

Abstract
Given a dictionary D = {dk} of vectors dk, we seek to represent a signal S as a linear combination S = ∑k γ(k)dk, with scalar coefficients γ(k). In particular, we aim for the sparsest representation possible. In general, this requires a combinatorial optimization process. Previous work considered the special case where D is an overcomplete system consisting of exactly two orthobases and has shown that, under a condition of mutual incoherence of the two bases, and assuming that S has a sufficiently sparse representation, this representation is unique and can be found by solving a convex optimization problem: specifically, minimizing the ℓ1 norm of the coefficients γ̱. In this article, we obtain parallel results in a more general setting, where the dictionary D can arise from two or several bases, frames, or even less structured systems. We sketch three applications: separating linear features from planar ones in 3D data, noncooperative multiuser encoding, and identification of over-complete independent component models.
Workers throughout engineering and the applied sciences frequently want to represent data (signals, images) in the most parsimonious terms. In signal analysis specifically, they often consider models proposing that the signal of interest is sparse in some transform domain, such as the wavelet or Fourier domain (1). However, there is a growing realization that many signals are mixtures of diverse phenomena, and no single transform can be expected to describe them well; instead, we should consider models making sparse combinations of generating elements from several different transforms (1–4). Unfortunately, as soon as we start considering general collections of generating elements, the attempt to find sparse solutions enters mostly uncharted territory, and one expects at best to use plausible heuristic methods (5–8) and certainly to give up hope of rigorous optimality. In this article, we will develop some rigorous results showing that it can be possible to find optimally sparse representations by efficient techniques in certain cases.
Suppose we are given a dictionary D of generating elements {dk}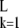 , each one a vector in CN, which we assume normalized: d
, each one a vector in CN, which we assume normalized: d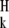 dk = 1. The dictionary D can be viewed a matrix of size N × L, with generating elements for columns. We do not suppose any fixed relationship between N and L. In particular, the dictionary can be overcomplete and contain linearly dependent subsets, and in particular need not be a basis. As examples of such dictionaries, we can mention: wavelet packets and cosine packets dictionaries of Coifman et al. (3), which contain L = N log(N) elements, representing transient harmonic phenomena with a variety of durations and locations; wavelet frames, such as the directional wavelet frames of Ron and Shen (9), which contain L = CN elements for various constants C > 1; and the combined ridgelet/wavelet systems of Starck, Candès, and Donoho (8, 10). Faced with such variety, we cannot call individual elements in the dictionary basis elements; we will use the term atom instead; see refs. 2 and 11 for elaboration on the atoms/dictionary terminology and other examples.
dk = 1. The dictionary D can be viewed a matrix of size N × L, with generating elements for columns. We do not suppose any fixed relationship between N and L. In particular, the dictionary can be overcomplete and contain linearly dependent subsets, and in particular need not be a basis. As examples of such dictionaries, we can mention: wavelet packets and cosine packets dictionaries of Coifman et al. (3), which contain L = N log(N) elements, representing transient harmonic phenomena with a variety of durations and locations; wavelet frames, such as the directional wavelet frames of Ron and Shen (9), which contain L = CN elements for various constants C > 1; and the combined ridgelet/wavelet systems of Starck, Candès, and Donoho (8, 10). Faced with such variety, we cannot call individual elements in the dictionary basis elements; we will use the term atom instead; see refs. 2 and 11 for elaboration on the atoms/dictionary terminology and other examples.
Given a signal S ∈ CN, we seek the sparsest coefficient vector γ̱ in CL such that Dγ̱ = S. Formally, we aim to solve the optimization problem
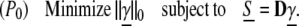 |
1 |
Here the ℓ0 norm ∥γ̱∥0 is simply the number of nonzeros in γ̱. While this problem is easily solved if there happens to be a unique solution Dγ̱ = S among general (not necessarily sparse) vectors γ̱, such uniqueness does not hold in any of our applications; in fact, these mostly involve L ≫ N, where such uniqueness is, of course, impossible. In general, solution of (P0) requires enumerating subsets of the dictionary looking for the smallest subset able to represent the signal; of course, the complexity of such a subset search grows exponentially with L.
It is now known that in several interesting dictionaries, highly sparse solutions can be obtained by convex optimization; this has been found empirically (2, 12) and theoretically (13–15). Consider replacing the ℓ0 norm in (P0) by the ℓ1 norm, getting the minimization problem
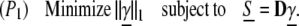 |
2 |
This can be viewed as a kind of convexification of (P0). For example, over the set of signals that can be generated with coefficient magnitudes bounded by 1, the ℓ1 norm is the largest convex function less than the ℓ0 norm; (P1) is in a sense the closest convex optimization problem to (P0).
Convex optimization problems are extremely well studied (16), and this study has led to a substantial body of algorithmic knowledge and high-quality software. In fact, (P1) can be cast as a linear programming problem and solved by modern interior point methods (2), even for very large N and L.
Given the tractability of (P1) and the general intractibility of (P0), it is perhaps surprising that for certain dictionaries solutions to (P1), when sufficiently sparse, are the same as the solutions to (P0). Indeed, results in refs. 13–15 show that for certain dictionaries, if there exists a highly sparse solution to (P0) then it is identical to the solution of (P1); and, if we obtain the solution of (P1) and observe that if it happens to be sparse beyond a certain specific threshold, then we know (without checking) that we have also solved (P0).
Previous work studying this phenomenon (13–15) considered dictionaries D built by concatenating two orthobases Φ and Ψ, thus giving that L = 2N. For example, one could let Φ be the Fourier basis and Ψ be the Dirac basis, so that we are trying to represent a signal as a combination of spikes and sinusoids. In this dictionary, the latest results in ref. 15 show that if a signal is built from <0.914 spikes and sinusoids, then this is the sparsest possible representation by spikes and sinusoids, i.e., the solution of (P0), and it is also necessarily the solution found by (P1).
spikes and sinusoids, then this is the sparsest possible representation by spikes and sinusoids, i.e., the solution of (P0), and it is also necessarily the solution found by (P1).
We are aware of numerous applications where the dictionaries would not be covered by the results just mentioned. These include: cases where the dictionary is overcomplete by more than a factor 2 (i.e., L > 2N), and where we have a collection of nonorthogonal elements, for example, a frame or other system. In this article, we consider general dictionaries D and obtain results paralleling those in refs. 13–15. We then sketch applications in the more general dictionaries.
We address two questions for a given dictionary D and signal S: (i) uniqueness, under which conditions is a highly sparse representation necessarily the sparsest possible representation; and (ii) equivalence, under which conditions is a highly sparse solution to the (P0) problem also necessarily the solution to the (P1) problem?
Our analysis avoids reliance on the orthogonal subdictionary structure in refs. 13–15; our results are just as strong as those of ref. 13 while working for a much wider range of dictionaries. We base our analysis on the concept of the Spark of a matrix, the size of the smallest linearly dependent subset. We show that uniqueness follows whenever the signal S is built from fewer than Spark(D)/2 atoms. We develop two bounds on Spark that yield previously known inequalities in the two-orthobasis case but can be used more generally. The simpler bound involves the quantity M(G), the largest off-diagonal entry in the Gram matrix G = DHD. The more general bound involves μ1(G), the size of the smallest group of nondiagonal magnitudes arising in a single row or column of G and having a sum ≥1. We have Spark(D) > μ1 ≥ 1/M. We also show, in the general dictionary case, that one can determine a threshold on sparsity whereby every sufficiently sparse representation of S must be the unique minimal ℓ1 representation; our thresholds involve M(G) and a quantity μ1/2(G) related to μ1.
We sketch three applications of our results.
Separating Points, Lines, and Planes: Suppose we have a data vector S representing 3D volumetric data. It is supposed that the volume contains some number of points, lines, and planes in superposition. Under what conditions can we correctly identify the lines and planes and the densities on each? This is a caricature of a timely problem in extragalactic astronomy (17).
Robust Multiuser Private Broadcasting: J different individuals encode information by superposition in a single signal vector S that is intended to be received by a single recipient. The encoded vector must look like random noise to anyone but the intended recipient (including the transmitters), it must be decodable perfectly, and the perfect decoding must be robust against corruption of some limited number of entries in the vector. We present a scheme that achieves these properties.
Blind Identification of Sources: Suppose that a random signal S is a superposition of independent components taken from an overcomplete dictionary D. Without assuming sparsity of this representation, we cannot in general know which atoms from D are active in S or what there statistics are. However, we show that it is possible, without any sparsity, to determine the activity of the sources, exploiting higher-order statistics.
Note: After presenting our work publicly we learned of related work about to be published by R. Gribonval and M. Nielsen (18). Their work initially addresses the same question of obtaining the solution of (P0) by instead solving (P1), with results paralleling ours. Later, their work focuses on analysis of more special dictionaries built by concatenating several bases.
The Two-Orthobasis Case
Consider a special type of dictionary: the concatenation of two orthobases Φ and Ψ, each represented by N × N unitary matrices; thus D = [Φ, Ψ]. Let φ̱i and ψ̱j (1 ≤ i, j ≤ N) denote the elements in the two bases. Following ref. 13 we define the mutual incoherence between these two bases by
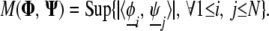 |
It is easy to show (13, 15) that 1/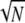 ≤ M ≤ 1; the lower bound is attained by a basis pair such as spikes and sinusoids (13) or spikes and Hadamard–Walsh functions (15). The upper bound is attained if at least one of the vectors in Φ is also found in Ψ. A condition for uniqueness of sparse solutions to (P0) can be stated in terms of M; the following is proved in refs. 14 and 15.
≤ M ≤ 1; the lower bound is attained by a basis pair such as spikes and sinusoids (13) or spikes and Hadamard–Walsh functions (15). The upper bound is attained if at least one of the vectors in Φ is also found in Ψ. A condition for uniqueness of sparse solutions to (P0) can be stated in terms of M; the following is proved in refs. 14 and 15.
Theorem 1: Uniqueness.
A representation S = Dγ̱ is necessarily the sparsest possible if ∥γ̱∥0 < 1/M.
In words, having obtained a sparse representation of a signal, for example by (P1) or by any other means, if the ℓ0 norm of the representation is sufficiently small (<1/M), we conclude that this is also the (P0) solution. In the best case where 1/M = 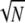 , the sparsity requirement translates into ∥γ̱∥0 <
, the sparsity requirement translates into ∥γ̱∥0 < 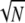 .
.
A condition for equivalence of the solution to (P1) with that for (P0) can also be stated in terms of M; see refs. 14 and 15.
Theorem 2: Equivalence.
If there exists any sparse representation of S satisfying ∥γ̱∥0 < (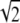 − 0.5)/M, then this is necessarily the unique solution of (P1).
− 0.5)/M, then this is necessarily the unique solution of (P1).
Note the slight gap between the criteria in the above two theorems. Recently, Feuer and Nemirovsky (19) managed to prove that the bound in the equivalence theorem is sharp, so this gap is unbridgeable.
To summarize, if we solve the (P1) problem and observe that it is sufficiently sparse, we know we have obtained the solution to (P0) as well. Moreover, if the signal S has sparse enough representation to begin with, (P1) will find it.
These results correspond to the case of dictionaries built from two orthobases. Both theorems immediately extend in a limited way to nonorthogonal bases Φ and Ψ (13). We merely replace M by the quantity M̃ in the statement of both results:
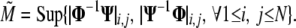 |
However, as we may easily have M̃ ≥ 1, this is of limited value.
A Uniqueness Theorem for Arbitrary Dictionaries
We return to the setting of the Introduction; the dictionary D is a matrix of size N × L, with normalized columns {dk}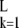 . An incoming signal vector S is to be represented by using the dictionary by S = Dγ̱. Assume that we have two different suitable representations, i.e.
. An incoming signal vector S is to be represented by using the dictionary by S = Dγ̱. Assume that we have two different suitable representations, i.e.
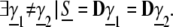 |
3 |
Thus the difference of the representation vectors, δ̲ = γ̱1 − γ̱2, must be in the null space of the representation: D(γ̱1 − γ̱2) = Dδ̲ = 0. Hence some group of columns from D must be linearly dependent. To discuss the size of this group we introduce terminology.
Definition 1, Spark:
Given a matrix A we define σ = Spark(A) as the smallest possible number such that there exists a subgroup of σ columns from A that are linearly dependent.
Clearly, if there are no zero columns in A, then σ ≥ 2, with equality only if two columns from A are linearly dependent. Note that, although spark and rank are in some ways similar, they are totally different. The rank of a matrix A is defined as the maximal number of columns from A that are linearly independent, and its evaluation is a sequential process requiring L steps. Spark, on the other hand, is the minimal number of columns from A that are linearly dependent, and its computation requires a combinatorial process of complexity 2L steps. The matrix A can be of full rank and yet have σ = 2. At the other extreme we get that σ ≤ Min{L, Rank(A) + 1}.
As an interesting example, let us consider a two-ortho basis case made of spikes and sinusoids. Here D = [Φ, Ψ], Φ = IN the identity matrix of size N × N, and Ψ = FN the discrete Fourier transform matrix of size N × N. Then, supposing N is a perfect square, using the Poisson summation formula we can show (13) that there is a group of 2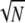 linearly-dependent vectors in this D, and so Spark(D) ≤ 2
linearly-dependent vectors in this D, and so Spark(D) ≤ 2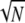 . As we shall see later, Spark(D) = 2
. As we shall see later, Spark(D) = 2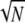 .
.
We now use the Spark to bound the sparsity of nonunique representations of S. Let σ = Spark(D). Every nonuniqueness pair (γ̱1, γ̱2) generates δ̲ = γ̱1 − γ̱2 in the column null-space; and
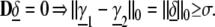 |
4 |
On the other hand, the ℓ0 pseudo-norm obeys the triangle inequality ∥γ̱1 − γ̱2∥0 ≤ ∥γ̱1∥0 + ∥γ̱2∥0. Thus, for the two supposed representations of S, we must have
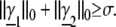 |
5 |
Formalizing matters:
Theorem 3: Sparsity Bound.
If a signal S has two different representations S = Dγ̱1 = Dγ̱2, the two representations must have no less than Spark(D) nonzero entries combined.
From Eq. 5, if there exists a representation satisfying ∥γ̱1∥0 < σ/2, then any other representation γ̱2 must satisfy ∥γ̱2∥0 > σ/2, implying that γ̱1 is the sparsest representation. This gives:
Corollary 1: Uniqueness.
A representation S = Dγ̱ is necessarily the sparsest possible if ∥γ̱∥0 < Spark(D)/2.
We note that these results are sharp, essentially by definition.
Lower Bounds on Spark(D).
Let G = DHD be the Gram matrix of D. As every entry in G is an inner product of a pair of columns from the dictionary, the diagonal entries are all 1, owing to our normalization of D's columns; the off-diagonal entries have magnitudes between 0 and 1.
Let 𝒮 = {k1, … , ks} be a subset of indices, and suppose the corresponding columns of D are linearly independent. Then the corresponding leading minor G𝒮 = (Gki, kj : i, j = 1, … , s) is positive definite (20). The converse is also true. This proves
Lemma 1.
σ ≤ Spark(D) if and only if every (σ − 1) × (σ − 1) leading minor of G is positive definite.
To apply this criterion, we use the notion of diagonal dominance (20): If a symmetric matrix A = (Aij) satisfies Aii > ∑j≠i |Aij| for every i, then A is positive definite. Applying this criterion to all principal minors of the Gram matrix G leads immediately to a lower bound for Spark(G).
Theorem 4: Lower-Bound Using μ1.
Given the dictionary D and its Gram matrix G = DHD, let μ1(G) be the smallest integer m such that at least one collection of m off-diagonal magnitudes arising within a single row or column of G sums at least to 1. Then Spark(D) > μ1(G).
Indeed, by hypothesis, every μ1 × μ1 principal minor has its off-diagonal entries in any single row or column summing to <1. Hence every such principal minor is diagonally dominant, and hence every group of μ1 columns from D is linearly independent.
For a second bound on Spark, define M(G) = maxi≠j |Gi,j|, giving a uniform bound on off-diagonal elements. Note that the earlier quantity M(Ψ, Φ) defined in the two-orthobasis case agrees with the new quantity. Now consider the implications of M = M(G) for μ1(G). Since we have to sum at least 1/M off-diagonal entries of size M to reach a cumulative sum equal or exceeding 1, we always have μ1(G) ≥ 1/M(G). This proves
Theorem 5: Lower Bound Using M.
If the Gram matrix has all off-diagonal entries ≤ M,
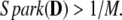 |
6 |
Combined with our earlier observations on Spark, we have: a representation with fewer than (1 + 1/M)/2 nonzeros is necessarily maximally sparse.
Refinements.
In general, Theorems 4 and 5 can contain slack, in two ways. First, there may be additional dictionary structure to be exploited. For example, return to the special two-orthobasis case of spikes and sinusoids: D = [Φ, Ψ], Φ = IN and Ψ = FN. Here M = 1/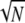 , and so the theorem says that Spark(D) >
, and so the theorem says that Spark(D) >  . In fact, the exact value is 2
. In fact, the exact value is 2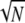 , so there is room to do better. This improvement follows directly from the uncertainty theorem given in refs. 14 and 15, leading to Spark(D) ≥ 2/M. The reasoning is general and applies to any two-orthobasis dictionary, giving
, so there is room to do better. This improvement follows directly from the uncertainty theorem given in refs. 14 and 15, leading to Spark(D) ≥ 2/M. The reasoning is general and applies to any two-orthobasis dictionary, giving
Theorem 6: Improved Lower Bound, Two Orthobasis Case.
Given a two-orthobasis dictionary with mutual coherence value at most M, Spark(D) ≥ 2/M.
This bound, together with Corollary 1, gives precisely theorem 1 in refs. 14 and 15. Returning again to the spikes/sinusoids example, from M = 1/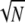 we have Spark(D) ≥ 2
we have Spark(D) ≥ 2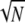 . On the other hand, if N is a perfect square, the spike train example provides a linearly-dependent subset of 2
. On the other hand, if N is a perfect square, the spike train example provides a linearly-dependent subset of 2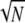 atoms, and so in fact σ = 2
atoms, and so in fact σ = 2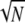 .
.
Second, Theorem 5 can contain slack simply because the metric information in the Gram matrix is not sufficiently expressive on linear dependence issues. We may construct examples where Spark(D) ≫ 1/M(G). Our bounds measure diagonal dominance rather than positive definiteness, and this is well known to introduce a gap in a wide variety of settings (20).
For a specific example, consider a two-basis dictionary made of spikes and exponentially decaying sinusoids (13). Thus, let Φ = IN and, for a fixed α ∈ (0, 1), construct the nonorthogonal basis Ψ = {ψ
= {ψ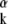 }, where ψ
}, where ψ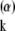 (i) = αi exp{
(i) = αi exp{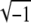 (2πk/N)i}. Let 𝒮1 and 𝒮2 be subsets of indices in each basis. Now suppose this pair of subsets generates a linear dependency in the combined representation, so that, for appropriate N vectors of coefficients ρ and ω,
(2πk/N)i}. Let 𝒮1 and 𝒮2 be subsets of indices in each basis. Now suppose this pair of subsets generates a linear dependency in the combined representation, so that, for appropriate N vectors of coefficients ρ and ω,
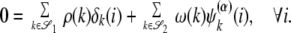 |
Then, as ψ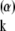 (i) = αiψ
(i) = αiψ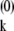 (i) it is equally true that
(i) it is equally true that
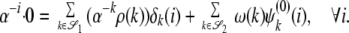 |
Hence, there would have been a linear dependency in the two-orthobasis case [IN, FN], with the same subsets and with coefficients ρ̃(k) = αkρ(k), ∀k, and ω̃(k) = ω(k). In short, we see that
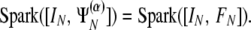 |
On the other hand, picking α close to zero, we get that the basis elements in Ψ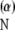 decay so quickly that the decaying sinusoids begin to resemble spikes; thus M(IN, Ψ
decay so quickly that the decaying sinusoids begin to resemble spikes; thus M(IN, Ψ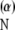 ) → 1 as α → 0.
) → 1 as α → 0.
This is a special case of a more general phenomenon, invariance of the Spark under row and column scaling, combined with noninvariance of the Gram matrix under row scaling. For any diagonal nonsingular matrices W1 (N × N) and W2 (L × L), we have
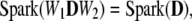 |
while the Gram matrix G = G(D) exhibits no such invariance; even if we force normalization so that diag(G) = IL, we have only invariance against the action of W2 (column scaling), but not W1 (row scaling). In particular, while the positive definiteness of any particular minor of G(W1D) is invariant under such row scaling, the diagonal dominance is not.
Upper Bounds on Spark.
Consider a concrete method for evaluating Spark(D). We define a sequence of optimization problems, for k = 1, … , L:
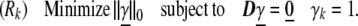 |
7 |
Letting γ̱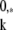 denote the solution of problem (Rk), we get
denote the solution of problem (Rk), we get
 |
8 |
The implied ℓ0 optimization is computationally intractable. Alternatively, any sequence of vectors obeying the same constraints furnishes an upper bound. To obtain such a sequence, we replace minimization of the l0 norm by the more tractable ℓ1 norm. Define the sequence of optimization problems for k = 1, 2, … , L:
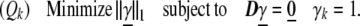 |
9 |
(The same sequence of optimization problems was defined in ref. 13, which noted the formal identity with the definition of analytic capacities in harmonic analysis, and called them capacity problems.) The problems can in principle be tackled straightforwardly by using linear programming solvers. Denote the solution of the (Qk) problem by γ̱ . Then, clearly ∥γ̱
. Then, clearly ∥γ̱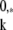 ∥0 ≤ ∥γ̱
∥0 ≤ ∥γ̱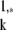 ∥0, so
∥0, so
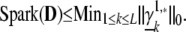 |
10 |
An Equivalence Theorem for Arbitrary Dictionaries
We now set conditions under which, if a signal S admits a highly sparse representation in the dictionary D, the ℓ1 optimization problem (P1) must necessarily obtain that representation.
Let γ̱0 denote the unique sparsest representation of S, so Dγ̱0 = S. For any other γ̱1 providing a representation (i.e. Dγ̱1 = S) we therefore have ∥γ̱1∥0 > ∥γ̱0∥0. To show that γ̱0 solves (P1), we need to show that ∥γ̱1∥1 ≥ ∥γ̱0∥1. Consider the reformulation of (P1):
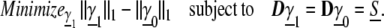 |
11 |
If the minimum is no less than zero, the ℓ1 norm for any alternate representation is at least as large as for the sparsest representation. This in turn means that the (P1) problem admits γ̱0 as a solution. If the minimum is uniquely attained, then the minimizer of (P1) is γ̱0.
As in refs. 13 and 15, we develop a simple lower bound. Let 𝒮 denote the support of γ̱0. Writing the difference in norms in Eq. 11 as a difference in sums, and relabeling the summations, gives
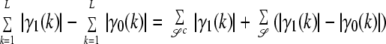 |
12 |
 |
where we introduced the vector δ̱ = γ̱1 − γ̱0. Note that the right side of this display is positive only if
 |
i.e., only if at least 50% of the magnitude in δ is concentrated in 𝒮. This motivates a constrained optimization problem:
 |
13 |
This new problem is closely related to Eq. 11 and hence also to (P1). It has this interpretation: if val(C𝒮) < ½, then every direction of movement away from γ̱0 that remains a representation of S (i.e., stays in the nullspace) causes a definite increase in the objective function for Eq. 11. Recording this formally,
Lemma 2: Less than 50% Concentration Implies Equivalence.
If supp(γ̱0) ⊂ 𝒮, and val(C𝒮) < ½, then γ̱0 is the unique solution of (P1) from data S = Dγ̱0.
On the other hand, if val(C𝒮) ≥ ½, it can happen that γ̱0 is not a solution to (P1).
Lemma 3.
If val(C𝒮) ≥ ½, there exists a vector γ̱0 supported in 𝒮, and a corresponding signal S = Dγ̱0, such that γ̱0 is not a unique minimizer of (P1).
Proof:
Given a solution δ̱* to problem (C𝒮) with value ≥ ½, pick any γ̱0 supported in 𝒮 with sign pattern arranged so that sign(δ*(k)γ̱0(k)) < 0 for k ∈ 𝒮. Then consider γ̱1 of the general form γ̱1 = γ̱0 + tδ̱*, for small t > 0. Equality must hold in Eq. 12 for sufficiently small t, showing that ∥γ̱1∥1 < ∥γ̱0∥1 and so γ̱0 is not the unique solution of (P1) when S = Dγ̱0.
We now bring the Spark into the picture.
Lemma 4.
Let σ = Spark(D). There is a subset 𝒮* with #(𝒮*) ≤ σ/2 + 1 and val(C𝒮*) ≥ ½.
Proof:
Let 𝒮 index a subset of dictionary atoms exhibiting linear dependence. There is a nonzero vector δ̱ supported in 𝒮 with Dδ̱ = 0. Let 𝒮* be the subset of 𝒮 containing the ⌈#(𝒮)/2⌉ largest-magnitude entries in δ̱. Then #(𝒮*) ≤ #(𝒮)/2 + 1 while
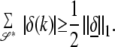 |
It follows necessarily that val(C𝒮*) > ½.
In short, the size of Spark(D) controls uniqueness not only in the ℓ0 problem, but also in the ℓ1 problem. No sparsity bound ∥γ̱0∥0 < s can imply (P0)–(P1) equivalence in general unless s ≤ Spark(D)/2.
Equivalence Using M(G). Theorem 7.
Suppose that the dictionary D has a Gram matrix G with off-diagonal entries bounded by M. If S = Dγ̱0 where ∥γ̱0∥0 < (1 + 1/M)/2, then γ̱0 is the unique solution of (P1).
We prove this by showing that if Dδ̱ = 0, then for any set 𝒮 of indices,
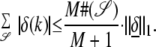 |
14 |
Then because #(𝒮) < (1 + 1/M)/2, it is impossible to achieve 50% concentration on 𝒮, and so Lemma 2 gives our result.
To get Eq. 14, we recall the sequence of capacity problems (Qk) introduced earlier. By their definition, if δ̱ obeys Dδ̱ = 0,
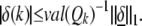 |
It follows (see also ref. 13) that for any set 𝒮,
 |
Result 14 and hence Theorem 7 follow immediately on substituting the following bound for the capacities:
Lemma 5.
Suppose the Gram matrix has off-diagonal entries bounded by M. Then
 |
To prove the lemma, we remark that as Dδ̱ = 0 then also Gδ̱ = DHDδ̱ = 0. In particular, (Gδ̱)k = 0, where k is the specific index mentioned in the statement of the lemma. Now as δk = 1 by definition of (Qk), and as Gk,k = 1 by normalization, in order that (Gδ̱)k = 0 we must have 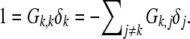 Now
Now
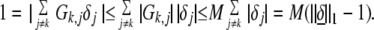 |
Hence ∥δ̱∥1 ≥ 1/M + 1, and the lemma follows.
Equivalence Using μ1/2(G).
Recall the quantity μ1 defined in our analysis of the uniqueness problem in the previous section. We now define an analogous concept relevant to equivalence.
Definition 2:
For G a symmetric matrix, μ1/2(G) denotes the smallest number m such that some collection of m off-diagonal magnitudes arising in a single row or column of G sums at least to ½.
We remark that μ1/2(G) ≤ ½μ1(G) < μ1(G). Using this notion, we can show:
Theorem 8.
Consider a dictionary D with Gram matrix G. If S = Dγ̱0 where ∥γ̱0∥0 < μ1/2(G), then γ̱0 is the unique solution of (P1).
Indeed, let 𝒮 be a set of size #(𝒮) < μ1/2(G). We show that any vector in the nullspace of D exhibits <50% concentration to 𝒮, so
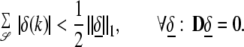 |
15 |
The theorem then follows from Lemma 2.
Note again that Dδ̱ = 0 implies Gδ̱ = 0. In particular, (G − I)δ̱ = −δ̱. Let m = #𝒮 and let H = (Hi,k) denote the m × L matrix formed from the rows of G − I corresponding to indices in 𝒮. Then (G − I)δ̱ = −δ̱ implies
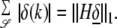 |
16 |
As is well known, H, viewed as a matrix mapping ℓ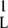 into ℓ
into ℓ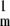 , has its norm controlled by its maximum ℓ1 column sum:
, has its norm controlled by its maximum ℓ1 column sum:
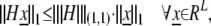 |
where  By the assumption that μ1/2(G) > #𝒮,
By the assumption that μ1/2(G) > #𝒮,
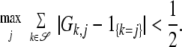 |
It follows that |∥H|∥(1,1) < ½. Together with Eq. 16 this yields Eq. 15 and hence also the theorem.
Stylized Applications
We now sketch a few application scenarios in which our results may be of interest.
Separating Points, Lines, and Planes.
A timely problem in extragalactic astronomy is to analyze 3D volumetric data and quantitatively identify and separate components concentrated on filaments and sheets from those scattered uniformly through 3D space; see ref. 17 for related references, and ref. 8 for some examples of empirical success in performing such separations. It seems of interest to have a theoretical perspective assuring us that, at least in an idealized setting, such separation is possible in principle.
For sake of brevity, we work with specific algebraic notions of digital line, digital point, and digital plane. Let p be a prime (e.g., 127, 257) and consider a vector to be represented by a p × p × p array S(i1, i2, i3) = S(i). As representers of digital points we consider the Kronecker sequences Pointk(i) = 1{k1=i1,k2=i2,k3=i3} as k = (k1, k2, k3) ranges over all triples with 0 ≤ ki < p. We consider a digital plane Planep(j̱, k1, k2) to be the collection of all triples (i1, i2, i3) obeying ij3 = k1ij1 + k2ij2 mod p, and a digital line Linep(io, k) to be the collection of all triples i = i0 + ℓk mod p, ℓ = 0, … , p.
By using properties of arithmetic mod p, it is not hard to show the following:
Any digital plane contains p2 points.
Any digital line contains p points.
Any two digital lines are disjoint, or intersect in a single point.
Any two digital planes are parallel, or intersect in a digital line.
Any digital line intersects a digital plane not at all, in a single point, or along the whole extent of the digital line.
Suppose now that we construct a dictionary D consisting of indicators of points, of digital lines and of digital planes. These should all be normalized to unit ℓ2 norm. Let G denote the Gram matrix. We make the observation that
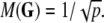 |
Indeed, if d1 and d2 are each normalized indicator functions corresponding to subsets I1, I2 ⊂ Z , then
, then
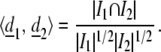 |
Using this fact and the above incidence estimates we get that the inner product between two planes or two lines could not exceed 1/p, while an inner product between a plane and a line or line and a point cannot exceed 1/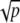 . We obtain immediately:
. We obtain immediately:
Theorem 9.
If the 3D array can be written as a superposition of <
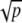 |
digital planes, lines, and points, this is the unique sparsest representation, and it is also the unique minimal ℓ1 decomposition.
This shows that there is at least some possibility to separate 3D data rigorously into unique geometric components. It is in accord with recent experiments in ref. 8 successfully separating data into a relatively few such components.
Robust Multiuser Private Broadcasting.
Consider now a stylized problem in private digital communication. Suppose that J individuals are to communicate privately and without coordination over a broadcast channel with an intended recipient. The jth individual is to create a signal Sj that is superposed with all the other individuals' signals, producing S = ∑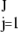 Sj. The intended recipient gets a copy of S. The signals Sj are encoded in such a way that, to everyone but the intended recipient, encoders included, S looks like white Gaussian noise; participating individuals cannot understand each other's messages, but nevertheless the recipient is able to separate S unambiguously into its underlying components Si and decipher each such apparent noise signal into meaningful data. Finally, it is desired that all this remain true even if the recipient gets a defective copy of S that may be badly corrupted in a few entries.
Sj. The intended recipient gets a copy of S. The signals Sj are encoded in such a way that, to everyone but the intended recipient, encoders included, S looks like white Gaussian noise; participating individuals cannot understand each other's messages, but nevertheless the recipient is able to separate S unambiguously into its underlying components Si and decipher each such apparent noise signal into meaningful data. Finally, it is desired that all this remain true even if the recipient gets a defective copy of S that may be badly corrupted in a few entries.
Here is a way to approach this problem. The intended recipient arranges things in advance so that each of the J individuals has a private codebook Cj containing K different N vectors whose entries are generated by sampling independent Gaussian white noises. The codebook is known to the jth encoder and to the recipient. An overall dictionary is created by concatenating these together with an identity matrix, producing
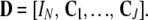 |
The jth individual creates a signal by selecting a random subset of Ij indices in Cj and generating
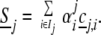 |
The positions of the indices i ∈ Ij and coefficients α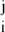 are the meaningful data to be conveyed. Now each cj,i is the realization of a Gaussian white noise; hence each Sj resembles such a white noise. Individuals don't know each other's codebooks, so they are unable to decipher each other's meaningful data (in a sense that can be made precise; compare ref. 21).
are the meaningful data to be conveyed. Now each cj,i is the realization of a Gaussian white noise; hence each Sj resembles such a white noise. Individuals don't know each other's codebooks, so they are unable to decipher each other's meaningful data (in a sense that can be made precise; compare ref. 21).
The recipient can extract all the meaningful data simply by performing minimum ℓ1 atomic decomposition in dictionary D. This will provide a list of coefficients associated with spikes and with the components associated with each codebook. Provided the participants encode a sparse enough set of coefficients, the scheme works perfectly to separate errors and the components of the individual message.
To see this, note that by using properties of extreme values of Gaussian random vectors (compare ref. 13) we can show that the normalized dictionary obeys
 |
where ɛN is a random variable that tends to zero in probability as N → ∞. Hence we have:
Theorem 10.
There is a capacity threshold C(D) such that, if each participant transmits an Sj using at most #(Ij) ≤ C(D) coefficients and if there are < C(D) errors in the recipient's copy of 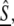 then the minimum ℓ1 decomposition of
then the minimum ℓ1 decomposition of 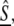 precisely recovers the indices Ij and the coefficients α
precisely recovers the indices Ij and the coefficients α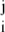 . We have
. We have
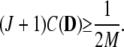 |
Identification of Overcomplete Blind Sources.
Suppose that a statistically independent set of random variables X = (Xi) generates an observed data vector according to
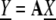 |
17 |
where Y is the vector of observed data and A represents the coupling of independent sources to observable sensors. Such models are often called independent components models (22). We are interested in the case where A is known, but is overcomplete, in the sense that L ≫ N (many more sources than sensors, a realistic assumption). We are not supposing that the vector X is highly sparse; hence there is no hope in general to recover uniquely the components X generating a single realization Y. We ask instead whether it is possible to recover statistical properties of X; in particular higher-order cumulants.
The order 1 and 2 cumulants (mean and variance) are well known; the order 3 and 4 cumulants (essentially, skewness and kurtosis) are also well known; for general definitions see ref. 22 and other standard references, such as McCullagh (23). In general, the mth order joint cumulant tensor of a random variable U ∈ CN is an m-way array Cum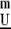 (i1, … , im) with 1 ≤ im ≤ N. If Y is generated in terms of the independent components model Eq. 17 then we have an additive decomposition:
(i1, … , im) with 1 ≤ im ≤ N. If Y is generated in terms of the independent components model Eq. 17 then we have an additive decomposition:
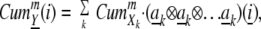 |
where Cum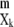 is the mth order cumulant of the scalar random variable Xk. Here (ak ⊗ ak ⊗ … ak) denotes an m-way array built from exterior powers of columns of A:
is the mth order cumulant of the scalar random variable Xk. Here (ak ⊗ ak ⊗ … ak) denotes an m-way array built from exterior powers of columns of A:
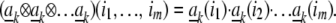 |
Define then a dictionary D(m) for m-way arrays with k-th atom the m-the exterior power of ak: 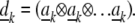 Now let S(m) denote the m-order cumulant array Cum
Now let S(m) denote the m-order cumulant array Cum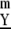 . Then
. Then
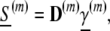 |
18 |
where D(m) is the dictionary and γ̱(m) is the vector of m-order scalar cumulants of the independent components random variable X. If we can uniquely solve this system, then we have a way of learning cumulants of the (unobservable) X from cumulants of the (observable) Y. Abusing notation so that M(D) ≡ M(DHD) etc., we have
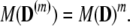 |
In short, if M(D) < 1 then M(D(m)) can be very small for large enough m. Hence, even if the M value for determining a not-very-sparse X from Y is unfavorable, the corresponding M value for determining Cum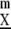 from Cum
from Cum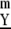 can be very favorable, for m large enough. Suppose for example that A is an N by L system with M(A)= 1/
can be very favorable, for m large enough. Suppose for example that A is an N by L system with M(A)= 1/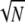 , but X has (say) N/3 active components. This is not very sparse; on typical realizations ∥X∥0 = N/3 ≫
, but X has (say) N/3 active components. This is not very sparse; on typical realizations ∥X∥0 = N/3 ≫ 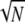 = 1/M. In short, unique recovery of X based on sparsity will not hold. However, the second-order cumulant array (the covariance) Cum
= 1/M. In short, unique recovery of X based on sparsity will not hold. However, the second-order cumulant array (the covariance) Cum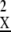 still has N/3 active components, while M(D(2)) = M(D(2))2 = 1/N; as N/3 < 1/2M, the cumulant array Cum
still has N/3 active components, while M(D(2)) = M(D(2))2 = 1/N; as N/3 < 1/2M, the cumulant array Cum is sparsely represented and Cum
is sparsely represented and Cum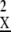 is recovered uniquely by ℓ1 optimization. Generalizing, we have
is recovered uniquely by ℓ1 optimization. Generalizing, we have
Theorem 11.
Consider any coupling matrix A with M < 1. For all sufficiently large m ≥ m*(L, M), the minimum ℓ1 solution of the cumulant decomposition problem (18) is unique (and correct!).
Acknowledgments
Partial support was from National Science Foundation Grants DMS 00-77261, ANI-008584 (ITR), DMS 01-40698 (FRG), and DMS 98-72890 (KDI), the Defense Advanced Research Projects Agency, the Applied and Computational Mathematics Program, and Air Force Office of Scientific Research Multidisciplinary University Research Initiative Grant 95-P49620-96-1-0028.
References
- 1.Mallat S. A Wavelet Tour of Signal Processing. 2nd Ed. London: Academic; 1998. [Google Scholar]
- 2.Chen S S, Donoho D L, Saunders M A. SIAM Rev. 2001;43:129–59. [Google Scholar]
- 3.Coifman R, Meyer Y, Wickerhauser M V. ICIAM 1991, Proceedings of the Second International Conference on Industrial and Applied Mathematics. Philadelphia: Society for Industrial and Applied Mathematics; 1992. pp. 41–50. [Google Scholar]
- 4.Wickerhauser M V. Adapted Wavelet Analysis from Theory to Software. Reading, MA: Addison–Wesley; 1994. [Google Scholar]
- 5.Berg A P, Mikhael W B. Proceedings of the 1999 IEEE International Symposium on Circuits and Systems. Vol. 4. New York: IEEE; 1999. pp. 106–109. [Google Scholar]
- 6.DeBrunner V E, Chen L X, Li H J. IEEE Trans Image Proc. 1997;6:1316–1322. doi: 10.1109/83.623194. [DOI] [PubMed] [Google Scholar]
- 7.Huo X. Ph.D. dissertation. Stanford, CA: Stanford University; 1999. [Google Scholar]
- 8. Starck, J. L., Donoho, D. L. & Candès, E. J. (2002) Astron. Astrophys., in press.
- 9.Ron A, Shen X. Math Comp. 1996;65:1513–1530. [Google Scholar]
- 10.Starck J L, Candès E J, Donoho D L. IEEE Trans Signal Processing. 2002;11:670–684. doi: 10.1109/TIP.2002.1014998. [DOI] [PubMed] [Google Scholar]
- 11.Mallat S, Zhang Z. IEEE Trans Signal Processing. 1993;41:3397–3415. [Google Scholar]
- 12.Chen S S. Ph.D. dissertation. Stanford, CA: Stanford University; 1995. [Google Scholar]
- 13.Donoho D L, Huo X. IEEE Trans Inf Theory. 2001;47:2845–2862. [Google Scholar]
- 14.Elad M, Bruckstein A M. Proceedings of the IEEE International Conference on Image Processing (ICIP) New York: IEEE; 2001. [Google Scholar]
- 15.Elad M, Bruckstein A M. IEEE Trans Inf Theory. 2002;48:2558–2567. [Google Scholar]
- 16.Gill P E, Murray W, Wright M H. Numerical Linear Algebra and Optimization. London: Addison–Wesley; 1991. [Google Scholar]
- 17.Donoho D L, Levi O, Starck J L, Martinez V. Proceedings of SPIE on Astronomical Telescopes Instrumentations. Bellingham, WA: International Society for Optical Engineering; 2002. [Google Scholar]
- 18. Gribonval, R. & Nielsen, M. (2002) IEEE Trans. Inf. Theory, in press.
- 19. Feuer, A. & Nemirovsky, A. (2002) IEEE Trans. Inf. Theory, in press.
- 20.Horn R A, Johnson C R. Matrix Analysis. Redwood City, CA: Addison–Wesley; 1991. [Google Scholar]
- 21.Sloane N J A. Cryptography, Lecture Notes in Computer Science. Vol. 149. Heidelberg: Springer; 1983. pp. 71–128. [Google Scholar]
- 22.Hyvarinen A, Karhunen J, Oja E. Independent Components Analysis. New York: Wiley; 2001. [Google Scholar]
- 23.McCullagh P. Tensor Methods in Statistics. London: Chapman & Hall; 1987. [Google Scholar]