d mask presentation attack detection and countermeasures. Pattern Recognition98, 107032. 10.1016/j.patcog.2019.107032 (2019). [Google Scholar]
- 67.Sebastien, M., Nixon, M. & Li, S. Handbook of Biometric Anti-Spoofing: Trusted Biometrics Under Spoofing Attacks (Springer, 2014). [Google Scholar]
- 68.Manjani, I., Tariyal, S., Vatsa, M., Singh, R. & Majumdar, A. Detecting silicone mask-based presentation attack via deep dictionary learning. IEEE Transactions on Information Forensics and Security12(7), 1713–1723. 10.1109/TIFS.2017.2676720 (2017). [Google Scholar]
- 69.Xu, Y., Price, T., Frahm, J.-M., & Monrose, F. Virtual u: Defeating face liveness detection by building virtual models from your public photos. In 25th USENIX Security Symposium (USENIX Security 16), pp. 497–512. USENIX Association, (2016). https://www.usenix.org/conference/usenixsecurity16/technical-sessions/presentation/xu
- 70.Szegedy, C., Zaremba, W., Sutskever, I., Bruna, J., Erhan, D., Goodfellow, I., & Fergus, R. Intriguing properties of neural networks. arXiv preprint arXiv:1312.6199 (2013).
- 71.Papernot, N. et al. Practical Black-Box Attacks against Machine Learning (2017).
- 72.Hendrycks, D., & Gimpel, K. Early methods for detecting adversarial images. arXiv preprint arXiv:1608.00530 (2016).
- 73.Thies, J., Zollhöfer, M., Stamminger, M., Theobalt, C., & Nießner, M. Face2Face: Real-time Face Capture and Reenactment of RGB Videos (2020).
- 74.Rossler, A. et al. Faceforensics++: Learning to detect manipulated facial images. In 2019 IEEE/CVF International Conference on Computer Vision (ICCV), pp. 1–11 (2019). 10.1109/ICCV.2019.00009
- 75.Choi, Y. et al. Stargan: Unified generative adversarial networks for multi-domain image-to-image translation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 8789–8797 (2018). 10.1109/CVPR.2018.00916
- 76.Liu, M. et al. Stgan: A unified selective transfer network for arbitrary image attribute editing. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 3673–3682 (2019).
- 77.Karras, T. et al. Analyzing and improving the image quality of stylegan. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8110–8119 (2020). 10.1109/CVPR42600.2020.00813
- 78.Moosavi-Dezfooli, S.-M., Fawzi, A., & Frossard, P. DeepFool: a simple and accurate method to fool deep neural networks (2016).
- 79.Papernot, N. et al. The limitations of deep learning in adversarial settings. In 2016 IEEE European Symposium on Security and Privacy (EuroS &P), pp. 372–387 (2016). IEEE
- 80.Carlini, N., & Wagner, D. Towards Evaluating the Robustness of Neural Networks (2017).
- 81.Sabour, S., Cao, Y., Faghri, F., & Fleet, D. J. Adversarial Manipulation of Deep Representations (2016)
- 82.Zhou, F., Yin, B., Ling, H., Zhou, Q., & Wang, W. Improving the transferability of adversarial attacks on face recognition with diverse parameters augmentation. In Proceedings of the Computer Vision and Pattern Recognition Conference (CVPR), pp. 3516–3527 (2025)
- 83.Yu, Y. et al. Toward model resistant to transferable adversarial examples via trigger activation. IEEE Transactions on Information Forensics and Security20, 3745–3757. 10.1109/TIFS.2025.3553043 (2025). [Google Scholar]
- 84.Song, Q., Wu, Y., & Yang, L. Attacks on state-of-the-art face recognition using attentional adversarial attack generative network. CoRR arXiv:1811.12026 (2018)
- 85.Dabouei, A., Soleymani, S., Dawson, J., & Nasrabadi, N. Fast geometrically-perturbed adversarial faces. In 2019 IEEE Winter Conference on Applications of Computer Vision (WACV), pp. 1979–1988. IEEE Computer Society, (2019). 10.1109/WACV.2019.00215 .
- 86.Guo, W., Tondi, B. & Barni, M. A master key backdoor for universal impersonation attack against dnn-based face verification. Pattern Recognition Letters144, 61–67 (2021). [Google Scholar]
- 87.Park, J., McLaughlin, N., & Alouani, I. Mind the gap: Detecting black-box adversarial attacks in the making through query update analysis. In Proceedings of the Computer Vision and Pattern Recognition Conference (CVPR), pp. 10235–10243 (2025).
- 88.Mao, X., Chen, Y., Li, Y., He, Y., & Xue, H. GAP++: learning to generate target-conditioned adversarial examples. CoRR arXiv:2006.05097 (2020).
- 89.Bose, A., & Aarabi, P. Adversarial attacks on face detectors using neural net based constrained optimization. In 2018 IEEE 20th International Workshop on Multimedia Signal Processing (MMSP), pp. 1–6 (2018). IEEE
- 90.Kilany, S. A., Mahfouz, A., Zaki, A. M., & Sayed, A. Analysis of adversarial attacks on face verification systems. In Proceedings of the International Conference on Artificial Intelligence and Computer Vision (AICV2021), pp. 463–472. Springer, Cham (2021).
- 91.Zhang, J. et al. Anyattack: Towards large-scale self-supervised adversarial attacks on vision-language models. In Proceedings of the Computer Vision and Pattern Recognition Conference (CVPR), pp. 19900–19909 (2025).
- 92.Liu, Y. et al. Projattacker: A configurable physical adversarial attack for face recognition via projector. In Proceedings of the Computer Vision and Pattern Recognition Conference (CVPR), pp. 21248–21257 (2025).
- 93.Wang, J., Zhang, H., & Yuan, Y. Adv-cpg: A customized portrait generation framework with facial adversarial attacks. In Proceedings of the Computer Vision and Pattern Recognition Conference (CVPR), pp. 21001–21010 (2025).
- 94.Kong, D., Liang, S., Zhu, X., Zhong, Y. & Ren, W. Patch is enough: naturalistic adversarial patch against vision-language pre-training models. Visual Intelligence2(1), 1–10 (2024). [Google Scholar]
-
95.Kong, C. et al. M
 3fas: An accurate and robust multimodal mobile face anti-spoofing system. IEEE Transactions on Dependable and Secure Computing21(6), 5650–5666. 10.1109/TDSC.2024.3381598 (2024). [Google Scholar]
3fas: An accurate and robust multimodal mobile face anti-spoofing system. IEEE Transactions on Dependable and Secure Computing21(6), 5650–5666. 10.1109/TDSC.2024.3381598 (2024). [Google Scholar] - 96.Cai, R. et al. S-adapter: Generalizing vision transformer for face anti-spoofing with statistical tokens. IEEE Transactions on Information Forensics and Security19, 8385–8397. 10.1109/TIFS.2024.3420699 (2024). [Google Scholar]
- 97.Kong, C. et al. Digital and physical face attacks: Reviewing and one step further. APSIPA Transactions on Signal and Information Processing, 12(1), (2022)
- 98.Liu, Y., Stehouwer, J., & Liu, X. On Disentangling Spoof Trace for Generic Face Anti-Spoofing (2020).
- 99.Rudin, L. I., Osher, S. & Fatemi, E. Nonlinear total variation based noise removal algorithms. Physica D: Nonlinear Phenomena60(1), 259–268 (1992). [Google Scholar]
- 100.Efros, A. A., & Freeman, W. T. Image quilting for texture synthesis and transfer. In Proceedings of the 28th Annual Conference on Computer Graphics and Interactive Techniques, pp. 341–346 (2001)
- 101.Deng, J. et al. Imagenet: A large-scale hierarchical image database. In 2009 IEEE Conference on Computer Vision and Pattern Recognition, pp. 248–255 (2009). 10.1109/CVPR.2009.5206848
- 102.Dziugaite, G. K., Ghahramani, Z., & Roy, D. M. A study of the effect of JPG compression on adversarial images (2016).
- 103.Das, N., Shanbhogue, M., Chen, S.-T., Hohman, F., Chen, L., Kounavis, M. E., & Chau, D. H. Keeping the bad guys out: Protecting and vaccinating deep learning with jpeg compression. arXiv:1705.02900 (2017)
- 104.Liu, Z. et al. Feature distillation: Dnn-oriented jpeg compression against adversarial examples. In 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pp. 860–868 (2019). IEEE.
- 105.Y., L. The mnist database of handwritten digits. http://yann.lecun.com/exdb/mnist/ (1998)
- 106.Krizhevsky, A., & Hinton, G. Learning multiple layers of features from tiny images. Master’s thesis, Department of Computer Science, University of Toronto, 32–33 (2009).
- 107.Kurakin, A., Goodfellow, I. J., & Bengio, S. Adversarial examples in the physical world. CoRR arXiv:abs/1607.02533 (2016).
- 108.Georghiades, A. S., Belhumeur, P. N. & Kriegman, D. J. From few to many: illumination cone models for face recognition under variable lighting and pose. IEEE Transactions on Pattern Analysis and Machine Intelligence23(6), 643–660. 10.1109/34.927464 (2001). [Google Scholar]
- 109.Chen, P.-Y., Sharma, Y., Zhang, H., Yi, J., & Hsieh, C.-J. Ead: Elastic-net attacks to deep neural networks via adversarial examples 32(1), 10–17 (2018).
- 110.Goswami, G., Agarwal, A., Ratha, N., Singh, R. & Vatsa, M. Detecting and mitigating adversarial perturbations for robust face recognition. International Journal of Computer Vision127(6), 719–742 (2019). [Google Scholar]
- 111.Founds, A., Orlans, N., Genevieve, W., & Watson, C. NIST Special Databse 32 - Multiple Encounter Dataset II (MEDS-II). NIST Interagency/Internal Report (NISTIR), National Institute of Standards and Technology, Gaithersburg, MD (2011). 10.6028/NIST.IR.7807 . https://tsapps.nist.gov/publication/get_pdf.cfm?pub_id=908383
- 112.Beveridge, J. R. et al. The challenge of face recognition from digital point-and-shoot cameras. In 2013 IEEE Sixth International Conference on Biometrics: Theory, Applications and Systems (BTAS), pp. 1–8. IEEE, (2013). 10.1109/BTAS.2013.6712704
- 113.Phillips, P. et al. Overview of the Multiple Biometrics Grand Challenge. NIST Interagency/Internal Report (NISTIR), National Institute of Standards and Technology, Gaithersburg, MD (2009). https://tsapps.nist.gov/publication/get_pdf.cfm?pub_id=903086
- 114.Gross, R., Matthews, I., Cohn, J., Kanade, T. & Baker, S. Multi-pie. Image and Vision Computing28(5), 807–813. 10.1016/j.imavis.2009.08.002 (2010). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 115.Mopuri, K. R., Garg, U., & Babu, R. V. Fast feature fool: A data independent approach to universal adversarial perturbations. CoRR arXiv:1707.05572 (2017).
- 116.Sayed, A., Kinlany, S., Zaki, A. & Mahfouz, A. Veriface: Defending against adversarial attacks in face verification systems. Computers, Materials & Continua76(3), 3151–3166. 10.32604/cmc.2023.040256 (2023). [Google Scholar]
- 117.Liu, Z., Luo, P., Wang, X., & Tang, X. Deep learning face attributes in the wild, 3730–3738 (2015).
- 118.Karras, T., Laine, S., & Aila, T. A style-based generator architecture for generative adversarial networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 4401–4410 (2019). 10.1109/CVPR.2019.00453 [DOI] [PubMed]
- 119.Qiu, H. et al. Semanticadv: Generating adversarial examples via attribute-conditional image editing. CoRR arXiv:1906.07927 (2019).
- 120.Carlini, N., & Wagner, D. Adversarial Examples Are Not Easily Detected: Bypassing Ten Detection Methods (2017).
- 121.Athalye, A., Carlini, N., & Wagner, D. Obfuscated Gradients Give a False Sense of Security: Circumventing Defenses to Adversarial Examples (2018).
- 122.Carlini, N., & Wagner, D. MagNet and “Efficient Defenses Against Adversarial Attacks” are Not Robust to Adversarial Examples (2017).
- 123.Grosse, K., Manoharan, P., Papernot, N., Backes, M., & McDaniel, P. On the (Statistical) Detection of Adversarial Examples (2017).
- 124.Guo, W., Tondi, B. & Barni, M. Universal detection of backdoor attacks via density-based clustering and centroids analysis. IEEE Transactions on Information Forensics and Security19, 970–984. 10.1109/TIFS.2023.3329426 (2024). [Google Scholar]
- 125.Wang, H. et al. Cosface: Large margin cosine loss for deep face recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (2018).
- 126.Zhang, H. et al. Theoretically principled trade-off between robustness and accuracy. In International Conference on Machine Learning, pp. 7472–7482 (2019). PMLR
- 127.Radford, A. et al. Learning transferable visual models from natural language supervision. In Meila, M., Zhang, T. (eds.) Proceedings of the 38th International Conference on Machine Learning. Proceedings of Machine Learning Research, vol. 139, pp. 8748–8763. PMLR, (2021). https://proceedings.mlr.press/v139/radford21a.html
- 128.Mao, C., Geng, S., Yang, J., Wang, X., & Vondrick, C. Understanding zero-shot adversarial robustness for large-scale models. arXiv preprint arXiv:2212.07016 (2022).
- 129.Schlarmann, C., Singh, N. D., Croce, F., & Hein, M. Robust clip: Unsupervised adversarial fine-tuning of vision embeddings for robust large vision-language models. arXiv preprint arXiv:2402.12336 (2024).
- 130.Zhou, W., Bai, S., Mandic, D. P., Zhao, Q., & Chen, B. Revisiting the adversarial robustness of vision language models: a multimodal perspective. arXiv preprint arXiv:2404.19287 (2024).
- 131.Ghiasvand, S., Oskouie, H. E., Alizadeh, M., & Pedarsani, R. Few-shot adversarial low-rank fine-tuning of vision-language models. arXiv preprint arXiv:2505.15130 (2025).
- 132.Kong, C. et al. Detect and locate: Exposing face manipulation by semantic- and noise-level telltales. IEEE Transactions on Information Forensics and Security17, 1741–1756. 10.1109/TIFS.2022.3169921 (2022). [Google Scholar]
- 133.Zhang, J. et al. Adversarial prompt tuning for vision-language models. In European Conference on Computer Vision, pp. 56–72 (2024). Springer.
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.
Data Availability Statement
The datasets used and/or analysed during the current study are available from the corresponding author on reasonable request.