

Abstract
The heterogeneity of medical images poses significant challenges to accurate disease diagnosis. To tackle this issue, the impact of such heterogeneity on the causal relationship between image features and diagnostic labels should be incorporated into model design, which however remains under explored. In this paper, we propose a mixed prototype correction for causal inference (MPCCI) method, aimed at mitigating the impact of unseen confounding factors on the causal relationships between medical images and disease labels, so as to enhance the diagnostic accuracy of deep learning models. The MPCCI comprises a causal inference component based on front-door adjustment and an adaptive training strategy. The causal inference component employs a multi-view feature extraction (MVFE) module to establish mediators, and a mixed prototype correction (MPC) module to execute causal interventions. Moreover, the adaptive training strategy incorporates both information purity and maturity metrics to maintain stable model training. Experimental evaluations on four medical image datasets, encompassing CT and ultrasound modalities, demonstrate the superior diagnostic accuracy and reliability of the proposed MPCCI. The code will be available at https://github.com/Yajie-Zhang/MPCCI.
Keywords: Disease diagnosis, Causal inference, Front-door adjustment, Multiview prototype learning, Medical image
Subject terms: Cancer, Diseases, Health care, Mathematics and computing
Introduction
Medical image classification provides essential support to the clinicians and other medical professionals in diagnosing and treating patients by analyzing lesion features of the human body within medical images1. With wide applications in the real world, this problem has been extensively researched. In the past few decades, especially driven by the application of deep learning technologies, a significant body of methods have been developed, which can generally be categorized into detection-based approaches2,3, segmentation-based approaches4–6 and feature extraction approaches7–10. Despite the remarkable advancements in previous studies, classifying images in the medical domain remains much more challenging than it is for natural images. This is primarily attributed to the inherently complex nature of the medical images. Compared with the natural images, the medical images often contain more noise and artifacts, due to the limitations of current imaging technologies, such as weak X-ray penetration of the equipment, presence of gas in the body, and motion artifacts11. In addition to these two factors that have received more attention in previous research, lesion heterogeneity is also a crucial challenge to the classifiers, which however is much less exploited.
Lesion heterogeneity in the medical imaging refers to the variability in features and appearances of the same disease, encompassing variations in terms of shape, size, density, intensity, texture, and other lesion characteristics. An exemplar illustration is given in Fig. 1. As shown in the figure, breast cancer may exhibit pronounced heterogeneity in ultrasound images, with lesions varying significantly in appearance. For example, the lesion shapes may be oval, round, or irregular, and the complexity is further exacerbated when combined with other varied attributes as shown in the table below the images. The impact of heterogeneity on model performance has been acknowledged in previous studies12,13, and there have been some attempts to alleviate its negative effects through variance pooling structures14 and data augmentation15. However, these methods often yield suboptimal outcomes due to the lack of a thorough examination on the root causes of heterogeneity.
Fig. 1.

Illustration of different manifestations for the same type of lesion in breast cancer ultrasound images. Lesion attributes are also provided in the table below images.
Lesion heterogeneity is caused by various factors, such as the diverse origins of cancer cells, variable gene expressions, and patient specific susceptibilities16. These factors have significant influences upon the prediction of a diagnostic label from the medical image. For example, the patients with genetic predispositions are more susceptible to the illness16. Hence in this work, we propose to model these factors by leveraging causal inference17, for enhanced medical image classification. To enunciate our idea, we establish a structural causal model for the medical image classification task, as shown in Fig. 2. In this figure, the underlying causes of heterogeneity, denoted as C, involve various factors as above mentioned; the medical images X and the diagnostic outcomes Y are both impacted by the heterogeneity cause factors C. In formulation, there exist X → Y, denoting the causal path that image X contains the lesion representations related to the given label Y, and X ← C → Y representing the backdoor path that X and Y exhibit spurious correlation through C. That is, the factors in C affect the characterization of medical imaging (X ← C); in addition, these factors influence the probability of a patient contracting a particular disease (C → Y). Following the Pearl’s causal inference theory17, when we try to find the causal effect of X on Y, we want the nodes we condition on to block any “backdoor” path in which one end has an arrow to X, because such paths may make X and Y dependent, but are obviously not transmitting causal influences from X; and if we do not block them, they will confound the effect that X has on Y. Therefore, we should adjust the confounders “C” to block the backdoor path for better inference from X to Y. However, given the inherent difficulty or even impossibility of quantifying these confounders, their adverse impact upon the image-based diagnostic procedures remains elusive and unaddressed.
Fig. 2.

The structural causal model for a disease with heterogeneity. C represents the cause of heterogeneity, X denotes medical images, and Y represents diagnostic results.
In this work, we propose a novel approach for enhanced medical image classification, named mixed prototype correction for causal inference (MPCCI), which mitigates the influences of the confounding factors on the medical diagnosis by exploiting front-door adjustment (FDA)17. The FDA introduces a mediator variable, denoted as A in Fig. 3, between the causal path of variables X and Y, to adjust the causal pathway between them, which well addresses the immeasurability of the elusive confounding factors. To implement MPCCI, we first design a multi-view feature extraction (MVFE) module with spatial-channel attention that allows these multi-view features to serve as mediators in FDA to link the causal effect from images to labels. We also develop a mixed prototype correction (MPC) module that exchanges some features of the multi-view features and the multi-view prototypes to effectively apply causal intervention on the mediators. The multi-view prototypes contain meta-knowledge of various disease categories, and the causal intervention mechanism that exchanges features with them can correct the spurious association between X and Y formed by the confounders. To improve the smoothing of the feature exchange process, an adaptive training strategy is presented, comprising two key components: information purity (IP) and maturity (MT). The IP module is used to measure the proportion of noise in the feature exchange process, and MT is used to measure the stability of the model to noise in different training stages. Experiments on four medical datasets verify the effectiveness of the proposed MPCCI on diagnosing covid, breast cancer, lymph node metastasis, and thyroid. In summary, the contributions of this work are as followings:1. This work conducts cause-effect analysis to alleviate the immeasurable confounders for enhancing medical image classification. The proposed method solves the problem by applying an FDA strategy, treating the multiview features as mediators to infer the causalities from images to labels. 2.The proposed MPCCI includes two key modules (MVFE and MPC) to achieve FDA step by step, which effectively mitigates the adverse effects of the confounders upon medical diagnosis. An adaptive training strategy, consisting of IP and MT modules, is introduced to mitigate the noise effect in the MPC module. 3.The proposed MPCCI exhibits promising performance across four distinct disease diagnosis tasks, yielding dependable interpretability results.
Fig. 3.

(a) A structural causal model for medical image classification. (b) (c) Two steps of FDA, representing calculations of P (A |do (X)) and P (Y |do (A)) (red lines). Red fork denotes the causal intervention from X to A.
Related work
Medical image classification
Currently, medical image classification, a task aiming to identify disease categories from unseen medical images, is generally tackled by training deep learning models over annotated training datasets. The model performance is mainly dependent on its architecture design as well as the scale of the training data. Some methods adopt advanced architectures, such as AlexNet18, ResNet19, VGG20, and ViT3 for good classification performance. In recent year, some works propose to extract and integrate multi-scale information to improve classification accuracy, utilizing feature pyramid networks6, dilated convolutions21, and attention mechanisms10,22, etc. There are also models fusing local and global features23,24 to achieve lifted efficacy in medical image classification. These methods are all based on the assumptions of sufficient high quality training data, which are not always true. In addition to these model-centric approaches, some other methods broaden the diversity and volume of training data to enhance model generalization by utilizing GANs25, variational autoencoders26, MixUp27, and diffusion models28. These data-centric approaches also demonstrate strong effectiveness on medical image classification tasks. However, either the model-centric models, or the data-centric ones, fall short on addressing disease heterogeneity and its related confounding factors, which hampers their performance.
Causal inference in medical image classification
The goal of causal inference is to unravel the complex causal relationships between variables, far beyond the mere correlations29. It serves as a powerful tool for understanding the roots and implications of phenomena and thereby supports informed decision making and interventions. For its potent analytical power, causal inference has been applied in various domains, such as medical image classification30–34, domain generalization35, and medical image segmentation36–39,39. In medical image analysis, some methods35–37 treat complex organ co-occurrences and background phenomena such as pseudo artifacts as observable confounding factors, and leverage the backdoor adjustment strategy17 for causal intervention. Some works30 harness counterfactual reasoning for medical image analysis by crafting counterfactual samples to neutralize the effects of observable confounding factors. These causal inference based methods achieve promising results. Yet, they tend to focus on observable confounding factors, which constrains their effectiveness in handling cases with unobservable confounders. In this work, we propose to utilize the FDA strategy to mitigate the impact of unmeasured confounders for better medical image classification performance.
Cause-effect analysis
In this section, we provide a brief analysis of the causal relationships among the elements in our tasks, namely the input image X, multiview features A, image label Y, and confounders C, using a structural causal model (SCM) illustrated in Fig. 3(a). We also describe how FDA is used in this context.
The main causal relationships in Fig. 3 (a) include X → A → Y,C → X, and C → Y. (1) For X → A → Y, the input image X is fed into a deep neural network to extract multi-view features A, which are then used to predict the label Y. (2) For C → X, the confounders C like genetics, origins of cancer cells, patient habits, etc. Influence the lesion manifestation X. (3) For C → Y, the confounders C can also affect the disease category Y of a patient. For example, the patients with genetic predisposition for breast cancer have a higher risk of malignancy.
Note that there are two paths connecting X and Y: the frontdoor path X → A → Y and the backdoor path X ← C → Y. The existence of the backdoor path makes it difficult to evaluate the true causality from X to Y through deep networks. If C is measurable, the backdoor adjustment can be used to eliminate the link of C ← X. However, since most of C in this work are not measurable, we turn to use front-door adjustment17 to estimate the causality from X to Y. To achieve this, FDA employs a mediator A to transmit knowledge of X to Y through the front-door path, and then evaluates the causalities from X to Y by combining the causal effects of X to A and A to Y, i.e., to estimate the probabilities P (A|do (X)) and P (Y |do (A)), respectively.The do-operation represents an active intervention to a cause rather than a passive observation.
The P(A|do(X)) represents the causal relationship between X and A, as illustrated in Fig. 3 (b). Since the path of X ← C → Y ← A is blocked by the collider17, we can write
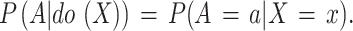 |
1 |
The P(Y|do(A)) (Fig. 3 (c)) pursues the true causality between A and Y without confounders C. There are two paths from A to Y: A → Y and the backdoor path A ← X ← C → Y. Due to the existence of the backdoor path, we need to cut off the link between A and X by controlling X, and we can write P (Y |do (A)) as
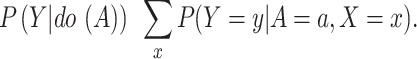 |
2 |
Through layer-by-layer causal effect calculation, the causality from X to Y can be represented as
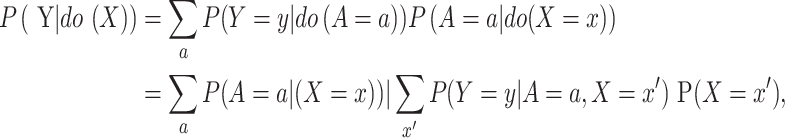 |
3 |
where x′ is an index of summation in P (Y |do (A)).
Methodology
The Fujian Provincial Hospital review committee gave their approval to this study. All experimental protocols were approved by Fujian Provincial Hospital review committee.All participants provided informed consent to participate in the study.The study adhered to the Declaration of Helsinki and relevant national guidelines. All experiments and methods were performed in accordance with relevant guidelines and regulations. In this section, we introduce the proposed Mixed Prototype Correction for Causal Inference (MPCCI) approach in medical image classification. As shown in Fig. 4, it involves multi-view feature extraction (MVFE) and mixed prototype correction (MPC) modules to implement the FDA strategy. Additionally, we present an adaptive training approach, incorporating the information purity (IP) and the maturity (MT), to alleviate the noise at MPC. The IP module quantifies the noise proportion during the feature exchange process, while MT assesses the model’s robustness to noise across various training phases.
Fig. 4.

Illustration of the MPCCI framework. MPCCI consists of three main components: the MVFE, MPC, and the adaptive training strategy. MVFE involves expert networks that use spatial-channel attention to generate multi-view features. MPC is implemented by fusing mixed prototypes with original multi-view features to simulate  P (Y |A,
P (Y |A,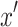 ). In addition, the adaptive training strategy, consisting of IP and MT, is adopted to improve the smoothing of the feature exchange process.
). In addition, the adaptive training strategy, consisting of IP and MT, is adopted to improve the smoothing of the feature exchange process.
Multi-View feature extraction
The MVFE module is responsible for generating multi-view features A, which serve as the mediator in Fig. 3 (a) and are used to implement P (A|do (X)) in Eq. (1). First, we input the image into a convolutional neural network (CNN) such as ResNet1840 to obtain feature maps E =  b
(x)ϵ ℜD×H×W, where
b
(x)ϵ ℜD×H×W, where  b is the function of the CNN, and D, H, W represent the number of channels, height, and width of E, respectively. To extract multi-view features from the E, we employ two parallel paths. We apply global average pooling to E to obtain a global feature vector ℊ ϵ ℜD and construct expert networks41 with spatial-channel attention following CBAM42. Spatial-channel attention adopted in CNN allows for the adaptive weighting of feature maps across both spatial and channel dimensions.This enables the network to selectively focus on informative features, enhancing its ability to learn and identify complex visual patterns. To ensure that each expert network learns different features of an image, they are initialized with different parameters.The formulation of the expert networks can be expressed as
b is the function of the CNN, and D, H, W represent the number of channels, height, and width of E, respectively. To extract multi-view features from the E, we employ two parallel paths. We apply global average pooling to E to obtain a global feature vector ℊ ϵ ℜD and construct expert networks41 with spatial-channel attention following CBAM42. Spatial-channel attention adopted in CNN allows for the adaptive weighting of feature maps across both spatial and channel dimensions.This enables the network to selectively focus on informative features, enhancing its ability to learn and identify complex visual patterns. To ensure that each expert network learns different features of an image, they are initialized with different parameters.The formulation of the expert networks can be expressed as
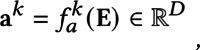 |
4 |
where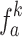 represents the k-view feature vector ak generated by the k-th function of spatial-channel attention.
represents the k-view feature vector ak generated by the k-th function of spatial-channel attention.
After extracting the mediator A, it is crucial to ensure that the learned multi-view features are distinct across classes. To achieve this goal, the multi-view features and global feature are concatenated and then fed into the classifier (a fully-connected layer is used in this work) denoted as  c, to produce the predicted label y of the image x:
c, to produce the predicted label y of the image x:
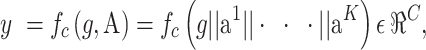 |
5 |
where || represents the concatenation operation, C is the number of categories, and K is the number of expert networks. The crossentropy loss is used to optimize fc :
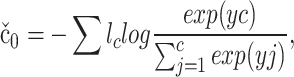 |
6 |
where l ϵ ℜC denotes the ground-truth label of x. If x belongs to the c-th category, lc = 1; otherwise lc = 0.
Mixed prototype correction
The MPC module aims to correct the side-effects of confounders and further explore the causality of A on Y by estimating
 |
7 |
However, it is infeasible to collect all possible  (lesions that might appear in reality) with A for predicting Y. Thus we use mixed multi-view prototypes to approximate
(lesions that might appear in reality) with A for predicting Y. Thus we use mixed multi-view prototypes to approximate  . Multi-view prototype learning43 is an emerging machine learning technique that aims to learn a set of prototypes across different views to capture the underlying structure of representative examples for each category.Specifically, we use the c-th class-specific average multi-view features to approximate the c-th multi-view prototypes, denoted as Sc = {
. Multi-view prototype learning43 is an emerging machine learning technique that aims to learn a set of prototypes across different views to capture the underlying structure of representative examples for each category.Specifically, we use the c-th class-specific average multi-view features to approximate the c-th multi-view prototypes, denoted as Sc = {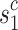 ,· · ·,
,· · ·,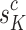 } ϵ ℜK×D. We then generate the mixed multi-view prototypes
} ϵ ℜK×D. We then generate the mixed multi-view prototypes 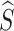 ,which partially come from the source multi-view prototypes (c-th) and another random counterparts (c′-th), to express x′ as
,which partially come from the source multi-view prototypes (c-th) and another random counterparts (c′-th), to express x′ as
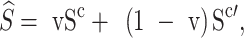 |
8 |
where v ϵ {0, 1}K represents the random exchanging index vector of Sc. Namely, each ʋ k represents whether the k-th prototype in Sc should be exchanged by the k-th prototype in Sc′. Since 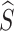 captures lesions that have distinct characteristics in specific view features, it can serve as a substitute for x′. To predict label Y, we fuse
captures lesions that have distinct characteristics in specific view features, it can serve as a substitute for x′. To predict label Y, we fuse  with A via a fusion module. Cross-attention10 is a mechanism that enables neural networks to capture the interdependent relationship between two heterogeneous features using a learnable similarity matrix. In this work, we incorporate cross-attention with the feature mapping function ℎ(·) into the fusion module to explore this independence. The output is fused multi-view features denoted as
with A via a fusion module. Cross-attention10 is a mechanism that enables neural networks to capture the interdependent relationship between two heterogeneous features using a learnable similarity matrix. In this work, we incorporate cross-attention with the feature mapping function ℎ(·) into the fusion module to explore this independence. The output is fused multi-view features denoted as 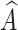 :
:
 |
9 |
We can concatenate 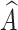 with global feature vector g to predict label as
with global feature vector g to predict label as 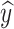 =
= 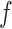 c (ℊ,
c (ℊ, 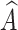 ) using Eq. (5).
) using Eq. (5).
Adaptive training strategy
We utilize an adaptive training strategy to maintain stable model training. Since 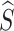 randomly mixes the c-th and c′-th multi-view prototypes, there is a possibility that
randomly mixes the c-th and c′-th multi-view prototypes, there is a possibility that 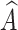 is predicted as the c′-th category. In this study, we hypothesize that two factors are related to this situation: (1) the information purity (IP) in
is predicted as the c′-th category. In this study, we hypothesize that two factors are related to this situation: (1) the information purity (IP) in  , and (2) the maturity (MT) of the fusion module.
, and (2) the maturity (MT) of the fusion module.
The IP refers to the amount of prototype information from the source category contained in 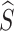 . If
. If 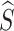 contains a large amount of prototype information from other categories, the probability of
contains a large amount of prototype information from other categories, the probability of 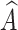 being predicted as other categories increases. Therefore, we use
being predicted as other categories increases. Therefore, we use 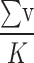 and
and 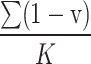 to represent the possibility of
to represent the possibility of 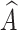 being predicted as the c-th class and c′-th class, respectively.
being predicted as the c-th class and c′-th class, respectively.
The MT represents the ability of the fusion module to accurately fuse label-related prototype information to  . When the fusion module cannot fuse multi-view prototypes well, the probability of accurately predicting
. When the fusion module cannot fuse multi-view prototypes well, the probability of accurately predicting  c decreases. We assume that MT increases with the process of network iterative optimization, and we denote MT as ɑ = ɑ0 +
c decreases. We assume that MT increases with the process of network iterative optimization, and we denote MT as ɑ = ɑ0 +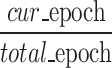 , where ɑ0 represents the initialized maturity. Based on these two factors, we can write the probabilities of
, where ɑ0 represents the initialized maturity. Based on these two factors, we can write the probabilities of 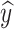 to be
to be 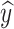 c and
c and 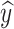 c′ :
c′ :
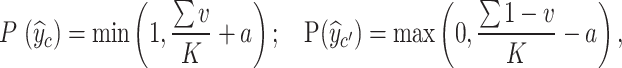 |
10 |
Based on this adaptive training strategy, the optimization goal of MPC can be formulated as:
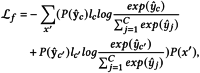 |
11 |
where P(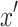 ) is set to a uniform distribution
) is set to a uniform distribution 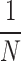 because
because  is generated from a random mixture with equal probability.
is generated from a random mixture with equal probability.
Overall loss function
By combining the MVFE, MPC, and the adaptive training strategy, the overall loss function £, which is the optimization objective to be minimized during training iterations, is a combination of the original loss £0 and the fusion loss £f :
 |
12 |
where ℷ is a hyperparameter that controls the relative weight of the fusion loss. To ease the understanding of MPCCI, the pseudo-code is presented as Algorithm 1.
Algorithm 1:

The pseudo-code of MPCCI
Experiment
We conduct comprehensive experiments to evaluate the performance of the proposed MPCCI approach. At below, we first introduce the datasets used for experiments, evaluation protocols, compared methods, and implementation details. Then, we report and analyze the quantitative results obtained across four medical datasets. Moreover, the validation of heterogeneity cause C and data set analysis are conducted to systematically evaluate MPCCI.We also take further experimental analysis to assess the capabilities of MPCCI. This analysis encompasses an examination of the number of features, the function of the mixing mechanism, and the visualization results.
Datasets
Four medical image datasets are utilized for the evaluation of MPCCI. The details of the datasets are provided as follows:
The CT COVID-1944 dataset comprises 7,593 COVID-19 CT images sourced from 466 patients, 6,893 normal CT images from 604 patients, and 2,618 CAP CT images from 60 patients. For experimentation purposes, a total of 14,486 images from the normal and COVID-19 categories are selected. These images are randomly partitioned into training, validation, and test sets at a ratio of 7:1:2.
The BUSI45 is a publicly available dataset consisting of 780 ultrasound images of three classes, i.e., normal, benign, and malignant. In this work, we follow the setting of MIB Net46 which achieves the best result reported to date and use only the benign images (437) and malignant images (210). Conforming to the protocol of MIB Net, the dataset is partitioned into training, validation, and test sets at a ratio of 8:1:1.
The FJPH is a dataset established by ourselves for predicting the likelihood of lymph node metastasis. The data inside are obtained anonymously from a local hospital (Fujian Provincial Hospital) to ensure the privacy of all involved patients. It consists of 889 ultrasound images categorized into two classes: metastasis (500 ultrasound images) and non-metastasis (389 ultrasound images). We employ this dataset to demonstrate the versatility of the proposed method in different ultrasound imaging scenarios. Adhering to the settings of BUSI, we partition this dataset into training, validation, and test sets at a ratio of 8:1:1.
The FJTU is a thyroid ultrasound dataset established from the Fujian Provincial Hospital for four sub-types of thyroid, e.g., thyroid adenoma (TA), follicular carcinoma (FC), follicular variant of PTC (FV-PTC), and medullary carcinoma (MC). It consists of 1,969 ultrasound images from 290 patients. Five-fold cross-validation is utilized for this dataset. In addition, a subset of the data, FJTUH(349 images from FC and 174 images from FV-PTC), includes gender information and 9 heterogeneous attributes annotated by professional doctors. The attribute distribution exhibits severe heterogeneity within the same category as in Fig. 5. The FJTU-H is utilized for dataset analysis of heterogeneity and validation of heterogeneity cause C.
Fig. 5.
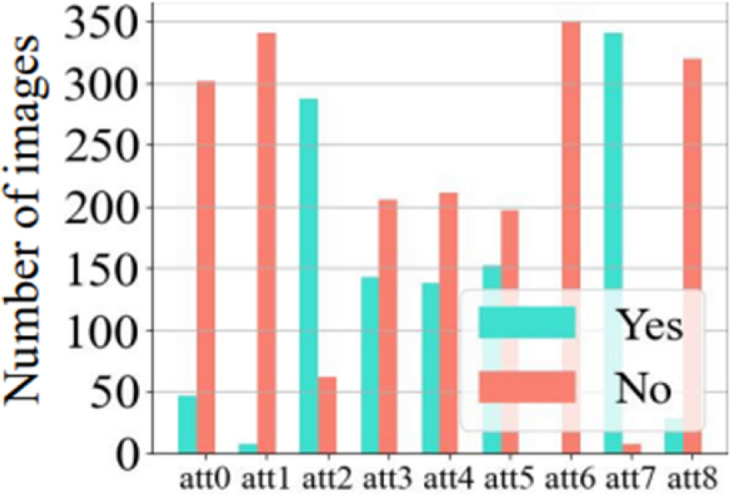
Distribution of 9 heterogeneous attributes for follicular carcinoma (FC) in the FJTU-H dataset. Each bar represents the frequency of a specific attribute (e.g., shape, echogenicity, margin) annotated by professional radiologists. Severe intra-class heterogeneity is evidenced by the varied distribution of attributes (e.g., irregular shape, calcification status) within the same pathology category. This visualization validates the role of unmeasurable confounders C (e.g., biological variability) in lesion heterogeneity, supporting the evaluation of MPCCI’s robustness in Sect."Experimental Results".
Compared methods and evaluation metrics
Compared methods
In order to comprehensively validate the effectiveness of MPCCI, we make comparisons with various methods. Initially, we select four representative deep learning models with backbone architectures of ResNet1847, VGG1648, ViT49, and Mamba50 for image processing. These four methods utilize distinct feature extraction mechanisms to identify image features, facilitating the assessment of MPCCI performance across different architectures. Additionally, we employ several representative supervised learning methods for image classification, such as CABNet40 and CAD_PE51, along with data augmentation techniques like MixupNet52 and MixStyleNet53, as well as invariant feature learning method Fishr54, to further evaluate the performance of MPCCI. It is noteworthy that for the BUSI dataset, we also incorporate state-of-the-art modality-speciffc methods for breast cancer disease, including TNTs55, BVA Net56, HoVer-Trans57, and MIB Net46, for comparative analysis with MPCCI.Evaluation metrics. We evaluate MPCCI using four commonly used metrics in classification tasks: accuracy (Acc), precision (P), recall (R), and F1-score (F1).
Evaluation metrics
We evaluate MPCCI using four commonly used metrics in classification tasks: accuracy (Acc), precision (P), recall (R), and F1-score (F1).
Experimental details
In our experiments, we utilize ResNet18 as the backbone of MPCCI.All medical images are resized to 128 × 128 pixels. The model is trained using the SGD optimizer, with learning rates set to 0.0001/0.0001/0.001/0.0001 for the CT COVID-19, BUSI, FJPH, and FJTU datasets respectively. All experiments are conducted on a single Nvidia RTX3090 GPU, with batch sizes set to 10/10/128/10.The hyperparameter a is set to 0.5, while ℷis set to 0.1/0.1/1/0.1 for the four datasets respectively.
For the baseline methods, we reproduce the source codes of ResNet1847, VGG1648, ViT49, Mamba50, CABNet40, MixupNet52, MixStyleNet53, Fishr54, and CAD_PE51. All experimental results are based on the average of five experiments conducted with different random seeds. The results of TNTs55, BVA Net56, HoVer-Trans57, and MIB Net46 are directly cited from the original papers, as their source codes are not publicly accessible.
Experimental results
Tables 1, 2, and 3 present the overall performance of MPCCI and the compared methods. On CT COVID-19 dataset, our MPCCI method exhibits strong performance, underscoring its efficacy and robustness in COVID-19 image classification tasks. Specifically, it achieves the highest performances of 96.10% and 96.28% on precision and F1-score respectively. On the BUSI dataset, MPCCI achieves the best average results of four evaluation metrics, demonstrating its superiority. Compared to MIB Net, which takes advantages of multi-task learning method in both classification and segmentation, our MPCCI outperforms it with improvements of 0.26%, 0.99%, 2.94%, and 2.19% in accuracy, precision, recall, and F1-score, respectively. This demonstrates that our approach can perform well in diagnosing breast cancer in ultrasound images with only instance-level labels. On the FJPH dataset, the performance of MPCCI consistently surpasses the runner-up by 1.36%, 1.20%, and 3.83% in accuracy, recall, and F1-score, respectively. The results highlight its consistent superiority across various datasets and underscores its potential for practical applications in medical image analysis. On the FJTU dataset, we test the accuracy for the four sub-types. Compared to SOTA and baseline methods, the proposed MPCCI achieves the best performance across all categories. While our method generally outperforms the compared methods, it occasionally lags behind by 1–2% in Precision or Recall. This discrepancy may stem from our method’s suboptimal performance in handling specific categories. A potential improvement direction is to leverage prototype learning for enhancing the classification boundaries58.
Table 1.
Performance comparison between MPCCI and compared methods on the CT COVID-19 dataset. The best and second best results are marked in bold and with underline respectively.
| Method | ACC (%) | P (%) | R (%) | F1 (%) |
|---|---|---|---|---|
| ResNet1818 | 95.44 ± 0.71 | 98.87 ± 0.94 | 92.36 ± 1.03 | 95.50 ± 0.36 |
| Fishr39 | 96.06 ± 1.30 | 94.57 ± 0.28 | 97.31 ± 0.94 | 95.92 ± 0.73 |
| CABNet17 | 95.89 ± 0.64 | 95.06 ± 1.04 | 96.37 ± 1.50 | 95.71 ± 0.83 |
| MixupNet51 | 95.10 ± 0.45 | 96.82 ± 1.51 | 92.74 ± 1.89 | 94.74 ± 0.57 |
| MixStyleNet54 | 95.10 ± 1.49 | 96.82 ± 1.42 | 92.47 ± 1.76 | 94.72 ± 0.82 |
| VGG1640 | 93.96 ± 1.84 | 94.68 ± 2.59 | 93.74 ± 1.86 | 94.21 ± 1.58 |
| ViT9 | 95.22 ± 0.21 | 95.59 ± 0.58 | 94.52 ± 0.71 | 95.06 ± 0.63 |
| Mamba15 | 79.67 ± 0.00 | 77.38 ± 0.00 | 86.50 ± 0.00 | 81.69 ± 0.00 |
| MPCCI (Ours) | 96.10 ± 0.51 | 96.18 ± 0.24 | 96.37 ± 0.84 | 96.28 ± 0.18 |
Table 2.
Performance comparison between MPCCI and compared methods on the BUSI and FJPH datasets for ultrasound images. The best and second best results are marked in bold and with underline respectively.
| Method | BUSI | FJPH | ||||||
|---|---|---|---|---|---|---|---|---|
| ACC (%) | P (%) | R (%) | F1(%) | ACC (%) | P (%) | R (%) | F1(%) | |
| TNTs*16 | 81.20 ± 3.20 | 76.30 ± 5.70 | 61.10 ± 10.40 | 67.9 ± 5.70 | - | - | - | - |
| BVA Net*46 | 84.3 | 88.3 | 75.1 | - | - | - | - | - |
| HoVer-Trans*35 | 85.50 ± 5.00 | 87.60 ± 6.20 | 86.70 ± 11.50 | 87.20 ± 8.00 | - | - | - | - |
| MIB Net*42 | 92.97 ± 1.11 | 93.21 ± 1.50 | 92.97 ± 1.10 | 92.85 ± 1.01 | - | - | - | - |
| ResNet1818 | 91.39 ± 2.48 | 91.76 ± 1.72 | 95.91 ± 1.82 | 93.75 ± 1.78 | 80.90 ± 1.12 | 80.31 ± 1.17 | 87.60 ± 4.40 | 83.74 ± 0.87 |
| Fishr39 | 93.04 ± 2.74 | 96.61 ± 1.34 | 93.18 ± 2.36 | 94.34 ± 1.23 | 84.26 ± 0.84 | 87.87 ± 2.91 | 74.35 ± 3.77 | 80.55 ± 2.45 |
| CABNet17 | 89.23 ± 5.37 | 95.12 ± 1.78 | 88.63 ± 3.63 | 91.76 ± 3.15 | 83.14 ± 1.49 | 83.33 ± 4.63 | 76.92 ± 9.92 | 80.00 ± 7.17 |
| MixupNet51 | 92.30 ± 2.69 | 95.34 ± 1.68 | 93.18 ± 2.51 | 94.25 ± 1.83 | 84.26 ± 2.34 | 79.06 ± 3.21 | 87.17 ± 2.95 | 82.92 ± 2.14 |
| MixStyleNet54 | 86.15 ± 5.04 | 90.69 ± 4.93 | 88.63 ± 6.42 | 89.65 ± 4.64 | 76.40 ± 1.18 | 76.47 ± 2.43 | 66.66 ± 3.88 | 71.23 ± 2.94 |
| VGG1640 | 93.12 ± 1.08 | 94.45 ± 1.26 | 94.45 ± 1.45 | 94.45 ± 1.31 | 82.47 ± 1.80 | 83.33 ± 0.98 | 85.60 ± 4.40 | 84.41 ± 0.74 |
| ViT9 | 90.76 ± 3.72 | 93.18 ± 3.55 | 93.18 ± 4.16 | 93.18 ± 3.77 | 74.83 ± 0.45 | 74.33 ± 0.67 | 84.40 ± 1.60 | 79.03 ± 0.21 |
| Mamba15 | 67.69 ± 0.00 | 67.69 ± 0.00 | 100.00 ± 0.00 | 80.73 ± 0.00 | 68.53 ± 0.00 | 68.33 ± 0.00 | 82.00 ± 0.00 | 74.54 ± 0.00 |
| MPCCI (Ours) | 93.23 ± 2.15 | 94.20 ± 1.36 | 95.91 ± 1.82 | 95.04 ± 1.59 | 85.62 ± 3.14 | 86.62 ± 5.05 | 88.80 ± 3.20 | 87.57 ± 2.23 |
*These results are directly cited from the original papers, as their source codes are not publicly accessible.
Table 3.
Performance comparison on FJTU. The best and second best results are marked in bold and with underline respectively.
| Method | FV-PTC | FC | TA | MC |
|---|---|---|---|---|
| Fishr | 85.42 | 70.68 | 57.77 | 71.02 |
| CABNet | 86.99 | 71.3 | 58.03 | 71.73 |
| MixupNet | 86.79 | 65.15 | 56.63 | 70.03 |
| MixStyleNet | 86.86 | 62.28 | 57.45 | 66.33 |
| CAD_PE | 86.84 | 71.48 | 57.91 | 72.46 |
| ResNet18 | 86.05 | 68.98 | 57.52 | 74.67 |
| MPCCI | 87.15 | 72.77 | 59.26 | 77.99 |
Ablation study
We conduct ablation studies on CT COVID-19 and FJPH datasets to explore the individual contributions of each component of the proposed MPCCI. The four components evaluated are MVFE, MPC, and its two contained criteria (i.e., IP & MT). The results of ablation studies are presented in Table 4 with AB1: ResNet18 (baseline), AB2: AB1 + MVFE, AB3: AB2 + MPC, AB4: AB3 + IP, and AB5: MPCCI (AB4 + MT). The results show that both MVFE and MPC contribute to the improvements in performance compared to the baseline, demonstrating that MPCCI based on FDA can effectively evaluate the causal effect from image to label. Moreover, the results also reveal that it is crucial to consider both IP and MT factors simultaneously, as the performance drops significantly when only IP is considered.
Table 4.
Ablation study of MPCCI on CT COVID-19 and FJPH. AB1: ResNet18 (baseline), AB2: AB1 + MVFE, AB3: AB2 + MPC, AB4: AB3 + IP, and AB5: MPCCI (AB4 + MT). The best and second best results are marked in bold and with underline respectively.
| Method | CT COVID-19 | FJPH | ||||||
|---|---|---|---|---|---|---|---|---|
| ACC (%) | P (%) | R (%) | F1(%) | ACC (%) | P (%) | R (%) | F1(%) | |
| AB1 | 95.44 ± 0.71 | 98.87 ± 0.94 | 92.36 ± 1.03 | 95.50 ± 0.36 | 80.90 ± 1.12 | 80.31 ± 1.17 | 87.60 ± 4.40 | 83.74 ± 0.87 |
| AB2 | 95.47 ± 0.33 | 95.47 ± 0.57 | 95.91 ± 0.75 | 95.69 ± 0.25 | 81.57 ± 0.45 | 80.54 ± 3.46 | 88.80 ± 3.20 | 84.41 ± 0.50 |
| AB3 | 95.72 ± 1.13 | 98.20 ± 1.61 | 93.54 ± 1.34 | 95.81 ± 1.42 | 84.95 ± 2.69 | 83.93 ± 5.87 | 90.40 ± 1.60 | 86.99 ± 1.90 |
| AB4 | 95.92 ± 0.47 | 97.68 ± 1.21 | 94.47 ± 1.13 | 96.05 ± 0.24 | 83.37 ± 0.90 | 82.36 ± 0.97 | 89.60 ± 0.40 | 85.82 ± 0.71 |
| AB5 | 96.10 ± 0.51 | 96.18 ± 0.24 | 96.37 ± 0.84 | 96.28 ± 0.18 | 85.62 ± 3.14 | 86.62 ± 5.05 | 88.80 ± 3.20 | 87.57 ± 2.23 |
Validation of heterogeneity cause C
The gender/age is the unobserved confounding factor C59. Inspired by this work59, the FJTU-H dataset is divided into male and female groups. Subsequently, we conduct generalization tests on these two groups separately. The higher generalizability indicates that the algorithm is less influenced by the confounding factor of gender. The results are shown in Table 5. It can be seen that MPCCI is less affected by the confounding factor C (gender).
Table 5.
Results of generalization ability for the unoberserved confounder C (gender) on FJTU-H dataset.
| Method | Male2Female | Female2Male | ||
|---|---|---|---|---|
| ACC(%) | F1 (%) | ACC(%) | F1 (%) | |
| ResNet18 | 70.43 | 78.96 | 66.55 | 77.02 |
| MPCCI | 74.20 | 85.16 | 67.21 | 77.88 |
Data set analysis
We utilize the FJTU-H dataset to validate the effectiveness of our method in addressing heterogeneity. Two sets of control experiments are conducted: random splitting and splitting by low/high heterogeneity. The Pearson correlation in low and high heterogeneity groups are 0.8 and 0.5, respectively. The experimental results are shown in Table 6. It can be found that in the random splitting group, the baseline method (ResNet18) and our MPCCI method achieve similar results. However, in the splitting by heterogeneity group, our method significantly outperforms the baseline, demonstrating its effectiveness in handling the heterogeneity issue.
Table 6.
Results of heterogeneous generalization on FJTU-H dataset.
| Method | Random Group | Heterogeneous Group | ||
|---|---|---|---|---|
| ACC(%) | F1 (%) | ACC(%) | F1 (%) | |
| ResNet18 | 93.67 | 95.43 | 73.41 | 81.29 |
| MPCCI | 93.74 | 95.68 | 77.63 | 83.29 |
Experimental extensions
In this section, we aim to address three questions to provide more detailed analysis of the proposed method: (1) What is the optimal number of expert networks required to optimize feature views? (2) How do the mixing mechanism and fusion module contribute to the performance of MPC? (3) Can the interpretability of MPCCI be quantitatively assessed? To answer the first question, we conduct experiments by changing the number of expert networks from one to nine on the FJPH dataset and observe the performance. The results in Fig. 6 (a) show that the optimal performance is achieved with five expert networks, indicating that an increased number of views does not correlate directly with enhanced performance. To address the second question, we assess the performance of “MPC1” mode (where the mixing mechanism is removed, and A is fused with only the source multi-view prototypes 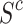 ) and “MPC2” mode (where the fusion module is removed, and
) and “MPC2” mode (where the fusion module is removed, and 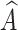 is calculated by randomly mixing A and
is calculated by randomly mixing A and  ). From Fig. 6 (b), we observe that both the mixing mechanism and the fusion module are necessary for MPC, demonstrating its ability to simulate the feature representation of lesions in various states. To answer the third question, we visualize the class activation maps (CAM)60 for four samples in the FJPH and CT COVID-19 datasets using baseline (ResNet18), Fishr, and MPCCI in Fig. 7. The lesions in the original images have been marked by professional doctors and shown with red circles. By comparing the locations of the lesions and visualization results, we can see that MPCCI can attend to the entire lesion, while ResNet18 and Fishr can only focus on a small part of the lesion or miss it entirely. Therefore, the CAM results of MPCCI can provide interpretable results to doctors, thereby facilitating medical diagnosis.
). From Fig. 6 (b), we observe that both the mixing mechanism and the fusion module are necessary for MPC, demonstrating its ability to simulate the feature representation of lesions in various states. To answer the third question, we visualize the class activation maps (CAM)60 for four samples in the FJPH and CT COVID-19 datasets using baseline (ResNet18), Fishr, and MPCCI in Fig. 7. The lesions in the original images have been marked by professional doctors and shown with red circles. By comparing the locations of the lesions and visualization results, we can see that MPCCI can attend to the entire lesion, while ResNet18 and Fishr can only focus on a small part of the lesion or miss it entirely. Therefore, the CAM results of MPCCI can provide interpretable results to doctors, thereby facilitating medical diagnosis.
Fig. 6.

(a) Performance change by increasing the number of expert networks in MVFE. (b) Effect exploration to the contributions of different mixing mechanisms and fusion modules in MPC.
Fig. 7.

Comparative visualization of lesion detection by ResNet18, Fishr, and MPCCI on FJPH and CT COVID-19 datasets. Professional doctors have annotated the lesions in the original images, which are delineated in red for clarity.
Conclusion
In this paper, we propose a novel approach MPCCI for enhanced medical image classification by addressing the unmeasurable confounding factors present in medical imaging analysis. Leveraging FDA, MPCCI estimates the total causal effect of an image on its corresponding label, thus mitigating the negative effects of the confounders. The proposed approach comprises an MVFE module with spatial-channel attention, allowing multi-view features to serve as mediators in FDA, and an MPC module to effectively apply causal intervention on the mediators. An adaptive training strategy, including IP and MT, is introduced to maintain the stable training during the feature exchange process. Experimental results on four medical datasets demonstrate the effectiveness of MPCCI, achieving high accuracy, precision, recall, and F1-score in diagnosing COVID-19, breast cancer, lymph node metastasis, and thyroid. In the future, we plan to conduct extensive validation studies across a wider spectrum of medical conditions and imaging modalities. By rigorously evaluating the performance of MPCCI on diverse datasets encompassing a myriad of medical scenarios, we aim to demonstrate its efficacy and versatility in facilitating accurate and reliable diagnostic decision-making.
Acknowledgements
The authors are thankful to Fujian Provincial Hospital and Fujian Medical University for their management of our patient database. The authors are thankful to Song-Song Wu for helping critically revise the manuscript for important intellectual content and helping collect data and design the study.
Author contributions
H.P. and W.Y. wrote the main manuscript text and H.P. prepared Figs. 1, 2, 3, 4 and 5. All authors reviewed the manuscript.
Funding
Project of the Department of Finance of Fujian Province (0060092410).
Data availability
Excel files containing raw data included in the main figures and tables can be found in the Source Data File in the article. All other data including the imaging data can be provided upon reasonable request to the corresponding author.
Declarations
Competing interests
The authors declare no competing interests.
Footnotes
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Zhi-Liang Hong, Jian-Chuan Yang and Xiao-Rui Peng contributed equally to this work.
References
- 1.Bradley, J., Erickson, P., Korffatis, Z., Akkus & Timothy, L. K. Machine learning for medical imaging. Radiographics 37, 2 (2017), 505–515. (2017). [DOI] [PMC free article] [PubMed]
- 2.Duan, J. et al. Normality learning-based graph anomaly detection via multi-scale contrastive learning. In Proceedings of the ACM International Conference on Multimedia. 7502–7511. (2023).
- 3.Neelu Madan, N. C. et al. Selfsupervised masked convolutional transformer block for anomaly detection. IEEE Transactions on Pattern Analysis and Machine Intelligence (2023). (2023). 10.1109/TPAMI.2023.3322604 [DOI] [PubMed]
- 4.Li, Z., Zheng, Y., Luo, X. & Shan, D. and Qingqi Hong. Scribblevc: scribble-supervised medical image segmentation with vision-class embedding. In Proceedings of the ACM International Conference on Multimedia. 3384–3393. (2023).
- 5.Yixuan Wu, J., Chen, J., Zhu, Y. Y., Danny, Z. & Chen and Jian Wu. GCL: gradient-guided contrastive learning for medical image segmentation with multi-perspective meta labels. In Proceedings of the ACM International Conference on Multimedia. 463–471. (2023).
- 6.Xie, X., Jin, T., Yun, B., Li, Q. & Wang, Y. Exploring hyperspectral histopathology image segmentation from a deformable perspective. In Proceedings of the ACM International Conference on Multimedia. 242–251. (2023).
- 7.Huang, Z. A., Liu, R., Zhu, Z. & Kay Chen, T. Multitask learning for joint diagnosis of multiple mental disorders in resting-state fmri. IEEE Transactions on Neural Networks and Learning Systems (2022). (2022). 10.1109/TNNLS.2022.3225179 [DOI] [PubMed]
- 8.Huang, Z. A. et al. Identification of autistic risk candidate genes and toxic chemicals via multilabel learning. IEEE Transactions on Neural Networks and Learning Systems 32, 9 (2020), 3971–3984. (2020). 10.1109/TNNLS.2020.3016357 [DOI] [PubMed]
- 9.Wu Lin, Q., Lin, L., Feng & Kay Chen, T. Ensemble of domain adaptation-based knowledge transfer for evolutionary multitasking. IEEE Transactions on Evolutionary Computation (2023). (2023). 10.1109/TEVC.2023. 3259067.
- 10.Rui Liu, Z. A., Huang, Y., Zhu, H. Z., Wong, K. C. & Kay Chen, T. Spatial–temporal co-attention learning for diagnosis of mental disorders from resting-state fmri data. IEEE Transactions on Neural Networks and Learning Systems (2023). (2023). 10.1109/TNNLS.2023. 3243000. [DOI] [PubMed]
- 11.Fouras, A. et al. The past, present, and future of x-ray technology for in vivo imaging of function and form. Journal of Applied Physics 105, 10 (2009). (2009).
- 12.Li, X., Liu, L. & Wang, C. Juan Zhou, and Heterogeneity analysis and diagnosis of complex diseases based on deep learning methods. Scientific Reports 8, 1 (2018), 6155. (2018). [DOI] [PMC free article] [PubMed]
- 13.Lin Yue, D., Tian, W., Chen, X., Han & Yin, M. Deep learning for heterogeneous medical data analysis. World Wide Web 23 (2020), 2715–2737. (2020).
- 14.Iain Carmichael, A. H., Song, R. J., Chen, Drew, F. K., Williamson, T. Y. & Chen and Faisal Mahmood. Incorporating intratumoral heterogeneity into weakly-supervised deep learning models via variance pooling. In International Conference on Medical Image Computing and Computer-Assisted Intervention. Springer, 387–397. (2022).
- 15.Zhang, L. et al. Generalizing deep learning for medical image segmentation to unseen domains via deep stacked transformation. IEEE Transactions on Medical Imaging 39, 7 (2020), 2531–2540. (2020). 10.1109/TMI. 2020.2973595. [DOI] [PMC free article] [PubMed]
- 16.François Bertucci and Daniel Birnbaum. Reasons for breast cancer heterogeneity. Journal of Biology 7 (2008), 1–4. (2008). [DOI] [PMC free article] [PubMed]
- 17.Judea et al. Models, reasoning and inference. Cambridge, UK: CambridgeUniversityPress 19, 2 (2000), 3. (2000).
- 18.Kumar, A., Kim, J., Lyndon, D., Fulham, M. & Feng, D. An ensemble of fine-tuned convolutional neural networks for medical image classification. IEEE Journal of Biomedical and Health Informatics 21, 1 (2016), 31–40. (2016). 10.1109/JBHI.2016.2635663 [DOI] [PubMed]
- 19.Yao, H. et al. Source free semi-supervised transfer learning for diagnosis of mental disorders on fmri scans. IEEE Transactions on Pattern Analysis and Machine Intelligence (2023). (2023). 10.1109/TPAMI.2023.3298332 [DOI] [PubMed]
- 20.Yun Yang, Y., Hu, X., Zhang & Wang, S. Two-stage selective ensemble of Cnn via deep tree training for medical image classification. IEEE Trans. Cybernetics. 52 (2021), 9194–9207. 10.1109/TCYB.2021.3061147 (2021). [DOI] [PubMed] [Google Scholar]
- 21.Graham, S. et al. Yee Wah tsang, and Nasir rajpoot. 2019. MILD-Net: minimal information loss dilated network for gland instance segmentation in colon histology images. Med. Image. Anal.52, 199–211 (2019). [DOI] [PubMed] [Google Scholar]
- 22.Hong, H., Jiang, M., Feng, L., Lin, Q. & Tan, K. C. Balancing exploration and exploitation for solving large-scale multiobjective optimization via attention mechanism. In 2022 IEEE Congress on Evolutionary Computation (CEC), 1–8 (IEEE, 2022).
- 23.Junlong Cheng, C., Gao, F., Wang & Zhu, M. Segnetr: rethinking the local-global interactions and skip connections in u-shaped networks. In International Conference on Medical Image Computing and Computer-Assisted Intervention. Springer, 64–74. (2023).
- 24.Ma, C., Wu, J., Si, C. & Tan, K. C. Scaling supervised local learning with augmented auxiliary networks. In The Twelfth International Conference on Learning Representations. (2023).
- 25.Bissoto, A. & Valle, E. and Sandra Avila. Gan-based data augmentation and anonymization for skin-lesion analysis: a critical review. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 1847–1856. (2021).
- 26.Irem Cetin, M., Stephens, O., Camara, Miguel, A. G. & Ballester Attri-VAE: attribute-based interpretable representations of medical images with variational autoencoders. Computerized Medical Imaging and Graphics 104 (2023), 102158. (2023). [DOI] [PubMed]
- 27.Haifan Gong, G., Chen, M., Mao, Z., Li & Li, G. Vqamix: conditional triplet mixup for medical visual question answering. IEEE Transactions on Medical Imaging 41, 11 (2022), 3332–3343. (2022). 10.1109/TMI. 2022.3185008. [DOI] [PubMed]
- 28.Amirhossein Kazerouni, E. K. et al. and. Diffusion models in medical imaging: a comprehensive survey. Medical Image Analysis (2023), 102846. (2023). [DOI] [PubMed]
- 29.Zhang, D., Zhang, H., Tang, J. & Hua, X. S. and Qianru Sun. Causal intervention for weakly-supervised semantic segmentation. Advances in Neural Information Processing Systems 33 (2020), 655–666. (2020).
- 30.Mattia Prosperi, Y. et al. and. Causal inference and counterfactual prediction in machine learning for actionable healthcare. Nature Machine Intelligence 2, 7 (2020), 369–375. (2020).
- 31.Li, X. et al. A causality-informed graph intervention model for pancreatic cancer early diagnosis. IEEE Trans. Artif. Intell. (2024).
- 32.Tang, X. et al. A causal counterfactual graph neural network for arising-from-chair abnormality detection in parkinsonians. Med. Image. Anal.97, 103266 (2024). [DOI] [PubMed] [Google Scholar]
- 33.Qu, J. et al. A causality-inspired generalized model for automated pancreatic cancer diagnosis. Med. Image. Anal.94, 103154 (2024). [DOI] [PubMed] [Google Scholar]
- 34.Li, X. et al. Causality-driven graph neural network for early diagnosis of pancreatic cancer in non-contrast computerized tomography. IEEE Trans. Med. Imaging. 42 (6), 1656–1667 (2023). [DOI] [PubMed] [Google Scholar]
- 35.Cheng Ouyang, C. et al. and Daniel Rueckert. Causality-inspired single-source domain generalization for medical image segmentation. IEEE Transactions on Medical Imaging 42, 4 (2022), 1095–1106. (2022). 10.1109/TMI. 2022.3224067. [DOI] [PubMed]
- 36.Zhang Chen, Z. et al. C-cam: causal cam for weakly supervised semantic segmentation on medical image. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 11676–11685. (2022).
- 37.Miao, J., Chen, C., Liu, F., Wei, H. & Pheng-Ann Heng Caussl: causality-inspired semi-supervised learning for medical image segmentation. In Proceedings of the IEEE/CVF International Conference on Computer Vision. 21426–21437. (2023).
- 38.Guanqun, S. et al., Le-Minh Nguyen, Junyi Xin. DA-TransUNet: integrating spatial and channel dual attention with transformer U-net for medical image segmentation.Front Bioeng Biotechnol.16:12:1398237. (2024). 10.3389/fbioe.2024.1398237 [DOI] [PMC free article] [PubMed]
- 39.Yizhi Pan, J. et al. Sun.2024.A mutual inclusion mechanism for precise boundary segmentation in medical images. Front Bioeng. Biotechnol. 2024 Dec.24:121504249doi : 10.3389/fbioe.2024.1504249 [DOI] [PMC free article] [PubMed]
- 40.He, A., Li, T., Li, N., Wang, K. & Fu, H. CABNet: category attention block for imbalanced diabetic retinopathy grading. IEEE Transactions on Medical Imaging 40, 1 (2020), 143–153. (2020). 10.1109/TMI.2020.3023463 [DOI] [PubMed]
- 41.Zhi-An Huang, Y. et al. Federated multi-task learning for joint diagnosis of multiple mental disorders on mri scans. IEEE Transactions on Biomedical Engineering 70, 4 (2022), 1137–1149. (2022). 10.1109/TBME.2022.3210940 [DOI] [PubMed]
- 42.Woo, S., Park, J. & Lee, J. Y. and In So Kweon. Cbam: convolutional block attention module. In Proceedings of the European Conference on Computer Vision. 3–19. (2018).
- 43.Chunyan Yu, B. et al. Multiview calibrated prototype learning for few-shot hyperspectral image classification. IEEE Transactions on Geoscience and Remote Sensing 60 (2022), 1–13. (2022). 10.1109/TGRS. 2022.3225947.
- 44.Maede Maftouni, A. C. C. et al. A robust ensemble-deep learning model for COVID-19 diagnosis based on an integrated CT scan images database. In IIE annual conference. Proceedings. Institute of Industrial and Systems Engineers (IISE), 632–637. (2021).
- 45.Al-Dhabyani, W., Gomaa, M., Khaled, H. & Fahmy, A. Dataset of breast ultrasound images. Data in Brief 28 (2020), 104863. (2020). [DOI] [PMC free article] [PubMed]
- 46.Wang, J. et al. and. Information bottleneck-based interpretable multitask network for breast cancer classification and segmentation. Medical Image Analysis 83 (2023), 102687. (2023). [DOI] [PubMed]
- 47.He, K., Zhang, X. & Ren, S. and Jian Sun. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 770–778. (2016).
- 48.Karen Simonyan and Andrew Zisserman. Very deep convolutional networks for large-scale image recognition. arXiv preprint arXiv:1409.1556 (2014). (2014).
- 49.Alexey Dosovitskiy, L. et al. An image is worth 16x16 words: transformers for image recognition at scale. In International Conference on Learning Representations. (2020).
- 50.Albert Gu and Tri Dao. Mamba: linear-time sequence modeling with selective state spaces. arXiv preprint arXiv:2312.00752 (2023). (2023).
- 51.Islam, N. U., Zhou, Z., Gehlot, S., Gotway, M. B. & Liang, J. Seeking an optimal approach for Computer-aided Diagnosis of Pulmonary Embolism. Medical image analysis 91 (2024), 102988. (2024). [DOI] [PMC free article] [PubMed]
- 52.Zhang, H., Cisse, M., Yann, N., Dauphin & Lopez-Paz, D. Mixup: beyond empirical risk minimization. In International Conference on Learning Representations. (2018).
- 53.Kaiyang Zhou, Y., Yang, Y., Qiao & Xiang, T. Domain generalization with mixstyle. In International Conference on Learning Representations. (2020).
- 54.Alexandre Rame, C., Dancette & Cord, M. Fishr: invariant gradient variances for out-of-distribution generalization. In International Conference on Machine Learning. PMLR, 18347–18377. (2022).
- 55.Han, K. et al. Transformer in transformer. Advances in Neural Information Processing Systems 34 (2021), 15908–15919. (2021).
- 56.Xing, J. et al. Jing Xiao, and Using BI-RADS stratifications as auxiliary information for breast masses classification in ultrasound images. IEEE Journal of Biomedical and Health Informatics 25, 6 (2020), 2058–2070. (2020). 10.1109/JBHI. 2020.3034804. [DOI] [PubMed]
- 57.Yuhao Mo, C. et al. Hover-trans: anatomy aware hover-transformer for roi-free breast cancer diagnosis in ultrasound images. IEEE Transactions on Medical Imaging (2023). (2023). 10.1109/TMI. 2023.3236011. [DOI] [PubMed]
- 58.Chong Wang, Y. et al. and. Learning support and trivial prototypes for interpretable image classification. In Proceedings of the IEEE/CVF International Conference on Computer Vision. 2062–2072. (2023).
- 59.Raumanns, S. A. S. R., Britt, E. J., Michels, G. & Schouten and Veronika Cheplygina. Risk of training diagnostic algorithms on data with demographic bias. In Interpretable and Annotation-Efffcient Learning for Medical Image Computing: Third International Workshop, iMIMIC 2020, Second International Workshop, MIL3ID 2020, and 5th International Workshop, LABELS 2020, Held in Conjunction with MICCAI 2020, Lima, Peru, October 4–8, 2020, Proceedings 3. Springer, 183–192. (2020).
- 60.Bolei Zhou, A., Khosla, A., Lapedriza, A., Oliva & Torralba, A. Learning deep features for discriminative localization. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2921–2929. (2016).
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.
Data Availability Statement
Excel files containing raw data included in the main figures and tables can be found in the Source Data File in the article. All other data including the imaging data can be provided upon reasonable request to the corresponding author.