

Abstract
Background
Oxygen saturation (SpO₂) is a crucial parameter for monitoring the health of cardiac patients. It measures the percentage of hemoglobin in the blood that is saturated with Oxygen. The study aims to analyze longitudinal Oxygen saturation (SpO2) levels and identify its determinants among cardiac patients.
Methods
Bayesian linear mixed-effects model with the asymmetric generalized error distribution (AGED) was used to analyze the data. The data comprises 323 children diagnosed with cardiac disease. AGED outperforms the others distributions and indicates robust and effective choice to analysis the data.
Results
The estimated shape parameters of AGED are significant 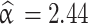 (95% CI: 2.31, 2.58) which is degree of asymmetry, and
(95% CI: 2.31, 2.58) which is degree of asymmetry, and 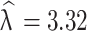 (95% CI: 3.18, 3.46) is associated with peakedness of the distribution. The finding reveals that corrective surgery, pulmonary hypertension, cardiomyopathy, anemia, nutritional status, and hemoglobin levels are significantly associated with Oxygen saturation (SpO2). Pulmonary hypertension, cardiomyopathy, and under nutrition are found to lower SpO2. In contrast, higher hemoglobin and corrective surgery are significantly associated with higher SpO2. The AGED fitted to the data, and found to be important for analyzing data characterized by asymmetry and excess kurtosis.
(95% CI: 3.18, 3.46) is associated with peakedness of the distribution. The finding reveals that corrective surgery, pulmonary hypertension, cardiomyopathy, anemia, nutritional status, and hemoglobin levels are significantly associated with Oxygen saturation (SpO2). Pulmonary hypertension, cardiomyopathy, and under nutrition are found to lower SpO2. In contrast, higher hemoglobin and corrective surgery are significantly associated with higher SpO2. The AGED fitted to the data, and found to be important for analyzing data characterized by asymmetry and excess kurtosis.
Keywords: Asymmetry, Cardiac disease, Children, Linear mixed model, Oxygen saturation, Patients
Introduction
Oxygen saturation (SpO₂) is a crucial parameter for monitoring the health of children with cardiac disease [1]. It measures the percentage of hemoglobin in the blood that is saturated with Oxygen. In children with cardiac disease, maintaining adequate Oxygen levels is essential for ensuring overall health [2].
Accurate and continuous monitoring of SpO₂ is vital for several reasons, including assessment of cardiac function, valuation of disease progression, guidance for clinical interventions, and early detection of complications [3]. It helps clinicians to assess disease severity and guide treatment decisions, such as the timing of surgical interventions or the need for supplemental Oxygen [3]. Furthermore, SpO₂ monitoring is critical as indicate complications like pulmonary hypertension or residual shunts [3, 4].
Despite its use, interpreting SpO₂ in children with cardiac disease requires careful consideration. Normal SpO₂ levels in healthy children range from 95 to 100%, indicating efficient Oxygen uptake in the lungs and adequate delivery [4]. However, in children with cardiac disease, this process is often disrupted due to structural or functional abnormalities in the heart [5]. Factors such as anemia and the presence of abnormal hemoglobin can affect SpO₂ [4, 6]. The minor deviations from normal levels can have significant implications for growth, development, and survival [6].
This study aims to explore SpO₂ measures among cardiac patients. By understanding the relationship between SpO₂ and various covariates, healthcare providers can optimize care strategies to improve outcomes for this vulnerable population [4, 5]. This understanding can lead to more effective treatment plans, and ultimately enhancing the quality of life [6].
To achieve this objective, a linear mixed-effects model is used. In these models, the response is a function of fixed effects, unobservable individual-specific random effects, and an error term [7]. A mixed-effects model, in which both the fixed and random effects contribute linearly to the response variable, is known as the Linear Mixed-Effects Model (LMM) [8].
Linear mixed effect model (LMM) is not sufficient for modelling a non-normal data [8, 9]. A typical assumption of LMM is the normality of the random error, which is unrealistic and overly restrictive [9, 10]. The distribution of random error may become asymmetric due to the presence of outliers, making it impossible to realize the normality assumption. The use of asymmetric distribution is needed to overcome the problem of deviation from normality. The idea of using generalized error distribution (GED) instead of the classical normal distribution in linear mixed modelling is suggested and demonstrated by Markos and Ayele [11]. Here we apply this idea for the new asymmetric generalized error distribution (AGED) developed by Tayu and Ayele [12], which have capable of modelling data with various degrees of asymmetry and outliers.
The aim of this study is Bayesian modelling of longitudinal SpO2 measures using AGED and identifies determinants of SpO2 among cardiac patients having clinical follow-up at the Cardiac Center. The linear mixed effects model with the asymmetric generalized error distribution is integrated into the analysis.
Research method
Research philosophical worldviews
The post-positivist philosophical worldview is adopted for this study, which is applicable to both quantitative and qualitative research methodologies [13]. This philosophy focused on identifying and assessing the causes that determine outcomes, through the observation and measurement of objective reality or theory verification.
Study design
Observational study design is employed [14]. Researchers investigate the effects of certain factors without manipulating who is, or isn’t, exposed to them. A retrospective cohort study design is used, where the cohort is identified from past records, and outcomes are measured from that point forward. We used retrospective cohort study design due to costly to conduct a prospective study [15]. We use inclusion and exclusion criteria, and minimize loss to follow-up to reduce the potential selection bias.
Study setting
The Cardiac Center-Ethiopia, located in Addis Ababa city, is chosen for the study. The Center is a non-profit organization that serves children with cardiac case and receives referral from nearby states. Currently, the Center provides the largest cardiac surgery in Ethiopia.
Study population and sampling
The study population is children with cardiac disease follow-up at the Center. Children under the age of 18 years are recruited for the study. The study encompasses patients admitted to the center and followed-up from September 2021 to August 2022. A simple random sampling technique [16] with a check list is used to select a representative samples. The inclusion criteria: children under the age of 18 years who have been diagnosed with cardiac disease and are under follow-up at the Center. Participants must have been admitted and followed at the Center between September 2021 and August 2022 and must have attended at least three follow-up visits during this period. Exclusion criteria include patients who have attended fewer than three follow-up visits or have incomplete or missing information in their medical records.
Sample size determination
Before data is collected, emphasis is needed on determination of sample size. The sample size is determined based on financial affordability, time constraints, and data analysis method [16]. When we determine the sample size ( ), it must at the very least meet criteria: optimum in predictor effect, small absolute difference and precise estimation [17]. The sample size
), it must at the very least meet criteria: optimum in predictor effect, small absolute difference and precise estimation [17]. The sample size  that meet al.l the three criteria provide the optimum values required for the study [17].
that meet al.l the three criteria provide the optimum values required for the study [17].
We design a study to fit a model, we ensure the sample size is adequate in terms of the number of participants ( ) and events (
) and events (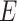 ) relative to the number of predictor parameters (
) relative to the number of predictor parameters ( ). We assume there are
). We assume there are  potential predictors for inclusion in the model, and for suitable choice of
potential predictors for inclusion in the model, and for suitable choice of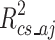 and
and 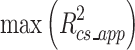 based on previous study, the required sample can be determined [17, 18]. We need to include
based on previous study, the required sample can be determined [17, 18]. We need to include 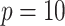 predictor used in the model with targeted expected shrinkage of 0.90, and the required sample size can be obtained by:
predictor used in the model with targeted expected shrinkage of 0.90, and the required sample size can be obtained by:
 |
1 |
Therefore the optimum sample size required for study is 323 participants.
Data
The data were extracted from patients’ medical records, which include demographics and clinical information. To collect data, ethical approval was obtained from the relevant institutional review boards. The data collection protocols adhered strictly to confidentiality standards, ensuring the protection of sensitive information.
Missing data in longitudinal studies is a common challenge arising from reasons such as participant dropouts or intermittent data collection issues [19]. It can be either Missing Completely at Random (MCAR), Missing at Random (MAR) or Missing Not at Random (MNAR). The missing considered in the data is MCAR, where the missing data is independent of both observed and unobserved data [19].
The study variables
The outcome variable considered in this study is the longitudinal Oxygen saturation (SpO2), which is measured repeatedly for patient follow-ups from the start of diagnosis until either mortality, loss to follow-up, or continue follow-up. The covariates are: gender (boy, girl), residence (rural, urban), age, weight, cardiac disease (congenital, acquired), corrective surgery (yes, no), chamber enlargement (yes, no), pulmonary hypertension (yes, no), cardiomopthy (yes, no), pneumonia (yes, no), anemia (yes, no), New York Heart Association (I, II, III, IV), nutrition status (under weight, normal weight), ejection fraction, hemoglobin, birth order, and family size.
The asymmetric generalized error distribution
The asymmetric generalized error distribution (AGED) is a flexible statistical distribution that generalizes the traditional generalized error distribution [20] to allow for asymmetry and outliers or peakedness in data [12]. The distribution is developed by Tayu and Ayele [12] and suggested for modelling data that exhibit asymmetry and peakedness. The probability density function 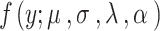 of AGED model is expressed as:
of AGED model is expressed as:
 |
2 |
where function 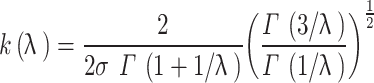 and
and 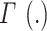 is Euler gamma function. The distribution is denoted by AGED
is Euler gamma function. The distribution is denoted by AGED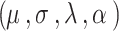 with four parameters representing location
with four parameters representing location 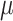 , scale
, scale 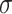 , and degree of peakedness
, and degree of peakedness  , and asymmetry parameter
, and asymmetry parameter 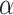 of the distribution.
of the distribution.
The three special futures are considered within the AGED, which include the generalized error distribution, normal distribution and skew normal distributions. If the shape parameter  , the distribution is generalized error distribution, If
, the distribution is generalized error distribution, If 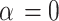 and
and  , the distribution is skew normal distribution, and If
, the distribution is skew normal distribution, and If 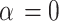 and
and  , the distribution is the normal distribution.
, the distribution is the normal distribution.
Linear mixed effects model with the new distribution AGED
The LMM is popular for modelling normally distributed data [21]. However, the normal distribution is not good enough to model data having asymmetry and outliers [22, 23]. The idea of using generalized error distribution instead of the classical normal distribution in LMM is suggested and demonstrated by Markos and Ayele [11]. We apply this idea for the new asymmetric generalized error distribution (AGED) developed by Tayu and Ayele [12], which have capable of modelling data with various degrees of asymmetry and outliers. The most commonly used linear mixed model (LMM) was proposed by Laird and Ware [24] for a continuous response. The LMM using asymmetric generalized error distribution or AGED-LMM proposed in this study extends the linear mixed model proposed by Laird and Ware [24].
Let 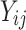 be the observations on Oxygen saturation SpO2 for a patient
be the observations on Oxygen saturation SpO2 for a patient 
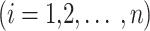 at visiting time
at visiting time  . The linear mixed model with asymmetric generalized error distribution or AGED-LMM is defined as follows:
. The linear mixed model with asymmetric generalized error distribution or AGED-LMM is defined as follows:
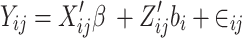 |
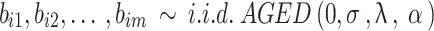 |
 |
3 |
where  denotes the design matrix consisting of
denotes the design matrix consisting of  predictors of the response and a vector of 1’s for constant intercept, combined with vector of
predictors of the response and a vector of 1’s for constant intercept, combined with vector of 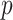 fixed effects
fixed effects 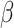 . For the random component,
. For the random component, 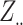 denotes the design matrix consisting of
denotes the design matrix consisting of 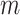 predictors combined with vector of
predictors combined with vector of 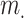 random effects
random effects  . All the random errors and random effects in the linear mixed effects model (3) are assumed to be pairwise independent and each having AGED instead of normal distribution. Some of the predictors can be time varying.
. All the random errors and random effects in the linear mixed effects model (3) are assumed to be pairwise independent and each having AGED instead of normal distribution. Some of the predictors can be time varying.
Bayesian estimation
Bayesian estimation is defined by posterior distribution [25]. The posterior distribution 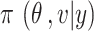 involves the product of the likelihood function
involves the product of the likelihood function  and prior distribution
and prior distribution 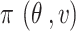 with normalizing constant [25].
with normalizing constant [25].
Likelihood function
We assume that observation of the longitudinal outcome 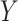 is independent given the random effects
is independent given the random effects  and parameters
and parameters 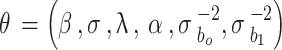 of the longitudinal model with distribution.
of the longitudinal model with distribution.
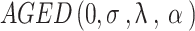 . The random effects are
. The random effects are 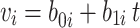 . The likelihood functions can be written as the forms [26]:
. The likelihood functions can be written as the forms [26]:
 |
4 |
Prior distribution
Prior distribution of the parameters  are: individual parameters
are: individual parameters 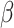 are assumed to be random variables having independently normally distributed with mean zero and larger variance 1000, shape parameters
are assumed to be random variables having independently normally distributed with mean zero and larger variance 1000, shape parameters  of AGED both assume
of AGED both assume 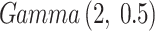 prior density function, and variance term have
prior density function, and variance term have 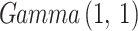 .
.
Posterior distribution
The posterior distribution 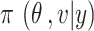 is given by,
is given by,
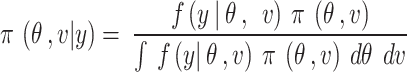 |
5 |
where 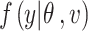 is the likelihood function for the Oxygen saturation response
is the likelihood function for the Oxygen saturation response  , with
, with  being the prior probability distribution, and
being the prior probability distribution, and  is the normalizing constant. The Markov Chain Monte Carlo (MCMC) is applied [25, 26] to simulate from the posterior distribution.
is the normalizing constant. The Markov Chain Monte Carlo (MCMC) is applied [25, 26] to simulate from the posterior distribution.
Implementation and model selection
The models were fitted using Stan software [27]. Stan is a better choice in fitting complex models with complicated posteriors that usually involve high correlation among parameters [27]. Implementation of complex models in Stan is much easier as computational issues may arise in other software’s [28].
We used two criteria for model selection. The first one is Leave-One-Out Information Criterion (LOOIC), is a Bayesian model evaluation metric that estimates the predictive accuracy of a model by using leave-one-out cross-validation [29]. The lower LOOIC values indicating better predictive accuracy. LOOIC is robust against improper priors and is computationally stable [29]. The second criterion is the Widely Applicable Information Criterion (WAIC). Smaller values of WAIC indicate better fit [30].
Widely applicable information criterion
The widely applicable information criterion (WAIC) is a fully Bayesian estimator that averages over the posterior distribution of  . For a observation
. For a observation 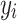 , this criterion measures the predictive accuracy of the model based on the log-posterior predictive distribution
, this criterion measures the predictive accuracy of the model based on the log-posterior predictive distribution 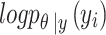 of the parameter vector
of the parameter vector 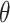 [30]. WAIC can be expressed as [30]
[30]. WAIC can be expressed as [30]
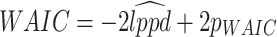 |
6 |
Where lppd (Log Pointwise Predictive Density)
 |
7 |
Lower WAIC values indicate a better model fit with higher predictive accuracy. The penalty term 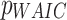 accounts for model complexity, balancing goodness-of-fit and overfitting.
accounts for model complexity, balancing goodness-of-fit and overfitting.
Leave-one-out information criterion
The Leave-One-Out Information Criterion (LOOIC) is a Bayesian model evaluation metric that estimates the predictive accuracy of a model by using leave-one-out cross-validation [29]. It is particularly useful for comparing models and assessing their generalization to unseen data [29]. The LOOIC is calculated as [29]
 |
8 |
where 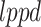 (Log Pointwise Predictive Density):
(Log Pointwise Predictive Density):
 |
9 |
LOOIC stabilize computations, especially in cases with influential observations. It allows for direct comparison between models, with lower LOOIC values indicate better predictive accuracy and less overfitting [29]. It is often used to compare multiple models fitted to the same data.
Results and discussion
Descriptive analysis
The study included 323 children diagnosed with cardiac disease (CD). Of these, 182 (56.35%) are girls, and 56.04% are under the age of 5 years. The mean age is 7.73 years, ranging from 1 day to 18 years. Two hundred fifteen (66.56%) of the children resides in urban areas (Table 1).
Table 1.
Demographic characteristics of study participants under follow-up
| Covariates | Attributes | Total | (%100) |
|---|---|---|---|
| Gender | Boy | 141 | 43.65 |
| Girl | 182 | 56.35 | |
| Age (months) | < 24 | 52 | 16.10 |
| 24–59 | 129 | 39.94 | |
| 60–143 | 92 | 28.48 | |
| >=144 | 50 | 15.48 | |
| Birth order | First | 123 | 38.08 |
| Second and third | 159 | 49.23 | |
| Forth or more | 41 | 12.69 | |
| Residence | Urban | 215 | 66.56 |
| Rural | 108 | 33.44 | |
| Father occupation | Employed | 141 | 43.65 |
| Farmer | 98 | 30.34 | |
| Merchant | 34 | 10.53 | |
| Other | 50 | 15.48 | |
| Mother occupation | Housewife | 182 | 56.35 |
| Employed | 97 | 30.03 | |
| Merchant | 20 | 6.19 | |
| Other | 24 | 7.43 | |
| Economic status | Below | 160 | 49.54 |
| Average | 122 | 37.77 | |
| Above | 41 | 12.69 | |
| Family size | < 4 | 242 | 74.92 |
| >= 4 | 81 | 25.08 |
Regarding the occupational status of their families, 43.65% of fathers and 30.03% of mothers are employed by the government, and 74.82% of families have fewer than four members (Table 1).
Pneumonia is identified in 17.96% of the children, and anemia is also common in the study area, with a prevalence rate of 35.29%. Regarding family history of cardiac disease, 27 (8.36%) participants have a history of cardiac disease. Among the study participants, 129 (39.96%) are between the ages of 24–59 months, followed by 92 (28.48%) between the ages of 60–144 months. Of the study participants, 47(14.55%) children underwent corrective surgery, while the remaining 276 (85.45%) are awaiting surgery (Table 2).
Table 2.
Clinical characteristics of study participants under follow-up
| Covariates | Attributes | Total | Percent |
|---|---|---|---|
| Cardiac disease | Congenital | 230 | 71.21 |
| Acquired | 93 | 28.79 | |
| Chamber enlargements | Yes | 167 | 51.70 |
| No | 156 | 48.30 | |
| Pulmonary hypertension | Yes | 52 | 16.10 |
| No | 271 | 83.90 | |
| Corrective surgery | Yes | 47 | 14.55 |
| No | 276 | 85.45 | |
| Nutritional status | Under weight | 192 | 59.40 |
| Healthy weight | 131 | 40.60 | |
| ROSS/NYHA | I | 110 | 34.05 |
| II | 125 | 38.69 | |
| III | 62 | 19.19 | |
| IV | 26 | 8.05 | |
| Anemia | Yes | 114 | 35.29 |
| No | 209 | 64.71 | |
| Pneumonia | Yes | 58 | 17.96 |
| No | 265 | 82.04 | |
| Cardiomopthy | Yes | 78 | 24.15 |
| No | 245 | 75.85 |
Analysis of the longitudinal data
When data are repeatedly measured over time, detecting the differences from an individual’s evolve through time is important. Table 3 indicates the average estimate of Oxygen saturation (SpO2) measures over follow-up periods. As depicted in the Table 3, the baseline average of SpO2 is estimated to be 92.947 with standard deviation of 4.959. But, by the end of follow-up period, the average of SpO2 measures is estimated to be 91.901 with standard deviation of 3.489.
Table 3.
Average estimate of oxygen saturation (SpO2) over follow-up periods
| Follow-up periods | 1 | 2 | 3 | 4 | 5 | 6 |
|---|---|---|---|---|---|---|
| Mean | 92.947 | 92.706 | 91.524 | 92.050 | 91.654 | 91.901 |
| Variance | 24.596 | 27.208 | 25.640 | 20.379 | 16.721 | 12.175 |
| Standard deviation | 4.959 | 5.216 | 5.064 | 4.514 | 4.089 | 3.489 |
| CV | 5.335 | 5.626 | 5.532 | 4.903 | 4.461 | 3.796 |
The analysis also reveals the variability in SpO2 measures over the follow-up periods, as indicated by the coefficient of variation (CV). The variability in SpO2 measures at the start of follow-up is 5.335% and at the second follow-up period is about 3.796% as indicated by coefficient of variation. Based on the result, the variability in SpO2 measures is slightly decreases over follow-up periods. It shows that the patients begin with varying at baseline and differ at different follow-up period. We also indicate the declines of SpO2 measures during the study periods (Fig. 1) and (Table 3).
Fig. 1.

Box plot of longitudinal SpO2 measures over follow-up or visit time
To understand the relationship between the longitudinal SpO2 measures and follow-up periods, mean structures is plotted in Fig. 2. The figure shows the mean of SpO2 measures over follow-up periods, which indicates slight decrease in the mean of SpO2 of cardiac patients during follow-up periods (Fig. 2).
Fig. 2.

Profiles plot of oxygen saturation (SpO2) over follow-up period
Before proceed to further analysis, the distribution of the data are assessed. Various distributions are considered to model the data, including the AGED, generalized error distribution, skew normal distribution, and normal distribution. These distributions are fitted to the data and compared using common goodness-of-fit (GOF) statistics (Table 4): Akaike’s Information Criteria (AIC), Consistent Akaike Information Criteria (CAIC), Hannan–Quinn Information Criteria (HQIC), Kolmogorov–Smirnov Statistics (K-S), and Bayesian Information Criterion (BIC) [31, 32].
Table 4.
MLEs and GOF statistics results of the oxygen saturation (SpO2) data
| Parameter | Distributions | |||
|---|---|---|---|---|
| AGED | GED | Normal | Skew Normal | |
Location 
|
95.04 | 91.43 | 91.58 | 93.07 |
Scale 
|
1.647 | 0.530 | 0.457 | 0.438 |
Shape 
|
3.530 | 1.848 | - | - |
Shape 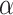
|
3.331 | - | - | - |
| AIC | 1433.176 | 2047.525 | 2035.355 | 1911.583 |
| CAIC | 1433.204 | 2047.542 | 2035.363 | 1911.592 |
| BIC | 1454.26 | 2063.338 | 2045.897 | 1922.126 |
| HQIC | 1441.047 | 2053.428 | 2039.291 | 1915.519 |
When estimating the parameters of the distributions, we examine them through goodness-of-fit (GOF) statistics to identify which distribution is best fits the data. Lower values indicate a better fit to the data [31, 32]. The parameter estimates and GOF statistics value of the distributions are presented in Table 4, including skewness and kurtosis coefficients. It is evident that the goodness-of-fit (GOF) statistic values of the AGED are lower, indicating its superiority in fitting the data compared to other distributions.
Figure 3 displays the histogram and the estimated density function of the Asymmetric Generalized Error Distribution (AGED). The figure demonstrates that the AGED provides a closer fit to the data, indicating that the AGED is best fit to the data.
Fig. 3.

Histogram and fitted density function of AGED to Oxygen saturation (SpO2) data specific to an individuals
We analyzed SpO2 measures using different distributions. We found AGED useful for data with variations in degrees of asymmetry and peakedness. We utilized this distribution in the linear mixed-effects model. As shown in Fig. 3, the histogram of SpO2 clearly indicates non-normality or asymmetric nature. Also, the residual plot suggests deviation from normality. Nevertheless, the plot triggered us to consider additional models. Along with this information, the four statistical models with different error distributions are employed and compared Table 5.
Table 5.
Model comparison
| Model | Normal | Skew Normal | GED | AGED |
|---|---|---|---|---|
| WAIC | 1120.33 | 1088.46 | 1054.24 | 1040.59 |
| LOOIC | 1144.10 | 1090.30 | 1059.02 | 1044.90 |
The results presented in Table 5 indicate that the AGED model outperforms the normal, Skew normal and GED, as evidenced by lower WAIC and LOOIC values [29, 30]. These metrics are particularly advantageous for Bayesian model comparison, as they balance model fit with complexity to prevent overfitting. In conclusion, the AGED model provides a more generalizable and robust framework for analyzing SpO2 data, validating its selection as the most appropriate model for this study.
AGED-linear mixed effect model analysis
The results of the Bayesian linear mixed model analysis with the asymmetric generalized error distribution for the SpO2 measures of cardiac patients is displayed in Table 6. The table includes the estimated posterior mean, standard deviation, 95% credible intervals, and estimated parameters of AGED. The results reveal that pulmonary hypertension, corrective surgery, anemia, hemoglobin levels, nutritional status, cardiomyopathy, and observation time are significantly associated with Oxygen saturation (SpO2), as their corresponding credible intervals do not include zero. The estimated parameters of the AGED are also significant, indicates a fit of the distribution to the data (Table 6).
Table 6.
Parameter estimates with 95% credible intervals of the bayesian linear mixed models fitted to the oxygen saturation (SpO2) data
| Covariates |
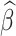
|
SD | 95% CI |
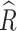
|
|---|---|---|---|---|
| Intercept | 85.44 | 2.18 | (81.16, 89.75) | 1.00 |
| Observation time | 0.09 | 0.02 | (0.06, 0.13) | 1.00 |
| Observation time2 | −1.44 | 0.33 | (−0.2.13,−0.077) | 1.02 |
| Age | −0.19 | 0.24 | (−0.66, 0.27) | 1.00 |
| Residence: Urban | 0.49 | 0.16 | (−0.43, 1.39) | 1.00 |
| Gender: Male | 0.06 | 0.34 | (−0.80, 0.93) | 1.00 |
| Surgery: Yes | 0.45 | 0.22 | (0.11, 0.78) | 1.00 |
| Anemia: Yes | −0.67 | 0.12 | (−1.312, −0.028) | 1.00 |
| Pulmonary: Yes | −0.44 | 0.34 | (−0.84, −0.05) | 1.02 |
| Pneumonia: Yes | −0.50 | 0.11 | (−1.70, 0.69) | 1.00 |
| Cardiompathy: Yes | −0.32 | 0.29 | (−0.65, −0.09) | 1.00 |
| BMI: Under Weight | −1.33 | 0.18 | (−2.29, −0.39) | 1.00 |
| Hemoglobin | 0.71 | 0.18 | (0.37, 1.05) | 1.00 |
| Parameters | Estimate | SD | 95% CI |

|

|
4.02 | 0.13 | (3.59, 4.47) | 1.00 |

|
0.55 | 0.11 | (0.30, 0.75) | 1.01 |

|
0.53 | 0.12 | (0.28, 0.74) | 1.00 |
sigma
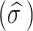
|
3.31 | 0.09 | (3.17, 3.45) | 1.00 |
lamda
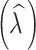
|
3.32 | 0.08 | (3.18, 3.46) | 1.00 |
alpha
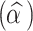
|
2.44 | 0.07 | (2.31, 2.58) | 1.00 |
The estimated shape parameters of the asymmetric generalized error distribution are significant:  (CI: 2.31, 2.58) is associated with degree of asymmetry, and
(CI: 2.31, 2.58) is associated with degree of asymmetry, and 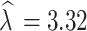 (CI: 3.18, 3.46) is associated with peakedness of the distribution. This significance is indicated by the 95% credible intervals, which do not contain zero. The estimated standard deviation of the random intercepts and slope is 4.02 (CI: 3.59, 4.47) and 0.55 (CI: 0.30, 0.75). The lower estimated variance of the random slope compared to the intercept indicates higher between-subject variability at baseline. It was found that the intercept and slope parameters is positively correlated as
(CI: 3.18, 3.46) is associated with peakedness of the distribution. This significance is indicated by the 95% credible intervals, which do not contain zero. The estimated standard deviation of the random intercepts and slope is 4.02 (CI: 3.59, 4.47) and 0.55 (CI: 0.30, 0.75). The lower estimated variance of the random slope compared to the intercept indicates higher between-subject variability at baseline. It was found that the intercept and slope parameters is positively correlated as 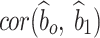 = 0.53 (CI: 0.28, 0.74) (Table 6).
= 0.53 (CI: 0.28, 0.74) (Table 6).
Based on the results presented in Table 6, we found that corrective surgery, pulmonary hypertension, cardiomyopathy, anemia, nutritional status, hemoglobin levels, and observation time are significantly associated with Oxygen saturation (SpO2) among cardiac patients under follow-up. Pulmonary hypertension, cardiomyopathy, and nutritional status can lower SpO2 by 0.44 (CI: −0.84,−0.05), 0.32 (CI: −0.65,−0.09), and 1.33 (CI: −2.29,−0.39), respectively. Higher Oxygen saturation (SpO2) indicates a better cardiac condition in patients. Corrective surgery is associated with improved SpO2 in cardiac patients, with an effect size of 0.45 (CI: 0.11, 0.78). Patients who underwent corrective surgery shows improved SpO2 measures. Thus, pulmonary hypertension, cardiomyopathy, and under nutrition are associated to lower SpO2, whereas hemoglobin levels and corrective surgery are associated with improved SpO2 in cardiac patients (Table 6).
Assessment of convergence
Convergence assessment is important in data analysis. It helps to determine whether the model is adequately converged and estimated parameters are stable and reliable [33]. The convergence of the MCMC was monitored using the trace plots and Gelman-Rubin 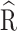 diagnostics [34].
diagnostics [34].
The 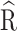 values given in Table 6 along with the trace plots shown in Figs. 4 indicate that the MCMC runs attained convergence. The trace plots indicate stable mixing of chains; with no evidence of divergent transitions. Additionally,
values given in Table 6 along with the trace plots shown in Figs. 4 indicate that the MCMC runs attained convergence. The trace plots indicate stable mixing of chains; with no evidence of divergent transitions. Additionally,  values are precisely less than 1.05 [34] for all parameters, signifying perfect convergence of the Markov Chain Monte Carlo (MCMC) sampler and ensuring the stability and reproducibility of the results.
values are precisely less than 1.05 [34] for all parameters, signifying perfect convergence of the Markov Chain Monte Carlo (MCMC) sampler and ensuring the stability and reproducibility of the results.
Fig. 4.

Histogram of posterior distributions and trace plots for estimates of parameters of AGED; sigma scale parameter, (lamda) and (alpha) shape parameter
Sensitivity Analysis
Sensitivity to prior distribution in Bayesian models evaluates how the choice of prior impacts posterior results [35]. It identifies whether conclusions are influenced more by data or prior assumptions. We used alternative priors, performing prior predictive and posterior predictive checks, and using metrics like Kullback-Leibler [36] divergence to measure differences. Visual diagnostics such as density plots also used to assess the effects of varying priors, ensuring the model is robust and conclusions are reliable and the result was does not sensitive to prior distribution.
Discussion
In this work, we discussed implementation of Bayesian linear mixed effects models using AGED for the distribution of Oxygen saturation (SpO2) of cardiac patients. The common assumption of normality is relaxed. Instead, we use a flexible distribution, including generalized error distribution, skew normal distribution and AGED. We have compared the models using WAIC and LOOIC, as evidenced by lower WAIC and LOOIC values [29, 30] indicate better model fit. Our results confirm the results of LMM with AGED over the other models based on the criteria. These metrics are advantageous for Bayesian model comparison, as they balance model fit with complexity to prevent overfitting [29, 30]. Finally, the Bayesian linear mixed model with AGED is introduced, which can handle outliers and asymmetry in the data effectively.
Sensitivity to prior distribution was evaluates using alternative priors, performing prior predictive and posterior predictive checks [35], and using metrics like Kullback-Leibler [36] divergence to measure differences. Visual diagnostics such as density plots also used to assess the effects of varying priors, ensuring the model is robust and conclusions are reliable and the result was does not sensitive to prior distribution [35].
The finding from this study is consistent with the study by [37], they compared different distribution for the data while only one is selected. The asymmetric generalized error distribution is selected in this study and as indicated in [12], the AGED can gain more insight than the other distributions. This choice underscores the flexibility and robustness of AGED in handling data with outliers and asymmetry, making it a valuable in modeling the Oxygen saturation (SpO2) levels in cardiac patients.
The finding reveals that pulmonary hypertension, cardiompathy, and nutritional status are lowers the Oxygen saturation (SpO2) by 0.44, 0.32, and − 1.33, respectively and concordance with the study by [2] and [38]. Higher Oxygen saturation (SpO2) associated in better cardiac condition of patients as indicated in [38]. Additionally, anemia also significantly lower the SpO2 as in [39].
Patients who undergo corrective surgery is associated with improved SpO2 levels, which is support by the finding by [39]. This suggests that surgical intervention can lead to better Oxygenation and overall enhanced cardiac health. Additionally, a higher rate of change in biomarker is associated with good health conditions in cardiac patients.
Pulmonary hypertension, cardiompathy, and under nutrition are significant factors associated with lower SpO2 level, corroborating the results presented in studies [39, 40]. Conversely, hemoglobin levels and corrective surgery are positively associated with SpO2 measures, as also noted in study [39]. This indicates that improving hemoglobin levels and undergoing corrective surgical procedures can enhance Oxygen saturation, contributing to better overall cardiac patients.
Despite the valuable insights provided, this study has several limitations. First, the data were collected from a single center, which may limit the generalizability of the findings to broader populations or settings. Second, although the Bayesian linear mixed-effects model with AGED accounts for asymmetry and excess kurtosis, the model assumptions may still be sensitive to unmeasured confounding variables or model misspecification. Finally, the exclusion of patients with fewer than three follow-up visits or missing data may have introduced selection bias, potentially affecting the representativeness of the sample.
Conclusions
The study focuses on developing a Bayesian linear mixed-effects model using the asymmetric generalized error distribution (AGED) to analyze longitudinal Oxygen saturation (SpO2) levels among cardiac patients. By comparing the AGED with other distributions such as the generalized error distribution, normal, and skew normal distributions, it is evident that AGED outperforms the distributions. This indicates that AGED is a robust and effective choice to analysis SpO2 data, especially in the presence of asymmetry and outliers. The estimated shape parameters of the asymmetric generalized error distribution are significant 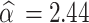 (95% CI: 2.31, 2.58) indicates asymmetry of the distribution and
(95% CI: 2.31, 2.58) indicates asymmetry of the distribution and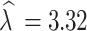 (95% CI: 3.18, 3.46) associated with peakedness of the distribution. The analysis shows that the variables; corrective surgery, pulmonary hypertension, cardiomyopathy, anemia, nutritional status, hemoglobin, and observation time are significantly associated with Oxygen saturation (SpO2) level of cardiac patients under clinical follow-up. Pulmonary hypertension, cardiomyopathy, and under nutrition are found to significantly lower SpO2 levels. In contrast, higher hemoglobin and corrective surgery are significantly associated with higher SpO2 levels. Specifically, low hemoglobin level is associated with a decline in SpO2, whereas patients undergoing corrective surgery exhibited improved SpO2. A higher rate of change in biomarkers indicates better health conditions in cardiac patients. The Bayesian linear mixed model with AGED can model data with various degrees of asymmetry and excess kurtosis. Future studies could investigate models with various types of random effects and include more covariates to further enhance the insights.
(95% CI: 3.18, 3.46) associated with peakedness of the distribution. The analysis shows that the variables; corrective surgery, pulmonary hypertension, cardiomyopathy, anemia, nutritional status, hemoglobin, and observation time are significantly associated with Oxygen saturation (SpO2) level of cardiac patients under clinical follow-up. Pulmonary hypertension, cardiomyopathy, and under nutrition are found to significantly lower SpO2 levels. In contrast, higher hemoglobin and corrective surgery are significantly associated with higher SpO2 levels. Specifically, low hemoglobin level is associated with a decline in SpO2, whereas patients undergoing corrective surgery exhibited improved SpO2. A higher rate of change in biomarkers indicates better health conditions in cardiac patients. The Bayesian linear mixed model with AGED can model data with various degrees of asymmetry and excess kurtosis. Future studies could investigate models with various types of random effects and include more covariates to further enhance the insights.
Acknowledgements
The authors would like to sincerely thank the Cardiac Center-Ethiopia and staff for providing us the data used in this study. We extend our sincere gratitude to the Kotebe University of Education for supports and coordination.
Authors’ contributions
TA and AG contributed to conceptualization and design of the study. TA and AG critically revised the paper. TA and AG analysis the data and wrote the initial draft of the manuscript. All authors participated in the revision, read and approved the final version for submission.
Funding
The author(s) declare that no financial support was received for the research, authorship, and/or publication of this article.
Data availability
The datasets used and/or analysed during the current study available from the corresponding author on reasonable request.
Declarations
Competing interests
The authors declare no competing interests.
Footnotes
Publisher’s Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
References
- 1.Nield LE, Qi X, Yoo S-J, Valsangiacomo ER, Hornberger LK, Wright GA. MRI-based blood oxygen saturation measurements in infants and children with congenital heart disease. Pediatr Radiol. 2002;32:518–22. [DOI] [PubMed] [Google Scholar]
- 2.Kussman BD, Laussen PC, Benni PB, McGowan FX Jr, McElhinney DB. Cerebral oxygen saturation in children with congenital heart disease and chronic hypoxemia. Anesth Analg. 2017;125(1):234–40. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 3.de Rosa A, Betini RC. Noncontact SpO 2 measurement using Eulerian video magnification. IEEE Trans Instrum Meas. 2019;69(5):2120–30. [Google Scholar]
- 4.Binene V, Panauwe D, Kauna R, Vince JD, Duke T. Oxygen saturation reference ranges and factors affecting SpO2 among children living at altitude. Arch Dis Child. 2021;106(12):1160–4. [DOI] [PubMed] [Google Scholar]
- 5.Garde A, Karlen W, Dehkordi P, Wensley D, Ansermino JM, Dumont GA. Oxygen saturation in children with and without obstructive sleep apnea using the phone-oximeter. 2013 35th Annual Int Conf IEEE Eng Med Biology Soc (EMBC). 2013;IEEE:2531–4. [DOI] [PubMed] [Google Scholar]
- 6.Pons-Odena M, et al. SpO2/FiO2 as a predictor of non-invasive ventilation failure in children with hypoxemic respiratory insufficiency. J Pediatr Intensive Care. 2013;2(03):111–9. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 7.Pinheiro JC, Bates DM. Mixed-effects models in S and S-PLUS. New York: Springer New York; 2000.
- 8.Peng H, Lu Y. Model selection in linear mixed effect models. J Multivar Anal. 2012;109:109–29. [Google Scholar]
- 9.Jiang J, Nguyen T. Linear Mixed Models: Part I. InLinear and Generalized Linear Mixed Models and Their Applications. New York: Springer New York. 2021;23:1–61.
- 10.Gałecki A, Burzykowski T. Linear mixed-effects model. InLinear mixed-effects models using R: a step-by-step approach. New York: Springer New York. 2012;28:245–273.
- 11.Erango MA, Goshu AT. Bayesian joint modelling of survival time and longitudinal CD4 cell counts using accelerated failure time and generalized error distributions. Open J Model Simul. 2019;7(01):79. [Google Scholar]
- 12.Abebe TN, Goshu AT. Asymmetric generalized error distribution with its properties and applications. Front Appl Math Stat. 2024;10:1398137. [Google Scholar]
- 13.Crook C, Garratt D. The positivist paradigm in contemporary social science research. Research methods in the social sciences. 2005;207:214.
- 14.Carlson MDA, Morrison RS. Study design, precision, and validity in observational studies. J Palliat Med. 2009;12(1):77–82. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 15.Talari K, Goyal M. Retrospective studies–utility and caveats. J R Coll Physicians Edinb. 2020;50(4):398–402. [DOI] [PubMed] [Google Scholar]
- 16.Cochran WG. Sampling techniques. Johan Wiley Sons Inc. 1977.
- 17.Riley RD, et al. Minimum sample size for developing a multivariable prediction model: part I–continuous outcomes. Stat Med. 2019;38(7):1262–75. [DOI] [PubMed] [Google Scholar]
- 18.Chen LM, Ibrahim JG, Chu H. Sample size and power determination in joint modeling of longitudinal and survival data. Stat Med. 2011;30(18):2295–309. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 19.Ibrahim JG, Molenberghs G. Missing data methods in longitudinal studies: a review. Test. 2009;18(1):1–43. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 20.McDonald JB. 14 Probability distributions for financial models. Handbook of statistics. 1996;14:427–61.
- 21.Bolker BM. Linear and generalized linear mixed models. Ecological statistics: contemporary theory and application. 2015;2015:309–33.
- 22.Arellano-Valle RB, Bolfarine H, Lachos VH. Bayesian inference for skew-normal linear mixed models. J Appl Stat. 2007;34(6):663–82. [Google Scholar]
- 23.Lachos VH, Ghosh P, Arellano-Valle RB. Likelihood based inference for skew-normal independent linear mixed models. Statistica Sinica. 2010:303–22.
- 24.Laird N. Random effects and the linear mixed model, in Analysis of Longitudinal and Cluster-Correlated Data. Institute of Mathematical Statistics. 2004;8:79–96. [Google Scholar]
- 25.Forbes C, Evans M, Hastings N, Peacock B. Statistical distributions. John Wiley & Sons; 2011 Mar 21.Forbes C, Evans M, Hastings N, Peacock B. Statistical distributions. Wiley; 2011.
- 26.Barnard GA. The use of the likelihood function in statistical practice. InProceedings of the Fifth Berkeley Symposium on Mathematical Statistics and Probability. Univ of California Press; 1967;1:27–40.
- 27.Carpenter B, et al. Stan: A probabilistic programming Language. J Stat Softw. 2017;76:1–32. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 28.Beraha M, Falco D, Guglielmi A. JAGS, NIMBLE, Stan: a detailed comparison among Bayesian MCMC software, arXiv Prepr. arXiv2107.09357. 2021.
- 29.Yuan J, Li Y-M, Liu C-L, Zha XF. Leave-one-out cross-validation based model selection for manifold regularization, in International Symposium on Neural Networks. Springer. 2010:457–464.
- 30.Watanabe S. A widely applicable Bayesian information criterion. The Journal of Machine Learning Research. 2013;14(1):867–97.
- 31.McKinley RL, Mills CN. A comparison of several goodness-of-fit statistics. Applied Psychological Measurement. 1985;9(1):49–57.
- 32.Xavier T. Goodness of fit tests for Rayleigh distribution, arXiv Prepr. arXiv2208.08698. 2022.
- 33.Fabreti LG, Höhna S. Convergence assessment for bayesian phylogenetic analysis using MCMC simulation. Methods Ecol Evol. 2022;13(1):77–90. [Google Scholar]
- 34.Peskun PH. Optimum monte-carlo sampling using markov chains. Biometrika. 1973;60(3):607–12. 10.2307/2334940.
- 35.Oakley JE, O’Hagan A. Probabilistic sensitivity analysis of complex models: a bayesian approach. J R Stat Soc Ser B Stat Methodol. 2004;66(3):751–69. [Google Scholar]
- 36.Teixeira R, O’Connor A, Nogal M. Probabilistic sensitivity analysis of offshore wind turbines using a transformed kullback-leibler divergence. Struct Saf. 2019;81:101860. [Google Scholar]
- 37.Ferreira CS, Bolfarine H, Lachos VH. Linear mixed models based on skew scale mixtures of normal distributions. Commun Stat Comput. 2022;51(12):7194–214. [Google Scholar]
- 38.Ucrós S, Granados CM, Castro-Rodríguez JA, Hill CM. Oxygen saturation in childhood at high altitude: a systematic review. High Alt Med Biol. 2020;21(2):114–25. [DOI] [PubMed] [Google Scholar]
- 39.Hirai N, Saito J, Nakai K, Noguchi S, Hashiba E, Hirota K. Association between regional oxygen saturation and central venous saturation in pediatric patients undergoing cardiac surgery: A prospective observational study. Pediatr Anesth. 2023;33(11):913–22. [DOI] [PubMed] [Google Scholar]
- 40.Fenton KN, Freeman K, Glogowski K, Fogg S, Duncan KF. The significance of baseline cerebral oxygen saturation in children undergoing congenital heart surgery. Am J Surg. 2005;190(2):260–3. [DOI] [PubMed] [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.
Data Availability Statement
The datasets used and/or analysed during the current study available from the corresponding author on reasonable request.