

Abstract
The prediction of protein structure from sequence remains a major unsolved problem in biology. The most successful protein structure prediction methods make use of a divide-and-conquer strategy to attack the problem: a conformational sampling method generates plausible candidate structures, which are subsequently accepted or rejected using an energy function. Conceptually, this often corresponds to separating local structural bias from the long-range interactions that stabilize the compact, native state. However, sampling protein conformations that are compatible with the local structural bias encoded in a given protein sequence is a long-standing open problem, especially in continuous space. We describe an elegant and mathematically rigorous method to do this, and show that it readily generates native-like protein conformations simply by enforcing compactness. Our results have far-reaching implications for protein structure prediction, determination, simulation, and design.
Synopsis
Protein structure prediction is one of the main unsolved problems in computational biology today. A common way to tackle the problem is to generate plausible protein conformations using a fairly inaccurate but fast method, and to evaluate the conformations using an accurate but slow method. The main bottleneck lies in the first step, that is, efficiently exploring protein conformational space. Currently, the best way to do this is to construct plausible structures by stringing together fragments from experimentally determined protein structures, a method called fragment assembly. Hamelryck, Kent, and Krogh present a new method that can efficiently generate protein conformations that are compatible with a given protein sequence. Unlike for existing methods, the generated conformations cover a continuous range and come with an associated probability. The method shows great promise for use in protein structure prediction, determination, simulation, and design.
Introduction
The prediction of a protein's structure from its amino acid sequence remains one of the greatest unsolved problems in computational molecular biology. The problem attracts much interest because it both is intellectually challenging and has important practical applications such as drug development and genome annotation.
According to Anfinsen's famous hypothesis, a protein's native structure is determined by its sequence and corresponds to minimal Gibbs energy [1]. Levinthal's paradox implies that a brute force enumeration of all possible conformations for a given sequence is both computationally and physically impossible [2]. This paradox is solved, at least in part, by the fact that the sequence introduces local structural bias, which narrows the conformational search space [3–6]. The native fold is thought to be the result of favorable local and long-range interactions [7,8]. As a consequence, protein structure prediction methods need two key ingredients: an energy function and an efficient method to explore the relevant parts of the conformational space associated with the sequence. The latter problem is considered to be the primary bottleneck in protein structure prediction today [9].
In practice, one first chooses a particular representation of a protein, ranging from a full-atom model to a Cα-atom–only model. Based on the amino acid sequence of the protein, plausible protein-like conformations called decoys are generated. These decoys are subsequently accepted or rejected based on an energy function.
The strategy to generate decoys that are subsequently rejected or accepted comes in different flavors. One can generate a large set of decoys, and then select the decoy with the lowest energy [10–13]. The ROSETTA method generates decoys as part of a simulated annealing procedure to identify structures with minimum energy [9,14]. Markov Chain Monte Carlo (MCMC)–based methods [3,15,16] propose decoys that are accepted or rejected depending on their Boltzmann weights. The subject of this paper is the generation of decoys, that is, the exploration of the conformational space that is compatible with a given sequence. In particular, our goal is to generate decoys based on local sequence/local structure preferences [7,8], which we will refer to as “local structural bias.”
Recently, important progress in structure prediction was made due to the use of fragment libraries for decoy generation [9,14]. Fragment libraries consist of fragments derived from experimentally determined high-quality protein structures [17–20]. By combining fragments that are chosen based on sequence information, one can generate decoys that have a protein-like local structure [6,9,14]. The main idea behind the use of fragment libraries is to decrease the size of the vast conformational search space by taking local structural bias into account and using a finite set of fragments.
Despite the clear success of the fragment library approach, the method has some important shortcomings. The limited size of the Protein Data Bank (PDB) makes it very difficult to map a sequence stretch of even moderate length to a relevant set of structure fragments. Using fragment libraries in MCMC simulations is problematic because of their incomplete covering of the conformational space and nonprobabilistic nature [16,21]. Finally, the inherent discrete nature of fragment libraries conflicts with the continuous character of a protein's conformational space.
An important step forward was the HMMSTR method [22,23], which uses a Hidden Markov Model (HMM), trained from a fragment library [24], to predict local structure based on sequence. HMMSTR, and HMM-based approaches that do not include sequence information but are purely geometric [25,26], can be considered as probabilistic versions of fragment libraries.
Despite these advancements, probabilistic sampling in continuous space of plausible protein-like conformations that display realistic dihedral angles and secondary structure content is still an important unsolved problem [27–32]. A solution to this problem could have a profound effect on the success of protein structure prediction, design, and simulation [9].
Here, we provide such a solution by developing a probabilistic model that uses directional statistics to describe protein geometry in a natural, continuous space. The model makes it possible to sample plausible protein backbone conformations for a given sequence. We show that we readily generate near-native decoys for several proteins simply by enforcing compactness and self-avoidance, without using any additional energy terms. Our results thus support the view that relatively few compact structures are compatible with the sequence-encoded local structural bias [6], and provide the means to capture this bias in protein structure prediction, simulation, and design.
Results/Discussion
FB5–HMM: A Probabilistic Model of Local Protein Structure
Our goal is probabilistic sampling of plausible backbone conformations given a protein's sequence, and, optionally, given secondary structure information as well. A protein's backbone conformation, here taken to be characterized by the sequence of Cα positions, can be effectively represented as a sequence of (θ,τ) angle pairs (Figure 1) [33,34]. Such a (θ,τ) sequence is equivalent to a sequence of unit vectors, each vector pinpointing the Cα position of one amino acid (see Materials and Methods). Hence, a probabilistic model needs to be developed that allows sampling a sequence of unit vectors based on one or two sequences, respectively specifying amino acid type and secondary structure class (that is, helix, β-strand, and coil).
Figure 1. Schematic Representation of a Protein's Cα Backbone.

The Cα positions are numbered, and the pseudo bond angles θ and pseudo dihedral angles τ are indicated. The segment has length 5, and is thus fully described by two pseudo dihedral and three pseudo bond angles. The numbering scheme of the angles is chosen so that the angle pair (θi,τi), associated with position i, specifies the position of the Cα atom at position i + 1.
An HMM can deal with the sequential aspect of the problem [35], provided a way can be found to represent the unit vectors. A solution to this problem comes from the field of directional statistics, a branch of statistics that deals with probability distributions over orientations, directions, or angles [36]. Directional statistics has for example been applied to the modelling of wind directions and astronomical observations on the celestial sphere. To represent the unit vectors, we used the 5-parameter Fisher-Bingham (FB5) distribution [37], which is the equivalent on the sphere of the Gaussian distribution in the plane.
Figure 2 shows the conditional dependency graph of an HMM (called FB5–HMM) that combines amino acid sequence, secondary structure, and detailed geometric information. Two discrete nodes, A and S, represent the 20 amino acid types and the three secondary structure classes, while the continuous node F represents the unit vector describing Cα geometry. The three nodes A, S, and F are conditionally dependent on a hidden, discrete node H. That is, the hidden node value at a given sequence position specifies the probabilities of observing a specific amino acid type, secondary structure class, and unit vector at that position. The dependencies between the sequence positions are encoded in the transition probabilities of going from one hidden node value to another. Hence, FB5–HMM aims to capture the joint probability distribution of an amino acid sequence A, a secondary structure sequence S, and a sequence of unit vectors or angle pairs X describing the backbone geometry. The joint probability distribution is given by
where the sum runs over all possible hidden node sequences H. In the trained model, each hidden node value ties together matching preferences for amino acid type, secondary structure, and local geometry. The use of an HMM with multiple outputs makes challenging operations such as sampling a set of backbone angles given an amino acid sequence computationally feasible.
Figure 2. Conditional Dependency Graph of FB5–HMM.

Squares represent discrete nodes, circles represent the FB5 node with unit vector output. The arrows indicate conditional dependencies. Three slices are shown, corresponding to three consecutive amino acid positions. A possible set of node values is shown in color (v1, v2, and v3 are unit vectors). The hidden node sequence (34,34,3) corresponds to two C-terminal positions of an α-helix, followed by a coil residue.
A, amino acid node; F, FB5 node; H, hidden node; S, secondary structure node.
The optimal number of hidden node values (which is 75) and all other associated parameters of FB5–HMM were determined by training the HMM using a large set of representative protein structures (see Materials and Methods). Figure 3, which shows the most important transitions between the hidden node vales, gives an impression of the overall structure of FB5–HMM.
Figure 3. Transitions Occurring between (θ,τ) Angle Pairs in Proteins according to FB5–HMM.

The graph shows some of the most important possible hidden node transitions in FB5–HMM. Each hidden node value is represented as a box, showing the associated mean direction as a pair of (θ,τ) angles. For clarity, only a subset of all transitions is shown: for each hidden node value, the incoming and the outgoing transition with the highest probability is shown as an arrow. If one of them is a self-transition, the second best incoming or outgoing transition is also shown. Hidden node values mainly associated with α-helices are shown in light red, with β-strands in light blue, and with coils in white.
Nearly all hidden node values (73 out of 75) are associated with a strong preference (P > 0.8) for a single secondary structure class (helix = 16, β-strand = 21, coil = 36). The only amino acid types that are associated with a probability greater than 0.3 (given a hidden node value) are Gly and Pro, which reflects their special geometric preferences. The trained HMM is quite sparse: only 1,352 (24%) of all possible hidden node transitions occur with a probability above 0.0001. The parameters of FB5–HMM are available online as supporting information (Dataset S1).
The HMMSTR method [22,23] also uses an HMM approach to represent local structural bias, but makes use of a discretized representation of the full-atom protein backbone. Here, the final number of hidden node values was considerably higher (281), but the number of nonzero transitions was lower (371) than for FB5–HMM. It should be noted that HMMSTR was extensively manually optimized for prediction, while training of our model was fully automated.
Generating Protein-Like Backbones
In this section, we show that FB5–HMM generates Cα backbones with realistic, protein-like geometries, and briefly explain the sampling method.
To sample a Cα backbone given an amino acid sequence, and optionally given a secondary structure sequence as well, a sequence of hidden node values needs to be sampled from FB5–HMM first. Once the hidden node values are sampled, it is trivial to sample a sequence of unit vectors describing a Cα backbone (see Materials and Methods, and the example discussed below). The classic inference methods for HMMs, Viterbi path decoding, and posterior decoding [35], do not apply here because they are not aimed at sampling but predicting. However, the problem can be solved using Forward-Backtrack (FwBt) sampling, a little-used inference method previously used in gene finding [38]. Using FwBt sampling, it also becomes possible to resample the angles of a stretch of residues seamlessly. Note that the Forward-Backtrack algorithm (a sampling method) should not be confused with the related Forward-Backward algorithm (a method to calculate the posterior distribution) [35].
How a hidden node value specifies a probability distribution over unit vectors deserves some more explanation. Each hidden node value is associated with a set of parameter values for the FB5 distribution that specify its mean direction, shape, extent, and orientation. For example, in Figure 4, three sets of 1,000 points sampled from the FB5 distributions associated with hidden node values 3, 34, and 44 are shown on the unit sphere. These hidden node values are associated with coils, α-helices, and β-strands, respectively.
Figure 4. Three Point Sets Sampled from the FB5 Distribution on the Sphere.

The three sets consist of 1,000 unit vectors sampled from the FB5 distributions associated with hidden node values 3 (blue), 34 (red), and 44 (green), respectively These three node values are typical representatives of coil, α-helix, and β-strand geometry. The samples were plotted on the unit sphere, and the mean directions of the three FB5 distributions are indicated with arrows.
The entire (θ,τ) space accessible to proteins is covered by a mixture of 75 FB5 distributions, of which the 75 mean directions are shown in Figure 5. It should be noted that mean directions that are close together in the plot might belong to hidden node values that specify very different secondary structure class and amino acid type preferences.
Figure 5. Scatter Plot of the (θ,τ) Angles in a Sampled Dataset.

The dataset consisted of 500 sequences of length 100 generated using FB5–HMM. The ideal (θ,τ) values of some conformations are indicated: α: α-helix, β: β-strand, π: π-helix, L: left-handed α-helix, 3: 310-helix, 1 & 2: Poly-Proline helices types I and II. The open circles indicate the mean directions of the 75 FB5 distributions. Angle pairs generated by hidden node values 3, 34, and 44 are plotted in blue, red, and green, respectively. These three hidden node values are typical representatives of hidden node values that correspond to coil, α-helix, and β-strand geometry, respectively.
A simple example will serve to explain the process of sampling a Cα trace given a sequence. Suppose we want to sample a set of (θ,τ) angles given the sequence (Ala, Leu, Gly). In the first step, a hidden node sequence of length three is sampled using the FwBt method with the (Ala, Leu, Gly) sequence as input. Note that if a secondary structure assignment is given as well, the hidden node sequence can be sampled using both the amino acid sequence and the secondary structure sequence. A plausible hidden node sequence resulting from the sampling from the amino acid sequence (Ala, Leu, Gly) is, for example, (34,34,3). Examining these hidden node values shows that hidden node value 34 is associated with a high probability of emitting Leu and Ala as amino acid symbol and helix as secondary structure symbol, while hidden node value 3 is mainly associated with Gly and coil. Hence, the sampled sequence of hidden nodes corresponds to the two hydrophobic C-terminal residues of a helix, followed by a coil beginning with a Gly residue. Next, the (θ,τ) angle pairs are sampled from the FB5 distributions associated with hidden node values 34 and 3. The FB5 distributions associated with hidden node values 34 and 3 have (θ = 90.5,τ = 50.4) and (θ = 95.1,τ = 116.3) as mean directions, respectively. A possible sampled sequence of (θ,τ) angle pairs could be for example:
Note that the two first (θ,τ) pairs have values that are typical for an α-helix (Figure 5).
The FB5–HMM model correctly captures the distribution of pseudo bond and dihedral angles found in proteins. To show this, we sampled a set of backbone angle sequences with the same total number of residues as the dataset and constructed histograms of the (θ,τ) angles. The (θ,τ) plot can be considered as the Cα equivalent of the classic Ramachandran plot [34,39]. The similarity of the resulting 2-D histograms, both in terms of overall shape and detailed angle pair frequencies, indicates that FB5–HMM accurately reproduces the (θ,τ) distribution found in real proteins (Figure 6).
Figure 6. Histograms of the (θ,τ) Angle Pairs.

Histograms are shown for the training set (upper) and the decoy set (lower). The bin size is 1° × 1°. The color scale refers to the number of counts per bin. Bins with a count below 4 are white.
Secondary Structure Content
FB5–HMM not only captures the distribution of the (θ,τ) angles, but also their sequential dependencies, and as a consequence generates secondary structures that follow realistic length distributions. To show this, we generated a large set of decoys, and analyzed the lengths of their secondary structures.
For each protein in the dataset, a matching decoy with the same length was generated. Secondary structure was assigned using the program P-SEA [40]. This program only makes use of the Cα coordinates and evaluates local geometry, which allowed us to use exactly the same secondary structure definitions for both dataset and decoys.
The overall secondary structure content of the protein dataset and the decoy set are remarkably close to each other (helix, including α-helix, 310-helix, and π-helix: 34% and 32%; β-strand: 25% and 24%; coil: 41% and 44%). Figure 7 shows the length distributions of helices, β-strands, and coils in the protein dataset and the decoy set. The length distributions of the secondary structures in the decoys closely match those in the protein structures, especially in the case of β-strands. As the generated decoys were not enforced to be compact, the secondary structure content cannot be ascribed to compactification effects that can give rise to extensive secondary structure formation in lattice [41] and tube [42,43] models.
Figure 7. Histograms of Secondary Structure Element Length.

Histograms of the lengths of the secondary structure elements in the training set (white bars) and the decoy set (black bars).
The quality of the generated decoys was confirmed by constructing all-atom backbones from the Cα coordinates using the program MAXSPROUT [44]. According to the DSSP program [45], which requires proper hydrogen bonding for secondary structure assignment, the dataset contains 32% helix (of which 30% is α-helix), which is identical to the percentage calculated by PSEA. Note that the same procedure does not apply to β-strands because DSSP requires interstrand hydrogen bonds to recognize β-strands and β-sheets, while our model is not meant to incorporate nonlocal interactions and hence does not bring β-strands together into β-sheets. However, manual inspection of the generated β-strands confirms they have the expected geometry, including the distinct right-handed twist observed in real proteins [46].
Compact Decoys Using Sequence Information
We used FB5–HMM to generate compact decoys for six target proteins that were the subject of two previous studies [13,14]. Four of them are all-helical, while two consist of α-helices and a single β-sheet (Table 1).
Table 1.
Generation of Compact Decoys Using Sequence Information

For each of these proteins, we generated 100,000 compact decoys using the radius of gyration (Rg) of the target proteins (see Materials and Methods). Apart from compactness and self-avoidance, no additional energy terms were used. We consider decoys with a Cα-based root mean square deviation (RMSD) with the native structure that is below 6 Å as “good” decoys [28]. We emphasize that the dataset used to train FB5–HMM did not contain any proteins that are homologous to the target proteins, or any proteins with a fold identical to that of a target protein.
To evaluate the results of the default FB5–HMM method that generates compact decoys using amino acid sequence information (Table 1, Method S), we used three baselines. The S0 baseline does not make use of amino acid sequence information for sampling the backbone angles. The Markov0 (M0) baseline uses the target sequence but uses a uniform transition matrix for the hidden nodes, which corresponds to removing the arrows between the hidden nodes in Figure 2. Finally, the MS0 baseline uses a uniform transition matrix and does not make use of sequence information.
The use of the S0 and M0 baselines is challenging, because they are expected to generate decoys that are much better than truly random decoys. The S0 baseline generates random compact decoys with a protein-like geometry, and is thus expected to generate protein-like folds by chance [47]. The M0 baseline generates decoys with realistic (θ,τ) angles for the given amino acid sequence, but neglects the dependencies between consecutive (θ,τ) pairs. The MS0 baseline simply generates random compact structures with (θ,τ) pairs that fall in the range that is allowed for proteins. The results are shown in Table 1.
Strikingly, FB5–HMM generates good decoys for all targets (Table 1, S). The best decoys for targets 1ENH and 2CRO are shown in Figure 8. The number of good decoys ranges from almost 10% for the smallest helical target (1FC2) to several good decoys (37 and 9) for the targets containing a β-sheet (2GB1 and 1CTF). Given the fact that no energy function was used to handle the nonlocal interactions during decoy generation, besides enforcing compactness and absence of steric clashes, this result is quite remarkable.
Figure 8. Best Compact Decoys Generated Using FB5–HMM.

The best compact decoys generated using sequence information (Table 1, S) are shown for 1ENH (top) and 2CRO (bottom). From left to right: crystal structure, FB5–HMM, S0 baseline, M0 baseline, MS0 baseline. The N-terminus is shown in blue. The figure was made with PyMol (DeLano Scientific, http://www.delanoscientific.com).
Indeed, the (modest) success for the β-sheet containing targets is noteworthy since our model does not incorporate the long-range interactions that assemble β-strands into β-sheets. In general, proteins containing β-sheets are challenging targets [13,14].
The S0 baseline, which does not take the target sequence into account, generates significantly fewer good decoys for all targets (Table 1, S0). In addition, the RMSD between the best decoy and the native structure is consistently higher for the S0 baseline than for FB5–HMM. Both FB5–HMM and the S0 baseline generates compact, protein-like decoys. Since FB5–HMM performs significantly better than the S0 baseline, we can conclude that the model successfully captures at least a significant part of the local structural bias encoded in an amino acid sequence.
The M0 baseline performs much worse than FB5–HMM for all targets and does not generate a single good decoy for two of them (Table 1, M0, targets 2GB1 and 4ICB). This points out that the sequential dependencies between the (θ,τ) angle pairs are extremely important for obtaining good decoys. Surprisingly, it is even better to neglect target sequence information (S0 baseline) than to neglect the dependencies between the angles (M0 baseline).
In fact, the M0 baseline does not seem to perform significantly better than the MS0 baseline, which essentially only depends on the length of the protein (Table 1, MS0). Both the M0 and MS0 baseline produce decoys that do not resemble proteins because they lack realistic secondary structure content (Table 2). Indeed, all “good” M0 and MS0 decoys have a very low helix and strand content (more than 90% of the residues are coil), which corresponds to the low helix and strand content reported for random compact polymer conformations [48–50], when the polymers are not represented as tubes with a certain thickness [42,43] or confined to a lattice [41]. This is in strong contrast to the decoys generated by FB5–HMM and the S0 baseline (Figure 8, Table 2), which again emphasizes the importance of taking the sequential angle dependencies into account.
Table 2.
Secondary Structure Content of the Good Decoys

Adding Secondary Structure Information
One of the great advantages of incorporating secondary structure information into the model is that sampling from the conformational space associated with both an amino acid sequence and a secondary structure sequence becomes possible. The latter sequence could come from a prediction algorithm, but also from experimental data.
To show that our model incorporates secondary structure information successfully, we sampled compact decoys using both amino acid sequence and secondary structure information derived from the native structure (Table 3, XS). Again, we make use of two baselines. The XS0 baseline makes use of secondary structure, but not sequence. The XM0 baseline includes secondary structure and sequence, but uses a uniform transition matrix and hence neglects the dependencies between consecutive (θ,τ) pairs.
Table 3.
Generation of Compact Decoys Using Sequence and Secondary Structure Information

As expected, and as was previously shown for a fragment assembly method [19], structure information indeed boosts the generation of close-to-native decoys dramatically (Table 3, XS). The most impressive improvement occurs for 2GB1, where including secondary structure information increases the number of good decoys from 0.037% to 13.5%. In addition, the RMSD of the best decoy improves considerably in all but one case. For all targets, more than 90% of the residues in the good decoys have the correct secondary structure (Table 2).
Two additional observations deserve to be highlighted. Even in the presence of secondary structure information, sequence information matters (Table 3, compare XS and XS0). Clearly, FB5–HMM does more than simply translating secondary structure into bond angles. Rather, secondary structure information narrows the sampling space but leaves ample room for inference of local structural bias.
A second observation is that even in the presence of secondary structure information, the Markov0 model (baseline XM0) still performs much worse than FB5–HMM (XS) and the XS0 baseline. This implies that the sequential dependencies of the (θ,τ) angles remain important even within the constraints of a secondary structure assignment. In fact, generating compact decoys using sequence only (Table 1, S) generally performs better than using both secondary structure and sequence information but neglecting the sequential dependencies of the angles (Table 3, baseline XM0). This is true in terms of the number of good decoys generated, the RMSD values of the best decoys, and the secondary structure similarity to the native structure (Table 2).
The question naturally arises whether noisy secondary structure and Rg information, for example derived from predictions, still improves decoy generation. To address this question, we generated decoys using predicted secondary structure and predicted Rg.
Using sequence, predicted secondary structure information, and predicted Rg (Table 3, XP) generates more good decoys than using sequence and structure-derived Rg only (Table 1, S). In most cases, this comes at the expense of a higher RMSD for the best decoys, presumably due to the secondary structure prediction errors. The bad performance in the case of 2GB1 is probably due to the prediction of one of the β-strands as coil (Figure 9). Hence, FB5–HMM provides a convenient way to shuttle secondary structure prediction results into 3-D structure prediction methods.
Figure 9. Secondary Structure of the Target Proteins.

(First line) Secondary structure assignment derived from the crystal structure.
(Second line) Predicted secondary structure assignment.
Comparison with Two Fragment Assembly Methods
We have used the same target proteins as two previous studies that focus on decoy generation using fragment assembly methods [13,14]. Both studies also use the same criteria for good decoys, that is, having a Cα-based RMSD below 6 Å with the native structure. As a result, we can directly compare our results with the results reported in these two studies.
The fragment assembly method in the first study forms the basis of the ROSETTA de novo protein structure prediction method [14,51]. Fragments are selected based on multiple sequence information, and assembled into decoys using a simulated annealing procedure and a probabilistic nonlocal energy function. A direct comparison of the two methods is of course extremely unfair, since FB5–HMM is a local structure sampling method, while ROSETTA is a complete structure prediction method incorporating nonlocal interactions. In addition, ROSETTA has a clear advantage because it uses multiple sequence information in the selection of the fragments, while FB5–HMM only uses a single sequence. Nonetheless, the comparison offers some interesting insights.
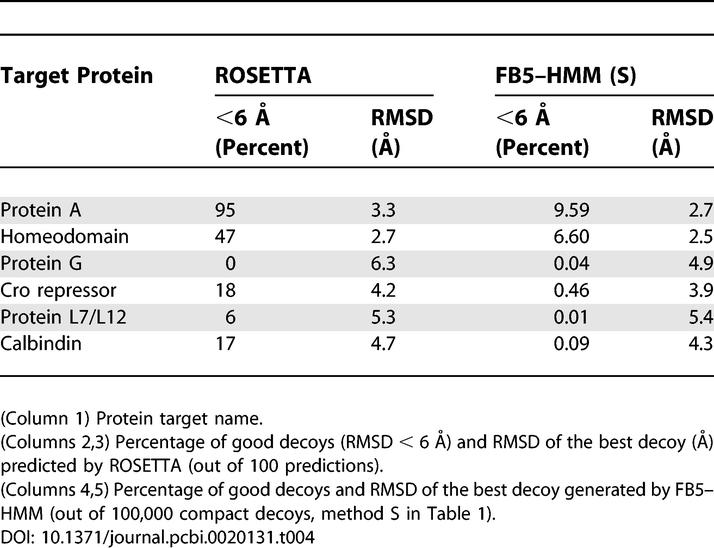
As expected, the percentage of good decoys is much higher for ROSETTA than for FB5–HMM for most target proteins (Table 4). However, in some respects FB5–HMM clearly performs better. First, ROSETTA does not generate a single good decoy in the case of Protein G, while FB5–HMM does produce good decoys. Second, the RMSD values of the best decoys are in general lower for FB5–HMM than for ROSETTA. Hence, in this view, generating a large set (100,000) of compact decoys using FB5–HMM leads to better results than carefully predicting relatively few (100) candidate structures using ROSETTA, at least according to the results given by Simons et al. [14] for these six small target proteins. This is an important point, as combining a fairly inaccurate, but computationally cheap method to generate decoys with an accurate, but computationally expensive method to identify and refine promising structures has recently led to considerable success [9].
Table 4.
Comparison of FB5–HMM and ROSETTA
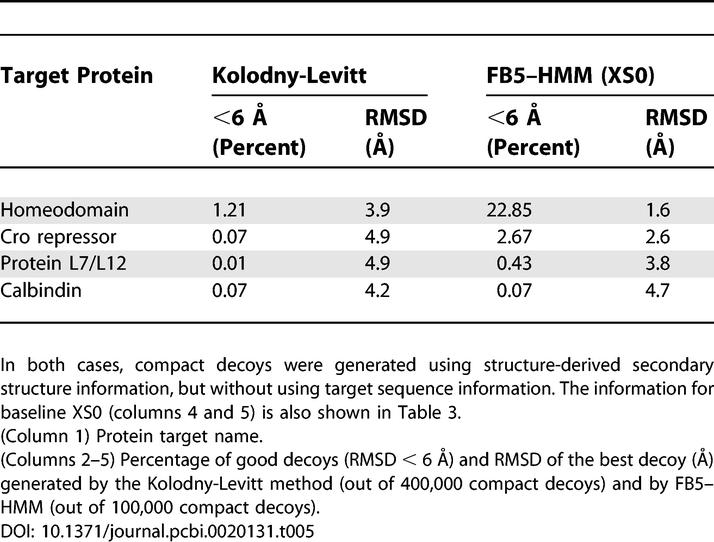
The second study we use for comparison describes a fragment assembly method that uses secondary structure information derived from the true structure to produce compact decoys [13]. This method does not make use of sequence information, but only secondary structure information. The results of this study can thus be directly compared with those produced by FB5–HMM using secondary structure information, but not sequence (Table 3, XS0). Table 5 compares both methods for the four common target proteins. FB5–HMM performs considerably better than the fragment assembly method, judging by the number of good decoys and the RMSD values of the best decoys.
Table 5.
Comparison of FB5–HMM and the Kolodny-Levitt Fragment Assembly Method
Conclusions
We described a probabilistic model that can be used to sample Cα backbones based on a protein's amino acid sequence, incorporating secondary structure information if available. The method is conceptually elegant, has excellent computational complexity [38], and handles in principle any sequence or fragment length. The generated decoys have protein-like geometry, reflected in realistic angle and secondary structure length distributions.
The potential applications of FB5–HMM are numerous. In de novo protein structure prediction, the use of local structural bias can avoid generating misfolded conformations that are due to an imperfect energy function [6]. In homology modelling, FB5–HMM could guide the construction of variable loops [52,53]. Because of the probabilistic nature of the model, it can be used to propose local conformational changes that respect the detailed balance condition [16,21], making it possible to estimate thermodynamic averages using MCMC simulations [54]. In experimental methods such as NMR, X-ray crystallography, or Small Angle X-ray Scattering, the model could be used to generate conformations that take the local structural bias and the experimental data into account [55–57]. By inference of optimal sequences for a given backbone conformation, for example using Viterbi decoding [35], FB5–HMM could also be helpful in fold recognition [58] or protein design [59,60].
The model could in principle be extended in several ways, including using Dirichlet nodes to incorporate multiple sequence information [61], explicitly modelling the length distributions of the secondary structure elements [62] or adding additional hidden nodes and dependencies. A model with a very similar architecture would make an excellent probabilistic model of the full backbone structure of proteins, provided a tractable distribution to represent the joint probability distribution of two dihedral angles (that is, a distribution on the torus) is available. Preliminary results obtained using a bivariate von Mises distribution [63] confirm this approach is indeed quite feasible. Many of the extensions mentioned above pose considerable computational and statistical challenges, and will be the subject of future studies.
Surprisingly, FB5–HMM readily generated native-like decoys for several proteins when merely self-avoidance and compactness were enforced. Our results thus support the view that the native fold of a protein is at least partly encoded by the local structural bias associated with its amino acid sequence [3–6,15]. Recently, it was suggested that only relatively few compact structures are compatible with the local structural bias imposed by a protein's amino acid sequence [6]. Our results are in accordance with this, and also point out the importance of the detailed sequential dependencies of the backbone angles, even within the constraints of a given secondary structure assignment.
Materials and Methods
Cα backbone parameterization.
The Cα backbone of a protein can be considered as a string of beads (Figure 1), in which each bead corresponds to the Cα atom of an amino acid. Since the distance between two consecutive Cα atoms in a protein can be considered constant (3.8 Å), the conformation of the Cα backbone can be described using a sequence of pseudo angles and pseudo dihedral angles [33,34], called θ and τ, respectively (Figure 1). The term pseudo points to the fact that the consecutive Cα atoms are not actually connected by a single chemical bond. In proteins, the angle θ lies in [80,150], while the dihedral angle τ can adopt all values in [−180,180].
The conformation of n Cα atoms is fully described by n − 2 pseudo angles and n − 3 pseudo dihedral angles. Adding one Cα atom to a given Cα backbone corresponds to adding one (θ,τ) pair. Hence, the geometry of n Cα atoms can be described by n − 2 (θ,τ) angle pairs, where each angle pair positions one Cα atom. Note that the first three Cα positions are fixed by the first θ angle, and that the first τ angle can be ignored.
Each (θ,τ) pair is conveniently represented as a unit vector v = (x,y,z) (that is, a point on the unit sphere), simply by interpreting the (θ,τ) pair as a set of polar coordinates:
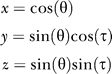 |
Hence, the Cα backbone of a protein can also be encoded as a sequence of unit vectors.
The Fisher-Bingham distribution.
We use the FB5 distribution [37] to create probability distributions over unit vectors. FB5 is the analogue on the unit sphere of the bivariate normal distribution with an unconstrained covariance matrix.
The probability density function of the FB5 distribution is given by:
where x is a unit vector and c(κ,β) is a normalizing constant [37]. The parameter κ (with κ > 0) determines the concentration or spread of the distribution, while β (with 0 ≤ 2β < κ) determines the ellipticity of the contours of equal probability. The higher the κ and β parameters, the more concentrated and elliptical the distribution will be, respectively. Vector γ 1 is the mean direction, and vectors γ 2, γ 3 are the major and minor axes. The latter two vectors γ determine the orientation of the equal probability contours on the sphere, while the first vector determines the common center of the contours.
Training FB5–HMM using protein data.
Parameter learning for FB5–HMM was done using Stochastic Expectation-Maximization (S-EM) [64,65]. Briefly, S-EM consists of the following steps. First, the FB5–HMM is initialised using random parameters and hidden node values. In the Expectation step, the values of the hidden nodes are filled in using a single sweep of Gibbs sampling, while the values of the observed nodes are kept fixed [65]. In the Maximization step, the filled-in values of the hidden nodes are used to update the FB5–HMM's parameters. Advantages of S-EM compared with classic deterministic learning methods include less dependence on the starting parameters of the model and a lower chance of getting stuck in local maxima [64].
Choosing an appropriate hidden node size is vital for the success of the model. If the size is too low, the model will be too coarse, while if the size is too high, it will lead to overfitting. We estimated the ideal hidden node size using the Integrated Completed Likelihood Criterion (ICL) [66], an entropy penalized version of the Bayesian Information Criterion [67,68] :
where L(M) is the logarithm of the likelihood (LogLik) of the completed data after convergence, M is the hidden node size, p is the number of parameters of the model, and n is the number of observations. The ICL value reaches a maximal value for the best model.
We trained FB5–HMM using 1,428 protein domains, all belonging to different superfamilies, from the SABmark dataset, version 1.65 [69]. The list of structures is available in Dataset S2. Secondary structure was assigned using P-SEA [40]. P-SEA assigns secondary structure (helix, β-strand, and coil) based on Cα coordinates only, which allowed us to use the program on the full backbone structures in the training set and the Cα-only decoys. The training set contained information for 228,842 residues.
The ICL was calculated for hidden node sizes 15 to 120 (with a step size of 5), using the LogLik obtained after convergence of the S-EM algorithm (Figure 10). For each node size, the training was repeated four times with different starting conditions to lower the chance of picking a model that got stuck in a local minimum. For a model with a hidden node size of 75, resulting in an HMM with 7,800 parameters, the ICL value reached its maximum value. It is this model that is used in the article. The parameters of the model are available in Dataset S1.
Figure 10. Training FB5–HMM.

(Left) ICL plotted versus hidden node size. For each hidden node size, four models were trained. The ICL reaches a maximum for one of the models with a hidden node size of 75 (indicated with a solid dot).
(Right) Evolution of the LogLik of the completed data during training. The LogLik is plotted against the number of EM iterations.
Sampling a Cα backbone.
FB5–HMM (Figure 2) has one discrete hidden node H, two discrete nodes A,S, and one continuous node F. The three nodes A,S,F represent the amino acid type, the secondary structure class, and the unit vector at a given sequence position, respectively.
FB5–HMM can be used to generate a sequence of unit vectors given an amino acid sequence A = a 0,…,aL −1 and secondary structure sequence S, if available. Each unit vector corresponds to one (θ,τ) pair, and specifies the position of one Cα atom. For simplicity, we will assume amino acid information only here.
The problem can be reduced to sampling a sequence H of hidden node values conditional on the amino acid sequence A. Once the hidden node sequence is sampled, a sequence of vectors describing the backbone can be obtained as follows. A hidden node value h at position l in H specifies a parameter set (κ,β,γ 1,γ 2,γ 3)h for node F at that position. Hence, a unit vector v at position l can be generated by sampling from the FB5 distribution [37,70] using the parameters that are specified by h.
Hidden node sequences H can be sampled from P(H|A) using the FwBt algorithm [35,38]. Note that this algorithm should not be confused with the related Forward-Backward algorithm used in posterior decoding. The FwBt algorithm is, in contrast to the Viterbi and posterior decoding algorithms [35], not widely used. Therefore, we describe its application to FB5–HMM here in some detail.
Essentially, the method calculates the forward variables [35] and performs a stochastic backtrack. The forward variables fh(l), which represent the probability of hidden node value h at position l given the amino acid sequence segment a 0,…,al, are recursively calculated as follows:
where eh(al) is the emission probability of amino acid type al given hidden node value h, th is the probability of hidden node value h at position 0, tgh is the transition probability for hidden node values g and h, and M is the maximum hidden node value (which is equal to 75 for FB5–HMM).
To start the stochastic backtrack, a hidden node value h is sampled for the final sequence position L − 1, proportional to fh (L − 1). The backtrack is then continued recursively for the previous positions by sampling hidden node value g at position l proportional to fg(l)tgh, where h is the hidden node value at position l + 1. From the sampled hidden node sequence H, a sequence of unit vectors (and corresponding angle pairs) can then easily be sampled as described above.
Resampling a segment of the backbone.
Given a previously sampled Cα backbone (and a corresponding sequence of hidden node values), the FwBt algorithm can be used to resample a segment of the backbone. This corresponds to “rebuilding” a part of the structure seamlessly, which has important applications in MCMC simulations of proteins [16,21].
Starting from the previously sampled hidden node sequence H, a segment Hs j:k from position j to k in H is selected and filled in with new hidden node values using the FwBt algorithm. In particular, the segment Hs j:k is resampled conditioned on the amino acid sequence A, and the hidden node sequence segments from the start of the sequence to j − 1 and from k + 1 to the end of the sequence:
Let p,q be the hidden node values at positions j − 1, k + 1, respectively. First, we calculate the forward variables from j to k:
Backtracking starts at position k by sampling h proportional to fh(k)thq, and continues recursively from k − 1 to j, by sampling g at position l proportional to fg(l)tgh, where h is the hidden node value at position l + 1. Once the hidden nodes in the segment are filled in, the (θ,τ) angle pairs in the segment from j to k are sampled as before, while the angle pairs outside the segment remain unaltered. How this application of the FwBt algorithm, which we call FwBt resampling, is used for compact decoy generation is explained in the next section.
Generating compact decoys.
Generating compact decoys without steric clashes involves three steps: initialization, steric clash removal, and collapse. First, a sequence of angles is sampled using FwBt sampling and a corresponding Cα backbone is constructed. In the next step, any steric clashes (defined as two Cα atoms that are closer than 4.0 Å from each other) are iteratively removed by FwBt resampling of random stretches of the sequence and only accepting structures that diminish the number of steric clashes. Positions and lengths (from 1 to 15) of the segments to be resampled were chosen at random.
Once the steric clashes are removed, the structure is collapsed in a greedy way to produce a compact conformation. Random stretches are resampled as before, and the corresponding structure is accepted if the Rg is lower than or equal to that of the previous structure. Cα backbones that contain steric clashes are rejected. The collapse stage is stopped when the Rg value falls below a given threshold (predicted or structure-derived Rg) or after a maximum number of iterations (set to 1,000). Secondary structure was predicted using JPRED [71]. The predicted Rg was calculated from the length L of the protein [72]:
Supporting Information
(291 KB TXT)
(11 KB TXT)
Acknowledgments
We thank Jesper Borg, Paul Gardner, Kresten Lindorff-Larsen, Kanti Mardia, Charles Taylor, and Ole Winther for valuable suggestions and discussions, and Wouter Boomsma for help with the implementation of greedy collapse in C++ as well. All computations were done on the 240 CPU cluster computer of the Bioinformatics Center/Zoological museum, University of Copenhagen.
Abbreviations
- FB5
5-parameter Fisher-Bingham distribution
- FwBt
Forward-Backtrack
- HMM
Hidden Markov Model
- ICL
Integrated Completed Likelihood Criterion
- MCMC
Markov Chain Monte Carlo
- PDB
Protein Data Bank
- Rg
radius of gyration
- RMSD
root mean square deviation
- S-EM
Stochastic Expectation-Maximization
Footnotes
Competing interests. The authors have declared that no competing interests exist.
A previous version of this article appeared as an Early Online Release on August 21, 2006 (DOI: 10.1371/journal.pcbi.0020131.eor).
Author contributions. TH conceived and implemented FB5–HMM and wrote the article. JTK devised the sampling method for the FB5 distribution. AK suggested using FwBt for sampling and provided advice during the course of the project.
Funding. TH is supported by a Marie Curie Intra-European Fellowship within the Sixth European Community Framework Programme.
References
- Anfinsen CB. Principles that govern the folding of protein chains. Science. 1973;181:223–230. doi: 10.1126/science.181.4096.223. [DOI] [PubMed] [Google Scholar]
- Levinthal C. Mössbauer spectroscopy in biological systems. Springfield (Illinois): University of Illinois Press; 1969. pp. 22–24. “How to Fold Graciously” chapter. pp. [Google Scholar]
- Srinivasan R, Rose GD. A physical basis for protein secondary structure. Proc Natl Acad Sci U S A. 1999;96:14258–14263. doi: 10.1073/pnas.96.25.14258. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Street AG, Mayo SL. Intrinsic β-sheet propensities result from van der Waals interactions between side chains and the local backbone. Proc Natl Acad Sci U S A. 1999;96:9074–9076. doi: 10.1073/pnas.96.16.9074. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Honig B. Protein folding: From the levinthal paradox to structure prediction. J Mol Biol. 1999;293:283–293. doi: 10.1006/jmbi.1999.3006. [DOI] [PubMed] [Google Scholar]
- Chikenji G, Fujitsuka Y, Takada S. Shaping up the protein folding funnel by local interaction: Lesson from a structure prediction study. Proc Natl Acad Sci U S A. 2006;103:3141–3146. doi: 10.1073/pnas.0508195103. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Baldwin RL, Rose GD. Is protein folding hierarchic? I. Local structure and peptide folding. Trends Biochem Sci. 1999;24:26–33. doi: 10.1016/s0968-0004(98)01346-2. [DOI] [PubMed] [Google Scholar]
- Baldwin RL, Rose GD. Is protein folding hierarchic? II. Folding intermediates and transition states. Trends Biochem Sci. 1999;24:77–83. doi: 10.1016/s0968-0004(98)01345-0. [DOI] [PubMed] [Google Scholar]
- Bradley P, Misura KMS, Baker D. Toward high-resolution de novo structure prediction for small proteins. Science. 2005;309:1868–1871. doi: 10.1126/science.1113801. [DOI] [PubMed] [Google Scholar]
- Park B, Levitt M. Energy functions that discriminate X-ray and near native folds from well-constructed decoys. J Mol Biol. 1996;258:367–392. doi: 10.1006/jmbi.1996.0256. [DOI] [PubMed] [Google Scholar]
- Fain B, Levitt M. A novel method for sampling α-helical protein backbones. J Mol Biol. 2001. pp. 191–201. [DOI] [PubMed]
- Keasar C, Levitt M. A novel approach to decoy set generation: Designing a physical energy function having local minima with native structure characteristics. J Mol Biol. 2003;329:159–174. doi: 10.1016/S0022-2836(03)00323-1. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Kolodny R, Levitt M. Protein decoy assembly using short fragments under geometric constraints. Biopolymers. 2003;68:278–285. doi: 10.1002/bip.10262. [DOI] [PubMed] [Google Scholar]
- Simons K, Kooperberg C, Huang E, Baker D. Assembly of protein tertiary structures from fragments with similar local sequences using simulated annealing and Bayesian scoring functions. J Mol Biol. 1997;268:209–225. doi: 10.1006/jmbi.1997.0959. [DOI] [PubMed] [Google Scholar]
- Srinivasan R, Rose GD. LINUS: A hierarchic procedure to predict the fold of a protein. Proteins. 1995;22:81–99. doi: 10.1002/prot.340220202. [DOI] [PubMed] [Google Scholar]
- Przytycka T. Significance of conformational biases in Monte Carlo simulations of protein folding: Lessons from Metropolis–Hastings approach. Proteins. 2004;57:338–344. doi: 10.1002/prot.20210. [DOI] [PubMed] [Google Scholar]
- Jones T, Thirup S. Using known substructures in protein model building and crystallography. EMBO J. 1986;5:819–822. doi: 10.1002/j.1460-2075.1986.tb04287.x. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Unger R, Harel D, Wherland S, Sussman JL. A 3D building blocks approach to analyzing and predicting structure of proteins. Proteins. 1989;5:355–373. doi: 10.1002/prot.340050410. [DOI] [PubMed] [Google Scholar]
- Kolodny R, Koehl P, Guibas L, Levitt M. Small libraries of protein fragments model native protein structures accurately. J Mol Biol. 2002;323:297–307. doi: 10.1016/s0022-2836(02)00942-7. [DOI] [PubMed] [Google Scholar]
- Camproux A, Gautier R, Tuffery P. A hidden Markov model derived structural alphabet for proteins. J Mol Biol. 2004;339:591–605. doi: 10.1016/j.jmb.2004.04.005. [DOI] [PubMed] [Google Scholar]
- Chikenji G, Fujitsuka Y, Takada S. A reversible fragment assembly method for de novo protein structure prediction. J Chem Phys. 2003;119:6895–6903. [Google Scholar]
- Bystroff C, Thorsson V, Baker D. HMMSTR: A hidden Markov model for local sequence–structure correlations in proteins. J Mol Biol. 2000;301:173–90. doi: 10.1006/jmbi.2000.3837. [DOI] [PubMed] [Google Scholar]
- Bystroff C, Shao Y. Fully automated ab initio protein structure prediction using I-SITES, HMMSTR, and ROSETTA. Bioinformatics. 2002;18((Supplement 1)):S54–S61. doi: 10.1093/bioinformatics/18.suppl_1.s54. [DOI] [PubMed] [Google Scholar]
- Bystroff C, Baker D. Prediction of local structure in proteins using a library of sequence–structure motifs. J Mol Biol. 1998;281:565–577. doi: 10.1006/jmbi.1998.1943. [DOI] [PubMed] [Google Scholar]
- Edgoose T, Allison L, Dowe D. An MML classification of protein structure that knows about angles and sequence. Pac Symp Biocomput. 1998;3:585–596. [PubMed] [Google Scholar]
- Camproux A, Tuffery P, Chevrolat J, Boisvieux J, Hazout S. Hidden Markov model approach for identifying the modular framework of the protein backbone. Protein Eng. 1999;12:1063–1073. doi: 10.1093/protein/12.12.1063. [DOI] [PubMed] [Google Scholar]
- Aszodi A, Taylor W. Folding polypeptide α-carbon backbones by distance geometry methods. Biopolymer. 1994;34:489–505. [Google Scholar]
- Reva BA, Finkelstein AV, Skolnick J. What is the probability of a chance prediction of a protein structure with an rmsd of 6 Å? Fold Des. 1998;3:141–147. doi: 10.1016/s1359-0278(98)00019-4. [DOI] [PubMed] [Google Scholar]
- Feldman HJ, Hogue CW. A fast method to sample real protein conformational space. Proteins. 2000;39:112–131. [PubMed] [Google Scholar]
- Feldman HJ, Hogue CWV. Probabilistic sampling of protein conformations: New hope for brute force? Proteins. 2002;46:8–23. [PubMed] [Google Scholar]
- Jha AK, Colubri A, Zaman MH, Koide S, Sosnick TR, et al. Helix, sheet, and polyproline II frequencies and strong nearest neighbor effects in a restricted coil library. Biochemistry. 2005;44:9691–9702. doi: 10.1021/bi0474822. [DOI] [PubMed] [Google Scholar]
- Taylor WR. Decoy models for protein structure comparison score normalisation. J Mol Biol. 2006;357:676–699. doi: 10.1016/j.jmb.2005.12.084. [DOI] [PubMed] [Google Scholar]
- Levitt M. A simplified representation of protein conformations for rapid simulation of protein folding. J Mol Biol. 1976;104:59–107. doi: 10.1016/0022-2836(76)90004-8. [DOI] [PubMed] [Google Scholar]
- Oldfield T, Hubbard R. Analysis of Cα geometry in protein structures. Proteins. 1994;18:324–337. doi: 10.1002/prot.340180404. [DOI] [PubMed] [Google Scholar]
- Durbin R, Eddy SR, Krogh A, Mitchison G. Biological sequence analysis. Cambridge University Press; 1998. p. 368. p. [Google Scholar]
- Mardia KV, Jupp P. Directional statistics. 2nd edition. John Wiley. 2000. p. 350. p.
- Kent J. The Fisher–Bingham distribution on the sphere. J Royal Stat Soc. 1982;44:71–80. [Google Scholar]
- Cawley S, Pachter L. HMM sampling and applications to gene finding and alternative splicing. Bioinformatics. 2003;19((Supplement 2)):II36–II41. doi: 10.1093/bioinformatics/btg1057. [DOI] [PubMed] [Google Scholar]
- Ramachandran G, Ramakrishnan C, Sasisekharan V. Stereochemistry of polypeptide chain configurations. J Mol Biol. 1963;7:95–99. doi: 10.1016/s0022-2836(63)80023-6. [DOI] [PubMed] [Google Scholar]
- Labesse G, Colloc'h N, Pothier J, Mornon JP. P-SEA: A new efficient assignment of secondary structure from Cα trace of proteins. Comput Appl Biosci. 1997;13:291–295. doi: 10.1093/bioinformatics/13.3.291. [DOI] [PubMed] [Google Scholar]
- Chan H, Dill K. Origins of structure in globular proteins. Proc Natl Acad Sci U S A. 1990;87:6388–6392. doi: 10.1073/pnas.87.16.6388. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Maritan A, Micheletti C, Trovato A, Banavar JR. Optimal shapes of compact strings. Nature. 2000;406:287–290. doi: 10.1038/35018538. [DOI] [PubMed] [Google Scholar]
- Hoang TX, Trovato A, Seno F, Banavar JR, Maritan A. Geometry and symmetry presculpt the free-energy landscape of proteins. Proc Natl Acad Sci U S A. 2004;101:7960–7964. doi: 10.1073/pnas.0402525101. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Holm L, Sander C. Database algorithm for generating protein backbone and side-chain co-ordinates from a Cα trace application to model building and detection of co-ordinate errors. J Mol Biol. 1991;218:183–194. doi: 10.1016/0022-2836(91)90883-8. [DOI] [PubMed] [Google Scholar]
- Kabsch W, Sander C. Dictionary of protein secondary structure: Pattern recognition of hydrogen-bonded and geometrical features. Biopolymers. 1983;22:2577–2637. doi: 10.1002/bip.360221211. [DOI] [PubMed] [Google Scholar]
- Chothia C. Conformation of twisted β-pleated sheets in proteins. J Mol Biol. 1973;75:295–302. doi: 10.1016/0022-2836(73)90022-3. [DOI] [PubMed] [Google Scholar]
- Zhang Y, Hubner IA, Arakaki AK, Shakhnovich E, Skolnick J. On the origin and highly likely completeness of single-domain protein structures. Proc Natl Acad U S A. 2006;103:2605–2610. doi: 10.1073/pnas.0509379103. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Yee DP, Chan HS, Havel TF, Dill KA. Does compactness induce secondary structure in proteins? A study of poly-alanine chains computed by distance geometry. J Mol Biol. 1994;241:557–573. doi: 10.1006/jmbi.1994.1531. [DOI] [PubMed] [Google Scholar]
- Hunt NG, Gregoret LM, Cohen FE. The origins of protein secondary structure. Effects of packing density and hydrogen bonding studied by a fast conformational search. J Mol Biol. 1994;241:214–225. doi: 10.1006/jmbi.1994.1490. [DOI] [PubMed] [Google Scholar]
- Socci ND, Bialek WS, Onuchic JN. Properties and origins of protein secondary structure. Phys Rev E. 1994;49:3440–3443. doi: 10.1103/physreve.49.3440. [DOI] [PubMed] [Google Scholar]
- Simons K, Bonneau R, Ruczinski I, Baker D. Ab initio protein structure prediction of CASP III targets using ROSETTA. Proteins. 1999;(Supplement 3):171–176. doi: 10.1002/(sici)1097-0134(1999)37:3+<171::aid-prot21>3.3.co;2-q. [DOI] [PubMed] [Google Scholar]
- Canutescu A, Dunbrack R., Jr Cyclic coordinate descent: A robotics algorithm for protein loop closure. Protein Sci. 2003;12:963–972. doi: 10.1110/ps.0242703. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Boomsma W, Hamelryck T. Full cyclic coordinate descent: Solving the protein loop closure problem in Cα space. BMC Bioinformatics. 2005;6:159. doi: 10.1186/1471-2105-6-159. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Winther O, Krogh A. Teaching computers to fold proteins. Phys Rev E. 2004;70:030903. doi: 10.1103/PhysRevE.70.030903. [DOI] [PubMed] [Google Scholar]
- Oldfield TJ. A number of real-space torsion-angle refinement techniques for proteins, nucleic acids, ligands, and solvent. Acta Cryst D. 2001;57:82–94. doi: 10.1107/s0907444900014098. [DOI] [PubMed] [Google Scholar]
- Zheng W, Doniach S. Protein structure prediction constrained by solution x-ray scattering data and structural homology identification. J Mol Biol. 2002;316:173–187. doi: 10.1006/jmbi.2001.5324. [DOI] [PubMed] [Google Scholar]
- Meiler J, Baker D. Rapid protein fold determination using unassigned NMR data. Proc Natl Acad Sci U S A. 2003;100:15404–15409. doi: 10.1073/pnas.2434121100. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Karchin R, Cline M, Mandel-Gutfreund Y, Karplus K. Hidden Markov models that use predicted local structure for fold recognition: Alphabets of backbone geometry. Proteins. 2003;51:504–514. doi: 10.1002/prot.10369. [DOI] [PubMed] [Google Scholar]
- Dahiyat B, Mayo S. De novo protein design: Fully automated sequence selection. Science. 1997;278:82–87. doi: 10.1126/science.278.5335.82. [DOI] [PubMed] [Google Scholar]
- Kuhlman B, Dantas G, Ireton GC, Varani G, Stoddard BL, et al. Design of a novel globular protein fold with atomic-level accuracy. Science. 2003;302:1364–1368. doi: 10.1126/science.1089427. [DOI] [PubMed] [Google Scholar]
- Xing EP, Karp RM. MotifPrototyper: A Bayesian profile model for motif families. Proc Natl Acad Sci U S A. 2004;101:10523–10528. doi: 10.1073/pnas.0403564101. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Chu W, Ghahramani Z, Wild DL. A graphical model for protein secondary structure prediction; Proceedings of the 21st International Conference on Machine Learning; 4–8 July 2004;; Banff, Canada.. New York: ACM Press; 2004. p. 21. p. [Google Scholar]
- Mardia K. Statistics of directional data (with discussion) J Royal Stat Soc. 1975;B37:349–393. [Google Scholar]
- Diebolt J, Ip E. Stochastic EM: Method and application. In: Gilks WR, Richardson S, Spiegelhalter DJ, editors. Markov Chain Monte Carlo in practice. Chapter 15. New York: Chapman and Hall/CRC Press; 1996. pp. 259–273. [Google Scholar]
- Ghahramani Z. Learning dynamic Bayesian networks. Lect Notes Comput Sci. 1997;1387:168–197. [Google Scholar]
- Biernacki C, Celeux G, Govaert G. Assessing a mixture model for clustering with the integrated completed likelihood. IEEE Trans Patt Anal Mach Intell. 2000;22:719–725. [Google Scholar]
- Schwarz G. Estimating the dimension of a model. Ann Stat. 1978;6:461–464. [Google Scholar]
- Fraley C, Raftery A. How many clusters? Which clustering method? Answers via model-based cluster analysis. Comp J. 1998;41:578–588. [Google Scholar]
- Van Walle I, Lasters I, Wyns L. SABmark—A benchmark for sequence alignment that covers the entire known fold space. Bioinformatics. 2005;21:1267–1268. doi: 10.1093/bioinformatics/bth493. [DOI] [PubMed] [Google Scholar]
- Kent J, Hamelryck T. Quantitative biology, shape analysis, and wavelets. Leeds: Leeds University Press; 2005. pp. 57–60. Chapter “Using the Fisher-Bingham distribution in stochastic models for protein structure.”. [Google Scholar]
- Cuff JA, Clamp ME, Siddiqui AS, Finlay M, Barton GJ. JPred: A consensus secondary structure prediction server. Bioinformatics. 1998;14:892–893. doi: 10.1093/bioinformatics/14.10.892. [DOI] [PubMed] [Google Scholar]
- Skolnick J, Kolinski A, Ortiz AR. MONSSTER: A method for folding globular proteins with a small number of distance restraints. J Mol Biol. 1997;265:217–241. doi: 10.1006/jmbi.1996.0720. [DOI] [PubMed] [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.
Supplementary Materials
(291 KB TXT)
(11 KB TXT)