

Abstract
Background
Hospitals struggle to predict critical outcomes. Traditional early warning systems, like NEWS and MEWS, rely on static variables and fixed thresholds, limiting their adaptability, accuracy, and personalization.
Methods
We previously developed the Enhanced Transformer for Health Outcome Simulation (ETHOS), an artificial intelligence (AI) model that tokenizes patient health timelines (PHTs) from electronic health records and uses transformer-based architectures to predict future PHTs. ETHOS is a versatile framework for developing a wide range of applications. In this work, we develop the Adaptive Risk Estimation System (ARES) that leverages ETHOS to compute dynamic, personalized risk probabilities for clinician-defined critical events. ARES also features a personalized explainability module that highlights key clinical factors influencing risk estimates. We evaluated ARES using the MIMIC-IV v2.2 dataset, together with its emergency department extension, and benchmarked performance against both classical early warning systems and contemporary machine learning models.
Results
The entire dataset was tokenized, resulting in 285,622 PHTs (63% with at least 1 hospital admission), comprising over 357 million tokens. ETHOS outperformed benchmark models in predicting hospital admissions, intensive care unit admissions, and prolonged stays, achieving superior area under the curve scores. Its risk estimates were robust across demographic subgroups, with calibration curves confirming model reliability. The explainability module provided valuable insights into patient-specific risk factors
Conclusions
ARES, powered by ETHOS, advances predictive health care AI by delivering dynamic, real-time, personalized risk estimation with patient-specific explainability. Although our results are promising, the clinical impact remains uncertain. Demonstrating ARES’s true utility in real-world settings will be the focus of our future work.
Keywords: early warning scores, EHR, foundation model, transformer, zero-shot inference, patient health trajectories
Key Points:
Adaptive Risk Estimation System (ARES) enables dynamic, real-time risk estimation by predicting patient health timelines (PHTs) from electronic health records using a transformer-based model.
ARES enhances clinical decision-making by leveraging Enhanced Transformer for Health Outcome Simulation–generated future PHTs to provide personalized risk predictions with explainability.
Methods used outperform traditional models in predicting critical outcomes while demonstrating strong calibration and equitable performance across demographic subgroups.
Background
The United States allocates nearly 18% of its gross domestic product (GDP) to health care [1], yet Americans have shorter life spans and poorer health than residents of other high-income nations. Among these countries, the United States not only has the lowest life expectancy but also the highest rates of preventable deaths [2]. Hospitals face mounting challenges managing patient influx and identifying individuals at risk for critical outcomes, including mortality, intensive care unit (ICU) admission, or prolonged hospital stays [3]. Accurate prediction of critical clinical events is essential for enhancing patient care and optimizing the timely allocation of limited health care resources [4]. Early identification of at-risk patients enables clinicians to prioritize interventions, anticipate potential escalations in care, and improve outcomes while simultaneously reducing costs [5, 6]. However, current methodologies often fail to fully utilize the vast and complex data available in electronic health records (EHRs), a limitation that becomes particularly evident in emergency settings where time-sensitive decisions are critical [7–11]. Traditional scoring systems, such as the National Early Warning Score (NEWS) [12] and the Modified Early Warning Score (MEWS) [13], rely on static variables and predefined thresholds, constraining their ability to adapt to dynamic and multifaceted patient data. These approaches are further hindered by their reliance on specific cutoff points for data inclusion (e.g., triage, 24-hour windows), which can overlook valuable longitudinal patterns.
Recent advances in generative machine learning—particularly transformer architectures [14–17] that underpin large language models [18, 19]—have unlocked unprecedented capabilities for processing high-dimensional, heterogeneous, time-stamped health data from EHRs [20–24]. In this work, we build on our Enhanced Transformer for Health Outcome Simulation (ETHOS) [15], which differs from prior efforts in its tokenization and handling of EHR events. ETHOS is autoregressively pretrained—without any task-specific labels—on over 321 million tokens drawn from 269,741 patient health timelines (PHTs), learning broad, high-dimensional representations that transfer across tasks. Operating on PHTs (tokenized sequences of demographics, diagnoses, medications, etc.; see Supplementary Table S7), ETHOS generates plausible future timelines (Fig. 1) and delivers zero-shot predictions for mortality, ICU admission, prolonged stay, and composite endpoints without any additional fine-tuning. By virtue of its scale, generalizability, and multitask adaptability, ETHOS serves as a foundation model for PHT generation.
Figure 1:

Workflow of the Adaptable Risk Estimation Score (ARES) Framework. This figure illustrates the ARES framework, developed on the ETHOS model, for dynamic and explainable risk evaluation. Panel 1 depicts the tokenization of a patient’s entire health history into structured events represented as a sequence of tokens (PHTs), incorporating standardized coding systems such as ATC for medications, ICD-PCS for procedures, and others. Panel 2 demonstrates how the ETHOS model trained on a large dataset of PHTs to simulate potential future patient health timelines (fPHTs). By analyzing a particular patient’s known PHT and generating multiple fPHTs, the model estimates the probabilities of critical outcomes, such as inpatient death, ICU admission, or a prolonged hospital stay exceeding 10 days. Panel 3 showcases the result of processing of fPHTs to calculate event-specific risks and predict the timing of these events, should they occur. Risk levels are defined across 5 categories, color-coded for enhanced clinical interpretability. Panel 4 showcases the explainability module, which identifies the key factors influencing specific risk estimates, offering personalized and actionable insights to support clinical decision-making. In this example, blue tokens indicate factors contributing to an increased risk of ICU admission.
Once trained, ETHOS can generate multiple simulated future patient health timelines (fPHTs) and estimate the probability of clinical events occurring within those trajectories (e.g., ICU admission). For adverse events during an inpatient stay, these probabilities serve as dynamic risk estimates, effectively functioning as an early warning system. Unlike traditional methods that require separate models or task-specific retraining, ETHOS operates as a unified model capable of concurrently assessing multiple clinical endpoints. As new patient data become available, risk estimates are automatically updated. This flexible and scalable risk prediction framework, built on ETHOS, is referred to as the Adaptive Risk Estimation System (ARES), as illustrated in Fig. 2. Risk is quantified into 5 ordinal categories (levels 1 through 5) based on the predicted probability: 0–20% corresponds to level 1, 20–40% to level 2, and so on.
Figure 2:

Timeline of a patient’s hospital stay and hypothetical risk predictions by ARES. This figure illustrates the timeline of a patient’s hospital stay, from admission to discharge around day 14, demonstrating how ARES dynamically adjusts its predictions based on the patient’s evolving clinical status and medical history. By day 5, ARES predicts a high risk of ICU admission, which is subsequently confirmed as the patient is admitted around day 6. Once the patient is in the ICU, ARES discontinues ICU risk evaluation, as indicated by the “Deactivated Component” label. After the ICU stay, ARES identifies an increased likelihood of a hospital stay exceeding 10 days. Upon reaching the 10-day threshold, ARES automatically recalibrates its predictions, replacing the previous risk estimation with the likelihood of a 15-day stay, now categorized as a “New Component” in the risk assessment.
In this article, we present ARES and introduce a novel explainability framework that delivers fully personalized insights, potentially allowing clinicians to understand the specific factors influencing the system’s risk predictions for individual patients. We benchmark the performance of ARES against state-of-the-art methods across multiple clinically relevant tasks, demonstrating its superior predictive accuracy. We validate its effectiveness and provide the accompanying code for the full reproduction of all the experiments by other researchers.
Data Description
In this study, we used the Medical Information Mart for Intensive Care (MIMIC-IV) version 2.2 database [25, 26], including its emergency department (ED) extension. MIMIC-IV, developed by the Massachusetts Institute of Technology and Beth Israel Deaconess Medical Center (BIDMC), contains deidentified health records for almost 300,000 patients either admitted to the ED and/or hospital at BIDMC from 2008 to 2019. Detailed patient demographics are presented in Supplementary Table S2.
Evaluation
Following the tokenization process, the data of 299,721 unique patients from the MIMIC-IV dataset were converted into 285,622 PHTs, which were subsequently used for training and testing. Patients were excluded if they had no usable data after tokenization. This occurs when patients in MIMIC have little or no structured information available or when the available information (e.g., clinical notes, imaging) is not tokenized in the current ETHOS version. Of the total PHTs, approximately 63% (180,733) contained hospital admissions records. The tokenized dataset comprised over 360 million tokens in total. In the Supplementary Materials, we provide detailed information regarding the MIMIC-IV data used (Supplementary Table S7), patient demographics (Supplementary Table S2), characteristics of the PHTs (Supplementary Table S6), and tokens (Supplementary Table S11). The model was trained and validated on 90% of the PHTs, with the remaining 10% reserved for testing. During inference, at least  fPHTs were generated for each investigated task.
fPHTs were generated for each investigated task.
The predictive performance of ARES and Medical Event Data Standard (MEDS)–Tab was evaluated on 3 individual clinical endpoints—hospital mortality (HM), ICU admission (IA), and prolonged hospital stay (PS; defined as length of stay >90th percentile)—and, as an illustrative demonstration of joint risk modeling, on a composite criterion combining these events (HM-IA-PS). The prevalence of these tasks is 1.85%, 15.44%, 9.01%, and 20.39%, respectively. This composite endpoint demonstrates ARES’s capacity to compute joint probabilities across heterogeneous outcomes and to naturally model their statistical dependencies. The composite score represents the cumulative risk of clinician-defined critical events. All predictions were generated at the hospital admission. As summarized in Fig. 3, Fig. 5, and Supplementary Table S1, ARES consistently outperformed MEDS-Tab across both individual and composite endpoints, achieving higher area under the curve (AUC) values in every case. Notably, these gains were observed across all racial subgroups, with the most pronounced improvements for Asian and Hispanic patients, indicating ARES’s robustness and its potential to reduce disparities in predictive accuracy.
Figure 3:

Predictive results for the ED benchmark tasks. Fewer methods appear in the ED re-presentation task (right) because score-based approaches, designed specifically to estimate in-hospital deterioration, are not applicable once the patient has left the ED. ETHOS consistently achieves the best performance across all evaluated tasks.
Figure 5:

AUC comparison between ETHOS and MEDS-Tab across demographic subgroups and prediction tasks. AUC scores with 95% confidence intervals are shown for ETHOS (orange) and MEDS-Tab (gray) across 4 prediction tasks: hospital mortality, ICU admission, prolonged stay, and composite outcome (hospital mortality + ICU admission + prolonged stay). Performance is reported for the overall population and stratified by gender (female, male) and race (Asian, Black, Hispanic, other, unknown, White). ETHOS consistently outperforms MEDS-Tab across all demographic subgroups and tasks.
Figure 4 illustrates the dynamic risk trajectories generated by ARES, showcasing how the system continuously updates probability estimates for key clinical outcomes, including ICU admission, prolonged hospital stay, and mortality, as new clinical events occur. The figure highlights specific medical interventions, such as laboratory tests and procedures, that drive significant changes in risk estimates, demonstrating ARES’s ability to integrate evolving patient data into real-time risk assessment. The results underscore the model’s capacity to capture complex temporal relationships between clinical events, dynamically recalibrating risk scores based on patient status and treatment progression.
Figure 4:

ares Risk Trajectories. This figure illustrates risk trajectories for nearly 1,000 tokens preceding patient death, as monitored by ARES, which evaluates the probability of death, ICU admission, prolonged hospital stay, and a composite risk score. The lower panel provides a color-coded representation of risk with the actual time since the ED presentation. In contrast, the upper panel highlights three 5-token regions influencing risk predictions at areas marked by the thin gray bar. In the first region, token LAB-50813 (Lactate Blood Test) increases the composite risk score from 0.41 to 0.56, but since the result falls in Q9 (80th–90th percentile), ETHOS downgrades the risk estimate back to the previous level. In the second region (close to the end), a sharp increase in composite risk occurs due to heightened ICU admission triggered by ICD-PCS code 0BH17EZ, which is coded by 7 tokens (only 5 visible), which represents endotracheal airway insertion into the trachea via natural or artificial opening. The “H” token specifically signals ETHOS to escalate the ICU risk to nearly 1.0, indicating that the patient is being intubated de novo. The ICD-10-PCS breakdown confirms the procedure as a respiratory intervention involving tracheal insertion via a natural or artificial opening. ICD-PCS 0BH17EZ does not increase the risk of death, but the next ICD-PCS 5A12012 (5 tokens coding A1202 visible) raises the risk of death to about 0.25. We note that an increased risk of death is associated with a decreased risk of ICU admission, as these are competing risks. This visualization demonstrates how ARES dynamically adjusts risk scores based on evolving patient data, integrating clinical trajectories into real-time risk assessment. In this example, the rapid risk that increases immediately following invasive procedures (e.g., intubation) should be interpreted as retrospective severity markers rather than actionable alerts, since they occur too late to guide effective intervention. Shaded bands around each trajectory denote the 95% confidence intervals arising from Monte Carlo sampling.
In addition to the risks inherent in ARES, we compared ETHOS’s predictive capabilities with those of traditional early warning scores and other machine learning (ML) models. Figure 3 presents the AUC values (receiver operating characteristic [ROC] curves in Supplementary Fig. S2) for key ED benchmark tasks: hospitalization at triage, critical outcomes within 12 hours of triage, and ED re-presentation within 72 hours postdischarge. ETHOS demonstrated consistently superior predictive accuracy across all evaluated tasks. We provide detailed numerical values in Supplementary Tables S3, S4, and S5.
The risks provided by ETHOS were also found to be well calibrated, as tested by calibration curves. Brier scores were found in the range 0.01–0.14, depending on the task, indicating excellent to good performances, as shown in Supplementary Figure 4.
Discussion
The ARES framework introduces an innovative approach to building predictive models by leveraging cutting-edge artificial intelligence (AI) technology. Several aspects of this approach distinguish it from traditional models. First, ARES enables dynamic risk estimation at any time during a patient’s stay, from admission to discharge. Powered by ETHOS [15], ARES utilizes PHTs and incorporates all available clinical information at the time of risk estimation. Unlike traditional models, which rely on static data points, such as information collected within 24 hours after admission or ED presentation or data up to triage [27, 28], ARES continuously adapts to the patient’s evolving clinical status. This adaptability overcomes a key limitation of static models, which may not perform optimally outside the narrow time frames for which they are designed. This capability is demonstrated in Fig. 4 and Supplementary Table S10, which illustrate how risk evolves over time during a patient’s hospital stay. These visualizations, which depict how personalized risk evolves over time to reach the current estimates, provide insights into the specific factors driving model predictions for each patient. They highlight clinical events associated with increased or decreased risk, offering real-time explainability. By identifying the most influential features contributing to an individual’s risk assessment, ARES has the potential to empower clinicians with a clearer understanding of the rationale behind each prediction.
As illustrated in Fig. 1, ARES can estimate risk for various critical events, such as in-hospital mortality, ICU admission, and prolonged hospital stays. Beyond these standard metrics, additional indicators can be integrated seamlessly, including the risk of ICU admission during a specific length of stay, ICU readmission, acute kidney injury, sepsis, cardiac arrest, or 30-day readmission, and others. The ETHOS model, which underpins ARES, allows for the dynamic combination of these risks into composite measures while accounting for their interdependencies. For example, the occurrence of mortality on day 8 would render the probability of a 10-day hospital stay zero. This ability to incorporate conditional and causal relationships between tracked events is another strength of ARES. Importantly, integrating additional metrics does not require model retraining or modifications of ETHOS. Once a range of possible future PHTs has been generated, any additional metrics can be calculated with minimal computational resources, making ARES scalable and adaptable to diverse health care settings.
In its current implementation, ETHOS distills multiple fPHTs into a single predictive decision, such as inpatient mortality. However, this approach overlooks the wealth of longitudinal information contained in these trajectories, including the sequence of clinical events that lead to a particular outcome, or the absence thereof. By merely predicting the likelihood of an adverse event, valuable insights into the pathways that contribute to deterioration or recovery remain underutilized. Expanding ARES to provide a more granular, trajectory-based interpretation of risk would allow clinicians not only to assess a patient’s probability of experiencing a critical event but also to understand the evolving clinical course leading to that outcome including the cost. This enhanced approach would address a key limitation highlighted in the early warning paradox [29], where models trained on retrospective data may fail to capture the full complexity of clinical interventions and their effects on patient outcomes. Moving forward, we aim to refine ARES to incorporate and visualize these probabilistic trajectories. This will equip clinicians with deeper, more actionable insights into clinical risk dynamics and potentially provide new information about causality in patient outcomes.
We recognize that, to date, ARES has not undergone formal usability testing with frontline clinicians, yet their ultimate impact depends on seamless integration into real-world workflows. Emergency medicine specialists on our team have provided informal feedback on feasibility and clarity of the risk estimates and explanatory highlights, and we are now designing pilot simulations in which physicians will “round” on deidentified patient cases presented through mock electronic charts powered by ARES. These studies, first leveraging MIMIC-derived timelines and subsequently our own Mass General Brigham data, will allow us to observe decision points, gather qualitative feedback on timing and interpretability of alerts, and refine both the user interface and explanation formats. We anticipate that iterative, case-based testing will guide the development of a clinician-centered dashboard, ensuring that ARES’s predictions align with care priorities and support timely, actionable insights in the emergency setting.
This study has several important limitations. First, although we demonstrated ETHOS using PHTs derived from the MIMIC-IV-ED dataset, its performance on data from other institutions may be compromised without retraining on external cohorts. Electronic health record systems and clinical workflows differ substantially across hospitals—driven by variations in documentation practices, patient case mix, and care protocols—so models trained on one site can yield misleading risk estimates when deployed elsewhere. Moreover, our training data may harbor demographic and institutional biases (e.g., overrepresentation of certain age, race, or socioeconomic groups), which could impair generalizability and exacerbate health inequities if unaddressed. The MIMIC dataset is relatively small, and although it contains dense, diverse information, the limited cohort size inevitably constrains generalization. Our model is explicitly designed to scale, and we expect its performance to further improve when trained on larger and more diverse datasets that capture a broader range of clinical variability. We have not yet conducted a thorough fairness audit to quantify potential disparities in ETHOS’s predictions across sex, race, or ethnicity. By contrast, in domains such as radiology or pathology, data inputs like images are relatively standardized, enabling easier cross-institution transfer. To facilitate broader validation and retraining, we have ensured that the ETHOS-ARES codebase is fully compatible with the MEDS health AI data standard [30]. This interoperability simplifies the process for other researchers to apply identical model architectures to their local data, perform bias and subgroup analyses, and iteratively refine ETHOS for diverse patient populations.
We also recognize that our evaluation on the extensively curated MIMIC-IV dataset may underestimate challenges encountered in real-world EHRs, which often exhibit higher rates of missing or irregular data, temporal shifts in documentation and care processes, and evolving patient populations. Although ETHOS is designed to operate on incomplete timelines, elevated missingness will still impair model accuracy. It is unclear if temporal biases or practice changes may introduce drift over time for ETHOS because the inferences are based on the context, whichis contemporary to predictions, but this has not been investigated yet. Future work will systematically assess ETHOS’s resilience to these factors and develop strategies for ongoing recalibration in heterogeneous clinical environments. In addition, our current benchmarking employed only classical risk prediction methods. While sufficient to demonstrate ETHOS’s competitiveness on established tasks, more sophisticated approaches could yield higher benchmark scores. Even if such models were to match or slightly exceed our performance on static benchmarks, this would not diminish ETHOS’s primary contribution: a dynamic, explainable framework that adapts predictions in real time as new clinical data become available. Future work will expand benchmarking to include a broader set of advanced methods (e.g,. [22]).
In current implementation, we exclude unstructured clinical text, and because of that, ETHOS may miss nuanced patient information, such as narrative impressions or social determinants, that could enhance risk estimation and zero-shot generalizability. Integrating free-text notes poses challenges in segmenting and embedding variable-length narratives alongside structured events without overwhelming the model’s capacity. In future work, we will explore the use of pretrained clinical-language-model embeddings, hierarchical chunking of note content, and multimodal fusion techniques to incorporate these rich data into the PHTs.
Data standardization is often proposed as a solution to address the challenges of variability in health care data. However, achieving meaningful standardization would require identifying commonalities between health care systems, an endeavor that may not be feasible given the diversity of clinical practices, patient populations, and institutional workflows. An alternative is to train AI models, such as ETHOS, on raw data from diverse institutions, allowing the model itself to learn and interpret the underlying patterns and clinical pathways. This approach mirrors the capability of large language models (LLMs) to discern meaning from vastly different styles of text and presentations or even different languages, leveraging the same transformer architecture as ETHOS. We performed an energy consumption analysis comparing training of ETHOS to other known LLMs that can be seen in Supplementary Table S9.
In summary, recent advances in AI have created unprecedented opportunities for innovative solutions like ARES, which harness large volumes of heterogeneous data to build general-purpose models whose predictive performance exceeds state-of-the-art methods. ARES delivers dynamic, personalized risk estimates and offers real-time explainability, empowering clinicians to make better-informed decisions. Moreover, its modular architecture and the underlying ETHOS framework enable seamless integration of additional data modalities, such as radiology, genomics, and other institutional datasets, further enhancing predictive accuracy and broadening applicability across diverse health care environments. Although our results are promising, the clinical impact remains uncertain. Demonstrating ARES’s true utility in real-world settings will be the focus of our future work.
As health care costs and complexity continue to rise, PHT-based frameworks like ARES show a promising pathway toward data-driven AI-enabled individualized patient care with the potential to reduce morbidity, improve outcomes, and lower health care costs.
Potential Implications
ARES offers several near-term opportunities to enhance clinical care beyond emergency early warning. First, by continuously updating personalized risk profiles, ARES can inform dynamic triage and resource allocation decisions across hospital units. For example, bed managers could use the ARES scores to anticipate ICU demand several hours in advance, improving staff deployment and reducing admission delays.
Second, ARES’s real-time explainability module—highlighting the specific tokens driving risk changes—can support shared decision-making at the bedside. Clinicians may review the key factors that elevated a patient’s risk, facilitating targeted interventions, such as order adjustments, specialist consults, or heightened monitoring, and enabling more transparent discussions with patients and families.
Third, ARES can serve as a decision support tool in clinical research and quality improvement initiatives. Embedded within institutional dashboards, ARES could identify patient subgroups with unexpectedly high- or low-risk trajectories, prompting retrospective chart reviews or prospective studies to refine care pathways. Its use in pilot implementation studies may reveal workflow integrations that optimize alert timing and reduce alarm fatigue.
Methods
ETHOS and probabilistic inference
We introduced ETHOS in [15]. It operates on PHTs, which are tokenized chronological representations of patient medical histories (see Supplementary Table S8). Here, tokenization refers to encoding clinical events, such as inpatient visits, procedures, laboratory results, medication administrations, and vital signs, as sequences of discrete tokens. The intervals between events are captured using specialized time-interval tokens. Formally, a PHT is a sequence of integer labels corresponding to these tokens, and its length can reach hundreds of thousands of tokens.
ETHOS employs a transformer-based generative model to predict future clinical events from tokenized PHTs. During inference, ETHOS generates successive tokens, each denoting a prospective future event, until a predefined stopping condition is met, such as the appearance of a target event token or the attainment of a simulation time limit. By repeatedly simulating multiple fPHTs for each patient, ETHOS explores a range of possible trajectories, thereby quantifying the inherent uncertainty in its predictions. For instance, if N fPHTs are simulated and M of these trajectories include an inpatient mortality token, the estimated mortality probability is given by  (see “Monte Carlo justification for probability estimation” in Supplementary). All probabilistic inferences in this article utilize Monte Carlo (MC) sampling with
(see “Monte Carlo justification for probability estimation” in Supplementary). All probabilistic inferences in this article utilize Monte Carlo (MC) sampling with 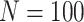 simulated fPHTs per patient, which inevitably introduces variability due to finite draws. We quantify this uncertainty by modeling the number of positive outcomes as a
simulated fPHTs per patient, which inevitably introduces variability due to finite draws. We quantify this uncertainty by modeling the number of positive outcomes as a 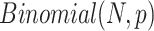 random variable, computing 95% confidence intervals, and visualizing these as shaded bands around the mean risk trajectory (e.g., Fig. 4).
random variable, computing 95% confidence intervals, and visualizing these as shaded bands around the mean risk trajectory (e.g., Fig. 4).
For detailed information on the transformer architecture, PHT statistics, and tokenization procedures, as well as intuitive explanation of ETHOS, please refer to our first publication [15] and “Intuitive operation of ETHOS.” in Supplementary.
Data preprocessing
We extracted relevant data from the MIMIC-IV tables, as detailed in Supplementary Table S7. Laboratory tests and medications were standardized using Anatomical Therapeutic Chemical (ATC) codes, and all diagnostic and procedural codes were mapped to International Classification of Diseases, 10th Revision (ICD-10) when necessary, as described in [15]. Additional tables requiring advanced processing, such as clinical notes, were not included in the current implementation of ETHOS.
The dataset was split into 2 disjoint groups: training/validation (90%) and testing (10%). Exactly the same splits were used for all methods investigated.
Tokenization, PHT construction, model training
The core of ETHOS lies in constructing PHTs from electronic medical records (EMRs) using a tokenization strategy that captures diverse clinical events. A PHT represents a patient’s medical history as a sequence of tokens, each encoding specific health-related information organized chronologically. This structured representation enables comprehensive modeling of patient journeys and more accurate clinical predictions. To build PHTs, we used the MEDS-DEV [31] extraction pipeline that converts EHR data to an intermediate format called MEDS [30] to facilitate further data transformations. Advanced transformation operations were subsequently applied, breaking down each event into 1 to 7 tokens based on its complexity.
For example, lab test results were encoded using quantile-based tokens to represent clinical significance. Time-interval tokens were added to mark the elapsed time between successive events, with intervals shorter than 5 minutes omitted and longer gaps tokenized into 19 distinct interval tokens. Continuous numerical values, such as lab test results, were similarly quantile-encoded using 10 quantiles, balancing clinical interpretability and predictive precision. Diagnostic and procedural codes, including ICD-10-CM, ICD-10-PCS, and ATC drug codes, were encoded hierarchically, which leveraged their inherent structure to enhance the transformer model’s attention mechanisms. For more details, refer to [15].
Static patient attributes such as gender, marital status, race, and body mass index were encoded using a single token depending on the value. For age, tokens of quantiles were reused, allowing age representation from 0 to 99. For instance, a 46-year-old patient would be coded as Q5 and Q7. Attributes with potential variability were represented using their most recently known value at the start of the timeline. By incorporating these elements, ETHOS ensured a richer and more adaptable representation of patient timelines.
During the training phase, 6 million tokens (1.8% of the train/validation dataset) were used for validation to balance model optimization and computational efficiency. The detailed statistics about the tokenized dataset are available in Supplementary Tables S6 and S11, and information about the model is in Supplementary Fig. S1.
Explainability
As illustrated in Fig. 4, stochastic simulations can be initiated not only from the most recent token representing current information but also from any preceding token in the patient’s history. This allows risk estimates to be visualized as a time series, highlighting how specific medical events affect risk over time. This approach provides intuitive visualizations, offering clinicians clear insights into the factors contributing to current risk values.
Methods used for benchmarking
We followed benchmarking tasks for emergency department models presented in the Emergency Department MIMIC-IV-ED benchmark study [27]. Three tasks were defined: prediction of the hospital admission at triage, prediction of the critical outcome (death or transfer to ICU within 12 hours) at triage, and ED re-presentation within 72 hours after discharge from ED. We applied machine learning methods (logistic regression, random forest, gradient boosting), scoring systems MEWS [13], NEWS [12, 32, 33], Rapid Emergency Medicine Scores (REMS) [34], cardiac arrest risk triage (CART) [35], 5-level triage system Emergency Severity Index (ESI) [36], and neural network–based models, including multilayer perceptron, Med2Vec [37], and long short-term memory (LSTM) [38].
To compare tasks used for early warning scores, we compared the MEDS-Tab library [39], which was used to establish a baseline. MEDS-Tab converts time-series EHR data into a tabular format by aggregating features across multiple time windows. It takes longitudinal patient data and applies various aggregation functions (e.g., sum, count, min, max) over different historical window sizes to create fixed-size feature vectors, where each feature represents a combination of a medical code, time window, and aggregation method. XGBoost [40] models are trained on these tabular features computed from data windows prior to each prediction time point for each clinical task.
Statistical methods
The performance of predictive models was evaluated using ROC curves and corresponding AUC values. Bootstrapping techniques were employed to estimate 95% confidence intervals for AUCs. Model predicted probabilities were compared with observed event frequencies using calibration curves to evaluate ETHOS’s reliability and alignment with real-world clinical outcomes. All statistical analyses were conducted using Python-based libraries, including scipy and scikit-learn [41, 42]. Data visualization, including ROC curves, calibration plots, and other statistical figures, was performed using matplotlib, seaborn, and altair.
Availability of Source Code and Requirements
Project name: ETHOS-ARES
Project homepage: https://github.com/ipolharvard/ethos-ares[43]
Operating system(s): Platform independent
Programming language: Python
Other requirements: Polars, Pytorch, etc. (see pyproject.toml)
License: MIT
Supplementary Material
Jean-Luc Bosson -- 4/4/2025
Jean-Luc Bosson -- 5/28/2025
Heloisa Oss Boll -- 4/21/2025
Guishen Wang -- 4/26/2025
W Jim Zheng -- 4/26/2025
Acknowledgments
We thank Kinga Renc, M.Arch, for her invaluable assistance with graphic design and Ethan Steinberg for the careful and very helpful review of our codebase.
Contributor Information
Pawel Renc, AGH University of Krakow, Department of Applied Computer Science, al. Mickiewicza 30, 30-059 Kraków, Poland; Massachusetts General Hospital, Department of Radiology, 55 Fruit St, Suite 427, Boston, MA 02114, USA; Harvard Medical School, 25 Shattuck Street Boston, MA 02115, USA.
Michal K Grzeszczyk, Massachusetts General Hospital, Department of Radiology, 55 Fruit St, Suite 427, Boston, MA 02114, USA; Harvard Medical School, 25 Shattuck Street Boston, MA 02115, USA.
Nassim Oufattole, Massachusetts Institute of Technology, Electrical Engineering and Computer Science (EECS), 143 Albany St, Cambridge, MA 02139 Unit 133B, USA.
Deirdre Goode, Harvard Medical School, 25 Shattuck Street Boston, MA 02115, USA; Newton Wellesley Hospital, Emergency Department, 2014 Washington St, Newton, MA 02462, USA.
Yugang Jia, Massachusetts Institute of Technology, Laboratory for Computational Physiology, Institute for Medical Engineering and Science, Building E25-505 77 Massachusetts Avenue Cambridge, MA 02139, USA.
Szymon Bieganski, Central Clinical Hospital of the Medical University in Lodz, Cardiology - Department of Electophysiolygy, 251 Pomorska Street, 92-213 Lodz, Poland.
Matthew B A McDermott, Columbia University, Department of Biomedical Informatics, 622 W 168th St PH20 3720, New York, NY 10032, USA.
Jaroslaw Was, AGH University of Krakow, Department of Applied Computer Science, al. Mickiewicza 30, 30-059 Kraków, Poland.
Anthony E Samir, Massachusetts General Hospital, Department of Radiology, 55 Fruit St, Suite 427, Boston, MA 02114, USA; Harvard Medical School, 25 Shattuck Street Boston, MA 02115, USA.
Jonathan W Cunningham, Harvard Medical School, 25 Shattuck Street Boston, MA 02115, USA; Brigham and Women's Hospital, Cardiovascular Division, Brigham and Women's Hospital, 75 Francis St., Boston MA 02115, USA.
David W Bates, Harvard Medical School, 25 Shattuck Street Boston, MA 02115, USA; Brigham and Women’s Hospital, Department of Medicine, Division of General Internal Medicine, 75 Francis St., Boston MA 02115, USA; Harvard Chan School of Public Health, Department of Health Policy and Management, 677 Huntington Ave, Boston, MA 02115, USA.
Arkadiusz Sitek, Massachusetts General Hospital, Department of Radiology, 55 Fruit St, Suite 427, Boston, MA 02114, USA; Harvard Medical School, 25 Shattuck Street Boston, MA 02115, USA.
Additional Files
Supplementary Fig. S1. Model architecture and hyperparameter overview. (Left) The architecture of the transformer-based model, following the standard GPT design, includes multiple layers of masked multihead attention and feed-forward modules, normalized at each step and combined with positional encodings. (Right) Summary of the hyperparameters used for model training and their explored ranges. The final model uses 6 layers, a context size of 2,048, an embedding size of 768, 12 attention heads, a dropout rate of 0.3, and a batch size of 32. Additional information includes the percentage of discarded ambiguous inference repetitions (0.2–0.3%) that appear when doing zero-shot inference.
Supplementary Fig. S2. ROC curves for ETHOS across all prediction tasks. ROC curves and corresponding area under the curve (AUC) values with 95% confidence intervals are shown for 7 prediction tasks: hospital mortality, ICU admission, prolonged stay (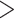 10 days), composite outcome (hospital mortality + ICU admission + prolonged stay), hospitalization at triage, critical outcome within 12 hours at triage, and emergency department (ED) re-presentation within 72 hours. Each plot includes the fitted ROC curve (orange), unique thresholds (crosses), and the 95% confidence interval (gray shading). ETHOS demonstrates high predictive performance across all tasks, with AUC values ranging from 0.740 (ED re-presentation) to 0.936 (hospital mortality).
10 days), composite outcome (hospital mortality + ICU admission + prolonged stay), hospitalization at triage, critical outcome within 12 hours at triage, and emergency department (ED) re-presentation within 72 hours. Each plot includes the fitted ROC curve (orange), unique thresholds (crosses), and the 95% confidence interval (gray shading). ETHOS demonstrates high predictive performance across all tasks, with AUC values ranging from 0.740 (ED re-presentation) to 0.936 (hospital mortality).
Supplementary Fig. S3. AUPRC curves for ETHOS across all prediction tasks. Precision-recall (PR) curves and corresponding area under the precision-recall curve (AUPRC) values are shown for 7 prediction tasks: hospital mortality, ICU admission, prolonged stay (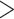 10 days), composite outcome (hospital mortality + ICU admission + prolonged stay), hospitalization at triage, critical outcome within 12 hours at triage, and emergency department (ED) re-presentation within 72 hours. Each plot includes the PR curve (orange) and unique thresholds (crosses). ETHOS shows good precision-recall performance across several tasks, with AUPRC values ranging from 0.199 (ED re-presentation) to 0.887 (hospitalization at triage), reflecting the class imbalance present in each task.
10 days), composite outcome (hospital mortality + ICU admission + prolonged stay), hospitalization at triage, critical outcome within 12 hours at triage, and emergency department (ED) re-presentation within 72 hours. Each plot includes the PR curve (orange) and unique thresholds (crosses). ETHOS shows good precision-recall performance across several tasks, with AUPRC values ranging from 0.199 (ED re-presentation) to 0.887 (hospitalization at triage), reflecting the class imbalance present in each task.
Supplementary Fig. S4. Calibration curves for ETHOS predictions across clinical outcomes with 95% confidence intervals determined by bootstrapping. This figure presents calibration curves evaluating the reliability of ETHOS probability predictions across 7 key clinical outcomes: hospital mortality, ICU admission, prolonged hospital stay, composite risk score (HM + IA + PS), hospitalization at triage, critical outcome within 12 hours at triage, and ED re-presentation within 72 hours. The calibration curves compare predicted probabilities (x-axis) against observed event frequencies (y-axis), with perfect calibration represented by the dashed diagonal line, while the solid orange line shows ETHOS calibration performance, and the shaded gray region represents the 95% confidence interval (CI) derived from bootstrapping. Each plot includes the Brier score, a metric assessing probabilistic prediction accuracy, where lower values indicate better calibration, with 0.00–0.05 classified as excellent, 0.05–0.10 as good, 0.10–0.20 as acceptable, and values above 0.20 as poor calibration. ETHOS demonstrates excellent calibration for hospital mortality (Brier score: 0.014), critical outcome within 12 hours (0.031), and ED re-presentation (0.041), while ICU admission (0.064), prolonged stay (0.067), and the composite risk score (0.090) exhibit good calibration, closely following the ideal calibration curve. Hospitalization at triage (0.143) is categorized as acceptable calibration, with some deviations at higher predicted probabilities, suggesting areas for potential improvement. Overall, ETHOS exhibits strong calibration across most clinical tasks, particularly in predicting mortality, early critical deterioration, and ED re-presentation, with acceptable performance for hospitalization risk at triage. These findings highlight ETHOS’s reliability in translating probability estimates into clinically meaningful risk stratifications, supporting its potential as a robust AI-driven decision support tool for real-time risk prediction and clinical decision-making.
Supplementary Table S1. ETHOS performance on ARES tasks with a breakdown for demographic subgroups. This table presents the predictive performance (AUROC with 95% confidence intervals) of ETHOS (top) and MEDS-Tab (bottom) for 4 critical clinical outcomes used in ARES: hospital mortality, ICU admission, prolonged hospital stay (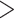 10 days), and a composite risk score (HM + IA + PS). The prevalence rates of each outcome are provided for reference. Performance metrics are further stratified by gender and race to assess potential disparities in model performance across demographic subgroups.
10 days), and a composite risk score (HM + IA + PS). The prevalence rates of each outcome are provided for reference. Performance metrics are further stratified by gender and race to assess potential disparities in model performance across demographic subgroups.
Supplementary Table S2. Demographic characteristics of the dataset analyzed in this study. The table summarizes key demographic attributes of the dataset, stratified into train/validation, test, and total splits. Patient numbers, mean age (with standard deviation), and distribution across gender, race, and marital status are shown, with percentages provided in parentheses. The data highlight the representation of each subgroup within the splits, providing context for the population characteristics in the dataset.
Supplementary Table S3. Prediction of hospitalization at triage. Performance comparison of various models for predicting hospitalization at triage, evaluated using AUROC, AUPRC, sensitivity, and specificity (95% confidence intervals in brackets). The thresholds for sensitivity and specificity were determined by finding the operating point on the ROC curve closest to (0,1). ETHOS demonstrates superior performance across all metrics, outperforming all other methods, including traditional scoring systems and machine learning models.
Supplementary Table S4. Prediction of critical outcome within 12 hours at triage. Performance comparison of various models for predicting critical outcomes within 12 hours of triage, evaluated using AUROC, AUPRC, sensitivity, and specificity (95% confidence intervals in brackets). The thresholds for sensitivity and specificity were determined by finding the operating point on the ROC curve closest to (0,1). ETHOS achieves the highest performance across most of the metrics, substantially outperforming all other methods, including traditional scoring systems and machine learning models.
Supplementary Table S5. Prediction of emergency department re-presentation within 72 hours. Performance comparison of various models for predicting emergency department re-presentation within 72 hours, evaluated using AUROC, AUPRC, sensitivity, and specificity (95% confidence intervals in brackets). The thresholds for sensitivity and specificity were determined by finding the operating point on the ROC curve closest to (0,1). ETHOS demonstrates superior performance, outperforming all other methods and showcasing its effectiveness for this challenging task.
Supplementary Table S6. Summary of token and timeline statistics. This table presents a comprehensive overview of the token and timeline data in the training, test, and combined datasets. Key metrics include the total number of tokens and timelines, along with statistics on timeline lengths such as the longest timeline, median, mean, and shortest timeline. The number of unique timeline tokens is also reported. The final section breaks down the encoding of timeline tokens into categories, such as time intervals, quantiles, medications, diagnoses, procedures, laboratory results, vitals, and other clinical features. This summary highlights the diversity and complexity of the tokenized data used in the study.
Supplementary Table S7. Overview of the data sources and their corresponding columns used in this work from the MIMIC-IV database and its extension, MIMIC-IV-ED. The table groups the data into 3 main categories: ED (emergency department), hosp (hospital), and ICU (intensive care unit). For each category, the associated tables and the specific columns extracted for the study are listed, highlighting key variables relevant to patient care and outcomes, such as identifiers (e.g., stay_id, hadm_id), timestamps (e.g., intime, charttime), and clinical observations (e.g., vitalsign, labresults). These selections were guided by the objectives of the study to comprehensively model patient trajectories and outcomes.
Supplementary Table S8. Side-by-side view of selected columns from the original sample tables (sourced from MIMIC-IV-DEMO) compared with the format of the tokenized timelines in ETHOS.
Supplementary Table S9. Estimated energy consumption of training ETHOS compared to training large language models. ETHOS is a dedicated model specifically designed for the electronic health record (EHR) domain, which allows it to be substantially smaller and more efficient to train than general-purpose large language models. With only 45 million parameters, ETHOS was trained on 8 A100 GPUs over 46 hours, consuming an estimated 220 kWh of energy. In contrast, universal LLMs such as GPT-3 (175B parameters), LLaMA 3 (8B), and Falcon (40B) require significantly more computational resoures and energy , consuming between 307,000 and over 1.2 million kWh.
Supplementary Table S10. Risk trajectories for 8 patients from ED presentation to discharge, ICU admission, or death. This figure presents examples of risk trajectories for 8 different patients, illustrating the dynamic evolution of risk predictions following presentation at the emergency department (ED). Each risk value is estimated from multiple (N=100) simulated fPHTs. The shaded area around each risk curve represents the 95% confidence interval (CI) for the predicted risk. The primary graphs plot risk progression as a function of the number of tokens generated since ED presentation, effectively modeling the temporal evolution of patient risk. The visualization of ARES score is schematically represented below using 10 color-coded symbols corresponding to key risk categories (see Figs. 1 and 2 in main article). In some graphs, symbols corresponding to ICU admission risk are absent (e.g., E, F, G, and H) because these patients were already admitted to the ICU earlier, leading ARES to automatically exclude this risk component from consideration. The time axis under ARES represents actual elapsed time (in hours and days) since ED presentation. However, time progression on these axes is not linear, as the number of generated tokens does not directly correspond to real-time intervals. Instead, token generation occurs in discrete units determined by patient events. Notably, in case H, a sudden drop in prolonged stay risk occurs because ARES automatically reclassifies a risk of prolonged stay 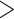 10 days into prolonged stay
10 days into prolonged stay 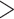 15 days, leading to an observed risk reduction. This drop is an inherent property of ARES modeling rather than a true change in patient status. All trajectories ultimately conclude when the patient either dies or is discharged.
15 days, leading to an observed risk reduction. This drop is an inherent property of ARES modeling rather than a true change in patient status. All trajectories ultimately conclude when the patient either dies or is discharged.
Supplementary Table S11. Detailed token statistics. The table provides a detailed breakdown of the total number of tokens and unique tokens for each code group in the training, test, and combined datasets. Each code group represents a specific type of information, such as laboratory results (LAB), clinical classifications (e.g., ATC, ICD_CM), time intervals (e.g., 15–45 minutes, 12–18 hours), and other key features like BMI, vitals, or discharge locations. The statistics summarize the diversity (#Unique) and frequency (Count) of tokens across datasets, offering insights into the distribution and variability of features used in the modeling process.
Abbreviations
AI: artificial intelligence; ARES: Adaptive Risk Estimation System; ATC: Anatomical Therapeutic Chemical (codes); AUC: area under the curve; BIDMC: Beth Israel Deaconess Medical Center; CART: cardiac arrest risk triage; ED: emergency department; EHR: electronic health record; EMR: electronic medical record; ESI: Emergency Severity Index; ETHOS: Enhanced Transformer for Health Outcome Simulation; fPHT: future patient health timeline; GDP: gross domestic product; HM: hospital mortality; IA: ICU admission; ICD-10: International Classification of Diseases, 10th Revision; ICU: intensive care unit; LLM: large language model; LSTM: long short-term memory; MEDS: Medical Event Data Standard; MEWS: Modified Early Warning Score; MIMIC-IV: Medical Information Mart for Intensive Care, version IV; ML: machine learning; NEWS: National Early Warning Score; PHT: patient health timeline; PS: prolonged hospital stay; REMS: Rapid Emergency Medicine Score; ROC: receiver operating characteristic; XGBoost: eXtreme Gradient Boosting.
Author Contributions
P.R.: conceptualization, methodology, formal analysis (lead), visualization, software (lead), writing—review and editing. M.K.G.: conceptualization, methodology, formal analysis, writing—review, editing, and visualization. N.O.: writing—review, formal analysis. D.G. writing—review and editing. Y.J.: methodology, writing—review and editing. S.B.: conceptualization. M.B.A.M.: methodology, writing—review and editing. J.W.: writing—review and editing. A.E.S.: writing—review and editing. J.W.C.: writing—review and editing. D.W.B.: writing—review and editing. A.S.: conceptualization (lead), methodology (lead), writing—original draft, preparation, and supervision.
Funding
J.W.C. reports grant support from the American Heart Association (23CDA1052151) and National Institutes of Health, National Heart, Lung, and Blood Institute (1K23HL168163).
Data Availability
The MIMIC-IV dataset and its emergency department extension are publicly available [25, 44]. These are controlled-access datasets; users need to sign in to PhysioNet, apply for a credentialed account, sign a Data Use Agreement, and follow training on human research data. Annotations to the code are available at ML-DOME [45]. Extra data further supporting this work are openly available in the GigaScience repository, GigaDB [46]. A Snapshot of the ETHOS-ARES GitHub is available in Software Heritage [47], and the workflow is available in WorkflowHub [48].
Competing Interests
Y.J. is also affiliated with Verily Life Science. J.W.C. reports consultancy for Edgewise Therapeutics, Occlutech, and us2.ai. D.W.B. reports grants and personal fees from EarlySense, personal fees from CDI Negev, equity from ValeraHealth, equity from Clew, equity from MDClone, personal fees and equity from AESOP, personal fees and equity from FeelBetter, and personal fees and equity from Guided Clinical Solutions, outside the submitted work. All other authors declare no competing interests.
References
- 1. Centers for Medicare and Medicaid Services . National Health Expenditure Data: Historical. 2024. https://www.cms.gov/data-research/statistics-trends-and-reports/national-health-expenditure-data/historical. Accessed 3 May 2025.
- 2. Gunja MZ, Gumas ED, Williams RD II. U.S. health care from a global perspective, 2022: accelerating spending, worsening outcomes. 2023, https://www.commonwealthfund.org/publications/issue-briefs/2023/jan/us-health-care-global-perspective-2022. Accessed 26 January 2025.
- 3. Committee on the Future of Emergency Care in the United States Health System . Hospital-based emergency care: at the breaking point. Washington, DC: National Academies Press; 2007. [Google Scholar]
- 4. Yang KK, Lam SSW, Low JMW, et al. Managing emergency department crowding through improved triaging and resource allocation. Oper Res Health Care. 2016;10:13–22. 10.1016/j.orhc.2016.05.001. [DOI] [Google Scholar]
- 5. Horton DJ, Graves KK, Kukhareva PV, et al. Modified early warning score-based clinical decision support: cost impact and clinical outcomes in sepsis. JAMIA Open. 2020;3(2):261–68. 10.1093/jamiaopen/ooaa014. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 6. Adams R, Henry KE, Sridharan A, et al. Prospective, multi-site study of patient outcomes after implementation of the TREWS machine learning-based early warning system for sepsis. Nat Med. 2022;28(7):1455–60. 10.1038/s41591-022-01894-0. [DOI] [PubMed] [Google Scholar]
- 7. Edelson DP, Churpek MM, Carey KA, et al. Early warning scores with and without artificial intelligence. JAMA Netw Open. 2024;7(10):e2438986. 10.1001/jamanetworkopen.2024.38986. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 8. Gerry S, Bonnici T, Birks J, et al. Early warning scores for detecting deterioration in adult hospital patients: systematic review and critical appraisal of methodology. BMJ. 2020;369:m1501. 10.1136/bmj.m1501. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 9. Winslow CJ, Edelson DP, Churpek MM, et al. The impact of a machine learning early warning score on hospital mortality: a multicenter clinical intervention trial. Crit Care Med. 2022;50(9):1339–47. 10.1097/CCM.0000000000005492. [DOI] [PubMed] [Google Scholar]
- 10. Escobar GJ, Liu VX, Schuler A, et al. Automated identification of adults at risk for in-hospital clinical deterioration. N Engl J Med. 2020;383(20):1951–60. 10.1056/NEJMsa2001090. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 11. Cummings BC, Blackmer JM, Motyka JR, et al. External validation and comparison of a general ward deterioration index between diversely different health systems. Crit Care Med. 2023;51(6):775–86. 10.1097/CCM.0000000000005837. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 12. Williams B. The National Early Warning Score: from concept to NHS implementation. Clin Med. 2022;22(6):499–505. 10.7861/clinmed.2022-news-concept. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 13. Subbe CP, Kruger M, Rutherford P, et al. Validation of a modified Early Warning Score in medical admissions. QJM. 2001;94(10):521–26. 10.1093/qjmed/94.10.521. [DOI] [PubMed] [Google Scholar]
- 14. Vaswani A, Shazeer N, Parmar N, et al. Attention is all you need. Adv Neur Inf Proc Syst. 2017;30:5998–6008. 10.48550/arXiv.1706.03762. [DOI] [Google Scholar]
- 15. Renc P, Jia Y, Samir AE, et al. Zero shot health trajectory prediction using transformer. NPJ Digit Med. 2024;7(1):256. 10.1038/s41746-024-01235-0. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 16. Yang Z, Mitra A, Liu W, et al. TransformEHR: transformer-based encoder-decoder generative model to enhance prediction of disease outcomes using electronic health records. Nat Commun. 2023;14(1):7857. 10.1038/s41467-023-43715-z. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 17. Li Y, Mamouei M, Salimi-Khorshidi G, et al. Hi-BEHRT: Hierarchical transformer-based model for accurate prediction of clinical events using multimodal longitudinal electronic health records. IEEE J Biomed Health Inform. 2023;27(2):1106–17. 10.1109/JBHI.2022.3224727. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 18. Luo X, Rechardt A, Sun G, et al. Large language models surpass human experts in predicting neuroscience results. Nat Hum Behav. 2025;9(2):305–15. 10.1038/s41562-024-02046-9. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 19. Thirunavukarasu AJ, Ting DSJ, Elangovan K, et al. Large language models in medicine. Nat Med. 2023;29(8):1930–40. 10.1038/s41591-023-02448-8. [DOI] [PubMed] [Google Scholar]
- 20. Kraljevic Z, Bean D, Shek A, et al. Foresight-a generative pretrained transformer for modelling of patient timelines using electronic health records: a retrospective modelling study. Lancet Digit Health. 2024;6(4):e281–90. 10.1016/S2589-7500(24)00025-6. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 21. McDermott MBA, Nestor BA, Argaw P, et al. Event Stream GPT: a data pre-processing and modeling library for generative, pre-trained transformers over continuous-time sequences of complex events. Adv Neur Inf Proc Syst. 2023;36:24322–34. 10.48550/arXiv.2306.11547. [DOI] [Google Scholar]
- 22. Steinberg E, Fries J, Xu Y, et al. MOTOR: A time-to-event foundation model for structured medical records. arXiv [csLG]. 2023. 10.48550/arXiv.2301.03150. Accessed 23 August 2025. [DOI] [Google Scholar]
- 23. Li Y, Rao S, Solares JRA, et al. BEHRT: transformer for electronic health records. Sci Rep. 2020;10(1):7155. 10.1038/s41598-020-62922-y. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 24. Jeong H, Oufattole N, Mcdermott M, et al. Event-based contrastive learning for medical time series. arXiv [csLG]. 2023. 10.48550/arXiv.2312.10308. Accessed 23 August 2025. [DOI] [Google Scholar]
- 25. Johnson AEW, Bulgarelli L, Shen L, et al. MIMIC-IV, a freely accessible electronic health record dataset. Sci Data. 2023;10(1):1. 10.1038/s41597-022-01899-x. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 26. Johnson A, Bulgarelli L, Pollard T, et al. Mimic-iv. PhysioNet. 2023. https://physionet.org/content/mimiciv/2.2/. Accessed 1 October 2023. [Google Scholar]
- 27. Xie F, Zhou J, Lee JW, et al. Benchmarking emergency department prediction models with machine learning and public electronic health records. Sci Data. 2022;9(1):658. 10.1038/s41597-022-01782-9. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 28. Meng C, Trinh L, Xu N, et al. Interpretability and fairness evaluation of deep learning models on MIMIC-IV dataset. Sci Rep. 2022;12(1):7166. 10.1038/s41598-022-11012-2. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 29. Logan Ellis H, Palmer E, Teo JT, et al. The early warning paradox. NPJ Digit Med. 2025;8(1):81. 10.1038/s41746-024-01408-x. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 30. Arnrich B, Choi E, Fries JA, et al. Medical Event Data Standard (MEDS): facilitating machine learning for health. In: ICLR 2024 Workshop on Learning from Time Series for Health. 2024. OpenReview https://openreview.net/pdf?id=IsHy2ebjIG. Acessed 9 September 2025. [Google Scholar]
- 31. MEDS-DEV: Establishing Reproducibility and Comparability in Health AI. https://github.com/mmcdermott/MEDS-DEV. Accessed 23 August 2025.
- 32. Smith GB, Prytherch DR, Meredith P, et al. The ability of the National Early Warning Score (NEWS) to discriminate patients at risk of early cardiac arrest, unanticipated intensive care unit admission, and death. Resuscitation. 2013;84(4):465–70. 10.1016/j.resuscitation.2012.12.016. [DOI] [PubMed] [Google Scholar]
- 33. Zhang S, Xu Y, Usuyama N, et al. A multimodal biomedical foundation model trained from fifteen million image–text pairs. NEJM AI. 2025;2(1):AIoa2400640. 10.1056/AIoa2400640. [DOI] [Google Scholar]
- 34. Olsson T, Terent A, Lind L. Rapid Emergency Medicine Score: a new prognostic tool for in-hospital mortality in nonsurgical emergency department patients. J Intern Med. 2004;255(5):579–87. 10.1111/j.1365-2796.2004.01321.x. [DOI] [PubMed] [Google Scholar]
- 35. Churpek MM, Yuen TC, Park SY, et al. Derivation of a cardiac arrest prediction model using ward vital signs. Crit Care Med. 2012;40(7):2102–108. 10.1097/CCM.0b013e318250aa5a. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 36. Eitel DR, Travers DA, Rosenau AM, et al. The Emergency Severity Index triage algorithm version 2 is reliable and valid. Acad Emerg Med. 2003;10(10):1070–80. 10.1197/S1069-6563(03)00350-6. [DOI] [PubMed] [Google Scholar]
- 37. Choi E, Bahadori MT, Searles E, et al. Multi-layer representation learning for medical concepts. In: Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. New York, NY: ACM; 2016. [Google Scholar]
- 38. Hochreiter S, Schmidhuber J. Long short-term memory. Neural Comput. 1997;9(8):1735–80. 10.1162/neco.1997.9.8.1735. [DOI] [PubMed] [Google Scholar]
- 39. Oufattole N, Bergamaschi T, Kolo A, et al. MEDS-Tab: Automated tabularization and baseline methods for MEDS datasets. arXiv [csLG]. 2024. 10.48550/arXiv.2411.00200. Acsessed 23 August 2025. [DOI]
- 40. Chen T, Guestrin C. XGBoost: a scalable tree boosting system. In: Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. KDD ’16. New York, NY: Association for Computing Machinery; 2016:785–94. [Google Scholar]
- 41. Virtanen P, Gommers R, Oliphant TE, et al. SciPy 1.0: fundamental algorithms for scientific computing in Python. Nat Methods. 2020;17(3):261–72. 10.1038/s41592-019-0686-2. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 42. Pedregosa F, Varoquaux G, Gramfort A, et al. Scikit-learn: machine learning in Python journal of machine learning research. J Machine Learn Res. 2011;12:2825–30. 10.48550/arXiv.1201.0490. [DOI] [Google Scholar]
- 43. Renc P, Sitek A. ETHOS–ARES. 2025. GitHub repository, MIT License. https://github.com/ipolharvard/ethos-ares. Accessed 23 August 2025.
- 44. Johnson A, Bulgarelli L, Pollard T, et al. MIMIC-IV (version 3.1). 2024. RRID:SCR_007345. PhysioNet. 10.13026/kpb9-mt58. Acessed 10 January, 2025 [DOI]
- 45. Renc P, Grzeszczyk MK, Oufattole N, et al. Foundation Model of Electronic Medical Records for Adaptive Risk Estimation [DOME-ML Annotations]. 2025. DOME-ML Registry. https://registry.dome-ml.org/review/jdqxjqrnsb.
- 46. Renc P, Grzeszczyk MK, Oufattole N, et al. Supporting data for “Foundation Model of Electronic Medical Records for Adaptive Risk Estimation.” GigaScience Database. 2025. 10.5524/102752. [DOI]
- 47. Renc P, Grzeszczyk MK, Oufattole N, et al. Foundation model of electronic medical records for adaptive risk estimation (version 1). Software Heritage. 2025. https://archive.softwareheritage.org/swh:1:snp:16fb97c3d29f1b134b8cf314463643d277f165d5;origin=https://github.com/ipolharvard/ethos-ares. [Google Scholar]
- 48. ETHOS-ARES Project Team . ETHOS-ARES: adaptive risk estimation system. 2025. WorkflowHub. https://workflowhub.eu/workflows/1857. Accessed 22 August 2025. [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.
Data Citations
- Renc P, Grzeszczyk MK, Oufattole N, et al. Supporting data for “Foundation Model of Electronic Medical Records for Adaptive Risk Estimation.” GigaScience Database. 2025. 10.5524/102752. [DOI]
Supplementary Materials
Jean-Luc Bosson -- 4/4/2025
Jean-Luc Bosson -- 5/28/2025
Heloisa Oss Boll -- 4/21/2025
Guishen Wang -- 4/26/2025
W Jim Zheng -- 4/26/2025
Data Availability Statement
The MIMIC-IV dataset and its emergency department extension are publicly available [25, 44]. These are controlled-access datasets; users need to sign in to PhysioNet, apply for a credentialed account, sign a Data Use Agreement, and follow training on human research data. Annotations to the code are available at ML-DOME [45]. Extra data further supporting this work are openly available in the GigaScience repository, GigaDB [46]. A Snapshot of the ETHOS-ARES GitHub is available in Software Heritage [47], and the workflow is available in WorkflowHub [48].