

Abstract
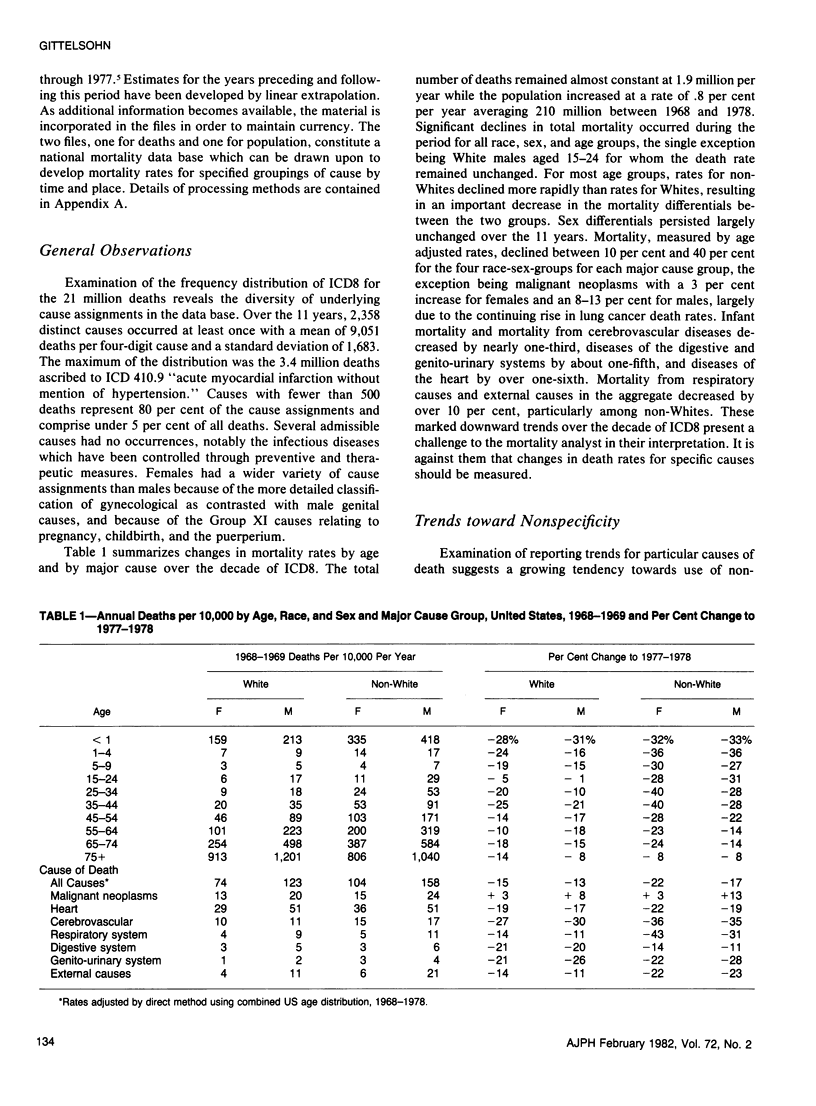
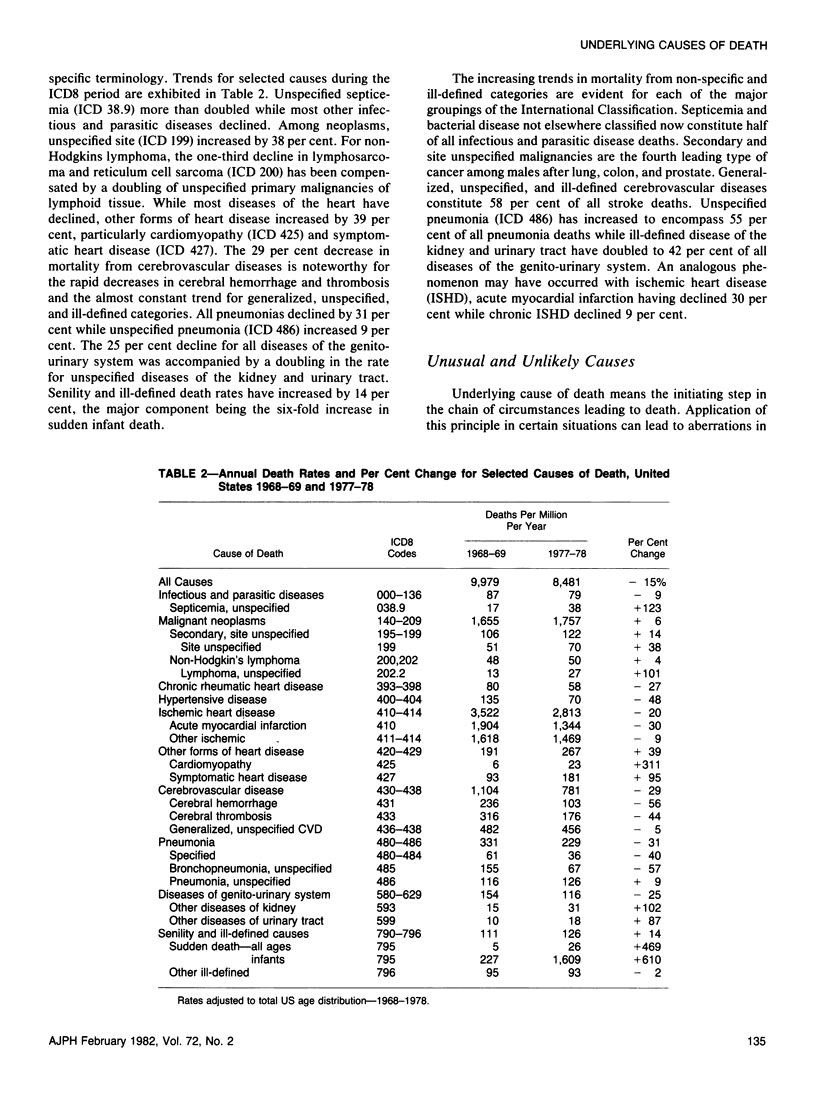
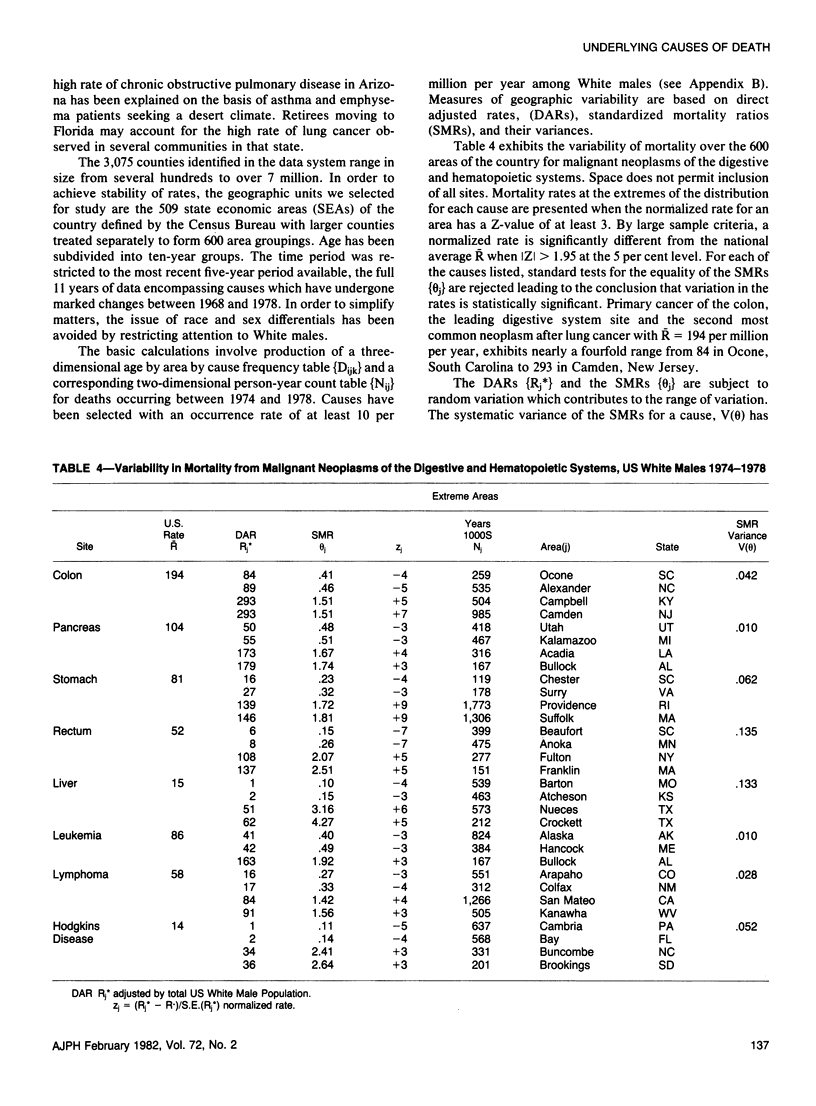
The feasibility of applying surveillance techniques to large health data sets is being explored through study of a national mortality data base encompassing 21 million United States death records for the period 1968--1978. Through the development of efficient file structures and information recovery techniques, it is possible to pose a series of questions and follow-up questions of the entire data set within budgetary constraints. Initial screening of the mortality data base reveals that major changes have occurred over the 11 years with marked declines for diseases of cardiovascular, respiratory, digestive and renal systems, and maternal and perinatal mortality. There is a tendency for increased usage of non-specific terminology. The occurrence of unlikely and unusual causes in the data set is documented and reasons for their inclusion discussed in terms of underlying cause of death logic. Problems in the study of geographic distributions of cause specific mortality are outlined with illustrations of the dispersion of standardized mortality ratios for major causes of death over areas of the country. Clusters of high mortality areas require interpretation in terms of underlying dispersion and possible reporting artifacts arising out of geographic differentials in diagnostic labeling practice.
Full text
PDF




Selected References
These references are in PubMed. This may not be the complete list of references from this article.
- McCarthy B. J., Terry J., Rochat R. W., Quave S., Tyler C. W., Jr The underregistration of neonatal deaths: Georgia 1974--77. Am J Public Health. 1980 Sep;70(9):977–982. doi: 10.2105/ajph.70.9.977. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Percy C., Stanek E., 3rd, Gloeckler L. Accuracy of cancer death certificates and its effect on cancer mortality statistics. Am J Public Health. 1981 Mar;71(3):242–250. doi: 10.2105/ajph.71.3.242. [DOI] [PMC free article] [PubMed] [Google Scholar]