

Introduction
One of the greatest headaches in the modern practice of medicine is documentation. Gone are the days when "WNL" (within normal limits) scribbled across a chart entry sufficed for reimbursement or in court; today, if a procedure isn't documented, it isn't performed. Various approaches have been used to facilitate this data entry, from pools of transcriptionists to special online forms with check-boxes for the most common procedures and findings. Voice recognition, the computer recognition of the spoken word, has been a "promising" technology for documenting clinical encounters since the 1980s. This article explores the status of voice-recognition technology, with a focus on medical transcription.
Technology Update
Computer-based voice recognition is often thought of in the context of future science fiction, when computers and robots would be able to converse with their human masters. In reality, voice recognition predates the development of the digital computer.[1] The most significant developments in the past 50 years have been in the areas of vocabulary size, the ability to handle natural language as opposed to single word recognition, recognition accuracy, and integration with telephony and other technologies.
For the purpose of medical transcription, the most important advances have been in the availability of affordable, large-vocabulary, natural language recognition systems. The most common incarnation of this technology is a local, PC-based voice-recognition engine that generates reports, often using macros and templates to make the process more efficient and reduce recognition errors. Figure 1 shows a common configuration for an interactive voice-recognition medical transcription system.
Figure 1.
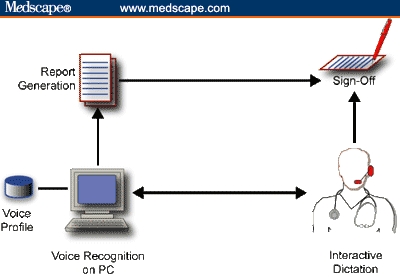
PC-based, interactive dictation. Note local voice profile.
As shown in Figure 1, the clinician interacts with the voice-recognition engine on a local PC until the report is to his or her liking. The report is generated, the clinician signs off on the report, and the process is complete. The advantage of this scenario is immediacy; the clinician works with the system in real time to correct recognition errors (typically in the 2% to 10% range), and the report is ready for signing as soon as it's printed. Faster turn-around means faster reimbursement, a good thing in large medical groups.
There are several major limitations of this approach. The greatest is that it demands much more time from clinicians than the alternative it typically replaces -- dictating into a telephone or a recorder. Instead of spending perhaps a minute dictating notes into a recorder or over a cell phone on the way home from the office, the clinician is stuck in front of a PC, correcting misrecognized words, a task once relegated to transcriptionists. Many clinicians argue that they would be better off financially by squeezing another patient into their schedule rather than spending the time it would take to edit a dozen reports.
There is also the issue of a local voice profile, which is a large file that defines how the clinician's particular voice qualities map onto (usually) the English language. It's the voice profile that makes it possible for a general-purpose voice-recognition engine to work with a clinician from Texas as well as it does with a clinician in Massachusetts. The voice profile is modified with each use of the program, allowing it to "learn" pronunciation subtleties and increase the recognition accuracy. But because the profile sits on one PC, the clinician is limited to one machine -- often a major limitation unless the machine is a laptop.
A partial solution to the portability and mobility issue is to use blind dictation and a digital recorder, as shown in Figure 2. In this scenario, the clinician has the freedom to dictate a report from anywhere and at any time. After the reports are dictated, the data from the recorder are downloaded to a PC running the voice-recognition software, a report is generated, and then it is printed for sign-off. There is still a limitation of one PC because of the voice profile.
Figure 2.
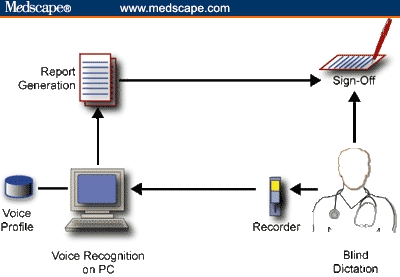
PC-based, blind dictation with a digital recorder.
There is a price for the freedom of mobility and time. One is the lack of immediacy. Reports may not be available for a day or 2 after the clinic visit, depending on when the clinician downloads the data. In addition, because the download process is often performed by an assistant, there is the cost of an office worker.
A larger issue is accuracy. Because dictation isn't interactive, the clinician can't correct the report in real time. The report is likely to have many more errors, meaning that the clinician will have more corrections to make during sign-off. One work-around is to have an assistant babysit the translation process and make changes on the PC before report generation. In fact, a common scenario is to have trained transcriptionists work with the raw documents, making corrections by listening to the dictated audio while reading the electronic report. This approach can save money because transcriptionists spend their time editing, not typing reports from scratch. But the scenario in Figure 2 still suffers from the limitation of a single voice profile and the need for someone to download the digital dictation file.
A natural extension of the "invisible" voice recognition system show in Figure 2 has been the relatively recent introduction of server-side recognition engines, similar to the automated voice response systems used by credit card and flight reservation companies. As shown in Figure 3, this model approximates the traditional dictation approach of calling in a dictation over a telephone and then reviewing and signing off on the report a day or later. The same limitations and features of the model shown in Figure 2 apply -- including the need for someone to verify and edit the document before it is printed -- with the major exception that the clinician's voice profile is no longer limited to a single PC used by one transcriptionist. In addition, the use of a telephone frees up the clinician and obviates the arduous process of downloading digital dictation files, returning memory sticks or chips, dealing with download cables, and the like.
Figure 3.
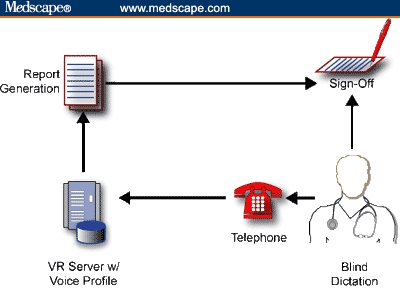
Server-side, blind dictation. Note server-based voice profile. Accuracy can be improved, and demand on physician's time is lessened by the addition of a transcriptionist prior to report generation.
The downside of server-side systems are slightly lower translation accuracies, in part because of the limitations of the telephone system. Most telephones are limited to a bandwidth of about 3000 Hertz, whereas a stand-alone voice-recognition system with a good microphone has an audio bandwidth approaching 15,000 Hertz. That is, there is simply more voice data to work with when a local microphone is used. Still, server-side dictation solves many of the issues that plague the stand-alone approach -- and it's invisible to the clinician.
The Players
If you're in a larger medical institution, you may be using a server-side transcription service and not even know it. However, if you have a small practice and report turn-around time is an issue, there are several options for dedicated PC systems. The 3 major players in the industry are Dragon Systems, IBM, and Philips.
I've used Dragon and IBM extensively, and find them to be different but equivalent. IBM is a little easier to use and seems faster, but Dragon has slightly better recognition accuracy. Also, Dragon's medical solution seems better integrated than IBM's, which is limited to an add-on medical vocabulary option. An advantage of the IBM solution is that it's available on the Macintosh. (Of note, Dragon was the only third-party voice-recognition solution available on the early Macs).
The Reality
A speech-recognition engine simply replaces the keyboard and mouse. To realize the potential benefits of a local, PC-based voice-recognition system (as in Figures 1 and 2), you probably have to change your workflow, and develop (or buy) macros and templates to automate the transcription process. In fact, these templates and macros, available from any number of system integrators and value-added resellers (see VARs in the "Resources" section below), save time, whether they're used with voice recognition or a keyboard and mouse.
Voice recognition may be a solution to the medical transcription conundrum for small practices with relatively small report volumes. However, it's much more demanding on the clinician than traditional transcription. If you're considering voice recognition as an option, I suggest you pick up a $100 general-purpose voice-recognition package from your local microcomputer center and work with it for a week. I've found that it's a love-it or hate-it affair.
Offshore Transcribing
It would be unfair to look at voice-recognition transcription options without mentioning one of the largest movements in the medical transcription industry -- outsourcing transcription offshore. As shown in Figure 4, the process is invisible to the user. In fact, it's exactly like "old-fashioned" transcription services, with banks of transcriptionists who listen to dictation, type in the report, and return it to the clinician for signing.
Figure 4.
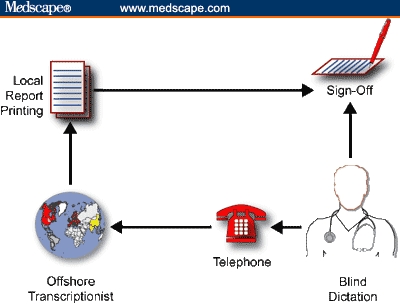
Offshore transcription. Clinicians use a toll-free number to leave a voice dictation, and the electronic reports are returned within a day or 2 for sign-off.
One difference is that the transcriptionists happen to be in India or Pakistan, and the dictation files and reports are transmitted electronically over the Internet. The other, major difference is cost. The cost of offshore transcription services can be so inexpensive relative to the alternatives available in United States, including voice recognition, that it's the obvious solution. If you're curious about offshore transcription, try a search on Google for "Medical Transcription India." As a point of reference, Outsource2India seems representative of the many offshore transcription options available.
In my view, there are only 2 impediments to offshore transcription -- volume and HIPAA. First, if you're a small practice, you many not have the volume necessary to set up an account with an offshore agency (currently, most offshore companies are marketing to the larger-volume users, such as hospitals). Second, HIPAA may make some medical institutions reconsider local options if they are uncertain of how the HIPAA rules on security and privacy apply.
Resources
Engines
Dragon is, in my experience, the easiest to use and most accurate of the engines on the market, followed very closely by IBM, which is a very solid product. Philips, which is more popular overseas, is a distant third.
VARs
This is a sample of the hundreds of medical voice-recognition value-added resellers (VARs) that offer voice recognition packages (engines + templates/macros).
References
- 1. Davis HK, Biddulph R, Balashek S. Automatic recognition of spoken digits. Am J Otolaryngol. 1952;24:637-642. [Google Scholar]