

Abstract
It is natural to think that in perceiving dynamic scenes, vision takes a series of snapshots. Motion perception can ensue when the snapshots are different. The snapshot metaphor suggests two questions: (i) How does the visual system put together elements within each snapshot to form objects? This is the spatial grouping problem. (ii) When the snapshots are different, how does the visual system know which element in one snapshot corresponds to which element in the next? This is the temporal grouping problem. The snapshot metaphor is a caricature of the dominant model in the field—the sequential model—according to which spatial and temporal grouping are independent. The model we propose here is an interactive model, according to which the two grouping mechanisms are not separable. Currently, the experiments that support the interactive model are not conclusive because they use stimuli that are excessively specialized. To overcome this weakness, we created a new type of stimulus—spatiotemporal dot lattices—which allow us to independently manipulate the strength of spatial and temporal groupings. For these stimuli, sequential models make one fundamental assumption: if the spatial configuration of the stimulus remains constant, the perception of spatial grouping cannot be affected by manipulations of the temporal configuration of the stimulus. Our data are inconsistent with this assumption.
Vision uses small receptors to sample optical information. Spatial grouping is the process by which samples are linked across space to form more complex visual entities, such as objects and surfaces. Temporal grouping is the process by which visual entities are linked over time. Spatial grouping and temporal grouping either are sequential or they interact. If the perception of dynamic scenes is the result of the successive application of these two kinds of grouping, we have a sequential model of motion perception. If the perception of dynamic scenes is the result of spatial and temporal grouping operating in parallel, we have an interactive model.
The Sequential Model.
Let us consider two versions of the sequential model: one in which spatial grouping comes first, the other in which temporal grouping comes first. The perception of most dynamic stimuli can be explained by describing them as a succession of snapshots (1). For example, according to Ullman (2), vision first does grouping within each snapshot and then finds a mapping between these groupings across the snapshots. These groupings are often called matching units. In this view, spatial grouping alone determines the matching units that will undergo temporal grouping.
Some stimuli, however, are designed to prevent us from applying spatial grouping first. These are, for example, random-dot cinematograms (3). These are dynamic displays in which each frame contains a different random texture. If the frames are not correlated, one sees random dynamic “snow.” If dots in a patch of the display are correlated across frames, the patch will segregate, and its shape will be visible. A sequential model can account for the perception of such displays by assuming that temporal grouping extracts coherently moving elements [a process known as grouping by common fate (4)], which then undergo spatial organization.
Some data that appear to imply an interactive model can actually be explained by a sequential model. Consider, for example, the Ternus display (5), which consists of two rapidly alternating frames—f1 and f2—in which dots can occupy four equally spaced collinear positions pqrs (Fig. 1). The dots in f1 are at pqr; the dots in f2 are at qrs. This display can give rise to two percepts: (i) Element motion (e-motion) is seen when the two dots in positions q and r appear immobile, while one dot appears to move between the positions p and s. (ii) Group motion (g-motion) is seen when three dots appear to move, as a group, back and forth between pqr and qrs. The longer the interstimulus interval (ISI; interframe interval in this context), the higher the likelihood of g-motion (6). This is called the ISI effect. It is tempting to view this phenomenon as evidence for an interactive model (7). To see why, assume that the shorter the ISI, the stronger the temporal grouping. When the ISI is sufficiently short, temporal grouping could be stronger than spatial grouping. Thus, rather than grouping with the dot at r in f1, the dot at q in f1 would group with the dot at q in f2. The result is e-motion. As ISI grows, the strength of temporal grouping drops, and concurrent dots group within frames, resulting in g-motion. However, a sequential model can also account for the ISI effect. Suppose that longer ISIs have two effects: (i) they weaken temporal grouping, and (ii) they give spatial grouping more time to consolidate the organization of concurrent dots. According to (ii), the ISI effect is caused by spatial rather than temporal grouping and is consistent with a sequential model (8).
Figure 1.

Ternus display. The dotted arrows show the directions of perceived motion. (a) Element motion. (b) Group motion.
The Interactive Model.
Only an interactive model can account for the perception of motion when neither spatial grouping alone nor successive spatial and temporal grouping operations could derive matching units. Unfortunately, the only persuasive evidence in favor of the interactive model comes from displays in which objects and surfaces (transparent or opaque) overlap, and their spatial relation changes dynamically. For example, in certain kinetic occlusion (9–11) displays, we see a hitherto visible part of the scene become occluded by an opaque surface. In such displays, there is no simple correspondence between successive frames, because one frame contains a different number of elements than the next.†
We are concerned that the evidence from such displays is not general enough to refute sequential models as a class, because such displays may trigger a specialized mechanism that processes kinetic occlusion in which spatial and temporal grouping interact. For example, kinetic occlusion offers two characteristic clues: (i) the accretion or deletion of texture, as a textured object emerges from or disappears behind an occluder (9), and (ii) the presence of “T-junctions” between the contours of an occluder and the contours of an object it occludes (14, 15). To address these concerns, we designed displays that are not likely to trigger specialized motion-perception mechanisms.
Motion Lattices.
To refute the sequential models, we will show that spatial and temporal grouping mechanisms interact even when simple matching between the successive frames is possible. We created spatiotemporal dot lattices (motion lattices) in which we could independently vary the strength of spatial and temporal grouping by manipulating the spatial proximity of concurrent and successive dots [a generalization of the stimuli used by Burt and Sperling (16)]. We varied the strength of temporal grouping by manipulating the spatial proximity between successive dots. To avoid ambiguities of data interpretation that beset the Ternus display (i.e., the ISI effect), we held ISI constant. In our displays, as in the Ternus display, observers see either e-motion or g-motion. The advantage of motion lattices over the Ternus display is that in lattices the directions of e-motion and g-motion differ. The direction of e-motion is determined by matching individual dots in successive frames of the display. The direction of g-motion is determined by the matching of dot groupings in successive frames.
If we show an observer a single frame of a motion lattice, its spatial grouping is determined by the relative distance between concurrent dots (17). Although we hold the ISI constant, temporal grouping can be determined only by spatial distances between successive dots. According to the sequential model, the propensity of dots to group within frames—and thus yield g-motion—is independent of the determinants of temporal grouping. To test this prediction, we ask whether the frequency of g-motion changes when we hold constant the relative distance between concurrent dots and vary the spatial distance between successive dots. We find that it does, and on this basis we will claim that we have refuted the sequential model in favor of the interactive model.
General Methods
A motion lattice is a lattice of locations, whose rows we call baselines (b1, b2, b3, … ; Fig. 2a), displayed in two frames, f1 and f2. In f1, dots occupy the locations of the odd-numbered baselines; in f2, dots occupy the locations of the even-numbered baselines. When these frames rapidly alternate (f1, f2, f1, …) under appropriate spatial and temporal conditions, motion lattices are perceived as a continuous flow of apparent motion. Motion lattices are specified by two temporal and three spatial parameters. The two temporal parameters were kept constant: ISI (= 0) and frame duration (= 176 ms). The three spatial parameters are: |b|, the distance between adjacent dots in a baseline; |m1|, the shortest distance between a dot in an f1-frame and a dot in an f2-frame; θ1, the angle between the orientations of b and m1.
Figure 2.

(a) Three rows (baselines) of a motion lattice. The solid and open circles stand for dots that appear in frames f1 and f2, respectively. The three spatial parameters of motion lattices are: |b|, the distance between adjacent dots in a baseline; |m1|, the shortest distance between successive dots; and θ1, the acute angle between the orientations b and m1. The acute angle between b and m2 is θ2. S is the second (after b) shortest distance within a frame. To minimize edge effects, we modulated the luminance of lattice dots [radius = 0.3 degrees of visual angle (dva)] according to a Gaussian distribution (σ = 1.5 dva). We held m1 (= 0.9 dva) constant. (b) Time line of each trial. We kept the total duration of each presentation at 1.76 s to prevent the percept of oscillatory motion, which sometimes is seen with longer presentations. (c and d) Two successive frames of a motion lattice captured from the computer screen (not to scale). (e) A response screen with three response options. (Labels were not presented in the display.)
Two kinds of apparent motion can be seen in motion lattices:
e-motion is based on element-to-element matching. In e-motion, each dot in a baseline is matched with a dot in an adjacent baseline. The three shortest distances between successive dots are |m1|≤|m2|≤|m3| (Fig. 2a). The shorter the distance between dots, the more often the dots are linked in apparent motion (18, 19). Motion along m1 is seen more often than along m2 and never along m3. The strength of grouping between successive elements is called affinity (2), which is inversely related to interdot distance.
g-motion is based on grouping-to-grouping matching. That is to say, in g-motion matching occurs between dot groupings (called virtual objects) as wholes. For example, in Figs. 2 c–d, suppose that the observer sees the lattice organized into virtual objects that coincide with the baselines, i.e., into horizontal strips of dots. If the observer sees vertical motion, it must be g-motion, because neither m1 nor m2 is vertical. In other cases, the virtual objects may not coincide with the baselines, but g-motion is always orthogonal to the virtual objects.‡
The sequential model predicts (for our stimuli) that the direction of motion will be determined solely by spatial grouping. To test this prediction, we measure the relative frequency of e-motion and g-motion, where we hold the determinants of spatial grouping constant and vary the spatial determinants of temporal grouping.
Spatial Grouping.
The determinants of spatial grouping in static lattices are known: the dots group by proximity alone independent of lattice configuration. The strength of this grouping is called attraction. Attraction decreases exponentially, as the relative distance between dots increases (17). Analogously, within each frame of a motion lattice, the likelihood of different spatial groupings is controlled by the ratio of the two shortest interdot distances, rs = (|s|/|b|) (Fig. 2a). (|S| is equal to the shortest of the two distances: 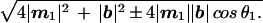 ) We call rs the static ratio. If we hold this ratio constant, the likelihood of different virtual objects within a frame will remain constant.
) We call rs the static ratio. If we hold this ratio constant, the likelihood of different virtual objects within a frame will remain constant.
Temporal Grouping.
In motion lattices temporal grouping is the outcome of two competitions:
e-motion vs. g-motion: Because we are holding the temporal parameters constant, the outcome of this competition is controlled by the baseline ratio, rb = (|b|/|m1|). For example, if rb is low, then attraction within the baselines is high; therefore, observers are likely to see g-motion orthogonal to the baseline. If rb is higher, then attraction within the baselines is lower; therefore, observers are less likely to see g-motion orthogonal to the baseline and—depending on the parameters of the motion lattice—they will see either e-motion or g-motion orthogonal to other virtual objects.
between alternative e-motions: The outcome of this competition is controlled by the motion ratio, rm = (|m2|/|m1|). If rm is high, then temporal grouping favors m1 motion over m2 motion.
The time line of a trial is shown in Fig. 2b. After fixating a central dot, observers viewed the motion sequence. In the trials with three response options, the response screen displayed three radial lines (Fig. 2e): two were parallel to the most probable orientations of e-motion (m1 and m2), and one was orthogonal to the baselines, orth. In the trials with two response options, the response screen displayed two radial lines, parallel to the orientations of m1 and m2. Observers reported the orientation of the motion by clicking on one of the circles attached to the lines on the response screen. The mask was an array of randomly moving dots. We randomized the orientation of the lattice between trials to minimize carryover from trial to trial.
Experiment 1
In Experiment 1, which is a control experiment, we show that changes in the frequency of g-motion are not attributable to observers' confusion between the response options. This possibility arises because as the orientations of m1 and m2 vectors approach the orthogonal to the baseline, confusion between orth and affinity responses (m1, m2) might increase. Response confusion might mimic an effect of interaction between the two types of grouping.
Methods.
We held θ1 (= 60°) constant and chose six motion lattices, each of which is defined by a (rm, rb) pair: (1.00, 1.00), (1.07, 1.13), (1.15, 1.24), (1.23, 1.35), (1.30, 1.44), (1.38, 1.54). Because of the geometry of motion lattices, when one holds θ1 constant, rm and rb covary: rm = rb ( /|b|).
/|b|).
Our six observers had normal or corrected-to-normal vision and were naive as to the purpose of the experiment. Each observer went through 100 trials per motion lattice (i.e., 600 trials) for each of two 1-hour sessions—one with two (m1 and m2) and the other with three (m1, m2, and orth) response options in the response screen.
Results and Discussion.
The pie charts in Fig. 3a represent the relative proportion of m1, m2, and orth responses as a function of rm, rb. Because θ2 varied, we represent this variation by changing the diameters of the pie charts in proportion to erθ, where rθ = [(tan θ2)/(tan θ1)]. We split this three-way variation into two independent parts:
Affinity function: In Fig. 3b, we plot the logarithm of odds (log-odds) with which observers chose e-motion along m2 over m1 for the two sessions. First, we note that because log-odds(m2, m1)§ decrease linearly as a function of rm = (|m2|/|m1|), the odds [p(m2)]/[p(m1)] decrease exponentially as a function of rm. Further, we note that the confusion between the orth responses and the affinity responses (m1, m2) had little effect on response frequencies in the three-response sessions. The affinity function with three response options (thick line, “○” symbols) differed little from the affinity function with two response options (thin line, “+” symbols), compared to the effect of rm.
Objecthood function: In Fig. 3c, we plot the log-odds with which observers chose g-motion over e-motion for the three-response session. This function reflects the tradeoff between group-to-group and element-to-element matching. Because log-odds (orth, m1 ∨ m2)¶ decrease linearly as a function of rb = (|b|/|m1|), the odds p(orth)/[p(m1) + p(m2)] decrease exponentially as a function of rb.
Figure 3.

Results of Experiment 1. (a) The pie charts (averaged over observers) show how the distribution of the responses (m1, m2, and orth) varied as a function of the motion ratio, rm, and the baseline ratio, rb, in the three-response sessions. These data are decomposed in (b and c). (b) Affinity function: the tradeoff between the probabilities of two alternative e-motions. Two affinity functions were obtained in different sessions: with three response options (the thick line through “○” symbols) and with two response options (the thin line through “+” symbols). (c) Objecthood function: the tradeoff between the probability of e-motion (m1 or m2) and the probability of g-motion (orth).
As in previous studies of perceptual grouping in space–time, these data cannot adjudicate between the sequential model and the interactive model. The sequential model implies that the frequency of g-motion will decrease as a function of rb because when baseline ratios are high, the tendency of concurrent dots to form virtual objects is low. The interactive model implies that the frequency of g-motion will decrease as a function of rm because larger motion ratios strengthen temporal grouping and thus favor element-to-element matching at the expense of group-to-group matching.
Experiment 2
Methods.
In Experiment 2, we crossed five values of rm (1.0, 1.1, 1.2, 1.3, and 1.4) with four values of rb (1.11, 1.43, 1.25, and 1.67) to create 20 types of motion lattices. This was possible because we allowed θ1 to vary. Our seven observers had normal or corrected-to-normal vision and were naive as to the purpose of the experiment. On each trial, they were offered three response options—m1, m2, and orth. Every observer went through 40 trials per motion lattice, i.e., 800 trials in one session. In all other respects, the experiment was identical to Experiment 1.
Results and Discussion.
The distribution of the three responses varied systematically as a function of rm, rb, and rθ (Fig. 4e). In Fig. 4g, we plot four linear objecthood functions to show the tradeoff between g-motion and e-motion as a function of both rm and rb. The statistical model used to fit these functions accounts for 98% of variance in the data. (We used this model to interpolate the response frequencies for Fig. 4h). The frames in Fig. 4 a–d illustrate different outcomes of spatial grouping within the frames. When spatial grouping favors the formation of salient virtual objects orthogonal to the baselines (Fig. 4a: low rm and high rb), g-motion orthogonal to the baselines is never seen, and e-motion dominates (Fig. 4g). As rb decreases within the same rm (Fig. 4, a and c), spatial grouping progressively favors the formation of objects within the baselines, and the frequency of g-motion grows relative to the frequency of e-motion. As rm increases within the high rbs (Fig. 4, a and b), the virtual objects not parallel to the baselines become less orthogonal to the baselines and less salient and thus allow a higher frequency of g-motion. Within the small rbs, the growing rm does not cause appreciable change in the high salience of virtual objects (Fig. 4, c and d), and the frequency of g-motion does not change.
Figure 4.

(a–d) Single frames captured from the computer screen with the extreme values of rm = (|m2|/|m1|) and rb = (|b|)/|m1|). The snapshots are arranged in the (rm, rb) space, parallel to the plot in e. (e) The pie charts show the distribution of the three responses in the 20 motion lattices. The gray lines on the background are the iso-rs lines, where rs = (|s|/|b|), which are the contours for which within-frame spatial grouping should remain constant. For the isoline rs = 1.0, the organizations along s and b are equiprobable. It is marked with an oblique arrow (Upper Right). Conditions that favor dot grouping within the baselines (rs > 1.0; e.g., c and d) lie to the right of the isoline of rs = 1.0; in the rest of the conditions (rs < 1.0), dots tend to form groupings not along the baselines (as in a). (f) Affinity function collapsed across the rb conditions. (g) Four objecthood functions summarize the effects of the baseline and motion ratios, rb and rm. The frequency of g-motion grows rapidly as rb drops and groupings along the baselines become more prominent. This effect is evident both when rb is low (high ambiguity of e-motion) and when rb is high (m1 wins the competition with m2). The plot in h explicates the effect of rs. Dot organizations within the baselines dissolve as rs grows, which reduces the frequency of g-motion. In contrast to the prediction of the sequential model, e-motion and g-motion tradeoff within the iso-rs sets.
The gray curves in the background of Fig. 4e are iso-rs lines. Each of these curves represents the set of lattice configurations for which spatial grouping favors the formation of identical virtual objects. As Fig. 4e shows, the frequency of g-motion changes along iso-rs lines. To make this observation explicit, we interpolated the empirical frequencies of g-motion and plotted them within the iso-rs sets in Fig. 4h: as rb increases, the frequency of g-motion within the iso-rs sets drops rapidly. As temporal grouping progressively becomes stronger than spatial grouping, observers tend to see g-motion less frequently and e-motion more frequently. (Note that as one moves within each iso-rs set from high to low g-motion frequencies, rm grows, and therefore one of the e-motions, m1 motion, becomes increasingly salient.) The interactive model can explain this result, for example by pitting against each other the two scales of spatial grouping (elements vs. element aggregates) after the temporal grouping operation (24): g-motion wins the competition with e-motion when the latter becomes ambiguous at low rm, so that the dot aggregates (virtual objects), and not the individual dots, become the moving entities. (We thank one of the anonymous reviewers for suggesting we emphasize this point.)
We conclude that the sequential model does not hold: Invariant conditions for spatial grouping contribute to the perception of apparent motion differently, depending on the conditions for temporal grouping.
General Discussion
Using spatiotemporal dot lattices, we varied the spatial distances between concurrent dots and spatiotemporal distances between successive dots. Each dot could be grouped either (i) with a successive dot to generate e-motion or (ii) with concurrent dots to form (virtual) objects that are matched to generate g-motion. According to the sequential model, the only factor that can determine which of these is seen is the attraction between concurrent dots. We held attraction between concurrent dots constant and found that affinity between successive dots determines whether e-motion or g-motion will be seen. Thus we have refuted the sequential model in favor of the interactive model. Our findings imply that matching units can arise at any level in the cascade of visual processes, as late as the level of complex objects (25), in contrast to the view that matching units were derived early in visual perception (2).
Current theories of motion perception distinguish between three systems that compute motion. The systems differ by the complexity of the spatial representations on which they are based (26–29). The first-order system can detect the temporal modulation of raw luminances but is insensitive to spatial configuration. In our stimuli, this system can detect e-motion, because the displacement of each dot is a temporal modulation of luminance, but it cannot detect g-motion, because the direction of g-motion does not correspond to the direction of motion of any dot. The perception of g-motion requires a system that can take advantage of the spatial organization of the stimulus. Thus, g-motion is detected either by a second-order system that matches spatial features or by a third-order system that derives motion of more complex visual constructs.
How does vision decide which of the spatial representations will determine what is moving? According to the sequential model, the alternative spatial representations compete before motion matching, whereas according to the interactive model these representations compete after motion matching, i.e., among the outputs of the alternative motion systems: first-, second-, or third-order (30).
Most theories of motion perception are versions of the sequential model (30). A notable theory that agrees with the interactive model has been proposed by Wilson, Ferrera, and Yo (24). According to this theory, matching is applied in parallel to the raw visual input (the first-order system) and to the output of a preprocessor (the second-order system). When the outputs of the two motion systems support different motion directions, they compete, and the winner takes all. Wilson et al.'s model is interactive because the competition between different spatial representations occurs after motion computation. As it happens, the evidence that inspired their model is actually consistent with a sequential model.‖ Our data, on the other hand, do support the model of Wilson et al. (24).
To summarize, the interactive model holds that spatial organization and motion matching are tightly integrated. The identity of moving visual entities is determined both by spatial proximities between elements at each moment and by spatial proximities between elements that occur at successive moments. Thus visual objects emerge when motion matching between element aggregates (Gestalts) is stronger than motion matching between elements.
Acknowledgments
We thank D. R. Proffitt, M. Shiffrar, J. Wagemans, and S. Yantis for valuable discussions; W. Epstein, J. Hochberg, C. Von Hofsten, and three anonymous reviewers for helpful comments on an earlier version of the manuscript; and D. M. Johnson and S. C. Haden for assistance in running the experiments. This work was supported by National Eye Institute Grant 9 R01 EY12926-06.
Abbreviations
- ISI
interstimulus interval
- element motion
e-motion
- group motion
g-motion
- log-odds
logarithm of odds
Footnotes
A similar problem occurs if the moving object or surface is transparent (12, 13): finding correspondence between successive frames is hampered because the appearance of the region that is seen through a transparent surface changes as it becomes uncovered.
Orthogonal motion in motion lattices is an outcome of the so-called aperture problem (20–22). The aperture problem arises, for example, when a bar is moved behind an aperture so that its terminators are hidden: only the motion orthogonal to the bar is visible, even if the true motion of the bar is different. However, when the bar has a gap (or some other conspicuous feature), the visual system's solution is surprising: the gap appears to slide along the bar and does not disambiguate the direction of motion (20, 21, 23). In motion lattices, when dot grouping within the virtual objects is strong, the dots appear to move along the objects, like beads on a string.
The two sources of evidence for the model of Wilson et al. (24) are: (i) Physiological evidence that the cortical areas responsible for motion perception receive both first- and second-order spatial information (31). This evidence is consistent with the sequential model because the two sources of information could compete before motion computation. (ii) Psychophysical evidence that two superimposed moving gratings may be perceived as either independently moving gratings or as a plaid moving in an orientation different from the motion of the individual gratings (20, 22). This evidence is also consistent with the sequential model because the gratings can group and form a plaid before motion computation (27).
(log-odds (m2, m1) = ln[p(m2)]/[p(m1)] = sm (rm − 1), where sm is the slope.
(log-odds (orth, m1 ∨ m2) = ln[p(orth)]/[p(m1) + p(m2)] = sbrb + k), where sb is the slope.
References
- 1.Neisser U. Cognitive Psychology. New York: Appleton Century Crofts; 1967. [Google Scholar]
- 2.Ullman S. The Interpretation of Visual Motion. Cambridge, MA: MIT Press; 1979. [Google Scholar]
- 3.Julesz B. Foundations of Cyclopean Perception. Chicago, IL: Univ. of Chicago Press; 1971. [Google Scholar]
- 4.Wertheimer M. In: A Source of Gestalt Psychology. Ellis W D, editor. London: Routledge & Kegan Paul; (1936; originally published in 1923). pp. 71–88. [Google Scholar]
- 5.Ternus J. In: A Source of Gestalt Psychology. Ellis W D, editor. London: Routledge & Kegan Paul; (1936; originally published in 1926). pp. 149–160. [Google Scholar]
- 6.Pantle A J, Picciano L. Science. 1976;193:500–502. doi: 10.1126/science.941023. [DOI] [PubMed] [Google Scholar]
- 7.Kramer P, Yantis S. Percept Psychophys. 1997;59:87–99. doi: 10.3758/bf03206851. [DOI] [PubMed] [Google Scholar]
- 8.He Z J, Ooi T L. Perception. 1999;28:877–892. doi: 10.1068/p2941. [DOI] [PubMed] [Google Scholar]
- 9.Kaplan G A. Percept Psychophys. 1969;6:193–198. [Google Scholar]
- 10.Kellman P J, Cohen M H. Percept Psychophys. 1984;35:237–244. doi: 10.3758/bf03205937. [DOI] [PubMed] [Google Scholar]
- 11.Tse P, Cavanagh P, Nakayama K. In: High-Level Motion Processing. Watanabe T, editor. Cambridge, MA: MIT Press; 1998. pp. 249–266. [Google Scholar]
- 12.Shipley T F, Kellman P J. Spatial Vision. 1993;7:323–339. doi: 10.1163/156856893x00478. [DOI] [PubMed] [Google Scholar]
- 13.Cicerone C M, Hoffman D D, Gowdy P D, Kim J S. Percept Psychophys. 1995;57:761–777. doi: 10.3758/bf03206792. [DOI] [PubMed] [Google Scholar]
- 14.Guzman A. In: Automatic Interpretation and Classification of Images. Griselli A, editor. New York: Academic; 1968. pp. 243–276. [Google Scholar]
- 15.Nakayama K, He Z J, Shimojo S. In: Visual Cognition. Kosslyn S M, Osherson N, editors. Cambridge, MA: MIT Press; 1995. pp. 1–70. [Google Scholar]
- 16.Burt P, Sperling G. Psychol Rev. 1981;88:171–195. [PubMed] [Google Scholar]
- 17.Kubovy M, Holcombe A O, Wagemans J. Cognit Psychol. 1998;35:71–98. doi: 10.1006/cogp.1997.0673. [DOI] [PubMed] [Google Scholar]
- 18.von Schiller P. Psychologische Forschung. 1933;17:179–214. [Google Scholar]
- 19.Ramachandran V S, Anstis S M. Nature (London) 1983;304:529–531. doi: 10.1038/304529a0. [DOI] [PubMed] [Google Scholar]
- 20.Wallach H. Psychologische Forschung. 1935;20:325–380. [Google Scholar]
- 21.Wuerger S, Shapley R, Rubin N. Perception. 1996;25:1317–1367. [Google Scholar]
- 22.Adelson E H, Movshon J A. Nature (London) 1982;300:523–525. doi: 10.1038/300523a0. [DOI] [PubMed] [Google Scholar]
- 23.Castet E, Wueger S. Vision Res. 1997;37:705–720. doi: 10.1016/s0042-6989(96)00205-2. [DOI] [PubMed] [Google Scholar]
- 24.Wilson H R, Ferrera V P, Yo C. Visual Neurosci. 1992;9:79–97. doi: 10.1017/s0952523800006386. [DOI] [PubMed] [Google Scholar]
- 25.Ramachandran V S, Armel C, Foster C. Nature (London) 1998;395:852–853. doi: 10.1038/27573. [DOI] [PubMed] [Google Scholar]
- 26.Cavanagh P, Mather G. Spatial Vision. 1990;4:103–129. doi: 10.1163/156856889x00077. [DOI] [PubMed] [Google Scholar]
- 27.Smith A T. In: Visual Detection of Motion. Smith A T, Snowden R J, editors. New York: Academic; 1994. pp. 145–176. [Google Scholar]
- 28.Lu Z-L, Sperling G. Vision-Res. 1995;35:2697–2722. doi: 10.1016/0042-6989(95)00025-u. [DOI] [PubMed] [Google Scholar]
- 29.Wilson H R, Wilkinson F. Perception. 1997;26:939–960. doi: 10.1068/p260939. [DOI] [PubMed] [Google Scholar]
- 30.Kubovy M, Gepshtein S. In: Perceptual Organization for Artificial Vision Systems. Boyer K, Sarkar S, editors. Dordrecht, The Netherlands: Kluwer; 2000. pp. 41–71. [Google Scholar]
- 31.Maunsell J H R, Newsome W T. Annu Rev Neurosci. 1987;10:363–401. doi: 10.1146/annurev.ne.10.030187.002051. [DOI] [PubMed] [Google Scholar]