

Abstract
Selecting prior distributions in Bayesian regression analysis is a challenging task. Even if knowledge already exists, gathering this information and translating it into informative prior distributions is both resource-demanding and difficult to perform objectively. In this paper, we analyze the idea of using large-language models (LLMs) to suggest suitable prior distributions. The substantial amount of information absorbed by LLMs gives them a potential for suggesting knowledge-based and more objective informative priors. We have developed an extensive prompt to not only ask LLMs to suggest suitable prior distributions based on their knowledge but also to verify and reflect on their choices. We evaluated the three popular LLMs Claude Opus, Gemini 2.5 pro, and ChatGPT 4o-mini for two different real datasets: an analysis of heart disease risk and an analysis of variables affecting the strength of concrete. For all the variables, the LLMs were capable of suggesting the correct direction for different associations, e.g., that the risk of heart disease is higher for males than females or that the strength of concrete is reduced with the amount of water added. The LLMs suggested both moderately and weakly informative priors, and the moderate priors were in many cases too confident, resulting in prior distributions with little agreement with the data. The quality of the suggested prior distributions was measured by computing the distance to the distribution of the maximum likelihood estimator (“data distribution”) using the Kullback-Leibler divergence. In both experiments, Claude and Gemini provided better prior distributions than ChatGPT. For weakly informative priors, ChatGPT and Gemini defaulted to a mean of 0, which was “unnecessarily vague” given their demonstrated knowledge. In contrast, Claude did not. This is a significant performance difference and a key advantage for Claude’s approach. The ability of LLMs to suggest the correct direction for different associations demonstrates a great potential for LLMs as an efficient and objective method to develop informative prior distributions. However, a significant challenge remains in calibrating the width of these priors, as the LLMs demonstrated a tendency towards both overconfidence and underconfidence. Our code is available at https://github.com/hugohammer/LLM-priors.
Subject terms: Engineering, Mathematics and computing
Introduction
Large Language Models (LLMs) can generate human-like text with remarkable fluency and coherence. Their learned parameters have also absorbed a substantial amount of knowledge, making them useful for many real-world tasks. Examples include clinical decision support and patient communication within healthcare1,2, fraud detection and market sentiment analysis within finance3,4, and enabling personalized learning and real-time student support within education 5,6, to name a few. However, the knowledge LLMs contain is inherently unstructured and derived from patterns in their training data. This can lead to outputs that are inconsistent, biased, or factually incorrect–a phenomenon often termed “hallucination” 7. Therefore, while LLMs are useful sources for quickly accessing information, relying on them in isolation carries significant risks.
Empirical reasoning is a fundamental part of scientific discovery and knowledge acquisition in general. Statistical modeling and analysis are the formal language of this process, allowing researchers to draw robust conclusions and quantify uncertainty. In many situations, it can be beneficial to combine pre-existing knowledge or beliefs with information from empirical data to leverage both sources of information 8. Bayesian statistics offers a popular framework for this, consisting of a likelihood function, which represents the information from the empirical data, and prior distributions, which are formulated to represent pre-existing knowledge and beliefs. These two sources of information are combined using Bayes’ rule, resulting in the posterior distribution. However, formulating informative prior distributions is often difficult, and practitioners frequently resort to using wide, non-informative priors 9.
Some statistical concepts aim to compute distributions for parameters without assuming a prior distribution. The Fiducial Distribution (FD), proposed by R. A. Fisher 10, begins with the sampling distribution of the data given the parameter and inverts this relationship to obtain a distribution for the parameter given the observed data. However, many statisticians consider this approach problematic because it conflates the probability of random variables with fixed parameters. A more modern but related concept is the Confidence Distribution (CD)11, which can be used to construct confidence intervals at any confidence level and to derive point estimates such as the mean, mode, or median. Other frameworks with similar aims include generalized fiducial inference12, inferential models 13, structural inference 14, and approaches based on likelihood functions 15 or Dempster–Shafer belief functions 16.
Whether using non-informative priors in Bayesian models or adopting FD, CD, or the other approaches above, existing knowledge is excluded from the analysis, potentially resulting in the loss of valuable information. While one could conduct a substantial literature review for a given problem to develop informative priors, this approach is highly resource-demanding and challenging to compile into objective and informative prior distributions 8.
Given the vast amount of knowledge absorbed by LLMs, an appealing idea is to combine this knowledge with the information in available empirical data. However, how to perform such a combination in practice is not obvious. In this paper, we analyse the idea of casting this problem into a Bayesian framework, where we let LLMs represent pre-existing knowledge in the form of informative prior distributions. To develop suitable LLM-based prior distributions, we describe the problem we want to study to the LLM – for instance, potential risk factors for a disease – and specify the Bayesian regression model we will use to analyze the data, such as a logistic regression model with Gaussian prior distributions for the regression coefficients. We then ask the LLM to use its knowledge to suggest suitable values for the hyperparameters of these prior distributions. We require the model to provide a detailed justification for the value selected for each hyperparameter. We also ask the LLM to suggest multiple sets of priors (e.g., moderately and weakly informative) based on its domain knowledge and to assign a relative weighting or confidence score to each suggested set. The exact prompts used in this study are available in the supplementary material.
Previous research has explored the idea of using Large Language Model (LLM) knowledge to improve models through methods such as feature selection and engineering17. For instance,18 use LLMs to incorporate user’s prior knowledge, while19 leverage them to suggest prior distributions for improving the prediction of urinary tract infections in people living with dementia. Others have used LLMs to generate synthetic data from public datasets, which define priors on linear models through a separate likelihood term20, or to search over a potentially infinite set of concepts within Concept Bottleneck Models21. In contrast to these works, our focus is on analyzing how the suggested prior distributions agree with the data and developing effective prompts for LLMs to obtain well-formed prior distributions.
The main contributions of this paper are:
We develop an extensive prompt for LLMs to suggest suitable prior distributions, requiring the LLM to reflect on its use of knowledge, propose multiple prior distribution sets, and critically justify its choices with confidence scores. This approach is a key contribution because it elevates the interaction from a simple query to a structured, interpretable knowledge elicitation process that produces more reliable outputs.
We visualize and systematically quantify the quality of the prior distributions suggested by the three popular LLMs. We find that the more confident “moderately informative” priors were often worse (had higher KL divergence) than the weakly informative ones. It suggests a meta-level overconfidence: the LLMs are not only overconfident in their parameter estimates but also in their assessment of which set of priors is better.
We evaluate whether the inclusion of LLM-based prior information can improve prediction performance.
Methodology
Let the stochastic variable  denote a dataset. For instance, may consist of p input features
denote a dataset. For instance, may consist of p input features 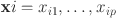 for
for 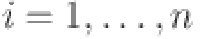 samples, along with their associated responses
samples, along with their associated responses 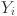 , for . The goal of Bayesian statistics is to infer unknown parameters
, for . The goal of Bayesian statistics is to infer unknown parameters 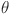 , for example regression coefficients, by incorporating both prior knowledge and the information contained in the data . Prior knowledge and beliefs are captured by the prior distribution
, for example regression coefficients, by incorporating both prior knowledge and the information contained in the data . Prior knowledge and beliefs are captured by the prior distribution 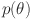 . The likelihood function
. The likelihood function  expresses the probability of observing the data given a specific set of parameter values .
expresses the probability of observing the data given a specific set of parameter values .
A common and intuitive approach to parameter inference is to find the value of that maximizes the likelihood function. This is known as the maximum likelihood estimator (MLE). Since the MLE is a function of the data , for example, the sample mean, it is also a stochastic variable that follows a distribution. In Bayesian statistics, by contrast, inference about is based on evaluating the posterior distribution:
| 1 |
A key distinction in Bayesian statistics is that the unknown parameter is treated as a stochastic variable, while in frequentist statistics it is considered fixed. The posterior distribution combines the information regarding from both the data and the prior distribution. Figure 1 illustrates two examples from the cement strength experiment in “Concrete compressive strength”, where the plots show the prior, MLE, and posterior distributions for the regression coefficients of the variables cement and blast furnace slag. The resulting posterior distributions lie between the prior and MLE distributions. Furthermore, we observe that there is little agreement between the data (represented by the MLE) and the prior distribution, which is generally undesirable. This issue will be discussed further in “Evaluation of LLM priors”.
Figure 1.

Cement strength example: Visualization of prior, MLE, and posterior distributions. The prior distributions were suggested by ChatGPT.
As described in the introduction, the aim of this paper is to evaluate the potential of state-of-the-art large language models (LLMs) to suggest informative and reliable prior distributions. This enables the use of both the knowledge encoded in LLMs and the observed data as sources of information. In “LLM prompts”, we describe the prompts sent to the LLMs, and in “Evaluation of LLM priors”, we outline how we evaluate the quality of the suggested prior distributions.
LLM prompts
Listing 1 shows the main components of the suggested prompt, illustrated using the heart disease example from “Heart disease”. The complete prompts used in this study are available in the supplementary material. The objective is not only to obtain prior distributions from the LLMs, but also to require them to explain their reasoning, propose multiple sets of priors, and discuss their strengths, weaknesses, and level of confidence. This structured elicitation process is a core part of our methodology; it is designed to move beyond a simple query that might yield an unsubstantiated number, and instead forces the LLM into a more rigorous process of justification. This makes the resulting suggestions more reliable and interpretable than those from a simple ’ask and receive’ approach. This prompt was not the first one used but was rather a result of iterative refinement that can provide valuable insights for other researchers looking to use LLMs for similar tasks.
Evaluation of LLM priors
In this section, we describe how we evaluate the quality of prior distributions suggested by LLMs. On the one hand, we require that the prior distribution is not in significant disagreement with the observed data, that is, the data should not be too “surprising” under the prior. In the examples in Fig. 1, the observed data are clearly a substantial surprise to the prior distributions. To avoid such surprises, it is common to select wide or uninformative priors. On the other hand, we also want the priors to be informative and contribute useful information to the analysis. Simply put, selecting a good prior involves a trade-off between reducing the risk of surprise and being informative.
A fundamental method for assessing how surprising the data are under the prior is to generate synthetic data,  , from the marginal data distribution:
, from the marginal data distribution:
| 2 |
also referred to as the prior predictive distribution 22. The degree of disagreement between the synthetic data and the observed data is then quantified using summary statistics such as the mean, standard deviation, and quantiles. A drawback of this method is that it can be challenging to identify suitable statistics, especially for high-dimensional data, to meaningfully capture the level of disagreement.
In this paper, we instead focus on directly comparing the two sources of information: the likelihood and the prior distribution, a comparison that has received less attention in the literature most probably because the MLE is more of a frequentist than Bayesian concept. While the exact distribution of the MLE is usually unknown, it can often be efficiently estimated from the data. For example, it is well known that the MLE is asymptotically Gaussian 23. Non-parametric approaches, such as bootstrapping, can also be used for estimation.
When assessing the quality of a prior distribution, we aim to evaluate both how surprising the data are under the prior and how informative the prior is. The Kullback–Leibler (KL) divergence is a metric well suited for this purpose:
| 3 |
where 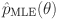 denotes the approximation of the MLE distribution based on the observed data. The intuition is that if the prior assigns low probability mass to regions where is high, then the KL divergence will be large, as the prior appears to be surprised by the data. Since appears in the denominator, the divergence substantially penalizes prior distributions that are in conflict with the data. In contrast, if the MLE is a surprise to the prior, the penalty is smaller, an asymmetry that aligns well with practical reasoning.
denotes the approximation of the MLE distribution based on the observed data. The intuition is that if the prior assigns low probability mass to regions where is high, then the KL divergence will be large, as the prior appears to be surprised by the data. Since appears in the denominator, the divergence substantially penalizes prior distributions that are in conflict with the data. In contrast, if the MLE is a surprise to the prior, the penalty is smaller, an asymmetry that aligns well with practical reasoning.
The KL divergence has previously been used to measure prior–data conflict, e.g., in Nott et al. 24, but typically with the focus on comparing the prior with the posterior. However, in our experiments we observed that in many cases where the MLE was a substantial surprise to the prior distribution, it could still be a substantial overlap between the prior and the posterior. Therefore we find it more useful to compare the prior directly with the MLE distribution.
Finally it is important to remark that in a pure Bayesian framework, a prior distribution is not inherently ’wrong’ simply because it diverges from the observed data. For the purpose of evaluating the quality of the suggested LLM priors, we utilize the MLE distribution as a practical, data-driven benchmark even if it is not so common to include in Bayesian analysis.
Experiments and results
To evaluate the potential for LLMs to suggest useful informative prior distributions, we used three state-of-the-art models: ChatGPT-4o-mini25, Gemini 2.5 Pro26, and Claude Opus27. The complete prompts sent to the LLMs and their responses are available in the supplementary material.
Heart disease
In this example, we consider the Cleveland Heart Disease dataset 28. The dataset contains 14 variables. A common application is to predict the presence or absence of coronary artery disease (CAD) in a patient based on 13 other patient characteristics, or to analyse associations between the variables. The dataset comprises 303 patients and has no missing data. In our experiments, we used only the continuous variables in the dataset, along with sex. The other categorical variables were omitted because one-hot encoding would generate many explanatory variables (one for each category except one), which would make the analyses in this section unwieldy. The variables used in this experiment to analyse associations with CAD are shown in Table 1.
Table 1.
Heart disease example: description of the variables.
| Variable name | Description | Measuring unit |
|---|---|---|
| age | Age of the individual | years |
| sex | Biological sex (binary, male = 1, female = 0) | dimensionless |
| trestbps | Resting blood pressure on admission | mmHg |
| chol | Serum cholesterol level | mg/dl |
| thalach | Maximum heart rate achieved | beats per minute |
| oldpeak | ST depression induced by exercise relative to rest | mm |
We assume a logistic regression model relating CAD to the variables in Table 1, with Gaussian prior distributions for the regression coefficients. When running the prompt in Sect. 1.1 in the supplementary material, with a compressed version shown in Listing 1, all three LLMs responded convincingly, referring to reliable sources such as the Framingham Heart Study 29, the MONICA project 30, and various meta-analyses. All the LLMs were able to recall that the regression coefficients in logistic regression are represented by log-odds ratios. This required the LLMs to convert any known odds ratio and linear associations into the log-odds format. All of the LLMs successfully performed this conversion. The LLMs suggested two sets of priors: moderately and weakly informative. ChatGPT was 60% and 40% confident in the moderately and weakly informative priors, respectively, while Gemini and Claude were 65% and 35% confident, respectively. In other words, all three LLMs expressed the highest confidence in the moderately informative priors.
Figure 2 shows the Gaussian approximation of the Maximum Likelihood Estimation (MLE) distribution and the suggested moderately informative priors for the three LLMs. Inspection of the plots reveals that in all cases, the prior distributions suggest the same sign for the log-odds ratio as the MLE. That is, if the data indicate that an increased value of a predictor increases the probability of CAD, the priors reflect the same directional belief. However, the expected magnitudes of the log-odds ratios can differ substantially. For the variable age, all three priors assume a far stronger association with CAD than what is observed in the data. This weak association is somewhat surprising, as it is well-established that the risk of CAD increases with age. The three prior distributions only partly overlap with the MLE, which indicates a significant discrepancy between the prior beliefs and the data. Similarly, for the variable sex, there is a disagreement, with the priors suggesting a lower log-odds ratio compared to the MLE. The narrowness of these priors suggests overconfidence from the LLMs, as the data are quite surprising relative to these distributions. For trestbps, Claude’s prior aligns well with the MLE, while the other two LLMs suggest smaller log-odds ratios. For chol and oldpeak, the prior distributions appear to overlap well with the likelihood and show good agreement on the log-odds ratio. Finally, for thalach, the prior distributions suggest smaller log-odds ratios compared to the data. Furthermore, the priors are overly confident, resulting in poor coverage of the MLE distribution.
Figure 2.

Heart disease example: MLE distributions and the moderately informative LLM prior distributions for the different variables.
Since some of the prior distributions were exactly the same for two of the LLMs, this raises the concern that they might have relied on identical information, which is not necessarily reliable. However, inspecting their outputs shows that ChatGPT specifically referred to the Framingham Heart Study, the MESA study, and meta-analyses, while Claude referred to the Framingham Heart Study, the MONICA project, and meta-analyses. This indicates that they do, to some extent, focus on similar data sources, so it is unsurprising that they suggest similar prior distributions. The fact that they suggested exactly the same distribution for sex, N(0.7, 0.3), is probably partly due to chance, as both specify hyperparameters with only one decimal place.
ChatGPT referred to literature reporting odds ratios in the range 1.8–2.5, which corresponds to log odds ratios in the range 0.6–0.9, and ultimately selected a mean of 0.7. It chose a standard deviation of 0.3 to cover the interval 0.6–0.9 with a moderately safe margin. Claude referred to males typically having twice the risk compared to females, leading to a log odds ratio of  , and described 0.3 as representing moderate uncertainty around 0.7.
, and described 0.3 as representing moderate uncertainty around 0.7.
Figure 3 shows the Gaussian approximation of the MLE distribution and the weakly informative priors suggested by the three LLMs. Comparing Figs. 2 and 3 reveals that the suggested weakly informative priors are substantially wider than the moderately informative ones. For the variable sex, the prior distributions suggested by Gemini and Claude are still somewhat overconfident, resulting in fairly poor coverage of the MLE. Apart from this, the other suggested prior distributions appear to cover the MLE well. Furthermore, the priors suggested by ChatGPT are extremely wide, rendering them unnecessarily non-informative. A further disadvantage with the priors suggested by ChatGPT and Gemini is that the expected value of the prior distributions was set to 0, meaning that, a priori, they did not suggest any effect for the variables. We observed from the moderately informative priors that the LLMs had good knowledge about the effect of the different variables on CAD, so this seems unnecessarily vague. Claude, in contrast, maintained a non-zero expected effect in its priors while still achieving good coverage of the MLE.
Figure 3.

Heart disease example: MLE distributions and the weakly informative LLM prior distributions for the different variables.

Listing 1 Main components for the prompt used in the heart disease example in Section 3.1.
Table 2 shows the computed Kullback-Leibler (KL) divergence between the MLE distribution and the different prior distributions. We see that Claude’s weakly informative prior has the lowest average KL divergence and thus represents the best prior distribution according to this metric. This was the only prior set that was both informative (i.e., having an expected log-odds ratio different from zero) and not overly confident. Overall, Claude Opus and Gemini 2.5 Pro performed better than ChatGPT-4o-mini. As all three are top-performing models, it was not obvious beforehand which would perform best in these experiments. The LLMs had substantially more difficulty with some variables than others, with sex proving to be particularly challenging. The reason for this difficulty is not immediately clear. The weakly informative prior from ChatGPT performed poorly due to its excessive width. With the exception of ChatGPT, the weakly informative prior sets appear to be superior to the moderately informative ones, in which the LLMs were generally overconfident. The average KL divergence for Claude–moderate is 1.07, which can be considered a high value (see, e.g., 31). This highlights the difficulty of specifying highly informative priors for which the data are not surprising relative to the prior.
Table 2.
Heart disease example: KL divergence between the MLE distribution and the different suggested prior sets.
| LLM | Claude | Gemini | Claude | ChatGPT | Gemini | ChatGPT |
|---|---|---|---|---|---|---|
| Informative | Weak | Weak | Mod | Mod | Mod | Weak |
| Age | 0.60 | 1.21 | 2.77 | 1.72 | 3.32 | 4.40 |
| Sex | 2.21 | 2.05 | 5.61 | 5.61 | 18.00 | 1.70 |
| Trestbps | 0.44 | 1.29 | 0.13 | 3.98 | 1.04 | 5.14 |
| Chol | 0.79 | 1.49 | 0.24 | 0.78 | 0.27 | 6.25 |
| Thalach | 1.44 | 1.63 | 3.83 | 1.58 | 1.58 | 5.24 |
| Oldpeak | 0.92 | 1.64 | 0.30 | 0.64 | 0.05 | 2.38 |
| Avg KL Div. | 1.07 | 1.55 | 2.15 | 2.38 | 4.04 | 4.19 |
| Avg Rank | 2.50 | 3.67 | 2.83 | 3.33 | 3.17 | 5.17 |
The first row shows which LLM suggested the prior sets and how informative they are (weak or moderate). The second to last row shows the average of the KL divergence for the different variables, and the last row shows the average ranking in terms of the best score (lower KL divergence is better).
We now analyse the best performing priors according to Table 2 a bit further, i.e. the Claude weakly informative priors. Figure 4 shows the MLE, Claude weakly informative priors and the resulting posterior distributions. We observe that a benefit of using the informative prior distributions is that the variances of the parameter estimates are smaller for the posterior distribution compared to the MLE. We see this by observing that the posterior distributions are higher/sharper. The reduction in variance is not large, as the priors are fairly wide and the sample size is high. By incorporating information from both the data and the priors, the posterior distributions are also slightly shifted relative to the MLE.
Figure 4.

Heart disease example: MLE, Claude weakly informative priors and the resulting posterior distributions.
Finally, we explored the prediction performance for the logistic Bayesian models using the different prior sets. The models were evaluated using five-fold cross-validation, and the performance was measured using the Brier score, mean negative log-score (MNLS), and AUC. We fitted the models using the R-INLA package 32. The method approximates the posterior distribution using sophisticated integrated nested Laplace approximations. It is a specialized and robust alternative to the more general variational inference method and is also far more computationally efficient than commonly used Markov chain Monte Carlo methods. The results are shown in Table 3, where the ’Frequentist’ model refers to the logistic regression model fitted without the use of prior distributions. The results show some improvements in prediction performance for the Bayesian models using the LLM priors compared to the standard logistic regression model, but not statistically significant. P-values were computed using the Nadeau-Bengio corrected t-test 33 and corrected for multiple testing using the Benjamini–Hochberg procedure34. This is an important finding in itself and is consistent with Bayesian theory. Given the large size of the heart disease dataset, the information from the likelihood naturally dominates the prior, meaning significant performance gains from including prior information were not expected. This highlights that the real predictive utility of these priors is likely to be found in scenarios where prior information is more influential, such as in smaller datasets or for out-of-distribution generalization, representing an interesting direction for future research.
Table 3.
Heart disease example: prediction performance for the different Bayesian models and a frequentist logistic regression model.
| Model | Brier score 
|
Mean neg log score
|
AUC 
|
|---|---|---|---|
| Frequentist | 0.1753 | 0.5281 | 0.8131 |
| Claude_Mod | 0.1743 (p = 0.488) | 0.5230 (p = 0.488) | 0.8153 (p = 0.488) |
| Claude_Weak | 0.1737 (p = 0.488) | 0.5219 (p = 0.488) | 0.8158 (p = 0.488) |
| Gemini_Mod | 0.1737 (p = 0.488) | 0.5207 (p = 0.488) | 0.8156 (p = 0.488) |
| Gemini_Weak | 0.1743 (p = 0.488) | 0.5244 (p = 0.488) | 0.8147 (p = 0.488) |
| ChatGPT_Mod | 0.1739 (p = 0.488) | 0.5209 (p = 0.488) | 0.8165 (p = 0.488) |
| ChatGPT_Weak | 0.1749 (p = 0.488) | 0.5262 (p = 0.488) | 0.8135 (p = 0.488) |
The values in the parentheses are Benjamini–Hochberg adjusted p-values testing if the Bayesian models perform better than the frequentist model (correction across all 18 tests). The arrows indicate whether lower () or higher () values for the performance metrics are better.
Concrete compressive strength
In this example, we used a dataset from the UCI Machine Learning Repository 35 to analyse the association between the variables in Table 4 and the compressive strength (CCS), measured in MPa, of the resulting concrete. In the experiments we used all the variables in the dataset. The dataset consists of 1030 samples and no missing data. The Age variable refers to how long the concrete was allowed to cure before the compressive strength test was performed. The other variables represent the quantity of each component in the concrete mixture. We model the association between CCS and the variables using a multiple linear regression model with Gaussian prior distributions for the regression coefficients.
Table 4.
Concrete strength example: description of the concrete components.
| Variable name | Description | Measuring unit |
|---|---|---|
| Age | Curing time | day |
| Cement (component 1) | Binder | 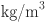 |
| Blast Furnace Slag (component 2) | Cement replacement | |
| Fly Ash (component 3) | Cement replacement | |
| Water (component 4) | Activates cement | |
| Superplasticizer (component 5) | Water reducer | |
| Coarse Aggregate (component 6) | Filler, strength | |
| Fine Aggregate (component 7) | Filler, workability | |
Figures 5 and 6 show the MLE distributions and the moderately and weakly informative prior distributions, respectively. The findings from this example were largely consistent with those from the heart disease example. For the moderately informative priors, all LLMs correctly identified the direction of the effects, for instance, that CCS is positively associated with the quantity of cement and negatively associated with the quantity of water. While there was some disagreement on the magnitude of these effects, both Claude and Gemini adjusted the width of their prior distributions to avoid overconfidence. ChatGPT, on the other hand, was too confident for many of the variables. For the weakly informative priors, again, only Claude suggested priors that were simultaneously informative (i.e., with an expected effect different from zero) and weak. All LLMs provided wide prior distributions, and none of the weakly informative priors were overly confident. ChatGPT’s priors were extremely wide, making them unnecessarily non-informative.
Figure 5.

Concrete strength example: MLE distributions and the moderately informative LLM prior distributions for the different variables.
Figure 6.

Concrete strength example: MLE distributions and the weakly informative LLM prior distributions for the different variables.
When running the prompt in Sect. 2 of the supplementary material, the models referred to their “knowledge of concrete technology” (Gemini), “civil-engineering domain knowledge” (ChatGPT), and “civil engineering principles and typical effect sizes from concrete materials research” (Claude). In other words, the LLMs were less specific about the studies used to obtain the prior distributions than they were for the heart disease example. For this example as well, the LLMs suggested two sets of priors: weakly informative and moderately informative. Gemini and Claude reported 65% and 35% confidence in the moderately and weakly informative priors, respectively, while ChatGPT reported 70% and 30% confidence, respectively.
Table 5 shows the computed KL divergence between the MLE distribution and the different prior distributions. The moderately informative priors from both Gemini and Claude resulted in a low average KL divergence, indicating they were informative without being overconfident. All models struggled with the Age variable, generally defaulting to wide prior distributions. The association between CCS and age is highly non-linear; the strength increases rapidly during the first few days and weeks before gradually stabilizing. The prompt informed that the time span for the age variable was from one to 365 days, but it is possible that the LLMs struggled to effectively utilize this information, thus resorting to wider priors. ChatGPT generally struggled to provide suitable prior distributions, resulting in high KL divergence values.
Table 5.
Concrete strength example: KL divergence between the MLE distribution and the different suggested prior sets.
| LLM | Gemini | Claude | Gemini | Claude | ChatGPT | ChatGPT |
|---|---|---|---|---|---|---|
| Informative | Mod | Mod | Weak | Weak | Weak | Mod |
| Cement | 1.37 | 1.37 | 2.84 | 2.72 | 4.28 | 10.53 |
| Blast furnace slag | 1.51 | 1.08 | 2.62 | 2.55 | 4.10 | 9.10 |
| Fly ash | 1.16 | 1.16 | 2.36 | 2.33 | 3.88 | 13.52 |
| Water | 0.22 | 1.62 | 1.41 | 1.53 | 2.73 | 0.54 |
| Superplasticizer | 0.21 | 3.33 | 1.37 | 3.00 | 1.92 | 0.95 |
| Coarse aggregate | 0.37 | 0.37 | 1.89 | 1.87 | 4.17 | 41.33 |
| Fine aggregate | 0.27 | 0.27 | 1.76 | 1.75 | 4.04 | 68.27 |
| Age | 3.59 | 4.14 | 4.72 | 4.04 | 4.72 | 35.73 |
| Avg KL Div. | 1.09 | 1.67 | 2.37 | 2.47 | 3.73 | 22.50 |
| Avg rank | 1.12 | 2.38 | 3.75 | 3.25 | 4.88 | 5.00 |
The first row shows which LLM suggested the prior sets and how informative they are (weak or moderate). The second to last row shows the average of the KL divergence for the different variables, and the last row shows the average ranking in terms of the best score (lower KL divergence is better).
Figure 7 shows the MLE, the best-performing prior from Table 5 (Gemini–moderate), and the resulting posterior. Similar to the heart disease example, the variance of the posterior distributions is smaller than that of the MLE distributions, indicating that the LLM priors help reduce estimation uncertainty. By incorporating information from both the data and the priors, the posterior distributions are also slightly shifted relative to the MLE.
Figure 7.

Concrete strength example: MLE, Gemini moderately informative priors and the resulting posterior distributions.
Table 6 shows the prediction performance in a five-fold cross-validation experiment using the metrics MNLS, root mean squared error (RMSE), and mean absolute error (MAE). As with the heart disease example, the Bayesian models demonstrated slight but not statistically significant improvements in performance. This result was expected, as the large sample size of the concrete dataset means the information from the data outweighs the contribution of the prior, a standard outcome in Bayesian analysis.
Table 6.
Concrete strength example: prediction performance for the different Bayesian models and a frequentist multiple regression model.
| Model | MNLS
|
RMSE
|
MAE
|
|---|---|---|---|
| Frequentist | 3.770 | 10.492 | 8.293 |
| Gemini_Mod | 3.768 (p = 0.566) | 10.474 (p=0.566) | 8.289 (p = 0.566) |
| Gemini_Weak | 3.770 (p = 0.566) | 10.489 (p=0.566) | 8.292 (p = 0.566) |
| ChatGPT_Mod | 3.780 (p = 0.566) | 10.596 (p=0.566) | 8.496 (p = 0.585) |
| ChatGPT_Weak | 3.770 (p = 0.566) | 10.492 (p=0.566) | 8.293 (p = 0.566) |
| Claude_Mod | 3.769 (p = 0.566) | 10.480 (p=0.566) | 8.296 (p = 0.566) |
| Claude_Weak | 3.770 (p = 0.566) | 10.490 (p=0.566) | 8.294 (p = 0.566) |
The values in the parentheses are Benjamini–Hochberg adjusted p-values testing if the Bayesian models perform better than the frequentist model (correction across all 18 tests). The arrows () indicate that lower values for the performance metrics are better.
Closing remarks
In this paper, we have analysed the approach of using LLMs to generate prior distributions for Bayesian regression models. While19 document improvement in prediction performance using priors based on LLM information, we didn’t observe similar improvements in our experiments. However, the LLMs were generally capable of identifying the correct direction for the different associations, e.g., that the strength of concrete is reduced by the amount of water. Using the prior information, the uncertainty in the parameter estimates was reduced compared to the MLE. The magnitude of the association often differed between the data and the prior expectations. This was particularly evident with the moderately informative priors for the heart disease example, where many of the suggested priors were overconfident. Among the weakly informative priors, only Claude was able to suggest priors that were informative (i.e., where the expected association was non-zero) while remaining suitably wide.
In conclusion, our findings indicate that LLMs show considerable potential as an efficient and objective tool for generating informative prior distributions. Particularly encouraging is their consistent ability to identify the correct directional nature of various associations. Nevertheless, a significant challenge remains in calibrating the width of these priors, as the LLMs demonstrated a tendency towards both overconfidence and underconfidence. It is interesting to reflect on why they in many cases were overconfident. Is it an inherent artifact of how LLMs are trained to provide confident-sounding answers? Could the “simulated literature review” part of the prompt encourage the models to recall strong, textbook associations without the necessary nuance for a specific dataset’s context?
Some of the observed differences in effect sizes between the data and the LLM-generated priors could also be attributable to biases in the data. Although the data collection protocols for both datasets are considered reliable, the potential for sampling bias always exists. For instance, in the heart disease dataset, the proportion of individuals with heart disease is 46%, a much higher prevalence than in the general population. This could lead to a case-control sampling bias, creating discrepancies between the data and the prior distributions informed by population-level knowledge. Whether the disagreements between the data and the priors stem from biases in the data or from incorrect assessments by the LLMs is difficult to ascertain. However, for this analysis, we have proceeded under the assumption that the data are not severely biased, and we have evaluated the priors based on the criterion that they should not be overly surprised by the data.
It is also worth noting that, because LLMs are generative models, rerunning our prompts could yield different reasoning and suggested values for the prior hyperparameters. However, we did rerun our prompts, and in our reruns the suggested values of the prior hyperparameters were consistent between the runs.
There are several directions for future work. The prompts used in this study could likely be improved to increase the quality of the suggested priors. It is also interesting to explore this approach for other Bayesian models, such as latent variable models, hierarchical models, and graphical/causal models. Finally, exploring the potential of LLMs in out-of-distribution generalization, where the test data differs systematically from the training data, is a promising avenue. In such scenarios, LLM-generated priors could potentially serve as a bridge between the two data distributions, improving model robustness and performance.
Supplementary Information
Author contributions
H.L.H organized the work with the manuscript and wrote the first draft. M.R. developed the LLM prompts and contributed with the writing. V.T. and K.H.H. contributed with literature review and the writing. All authors reviewed the manuscript.
Funding
Open access funding provided by OsloMet - Oslo Metropolitan University. This research received no specific grant from any funding agency in the public, commercial, or not-for-profit sectors.
Data availability
The datasets used and/or analysed during the current study are available from the corresponding author on reasonable request. In addition, the datasets are openly available and can be accessed using the links in the dataset references in the paper.
Declarations
Competing interests
The authors declare no competing interests.
Footnotes
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
The online version contains supplementary material available at 10.1038/s41598-025-18425-9.
References
- 1.Zhang, K. et al. Revolutionizing health care: The transformative impact of large language models in medicine. J. Med. Internet Res.27, e59069 (2025). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 2.Busch, F. et al. Current applications and challenges in large language models for patient care: a systematic review. Commun. Med.5(1), 26 (2025). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 3.Nie, Y. et al. A survey of large language models for financial applications: Progress, prospects and challenges. arXiv preprint arXiv:2406.11903, (2024).
- 4.European Securities and Markets Authority (ESMA). Leveraging large language models in finance: Pathways to responsible adoption, 2024. Available at: https://www.esma.europa.eu/.
- 5.Wang, S., et al. Philip S Yu, and Qingsong Wen. Large language models for education: A survey and outlook. arXiv preprint arXiv:2403.18105, (2024).
- 6.Alhafni, B., Vajjala, S., Bannò, S., Maurya, K. K., & Kochmar, E. LLMs in education: Novel perspectives, challenges, and opportunities. arXiv preprint arXiv:2409.11917 (2024).
- 7.Ji, Z. et al. Survey of hallucination in natural language generation. ACM Comput. Surv.55(12), 1–38 (2023). [Google Scholar]
- 8.Gelman, A., Carlin, J. B., Stern, H. S., Dunson, D. B., Vehtari, A., & Rubin, D. B. Bayesian Data Analysis. CreateSpace, United States, 3rd ed edition, (2013).
- 9.Mikkola, P. et al. Prior knowledge elicitation: The past, present, and future. Bayesian Anal.19(4), 1129–1161 (2024). [Google Scholar]
- 10.Fisher, R. A. The fiducial argument in statistical inference. Ann. Eugen.6(4), 391–398 (1935). [Google Scholar]
- 11.Xie, M. & Singh, K. Confidence distribution, the frequentist distribution estimator of a parameter: A review. Int. Stat. Rev.81(1), 3–39 (2013). [Google Scholar]
- 12.Hannig, J. On generalized fiducial inference. Stat. Sin.19(2), 491–544 (2009). [Google Scholar]
- 13.Martin, R. & Liu, C. Inferential models: A framework for prior-free posterior probabilistic inference. J. Am. Stat. Assoc.108(501), 301–313 (2013). [Google Scholar]
- 14.Donald, A. S. Fraser (The Structure of Inference. Wiley, New York, NY, 1968). [Google Scholar]
- 15.Royall, R. Statistical Evidence: A Likelihood Paradigm (Chapman & Hall/CRC, Boca Raton, FL, 1997). [Google Scholar]
- 16.Shafer, G. A Mathematical Theory of Evidence. Princeton University Press, (1976).
- 17.Hollmann, N. et al. Accurate predictions on small data with a tabular foundation model. Nature637(8045), 319–326 (2025). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 18.Numerical predictive distributions conditioned on natural language. James Requeima, John Bronskill, Dami Choi, Richard Turner, and David K Duvenaud. Llm processes. Adv. Neural. Inf. Process. Syst.37, 109609–109671 (2024). [Google Scholar]
- 19.Capstick, A., Krishnan, R. G., & Barnaghi, P. Using large language models for expert prior elicitation in predictive modelling. arXiv preprint arXiv:2411.17284, (2024).
- 20.Gouk, H., & Boyan, G. Automated prior elicitation from large language models for bayesian logistic regression. In The 3rd International Conference on Automated Machine Learning (2024).
- 21.Feng, J., Kothari, A., Zier, L., Singh, C., & Tan, Y. S. Bayesian concept bottleneck models with llm priors. arXiv preprint arXiv:2410.15555 (2024).
- 22.Evans, M. & Moshonov, H. Checking for prior-data conflict. Bayesian Anal.1, 12 (2006). [Google Scholar]
- 23.Casella, G., & Roger, B. Statistical inference (CRC press, 2024).
- 24.Nott, D. J., Wang, X., Evans, M. & Englert, B.-G. Checking for prior-data conflict using prior-to-posterior divergences. Stat. Sci.35(2), 234–253 (2020). [Google Scholar]
- 25.OpenAI. ChatGPT-4o-mini. https://openai.com/chatgpt, 2024. Accessed: 2024-06-25.
- 26.Google. Gemini 1.5 Pro. https://gemini.google.com/, 2024. Accessed: 2024-06-25.
- 27.Anthropic. Claude 3 Opus. https://www.anthropic.com/claude, 2024. Accessed: 2024-06-25.
- 28.Janosi, A., Steinbrunn, W., Pfisterer, M., & Detrano, R. Heart Disease. UCI Machine Learning Repository10.24432/C52P4X. (1989).
- 29.Mahmood, S. S., Levy, D., Vasan, R. S. & Wang, T. J. The Framingham Heart Study and the epidemiology of cardiovascular diseases: a historical perspective. The Lancet383(9921), 999–1008 (2014). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 30.Tunstall-Pedoe, H., editor. MONICA: Monograph and Multimedia Sourcebook: World’s largest study of heart disease, stroke, risk factors, and population trends, 1979-2002. World Health Organization, Geneva, 2003. Prepared on behalf of the WHO MONICA Project.
- 31.McCulloch, R. E. Local model influence. J. Am. Stat. Assoc.84(406), 473–478 (1989). [Google Scholar]
- 32.Rue, H., Martino, S. & Chopin, N. Approximate bayesian inference for latent gaussian models by using integrated nested laplace approximations. J. R. Stat. Soc. Ser. B Stat Methodol.71(2), 319–392 (2009). [Google Scholar]
- 33.Nadeau, C., & Bengio, Y. Inference for the generalization error. Adv. Neural Inf. Process. Syst.12 (1999).
- 34.Benjamini, Y. & Hochberg, Y. Controlling the false discovery rate: a practical and powerful approach to multiple testing. J. Roy. Stat. Soc.: Ser. B (Methodol.)57(1), 289–300 (1995). [Google Scholar]
- 35.I-Cheng Yeh. Concrete Compressive Strength. UCI Machine Learning Repository, 10.24432/C5PK67. (1998)
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.
Supplementary Materials
Data Availability Statement
The datasets used and/or analysed during the current study are available from the corresponding author on reasonable request. In addition, the datasets are openly available and can be accessed using the links in the dataset references in the paper.