

Abstract
Accurate real-time heat release rate (HRR) measurement is critical in fire safety engineering. This study proposes a cascaded deep learning framework integrating visual flame detection and thermodynamic analysis. The detection module uses an enhanced YOLOv8n with efficient channel attention (ECA) and bidirectional feature pyramid network (BiFPN), achieving 95.2% precision and 88.3% recall. For HRR quantification, a parameter-efficient dual-branch CNN (5.2 M) processes spatial and frequency-domain flame features, showing superior performance (R2 = 0.976)—58.5%/78.2% fewer parameters than VGG16/ResNet50 and lower MAE than Vision Transformers (32.47 vs. 41.98). Validated on the NIST fire database, the framework demonstrates robust performance across flame growth and decay phases, with deviations during peak HRR. The cascaded design ensures efficiency by activating HRR analysis only post-detection, which reduces false alarms to a certain extent and establishing a new non-contact fire risk assessment paradigm.
Keywords: Fire safety, Deep learning, Fire detection, Fire quantification, Heat release rate
Introduction
Fire represents one of the most significant dangers that human society faces, with its sudden onset and destructive potential posing severe threats to life and property. According to the U.S. Fire Administration, approximately 1.389 million fire incidents occurred in the United States in 2023 alone, resulting in 3670 fatalities, 13,350 injuries, and $23.2 billion in direct economic losses. Notably, since 2014, the frequency of fire incidents, number of resulting casualties, and economic damage have all exhibited an upward trend. The heat release rate (HRR), defined as the amount of thermal energy released per unit time during combustion, serves as a critical indicator for assessing the intensity and hazard level of fires1. Accurate HRR quantification enables fire departments to develop effective suppression strategies, evaluate fire damage, and improve risk prediction2. However, conventional HRR measurement typically relies on specialized experimental apparatus and complex testing procedures, making it difficult to apply in actual fire scenarios.
In modern society, video surveillance systems have become indispensable, with cameras and mobile devices ubiquitously capture visual data of dynamic events including fires. Flames, as the most distinctive feature of combustion, carry rich information about fire behavior, making real-time flame detection and analysis pivotal for effective fire prevention and control. Against this backdrop, computer vision and deep learning have emerged as powerful non-contact tools for analyzing fire-related visual information, enabling the extraction of critical fire characteristics from captured images and videos. Ramasubramanian et al.3 utilized transfer learning with a pre-trained YOLOv3 model for indoor firefighting robots; Wu et al.4 combined background subtraction and YOLO-based detection to reduce false alarms; and Gotthans et al.5 optimized a deep CNN for efficient fire detection on edge devices.
In parallel, research on HRR quantification has advanced6,7, Richards et al.8 proposed a method based on the inverse heat transfer problem, using the LAVENT model to generate a fire scenario database and inversely estimate fire locations and HRR values, though it suffered from systematic underestimation and widened prediction distributions due to random errors. Lee et al.9 applied a sequential inverse method to infer indoor fire locations and scales via temperature field analysis, while Guo et al.10 employed Bayesian inference for similar tasks, finding that smaller sampling intervals improved parameter estimation accuracy more significantly than reduced sensor spacing. Beyond inverse methods, data-driven approaches have shown promise: Gu11 developed a GA-BPNN model for HRR prediction in hybrid fuels, alongside correlations for flame extensions and temperature distributions; Yang et al.12 used a fire dynamics simulator to generate temperature data, optimizing HRR prediction with RFE-selected features and a LightGBM model; Kou et al.13 leveraged GRU networks on simulated data for rapid fire source parameter prediction, noting sensitivity of intensity inversion to simulation accuracy. In flame image analysis, the National Institute of Standards and Technology (NIST)14 trained recurrent neural networks on annotated video sequences from its Fire Calorimetry Database for transient HRR prediction. Wang et al.15 developed a Swin Transformer framework using over 50,000 NIST images, achieving strong performance for moderate HRR but declining accuracy in high-intensity scenarios due to limited training data. Xu et al.16 proposed an Att-BiLSTM model to exploit temporal correlations in fire image sequences, demonstrating robust predictive capabilities in complex scenarios with 27,231 NIST images.
Notably, a critical gap remains: flame detection and HRR quantification have typically been treated as isolated tasks. Existing HRR models often process entire images, including non-flame regions, which not only introduces noise but also subjects the estimation to interference from flame-like objects (e.g., high-temperature incandescent sources or colored light reflections). These objects, though visually similar to flames, lack the actual combustion characteristics, leading to erroneous HRR predictions. Conversely, fire detection methods rarely link their outputs to subsequent thermodynamic parameter quantification, limiting their practical value for risk assessment.
To address this gap, this study proposes a vision-based cascaded deep learning framework (Fig. 1) that synergistically integrates flame detection and HRR quantification, comprising the following components:
Constructing a large-scale fire image dataset by accurately matching flame images with the HRR data from the NIST database, providing a solid data foundation for model training.
Enhancing flame detection accuracy and robustness by introducing an attention mechanism into the YOLOv8 model and optimizing its multi-scale feature fusion structure to address false positives and failure to detect small targets;
Developing a dual-branch CNN to extract flame dynamics from both the spatial and frequency domains, establishing a nonlinear mapping between visual parameters and the HRR, and thus providing a more reliable basis for fire information identification.
Fig. 1.

The research framework for fire images uses cascaded deep learning for flame detection and prediction of heat release rate.
The remainder of this work is organized as follows. Section “Methodology” details the construction of the flame objection detection model and HRR image quantification model, along with the multimodal dataset used for related research. Section “Results” evaluates model performance, discusses key challenges encountered during the research process, and proposes potential solutions. Finally, Section “Conclusions” presents concluding remarks and summarizes the study’s contributions.
Methodology
The cascade AI processing engine achieves efficient fire behavior assessment through a phased process. First, a flame is detected and located by the improved YOLOv8 model; after successful identification, the HRR prediction module is activated. Subsequently, the images analyzed by the two-branch CNN model are quantified in terms of HRR. This serial processing ensures that calorimetric analysis is performed only after a flame is detected, effectively avoiding interference from suspected flames in nonfire scenarios. This method simulates the logic of expert analysis but has the advantage of automation, thereby providing a reliable and efficient solution for fire assessment.
Flame detection
YOLOv8 is an advanced object-detection algorithm that incorporates multiple improvements over the YOLO model series to enhance detection performance and efficiency. It adopts an anchor-free mechanism, eliminating the traditional anchor-based design to simplify the object detection pipeline. Additionally, YOLOv8 introduces a decoupled head structure, separating classification and detection tasks to further optimize detection accuracy. The algorithm also implements a task-aligned assigner strategy for positive sample selection, which measures the alignment between the predicted and ground-truth bounding boxes by combining the classification confidence and IoU scores, thereby enabling a more precise selection of positive samples. These innovations allow YOLOv8 to excel in real-time data analysis in complex scenarios, making it particularly suitable for applications requiring fast, accurate detection17,18.
To address the difficulty of discriminating between flames and similarly colored objects, this study incorporates an efficient channel attention (ECA) module19 at the end of the backbone network that enhances the discriminative representation of flame features through channel attention mechanisms. As illustrated in Fig. 2, the module employs adaptive 1D convolution to achieve cross-channel interaction, which overcomes the information loss caused by the dimension reduction in conventional SE modules. Given the input features 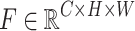 , the processing pipeline of the ECA module can be formulated as follows:
, the processing pipeline of the ECA module can be formulated as follows:
 |
1 |
 |
2 |
 |
3 |
where  represents a Sigmoid activation function that generates channel-wise attention weights. The kernel size
represents a Sigmoid activation function that generates channel-wise attention weights. The kernel size  of the 1D convolution operation
of the 1D convolution operation  is determined dynamically through an adaptive strategy.
is determined dynamically through an adaptive strategy.
Fig. 2.
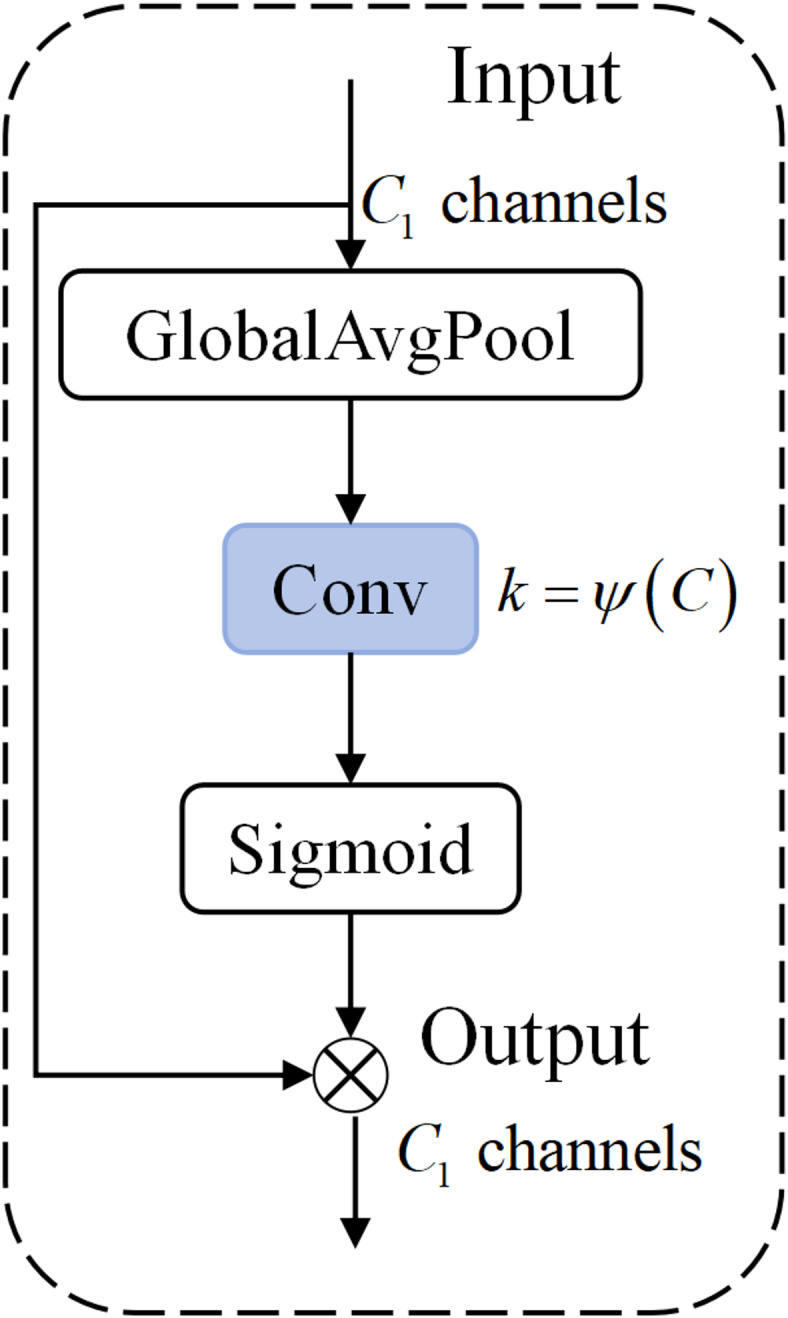
The structure of ECA module.
To address the missed detection problem caused by scale variance in flame detection, this study replaces the original PANet in YOLOv8 with a bidirectional weighted feature pyramid network (BiFPN). As illustrated in Fig. 3, the proposed network enables cross-scale dynamic feature fusion through learnable feature weights. Taking the fusion of the  -th feature
-th feature  as an example, the computation can be formulated as:
as an example, the computation can be formulated as:
 |
4 |
where  is the learnable weights, constrained by Softmax + normalization;
is the learnable weights, constrained by Softmax + normalization;  is a small constant (= 0.0001) used to prevent division-by-zero instability;
is a small constant (= 0.0001) used to prevent division-by-zero instability;  includes upsampling and downsampling operations; and
includes upsampling and downsampling operations; and  denotes a 1 × 1 convolutional layer for feature dimension alignment. The overall architecture of the modified network is shown in Fig. 4.
denotes a 1 × 1 convolutional layer for feature dimension alignment. The overall architecture of the modified network is shown in Fig. 4.
Fig. 3.

The diagram of advanced feature pyramid networks: (a) FPN, (b) PANet, and (c) BiFPN.
Fig. 4.

YOLOv8 + model: architectural enhancements for object detection.
Heat release rate quantification
The proposed deep CNN for HRR quantification employs a heterogeneous dual-branch architecture, which achieves robust feature representation through the synergistic optimization of spatial and frequency domain features. This model is designed for instantaneous HRR inversion from single flame images—it maps visual features extracted from a single frame to the corresponding HRR value, without relying on temporal sequences or historical data. As illustrated in Fig. 5, the model consists of three core components: (1) a spatial feature extraction branch, (2) a frequency domain analysis branch, and (3) an adaptive attention fusion module with a total network depth of 81 layers.
Fig. 5.

The dual-branch network for HRR quantification.
The spatial branch captures hierarchical morphological characteristics (e.g., flame shape, edge contours) through residual blocks with shortcut connections, directly encoding static visual properties of the flame in the input image. The frequency branch, via spatial domain Fourier transform and subsequent convolutional processing, extracts implicit dynamic patterns (e.g., oscillation rhythm) that are spatially imprinted in the single frame—such as textural periodicities and intensity fluctuations that correlate with flame movement. These complementary features are fused through the adaptive module, which dynamically weights their contributions via a multi-layer perception mechanism to establish a nonlinear mapping between visual parameters and instantaneous HRR, ensuring real-time applicability in fire monitoring scenarios.
-
Spatial feature extraction branch
This branch adopts improved bottleneck residual blocks for hierarchical feature abstraction. The input image (224 × 224 × 3) first undergoes 7 × 7 convolution (stride = 2) for low-level edge-feature extraction, followed by 3 × 3 max pooling (stride = 2) to reduce the feature map resolution to 56 × 56 × 64. Four stages of residual modules (detailed in Fig. 6) are then connected, each strictly following a “dimension-reduction spatial-convolution dimension expansion” sandwich structure: 1 × 1 convolution reduces the channels to 1/4, 3 × 3 convolution performs spatial feature extraction, and 1 × 1 convolution restores the channel dimensions. The first module in each stage uses stride = 2 convolution for feature map downsampling (56 × 56 → 28 × 28 → 14 × 14 → 7 × 7), with the number of filters growing geometrically (64 → 128 → 256 → 512). All convolutional layers are followed by batch normalization and swish activation. When there is a mismatch between input and output channel dimensions, 1 × 1 projection convolution adjusts the skip connection dimensions. Finally, global average pooling generates a 512-dimensional spatial-feature vector (
 ) that effectively preserves the spatial saliency patterns.
) that effectively preserves the spatial saliency patterns. -
Frequency domain analysis branch
This branch establishes a spectral-feature enhancement pathway that complements the spatial domain. The input image is first transformed from the temporal to the frequency domain via a Lambda layer that performs a fast Fourier transform and a log amplitude spectrum calculation. A lightweight convolutional sequence is then employed that comprises initial wide-band correlation-feature extraction using 5 × 5 large-kernel convolution (16 filters, stride = 2), followed by 3 × 3 max pooling (stride = 2) to suppress low-frequency noise while enhancing high-frequency components. Two subsequent 3 × 3 convolutional layers (increasing filters from 32 to 64) refine the spectral features, culminating in a 512-dimensional frequency domain feature vector
 generated through global pooling and fully connected layers. The channel dimension is meticulously maintained at 1/8 of the spatial branch, ensuring effective cross-domain feature fusion while substantially reducing the computational overhead.
generated through global pooling and fully connected layers. The channel dimension is meticulously maintained at 1/8 of the spatial branch, ensuring effective cross-domain feature fusion while substantially reducing the computational overhead. -
Adaptive attention fusion module
This module employs an enhanced channel attention mechanism for dynamic feature fusion. The spatial-feature vector and the frequency-domain vector
and the frequency-domain vector  are first concatenated along the channel dimension to form a joint representation
are first concatenated along the channel dimension to form a joint representation  . A two-layer, fully connected network with dropout (rate = 0.3) then learns the attention weight distribution as follows:
. A two-layer, fully connected network with dropout (rate = 0.3) then learns the attention weight distribution as follows:
where
5  and
and  are learnable parameter matrices, and
are learnable parameter matrices, and 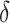 denotes the Swish activation. The features are dynamically recomposed using attention weights
denotes the Swish activation. The features are dynamically recomposed using attention weights  :
:
where
6  represents BN-equipped fully-connected (FC) networks that ensure linear additivity between the spatial and spectral features. The regression prediction is achieved through a three-layer FC network with hidden dimensions of 256 and 128, each followed by Swish activation and dropout regularization (rate = 0.4), while the output layer uses linear activation. All convolutional weights are initialized via the He-normal distribution with L2 regularization (
represents BN-equipped fully-connected (FC) networks that ensure linear additivity between the spatial and spectral features. The regression prediction is achieved through a three-layer FC network with hidden dimensions of 256 and 128, each followed by Swish activation and dropout regularization (rate = 0.4), while the output layer uses linear activation. All convolutional weights are initialized via the He-normal distribution with L2 regularization ( ). The model is trained end-to-end using the Adam optimizer.
). The model is trained end-to-end using the Adam optimizer.
Fig. 6.

Four bottleneck blocks in the dual-branch network.
Fire-image database
-
Data acquisition
Data and labels are indispensable when training deep learning (supervised) models. At present, the only public data that can be used to establish the relationship between a fire image and the HRR is the NIST Fire Calorimetry Database (FCD). The database is a dataset collected by the NIST National Fire Research Laboratory from fire experiments20,21. The database covers a variety of types of fire experiment records. In these experiments, not only was a camera used to record the combustion process of the fuel but an oxygen consumption calorimeter was also used to measure the HRR during the combustion process, which provides valuable data support for establishing the relationship between the fire image and the HRR.
The study selected representative experimental data with distinct flame characteristics, including “vertical upward flamespread on parallel panels,” “structure separation experiments shed burns without wind,” and “fire barriers in full-scale chair mock-ups.” The samples cover various common combustibles (cardboard, upholstered chairs, plastics, etc.) and simple structural elements, with HRR measurements spanning a wide dynamic range up to 8,403.1 kW (see distribution in Fig. 7). This diverse and representative dataset provides solid support for the training and validation of deep learning models.
-
Data processing
To establish a robust correlation between flame images and corresponding HRR values, we implemented a comprehensive data processing protocol. The video data from the FCD exhibited varying degrees of temporal compression, necessitating frame restoration to achieve optimal temporal resolution. Through frame interpolation techniques, we targeted a sampling rate of 1 fps to capture fine-scale flame dynamics. However, practical constraints limited most extractions to 2-s intervals while maintaining data integrity.
The HRR data were then temporally aligned with the extracted image frames. By filtering out HRR entries that lacked corresponding image frames at the same timestamp, we achieved high-precision synchronization between flame morphological features and their corresponding HRR values. To avoid redundancy and ensure representativeness, subsampling was performed across experimental groups within each major category (e.g., different fuel types, experimental conditions). Rather than random selection, samples were strategically chosen based on the diversity of combustion conditions (e.g., fuel type, size variations) and completeness of recorded data, ensuring coverage of distinct flame behaviors while excluding redundant trials. Similarly, frames from the blurred decay phase of the flames, where the flame was dying out and the image quality was compromised, were not included in our dataset.
Flame regions were annotated using LabelImg, an open-source annotation tool, with rigorous quality control. After rigorous screening and standardized processing, a flame characteristic database was successfully established. This database consists of 31,333 samples, with each image precisely annotated with the corresponding, synchronously recorded HRR values and annotations. To facilitate model training and evaluation, the images were divided into training and validation sets at an 8:2 ratio to ensure that the model was trained on a sufficiently large dataset while also allowing for robust evaluation of its performance.
Fig. 7.

Typical burning items in the NIST fire database, (a) paper box, (b) chair, and (c) auxiliary structures, e.g., sheds.
Results
The experiments in this study were conducted on a computational platform equipped with an Intel i9-10900K CPU and an NVIDIA GeForce RTX 3080 GPU that was running the Windows 10 operating system. The deep learning models were developed and trained using Python 3.8.3 in combination with the PyTorch 1.7.1, TensorFlow 2.10.0 (with CUDA 11.0 support), and OpenCV 3 libraries.
Flame detection
As shown in Fig. 8, the optimized YOLOv8n + model demonstrated excellent convergence characteristics during training, with both the training and validation loss curves stabilizing at approximately 130 epochs. The final model achieved a precision value of 95.2% and a recall value of 88.3%, which are modest improvements over the baseline model and validate the effectiveness of the optimization strategy.
Fig. 8.

YOLOv8n + model’s training loss and evaluation metrics.
Through systematic ablation experiments based on the YOLOv8n architecture, we investigated the impact of the ECA module and BiFPN on fire detection tasks using modular combination strategies. As presented in Table 1, the experimental data reveal the complexity of the module interactions and the performance trade-off patterns. The results demonstrate that the insertion position of the ECA module significantly affected the model accuracy. When the module is placed before SPPF, model precision decreased by 2.3% while recall increased by 2%, indicating that channel attention at low-level features is susceptible to local noise interference. While placing the module before SPPF enhances the models small-target detection capability, this comes at the sacrifice of global discrimination accuracy. When the module is placed after the SPPF layer, model precision increased to 0.965 (1.9% improvement over baseline), which can be attributed to the channel attention mechanism’s enhanced ability to focus on the global brightness distribution characteristics of flame regions in the high-level features after multi-scale pooling. However, this configuration suffered a 0.9% recall drop, suggesting that channel attention may suppress sensitivity to small flame targets. This comparison reveals markedly different effects when applying attention mechanisms at different feature levels. After introducing the BiFPN, the parameter count increased by 0.5% while the computational load was maintained at 8.2 GFLOPs. The model achieved 96.3% precision and 86.5% recall in this configuration. Notably, when combining BiFPN with post-SPPF ECA, the model achieved optimally balanced performance with 95.2% precision and 88.3% recall while maintaining the 8.2 GFLOPs computational budget.
Table 1.
Ablation study and comparative performance evaluation of flame detection models.
| Configuration | Total Params | GFLOPs | Precision (P) | Recall (R) |
|---|---|---|---|---|
| YOLOv8n | 3,011,043 | 8.2 | 0.946 | 0.875 |
| YOLOv8n + ECA before SPPF | 3,011,046 | 8.2 | 0.923 | 0.894 |
| YOLOv8n + ECA after SPPF | 3,011,046 | 8.2 | 0.965 | 0.866 |
| YOLOv8n + BiFPN | 3,027,436 | 8.2 | 0.963 | 0.865 |
| YOLOv8n + ECA after SPPF + BiFPN | 3,027,439 | 8.2 |
0.952 (+ 0.6%) |
0.883 (+ 0.8%) |
Significant values are in bold.
Comprehensive analysis indicates that under the 8.2 GFLOP computational constraint, the combined strategy of high-level feature channel attention (post-SPPF ECA) and BiFPN is the most advantageous approach. This combination preserves the selective enhancement of high-level features (improving precision) of ECA while compensating for recall loss through BiFPN’s multi-scale fusion, ultimately achieving more balanced performance improvements over the baseline model.
To assess the model’s generalization capability, we conducted tests on three previously unseen fire scenarios from NIST’s TCC dataset (TrashCanHalf_R3, PatioChair_R3, and WorkCart_R2). The enhanced YOLOv8n model demonstrated reliable flame detection performance across all test cases, while effectively capturing the complete fire development cycle from initial ignition to near-extinction (Figs. 9, 10). These results validate the model’s robustness for diverse fire conditions and its practical applicability for real-world fire monitoring systems.
Fig. 9.

Performance comparison of YOLOv8n and YOLOv8n +.
Fig. 10.

Burning of three items that did not appear, (a) Trash, (b) PatioChair, and (c) WorkCart; Initial, peak, and extinction periods.
HRR quantification
As illustrated in Fig. 11, the dual-branch CNN model developed in this study demonstrated excellent convergence characteristics during the training process. Specifically, both the training and validation sets exhibited a significant decreasing trend in their mean absolute error (MAE) with increasing training epochs, eventually stabilizing after approximately 110 epochs. This indicates that the model effectively reduced the prediction errors and achieved a satisfactory learning performance. Notably, R2 for the validation set rapidly improved during training, ultimately reaching a maximum of 0.976, which convincingly demonstrates the model’s exceptional explanatory power and predictive accuracy for unseen data.
Fig. 11.

Training and validation MAE losses and R2 during model training.
As evidenced in Table 2 and Fig. 12, our dual-branch CNN demonstrated significant performance improvements due to its innovative heterogeneous feature fusion architecture and parameter-efficient design. These advantages arise from three key aspects. First, the model employs a dual-path complementary architecture: the main branch extracts high-level semantic features through residual connections (e.g., add_1), while the auxiliary branch preserves fine-grained spatial details via Lambda layers, with multi-scale fusion achieved through concatenation. Second, progressive channel expansion (64 → 128 → 256 → 512) and a streamlined fully connected layer (128-D output) enhance parameter efficiency, avoiding the redundancy seen in VGG16’s large convolutional kernels or ResNet50’s complex residual blocks. Finally, a dynamic feature-weighting mechanism based on dense_1 adaptively adjusts branch contributions using 2D gating weights, overcoming the limitations of static fusion in traditional multi-branch networks.
Table 2.
Structural comparison and performance overview: Dual-Branch variants (Attention vs. Concatenation Fusion) versus Vision Transformer/VGG16/ResNet50.
| Evaluation model | Total params | Val r2_score |
Val Mae(kW) |
|---|---|---|---|
| Dual-branch (adaptive attention fusion) | 5,207,619 | 0.976 | 32.47 |
| Dual-branch (concatenation fusion) | 5,301,633 | 0.971 | 48.24 |
| Vision transformer | 5,304,737 | 0.977 | 41.98 |
| VGG16 | 14,780,481 | 0.945 | 78.16 |
| ResNet50 | 24,112,513 | 0.869 | 148.82 |
Significant values are in bold.
Fig. 12.

Comparative analysis of performance between the self-developed model and VGG16/ResNet50.
To validate the effectiveness of the adaptive attention fusion mechanism, we conducted ablation experiments comparing it to a simple concatenation-based fusion approach. In the baseline variant, frequency-domain features were aligned to spatial dimensions via a 512-D fully connected layer before direct concatenation. As shown in Table 2, this version achieved a validation R2 of 0.971 and MAE of 48.24 with 5,301,633 parameters. In contrast, our adaptive fusion model not only reduced parameters by ~ 1.8% (5,207,619) but also improved performance—increasing R2 by 0.52% (0.976) and reducing MAE by 32.7% (32.47). These results confirm that dynamic weight allocation (learned via a two-layer MLP) enhances spatial-frequency feature complementarity, leading to superior HRR quantification accuracy while maintaining higher parameter efficiency.
Despite its lightweight structure (only 5.2 M parameters), our dual-branch model outperforms traditional architectures. It achieves an R2 of 0.976, surpassing VGG16 (0.945, + 3.3%) and ResNet50 (0.869, + 12.3%), while its MAE of 32.47 represents reductions of 58.5% (vs. VGG16’s 78.16) and 78.2% (vs. ResNet50’s 148.82). Notably, when compared to a Vision Transformer (ViT) of similar size (5.3 M parameters), an interesting performance trade-off emerged: the ViT achieves a marginally higher R2 (0.977), while our model delivers a significantly lower MAE (32.47 vs. 41.98). This difference highlights the distinct capabilities of the two architectures. R2, which gauges the model’s ability to account for the overall variance in HRR data, is more sensitive to global trend fitting. The Vision Transformer’s self—attention mechanism is well—equipped for this task, effectively capturing long—range dependencies in flame dynamics. Conversely, MAE, which reflects the average prediction deviation, showcases the dual—branch model’s superiority in minimizing local errors. Its adaptive attention fusion mechanism dynamically weights spatial and frequency—domain features, enabling more accurate alignment with fine—grained HRR fluctuations.
Demonstration using the NIST database
The experimental results (Fig. 13) illustrate that in medium-scale fire scenarios, the dual-branch CNN demonstrated significant advantages. Its prediction accuracy, as reflected by R2 values, notably outpaces VGG16, ResNet50, and also surpasses Vision Transformer (e.g., in relevant medium-scale sub-scenarios, dual-branch CNN achieves higher R2 compared to the others), validating the efficacy of the spatial-frequency feature fusion architecture in modeling typical fire dynamics. However, in extreme fire scenarios, all models experience performance degradation; the predictive performance of the dual-branch CNN plummeted sharply, though it still maintains a slight edge over Vision Transformer, which also performs poorly in such cases. Meanwhile, ResNet50 exhibits stronger robustness, revealing distinct architectural adaptability under extreme conditions.
Fig. 13.

Comparison of experimental and model-predicted HRR across different combustion scenarios.
This discrepancy stems from multiple factors: First, data imbalance plays a critical role. Peak HRR phases are inherently short-lived (often lasting only a few seconds in experiments), resulting in underrepresentation in the dataset. This limits the model’s exposure to high-intensity combustion patterns, hindering its ability to learn stable feature mappings for such scenarios. Second, flame feature complexity at peaks exacerbates the issue: At maximum heat release, high temperatures trigger intense airflow disturbances, causing flames to exhibit irregular jitter, fragmented edges (e.g., random bifurcation of flame tips), and abrupt shape transitions. These chaotic morphological changes destabilize the “morphological features” (e.g., contour continuity, area distribution) that the spatial branch relies on, making it difficult to extract consistent discriminative patterns. Concurrently, local overexposure in high-temperature core regions (manifested as pixel saturation) erodes textural details, while smoke-flame interactions introduce discontinuous visual interruptions—both factors disrupt the spatial-frequency branch’s ability to decode implicit dynamic patterns (e.g., oscillation rhythms) from frequency-domain features, as the original periodic energy distributions become obscured by noise. Third, although the lightweight design of the dual-branch CNN improves computational efficiency, it compromises the model’s capacity to characterize the complex nonlinear dynamics of extreme scenarios.
These findings suggest important directions for subsequent model optimization: On the one hand, it is necessary to construct a more balanced fire scene dataset (e.g., augmenting peak-phase samples via synthetic generation). On the other hand, it is necessary to consider the balance between computational efficiency and feature extraction capabilities in network design. Additionally, incorporating time-series prediction frameworks could be promising. By leveraging consecutive flame images to model temporal evolution patterns of flames, the model may better capture the transient dynamics of peak phases, complementing the static features from single images and improving prediction stability.
Discussion
The complexity and chaotic nature of fire behavior pose significant challenges to the practical deployment of AI models. Our study reveals that flame occlusion not only compromises detection accuracy but also leads to erroneous HRR predictions. Furthermore, variations in the image acquisition distance and the viewing angle of the recording device critically influence CNN-based HRR estimations, as they introduce inconsistencies in the scale and morphological features of flames in the images captured. To address this issue, the development of a precise flame location method is necessary. This method would enable the spatial normalization of the input images by establishing a mapping between the spatial coordinates and the visual features, thereby ensuring that the recorded feature scales are consistent with those of the training dataset. This standardization is anticipated to greatly enhance the robustness and reliability of fire monitoring systems in practical applications.
Conclusions
This study presents an advanced cascaded deep learning framework that achieves intelligent fire behavior assessment through the synergistic integration of computer vision and thermodynamic analysis. The system demonstrates exceptional performance, with an optimized YOLOv8 detector attaining a precision of 95.2% and a recall of 88.3%, and an innovative detection-activation mechanism that effectively minimizes false alarms in nonfire scenarios. A subsequent HRR prediction module, implemented through a computationally efficient dual-branch CNN architecture, successfully captures both the spatial and frequency domain characteristics of fire dynamics, achieving superior prediction accuracy (R2 = 0.976) while maintaining significantly reduced model complexity compared to conventional approaches.
While real-world validation would be valuable, the current lack of oxygen consumption calorimetry capabilities prevents experimental validation with complex field scenarios. Future work will pursue this important validation when the necessary measurement infrastructure becomes available, building upon the framework established in this study.
Author contributions
Shiqiang Deng: Methodology, Writing—original draft preparation, Visualization, Software. Shuai Liu: Methodology, Supervision. Maogui Sun: Formal analysis and investigation, Data curation. Meng Yang & Shuping Jiang: Writing—review and editing. Jianzhong Chen: Conceptualization, Funding acquisition, Resources.
Funding
This work is Supported by National Key R&D Program of China (Grant No. 2024YFC3016902) and the Natural Science Foundation of Chongqing (Grant No. cstc2021jcyj-msxmX1052).
Data availability
The data supporting this study are openly available in the NIST Fire Calorimetry Database (FCD) at https://www.nist.gov/el/fcd.
DeclarationsDeclarations
Competing interests
The authors declare no competing interests.
Ethical approval
Not applicable.
Consent to participate
Not applicable.
Consent for publication
Not applicable.
Footnotes
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
References
- 1.Babrauskas, V. & Peacock, R. D. Heat release rate: The single most important variable in fire hazard. Fire Saf. J.18(3), 255–272. 10.1016/0379-7112(92)90019-9 (1992). [Google Scholar]
- 2.Johansson, N. & Svensson, S. Review of the use of fire dynamics theory in fire service activities. Fire Technol.55, 81–103. 10.1007/s10694-018-0774-3 (2019). [Google Scholar]
- 3.Ramasubramanian, S., Muthukumaraswamy, S. A., Sasikala, A. Fire detection using artificial intelligence for fire-fighting robots, in 2020 4th Int. Conf. Intell. Comput. Control Syst. (ICICCS), IEEE, 180–185 (2020). 10.1109/ICICCS48265.2020.9121017
- 4.Wu, H., Wu, D. & Zhao, J. An intelligent fire detection approach through cameras based on computer vision methods. Process Saf. Environ. Prot.127, 245–256. 10.1016/j.psep.2019.05.016 (2019). [Google Scholar]
- 5.Gotthans, J., Gotthans, T., Marsalek, R. Deep convolutional neural network for fire detection, in 2020 30th Int. Conf. Radioelektronika (RADIOELEKTRONIKA), IEEE, 1–6 (2020). 10.1109/RADIOELEKTRONIKA49387.2020.9092344
- 6.Wu, X. et al. Smart detection of fire source in tunnel based on the numerical database and artificial intelligence. Fire Technol.57, 657–682. 10.1007/s10694-020-00985-z (2021). [Google Scholar]
- 7.Wu, X., Zhang, X., Huang, X., Xiao, F., Usmani, A. A real-time forecast of tunnel fire based on numerical database and artificial intelligence, in Building Simulation, 1–14 (Tsinghua University Press, 2022). 10.1007/s12273-021-0775-x
- 8.Richards, R. F., Munk, B. N. & Plumb, O. A. Fire detection, location and heat release rate through inverse problem solution. Part I Theory Fire Saf. J.28(4), 323–350. 10.1016/S0379-7112(97)00005-2 (1997). [Google Scholar]
- 9.Lee, W. S. & Lee, S. K. Estimation of fire location and heat release rate by using sequential inverse method. J. Chin. Soc. Mech. Eng. Trans. Chin. Inst. Eng. Ser. C/Chung-Kuo Chi Hsueh Kung Ch’eng Hsuebo Pao26(12), 201–207 (2005). [Google Scholar]
- 10.Guo, S., Yang, R., Zhang, H. Development and validation of inverse model to detect fire source and intensity, in AIP Conference Proceedings, Vol. 1233, No. 1, 1291–1296 (American Institute of Physics, 2010). 10.1063/1.3452090
- 11.Gu, M., He, Q. & Tang, F. Experimental and machine learning studies of thermal impinging flow under ceiling induced by hydrogen-blended methane jet fire: Temperature distribution and flame extension characteristics. Int. J. Heat Mass Transf.215, 124502. 10.1016/j.ijheatmasstransfer.2023.124502 (2023). [Google Scholar]
- 12.Yang, Y., Zhang, G., Zhu, G., Yuan, D. & He, M. Prediction of fire source heat release rate based on machine learning method. Case Stud. Therm. Eng.54, 104088. 10.1016/j.csite.2024.104088 (2024). [Google Scholar]
- 13.Kou, L., Wang, X., Guo, X., Zhu, J. & Zhang, H. Deep learning based inverse model for building fire source location and intensity estimation. Fire Saf. J.121, 103310. 10.1016/j.firesaf.2021.103310 (2021). [Google Scholar]
- 14.Prasad, K. Predicting heat release rate from fire video data part 1. Appl. Deep Learn. Tech.10.6028/NIST.IR.8521 (2024). [Google Scholar]
- 15.Wang, Z., Zhang, T. & Huang, X. Predicting real-time fire heat release rate by flame images and deep learning. Proc. Combust. Inst.39(3), 4115–4123. 10.1016/j.proci.2022.07.062 (2023). [Google Scholar]
- 16.Xu, L., Dong, J. & Zou, D. Predict future transient fire heat release rates based on fire imagery and deep learning. Fire7(6), 200. 10.3390/fire7060200 (2024). [Google Scholar]
- 17.Lou, H. et al. DC-YOLOv8: Small-size object detection algorithm based on camera sensor. Electronics12(10), 2323. 10.3390/electronics12102323 (2023). [Google Scholar]
- 18.Yi, H., Liu, B., Zhao, B. & Liu, E. Small object detection algorithm based on improved YOLOv8 for remote sensing. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens.17, 1734–1747. 10.1109/JSTARS.2023.3339235 (2023). [Google Scholar]
- 19.Wang, Q., Wu, B., Zhu, P., Li, P., Zuo, W., Hu, Q. ECA-Net: Efficient channel attention for deep convolutional neural networks, in Proc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit., IEEE, 11534–11542 (2020).
- 20.Bryant, R. A., Ohlemiller, T. J., Johnsson, E. L., Hamins, A., Grove, B. S., Guthrie, W. F., Mulholland, G. W. et al. The NIST 3 megawatt quantitative heat release rate facility. US Department of Commerce, National Institute of Standards and Technology (2004).
- 21.National Institute of Standards and Technology. Fire calorimetry database (FCD). 10.18434/mds2-2314
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.
Data Availability Statement
The data supporting this study are openly available in the NIST Fire Calorimetry Database (FCD) at https://www.nist.gov/el/fcd.