

Abstract
Much contemporary research has suggested that memories for spatial layout are stored with a preferred orientation. The present paper examines whether spatial memories are also stored with a preferred viewpoint position. Participants viewed images of an arrangement of objects taken from a single viewpoint, and were subsequently tested on their ability to recognize the arrangement from novel viewpoints that had been translated in either the lateral or depth dimension. Lateral and forward displacements of the viewpoint resulted in increasing response latencies and errors. Backward displacement showed no such effect, nor did lateral translation that resulted in a centered “canonical” view of the arrangement. These results further constrain the specificity of spatial memory, while also providing some evidence that nonegocentric spatial information is coded in memory.
Egocentric and nonegocentric coding in memory for spatial layout: Evidence from scene recognition
A persistent issue in the study of spatial cognition has concerned the degree to which mental representations of space are specific. On one hand, the perceptual bases for spatial memories are extremely specific: at any given time, the spatial information available from the senses signifies only a particular egocentric experience. On the other hand, humans (and many other mobile organisms) can engage in flexible, unpracticed spatial behavior, such as shortcutting, that appears to be driven by relatively abstract representations of space. To enable these more flexible behaviors, one's specific egocentric experiences must, at some point, be transformed into a more abstract spatial representation. Yet it is an open question whether these transformations occur before or after spatial memories are stored. In the present paper, I provide evidence for specificity in spatial memory, but also evidence for psychological mechanisms that work before storage to transform one's specific experience into a more abstract representation of space.
A great deal of evidence in the past two decades has suggested that memories for space are often – perhaps typically – quite specific. Nearly all of this work has examined orientation specificity – the property by which spatial representations are coded in a specific, preferred orientation. Evidence for orientation specific representations is often used to assess the degree to which spatial memory is based on egocentric experience and coded by means of egocentric reference systems (Shelton & McNamara, 2001). Perhaps more than any other aspect of spatial memory, orientation specificity has been the major characteristic on which current theoretical accounts of spatial representation rely (McNamara, 2003; Mou, McNamara, Valiquette, & Rump, 2004).
Diwadkar and McNamara (1997, Experiment 1) conducted an illustrative experiment that demonstrated the orientation specificity of spatial memory. In this experiment, participants studied an array of objects from a single point of view. They were then asked to recognize photographs of the array that had been taken from a number of different positions on the circumference of an imaginary circle around the array. The central finding was that people required progressively more time to recognize the array as it was depicted from orientations that were progressively more disparate from the orientation of the trained view. This is the pattern of results that would be expected if the orientation of the view shown at training was preferred in memory, and if recognition of other views required mental transformations that matched novel views to the trained view. Very similar conclusions have been reached in other studies that require people either to recognize (Christou & Bülthoff, 1999; Chua & Chun, 2003; Nakatani, Pollatsek, & Johnson, 2002; Shelton & McNamara, 2004a) or recall (Shelton & McNamara, 1997, 2001; Sholl & Nolin, 1997) information about spatial layout.
In all of the aforementioned research, when participants are asked to recognize, recall, or imagine a previously viewed layout from a novel orientation, they are also required to recognize, recall, or imagine the layout from a novel position. In Diwadkar and McNamara's experiment, for example, images that depicted the array from a novel orientation were made by both translating and rotating the camera to different poses around the circumference of the testing space. In most cases, both translations and rotations of the viewpoint are required because, in order to view the entire array from another orientation, it is necessary to change one's position. However, this requirement creates a confound between the degree to which participants must recognize or imagine viewpoints that have been translated (i.e., changed position) and the degree to which they must recognize or imagine viewpoints that have been rotated (i.e., changed orientation). As a result, most conclusions in the literature about orientation specificity must be qualified by the idea that changes in viewpoint position were left uncontrolled.
There is good evidence that accounting for translations of one's viewpoint is faster and easier than accounting for viewpoint rotations (Klatzky, Loomis, Beall, Chance, & Golledge, 1998; May, 2004; Presson & Montello, 1994; Price & Gilden, 2000; Rieser, 1989). Indeed, Rieser (1989) has argued that there is essentially no cost to imagining viewpoint translations. This was demonstrated in a experiment in which people viewed an object array that surrounded them and then were asked, while blindfolded, to point to target objects after imagining either facing another object or translating to another object. Rieser found that, unlike imagined rotations, participants' speed and accuracy with pointing after imagined translations did not vary as a function of the to-be-imagined orientation and was always as fast as pointing from their current position. This finding has been used to argue that even though most tasks used to illustrate orientation specificity involve both imagined viewpoint translations and rotations, the underlying reason for the observed effect of viewpoint transformations derives from difficulties with recognizing or imagining alternative orientations – not with recognizing or imagining alternative positions. (Shelton & McNamara, 1997; Sholl & Nolin, 1997; Tlauka, 2002).
Despite Rieser's (1989) conclusions, there is some evidence to suggest that accounting for changes in viewpoint position can require measurable mental resources. Easton and Sholl (1995) noted that in Rieser's experiment, the distance by which the to-be-imagined viewpoint translated was always constant, and thus the effect of imagined viewpoint translations could not be adequately measured. When Easton and Sholl manipulated the amount of imagined translation, they found a small but significant effect of imagined translation on participants' time and accuracy in making direction judgments. Thus, pointing was faster and more accurate when people imagined that they were at nearby locations (e.g., 0.6 m away) than when they were at relatively distant locations (e.g., 2.7 m away). One of the implications of this result is that spatial memory may be specific not just to a particular orientation, but also to a particular position. For some, this may not be surprising. If, as Shelton (1999) has claimed, spatial memory is truly specific to one's prior experience, we would expect it to be specific to other dimensions of that experience than merely orientation. In this case, it appears that spatial memory may, in addition to being orientation specific, also be position specific1.
The present experiments sought to complement and extend the work of Easton and Sholl (1995) by showing that accounting for viewpoint translations exerts a measurable cost on memory-based performance. Unlike Easton and Sholl's study, which measured spatial memory by means of a pointing task, the present experiments examine participants' ability to recognize scenes. One of the goals of these experiments was thus to generalize the phenomenon of position specificity found by Easton and Sholl to the realm of scene recognition. A second goal, pursued in Experiment 1, was to determine possible effects of the dimension in which viewpoint translation occurs. Thus, Experiment 1 examines recognition performance after both lateral (left/right) and depth (front/back) displacements of the viewpoint. Experiment 2 replicates the central findings of Experiment 1 using rapid presentation of the stimuli. Experiments 3 and 4 examine the effect of viewpoint translations when people train on a view of the layout that is translated laterally from center.
Experiment 1
In Experiment 1, participants were shown a layout of objects from one viewpoint and were subsequently asked to recognize the layout from views that had been translated in either the lateral or depth dimension. Based on Easton and Sholl's (1995) findings, it was anticipated that scenes shown from viewpoints that had been displaced in the lateral dimension would be recognized more slowly and less accurately than scenes shown from the viewpoint position presented during training.
Predictions for scene recognition after displacement of the viewpoint in depth were based on the phenomenon of boundary extension that has been demonstrated and investigated by Intraub and her colleagues (Intraub & Berkowits, 1996; Intraub & Bodamer, 1993; Intraub, Gottesman, & Bills, 1998; Intraub, Gottesman, Willey, & Zuk, 1996; Intraub & Richardson, 1989). Boundary extension refers to the tendency for people to remember areas beyond the edges of a scene depicted in a photograph. Intraub and her colleagues have shown convincingly that this tendency is the result of a distorted memory for one's experience during the learning of the picture. A virtually equivalent way to conceptualize the phenomenon of boundary extension is as memory for a scene that is displaced behind the original position of the viewpoint. Such displacement serves to reduce the visual extent of the learned layout and to increase the space around the center of the scene. If what is stored in memory is similar to a view of the scene that has been displaced backwards, then we might expect recognition accuracy and latency for viewpoint displacements backwards in depth to show little or no effect of viewpoint displacement. Indeed, the effect of boundary extension implies that it may actually be easier to recognize backwards-displaced views than views presented during training. On the other hand, views of a scene from a position that has been displaced in the forward direction would differ more substantially from what is stored in memory. We expected that such views would require additional time to recognize and would be more subject to errors than would recognition of the view presented during training.
Method
Participants. Twenty-eight undergraduate students (14 men and 14 women) from Miami University participated in the experiment in return for credit in their introductory Psychology course. Mean age of the participants was 19.5 years (SD = 0.8).
Materials. As depicted in Figure 1, stimuli were color digital photographs of an array of small toys that had been laid-out on a uniform black tile floor. The array was photographed at ground-level, from nine different viewpoint positions (see Figure 2). At each of these positions, the orientation of the camera was aligned with the training view. The nine viewpoint positions consisted of a central location (the training viewpoint) that was positioned 39.6 cm from the center object in the array, four positions that spanned the lateral dimension of the array (3 and 6 cm to the left of the training view and 3 and 6 cm to its right), and four positions that varied along the depth dimension (7 and 14 cm in front of the training view, and 7 and 14 cm behind it). Intervals between the viewpoint positions were chosen such that, even at the most extreme deviations from the training view, all of the toys were clearly visible in each photograph.
Figure 1.

Target stimuli for Experiments 1 – 3. The center photograph depicts the learned view in Experiments 1 and 2. Images on the far-left and far-right were also learned in Experiment 3. Stimuli arranged horizontally depict views of the layout resulting from lateral displacement of the viewpoint. Those arranged vertically represent changes of the viewpoint in depth. (Unlike this reproduction, the stimuli were displayed in color.)
Figure 2.
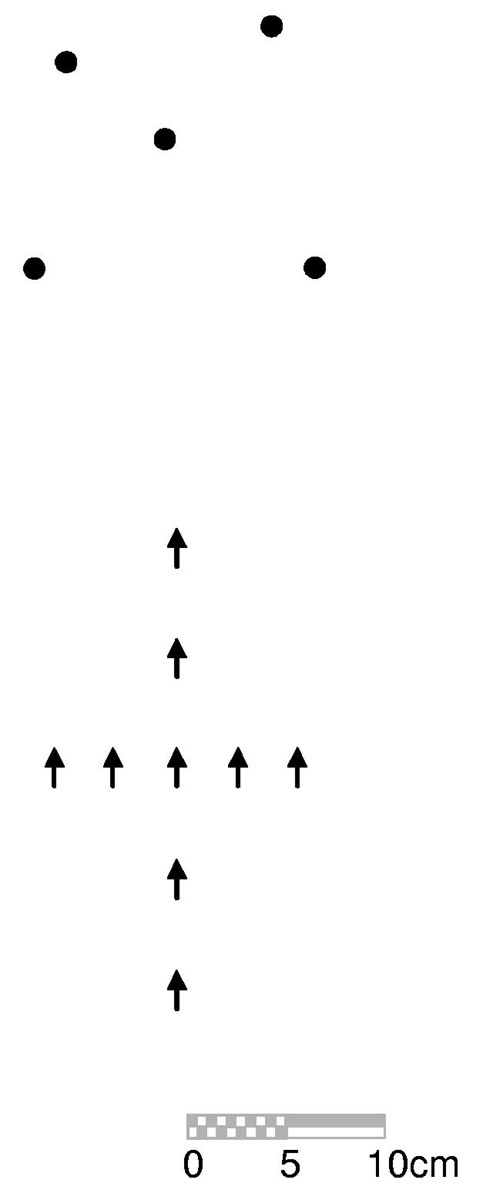
Schematic plan view of the stimulus arrangement and camera placements in Experiments 1 - 3. Locations of the stimuli are represented by circles. Camera positions (and orientations) are indicated by arrows.
At each of the nine viewpoint positions, eleven photographs were taken. One of the eleven photographs was a target stimulus, and portrayed the correct, to-be-learned arrangement of the toys. The other photographs were distractors, and portrayed the ten possible arrays that could be formed by switching the positions (not the orientations) of two of the toys.
Presentation of the stimuli and collection of participants' responses was controlled through a computer using EPrime experiment generating software from Psychological Software Tools. Stimuli were presented on a 32.5 cm × 24 cm CRT monitor (85 Hz. refresh rate). Participants responded by pressing buttons on a response box connected to the serial port of the computer.
Procedure. Participants were run individually through the experiment. After being given a brief description of the experiment, the participant sat at the computer and read detailed task instructions. These instructions informed participants that they would be viewing many different arrangements of toys and that one particular arrangement was “correct.” They were instructed to press a green button labeled “Correct” if the arrangement was correct, and a red button labeled “Incorrect” otherwise. Participants were also told that a randomized half of the pictures depicted the correct arrangement and that the other half were incorrect.
During training, participants were shown only the eleven photographs from the training viewpoint (see Figure 1 - center), and were required to distinguish the target photograph from the ten distractors. Participants received feedback over headphones during training. The feedback message said “two points” if they were correct and answered in less than one second, “one point” if they were correct and answered in one second or more, or “wrong” if they were incorrect. Participants were told that, initially, they must guess about which arrangement was the target, but that once they had determined which scene was the correct arrangement they should respond as quickly and as accurately as possible. They were told that the feedback would stop partway through the experiment, but that they would still receive points for correct responses and none for wrong responses. (This point system had no tangible consequences for participants and was used solely to increase their motivation to perform the task efficiently.)
Each training trial began with a warning beep for one second, followed immediately by the presentation of the stimulus. The stimulus was displayed continuously until the participant responded, at which time it disappeared. There was a one second delay before the feedback message was played, and then a 250 ms delay before the next trial. Trials for the testing portion of the experiment were identical to training trials, except there was no feedback message.
Training trials were administered in blocks of 20. In each block, the ten distractors were each presented once, and the target was presented ten times. The presentation order of targets and distractors was randomized within each block, and separately for each participant. Participants were required to complete at least two training blocks. If accuracy exceeded 80% in the second or any subsequent training block, then the participant proceeded to the testing portion of the experiment. Participants were told immediately before testing that they would be asked to recognize pictures of the layout that had been taken from different places. They were reminded that their task was to recognize the correct layout of objects, regardless of where the viewpoint was.
Testing consisted of 180 trials, composed of 90 target stimuli and 90 distractors. Each target arrangement for each of the nine viewpoint positions was presented ten times. The order of these 180 trials was randomized separately for each participant. Testing trials were presented in nine blocks of 20 trials. Very short breaks (i.e., ten seconds) between these blocks were encouraged in order to allow participants time to relax and refocus their attention.
Design. In all experiments reported in this paper, gender and response assignment (i.e., left button = correct vs. right button = correct) were counterbalanced across participants. After averaging over these factors (neither of which ever had a significant effect or a significant interaction with any other factor), Experiment 1 represents a 2 (dimension: lateral vs. depth) × 5 (displacement: far-negative, near-negative, zero, near-positive, and far-positive) within-subjects design. An unusual aspect of this experiment is that, because the training view is not displaced in either the lateral or the depth dimension, stimuli presented from the training view occupy two cells of the design (zero/lateral, and zero/depth). To ensure that each cell contained independent observations, for each participant, five (every other one) of the ten responses to target stimuli shown at test were assigned to either the zero/lateral or the zero/depth cell of the design.
Results
In general, recognition accuracy for targets was high, averaging 97.18% (SD = 2.47) across all participants. Nonetheless, there was a large (η2 = 0.51) and significant effect on accuracy of displacement from the trained view. As Figure 3 illustrates, accuracy declined from a mean of 99.29% (SD = 2.62) at the trained view steadily down to a mean of 95.63% (SD = 4.23) at the most extreme displacements. This effect was particularly pronounced in the lateral dimension. In the depth dimension, accuracy for target views displaced behind the training view (M = 98.75%, SD = 2.59) was nearly as high as for the trained view.
Figure 3.

Mean reaction times and accuracy for recognition of target stimuli in Experiment 1. Error bars represent 95% within-subject confidence intervals (Loftus & Masson, 1994).
These effects were confirmed in a 2 × 5 repeated measures ANOVA with factors for dimension (lateral vs.depth) and displacement (far negative, near negative, zero, near positive, and far positive). Participants' relatively greater accuracy for translations in depth compared to that for translations in the lateral dimension rendered the effect of dimension significant (F(1, 27) = 5.29, p = .029). More importantly, the trend for accuracy to decrease with distance from the trained view rendered the effect of displacement significant (F(4, 24) = 5.82, p = .002). The interaction between dimension and displacement was not significant (F(4, 23) < 1). Tests of simple main effects of displacement at each dimension revealed significant quadratic trends in both the lateral (F(1,27) = 20.45, p < .001), and depth (F(1,27) = 4.84, p = .037) dimensions, indicating highest accuracy at the training position and reduced accuracy with displacement away from the training position.
Recognition accuracy for distractor stimuli was uniformly high, and there was no evidence for a differential response bias across views. In the lateral dimension, false alarm rates averaged 5.36% (SD = 4.80) for far-displaced scenes, 5.36% (SD = 4.75) for near-displaced scenes, and 4.82% (SD = 5.00) for the trained scene. In the depth dimension, false alarm rates averaged 6.07% (SD = 5.35) for far-displaced scenes and 4.73% (SD = 4.32) for near-displaced scenes. Neither the dimension of the displacement (F(1,27) < 1), the amount of displacement (F(4,24) = 1.92, p =.14), nor their interaction (F(4,24) < 1) affected participants' false alarm rate.
Additional analyses examined response times (RTs) for correctly identified targets. Mirroring the trend for accuracy, these RTs increased steadily for views further away from the trained view; however, this trend was qualitatively different in the lateral dimension than in the depth dimension (see Figure 3). In the lateral dimension, recognition RTs ranged from a mean of 1102 ms (SD = 367) for the trained view to a mean of 1341 ms (SD = 445) for the extreme left and right views. On the other hand, views from behind the training view were recognized as quickly – or nearly as quickly – as the training view itself (M = 1102 ms, SD = 373 for the trained view, M = 1100 ms, SD = 277 for the view 7 cm behind, and M = 1138, SD = 297 for the view 14 cm behind.) Visual inspection of the data in Figure 3 suggested that a slow-rising quadratic trend (represented by the −2, −2, −2, 3, 3 contrast) best summarized the effect of displacement in the depth dimension, whereas a U-shaped trend (tested with the 2, −1, −2, −1, 2 contrast) best represented the effect of displacement in the lateral dimension.
These effects were confirmed in a 2 × 5 repeated measures ANOVA on RTs with factors for dimension (lateral vs. depth) and displacement (far negative, near negative, zero, near positive, and far positive). The ANOVA revealed a significant effect of displacement (F(4, 24) = 8.18, p < .001) and a significant interaction between displacement and dimension (F(4, 24) = 3.89, p = .014). The strongest contrasts testing for effects of displacement were those suggested above. Although the general nature of these effects had been predicted, the actual contrast weights were determined after having inspected the data, and were thus tested through post-hoc Scheffé tests. Based on these tests, the simple U-shaped quadratic trend for the effect of displacement was significant in the lateral (F(1, 27) = 26.03, p < .01), but not the depth dimension (F(1,27) = 7.66, p > .05). Conversely, the slow-rising quadratic contrast was significant in the depth dimension (F(1, 27) = 17.11, p < .05), but not in the lateral dimension (F(1, 27) = 4.25, p > .05).
Discussion
People were slower and less accurate recognizing views of a scene that were slightly displaced (either laterally or forward in depth) from the view on which they were trained. In conjunction with the existing body of evidence showing that spatial memory is typically orientation specific, this finding suggests that spatial memory may be further described as being position specific. The orientation of the depicted viewpoint for all stimuli in this experiment was constant. Nonetheless, there was a clear and significant effect of deviations from the trained view on recognition accuracy and latency. In this experiment, the most extreme deviations from the trained view required approximately 240 additional milliseconds to recognize. In other experiments, the effect of extreme orientation changes of the viewpoint was approximately 300 ms to recognize an array with six objects (Diwadkar & McNamara, 1997) and approximately 700 ms to recognize an array with seven objects (Shelton & McNamara, 2004a). Although the effect of position changes in the present experiment may be smaller than that of orientation changes in other experiments, it is clearly not negligible, and is large enough to warrant further scrutiny.
The strongest effect of viewpoint displacement was in the lateral dimension. Such viewpoint displacements produce small changes in the appearance of the array. These changes primarily consist of alterations in the projected inter-object distances and relative directions, and typically result in slightly different parts of the scene being occluded (see Figure 1). Although these changes are relatively subtle, people were clearly sensitive to them because they required more time to judge whether the depicted scene matched the scene on which they had been trained. These results add support to the findings of Easton and Sholl (1995), who showed that errors and latencies in pointing judgments from imagined locations were affected by the amount of imagined translation.
The symmetric effect of viewpoint displacement in the lateral dimension was significantly different from its asymmetric effect in the depth dimension. Although views of a scene that had been displaced forward from the trained view required additional time to judge, views that had been displaced backward were recognized as quickly and accurately as was the trained view. This effect is consistent with the phenomenon of boundary extension that has been explored by Intraub and her colleagues (Intraub & Berkowits, 1996; Intraub & Richardson, 1989). If, as Intraub's research suggests, participants stored an image of the scene with a wider field of view than was presented during training, this image would be virtually identical to a view of the scene from farther away than what was presented. Participants would thus readily recognize views of the scene displaced backwards from the training view because these views more closely match an image of the scene in memory. From a methodological point of view, it is important to note that, to date, boundary extension has been studied using primarily explicit ratings or reproductions of a remembered scene boundary or hand-drawn scene reconstructions. The present experiment illustrates that this phenomenon can also be effectively demonstrated (and hence investigated) in a recognition paradigm in which scene boundaries are not an aspect of the participants' task. Attributes of people's memory of a scene thus implicitly affect recognition judgments that are more general than those of scene boundaries.
Despite the clarity of most of the present results, one aspect of the method of Experiment 1 enables an alternate interpretation of these conclusions. During testing, the stimulus was available to participants to view constantly, until they decided whether it was a target. It is possible that increased response times for the displaced viewpoints were thus primarily a result of additional scanning time required by participants to view the entire stimulus. For example, if, during training, participants had learned to fixate at the center of the monitor to acquire information about the array, they would, during testing, be required to fixate on other locations in order to acquire the same information. The change in fixation locations would vary directly with the displacements of the viewpoint that we manipulated, and might thus confound our conclusions.
Experiment 2
Experiment 2 was designed to test the hypothesis that the effect of viewpoint position in Experiment 1 occurred because participants required additional scanning time to view the stimuli that depicted a viewpoint translation. Before presentation of each stimulus, a fixation cross was displayed at the location of the center of the to-be-displayed array. The stimulus was then displayed for 250 ms. Although the duration of the stimulus allowed enough time for participants to fixate on the array and to acquire spatial information about it, it did not allow participants to scan the array and make multiple fixations (Salthouse & Ellis, 1980). If the effects shown in Experiment 1 were primarily the result of visual scanning, then there should be no effect of viewpoint displacement in Experiment 2, in which visual scanning is not possible.
Because the most robust and symmetrical effect of viewpoint displacement in Experiment 1 was found in the lateral dimension, Experiments 2 through 4 manipulated viewpoint displacement only in this dimension.
Method
Participants. Twenty undergraduate students (10 men and 10 women) from Miami University participated in the experiment in return for credit in their introductory Psychology class. Mean age of the participants was 19.3 (SD = 0.9).
Materials. Materials for Experiment 2 were identical to those for Experiment 1 with the exception that only the 55 photographs from viewpoint positions involving lateral viewpoint displacements were used.
Procedure. The procedure for Experiment 2 was identical to that of Experiment 1 with the exception of a new method of presenting the stimuli on test trials. On each test trial, a fixation cross appeared for one second immediately after the warning beep. This fixation cross was presented on the screen at the exact location of the center of the to-be-presented object array. Immediately after the fixation cross disappeared, the stimulus was presented for 250 ms. Participants were warned immediately before testing that the stimuli would be presented much more rapidly than they had been in training, and that the fixation cross would indicate where to focus their attention.
Participants completed 100 trials during testing. These trials consisted of 50 target trials (ten replications of each of the five target views) and 50 distractor trials (each of the ten distractors from each of the five viewpoint positions).
Results and Discussion
As Figure 4 shows, recognition accuracy for targets was high (M = 91.40%, SD = 9.19), although not as high as in Experiment 1. The trained view was correctly recognized most frequently (M = 97.44%, SD = 5.59), with accuracy decreasing to a mean of 91.05% (SD = 13.86) for the views displaced laterally 3 cm from the training view and decreasing further to 88.92% (SD = 12.01) for views displaced by 6 cm. The effect on accuracy of displacement from the trained view was tested in a one-way repeated measures ANOVA, which revealed a significant effect of displacement (F(4, 16) = 4.89, p = .009). The test of the quadratic trend of displacement on accuracy was also significant (F(1, 19) = 9.13, p = .007).
Figure 4.

Mean reaction times and accuracy for recognition of target stimuli in Experiment 2. Error bars represent 95% within-subject confidence intervals (Loftus & Masson, 1994).
Recognition accuracy for distractors was also high, although not as high as in Experiment 1, and there was no evidence for a differential response bias across views. False-alarm rates were 8.60% (SD = 8.09) for the far-left displaced scenes, 9.60% (SD = 8.98) for the near-left displaced scenes, 7.49% (SD = 6.66) for the centered scenes, 7.45% (SD = 6.69) for the near-right displaced scenes, and 8.57% (SD = 6.74) for the far-right displaced scenes. Differences in false alarm rates among the tested views were not significant (F(4, 16) < 1).
An effect of displacement was also found in RTs to correctly answered targets. Overall, the mean RT to these stimuli was 1020 ms (SD = 611). On average, the training view was correctly recognized in 911 ms (SD = 572), with near targets averaging 1026 ms (SD = 662) and far targets averaging 1076 (SD = 672). The effect on RT of displacement from the trained view was tested in a one-way repeated measures ANOVA, which revealed a significant effect of viewpoint displacement (F(4, 16) = 4.47, p = .013), much of which was accounted for by a significant quadratic trend (F(1,19) = 4.79, p = .041). Figure 4 illustrates this effect.
This experiment closely replicated the results of Experiment 1 and in so doing, effectively eliminates the hypothesis that increases in reaction time in Experiment 1 were due to the added time available for visual scanning of the stimulus. In Experiment 2, it was not possible for participants to spend time visually scanning the stimuli; however, the same effect of viewpoint displacement was observed. Together, Experiments 1 and 2 establish a clear effect of viewpoint displacement on recognition accuracy and latency.
Experiment 3
In Experiments 1 and 2, participants viewed a layout of objects depicted from a central viewing position and were tested on scenes that were progressively displaced from this central view. Because the training view was always centered, its composition was balanced, with objects on both the left and right portion of the scene. On the other hand, the views that participants were asked to recognize during testing, especially at extreme lateral displacements, were less balanced, with relatively more objects on either the left or right sides of the scene. It is possible that in these experiments, the relative ease with which participants recognized the training view at testing did not derive principally from its having been experienced during training, but rather because it was a centered, balanced view. When people recognize real-world objects, for example, it is known that views providing a canonical perspective of an object are judged more accurately and rapidly than views that provide other perspectives (Newell & Findlay, 1997; Palmer, Rosch, & Chase, 1981; see also Gibson & Peterson, 1994). Moreover, canonical views are easily recognized even after people are exposed to many non-canoncial views (Ashworth & Dror, 2000; Murray, 1999; O'Reilly & Friedman, 2005). If the centered, balanced scene on which participants trained in Experiments 1 and 2 is analogous to a canonical view of an object, then it is possible that training on a “non-canoncial” laterally displaced view will lead to different effects from those found in Experiments 1 and 2.
In Experiment 3, different groups of participants viewed the object array from either a centered viewpoint position or a laterally displaced viewpoint position. All participants were subsequently asked to recognize both centered and displaced views of the scene. Testing stimuli were identical for both conditions, so that participants who were trained on the centered view tested on stimuli representing left and right lateral displacements, while participants who trained on a displaced view tested both on stimuli that were centered and displaced in the direction opposite to that on which they trained. If the effect of viewpoint displacement found in Experiments 1 and 2 arose because participants specifically encoded a centered view, then we would expect recognition performance at test in both training conditions to be better for the centered views than the displaced views. Alternatively, if the effect found in the previous experiments arose because participants encoded a specific memory of the trained view, then their performance at test should be facilitated for the trained view, regardless of whether it is centered.
Experiment 3 also introduced a mask that was presented immediately after each testing stimulus. The rationale for including this mask was similar to that for having introduced a very brief stimulus presentation in Experiment 2. Performance after the brief stimulus presentation in Experiment 2 served rule out the hypothesis that the effect of viewpoint displacement arose because of the time needed to scan the stimulus. Similarly, the backwards mask used in Experiment 3 will ensure that the effect of displacement does not occur because participants scan an image held in their sensory store (Averbach & Coriell, 1961; Sperling, 1960).
Method
Participants. Fifty-four undergraduate students (26 men and 28 women) from Miami University participated in the experiment in return for credit in their introductory Psychology class. Six participants (two men and four women) exhibited very low (below 60%) overall accuracy at test, and their data were not included in the analyses reported here. The final sample thus consisted of forty-eight participants (24 men and 24 women). Mean age of the participants was 19.2 (SD = 1.5).
Materials. Materials for Experiment 3 were identical to those for Experiment 2 with two exceptions. First, only 33 stimuli were used (11 from each of the far lateral displacements, and 11 from the center). Second, a backwards mask was displayed during each test trial. The mask was created by randomly scrambling 192 equally-sized areas (50 × 50 pixels) of the centered target stimulus.
Procedure. The procedures for Experiment 3 were identical to those of Experiment 2 with the following exceptions. Participants were randomly assigned to one of two training conditions. Half of the participants were trained on the centered scene, and the other half were trained on a scene that was displaced either to the far left (n = 13) or to the far right (n = 11).
Participants completed 60 trials during testing. These trials consisted of 30 target trials (ten replications of each of the three target views) and 30 distractor trials (each of the ten distractors from each of the three viewpoint positions). On each test trial, the stimulus was replaced after 250 ms with the mask, which was displayed until participants entered their response.
Results and Discussion
Within the group of participants who trained on a displaced scene, the direction of displacement (left or right) did not have an effect on performance, nor did it interact with other factors. Data from participants who trained on the left-displaced and the right-displaced scenes were thus combined into one group.
As depicted in Figure 5, mean accuracy for target stimuli for participants who trained on the centered scene replicated the pattern found in previous experiments, falling from a mean of 88.75% (SD = 12.27) for the trained scene to a mean of 79.17% (SD = 14.87) for the scenes with the displaced viewpoint. This pattern was qualitatively different for participants who trained on the scene from a displaced viewpoint. For these participants, accuracy was high for both the trained view (M = 90.83%, SD = 12.83) and the centered view (M = 89.58%, SD = 12.68), and dropped to a mean of 80.00% (SD = 24.14) for the non-trained displaced view. These effects were tested in a 2 (trained scene: centered or displaced) × 2 (tested scene: centered or displaced) ANOVA with repeated measures on the second factor. (Because the centered training group could not be tested on views that had been displaced as far as some of the tested views for the displaced group, the data from the non-trained displaced view for the displaced training group were not included in the analysis.) This analysis revealed a significant main effect of training condition (F(1, 46) = 4.34, p = .043) which was moderated by a significant training by testing interaction (F(1, 46) = 5.33, p = .026). Analyses of the simple main effects of tested scene revealed a significant effect of tested scene for the centered training group (F(1, 23) = 5.57, p = .027). The simple main effect of tested scene was small (f = 0.06) and not significant for the displaced training group (F(1, 23) < 1). (The power to detect this effect is discussed in Experiment 4, after pooling data from Experiments 3 and 4).
Figure 5.

Mean reaction times and accuracy for recognition of target stimuli in Experiment 3. Error bars represent 95% within-subject confidence intervals (Loftus & Masson, 1994).
Recognition accuracy for distractor scenes was generally high, and there was no evidence for a differential response bias across views. For participants who trained on the centered scene, false-alarm rates were 13.13% (SD = 8.18) for the centered scene and 11.98% (SD = 6.76) for the displaced scene. For participants who trained on the displaced scene, false-alarm rates were 14.38% (SD = 8.64) for the centered scene and 12.92% (SD = 8.46) for the displaced scene. Neither the trained scene (F(1, 46) < 1), the tested scene (F(1, 46) <1), nor their interaction (F(1, 46) <1) affected false alarm rates.
Further analyses examined RTs to correctly-answered targets, which are also illustrated in Figure 5. Response times for participants who trained on the centered view rose from a mean of 899 ms (SD = 436) for the trained view to a mean of 1075 (SD = 540) for the displaced view. This increased time to recognize a non-trained view was not as large in the group who trained on the displaced view. For these participants, RTs were comparable between the trained (M = 972, SD = 533) and centered (M = 1026, SD = 524) views, while the non-trained displaced view required more time to recognize (M = 1108, SD = 457). These effects were tested in a 2 (trained scene: centered or displaced) × 2 (tested scene: centered or displaced) ANOVA with repeated measures on the second factor. The only significant effect from this analysis was the training by testing interaction (F(1, 46) = 4.37, p = .042). Analyses of the simple main effects of tested scene revealed a significant effect of tested scene for the centered training group (F(1, 23) = 6.69, p = .016). The simple main effect of tested scene was small (f = 0.07) and not significant for the displaced training group (F(1, 23) < 1). (The power to detect this effect is also considered in Experiment 4, after pooling data from Experiments 3 and 4).
Experiment 3 again replicated the effect of viewpoint displacement found in Experiments 1 and 2. Participants who trained on the centered view of the array had greater error and longer recognition times for views that were displaced from the view on which they trained. Interestingly, though, participants who trained on the displaced view recognized both their trained view and the centered view with comparable efficiency. This result was unexpected, and suggests that the contents of spatial memory can be affected by the degree to which the training view is centered or well-composed. In particular, these data are consistent with the hypothesis that, in addition to storing a view of the scene during training, participants also store a centered, balanced view in memory. This hypothesis is elaborated more fully in the General Discussion, after replicating this effect in Experiment 4.
Experiment 4
The finding that people who trained on a scene that was depicted from a displaced viewpoint showed comparable performance on both the trained and centered scenes was unanticipated. Before drawing conclusions and interpreting these results in terms of underlying memory structures, it was important to replicate this finding. Experiment 4 sought to replicate this effect with a different group of participants, a different type of stimulus, and a different object arrangement. Because the effect of viewpoint displacement from a centered training view had been established and replicated twice in Experiments 1 - 3, Experiment 4 examined only the effect of displacement from a non-centered training view.
The new stimuli afforded the opportunity to generalize these findings in one additional way. In Experiment 4, instead of a real-world scene, the stimulus array was a computer-modeled environment. Transferring the stimulus layout to a computer model allowed extremely precise control over the object and viewpoint positions and orientations. Thus, small imperfections in the real-world digital photographs of Experiments 1 through 3 were eliminated. The increased control over the stimulus array and the viewing parameters came at the expense of creating stimuli that did not appear to be true real-world scenes. However, if the results of the previous experiment can be replicated with stimuli that are derived from computer models, this will further demonstrate the robustness of these effects.
Method
Participants. Thirty-three undergraduate students (17 men and 16 women) from Miami University participated in the experiment in return for credit in their introductory Psychology class. One participant correctly recognized fewer than 60% of the stimuli at test, and his data were not included in subsequent analyses. The final sample thus consisted of thirty-two participants (16 men and 16 women). Mean age of the participants was 19.0 (SD = 1.4).
Materials and Procedure. The stimuli for Experiment 4 consisted of 33 color digital images (three targets and 30 distractors) of a playground containing five objects (see Figure 6). The center of each of the five objects was equidistant from the center of the scene, on the vertex of an invisible regular pentagon with a radius (center to vertex) of 11.90 units. Although arbitrary, these units roughly corresponded to meters. The stimuli were generated from a 3-D computer model using 3-D Studio Max®, and employed lighting effects, shadows, and textures to enhance the realism of the scene.
Figure 6.

The centered target layout used in Experiment 4. (Unlike this reproduction, the stimuli were displayed in color.)
The centered viewpoint position was 40.00 units from the center of the scene. Other stimuli depicted viewpoints displaced laterally 8.80 units to both the left and right. For all stimuli, the orientation of the viewpoint was constant. In conjunction with a viewing angle of 70.00 degrees, these viewpoint positions ensured that each object was fully visible in each scene. As with the previous experiments, the 30 distractors consisted of all possible combinations of pairwise switches between two objects' positions.
The procedures for Experiment 4 were identical to those for Experiment 2 with the exception that participants were randomly assigned to one of two training conditions. Half of the participants viewed the scene from a right-displaced viewpoint during training; the other half trained on a left-displaced view. Participants completed 60 trials during testing, consisting of 30 target trials (ten replications of each of the three target views) and 30 distractor trials (each of the ten distractors from each of the three viewpoint positions).
Results and Discussion
The direction of displacement (left or right) of the trained scene did not have an effect on participants' performance; nor did it interact with other factors. Data from participants who viewed the left-displaced and the right-displaced scenes during training were thus combined into one group.
As depicted in Figure 7, mean accuracy on target stimuli was comparable for the trained (M = 94.37%, SD = 9.82) and centered (M = 91.56%, SD = 10.51) views, both of which were higher than the non-trained displaced view (M = 74.69%, SD = 24.49). The effect of displacement on accuracy was examined by orthogonal contrasts in a oneway repeated measures ANOVA. The first contrast (1, −1, 0) compared accuracy for trained views with that of centered views. This effect was small (f = 0.10) and was not significant (F(1, 31) = 1.26, p = .271). The second contrast (1, 1, −2) compared the accuracy for the trained and centered views with that for the non-trained displaced views. This contrast was significant (F(1,31) = 19.24, p < .001).
Figure 7.

Mean reaction times and accuracy for recognition of target stimuli in Experiment 4. Error bars represent 95% within-subject confidence intervals (Loftus & Masson, 1994).
False-alarm rates were 11.88% (SD = 7.80) for the centered scenes, 10.62% (SD = 8.68) for the near-displaced scenes, and 10.31% (SD = 9.06) for the far-displaced scenes. Differences in false alarm rates among the tested views were not significant (F(2, 30) < 1), providing no evidence for a differential response bias across views.
Additional analyses examined RTs to correctly-answered targets, which are also illustrated in Figure 7. Response times for trained (M = 654, SD = 272) and centered (M = 712, SD = 417) views were comparable, and both were faster than the mean RT for the non-trained displaced view (M = 910, SD = 594). The effect of displacement on RT was examined by orthogonal contrasts in a oneway repeated measures ANOVA. The contrast comparing accuracy for trained views with that of centered views revealed a small (f = .09) effect that was not significant (F(1, 31) = 1.41, p = .244). The contrast that compared the accuracy for the trained and centered views with that for the non-trained displaced views was significant (F(1,31) = 13.01, p = .001).
Because these results did not differ qualitatively from those of Experiment 3, data from the displaced training condition of Experiment 3 (n = 24) were combined with the data from Experiment 4 (n = 32) as well as the data from a pilot experiment (n = 22) for Experiment 3 that is not reported, but which also yielded similar results and identical conclusions. The combined data sets still failed to reveal a difference between accuracy (t(77) = 1.38, p = .172) or latency (t(77) = 1.63, p = .108) between a displaced trained view and a centered untrained view. To determine the power of these tests, effect sizes were calculated from Experiments 1 – 3 from participants who had trained on a centered view. The average effect size across these experiments was large for both accuracy (f = .43) and RT (f = .41). The power of the combined data sets to detect effects this large was estimated at .96 for accuracy and .95 for RTs (αtwo-tailed = .05).
This experiment effectively replicated the results of Experiment 3 in showing that after viewing a scene from a position that is displaced from the center, subsequent recognition of the scene is relatively fast and accurate from both the trained viewpoint and from an untrained but centered viewpoint. By generalizing this result to a different stimulus arrangement and to a different class of stimuli, these results provide promising evidence for the role of computer-generated stimuli in addressing these effects.
General Discussion
Contemporary research in spatial cognition has reached a general consensus that memory for spatial layout can be quite specific, and that spatial information is typically represented with a preferred orientation (McNamara, 2003; Roskos-Ewoldsen, McNamara, Shelton, & Carr, 1998; Shelton & McNamara, 1997, 2001; Sholl & Nolin, 1997; Waller, Montello, Richardson, & Hegarty, 2002). The present findings augment what is known about the specificity of spatial memory by suggesting that, in addition to being orientation-specific, recognition memory (for well-learned centered views) is also position-specific. In the same way that one requires additional time to recognize or imagine views with orientations that are different from what has been experienced, so it can also take time to account for views of a layout from positions that are different than that from which the layout was viewed. Importantly, though, these experiments have highlighted two apparent exceptions to the idea that a previously experienced view is easier to recognize than an unexperienced view. First, Experiment 1 showed that people recognized scenes from viewpoint positions that had been displaced backwards from the training position as quickly and accurately as they recognized the trained scene. Second, in Experiments 3 and 4, when the training view was uncentered, both the training view and the un-trained centered view were recognized with comparable efficiency. How can we interpret this combination of results?
Theoretical accounts of the effect of viewpoint orientation typically maintain that performance is enhanced at particular orientations because these are the orientations that are “preferred” – perhaps because they are stored – in memory (McNamara, 2003; Shelton & McNamara, 2001). Recognizing (or otherwise recovering) views that are not preferred requires processing time and is subject to errors. By the same logic, the current results suggest that the viewpoint positions that are preferred in memory are both those that are experienced and those that provide a centered, balanced view of the layout. The implications of each type of viewpoint – experienced and centered – will be discussed separately.
Implications of the facilitation in recognizing experienced views
In all of these experiments, the views that were experienced at training were generally recognized more efficiently than any others. This finding illustrates the importance of an individual's own experience in representing spatial information. Indeed, it is remarkably easy to conceptualize the nature of spatial memory in Experiments 1 and 2 as merely a “snapshot” of one's experience during training. The ease with which memory systems deal with the specific instances of one's own experience has led several researchers to conclude that in many circumstances, spatial information is organized by means of its relations to the viewer. Such a system of relations has been variously called in the literature an “egocentric reference system” (Shelton & McNamara, 2001; Wang, 2000), a “self-to-object system” (Easton & Sholl, 1995), or a “taxon system” (O'Keefe & Nadel, 1978). In all of these cases, spatial information is coded in and through its relationships to the individual. The present experiments, by demonstrating that a specific, previously experienced viewing location is facilitated in recognition, further add to the emerging consensus that spatial information is often – perhaps typically – coded by means of egocentric reference systems.
One apparent exception to the idea that spatial memory is organized around one's specific egocentric experience involved the finding from Experiment 1 that people recognized views of a layout from un-trained backwards-displaced viewpoint positions as efficiently as they recognized views that were displayed during training. With the present data, however, it is difficult to conclude that this finding truly represents an instance of non-specificity or non-egocentrism in spatial memory. Recall from the discussion of Experiment 1 that the finding of relative facilitation for backwards-displaced views was interpreted in the context of “boundary extension,” (Intraub & Berkowits, 1996; Intraub & Richardson, 1989). According to the boundary extension literature, participants in the present experiments would have encoded a view of the layout that had wider boundaries than those that were actually presented. Thus, the memory representation of the layout was essentially a backwards-displaced view. Subsequent recognition performance could still have been based on a specific egocentric experience, but merely an experience that had been biased to represent spatial information with a wider boundary. Thus, the finding of relative efficiency at recognizing backwards-displaced views in Experiment 1 is not necessarily evidence against the notion that recognition performance was based on a specific egocentric experience. In this case, one's specific egocentric experience at learning was simply not entirely veridical.
If, as suggested above, the spatial memory used after training on a centered scene amounted to little more than a “snapshot” of one's experiences during training, it seems quite possible that such a memory would not represent the 3D spatial structure of the depicted scene, but would merely code the 2D projection of that scene that the participants viewed. Based on such a representation, scene recognition after training on a centered scene may thus have consisted primarily of visual image matching – comparing the degree to which 2D images at test appeared to be similar to a remembered 2D image. This speculation is consistent with the recent work of Shelton and McNamara (2004b), who suggested that the memory system used for scene recognition may be distinct from the system that supports directional judgments in the environment. Shelton and McNamara call the former system the “visual memory system” and suggest that its purpose is to store images of the visual appearance of the environment. Described in this way, it is quite plausible that a visual memory system need not labor to construct a full-blown 3D model of the spatial structure of the environment, but can instead operate effectively on 2D images. That the resources used by this system do not capture the full richness of the environment does not limit their importance or effectiveness in understanding complex spatial behavior. Mental transformations on simple 2D images can enable quite flexible and sophisticated performance on navigation (Cartwright & Collett, 1983; Franz, Schölkopf, & Bülthoff, 1998; Wehner, 1981) and recognition (Bülthoff & Edelman, 1992) tasks in 3D space.
Implications of the facilitation in recognizing centered views
The finding from Experiments 3 and 4 that people recognize an un-trained, centered view as readily as a trained, displaced view is difficult to explain in terms of egocentric reference systems and “snapshot” models of spatial memory. Instead, these findings implicate some other kind of mental processing. If we adopt the typical assumption that the ease with which a person recognizes a stimulus is related to the degree to which that stimulus is similar to its mental representation (Shelton & McNamara, 2001), the findings from Experiments 3 and 4 suggest that, in addition to encoding one's specific experience, one encodes a centered view. When one is exposed to only a displaced view during training, determining and mentally representing the centered view requires mental resources, and thus implicates psychological mechanisms that work to transform egocentric experience into a more coherent or abstract mental representation. Such an additional spatial representation may resemble a prototype that is more enduring and categorical than is one based on one's immediate experience (see, for example, Huttenlocher, Hedges, & Duncan, 1991).
Contrary to the conclusions above about egocentric reference systems, 2D spatial representations, and visual image matching, the results of Experiments 3 and 4 are reminiscent of findings about how people remember large spaces in which they can navigate. For example, several investigators have found that people tend to remember turns along a traveled route as being closer to 90° than they are (Chase & Chi, 1981; Moar & Bower, 1983; Sadalla & Montello, 1989; see also Tversky, 1981). Such a “normalization” bias can be interpreted as evidence that people store a more efficient, canonical representation of the environment than what they experience, much as participants in the present experiments appeared to store a centered and balanced view after exposure to an un-centered view. Importantly, though, in the present study, because both the trained view and the centered view were recognized relatively efficiently, participants did not appear to replace their experiences at learning with a normalized view, but rather to supplement it with one.
The suggestion that an un-trained centered view of a layout is represented in memory and influences performance is not unlike findings in the object recognition literature that illustrate how people recognize canonical views of objects. Canonical views of objects are generally considered to be those that provide relatively greater information about the spatial structure of the object (Palmer et al., 1981), are more familiar, or are more functional (Blanz, Tarr, & Bülthoff, 1999). Such views are recognized with greater facility than non-canonical views, even when one is specifically trained on non-canonical views (Ashworth & Dror, 2000; O'Reiley & Friedman, 2005). In the present experiments, however, it is difficult to regard a centered view of a spatial layout as “canonical,” at least in the sense that it either provides more information about the layout or is more familiar. All of the stimuli in these experiments depicted the same layout, and each object in the layout was clearly visible from each viewpoint position. Moreover, the layout was clearly novel to participants. Rather than providing more spatial information or being more familiar, the centered views in these experiments were simply better composed, more balanced, and more symmetrical. It was thus by virtue of its composition – not its information content or familiarity – that the centered view was more prominently represented in memory. This is an important finding, and suggests that spatial properties of the combined layout and viewpoint itself can help to organize spatial memory (see also Mou & McNamara, 2002).
It is worth considering two possible limitations of the present finding that untrained views can obtain a preferred status in spatial memory. First, it could be argued that the stimuli in the present experiments are not representative of the scenes that people typically encounter. For example, one does not often experience a spatial layout in the real world as a picture that has boundaries or that can be well-composed or balanced. Indeed, in the real world, any view of a layout can appear “centered” if one chooses to fixate on it foveally. It is possible that un-centered training views such as those used in Experiments 3 and 4 are rarely encountered in every day life. Second, it is possible that the spatial elements of the task in these experiments specifically encouraged a strategy of storing a centered and balanced view. Slight variations in the present recognition task (e.g., asking participants to distinguish target scenes from distractors that contain different stimuli) could lead to different effects of viewpoint position. Although both of these considerations may limit the scope and generalizability of the present findings, neither should cast doubt on the conclusions that followed from participants' relatively efficient performance with un-trained views – that psychological mechanisms exist that serve to represent un-experienced spatial information in memory. Because such mechanisms require effort to engage, they presumably would only exist if they are adaptive and are used in some situations – even if these are not typically the situations encountered in these experiments.
Conclusions
Taken together, these experiments support the idea of both egocentric and nonegocentric coding of information about spatial layout. The strongest evidence, available in all experiments, supports a relatively simple conceptualization of spatial representation as being organized around an individual's own experience. Although it has been suggested that memory for object layout is relatively abstract (Evans & Pezdek, 1980; Presson, Delange, & Hazelrigg, 1989; Sholl & Nolin, 1997), recent work has increasingly shown that such memories may consist of little more than the views experienced during learning (Shelton, 1999). The present paper adds to the weight of this evidence by showing strong support for a specificity of viewpoint position (not, as is more typically shown, a specificity of viewpoint orientation) in memory for single, well-learned scenes. These findings also support speculations that when spatial knowledge is acquired and tested through scene recognition, what is stored may be little more than a 2-D image of the scene that was viewed during training. At the same time, however, a model of spatial representation that is limited to 2-D egocentric views cannot fully account for the present finding that non-trained views also appear to be prominently represented in memory. This finding suggests that, in addition to coding egocentric experience, spatial memory can work to code coherent, well-structured forms – even when the views of these forms are not directly experienced. Much like the Gestalt principle of Prägnanz helps to explain perceptual organization of groups of objects, a similar principle also appears to operate in spatial memory. Determining more precisely the circumstances under which this principle is applied and understanding better the psychological mechanisms that enable coding of nonegocentric information are important topics for further work on spatial memory.
Footnotes
The term viewpoint specific has been previously used to refer to representations that are specific to both a particular position and a particular orientation (Sholl & Nolin, 1997). Because the present experiments manipulate only the position of the viewpoint, I have adopted the more precise term, position specificity.
References
- Ashworth ARS, Dror IE. Object identification as a function of discriminability and learning presentations: The effect of stimulus similarity and canonical frame alignment on aircraft identification. Journal of Experimental Psychology: Applied. 2000;6:148–157. doi: 10.1037//1076-898x.6.2.148. [DOI] [PubMed] [Google Scholar]
- Averbach E, Coriell AS. Short-term memory in vision. Bell System Technical Journal. 1961;40:309–328. [Google Scholar]
- Blanz V, Tarr MJ, Bülthoff HH. What object attributes determine canonical views? Perception. 1999;28:575–599. doi: 10.1068/p2897. [DOI] [PubMed] [Google Scholar]
- Bülthoff HH, Edelman S. Psychophysical support for a two-dimensional view interpolation theory of object recognition. Proceedings of the National Academy of Science. 1992;89:60–64. doi: 10.1073/pnas.89.1.60. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Cartwright BA, Collett TS. Landmark learning in bees: Experiments and models. Journal of Comparative Physiology. 1983;151:521–543. [Google Scholar]
- Christou CG, Bülthoff HH. View dependence in scene recognition after active learning. Memory & Cogniton. 1999;27:996–1007. doi: 10.3758/bf03201230. [DOI] [PubMed] [Google Scholar]
- Chase WG, Chi MTH. Cognitive skill: Implications for spatial skill in large-scale environments. In: Harvey JH, editor. Cognition, social behavior, and the environment. Erlbaum; Hillsdale, NJ: 1981. pp. 111–135. [Google Scholar]
- Chua K, Chun MM. Implicit scene learning is viewpoint dependent. Perception & Psychophysics. 2003;65:72–80. doi: 10.3758/bf03194784. [DOI] [PubMed] [Google Scholar]
- Diwadkar VA, McNamara TP. Viewpoint dependence in scene recognition. Psychological Science. 1997;8:302–307. [Google Scholar]
- Easton RD, Sholl MJ. Object-array structure, frames of reference, and retrieval of spatial knowledge. Journal of Experimental Psychology: Learning, Memory, & Cognition. 1995;21:483–500. doi: 10.1037//0278-7393.21.2.483. [DOI] [PubMed] [Google Scholar]
- Evans GW, Pezdek K. Cognitive mapping: Knowledge of real-world distance and location information. Journal of Experimental Psychology: Human Learning & Memory. 1980;6:13–24. [PubMed] [Google Scholar]
- Franz MO, Schölkopf B, Bülthoff HH. Where did I take that snapshot? Scene-based homing by image matching. Biological Cybernetics. 1998;79:191–202. [Google Scholar]
- Gibson BS, Peterson MA. Does orientation-independent object recognition precede orientation-dependent recognition? Evidence from a cuing paradigm. Journal of Experimental Psychology: Human Perception & Performance. 1994;20:299–316. doi: 10.1037//0096-1523.20.2.299. [DOI] [PubMed] [Google Scholar]
- Huttenlocher J, Hedges LV, Duncan S. Categories and particulars: Prototype effects in spatial location. Psychological Review. 1991;98:352–376. doi: 10.1037/0033-295x.98.3.352. [DOI] [PubMed] [Google Scholar]
- Intraub H, Berkowits D. Beyond the edges of a picture. American Journal of Psychology. 1996;109:581–598. [Google Scholar]
- Intraub H, Bodamer JL. Boundary extension: Fundamental aspect of pictorial representation or encoding artifact? Journal of Experimental Psychology: Learning, Memory, & Cognition. 1993;19:1387–1397. doi: 10.1037//0278-7393.19.6.1387. [DOI] [PubMed] [Google Scholar]
- Intraub H, Gottesman CV, Bills AJ. Effects of perceiving and imagining scenes on memory for pictures. Journal of Experimental Psychology: Learning, Memory, & Cognition. 1998;24:186–201. doi: 10.1037//0278-7393.24.1.186. [DOI] [PubMed] [Google Scholar]
- Intraub H, Gottesman CV, Willey EV, Zuk IJ. Boundary extension for briefly glimpsed photographs: Do common perceptual processes result in unexpected memory distortions? Journal of Memory & Language. 1996;35:118–134. [Google Scholar]
- Intraub H, Richardson M. Wide-angle memories of close-up scenes. Journal of Experimental Psychology: Learning, Memory, & Cognition. 1989;15:179–187. doi: 10.1037//0278-7393.15.2.179. [DOI] [PubMed] [Google Scholar]
- Klatzky RL, Loomis JM, Beall AC, Chance SS, Golledge RG. Spatial updating of self-position and orientation during real, imagined, and virtual locomotion. Psychological Science. 1998;9:293–298. [Google Scholar]
- Loftus GR, Masson MEJ. Using confidence intervals in within-subject designs. Psychonomic Bulletin & Review. 1994;1:476–490. doi: 10.3758/BF03210951. [DOI] [PubMed] [Google Scholar]
- May M. Imaginal perspective switches in remembered environments: Transformation versus interference accounts. Cognitive Psychology. 2004;48:163–206. doi: 10.1016/s0010-0285(03)00127-0. [DOI] [PubMed] [Google Scholar]
- McNamara TP. How are the locations of objects in the environment represented in memory? In: Freksa C, Brauer W, Habel C, Wender K, editors. Spatial cognition III: Routes and navigation, human memory and learning, spatial representation and spatial reasoning. Springer-Verlag; Berlin: 2003. pp. 174–191. [Google Scholar]
- Moar I, Bower GH. Inconsistency in spatial knowledge. Memory & Cognition. 1983;11:107–113. doi: 10.3758/bf03213464. [DOI] [PubMed] [Google Scholar]
- Mou W, McNamara TP. Intrinsic frames of reference in spatial memory. Journal of Experimental Psychology: Learning, Memory, & Cognition. 2002;28:162–170. doi: 10.1037/0278-7393.28.1.162. [DOI] [PubMed] [Google Scholar]
- Mou W, McNamara TP, Valiquette CM, Rump B. Allocentric and egocentric updating of spatial memories. Journal of Experimental Psychology: Learning, Memory, & Cognition. 2004;30:142–157. doi: 10.1037/0278-7393.30.1.142. [DOI] [PubMed] [Google Scholar]
- Murray JE. Orientation-specific effects in picture matching and naming. Memory & Cognition. 1999;27:878–889. doi: 10.3758/bf03198540. [DOI] [PubMed] [Google Scholar]
- Nakatami C, Pollatsek A, Johnson SH. Viewpoint-dependent recognition of scenes. The Quarterly Journal of Experimental Psychology. 2002;55A:115–139. doi: 10.1080/02724980143000190. [DOI] [PubMed] [Google Scholar]
- Newell FN, Findlay JM. The effect of depth rotation on object identification. Perception. 1997;26:1231–1257. doi: 10.1068/p261231. [DOI] [PubMed] [Google Scholar]
- O'Keefe J, Nadel L. The Hippocampus as a Cognitive Map. Clarendon; Oxford: 1978. [Google Scholar]
- O'Reilly T, Friedman A.The influence of task context on object naming: Practice with single or multiple views 2005. Manuscript submitted for publication [Google Scholar]
- Palmer S, Rosch E, Chase P. Canonical perspective and the perception of objects. In: Long J, Baddeley A, editors. Attention & Performance IX. Erlbaum; Hillsdale, NJ: 1981. pp. 135–151. [Google Scholar]
- Presson CC, Delange N, Hazelrigg MD. Orientation specificity in spatial memory: What makes a path different from a map of the path? Journal of Experimental Psychology: Learning, Memory, & Cognition. 1989;15:887–897. doi: 10.1037//0278-7393.15.5.887. [DOI] [PubMed] [Google Scholar]
- Presson CC, Montello DR. Updating after rotational and translational body movements: Coordinate structure of perspective space. Perception. 1994;23:1447–1455. doi: 10.1068/p231447. [DOI] [PubMed] [Google Scholar]
- Price CM, Gilden DL. Representations of motion and direction. Journal of Experimental Psychology: Human Perception & Performance. 2000;26:18–30. doi: 10.1037//0096-1523.26.1.18. [DOI] [PubMed] [Google Scholar]
- Rieser JJ. Access to knowledge of spatial structure at novel points of observation. Journal of Experimental Psychology: Learning, Memory, & Cognition. 1989;15:1157–1165. doi: 10.1037//0278-7393.15.6.1157. [DOI] [PubMed] [Google Scholar]
- Roskos-Ewoldsen B, McNamara TP, Shelton AL, Carr W. Mental representations of large and small spatial layouts are orientation dependent. Journal of Experimental Psychology: Learning, Memory, & Cognition. 1998;24:215–226. doi: 10.1037//0278-7393.24.1.215. [DOI] [PubMed] [Google Scholar]
- Sadalla EK, Montello DR. Remembering changes in direction. Environment and Behavior. 1989;21:346–363. [Google Scholar]
- Salthouse TA, Ellis CL. Determinants of eye-fixation duration. American Journal of Psychology. 1980;93:207–234. [PubMed] [Google Scholar]
- Shelton AL.The role of egocentric orientation in human spatial memory 1999. Unpublished doctoral dissertation. Vanderbilt University, Nashville, TN [Google Scholar]
- Shelton AL, McNamara TP. Multiple views of spatial memory. Psychonomic Bulletin & Review. 1997;4:102–106. [Google Scholar]
- Shelton AL, McNamara TP. Systems of spatial reference in human memory. Cognitive Psychology. 2001;43:274–310. doi: 10.1006/cogp.2001.0758. [DOI] [PubMed] [Google Scholar]
- Shelton AL, McNamara TP. Spatial memory and perspective taking. Memory & Cognition. 2004a;32:416–426. doi: 10.3758/bf03195835. [DOI] [PubMed] [Google Scholar]
- Shelton AL, McNamara TP. Orientation and perspective dependence in route and survey learning. Journal of Experimental Psychology: Learning, Memory, & Cognition. 2004b;30:158–170. doi: 10.1037/0278-7393.30.1.158. [DOI] [PubMed] [Google Scholar]
- Sholl MJ, Nolin TL. Orientation specificity in representations of place. Journal of Experimental Psychology: Learning, Memory, & Cognition. 1997;23:1494–1507. [Google Scholar]
- Sperling G. The information available in brief visual presentations. Psychological Monographs: General and Applied. 1960;74:1–28. [Google Scholar]
- Tlauka M. Switching imagined viewpoints: The effects of viewing angle and layout size. British Journal of Psychology. 2002;93:193–201. doi: 10.1348/000712602162535. [DOI] [PubMed] [Google Scholar]
- Tversky B. Distortions in memory for maps. Cognitive Psychology. 1981;13:407–433. [Google Scholar]
- Waller D, Montello DR, Richardson AE, Hegarty M. Orientation specificity and spatial updating of memories for layouts. Journal of Experimental Psychology: Learning, Memory, & Cognition. 2002;28:1051–1063. doi: 10.1037//0278-7393.28.6.1051. [DOI] [PubMed] [Google Scholar]
- Wang RF. Representing a stable environment by egocentric updating and invariant representations. Spatial Cognition & Computation. 2000;1:431–445. [Google Scholar]
- Wehner R. Spatial vision in arthropods. In: Autrum H, editor. Handbook of Sensory Physiology. 6c. Vol. 7. Springer; Berlin: 1981. pp. 287–616. [Google Scholar]